MySQL 性能优化
未完待续...
1. 分库、分表结构优化
1.1 数据库设计
不规范的数据库设计存在数据冗余以及插入、更新、删除异常问题。

规范化(Normalization)是数据库设计的一系列原理和技术,主要用于减少表中数据的冗余,增加完整性和一致性,同时使得数据库易于维护和扩展。

对于大多数的数据库系统而言,到达第三范式就已经足够了。也就是说,表需要定义主键,表中的字段都是不可再分的单一属性。非主键字段必须完全依赖于主键,不能只依赖于主键的一部分。属性不依赖于其它的非主属性。
对于前三个范式而言,只需要将不同的实体/对象单独存储到一张表中,并且通过外键建立它们之间的联系即可满足。

规范化可能导致连接查询(JOIN)过多,从而降低数据库的性能。因此,有时候为了提高某些查询或者应用的性能而故意降低规范反的程度,也就是反规范化。
常用的反规范化方法包括:
- 增加冗余字段;
- 增加计算列;
- 将小表合成大表等。
例如,想要知道每个部门的员工数量,需要同时连接部门表和员工表;可以在部门表中增加一个字段(emp_numbers),查询时就不需要再连接员工表,但是每次增加或者删除员工时需要更新该字段。
反规范化可能带来数据完整性的问题;因此,通常我们应该先进行规范化设计,再根据实际情况考虑是否需要反规范化。一般来说,数据仓库(Data Warehouse)和在线分析系统(OLAP)会使用到反规范化的技术,因为它们以复杂查询和报表分析为主。
> 推荐图书:《数据库系统概念(第七版)》
1.2 选择数据类型
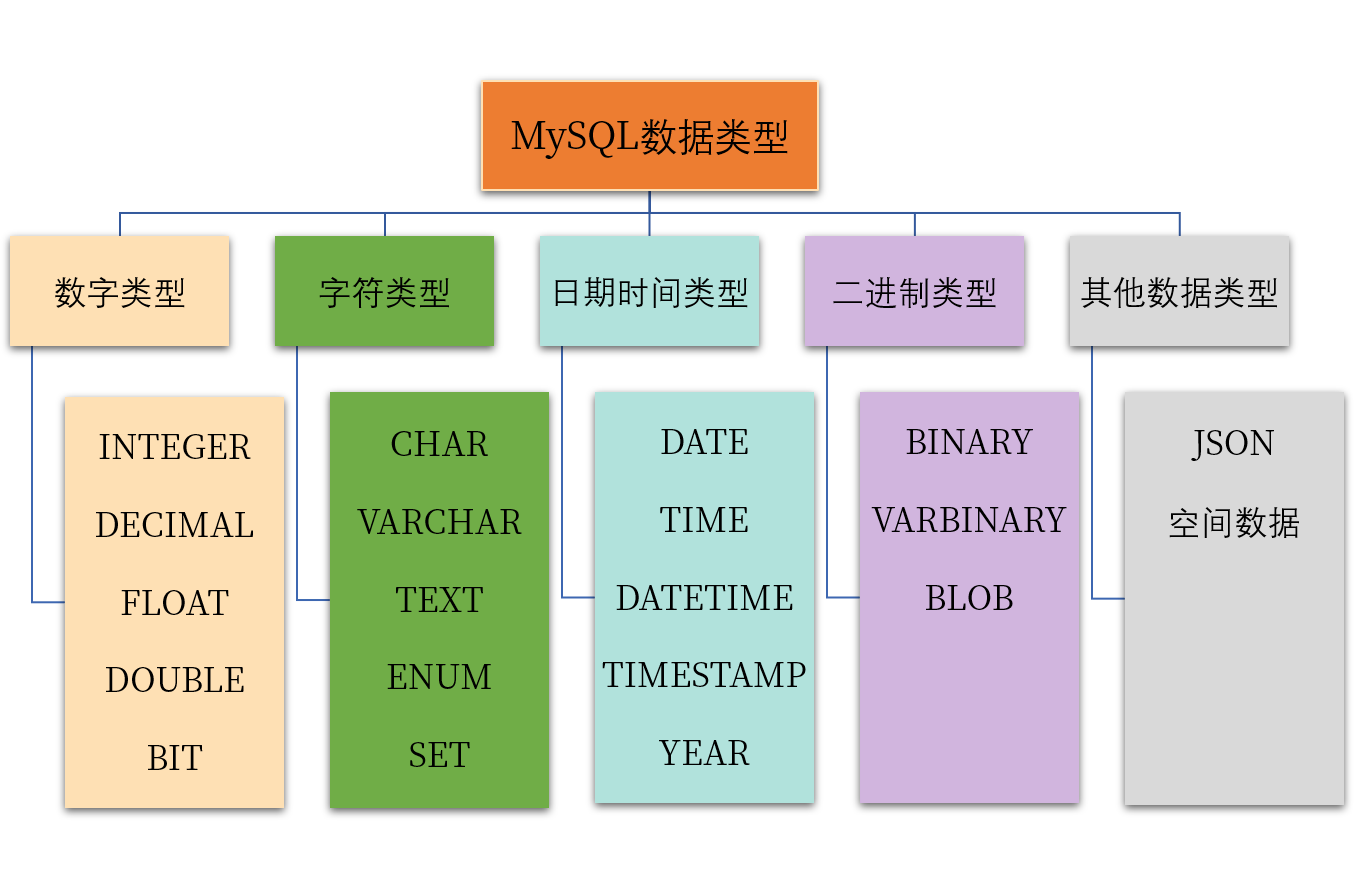
我们在选择字段的数据类型时,首先应该满足存储业务数据的要求,其次还需要考虑性能和使用的便捷性。
一般来说,我们可以先确定基本的类型:
- 文本数据使用字符串类型进行存储。
- 数值数据,尤其是需要进行算术运算的数据,使用数字类型。
- 日期和时间信息最好使用原生的日期时间类型。
- 文档、图片、音频和视频等使用二进制类型。但推荐存储在文件服务器上,数据库中存储文件的路径,以减少数据库的压力。
然后进一步确定具体的数据类型。
1)在满足数据存储和扩展的前提下,尽量使用更小的数据类型。这样可以节省一些存储,通常性能也会更好。例如,对于一个小型公司而言,员工人数通常不会超过几百,可以使用SMALLINT类型存储员工编号。
2)尽量避免使用NULL属性。NULL需要更多的存储和额外的处理,尽量使用NOT NULL加上默认值。
3)如果一个字段同时出现在多个表中,我们应该使用相同的数据类型。例如,员工表中的部门编号(dept\_id)字段与部门表的编号(dept\_id)字段应该保持名称和类型一致。
1.3 数字类型
1.3.1 整数类型
MySQL支持TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)以及BIGINT整数类型。如果为整数类型指定了UNSIGNED属性,可以存储的正整数范围将会扩大一倍。
| 数字类型 | 存储(字节) | 有符号类型最小值 | 有符号类型最大值 | 无符号类型最小值 | 无符号类型最大值 |
| :-------: | :----------: | :--------------: | :--------------: | :--------------: | :--------------: |
| TINYINT | 1 | -128 | 127 | 0 | 255 |
| SMALLINT | 2 | -32768 | 32767 | 0 | 65535 |
| MEDIUMINT | 3 | -8388608 | 8388607 | 0 | 16777215 |
| INT | 4 | -2147483648 | 2147483647 | 0 | 4294967295 |
| BIGINT | 8 | 2^63^ | 2^63^-1 | 0 | 2^64^-1 |MySQL 8.0.17开始,整数类型的显示宽度(例如INT(10))和ZEROFILL选项已经被弃用(非标准型),将来的版本中会删除。直接定义 INT 即可。
显示宽度被弃用的原因:
MySQL 8.0.17 弃用整数类型的显示宽度和 ZEROFILL 选项是因为它们在实际使用中没有实际影响。显示宽度仅仅是用于控制在显示查询结果时整数的宽度,并不会影响存储或计算。而 ZEROFILL 选项则是指定在显示整数时是否填充零。
