使用Pytorch从零开始实现CLIP
生成式建模知识回顾:
[1] 生成式建模概述
[2] Transformer I,Transformer II
[3] 变分自编码器
[4] 生成对抗网络,高级生成对抗网络 I,高级生成对抗网络 II
[5] 自回归模型
[6] 归一化流模型
[7] 基于能量的模型
[8] 扩散模型 I, 扩散模型 II

引言
2021 年 1 月,OpenAI 宣布了两种新模型:DALL-E 和 CLIP,这两种模型都是以某种方式连接文本和图像的多模态模型。在本文中,我们将在PyTorch中从零开始实现 CLIP 模型。OpenAI 开源了一些与 CLIP 模型相关的代码,但我发现它令人生畏,而且并不简洁。
CLIP 有什么作用?为什么有趣?
在《Learning Transferable Visual Models From Natural Language Supervision》论文中,OpenAI 介绍了他们的新模型,称为CLIP,用于Contrastive Language-Image Pre-training。简而言之,该模型学习整个句子与其描述的图像之间的关系;从某种意义上说,当训练模型时,给定一个输入句子,它将能够检索与该句子相对应的最相关的图像。这里重要的是,它是在完整的句子上进行训练,而不是像car、dog等单一类别一样。直觉上,当在整个句子上进行训练时,模型可以学习更多的东西,并找到图像和文本之间的一些模式。
他们还表明,当该模型在巨大的图像数据集及其相应文本上进行训练时,它也可以充当分类器。我鼓励你研究论文原文,以更多地了解这个令人兴奋的模型及其在基准数据集上的惊人结果。仅举一例,使用此策略训练的 CLIP 模型对 ImageNet 的分类效果比在 ImageNet 本身上训练的 SOTA 模型更好,该 SOTA 模型专门针对单一分类任务进行了优化!
先跳过过程,让我们看看我们将在本文中从头开始构建的最终模型能够实现什么功能:给出诸如“一个男孩用滑板跳跃”或“一个女孩从秋千上跳跃”这样的查询,模型将检索最相关的图像:

开始
让我们直接看它的 PyTorch 实现。首先,我们需要一个包含图像和一些描述它们的文本的数据集。坦率地说,网上有很多可用的。我们将使用Flickr 8k 数据集(您可以使用更大的 30k 版本,最终模型的性能会更好),该数据集主要用于图像字幕任务。但是, 我们也可以用它来训练 CLIP 模型。
以下代码将下载 8k(如果取消注释最后几行,则下载 30k)并解压缩它们。Kaggle数据集之下载可参考前文。
!pip install kaggle --upgrade
import os
os.environ['KAGGLE_USERNAME'] = "XXXXXX"
os.environ['KAGGLE_KEY'] = "XXXXXXXXXXXXXXXXXXXXXX" # Enter your Kaggle key here# For Flickr 8k
!kaggle datasets download -d adityajn105/flickr8k
!unzip flickr8k.zip
dataset = "8k"# For Flickr 30k
# !kaggle datasets download -d hsankesara/flickr-image-dataset
# !unzip flickr-image-dataset.zip
# dataset = "30k"
关于此数据集需要注意的一件事是: 每张图像都有 5 个标题。后面写损失函数的时候再讲这个!
数据集
正如您在本文的标题图片中看到的,我们需要对图像及其描述文本进行编码。因此,数据集需要返回图像和文本。当然,我们不会将原始文本提供给我们的文本编码器!我们将使用HuggingFace库中的DistilBERT模型(它比 BERT 小,但性能几乎与 BERT 一样)作为我们的文本编码器;因此,我们需要使用 DistilBERT 分词器对句子(标题)进行分词,然后将分词 id (input_ids) 和注意力掩码提供给 DistilBERT。因此,数据集也需要处理标记化。您可以在下面看到数据集的代码。下面我将解释代码中发生的最重要的事情。
关于配置和CFG的说明:我用 python 脚本编写了代码,然后将其转换为 Jupyter Notebook。因此,对于 python 脚本,config 是一个普通的 python 文件,我在其中放置所有超参数,对于 Jupyter Notebook,它是在笔记本开头定义的一个类,用于保留所有超参数。查看GitHub 存储库或笔记本以查看所有超参数。
import os
import cv2
import torch
import albumentations as Aimport config as CFGclass CLIPDataset(torch.utils.data.Dataset):def __init__(self, image_filenames, captions, tokenizer, transforms):"""image_filenames and cpations must have the same length; so, if there aremultiple captions for each image, the image_filenames must have repetitivefile names """self.image_filenames = image_filenamesself.captions = list(captions)self.encoded_captions = tokenizer(list(captions), padding=True, truncation=True, max_length=CFG.max_length)self.transforms = transformsdef __getitem__(self, idx):item = {key: torch.tensor(values[idx])for key, values in self.encoded_captions.items()}image = cv2.imread(f"{CFG.image_path}/{self.image_filenames[idx]}")image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = self.transforms(image=image)['image']item['image'] = torch.tensor(image).permute(2, 0, 1).float()item['caption'] = self.captions[idx]return itemdef __len__(self):return len(self.captions)def get_transforms(mode="train"):if mode == "train":return A.Compose([A.Resize(CFG.size, CFG.size, always_apply=True),A.Normalize(max_pixel_value=255.0, always_apply=True),])else:return A.Compose([A.Resize(CFG.size, CFG.size, always_apply=True),A.Normalize(max_pixel_value=255.0, always_apply=True),])
在 init 中,我们收到一个 tokenizer 对象,它实际上是一个 HuggingFace tokinzer;运行模型时将加载此标记生成器。我们将字幕填充并截断为指定的 max_length。在 getitem 中,我们将首先加载一个编码的标题,它是一个带有 input_ids 和 Attention_mask 键的字典,根据其值创建张量,然后我们将加载相应的图像,对其进行变换和增强(如果有的话!),然后我们将其设为张量并将其放入以“image”为键的字典中。最后,我们将带有“caption”键的标题的原始文本放入字典中,仅用于可视化目的。
我没有使用额外的数据增强,但如果您想提高模型的性能,可以添加它们。
图像编码器
图像编码器代码很简单。我在这里使用 PyTorch 图像模型库 (timm),它提供了从 ResNets 到 EfficientNets 等许多不同的图像模型。这里我们将使用ResNet50作为我们的图像编码器。如果您不想安装新的库,您可以轻松地使用 torchvision 库来使用 ResNets。
class ImageEncoder(nn.Module):"""Encode images to a fixed size vector"""def __init__(self, model_name=CFG.model_name, pretrained=CFG.pretrained, trainable=CFG.trainable):super().__init__()self.model = timm.create_model(model_name, pretrained, num_classes=0, global_pool="avg")for p in self.model.parameters():p.requires_grad = trainabledef forward(self, x):return self.model(x)
该代码将每个图像编码为固定大小的向量,其大小与模型输出通道的大小相同(在 ResNet50 的情况下,向量大小将为2048)。这是 nn.AdaptiveAvgPool2d() 层之后的输出。
文本编码器
正如我之前提到的,我将使用 DistilBERT 作为文本编码器。与它的大哥 BERT 一样,两个特殊的标记将被添加到实际的输入标记中:CLS和SEP,它们标记句子的开始和结束。为了获取句子的完整表示(正如相关的 BERT 和 DistilBERT 论文所指出的那样),我们使用 CLS 标记的最终表示,并且我们希望该表示能够捕获句子(标题)的整体含义。这样想的话,就类似于我们对图像的处理,将其转换为固定大小的向量。
