手撕八大排序(下)
目录
交换排序
冒泡排序:
快速排序
Hoare法
挖坑法
前后指针法【了解即可】
优化
再次优化(插入排序)
迭代法
其他排序
归并排序
计数排序
排序总结
结束了上半章四个较为简单的排序,接下来的难度将会大幅度上升,那么就开始本章的排序吧!
交换排序
基本思想:所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
冒泡排序:
冒泡排序是相对来说是最简单的排序,我们从c语言开始就接触过了冒泡排序,其主要思想如下:
- 它的基本思想是对所有相邻记录的关键字值进行比效,如果是逆顺(a[j]>a[j+1]),则将其交换,最终达到有序化。
具体的就不多说了,直接跳过;
代码如下:
/*** 冒泡排序*/public static void bubbleSort1(int[] array) {for (int i = 0; i < array.length; i++) {for (int j = 0; j < array.length; j++) {if (array[j] > array[j+1]) {swap(array,j,j+1);}}}}//优化public static void bubbleSort(int[] array) {for (int i = 0; i < array.length - 1; i++) {boolean flg = false;for (int j = 0; j < array.length - 1; j++) {if (array[j] > array[j+1]) {swap(array,j,j+1);flg = true;}}if ( !flg) {return;}}}【冒泡排序的特性总结】
- 冒泡排序是一种非常容易理解的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
而接下来要介绍的就是交换排序的大哥:快速排序
快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法。
无论是什么版本的快排,都是遵循一个原则:选 key划分,选取一个 key ,使 key 左边的值小于等于 key ,右边的值大于 key ,这是快排的核心思想。
Hoare提出的快排又叫做Hoare法。
Hoare法
其基本思想为:
任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
步骤如下:
- 选取最左边的值为 key,比较时右边先走
- 因选的是左边,所以右边会先走(向左走),当右边在走的过程中遇到小于等于 key 的值时停下
- 右边走完后,换左边走(向右走),当遇到大于 key 的值时停止
- 此时交换左右两处的值
- 当左遇到右时(必定相遇,因为一次走一步),终止循环
- 执行最后一步,交换此时左(右)与 key 值,此时就完成了需求:右边值 <= key < 左边值
这时单次排序;
为了方便动图演示,我就直接抄一个动图:

单次循环结束后,我们将整个区域分为了【begin,key - 1】 和 【key + 1, end】两个区域,将其中的两块区域传入函数,继续执行递归,当所有数据都排序完成后,快排就结束了
具体代码如下:
public static void quickSort(int[] array) {quick(array,0,array.length - 1);} public static void quick(int[] array,int start, int end) {if(start >= end) { // 为什么要大于end?如果是有序的情况,== 就会失效return;}int pivot = partition(array,start,end);quick(array,0,pivot - 1);quick(array,pivot+1,end);}private static int partition(int[] array,int left,int right) {int tmp = array[left];int i = left;while (left < right) { // 一趟排序while (left< right && array[right] >= tmp) {right--;}while (left< right && array[left] <= tmp) {left++;}swap(array,left,right);}swap(array,left,i);return left;}挖坑法
基本思想:
Hoare法的另一种思想,不过挖坑法为了便于理解,引入了坑位这个概念,简单来说就是先在 key 处挖坑,然后右边先走(假设 key 在最左边),找到小于等于 key 的值,就将此值放入到坑中,并在这里形成新坑;然后是左边走,同样的,找到值 -> 填入坑 -> 挖新坑,如此重复,直到左右相遇,此时的相遇点必然是一个未填充的坑,当然这个坑就是给 key 值准备的。
动图演示:

代码如下:
private static int partition2(int[] array,int left,int right) {int temp = array[left];while (left < right) { // 一趟排序while (left < right && array[right] >= temp) {right--;}array[left] =array[right];while (left < right && array[left] <= temp) {left++;}array[right] =array[left];}array[left] = temp;return left;}private static void swap(int[] array,int i,int j) {int tmp = array[i];array[i] = array[j];array[j] = tmp;}前后指针法【了解即可】
基本思想:
前后指针法不同于之前的两种思想,但是其核心依旧是利用 key ,找一个基准,创建两个指针,一个prev 指向 key 下标,一个cur指向 key 的下一个位置;
判断 cur 处的值是否小于等于 key 值,如果是,则先 ++prev 后再交换 prev 与 cur 处的值,如此循环,直到 cur 移动至数据尾,最后一次交换为 key 与 prev 间的交换,交换完后就达到快排的目的。
动图演示:

代码如下:
//前后指针法 【了解即可】private static int partition3(int[] array,int left,int right) {int prev = left ;int cur = left+1;while (cur <= right) {if(array[cur] < array[left] && array[++prev] != array[cur]) {swap(array,cur,prev);}cur++;}swap(array,prev,left);return prev;}private static void swap(int[] array,int i,int j) {int tmp = array[i];array[i] = array[j];array[j] = tmp;}【快速排序的特性总结】
快速排序不同于其他排序,快排需要区分最好情况和最坏情况;如果我们给定一个有序的数组,对其进行快排,无论是利用以上哪种方法,结果都如下:

由于有序,每一次排序都需要全部遍历一遍;如果是无序情况,每一次排序过程中都会使一部分数据趋近有序。
最好情况(无序):
- 时间复杂度:O(n*logn)
- 空间复杂度:
O(logN)
类似于一颗满二叉树:
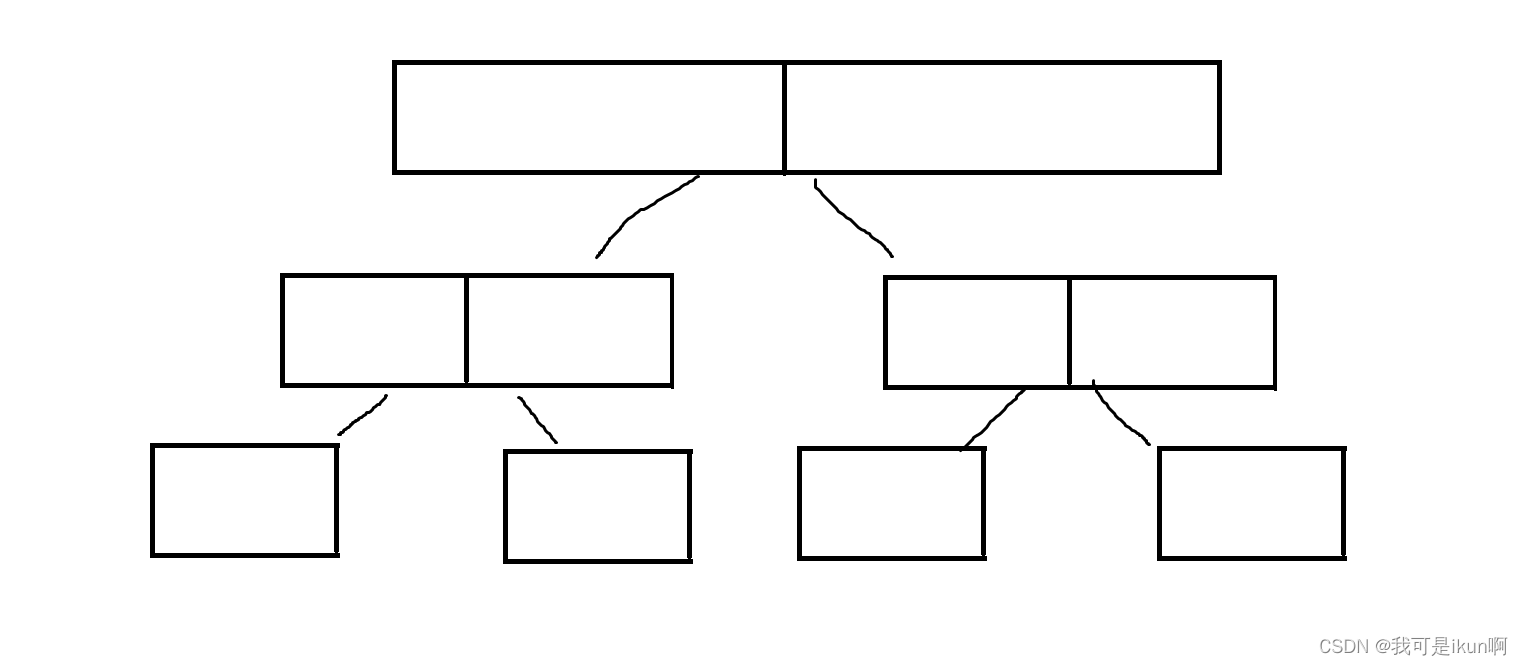
每次 key 都恰好是中间位置。
最坏情况(有序):
- 时间复杂度:O(n^2)
- 空间复杂度:
O(n)记住一句话,快速排序,越有序越慢,越无序越快。
- 稳定性:不稳定
对于最坏情况明显不能满足我们的需求,由于jdk默认分配的内存很小,对于一个很大的数据使用快排,递归太多了很可能照成栈溢出的情况,故此我们需要对其进行优化。
假设是一个升序的情况,没有左树:
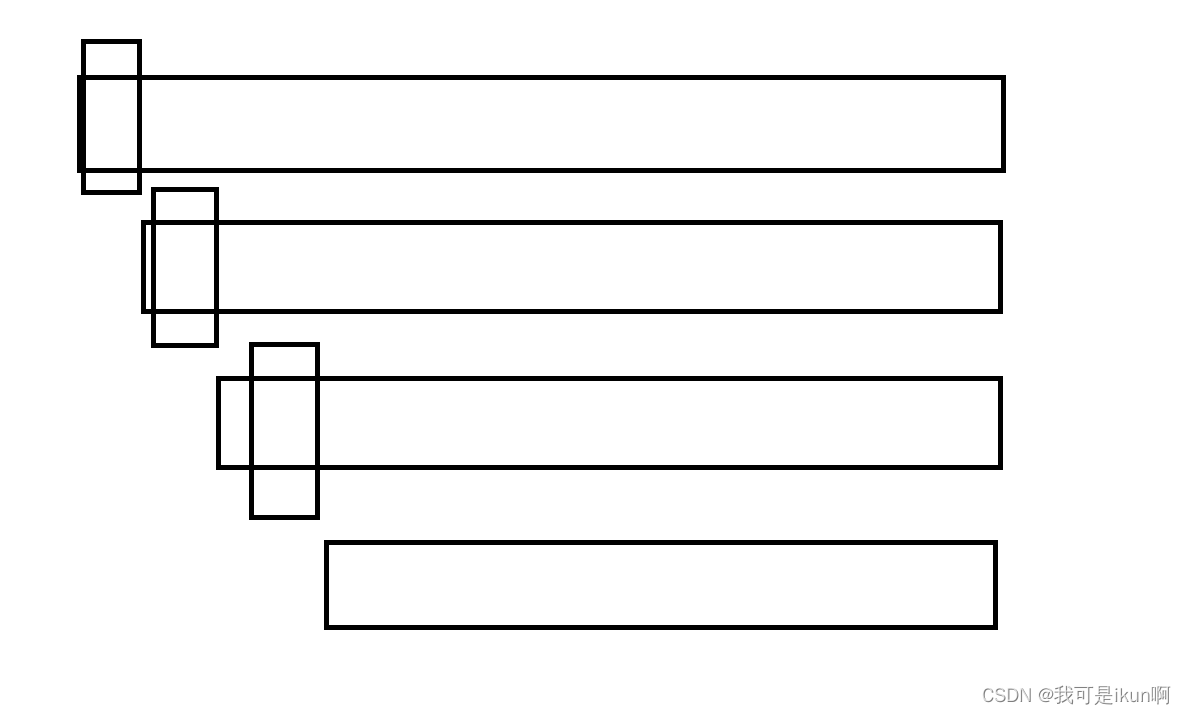
我们对其进行优化:
优化
方法1: 随机选取基准法
思想:

3的左边都小于3,3的右边都大于3;
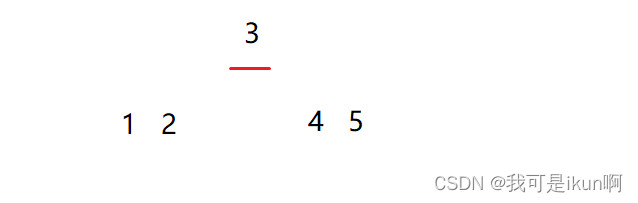
再对左右进行递归。
但是随机选取基准法,太随机了,也并不理想不是最好的优化方法。
方法2:三数取中法:
从最左边,中间和最右边三个数中选取中间的值作为基准:

这样做就可能变成二分查找,那么就不会出现最坏情况了。
代码如下:
//(初次优化)优化方法之一:三数取中法private static int midThree(int[] array,int left,int right) {int mid = (left + right) / 2;if (array[left] < array[right]) {if (array[mid] < array[left]) {return left;} else if (array[mid] > array[right]) {return right;} else {return mid;}} else {//array[left] > array[right]if (array[mid] < array[right]) {return right;} else if (array[mid] > array[left]) {return left;} else {return mid;}}}再次优化(插入排序)
对于一颗完全二叉树而言,最后两层占了大多数数据:

代码如下:
//再次优化private static void insertSort2(int[] array,int left,int right) {for (int i = left+1; i <= right; i++) {int tmp = array[i];int j = i-1;for (; j >= left ; j--) {if(array[j] > tmp) {array[j+1] = array[j];}else {break;}}array[j+1] = tmp;}}迭代法
利用栈的性质来完成快速排序
核心思想:
参照之前的代码:
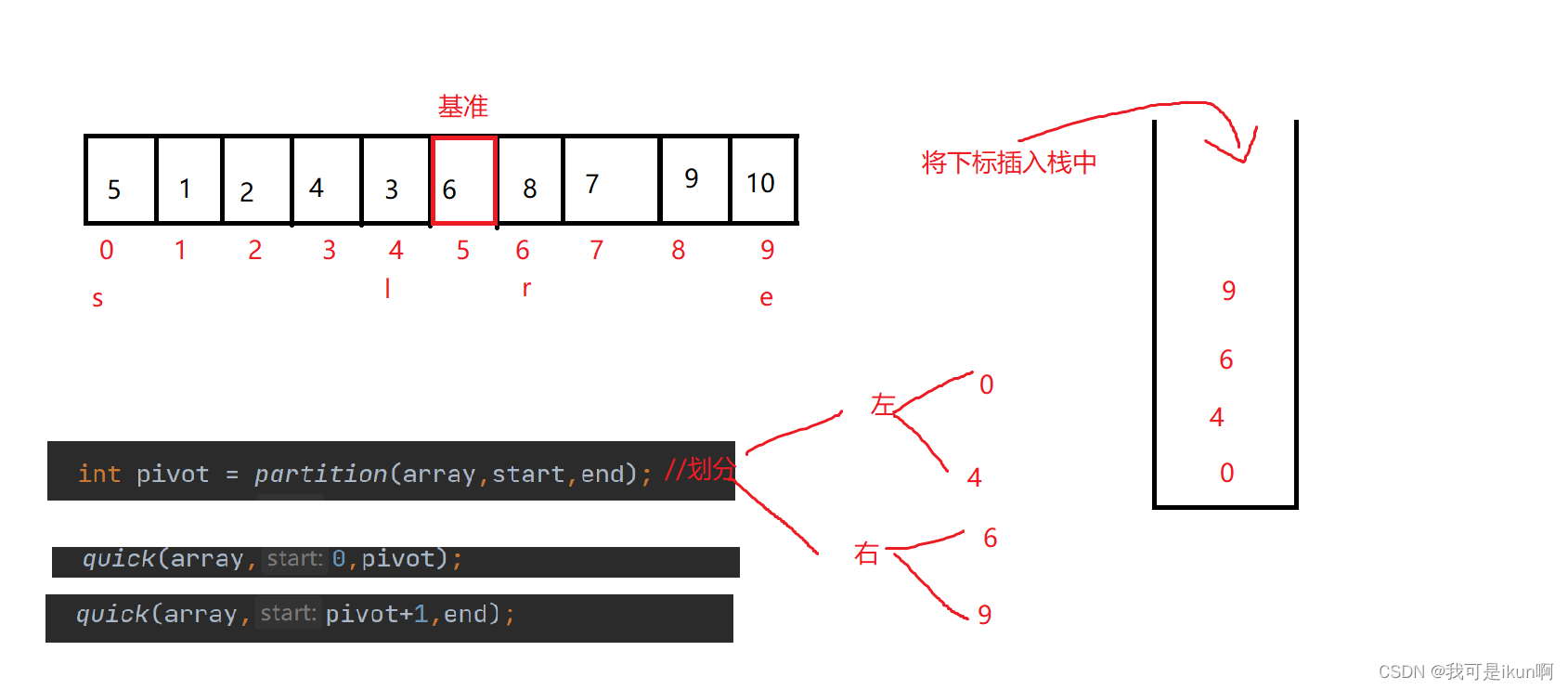
- 迭代法同样对此进行划分,【start,pivot - 1 】,【pivot + 1,end】,我们将下标压入栈中
- 对栈中元素进行弹出,每次弹出两个,分别用right和left来接收
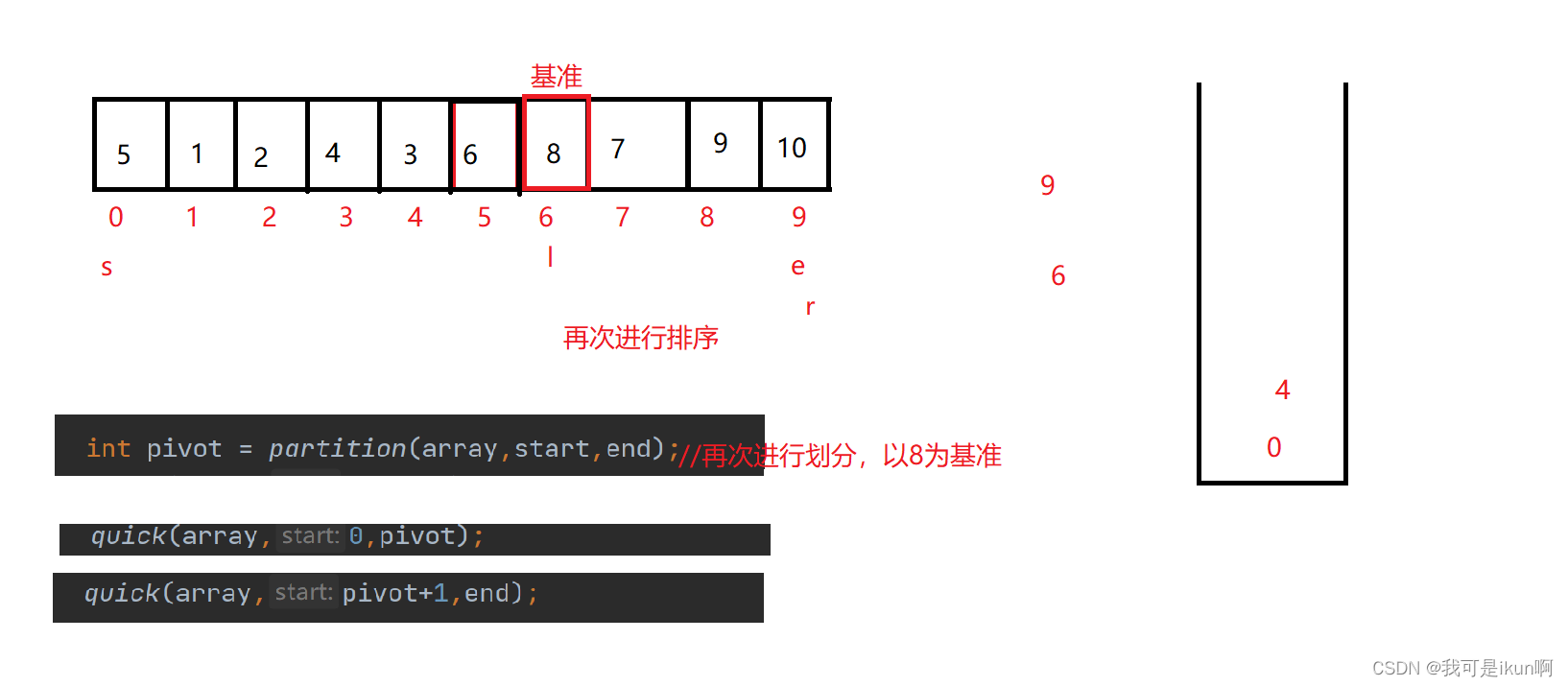
排序完后:
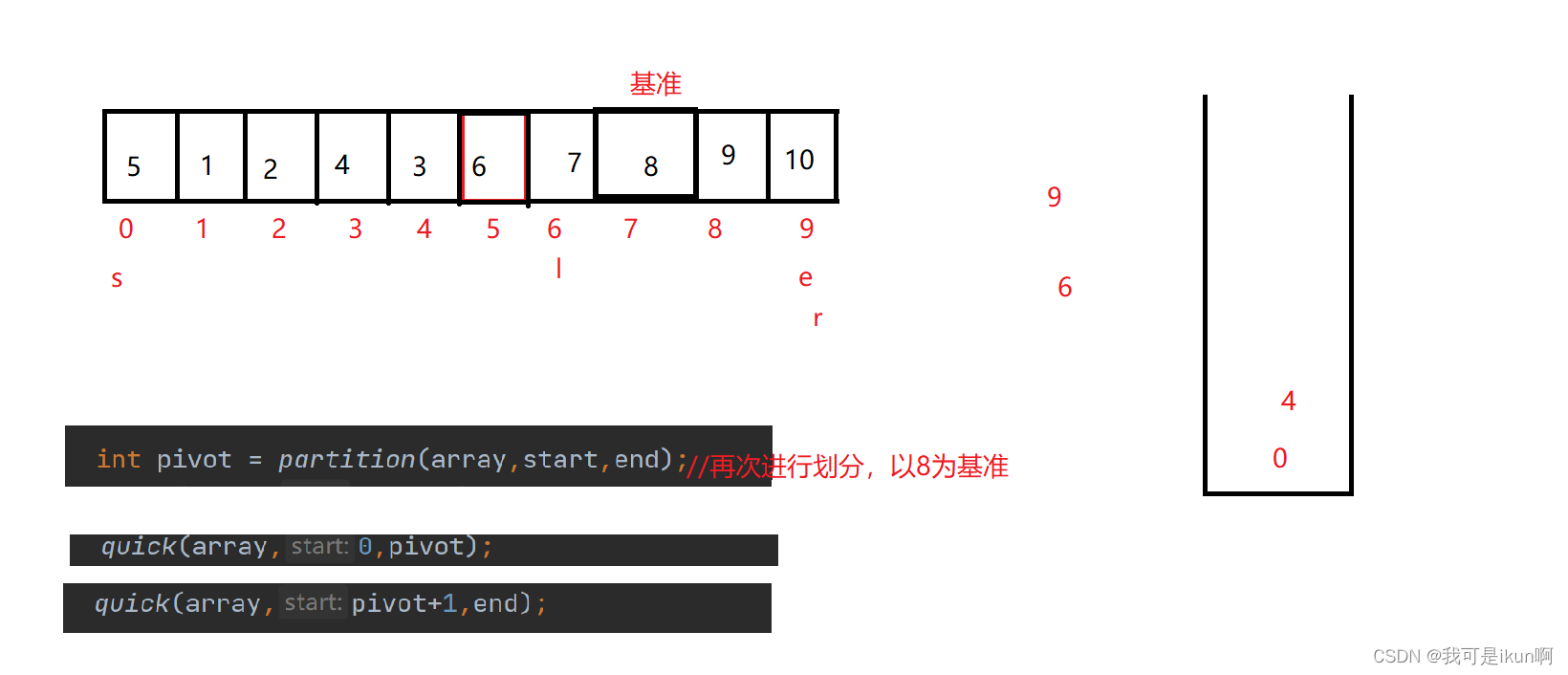
我们同样需要压入下标入栈,但是当左右有一边只有一个元素时,不用入栈。
如此反复就可以排序完。
代码如下:
//栈(利用栈的性质)public static void quickSort2(int[] array) {Deque<Integer> stack = new LinkedList<>();int left = 0;int right = array.length-1;int pivot = partition(array,left,right);if(pivot > left+1) {stack.push(left);stack.push(pivot-1);}if(pivot < right-1) {stack.push(pivot+1);stack.push(right);}while (!stack.isEmpty() ) {stack.pop();stack.pop();pivot = partition(array,left,right);if(pivot > left+1) {stack.push(left);stack.push(pivot-1);}if(pivot < right-1) {stack.push(pivot+1);stack.push(right);}}}其他排序
归并排序
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
基本思想:
每次将数据均分为两组,直不可再分;每次再将两组数据进行合并,如下图所示:

归并排序多用于外排序,即对磁盘中的大数据进行排序。
动图演示:

思路:首先要得到左右皆有序的数组,然后合并,显然这个需要借助递归实现,将大问题化小问题:将原数据分为左右两个区间,交给递归让他们变得有序,最后再执行有序数组合并。依靠递出,区间会慢慢变小,直到区间内只有两个数,执行合并,然后逐渐向上回归,回归的过程就是不断合并的过程,数据最开始的左右区间会逐渐变得有序,当回归到第一层时,执行最后一次有序数组合并,数据整体就变得有序了。
代码如下:
public static void mergeSort1(int[] array) {//保证接口的统一性,所以需要借组mergeSortFuncmergeSortFunc(array,0,array.length-1);}private static void mergeSortFunc(int[] array,int left,int right) {if(left >= right) {return;}int mid = (left+right) / 2;mergeSortFunc(array,left,mid);//将数据进行拆分mergeSortFunc(array,mid+1,right);merge(array,left,right,mid);//将数据合并}private static void merge(int[] array,int start,int end,int mid) {int s1 = start;//int e1 = mid;int s2 = mid+1;//int e2 = end;int[] tmp = new int[end-start+1];int k = 0;//tmp数组的下标while (s1 <= mid && s2 <= end) {if(array[s1] <= array[s2]) {tmp[k++] = array[s1++];}else {tmp[k++] = array[s2++];}}while (s1 <= mid) {tmp[k++] = array[s1++];}while (s2 <= end) {tmp[k++] = array[s2++];}for (int i = 0; i < tmp.length; i++) {array[i+start] = tmp[i];}}public static void mergeSort(int[] array) {int gap = 1;while (gap < array.length) {// i += gap * 2 当前gap组的时候,去排序下一组for (int i = 0; i < array.length; i += gap * 2) {int left = i;int mid = left + gap - 1;//有可能会越界if (mid >= array.length) {mid = array.length - 1;}int right = mid + gap;//有可能会越界if (right >= array.length) {right = array.length - 1;}merge(array, left, right, mid);}//当前为2组有序 下次变成4组有序gap *= 2;}}【归并排序总结】
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
计数排序

