最新版本——Hadoop3.3.6单机版完全部署指南

大家好,我是独孤风,大数据流动的作者。
本文基于最新的 Hadoop 3.3.6 的版本编写,带大家通过单机版充分了解 Apache Hadoop 的使用。本文更强调实践,实践是大数据学习的重要环节,也能在实践中对该技术有更深的理解,所以一些理论知识建议大家多阅读相关的书籍(都在资料包中)。
本文档版权归大数据流动所有,请勿商用,全套大数据、数据治理、人工智能相关学习资料,请关注大数据流动。
(本文所使用资料包位置: 大数据流动 VIP 知识库 》大数据技术 》Apache Hadoop 3.3.6 单机安装包)
一、Hadoop 概述
Apache Hadoop 是一个开源框架,用于存储和处理大规模数据集。它是用 Java 编写的,并支持分布式处理。Hadoop 的关键特点包括:
分布式存储:通过 Hadoop 分布式文件系统(HDFS),它可以跨多个节点存储大量数据,提供高可靠性和数据冗余。
分布式计算:Hadoop 使用 MapReduce 编程模型来并行处理大数据,这样可以有效地处理和分析存储在 HDFS 中的大规模数据集。
可扩展性:Hadoop 能够通过添加更多节点来轻松扩展,处理更大量的数据。
容错性:Hadoop 设计中考虑到了故障的可能性,能够在节点故障时继续运行,确保数据不丢失。
5. 生态系统:Hadoop 的生态系统包括各种工具和扩展(如 Hive、HBase、Spark 等),用于数据处理、分析和管理。
Hadoop 广泛应用于大数据分析、数据挖掘、日志处理等领域,特别是在需要处理 PB 级别数据的场景中非常有效。
所以我们可以理解为 Hadoop 是一个生态,有了 Hadoop 为基础,后续的 Spark,Flink 等组件才相继出现,让大数据技术持续的发展。
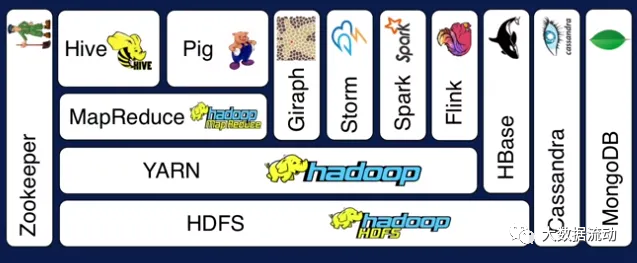
而从软件角度,Hadoop 本身自己是一个 Apache 的开源软件。

Apache Hadoop 主要由以下几个核心组件组成,每个组件都有其独特的功能:
1. Hadoop Common:这是 Hadoop 的基础库集合,提供了 Hadoop 模块所需要的通用工具和接口。它包括文件系统、操作系统级别的抽象,以及必要的 Java 库文件。
Hadoop MapReduce (MR):这是一个编程模型,用于处理大规模数据集的分布式计算。MapReduce 将作业分成两个阶段:Map(处理)和 Reduce(汇总)。这种方法使得并行处理大数据变得简单有效。
Hadoop YARN (Yet Another Resource Negotiator):YARN 是 Hadoop 的资源管理和任务调度器。它将计算资源管理和作业调度功能从 MapReduce 中分离出来,提高了 Hadoop 的灵活性和可扩展性。
Hadoop Distributed File System (HDFS):HDFS 是一个高度容错的分布式文件系统,设计用来存储大量数据。它可以在廉价的硬件上运行,提供高吞吐量以访问应用程序数据,并适用于具有大数据集的应用程序。
这些组件协同工作,使 Hadoop 成为一个强大的工具,用于存储、处理和分析大规模的数据集。

而 Common 是基础库,MapReduce 由于性能问题,分布式计算已经被更高效的 Spark,Flink 等计算引擎替代。
但是HDFS,YARN依然是最核心的两个组件,一定要认真学习,我也会单独发文章来学习这两个组件。