from transformers import DistilBertModel, DistilBertConfigclass TextEncoder(nn.Module):def __init__(self, model_name=CFG.text_encoder_model, pretrained=CFG.pretrained, trainable=CFG.trainable):super().__init__()if pretrained:self.model = DistilBertModel.from_pretrained(model_name)else:self.model = DistilBertModel(config=DistilBertConfig())for p in self.model.parameters():p.requires_grad = trainable# we are using the CLS token hidden representation as the sentence's embeddingself.target_token_idx = 0def forward(self, input_ids, attention_mask):output = self.model(input_ids=input_ids, attention_mask=attention_mask)last_hidden_state = output.last_hidden_statereturn last_hidden_state[:, self.target_token_idx, :]
对于 DistilBERT(以及 BERT),每个标记的输出隐藏表示是一个大小为768的向量。因此,整个标题将被编码为大小为 768 的 CLS 令牌表示形式。
Projection Head
我使用Keras 代码示例实现在 PyTorch 中编写了以下内容。
现在我们已经将图像和文本编码为固定大小的向量(图像为 2048,文本为 768),我们需要将它们带(投影)到一个图像和文本具有相似尺寸的新世界(!),以便能够对它们进行比较,将不相关的图像和文本分开,并将匹配的图像和文本放在一起。因此,以下代码将把 2048 和 768 维向量带入 256 (projection_dim) 维世界,我们可以在其中比较它们:
import torch
from torch import nnclass ProjectionHead(nn.Module):def __init__(self,embedding_dim,projection_dim=CFG.projection_dim,dropout=CFG.dropout):super().__init__()self.projection = nn.Linear(embedding_dim, projection_dim)self.gelu = nn.GELU()self.fc = nn.Linear(projection_dim, projection_dim)self.dropout = nn.Dropout(dropout)self.layer_norm = nn.LayerNorm(projection_dim)def forward(self, x):projected = self.projection(x)x = self.gelu(projected)x = self.fc(x)x = self.dropout(x)x = x + projectedx = self.layer_norm(x)return x
“embedding_dim”是输入向量的大小(图像为 2048,文本为 768),“projection_dim”是输出向量的大小,在我们的例子中为 256。要了解这部分的详细信息,您可以参考CLIP 论文。
CLIP模型
这部分是最有趣的!这里我还要讲一下损失函数。我将Keras 代码示例中的一些代码翻译成 PyTorch 来编写这部分。查看代码,然后阅读该代码块下面的说明。
import torch
from torch import nn
import torch.nn.functional as Fimport config as CFG
from modules import ImageEncoder, TextEncoder, ProjectionHeadclass CLIPModel(nn.Module):def __init__(self,temperature=CFG.temperature,image_embedding=CFG.image_embedding,text_embedding=CFG.text_embedding,):super().__init__()self.image_encoder = ImageEncoder()self.text_encoder = TextEncoder()self.image_projection = ProjectionHead(embedding_dim=image_embedding)self.text_projection = ProjectionHead(embedding_dim=text_embedding)self.temperature = temperaturedef forward(self, batch):# Getting Image and Text Featuresimage_features = self.image_encoder(batch["image"])text_features = self.text_encoder(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])# Getting Image and Text Embeddings (with same dimension)image_embeddings = self.image_projection(image_features)text_embeddings = self.text_projection(text_features)# Calculating the Losslogits = (text_embeddings @ image_embeddings.T) / self.temperatureimages_similarity = image_embeddings @ image_embeddings.Ttexts_similarity = text_embeddings @ text_embeddings.Ttargets = F.softmax((images_similarity + texts_similarity) / 2 * self.temperature, dim=-1)texts_loss = cross_entropy(logits, targets, reduction='none')images_loss = cross_entropy(logits.T, targets.T, reduction='none')loss = (images_loss + texts_loss) / 2.0 # shape: (batch_size)return loss.mean()def cross_entropy(preds, targets, reduction='none'):log_softmax = nn.LogSoftmax(dim=-1)loss = (-targets * log_softmax(preds)).sum(1)if reduction == "none":return losselif reduction == "mean":return loss.mean()
在这里,我们将使用之前构建的模块来实现主模型。init 函数是不言自明的。在前向函数中,我们首先将图像和文本分别编码为固定大小的向量(具有不同的维度)。之后,使用单独的投影模块,我们将它们投影到我之前谈到的共享世界(空间)。这里的编码将变得相似的形状(在我们的例子中是 256)。之后我们将计算损失。我再次建议阅读 CLIP 论文以使其更好,但我会尽力解释这部分。
在线性代数中,衡量两个向量是否具有相似特征(它们彼此相似)的一种常见方法是计算它们的点积(将匹配项相乘并取它们的总和);如果最终的数字很大,那么它们是相似的,如果最后的数字很小,那么它们就不相似(相对而言)!
好的!我刚才所说的是理解这个损失函数需要牢记的最重要的事情。我们继续吧。我们讨论了两个向量,但是,我们这里有什么?我们有 image_embeddings,形状为 (batch_size, 256) 的矩阵和形状为 (batch_size, 256) 的 text_embeddings。够简单的!这意味着我们有两组向量而不是两个单个向量。我们如何测量两组向量(两个矩阵)彼此的相似程度?同样,使用点积(在这种情况下,PyTorch 中的 @ 运算符执行点积或矩阵乘法)。为了能够将这两个矩阵相乘,我们转置第二个矩阵。好的,我们得到一个形状为 (batch_size, batch_size) 的矩阵,我们将其称为logits。(在我们的例子中,温度等于 1.0,因此,它没有什么区别。您可以使用它,看看它会产生什么差异。另请参阅论文,了解它为什么在这里!)。
我希望你还在我身边!如果不是也没关系,只需检查代码并检查它们的形状即可。现在我们有了逻辑,我们需要目标。我需要说的是,有一种更直接的方法来获取目标,但我必须为我们的案例这样做(我将在下一段中讨论原因)。
让我们考虑一下我们希望这个模型学习什么:我们希望它学习给定图像和描述它的标题的“相似表示(向量)”。这意味着我们要么给它一个图像,要么给它描述它的文本,我们希望它为两者生成相同的 256 大小的向量。
