R语言30分钟上手
文章目录
- 1. 环境&安装
- 1.1. rstudio保存工作空间
- 2. 创建数据集
- 2.1. 数据集概念
- 2.2. 向量、矩阵
- 2.3. 数据框
- 2.3.1. 创建数据框
- 2.3.2. 创建新变量
- 2.3.3. 变量的重编码
- 2.3.4. 列重命名
- 2.3.5. 缺失值
- 2.3.6. 日期值
- 2.3.7. 数据框排序
- 2.3.8. 数据框合并(合并沪深300和中证500收盘价日历)
- 2.3.9. 数据框子集
- 2.3.10. 随机抽样
- 2.3.11. sql操作数据框
- 2.3.12. 转置t
- 2.3.13. 聚合aggregate
- 2.3.14. reshape2
- 2.3.15. 其他常用
- 2.3.15.1. 区间均分:
- 2.3.15.2. 统计区间个数table(cut())
- 3. 数据标准化
- 3.1. 案例-学生成绩排名
- 3.2. 数学函数
- 3.3. 统计函数
- 3.4. 概率函数
- 3.5. 字符处理函数
- 3.6. 其他实用函数
- 4. 列表
- 5. 数据输入&输出
- 5.0.1. 读取、写入csv文件
- 6. 画图
- 6.1. 收盘价日历图
- 6.2. 2图2y轴多元素
- 6.2.1. mtcars点图
- 6.3. 条形图
- 6.4. 分组条形图
- 6.5. 饼图
- 6.6. 直方图
- 6.7. 核密度图
- 6.8. 点图
- 7. 统计分析
- 7.1. summary
- 7.2. cor相关系数
- 7.3. 回归
1. 环境&安装
R是支持win、linux合macos的
完整参考:https://zhuanlan.zhihu.com/p/596324321?utm_id=0
主要是安装:1、R环境;2、rstudio开发环境(后面主要是用rstudio,也可以用vscode)
1.1. rstudio保存工作空间
有2种东西关注:
1.是输入的命令历史
2.是一系列操作后,在工作空间里各种变量的数据值快照
答案:
1.在关闭rstudio的时候,会提示保存,输入的历史,会保存在工作空间的 .RHistory文件中,此文件在 getwd()输出的目录下。
2.通过save.image("myImage.RData")将变量数值快照保存到 myImage.RData 文件中,此文件在 getwd()输出的目录下。
2. 创建数据集
2.1. 数据集概念

- 变量类型:PatientID是行/实例标识符,AdmDate是日期型变量,Age是连续型变量,Diabetes是名义型变量(枚举),Status是有序型变量(有顺序的枚举)
不同变量类型,后面画图用到的plot函数会有不同的呈现效果。
-
R的数据结构:R中有许多用于存储数据的结构,包括标量、向量(一组相同的标量)、矩阵、数组、数据框和列表。
-
R将实例标识符称为rownames(行名),将类别型(包括名义型和有序型)变量称为因子(factors)。
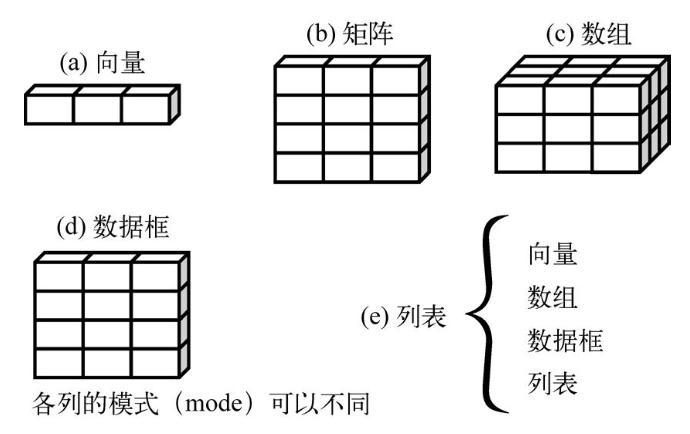
2.2. 向量、矩阵
向量
> a <- c("k", "j", "h", "a", "c", "m")
> a[c(1, 3, 5)]
[1] "k" "h" "c"
> a[2:6]
[1] "j" "h" "a" "c" "m"矩阵: 4行5列,默认是按照列来填充的
> y <- matrix(1:20, nrow = 4, ncol = 5)
> y[,1] [,2] [,3] [,4] [,5]
[1,] 1 5 9 13 17
[2,] 2 6 10 14 18
[3,] 3 7 11 15 19
[4,] 4 8 12 16 20指定列名、行名的矩阵
> mdata <- c(1,3,5,10)
> cnames <- c("c1", "c2")
> rnames <- c("r1", "r2")
> mymatrix <- matrix(mdata, nrow = 2, ncol = 2, dimnames = list(rnames, cnames), byrow = TRUE)
> mymatrixc1 c2
r1 1 3
r2 5 10访问矩阵的单个元素、行、列(接上例)
> mymatrixc1 c2
r1 1 3
r2 5 10
> mymatrix[2,2]
[1] 10
> mymatrix[1,]
c1 c2 1 3
> mymatrix[,2]
r1 r2 3 10
2.3. 数据框
由于不同的列可以包含不同模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。
每一列数据的模式必须唯一,不过你却可以将多个模式的不同列放到一起组成数据框。
# 创建数据框
> patientID <- c(1, 2, 3, 4)
> age <- c(25, 34, 28, 52)
> diabetes <- c("Type1", "Type2", "Type1", "Type1")
> status <- c("Poor", "Improved", "Excellent", "Poor")
> patientdata <- data.frame(patientID, age, diabetes, status) # 构建data.frame
> patientdatapatientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor> patientdata[c(1,2)] # 第1列和第2列patientID age
1 1 25
2 2 34
3 3 28
4 4 52> patientdata[1,2] # 第1行第2列的数据
[1] 25> patientdata[1,] # 第1行数据patientID age diabetes status
1 1 25 Type1 Poor> patientdata[,2] # 第2列数据
[1] 25 34 28 52
> patientdata[c("patientId", "age")]
Error in `[.data.frame`(patientdata, c("patientId", "age")) : undefined columns selected> patientdata[c("patientID", "age")] # 取出patientId、age这2列数据patientID age
1 1 25
2 2 34
3 3 28
4 4 52> patientdata$age # 使用$取出列的数据
[1] 25 34 28 52# 如果你想生成糖尿病类型变量diabetes和病情变量status的列联表,使用以下代码即可:
> patientdata['age']age
1 25
2 34
3 28
4 52
> table(patientdata$diabetes, patientdata$status)Excellent Improved PoorType1 1 0 2Type2 0 1 0# 使用 row.names 来指定data.frame数据框的行名
> patientdata <- data.frame(patientID, age, diabetes,
+ status, row.names=patientID)
> patientdatapatientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor# 因子 指定顺序
> status <- factor(status, order=TRUE,
+ levels=c("Poor", "Improved", "Excellent"))
> status
[1] Poor Improved Excellent Poor# 因子 在数据框中的使用 str(patientdata) summary(patientdata)
> patientID <- c(1, 2, 3, 4)
> age <- c(25, 34, 28, 52)
> diabetes <- c("Type1", "Type2", "Type1", "Type1")
> status <- c("Poor", "Improved", "Excellent", "Poor")
> diabetes <- factor(diabetes)
> status <- factor(status, order=TRUE)
> patientdata <- data.frame(patientID, age, diabetes, status)
> patientdatapatientID age diabetes status
1 1 25 Type1 Poor
2 2 34 Type2 Improved
3 3 28 Type1 Excellent
4 4 52 Type1 Poor
> str(patientdata)
'data.frame': 4 obs. of 4 variables:$ patientID: num 1 2 3 4$ age : num 25 34 28 52$ diabetes : Factor w/ 2 levels "Type1","Type2": 1 2 1 1$ status : Ord.factor w/ 3 levels "Excellent"<"Improved"<..: 3 2 1 3
> summary(patientdata)patientID age diabetes status Min. :1.00 Min. :25.00 Type1:3 Excellent:1 1st Qu.:1.75 1st Qu.:27.25 Type2:1 Improved :1 Median :2.50 Median :31.00 Poor :2 Mean :2.50 Mean :34.75 3rd Qu.:3.25 3rd Qu.:38.50 Max. :4.00 Max. :52.00
2.3.1. 创建数据框
> manager <- c(1, 2, 3, 4, 5)
> date <- c("10/24/08", "10/28/08", "10/1/08", "10/12/08", "5/1/09")
> country <- c("US", "US", "UK", "UK", "UK")
> gender <- c("M", "F", "F", "M", "F")
> age <- c(32, 45, 25, 39, 99)
> q1 <- c(5, 3, 3, 3, 2)
> q2 <- c(4, 5, 5, 3, 2)
> q3 <- c(5, 2, 5, 4, 1)
> q4 <- c(5, 5, 5, NA, 2)
> q5 <- c(5, 5, 2, NA, 1)
> leadership <- data.frame(manager, date, country, gender, age, q1, q2, q3, q4, q5, stringsAsFactors=FALSE)
> leadershipmanager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
2.3.2. 创建新变量
> mydata<-data.frame(x1 = c(2, 2, 6, 4), x2 = c(3, 4, 2, 8))
> mydatax1 x2
1 2 3
2 2 4
3 6 2
4 4 8
# 方式1
> mydata$sumx <- mydata$x1 + mydata$x2
> mydata$meanx <- (mydata$x1 + mydata$x2)/2
> mydatax1 x2 sumx meanx
1 2 3 5 2.5
2 2 4 6 3.0
3 6 2 8 4.0
4 4 8 12 6.0
# 方式2
> mydata <- transform(mydata, sumx = x1+x2, meanx = (x1 + x2)/2)
> mydatax1 x2 sumx meanx
1 2 3 5 2.5
2 2 4 6 3.0
3 6 2 8 4.0
4 4 8 12 6.0
2.3.3. 变量的重编码
重编码涉及根据同一个变量和/或其他变量的现有值创建新值的过程。举例来说,你可能想:
将一个连续型变量修改为一组类别值;
将误编码的值替换为正确值;
基于一组分数线创建一个表示及格/不及格的变量。
逻辑运算符:与&、或|、非!、测试x是否为TRUE isTRUE(x)
> leadershipmanager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
> leadership$age[leadership$age == 99] <- NA # ==判断,年龄99的,重新填充值为NA
> leadershipmanager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 US F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 UK M 39 3 3 4 NA NA
5 5 5/1/09 UK F NA 2 2 1 2 1# 根据条件创建新的一列
> leadership$agecat[leadership$age > 75] <- "Elder"
> leadership$agecat[leadership$age >= 55 & leadership$age <= 75] <- "Middle Aged"
> leadership$agecat[leadership$age < 55] <- "Young"
> leadershipmanager date country gender age q1 q2 q3 q4 q5 agecat
1 1 10/24/08 US M 32 5 4 5 5 5 Young
2 2 10/28/08 US F 45 3 5 2 5 5 Young
3 3 10/1/08 UK F 25 3 5 5 5 2 Young
4 4 10/12/08 UK M 39 3 3 4 NA NA Young
5 5 5/1/09 UK F NA 2 2 1 2 1 <NA>
2.3.4. 列重命名
> names(leadership)[2] <- "testDate"
> names(leadership)[6:10] <- c("item1", "item2", "item3", "item4", "item5")
2.3.5. 缺失值
> y <- c(1, 2, 3, NA)
> is.na(y)
[1] FALSE FALSE FALSE TRUE# 忽略缺失值 sum(x, na.rm=TRUE) 或者 na.omit(leadership)
> y <- c(1, 2, 3, NA)
> is.na(y)
[1] FALSE FALSE FALSE TRUE
> is.na(y)[4]
[1] TRUE
> x <- c(1, 2, NA, 3)
> y <- x[1] + x[2] + x[3] + x[4]
> y
[1] NA
> z <- sum(x)
> z
[1] NA
> y <- sum(x, na.rm=TRUE)
> y
[1] 6> leadershipmanager date country gender age q1 q2 q3 q4 q5 agecat
1 1 10/24/08 US M 32 5 4 5 5 5 Young
2 2 10/28/08 US F 45 3 5 2 5 5 Young
3 3 10/1/08 UK F 25 3 5 5 5 2 Young
4 4 10/12/08 UK M 39 3 3 4 NA NA Young
5 5 5/1/09 UK F NA 2 2 1 2 1 <NA>
> na.omit(leadership)manager date country gender age q1 q2 q3 q4 q5 agecat
1 1 10/24/08 US M 32 5 4 5 5 5 Young
2 2 10/28/08 US F 45 3 5 2 5 5 Young
3 3 10/1/08 UK F 25 3 5 5 5 2 Young
2.3.6. 日期值
日期值通常以字符串的形式输入到R中,然后转化为以数值形式存储的日期变量。函数 as.Date()用于执行这种转化。其语法为as.Date(x, “input_format”),其中x是字符型数据,input_format则给出了用于读入日期的适当格式(见表4-4)。
日期值的默认输入格式为yyyy-mm-dd。

