【Linux】Linux基础
文章目录
- 学习目标
- 操作系统
- 不同应用领域的主流操作系统
- 虚拟机
- Linux系统的发展史
- Linux内核版和发行版
- Linux系统下的文件和目录结构
- 单用户操作系统vs多用户操作系统
- Windows和Linux文件系统区别
- Linux终端命令格式
- 终端命令格式
- 查阅命令帮助信息
- 常用命令
- 显示文件和目录
- 切换工作目录
- 创建文件和文件夹
- 删除文件和文件夹
- 拷贝、移动文件和文件夹
- 其他
- 日期指令
- 历史指令
- 文件查看
- 数据流重定向、管道
- 建立链接
- 文件搜索
- 归档和压缩
- 文件权限
- 用户管理
- 关机、重启
- Ubuntu中软件安装与卸载
- ssh远程登录
- scp远程拷贝(上传/下载)
- 编辑器vi
- 系统性能定时监控
- 系统监控概述
- psutil
- python开发环境及网络基础
- 虚拟环境
- 为什么需要虚拟环境
- 虚拟环境搭建
- 网络通信概述
- IP地址
- IP地址查看
- 端口
- 网络-udp/tcp
- 网络传输方式(UDP\TCP)
- socket简介
- udp网络程序-发送、接收数据
- python3编码转换
- udp端口绑定
- udp广播
- udp聊天室
- TCP简介
- TCP客户端
- TCP服务器端
- 案例:文件下载器
- TCP的3次握手
- TCP的4次挥手
- 浏览器访问服务器的过程——IP地址、域名、DNS
- HTTP协议
- HTTP请求协议分析
- HTTP响应报文协议分析
- 长连接和短连接
- 案例:模拟浏览器实现
- 基于TCP的Web服务器案例
- 多任务 - 线程
- 多任务的介绍
- 线程
- 使用threading模块创建子线程
- 线程名称、总数量
- 线程参数及顺序
- 守护线程
- 并行和并发
- 自定义线程类
- 多线程-共享全局变量
- 同步和异步
- 互斥锁
- 死锁
- 案例
- 多任务版udp聊天器
- TCP服务器端框架
- 多任务 - 进程
- 进程的基本使用
- 进程名称、pid
- 进程参数、全局变量
- 守护主进程
- 进程、线程对比
- 消息队列 - 基本操作
- 消息队列 - 常见判断
- Queue实现进程间通信
- 进程池Pool
- 进程池中的Queue
- 案例:文件夹拷贝器(多进程版)
- 多任务 - 协程
- 可迭代对象及检测方法
- 迭代器及其使用方法
- 自定义迭代对象
- 迭代器案列 - 斐波那契数列
- 生成器
- 生成器案例 - 斐波那契数列
- 生成器 - 使用注意
- 协程 - yield
- 协程 - greenlet
- 协程 - gevent
- 进程、线程、协程对比
- 案例 - 并发下载器
学习目标
能够了解操作系统的历史
能够说出常见的操作系统的及其作用
能够掌握常见的linux文件目录结构
能够使用ls命令查看当前目录下的所有文件
能够使用pwd查看当前操作路径
能够说出绝对路径和相对路径及其作用
能够分别使用touch和mkdir创建文件和文件夹
能够使用cd切换根目录、家目录、当前目录和上层目录
能够使用tab自动补全功能
能够使用clear【Ctrl+L】清空屏幕操作
能够使用rm删除文件或者文件夹
能够使用mv移动或者重命名文件和文件夹
能够使用日历指令查看近3个月日历,并能把时间格式显示为:“xxxx年xx月xx日xx时xx分xx秒”
能够使用history显示近20条历史指令
能够使用cat命令、more查看文件以及管道|的使用方法
操作系统
操作系统(Operating System,简称OS)是管理和控制计算机硬件与软件资源的计算机程序,是直接运行在“裸机”上的最基本的系统软件,任何其他软件都必须在操作系统的支持下才能运行。
操作系统作为接口的示意图:
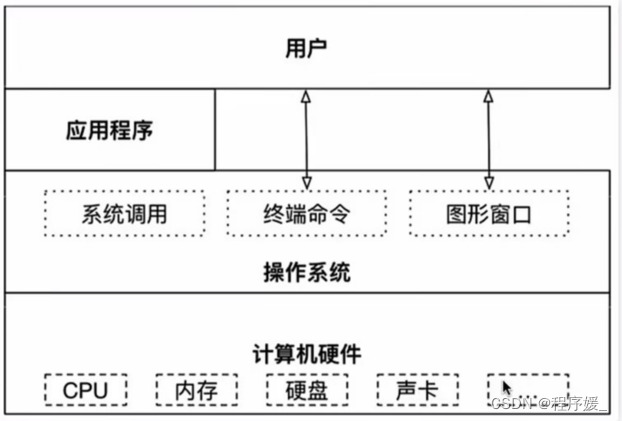
没有安装操作系统的计算机,通常被称为“裸机”
- 如果想在裸机上运行子所编写的程序,就必须用机器语言书写程序;
- 如果计算机上安装了操作系统,就可以在操作系统上安装支持的高级语言环境,用高级语言开发程序;
- 举例说明:
未安装操作系统播放音乐步骤如下:将歌曲文件从硬盘加载到内存>>使用声卡对音频数据进行解码>>将解码后的数据发送给音箱。
安装了操作系统播放音乐步骤如下:查找歌曲>>点击播放
操作系统的作用: 对下控制硬件运行,对上为应用程序提供支持。
不同应用领域的主流操作系统
-
桌面操作系统
操作系统 说明 Windows系列 用户群体大 macOS 适合开发人员 Linux 应用软件少 -
服务器操作系统
操作系统 说明 Linux 安全、稳定、免费
占有率高Windows Server 付费
占有率低 -
嵌入式操作系统
操作系统 说明 Linux - WinCE - -
移动设备操作系统
操作系统 说明 iOS 基于unix Android 基于Linux 虚拟机
虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。
- 虚拟系统通过生成现有操作系统的全新虚拟镜像,具有真实操作系统完全一样的功能;
- 进入虚拟系统后,所有操作都是在这个全新的独立的虚拟系统里面进行,可以独立安装运行软件,保存数据,拥有自己的独立桌面,不会对真正的系统产生任何影响;
- 而且能够在现有系统与虚拟镜像之间灵活切换的一类操作系统;
Linux系统的发展史
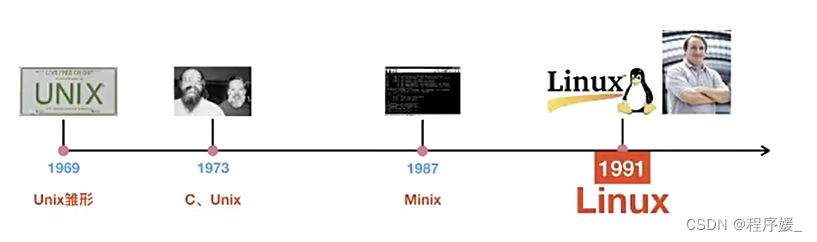
Linux内核版和发行版
Linux内核版本
内核(kernel)是系统的心脏,是运行程序和管理像磁盘和打印机等硬件设备的核心程序,它提供了一个在裸设备与应用程序间的抽象层。
Linux内核版本又分为稳定版和开发版,两种版本相互关联,相互循环。
- 稳定版:具有工业级强度,可以广泛地应用和部署。新的稳定版相对于旧的只是修正一些bug或加入一些新的驱动程序。
- 开发版:由于要试验各种解决方案,所以变化很快。
内核源码网站:http://www.kernel.org
所有来自全世界地对Linux源码地修改最终都会汇总到这个网站,又Linus领导的开源社区对其进行甄别和修改最终决定是否进入到Linux主线内核源码中。
Linux发行版
Linux发行版(也叫GNU/Linux发行版)通常包含了包括桌面环境、办公套件、媒体播放器、数据库等应用软件。
常见的发行版本如下:Ubuntu, Redhat, Fedora, openSUSE, Linux Mint, Debiian, Manjaro, Mageia, CentOS, Arch
Linux系统下的文件和目录结构
单用户操作系统vs多用户操作系统
单用户操作系统:指一台计算机在同一时间只能由一个用户使用,一个用户独享系统的全部硬件和软件资源;Windows XP之前的版本都是单用户操作系统。
多用户操作系统:指一台计算机在同一时间可以由多个用户使用,多个用户共享系统的全部硬件和软件资源;Unix, Linux的设计初衷就是多用户操作系统。
Windows和Linux文件系统区别
-
windows下的文件系统
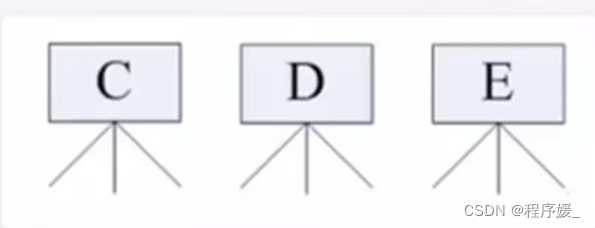
在Windows下,打开“计算机”,我们看到的是一个个的驱动器盘符:
每个驱动器都自己的根目录结构,这样形成了多个树并列的情形,如下所示:
-
Linux下的文件系统
在Linux下,我们是看不到这些驱动器盘符,我们看到的是文件夹(目录):
Ubuntu没有盘符这个概念,只有一个根目录/,所有文件都在它下面:
-
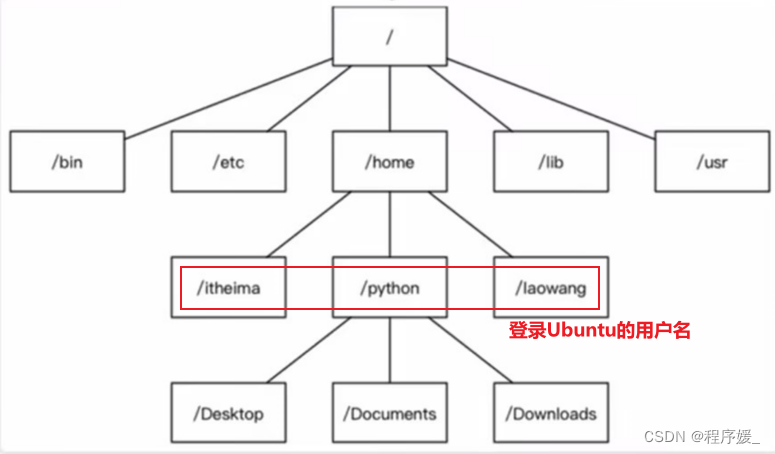
用户(主/家)目录
位于/home/user,称之为用户工作目录或家目录,表示方式:/home/user (注意:user表示当前登录用户名)

-
Linux主要目录速查表
目录 说明 / 根目录,一般根目录下只存放目录,在linux下有且只有一个根目录,所有的东西都是从这里开始。当在终端里输入/home,其实是在告诉电脑,先从/(根目录)开始,再进入到home目录(进入根目录的路径:文件>>其他位置>>计算机) /bin
/usr/bin可执行二进制文件的目录,如常用的命令ls、tar、mv、cat等 /etc 系统配置文件存放的目录,不建议在此且录下存放可执行文件,重要的配置文件有:
/etc/inittab; /etc/fstab; /etc/init.d; /etc/X11; /etc/sysconfig; /etc/xinetd.d/home 系统默认的用户家目录,新增用户账号时,用户的家目录都存放在此目录下
~ 表示当前用户的家目录
~ edu 表示用户edu的家目录/root 系统管理员root的家目录 /boot 放置linux系统启动时用到的一些文件,如linux的内核文件:/boot/vmlinuz,系统引导管理器:/boot/grub /dev 存放linux系统下的设备文件,访问该目录下某个文件,相当于访问某个设备,常用的是挂载光驱mount /dev/cdrom/mnt /lib
/usr/lib
/usr/local/lib系统使用的函数库的目录,程序在执行过程中,需要调用一些额外的参数时需要函数库的协助 /lost+found 系统异常产生错误时,会将一些遗失的片段放置于此目录下 /mnt:/media 光盘默认挂载点,通常光盘挂载于mnt/cdrom下,也不一定,可以选择任意位置进行挂载 /opt 给主机额外安装软件所摆放的目录 /proc 此目录的数据都在内存中,如系统核心,外部设备,网络状态,由于数据都存放于内存中,所以不占用磁盘空间,比较重要的文件有:/proc/cpuinfo、/proc/interrupts、/proc/dma、/proc/ioports、/proc/net/*等 /sbin
/usr/sbin
/usr/local/sbin放置系统管理员使用的可执行命令,如fdisk、shutdown、mount等。与/bin不同的是,这几个目录是给系统管理员root使用的命令,一般用户只能“查看”而不能设置和使用 /tmp 一般用户或正在执行的程序临时存放文件的目录,任何人都可以访问,重要数据不可放置在此目录下 /srv 服务启动之后需要访问的数据目录。如www服务需要访问的网页数据存放在/srv/www内 /usr 应用程序存放目录
/usr/bin:存放应用程序
/usr/share:存放共享数据
/usr/lib:存放不能直接运行的,确是许多程序运行所必需的一些函数库文件
/usr/local:存放软件升级包
/usr/share/doc:系统说明文件存放目录
/usr/share/man:程序说明文件存放目录/var 放置系统执行过程中经常变化的文件
/var/log:随时更改的日志文件
/var/spool/mail:邮件存放的目录
/var/run:程序或服务启动后,其PID存放在该目录下
Linux终端命令格式
终端(Terminal):通常是一个软件控制台,在终端中输入指令可以控制电脑的执行内容。
作用:大大提升操作系统的操控效率。
打开方式:
1. 桌面右键>>打开终端
2. 快捷键:【Ctrl+Alt+T】
终端命令格式
command [-options] [parameter]
说明:
command: 命令名,相应功能的英文单词或单词的缩写
[-options]:可用来对命令进行控制,也可以省略
[parameter]:传给命令的参数,可以是0个,1个或多个
查阅命令帮助信息
command --help
说明:显示command命令的帮助信息man command
说明:man是manual的缩写,是Linux提供的一个手册,包含了绝大部分的命令、函数的详细使用说明。使用man时的操作键:操作键 功能 Enter键 一次滚动手册页的一行 空格键 显示手册页的下一屏 f 前滚一屏 b 回滚一屏 q 退出 /word 搜索word字符串
常用命令
显示文件和目录
-
显示当前路径:
pwd -
以树状图列出目录的内容:
tree [dirName], 可指定目录,不指定显示当前目录下的所有内容。 -
查看文件信息:
ls
ls(list缩写),功能为列出目录的内容。Linux文件或者目录名称最长可以有265个字符,“.” 表当前目录,“…”代表上一级目录,以“.”开头的文件未隐藏文件。
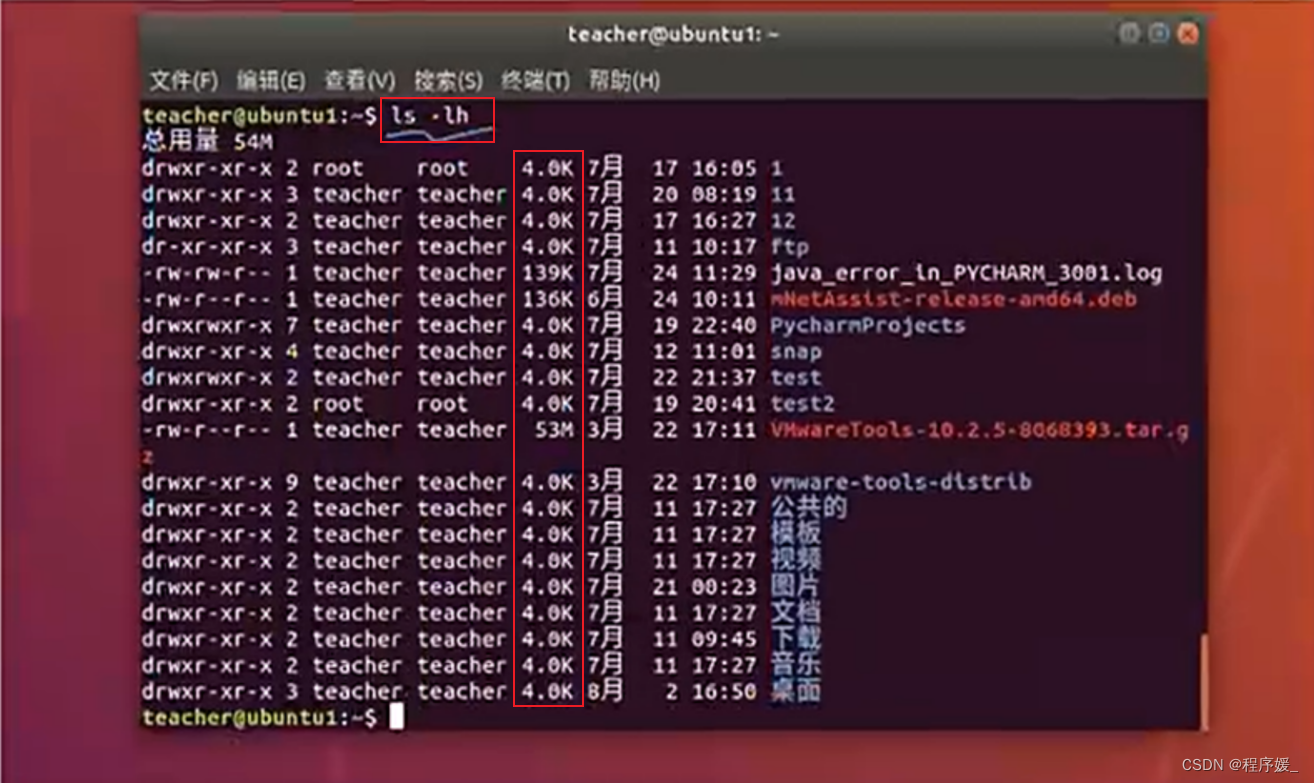
ls常用参数:选项 含义 -a 显示指定目录下所有子目录与文件,包括隐藏文件。 -l 以列表方式显示文件的详细信息 -h 配合-l以人性化的方式显示文件大小(无此选项文件大小单位为字节) 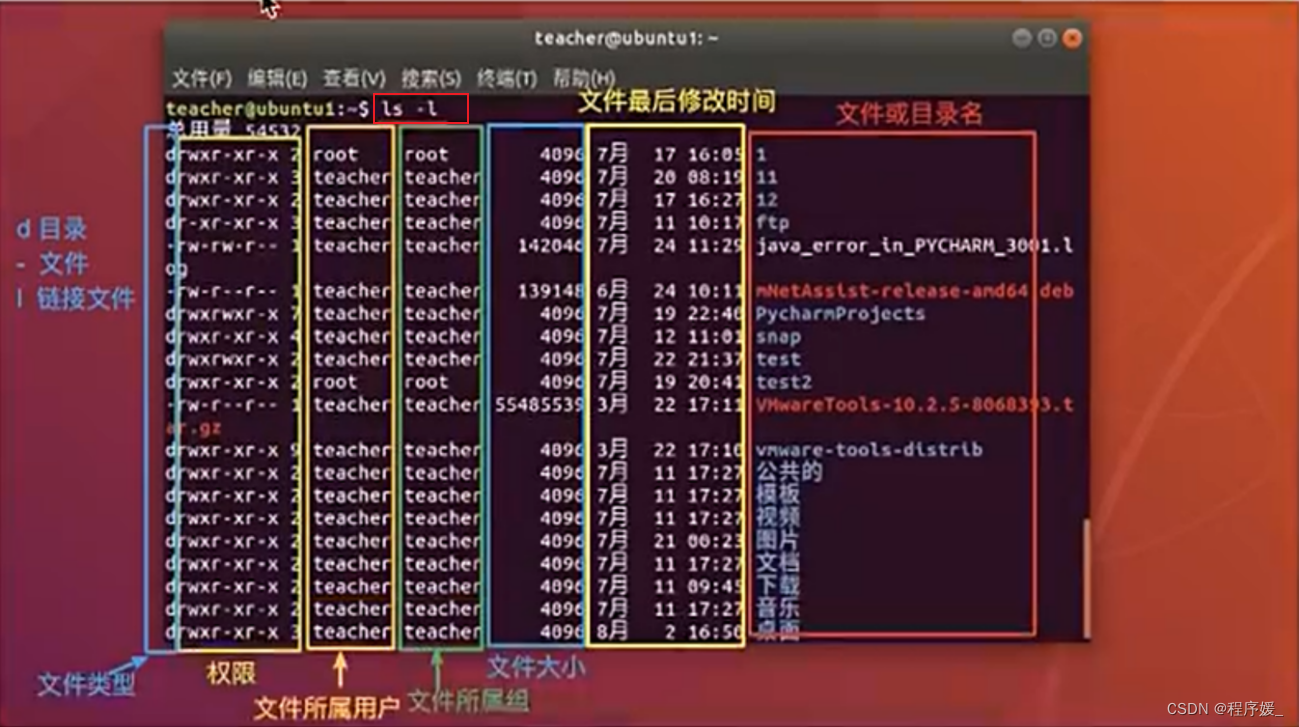
切换工作目录
cd后面可以跟绝对路径,也可以跟相对路径;cd后如果省略目录,则默认切换到当前用户的主(家)目录。
注:Linux所有的目录和文件名大小写敏感。
| 命令 | 含义 |
|---|---|
| cd | 切换到当前用户的主目录(/home/用户目录),用户登陆时,默认的目录就是用户的主目录。 |
| cd ~ | 切换到当前用户的主目录(/home/用户目录) |
| cd . | 切换到当前目录 |
| cd …(2个点) | 切换到上级目录 |
| cd - | 可进入上次所在的目录(注意不是上级目录) |
创建文件和文件夹
-
创建目录:
mkdir
通过mkdir可以创建一个新的目录。
注意:新建目录的名称不能与当前目录中已有的目录或文件同名,并且目录创建者必须对当前目录具有写权限。选项 含义 -p 递归创建目录 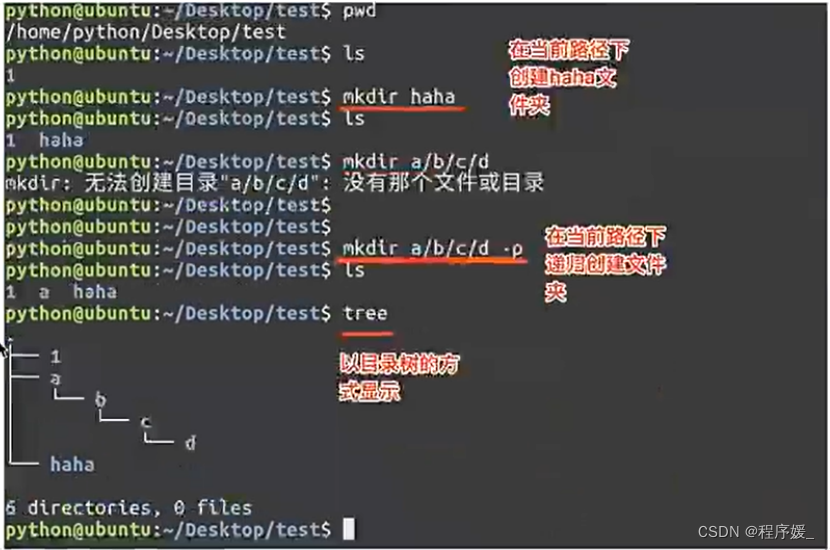
-
创建文件:
touch
用户可以通过touch来创建一个空文件,如下:touch hello.txt # 创建一个hello.txt文件 touch a.txt b.txt c.txt # 创建3个文件,分别为:a.txt, b.txt, c.txt注意:Linux系统中没有严格的后缀(格式),所以创建文件时可以命名为任意的文件名。
-
打开文件:
gedit
通过gedit可以打开文件并进行编辑,如下:gedit hello.txt # 打开并编辑单个hello.txt文件 gedit a.txt b.txt c.txt # 同时打开a.txt, b.txt, c.txt多个文件并编辑注意:打开文件后,终端进入等待状态。
删除文件和文件夹
-
删除文件:
rm
可通过rm刚除文件或目录。使用rm命令要小心,因为文件删除后不能恢复。为了防止文件误删,可以在rm后使用-i参数以逐个确认要删除的文件。
常用参数及含义如下表所示:选项 含义 -i 以交互模式删除(提示确认删除与否) -f 强制删除,忽略不存在的文件,无需提示 -r 递归地删除目录下的内容,删除文件夹(目录)时必须加此参数 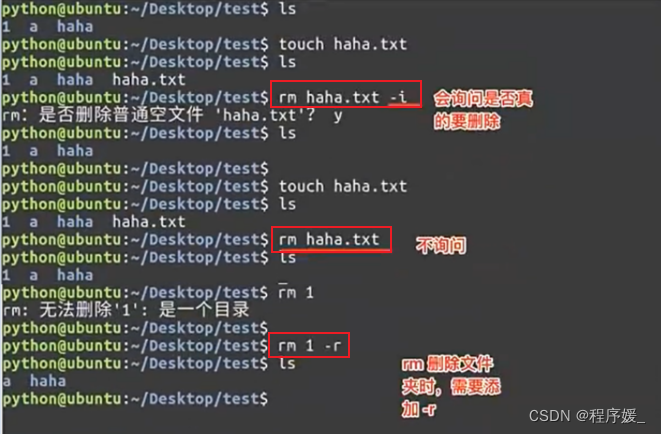
拷贝、移动文件和文件夹
-
拷贝:
cp 源路径 目标路径
cp命令的功能是将给出的文件或目录复制到另一个文件或目录中,相当于DOS下的copy命令。
常用选项说明:选项 含义 -a 该选项通常在复制目录时使用,它保留链接、文件属性,并递归地复制目录,简单而言,保持文件原有属性。 -f 已经存在的目标文件而不提示 -i 交互式复制,在覆盖目标文件之前将给出提示要求用户确认 -r 若给出的源文件是目录文件,则cp将递归复制该目录下的所有子目录和文件,目标文件必须为一个目录名。拷贝文件夹(目录)时必须加此参数 -v 显示拷贝进度 -
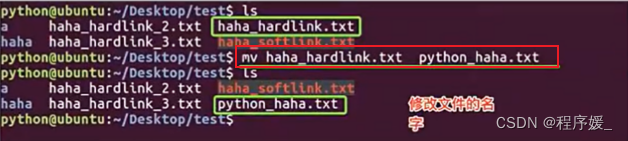
移动、重命名:
mv 源路径(原文件名) 目标路径(新文件名)
注意:移动文件夹不需要加-r选项!
常用选项说明:选项 含义 -f 禁止交互式操作,如有覆盖不会提示 -i 确认交互式操作,如有覆盖会提示 -v 显示移动进度 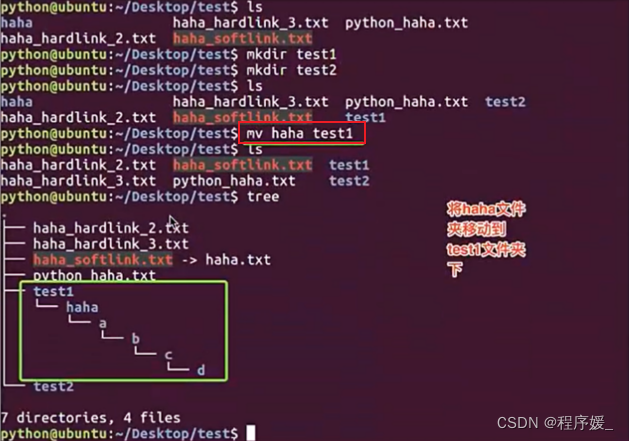
注意: 在一个目录中进行移动才能进行重命名!
其他
-
清屏:
clear
作用:清除终端上的显示,快捷键【Ctrl+L】 -
自动补全:
tab
在敲出文件/目录/命令的前几个字母之后,按下tab键:
如果输入的没有歧义,系统会自动补全;
如果还存在其他文件/目录/命令,再按下tab键,系统会提示可能存在的命令; -
查看命令位置:
which 命令
which命令用于查找并显示给定命令的绝对路径。

-
小技巧:
- 按 上/下光标键可以在曾经使用过的命令之间来回切换;
- 如果想要退出选择,并且不想执行当前选中的命令,可以按 【Ctrl+C】(示例:先cd到家目录,然后输入tree显示所有目录文件,按下Ctrl+C可中止)
- 【Ctrl+ShIft+=】 放大终端窗口的字体显示;
- 【Ctrl+ -】 缩小终端窗口的字体显示;
日期指令
-
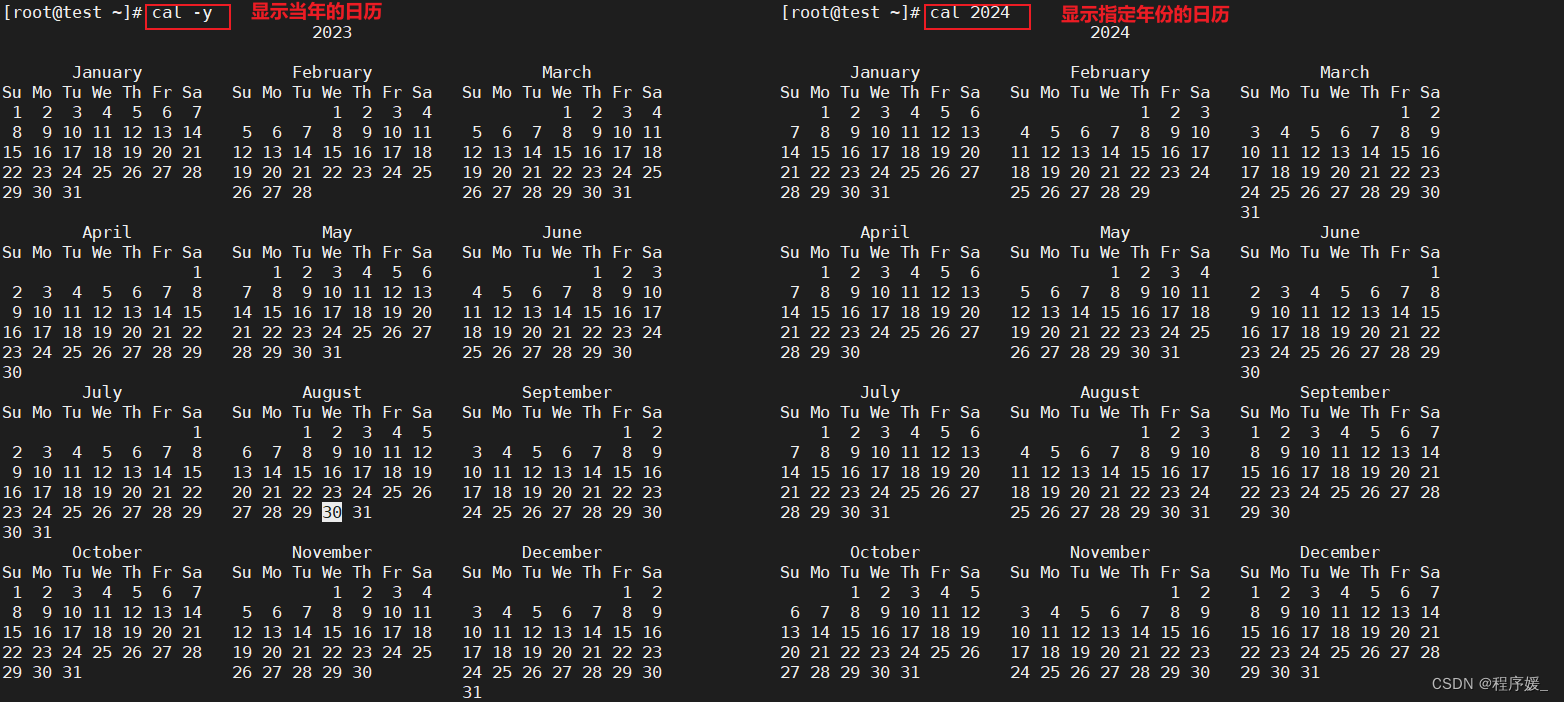
日历:
cal
cal命令可以用来显示日历。常用选项说明:选项 含义 -3 显示系统前一个月,当前月,下一个月的月历 -j 显示在当年中的第几天
(一年日期按天算,从1月1号算起,默认显示当前月在一年中的天数)-y 显示当前年份的日历 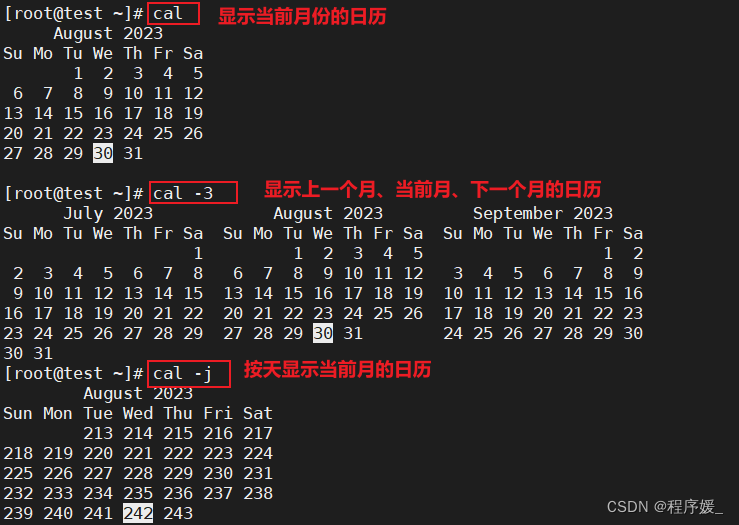
-
日期显示:
date “+%Y年%m月%d日 %H时%M分%S秒”
date命令根据给定格式显示日期或设置系统日期时间。常用选项说明:选项 含义 %Y 四位年份,%y两位年 %m 月份(1-12) %d 按月计的日期(1-31) %H 小时(0-23) %M 分钟(0-59) %S 秒数(0-59) %F 完整日期格式,等价于%Y-%m-%d %T 完整时间格式,等价于%H:%M:%S 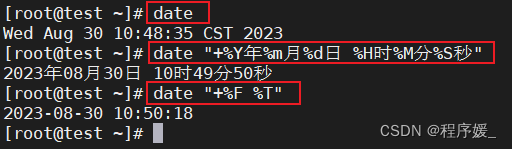
历史指令
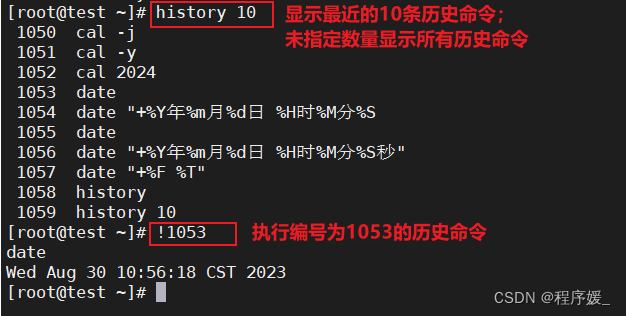
- 查看历史指令:
history
history命令用于显示指定数目的指令命令,读取历史命令文件中的目录到历史命令缓冲区和将历史命令缓冲区中的目录写入命令文件(存储在HOME目录中的,bash_history文件中)。 - 执行历史命令:
!历史命令编号
文件查看
-
查看或合并文件内容:
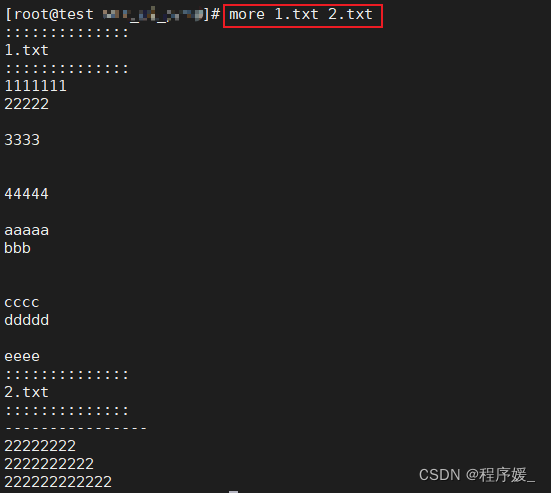
cat 文件名cat 文件名1 文件名2
cat命令用于查看、连接文件并打印到标准输出设备上。特点:一次性查看。
常用选项说明:选项 含义 -n 由1开始对所有输出的行数编号 -b -n相似,只不过对于空白行不编号 -s 遇到连续两行以上空白行,换为一行显示 通过配合重定向可合并多文件内容到一个文件中。
示例:
准备文件如下:===1.txt=== 1111111 22222333344444aaaaa bbbcccc dddddeeee===2.txt=== ---------------- 22222222 2222222222 222222222222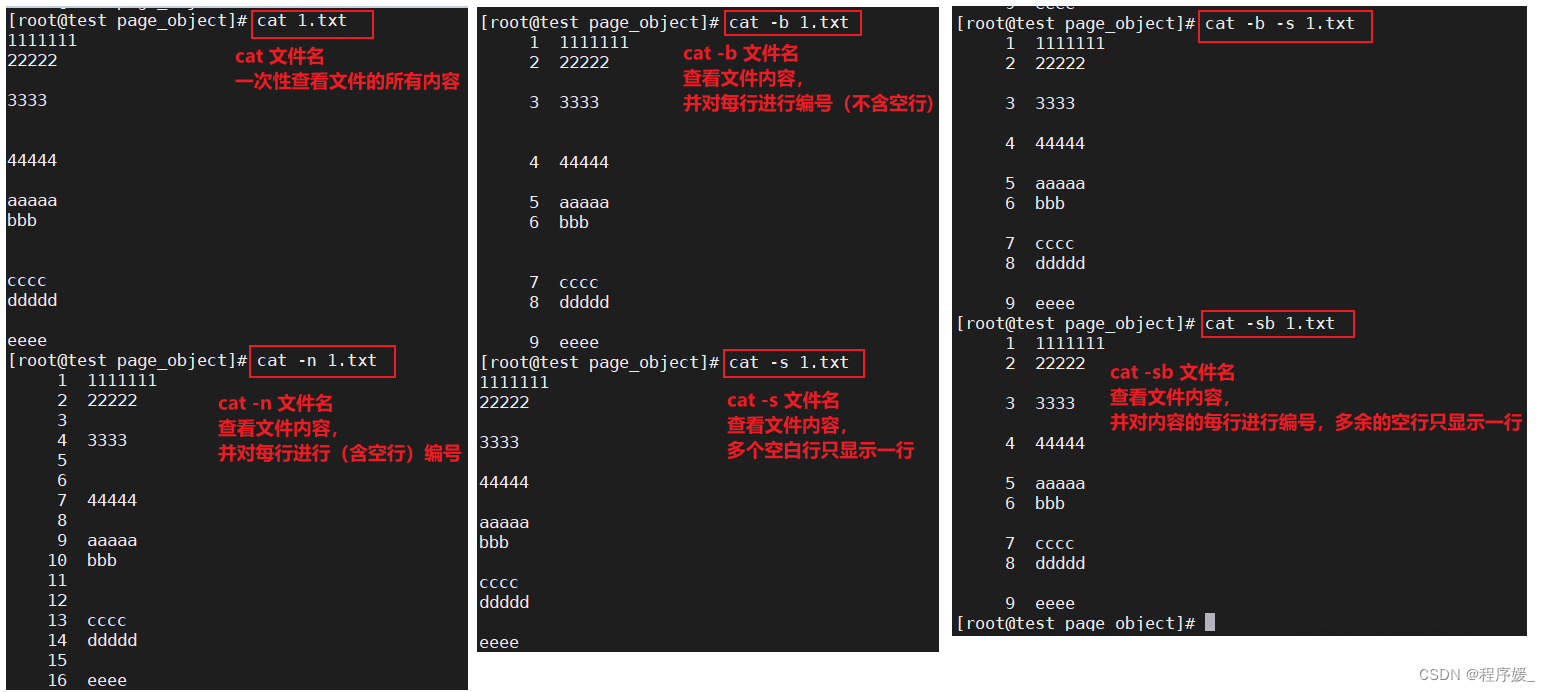