基本思想:
- (1)找出待排序的数组中最大和最小的元素
- (2)统计数组中每个值为i的元素出现的次数,存入数组C的第i项
- (3)对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- (4)反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
复制一个动图演示:
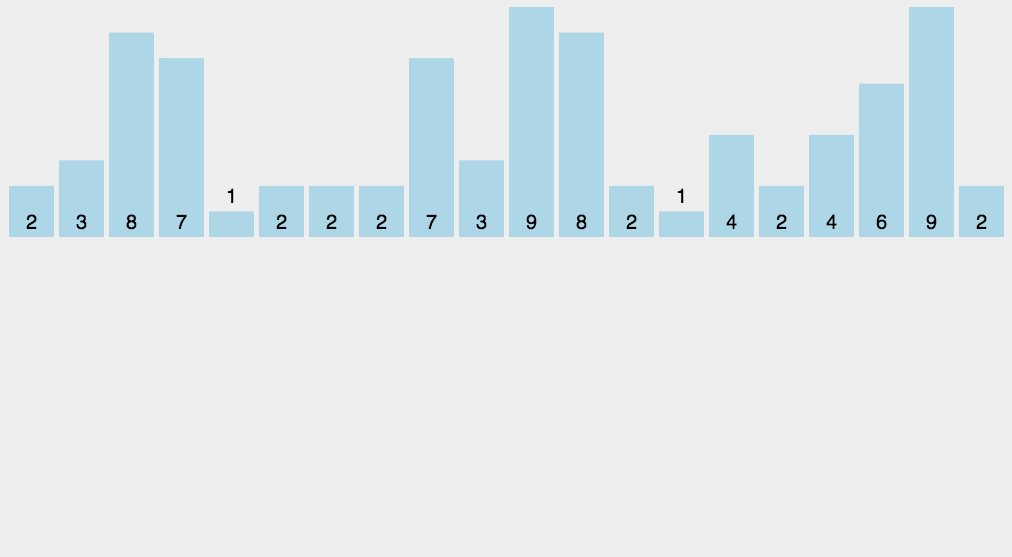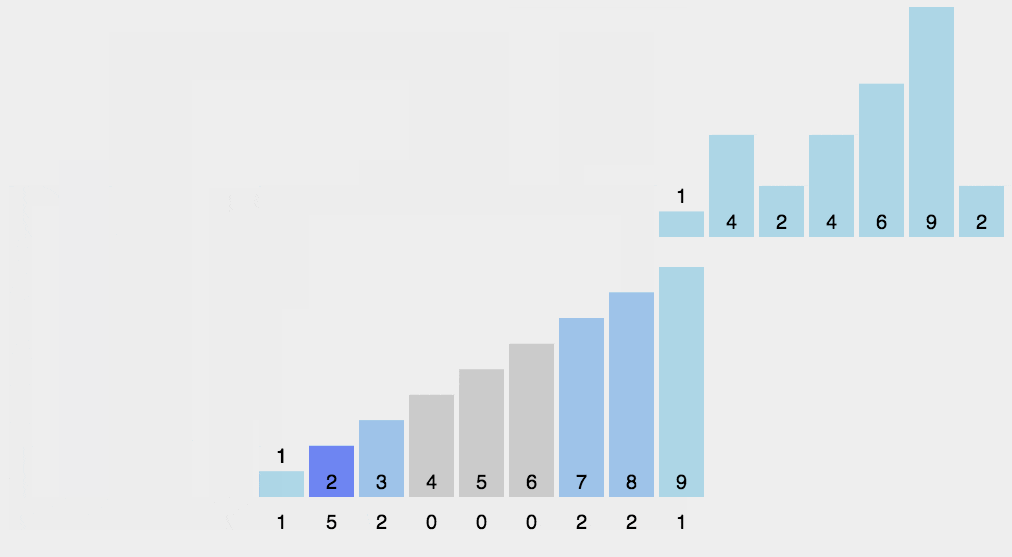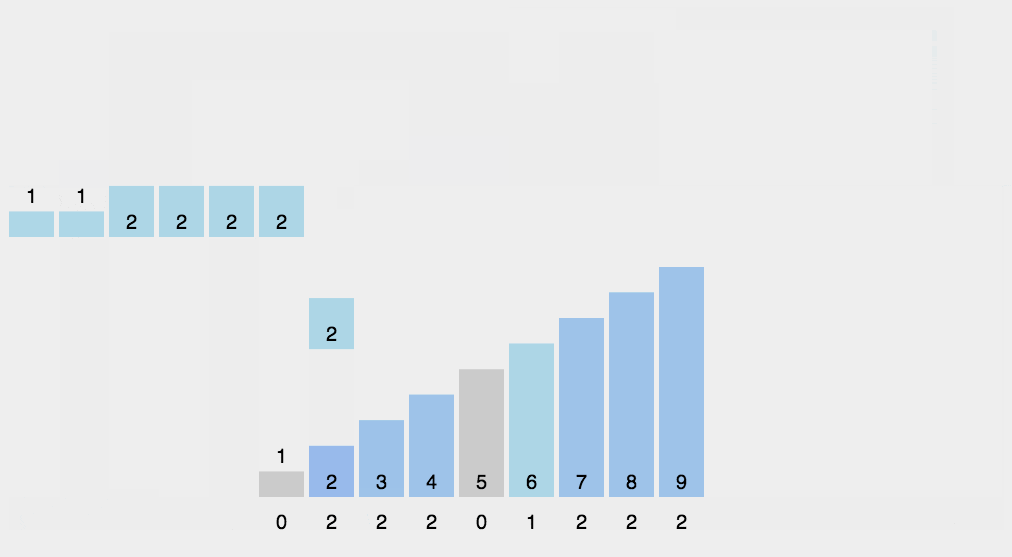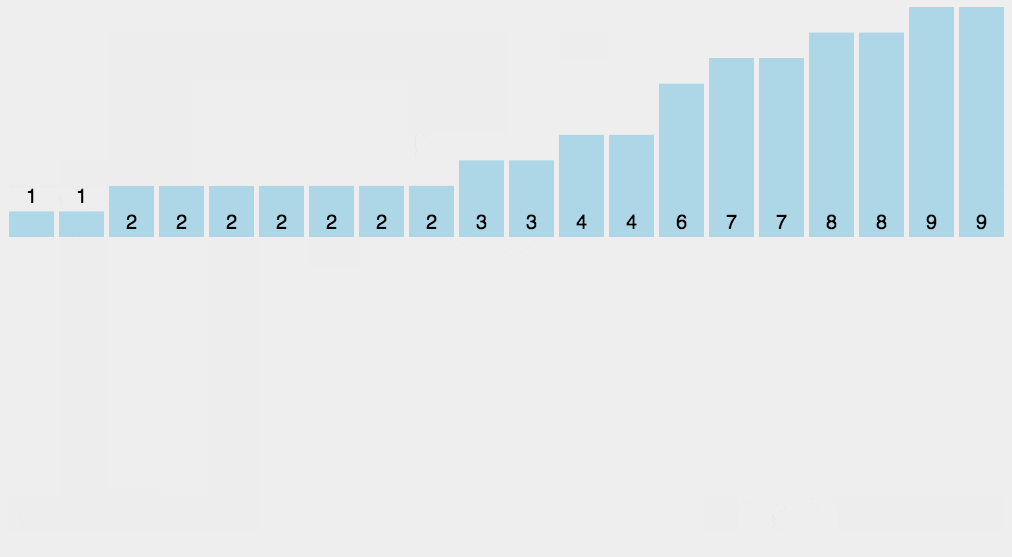
代码如下:
public static void countSort(int[] array) {//1. 遍历数组 找到最大值 和 最小值int max = array[0];int min = array[0];//O(N)for (int i = 1; i < array.length; i++) {if(array[i] < min) {min = array[i];}if(array[i] > max) {max = array[i];}}//2. 根据范围 定义计数数组的长度int len = max - min + 1;int[] count = new int[len];//3.遍历数组,在计数数组当中 记录每个数字出现的次数 O(N)for (int i = 0; i < array.length; i++) {count[array[i]-min]++;}//4.遍历计数数组int index = 0;// array数组的新的下标 O(范围)for (int i = 0; i < count.length; i++) {while (count[i] > 0) {//这里要加最小值 反应真实的数据array[index] = i+min;index++;count[i]--;}}}参考链接:
1.8 计数排序 | 菜鸟教程 (runoob.com)
【计数排序总结】