二、Hadoop 历史
当然,以下是用 Markdown 格式概述 Apache Hadoop 的历史:
2005 年 - 起源由 Doug Cutting 和 Mike Cafarella 创立,受 Google 的 MapReduce 和 GFS 论文启发。
(Google 三篇理论中文版资料位置: 大数据流动 VIP 知识库 》大数据技术 》Google 三家马车)
2006 年 - 加入Apache成为 Apache 软件基金会的一部分,最初是 Lucene 项目的一部分,后来在 2008 年成为顶级项目。
2008 年及以后 - 发展与普及快速获得关注,生态系统不断发展,增加了如 HBase、Hive 等工具。
2011 年 - Hadoop 1.0 发布标志着 Hadoop 的成熟,稳定 API 和核心组件,包括 HDFS 和 MapReduce。
2013 年 - Hadoop 2.0 和YARN的推出引入 YARN,将 Hadoop 从以 MapReduce 为中心的平台转变为更加多功能的数据处理平台。
持续演进 - Hadoop 不断更新,扩展其功能和生态系统,包括 Spark、Kafka、Flink 等工具。
云集成 - 近年来,与云服务集成,提供更灵活、可扩展的数据处理解决方案。
Hadoop 也不光只有 Apache Hadoop,很多公司都有自己的发行版本,不同的发行版针对不同的用途和场景进行了优化,用户可以根据自己的需求选择最适合的版本。随着时间的推移,这些发行版可能会有所变化,包括新的版本推出或旧版本停止维护。
除了 Apache Hadoop,还有 Cloudera 的 CDH(Cloudera Distribution Including Apache Hadoop)、Hortonworks Data Platform (HDP),也就是 CDH 和 Ambari,我也会在其他文章演示,本文我们带来 Apache Hadoop 的单机版本演示,Apache Hadoop 也是被使用最多的版本。
三、Hadoop 3.3.6 单机安装
下面我们进行 Hadoop3.3.6 的单机版安装。
1、版本情况与安装包准备
Apache Hadoop 的官网地址是 https://hadoop.apache.org/
我们在这里可以看到,最新的版本是 3.3.6,这也是 2023 年新发布的版本,各方面都做了很大的优化,本文也基于此版本进行演示。
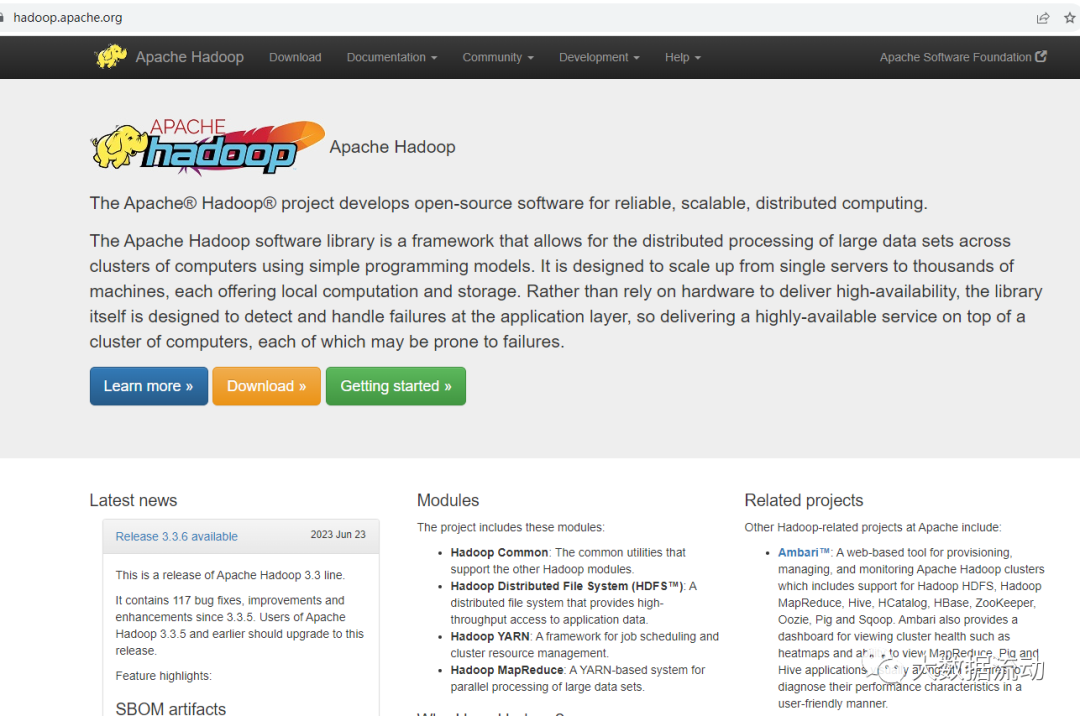
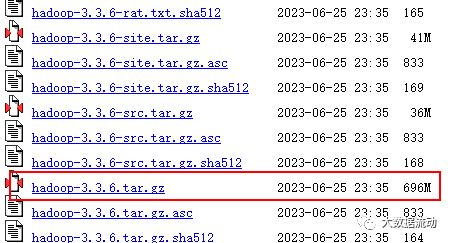
我们使用的 Hadoop 版本是 3.3.6,可以在官方网站进行下载:
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/
696MB 这个。
2、服务器环境准备
不管是服务器和虚拟机环境的准备,大家都可以参考我之前的文章,在本地搭一个虚拟机,也可以去买一个现成的,这里不做赘述。
我们使用的 CentOS 版本是 7.8,可以通过下面的命令来查看版本。
cat /etc/redhat-release