-
分屏查看文件内容:
more
有时信息过长无法在一屏上显示时,会出现快速滚屏,使得用户无法看清文件的内容,此时可以使more命令,每次只显示一页,按下空格键可以显示下一页,按下q键退出显示,按下键h可以获取帮助。
常用选项说明:选项 含义 +num 例如+5,从第5行开始查看文件内容 -p 先清屏再显示文件内容 -s 当两个以上连续空行,换成一行的空白行 常用选项说明:
选项 含义 Enter 向下n行,需要定义,默认为1行 Ctrl+F 向下滚动一屏,F(front,前进) Ctrl+B 返回上一屏,B(back,后退) 空格键 向下滚动一屏 q 退出more 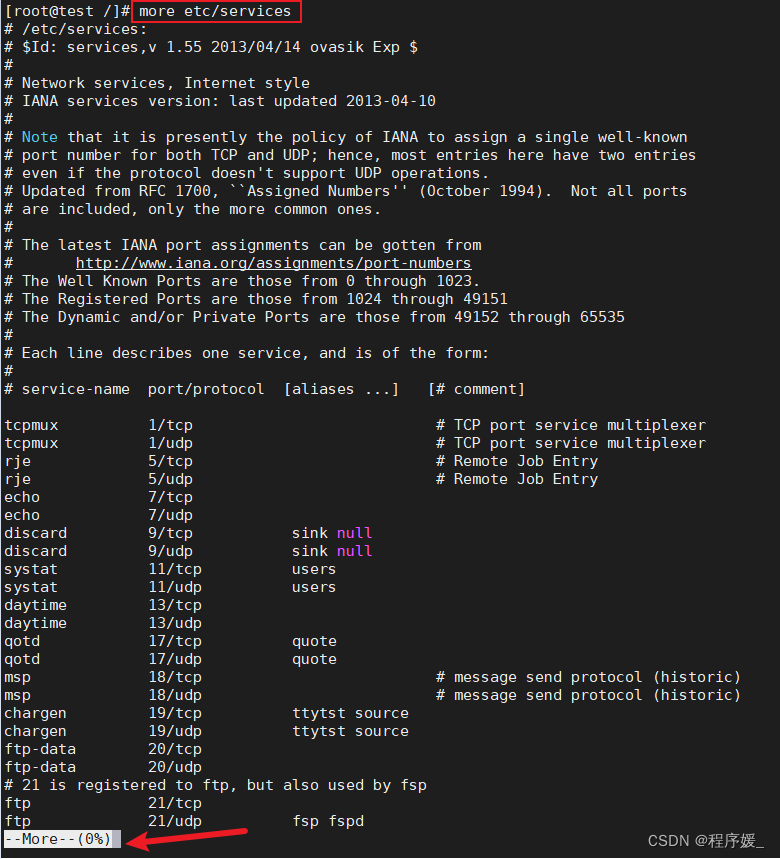
数据流重定向、管道
-
数据流及输出重定向:
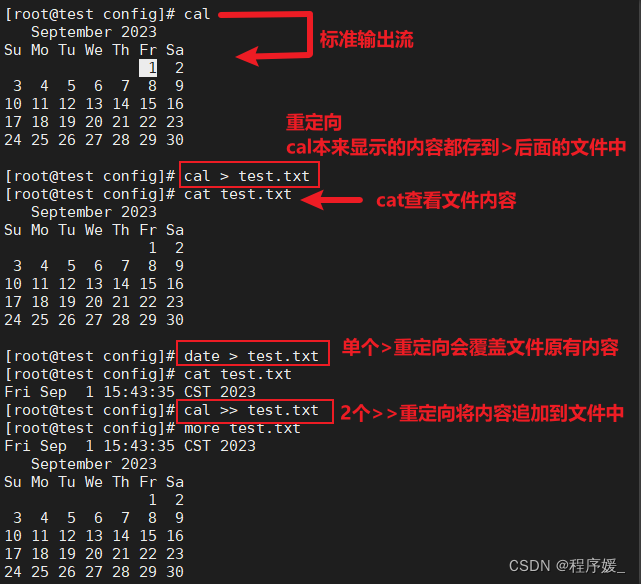
>>>
>输出重定向会覆盖原来的内容,>>输出重定向则会追加到文件的尾部。输入流:从键盘或者文件中读取内容到内存中;
输出流:从计算机内存中把数据写入到文件或者显示到显示器上;
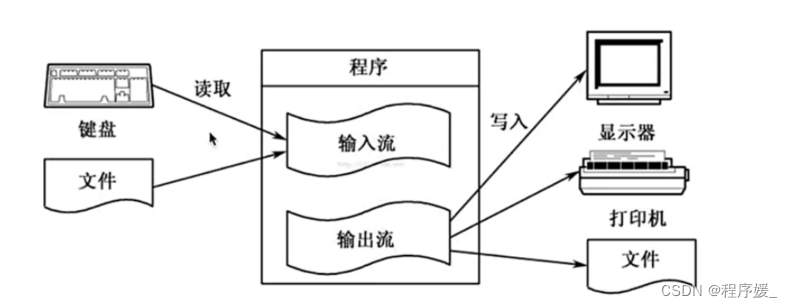
重定向:改变数据流的默认输出方向。
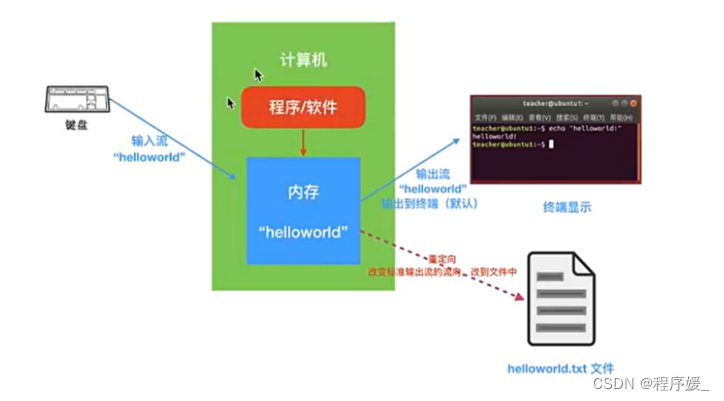
Linux中有三种流:标准输出流、标准错误输出流、标准输入流
- 标准输出流:stdout(标准输出,对应于终端的输出)
正常的数据–>终端(屏幕上),例如:cal指令输出当前月份日历,输出到哪?–>屏幕。 - 标准错误输出流:stderr (标准错误输出,对应于终端的输出)
错误信息–>终端(屏幕上),例如:cal指令输错成cale,错误会显示在屏幕上。 - 标准输入流:stdin(标准输入,对应于你在终端的输入)
向系统中输入数据,默认就是键盘输入的数据。
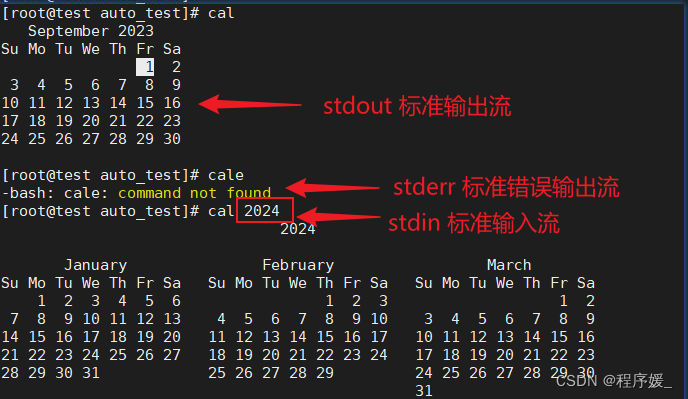
文件描述符 设备文件 说明 0 /dev/stdin 标准输入 1 /dev/stdout 标准输入 2 /dev/stderr 标准错误 我们可以通过重定向的技术,把输出、输入的信息重定向到其它的地方去。比如,我们可以把系统中的错误信息输出到一个文件中去。
如:cal > test.txt(test.txt如果不存在,则创建,存在则覆盖其内容)
- 标准输出流:stdout(标准输出,对应于终端的输出)
-
管道:
指令1 | 指令2
注意: 指令1必须要有输出。
管道我们可以理解现实生活中的管子,管子的一头塞东西进去,另一头取出来,这里“|“的左右分为两端,左端塞东西(写),右端取东西(读)。即:一个命令的输出作为另外一个命令的输入去使用。
管道命令操作符是:“|”,它只能处理经由前面一个指令传出的正确输出信息,对错误信息信息没有直接处理能力。然后,传递给下一个命令,作为标准的输入。
如:ls -lh | more
建立链接
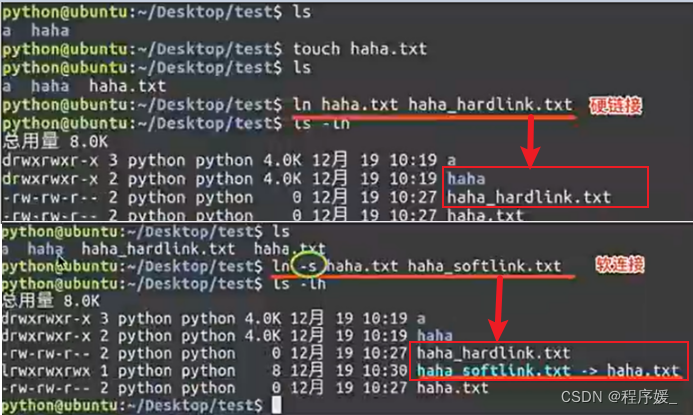
Linux链接文件类似于Windows下的快捷方式。链接文件分为:
软链接: 软链接不占用磁盘空间,源文件删除则软链接失效。 ln -s 源文件 链接文件
硬链接(hard link,也称链接): 就是文件的一个或多个文件名。 ln 源文件 链接文件
注意:
- 如果软链接文件和源文件不在同一个目录,源文件要使用绝对路径,不能使用相对路径.
- 如果没有-s选项代表建立一个硬链接文件,两个文件占用相同大小的硬盘空间,即使删除了源文件,链接文件还是存在,所以-s选项是更常见的形式。
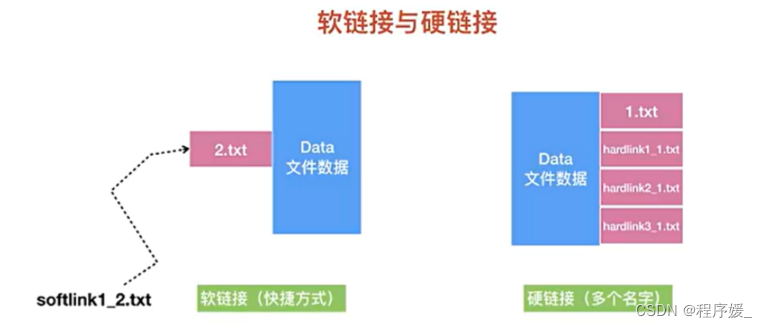
- 修改源文件对软硬链接文件的影响
- 修改源文件,对软硬链接均有影响;
- 修改软硬链接,对源文件均有影响;
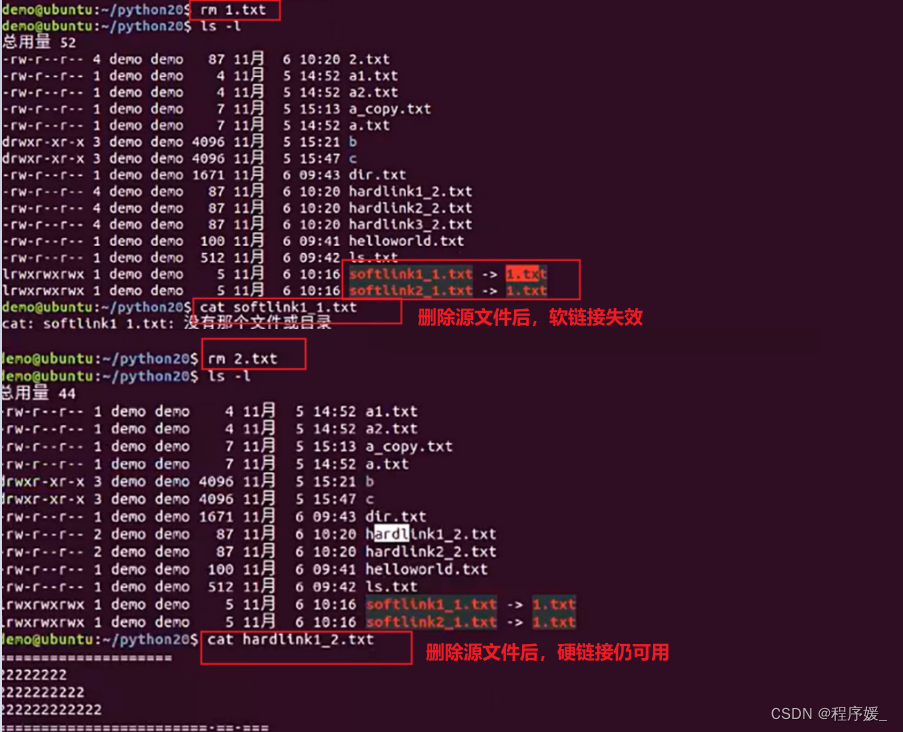
- 删除源文件对软硬链接文件的影响
- 删除软硬链接,对源文件均没有影响;
- 删除源文件:
软链接不可以用;
如果文件有的多个硬链接,则无影响;
- 软硬链接使用区别
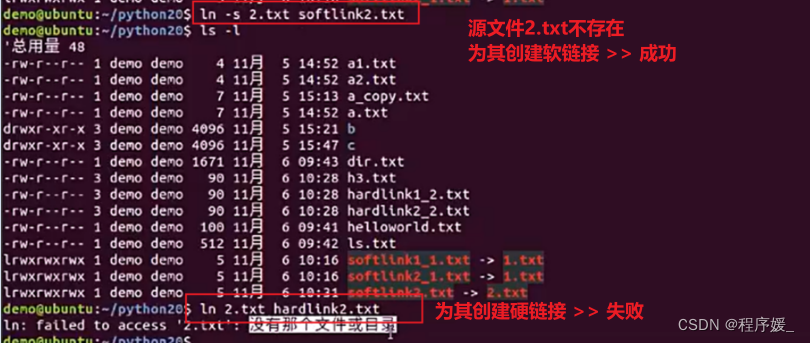
- 软链接可以跨文件系统,硬链接不可以;
- 软链接可以对一个不存在的文件名(filename)进行链接(当然此时如果你via这个软链接文件,linux会自动新建一个文件名为filename的文件),硬链接不可以(其源文件必须存在);
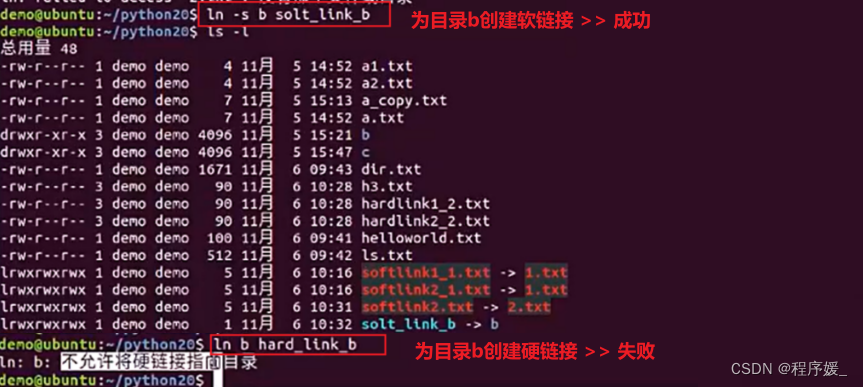
- 软链接可以对目录进行连接,硬链接不可以;
文件搜索
-
文本搜索:
grep
Linux系统中grep命令是一种强大的文本搜索工具,grep允许对文本文件进行模式查找,如果找到匹配模式,grep打印包含模式的所有行。grep一般格式为:grep [-选项] ‘搜索内容串’ 文件名。在在grep命令中输入字符串参数时,最好引号或双引号括起来。
常用选项说明:选项 含义 -v 显示不包含匹配文本的所有行(相当于求反) -n 显示匹配行及行号 -i 忽略大小写 grep搜索内容串可以是正则表达式,gerp常用正则表达式:
参数 含义 ^a 行首;搜寻以a开头的行: grep -n '^a' 1.txtke$ 行尾;搜寻以ke结束的行:`grep -n ‘ke$’ 1.txt `[Ss]igna[Ll] 匹配[ ]里中一系列字符中的一个;搜寻匹配单词signal、signaL、Signal、SignaL的行: grep -n '[Ss]ignal[Ll]' 1.txt. 点匹配一个非换行符的字符;匹配e和e之间有任意一个字符,可以匹配eee, eae, eve,但是不匹配ee, eaae: grep -n 'e.e' 1.txt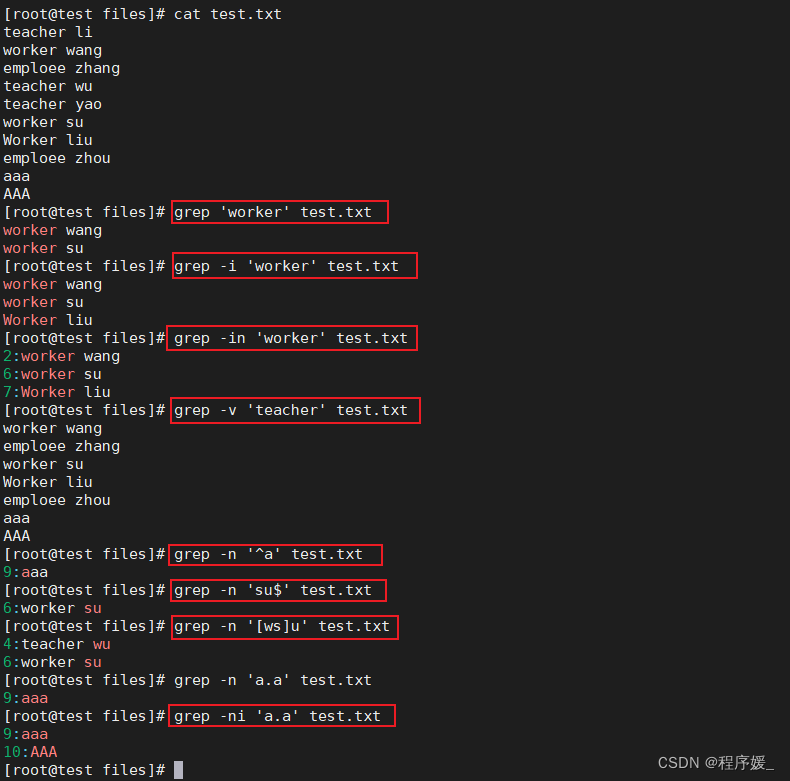
-
查找文件:
find
find命令功能非常强大,通常用来在特定的目录下搜索符合条件的文件,也可以用来搜索特定用户属主的文件。
常用用法:命令 含义 find ./ -name test.sh查找当前目录下所有名为test.sh的文件 find ./ -name '*.sh'查找当前目录下所有后缀为.sh的文件 find ./ -name '[A-Z]*'查找当前目录下所有以大写字母开头的文件
* 表示任意字符
?表示任意一个字符
[列举字符] 表示列举出的任意一个字符find /tmp -size 2M查找在/tmp目录下等于2M的文件 find /tmp -size +2M查找在/tmp目录下大于2M的文件 find /tmp -size -2M查找在/tmp目录下小于2M的文件 find ./ -size +4k -size -5M查找当前目录下大于4k,小于5M的文件 find ./ -perm 777查找当前目录下权限为777的文件或目录
归档和压缩
-
归档和压缩的概念:
归档: 归档就是将一些文件放在一起变成一个包,便于保存和传输,图片和视频数据因为不象文本一样,因此多个文件在压缩的时候没有明显效果,因此只能做归档,进行保存。
压缩: 压缩也是一种打包,压缩的原理是将文件中相同的信息用一个字符代替,致使文件体积变小达到压缩的目的,压缩对于文本类或数据类文件有较明显的作用。

-
归档管理:
tar
计算机中的数据经常需要备份,tar是Unix/Linux中最常用的备份工具,此命令可以把一系列文件归档到一个大文件中,也可以把档案文件解开以恢复数据。
tar使用格式:
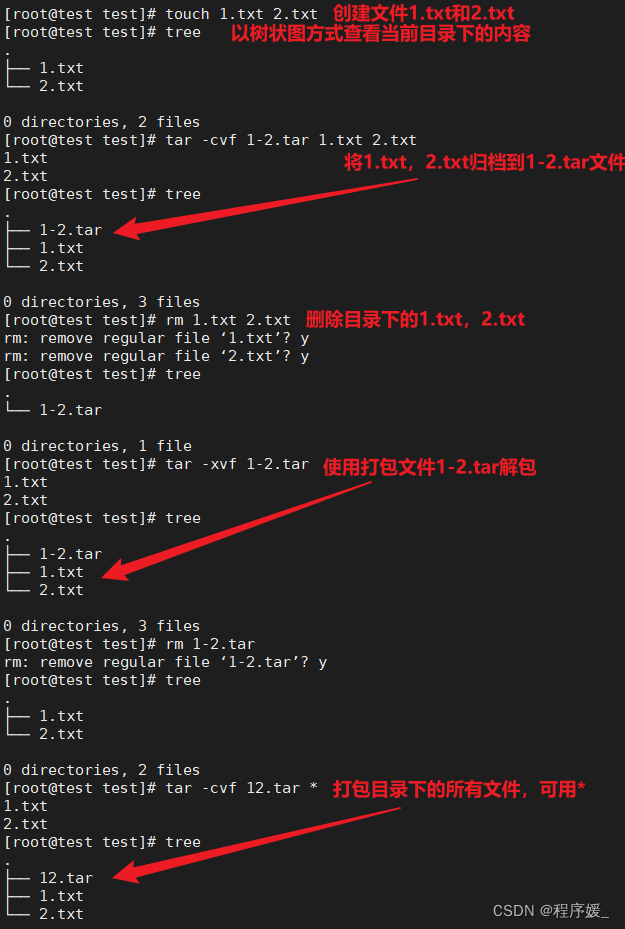
多文件归档:tar [参数] 打包文件名 文件1 文件2
目录归档:tar [参数] 打包文件名 目录
tar命令很特殊,其参数前面可以使用“-”,也可以不使用。
常用参数:命令 含义 -c 生成档案文件,创建打包文件 -v 列出归档解档的详细过程,显示进度 -f 指定档案文件名称,f后面一定是.tar文件,所以必须放 选项最后 \color{red}{选项最后} 选项最后 -x 解开档案文件 注意:除了f需要放在参数的最后,其它参数的顺序任意。
打包:tar -cvf 打包文件名.tar 要打包的文件,当要打包目录下所有文件的时候,可以使用*。
解包:tar -xvf 打包文件名.tar
-
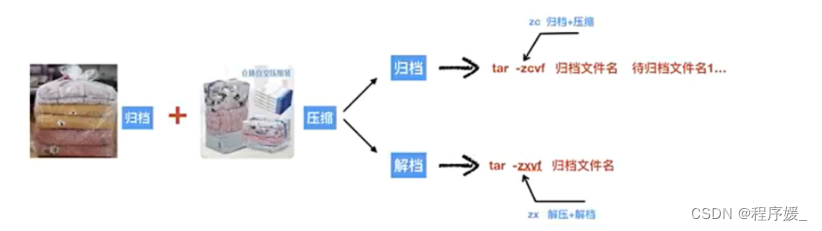
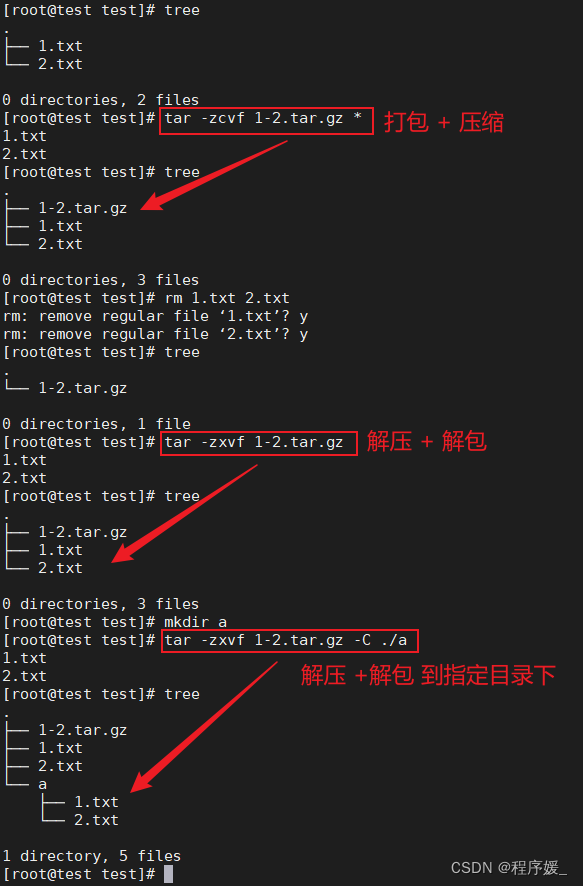
打包 + 压缩 和 解压 +解包
打包 + 压缩:tar -zcvf 压缩包文件名.tar.gz 待压缩文件或目录
解压 + 解包:tar -zxvf 压缩包文件名.tar.gz
解压+解包到指定目录中:tar -zxvf 压缩包文件名.tar.gz -C 指定目录
-
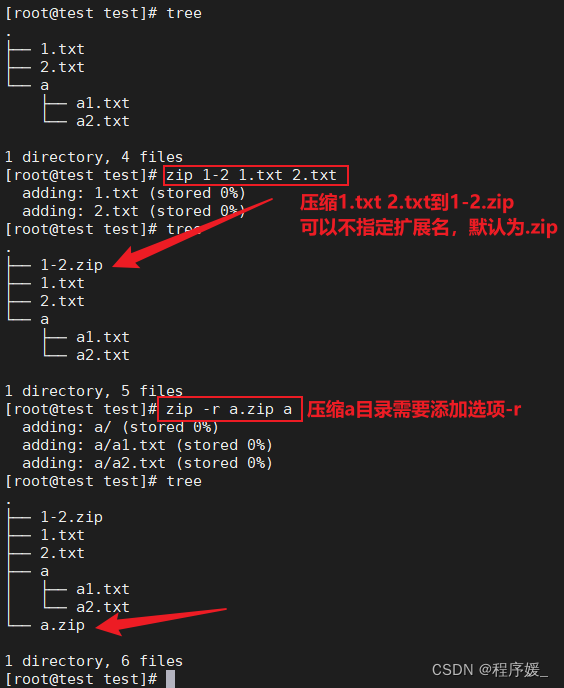
文件压缩解压:
zip、unzip
通过zip压缩文件的目标文件不需要指定扩展名,默认扩展名为zip。压缩目录需要添加选项-r。
压缩文件:zip -r 压缩目录 源目录、zip 压缩文件 源文件
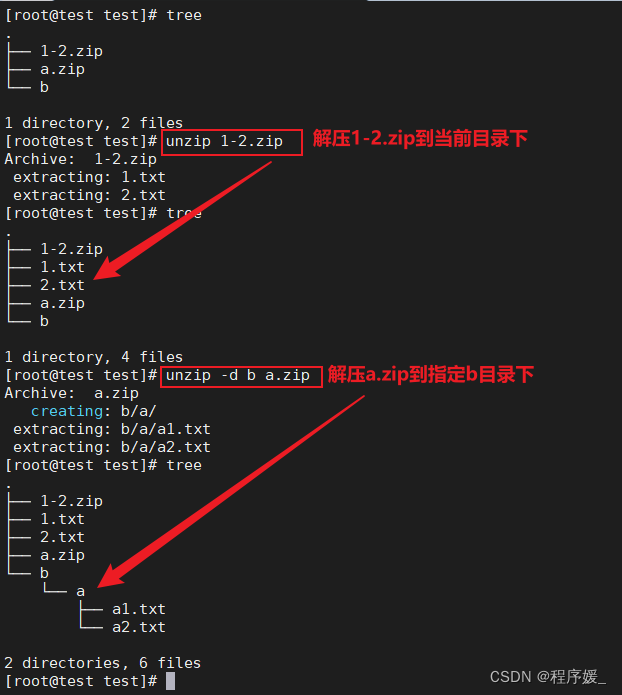
解压文件:unzip 压缩文件(解压到当前目录下);unzip -d 指定解压目录 压缩文件
-
几种压缩方式对比
tar.gz的打包和压缩方式相比zip或者bz2产生的压缩包文件更小,如下图:

文件权限
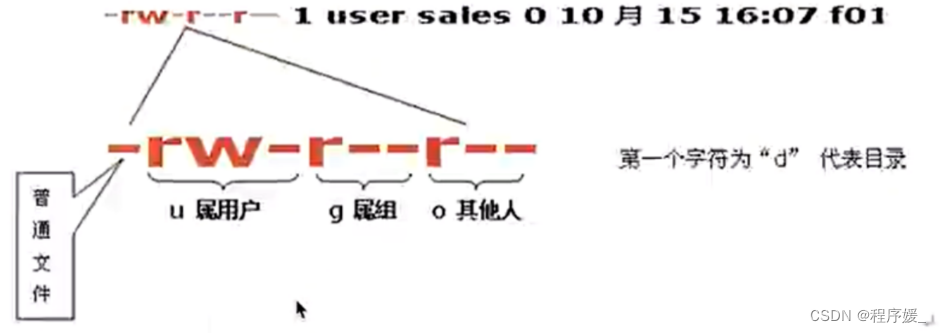
Linux中的权限系统和上面图中的内容类似:Linux中的每个文件、目录都可以分别对拥有者(u)、同组用户(g)、其他用户(o)设置权限。