时间复杂度:O(n + 范围)
空间复杂度:O(范围)
稳定性:稳定
计数排序只使用于数据范围集中的情况,使用场景较少
排序总结
排序分类:
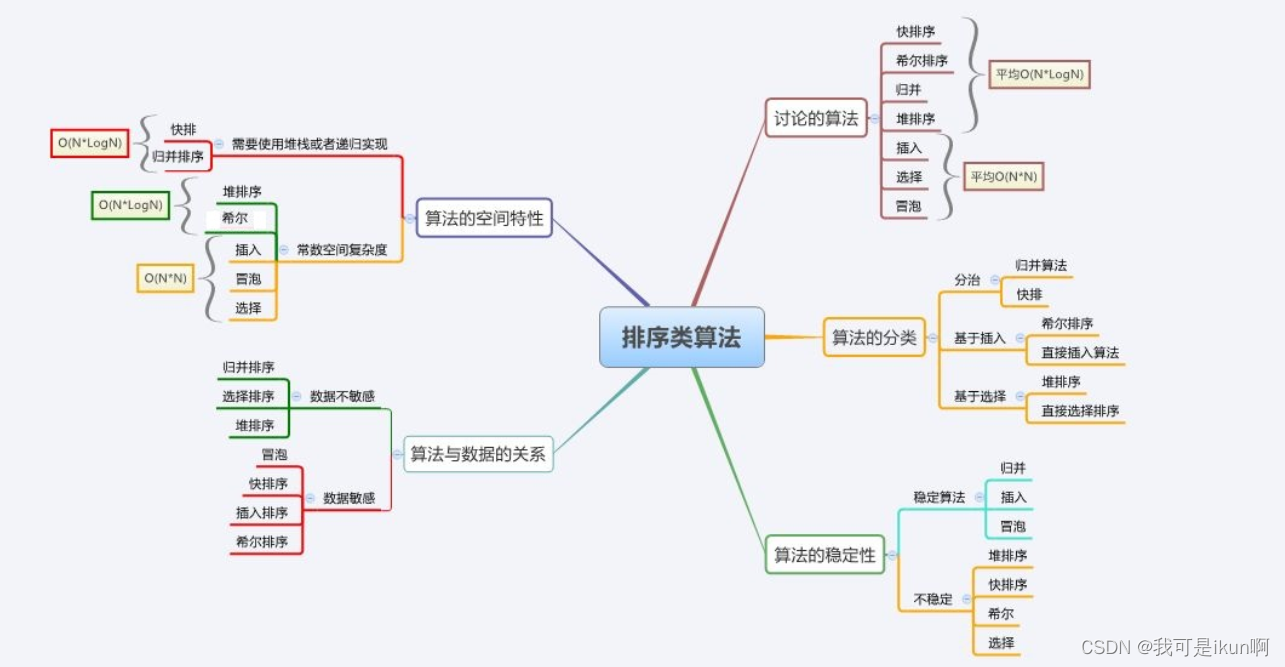
| 排序方法 | 最好 | 平均 | 最坏 | 空间复杂度 | 稳定性 |
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 希尔排序 | O(n) | O(n^1.3) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(n * log(n)) | O(n * log(n)) | O(n * log(n)) | O(1) | 不稳定 |
| 快速排序 | O(n * log(n)) | O(n * log(n)) | O(n^2) | O(log(n)) ~ O(n) | 不稳定 |
| 归并排序 | O(n * log(n)) | O(n * log(n)) | O(n * log(n)) | O(n) | 稳定 |
相关文章:
手撕八大排序(下)
目录 交换排序 冒泡排序: 快速排序 Hoare法 挖坑法 前后指针法【了解即可】 优化 再次优化(插入排序) 迭代法 其他排序 归并排序 计数排序 排序总结 结束了上半章四个较为简单的排序,接下来的难度将会大幅度上升&…...
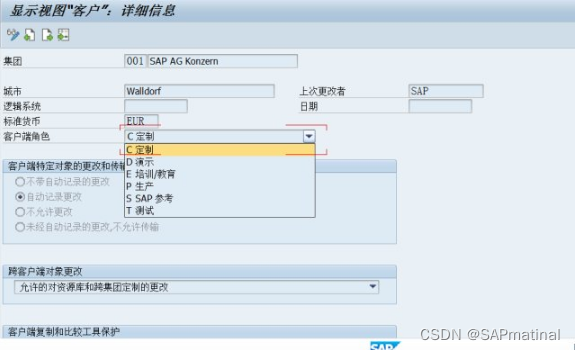
SAP 详细解析SCC4
事务代码:SCC4,选择一个客户端,点击进入,如图: 一、客户端角色 客户控制:客户的角色(生产性,测试,...) 此属性表示 R/3 系统中的客户端角色。其中可能包括…...
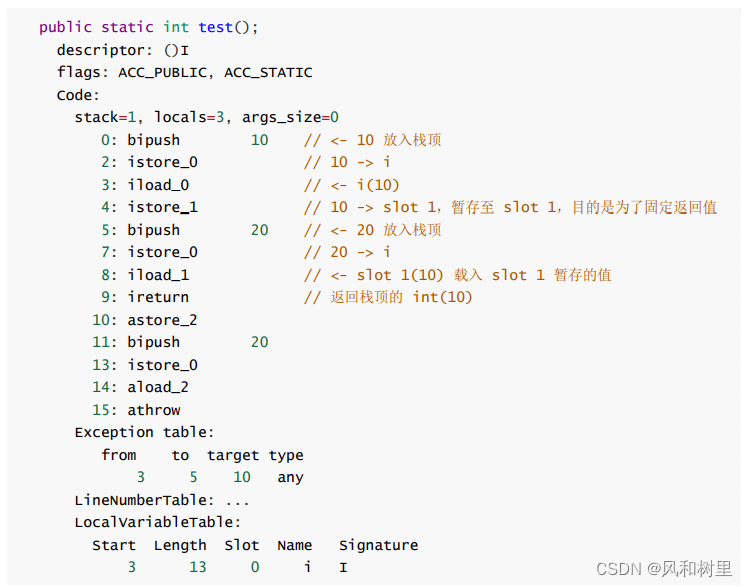
java异常分类和finally代码块中return语句的影响
首先看一下java中异常相关类的继承关系: 引用 1、分类 异常可以分为受查异常和非受查异常,Error和RuntimeException及其所有的子类都是非受查异常,其他的是受查异常。 两者的区别主要在: 受检的异常是由编译器(编译…...