因此,在最好的情况下,text_embeddings 和 image_embedding 矩阵应该相同,因为它们描述的是相似的事物。现在我们想一下:如果发生这种情况,logits 矩阵会是什么样子?让我们看一个简单的例子!
import torch
from torch import nn
import torch.nn.functional as F
import matplotlib.pyplot as pltbatch_size = 4
dim = 256
embeddings = torch.randn(batch_size, dim)
out = embeddings @ embeddings.T
print(F.softmax(out, dim=-1))-----------
# tensor([[1., 0., 0., 0.],
# [0., 1., 0., 0.],
# [0., 0., 1., 0.],
# [0., 0., 0., 1.]])
因此,在最好的情况下,logits 将是一个矩阵,如果我们采用其 softmax,对角线中将有 1.0(一个用奇特的词来称呼它的单位矩阵!)。由于损失函数的作用是使模型的预测与目标相似(至少在大多数情况下!),因此我们希望这样的矩阵作为我们的目标。这就是我们在上面的代码块中计算 images_similarity 和 texts_similarity 矩阵的原因。
现在我们已经有了目标矩阵,我们将使用简单的交叉熵来计算实际损失。我已经将交叉熵的完整矩阵形式编写为函数,您可以在代码块的底部看到。好的!我们完了!是不是很简单?!好吧,你可以忽略下一段,但如果你好奇的话,里面有一个重要的注释。
这就是为什么我没有使用更简单的方法:我需要承认在 PyTorch 中有一种更简单的方法来计算这种损失;通过这样做:nn.CrossEntropyLoss()(logits, torch.arange(batch_size))。为什么我这里没有使用它?有两个原因。1- 我们使用的数据集对单个图像有多个标题;因此,批次中可能存在两个具有相似标题的相同图像(这种情况很少见,但可能会发生)。使用这种更简单的方法获取损失将忽略这种可能性,并且模型学会分离实际上相同的两个表示(假设它们不同)。显然,我们不希望这种情况发生,因此我以照顾这些边缘情况的方式计算了整个目标矩阵。2-按照我的方式做,让我更好地理解了这个损失函数中发生的事情;所以,我认为这也会给你更好的直觉!
训练
这是一个训练模型的函数。这里没有发生太多事情;只需加载批次,将它们输入模型并步进优化器和 lr_scheduler。
def train_epoch(model, train_loader, optimizer, lr_scheduler, step):loss_meter = AvgMeter()tqdm_object = tqdm(train_loader, total=len(train_loader))for batch in tqdm_object:batch = {k: v.to(CFG.device) for k, v in batch.items() if k != "caption"}loss = model(batch)optimizer.zero_grad()loss.backward()optimizer.step()if step == "batch":lr_scheduler.step()count = batch["image"].size(0)loss_meter.update(loss.item(), count)tqdm_object.set_postfix(train_loss=loss_meter.avg, lr=get_lr(optimizer))return loss_meter
好的!我们已经完成了模型的训练。现在,我们需要进行推理,在我们的例子中,将给模型一段文本,并希望它从看不见的验证(或测试)集中检索最相关的图像。
获取图像嵌入
在此函数中,我们加载训练后保存的模型,向其提供验证集中的图像,并返回形状为 (valid_set_size, 256) 的 image_embeddings 和模型本身。
def get_image_embeddings(valid_df, model_path):tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)valid_loader = build_loaders(valid_df, tokenizer, mode="valid")model = CLIPModel().to(CFG.device)model.load_state_dict(torch.load(model_path, map_location=CFG.device))model.eval()valid_image_embeddings = []with torch.no_grad():for batch in tqdm(valid_loader):image_features = model.image_encoder(batch["image"].to(CFG.device))image_embeddings = model.image_projection(image_features)valid_image_embeddings.append(image_embeddings)return model, torch.cat(valid_image_embeddings)
寻找匹配项
该函数执行我们希望模型能够完成的最终任务:它获取模型、image_embeddings 和文本查询。它将显示验证集中最相关的图像!是不是很神奇呢?让我们看看它到底表现如何!
def find_matches(model, image_embeddings, query, image_filenames, n=9):tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)encoded_query = tokenizer([query])batch = {key: torch.tensor(values).to(CFG.device)for key, values in encoded_query.items()}with torch.no_grad():text_features = model.text_encoder(input_ids=batch["input_ids"], attention_mask=batch["attention_mask"])text_embeddings = model.text_projection(text_features)image_embeddings_n = F.normalize(image_embeddings, p=2, dim=-1)text_embeddings_n = F.normalize(text_embeddings, p=2, dim=-1)dot_similarity = text_embeddings_n @ image_embeddings_n.T# multiplying by 5 to consider that there are 5 captions for a single image# so in indices, the first 5 indices point to a single image, the second 5 indices# to another one and so on.values, indices = torch.topk(dot_similarity.squeeze(0), n * 5)matches = [image_filenames[idx] for idx in indices[::5]]_, axes = plt.subplots(math.sqrt(n), math.sqrt(n), figsize=(10, 10))for match, ax in zip(matches, axes.flatten()):image = cv2.imread(f"{CFG.image_path}/{match}")image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)ax.imshow(image)ax.axis("off")plt.show()
让我们看一些例子!此时,当我看到输出时,我高兴地尖叫起来,并惊讶于该模型实际上正在学习图像和文本之间的这种关系!这种感觉简直难以置信。
find_matches(model, image_embeddings,query="one dog sitting on the grass",image_filenames=valid_df['image'].values,n=9)
这就是我们使用这个函数的方式。结果如下:

我当时就想:哇!这个模型知道一些东西!当然它并不完美,因为有些图片中有两只狗,但考虑到训练集小和训练时间短,我认为这很棒!
让我们看看其他一些输出。Quert写在每个图像的顶部。

看!它还可以算数!将此与上一个进行比较。该模型知道“两个”的含义,并提供了有两只狗的图像,与之前的查询形成鲜明对比!这一刻我第二次震惊得尖叫起来:)
文章开头的输出:

对于下面的示例,模型犯了一些错误,但总的来说,它显然对文本和图像都有很好的理解。

资源
- 本文对应的Github代码库
本博文译自Moein Shariatnia的博客
相关文章:
使用Pytorch从零开始实现CLIP
生成式建模知识回顾: [1] 生成式建模概述 [2] Transformer I,Transformer II [3] 变分自编码器 [4] 生成对抗网络,高级生成对抗网络 I,高级生成对抗网络 II [5] 自回归模型 [6] 归一化流模型 [7] 基于能量的模型 [8] 扩散模型 I, 扩散模型 II…...

Java网络编程 *TCP与UDP协议*
网络编程 什么是计算机网络? 把分布在不同地理区域的具有独立功能的计算机,通过通信设备与线路连接起来,由功能完善的软件实现资源共享和信息传递的系统 简单来说就是把不同地区的计算机通过设备连接起来,实现不同地区之前的数据传输 网络编程是干什么的? 网络…...

校园外卖小程序源码系统 附带完整的搭建教程
随着大学生消费水平的提高,对于外卖服务的需求也在不断增加。很多学生都面临着课业繁重、时间紧张等问题,无法亲自到餐厅就餐。因此,开发一款适合校园外卖市场的应用软件,将为广大学生提供极大的便利。 以下是部分代码示例&#…...

TiDB专题---1、TiDB简介和特性
什么是TiDB TiDB 是一个分布式 NewSQL 数据库,它支持水平弹性扩展、ACID 事务、标准 SQL、MySQL 语法和 MySQL 协议,具有数据强一致的高可用特性,是一个不仅适合 OLTP 场景还适合 OLAP 场景的混合数据库。 TiDB 是 PingCAP 公司自主设计、研发…...