上图中第一列中从第2个字符开始的9个字符就代表这个文件的权限,每三个字母一组,每一组都分为
r(可读)、w(可写)、x(可执行;文件:文件可以直接运行,绿色;目录:表示这个目录可以打开)、-(没有权限)
-
修改文件权限:
chmod-
字母法:
chmod 用户(u/g/o/a) 权限设置(+/-/=) 具体权限(r/w/x) 文件名字母&符号 含义 u user表示该文件的所有者 g group表示与该文件的所有者属于同一组者,即用户组 o other表示其他以外的人 a all表示这三者皆是 + 增加权限 - 撤销权限 = 设定权限 r read表示可读取,对于一个目录,如果没有r权限,那么就意味着不能通过Is查看这个目录的内容。权限数字:4 w write表示可写入,对于一个目录,如果没有w权限,那么就意味着不能在目录下创建新的文件,权限数字:2 x execute表示可执行,对于一个目录,如果没有x权限,那么就意味着不能通过cd进入这个目录,权限数字:1 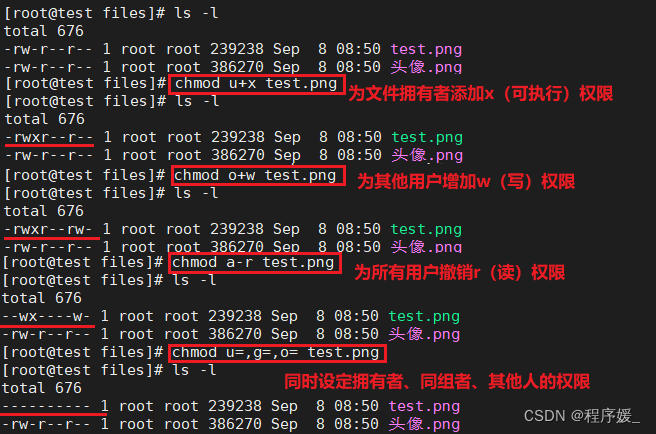
-
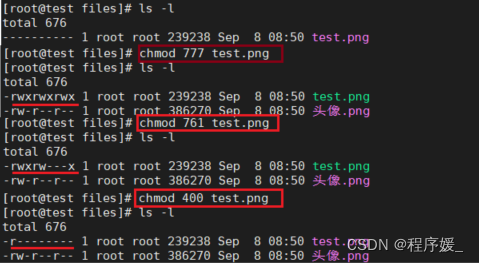
数字法:
chmod 权限数字 文件路径字母 说明 r 读取权限,数字代号为" 4 \color{red}{4} 4” w 写入权限,数字代号为“ 2 \color{red}{2} 2” x 执行权限,数字代号为“ 1 \color{red}{1} 1” - 不具任何权限,数字代号为“ 0 \color{red}{0} 0” 如执行:
chmod u=rwx,g=rx,o=r filename就等同于:chmod u=7,g-=5,o=4 filename
chmod 754 file表示:文件所有者:读、写、执行权限;同组用户:读、执行的权限;其它用户:读权限。
-
-
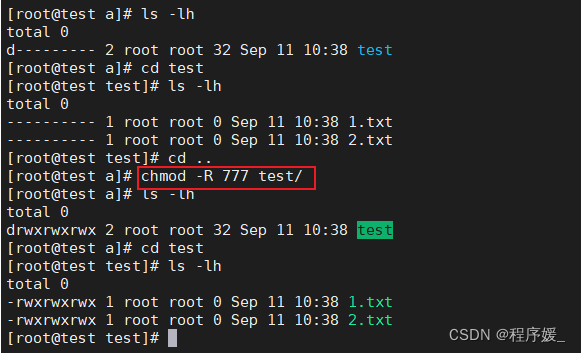
目录权限
注意:如果想递归所有目录加上相同权限,需要加上参数“-R”·如:chmod -R 777 test/递归test目录下所有文件加777权限。目录的可执行权限:一个目录具有可执行权限,表示可以切换到该目录。
用户管理
-
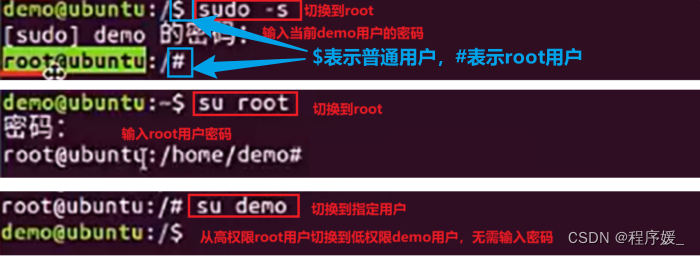
切换账号/用户(永久):
sudo -s:默认切换到root用户,需要输入当前用户的密码;
su root:切换到root用户,需要输入root用户密码;
su 用户名:切换到指定用户。注意:从高权限切换到低权限,不需要输入密码;反之需要。
sudo临时提升权限:sudo 命令
sudo命令用来以其他身份来执行命令,预设的身份为root。在/etc/sudoers中设置了可执行sudo指
令的用户。若其未经授权的用户企图使用sudo,则会发出警告的邮件给管理员。用户使用sudo时,必须先输入密码,之后有5分钟的有效期限,超过期限则必须重新输入密码。
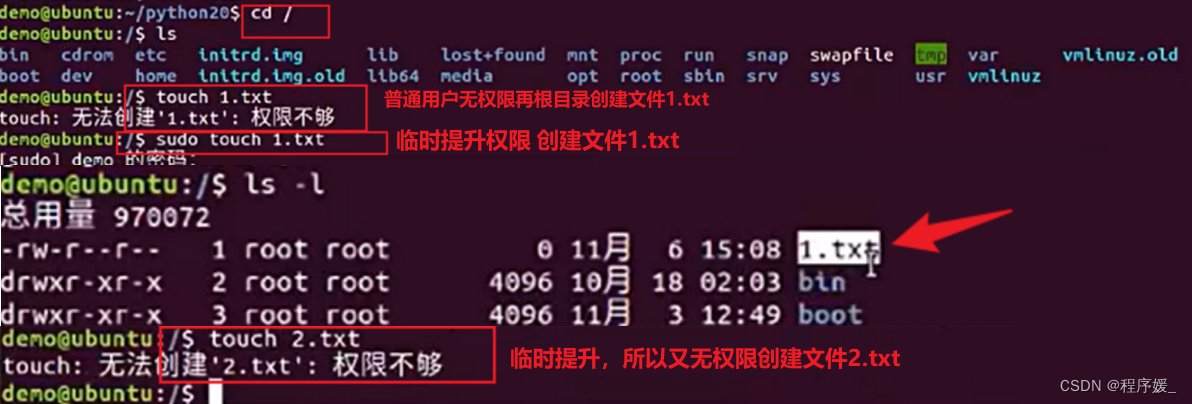
-
设置用户密码:
passwd 用户名:修改指定用户的密码
passwd:修改当前登录的用户密码
在Unix/Linux中,超级用户可以使用passwd命令为普通用户设置或修改用户密码。用户也可以直接使用该命令来修改自己的密码,而无需在命令后面使用用户名。
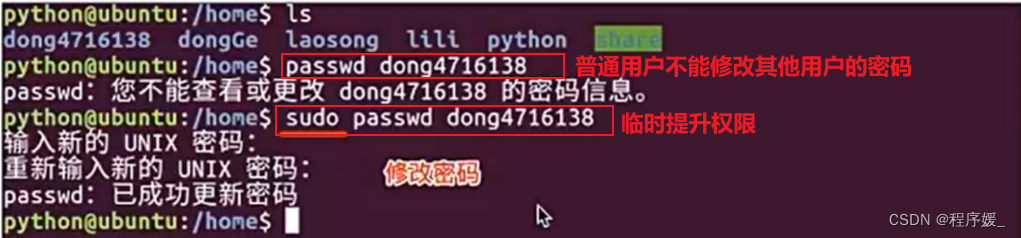
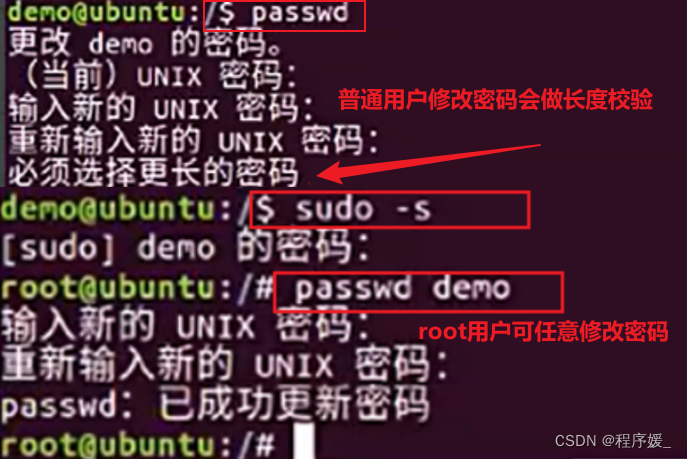
注意:
普通用户修改密码,系统默认对密码长度等信息进行验证,如果不合法提示修改失败(如修改密码为123提示密码太短,修改失败);
root超级管理员权限修改密码,密码长度可以任意设定,不进行验证(比如:修改密码为123,能够修改成功);
-
退出登录账号:
exit
如果没有用户在栈中,直接退出终端;
如果多次切换用户,退出到上次登录的用户;
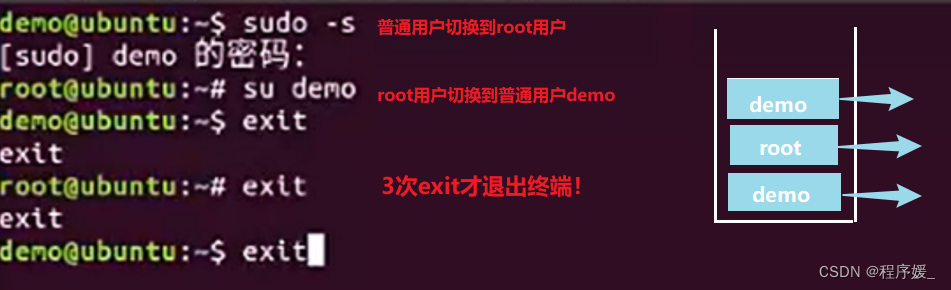
-
查看登录用户:
who
who命令用于查看当前所有登录系统的用户信息。
常用选项:选项 含义 -q或–count 只显示用户的登录账号和登录用户的数量(统计用户数) -u或–heading 显示列标题(显示最后一次操作距现在的时间) 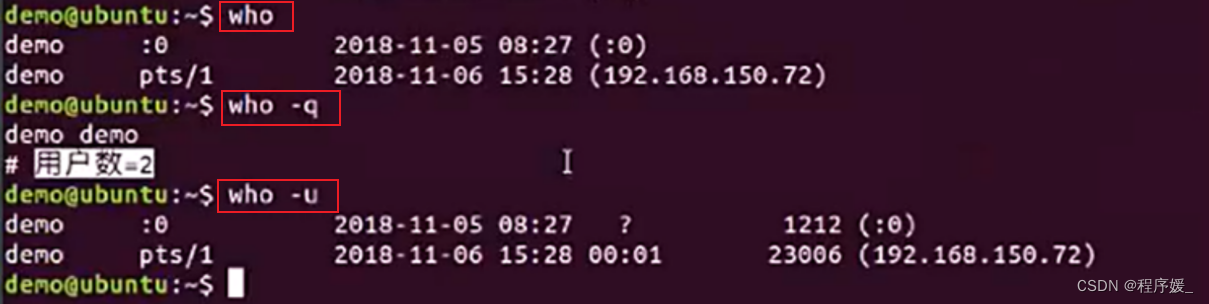
关机、重启
- 关机:
shutdown命令 含义 shutdown -h now 立即关机,其中now相当于时间为0的状态 shutdown -h 20:25 系统在今天的20:25会关机,可以取消关机 shutdown -h +10 系统再过十分钟后自动关机 shutdown -c 撤销关机 - 重启:
reboot命令 含义 reboot 重新启动操作系统 shutdown -r now 重新启动操作系统,shutdown会给别的用户提示
Ubuntu中软件安装与卸载
在ubuntu当中,安装应用程序常见的有三种方法,分别是make install, deb包方式 (类似windows.exe), apt-get,和安装源码包三种,下面针对每一种方法各举例来说明。
-
make install源代码安装包(也称:tarball)
优点:软件根据实际的机器硬件进行配置和编译,性能最好、最稳定。
缺点:需要使用源代码编译、安装,比较麻烦。
tarball就相当于我们自己做馒头一样,自己买面,合面,自己蒸,虽然比较麻烦,但是自己做的很香,还可以根据自己的口味调整。一般步骤如下:
1)./configure ##这个步骤是建立makefile这个文件。
2)makeclean ##消除下上次编泽过的目标文件之类的,不是必须要有,但保险起见还是做一下。
3)make ##会依据makefile当中默认工作(也就是第一个)进行编译行为,主要是进行gcc将源码编译成为可执行的目标文件,而这个可执行文件放置在目前所在的目录之下。
4)make install一般是最后的安装步骤,make会依据makefile关于install的选项,将上个步骤编译完
成的数据安装到默认的目录中。 -
dpkg安装deb包
优点:安装包直接运行安装,相对tarballi简单些。
缺点:存在包依赖的问题,安装时需要手动下载很多安装包。
包依赖:安装A包时,报错提示需要B包,下载安装B包时,报错提示需要C包····一直要把所有用的包都下载安装才可以。deb解决了这个问题。
Ubuntu软件包格式为deb,安装方法如下:sudo dpkg -i package.deb
这种方式类似于windows的软件安装方式,在ubuntul图形界面下,可以直接双击安装,也比较简单,但需要下载.deb格式的软件包。 -
apt-get方法
使用apt-get install来安装应用程序算是最常见的一种安装方法了。
优点:最简单方便的安装方式,只要一条指令,系统就可以自动下载并安装所有的包。
缺点:必须要有软件源(连网或者搭建软件源)
apt-get,就像外卖一样,一个电话,香喷喷的饼头和菜就送到家了,非常方便。
一般格式为:sudo apt-get install xxx
这种方式简单相暴、它能够帮我们联网自动下载安装包及其依赖包,然后安装。
apt-get方法安装/卸载软件
相关命令:
| 命令 | 说明 |
|---|---|
sudo apt-get update | 更新源 |
sudo apt-get insatll package | 安装包 |
sudo apt-get remove package | 删除包 |
-
寻找国内镜像源
所谓的镜像源,可以理解为提供下载软件的地方,比如Android手机上可以下载软件的91手机助手;iOS手机上可以下载软件的AppStore。
清华大学开源软件镜像站:https://mirrors.tuna.tsinghua.edu.cn
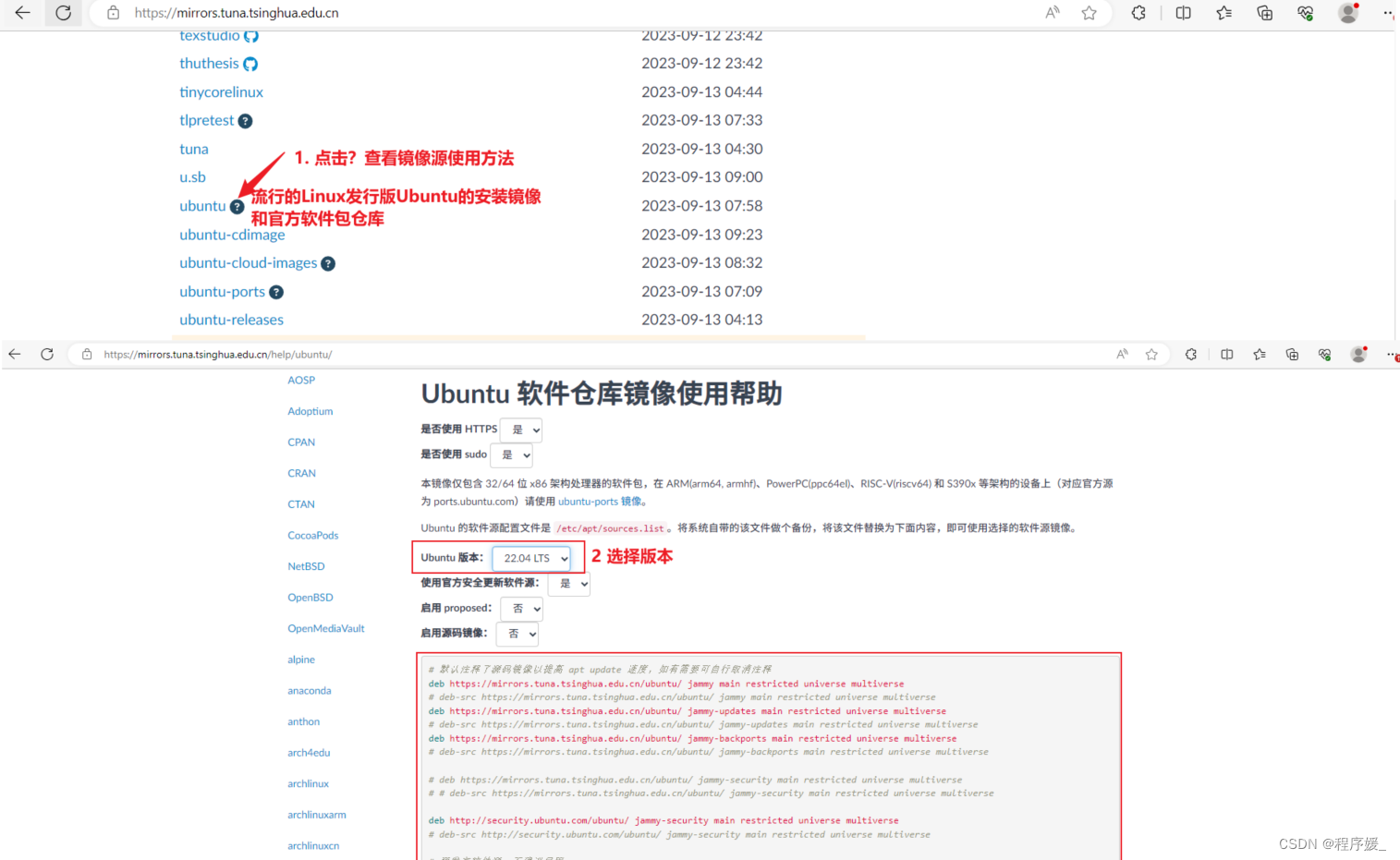
-
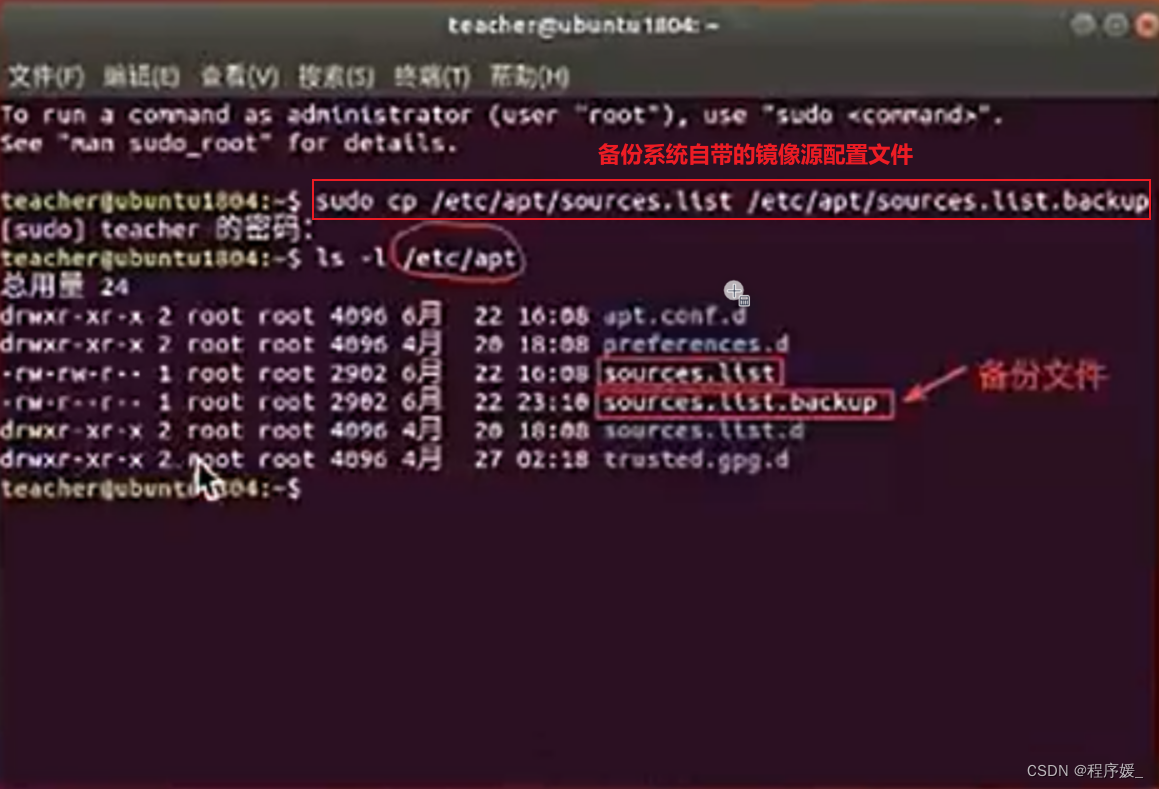
备份Ubuntu默认的源地址
sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup
-
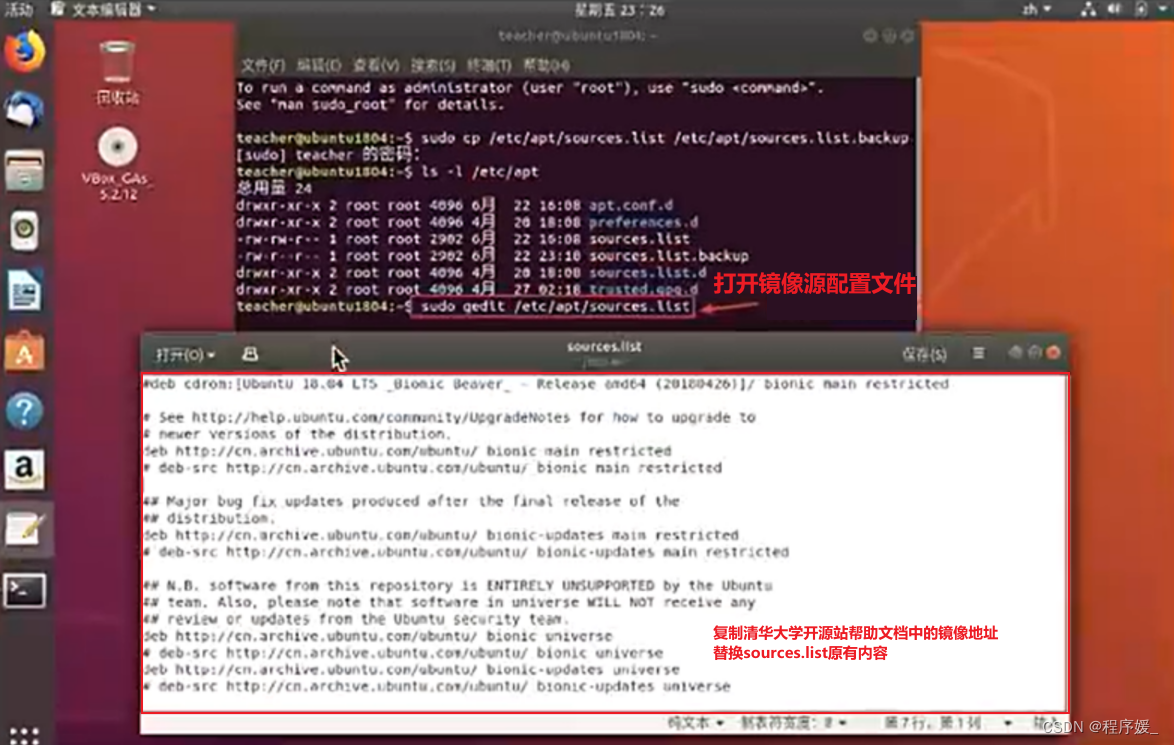
配置软件源
编辑源服务器列表文件:sudo gedit /etc/apt/sources.list
-
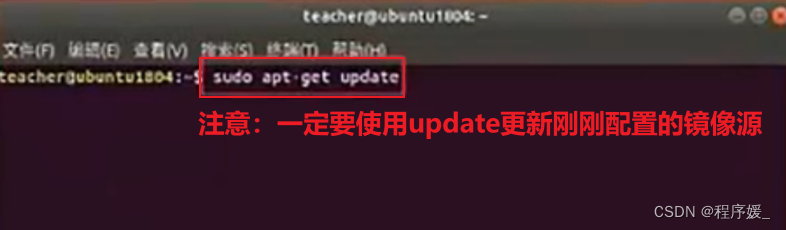
更新软件源
做完此步骤之后,就可以进行apt-get install下载了:sudo apt-get update
-
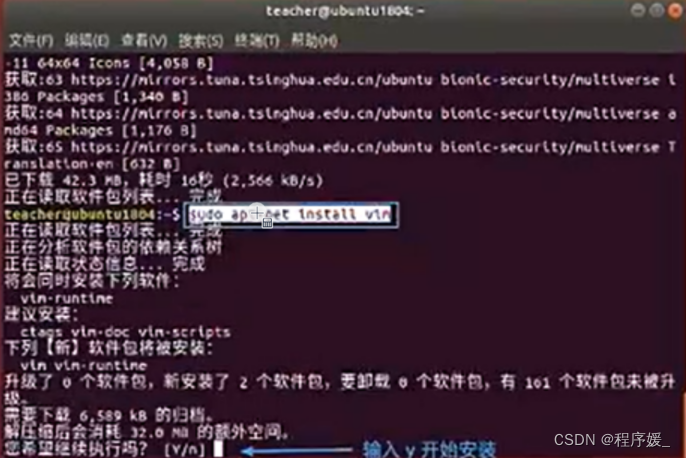
测试并安装vim编辑器
sudo apt-get install vim
ssh远程登录
- ssh介绍
SSH为Secure Shell的缩写,由IETF的网络工作小组(Network Working Group)所制定;SSH为建立在应用层和传输层基础上的安全协议。
SSH是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。常用于远程登录,以及用户之间进行资料拷贝。
利用SSH协议可以有效防止远程管理过程中的信息泄露问题。SSH最初是UNIX系统上的一个程序,后来又迅速扩展到其他操作平台。SSH在正确使用时可弥补网络中的漏洞。SSH客户端适用于多种平台。几乎所有UNIX平台一包括HP-UX、Linux、AIX、Solaris、Digital UNIX、Irix,以及其他平台,都可运行SSH。
使用SSH服务,需要安装相应的服务器和客户端。客户端和服务器的关系:如果,A机器想被B机器远程控制,那么,A机器需要安装SSH服务器,B机器需要安装SSH客户端。 - 安装ssh
服务器端安装ssh server:sudo apt-get install openssh-server
客户端远程登录:ssh 远程ssh服务器用户名@远程ssh服务器IP地址
使用ssh访问,如访问出现错误。可查看是否有该文件~/.ssh/known_ssh尝试删除该文件解决。 - 使用ssh链接服务器
SSH告知用户,这个主机不能识别,这时键入"yes",SSH就会将相关信息,写入"~/.ssh/know_hosts’"中,再次访问,就不会有这些信息了。然后输入完口令,就可以登录到主机了。
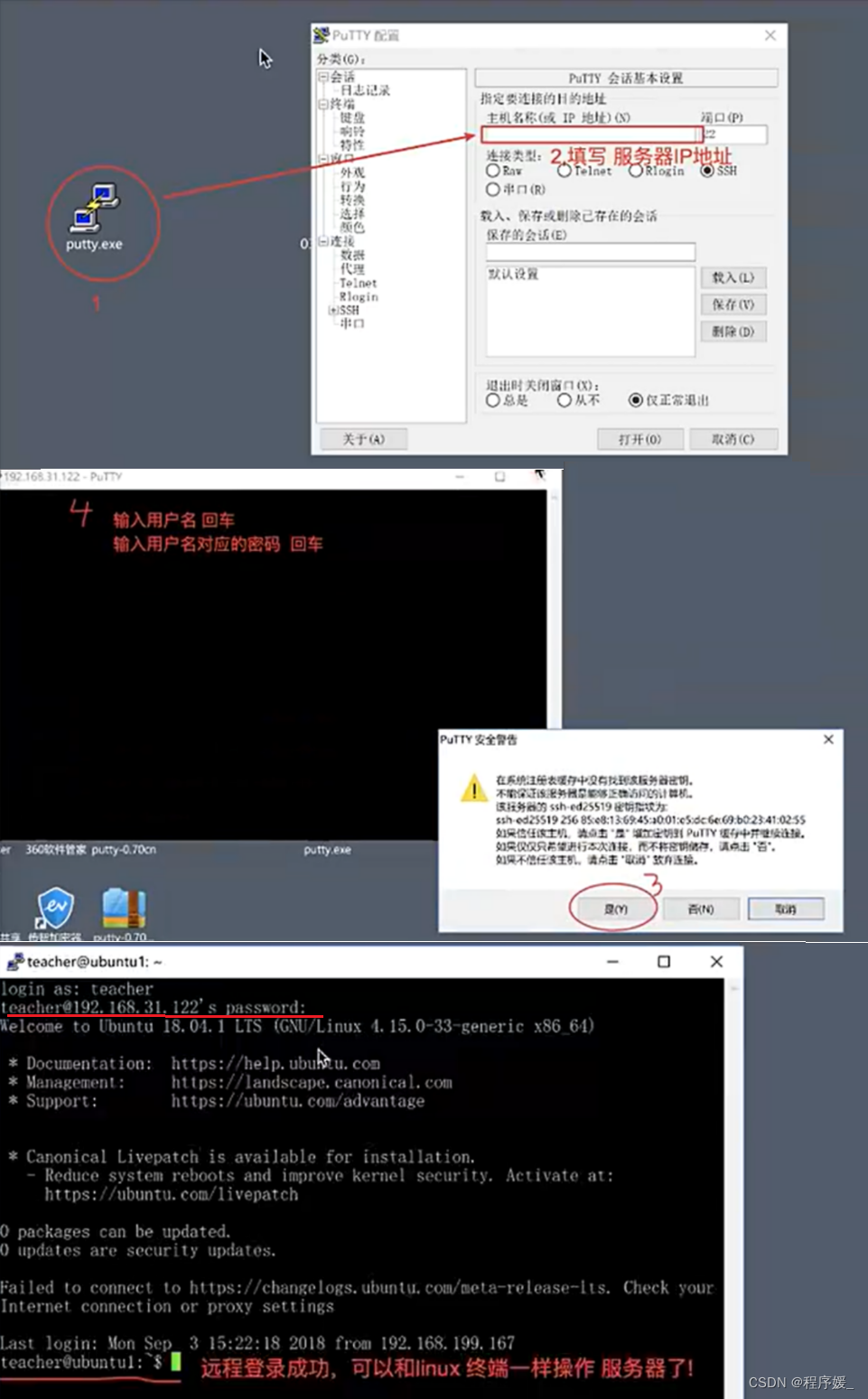
Mac OS/Window 10终端SSH远程连接步骤如下:
(1)输入ssh用户名@服务器ip地址:ssh teacher@192.168.31.178
(2)询问是否要继续连接,输入yes:Are you sure you want to continue connecting (yes/no) ? yes
(3)输入teacher用户的密码:teacher@192.168.31.178's password:,如果输入正确,会连接成功。
(4)exit退出ssh,关闭远程连接。
Window 7 SSH 工具——putty.exe:
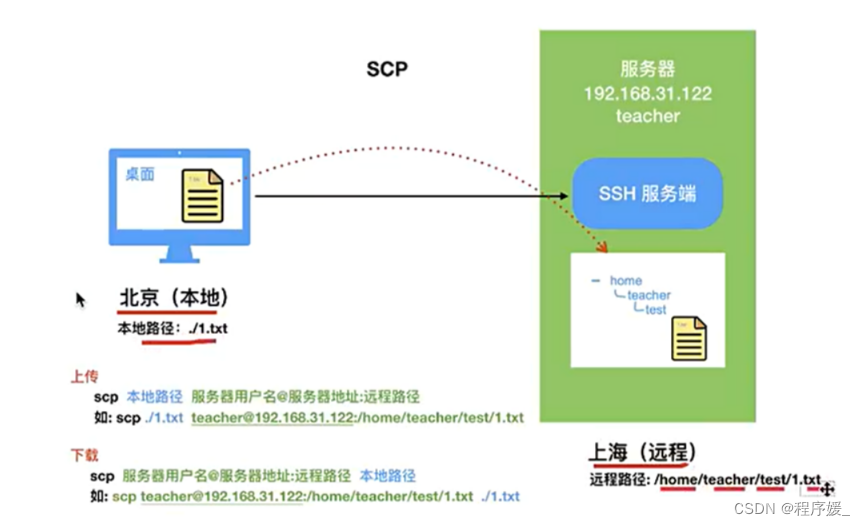
scp远程拷贝(上传/下载)
上传: scp 本地路径 服务器用户@服务器ip:服务器路径
下载: scp 服务器用户@服务器ip:服务器路径 本地路径
如果操作的是目录,使用:scp -r
使用该命令的前提条件要求目标主机已经成功安装openssh-server,如没有安装使用sudo apt-get install openssh-server来安装。
编辑器vi
-
vi简介
vi是“Visual interface“”的简称,它在Linux上的地位就仿佛Edit程序在DOS上一样。它可以执行输出、删除、查找、替换、块操作等众多文本操作,而且用户可以根据自己的需要对其进行定制,vi不是一个排版程序,它不象Word或WPS那样可以对字体、格式、段落等其他属性进行编排,它只是一个文本编辑程序。vi没有菜单,只有命令,且命令繁多。
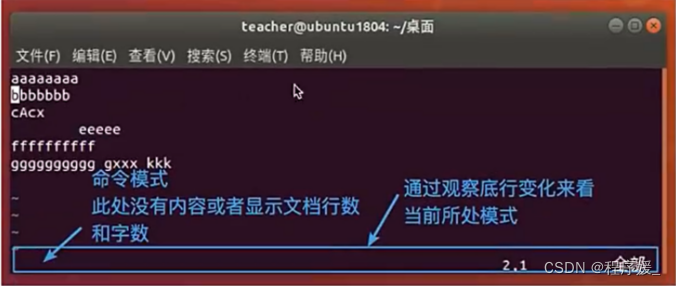
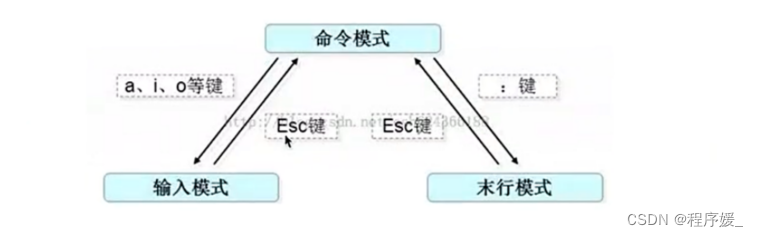
vi有三种基本工作模式:命令模式、文本输入模式、末行模式命令模式:
任何时候,不管用户处于何种模式,只要按一下ESC键,即可使vi进入命令模式;我们在shell环境(提示符为$)下输入启动vi命令,进入编辑器时,也是处于该模式下。在该模式下,用户可以输入各种合法的vi命令,用于管理自己的文档。此时从键盘上输入的任何字符都被当做编辑命令来解释,若输入的字符是合法的vi命令,则vi在接受用户命令之后完成相应的动作。但需注意的是,所输入的命令并不在屏幕上显示出来。若输入的字符不是vi的合法命令,vi会响铃报警。
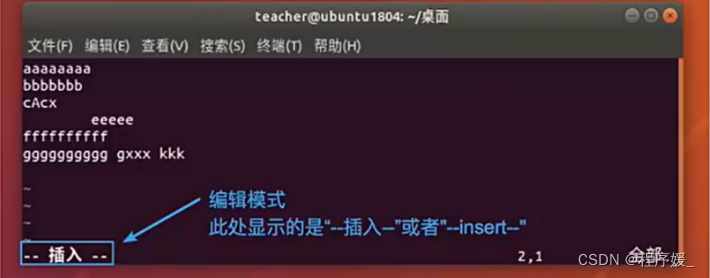
文本输入模式:
在命令模式下输入插入命令i、附加命令a、打开命令o、修改命令c、取代命令r或替换命令s都可以进入文本输入模式。在该模式下,用户输入的任何字符都被vi当做文件内容保存起来,并将其显示在屏幕上。在文本输入过程中,若想回到命令模式下,按键ESC即可。
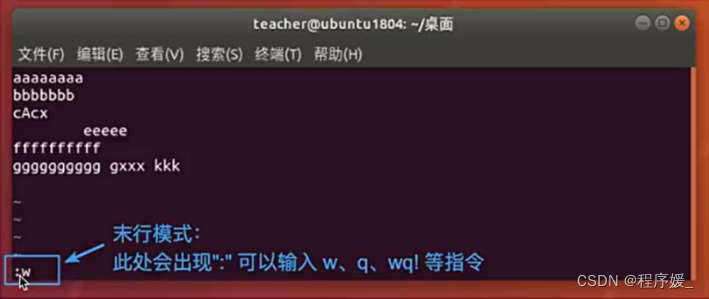
末行模式:
末行模式也称ex转义模或。在命令模式下,用户按“:"键即可进入末行模式下,此时vi会在显示窗口的最后一行(通常也是屏幕的最后一行)显示一个“:”作为末行模式的提示符,等待用户输入命令。多数文件管理命令都是在此模式下执行的(如把编辑缓冲区的内容写到文件中等),末行命令执行完后,vi自动回到命令模式。例如::sp newfile
则分出一个窗口编辑newfile文件。如果要从命令模式转换到编辑模式,可以键入命令a或者i;如果需要从文本模式返回,则按Esc键即可。在命令模式下输入“:"即可切换到末行模式,然后输入命令。
-
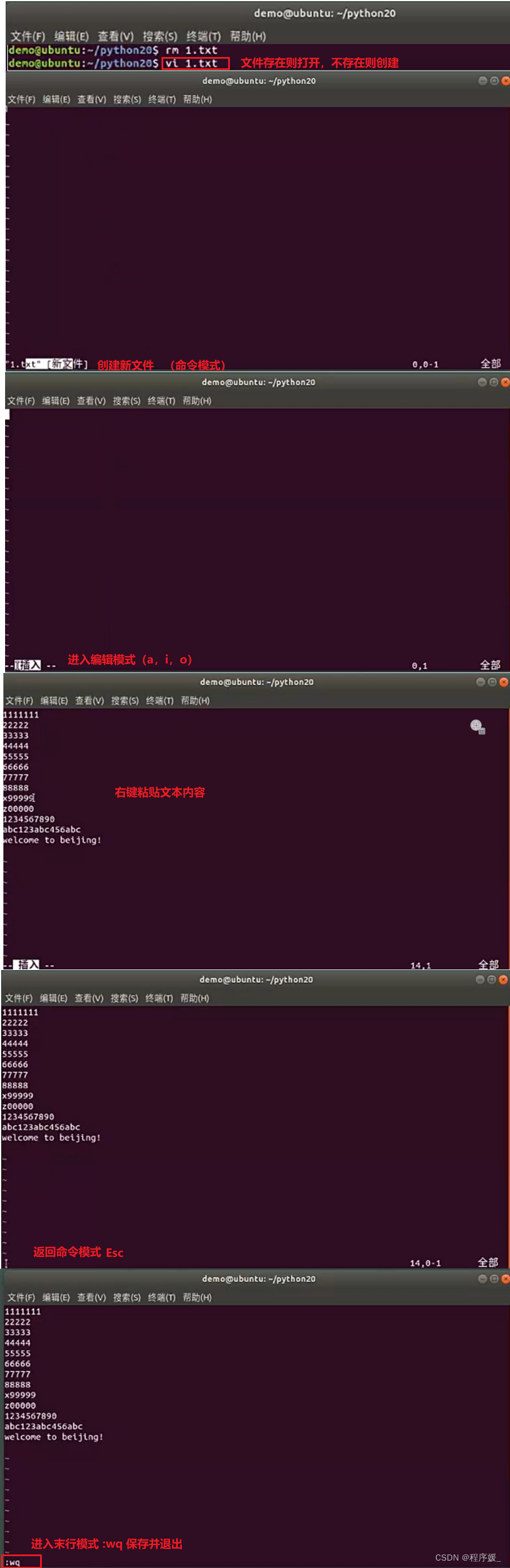
vim基础操作
vim是从vi发展出来的一个文本编辑器。代码补完、编译及错误跳转等做了一些增强。
步骤: 创建/打开文件:vi 文件名→a/i/o进入编辑模式→编辑文件→Esc到命令模式→:进入末行模式→wq保存并退出。
-
进入编辑模式
命令 含义 i和I i在光标前插入,I在行首插入 a和A a在光标后插入,A在行末插入 o和O o在光标所在行下一行插入,O在光标所在行上一行插入 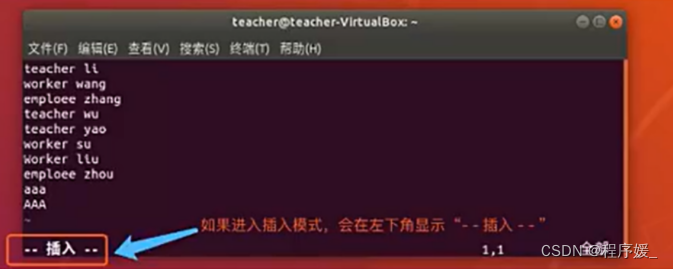
-
进入命令模式
【Esc】从插入模式/末行模式进入命令模式
2.1 移动光标命令 含义 h 光标向左移动 j 光标向下移动 k 光标向上移动 l 光标向右移动 H、M、L 光标移动到可见屏幕第一行(H),中间行(M),最后一行(L) ^和$ ^移动到行首,$移动到行末 G和gg G文档最后一行,gg文档第一行 Ctrl+f、Ctrl+b 向前翻屏、向后翻屏 Ctrl+d、Ctrl+u 向前半屏、向后半屏 {和} {向上移动一段,}向后移动一段 w和b w向前移动一个单词,b向后移动一个单词 2.2 删除命令
命令 含义 x和X x删除光标所在字符,X删除光标前一个字符,包含光标位置字符 dd和n dd dd删除所在行,5 dd刷除指定行数5 d0和D d0刚除光标前本行所有内容,D删除光标后本行所有内容,包含光标位置字符 dw 删除光标所在位置的字,包含光标所在位置字符 2.3 撤销命令
命令 含义 u 一步一步撤销 Ctrl+r 反撤销(重做) 2.4 重复命令
命令 含义 . 重复执行上一次操作的命令 2.5 移动命令
命令 含义 << 文本行向左移动 >> 文本行向右移动 2.6 复制粘贴
命令 含义 yy、n y yy复制当前行,5 yy复制5行 p 在光标所在位置向下新开一行粘贴 2.7 查找替换
命令 含义 命令模式下,r和R r替换当前字符,R替换光标后的字符 命令模式下,/ + str n查找下一个,N查找前一个 末行模式下,%s/abc/123/g 将文件中所有abc替换为123 末行模式下,1, 10s/abc/123/g 将第1行至第10行之间的abc替换成123 -
进入末行模式
命令 含义 :q 退出 :w 保存 :q! 强制退出,不保存(!强制的意思) :qw! 强制退出,并且保存
系统性能定时监控
系统监控概述
用Python来编写脚本简化日常的运维工作是Python的一个重要用途。在Linux下,有许多系统命令可以让我们时刻监控系统运行的状态,如ps, top, free等等。要获取这些系统信息,Python可以通过subprocess模块调用并获取结果,但这样做显得很麻烦,尤其要写很多解析代码。
psutil
在Python中获取系统信息的另一个好办法是使用psutil这个第三方模块。
psutil,是python system and process utilities的缩写,意思python的系统监控及进程的管理的工具,是一个功能很强大的跨平台的系统管理库。可以实现命令行中类似ps、top、lsof、netstat、ifconfig、who、df、kill、free、nice、ionice、iostat、iotop等等命令的功能,并且以python内置的数据结
构形式返回,官方文档(https://pythonhosted.org/psutil/)目前psutil支持的系统有Linux、Window os X和freeBSD等。
-
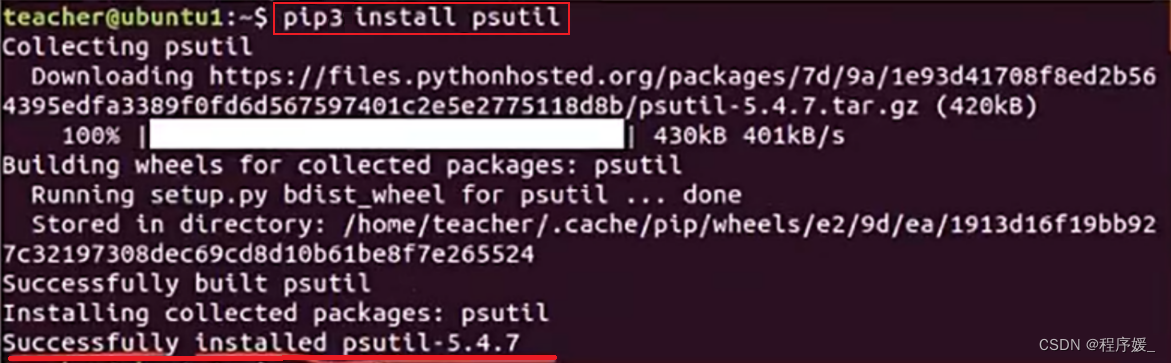
psutil安装
psutil是一个第三方的开源项目,因此,需要先安装才能够使用:pip3 install psutil
-
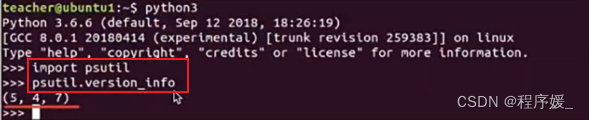
psutil版本查看
使用python3进入交互模式,查看版本:psutil.version_info
-
常见功能
-
获取CPU信息:
psutil.cpu_xxx()选项 含义 cpu_count() 逻辑CPU核数
可以通过设置logical=False来返回物理CPU的个数
psutil.cpu_count(logical=False)cpu_times() system:系统时间在内核中执行的进程占有CPU的时间
其中有些参数在不同的平台下也会有所不同
nice(UNIX):被优先级高的进程所占用的时间
iowait(Linux):等待l/O完成的时间
irq(Linux,BSD):硬件中断维持所花费的时间
softirq(Linux):软件中断维持所花费的时间
dpc(windows):花费在dpc((Deferred Procedure Call)Windows操作系统中的一种中断调用机制)过程中的时间cpu_percent() 获取CPU的使用率
cpu_percent方法会返回一个浮点值表示当前CPU的利用率,两个参数interval与percpu
interval表示间隔,默认为0.0,输入命令后直接返回
percpu是个bool值,等于Ture的时候输出每个CPU的利用率,此时返回一个列表。
interval=0.5设置刷新时间间隔为0.5秒
percpu=True获取每个CPU使用率
psutil.cpu_percent(interval=0.5, percpu=True) -
获取内存信息:
xxx_memory()选项 含义 virtual_memory() 在系统中内存的利用率信息通常有如下:
total:物理内存的总数
available:可用内存,表示没有进入交换区的内存,可以直接分配给进程
used:已经被使用的内存数
free:空闲内存,指完全没有被使用的内存
cache:缓存的使用数目
buffer:缓冲的使用数目
swap:交换分区使用的数目
如果需要获得某个具体的信息,可以进行如下操作:memory.free、memory.used等swap_memory() 用于获取交换分区的信息 -
磁盘信息:
disk_xxx()
使用psutil类似于Linux下的fdisk命令,我们比较关心的是磁盘的利用率以及I/O信息还有分区信息等。选项 含义 disk_partitions() 用于获取完整的分区信息(逻辑设备名,挂载点权限,文件系统等等),返回一个元组 disk_usage() 返回硬盘,分区或者目录的使用情况,单位字节“/”表示获取根目录(系统)磁盘使用情况 disk_io_counters() 获取硬盘的/O个数,读写信息,返回一个元组
perdisk参数,当为True时返回每个磁盘的信息,此时返回一个字典 -
网络信息:
net_xxx()选项 含义 net_io_counters() 用于获取网络总的l/O信息,返回一个元组,默认pernic=False
当pernic为True时返回每个网路接口的/O信息此时返回一个字典
bytes_sent:发出的比特数
bytes_recv:收到的比特数
packets_sent:发出的包数量
packets_recv:接受的包数量
errin:接收时出现的错误总数
errout:发送时出现的错误总数
dropin:发送过来时丢包的数量
dropout:发出时丢包的数量net_connection() 返回一个系统中的套接字的链接信息,以一个列表的形式返回 -
获取开机时间
psutil.boot_time() # 获取开机时间(Linux格式返回) datetime.datetime.fromtimestamp(psutil.boot_time()).strftime("%Y-%m-%d %H:%M:%S") # 2023-09-19 10:33:05 -
活动用户
psutil.users() # 获取用户的信息
-
代码示例
# 1 导入psutil模块 import psutil # 2 获取CPU信息 # 2.1 获取CPU核心数 print(psutil.cpu_count()) # 逻辑CPU核心数 16 print(psutil.cpu_count(logical=False)) # 获取物理的核心数 8 # 2.2 CPU使用率 print(psutil.cpu_percent(interval=0.5)) # 2.8 print(psutil.cpu_percent(interval=0.5, percpu=True)) # 获取每个核心的使用率 [0.0, 6.2, 3.2, 3.1, 0.0, 0.0, 0.0, 0.0, 0.0, 3.1, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0] # 3 获取内存信息 # 3.1 获取内存的整体信息 print(psutil.virtual_memory()) # svmem(total=34132516864, available=22007361536, percent=35.5, used=12125155328, free=22007361536) # 3.2 获取内存的使用率 print(psutil.virtual_memory().percent) # 35.5 # 4 获取硬盘信息 # 4.1 获取磁盘的分区信息 print(psutil.disk_partitions()) # [sdiskpart(device='C:\\', mountpoint='C:\\', fstype='NTFS', opts='rw,fixed', maxfile=255, maxpath=260), sdiskpart(device='D:\\', mountpoint='D:\\', fstype='NTFS', opts='rw,fixed', maxfile=255, maxpath=260)] # 4.2 获取指定目录的磁盘信息 print(psutil.disk_usage("/")) # sdiskusage(total=383954972672, used=28907421696, free=355047550976, percent=7.5) # 4.3 获取磁盘的使用率 print(psutil.disk_usage("/").percent) # 7.5 # 5 获取网络信息 # 5.1 获取收到的数据包数量 print(psutil.net_io_counters().bytes_recv) # 304114986 # 5.2 获取发送的数据包数量 print(psutil.net_io_counters().bytes_sent) # 171737823 -
实战
-
功能描述
能够显示当前服务器CPU、内存、硬盘的使用率,网络的收发情况;能够显示CPU总核心数、总内存、总硬盘;能够将日志信息保存到log.txt文件中;能够直接执行脚本,查看信息。 -
实现效果
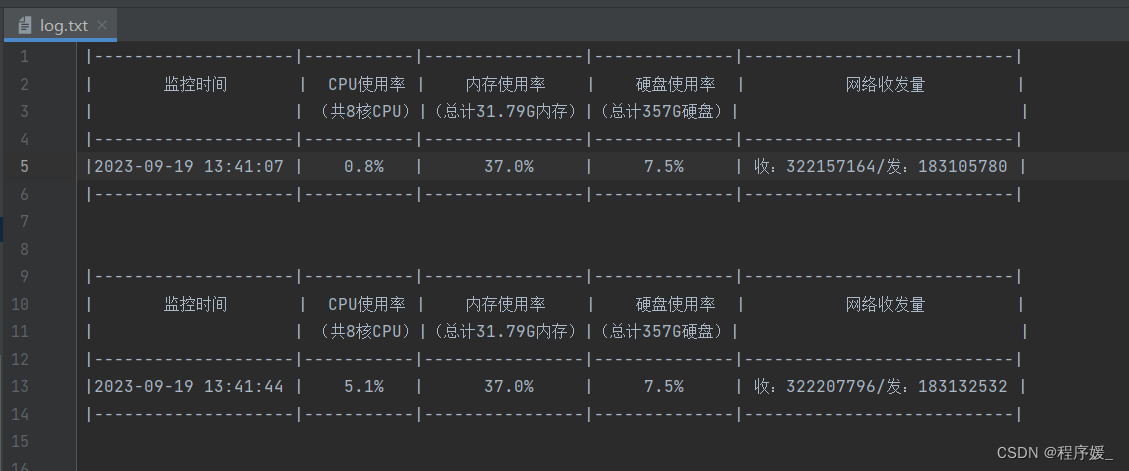
显示的表格样式的字符串代码:log_str = "|------------------|-------------|--------------|--------------|----------------------------|\n" log_str += "| 监控时间 | CPU使用率 | 内存使用率 | 硬盘使用率 | 网络收发量 |\n" log_str += "| |(共x核CPU) |(总计xG内存)|(总计xG硬盘)| |\n" log_str += "|------------------|-------------|--------------|--------------|----------------------------|\n" log_str += "| xx | xx% | x.x% | x.x% | 收:x/发:x |\n" log_str += "|------------------|-------------|--------------|--------------|----------------------------|\n" print(log_str) -
代码实现
# 1 导入模块 import psutil import datetime # 2 定义变量保存CPU的使用率 cpu_perc = psutil.cpu_percent(interval=0.5) # 3 定义变量保存内存信息 memory_info = psutil.virtual_memory() # 4 定义变量保存硬盘信息 disk_info = psutil.disk_usage("/") # 5 定义变量保存网络信息 net_info = psutil.net_io_counters() # 获取系统当前时间 current_time = datetime.datetime.now().strftime("%F %T") # 6 拼接字符串显示 log_str = "|--------------------|-----------|----------------|--------------|---------------------------|\n" log_str += "| 监控时间 | CPU使用率 | 内存使用率 | 硬盘使用率 | 网络收发量 |\n" log_str += "| | (共%d核CPU)|(总计%.2fG内存)|(总计%dG硬盘)| |\n" % (psutil.cpu_count(logical=False), memory_info.total/1024/1024/1024, disk_info.total/1024/1024/1024) log_str += "|--------------------|-----------|----------------|--------------|---------------------------|\n" log_str += "|%s | %s%% | %s%% | %s%% | 收:%s/发:%s |\n" % (current_time, cpu_perc, memory_info.percent, disk_info.percent, net_info.bytes_recv, net_info.bytes_sent) log_str += "|--------------------|-----------|----------------|--------------|---------------------------|\n" # print(log_str) # 7 保存监控信息到日志文件 f = open("log.txt", "a") f.write(log_str + "\n\n") f.close() -
代码优化——定时监控
a. 定义linux_monitor()实现监控
b. main()启动定时监控# 1 导入模块 import psutil import datetimedef linux_monitor(time):"""定义函数,实现信息的显示和日志的保存"""# 2 定义变量保存CPU的使用率cpu_perc = psutil.cpu_percent(interval=time)# 3 定义变量保存内存信息memory_info = psutil.virtual_memory()# 4 定义变量保存硬盘信息disk_info = psutil.disk_usage("/")# 5 定义变量保存网络信息net_info = psutil.net_io_counters()# 获取系统当前时间current_time = datetime.datetime.now().strftime("%F %T")# 6 拼接字符串显示log_str = "|--------------------|-----------|----------------|--------------|---------------------------|\n"log_str += "| 监控时间 | CPU使用率 | 内存使用率 | 硬盘使用率 | 网络收发量 |\n"log_str += "| | (共%d核CPU)|(总计%.2fG内存)|(总计%dG硬盘)| |\n" % (psutil.cpu_count(logical=False), memory_info.total/1024/1024/1024, disk_info.total/1024/1024/1024)log_str += "|--------------------|-----------|----------------|--------------|---------------------------|\n"log_str += "|%s | %s%% | %s%% | %s%% | 收:%s/发:%s |\n" % (current_time, cpu_perc, memory_info.percent, disk_info.percent, net_info.bytes_recv, net_info.bytes_sent)log_str += "|--------------------|-----------|----------------|--------------|---------------------------|\n"# print(log_str)# 7 保存监控信息到日志文件f = open("log.txt", "a")f.write(log_str + "\n\n")f.close()def main():"""程序的入口:死循环,每隔一段时间显示一次"""while True:linux_monitor(5) # 每隔5s# __name__值: # 1) 如果当前py文件被其他文件导入,则__name__的值是当前的py文件名 # 2) 如果直接运行当前py文件,则__name__的值是__main__ if __name__ == '__main__':main() -
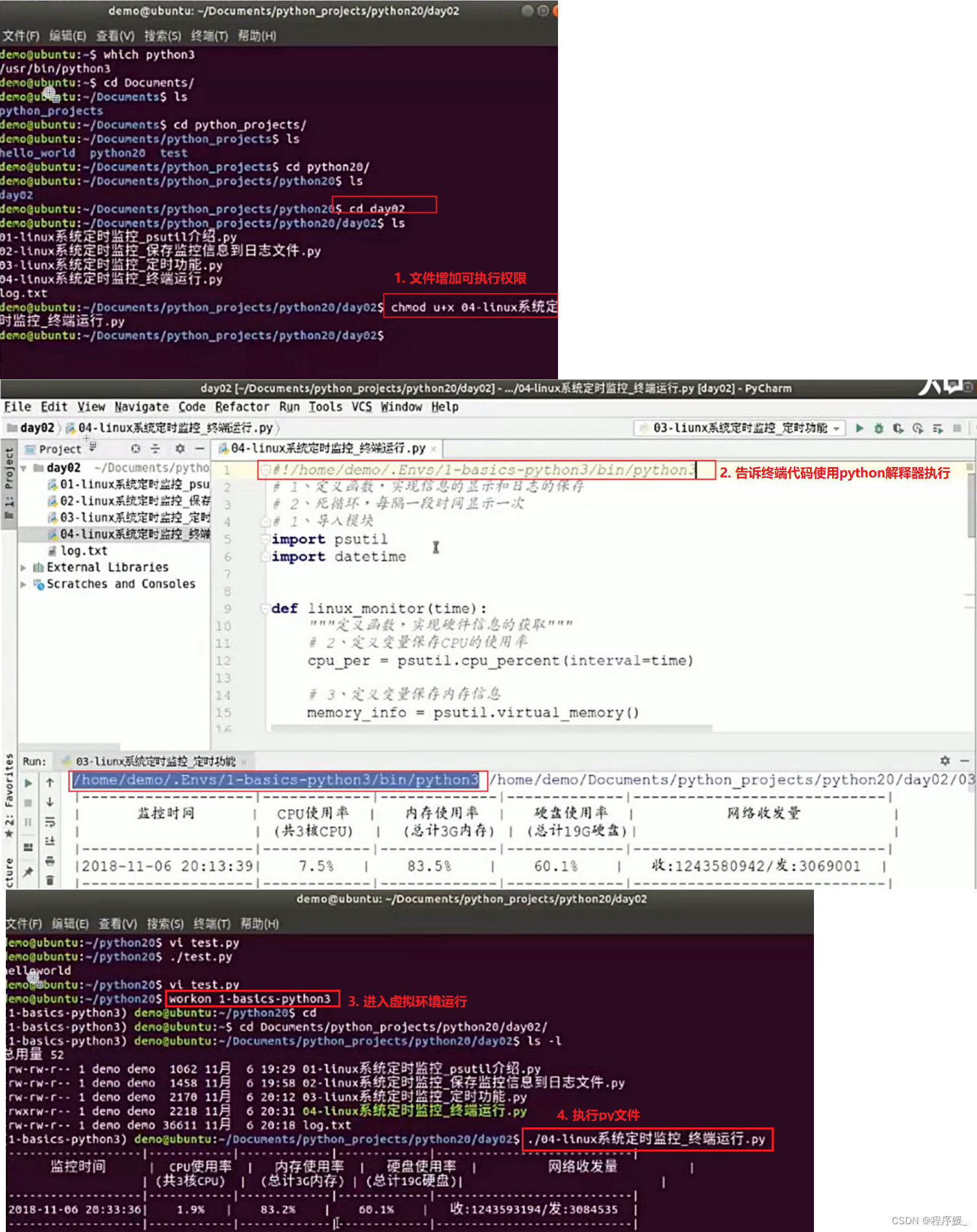
终端方式运行
a. 文件增加可执行权限:chmod u+x xxx.py
b. 告诉终端代码使用python解释器执行:#!/home/demo/.Envs/1-basics-python3/bin/python3
c. 进入虚拟环境运行:workon 1-basics-python3
d. 执行py文件:./xxx.py
-
邮件监控
yagmail模块使用
yagmail可以更简单地来实现自动发邮件功能。github项目地址:https://github.com/kootenpv/yagmail
安装:pip3 install yagmail
安装成功验证:
简单实现:""" yagmail 发送邮件: 1. 导入模块 2. 使用yagmail的类创建对象(发件人,发件人授权码,发件的服务器) 3. 使用yagmail对象发送邮件(指定接收人,邮件主题,发送的内容) """ # 1. 导入模块 import yagmail# 2. 使用yagmail的类创建对象(发件人,发件人授权码,发件的服务器) # 2.1 发件人:375898283@qq.com --> user="375898283@qq.com" # 2.2 发件人授权码:password="muwflwxwxdirbjgd" 非密码 # 2.3 发件服务器:host="smtp.qq.com" ya_obj = yagmail.SMTP(user="375898282@qq.com", password="muwflwxwxdirbjgd", host="smtp.qq.com")# 3. 使用yagmail对象发送邮件(指定收件人,邮件主题,发送的内容) content = "测试一下" ya_obj.send("734830953@qq.com", "邮件监控", content)代码实现:
# 1 导入模块 import psutil import datetimeimport yagmail import ygmaildef linux_monitor(time):"""定义函数,实现信息的显示和日志的保存"""# 2 定义变量保存CPU的使用率cpu_perc = psutil.cpu_percent(interval=time)# 3 定义变量保存内存信息memory_info = psutil.virtual_memory()# 4 定义变量保存硬盘信息disk_info = psutil.disk_usage("/")# 5 定义变量保存网络信息net_info = psutil.net_io_counters()# 获取系统当前时间current_time = datetime.datetime.now().strftime("%F %T")# 6 拼接字符串显示log_str = "|--------------------|-----------|----------------|--------------|---------------------------|\n"log_str += "| 监控时间 | CPU使用率 | 内存使用率 | 硬盘使用率 | 网络收发量 |\n"log_str += "| | (共%d核CPU)|(总计%.2fG内存)|(总计%dG硬盘)| |\n" % (psutil.cpu_count(logical=False), memory_info.total / 1024 / 1024 / 1024, disk_info.total / 1024 / 1024 / 1024)log_str += "|--------------------|-----------|----------------|--------------|---------------------------|\n"log_str += "|%s | %s%% | %s%% | %s%% | 收:%s/发:%s |\n" % (current_time, cpu_perc, memory_info.percent, disk_info.percent, net_info.bytes_recv, net_info.bytes_sent)log_str += "|--------------------|-----------|----------------|--------------|---------------------------|\n"# print(log_str)# 7 保存监控信息到日志文件f = open("log.txt", "a")f.write(log_str + "\n\n")f.close()# 8 发送邮件(判断内存超过80%,或CPU超过90%才发)if memory_info.percent > 80 or cpu_perc > 90 :ya_obj = yagmail.SMTP(user="375898282@qq.com", password="muwflwxwxdirbjac", host="smtp.qq.com")ya_obj.send("734830953@qq.com", "[系统监控报告]", log_str)def main():"""程序的入口:死循环,每隔一段时间显示一次"""while True:linux_monitor(5) # 每隔5sif __name__ == '__main__':main()
-
python开发环境及网络基础
虚拟环境
为什么需要虚拟环境
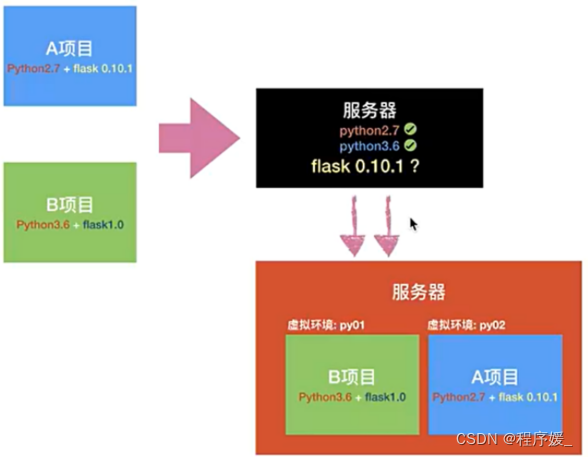
virtualenv用于创建独立的python环境,多个python相互独立,互不影响,它能够:
1.在没有权限的情况下安装新套件;
2.不同应用可以使用不同的套件版本;
3.套件升级不影响其他应用;
虚拟环境搭建
-
安装虚拟环境的命令
sudo pip install virtualenv sudo pip install virtualenvwrapper安装完虚拟环境后,如果提示找不到mkvirtualenv命令,须配置环境变量:
# 1 创建目录用来存放虚拟环境 mkdir $HOME/.virtualenvs# 2 打开~/.bashrc文件,并添加如下: export WORKON_HOME=$HOME/.virtualenvs source /usr/local/bin/virtualenvwrapper.sh# 3 运行 source ~/.bashrc -
创建虚拟环境
提示:如果不指定python版本,默认安装的是python2的虚拟环境。
创建默认python默认版本的虚拟环境:mkvirtualenv 虚拟环境名称)
虚拟环境的默认位置:用户目录(/home/demo)/.Envs/虚拟环境名