日期值的默认输入格式为yyyy-mm-dd。
> strDates <- c("01/05/1965", "08/16/1975")
> dates <- as.Date(strDates, "%m/%d/%Y")
> dates
[1] "1965-01-05" "1975-08-16"
> leadershipmanager date country gender age q1 q2 q3 q4 q5 agecat
1 1 10/24/08 US M 32 5 4 5 5 5 Young
2 2 10/28/08 US F 45 3 5 2 5 5 Young
3 3 10/1/08 UK F 25 3 5 5 5 2 Young
4 4 10/12/08 UK M 39 3 3 4 NA NA Young
5 5 5/1/09 UK F NA 2 2 1 2 1 <NA>
# 日期格式转换
> leadership$date <- as.Date(leadership$date, '%m/%d/%y')
> leadershipmanager date country gender age q1 q2 q3 q4 q5 agecat
1 1 2008-10-24 US M 32 5 4 5 5 5 Young
2 2 2008-10-28 US F 45 3 5 2 5 5 Young
3 3 2008-10-01 UK F 25 3 5 5 5 2 Young
4 4 2008-10-12 UK M 39 3 3 4 NA NA Young
5 5 2009-05-01 UK F NA 2 2 1 2 1 <NA>
有两个函数对于处理时间戳数据特别实用。Sys.Date()可以返回当天的日期,而date()则返回当前的日期和时间。
# Sys.Date() 与 date() 函数
> Sys.Date()
[1] "2023-11-28"
> str(Sys.Date)
function ()
> str(Sys.Date())Date[1:1], format: "2023-11-28"
> date()
[1] "Tue Nov 28 17:29:09 2023"
> format(date(), '%Y-%m-%d')
Error in format.default(date(), "%Y-%m-%d") : invalid 'trim' argument
> format(Sys.Date(), '%Y-%m-%d')
[1] "2023-11-28"
> format(Sys.Date(), '%Y/%m/%d')
[1] "2023/11/28"
> str(format(Sys.Date(), '%Y/%m/%d'))chr "2023/11/28"# 日期差
> startdate <- as.Date("2004-02-13")
> enddate <- as.Date("2011-01-22")
> days <- enddate - startdate
> days
Time difference of 2535 days# 间隔多少周?
> today <- Sys.Date()
> kelvin <- as.Date("1990-05-10")
> difftime(today, kelvin, units="weeks")
Time difference of 1750.714 weeks# 将日期转为字符串格式
> dates
[1] "1965-01-05" "1975-08-16"
> str(dates)Date[1:2], format: "1965-01-05" "1975-08-16"
> as.character(dates)
[1] "1965-01-05" "1975-08-16"
> str(as.character(dates))chr [1:2] "1965-01-05" "1975-08-16"

2.3.7. 数据框排序
> leadership[order(leadership$age)]country manager gender date age
1 US 1 M 2008-10-24 32
2 US 2 F 2008-10-28 45
3 UK 3 F 2008-10-01 25
4 UK 4 M 2008-10-12 39
5 UK 5 F 2009-05-01 NA> leadership[order(leadership$age),] # 这里的逗号,少了的话差异还是很大的,貌似是截取了!manager date country gender age q1 q2 q3 q4 q5 agecat
3 3 2008-10-01 UK F 25 3 5 5 5 2 Young
1 1 2008-10-24 US M 32 5 4 5 5 5 Young
4 4 2008-10-12 UK M 39 3 3 4 NA NA Young
2 2 2008-10-28 US F 45 3 5 2 5 5 Young
5 5 2009-05-01 UK F NA 2 2 1 2 1 <NA>> newdata <-leadership[order(gender, -age),] # 2列排序,正序和倒序
> newdatamanager date country gender age q1 q2 q3 q4 q5 agecat
5 5 2009-05-01 UK F NA 2 2 1 2 1 <NA>
2 2 2008-10-28 US F 45 3 5 2 5 5 Young
3 3 2008-10-01 UK F 25 3 5 5 5 2 Young
4 4 2008-10-12 UK M 39 3 3 4 NA NA Young
1 1 2008-10-24 US M 32 5 4 5 5 5 Young
2.3.8. 数据框合并(合并沪深300和中证500收盘价日历)
merge()函数。在多数情况下,两个数据框是通过一个或多个共有变量进行联结的(即一种内联结,inner join)。
# 读取沪深300收盘价
> sh300 <- read.csv("SH510300-收盘价.csv")
> head(sh300)date close
1 2012/5/28 2.2020
2 2012/5/29 2.2359
3 2012/5/30 2.2291
4 2012/5/31 2.2240
5 2012/6/1 2.2240
6 2012/6/4 2.1631# 读取中证500收盘价
> sh500 <- read.csv("SH510500-收盘价.csv")
> head(sh500)date close
1 2013/3/15 3.0215
2 2013/3/18 2.9717
3 2013/3/19 2.9904
4 2013/3/20 3.0683
5 2013/3/21 3.0994
6 2013/3/22 3.1119# 将2个dataframe合并(按照date列合并,没有的数据会自动补充为NA), merge默认是inner join,需要加 all = TRUE 参数
> merged_df <- merge(sh300, sh500, by = "date", all = TRUE)
> head(merged_df)date close.x close.y
1 2012/10/10 1.9923 NA
2 2012/10/11 1.9788 NA
3 2012/10/12 1.9771 NA
4 2012/10/15 1.9703 NA
5 2012/10/16 1.9712 NA
6 2012/10/17 1.9788 NA# 查看合并后的总行数
> nrow(merged_df)
[1] 2797
# 原沪深300行数
> nrow(sh300)
[1] 2797
# 原中证500行数
> nrow(sh500)
[1] 2600# 如果直接按照date列进行排序,是错的,可见是从 2012/10/10 开始。(应该是沪深300的2012-05-28) 需要对date列进行转日期格式。
> merged_df <- merged_df[order(merged_df$date),]
> head(merged_df)date close.x close.y
1 2012/10/10 1.9923 NA
2 2012/10/11 1.9788 NA
3 2012/10/12 1.9771 NA
4 2012/10/15 1.9703 NA
5 2012/10/16 1.9712 NA
6 2012/10/17 1.9788 NA
# 日期格式转换
> merged_df$date <- as.Date(merged_df$date, '%Y/%m/%d')
> head(merged_df)date close.x close.y
1 2012-10-10 1.9923 NA
2 2012-10-11 1.9788 NA
3 2012-10-12 1.9771 NA
4 2012-10-15 1.9703 NA
5 2012-10-16 1.9712 NA
6 2012-10-17 1.9788 NA
# 对数据框排序
> merged_df <- merged_df[order(merged_df$date),]
> head(merged_df)date close.x close.y
62 2012-05-28 2.2020 NA
63 2012-05-29 2.2359 NA
64 2012-05-30 2.2291 NA
65 2012-05-31 2.2240 NA
66 2012-06-01 2.2240 NA
81 2012-06-04 2.1631 NA
2.3.9. 数据框子集
> d1 <- read.csv("SH510300.csv")
> head(d1)date uuid date.1 volume open high low close chg
1 2012-05-28 SH510300|2012-05-28 2012-05-28 1277518769 2.1572 2.2046 2.1513 2.2020 0.0255
2 2012-05-29 SH510300|2012-05-29 2012-05-29 714949008 2.2004 2.2503 2.2004 2.2359 0.0339
3 2012-05-30 SH510300|2012-05-30 2012-05-30 265887198 2.2342 2.2384 2.2266 2.2291 -0.0068
4 2012-05-31 SH510300|2012-05-31 2012-05-31 178155984 2.2164 2.2367 2.2097 2.2240 -0.0051
5 2012-06-01 SH510300|2012-06-01 2012-06-01 179350035 2.2232 2.2494 2.2156 2.2240 0.0000
6 2012-06-04 SH510300|2012-06-04 2012-06-04 546074272 2.1995 2.2020 2.1606 2.1631 -0.0609percent turnoverrate amount
1 1.17 10.45 NA
2 1.54 5.85 NA
3 -0.30 2.17 NA
4 -0.23 1.46 NA
5 0.00 1.47 NA
6 -2.74 4.47 NA
# 取1,3,5行,以及 "date", "close" 列
> d2 <- d1[c(1,3,5), c("date", "close")]
> d2date close
1 2012-05-28 2.2020
3 2012-05-30 2.2291
5 2012-06-01 2.2240# 其他一些用法
newdata <- leadership[leadership$gender=="M" & leadership$age > 30,]leadership$date <- as.Date(leadership$date, "%m/%d/%y")
startdate <- as.Date("2009-01-01")
enddate <- as.Date("2009-10-31")
newdata <- leadership[which(leadership$date >= startdate & leadership$date <= enddate),]newdata <- subset(leadership, age >= 35 | age < 24, select=c(q1, q2, q3, q4)) # 选择所有age值大于等于35或age值 小于24的行,保留了变量q1到q4
newdata <- subset(leadership, gender == 'M' | age > 25, select=gender:q4) # 选择所有25岁以上的男性,并保留了变量gender 到q4(gender、q4和其间所有列)
2.3.10. 随机抽样
# 读取数据
> d1 <- read.csv("SH510300.csv")
> head(d1)date uuid date.1 volume open high low close chg
1 2012-05-28 SH510300|2012-05-28 2012-05-28 1277518769 2.1572 2.2046 2.1513 2.2020 0.0255
2 2012-05-29 SH510300|2012-05-29 2012-05-29 714949008 2.2004 2.2503 2.2004 2.2359 0.0339
3 2012-05-30 SH510300|2012-05-30 2012-05-30 265887198 2.2342 2.2384 2.2266 2.2291 -0.0068
4 2012-05-31 SH510300|2012-05-31 2012-05-31 178155984 2.2164 2.2367 2.2097 .2240 -0.0051
5 2012-06-01 SH510300|2012-06-01 2012-06-01 179350035 2.2232 2.2494 2.2156 2.2240 0.0000
6 2012-06-04 SH510300|2012-06-04 2012-06-04 546074272 2.1995 2.2020 2.1606 2.1631 -0.0609percent turnoverrate amount
1 1.17 10.45 NA
2 1.54 5.85 NA
3 -0.30 2.17 NA
4 -0.23 1.46 NA
5 0.00 1.47 NA
6 -2.74 4.47 NA# 查看总行数
> nrow(d1)
[1] 2797# 从 1:nrow(d1) 这个向量里面读取3个,不放回抽样
> s1 <- sample(1:nrow(d1), 3, replace = FALSE)
> s1
[1] 761 195 116
# 直接从数据集抽样语法:
> mysample <- d1[sample(1:nrow(d1), 3, replace=FALSE),]
> mysampledate uuid date.1 volume open high low close chg
808 2015-09-18 SH510300|2015-09-18 2015-09-18 258148381 2.9232 2.9347 2.8877 2.9046 -0.0008
1880 2020-02-18 SH510300|2020-02-18 2020-02-18 709950982 3.8817 3.8865 3.8386 3.8645 -0.0239
2772 2023-10-20 SH510300|2023-10-20 2023-10-20 1740446164 3.5830 3.6000 3.5650 3.5820 -0.0180percent turnoverrate amount
808 -0.03 4.42 NA
1880 -0.61 0.00 2867046795
2772 -0.50 0.00 6233727376# 抽样,是在 1:nrow(d1) 不放回,不影响原来的d1数据集
> nrow(d1)
[1] 2797
2.3.11. sql操作数据框
> install.packages("sqldf")
> install.packages("RSQLite")
> library(sqldf)
Loading required package: RSQLite
# 从数据框 sh300 提取 close > 3 的行,并按照close倒序排列。参数row.names=TRUE将原始数据框中的行名延续到了新数据框中。
> newdf <- sqldf("select * from sh300 where close > 3 order by close desc", row.names = TRUE)
> head(newdf)date close
2123 2021/2/10 5.6294
2125 2021/2/19 5.6188
2124 2021/2/18 5.5877
2122 2021/2/9 5.5179
2111 2021/1/25 5.4588
2102 2021/1/12 5.4231
> nrow(newdf)
[1] 1925
2.3.12. 转置t
行列名对换
> cars <- mtcars[1:5,1:4]
> carsmpg cyl disp hp
Mazda RX4 21 6 160 110
Mazda RX4 Wag 21 6 160 110
Datsun 710 23 4 108 93
Hornet 4 Drive 21 6 258 110
Hornet Sportabout 19 8 360 175
> t(cars)Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout
mpg 21 21 23 21 19
cyl 6 6 4 6 8
disp 160 160 108 258 360
hp 110 110 93 110 175
2.3.13. 聚合aggregate
类似按照条件分组聚合。
> mtcarsmpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21 6 160 110 3.9 2.6 16 0 1 4 4
Mazda RX4 Wag 21 6 160 110 3.9 2.9 17 0 1 4 4
Datsun 710 23 4 108 93 3.9 2.3 19 1 1 4 1
Hornet 4 Drive 21 6 258 110 3.1 3.2 19 1 0 3 1
Hornet Sportabout 19 8 360 175 3.1 3.4 17 0 0 3 2
Valiant 18 6 225 105 2.8 3.5 20 1 0 3 1
Duster 360 14 8 360 245 3.2 3.6 16 0 0 3 4
Merc 240D 24 4 147 62 3.7 3.2 20 1 0 4 2
Merc 230 23 4 141 95 3.9 3.1 23 1 0 4 2
Merc 280 19 6 168 123 3.9 3.4 18 1 0 4 4
Merc 280C 18 6 168 123 3.9 3.4 19 1 0 4 4
Merc 450SE 16 8 276 180 3.1 4.1 17 0 0 3 3
Merc 450SL 17 8 276 180 3.1 3.7 18 0 0 3 3
Merc 450SLC 15 8 276 180 3.1 3.8 18 0 0 3 3
Cadillac Fleetwood 10 8 472 205 2.9 5.2 18 0 0 3 4
Lincoln Continental 10 8 460 215 3.0 5.4 18 0 0 3 4
Chrysler Imperial 15 8 440 230 3.2 5.3 17 0 0 3 4
Fiat 128 32 4 79 66 4.1 2.2 19 1 1 4 1
Honda Civic 30 4 76 52 4.9 1.6 19 1 1 4 2
Toyota Corolla 34 4 71 65 4.2 1.8 20 1 1 4 1
Toyota Corona 22 4 120 97 3.7 2.5 20 1 0 3 1
Dodge Challenger 16 8 318 150 2.8 3.5 17 0 0 3 2
AMC Javelin 15 8 304 150 3.1 3.4 17 0 0 3 2
Camaro Z28 13 8 350 245 3.7 3.8 15 0 0 3 4
Pontiac Firebird 19 8 400 175 3.1 3.8 17 0 0 3 2
Fiat X1-9 27 4 79 66 4.1 1.9 19 1 1 4 1
Porsche 914-2 26 4 120 91 4.4 2.1 17 0 1 5 2
Lotus Europa 30 4 95 113 3.8 1.5 17 1 1 5 2
Ford Pantera L 16 8 351 264 4.2 3.2 14 0 1 5 4
Ferrari Dino 20 6 145 175 3.6 2.8 16 0 1 5 6
Maserati Bora 15 8 301 335 3.5 3.6 15 0 1 5 8
Volvo 142E 21 4 121 109 4.1 2.8 19 1 1 4 2
# 在结果中,Group.1表示汽缸数量(4、6或8),Group.2代表挡位数(3、4或5)。举例来说, 拥有4个汽缸和3个挡位车型的每加仑汽油行驶英里数(mpg)均值为22。
# 跟书上数据不同,可能是小数点位没有恢复设置。
# 在使用aggregate()函数的时候,by中的变量必须在一个列表中(即使只有一个变量)。你可以在列表中为各组声明自定义的名称,例如by=list(Group.cyl=cyl, Group.gears=gear)。
> aggdata <-aggregate(mtcars, by=list(mtcars$cyl,mtcars$gear), FUN=mean, na.rm=TRUE)
> aggdataGroup.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb
1 4 3 22 4 120 97 3.7 2.5 20 1.0 0.00 3 1.0
2 6 3 20 6 242 108 2.9 3.3 20 1.0 0.00 3 1.0
3 8 3 15 8 358 194 3.1 4.1 17 0.0 0.00 3 3.1
4 4 4 27 4 103 76 4.1 2.4 20 1.0 0.75 4 1.5
5 6 4 20 6 164 116 3.9 3.1 18 0.5 0.50 4 4.0
6 4 5 28 4 108 102 4.1 1.8 17 0.5 1.00 5 2.0
7 6 5 20 6 145 175 3.6 2.8 16 0.0 1.00 5 6.0
8 8 5 15 8 326 300 3.9 3.4 15 0.0 1.00 5 6.0
2.3.14. reshape2
> ID <- c(1,1,2,2)
> Time <- (1,2,1,2)
Error: unexpected ',' in "Time <- (1,"
> Time <- c(1,2,1,2)
> X1 <- c(5,3,6,2)
> X2 <- c(6,5,1,4)
> mydata <- data.frame(ID, Time, X1, X2)
> mydataID Time X1 X2
1 1 1 5 6
2 1 2 3 5
3 2 1 6 1
4 2 2 2 4
> library(reshape2)
> md <- melt(mydata, id=c("ID", "Time"))
> mdID Time variable value
1 1 1 X1 5
2 1 2 X1 3
3 2 1 X1 6
4 2 2 X1 2
5 1 1 X2 6
6 1 2 X2 5
7 2 1 X2 1
8 2 2 X2 4
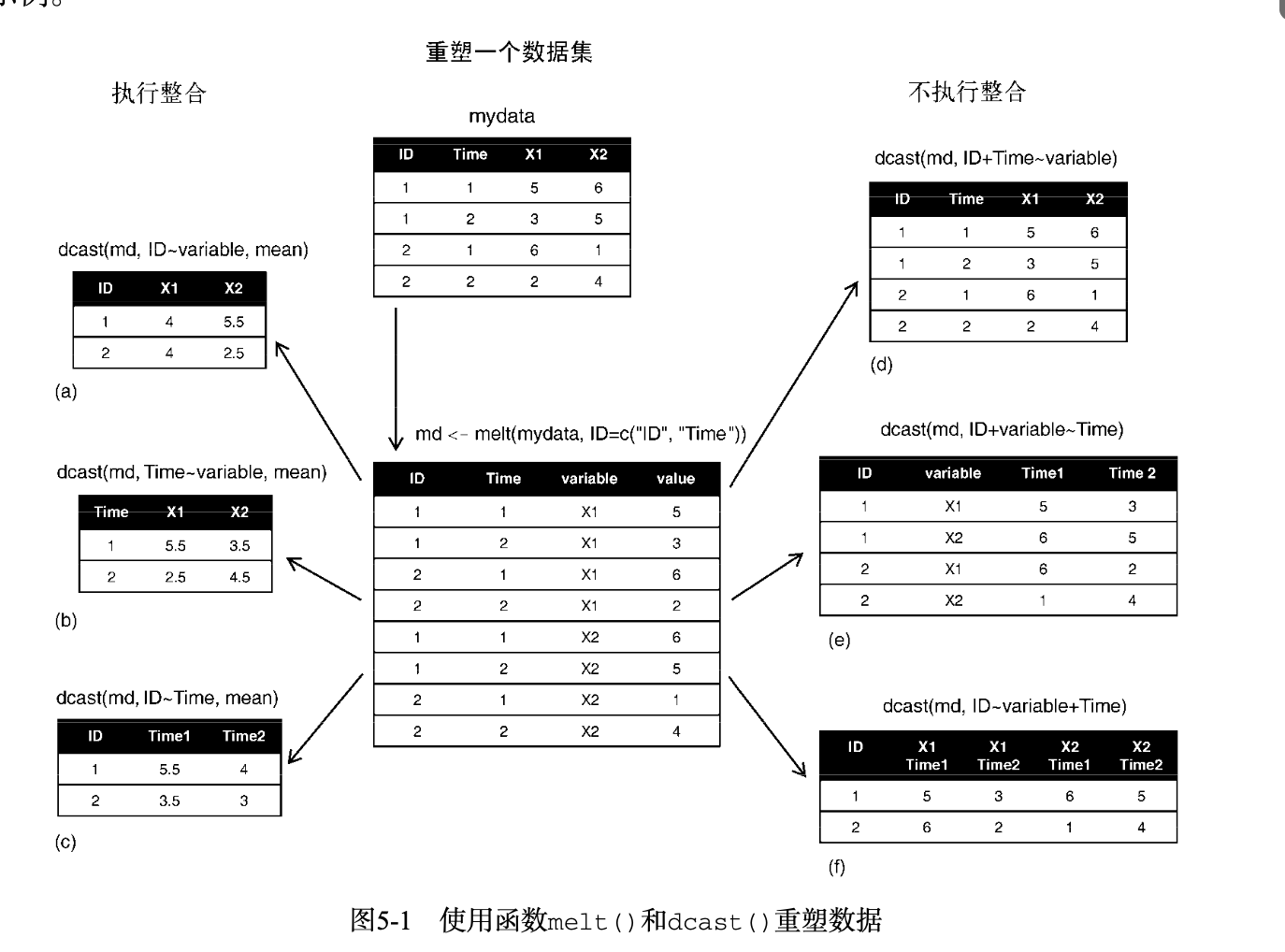
2.3.15. 其他常用
2.3.15.1. 区间均分:
从from到to,平均分成10份
> min(sh500$close)
[1] 2.816
> max(sh500$close)
[1] 10.216
> seq(from=min(sh500$close), to=max(sh500$close), length.out = 11) # 从from到to,平均分成10份[1] 2.8160 3.5560 4.2959 5.0359 5.7759 6.5159 7.2558 7.9958 8.7358 9.4757 10.2157
2.3.15.2. 统计区间个数table(cut())
场景:将沪深300的收盘价,均匀分10份,每份是多少个,各份区间大小?
# 最小值
> min300 <- min(sh300$close)
> min300
[1] 1.8139# 最大值
> max300 <- max(sh300$close)
> max300
[1] 5.6294# 从[最小:最大],生成11个均分数(即10个区间)
> myseq <- seq(min300, max300, length.out = 11)
> myseq[1] 1.8139 2.1955 2.5770 2.9585 3.3401 3.7217 4.1032 4.4848 4.8663 5.2478 5.6294# 统计收盘价在10个区间内的个数
> mytable <- table(cut(sh300$close, breaks = myseq))
> mytable(1.81,2.2] (2.2,2.58] (2.58,2.96] (2.96,3.34] (3.34,3.72] (3.72,4.1] (4.1,4.48] 526 85 200 447 469 523 145
(4.48,4.87] (4.87,5.25] (5.25,5.63] 245 126 30
> mytable[1]
(1.81,2.2] 526# 绘制条形图
> barplot(mytable)