【链表OJ题(二)】链表的中间节点
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:数据结构 🎯长路漫漫浩浩,万事皆有期待 文章目录链表OJ题(二)1. 链表…...
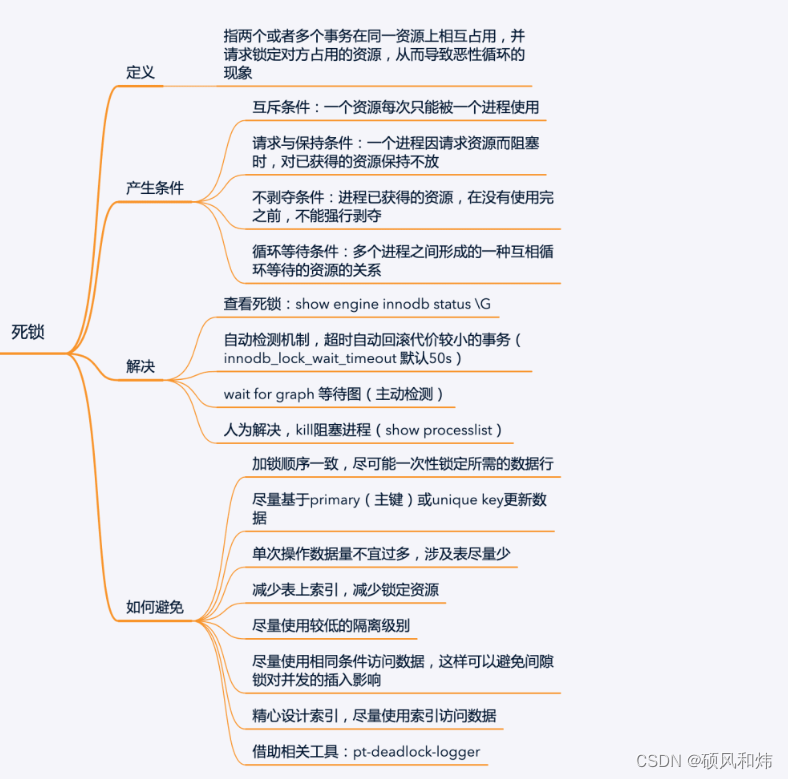
【强烈建议收藏:MySQL面试必问系列之并发事务锁专题】
一.知识回顾 上节课我们一起学习了MySQL面试必问系列之事务,没有学习的同学可以看一下上一篇文章,肯定对你会有帮助,学习过的同学肯定知道,上节课我们留了一个小尾巴,这个小尾巴是什么呢?就是没有详细展开…...
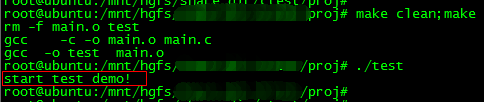
Linux下使用Makefile实现条件编译
在Linux系统下Makefile和C/C语言都有提供条件选择编译的语法,就是在编译源码的时候,可以选择性地编译指定的代码。这种条件选择编译的使用场合有好多,例如我们开发一个兼容标准版本与定制版本兼容的项目,那么,一些与需…...
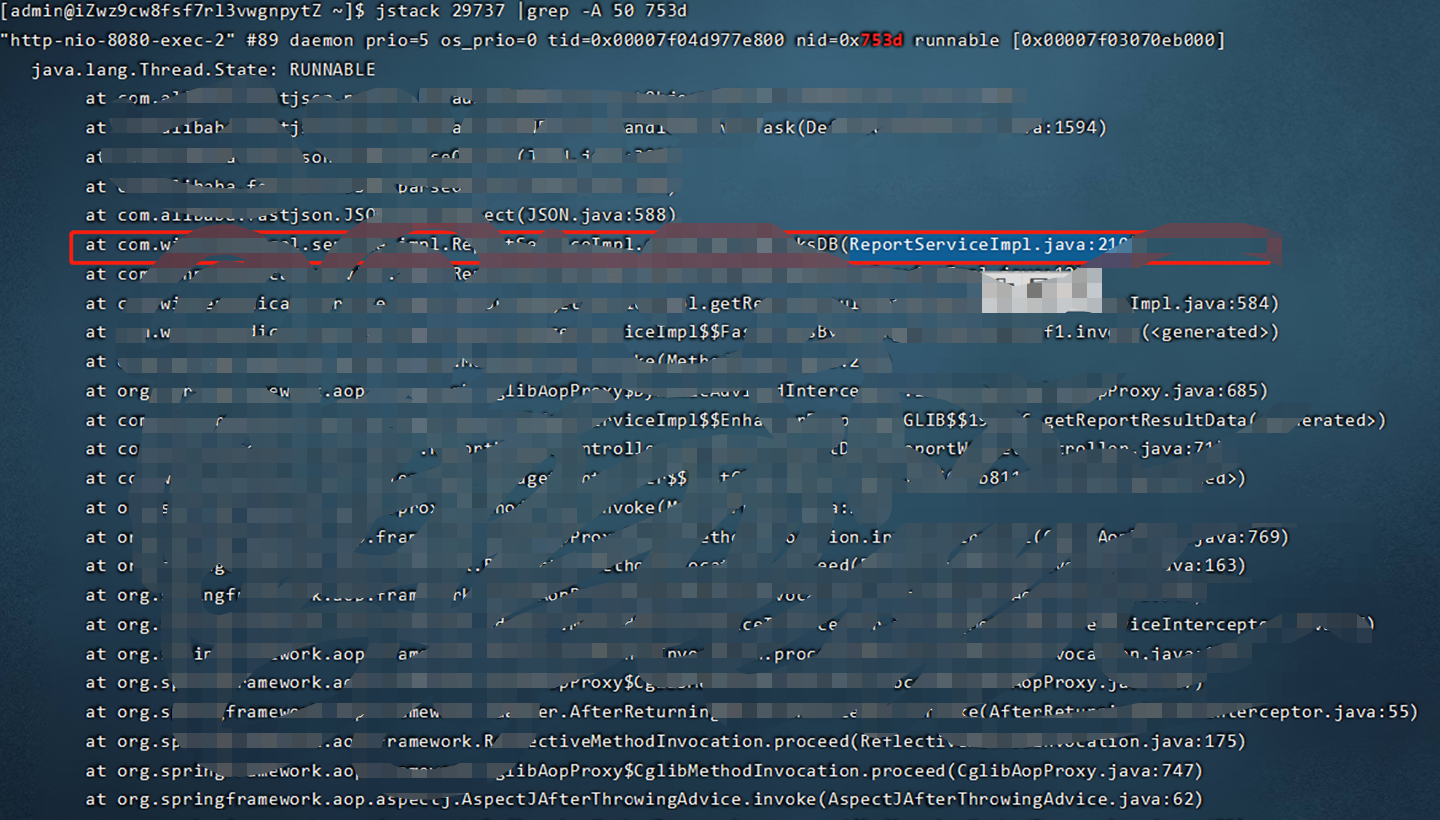
java 应用cpu飙升(超过100%)故障排查
前言害。。。昨天刚写完一份关于jvm问题排查相关的博客,今天线上项目就遇到了一个突发问题。现象是用户反映系统非常卡,无法操作。然后登录服务器查看发现cpu 一直100%以上。具体排查步骤:1,首先top命令查看服务器cpu等情况&#…...
光学设计软件Ansys的Lumerical 2023版本下载与安装使用
文章目录前言一、许可管理工具安装二、许可管理器配置三、Lumerical安装四、工具使用配置总结前言 Lumerical是一款功能强大的软件,用于设计和分析从组件到系统阶段的光子学和电磁学。这个版本的Lumerical改进了电子和光子学设计工具,用于复杂光子学&am…...
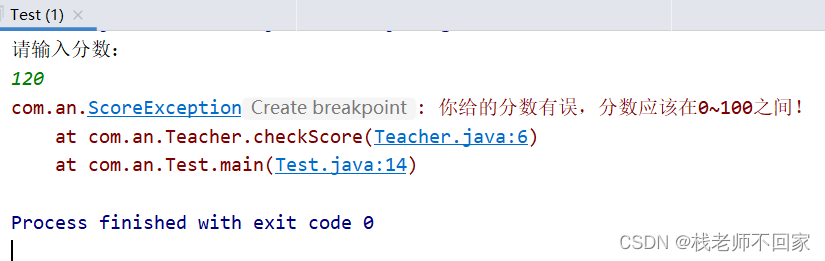
Java 异常
文章目录1. 异常概述2. JVM 的默认处理方案3. 异常处理之 try...catch4. Throwable 的成员方法5. 编译异常和运行异常的区别6. 异常处理之 throws7. 自定义异常8. throws 和 throw 的区别1. 异常概述 异常就是程序出现了不正常的情况。 ① Error:严重问题ÿ…...
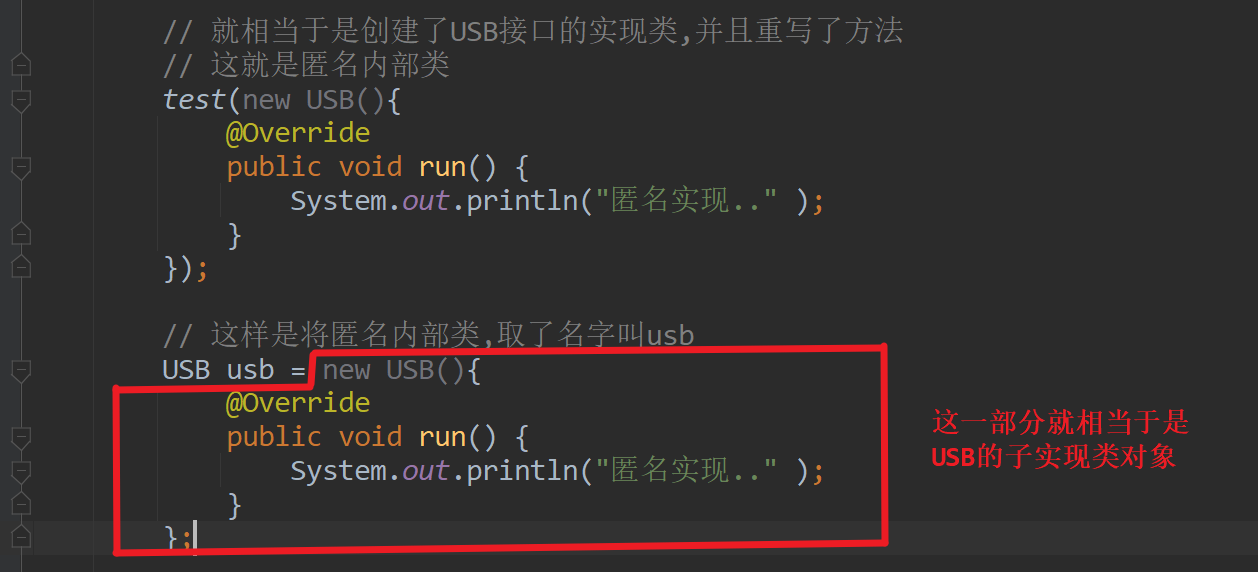
JavaSE学习笔记day17
零、 复习昨日 File: 通过路径代表一个文件或目录 方法: 创建型,查找类,判断类,其他 IO 输入& 输出字节&字符 try-catch代码 一、作业 给定路径删除该文件夹 public static void main(String[] args) {deleteDir(new File("E:\\A"));}// 删除文件夹public s…...
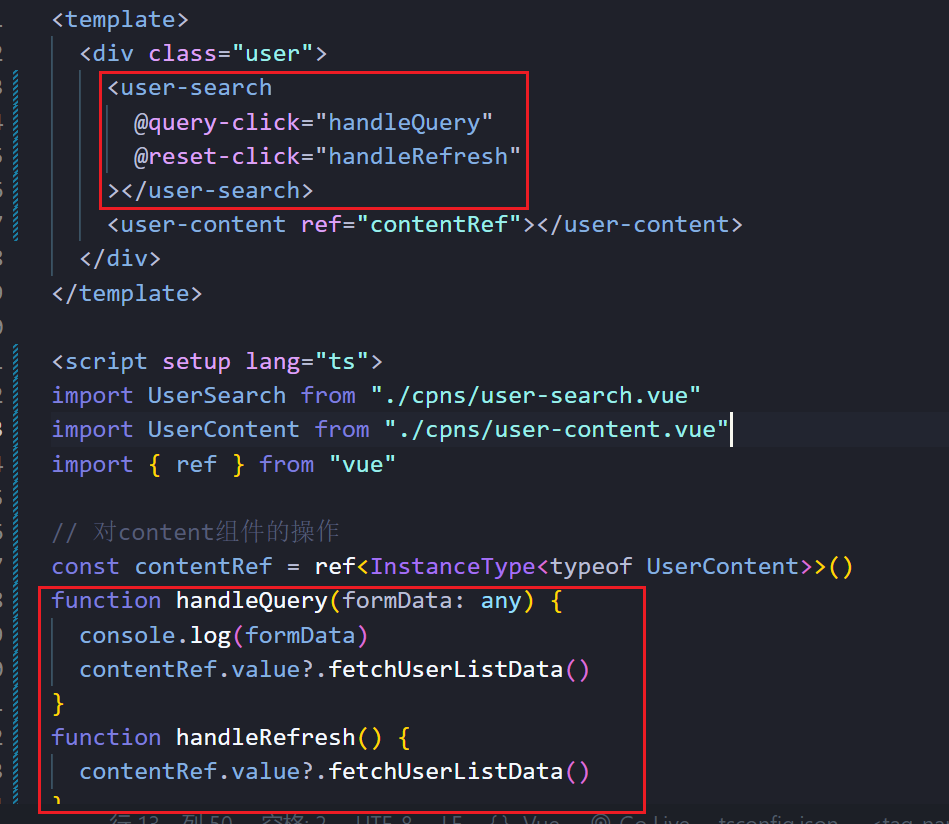
【项目】Vue3+TS 动态路由 面包屑 查询重置 列表
💭💭 ✨:【项目】Vue3TS 动态路由 面包屑 查询重置 列表 💟:东非不开森的主页 💜: 热烈的不是青春,而是我们💜💜 🌸: 如有错误或不足之处࿰…...