然而,这些选项在实际的数据存储和计算过程中并没有实际意义。整数类型在数据库中的存储大小是固定的,不受显示宽度的影响。而 ZEROFILL 选项只是在显示整数时添加了填充零的功能,并不会改变实际存储的值。
因此,MySQL 社区决定弃用这些选项,以简化整数类型的使用和理解。通过直接定义 INT 类型,可以更清晰地表示整数类型的含义,而无需关注显示宽度或 ZEROFILL 选项。
1.3.2 实数类型
MySQL提供了精确数字类型DECIMAL,也支持浮点数类型FLOAT和DOUBLE。
DECIMAL(p, s)用于存储对精度要求严格的数据(计算速度较慢),例如财务。其中精度p表示总的有效位数,刻度s表示小数点后允许的位数。例如,123.04的精度为5,刻度为2。
DECIMAL使用二进制格式存储,每9个数字使用4字节表示。NUMERIC是DECIMAL的同义词。
FLOAT是单精度浮点数,需要4字节存储空间;DOUBLE是双精度浮点数,需要8字节存储空间。浮点数使用近似运算,速度比DECIMAL更快但可能丢失精度。
CREATE TABLE t(d1 DOUBLE, d2 DOUBLE);
INSERT INTO t(d1, d2) VALUES (101.40, 80.0);// 此时查不到数据,因为 21.4 只是近似数据,和真实情况不完全匹配
SELECT * FROM t WHERE d1-d2=21.4; -- 101.40-80.0d1|d2|
--+--+一种折衷的方案是使用BIGINT替代DECIMAL存储财务数据(整数相对于DECIMAL计算速度更快,所以可以考虑先将DECIMAL转换为整数,然后使用BIGINT存储)。例如要存储精确到万分之一分的金额,可以将数据乘以100万倍之后存储到BIGINT,可以减少存储并优化计算性能,不过应用程序可能需要增加额外的处理。
1.4 字符串类型
1.4.1 CHAR与VARCHAR
1.4.2 BINARY与VARBINARY
1.4.3 TEXT与BLOB
1.4.4 ENUM类型
1.4.5 SET类型
1.5日期时间类型
1.5.1 日期类型
1.5.2 时间类型
2. 索引优化
2.1 索引简介
以下是一个简单的查询语句,它的作用是查找编号为5的员工:
SELECT * FROM employee WHERE emp_id = 5;如果没有索引,数据库就只能扫描整个员工表,然后依次判断每个数据记录中的员工编号是否等于5并且返回满足条件的数据。这种查找数据的方法被称为**全表扫描**(Full Table Scan)。
全表扫描最大的一个问题,就是当表中的数据量逐渐增加时性能随之明显下降,因为磁盘 I/O 是数据库最大的性能瓶颈。
当表中的数据量很小(例如配置表),或者查询需要访问表中大量数据(数据仓库),索引对查询的优化效果不会很明显。
为了解决大量磁盘访问带来的性能问题,MySQL引入了一个新的数据结构:索引(Index)。索引在MySQL中也被称为键(Key)。MySQL默认使用B-树(B+树)索引,它就像图书后面的关键字索引一样,按照关键字进行排序并且提供了指向具体内容的页码。
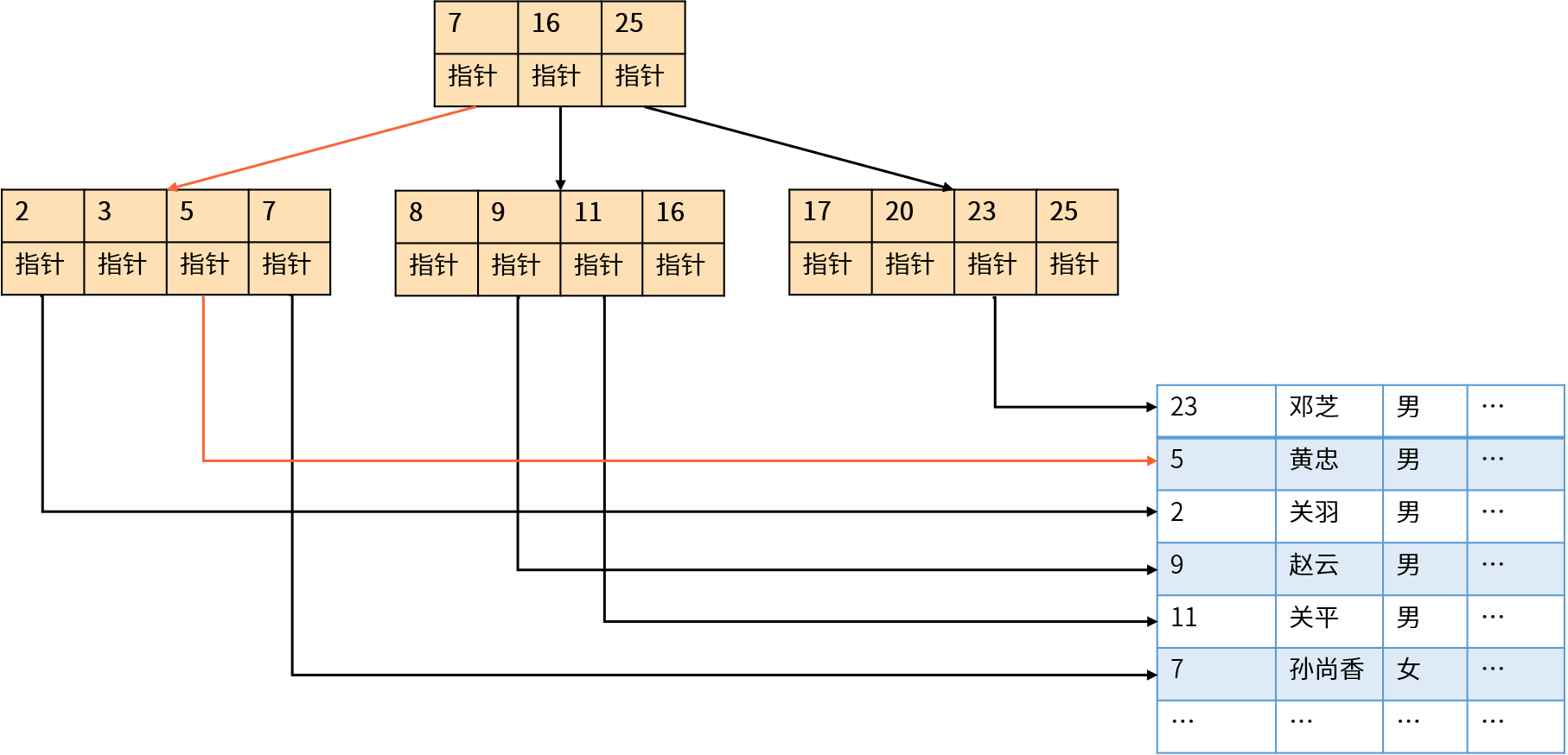
B-树索引就像是一棵倒立的树,树的节点按照顺序进行组织,节点左侧的数据都小于该节点的值,节点右侧的数据都大于该节点的值。B+树索引基于B-树索引进行了优化, 它们只在叶子节点存储索引数据(降低树的高度,从而减少了磁盘访问次数) ,并且增加了叶子节点或者兄弟节点之间的指针(优化范围查询)。
举例来说,假设索引的每个分支节点可以存储100个键值,100万条记录只需要3层B-树即可完成索引。 数据库通过索引查找指定数据时需要读取3次磁盘I/O(每次磁盘I/O读取整个索引节点)就可以得到查询结果。
如果采用全表扫描的方式,数据库需要执行的磁盘I/O可能高出几个数量级。 当数据量增加到1亿条记录时, 通过索引访问只需要增加一次磁盘I/O即可, 全表扫描则需要再增加几个数量级的磁盘I/O。
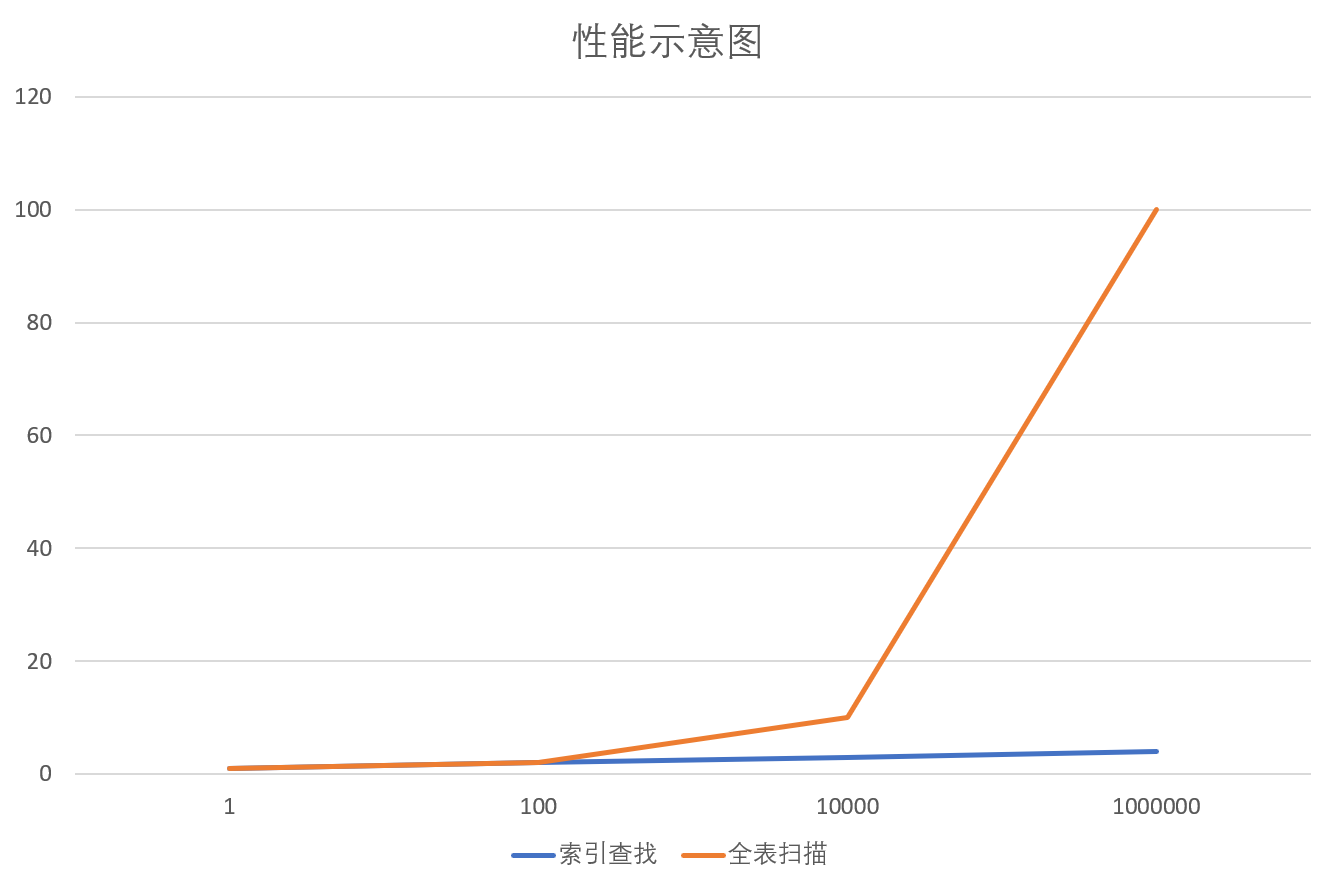
主流数据库默认使用的都是B-树(B+树、 B*树)索引,它们实现了稳定且快速的数据查找(O(log n) 对数时间复杂度),可以用于优化=、、 BETWEEN、 IN运算符以及字符串的前向匹配(“ABC%”)等查询条件。
2.2 聚簇索引
聚集索引(Clustered Index)将表中的数据按照索引(通常是主键) 的结构进行存储。 也就是说,聚集索引的叶子节点中直接存储了表的数据,而不是指向数据的指针。