3. 数据标准化
默认情况下,函数scale()对矩阵或数据框的指定列进行均值为0、标准差为1的标准化:
newdata <- scale(mydata)
要对每一列进行任意均值和标准差的标准化,可以使用如下的代码:
newdata <- scale(mydata)*SD + M
其中的M是想要的均值,SD为想要的标准差。在非数值型的列上使用scale()函数将会报错。
要对指定列而不是整个矩阵或数据框进行标准化,你可以使用这样的代码:
newdata <- transform(mydata, myvar = scale(myvar)*10+50)
此句将变量myvar标准化为均值50、标准差为10的变量。你将在5.3节数据处理问题的解决方法中用到scale()函数。
3.1. 案例-学生成绩排名
一组学生参加了数学、科 10 学和英语考试。为了给所有学生确定一个单一的成绩衡量指标,需要将这些科目的成绩组合起来。
另外,你还想将前20%的学生评定为A,接下来20%的学生评定为B,依次类推。最后,你希望按字母顺序对学生排序。数据如表5-1所示。
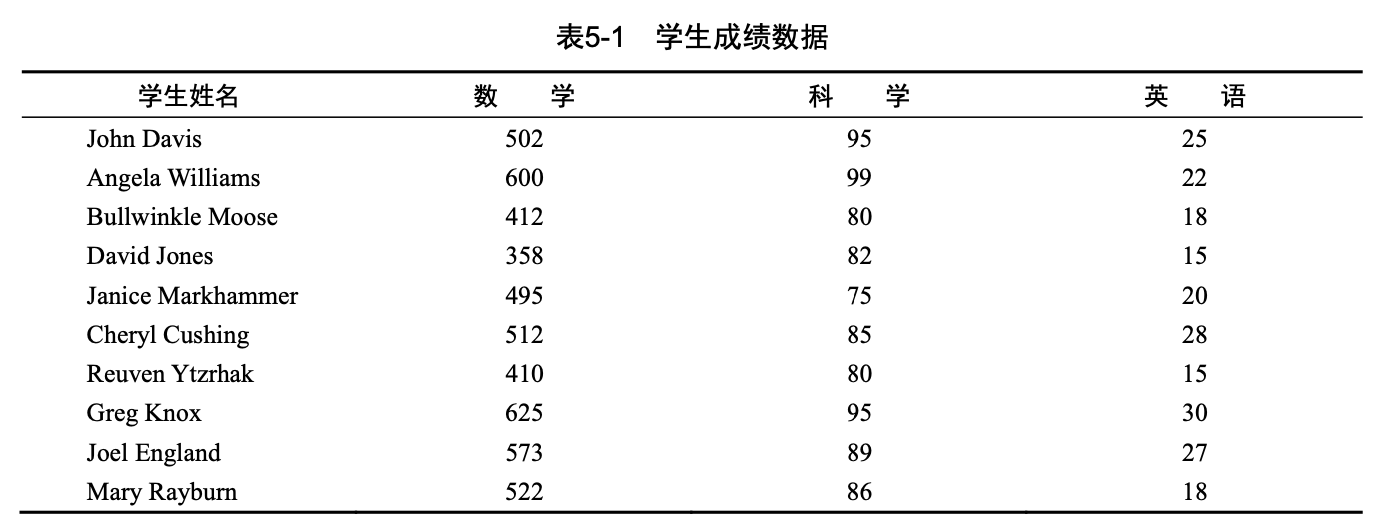
说明:
按照数值,横向的数学、科学、英语是无法直接比较的,需要对数据进行标准化处理。
# options(digits=2)限定了输出小数点后数字的 位数
> options(digits=2)# 准备数据框
> Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose",
+ "David Jones", "Janice Markhammer", "Cheryl Cushing",
+ "Reuven Ytzrhak", "Greg Knox", "Joel England",
+ "Mary Rayburn")
> Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
> Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
> English <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18)
> roster <- data.frame(Student, Math, Science, English,
+ stringsAsFactors=FALSE)
> rosterStudent Math Science English
1 John Davis 502 95 25
2 Angela Williams 600 99 22
3 Bullwinkle Moose 412 80 18
4 David Jones 358 82 15
5 Janice Markhammer 495 75 20
6 Cheryl Cushing 512 85 28
7 Reuven Ytzrhak 410 80 15
8 Greg Knox 625 95 30
9 Joel England 573 89 27
10 Mary Rayburn 522 86 18# 对2:4列进行标准化处理,以便于横向比较。函数scale()对矩阵或数据框的指定列进行均值为0、标准差为1的标准化。
> z <- scale(roster[,2:4])
> zMath Science English[1,] 0.013 1.078 0.587[2,] 1.143 1.591 0.037[3,] -1.026 -0.847 -0.697[4,] -1.649 -0.590 -1.247[5,] -0.068 -1.489 -0.330[6,] 0.128 -0.205 1.137[7,] -1.049 -0.847 -1.247[8,] 1.432 1.078 1.504[9,] 0.832 0.308 0.954
[10,] 0.243 -0.077 -0.697
attr(,"scaled:center")Math Science English 501 87 22
attr(,"scaled:scale")Math Science English 86.7 7.8 5.5 # 通过函数mean()来计算各行的均值以获得综合得分,并使用函数cbind()将其添加到花名册中
# apply函数常用来代替for循环。apply函数可以对数据(矩阵、数据框、数组),按行或列循环计算,对子元素进行迭代,并把子元素以参数传递的形式给自定义的FUN函数中,并以返回计算结果。
# apply(X, MARGIN, FUN, ...) X:数据 MARGIN: 按行或按按列计算,1代表按行,2代表按列 FUN: 自定义函数
> score <- apply(z, 1, mean)
> score[1] 0.56 0.92 -0.86 -1.16 -0.63 0.35 -1.05 1.34 0.70 -0.18
> roster <- cbind(roster, score)# quantile,是计算百分位数。计算结果的解读是:如果 标准化后的分值>0.74,那么这个分值就超过了80%的
> y <- quantile(score, c(.8,.6,.4,.2))
> y80% 60% 40% 20% 0.74 0.44 -0.36 -0.89 # 对 标准化分值 判断是落在了哪个区间。
> roster$grade[score >= y[1]] <- "A"
> roster$grade[score < y[1] & score >= y[2]] <- "B"
> roster$grade[score < y[2] & score >= y[3]] <- "C"
> roster$grade[score < y[3] & score >= y[4]] <- "D"
> roster$grade[score < y[4]] <- "F"# 将Student列按照空格拆开。把 strsplit()应用到一个字符串组成的向量上会返回一个列表
> name <- strsplit((roster$Student), " ")
> name
[[1]]
[1] "John" "Davis"[[2]]
[1] "Angela" "Williams"[[3]]
[1] "Bullwinkle" "Moose"
....
# 函数sapply()提取列表中每个成分的第一个元素,放入一个储存名字 的向量Firstname,并提取每个成分的第二个元素,放入一个储存姓氏的向量Lastname。
# "[" 是一个可以提取某个对象的一部分的函数——在这里它是用来提取列表name各成分中的第一个或第二个元素的。
> Firstname <- sapply(name, "[", 1)
> Lastname <- sapply(name, "[", 2)
# 在数据框的左侧加入 Firstname、Lastname 2列
> roster <- cbind(Firstname,Lastname, roster[,-1])
> rosterFirstname Lastname Math Science English score grade
1 John Davis 502 95 25 0.56 B
2 Angela Williams 600 99 22 0.92 A
3 Bullwinkle Moose 412 80 18 -0.86 D
4 David Jones 358 82 15 -1.16 F
5 Janice Markhammer 495 75 20 -0.63 D
6 Cheryl Cushing 512 85 28 0.35 C
7 Reuven Ytzrhak 410 80 15 -1.05 F
8 Greg Knox 625 95 30 1.34 A
9 Joel England 573 89 27 0.70 B
10 Mary Rayburn 522 86 18 -0.18 C# 根据Lastname、Firstname升序排列
> roster <- roster[order(Lastname,Firstname),]
> rosterFirstname Lastname Math Science English score grade
6 Cheryl Cushing 512 85 28 0.35 C
1 John Davis 502 95 25 0.56 B
9 Joel England 573 89 27 0.70 B
4 David Jones 358 82 15 -1.16 F
8 Greg Knox 625 95 30 1.34 A
5 Janice Markhammer 495 75 20 -0.63 D
3 Bullwinkle Moose 412 80 18 -0.86 D
10 Mary Rayburn 522 86 18 -0.18 C
2 Angela Williams 600 99 22 0.92 A
7 Reuven Ytzrhak 410 80 15 -1.05 F
数学函数等
3.2. 数学函数