前脚背完这些接口自动化测试面试题,后脚就进了字节测试岗
1、请结合你熟悉的项目,介绍一下你是怎么做测试的? -首先要自己熟悉项目,熟悉项目的需求、项目组织架构、项目研发接口等 -功能 接口 自动化 性能 是怎么处理的? -第一步: 进行需求分析,需求评审&#…...

termux 安装centos
相关链接 centos官网rootfs制作其他人提供的安装脚本centos镜像列表其他人提供的安装脚本的说明 如果想使用老版本的centos7跟着上面链接5走就行 如果想用新系统比如centos9 stream,就跟我来 Q:为什么要装新系统? A:旧系统太多软件已过时,升级费时费…...
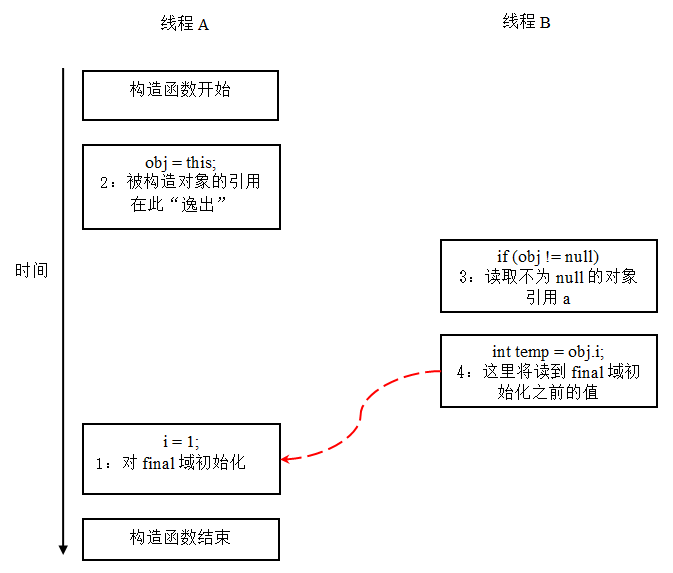
从菜鸟程序员到高级架构师,竟然是因为这个字final
final实现原理 简介 final关键字,实际的含义就一句话,不可改变。什么是不可改变?就是初始化完成之后就不能再做任何的修改,修饰成员变量的时候,成员变量变成一个常数;修饰方法的时候,方法不允…...
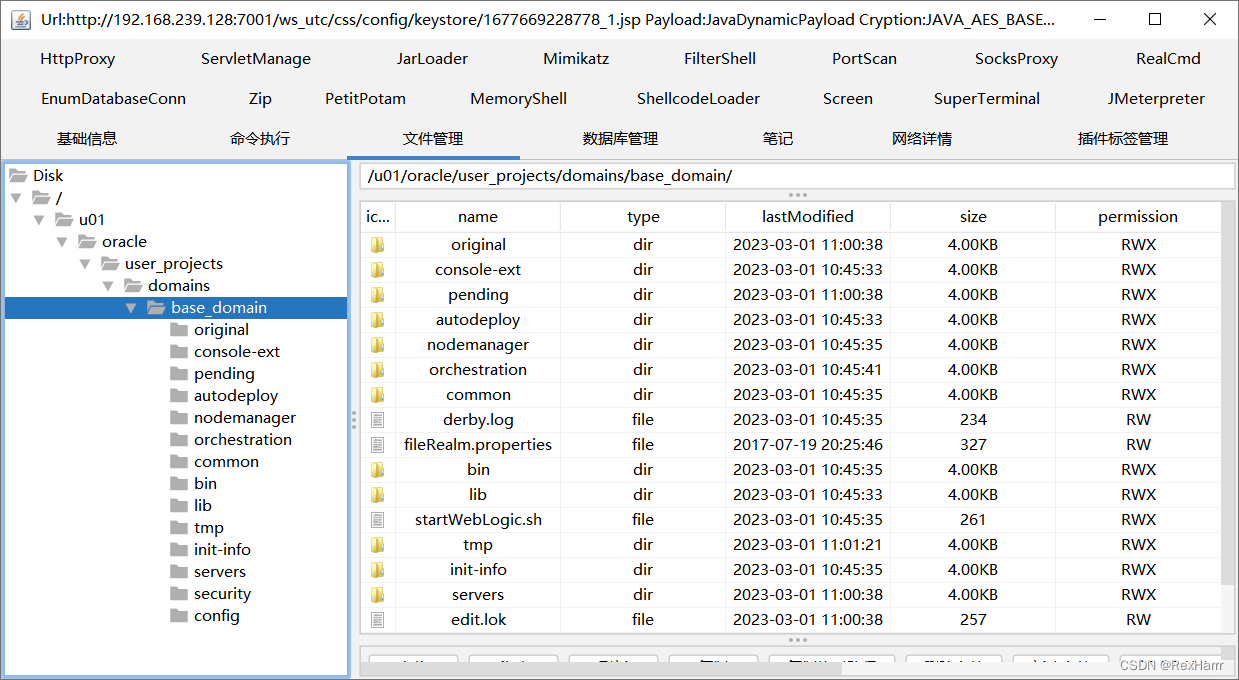
【vulhub漏洞复现】CVE-2018-2894 Weblogic任意文件上传漏洞
一、漏洞详情影响版本weblogic 10.3.6.0、weblogic 12.1.3.0、weblogic 12.2.1.2、weblogic 12.2.1.3WebLogic是美国Oracle公司出品的一个application server,确切的说是一个基于JAVAEE架构的中间件,WebLogic是用于开发、集成、部署和管理大型分布式Web应…...
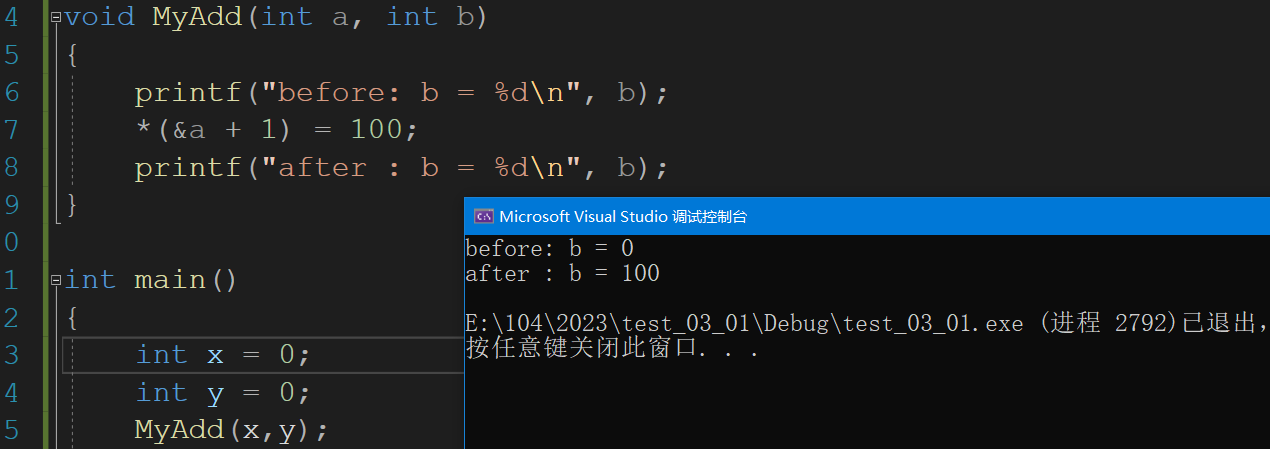
函数栈帧详解
写在前面 这个模块临近C语言的边界,学起来需要一定的时间,不过当我们知道这些知识后,在C语言函数这块我们看到的不仅仅是表象了,可以真正了解函数是怎么调用的。不过我的能力有限,下面的的知识若是不当,还…...
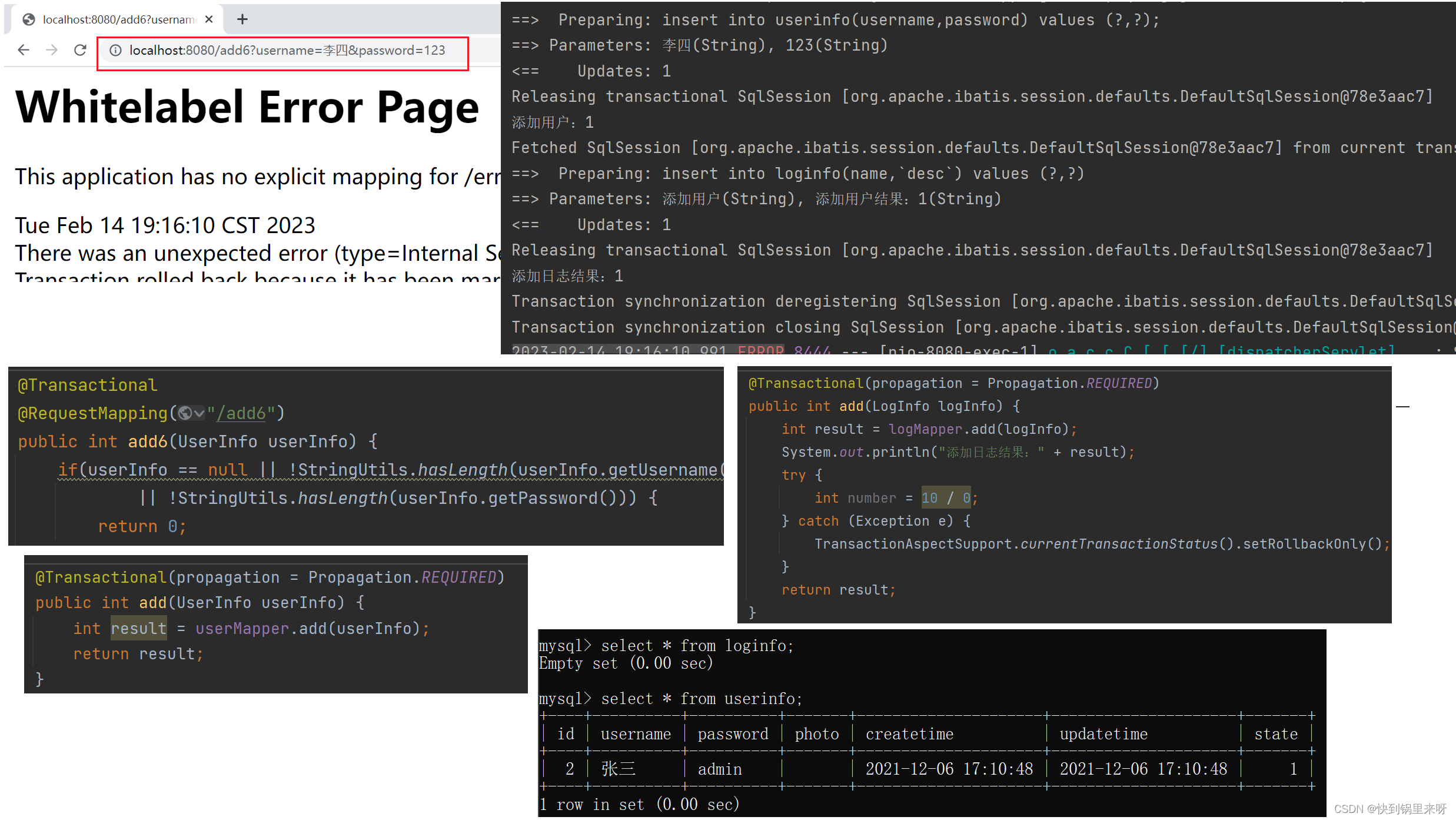
Spring 事务(编程式事务、声明式事务@Transactional、事务隔离级别、事务传播机制)
文章目录1. 事务的定义2. Spring 中事务的实现2.1 MySQL 中使用事务2.2 Spring 中编程式事务的实现2.3 Spring 中声明式事务2.3.1 声明式事务的实现 Transactional2.3.2 Transactional 作用域2.3.3Transactional 参数设置2.3.4 Transactional 异常情况2.3.5 Transactional 工作…...