CentOS7 的安装步骤基本一致,都可以参考本文档。
服务器需要做一下免密登陆设置,不然后面会有问题
ssh-keygen -t rsa -P ""回车即可,随后复制密钥
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys可以验证一下
ssh bigdataflowing正常会直接登录过去。
3、JDK 安装
先卸载系统自带的 java
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
上传安装包到服务器,安装包可在 Oracle 官网下载:https://www.oracle.com/java/technologies/downloads/
也可以用我的资料包里的。
jdk-8u221-linux-x64.tar.gz
建立文件夹。
mkdir /opt/jdk/
进入该文件夹,上传文件。
cd /opt/jdk/
解压安装包 tar -zxvf jdk-8u221-linux-x64.tar.gz
没有报错证明解压成功。
随后我们把 JDK 配置到环境变量里就可以了。
vi /etc/profile
在最下面加入这两句,其实就是我们刚刚解压 jdk 的位置。
export JAVA_HOME=/opt/jdk/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
最后让环境变量生效
source /etc/profile
查看 java 版本验证一下,java -version 成功!

这样我们这台机器就有 java 环境可用了。
4、Hadoop3.3.6 安装
有了 java 环境,hadoop 的依赖问题就解决了,可以直接进行安装。
将之前准备好的 hadoop 安装包,上传到 /opt/hadoop3.3.6 目录下
解压,tar -zxvf hadoop-3.3.6.tar.gz 没报错就是成功。
还是增加环境变量
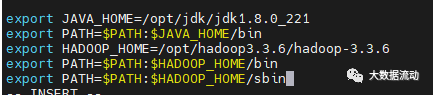
vi /etc/profile
在最下面加入这三句,hadoop 的位置
export HADOOP_HOME=/opt/hadoop3.3.6/hadoop-3.3. 6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
最后让环境变量生效
source /etc/profile
查看 java 版本验证一下,hadoop-version 成功!
使用 hadoop version 命令验证安装成功