3.3. 统计函数

3.4. 概率函数

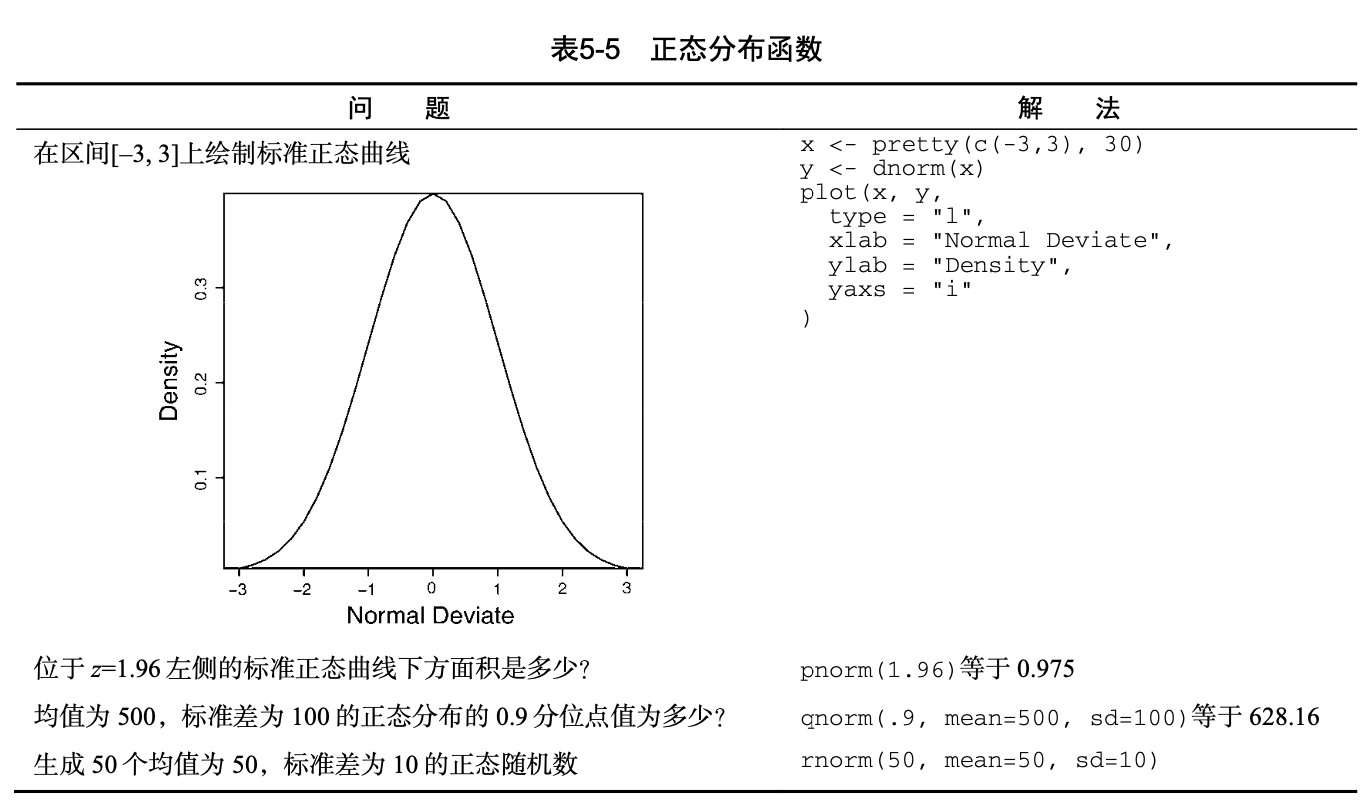
> x <- pretty(c(-3,3), 30)
> length(x)
[1] 31
> x[1] -3.0 -2.8 -2.6 -2.4 -2.2 -2.0 -1.8 -1.6 -1.4 -1.2 -1.0 -0.8 -0.6 -0.4 -0.2 0.0 0.2 0.4
[19] 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.2 2.4 2.6 2.8 3.0
> y <- dnorm(x)
> y[1] 0.004431848 0.007915452 0.013582969 0.022394530 0.035474593 0.053990967 0.078950158[8] 0.110920835 0.149727466 0.194186055 0.241970725 0.289691553 0.333224603 0.368270140
[15] 0.391042694 0.398942280 0.391042694 0.368270140 0.333224603 0.289691553 0.241970725
[22] 0.194186055 0.149727466 0.110920835 0.078950158 0.053990967 0.035474593 0.022394530
[29] 0.013582969 0.007915452 0.004431848
> plot(x, y,
+ type = "l",
+ xlab = "Normal Deviate",
+ ylab = "Density",
+ yaxs = "i"
+ )
>
3.5. 字符处理函数

3.6. 其他实用函数

4. 列表
> g <- "My First List"
> h <- c(25, 26, 18, 39)
> j <- matrix(1:10, nrow=5)
> k <- c("one", "two", "three")
> mylist <- list(title=g, ages=h, j, k)
> mylist
$title
[1] "My First List"$ages
[1] 25 26 18 39[[3]][,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10[[4]]
[1] "one" "two" "three"> mylist['title']
$title
[1] "My First List"> mylist[3] # 这种操作很奇怪,取出来的矩阵matrix无法直接取数操作,要用下面的方法,双[[]]
[[1]][,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
# 你也可以通过在双重方括号中指明代表某个成分的数字或名称来访问列表中的元素。
> mylist[[3]][,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
> mylist[[3]][2,2]
[1] 7
5. 数据输入&输出
# 通过edit输入
> mydata <- data.frame(age=numeric(0),
+ gender=character(0), weight=numeric(0))
> mydata <- edit(mydata)
Error in check_for_XQuartz(file.path(R.home("modules"), "R_de.so")) : X11 library is missing: install XQuartz from www.xquartz.org
> install.packages("XQuartz")
Warning in install.packages :package ‘XQuartz’ is not available for this version of RA version of this package for your version of R might be available elsewhere,
see the ideas at
https://cran.r-project.org/doc/manuals/r-patched/R-admin.html#Installing-packages
5.0.1. 读取、写入csv文件
# 读取csv文件,逗号分隔,列date作为行名(date作为行名,那date那一列就没了)
> sh510300 <- read.csv("SH510300.csv", header = TRUE, sep = ",", row.names = "date")
> head(sh510300)uuid date.1 volume open high low close chg
2012-05-28 SH510300|2012-05-28 2012-05-28 1277518769 2.1572 2.2046 2.1513 2.2020 0.0255
2012-05-29 SH510300|2012-05-29 2012-05-29 714949008 2.2004 2.2503 2.2004 2.2359 0.0339
2012-05-30 SH510300|2012-05-30 2012-05-30 265887198 2.2342 2.2384 2.2266 2.2291 -0.0068
2012-05-31 SH510300|2012-05-31 2012-05-31 178155984 2.2164 2.2367 2.2097 2.2240 -0.0051
2012-06-01 SH510300|2012-06-01 2012-06-01 179350035 2.2232 2.2494 2.2156 2.2240 0.0000
2012-06-04 SH510300|2012-06-04 2012-06-04 546074272 2.1995 2.2020 2.1606 2.1631 -0.0609
> sh510300[,'date']
Error in `[.data.frame`(sh510300, , "date") : undefined columns selected# 取出一行,2012-05-28这个日期的行数据
> sh510300['2012-05-28',]uuid date.1 volume open high low close chg percent
2012-05-28 SH510300|2012-05-28 2012-05-28 1277518769 2.1572 2.2046 2.1513 2.202 0.0255 1.17turnoverrate amount
2012-05-28 10.45 NA# 写入csv文件
> write.csv(sh510300, "new_file.csv")6. 画图
6.1. 收盘价日历图
1.事先已准备好“日期date-收盘价close”的csv文件
2.读取csv
3.将日期x轴进行类型转换
4.使用plot画图
> sh300 <- read.csv("SH510300-收盘价.csv") # 读取csv数据
> head(sh300)date close
1 2012/5/28 2.2020
2 2012/5/29 2.2359
3 2012/5/30 2.2291
4 2012/5/31 2.2240
5 2012/6/1 2.2240
6 2012/6/4 2.1631
> date300 <- as.Date(sh300$date, "%Y/%m/%d",) # 将日期字符串转为日期格式
> plot(date300, sh300$close) # 画图
下面就是画出来的图:1、圆圈点太大;2、没有连线;3、x轴比较散;4、图是无交互式的,只能看(有很多调节参数,这里只是简单实用了plot函数,并没有进行低级调整。)
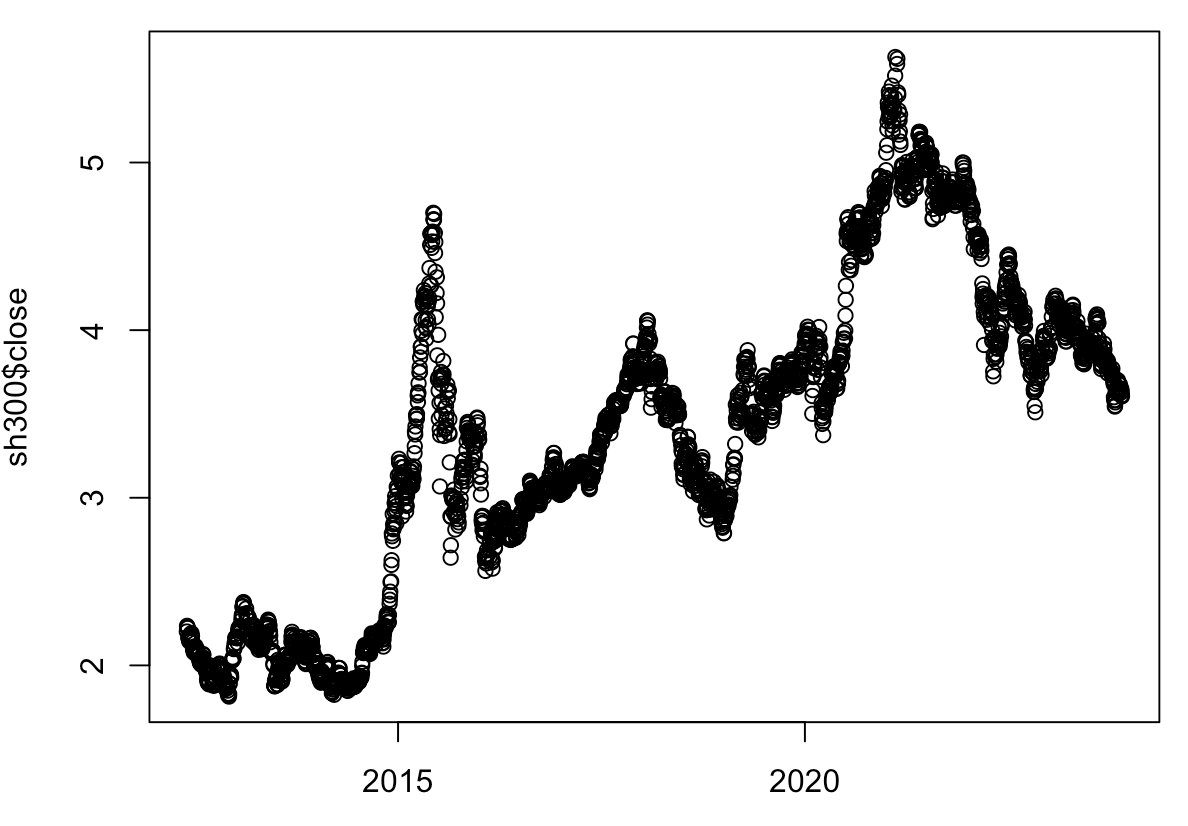
使用plot(date300, sh300$close, type = "b", lty = 1, pch = 20)