聚集索引其实是一种特殊的表, MySQL(InnoDB)和 Microsoft SQL Server 将这种结构的表称为聚集索引, Oracle数据库中将其称为索引组织表(IOT)。这种存储数据的方式类似于Key-Value存储,适合基于主键进行查询的应用。
聚簇索引生成方式:
- 如果定义了主键,InnoDB使用主键聚集数据;
- 如果没有定义主键,InnoDB使用第一个非空的UNIQUE索引聚集数据;
- 如果没有主键和可用的UNIQUE索引,InnoDB使用一个隐藏的内部ID字段聚集数据。(存在问题:只有一个字段ID,如果多个表都是用该方式构建聚簇索引,此时内部ID的自增都是在同一个ID上自增)。
2.3 辅助索引
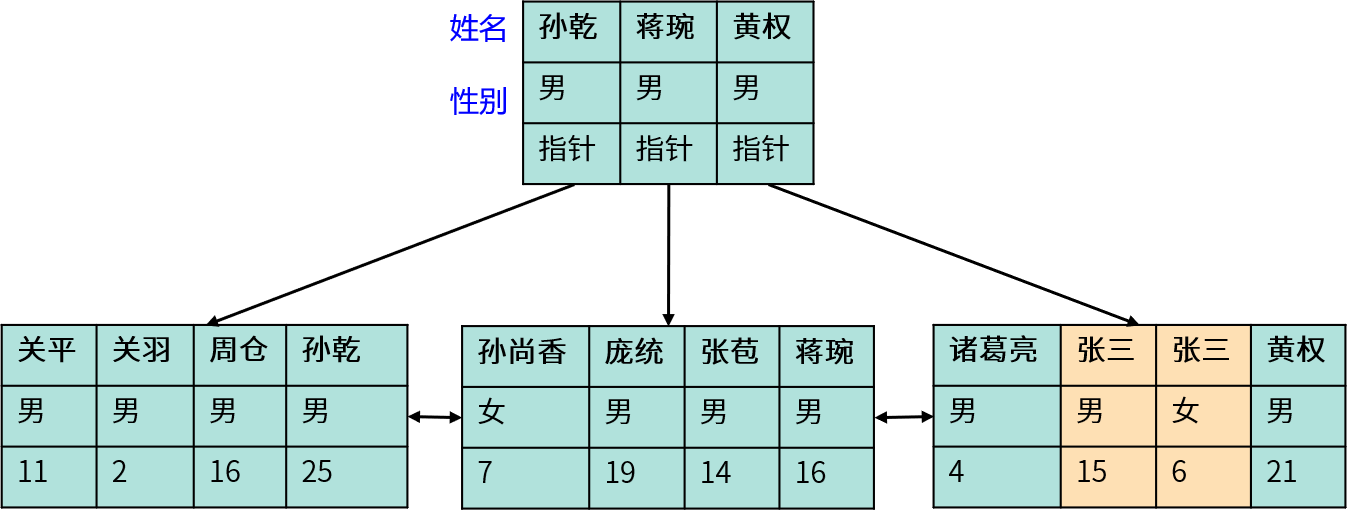
MySQL(InnoDB)中的辅助索引也被称为二级索引(Secondary Index),叶子节点存储了聚集索引的键值(通常是主键)。
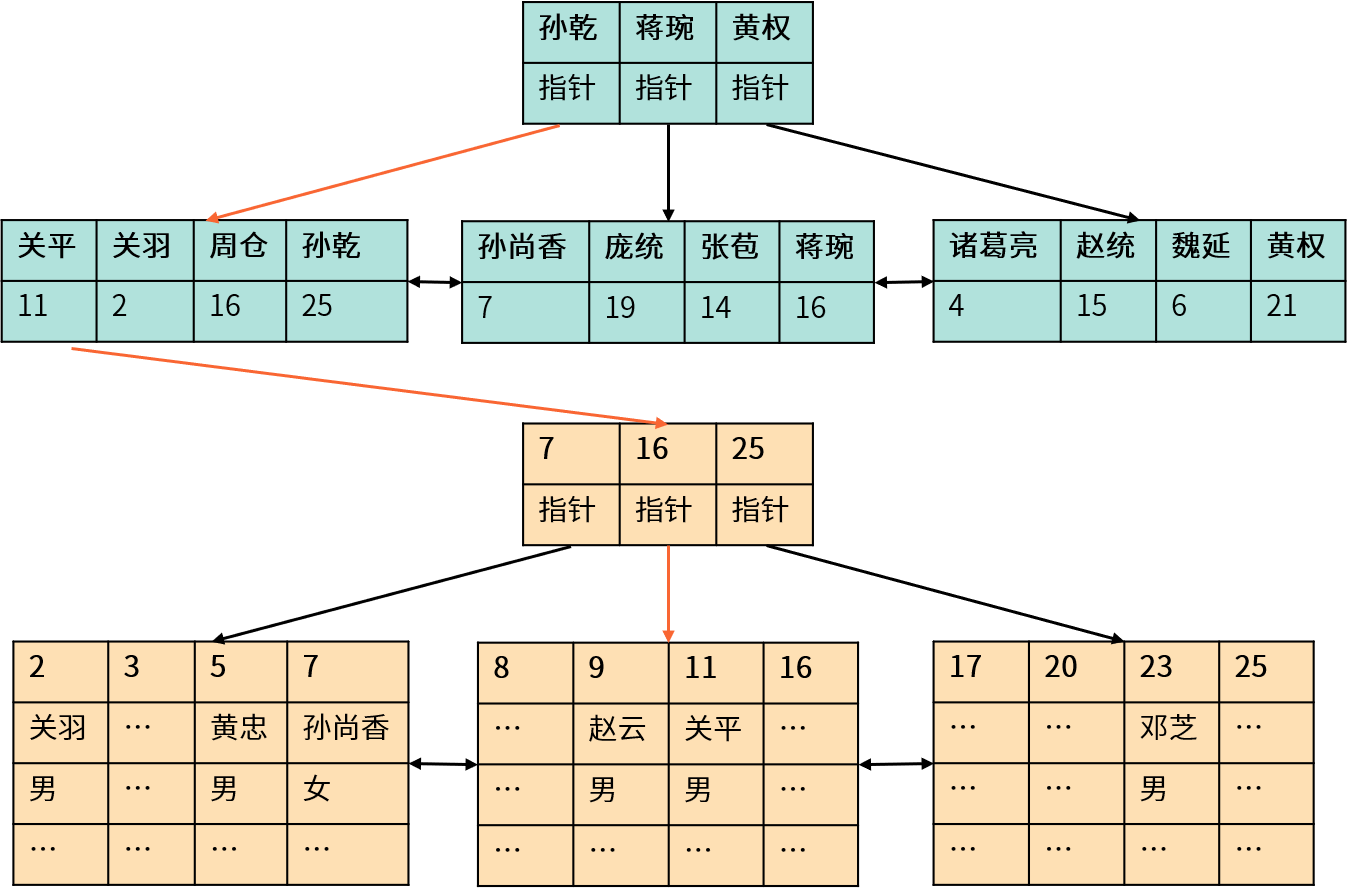
我们通过二级索(上图中使用 name 作为二级索引)引查找数据时,系统需要先找到相应的主键值,再通过主键索引查找相应的数据(回表)。因此,创建聚集索引的主键字段越小,二级索引就越小。这也是我们通常使用自增数字而不是UUID作为MySQL主键的原因之一。
二级索引叶子节点存储聚集索引键值的好处:当当数据发生改变或移动时,可以保证二级索引的稳定性(只要ID不变则无需修改二级索引)。
二级索引叶子节点存储聚集索引键值的缺点:增加了一次回表操作。
2.4 复合索引
复合索引是基于多个字段创建的索引,也叫多列索引。
复合索引可以避免为每个字段创建单独的索引,使用复合索引时最重要的是索引字段的顺序。
复合索引首先按照第一个(最左侧)字段排序,然后按照第二个字段排序,以此类推。因此,一个选择索引字段顺序的经验法则是:将选择性最高的字段放在最前面。
通过如下命令可以查看不同前缀长度的选择性:
SELECT count(DISTINCT emp_name)/count(*) emp_name_sel,count(DISTINCT sex)/count(*) sex_sel
FROM employee;emp_name_sel|sex_sel|
------------+-------+1.0000| 0.0800|注意:如果数据分布不均匀,这种经验法则可能对于特定值的查询性能很差。
最左前缀匹配原则:复合索引(col1, col2, col3),相当于以下三个索引:
- (col1)
- (col1, col2)
- (col1, col2, col3)
举例来说,它可以用于优化以下查询条件(左侧的确定了才能使用索引查找右侧的):
- WHERE col1 = val1 AND col2 = val2 AND col3 = val3
- WHERE col1 = val1 AND col2 = val2
- WHERE col1 = val1
- WHERE col1 = val1 AND col2 BETWEEN val2 AND val3
- WHERE col1 BETWEEN val1 AND val2
- WHERE col1 LIKE 'ABC%'
2.5 前缀索引
前缀索引(Prefix Index)是指基于字段的前一部分内容创建的索引。BLOB 、TEXT或者很长的VARCHAR类型字段必须使用前缀索引,因为MySQL对索引的长度有限制。MySQL 5.7默认不能超过3072字节。
前缀索引的优点是可以节省空间, 提高索引性能,但缺点是会降低索引的选择性。
索引的选择性是指不重复的索引值(基数)和表中的数据总量的比值,范围处于(1/总数据量)到1之间。选择性越高的索引查询效率越高,因为可以过滤掉更多的数据。主键和唯一索引的选择性是1。
通过如下命令可以查看不同前缀长度的选择性:
SELECT count(DISTINCT LEFT(email,3))/count(DISTINCT email) left3,count(DISTINCT LEFT(email,4))/count(DISTINCT email) left4,count(DISTINCT LEFT(email,5))/count(DISTINCT email) left5,count(DISTINCT LEFT(email,6))/count(DISTINCT email) left6
FROM employee;left3 |left4 |left5 |left6 |
------+------+------+------+
0.6000|0.7200|0.9200|1.0000|示例中,当前缀长度到达6的时候,选择性和索引整个email字段没有区别。因此,可以基于该字段创建一个前缀索引:
CREATE INDEX idx_employee_email ON employee(email(6));前缀索引也存在缺点,MySQL不能使用前缀索引进行排序(ORDER BY)和分组(GROUP BY),也不能实现索引覆盖扫描。
前缀索引的设计关键在于保证足够的选择性,同时又不能太长,以便节约存储。
2.6 函数索引
MySQL 8.0支持函数索引(Function-Based Index),也被称为表达式索引(Expression-Based Index),是基于函数或者表达式创建的索引。
例如,员工的电子邮箱不区分大小写并且唯一,我们可以基于LOWER(email)函数创建一个唯一的函数索引。
explain select * from employee where lower(email) = lower('ZhangFei@shuguo.com');Name |Value |
-------------+-----------+
id |1 |
select_type |SIMPLE |
table |employee |
partitions | |
type |ALL | // 代表全表扫描,因为email建立的索引,包含大小写,上述查询时都转化为了小写
possible_keys| |
key | |
key_len | |
ref | |
rows |25 |
filtered |100.0 |
Extra |Using where|create unique index uk_emp_email_lower on employee((lower(email))); // 使用小写创建索引
analyze table test;explain select * from employee where lower(email) = lower('ZhangFei@shuguo.com');Name |Value |
-------------+------------------+
id |1 |
select_type |SIMPLE |
table |employee |
partitions | |
type |const |
possible_keys|uk_emp_email_lower|
key |uk_emp_email_lower| // 使用新建的索引查询
key_len |403 |
ref |const |
rows |1 |
filtered |100.0 |
Extra | |函数索引能够支持其他方式无法使用的数据类型,例如JSON数据。
CREATE TABLE employees (data JSON,INDEX idx ((CAST(data->>"$.name" AS CHAR(30)) COLLATE utf8mb4_bin))
);
INSERT INTO employees VALUES('{ "name": "james", "salary": 9000 }'),('{ "name": "James", "salary": 10000 }'),('{ "name": "Mary", "salary": 12000 }'),('{ "name": "Peter", "salary": 8000 }');SELECT * FROM employees WHERE data->>'$.name' = 'James';函数索引要求完全按照索引定义的相同方式指定查询中的条件。
扩展:什么是 JSON 数据?