如何二次封装一个Vue3组件库?
为什么要二次封装组件库 目前开源的Vue3组件库有很多,包括Element Plus、Ant Design Vue、Naive UI、Vuetify、Varlet等等。 在大部分场景中,我们直接使用现有组件库中的组件即可实现功能。如果遇到部分组件的特殊配置或者特殊逻辑,或者当前…...
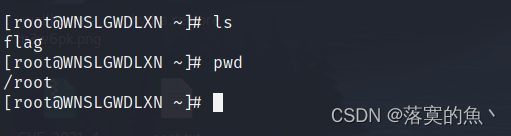
2024年网络安全比赛--系统渗透测试(超详细)
一、竞赛时间 180分钟 共计3小时 二、竞赛阶段 竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 1.在渗透机中对服务器主机进行信息收集,将服务器开启的端口号作为 Flag 值提交; 2.在渗透机中对服务器主机进行渗透,在服务器主机中获取服务器主机名称ÿ…...

高效的单行python脚本
#-- coding: utf-8 -- “”" Created on Wed Dec 6 13:42:00 2023 author: czliu “”" 1. 平方列表推导 #使用列表推导法计算从 1 到 10 的数字平方 squares [x**2 for x in range(1, 11)] print(squares)2.求偶数 #可以使用列表推导式从列表中筛选偶数。还可以…...
如何通过内网穿透实现无公网IP也能远程访问内网的宝塔面板
文章目录 一、使用官网一键安装命令安装宝塔二、简单配置宝塔,内网穿透三、使用固定公网地址访问宝塔 宝塔面板作为建站运维工具,适合新手,简单好用。当我们在家里/公司搭建了宝塔,没有公网IP,但是想要在外也可以访问内…...

【广州华锐互动】VR沉浸式体验铝厂安全事故让伤害教育更加深刻
随着科技的不断发展,虚拟现实(VR)技术已经逐渐渗透到各个领域,为我们的生活带来了前所未有的便捷和体验。在安全生产领域,VR技术的应用也日益受到重视。 VR公司广州华锐互动就开发了多款VR安全事故体验系统,…...