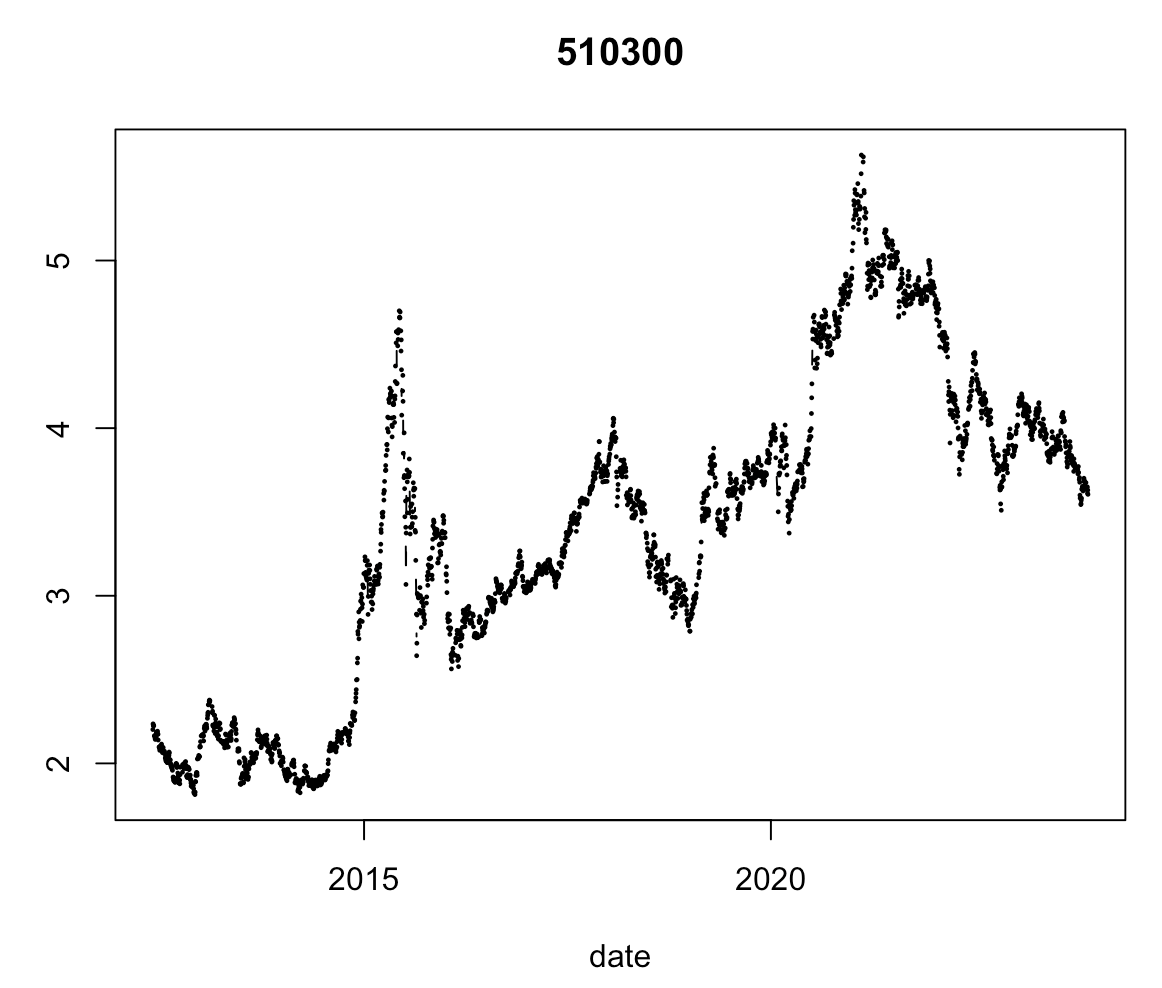
标题、cex缩放、x轴标题,y轴标题
plot(date300, sh300$close, type = "b", lty = 1, pch = 20, cex = 0.3, main="510300", xlab = "date", ylab = "close price")
关于生成的图片的尺寸,试了效果不好,还需要进一步研究。
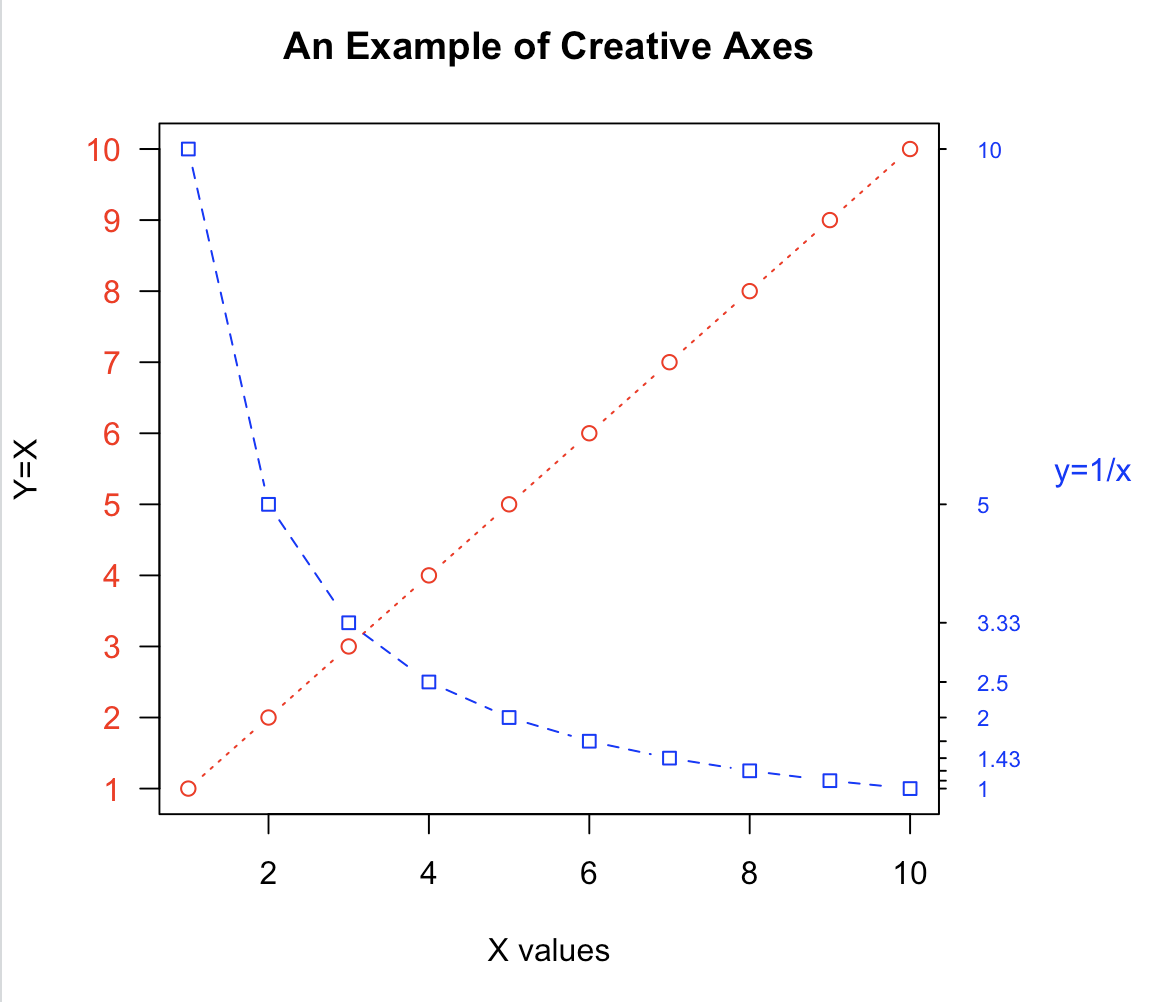
6.2. 2图2y轴多元素
> x <- c(1:10)
> y <- x
> z <- 10/x # 10.000000 5.000000 3.333333 2.500000 2.000000 1.666667 1.428571 1.250000 1.111111 1.000000
> opar <- par(no.readonly=TRUE) # 添加参数no.readonly=TRUE可以生成一个可以修改的当前图形参数列表。将原始参数保留为副本opar,便于参数恢复
> par(mar=c(5, 4, 4, 8) + 0.1) # mar以数值向量表示的边界大小,顺序为“下、左、上、右”,单位为英分1。默认值为 c(5, 4, 4, 2) + 0.1
> plot(x, y, type="b", pch=21, col="red", yaxt="n", lty=3, ann=FALSE)
# 上句:x轴是向量x,y轴是向量y,pch21是空心圆点,col是red红色线条和点,yaxt n禁用默认生成的y轴,lty 3是dot点线,ann 逻辑值,是否使用默认的x、y轴标注注释
> lines(x, z, type="b", pch=22, col="blue", lty=2)
# 上句:x轴是向量x,y轴是向量z,pch 22是空心方块,col颜色是蓝色,lty 2是虚线
> axis(2, at=x, labels=x, col.axis="red", las=2) # 使用函数axis()来创建自定义的坐标轴,而非使用R中的默认坐标轴(下面有详细介绍)
# 2代表在左侧y轴。at 一个数值型向量,表示需要绘制刻度线的位置,从(1:10)都要绘制。
# labels 一个字符型向量,表示置于刻度线旁边的文字标签(如果为 NULL,则将直接使用 at 中的值)
# las 标签是否平行于(=0)或垂直于(=2)坐标轴
> axis(4, at=z, labels=round(z, digits=2), col.axis="blue", las=2, cex.axis=0.7, tck=-.01)
# 4代表右侧y轴。at代表的刻度(显示的数值需要用label画)。round(z, digits=2)取2位小数。col.axis蓝色坐标轴。las 垂直于(=2)坐标轴。cex.axis 0.7倍缩放。
# tck 刻度线的长度,以相对于绘图区域大小的分数表示(负值表示在图形外侧,正值表示在图形内侧,0 表示禁用刻度,1 表示绘制网格线);默认值为–0.01
> mtext("y=1/x", side=4, line=3, cex.lab=1, las=2, col="blue")
# side 指定用来放置文本的边。1=下,2=左,3=上,4=右。你可以指定参数 line=来内移或外移文本,随着值的增加,文本将外移。也可使用 adj=0 将文本向左下对齐,或使用 adj=1 右上对齐
> title("An Example of Creative Axes", xlab="X values", ylab="Y=X")
> par(opar) # #恢复原始参数
绘制的结果:(值得说的是,随着每一行代码的执行,图上的线、轴、图例是逐渐丰富起来的!magic!)
可以使用函数 axis() 来创建自定义的坐标轴,而非使用R中的默认坐标轴。其格式为: axis(side, at=, labels=, pos=, lty=, col=, las=, tck=, …)









6.2.1. mtcars点图
一幅散点图(车重与每加仑汽油行驶英里数)的示例,各点均添加了标签(车型)
> attach(mtcars)
> plot(wt, mpg,main="Mileage vs. Car Weight",xlab="Weight", ylab="Mileage",pch=18, col="blue")
> text(wt, mpg,row.names(mtcars),cex=0.5, pos=4, col="red")
> detach(mtcars)