在数据库中,JSON(JavaScript Object Notation)是一种用于存储和表示结构化数据的格式。它是一种轻量级的数据交换格式,常用于Web应用程序和分布式系统中的数据传输和存储。
JSON数据由键值对组成,使用大括号 {} 包围。每个键值对由冒号 : 分隔,键是一个字符串,值可以是字符串、数字、布尔值、数组、对象或null。JSON数据具有以下特点:
1)简洁性:JSON使用简洁的语法表示数据,易于阅读和编写。
2)可读性:JSON数据采用文本格式,可被人类读取和理解。
3)可扩展性:JSON支持嵌套结构,可以构建复杂的数据层次。
下面是一个示例JSON数据:
{"name": "John Doe","age": 30,"email": "johndoe@example.com","address": {"street": "123 Main St","city": "New York","state": "NY"},"hobbies": ["reading", "traveling", "photography"]
}在这个例子中,JSON数据表示一个人的信息。它包含了姓名、年龄、电子邮件和地址等属性。其中,地址是一个嵌套的对象,包含街道、城市和州。而兴趣爱好是一个数组,包含多个字符串元素。
在数据库中,JSON数据可以存储在特定的JSON字段中,例如MySQL中的JSON数据类型或PostgreSQL中的JSONB数据类型。这样可以方便地存储和查询具有不同结构的数据,而无需提前定义固定的表结构。
使用JSON数据类型,数据库可以存储和检索非结构化或半结构化的数据,适用于存储用户配置、日志、文档、社交媒体数据等。同时,数据库系统提供了一系列的JSON函数和操作符,用于在查询中处理和操作JSON数据。
2.7 降序索引
MySQL 8.0支持降序索引(Descending index):索引定义中的DESC不再被忽略,而是以降序方式存储索引键值。
在之前的版本中,索引支持反向扫描,但是性能稍差一些。降序索引可以进行正向扫描,效率更高。当查询需要针对某些列升序排序,同时针对另一些列降序排序时,降序索引使得优化器可以使用多列混合索引扫描。
CREATE TABLE t (id INT AUTO_INCREMENT PRIMARY KEY, c1 INT, c2 INT,INDEX idx1 (c1 ASC, c2 ASC),INDEX idx2 (c1 ASC, c2 DESC),INDEX idx3 (c1 DESC, c2 ASC),INDEX idx4 (c1 DESC, c2 DESC)
);优化器可以为不同的ORDER BY子句使用正向索引扫描,而不需要执行 *filesort* 排序。
explain select * from t ORDER BY c1 ASC, c2 DESC; // 会自动使用最适合的索引方式进行查找Name |Value |
-------------+-----------+
id |1 |
select_type |SIMPLE |
table |t |
partitions | |
type |index |
possible_keys| |
key |idx2 |
key_len |10 |
ref | |
rows |1 |
filtered |100.0 |
Extra |Using index|MySQL 8.0不再对GROUP BY操作进行隐式排序,排序需要明确指定ORDER BY。
2.8 隐藏索引
MySQL 8.0支持隐藏索引(invisible index),也称为不可见索引。隐藏索引不会被优化器使用。
主键不能设置为隐藏(包括显式设置或隐式设置)。
CREATE TABLE t1 (i INT,j INT,k INT,INDEX i_idx (i) INVISIBLE
) ENGINE = InnoDB;CREATE INDEX j_idx ON t1 (j) INVISIBLE; // 创建一个名为 j_idx 的隐藏索引
ALTER TABLE t1 ADD INDEX k_idx (k) INVISIBLE; // 添加一个名为 k_idx 的隐藏索引ALTER TABLE t1 ALTER INDEX m_idx INVISIBLE; // 将一个已经创建的索引修改为隐藏索引(假设 m_idx 索引已经被创建)索引的可见性不会影响索引的维护。例如,无论索引是否可见,每次修改表中的数据时都需要对相应索引进行更新,而且唯一索引都会阻止插入重复的列值。
MySQL系统变量optimizer_switch中的use_invisible_indexes设置控制了优化器构建执行计划时是否使用隐藏索引。如果设置为off(默认值),优化器将会忽略隐藏索引(与引入该属性之前的行为相同)。如果设置为on,隐藏索引仍然不可见,但是优化器在构建执行计划时将会考虑这些索引。
不可见索引特性可以用于测试删除某个索引对于查询性能的影响,同时又不需要真正删除索引,也就避免了错误删除之后的索引重建。对于一个大表上的索引进行删除重建将会非常耗时,而将其设置为不可见或可见将会非常简单快捷。
隐藏索引应用场景:软删除、灰度发布。
2.9 覆盖索引
在某些情况下,查询语句通过索引访问就可以返回所需的结果,不需要访问表中的数据(回表),此时我们把这个索引称为覆盖索引(Covering Index)。某些数据库中称之为Index Only Scan。
// emp_id 是主键 id,在 dept_id 上面建立了辅助索引
explain select emp_id, dept_id from employee where dept_id = 5; Name |Value |
-------------+------------+
id |1 |
select_type |SIMPLE |
table |employee |
partitions | |
type |ref | // 等值查询
possible_keys|idx_emp_dept| // dept_id 索引
key |idx_emp_dept|
key_len |4 |
ref |const |
rows |8 |
filtered |100.0 |
Extra |Using index | // 使用索引查询且没有回表上述查询语句要查询的值是 emp_id(主键id)和 dept_id,而辅助索引 dept_id 本身包含了 dept_id,叶节点中包含了emp_id(主键id),所以在查询这两个值时,无需回表即可获得想要结果。此时的执行计划中Extra列显示Using index。
覆盖索引是优化器选择的一种执行计划;或者也可以说,任何索引在某种情况下都可能称为覆盖索引。
任何索引都包含了主键列,可用覆盖通过索引查找主键的查询语句。
2.10 索引和排序
MySQL数据排序可通过 *filesort* 或者索引顺序扫描的方式实现。
- 文件排序(filesort):当查询中没有适用于排序的索引或无法使用现有索引时,MySQL会使用文件排序。它的工作原理是将查询结果加载到临时文件中,然后在文件中进行排序操作。这种方式需要将数据加载到磁盘上的临时文件中,然后进行排序,可能会导致较高的磁盘I/O和内存消耗。
- 索引顺序扫描:当查询中存在适用于排序的索引时,MySQL可以直接利用索引的顺序来避免文件排序。它会按照索引的顺序扫描数据,并返回按照排序要求的结果(索引一般默认升序)。
示例一:
EXPLAIN SELECT * FROM employee e ORDER BY emp_name;Name |Value |
-------------+--------------+
id |1 |
select_type |SIMPLE |
table |e |
partitions | |
type |ALL | // 全表扫描
possible_keys| |
key | |
key_len | |
ref | |
rows |25 |
filtered |100.0 |
Extra |Using filesort| // 此处代表排序,但不一定是 filesort 排序,也可能是内存排序上述查询中,由执行计划可看出,在查询时走的是全表扫描。
走全表扫描而没有走索引扫描的原因:查询语句中要查询的是记录的所有字段,如果直接通过辅助索引(emp_name)进行查找,会涉及到回表操作;虽然辅助索引是有序的,但辅助索引叶节点包含的主键 id 是无序的,也就是说,在进行回表时需要进行大量的随机 IO(可参考优化器:MRR),最终导致查询性能低下,不如直接进行全表扫描,然后再排序。