5、配置
虽然安装成功,但是我们要使用的是单机伪集群,还需要进行一些配置。
hadoop 的目录有如下的文件夹
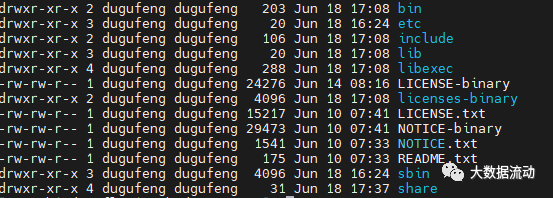
bin 目录:Hadoop 主服务脚本
etc 目录:Hadoop 的配置文件目录
lib 目录:存放 Hadoop 的本地库
sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
首先进入 etc 配置文件夹 cd ``etc/hadoop 有如下配置,我们只修改核心的就可以。
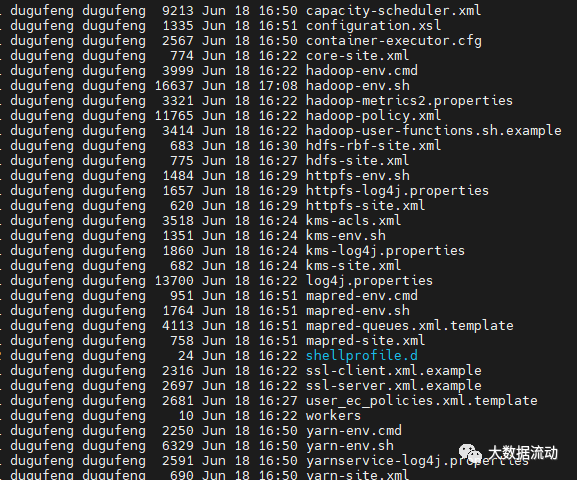
首先修改 hadoop-env.sh 将 java 和 hadoop 的根路径加入
export JAVA_HOME=/opt/jdk/jdk1.8.0_221
export HADOOP_HOME=/opt/hadoop3.3.6/hadoop-3.3.6
同时加入 root 权限
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root修改 core-site.xml
在 configuration 标签中,添加如下内容:
<property><name>fs.defaultFS</name><value>hdfs://bigdataflowing:9090</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/hadoop3.3.6/hdfs/tmp</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>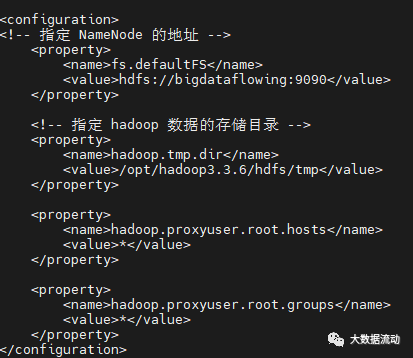
修改 hdfs-site.xml,在 configuration 标签中,添加如下内容:
<property><name>dfs.replication</name> <value>1</value></property> <property><name>dfs.namenode.name.dir</name> <value>/opt/hadoop3.3.6/hdfs/name</value> <final>true</final></property> <property><name>dfs.datanode.data.dir</name> <value>/opt/hadoop3.3.6/hdfs/data</value> <final>true</final></property> <property><name>dfs.http.address</name><value>0.0.0.0:50070</value></property><property><name>dfs.permissions</name> <value>false</value></property>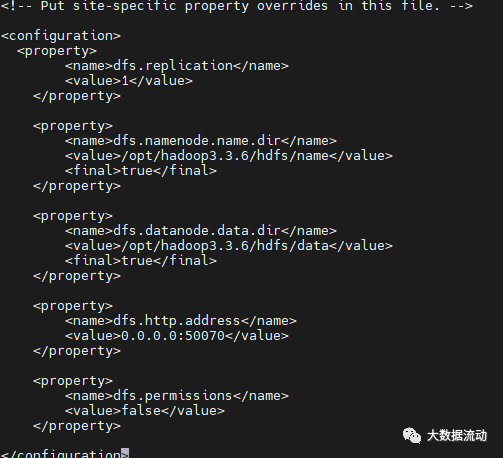