6.3. 条形图
> install.packages("vcd")
> head(Arthritis)ID Treatment Sex Age Improved
1 57 Treated Male 27 Some
2 46 Treated Male 29 None
3 77 Treated Male 30 None
4 17 Treated Male 32 Marked
5 36 Treated Male 46 Marked
6 23 Treated Male 58 Marked
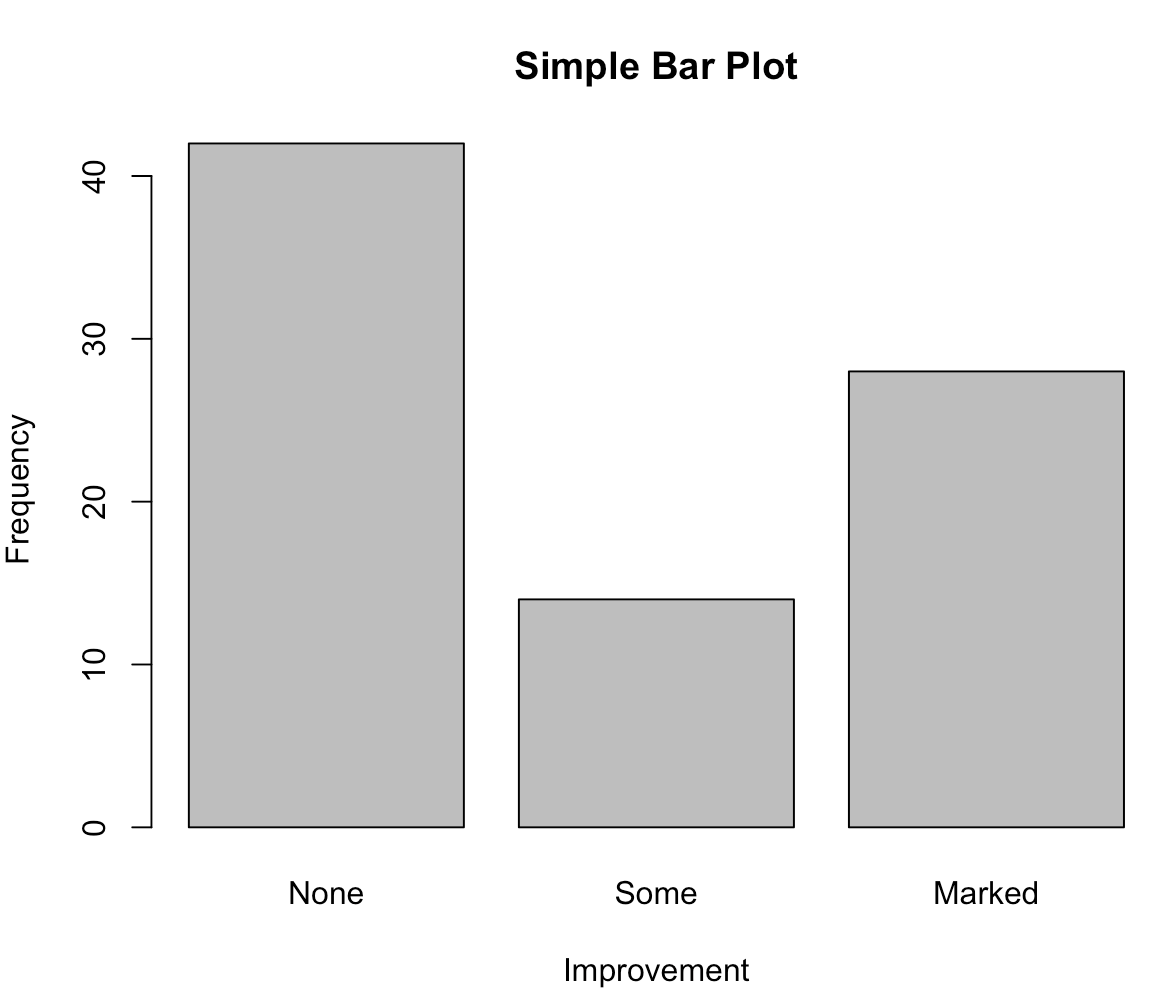
> counts <- table(Arthritis$Improved)
> countsNone Some Marked 42 14 28
> barplot(counts,
+ main="Simple Bar Plot",
+ xlab="Improvement", ylab="Frequency")
# 在这个case,barplot和plot函数绘制的图形是一样的。上面table()函数的作用是表格化。
> plot(Arthritis$Improved, main="Simple Bar Plot",
+ xlab="Improved", ylab="Frequency")
6.4. 分组条形图
> head(Arthritis)ID Treatment Sex Age Improved
1 57 Treated Male 27 Some
2 46 Treated Male 29 None
3 77 Treated Male 30 None
4 17 Treated Male 32 Marked
5 36 Treated Male 46 Marked
6 23 Treated Male 58 Marked
> counts <- table(Arthritis$Improved, Arthritis$Treatment)
> countsPlacebo TreatedNone 29 13Some 7 7Marked 7 21
> # [pləˈsiːbəʊ]
> barplot(counts,
+ main="Grouped Bar Plot",
+ xlab="Treatment", ylab="Frequency",
+ col=c("red", "yellow", "green"),
+ legend=rownames(counts), beside=TRUE)
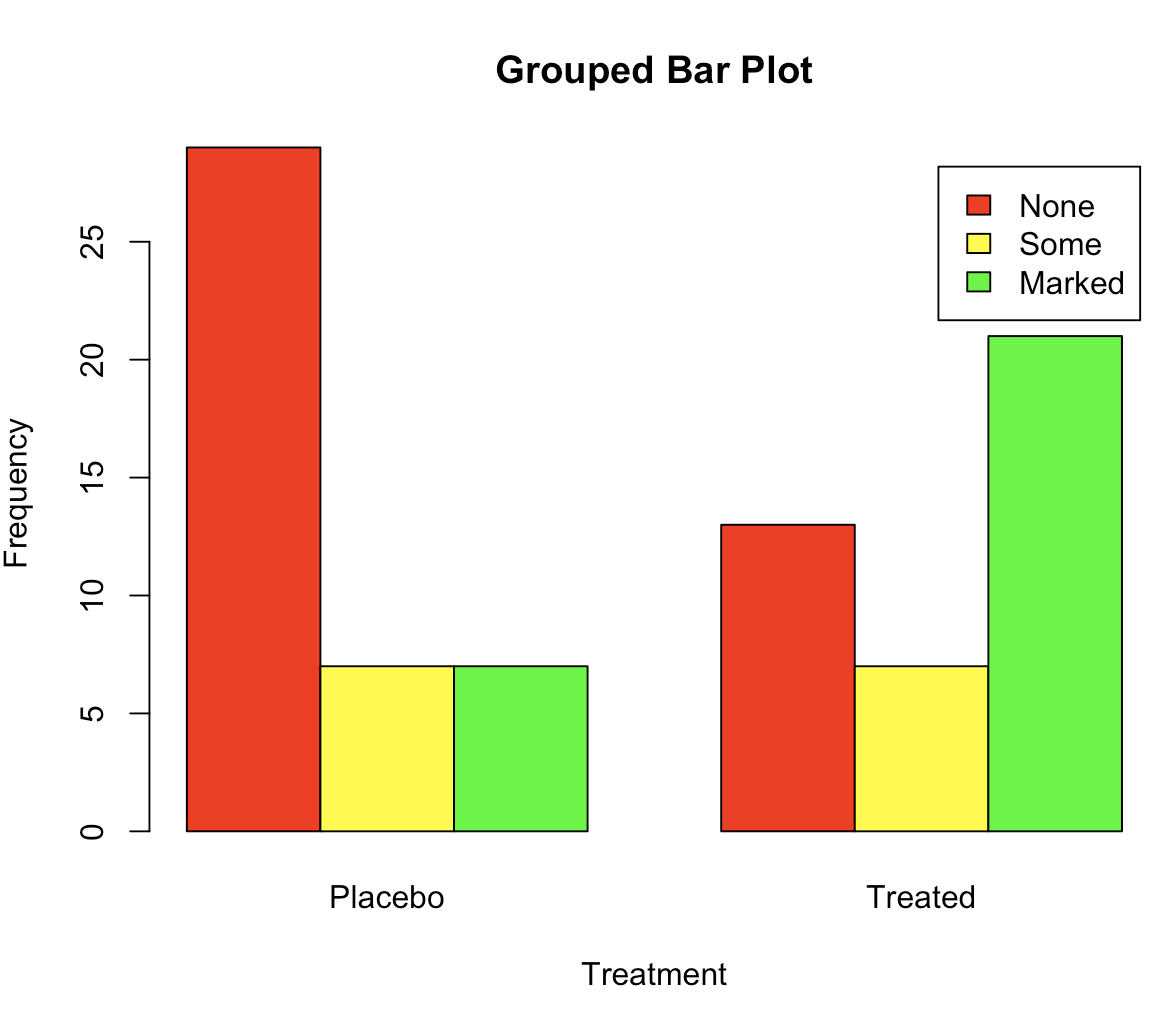
均值条形图:奇怪的概念
> states <- data.frame(state.region, state.x77)
> head(states)state.region Population Income Illiteracy Life.Exp Murder HS.Grad Frost Area
Alabama South 3615 3624 2.1 69.05 15.1 41.3 20 50708
Alaska West 365 6315 1.5 69.31 11.3 66.7 152 566432
Arizona West 2212 4530 1.8 70.55 7.8 58.1 15 113417
Arkansas South 2110 3378 1.9 70.66 10.1 39.9 65 51945
California West 21198 5114 1.1 71.71 10.3 62.6 20 156361
Colorado West 2541 4884 0.7 72.06 6.8 63.9 166 103766
> means <- aggregate(states$Illiteracy, by=list(state.region), FUN=mean)
> meansGroup.1 x
1 Northeast 1.0000
2 South 1.7375
3 North Central 0.7000
4 West 1.0231
> barplot(means$x, names.arg=means$Group.1)
> title("Mean Illiteracy Rate")
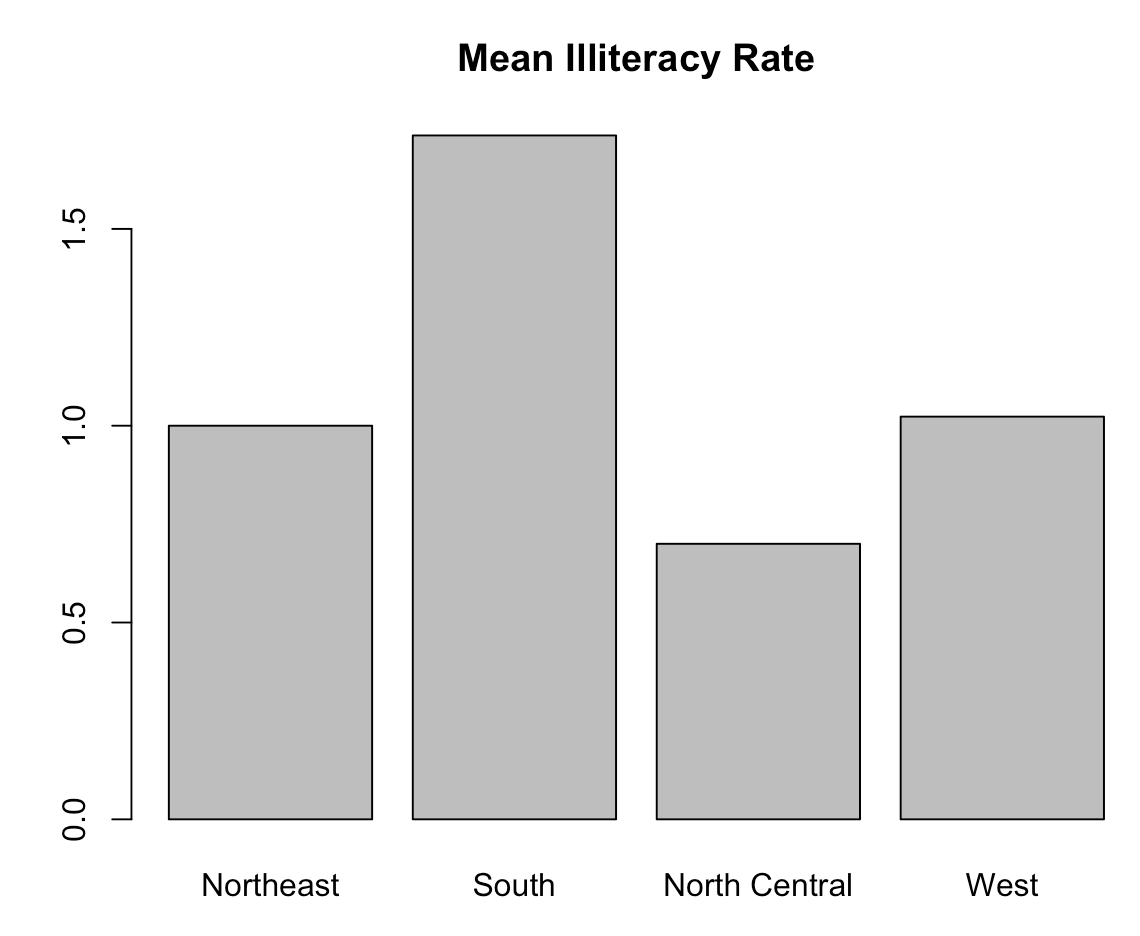
6.5. 饼图
> meansGroup.1 x
1 Northeast 1.0000
2 South 1.7375
3 North Central 0.7000
4 West 1.0231> labels <- paste(means$Group.1, round(means$x, digits = 3), sep = "=")
> labels
[1] "Northeast=1" "South=1.738" "North Central=0.7" "West=1.023"
> pie(means$x, labels = labels)
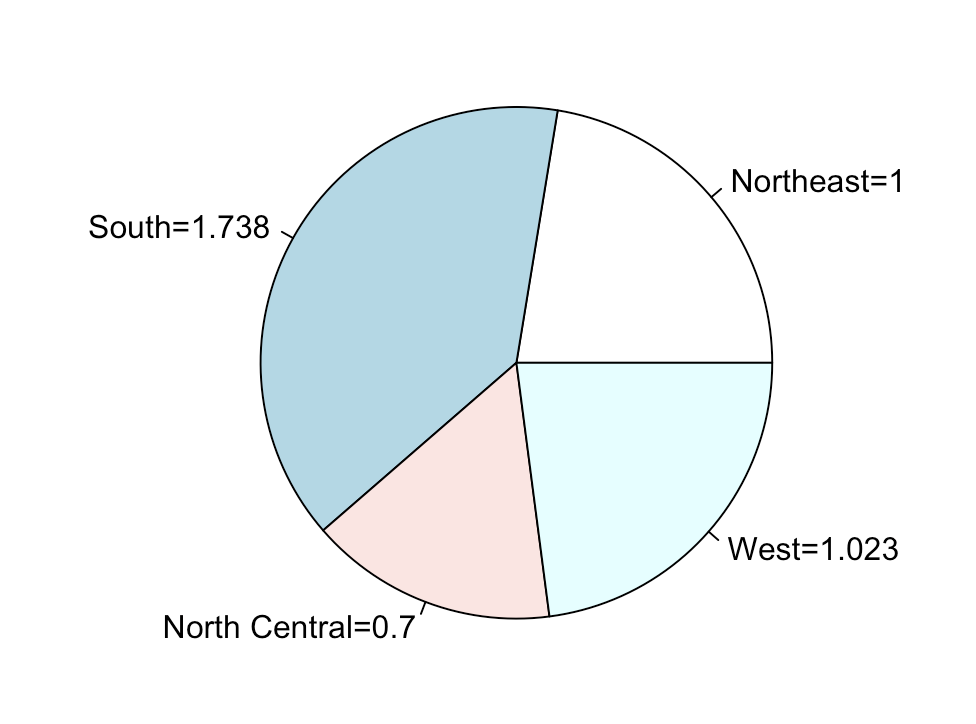
6.6. 直方图
> par(mfrow=c(2,2))
> hist(mtcars$mpg)
> mtcars$mpg[1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4 10.4 14.7 32.4 30.4
[20] 33.9 21.5 15.5 15.2 13.3 19.2 27.3 26.0 30.4 15.8 19.7 15.0 21.4
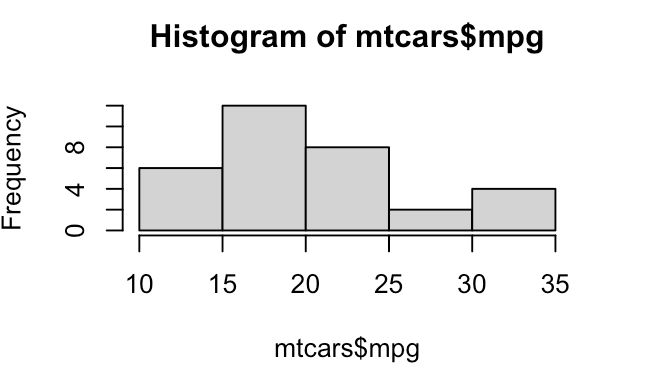
# 参数breaks用于控制组的数量,也就是说会展示12个柱子,这样的话,如果是绘制收盘价区间分布,就不用那么复杂计算了。
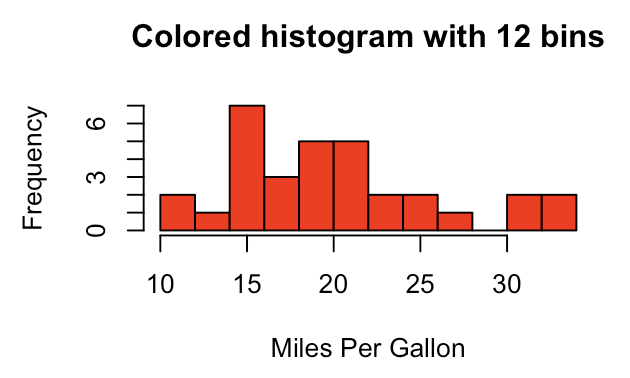
> hist(mtcars$mpg,breaks=12,
+ col="red",
+ xlab="Miles Per Gallon",
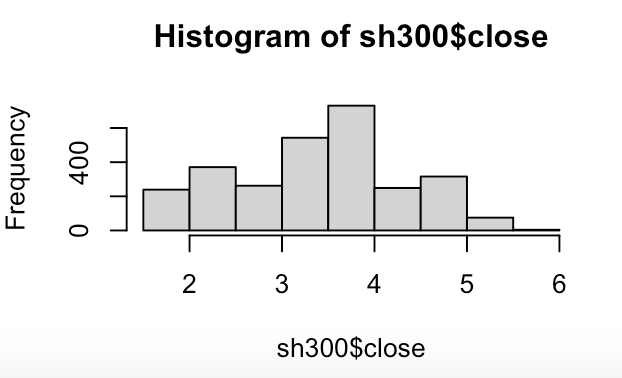
+ main="Colored histogram with 12 bins")# 沪深300收盘价分布直方图(图显示的内容还是比较少的,能看出来的还是收盘价集中在3-4元之间。)
> sh300 <- read.csv("SH510300-收盘价.csv")
> head(sh300)date close
1 2012/5/28 2.2020
2 2012/5/29 2.2359
3 2012/5/30 2.2291
4 2012/5/31 2.2240
5 2012/6/1 2.2240
6 2012/6/4 2.1631
> hist(sh300$close, breaks = 10)> density(sh300$close)Call:density.default(x = sh300$close)Data: sh300$close (2790 obs.); Bandwidth 'bw' = 0.1528x y Min. :1.356 Min. :0.0000252 1st Qu.:2.539 1st Qu.:0.0661411 Median :3.722 Median :0.1852631 Mean :3.722 Mean :0.2111115 3rd Qu.:4.905 3rd Qu.:0.3639130 Max. :6.088 Max. :0.5344925