CFLAGS、CXXFLAGS、FFLAGS、FCFLAGS、LDFLAGS、LD_LIBRARY_PATH区别
这些环境变量在编译和链接过程中扮演着重要的角色。下面是对每个环境变量的详细说明及示例: CFLAGS:用于设置C编译器的编译选项。 示例:将优化级别设置为最高,启用所有警告信息,并指定目标体系结构为x86-64。 export C…...
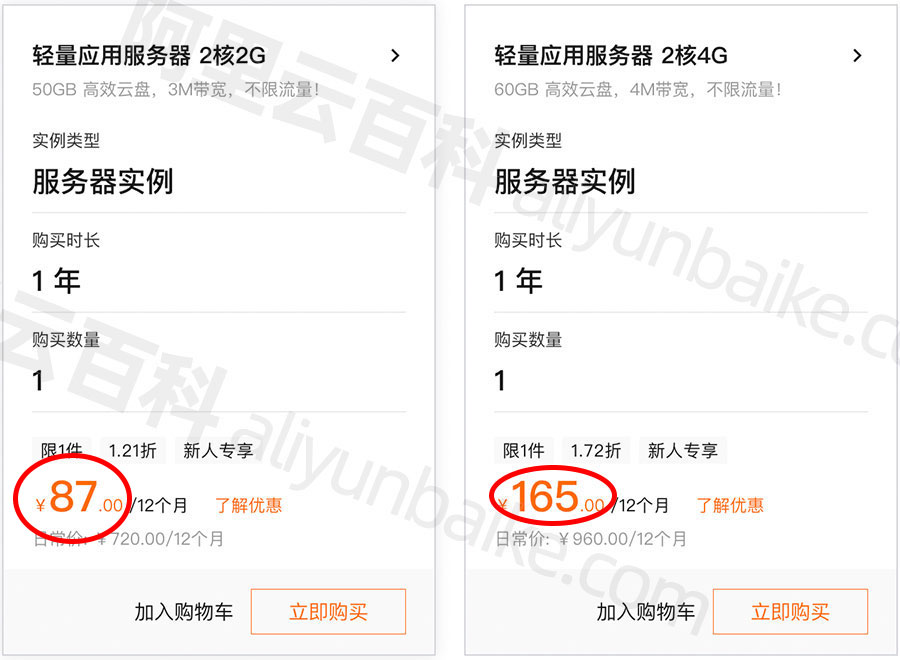
阿里云租赁费用_阿里云服务器多配置报价表
阿里云服务器租用费用,云服务器ECS经济型e实例2核2G、3M固定带宽99元一年、轻量应用服务器2核2G3M带宽轻量服务器一年87元,2核4G4M带宽轻量服务器一年165元12个月,ECS云服务器e系列2核2G配置99元一年、2核4G配置365元一年、2核8G配置522元一年…...
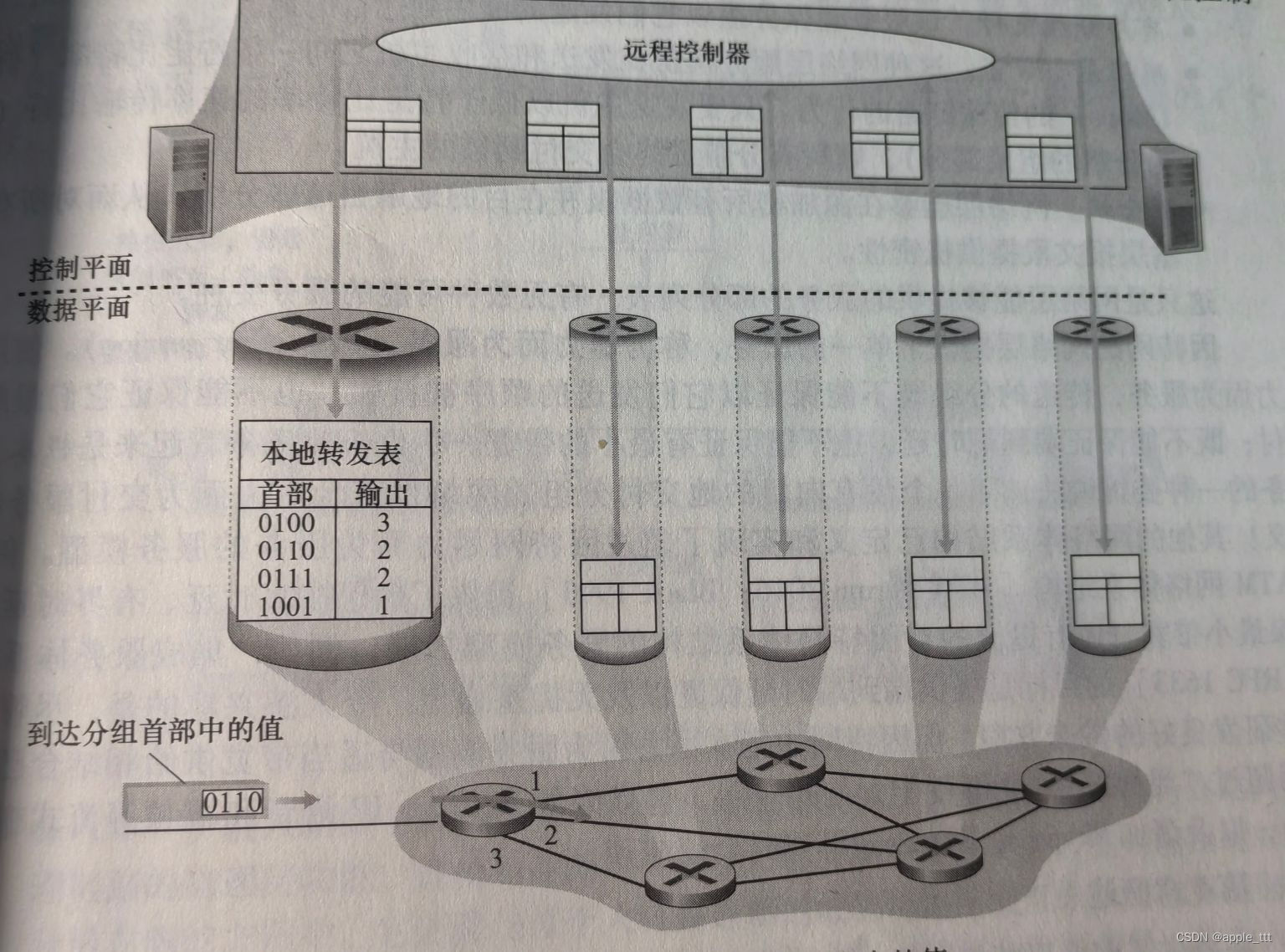
网络层(1)——概述
一、概述 网络层毫无疑问是最复杂的一层,涉及到大量的协议与结构的内容。在如今主流的设计中,大家都会把网络层分成两个部分:数据平面、控制平面。其中数据平面指的是网络层中每台路由器的功能,它决定了到达路由器端口输入链路之一…...