优化器 MRR:MySQL 优化器 MRR_mysql优化器-CSDN博客
示例二:
EXPLAIN SELECT emp_id, emp_name FROM employee e ORDER BY emp_name;Name |Value |
-------------+------------+
id |1 |
select_type |SIMPLE |
table |e |
partitions | |
type |index |
possible_keys| |
key |idx_emp_name|
key_len |202 |
ref | |
rows |25 |
filtered |100.0 |
Extra |Using index |上述查询语句要查询的值是 emp_id(主键id)和 emp_name,而辅助索引 emp_name 本身包含了 dept_id,叶节点中包含了emp_id(主键id),所以在查询这两个值时,无需回表即可获得想要结果。此时的执行计划中Extra列显示Using index,即没有使用回表直接进行查询。
MySQL索引即可以用于查询数据,也可以用于实现排序。前提是索引字段的顺序和ORDER BY子句字段的顺序完全一致(最左前缀原则)。
对于复合索引(col1, col2, col3),可以用于优化以下查询:
- WHERE col1 = val1 ORDER BY col2, col3
- WHERE col1 = val1 ORDER BY col2 DESC
- WHERE col1 BETWEEN val1 AND val2 ORDER BY col1, col2(col1是范围查询,必须出现在ORDERR BY里面)
但是无法使用该索引实现以下查询中的排序:
- WHERE col1 = val1 ORDER BY col2 DESC, col3(复合索引中 col1, col2, col3 都是默认升序)
- WHERE col1 = val1 ORDER BY col3
- WHERE col1 BETWEEN val1 AND val2 ORDER BY col2, col3
如果查询连接了多个表,只有ORDER BY子句字段全部属于第一个表时,才能利用索引进行排序。
2.11 重复索引和冗余索引
MySQL允许在相同的字段上按照相同的顺序创建多个相同类型的索引,也就是**重复索引**。这样会占用更多存储空间,也导致优化器需要进行更多的评估。
CREATE TABLE t (id INT AUTO_INCREMENT PRIMARY KEY,c1 INT UNIQUE, c2 INT,INDEX idx_pk (id),INDEX idx1 (c1)
);以上示例中的索引idx_pk和idx1都属于重复索引(MySQL(InnoDB)自动为主键、唯一约束以及外键约束创建相应的索引)。
复合索引字段顺序不同,则不算重复索引。例如(col1, col2)和(col2, col1)不是重复索引。
索引类型不同,则不算重复索引。例如INDEX(col)和FULLTEXT INDEX(col)不是重复索引。
**冗余索引**是指字段已经被其他索引包含的索引。
如果已经存在复合索引(col1, col2),那么索引(col1)就是冗余索引,因为前者可用替代索引(col1)。不过需要注意,索引(col2)不是冗余索引,因为col2不是索引(col1, col2)的最左前缀列。
索引(col1, id)是一个冗余索引,因为辅助索引中一定会包含主键字段。
一般建议基于已有的索引进行扩展,而不是不断增加新的冗余索引,但是也存在例外。
重复索引和冗余索引的处理方法就是删除索引,但是删除之前需要确认不会产生副作用。MySQL 8.0可用利用不可见索引特性减少影响。
另外,可能会存在从未使用过的索引,通过系统视图sys.schema_unused_indexes查看,建议确认后删除。
2.12 索引和DML
索引不仅会对查询产生影响,对数据进行插入、更新和删除操作时也需要同步维护索引结构。
INSERT语句
对于INSERT语句而言,索引越多执行越慢。插入数据必然导致增加索引项,这种操作的成本往往比插入数据本身更高,因为索引必须保持顺序和B+树的平衡(索引节点拆分)。因此,优化插入语句的最好方法就是减少不必要的索引。
没有任何索引时的插入性能是最好的,因此在加载大量数据时,可以临时删除所有的索引并在加载完成后重建索引。
UPDATE语句
UPDATE语句如果指定了查询条件,可以通过索引提高更新操作的性能,因为通过索引可以快速找到需要修改的数据。
另一方面,UPDATE语句如果修改了索引字段的值,需要删除旧的索引项并增加新的索引项。因此,更新操作的性能通常也取决于索引的数量。为了优化UPDATE语句,频繁更新的字段不适合创建索引;同时应该尽量避免修改过多的字段。
**DELETE语句**
对于DELETE语句而言,如果指定了查询条件,可以通过索引提高删除操作的性能。因为它和UPDATE语句一样,需要先执行一个SELECT语句找到需要删除的数据。
删除操作涉及的索引更新和插入操作类似,只不过它是删除一些索引项并确保索引树的平衡。因此,索引越多删除性能越差。不过有一个例外就是没有任何索引,这个时候性能会更差,因为数据库需要执行全表扫描才能找到需要删除的数据。
2.13 索引设计原则
> 推荐图书:《数据库索引设计与优化》
三星索引:
- 索引将相关的数据存储在一起,减少需要扫描的数据量,获得一星(即针对需要查询字段建立索引);
- 索引中的数据顺序和查询排序顺序一致,避免排序操作,获得二星;
- 索引包含了查询所需的全部字段,避免随机IO,获得三星。
CREATE TABLE t (id INT AUTO_INCREMENT PRIMARY KEY, c1 INT,c2 INT,INDEX idx1 (c1, c2)
);EXPLAIN SELECT * FROM t WHERE c1>100 ORDER BY c1, c2;Name |Value |
-------------+------------------------+
id |1 |
select_type |SIMPLE |
table |t |
partitions | |
type |index | // 使用了索引查找
possible_keys|idx1 |
key |idx1 |
key_len |10 |
ref | |
rows |1 |
filtered |100.0 |
Extra |Using where; Using index| // Using where 指 where 判断,Using index 指使用 index 查找且无需进行回表既然索引可以优化查询的性能,那么我们是不是遇到性能问题就创建一个新的索引,或者直接将所有字段都进行索引?显然并非如此,因为索引在提高查询速度的同时也需要付出一定的代价:
- 首先,索引需要占用磁盘空间。索引独立于数据而存在,过多的索引会导致占用大量的空间。
- 其次,进行DML操作时,也需要对索引进行维护;维护索引有时候比修改数据更加耗时。
一般来说,可以考虑为以下情况创建索引:
- 经常出现在WHERE条件或者ORDER BY中的字段创建索引,可以避免全表扫描和额外的排序操作;
- 多表连接查询的关联字段或者外键涉及的字段,可以避免全表扫描和外键级联操作导致的锁表;
- 查询中的GROUP BY分组操作字段。
对于交易类型的系统,首先找出查询时间最长或者占用资源最多的语句,检查它们涉及的表结构、索引结构,判断表结构和索引是否合理。如果这些优化还不能满足要求,另一个方法就是SQL查询优化。
如果需要本文 WORD、PDF 相关文档请在评论区留言!!!
如果需要本文 WORD、PDF 相关文档请在评论区留言!!!
如果需要本文 WORD、PDF 相关文档请在评论区留言!!!
相关文章:
MySQL 性能优化
未完待续... 1. 分库、分表结构优化 1.1 数据库设计 不规范的数据库设计存在数据冗余以及插入、更新、删除异常问题。 规范化(Normalization)是数据库设计的一系列原理和技术,主要用于减少表中数据的冗余,增加完整性和一致性&…...