注意:
- 创建虚拟环境需要联网;
- 创建成功后,会自动工作在这个虚拟环境上;
- 工作在虚拟环境上,提示符最前面会出现“虚拟环境名称”;
创建指定python版本的虚拟环境:
mkvirtualenv -p python路径 虚拟环境名称
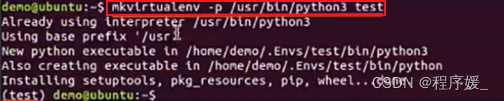
-p指的是path的简写。
Python安装的路径,默认安装再/usr/bin/目录下。如果找不到,使用命令:whereis python3 -
使用虚拟环境
查看虚拟环境的命令:workon 两次tab键 或者 lsvirtualenv

启动/切换虚拟环境:workon 虚拟环境名称

对比使用虚拟环境前后变化:查看虚拟环境中的python位置:which python

退出虚拟环境:deactivate
删除虚拟环境:rmvirtualenv 虚拟环境名称注意:
如果目前的位置在虚拟环境中,需要先退出虚拟环境,然后才能执行删除;
如:先退出:deactivate 再删除:rmvirtualenv py3_f3sk
可以在任何目录执行删除操作,如果不知道名字,可以rmvirtualen+两次Tab键,提示所有的虚拟环境;

-
在虚拟环境中安装工具包
提示:工具包安装的位置:
python2版本:~/.virtualenvs/py_flask/lib/python2.7/site-packages/
python3版本:~/.virtualenvs/py3_flask/lib/python3.5/site-packages/
安装包命令:pip install 包名称==版本

注意:一定不要使用sudo pip …,这里是在虚拟环境中安装python包,如果使用了sudo权限,python包会被安装在主机非虚拟环境下,在虚拟环境中找不到这个包。
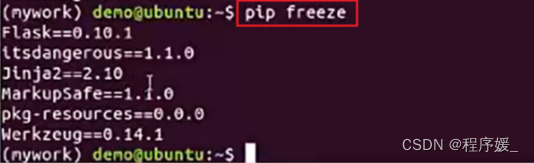
查看虚拟环境中安装的包:
pip freeze
网络通信概述
网络的概念: 一些相互连接的、以共享资源为目的的计算机的集合。使用网络能够把多方连接在一起,然后可以进行数据传递。
网络编程的概念: 指的是让在不同的电脑上的软件能够进行数据传递。
学习网络的目的: 能够编写基于网络通信的软件。
IP地址
地址: 地址就是用来标记地点的。
IP地址: IP地址是指互联网协议地址(英语:Internet Protocol Address,又译为网际协议地址),是IP Address的缩写。IP地址是P协议提供的一种统一的地址格式。IP地址被用来给Internet上的电脑一个编号。大家日常见到的情况是每台联网的PC上都需要有IP地址,才能正常通信。我们可以把“个人电脑”比作“一台电话”,那么“IP地址”就相当于“电话号码”。
IP地址的作用: 用来在网络中标记一台电脑,是网络设备为网络中的每台计算机分配的一个唯一标识。比如192.168.1.1;在本地局域网上是唯一的。
IP地址的组成: ip地址由两部分组成:网络号+主机号
表示的范围:xxx.xxx.xxx.0 ~ xxx.xxx.xxx.255
注意:前3段为网络号,最后1段0-255为主机号。xxx.xxx.xxx.0为内部ip;xxx.xxx.xxx.255为广播地址。
IP地址的分类:
生活中我们说的IP地址,通常指的是IPv4(IP协议的第4个板本)
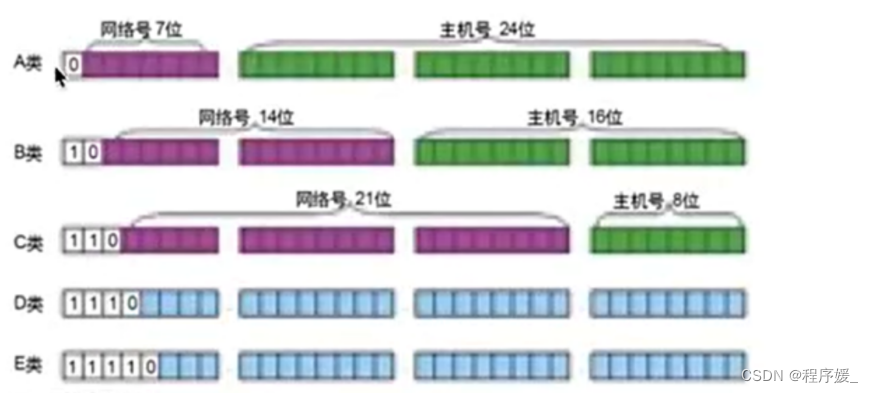
A类IP地址:
一个A类IP地址由1字节的网络地址和3字节主机地址组成,网络地址的最高位必须是“0“,地址范国1.0.0.1-126.255.255.254
二进制表示为:00000001 00000000 00000000 00000001-01111110 11111111 11111111 11111110
可用的A类网络有126个,每个网络能容纳1677214个主机。
B类IP地址:
一个B类IP地址由2个字节的网络地址和2个字节的主机地组成,网络地址的最高位必须是“10“,地址范国128.1.0.1-191.255.255.254
二进制表示为:10000000 00000001 00000000 00000001-100111111 11111111 11111111 11111110
可用的B类网络有16384个,每个网络能容纳65534主机。
C类IP地址(最常用):
一个C类IP地址由3字节的网络地址和1字节的主机地址组成,网络地址的最高位必须是“110”,范围192.0.1.1-223.255.255.254
二进制表示为:11000000 00000000 00000001 00000001-110111111 11111111 11111110 11111110
C类网络可达2097152个,每个网络能容纳254个主机。
C类地址中,一般xxx.xxx.xxx.0和xxx.xx.xxx.255两个IP地址有特殊用法!
所以理论上:xxx.xxx.xxx.0~xxx.xxx.xxx.255能容纳256台主机,但是因为2个IP地址不能使用,所以
最多能容纳254台。
主机全零(“0.0.0.0”)地址对应于当前主机。
全“1”的IP地址(“255.255.255.255”)是当前子网的广播地址。
D类IP地址:
D类地址用于多点广播。D类IP地址第一个字节以“1110”开始,它是一个专门保留的地址。
它并不指向特定的网络,目前这一类地址被用在多点广播(Multicast)中。多点广播地址用来一次寻址一组计算机。地址范围224.0.0.1-239.255.255.254
E类IP地址:
以“1111”开始,为将来使用保留。
私有IP:
在这么多网络IP中,国际规定有一部分IP地址是用于我们的局域网使用,也就是属于私网IP,不在公网中使用的,它们的范国是:
10.0.0.0~10.255.255.255(内网,虚拟机中常出现,A类)
172.16.0.0~172.31.255.255(内网,子网,B类)
192.168.0.0~192.168.255.255(内网,子网,C类)
注意:
IP地址127.0.0.1~127.255.255.255用于回路测试。
特殊的IP地址:127.0.0.1
127.0.0.1可以代表本机IP地址。用http://127.0.0.1就可以测试本机中配置的Web服务器。
特殊的域名:localhost
localhost是本机域名,用来解析到本机127.0.0.1ip地址上。
IPv4和IPv6
IPv4 ,是互联网网络协议(Internet Protocol ,IP)的第四版,也是第一个被广泛使用,构成现今互联网技术的基石的协议。采用“点分十进制”表示(如:192.168.1.100),一共有2^32-1个,估算约为42.9亿个,除去一些特用的IP和一些不能用的IP,剩下可用的不到40亿。IPv4发展到现在,最大的问题是网络地址严重不足。
IPv6是Internet Protocol Version6的缩写,其中Internet Protocol译为“互联网协议”。IPv6是IETF(互联网工程任务组,Internet Engineering Task Force)设计的用于替代现行版本IP协议(IPv4)的下一代IP协议。采用“冒分十六进制"表示(如:2031:0000:1F1F:0000:0000:0100:11A0:ADDF),而IPv6中IP地址的长度为128,即有2^128-1个地址,号称能够为“地球上每一粒沙子分配一个IP地址”
IPv6支持测试:http://test-ipv6.com/
上海交通大学IPv6站:http:/ipv6.sjtu.edu.cn/
IP地址查看
-
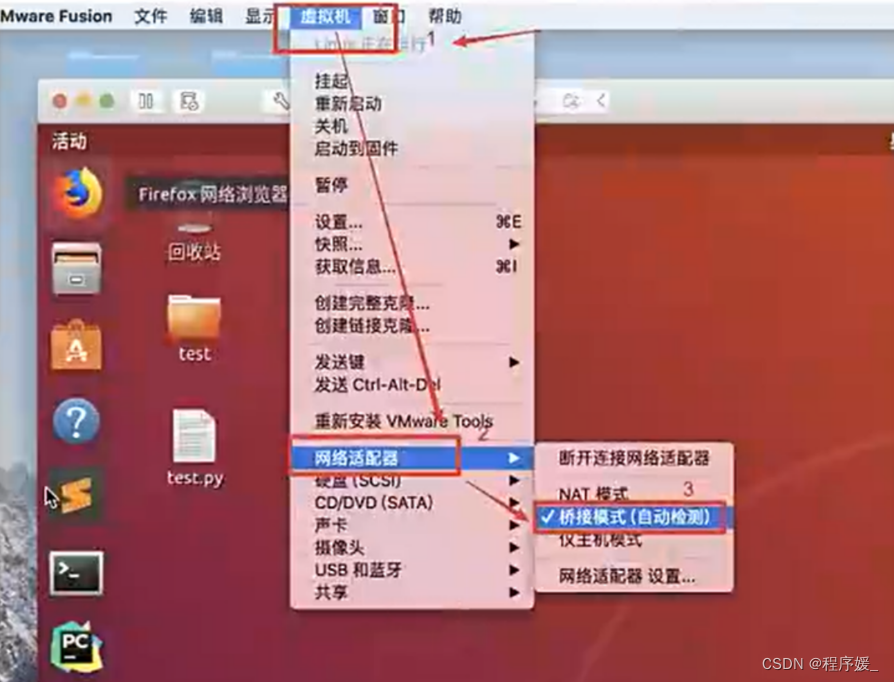
虚拟机网卡设置
NAT(网络地址转换模式):则虚拟机会使用主机VMnet8这块虚拟网卡与我们的真实机进行通信(虚拟机与物理主机公用网络)。
Bridged(桥接模式):虚拟机如同一台真实存在的计算机,在内网中获取和真实主机同网段IP地址。优点:不需要任何设置,虚拟机就可以直接和我们真实主机通信;缺点:虚拟机需要占用真实机网段的一个IP(虚拟机能够获取局域网的IP地址)。
Ubuntu虚拟机网络设置如下:
-
查看或配置网卡信息:
ifconfig
如果我们只是敲:ifconfig,它会显示所有网卡的信息:
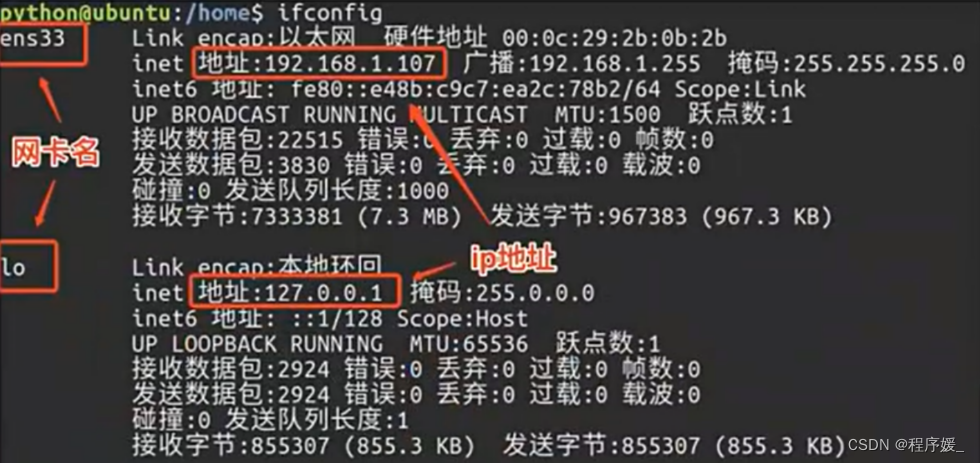
查看Window ip地址:【Win键R】打开运行 >> 输入“cmd”打开终端窗口 >> 输入命令
ipconfig
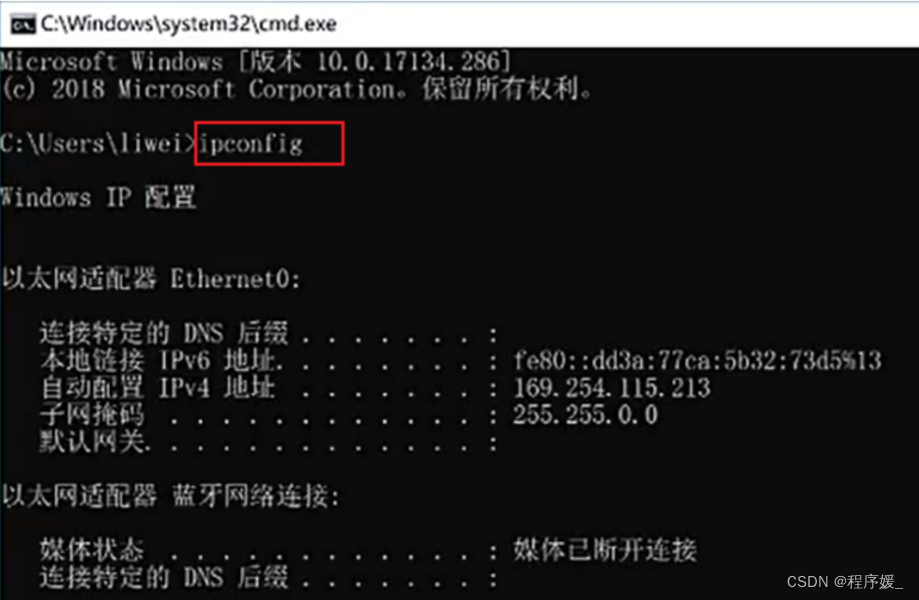
-
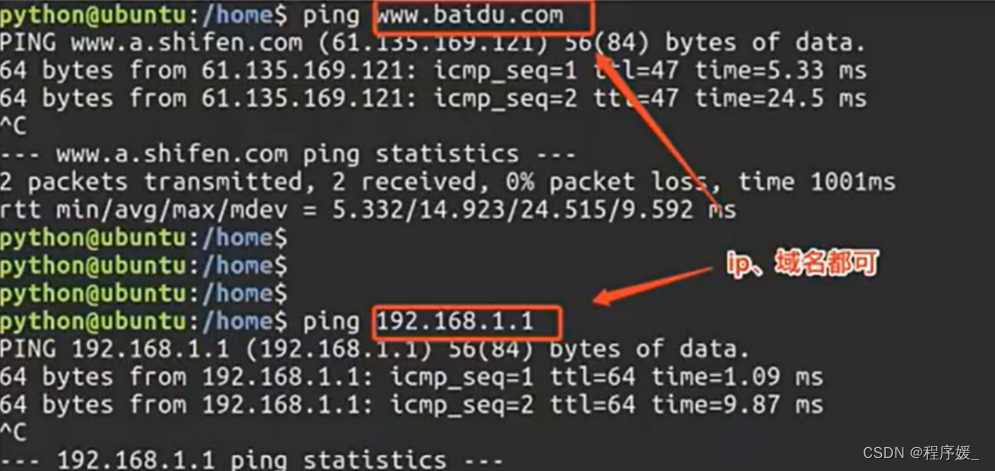
测试远程主机联通性能:
ping
通常用ping换检测网络是否正常或者某台主机是否可以连接。
端口
端口: 端口是英文port的意译,可以认为是设备与外界通讯交流的出口。端口可分为虚拟端口和物理端口,其中虚拟端口指计算机内部或交换机路由器内的端口,不可见。例如计算机中的80端口、21端口、23端口等。
端口号: 端口是通过端口号来标记的,端口号只有整数,范围是从0到65535。
-
端口分配:
端口号不是随意使用的,而是按照一定的规定进行分配。
端口的分类标准有好几种,我们这里不做详细讲解,只介绍一下知名端口和动态端口-
知名端口
知名端扣是众所周知的端口号,范围从0~1023。一般情况下,如果一个程序需要使用知名端口的需要有root权限。常见协议 默认端口号 协议基本作用 FTP 21 文件上传、下载 SSH 22 安全的远程登录 TELNET 23 远程登录 SMTP 25 邮件传输 DNS 53 域名解析 HTTP 80 超文本传输 POP3 110 邮件接收 HTTPS 443 加密传输的HTTPS -
动态端口
动态端口的范围是从1024~65535。
之所以称为动态端口,是因为它一般不固定分配某种服务,而是动态分配。动态分配是指当一个系统程序或应用程序程序需要网络通信时,它向主机申请一个端口,主机从可用的端口号中分配一个供它使用。当这个程序关闭时,同时也就释放了所占用的端口号。
-
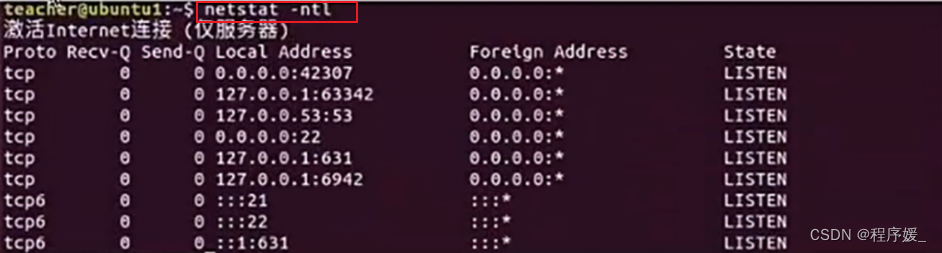
-
查看端口:
netstat
netstat命令是一个监控TCP/IP网络的非常有用的工具,可以显示网络连接、路由表和网络接口信息,可以让用户得知目前都有哪些网络连接正在运作。-a或–a:显示所有连线中的Socket;
-A<网络类型>或–<网络类型>:列出该网络类型连线中的相关地址;
-c或-continuous:持续列出网络状态;
-C或–cache:显示路由器配置的快取信息;
-e或–extend:显示网络其他相关信息;
-F或–fib:显示FIB;
-g或–groups:显示多重广播功能群组组员名单;
-h或–help:在线帮助;
-i或–interfaces:显示网络界面信息表单;
-l或–listening:显示监控中的服务器的Socket;
-H或–masquerade:显示伪装的网路连线;
-n或–numeric:直援使用ip地址,而不通过域名服务器;
-N或–netlink或–symbolic:显示网络硬件外国设备的符号连接名称;
-o或–timers:显示计时器;
-p或–programs:显示正在使用Socket的程序识别码和程序名称;
-r或–route:显示Routing Table;
-s或–statistice:显示网络工作信息统计表;
-t或–tcp:显示TCP传输协议的连线状况;
-u或–udp:显示UDP传输协议的连线状况;
-v或–verbose:显示指令执行过程;
-V或–version:显示版本信息;
-w或–raw:显示RAW传输协议的连线状况;
-x或–unix:此参数的效果和指定"-A unix"参数相同;
–ip或–inet:此参数的效果和指定”-A inet“参数相同;查看所有端口状态:
netstat -an
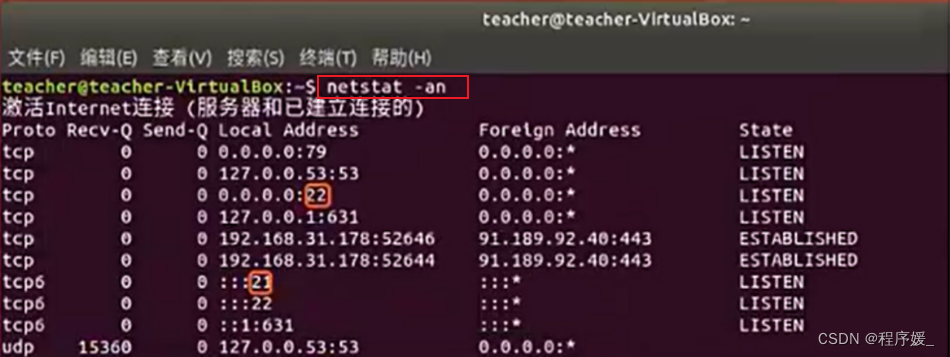
查询所有含有21的端口使用情况:netstat -an | grep 21
查看端口号被哪个程序占用:lsof -i [tcp/udp]:端口号