修改 mapre-site.xml,在 configuration 标签中,添加如下内容:
<property><name>mapreduce.framework.name</name><value>yarn</value></property>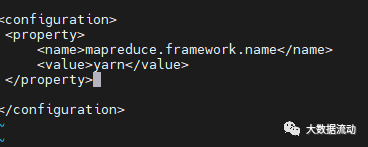
修改 yarn-site.xml,在 configuration 标签中,添加如下内容:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>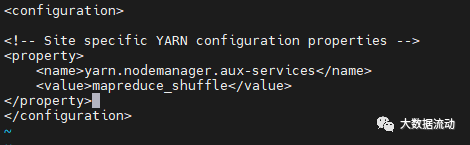
6、启动
首先格式化 HDFS,也就是对 hdfs 做最基本的配置:
hdfs namenode -format
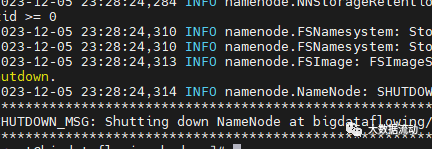
格式化完成。
随后我们进入 sbin 目录
cd /opt/hadoop3.3.6/hadoop-3.3.6/sbin/
这里脚本较多,我们可以选择启动全部
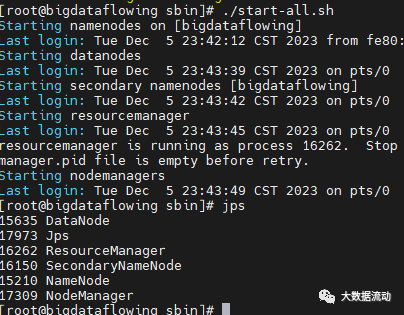
./start-all.sh
正常不会有报错,同时使用 jps 命令查看,会有 Datanode,ResourceManager,SecondaryNameNode,NameNode,NodeManager 五个进程。
另一个验证启动成功的方法,是访问 Hadoop 管理页面
http://IP:50070/
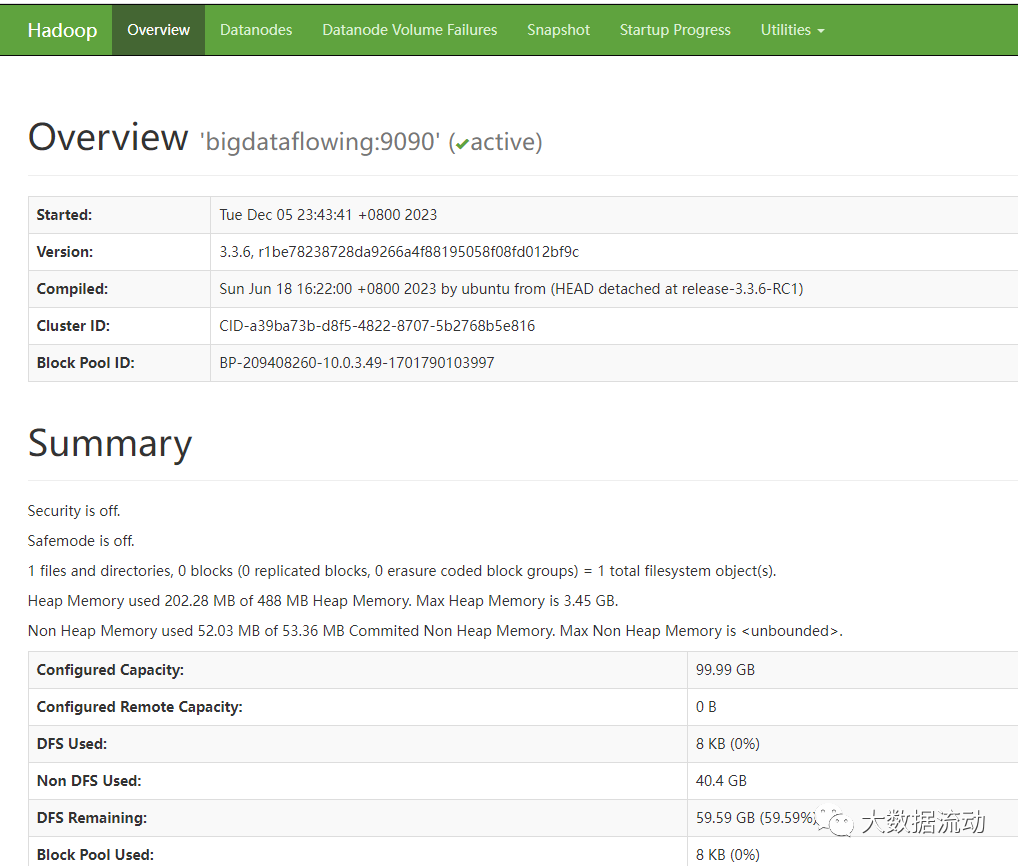
http://IP:8088/
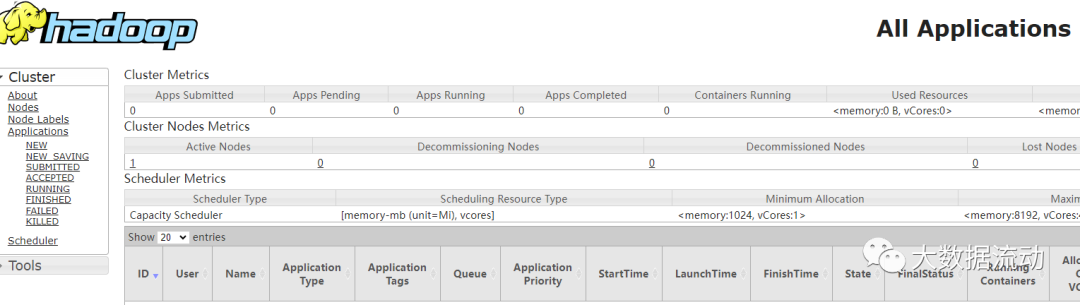
这些页面的使用,我们会在后续 Hdfs,Yarn 等章节再详细讲解。
7、报错汇总
启动报错,未设置 root 用户
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [bigdataflowing]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation。启动报错,为进行免密登陆设置
localhost: Permission denied (publickey,password更多【大数据、数据治理、人工智能知识分享】【开源项目推荐】【学习社群加入】,请关注大数据流动。
相关文章:
最新版本——Hadoop3.3.6单机版完全部署指南
大家好,我是独孤风,大数据流动的作者。 本文基于最新的 Hadoop 3.3.6 的版本编写,带大家通过单机版充分了解 Apache Hadoop 的使用。本文更强调实践,实践是大数据学习的重要环节,也能在实践中对该技术有更深的理解&…...