求职招聘小程序源码系统 全开源源代码:找工作+招人才 平台级别运营版 附带完整的搭建教程
在当前的求职招聘市场中,尽管存在大量的求职者和招聘者,但依然存在着信息不对称、沟通不畅等问题。小编来给大家分享一款求职招聘小程序源码系统,旨在提供一个高效、便捷、安全的求职招聘平台。 以下是部分代码示例: 系统特色功能…...

26、卷积 - 实际上是一个特征提取器
矩阵乘法的本质是特征的融合,卷积算法的本质是特征的提取。 回想一下之前所有介绍卷积的时候,描述了一种卷积运算的场景,那就是一个窗口在图片上滑动,窗口中的数值是卷积核的参数,也就是权值。 卷积的计算本质是乘累…...

web前端之vue3
MENU vue3响应式数据的判断、isRef、isReactive、isReadonly、isProxy、ref、reactive、readonlyvue3的生命周期vue3手写isRef、isReactive、isReadonly、isProxyvue3手写ref、深的refvue3手写shallowRef、浅的refvue3customRefvue3readonly与shallowReadonlyvue3toRaw与markRa…...

原来在C++的类中声明函数时可以不写参数名只写参数类型
2023年12月6日,周三上午 今天才发现原来可以这样写 在C的类中声明函数时可以不写参数名只写参数类型, 但是,在实现时必须写出参数名。 #include<iostream>class People { public:void move(int);void say(std::string);void doSomet…...

独孤思维:这里有蓝海项目,你要吗?
很多人,一看到蓝海项目,就趋之若鹜。 觉得红海项目太卷了,根本赚不到钱。 凡是认为蓝海项目不卷,可以做起来,做的轻松的,都是弱智和无能的表现。 你所能接触到的蓝海,根本就不是蓝海。 能够…...

外卖平台推荐算法的优化与实践
目录 引言 一、推荐算法的原理 二、推荐算法的挑战 三、实际案例分析 四、优化推荐算法的策略 五、结论 引言 在当今数字化社会,外卖平台成为了人们生活中不可或缺的一部分。为了提供更加个性化、高效的服务,外卖平台使用推荐算法成为了一项关键技…...

CONTROLLING VISION-LANGUAGE MODELS FOR MULTI-TASK IMAGE RESTORATION
CONTROLLING VISION-LANGUAGE MODELS FOR MULTI-TASK IMAGE RESTORATION (Paper reading) Ziwei Luo, Uppsala University, ICLR under review(6663), Cited:None, Stars: 350, Code, Paper. 1. 前言 像CLIP这样的视觉语言模型已经显示出对零样本或无标签预测的各种下游任务…...