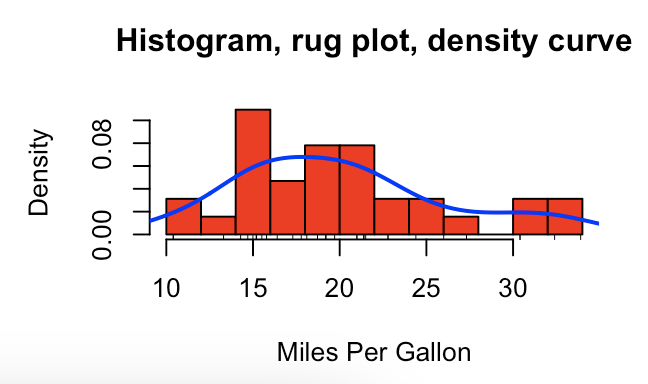
> hist(mtcars$mpg,
+ freq=FALSE,
+ breaks=12,
+ col="red",
+ xlab="Miles Per Gallon",
+ main="Histogram, rug plot, density curve")
# 轴须图 (x轴上多)
> rug(jitter(mtcars$mpg))
> lines(density(mtcars$mpg), col="blue", lwd=2)
> density(mtcars$mpg)Call:density.default(x = mtcars$mpg)Data: mtcars$mpg (32 obs.); Bandwidth 'bw' = 2.477x y Min. : 2.97 Min. :6.481e-05 1st Qu.:12.56 1st Qu.:5.461e-03 Median :22.15 Median :1.926e-02 Mean :22.15 Mean :2.604e-02 3rd Qu.:31.74 3rd Qu.:4.530e-02 Max. :41.33 Max. :6.795e-02
6.7. 核密度图
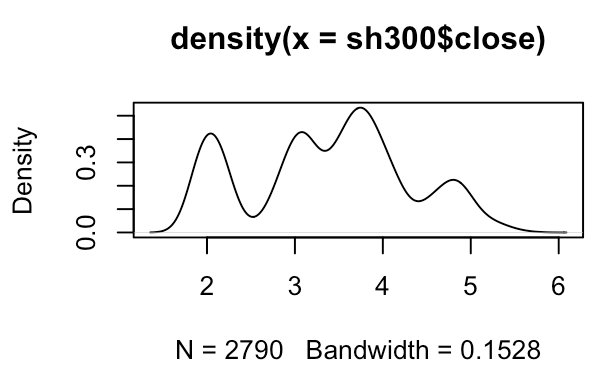
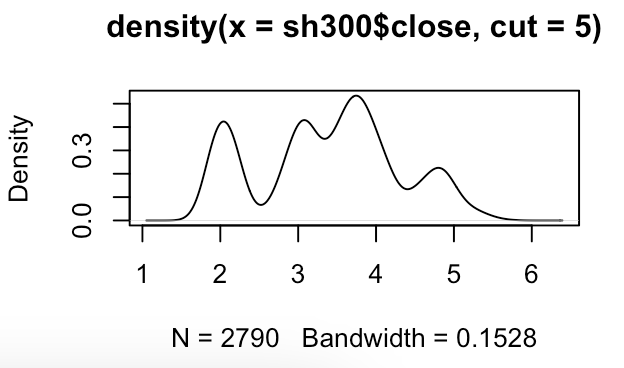
# 收盘价概率分布
> plot(density(sh300$close))
# 分成了6个区间?
> plot(density(sh300$close, cut = 5))
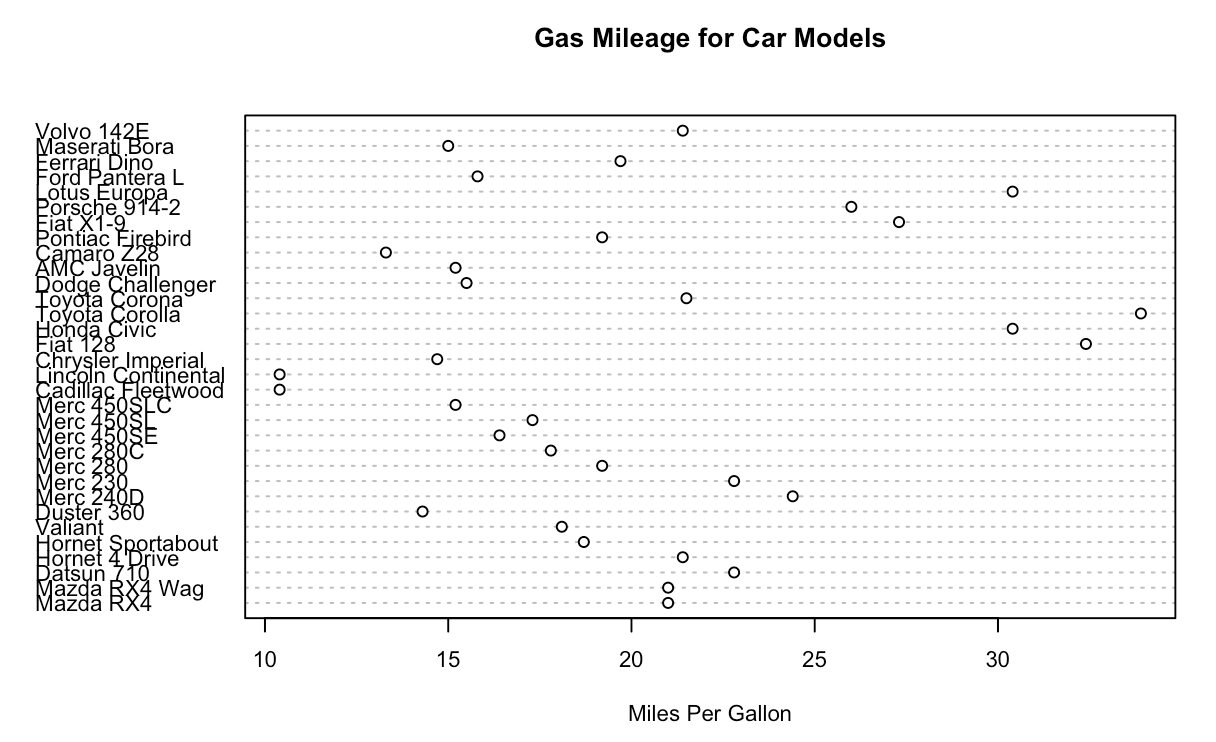
6.8. 点图
# 比较奇怪,点图的y轴数据是怎么来的?
> dotchart(mtcars$mpg, labels=row.names(mtcars), cex=.7,main="Gas Mileage for Car Models",xlab="Miles Per Gallon")
7. 统计分析
7.1. summary
> myvars <- c("mpg", "hp", "wt")
# summary()函数提供了最小值、最大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计。
> summary(mtcars[myvars])mpg hp wt Min. :10.4 Min. : 52.0 Min. :1.51 1st Qu.:15.4 1st Qu.: 96.5 1st Qu.:2.58 Median :19.2 Median :123.0 Median :3.33 Mean :20.1 Mean :146.7 Mean :3.22 3rd Qu.:22.8 3rd Qu.:180.0 3rd Qu.:3.61 Max. :33.9 Max. :335.0 Max. :5.42
mean()、sd()、var()、min()、max()、median()、length()、range()和quantile()。函数fivenum()可返回图基五数总括(Tukey’s five-number
summary,即最小值、下四分位数、中位数、上四分位数和最大值)。
7.2. cor相关系数
> states<- state.x77[,1:6]
> statesPopulation Income Illiteracy Life Exp Murder HS Grad
Alabama 3615 3624 2.1 69.05 15.1 41.3
Alaska 365 6315 1.5 69.31 11.3 66.7
Arizona 2212 4530 1.8 70.55 7.8 58.1
Arkansas 2110 3378 1.9 70.66 10.1 39.9
California 21198 5114 1.1 71.71 10.3 62.6
Colorado 2541 4884 0.7 72.06 6.8 63.9
......
> cor(states)Population Income Illiteracy Life Exp Murder HS Grad
Population 1.000000 0.20823 0.10762 -0.068052 0.34364 -0.09849
Income 0.208228 1.00000 -0.43708 0.340255 -0.23008 0.61993
Illiteracy 0.107622 -0.43708 1.00000 -0.588478 0.70298 -0.65719
Life Exp -0.068052 0.34026 -0.58848 1.000000 -0.78085 0.58222
Murder 0.343643 -0.23008 0.70298 -0.780846 1.00000 -0.48797
HS Grad -0.098490 0.61993 -0.65719 0.582216 -0.48797 1.00000
# 我们可以看到收入和高中毕业率之间存在很强的正相关,而文盲率和预期寿命之间存在很强的负相关。# 请注意,在默认情况下得到的结果是一个方阵(所有变量之间两两计算相关)。你同样可以计算非方形的相关矩阵。观察以下示例:
> x <- states[,c("Population", "Income", "Illiteracy", "HS Grad")]
> y <- states[,c("Life Exp", "Murder")]
> cor(x,y)Life Exp Murder
Population -0.068052 0.34364
Income 0.340255 -0.23008
Illiteracy -0.588478 0.70298
HS Grad 0.582216 -0.48797
7.3. 回归
回归分析都是统计学的核心。它其实是一个广义的概念,通指那些用一个或多个预测变量(也称自变量或解释变量)来预测响应变量(也称因变量、效标变量或结果变量)的方法。通常,回归分析可以用来挑选与响应变量相关的解释变量,可以描述两者的关系,也可以生成一个等式,通过解释变量来预测响应变量。
相关文章:
R语言30分钟上手
文章目录 1. 环境&安装1.1. rstudio保存工作空间 2. 创建数据集2.1. 数据集概念2.2. 向量、矩阵2.3. 数据框2.3.1. 创建数据框2.3.2. 创建新变量2.3.3. 变量的重编码2.3.4. 列重命名2.3.5. 缺失值2.3.6. 日期值2.3.7. 数据框排序2.3.8. 数据框合并(合并沪深300和中证500收盘…...
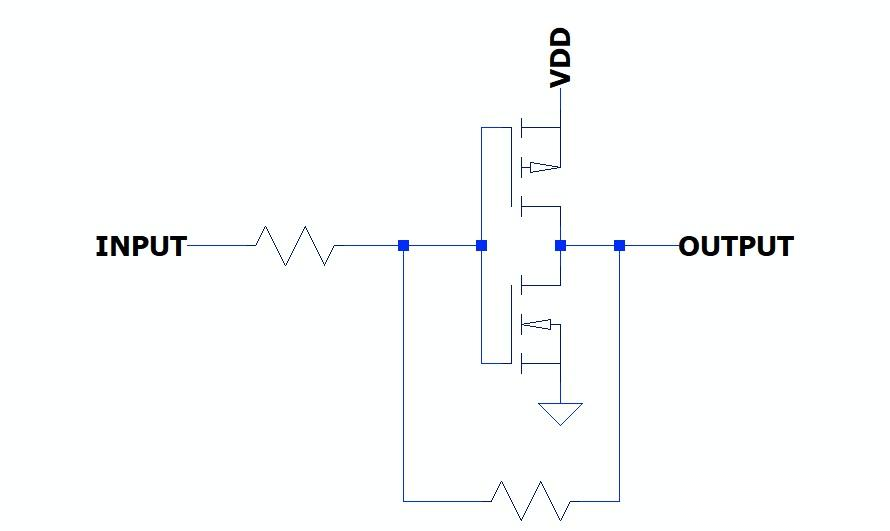
上下拉电阻会增强驱动能力吗?
最近看到一个关于上下拉电阻的问题,发现不少人认为上下拉电阻能够增强驱动能力。随后跟几个朋友讨论了一下,大家一致认为不存在上下拉电阻增强驱动能力这回事,因为除了OC输出这类特殊结构外,上下拉电阻就是负载,只会减…...