查看服务器socket:netstat -ntl
网络-udp/tcp
网络传输方式(UDP\TCP)
网络通信中根据数据发送方法进行多种分类,分类方法主要分为两种:面向无连接型、面向有连接型
- 面向无连接型
不要求建立和断开连接。发送端可于任何时候自由发送数据。反之,接收端也永远不知道自己会在何时从那里接收到数据。因此,面向无连接的情况下,接收端需要时常确认是否收到了数据。
在面向无连接的通信中,不需要确认对端是否存在,即使接收端不存在或无法接受数据,发送端也能将数据发送出去。-
UDP协议,用户数据报协议 (User Datagram Protocol)不提供复杂的控制机制,如果传输过程中出现丢包,UDP也不负责重发,甚至当出现包到达顺序乱掉时候也没有纠正的功能。由于UDP面向无连接,它可以随时发送数据。再加上UDP本身的处理既简单又高效,因此常用于以下几个方面:
包总量较少的通信(DNS)
视频、音频等多媒体通信(即时通信)
限定于LAN等特定网络中的应用通信
广播通信(广播、多播)选择UDP必须要谨慎,在网络质量令人十分不满意的环境下,UDP协议数据包丢失会比较严重。但是由于UDP的特性:它不属于连接型协议,因而具有资源消耗小,处理速度快的优点。所以通常音频、视频和普通数据在传送时使用UDP较多,因为它们即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。
-
- 面向有连接型
面向有连接型中,在发送数据之前,需要在收发主机之间建立一条连接通信线路。面向连接就好像我们平时打电话,输入完对方的电话号码拨出之后,只有对方拿起电话确认连接才能进行真正的通话,通话结束后将电话机扣上就如同切断电源。因此在面向有连接的方式下,必须在通信传输前后,专门进行建立和断开连接的处理。- TCP协议,传输控制协议(Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通信协议。TCP提供一种面向连接的通信服务,只有在确认通信对端存在时才会收发数据,从而可以控制通信流量的浪费。TCP提供了数据传输时的各种控制功能,丢包时可以进行重发控制,还可以将次序乱掉的分包进行顺序控制。
UDP与TCP两者区别:
| UDP | TCP |
|---|---|
| 面向无连接,不可靠的数据流传输 | 面向连接,可靠的数据流传输 |
| 尽最大努力交付,即不保证可靠交付 | 提供可靠的服务,通过TCP连接传送的数据,无差错、不丢失、不重复、按序到达 |
| 面向报文 | 面向字节流 |
| 支持一对一、一对多、多对一合多对多的交互通信 | 只能是点到点的 |
socket简介
-
什么是socket
socket(简称:套接字),是支持TCP/IP的网络通信的基本操作单元,提供的方法可以实现数据的发送和接收。
它能实现不同主机间的进程间通信,我们网络上各种各样的服务大多都是基于Socket来完成通信的,例如我们每天浏览网页、QQ聊天、收发email等等。 -
创建socket
socket起源于Unix,而Unix/Linux基本哲学之一就是"一切皆文件”,对于文件用【打开】【读写】【关闭】模式来操作,socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket类就是对其进行的操作(读/写IO、打开、关闭)
在Python中使用socket模块的socket类可以完成:import socket socket.socket(AddressFamily, Type)说明: 类socket.socket创建一个socket,该类实例化时需要两个参数,返回socket对象: 参数一:AddressFamily(地址簇) socket.AF_INET IPv4(默认)、socket.AF_INET6 IPv6 socket.AF_UNIX只能够用于单一的Unix系统进程间通信 参数二:Type(类型) socket.SOCK_STREAM:流式socket,for TCP(默认) socket.SOCK_DGRAM:数据报式socket,for UDP -------- socket.SOCK_RAW原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以;其次,SOCK_RAW也可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头。 socket.SOCK_RDM是一种可靠的UDP形式,即保证交付数据报但不保证顺序。SOCK RAM用来提供对原始协议的低级访问,在需要执行某些特殊操作时使用,如发送ICMP报文。SOCK_RAM通常仅限于高级用户或管理员运行的程序使用。 socket.SOCK_SEQPACKET可靠的连续数据包服务。
"""
1. 导入模块 socket
2. 创建套接字,使用IPv4 UDP/TCP方式
3. 数据的传递
4. 关闭套接字
"""# 1. 导入模块 socket
import socket# 2. 创建套接字,使用用IPv4 UDP方式
# 参数一:socket.AF_INET 使用IPv4; socket.AF_INET6 使用IPv6
# 参数二: socket.SOCK_DGRAM 使用UDP的传输方式(无连接);socket.SOCK_STREAM 使用TCP的传输方式(有连接)
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 3 数据的传递# 4 关闭套接字
udp_socket.close()
udp网络程序-发送、接收数据
"""
1. 导入模块socket
2. 创建socket套接字
3. 发送数据
4. 接收数据(二进制)
5. 解码数据,得到字符串
6. 输出显示接收到的内容
7. 关闭套接字
"""# 1. 导入模块socket
import socket# 2. 创建套接字(UDP)
"""
参数说明:
1. socket.AF_INET 表示IPv4地址;
2. socket.SOCK_DGRAM 表示使用UDP协议传输数据(无连接);
"""
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 3 发送数据 sendto()
"""
参数说明:
1. 要发送的二进制数据,字符串转换为二进制格式:字符串.encode()
2. 元组类型(字符串类型的ip地址, 整数类型的端口号),指定把(参数1的数据)发送给谁
"""
udp_socket.sendto('helloworld'.encode(), ('192.168.150.30', 8080))# 4 接收数据(二进制)recvfrom()
"""
recvfrom(1024)方法的作用
1. 从套接字中接收1024个字节的数据
2. 此方法会造成程序的阻塞,等待另外一台计算机发来的数据。如果对方发数据了,recvfrom会自动解除阻塞;如果对方未发送数据,会一直等待。
返回数组:(接收到的数据的二进制格式, (对方的ip地址, 端口号))
"""
recv_data = udp_socket.recvfrom(1024)
# print(recv_data[0])# 5 解码数据,得到字符串。二进制转换为字符串:二进制.decode('gbk')
recv_text = recv_data[0].decode('gbk')# 6 输出显示接收到的内容
print("来自:", recv_data[1], "的消息:", recv_text)
# 7 关闭套接字
udp_socket.close()
python3编码转换
-
编码和解码
文本总是Unicode,由str类型进行表示,二进制数据使用bytes进行表示。
网络中数据的传输是以**二进制(字节码)**的方式来进行的,所以我们需要通过对Unicode字符串内容进行编码和解码才能达到数据传输的目的。
在Python中:- str>>bytes: encode编码:编码就是将字符串转换成字节码,涉及到字符串的内部表示;
- bytes>>str: decode解码:解码就是将字节码转换为字符串,将比特位显示成字符;
其中encode()与decode()方法可以接收参数,其声明分别为:
# 编码 字符串.encode(encoding="utf-8", errors="strict") # 解码 bytes.decode(encoding="utf-8", errors="ignore")其中的encoding是指在编码解码过程中使用的编码,默认为UTF-8;errors是指错误的处理方案,有strict和ignore两种模式,默认为strict模式。
str = "你好" bytes = str.encode() print(bytes) # b'\xe4\xbd\xa0\xe5\xa5\xbd' str2 = bytes.decode() print(str2) # 你好
udp端口绑定
-
udp网络程序 - 会变得端口号
重新运行多次脚本,然后在“网络词试助手”中,看到的现象如下:
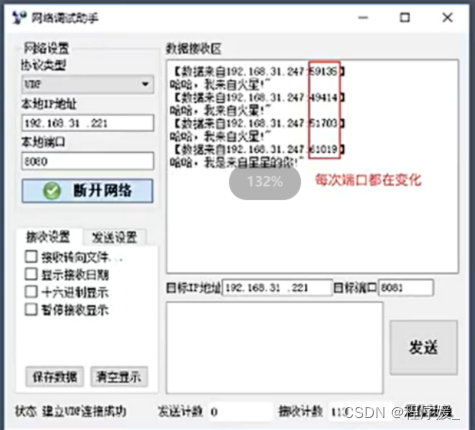
说明:
1)每重新运行一次网络程序,上图中红圈中的数字,不一样的原因在于,这个数字标识这个网络程序,当重新运行时,如果没有确定到底用哪个,系统默认会随机分配。
2)记住一点:这个网络程序在运行的过程中,这个就唯一标识这个程序,所以如果其他电脑上的网络程序如果想要向此程序发送数据,那么就需要向这个数字(即端口)标识的程序发送即可。 -
udp绑定信息
一般情况下,在一台电脑上运行的网络程序有很多,为了不与其他的网络程序占用同一个端口号,往往在编程中,udp的端口号一般不绑定。但是如果需要做成一个服务器端的程序的话,是需要绑定的。想想看这又是为什么呢?如果报警电话每天都在变,想必世界就会乱了,所以一般服务性的程序,往往需要一个固定的端口号,这就是所谓的端口绑定。
方法:socket.bind((ip, port))
注意:将socket对象绑定到一个地址,但这个地址必须是没有被占用的,否则会连接失败。
实例代码- udp接口绑定(发送端)
# 1 导入模块 import socket # 2 创建套接字 udp_socket =socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 3 绑定端口:socket.bind(address) # address是一个元组,元组第一个元素是字符串类型的IP地址,第二个元素是整数端口号 # ip地址可以省略,省略后表示自己的ip地址 #udp_socket.bind(('192.168.150.25', 8888)) udp_socket.bind(('', 8888)) # 4 发送数据 udp_socket.sendto('hello'.encode(), ('192.168.150.30', 8080)) # 5 关闭套接字 udp_socket.close()- udp接口绑定(接收端)
# 1 导入模块 from socket import * # 2 创建套接字 udp_socket = socket(socket.AF_INET, socket.SOCK_DGRAM) # 3 绑定端口:socket.bind(address) # address是一个元组,元组第一个元素是字符串类型的IP地址,第二个元素是整数端口号 # ip地址尽可能写成“”,好处当计算机有多个网卡的时候,不同网卡的数据都能被接收 #udp_socket.bind(('127.0.0.1', 8888)) udp_socket.bind(('', 8888)) # 4 接收对方发送的数据 recv_data, ip_port = udp_socket.recvfrom(1024) # 5 解码数据 recv_text = recv_data.decode() # 6 输出显示 print('接收[%s]的信息:%s' % (str(ip_port), recv_text)) # 7 关闭套接字 udp_socket.close()
udp广播
使用UDP的方式发送广播:广播地址(Broadcast Address)是专门用于同时向网络中所有工作站进行发送的一个地址。在使用TCP/IP协议的网络中,主机标识段host ID为全1的IP地址为广播地址。
IP地址的网络字段和主机字段全为1就是地址:255.255.255.255,所以,向255.255.255.255发送信息,就是发送广播消息。
# 1 导入模块
import socket
# 2 创建套接字
udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 3 设置广播权限(套接字默认不允许发送广播,需要开启相关权限),否则报错PermissionError
# udp_socket.setsockopt(套接字, 属性, 属性值): socket.SOL_SOCKET表示当前的套接字;socket.SO_BROADCAST表示广播属性
udp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, True)
# 4 发送数据
udp_socket.sendto('Hello'.encode(), ('255.255.255.255', 8080))
# 5 关闭套接字
udp_socket.close()
udp聊天室
说明: 在一个电脑中编写1个程序,有3个功能:1、获取键盘数据,并得其发送给对方;2、接收数据并显示;3、退出聊天系统
思路分析:
>>功能:1、发送信息;2、接收信息;3、退出系统>>架构:
1、发送信息:send_msg()
2、接收信息:recv_msg()
3、主入口:main()
4、当程序独立运行的时候,才启动聊天器>>实现步骤
1、发送信息 send_msg():
1)定义变量接收用户输入的接收方的IP地址
2)定义变量接收用户输入的接收方的端口号
3)定义变量接收用户输入的发送给接收方的内容
4)使用socket的sendto()发送信息2、接收信息recv_msg():
1)使用socket的recvfrom()接收数据
2)解码数据并输出显示3、 主入口main():
1)创建套接字
2)绑定端口
3)打印菜单(循环)
4)接收用户输入的选项
5)判断用户的选择,并且调用对应的函数
6)关闭套接字
代码实现:
import socket
# 1、发送信息 send_msg():
def send_msg(udp_socket):"""发送信息"""# 1)定义变量接收用户输入的接收方的IP地址ipaddr = input('请输入接收方的IP地址:\n')# 判断是否需要默认if len(ipaddr) == 0:ipaddr = '192.168.150.93'print('当前接收方默认IP设置为[%s]' % ipaddr)# 2)定义变量接收用户输入的接收方的端口号port = input('请输入接收方的端口号:\n')if len(port) == 0:port = '8080'print('当前接收方默认端口设置为[%s]' % port)# 3)定义变量接收用户输入的发送给接收方的内容content = input('请输入要发送的内容:\n')# 4)使用socket的sendto()发送信息udp_socket.sendto(content.encode(), (ipaddr, int(port)))# 2、接收信息recv_msg():
def recv_msg(udp_socket):"""接收信息"""# 1)使用socket的recvfrom()接收数据recv_data, ip_port = udp_socket.recvfrom(1024)# 2)解码数据recv_text = recv_data.decode()# 3)并输出显示print('接收到[%s]的消息:%s' % (str(ip_port), recv_text))# 3、 主入口main():
def main():"""程序的主入口"""# 1)创建套接字udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 2)绑定端口udp_socket.bind(('', 8080))# 3)打印菜单(循环)while True:print('***************************')print('****** 1、发送信息 ********')print('****** 2、接收信息 ********')print('****** 3、退出系统 ********')# 4)接收用户输入的选项sel_num = int(input("请输入选项:\n"))# 5)判断用户的选择,并且调用对应的函数if sel_num == 1:print('您选择的是发送信息')send_msg(udp_socket)elif sel_num == 2:print('您选择的是接收信息')recv_msg(udp_socket)elif sel_num == 3:print('系统正在退出中...')print('系统退出完成!')breakelse:print('输入有误,请重新输入!')# 6)关闭套接字udp_socket.close()if __name__ == '__main__':"""程序独立运行的时候,才去启动聊天室"""main()
TCP简介
-
TCP介绍
TCP协议,传输控制协议(英语:Transmission Control Protocol,缩写为TCP) 是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
TCP通信需要经过创建连接、数据传送、终止连接三个步骤。
TCP通信模型中,在通信开始之前,一定要先建立相关的链接,才能发送数据,类似于生活中,“打电话”。 -
TCP特点
- 面向连接
通信双方必须先建立连接才能进行数据的传输,双方都必须为该连接分配必要的系统内核资源,以管理连接的状态和连接上的传输。
双方间的数据传输都可以通过这一个连接进行。
完成数据交换后,双方必须断开此连接,以释放系统资源。
这种连接是一对一的,因此TCP不适用于广播的应用程序,基于广播的应用程序请使用UDP协议。 - 可靠传输
a. TCP采用发送应答机制
TCP发送的每个报文段都必须得到接收方的应答才认为这个TCP报文段传输成功。
b. 超时重传
发送端发出一个报文段之后就后动定时器,如果在定时时间内没有收到应答就重新发送这个报文段。
TCP为了保证不发生丢包,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的包发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据包就被假设为已丢失将会被进行重传。
c. 错误校验(顺序校验、去除重复)
TCP用一个校验和函数来检验数据是否有错误;在发送和接收时都要计算校验。
d. 流量控制和阻塞管理
流量控制用来避免主机发送得过快而使接收方来不及完全收下。
- 面向连接
-
TCP与UDP的不同点
面向连接(确认有创建三方交握,连接已创建才作传输)
有序数据传输
重发丢失的数据包
舍弃重复的数据包
无差错的数据传输
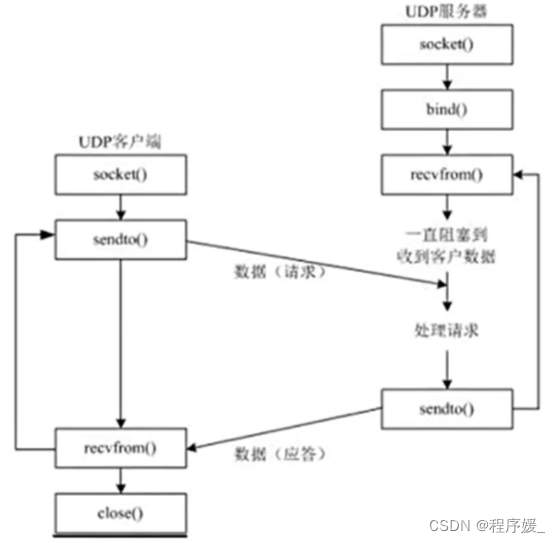
阻塞/流量控制TCP编程的服务器端一般步骤是: 1. 创建一个socket,用函数socket(); 2. 设置socket属性,用函数setsockopt(); 可选 3. 绑定IP地址、端口等信息到socket上,用函数bind(); 4. 开始监听,用listen(); 5. 接收客户端上来的连接,用函数accept(); 6. 收发数据,用函数send()和recv() 7. 关闭网络连接; 8. 关闭监听;TCP编程的客户端一般步骤是: 1)创建一个socket,用函数socket(): 2)设置socket属性,用函数setsockopt(); 可选 3)绑定IP地址、端口等信息到socket上,用函数bind();可选 4)设置要连接的对方的IP地址和端口等属性; 5)连接服务器,用函数connect(); 6)收发数据,用函数send()和recv() 7)关闭网络连接;与之对应的UDP编程步骤要简单许多,分别如下: UDP编程的服务器端一般步骤是: 1. 创建一个socket,用函数socket(); 2. 设置socket属性,用函数setsockopt();可选 3. 绑定IP地址、端口等信息到socket上,用函数bind(); 4. 循环接收数据,用recvfrom(); 5. 关闭网络连接;UDP编程的客户端一般步强是: 1)创建一个socket,用函数socket(); 2)设置socket属性,用函数setsockopt();可选 3)绑定IP地址、端口等信息到socket上,用函数bind();可选 4)设置对方的IP地址和端口等属性; 5)发送数据,用函数sendto(); 6)关闭网络连接;UDP通信模型
udp通信模型中,在通信开始之前,不需要建立相关的链接,只需要发送数据即可,类似于生活中的“写信"。
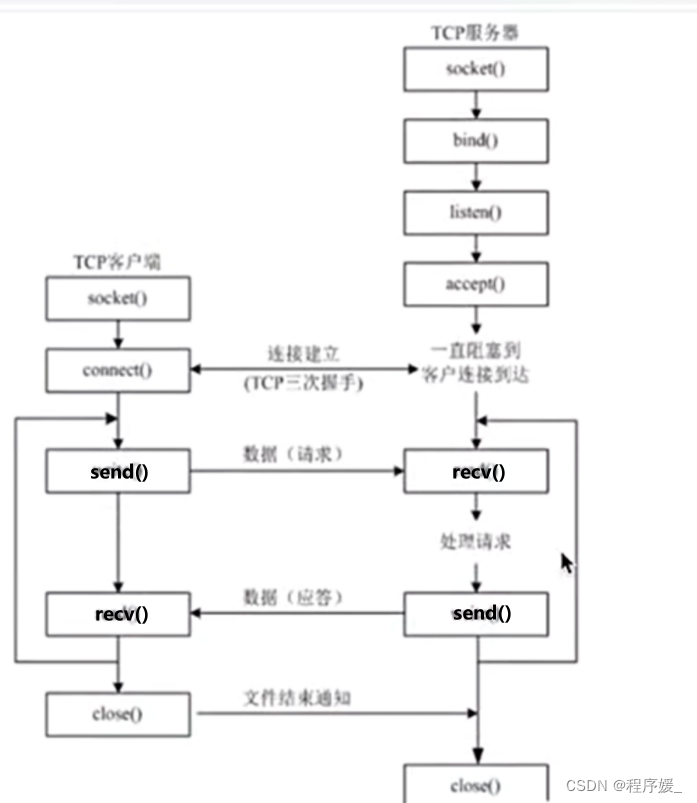
TCP通信模型——严格区分客户端、服务端
TCP通信模型中,在通信开始之前,需要建立相关的链接,类似于生活中的“打电话"。
TCP客户端
tcp的客户满要比服务器端简单很多,tcp和服务器建立连接后,直接发送数据。
"""
1. 导入模块socket
2. 创建socket套接字
3. 建立tcp连接(和服务端建立连接)
4. 开始发送数据(到服务端)
5. 接受数据
6. 关闭套接字
"""# 1. 导入模块socket
import socket
# 2. 创建socket套接字
tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # SOCK_STREAM TCP传输方式;SOCK_DGRAM UDP传输方式
# 3. 建立tcp连接 connect(('ip', port))
tcp_client_socket.connect(('192.168.150.71', 8080))
# 4. 开始发送数据(到服务端)send('内容'.encode())
tcp_client_socket.send('hello'.encode())
# 5. 接受数据 recv(bufsize) -- 接收TCP数据,数据以二进制形式返回,bufsize缓冲区大小指定要接收的最大数据量1024
recv_data = tcp_client_socket.recv(1024)
recv_text = recv_data.decode('GBK') # 解码
print('收到数据:', recv_text) # 输出显示
# 6. 关闭套接字
tcp_client_socket.close()
TCP服务器端
TCP服务器:和客户端建立连接后,接收/发送数据给客户端。
'''
1. 导入模块socket
2. 创建套接字
3. bind绑定ip和port
4. listen开启监听(设置套接字为被动模式)
5. accept等待客户端的连接
6. recv/send接收/发送数据
7. 关闭连接
'''# 1. 导入模块socket
import socket
# 2. 创建套接字
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 3. bind绑定ip和port
tcp_server_socket.bind(('', 8080))
# 4. listen开启监听(设置套接字为被动模式)
# listen() 作用设置tcp_server_socket套接字为被动监听模式,不能在主动发送数据
# 128允许接受的最大的连接数,在windows 128有效(最大允许128个连接),但是在linux此数字无效
tcp_server_socket.listen(128)
while True: #可以接受多个客户端连接,注意:必须等待第一个客户端断开后,第二个客户端才能有机会连接。# 5. accept等待客户端的连接# accept()开始接收客户端连接,程序会默认进入阻塞状态(等待客户端连接),如果由客户端连接后,程序自动解除阻塞# accept()返回的数据含有两部分:1. 返回一个新的套接字socket对象,只是服务当前的客户端;2. 客户端的ip地址和端口号 元组new_client_socket, client_ip_port = tcp_server_socket.accept()print('新客户端来了:%s' % str(client_ip_port))# 6. recv/send接收/发送数据while True: # 可以接受客户端发来的多条信息recv_data = new_client_socket.recv(1024) # 使用新的套接字接受客户端发送的信息if recv_data: # 如果recv_data非空即为真,否则为假recv_text = recv_data.decode('GBK')print('接收到[%s]的信息:%s' % (str(client_ip_port), recv_text))else:print('客户端已经断开连接!')break# 7. 关闭连接new_client_socket.close() # 表示不能再和当前的客户端通信了
# tcp_server_socket.close() # 表示程序不再接受新的客户端连接,已经连接的可以继续服务
案例:文件下载器
-
功能分析
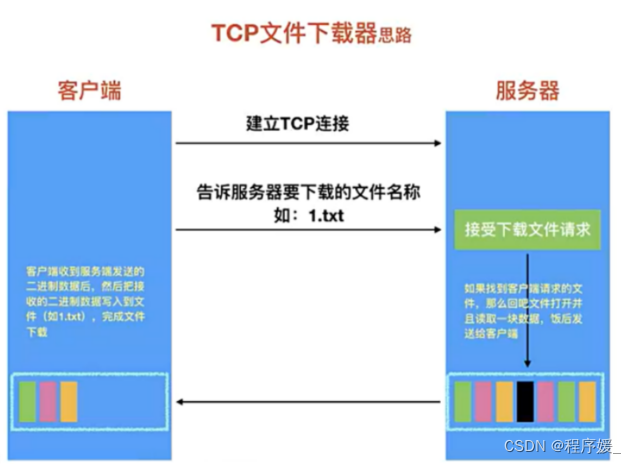
-
实现代码
TCP客户端:""" 目标: 将/home/demo/Document/python_projects/1.txt下载到/home/demo/Desktop/1.txt 客户端实现思路: 1. 导入模块 2. 创建套接字 3. 建立和服务器的连接 4. 接受用户输入的文件名 5. 发送文件名到服务器端 6. 创建文件,并且准备保存 7. 接受服务器发送的文件数据,保存到本地(循环) 8. 关闭套接字 """# 1. 导入模块 import socket # 2. 创建套接字 tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 3. 建立和服务器的连接 tcp_client_socket.connect(('192.168.150.71', 8080)) # 4. 接受用户输入的文件名 file_name = input('请输入要下载的文件名:\n') # 5. 发送文件名到服务器端 tcp_client_socket.send(file_name.encode()) # 6. 创建文件,并且准备保存 with open('/home/demo/Desktop/'+file_name, 'wb') as file:# 7. 接受服务器发送的文件数据,保存到本地(循环)while True:file_data = tcp_client_socket.recv(1024)if file_data: # 判读数据是否传送完毕file.write(file_data)else:break # 8. 关闭套接字 tcp_client_socket.close()TCP服务端:
""" 客户端实现思路: 1. 导入模块 2. 创建套接字 3. 绑定地址和端口 4. 开始监听,设置套接字由主动为被动监听模式 5. 等待客户端连接(如果有新客户端连接,会创建新的套接字) 6. 接受客户端发来的文件名 7. 根据文件名读取文件数据 8. 把读取的文件数据发送给客户端(循环) 9. 关闭和当前客户端的连接 10. 关闭套接字 """# 1. 导入模块 import socket # 2. 创建套接字 tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 3. 绑定地址和端口 tcp_server_socket.bind(('', 8080)) # 4. 开始监听,设置套接字由主动为被动监听模式 tcp_server_socket.listen(128) # 5. 等待客户端连接(如果有新客户端连接,会创建新的套接字) while True: # 存在问题:多个客户端下载是同步的,必须是一个下载完成后,另外一个客户端才能连接下载new_client_socket, ip_port = tcp_server_socket.accept()print('欢迎新客户端:', ip_port)# 6. 接受客户端发来的文件名recv_data = new_client_socket.recv(1024)file_name = recv_data.decode()try:# 7. 根据文件名读取文件数据with open(file_name, 'rb') as file:# 8. 把读取的文件数据发送给客户端(循环)while True:file_data = file.read(1024)if file_data: # 判断是否读到了文件的末尾new_client_socket.sendto(file_data)else:breakexcept Exception as e:print('文件%s下载失败!' % file_name)else:print('文件%s下载成功!' % file_name)# 9. 关闭和当前客户端的连接new_client_socket.close() # 10. 关闭套接字 # tcp_server_socket.close()
TCP的3次握手
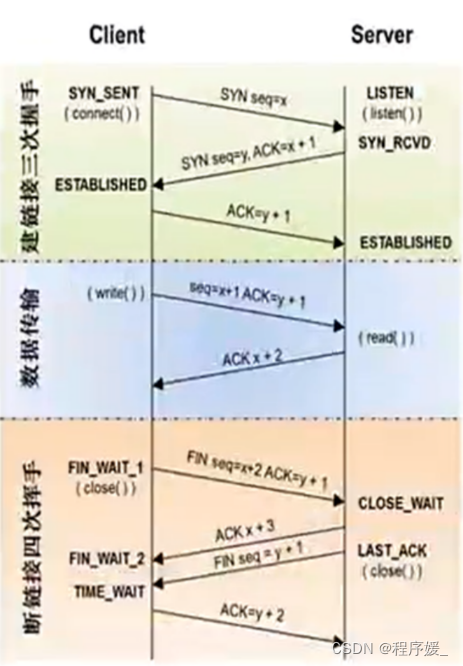
概念: 所谓三次握手(Three-Way Handshake),即建立TCP连接,就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。在socket编程中,这一过程由客户端执行connect来触发。
整体流程如下:
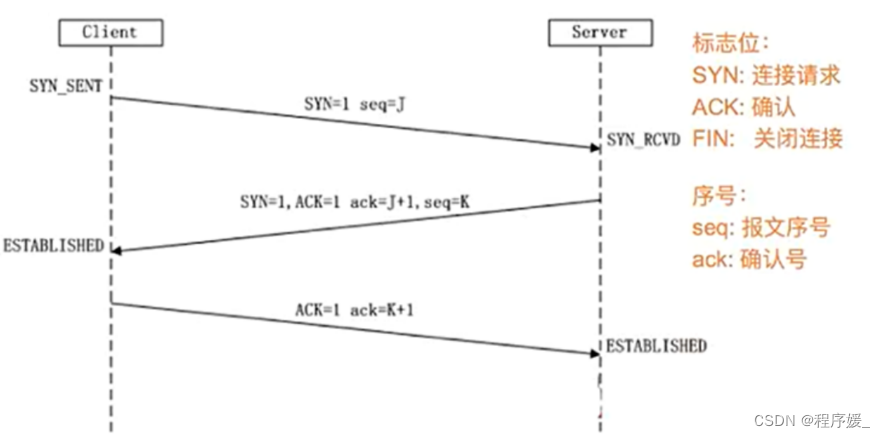
(1) 第一次握手:Client将标志位SYN(连接请求)置为1,随机产生一个值seq=J(报文序号),并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
(2) 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK(确认)都置为1,ack=J+1(确认号),随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
(3) 第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
常见面试题
问: 为什么需要三次握手,两次不可以吗?或者四次、五次可以吗?
答: 我们来分析一种特殊情况,假设客户端请求建立连接,发给服务器SYN包等待服务器确认,服务器收到确认后,如果是两次握手,假设服务器给客户端在第二次握手时发送数据,数据从服务器发出,服务器认为连接已经建立,但在发送数据的过程中数据丢失,客户端认为连接没有建立,会进行重传。假设每次发送的数据一直在丢失,客户端一直SYN,服务器就会产生多个无效连接,占用资源,这个时候服务器可能会挂掉。这个现象就是我们听过的“SYN的洪水攻击”。
总结: 第三次握手是为了防止:如果客户端迟迟没有收到服务器返回确认报文,这时会放弃连接,重新启动一条连接请求,但问题是:服务器不知道客户端没有收到,所以他会收到两个连接,浪费连接
开销。如果每次都是这样,就会浪费多个连接开销。
TCP的4次挥手
TCP的4次挥手,主要是说TCP断开连接的时候。
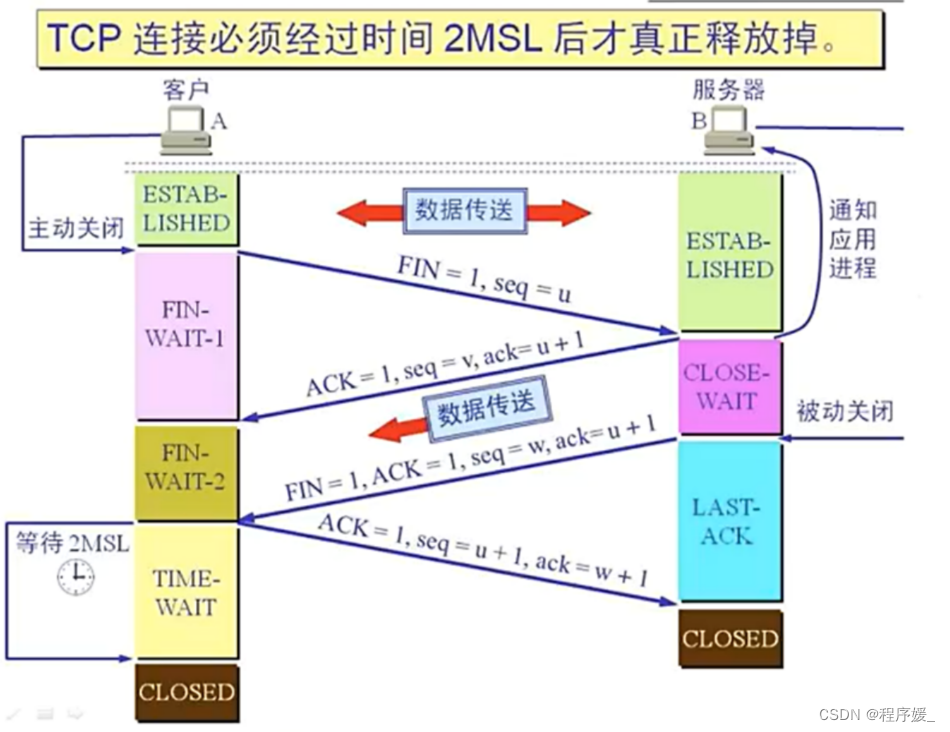
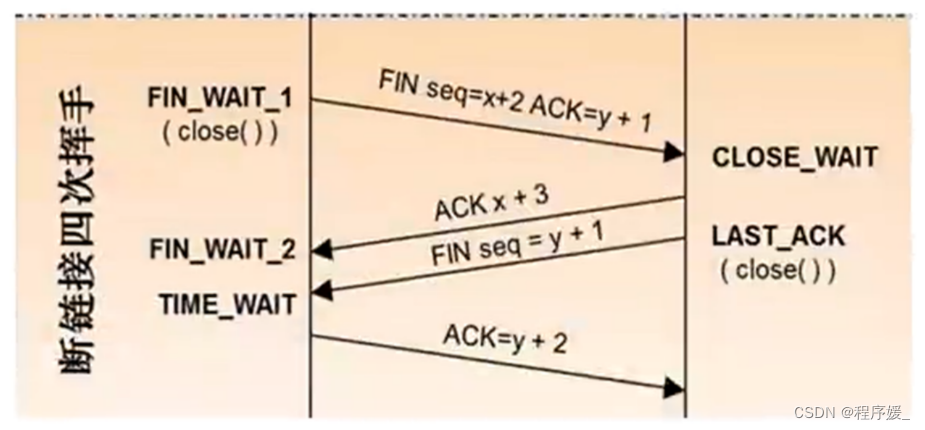
(1) 第一次挥手:主机1(可以是客户端,也可以是服务器端),设置Sequence Number和Acknowledgment Number,向主机2发送一个FIN(关闭连接)报文段;此时,主机1进入FIN_WAIT1状态:这表示主机1没有数据要发送给主机2了;
(2) 第二次挥手:主机2收到了主机1发送的FIN报文段,向主机1回一个ACK(确认)报文段,Acknowledgment
Number为Sequence Number加1;主机1进入FIN_WAIT2状态;主机2告诉主机1,我也没有数据要发送了,可以进行关闭连接了;
(3) 第三次挥手:主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入CLOSE_WAIT状态;
(4) 第四次挥手:主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。
三次握手、四次挥手完整图:
问题
- 为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
首先,MSL即Maximum Segnment Lifetime, 就是最大报文生存时间,是任何报文再网络上的存在的最长时间,超过这个时间的报文将被丢弃。MSL是任何报文段被丢弃前在网络内的最长时间,MSL规定为2分钟,实际应用中常用的是30秒、1分钟、2分钟等。
TCP的TIME_WAIT需要等待2MSL,当TCP的一端发送主动关闭,三次挥手完成后发送第四次挥手的ACK包就进入这个状态,等待2MSL时间主要目的是:防止最后一个ACK包对方没有收到,那么对方在超时后将重发第三次挥手的FIN包,主动关闭端接到重发的FIN包后可以再发一个ACK应答包。在TIME_WAIT状态时两端的接口不能使用,要等到2MSL时间结束才可以继续使用。当连接处于2MSL等待阶段时任何迟到的报文段都将被丢弃。- client发送完最后一个ack之后,进入time_wait状态,但是他怎么知道server有没有收到这个ack呢?莫非server也要等待一段时间,如果收到了这个ack就close,如果没有收到就再发一个fin给client?这么说server最后也有一个time_wait哦?求解答!
因为网络原因,主动关闭的一方发送的这个ACK包很可能延迟,从而触发被动连接一方重传FIN包。极端情况下,这一去一回,就是两倍的MSL时长。如果主动关闭的一方跳过TIME_WAIT直接进人CLOSED,或者在TIME_WAIT停留的时长不足两倍的MSL,那么当被动关闭的一方早先发出的延迟包到达后,就可能出现类似下面的问题:1. 旧的TCP连接已经不存在了,系统此时只能返回RST包。2. 新的TCP连接被建立起采了,延迟包可能干扰新的连接,这就是为什么time_wait需要等待2MSLB时长的原因。- 为什么连接的时候是三次握手,关闭的时候却是四次挥手?
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”,只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步挥手。
浏览器访问服务器的过程——IP地址、域名、DNS
-
IP地址
IP的全称是Internet Protocol Address互联网协议地址,就是网络地址。IP地址与我们的身份证一
样,都具有唯一性。
网络不分国界的,全球范国内的所有主机,都有一个“身份证号”,就是IP地址不能相同。
IP地址分为IPv4和IPV6,IP地址是由32位二进制构成,分成四段,每段8位二进制。
在现实中,我们用“点分十进制”来表示,形如“a.b.c.d”形式表示,每一段的取值范围是0-255。举例:192.168.2.234特殊的IP地址:127.0.0.1,每台电脑都有,是电脑内部的IP地址。
127.0.0.1代表自己的内部的IP地址,永远都是自己访问自己,外网无法访问。 -
域名
概念: 域名,简称DN(全称:Domain Name),域名可以理解为是一个网址,就是一个特殊的名字。
为什么要有域名: 互联网上的每台主机,都有一个唯一的IP地址,但是IP地址不方便记忆,因此,才有了域名。
域名的构成:由字母、数字、中划线(-),长度不超过255个字符。
例如:www.sina.com.cn、www.baidu.com、www.hao123.com其中,.com称为J顶级域名。
常见的顶级域名:域名 备注 .com 用于商业机构。它是最常见的顶级域名。任何人都可以注册.COM形式的域名 .cn 中国专用的顶级域名 .gov 国内域名,政府、企事业单位常见域名 .org 是为各种组织包括非盈利组织而定的,任何人都可以注册以.ORG结尾的域名 .net 最初是用于网络组织,例如因特网服务商和维修商。任何人都可以注册以.NET结尾的域名 .com.cn 国内常见二级域名 localhost是个特殊域名,不是地址,它可以被配置为任意的IP地址。
不过通常情况下都指向127.0.0.1(ipv4)和::1,永远都只能自己访问自己,不能访问其它人的localhost
域名。 -
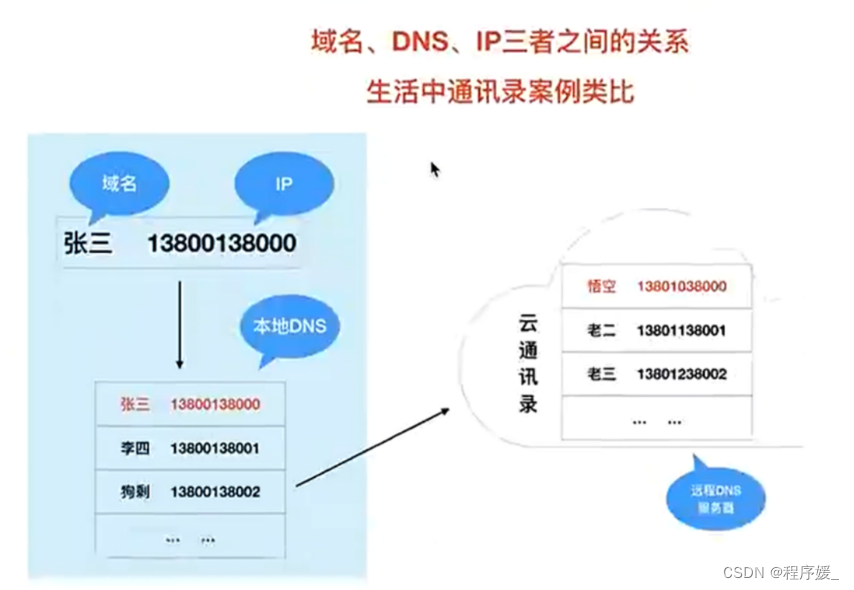
DNS服务器
DNS(Domain Name System 域名解析系统),主要用来将域名转成对应的IP地址。
DNS是一台运行在互联网上的服务器。
直白理解:DNS服务器就可以看做是一个通讯录(姓名>>域名,电话>>ip地址)
电脑之间的互访,只能识别IP地址的访问,不识别域名的访问。
本地DNS:
本地DNS服务器是一个文件hosts。hosts是本地的DNS,DNS中就是IP地址和域名的对应关系表。
hosts文件是隐藏文件、系统文件、没有扩展名的文件。Hosts文件路径:
windos:C:\Windows\System32\drivers\etc
linux: /etc/hosts,注意linux下修改hosts后需要重层网络,命令为:/etc/init.d/networking restart
浏览器请求的基本流程如下:
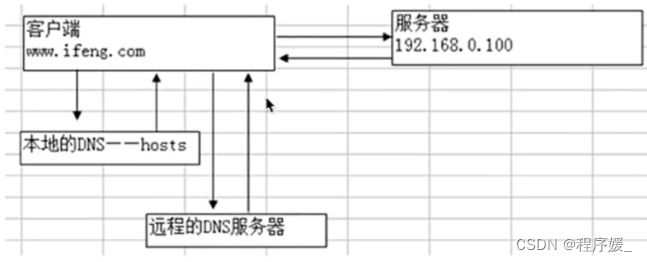
当我们在浏览器中输入网址,访问网站后,服务器会返回HTML标记给浏览器,浏览器负责渲染展现出来。(浏览器>>输入网址>>本地DNS服务器查询>>远程DNS服务器>>建立TCP连接)
HTTP协议
-
简介
超文本传输协议(HTTP,HyperTextTransferProtocol) 是互联网上应用最为广泛的一种网络协议,所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
HTTP是一个客户端和服务器端请求和应答的标准(TCP)。客户端是终端用户,服务器端是网站。通过使用Web浏览器、网络爬虫或者其它的工具,客户端发起一个到服务器上指定端口(默认端口为80)的HTTP请求。
超文本传输协议是一种应用层协议。
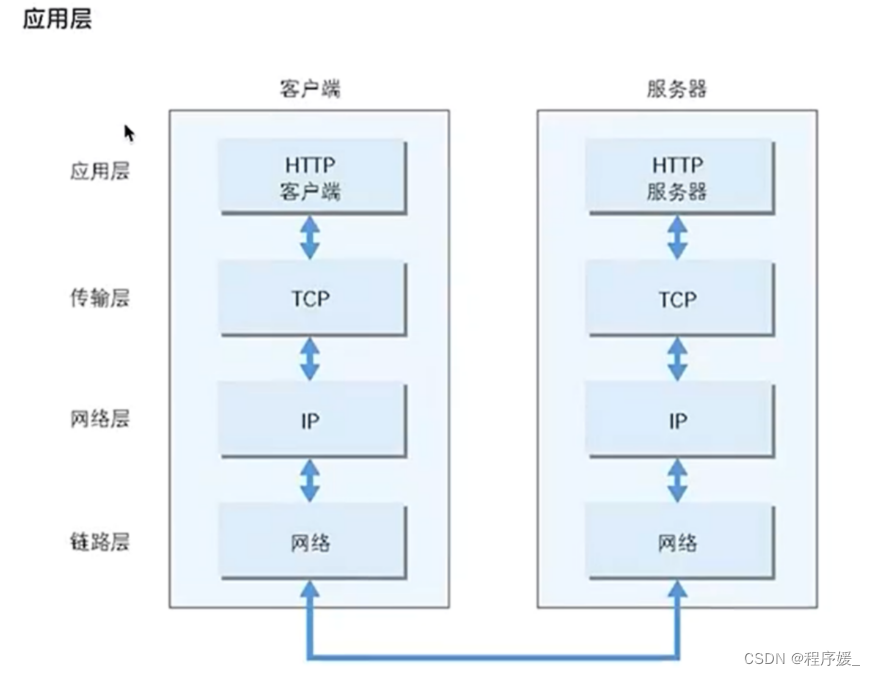
- 链路层(数据链路层/网络接口层):包括操作系统中的设备驱动程序、计算机中对应的网络接口卡。
- 网络层:处理分组在网络中的活动,比如分组的选路。
- 运输层:主要为两台主机上的应用提供端到端的通信。
- 应用层:负责处理特定的应用程序细节。
-
请求request-响应response式模式
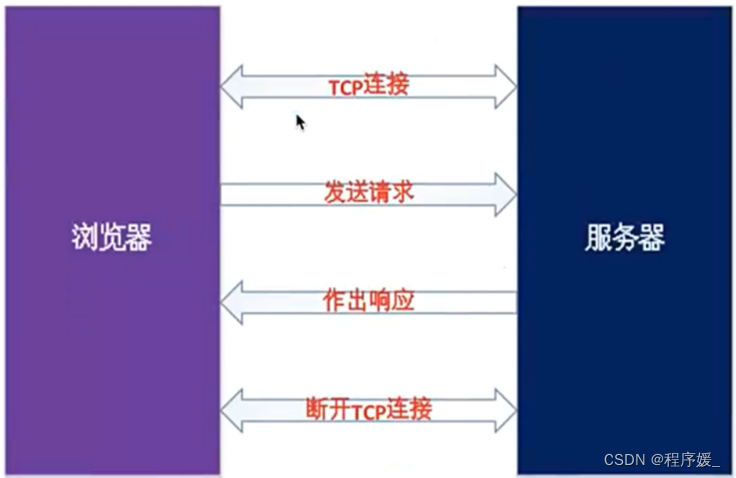
所以,http协议分为两个部分:请求协议、响应协议
不管是请求还是响应,其实http协议都是由一个一个的简单的协议项组成的,形式如下:
协议名:协议内容(值),比如:Host: www.itcast.cn
注意:每一个协议项都单独的占用一行! -
HTTP协议格式查看
在web应用中,服务器把网页传给浏览器,实际就是把网页的HTML代码发送给浏览器,浏览器解析显示出来。而浏览器和服务器之间的传输应用层协议就是HTTP,所以:- HTML是一种用来定义网页的文本,会HTML就可以编写网页。
- HTTP是用来在网络上传输HTML文本的协议,用于浏览器和服务器的通信。
HTTP协议报文格式查看:
- Windows/Linux平台:按F12调出开发者工具
- MAC选择视图>>开发者工具
HTTP请求协议分析
http请求又包含了四个部分:
1. 请求行(request-line)
2. 请求头(request-header)
3. 空行
4. 请求数据(request-content),也叫作请求内容或者请求主体
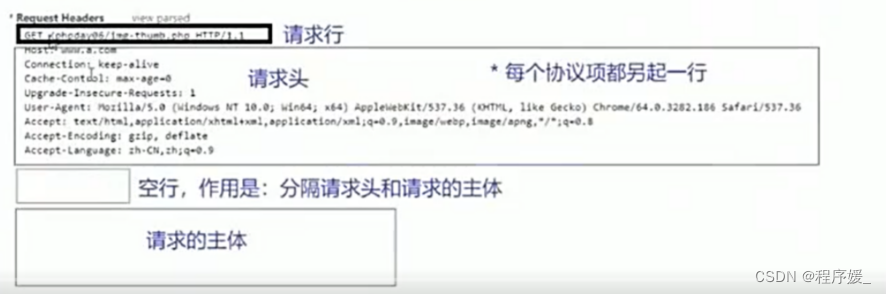
(1)请求行:请求方式 资源路劲 协议及版本\r\n
请求行又可以分成三个部分:请求方式 请求路径 协议版本