HarmonyOS应用开发——页面
我们将对于多页面以及更多有趣的功能展开叙述,这次我们对于 HarmonyOS 的很多有趣常用组件并引出一些其他概念以及解决方案、页面跳转传值、生命周期、启动模式(UiAbility),样式的书写、状态管理以及动画等方面进行探讨 页面之间…...
)
Java流Stream使用详解(练习)
练习 第一题 数据过滤 定义一个集合,并添加一些整数1,2,3,4,5,6,7,8,9,10过滤奇数,只留下偶数,并将结果保存起来 import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.stream.Collectors…...

请介绍一下MySQL的存储引擎及其特点
问题:请介绍一下MySQL的存储引擎及其特点。 回答: MySQL是一个开源的关系型数据库管理系统,它支持多种存储引擎,每个存储引擎都有其自身的特点和适用场景。下面是对MySQL常见存储引擎的简要介绍: InnoDB: …...

Python---魔术方法
1、什么是魔术方法 在Python中,__xxx__()的函数叫做魔法方法,指的是具有特殊功能的函数。 2、__init__()方法(初始化方法或构造方法) 思考:人的姓名、年龄等信息都是与生俱来的属性,可不可以在生产过程中就赋予这些属性呢&…...

手把手教你注册意大利商标
在当今全球商业环境中,拥有一个独特的商标可以为企业在市场竞争中提供重要优势。商标作为品牌形象的核心,有助于吸引潜在客户,提升品牌价值,增加客户忠诚度。在意大利,商标注册同样具有重要意义,它能为企业…...