题目:小明的彩灯(蓝桥OJ 1276)
题目描述: 解题思路: 一段连续区间加减,采用差分。最终每个元素结果与0比较大小,比0小即负数输出0。 题解: #include<bits/stdc.h> using namespace std;using ll long long; const int N 1e5 10; ll a[N],…...

换元法求不定积分
1.一般步骤:选取换元对象(不一定是式子中的值,也可以是式子中的最小公倍数或者最大公因数),然后将dx换为dt*t的导数,再用t将原式表示,化简计算即可 2. 3. 4. 5. 6....

在Docker容器中启用SSH服务,实现外部访问的详细教程
目录 步骤 1: 安装 SSH 服务器 步骤 2: 配置 SSH 服务器 步骤 3: 设置 SSH 用户 步骤 4: 重启 SSH 服务器 步骤 5: 映射容器端口 步骤 6: 使用 SSH 连接到容器 要在Docker容器中启用SSH服务,以便从外部访问,您需要执行以下步骤: 步骤 …...

Go 模块系统最小版本选择法 MVS 详解
目录 Golang 模块系统简介 包版本管理 最小版本选择(MVS)原理 MVS 的优点 MVS的缺点 实际使用MVS 小结 参考资料 Golang 模块系统简介 Golang 模块系统是 Go 1.11 版本引入的一个新特性,主要目的是解决 Go 项目中的依赖管理问题。在模…...

ifstream读取txt中的中文数据转成QString出现乱码
使用ifstream从txt文本中读取中文数据到string,再将string转成QString输出时出现了乱码。 分析:如果ifstream能成功从txt文本中读出中文数据,那大概率txt用的编码是ANSI编码(GBK就是ANSI的一种),那么在转成…...
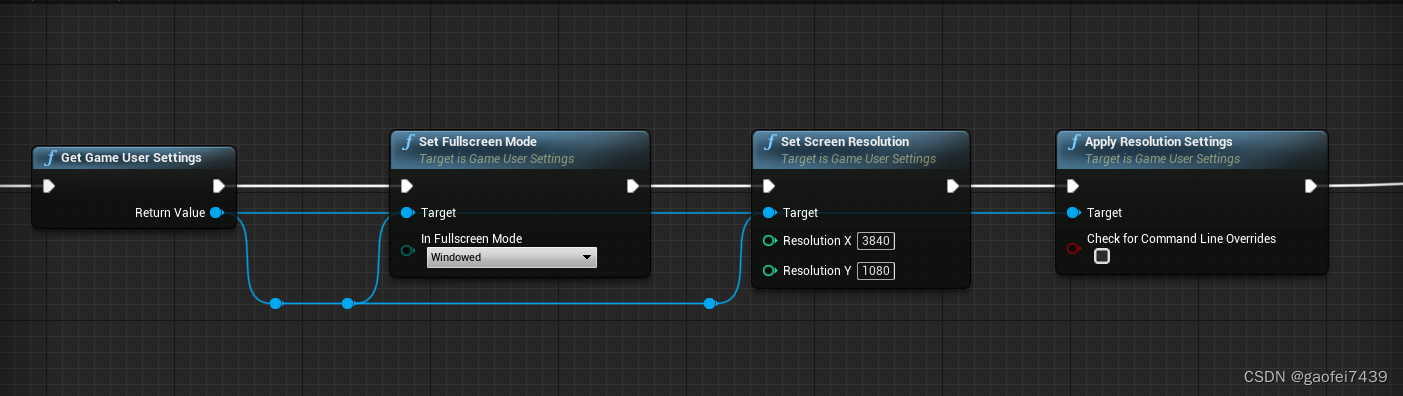
UE4 双屏分辨率设置
背景: 做了一个UI 应用,需要在双屏上进行显示。 分辨率如下:3840*1080; 各种折腾,其实很简单: 主要是在全屏模式的时候 一开始没有选对,双屏总是不稳定。 全屏模式改成:Windows 之…...

$sformat在仿真中打印文本名的使用
在仿真中,定义队列,使用任务进行函数传递,并传递文件名,传递队列,进行打印 $sformat(filename, “./data_log/%0d_%0d_%0d_0.txt”, f_num, lane_num,dt); 使用此函数可以自定义字符串,在仿真的时候进行文件…...

【Rust】结构体与枚举
文章目录 结构体struct基础用法使用字段初始化简写语法使用没有命名字段的元组结构体来创建不同的类型没有任何字段的类单元结构体方法语法关联函数多个 impl 块 枚举枚举值Option 结构体struct 基础用法 一个存储用户账号信息的结构体: struct User {active: bo…...

CentOS7 防火墙常用命令
以下是在 CentOS 7 上使用 firewall-cmd 命令管理防火墙时的一些常用命令: 检查防火墙状态: sudo firewall-cmd --state 启动防火墙: sudo systemctl start firewalld 停止防火墙: sudo systemctl stop firewalld 重启防火墙&…...

【无标题】什么是UL9540测试,UL9540:2023版本增加哪些测试项目
什么是UL9540测试,UL9540:2023版本增加哪些测试项目 UL 9540是美国安全实验室(Underwriters Laboratories)发布的标准,名称为"UL 9540: Energy Storage Systems and Equipment",翻译为中文为"能量存储…...
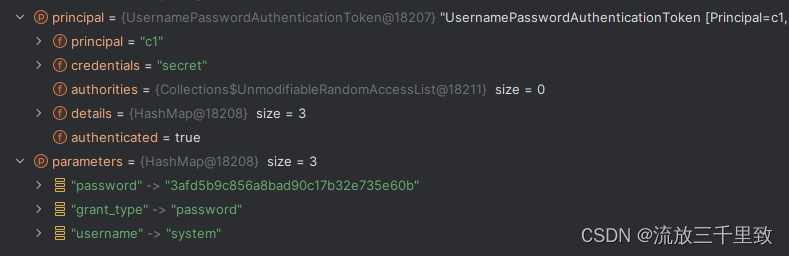
springcloud整合Oauth2自定义登录/登出接口
我使用的是password模式,并配置了token模式 一、登录 (这里我使用的示例是用户名密码认证方式) 1. Oath2提供默认登录授权接口 org.springframework.security.oauth2.provider.endpoint.postAccess; Tokenpublic ResponseEntity<OAuth2AccessToken> pos…...

Oracle常见内置程序包的使用Package
Oracle常见内置程序包的使用 点击此处可跳转至:Oracle的程序包(Package),对包的基础进行学习常见内置程序包的使用Package1、DBMS_OUTPUT包2、DBMS_XMLQUERY包3、DBMS_RANDOM包4、UTL_FILE包5、DBMS_JOB包6、DBMS_LOB包7、DBMS_SQL包8、DBMS_LOCK包9、DB…...
Flutter:视频下载案例
前言 最近在研究视频下载,因此打算一边研究一边记录一下。方便以后使用时查看。 使用到的库有: permission_handler 11.1.0 :权限请求 flutter_downloader 1.11.5:文件下载器 path_provider 2.1.1:路径处理 视频…...

要求CHATGPT高质量回答的艺术:提示工程技术的完整指南
要求CHATGPT高质量回答的艺术:提示工程技术的完整指南 第2章:指令提示技术 现在,让我们开始探索“指令提示技术”,以及如何使用它从ChatGPT生成高质量的文本。 指令提示技术是一种通过为模型提供特定指令来指导ChatGPT输出的方…...
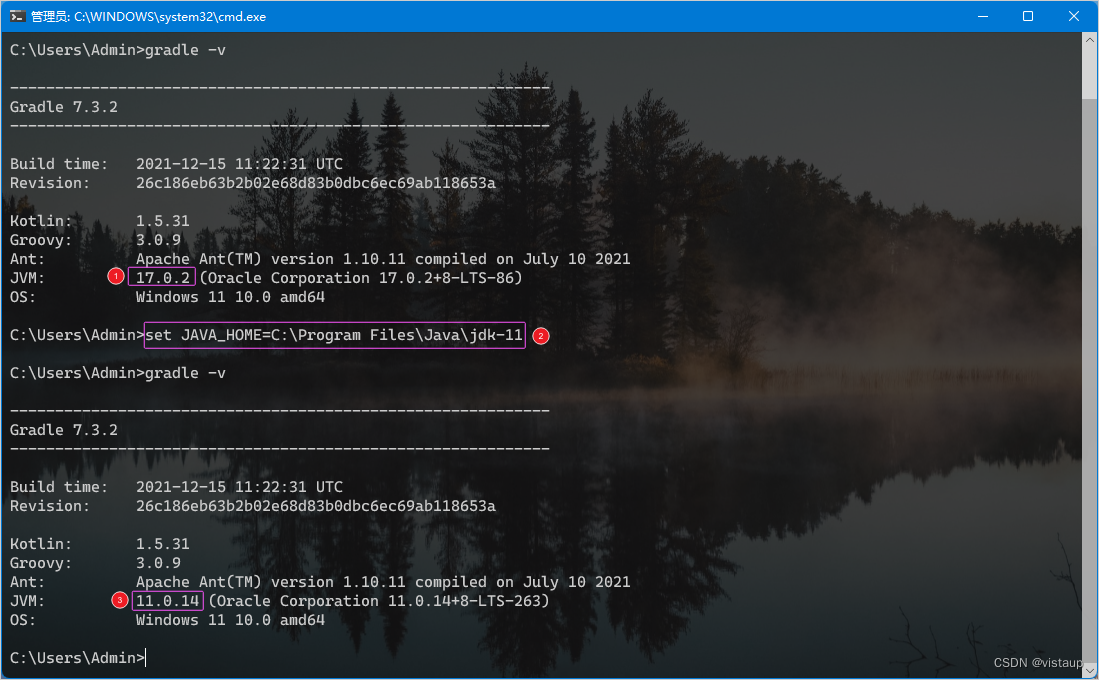
JDK 历史版本下载以及指定版本应用
参考: 官网下载JAVA的JDK11版本(下载、安装、配置环境变量)_java11下载-CSDN博客 Gradle:执行命令时指定 JDK 版本 - 微酷网 下载 打开官网地址 Java Downloads | Oracle 当前版本在这里,但是我们要下载历史版本 选…...

Linux基础项目开发1:量产工具——UI系统(五)
前言: 前面我们已经把显示系统、输入系统、文字系统搭建好了,现在我们就要给它实现按钮操作了,也就是搭建UI系统,下面让我们一起实现UI系统的搭建吧 目录 一、按钮数据结构抽象 ui.h 二、按键编程 1.button.c 2.disp_manager…...

面试就是这么简单,offer拿到手软(四)—— 常见java152道基础面试题
面试就是这么简单,offer拿到手软(一)—— 常见非技术问题回答思路 面试就是这么简单,offer拿到手软(二)—— 常见65道非技术面试问题 面试就是这么简单,offer拿到手软(三ÿ…...

深入理解Redis分片策略:提升系统性能的关键一步
目录 引言 1. 一致性哈希算法 2. 范围分片 3. 哈希槽分片 实战经验分享 结论 引言 Redis作为一款高性能的键值存储系统,为了应对大规模数据和高并发的访问,引入了分片策略,使得数据能够分布存储在多个节点上,实现系统的横向…...

WarcraftHelper:5分钟解决魔兽争霸III现代兼容性问题的终极指南
WarcraftHelper:5分钟解决魔兽争霸III现代兼容性问题的终极指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典魔兽争霸III在W…...

终极指南:Visual C++运行库合集AIO - 一站式解决Windows程序依赖问题
终极指南:Visual C运行库合集AIO - 一站式解决Windows程序依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在运行某些软件或游戏时…...

英雄联盟智能助手:League Akari 完全使用指南与本地化优势解析
英雄联盟智能助手:League Akari 完全使用指南与本地化优势解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款…...

P vs NP:西方哲学 × 西方计算理论 —— 人类思维的终极边界
P vs NP:西方哲学 西方计算理论 —— 人类思维的终极边界 华夏之光永存|七大数学猜想思维范式全链条 第一篇开篇 P vs NP 是计算机科学第一难题,克雷数学研究所七大千禧年难题之一。 本文不宣称证明、不跳步、不民科、不超纲。 只用哲学与数…...

源代码论文分享|基于 Spring Boot 的校园商铺管理系统!
很多同学选毕业设计时都会纠结:题目太简单,怕老师觉得没含金量;题目太复杂,又怕自己做不完。 其实像校园商铺管理系统这种项目,就挺适合拿来做毕设或课程设计。它有真实场景,功能也能展开,技术…...

SAP ABAP SOAUTH2 配置原理与 OAuth2 四要素落地解析
1. 为什么 SAP ABAP 系统里填个 OAuth2 参数总像在解谜题? 刚接手一个对接钉钉开放平台的 ABAP 项目时,我盯着事务码 SOAUTH2 的配置界面足足看了二十分钟——Client ID、Client Secret、Authorization Endpoint、Token Endpoint、Redirect URI……每个…...

TI MSPM0G3105-Q1汽车MCU实战解析:从核心特性到硬件设计
1. 项目概述:为什么是MSPM0G3105-Q1?在汽车电子和工业控制领域摸爬滚打十几年,我经手过的MCU型号少说也有几十款。每次启动一个新项目,选型都是头等大事,它直接决定了后续开发的难易度、系统的稳定性和最终产品的成本。…...

通过用量看板与成本管理功能实现团队API支出精细化管控
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板与成本管理功能实现团队API支出精细化管控 对于依赖大模型API进行开发的团队而言,成本控制与资源分配的透…...

2026年TOP5运营多年口碑平稳的金价查询app有哪些
前几天跟闺蜜约饭,她一坐下来就疯狂吐槽:前一周特意蹲了网上说的金价合适的时段,攒了好久的钱想去买那条种草了半年的金项链,结果到了线下门店才知道,当天大盘价已经涨了21块钱,比她查的那个三天没更新的小…...
原理与实践指南)
量子近似优化算法(QAOA)原理与实践指南
1. 量子近似优化算法(QAOA)基础解析 量子近似优化算法(QAOA)是近年来量子计算领域最具应用前景的混合算法之一。作为一名长期从事量子算法研究的工程师,我见证了QAOA从理论构想到实际应用的完整发展历程。这种算法巧妙地将经典优化技术与量子线路相结合,…...