其中,GET就是请求方式,/model/list_father.php就是请求路径,HTTP/1.1就是协议版本号。
注意:
1. 请求行需要单独的占一行,用来说明当前请求的最基本的信息
2. 请求路径是不包括域名的
3. HTTP协议以前是1.0版本,现在是1.1版本
(2)请求头:协议名:协议值\r\n
请求头就是所有当前需要用到的协议项的集合!
协议项就是浏览器在请求服务器的时候事先告诉服务器的一些信息,或者一些事先的约定!
常见的请求头有:
| 请求头 | 说明 |
|---|---|
| Host | 当前url所要请求的服务器的主机名(域名) |
| Accept-Encoding | 是浏览器发给服务器,声明浏览器支持的压缩编码类型,比如gzip |
| Accept-Language | 可以接收的语言类型:cn、en,有权重的高低之分 |
| Referer | 表示此次请求来自哪个网址 |
| Accept-Charset | 表示浏览器支持的字符集 |
| Cookie | 如果之前当前请求的服务器在浏览器端设置了数据(cookie),那么当前浏览器再次请求该服务器的时候,就会把对应的数据带过去 |
| User-Agent | 用户代理,当前发起请求的浏览器的内核信息 |
| Accept | 表示浏览器可以接收的据类型,text/html、image/img |
| Content-Length | 只有post提交的时候才会有的请求头,显示的是当前要提交的数据的长度(字节) |
| If-Modified-Since(get) | 表示在客户端向服务器请求某个资源文件时,询问此资源文件是否被修改过 |
(3)空行
就是用来分离请求头和请求数据,意思就是请求头到此结束!
(4)请求数据
只有post方式提交的时候,才有请求数据!是浏览器要发送给服务器端的内容。
请求报文格式总结:

HTTP响应报文协议分析
http响应也分成了四个部分:
1、响应行(状态行)
2、响应头
3、空行
4、响应主体(响应数据)
(1)响应行
第一行HTTP/1.1 200 OK叫做响应行,共分成3部分:协议版本号 状态码 状态描述
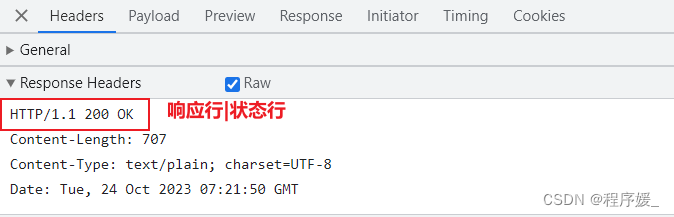
注意: 状态码和状态描速是一一对应的!
状态代码有三位应数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息–表示请求已接收,继续数处理;
2xx:成功–表示请求已被成功接收、理解、接受;
3xx:重定向–要完成请求必须进行更进一步的操作;
4xx:客户端错误–请求有语法错误或请求无法实现;
5xx:服务器端错误–服务器未能实现合法的请求。
常见的状态码:
| 状态码 | 含义 |
|---|---|
| 200 | OK,请求已成功。 |
| 302 | Move temporarilyi请求的资源临时从不同的URL响应请求。由于这样的重定向是在时的,客户端应当继续向原有地址发送以后的请求 |
| 304 | Not Modified文档的内容(自上次访问以来或者根据请求的条件)并没有改变 |
| 400 | Bad Reques语义有误,当前请求无法被服务器理解 |
| 401 | Unauthorized:当前请求需要用户验证 |
| 403 | Forbidden服务器收到请求,但是拒绝提供此服务 |
| 404 | Not Found请求资源不存在 |
| 408 | Request Timeouti请求超时 |
| 500 | Internal Server Error服务器发生不可预知的错误 |
| 503 | Server Unavailable服务器当前不能处理客户端的请求,一段时间后可能恢复正常 |
(2)响应头
也是一些协议的集合,也是协议名:值的形式!
常见的有:
| 响应头 | 说明 |
|---|---|
| Server | 服务器主机信息 |
| Date | 响应时间 |
| Last-Modified | 文件最后修改时间 |
| Content-Length | 响应主体的长度(字节) |
| Content-Type | 响应内容的数据类型:text/html, image/png等 |
| Location | 重定向,浏览器遇到这个选项,就立马跳转(不会解析后面的内容) |
| Refresh | 重定向(刷新),浏览器遇到这个选项就会准备跳转,刷新一般有时间限制,时间到了才跳转,浏览器会继续向下解析 |
| Content-Encoding | 文件编码格式 |
| Cache-Control | 缓存控制,no-cached不要缓存 |
(3)空行
用来分割响应头与响应主体,也就是响应头到此结束!
(4)响应主体
就是服务器反馈给浏览器的数据!
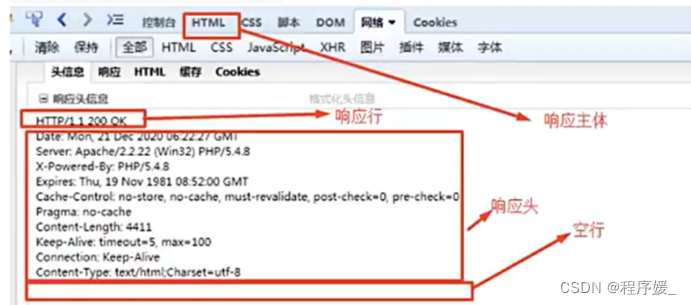
响应报文格式总结:

长连接和短连接

在HTTP/1.0中,默认使用的是短连接,也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。如果客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源,如js文件、图像文件、CSS文件等;当浏览器每遇到这样一个Web资源,就会建立一个HTTP会话。
但从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头有加入这行代码:Connection: keep-alive
在真正的读写操作之前,server与client之间必须建立一个连接;
当读写操作完成后,双方不再需要这个连接时它们可以释放这个连接;
连接的建立通过三次握手,释放则需要四次挥手;
所以说每个连接的建立都是需要资源消耗和时间消耗的。
-
TCP短连接
概述:一次连接,一次传输,就关闭。
特点:会频繁的建立和断开连接,当瞬间访问压力比较大的时候,服务器响应过慢。

- client向server发起连接请求;
- server接到请求,双方建立连接;
- client向server发送消息;
- server回应client;
- 一次读写完成,此时双方任何一个都可以发起close操作
在步骤5中,一般都是client先发起close操作。当然也不排除有特殊的情况。从上面的描述看,短连接一般只会在client/server间传递一次读写操作!
-
TCP长连接
概述:一次连接,多次数据传输,通信结束关闭连接。
特点:要不连不上,一旦连上,速度有保证,当瞬间访问压力比较大的时候,服务器不可用。