pandas详细笔记
一:什么是Pandas from matplotlib import pyplot import numpy as np import pandas as pdarange np.arange(1, 10, 2) series pd.Series(arange,indexlist("ABCDE")) print(series)二:索引 三:切片 位置索引切片(左闭…...
win11安装(未完待续)
学习补丁 test.bat 运行后需要重启 slmgr /ipk W269N-WFGWX-YVC9B-4J6C9-T83GX slmgr /skms kms.03k.org slmgr /ato 文件扩展名 主题 性能设置 开始按钮靠左 任务栏对齐方式-靠左 必备软件 f.lux redshift 360管家 驱动精灵 edge c*lash(v2*ray不支持w…...
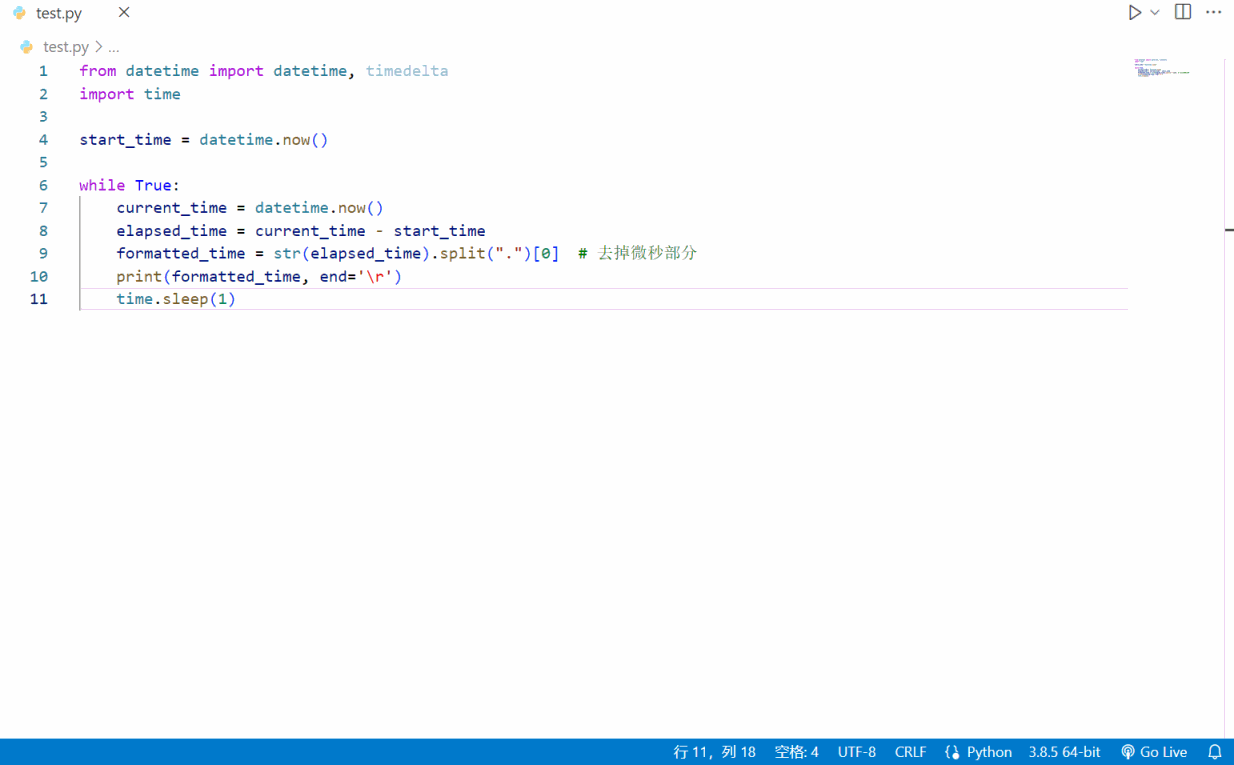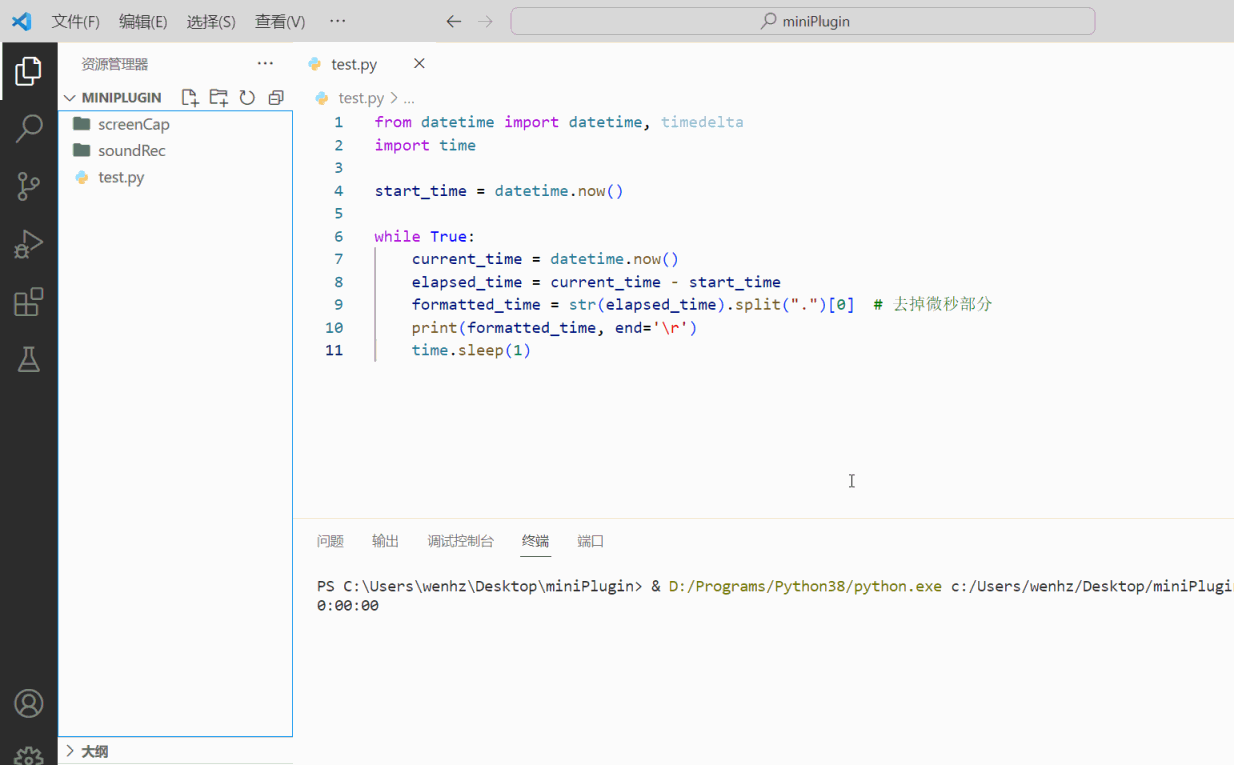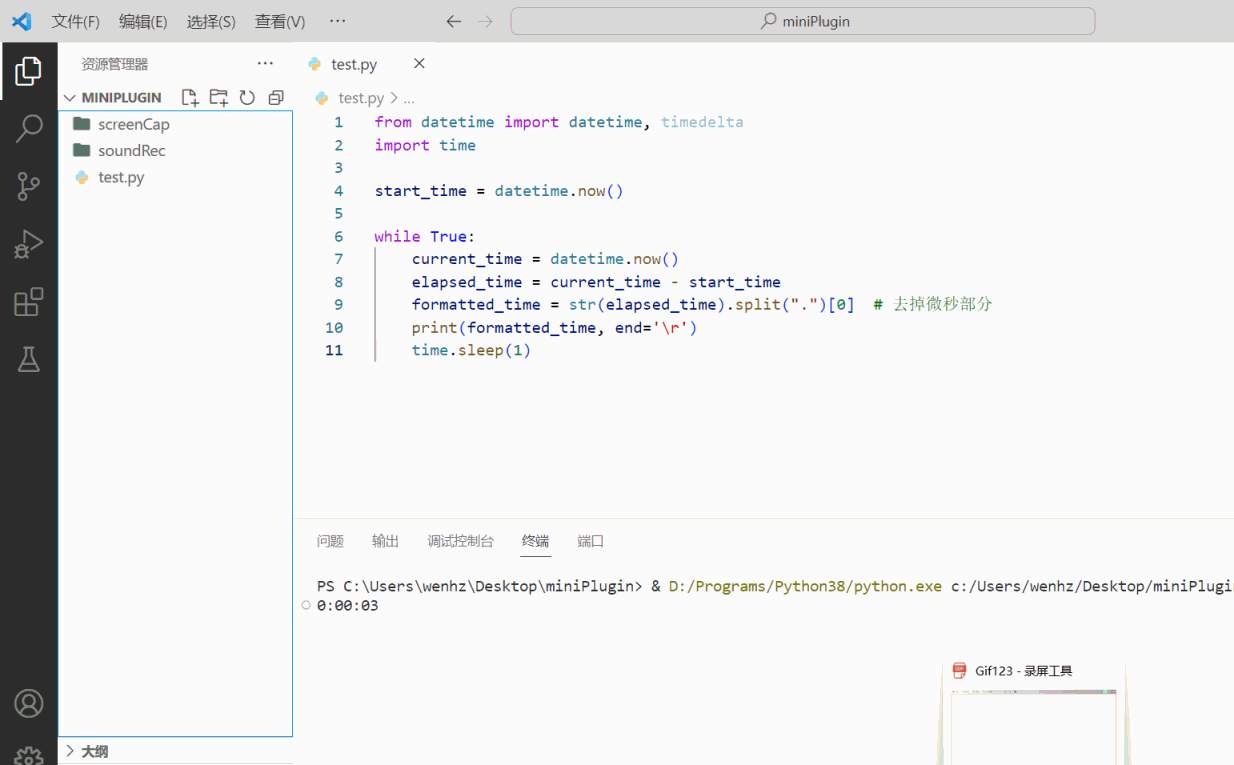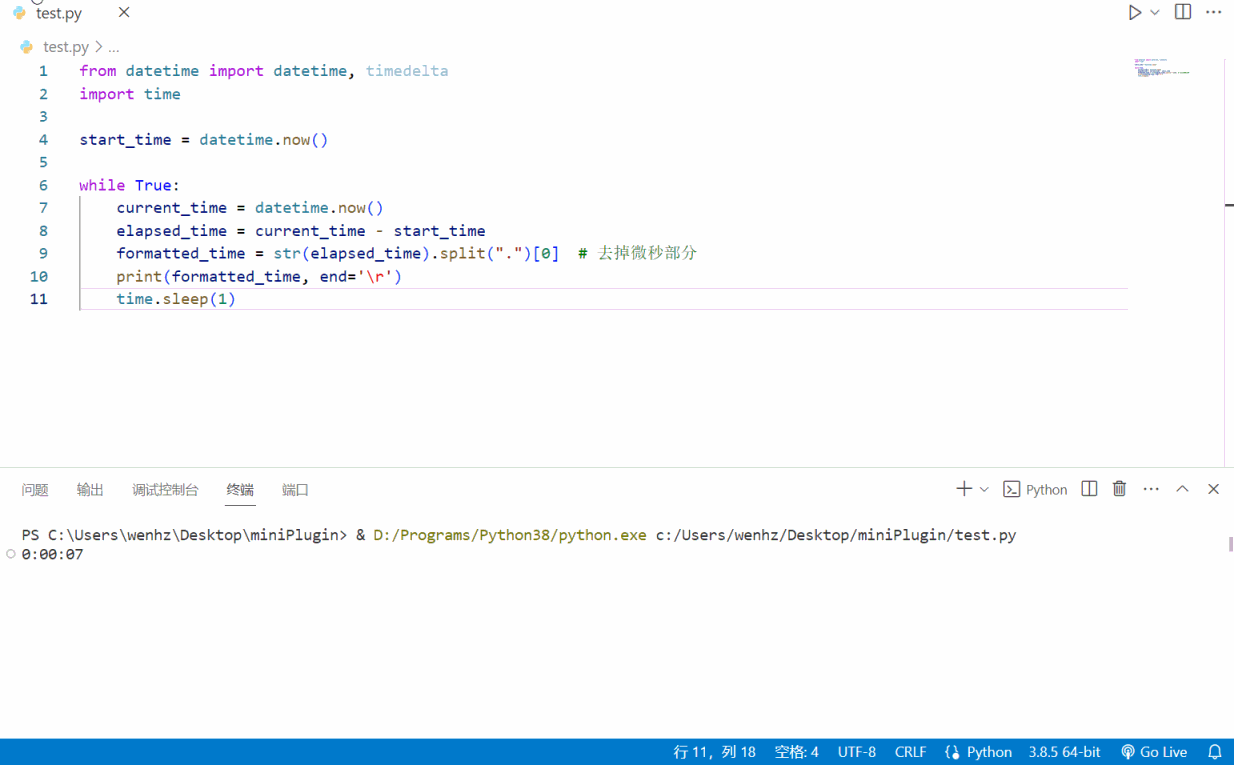
python之记录程序运行时长工具
python之记录程序运行时长工具 废话不多话,上代码 from datetime import datetime, timedelta import timestart_time datetime.now()while True:current_time datetime.now()elapsed_time current_time - start_timeformatted_time str(elapsed_time).split(…...
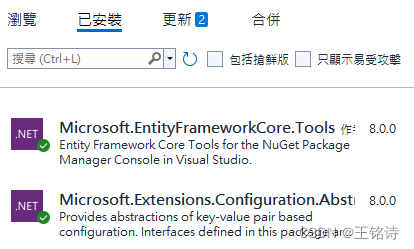
.Net core 6.0 升8.0
1 Update Visual Studio 2 3 用Nutget 更新不同套件版本 更新后结果如下:...

MacDroid Pro for Mac – 安卓设备文件传输助手,实现无缝连接与传输!
想要在Mac电脑上轻松管理和传输您的安卓设备文件吗?MacDroid Pro for Mac 是您的最佳选择!这款强大的文件传输助手可以让您在Mac上与安卓设备之间实现快速、方便的文件传输。 MacDroid Pro for Mac 提供了简单易用的界面,让您能够直接在Mac上…...

【EtherCAT详解】基于Wireshark的EtherCAT帧结构解析
写在前面 EtherCAT的报文比较繁琐,且一些参考书籍错误较多,且晦涩难懂,对于初学者,很难快速的入门。本文适用于有一定基础的研究者,如对报文有一些研究、对canopen协议有一定了解、并且对TwinCAT有了解的研究者。当然,对于初学者来说,也是很好的引导,少走很多弯路。本…...

C语言之程序的组成和元素格式
目录 关键字 运算符 标识符 姓名和标识符 分隔符 常量和字符串常量 自由的书写格式 书写限制 连接相邻的字符串常量 缩进 本节我们来学习程序的各组成元素(关键字、运算符等)和格式相关的内容。 关键字 在C语言中,相if和else这样的标识…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...