车载技术——Window Display之surface的绘制过程与原理
一、Surface 概述 OpenGL ES/Skia定义了一组绘制接口的规范,为什么能够跨平台? 本质上需要与对应平台上的本地窗口建立连接。也就是说OpenGL ES负责输入了绘制的命令,但是需要一个 “画布” 来承载输出结果,最终展示到屏幕。这个…...

2023年全国最新工会考试精选真题及答案10
百分百题库提供工会考试试题、工会考试预测题、工会考试真题、工会证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 51.()是企业工会的权力机关,每年召开一至两次会议。 A.会员大会 B.会…...

pytorch-复现经典深度学习模型-LeNet5
Neural Networks 使用torch.nn包来构建神经网络。nn包依赖autograd包来定义模型并求导。 一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。 一个简单的前馈神经网络,它接受一个输入,然后一层接着一层地传递,…...

SDMatte处理动物与宠物图像效果展示:毛发级精度的自然抠图
SDMatte处理动物与宠物图像效果展示:毛发级精度的自然抠图 1. 为什么宠物抠图这么难 给宠物照片抠图可能是设计师最头疼的任务之一。想象一下,一只金毛犬站在浅色地毯上,毛发边缘几乎和背景融为一体;或者一只黑猫蜷缩在深色沙发…...

BGV vs BFV:基于LWE的两大全同态加密方案,到底该怎么选?
BGV vs BFV:基于LWE的两大全同态加密方案技术选型指南 当隐私计算项目需要处理加密数据上的复杂运算时,全同态加密(FHE)方案的选择往往成为架构设计的核心决策点。作为第二代FHE方案的典型代表,BGV和BFV虽然同属基于L…...

SDMatte在智能硬件配套:嵌入式设备端Web服务裁剪、ARM64交叉编译与内存精简
SDMatte在智能硬件配套:嵌入式设备端Web服务裁剪、ARM64交叉编译与内存精简 1. 技术背景与挑战 在智能硬件领域,嵌入式设备通常面临资源受限的挑战: 计算能力有限:ARM架构处理器性能远低于服务器级GPU内存资源紧张:…...

OpenClaw轻量化方案实测:nanobot镜像性能与成本分析
OpenClaw轻量化方案实测:nanobot镜像性能与成本分析 1. 为什么需要轻量化OpenClaw方案 第一次听说OpenClaw时,我就被它的自动化能力吸引了——能让AI像人类一样操作我的电脑,完成各种重复性工作。但当我真正尝试在本地部署标准版OpenClaw时…...

一键体验OpenClaw:星图平台百川2-13B-4bits镜像快速部署方案
一键体验OpenClaw:星图平台百川2-13B-4bits镜像快速部署方案 1. 为什么选择星图平台体验OpenClaw 作为一个长期关注AI自动化工具的技术爱好者,我第一次接触OpenClaw时就被它的理念吸引了——一个能在本地电脑上像人类一样操作各种软件的AI助手。但当我…...

基于图像的深度学习与MVS三维重建全流程服务 支持远程部署定制 含pcl/c++/matlab...
基于图像的深度学习MVS三维重建全流程 可远程部署,可定制 点云pcl,c,matlab开发,基于图像三维重建,点云算法开发 只需要提供摄的图像,即可生成完整的三维模型(大小场景均可)上周去爬了个浙西的小众山&#…...

uniapp日期处理全攻略:获取某月首尾日、近七天日期等实用技巧
Uniapp日期处理实战:从基础格式化到高级业务场景解决方案 在移动应用开发中,日期处理几乎贯穿所有业务场景。无论是电商平台的限时抢购、医疗应用的预约挂号,还是企业系统的报表统计,精准高效的日期操作都是保障业务逻辑完整性的关…...

RouterOS L2TP服务器搭建与安全优化指南
1. L2TP协议基础与RouterOS适配性 L2TP协议全称为Layer 2 Tunneling Protocol,是一种工作在OSI模型第二层的隧道协议。我第一次接触这个协议是在2015年为企业部署远程办公系统时,当时发现它相比PPTP有着明显的安全优势。简单来说,L2TP就像是在…...

实时交易系统架构设计:从事件驱动到向量化框架的终极指南
实时交易系统架构设计:从事件驱动到向量化框架的终极指南 【免费下载链接】awesome-systematic-trading A curated list of insanely awesome libraries, packages and resources for systematic trading. Crypto, Stock, Futures, Options, CFDs, FX, and more | 量…...

C# IDisposable:3个致命陷阱+5个最佳实践,你踩过几个?
🔥关注墨瑾轩,带你探索编程的奥秘!🚀 🔥超萌技术攻略,轻松晋级编程高手🚀 🔥技术宝库已备好,就等你来挖掘🚀 🔥订阅墨瑾轩,智趣学习不…...