- client向server发起连接
- server接到请求,双方建立连接
- client向server发送消息
- server回应client
- 一次读写完成,连接不关闭
- 后续读写操作…
- 长时间操作之后client发起关闭请求
-
TCP长/短连接的优缺点
(1)长连接可以省去较多的TCP建立和关闭的作,节约时间。但是如果用户量太大容易造成服务器负载过高最终导致服务不可用。
(2)短连接对于服务器来说实现起来较为简单,存在的连接都是有用的连接,不需要额外的控制手段。但是如果用户访问量很大,往往可能在很短时间内需要创建大量的连接,造成服务器响应速度过慢。
总结:
(1)小的WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源来让套接字保持存活-keep alive
(2)对于中大型WEB网站一般都采用长连接,好处是响应用户请求的时间更短,用户体验更好,虽然更耗硬件资源一些,但这都不是事儿。另外,数据库的连接用长连接,如果用短连接频繁的通信会造成socket错误。
案例:模拟浏览器实现
模拟浏览器请求web服务器的网页过程,使用TCP实现HTTP协议(请求报文格式和响应报文格式)
'''
1、导入模块
2、创建套接字
3、建立连接
4、拼接请求协议
5、发送请求协议
6、接收服务器响应内容
7、保存内容
8、关闭连接
'''# 1、导入模块
import socket
# 2、创建套接字
tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 3、建立连接
tcp_client_socket.connect(("www.icoderi.com", 80))
# 4、拼接请求协议
# 4.1 请求行
request_line = "GET / HTTP/1.1\r\n"
# 4.2 请求头
request_header = "Host:www.icoder.com\r\n"
# 4.3 请求空行
request_blank = "\r\n"
# 整体拼接
request_data = request_line + request_header + request_blank
# 5、发送请求协议
tcp_client_socket.send(request_data.encode()) # 请求报文默认是字符串,必须转二进制
# 6、接收服务器响应内容
recv_data = tcp_client_socket.recv(4096) # 4096==4Kb
recv_text = recv_data.decode() # 解码
# 7、保存内容(响应内容)
# 7.1 查询\r\n\r\n(响应空行)的位置
loc = recv_text.find("\r\n\r\n") # find进行查找
# 7.2 截取字符串
html_data = recv_text[loc+4:] # 字符串切片截取
# 保存内容到文件中
with open('index.html', 'w') as file:file.write(html_data)
# 8、关闭准接
tcp_client_socket.close()
基于TCP的Web服务器案例
案例1——返回固定数据
目标/效果: 能够实现简单的Web服务器并返回固定数据给浏览器。
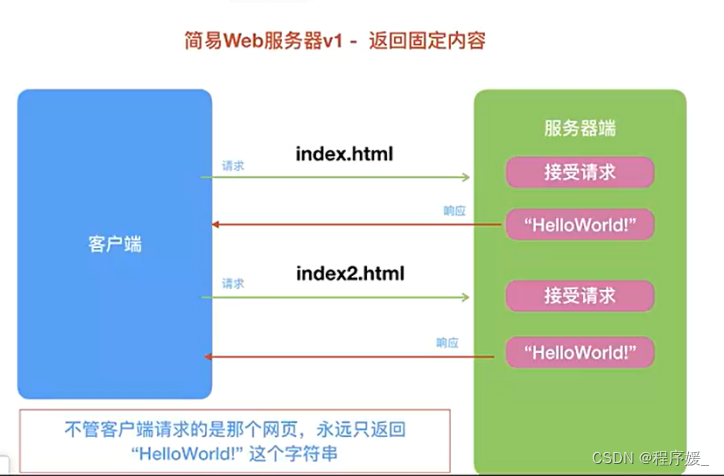
整体功能:
- Web服务器能够绑定固定端口
- Web服务器端能够接收浏览器请求
- Web服务器遵守HTTP协议,并返回“HelloWorld”字符串给浏览器
- 当浏览器关闭后,Web服务器能够显示断开连接
- Web服务器短时间内重后,不会提示address already in use错误
"""
TCP服务端
1、导入socket模块
2、创建tcp套接字
3、设置地址重用
4、绑定端口
5、设置监听,最大允许客户端连接数128(让套接字由主动变为被动接受)
6、接受客户端连接(定义函数request_handler())
7、接收客户端浏览器发送的请求协议
8、判断协议是否为空
9、拼接响应的报文
10、发送响应报文给客户端浏览器
11、关闭此次连接的套接字
"""import socketdef request_handler(new_client_socket, ip_port):"""接收信息,并且做出响应"""# 7、接收客户端浏览器发送的请求协议request_data = new_client_socket.recv(1024)# 8、判断协议是否为空if not request_data:print("%s客户端已经下线!" % str(ip_port))new_client_socket.close()return# 9、拼接响应的报文response_line = "HTTP/1.1 200 OK\r\n" # 响应行response_header = "Server:Python20WS/2.1\r\n" # 响应头response_blank = "\r\n" # 响应空行response_body = "HelloWorld!" # 响应主体response_data = response_line + response_header + response_blank + response_body# 10、发送响应报文给客户端浏览器new_client_socket.send(response_data.encode())# 11、关闭当前连接new_client_socket.close()def main():"""主函数"""# 1、导入socket模块# 2、创建tcp套接字tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 3、设置地址重用(当前套接字, 地址重用, 设置为True)tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 4、绑定端口tcp_server_socket.bind(("", 8080))# 5、设置监听,最大允许客户端连接数128(让套接字由主动变为被动接受)tcp_server_socket.listen(128)# 6、接受客户端连接(定义函数request_handler())while True:new_client_socket, ip_port = tcp_server_socket.accept()# 调用功能函数处理请求并且响应request_handler(new_client_socket, ip_port)# 11、关闭此次连接的套接字# tcp_server_socket.close()if __name__ == '__main__':main()
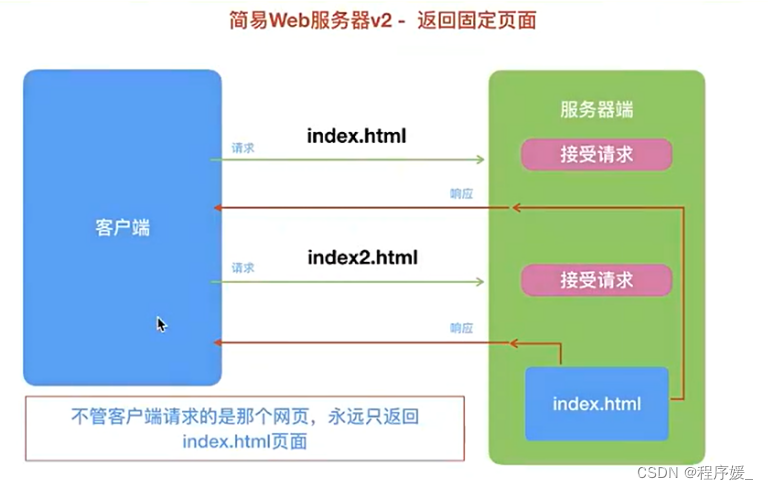
案例2——返回固定页面
目标/效果: 能够实现返回一个固定的html页面给浏览器的Web服务器。
"""
TCP服务端
1、导入socket模块
2、创建tcp套接字
3、设置地址重用
4、绑定端口
5、设置监听,最大允许客户端连接数128(让套接字由主动变为被动接受)
6、接受客户端连接(定义函数request_handler())
7、接收客户端浏览器发送的请求协议
8、判断协议是否为空
9、拼接响应的报文
10、发送响应报文给客户端浏览器
11、关闭此次连接的套接字
"""import socketdef request_handler(new_client_socket, ip_port):"""接收信息,并且做出响应"""# 7、接收客户端浏览器发送的请求协议request_data = new_client_socket.recv(1024)# 8、判断协议是否为空if not request_data:print("%s客户端已经下线!" % str(ip_port))new_client_socket.close()return# 9、拼接响应的报文response_line = "HTTP/1.1 200 OK\r\n" # 响应行response_header = "Server:Python20WS/2.1\r\n" # 响应头response_blank = "\r\n" # 响应空行# 通过with open读取文件with open("static/index.html", "rb") as file:# 把读取的文件内容返回给客户端浏览器response_body = file.read()response_data = (response_line + response_header + response_blank).encode() + response_body# 10、发送响应报文给客户端浏览器new_client_socket.send(response_data)# 11、关闭当前连接new_client_socket.close()def main():"""主函数"""# 1、导入socket模块# 2、创建tcp套接字tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 3、设置地址重用(当前套接字, 地址重用, 设置为True)tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 4、绑定端口tcp_server_socket.bind(("", 8080))# 5、设置监听,最大允许客户端连接数128(让套接字由主动变为被动接受)tcp_server_socket.listen(128)# 6、接受客户端连接(定义函数request_handler())while True:new_client_socket, ip_port = tcp_server_socket.accept()# 调用功能函数处理请求并且响应request_handler(new_client_socket, ip_port)# 11、关闭此次连接的套接字# tcp_server_socket.close()if __name__ == '__main__':main()
案例3——返回指定页面
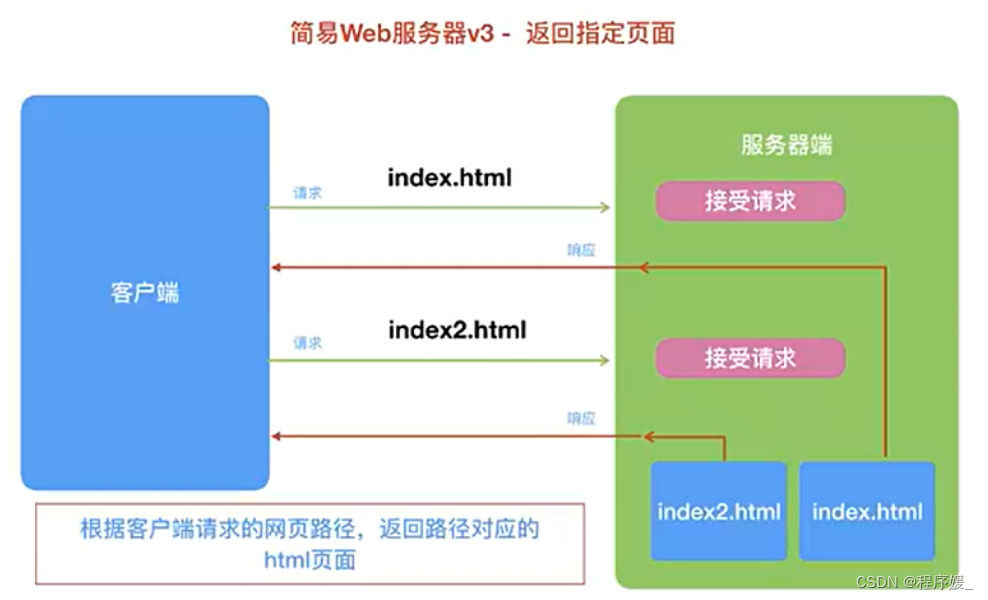
目标/效果: 能够实现根据浏览器不同请求,返回对应网页资源的Web服务器。
"""
TCP服务端
1、导入socket模块
2、创建tcp套接字
3、设置地址重用
4、绑定端口
5、设置监听,最大允许客户端连接数128(让套接字由主动变为被动接受)
6、接受客户端连接(定义函数request_handler())
7、接收客户端浏览器发送的请求协议
8、判断协议是否为空
9、拼接响应的报文
10、发送响应报文给客户端浏览器
11、关闭此次连接的套接字
"""import socketdef request_handler(new_client_socket, ip_port):"""接收信息,并且做出响应"""# 7、接收客户端浏览器发送的请求协议request_data = new_client_socket.recv(1024)# 8、判断协议是否为空if not request_data:print("%s客户端已经下线!" % str(ip_port))new_client_socket.close()return"""案例3:返回指定页面"""# 根据客户端浏览器请求的资源路径,返回请求资源# 1)把请求协议解码,得到请求报文的字符串request_text = request_data.decode()# 2)得到请求行# 2.1)查找第一个\r\n出现的位置loc = request_text.find("\r\n")# 2.2)截取字符串,从开头截取到第一个\r\n出现的位置request_line = request_text[:loc]# 3)把请求行按照空格拆分,得到列表request_line_list = request_line.split(' ')# 4)得到请求的资源路径file_path = request_line_list[1]print("[%s]正在请求:%s" % (str(ip_port), file_path))# 设置默认首页if file_path == '/':file_path = "/index.html"# 9、拼接响应的报文response_line = "HTTP/1.1 200 OK\r\n" # 响应行response_header = "Server:Python20WS/2.1\r\n" # 响应头response_blank = "\r\n" # 响应空行# 通过with open读取文件try:with open("static" + file_path, "rb") as file:# 把读取的文件内容返回给客户端浏览器response_body = file.read() # 响应主体except Exception as e:# 1) 重新修改响应行为404response_line = "HTTP/1.1 404 Not Found\r\n"# 2)响应的内容为错误信息response_body = "Error! (%s)" % str(e)# 3)把内容转换为字节码response_body = response_body.encode()response_data = (response_line + response_header + response_blank).encode() + response_body# 10、发送响应报文给客户端浏览器new_client_socket.send(response_data)# 11、关闭当前连接new_client_socket.close()def main():"""主函数"""# 1、导入socket模块# 2、创建tcp套接字tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 3、设置地址重用(当前套接字, 地址重用, 设置为True)tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 4、绑定端口tcp_server_socket.bind(("", 8080))# 5、设置监听,最大允许客户端连接数128(让套接字由主动变为被动接受)tcp_server_socket.listen(128)# 6、接受客户端连接(定义函数request_handler())while True:new_client_socket, ip_port = tcp_server_socket.accept()# 调用功能函数处理请求并且响应request_handler(new_client_socket, ip_port)# 11、关闭此次连接的套接字# tcp_server_socket.close()if __name__ == '__main__':main()
案例4——使用面向对象思想进行封装
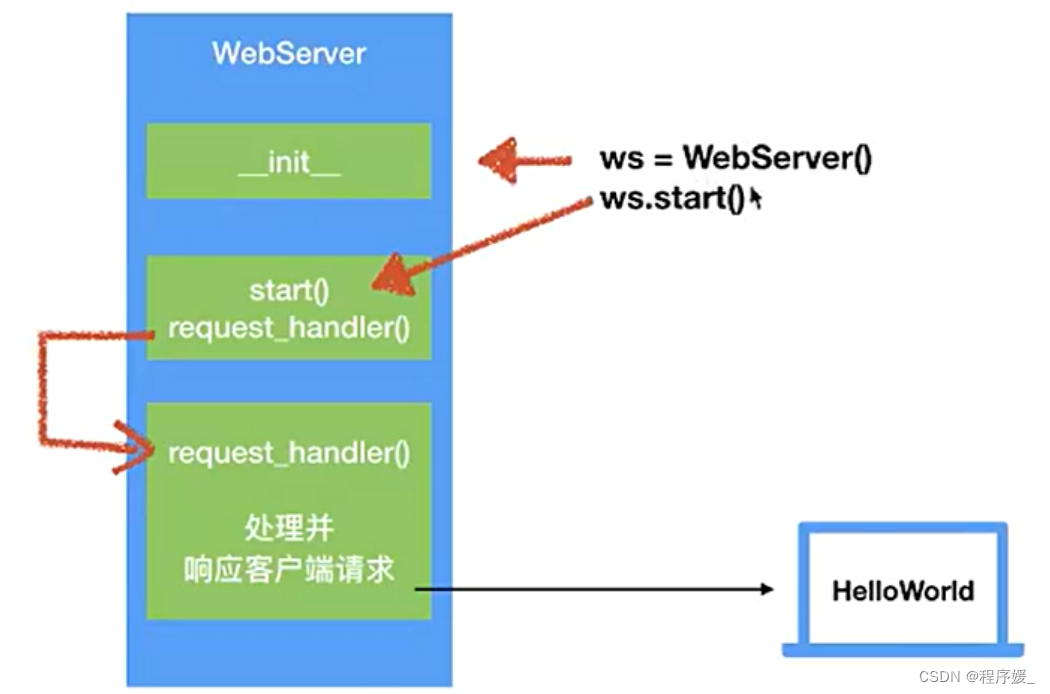
目标/效果: 能够使用面向对象思想,对Web服务器进行封装。
功能分析:
- 使用面向对象思想进行封装
- 通过对象方法.star()启动web服务器
实现思路:
1、创建WebServer类
2、创建WebServer类的构造方法__init__(),并在构造方法中对tcp_server_socket创建初始化
3、创建start0方法,用来启动Web服务器
4、修改如下代码:- 把套接字初始化的操作,放到__init__()中;
- 把接受客户端连接的代码放到start()方法中;
- 把request_handler()函数,变成对象方法(选中缩进)
- 在main()函数中创建对象ws=WebServer()然后启动ws.start()
"""
TCP服务端
1、导入socket模块
2、创建tcp套接字
3、设置地址重用
4、绑定端口
5、设置监听,最大允许客户端连接数128(让套接字由主动变为被动接受)
6、接受客户端连接(定义函数request_handler())
7、接收客户端浏览器发送的请求协议
8、判断协议是否为空
9、拼接响应的报文
10、发送响应报文给客户端浏览器
11、关闭此次连接的套接字
"""import socketclass WebServer(object):# 初始化方法def __init__(self):# 1、导入socket模块# 2、创建tcp套接字tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 3、设置地址重用(当前套接字, 地址重用, 设置为True)tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)# 4、绑定端口tcp_server_socket.bind(("", 8080))# 5、设置监听,最大允许客户端连接数128(让套接字由主动变为被动接受)tcp_server_socket.listen(128)# 定义实例属性,保存套接字对象self.tcp_server_socket = tcp_server_socketdef start(self):"""启动web服务器"""# 6、接受客户端连接(定义函数request_handler())while True:new_client_socket, ip_port = self.tcp_server_socket.accept()print('新客户来了:', ip_port)# 调用功能函数处理请求并且响应self.request_handler(new_client_socket, ip_port)# 11、关闭此次连接的套接字# tcp_server_socket.close()def request_handler(self, new_client_socket, ip_port):"""接收信息,并且做出响应"""# 7、接收客户端浏览器发送的请求协议request_data = new_client_socket.recv(1024)# 8、判断协议是否为空if not request_data:print("%s客户端已经下线!" % str(ip_port))new_client_socket.close()return"""案例3:返回指定页面"""# 根据客户端浏览器请求的资源路径,返回请求资源# 1)把请求协议解码,得到请求报文的字符串request_text = request_data.decode()# 2)得到请求行# 2.1)查找第一个\r\n出现的位置loc = request_text.find("\r\n")# 2.2)截取字符串,从开头截取到第一个\r\n出现的位置request_line = request_text[:loc]# 3)把请求行按照空格拆分,得到列表request_line_list = request_line.split(' ')# 4)得到请求的资源路径file_path = request_line_list[1]print("[%s]正在请求:%s" % (str(ip_port), file_path))# 设置默认首页if file_path == '/':file_path = "/index.html"# 9、拼接响应的报文response_line = "HTTP/1.1 200 OK\r\n" # 响应行response_header = "Server:Python20WS/2.1\r\n" # 响应头response_blank = "\r\n" # 响应空行# 通过with open读取文件try:with open("static" + file_path, "rb") as file:# 把读取的文件内容返回给客户端浏览器response_body = file.read() # 响应主体except Exception as e:# 1) 重新修改响应行为404response_line = "HTTP/1.1 404 Not Found\r\n"# 2)响应的内容为错误信息response_body = "Error! (%s)" % str(e)# 3)把内容转换为字节码response_body = response_body.encode()response_data = (response_line + response_header + response_blank).encode() + response_body# 10、发送响应报文给客户端浏览器new_client_socket.send(response_data)# 11、关闭当前连接new_client_socket.close()def main():"""主函数"""# 创建WebServer类的对象wb = WebServer()# 对象.start()启动web服务器wb.start()if __name__ == '__main__':main()
多任务 - 线程
多任务的介绍
概念: 多任务,简单地说,就是操作系统可以同时运行多个任务。现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。即:同一时间,多个任务同时执行。
表现形式: window下打开任务管理器可以很清晰看到多个进程在同时执行任务,qq、微信等都是已进程的形式寄存在window下。大多我们在写一些控制台程序真正执行的时候都是以进程调度。
python默认是单任务:
使用python代码来模拟“唱歌跳舞”这件事情:
import timedef sing():"""唱歌函数"""for i in range(3):print("正在唱歌...")time.sleep(0.5)def dance():""""跳舞函数"""for i in range(3):print("正在跳舞...")time.sleep(0.5)if __name__ == '__main__':sing()dance()
运行结果如下:
正在唱歌...
正在唱歌...
正在唱歌...
正在跳舞...
正在跳舞...
正在跳舞...Process finished with exit code 0
线程
概念: 线程,可简单理解为是程序执行的一条分支,也是程序执行流的最小单元。线程是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。
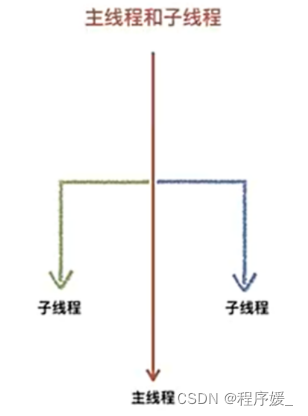
主线程: 当一个程序启动时,就有一个进程被操作系统(OS)创建,与此同时一个线程也立刻运行,该线程通常叫做程序的主线程,简而言之:程序启动就会创建一个主线程。
主线程的重要性有两方面:
1) 是产生其他子线程的线程;
2) 通常它必须最后完成执行比如执行各种关闭动作;
子线程: 可以看做是程序执行的一条分支,当子线程启动后会和主线程一起同时执行。
使用threading模块创建子线程
python的thread模块是比较底层的模块,python的threading模块是对thread做了一些包装的,可以更加方便的被使用。
核心方法:
导入模块:threading
threading模块的Thread类,创建子线程对象:t = threading.Thread(target=函数名)
启动子线程:t.start()
代码实现:
from time import sleep, ctime
import threadingdef sing():"""唱歌函数"""for i in range(3):print("正在唱歌...%d"%i)sleep(0.5)def dance():""""跳舞函数"""for i in range(3):print("正在跳舞...%d"%i)sleep(0.5)if __name__ == '__main__':print('---开始---:%s'%ctime())t1 = threading.Thread(target=sing)t2 = threading.Thread(target=dance)t1.start()t2.start()print('主线程!') # 子线程在执行的时候主线程也在执行sleep(3)print('---结束---:%s' % ctime()) # 主线程会等待所有子线程结束后才结束
运行结果如下:
---开始---:Tue Nov 14 10:24:04 2023
正在唱歌...0
正在跳舞...0主线程!正在跳舞...1
正在唱歌...1
正在跳舞...2正在唱歌...2---结束---:Tue Nov 14 10:24:07 2023Process finished with exit code 0
说明:
- 可以明显看出使用了多线程并发的操作,花费时间要短很多。
- 当调用start()时,才会真正的创建线程,并且开始执行。
- 每个线程都有一个唯一标示符,来区分线程中的主次关系。
- 主线程:mainThread,Main函数或者程序主入口,都可以称为主线程。
- 子线程:Thread-x使用threading.Thread()创建出来的都是子线程。
- 线程数量:主线程数+子线程数。
线程名称、总数量
获取当前活跃的线程对象列表:thread_list = threading.enumerate()
获取当前活跃的线程数量:len(threading.enumerate())
获取线程的名称:threading.current_thread() 获取当前的线程对象,对象中含有名称。
from time import sleep, ctime
import threadingdef sing():"""唱歌函数"""for i in range(3):print("正在唱歌...", threading.current_thread()) # 获取当前的线程对象sleep(0.5)def dance():""""跳舞函数"""for i in range(3):print("正在跳舞...", threading.current_thread())sleep(0.5)if __name__ == '__main__':print('---开始---:%s'%ctime())t1 = threading.Thread(target=sing)t2 = threading.Thread(target=dance)t1.start()t2.start()while True:thread_num = len(threading.enumerate()) # 获取当前活跃的线程数量print("当前线程的数量:", thread_num)# 如果只剩下主线程就停止if thread_num <= 1:breaksleep(0.5)
运行结果如下:
---开始---:Tue Nov 14 10:41:43 2023
正在唱歌... <Thread(Thread-1, started 22808)>
正在跳舞...当前线程的数量: 3<Thread(Thread-2, started 19404)>当前线程的数量: 3正在跳舞...<Thread(Thread-2, started 19404)>
正在唱歌... <Thread(Thread-1, started 22808)>
当前线程的数量:正在跳舞...正在唱歌... 3<Thread(Thread-1, started 22808)><Thread(Thread-2, started 19404)>
当前线程的数量: 3
当前线程的数量: 1Process finished with exit code 0
线程参数及顺序
线程参数有三种方式进行传递:
- 元组传递:
threading.Thread(target=函数名, args=(参数1,参数2,...))元组中元素的顺序和函数的参数顺序一致 - 字典传递:
threading.Thread(target=函数名, kwargs={"参数名": 参数值, ...}) - 元组、字典混合传递:
threading.Thread(target=函数名, args=(参数1, 参数2, ...), kwargs={"参数名": 参数值, ...})
from time import sleep
import threadingdef sing(a, b, c):"""唱歌函数"""print("参数:", a, b, c)for i in range(3):print("正在唱歌...")sleep(0.5)def dance():""""跳舞函数"""for i in range(3):print("正在跳舞~~~~~")sleep(0.5)if __name__ == '__main__':# 1、使用元组传递:# t1 = threading.Thread(target=sing, args=(1, 10, 100))# 2、使用字典传递:# t1 = threading.Thread(target=sing, kwargs={'a': 1, 'c': 100, 'b': 10})# 3、混合使用元组和字典t1 = threading.Thread(target=sing, args=(1,), kwargs={'c': 100, 'b': 10})t2 = threading.Thread(target=dance)t1.start()t2.start()
线程的执行顺序:
线程的调度是由CPU或者说操作系统根据当时的状态自行决定,所以多个线程的执行是无序的、随机的。
守护线程
守护线程: 如果在程序中将子线程设置为守护线程,则该子线程会在主线程结束时自动退出,设置方式为:thread.setDaemon(True), 要在thread.start()之前设置,默认是false的,也就是主线程结束时,子线程依然在执行。
对于python应用我们都知道main方法是入口,它的运行代表着主线程开始工作了,我们也知道Python虚拟机里面有垃级回收器的存在使得我们做心让main飞奔,然而这背后的故事是垃极回收线程作为守护着主线程的守护线程默默的付出着···
如下代码,主线程已经exit(),其实并没有真正结束,子线程还在继续执行。
import threading
import timedef work():for i in range(5):print('正在执行...', i)time.sleep(0.5)if __name__ == '__main__':thread_work = threading.Thread(target=work)thread_work.start()# 睡眠2stime.sleep(2)print('Game Over!!')# 让程序退出,主线程主动结束exit()
运行结果如下:
正在执行... 0
正在执行... 1
正在执行... 2
正在执行... 3
Game Over!!
正在执行... 4
添加守护线程的代码如下:
import threading
import timedef work():for i in range(5):print('正在执行...', i)time.sleep(0.5)if __name__ == '__main__':thread_work = threading.Thread(target=work)thread_work.setDaemon(True) # 表示子线程守护了主线程(主线程结束后,子线程也结束)thread_work.start()# 睡眠2stime.sleep(2)print('Game Over!!')# 让程序退出,主线程主动结束exit()
运行结果如下:
正在执行... 0
正在执行... 1
正在执行... 2
正在执行... 3
Game Over!!
并行和并发
多任务的原理剖析:
其实就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒…这样反复执行下去,表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
并发: 任务数量大于CPU的核心数。
指的是任务数多于cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
并行: 任务数量小于等于CPU的核心数,即任务真的是一起执行的。
自定义线程类
通过使用threading模块能完成多任务的程序开发,为了让每个线程的封装性更完美,所以使用threading模块时,往往会定义一个新的子类class,只要:
- 让自定义类继承threading.Thread
- 让自定义类重写run方法
- 通过实例化自定义类对象.start()方法启动自定义线程
"""
1、让自定义类继承thread.Thread类
2、重写父类(threading.Thread)run方法
3、通过创建子类对象,让子类对象.start()就可以启动子线程
"""
# 1 导入模块
import threading
import time# 2 自定义线程类并继承threading.Thread
class MyThread(threading.Thread):def __init__(self, num):# 子类先通过super调用父类的初始化方法,子类再初始化super().__init__()self.num = num# 3 重写父类的run方法def run(self):for i in range(3):# self.name 从父类继承的一个属性print('正在执行子线程的run方法...', i, self.name)time.sleep(0.5)if __name__ == '__main__':# 4 创建对象mythread = MyThread(10)# 5 线程对象.start() 启动线程;子类从父类继承了start()方法mythread.start()print('Done!')
运行结果如下:
正在执行子线程的run方法... 0 Thread-1
Done!
正在执行子线程的run方法... 1 Thread-1
正在执行子线程的run方法... 2 Thread-1
底层原理:
Thread类
run方法
start()
start()中调用了run方法
多线程-共享全局变量
多个线程方法中可以共用全局变量:
"""
看看work1线程对全局变量的修改,在work2中能否查看修改后的结果
"""# 定义全局变量
import threading
import timeg_num = 0def work1():# 声明g_num是一个全局变量global g_numfor i in range(3):g_num += 1print('work1-----', g_num)def work2():print('work2-----', g_num)if __name__ == '__main__':# 创建2个子线程t1 = threading.Thread(target=work1)t2 = threading.Thread(target=work2)# 启动线程t1.start()t2.start()while len(threading.enumerate()) != 1:time.sleep(0.5)# 在t1和t2线程执行完毕后打印g_numprint('main-----', g_num)
运行结果如下:
work1----- 3
work2----- 3
main----- 3
问题: 多个线程同时访问同一个资源,出现资源竞争的问题
假设两个线程t1和t2都要对全局变量g_num(默认是0)进行加1运算,t1和t2都各对g_num加3次,g_num的最终的结果应该为6,但是由于是多线程同时操作,有可能出现下面情况:
1)g_num=0时,t1取得g_num=0,此时系统把t1调度为"sleeping"状态,把t2转换为"running"状态,t2也获得g_num=0
2)然后t2对得到的值进行加1并赋给g_num,使得g_num=1
3)然后系统又把t2调度为"sleeping”,把t1转为"running",线程t1又把它之前得到的0加1后赋值给g_num
4)这样导致虽然t1和t2都对g_num加1,但结果仍然是g_num=1
解决方法1:
优先让某个线程先执行:线程对象.join()
缺点:把多线程变成了单线程,影响整体性能。
"""
看看work1线程对全局变量的修改,在work2中能否查看修改后的结果
"""# 定义全局变量
import threading
import timeg_num = 0def work1():# 声明g_num是一个全局变量global g_numfor i in range(1000000):g_num += 1print('work1-----', g_num)def work2():# 声明g_num是一个全局变量global g_numfor i in range(1000000):g_num += 1print('work2-----', g_num)if __name__ == '__main__':# 创建2个子线程t1 = threading.Thread(target=work1)t2 = threading.Thread(target=work2)# 启动线程t1.start()# 让t1线程优先执行,t1执行完毕后,t2才能执行t1.join()t2.start()while len(threading.enumerate()) != 1:time.sleep(0.5)# 在t1和t2线程执行完毕后打印g_numprint('main-----', g_num)
运行结果如下:
注释t1.join()代码行的运行结果:
work1----- 1000000
work2----- 1429445
main----- 1429445未注释t1.join()代码行的运行结果:
work1----- 1000000
work2----- 2000000
main----- 2000000
解决方法2:
可以通过线程同步来进行解决,思路如下:
1、系统调用t1,然后获取到g_num的值为0,此时上一把锁,即不允许其他线程操作g_num
2、t1对g_num的值进行+1
3、t1解锁,此时g_num的值为1,其他的线程就可以使用g_num了,而且是g_num的值不是0而是1
4、同理其他线程在对g_num进行修改时,都要先上锁,处理完后再解锁,在上锁的整个过程中不允许其他线程访问,就保证了数据的正确性。
同步和异步
同步: 在多任务中,多个任务执行有先后顺序,一个执行完毕后,另外一个再执行。只有一个主线。如:你说完,我再说(同一时间只能做一件事情)
异步: 在多任务中,多个任务执行没有先后顺序,多个任务同时执行。存在多条运行主线。如:发微信(可以不用等对方回复,继续发)、点外卖(点了外卖后,可以继续忙其他的事情,而不是坐等外卖,啥也不做)
线程的锁机制: 当线程获取资源后,立刻进行锁定,资源使用完毕后再解锁,有效的保证同一时间只有一个线程在使用资源。
互斥锁
当多个线程几平同时修改某一个共享数据的时候,需要进行同步控制。
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
threading模块中定义了Lock类,可以方便的处理锁定:
创建锁:mutex = threading.Lock()
锁定:metex.acquire()
释放:mutex.release()
注意:
(1)如果这个锁之前是没有上锁的,那么acquire不会堵塞。
(2)如果在调用acquire对这个锁上锁之前,它已经被其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止。
(3)使用原则:尽可能少的锁定竞争资源。
"""
1、创建一把互斥锁
2、在使用资源前要锁定资源
3、使用完资源后,要解锁资源
"""# 定义全局变量
import threading
import timeg_num = 0def work1():# 声明g_num是一个全局变量global g_numfor i in range(1000000):# 上锁lock.acquire()g_num += 1# 解锁lock.release()print('work1-----', g_num)def work2():# 声明g_num是一个全局变量global g_numfor i in range(1000000):# 上锁lock.acquire()g_num += 1# 解锁lock.release()print('work2-----', g_num)if __name__ == '__main__':# 创建一把互斥锁lock = threading.Lock()# 创建2个子线程t1 = threading.Thread(target=work1)t2 = threading.Thread(target=work2)# 启动线程t1.start()t2.start()while len(threading.enumerate()) != 1:time.sleep(0.5)# 在t1和t2线程执行完毕后打印g_numprint('main-----', g_num)
运行结果:
work1----- 1882544
work2----- 2000000
main----- 2000000
死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。尽管死锁很少发生,但一旦发生就会造成应用的停止响应。下面看一个死锁的例子:
import threading# 定义函数,根据下标获取列表元素值
def get_value(index):data_list = [1, 3, 5, 7, 9]# 上锁lock.acquire()# 判断下标位置是否正确if index >= len(data_list):print('下标越界!', index)# 释放锁(没有这句会造成死锁!!线程6-9都在等待线程5解锁)# lock.release()returnprint(data_list[index])# 解锁lock.release()# 创建10个线程,观察资源的等待状态
if __name__ == '__main__':# 创建一把锁lock = threading.Lock()# 循环创建10个线程for i in range(10):t1 = threading.Thread(target=get_value, args=(i,))t1.start()
运行结果如下:
1
3
5
7
9
下标越界! 5
避免:锁使用完毕后,要及时释放。
案例
多任务版udp聊天器
原版效果:无法实现收发信息同时进行,必须先选1发送信息,再选2接收信息
优化效果:发送消息的同时,可以同时接收多条信息
程序分析
说明:
1)编写一个有2个线程的程序
2)线程1用来接收数据然后显示
3)线程2用来检测健盘数据然后通过udp发送数据
改进思路:
1)单独开子线程用于接收消息,以达到收发消息可以同时进行
2)接收消息要能够连续接收多次,而不是一次
3)设置子线程守护主线程(解决无法正常退出问题)
参考代码:
import socket
import threadingdef send_msg(udp_socket):"""发送信息"""# 1)定义变量接收用户输入的接收方的IP地址ipaddr = input('请输入接收方的IP地址:\n')# 判断是否需要默认if len(ipaddr) == 0:ipaddr = '192.168.150.93'print('当前接收方默认IP设置为[%s]' % ipaddr)# 2)定义变量接收用户输入的接收方的端口号port = input('请输入接收方的端口号:\n')if len(port) == 0:port = '8080'print('当前接收方默认端口设置为[%s]' % port)# 3)定义变量接收用户输入的发送给接收方的内容content = input('请输入要发送的内容:\n')# 4)使用socket的sendto()发送信息udp_socket.sendto(content.encode(), (ipaddr, int(port)))def recv_msg(udp_socket):"""接收信息"""while True:# 1)使用socket的recvfrom()接收数据recv_data, ip_port = udp_socket.recvfrom(1024)# 2)解码数据recv_text = recv_data.decode()# 3)并输出显示print('接收到[%s]的消息:%s' % (str(ip_port), recv_text))def main():"""程序的主入口"""# 1)创建套接字udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 2)绑定端口udp_socket.bind(('', 8080))# 创建子线程,单独接收用户发送的消息thread_recvmsg = threading.Thread(target=recv_msg, args=(udp_socket,))# 设置子线程守护主线程(子线程会在主线程结束时自动退出)thread_recvmsg.setDaemon(True)# 启动子线程thread_recvmsg.start()# 3)打印菜单(循环)while True:print('***************************')print('****** 1、发送信息 ********')print('****** 2、退出系统 ********')# 4)接收用户输入的选项sel_num = int(input("请输入选项:\n"))# 5)判断用户的选择,并且调用对应的函数if sel_num == 1:print('您选择的是发送信息')send_msg(udp_socket)elif sel_num == 2:print('系统正在退出中...')print('系统退出完成!')breakelse:print('输入有误,请重新输入!')# 6)关闭套接字udp_socket.close()if __name__ == '__main__':"""程序独立运行的时候,才去启动聊天室"""main()
TCP服务器端框架
目标: 能够使用多线程实现同时接收多个客户端的多条信息
思想: 每来一个新的客户端,就创建一个新的线程。
参考代码:
"""
1、导入模块
2、创建套接字
3、设置地址可以重用
4、绑定端口
5、设置监听,套接字有主动设置为被动
6、接受容户瑞连接
7、接收容户瑞发送的信息
8、解码数据并且进行输出
9、关闭和当前容户瑞的连接
"""
# 1、导入模块
import socket
import threadingdef recv_msg(new_client_socket, ip_port):while True:# 7、接收容户瑞发送的信息recv_data = new_client_socket.recv(1024)if recv_data:# 8、解码数据并且进行输出recv_text = recv_data.decode("GBK")print("收到来自[%s]的信息:%s" % (str(ip_port), recv_text))else:break# 9、关闭和当前容户瑞的连接new_client_socket.close()# 2、创建套接字
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 3、设置地址可以重用
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 4、绑定端口
tcp_server_socket.bind(("", 8080))
# 5、设置监听,套接字有主动设置为被动
tcp_server_socket.listen()
while True:# 6、接受容户瑞连接new_client_socket, ip_port = tcp_server_socket.accept()print("新用户上线:", ip_port)# recv_msg(new_client_socket, ip_port)# 创建线程thread_recvmsg = threading.Thread(target=recv_msg, args=(new_client_socket, ip_port))# 设置线程守护thread_recvmsg.setDaemon(True)# 启动线程thread_recvmsg.start()
# tcp_server_socket.close()
多任务 - 进程
进程: 进程(Process)是资源分配的最小单位,也是线程的容器。
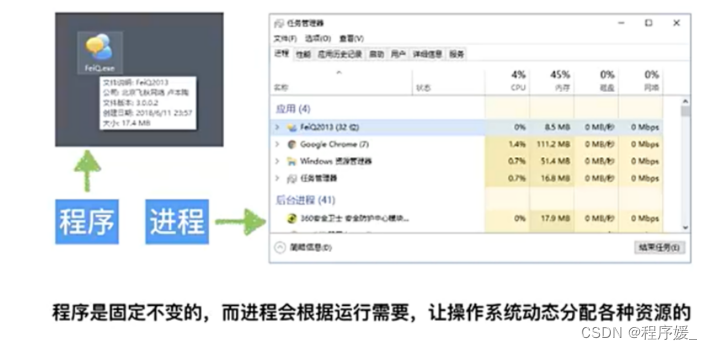
CPU的时间片轮转,在不同的时间段切换执行不同的进程,但是切换进程是比较耗时的;就引来了轻量级进程,也就是所谓的线程,一个进程中包括多个线程(代码流,其实也就是进程中同时跑的多个方法体)
程序:测如xxx.py这是程序,是一个静态的。
进程:一个程序运行起来后,代码+用到的资源称之为进程,它是操作系统分配资源的基本单元。
进程的状态: 工作中,任务数往往大于CPU的核数,即一定有一些任务正在执行,而另外一些任务在等待CPU进行执行,因此导致了有了不同的状态。
- 就绪态:运行的条件都已经满足,正在等在cpu执行
- 执行态:cpu正在执行其功能
- 等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
进程的基本使用
multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情。
进程使用步骤:
导入模块:import multiprocessing
创建子进程对象:process_obj = multiprocessing.Process(target=functionName)
启动子进程:process_obj.start()
说明:
- 创建子进程跟创建线程十分类似,只需要传入一个执行函数和函数的参数,创建一个Procecss实例,用start()方法启动
- Process语法结构如下:Process([group [, target [, name [, args [, kwargs]]]]])
target:如果传递了函数的引用,这个子进程就执行这里(函数)的代码。
args:给target指定的函数传递的参数,以元组的方式传递
kwargs:给target指定的函数传递命名参数
name:给进程设定一个名字,可以不设定
group:指定进程组,大多数情况下用不到- Process创建的实例对象的常用方法:
start():启动子进程实例(创建子进程)
is_alive():判断进程子进程是否还在活着
join([timeout]) :是否等待子进程执行结束,或等待多少秒
terminate():不管任务是否完成,立即终止子进程- Process创建的实例对象的常用属性:
name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
pid:当前进程的pid(进程号)
"""
1、导入模块
2、通过模块提供的Process类创建进程对象
3、启动进程
"""
import time
import multiprocessingdef work():for i in range(3):print('正在运行work...')time.sleep(0.5)if __name__ == '__main__':# 2、通过模块提供的Process类创建进程对象process_obj = multiprocessing.Process(target=work)# 3、启动进程process_obj.start()print('Done')
运行结果如下:
Done
正在运行work...
正在运行work...
正在运行work...
进程名称、pid
获取进程名称: multiprocessing.current_process()
设置子进程名称: multiprocessing.Process(target=xxx, name='进程名称')
获取进程id: multiprocessing.current_process().pid、os.getpid()
获取进程父id: os.getppid()
杀掉进程: kill -9 进程号 可以强制结束某个进程
"""
1、导入模块
2、通过模块提供的Process类创建进程对象
3、启动进程
"""
import time
import multiprocessing
import osdef work():print('子进程名称:', multiprocessing.current_process()) # 获取子进程名称print('子进程编号:', multiprocessing.current_process().pid) # 获取子进程的编号for i in range(3):# 获取进程的父idprint('正在运行work...', os.getpid(), '->父id:', os.getppid())time.sleep(0.5)if __name__ == '__main__':# 获取主进程名称print('主进程名称:', multiprocessing.current_process())# 获取主进程的编号print('主进程编号:', multiprocessing.current_process().pid)# 2、通过模块提供的Process类创建进程对象# target:知道子进程要执行的分支函数# name:知道子进程的名称process_obj = multiprocessing.Process(target=work, name='P1')# 3、启动进程process_obj.start()print('Done')
运行结果如下:
主进程名称: <_MainProcess(MainProcess, started)>
主进程编号: 21548
Done
子进程名称: <Process(P1, started)>
子进程编号: 15408
正在运行work... 15408 ->父id: 21548
正在运行work... 15408 ->父id: 21548
正在运行work... 15408 ->父id: 21548
进程参数、全局变量
进程的参数传递: args元组、kwargs字段、args和kwargs混合
import multiprocessing
import timedef work(a, b, c):print('参数:', a, b, c)for i in range(3):print('正在运行work...')time.sleep(0.5)if __name__ == '__main__':# 1、使用args传递元组# process_obj = multiprocessing.Process(target=work, args=(1, 10, 100))# 2、使用kwargs传递字典# process_obj = multiprocessing.Process(target=work, kwargs={'c':100, 'a':1, 'b':10})# 3、混合使用args和kwargsprocess_obj = multiprocessing.Process(target=work, args=(1,), kwargs={'c':100, 'b':10})process_obj.start()print('Done')
运行结果如下:
Done
参数: 1 10 100
正在运行work...
正在运行work...
正在运行work...
进程间是不能够共享全局变量!!! 底层原理:子进程会复制主进程的资源到内部运行。
import multiprocessing
import time# 定义全局变量
g_num = 10# work1 对全局变量累加
def work1():global g_numfor i in range(10):g_num += 1print('---work1---', g_num)# work2 读取全局变量的值,如果能读取到,说明全局变量能共享,否则不能
def work2():print('---work2---', g_num)if __name__ == '__main__':work1_process = multiprocessing.Process(target=work1)work2_process = multiprocessing.Process(target=work2)work1_process.start()work2_process.start()time.sleep(3)print('---main---', g_num)
运行结果如下:
---work1--- 20
---work2--- 10
---main--- 10
守护主进程
进程守护: 子进程和主进程的一种约定,当主进程结束的时候,子进程也随之结束:process_obj.daemon=True
结束子进程: 终止进程执行,并非是守护进程:process_obj.terminate()
import multiprocessing
import timedef work():for i in range(5):print('正在运行work...')time.sleep(0.5)if __name__ == '__main__':process_obj = multiprocessing.Process(target=work)# 设置process_obj 子进程守护主进程process_obj.daemon = Trueprocess_obj.start()time.sleep(2)print('Done')exit()
运行结果如下:
>>未设置守护进程:
正在运行work...
正在运行work...
正在运行work...
正在运行work...
Done
正在运行work...>>设置守护进程:
正在运行work...
正在运行work...
正在运行work...
正在运行work...
Done
import multiprocessing
import timedef work():for i in range(5):print('正在运行work...')time.sleep(0.5)if __name__ == '__main__':process_obj = multiprocessing.Process(target=work)process_obj.start()time.sleep(2)print('Done')# 终止子进程的执行process_obj.terminate()exit()
运行结果如下:
正在运行work...
正在运行work...
正在运行work...
正在运行work...
Done
进程、线程对比
-
功能
进程: 能够完成多任务,比如在一台电脑上能够同时运行多个QQ
线程: 能够完成多任务,比如一个QQ中的多个聊天窗口 -
使用区别
(1)进程是资源分配的基本单位,线程是CPU调度的基本单位;
(2)进程运行需要独立的内存资源,线程需要到的是必不可少的一点资源;
(3)进程切换慢,线程切换更快;
(4)线程不能独立运行,必须运行在进程中(进程能提供资源);
(5)CPU密集型进程优先,I/O密集型使用线程;
(6)一个程序至少有一个进程,一个进程至少有一个线程;进程更稳定相较线程更稳定;
(7)可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人。
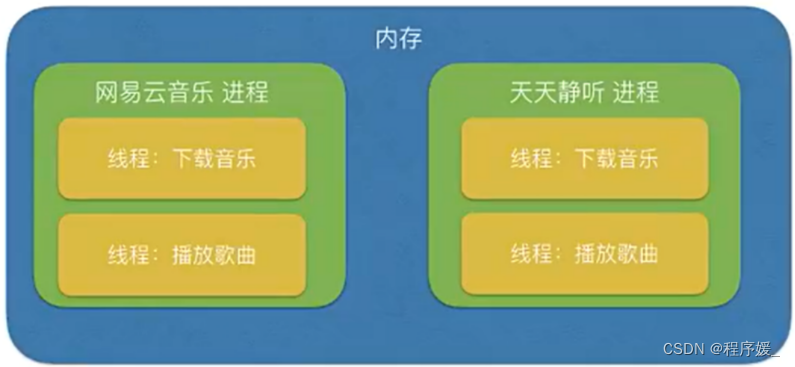
-
进程与线程的选择取决以下几点:
对比维度 多进程 多线程 总结 数据共享、同步 数据共享复杂,需要用IPC
数据是分开的,同步简单因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂 各有优势 内存、CPU 占用内存多,切换复杂,CPU利用率低 占用内存少,切换简单,CPU利用率高 线程占优 创建销毁、切换 创建销毁、切换复杂,速度慢 创建销毁、切换简单,速度很快 线程占优 编程、调试 编程、调试简单 编程、调试复杂 进程占优 可靠性 进程间不会互相影响 一个线程挂掉将导致整个进程挂掉 进程占优 分布式 适应于多核、多机分布式
如果一台机器不够,扩展到多台机器比较简单适用于多核分布式 进程占优
选择原则:
- 需要频繁创建销的优先使用线程;(如:Web服务器)
- 线程的切换速度快,所以在需要大量计算,切换频繁时用线程(如图像处理、算法处理)
- 因为对CPU系统的效率使用上线程更占优,所以可能要发展到多机分布的用进程,多核分布用线程。
- 需要更稳定安全时,适合选择进程;需要速度时,选择线程更好。
- 都满足需求的情况下,用你最熟悉、最拿手的方式。
需要提醒的是:虽然我给了这么多的选择原则,但实际应用中基本上都是“进程+线程”的结合方式,千万不要真的陷入一种非此即彼的误区。
在Python的原始解释器CPython中存在着GIL(Global Interpreter Lock,全局解释器锁),因此在解释执行python代码时,会产生互斥锁来限制线程对共享资源的访问,直到解释器遇到/IO操作或者操作次
数达到一定数目时才会释放GIL,造成了即使在多核CPU中,多线程也只是做着分时切换而已。
消息队列 - 基本操作
Queue: 可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue本身是一个消息列队程序。
创建队列: multiprocessing.Queue(5) # 队列长度为5
放入值: queue.put(值) # 从队列尾部放入值
取值: queue.get() # 从队列头部取值
queue.put_nowait(): 队列未满,同queue.put();但是队列已满,会报错,不等待。
queue.get_nowait(): 队列未空,同queue.get();但是队列已空,会报错,不等待。
"""
队列是multiprocessing模块提供的一个类
1、创建队列(指定长度)
2、放值
3、取值
"""
import multiprocessing# 1、创建队列(指定长度)
queue = multiprocessing.Queue(5)
# 2、放值
queue.put(1)
queue.put('hello')
queue.put([1, 2, 3])
queue.put((4, 5, 6))
queue.put({'a': 10, 'b': 100})
# queue.put(6) # 长度为5,放入第6个数据后,队列就进入了阻塞状态,默认会等待队列先取出值再放入新的值(程序不会结束,也不会报错)
# queue.put_nowait(6) # 长度为5,放入第6个数据后,队列已满,不会等待,直接报错queue.Full
# 3、取值
for i in range(5):value = queue.get()print(value)print('--'*20)
# -------队列中已经没有值了-------
# print(queue.get()) # 当队列已经为空时,再次get(),程序进入阻塞状态,等待放入新的值到队列,然后再取(程序不会结束,也不会报错)
# print(queue.get_nowait()) # 当队列已经为空时,不会等待放入新的值,直接报错_queue.Empty
说明:
初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头);
>> Queue.qsize(): 返回当前队列包含的消息数量;
>> Queue.empty(): 如果队列为空,返回True,反之False;
>> Queue.full(): 如果队列满了,返回True,反之False;
>> Queue.get([block[, timeout]]): 获取队列中的一条消息,然后将其从列队中移除,block默认值为True;如果block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常;如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常;
>> Queue.get_nowait():相当Queue.get(False);
>> Queue.put(item,[block[,timeout]]): 将item消息写入队列,block默认值为True;如果block使用默认值,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常;如果block值为False,消息队列如果没有空间可写入,则会立刻抛出"Queue.Full"异常;
>> Queue.put_nowait(item): 相当Queue.put(item, False);
消息队列 - 常见判断
判断队列是否已满:queue.full()
判断队列是否为空:queue.empty()
获取队列中消息的个数:queue.qsize(),队列每get()一次,数量就会-1
"""
1、判断是否已满
2、判断是否为空
3、获取队列中消息的个数
"""
import multiprocessing# 创建一个长度为3的消息队列
queue = multiprocessing.Queue(3)
# 放值
queue.put(1)
queue.put(2)
queue.put(3)
# 1、判断是否已满,True满,False未满
isFull = queue.full()
print('isFull -->', isFull) # isFull --> True# 取值
for i in range(3):queue.get()
# 2、判断是否为空,True空,False未空
isEmpty = queue.empty()
print('isEmpty -->', isEmpty) # isEmpty --> True# 3、获取队列中消息的个数
print('队列中消息的个数:', queue.qsize()) # 队列中消息的个数: 0
Queue实现进程间通信
思路: 利用队列在两个进程间进行传递,进而实现数据共享。join()优先让一个进程先执行完成,另外一个进程才能启动。
"""
思路:
1、准备2个进程
2、准备1个队列,1个进程向队列中写入数据,然后把队列传递到另一个进程
3、另外1个进程读取数据
"""# 1、写入数据到队列的函数
import multiprocessing
import timedef write_queue(queue):for i in range(10):# 判断队列是否已满if queue.full():print('队列已满!')break# 向队列中放入值queue.put(i)print('成功写入:', i)time.sleep(0.5)# 2、 读取队列数据并显示的函数
def read_queue(queue):while True:# 判断队列是否已经为空if queue.qsize() == 0:print('队列已空!')break# 从队列中读取数据value = queue.get()print('成功读取:', value)if __name__ == '__main__':# 3、创建一个空的队列queue = multiprocessing.Queue(5)# 4、创建2个进程,分别写、读数据write_process = multiprocessing.Process(target=write_queue, args=(queue,))read_process = multiprocessing.Process(target=read_queue, args=(queue,))# 启动进程write_process.start()# 优先让写数据的进程执行结束后,再启动读取数据的进程write_process.join()read_process.start()
运行结果如下:
成功写入: 0
成功写入: 1
成功写入: 2
成功写入: 3
成功写入: 4
队列已满!
成功读取: 0
成功读取: 1
成功读取: 2
成功读取: 3
成功读取: 4
队列已空!
进程池Pool
进程池概述: 进程池是一个进程的容器,可以自动帮我们创建指定数量的进程,并且管理进程及工作。
当需要创建子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。