理解自我效能感:你的内在动力来源
1. 自我效能感:开启个人潜能的心理动力 想象一下,面对生活的挑战和机遇时,是什么内在力量驱使你去采取行动,或者让你犹豫不决?这种力量,与我们的心理状态紧密相关,其中一个关键因素就是我们的自…...
Java第二十一章
一.网络程序设计基础 1.网络协议 网络协议规定了计算机之间连接的物理、机械(网线与网卡的连接规定)、电气(有效的电平范围)等特征,计算机之间的相互寻址规则,数据发送冲突的解决方式,长数据如何分段传送与接收等内容.就像不同的国家有不同的…...

Redis交互速度慢,CPU占用100%,集群方案,报错等问题
Redis交互速度很慢,达到几十到一百毫秒一次 问题描述: 执行top命令发现redis占用达到100% redis交互速度慢,一次要几十到一百毫秒一次 解决思路 查看redis数据量,比如我这里达到了30万 经过本地测试,redis交互的速…...

wpf 系统在显示器分辨率和缩放设置为非1920*1080和100%时,SelectionChanged事件响应问题分析?
系统在显示器分辨率和缩放设置为1920*1080和100%时,窗口四分格能正常响应SelectionChanged事件,但是当缩放为125%时,或是分辨率大于1920*1080时四分格其中一个格子的下侧和右侧点击不响应,什么原因? 描述的问题可能由以…...

刷题记录--算法--简单
第一题 2582. 递枕头 已解答 简单 相关标签 相关企业 提示 n 个人站成一排,按从 1 到 n 编号。 最初,排在队首的第一个人拿着一个枕头。每秒钟,拿着枕头的人会将枕头传递给队伍中的下一个人。一旦枕头到达队首或队尾,传递…...
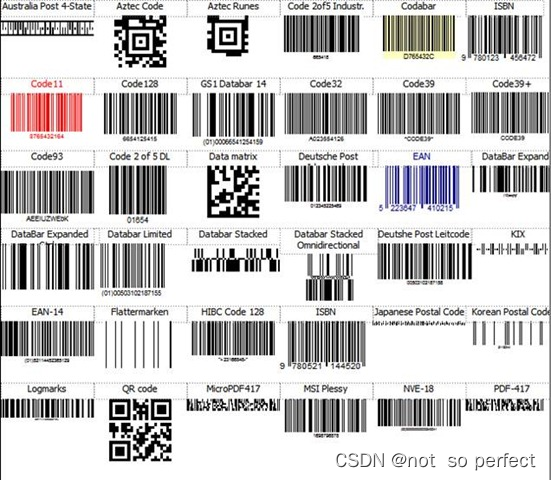
条码生成器与Zint使用
文章目录 目的条形码zint支持条形码种类下载编译qt pro配置code保存条形码目的 1: 了解条形码数据理论知识 2: 了解zint第三方库相关, 如何编译引用到项目中 条形码 条形码(Barcode)一维码 和二维码(QR code)都是用于存储信息的图形化表示方式,通常应用于商品标识、库…...
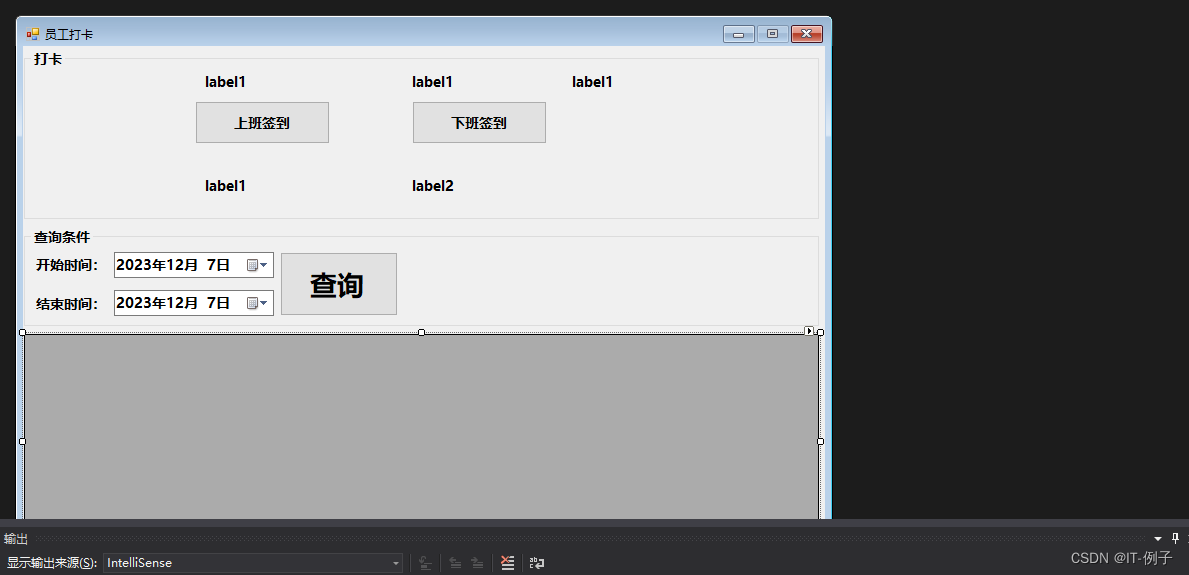
C#winform上下班打卡系统Demo
C# winform上下班打卡系统Demo 系统效果如图所示 7个label控件(lblUsername、lblLoggedInEmployeeId、lab_IP、lblCheckOutTime、lblCheckInTime、lab_starttime、lab_endtime)、3个按钮、1个dataGridView控件、2个groupBox控件 C#代码实现 using System; using System.Dat…...