计算机网络——网络层
目录 一、网络层的作用 二、网络层的协议 (一)ARP地址解析协议 (二)ICMP国际控制报文协议 (三)IGMP网际组织管理协议 三、ip地址 (一)ip地址的概念 (二ÿ…...

Antd search input无中框
发现input.search, 搜索图标的左侧有个竖线,不是很好看 把它改掉, 新建一个自己的CSS .custom-search-input{.ant-input-affix-wrapper{border-right: none !important;}.ant-input-group-addon{.ant-btn{border-left: none !important;}}}应用 <S…...

【PyTorch】概述
文章目录 1. PyTorch是什么?2. PyTorch的特点3. PyTorch的架构 1. PyTorch是什么? PyTorch是一个深度学习框架,由Facebook于2016年开源发布。PyTorch是基于Torch框架的Python接口,旨在提供易用的强大工具来进行神经网络的构建和训…...

非对象集合交、并、差处理
对于集合取交集、并集的处理其实有很多种方式,这里就介绍3种 第一种 是CollectionUtils工具类 第二种 是List自带方法 第三种 是JDK1.8 stream 新特性 1、CollectionUtils工具类 下面对于基本数据(包扩String)类型中的集合进行demo示例。 public static void main(String[]…...

时间序列预测实战(二十五)PyTorch实现Seq2Seq进行多元和单元预测(附代码+数据集+完整解析)
一、本文介绍 本文给大家带来的时间序列模型是Seq2Seq,这个概念相信大家都不陌生了,网上的讲解已经满天飞了,但是本文给大家带来的是我在Seq2Seq思想上开发的一个模型和新的架构,架构前面的文章已经说过很多次了,其是…...

电子学会C/C++编程等级考试2022年09月(三级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:课程冲突 小 A 修了 n 门课程, 第 i 门课程是从第 ai 天一直上到第 bi 天。 定义两门课程的冲突程度为 : 有几天是这两门课程都要上的。 例如 a1=1,b1=3,a2=2,b2=4 时, 这两门课的冲突程度为 2。 现在你需要求的是这 n 门课…...

【数据库】基于时间戳的并发访问控制,乐观模式,时间戳替代形式及存在的问题,与封锁模式的对比
使用时间戳的并发控制 专栏内容: 手写数据库toadb 本专栏主要介绍如何从零开发,开发的步骤,以及开发过程中的涉及的原理,遇到的问题等,让大家能跟上并且可以一起开发,让每个需要的人成为参与者。 本专栏会…...
Python 日志(略讲)
日志操作 日志输出: # 输出日志信息 logging.debug("调试级别日志") logging.info("信息级别日志") logging.warning("警告级别日志") logging.error("错误级别日志") logging.critical("严重级别日志")级别设置…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...
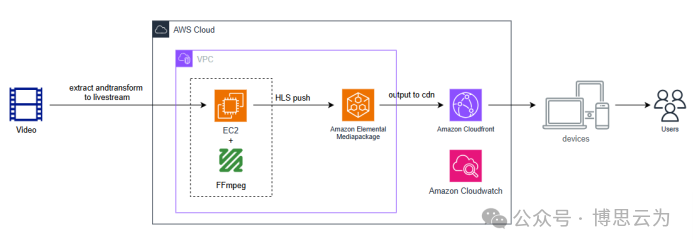
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...
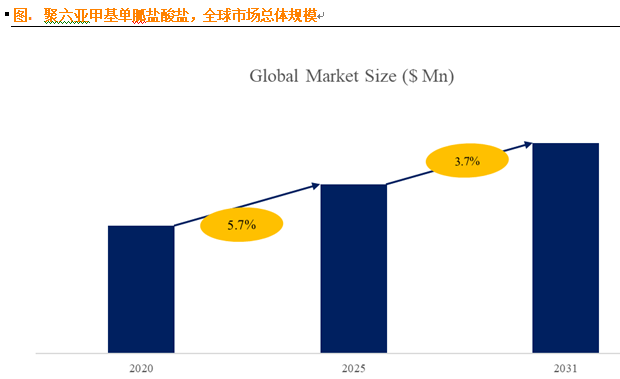
聚六亚甲基单胍盐酸盐市场深度解析:现状、挑战与机遇
根据 QYResearch 发布的市场报告显示,全球市场规模预计在 2031 年达到 9848 万美元,2025 - 2031 年期间年复合增长率(CAGR)为 3.7%。在竞争格局上,市场集中度较高,2024 年全球前十强厂商占据约 74.0% 的市场…...