初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
创建进程池方法: pool = multiprocessing.Pool(3)
工作方式:
- 同步方式 (进程池中的进程,一个执行完毕后另一个才能执行,多个进程执行有先后顺序):
pool.apply(函数名, (参数1, 参数2, ...)) - 异步方式(进程池中的进程,多个进程同时执行,没有先后顺序):
pool.apply_async(函数名, (参数1, 参数2, ...))
注意:
1)进程池要close(),表示不再接受新的任务:pool.close()
2)还要join()表示让主进程等待进程池执行结束后再退出:pool.join()
"""
1、创建一个函数,用于模拟文件拷贝
2、创建一个进程池,长度为3,(表示进程池中最多能够创建3个进程)
3、先用进程池同步方式拷贝文件
4、再用进程池异步方式拷贝文件
"""import multiprocessing
import time# 1、创建一个函数,用于模拟文件拷贝
def copy_work():print('正在拷贝文件...', multiprocessing.current_process())time.sleep(0.5)if __name__ == '__main__':# 不使用进程拷贝文件time1 = time.time()for i in range(10):copy_work()time2 = time.time()print('不使用进程拷贝文件用时:', time2-time1) # 5.115655422210693# 2、创建一个进程池,长度为3,(表示进程池中最多能够创建3个进程)pool = multiprocessing.Pool(3)# # 3、先用进程池同步方式拷贝文件time3 = time.time()pool.apply(copy_work)time4 = time.time()print('使用进程池同步方式拷贝文件用时:', time4 - time3) # 0.5013861656188965# 4、再用进程池异步方式拷贝文件time5 = time.time()pool.apply_async(copy_work)time6 = time.time()pool.close() # 不再接受新的任务pool.join() # 主进程等待进程池执行结束后再退出print('使用进程池异步方式拷贝文件用时:', time6 - time5) # 0.0
进程池中的Queue
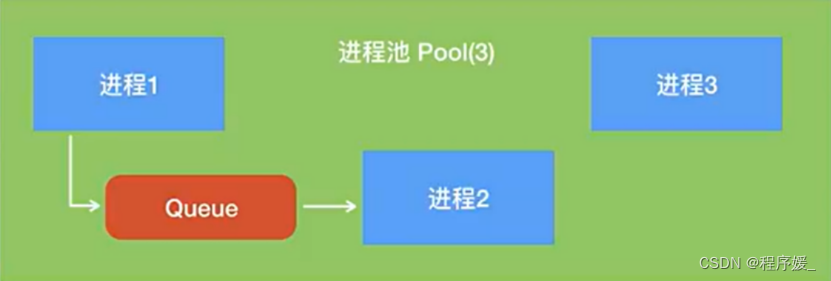
创建进程池中的队列: queue = multiprocessing.Manager().Queue(3)
异步方式注意2点: pool.close() pool.join()
import multiprocessing
import time# 1、写入数据到队列的函数
def write_queue(queue):for i in range(5):# 判断队列是否已满if queue.full():print('队列已满!')break# 向队列中放入值queue.put(i)print('成功写入:', i)time.sleep(0.5)# 2、 读取队列数据并显示的函数
def read_queue(queue):while True:# 判断队列是否已经为空if queue.qsize() == 0:print('队列已空!')break# 从队列中读取数据value = queue.get()print('成功读取:', value)time.sleep(0.5)if __name__ == '__main__':# 1、创建进程池pool = multiprocessing.Pool(2)# 2、创建进程池队列queue = multiprocessing.Manager().Queue(3)# 3、使用进程池执行任务# 3.1 同步方式time1 = time.time()pool.apply(write_queue, (queue,))pool.apply(read_queue, (queue,))time2 = time.time()print('同步用时:', time2-time1) # 3.077965021133423# 3.2 异步方式time3 = time.time()# apply_sync()返回ApplyResult对象result = pool.apply_async(write_queue, (queue,))# ApplyResult对象有一个wait()方法,类似join(),表示后续进程必须等待当前进程执行完再继续result.wait()pool.apply_async(read_queue, (queue,))time4 = time.time()print('异步用时:', time4 - time3) # 1.5298125743865967pool.close() # 表示不再接收新的任务pool.join() # 主进程会等待进程池结束后再退出
案例:文件夹拷贝器(多进程版)
"""
将D:/test文件夹拷贝到d:/Users/Desktop/test
思路:
1、定义变量,保存源文件夹、目标文件夹所在的路径
2、在目标路径创建新的文件夹
3、获取源文件夹中的所有文件(列表)
4、遍历列表,得到所有文件名
5、定义函数,进行文件拷贝文件拷贝函数:
参数:源文件夹路径、目标文件夹路径、文件名
1、拼接源文件和目标文件的具体路径
2、打开源文件,创建目标文件
3、读取源文件的内容,写入到目标文件中
"""
import multiprocessing
import osdef copy_work(source_dir, dest_dir, file_name):"""根据参数,拷贝文件"""print(multiprocessing.current_process())# 1、拼接源文件和目标文件的具体路径source_path = source_dir + '/' + file_namedest_path = dest_dir + '/' + file_nameprint(source_path, '--->', dest_path)# 2、打开源文件with open(source_path, 'rb') as source_file:# 2、创建目标文件with open(dest_path, 'wb') as dest_file:while True:# 3、读取源文件的内容,写入到目标文件中file_data = source_file.read(1024)# 判断文件是否读取完成if file_data:dest_file.write(file_data)else:breakif __name__ == '__main__':# 1、定义变量,保存源文件夹、目标文件夹所在的路径source_dir = 'D:/test'dest_dir = 'd:/Users/Desktop/test'# 2、在目标路径创建新的文件夹:os.mkdir(路径)在指定位置创建文件夹try:os.mkdir(dest_dir)except Exception as e:print('文件夹已经存在!')# 3、获取源文件夹中的所有文件(列表):os.listdir(路径)file_list = os.listdir(source_dir)# 创建进程池pool = multiprocessing.Pool(3)# 4、遍历列表,得到所有文件名for file_name in file_list:# 5、定义函数,进行文件拷贝# copy_work(source_dir, dest_dir, file_name) # 效率低# 使用进程持异步方式拷贝文件pool.apply_async(copy_work, (source_dir, dest_dir, file_name))pool.close() # 表示不再接收新的任务pool.join() # 主进程会等待进程池结束后再退出
运行结果:
<SpawnProcess(SpawnPoolWorker-1, started daemon)>
D:/test/1.txt ---> d:/Users/Desktop/test/1.txt
<SpawnProcess(SpawnPoolWorker-2, started daemon)>
D:/test/2.txt ---> d:/Users/Desktop/test/2.txt
<SpawnProcess(SpawnPoolWorker-1, started daemon)>
D:/test/3.txt ---> d:/Users/Desktop/test/3.txt
<SpawnProcess(SpawnPoolWorker-2, started daemon)>
D:/test/4.txt ---> d:/Users/Desktop/test/4.txt
<SpawnProcess(SpawnPoolWorker-1, started daemon)>
D:/test/5.txt ---> d:/Users/Desktop/test/5.txt
多任务 - 协程
可迭代对象及检测方法
迭代是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
我们已经知道可以对list、tuple、str等类型的数据使用for…in…的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫选代。
可迭代对象:
1、可遍历对象就是可迭代对象。
2、列表、元组、字典、字符串都是可迭代对象。
3、100和自定义myclass对象,默认都是不可迭代的。
4、myclass对象所属的类MyClass如果包含了__iter__()方法,此时myclass就是一个可迭代对象。
5、可迭代对象的本质:对象所属的类中包含了__iter__()方法。
可迭代对象的检测: from collections import Iterable result = isinstance(待检测对象,Iterable)
from collections import Iterabler = isinstance({'a':1, 'b':2}, Iterable)
print(r) # Truer = isinstance(10, Iterable)
print(r) # False# 自定义一个类
class MyClass(object):pass
# 创建对象
myclass = MyClass()
r = isinstance(myclass, Iterable)
print(r) # False# 自定义一个类
class MyClass2(object):# 增加一个__iter__方法,该方法就是一个迭代器def __iter__(self):pass
# 创建对象
myclass2 = MyClass2()
r = isinstance(myclass2, Iterable)
print(r) # True
迭代器及其使用方法
迭代器的作用:
1、记录当前迭代的位置
2、配合next()获取可迭代对象的下一个元素值
获取迭代器: iter(可迭代对象)
获取可迭代对象的值: next(迭代器)
for循环的本质:
1)通过iter(要遍历的对象)获取要遍历的对象的迭代器
2)next(迭代器)获取下一个元素
3)帮我们捕获了StopIteration异常
自定义迭代器类:
必须满足以下2点:
1)必须含有__iter__()
2)必须含有__next__()
class MyIterator(object):def __iter__(self):pass# 当next(迭代器)的时候,会自动调用该方法 def __next__(self):pass
# 可迭代对象
data_list = [1, 3, 5]
# for data in data_list:
# print(data)# 获取迭代器
data_iterator = iter(data_list)# 根据迭代器,获取下一个元素
value = next(data_iterator)
print(value) # 1
value = next(data_iterator)
print(value) # 3
value = next(data_iterator)
print(value) # 5
value = next(data_iterator)
print(value) # StopIteration
自定义迭代对象
目标: 能够自定义一个列表
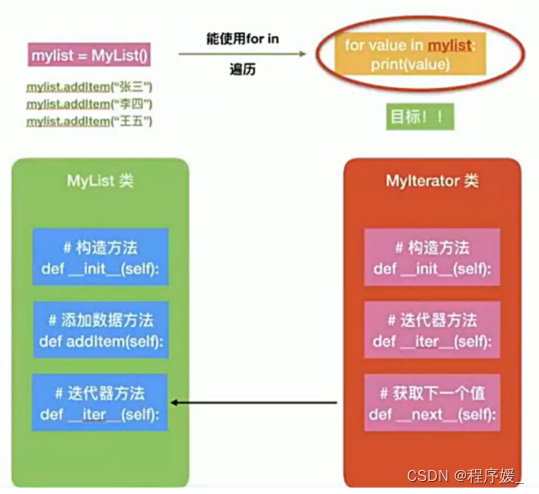
"""
1、MyList类
1)初始化方法
2)__iter__()方法,对外提供迭代器
3)addItem()方法,用来添加数据2、自定义迭代器类:MyListIterator
1)初始化方法
2)迭代器方法 __iter__()
3)获取下一个元素值的方法 __next__()目标:
mylist = MyList()
for value in mylist:print(value)
"""# 1、MyList类
class MyList(object):# 1)初始化方法def __init__(self):# 定义实例属性,保存数据self.items = []# 2)__iter__()方法,对外提供迭代器def __iter__(self):# 创建MyListIterator对象,无此代码会报错:iter() returned non-iterator of type 'NoneType'mylistIterator = MyListIterator(self.items)# 返回迭代器return mylistIterator# 3)addItem()方法,用来添加数据def addItem(self, data):# 追加保存数据self.items.append(data)# 2、自定义迭代器类:MyListIterator
class MyListIterator(object):# 1)初始化方法def __init__(self, items):# 定义实例属性,保存MyList类传递过来的Itemsself.items = items# 记录迭代器迭代的位置self.current_index = 0# 2)迭代器方法 __iter__()def __iter__(self):pass# 3)获取下一个元素值的方法 __next__()# next(mylistIterator)就会调用__next__()方法def __next__(self):# 判断当前的下标是否越界if self.current_index < len(self.items):# 1)根据下标获取下标对应的元素值data = self.items[self.current_index]# 2)下标位置+1self.current_index += 1# 3)返回下标对应的数据return data# 如果越界,直接抛出异常else:# raise 用于主动抛出异常;StopIteration 停止迭代raise StopIterationif __name__ == '__main__':# 1、创建自定义列表对象mylist = MyList()mylist.addItem('a')mylist.addItem('b')mylist.addItem('c')# 2、遍历"""for循环本质:1)iter(mylist)获取mylist对象的迭代器 --> MyList --> __iter__()2)next(迭代器) 获取下一个值3)捕获异常"""for value in mylist:print(value, end=' ') # 运行结果:a b c
迭代器案列 - 斐波那契数列
迭代器应用:
我们发现迭代器最核心的功能就是可以通过next()函数的调用来返回下一个数据值。如果每次返回的数据值不是在一个己有的数据集合中读取的,而是通过程序按照一定的规律计算生成的,那么也就意味着可以不用再依赖一个已有的数据集合,也就是说不用再将所有要迭代的数据都一次性缓存下来供后续依次读取,这样可以节省大量的存储(内存)空间。
举个例子,比如,数学中有个著名的斐波拉契数列(Fibonacci),数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:1 1 2 3 5 8 13 …
现在我们想要通过for…in…循环来遍历迭代斐波那契数列中的前n个数。那么这个斐波那契数列我们就可以用迭代器来实现,每次迭代都通过数学计算来生成下一个数。
核心思想:
1)a保存第一列的值,b保存第二列的值
2)a=b,b=a+b
3)取a的值,得到斐波那契数列
"""
自定义迭代器:
1)定义迭代器类
2)类中必须有__iter__()方法
3)类中必须有__next()方法目标:
指定生成5列的斐波那契数列
fib = Fibonacci(5)
value = next(fib)
print(value)
"""class Fibonacci(object):def __init__(self, num):# 定义实例属性,报错生成的列数self.num = num# 定义变量保存斐波那契数列的第一列和第二列self.a = 1self.b = 1# 记录下标位置的实例属性self.current_index = 0def __iter__(self):# 返回自己return selfdef __next__(self):# 判断列数是否超过生成的总列数if self.current_index < self.num:# 定义变量,保存a的值data = self.aself.a, self.b = self.b, self.a+self.bself.current_index += 1return dataelse:raise StopIterationif __name__ == '__main__':# 创建迭代器对象fib = Fibonacci(6)# 迭代器本身又是一个迭代器for value in fib: # 运行结果:1 1 2 3 5 8 print(value, end=' ')
生成器
生成器: 利用迭代器,我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。生成器是一类特殊的迭代器(按照一定的规律生成数列)。
创建生成器的方法:
方法一:列表推导式
方法二:函数中使用yield
yield的作用:
1、充当return作用
2、保存程序的运行状态,并且暂停程序执行
3、当next的时候,可以继续唤醒程序从yield位置继续向下执行
# 列表推导式
data_list = [x*2 for x in range(10)]
print(data_list) # [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
for value in data_list:print(value, end=' ') # 0 2 4 6 8 10 12 14 16 18# 生成器的创建方法一:列表推导式
data_generator = (x*2 for x in range(10))
print(data_generator) # <generator object <genexpr> at 0x010E27B0>
# next(生成器)也能够得到下一个值
value = next(data_generator)
print('--->', value) # ---> 0
for value in data_generator:print(value, end=' ') # 2 4 6 8 10 12 14 16 18# 普通函数
def test():return 10
r = test()
print('r =', r) # r = 10# 生成器的创建方法二:函数中使用了yield
def test1():yield 10
# g是一个生成器对象
g = test1()
print(g) # <generator object test1 at 0x014227F0>
value = next(g)
print('--->', value) # ---> 10
生成器案例 - 斐波那契数列
"""
思路:
1、创建一个生成器目标:实现斐波那契数列1)定义变量a、b保存第一列和第二列2)定义变量保存当前生成的位置3)循环生成数据,条件:当前列数<总列数4)保存a的值5)修改a和b的值(a=b,b=a+b)6)返回a的值 yield2、定义变量保存生成器
next(生成器)得到下一个元素值
"""# 1、创建一个生成器
def fibonacci(n):# 目标:实现斐波那契数列# 1)定义变量a、b保存第一列和第二列a = 1b = 1# 2)定义变量保存当前生成的位置current_index = 0print('11111111111111')# 3)循环生成数据,条件:当前列数 < 总列数while current_index < n:# 4)保存a的值data = a# 5)修改a和b的值(a = b,b = a + b)a, b = b, a+bcurrent_index += 1print('2222222222222')# 6)返回a的值# yield作用:1.充当return作用;2.保存程序的运行状态并且暂停程序执行;3.当next的时候,可以继续换新程序从yield位置继续向下执行yield dataprint('33333333333333')if __name__ == '__main__':# 2、定义变量保存生成器fib = fibonacci(6)# next(生成器)得到下一个元素值value = next(fib)print('第1列:', value)value = next(fib)print('第2列:', value)value = next(fib)print('第3列:', value)
运行结果如下:
11111111111111
2222222222222
第1列: 1
33333333333333
2222222222222
第2列: 1
33333333333333
2222222222222
第3列: 2
生成器 - 使用注意
- return作用:可以结束生成器的运行。执行到return以后看,生成器会停止迭代,抛出停止迭代的异常。
- send的作用:能够启动生成器、并传递参数:
生成器.send(传递给生成器的值)
def fibonacci(n):a = 1b = 1current_index = 0print('11111111111111')while current_index < n:data = aa, b = b, a+bcurrent_index += 1print('2222222222222')# 通过send传递参数给生成器xx = yield dataprint('33333333333333')if xx == 1:# 生成器中能使用return让生成器结束return "return结束生成器的运行"if __name__ == '__main__':fib = fibonacci(6)value = next(fib)print('第1列:', value)try:value = next(fib)print('第2列:', value)# fib.send(1) xxx=yield data 则xxx=1value = fib.send(1)print('第3列', value)except Exception as e:print(e)
运行结果如下:
11111111111111
2222222222222
第1列: 1
33333333333333
2222222222222
第2列: 1
33333333333333
return结束生成器的运行
协程 - yield
协程: 在不开辟新的线程的基础上,实现多个任务。协程是一个特殊的生成器。
协程,又称微线程,纤程。英文名Coroutine。从技术的角度来说,“协程就是你可以暂停执行的函数”。如果你把它理解成“就像生成器一样”,那么你就想对了。
线程和进程的操作是由程序触发系统接口,最后的执行者是系统;协程的操作则是程序员。
协程存在的意义: 对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次维续)。协程,则只使用一个线程(单线程),在一个线程中规定某个代码块执行顺序。
协程的适用场景: 当程序中存在大量不需要CPU的操作时(IO),适用于协程。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定。
协程和线程差异:
在实现多任务时,线程切换从系统层面远不止保存和恢复CPU上下文这么简单。操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
协程的基本实现:
"""
1、创建work1的生成器
2、创建work2的生成器
3、获取生成器,通过next运行生成器
"""import time# 1、创建work1的生成器
def work1():while True:print('正在执行work1...')yieldtime.sleep(0.5)# 2、创建work2的生成器
def work2():while True:print('正在执行work2......')yieldtime.sleep(0.5)if __name__ == '__main__':# 3、获取生成器,通过next运行生成器w1 = work1()w2 = work2()while True:next(w1)next(w2)
协程 - greenlet
目标: 使用greenlet实现协程
greenlet是一个第三方的模块,自行的调度的微线程。
Greenlet是python的一个C扩展,来源于Stackless python,旨在提供可自行调度的“微线程”,即协程。generator实现的协程在yield value时只能得value返回给调用者(caller)。而在greenlet中,target.switch(value)可以切换到指定的协程(target),然后yield value。greenlet用switch来表示协程的
切换,从一个协程切换到另一个协程需要显式指定。
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单。
使用步骤:
1、安装greenlet模块: sudo pip3 install greenlet
2、导入greenlet模块:from greenlet import greenlet
3、创建greenlet对象:g1 = greenlet(函数名)
4、切换任务:g1.switch()
"""
greenlet 实现协程的步骤:
1、导入模块
2、创建任务work1,work2
3、创建greenlet对象
4、手动switch任务
"""import time
from greenlet import greenletdef work1():while True:print('正在执行work1...')time.sleep(0.5)# 切换到第二个任务g2.switch()def work2():while True:print('正在执行work2......')time.sleep(0.5)g1.switch()if __name__ == '__main__':# 创建greenlet的对象g1 = greenlet(work1)g2 = greenlet(work2)# 执行work1任务g1.switch()
协程 - gevent
gevent也是第三方库,自动调度协程,自动识别程序中的耗时操作。
greenlet已经实现了协程,但是这个需要人工切换,是不是觉得太麻烦了,不要捉急,python还有一个比greenlet更强大的并且能够自动切换任务的第三方库gevent。
其原理是当一个greenlet遇到lO(指的是input output输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
使用步骤:
1、安装gevent模块: sudo pip3 install gevent
2、导入gevent模块:import gevent
3、指派任务:g1 = gevent.spawn(函数名, 参数1, 参数2, ...)
4、让主线程等待协程执行完毕后再退出:g1.join
5、查看当前执行任务的协程名称:gevent.getcurrent()
Gevent不能识别time.sleep(0.5)耗时操作的问题:
方法一:替换time.sleep(0.5) >> gevent.sleep(0.5)
方法二:打猴子补丁。
打猴子补丁步骤:
1. 导入模块:from gevent import monkey
2. 破解所有:monkey.patch_all()
猴子补丁的作用:
1)在运行时替换方法、属性等
2)在不修改第三方代码的情况下增加原来不支持的功能
3)在运行时为内容中的对象增加patch而不是在磁盘中的源代码中增加
"""
gevent好处:能够自动识别程序中的耗时操作,在耗时的时候自动切换到其他的任务
1、导入模块
2、指派任务
"""
import time
import gevent
# 打补丁:
# 导入monkey模块
from gevent import monkey
# 2.破解
monkey.patch_all()def work1():# 获取当前协程名称print('work1的协程名称:', gevent.getcurrent())while True:print('正在执行work1...')# 默认情况下,time.sleep()不能被gevent识别为耗时操作# 方法一: 把time.sleep() --> gevent.sleep()# time.sleep(0.5)gevent.sleep(0.5)def work2():# 获取当前协程名称print('work2的协程名称:', gevent.getcurrent())while True:print('正在执行work2......', gevent.getcurrent())# 方法二:给gevent打补丁(在不修改程序源代码的情况下,为程序增加新的功能)(目的:让gevent识别time.sleep())time.sleep(0.5)if __name__ == '__main__':# 指派任务g1 = gevent.spawn(work1)g2 = gevent.spawn(work2)# 让主线程等待协程执行完毕再退出g1.join()g2.join()
运行结果如下:
work1的协程名称: <Greenlet at 0x3986710: work1>
正在执行work1...
work2的协程名称: <Greenlet at 0x3a29be0: work2>
正在执行work2......
正在执行work1...
正在执行work2......
正在执行work1...
正在执行work2......
进程、线程、协程对比
(1)概念
- 进程: 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。(资源分配的基本单位)
- 线程: 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定,容易丢失数据。(CPU调度的基本单位)
- 协程: 协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。(协程单线程执行多任务)
(2)三者之间的关系
切换效率: 协程>线程>进程
高效率方式: 进程+协程
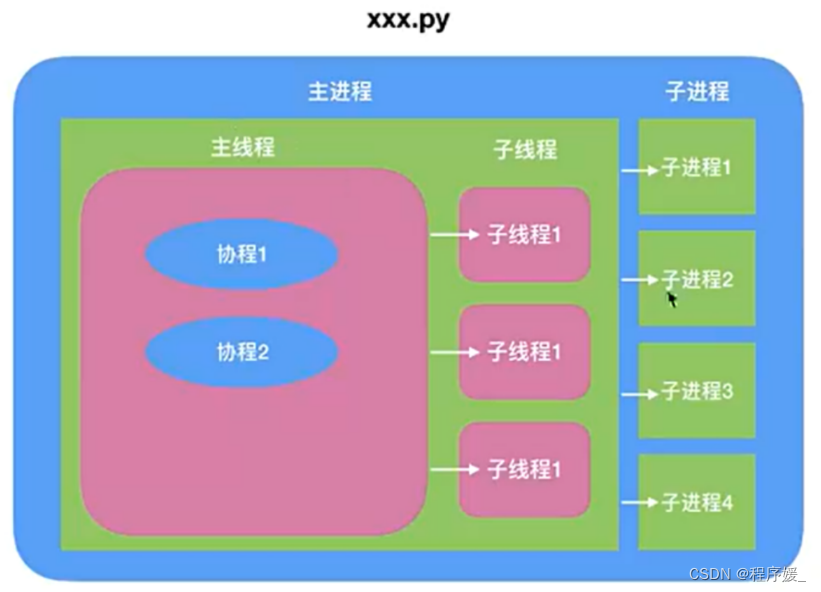
(3)应用场景
- 多进程:
密集CPU任务,需要充分使用多核CPU资源(服务器,大量的并行计算)的时候,用多进程。
缺陷:多个进程之间通信成本高,切换开销大。 - 多线程:
密集I/O任务(网络I/O,磁盘I/O,数据库I/O)使用多线程合适。
缺陷:同一个时间切片只能运行一个线程,不能做到高并行,但是可以做到高并发。 - 协程:
当程序中存在大量不需要CPU的操作时(IO),适用于协程。
注意:多线程请求返回是无序的,那个线程有数据返回就处理那个线程,而协程返回的数据是有序的。
缺陷:单线程执行,处理密集CPU和本地磁盘IO的时候,性能较低。处理网络I/O性能还是比较高。
案例 - 并发下载器
目标: 能够使用协程实现网络图片下载
核心方法:
打开网址并返回对应的内容(二进制流):response_data = urllib.request.urlopen(img_url)
批量把协程添加join:gevent.joinall([gevent.spawn(函数1名, 参数1, 参数2, ...), gevent.spawn(函数2名, 参数1, 参数2, ...), ...])
"""
思路:
1、定义要下载的图片路径
2、调用文件下载的函数,专门下载文件文件下载函数:
1、根据url地址请求网络资源
2、在本地创建文件,准备保存
3、读取网络资源数据(循环)
4、把读取的网络资源写入到本地文件中
5、做异常捕获
"""
import urllib.request
import gevent
from gevent import monkey
monkey.patch_all()def download_img(imgUrl, file_name):# 1、根据url地址请求网络资源response_data = urllib.request.urlopen(imgUrl)# 2、在本地创建文件,准备保存try:with open(file_name, 'wb') as file:while True:# 3、读取网络资源数据(循环)file_data = response_data.read(1024)# 判断读取的数据不为空if file_data:# 4、把读取的网络资源写入到本地文件中file.write(file_data)else:break# 5、做异常捕获except Exception as e:print('文件%s下载失败!' % file_name)else:print('文件%s下载成功!' % file_name)def main():# 1、定义要下载的图片路径img_url1 = 'https://img0.baidu.com/it/u=2617416616,2174928901&fm=253&fmt=auto&app=138&f=JPEG?w=342&h=500'img_url2 = 'https://img2.baidu.com/it/u=3793863728,1272380745&fm=253&fmt=auto&app=138&f=JPEG?w=889&h=500'img_url3 = 'https://img2.baidu.com/it/u=2535596420,3225767821&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=731'# 2、调用文件下载的函数,专门下载文件# 2.1 普通下载# download_img(img_url1, '1.jpg')# download_img(img_url2, '2.jpg')# download_img(img_url3, '3.jpg')# 2.2 协程下载:# 批量把协程给join(): 主线程等待所有协程执行完毕再退出gevent.joinall([gevent.spawn(download_img, img_url1, '1.jpg'),gevent.spawn(download_img, img_url2, '2.jpg'),gevent.spawn(download_img, img_url3, '3.jpg')])if __name__ == '__main__':main()
相关文章:
【Linux】Linux基础
文章目录 学习目标操作系统不同应用领域的主流操作系统虚拟机 Linux系统的发展史Linux内核版和发行版 Linux系统下的文件和目录结构单用户操作系统vs多用户操作系统Windows和Linux文件系统区别 Linux终端命令格式终端命令格式查阅命令帮助信息 常用命令显示文件和目录切换工作目…...

动态规划求解 fibonacci 数列
动态规划: 动态规划的基本思想是:将原问题拆分为若干子问题,自底向上的求解。是自底向上的求解,即是先计算子问题的解,再得出原问题的解。 思路: 创建一个数组,大小为n1,用于存储斐波那契数列的值。数组的…...

js最大公约数的实现有哪些办法
在JavaScript中,有几种常见的方法可以实现最大公约数(GCD)的计算。以下是其中一些方法: 辗转相除法(欧几里德算法): 辗转相除法是一种基于递归的算法,用于计算两个数的最大公约数。它…...
盘后股价狂飙16% — GitLab的DevOps产品在AI时代展现强劲财务业绩
12月4日(周一)在美股收盘后,GitLab的股价狂飙16%!人工智能驱动的DevOps产品继续凸显其平台能力的优势。 GitLab 12 月 4 日股价图 GitLab报告第三季度收入同比增长32%!根据粗略统计,全球已经有接近1万家企…...
unity UI特效遮罩
using System.Collections; using System.Collections.Generic; using UnityEngine;/**UI特效遮罩 1.需要将ScrollRect 的遮罩Mask 换为 2D Mask2.将特效的Render里面的 Masking 设置为*/ public class UIParticleMaskControll : MonoBehaviour {// Start is called before …...

编程模拟支付宝能量产生过程--数据控制流
#模拟支付宝蚂蚁森林的能量产生过程 behavior_points { # 定义行为对应的积分"步行": 2,"生活缴费": 10,"线下支付": 5,"网络购票": 5,"共享单车": 10 }total_points 0 # 初始化总积分while True: # 开…...
SQL Sever 基础知识 - 数据筛选(1)
SQL Sever 基础知识 - 四、数据筛选 四、筛选数据第1节 DISTINCT - 去除重复值1.1 SELECT DISTINCT 子句简介1.2 SELECT DISTINCT 示例1.2.1 DISTINCT 一列示例1.2.2 DISTINCT 多列示例 1.2.3 DISTINCT 具有 null 值示例1.2.4 DISTINCT 与 GROUP BY 对比 第2节 WHERE - 过滤查询…...

2024 Move 中文开发者大会将于1月13–14日在上海举办
*以下文章来源于MoveFuns ,作者MoveFunsDAO 2024 Move 中文开发者大会将于1月13日-1月14日在上海举办。本届 Move 开发者大会以 “Move 生态关键的一年” 为主题。 由 MoveFuns 、OpenBuild 和 MoveBit 主办,Rooch、AptosGlobal、alcove、zkMove 和 Ti…...
基于PHP的在线日语学习平台
有需要请加文章底部Q哦 可远程调试 PHP在线日语学习平台 一 介绍 此日语学习平台基于原生PHP开发,数据库mysql。系统角色分为用户和管理员。(附带参考设计文档) 技术栈:phpmysqlphpstudyvscode 二 功能 学生 1 注册/登录/注销 2 个人中心 3 查看课程…...
解决element ui tree组件不产生横向滚动条
结果是这样的 需要在tree的外层,包一个父组件 <div class"tree"><el-tree :data"treeData" show-checkbox default-expand-all></el-tree></div> 在css里面这样写,样式穿透按自己使用的css编译器以及框架要求就好 &l…...
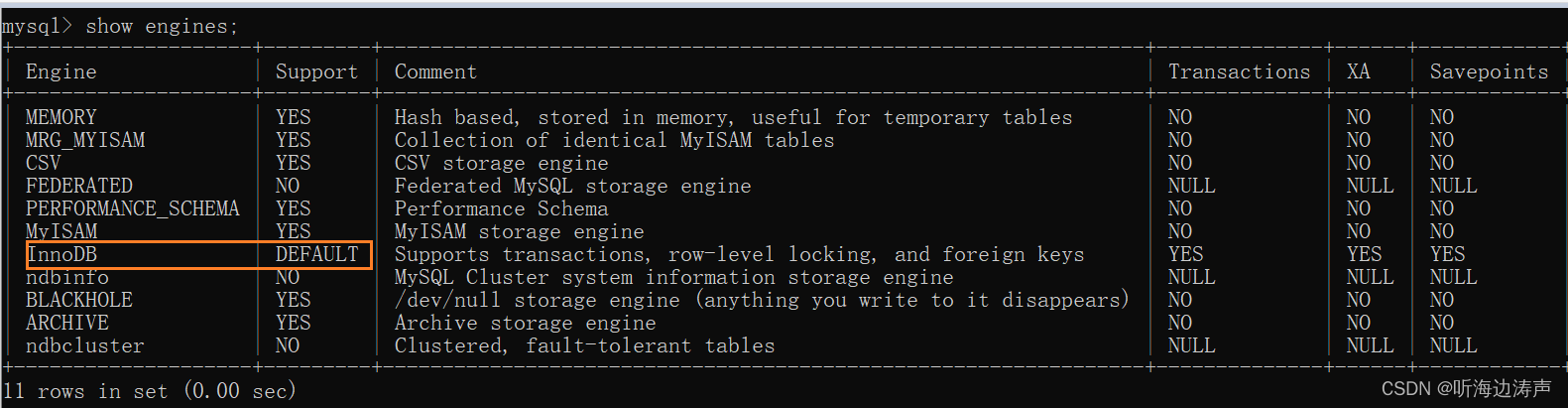
mysql的InnoDB存储引擎
详情请参考:https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html InnoDB 是一个通用目的的存储引擎,它在高可用性、高性能方面做了平衡。MySQL 8.0,InnoDB 是默认的存储引擎。在创建表的时候,如果没有使用ENGIN…...

MCU 的 TOP 15 图形GUI库:选择最适合你的图形用户界面(二)
在嵌入式系统开发中,选择一个合适的图形用户界面(GUI)库是至关重要的。在屏幕上显示的时候,使用现成的图形库,这样开发人员就不需要弄清楚底层任务,例如如何绘制像素、线条、形状,如果再高级一点…...

软件工程 单选多选补充 复刻
原文 软件的主要特性:无形、高成本、包括程序和文档 软件工程三要素:方法、工具、过程 螺旋模型包含风险分析 软件工程的主要目标:风险分析 面向对象开发:Booch、UML、Coad、OMT 软件危机的主要表现:软件成本太高…...

微前端个人理解与简单总结
最近一段时间在学习微前端,一开始是看各种博客了解微前端含义、对比多种微前端框架优劣,最后选择了qiankun、micro-app、wujie这三种微前端框架进行深入研究、对比。 微前端框架 推出时间 官方文档易读性 社区讨论活跃度 配置难度 Qiankunÿ…...

PC端企业微信hook协议开发,获取要群发的客户群id
产品说明 一、 hook版本:企业微信hook接口是指将企业微信的功能封装成dll,并提供简易的接口给程序调用。通过hook技术,可以在不修改企业微信客户端源代码的情况下,实现对企业微信客户端的功能进行扩展和定制化。企业微信hook接口…...
RabbitMQ安装说明
注意: 本次安装以 CentOS 7为例 1、 准备软件 erlang 18.3 1.el7.centos.x86_64.rpm socat 1.7.3.2 5.el7.lux.x86_64.rpm rabbitmq server 3.6.5 1.noarch.rpm 2、安装Erlang rpm -ivh erlang-18.3-1.el7.centos.x86_64.rpm 3.、安装RabbitMQ 安装 rpm -ivh socat-1.7.3.2-…...

scrapy的建模及管道的使用
一、数据建模 通常在做项目的过程中,在items.py中进行数据建模 为什么建模 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查,配合注释一起可以清晰的知道要抓…...
-Part.04 基础环境配置)
Hadoop学习笔记(HDP)-Part.04 基础环境配置
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...

【Linux】进程控制--进程创建/进程终止/进程等待/进程程序替换/简易shell实现
文章目录 一、进程创建1.fork函数2.fork函数返回值3.写时拷贝4.fork常规用法5.fork调用失败的原因 二、进程终止1.进程退出码2.进程退出场景3.进程常见退出方法 三、进程等待1.为什么要进行进程等待2.如何进行进程等待1.wait方法2.waitpid方法3.获取子进程status4.进程的阻塞等…...

用pip更新、安装python的包
查看pip的版本:python -m pip --version 例如,查看下pip的版本,在cmd下输入命令python -m pip --version,可以发现当前安装的pip的版本是23.2.1: 查看一个包的详情:python -m pip show 例如,…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...

【实施指南】Android客户端HTTPS双向认证实施指南
🔐 一、所需准备材料 证书文件(6类核心文件) 类型 格式 作用 Android端要求 CA根证书 .crt/.pem 验证服务器/客户端证书合法性 需预置到Android信任库 服务器证书 .crt 服务器身份证明 客户端需持有以验证服务器 客户端证书 .crt 客户端身份…...

C++ 类基础:封装、继承、多态与多线程模板实现
前言 C 是一门强大的面向对象编程语言,而类(Class)作为其核心特性之一,是理解和使用 C 的关键。本文将深入探讨 C 类的基本特性,包括封装、继承和多态,同时讨论类中的权限控制,并展示如何使用类…...

Cursor AI 账号纯净度维护与高效注册指南
Cursor AI 账号纯净度维护与高效注册指南:解决限制问题的实战方案 风车无限免费邮箱系统网页端使用说明|快速获取邮箱|cursor|windsurf|augment 问题背景 在成功解决 Cursor 环境配置问题后,许多开发者仍面临账号纯净度不足导致的限制问题。无论使用 16…...