P1 Qt的认识及环境配置
目录 前言 01 下载Qt Creator windows下载安装包拷贝到Linux Linux直接下载 02 Linux 安装Qt 前言 🎬 个人主页:ChenPi 🐻推荐专栏1: 《C_ChenPi的博客-CSDN博客》✨✨✨ 🔥 推荐专栏2: 《Linux C应用编程(概念类…...

单元测试Nunit的几种断言
Nunit提供了一些辅助函数用于确定好某个被测试函数是否正常工作。通常把这些函数称为断言 断言是单元测试最基本的组成部分。因此,NUnit程序库以Assert类的静态方法的形式提供了不同形式的多种断言 1. Assert.AreEqual:比较两个值是否相等。用于比较数…...

前端中的响应式布局与各个端适配
什么是响应式布局? 响应式布局指的是同一页面在不同屏幕尺寸下有不同的布局。在移动互联网高度发达的今天,我们在桌面浏览器上开发的网页已经无法满足在移动设备上查看的需求。传统的开发方式是PC端开发一套页面,手机端再开发一套页面。但是…...
2023年5个自动化EDA库推荐
EDA或探索性数据分析是一项耗时的工作,但是由于EDA是不可避免的,所以Python出现了很多自动化库来减少执行分析所需的时间。EDA的主要目标不是制作花哨的图形或创建彩色的图形,而是获得对数据集的理解,并获得对变量之间的分布和相关…...

7-1 查找书籍
给定n本书的名称和定价,本题要求编写程序,查找并输出其中定价最高和最低的书的名称和定价。 输入格式: 输入第一行给出正整数n(<10),随后给出n本书的信息。每本书在一行中给出书名,即长度不超过30的字…...

【无线网络技术】——无线广域网(学习笔记)
📖 前言:无线广域网(WWAN)是指覆盖全国或全球范围内的无线网络,提供更大范围内的无线接入,与无线个域网、无线局域网和无线城域网相比,它更加强调的是快速移动性。典型的无线广域网:蜂窝移动通信系统和卫星…...

【java+vue+微信小程序项目】从零开始搭建——健身房管理平台(2)后端跨域、登录模块、springboot分层架构、IDEA修改快捷键、vue代码风格
项目笔记为项目总结笔记,若有错误欢迎指出哟~ 【项目专栏】 【java+vue+微信小程序项目】从零开始搭建——健身房管理平台(1)spring boot项目搭建、vue项目搭建、微信小程序项目搭建 【java+vue+微信小程序项目】从零开始搭建——健身房管理平台(2)后端跨域、登录模块、sp…...

NGINX相关配置
全局配置 NGINX配置信息 nginx 官方帮助文档:http://nginx.org/en/docs/Nginx的配置文件的组成部分: 主配置文件:/conf/nginx.conf(/nginx/conf/nginx.conf) 子配置文件: include conf.d/*.conf#事件驱动相关的配置 同步 event { worker_…...
如何将idea中导入的文件夹中的项目识别为maven项目
问题描述 大家经常遇到导入某个文件夹的时候,需要将某个子文件夹识别为maven项目 解决方案...

CleanMyMac4.16中文最新版本下载
当很多人还在为电脑运行缓慢、工作问题不能快速得到解决而烦恼的时候,我已经使用过了多款系统清理工具,并找到了最适合我的那一款。我的电脑是超耐用的Mac book,接下来给大家介绍三种在众多苹果电脑清理软件的排名较高的软件。 一、Maintena…...

谷歌正式发布最强 AI 模型 Gemini
2023年12月6日,谷歌公司宣布推出其被认为是规模最大、功能最强大的人工智能模型 Gemini。 Gemini将分为三个不同的套件:Gemini Ultra、Gemini Pro和Gemini Nano。 Gemini Ultra被认为具备最强大的能力,Gemini Pro则可扩展至多任务&#x…...
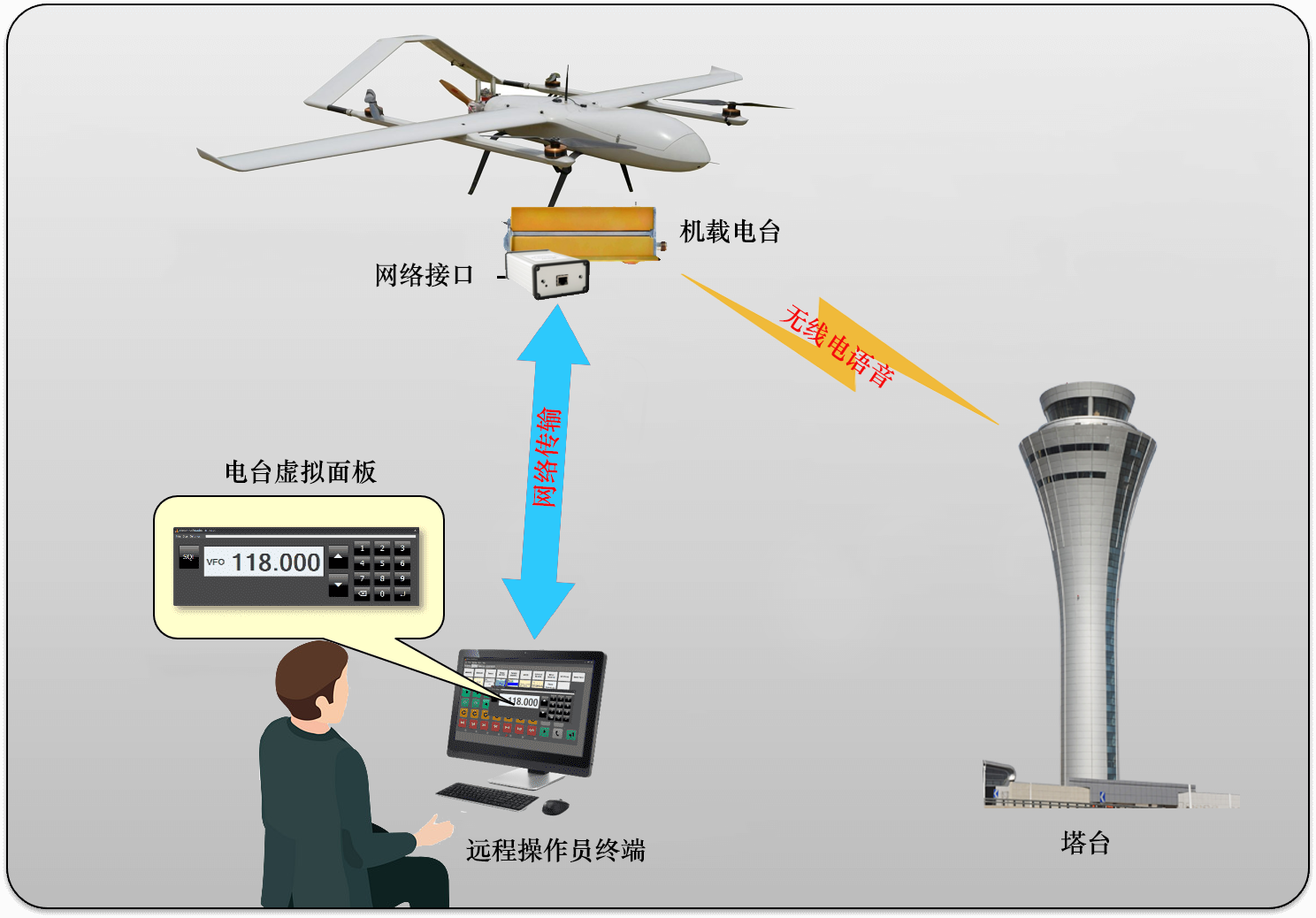
无人机语音中继电台 U-ATC118
简介 甚高频无线电中继通讯系统使用经过适航认证的机载电台连接数字网络传输模块,通过网络远程控制无缝实现无人机操作员与塔台直接语音通话。无人机操作员可以从地面控制站远程操作机载电台进行频率切换、静噪开关、PTT按钮,电台虚拟面板与真实面板布局…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...