RocksDB实现原理
文章目录
- 简介
- 编译安装RocksDB
- 压缩库
- Ubuntu
- Centos
- 基本接口
- 高度分层架构
- LSM-Tree
- 关于访问速度
- MemTable
- 落盘策略
- WAL
- RocksDB 中的每个更新操作都会写到两个地方:
- WAL 创建时机:
- 重要参数
- Immutable MemTable
- SST
- BlockCache
- LRU 缓存
- Clock缓存
- 写入流程
- 读取流程
- LSM-Tree 三大问题
- 读放大
- 空间放大
- 写放大
- 列族(column family)
- 事务
- 悲观事务(TransactionDB)
- 乐观事务(OptimisticTransactionDB)
简介
- RocksDB 是 Facebook 的一个实验项目,目的是希望能开发一套能在服务器压力下,真正发挥高速存储硬件性能的高效数据库系统。这是一个 C++ 库,允许存储任意长度二进制 KV 数据。支持原子读写操作。
- RocksDB 依靠大量灵活的配置,使之能针对不同的生产环境进行调优,包括直接使用内存,使用 Flash,使用硬盘或者HDFS。支持使用不同的压缩算法,并且有一套完整的工具供生产和调试使用。
- RocksDB 大量复用了 levedb 的代码,并且还借鉴了许多HBase 的设计理念。原始代码从 leveldb 1.5 上fork 出来。同时RocksDB 也借用了一些 Facebook 之前就有的理念和代码。
- RocksDB 应用场景非常广泛;比如支持 redis 协议的 pika 数据库,采用 RocksDB 持久化 Redis 支持的数据结构;MySQL 中支持可插拔的存储引擎,Facebook 维护的 MySQL 分支中支持RocksDB;
编译安装RocksDB
git clone https://github.com/facebook/rocksdb.git
cd rocksdb
# 编译成调试模式
make
# 编译成发布模式
make static_lib
############################ 使用 cmake
######################
mkdir build
cd build
cmake ..
压缩库
Ubuntu
# rocksdb 支持多种压缩模式
# gflags
sudo apt-get install libgflags-dev
# snappy
sudo apt-get install libsnappy-dev
# zlib
sudo apt-get install zlib1g-dev
# bzip2
sudo apt-get install libbz2-dev
# lz4
sudo apt-get install liblz4-dev
# zstandard
sudo apt-get install libzstd-dev
Centos
# gflags
git clone https://github.com/gflags/gflags.git
cd gflags
git checkout v2.0
./configure && make && sudo make install
# snappy
sudo yum install snappy snappy-devel
# zlib
sudo yum install zlib zlib-devel
# bzip2
sudo yum install bzip2 bzip2-devel
# lz4
sudo yum install lz4-devel
# ASAN (optional for debugging)
sudo yum install libasan
# zstandard
sudo yum install libzstd-devel
基本接口
Status Open(const Options& options, const std::string& dbname, DB** dbptr);
Status Get(const ReadOptions& options, const Slice& key, std::string* value);
Status Get(const ReadOptions& options, ColumnFamilyHandle* column_family, const Slice& key, std::string* value);
Status Put(const WriteOptions& options, const Slice& key, const Slice& value);
Status Put(const WriteOptions& options, ColumnFamilyHandle* column_family, const Slice& key, const Slice& value);// fix read-modify-write 将 读取、修改、写入封装到一个接口中
Status Merge(const WriteOptions& options, const Slice& key, const Slice& value);
Status Merge(const WriteOptions& options, ColumnFamilyHandle* column_family, const Slice& key, const Slice& value);// 标记删除,具体在 compaction 中删除
Status Delete(const WriteOptions& options, const Slice& key);
Status Delete(const WriteOptions& options, ColumnFamilyHandle* column_family, const Slice& key, const Slice& ts);// 针对从来不修改且已经存在的key; 这种情况比 delete 删除的快;
Status SingleDelete(const WriteOptions& options, const Slice& key);
Status SingleDelete(const WriteOptions& options, ColumnFamilyHandle* column_family, const Slice& key);// 迭代器会阻止 compaction 清除数据,使用完后需要释放;
Iterator* NewIterator(const ReadOptions& options);
Iterator* NewIterator(const ReadOptions& options,ColumnFamilyHandle* column_family)
高度分层架构
- RocksDB 是一种可以存储任意二进制KV数据的嵌入式存储。
- RocksDB 按顺序组织所有数据,他们的通用操作是 Get(key) , NewIterator() , Put(key, value) , Delete(Key) 以及SingleDelete(key)。
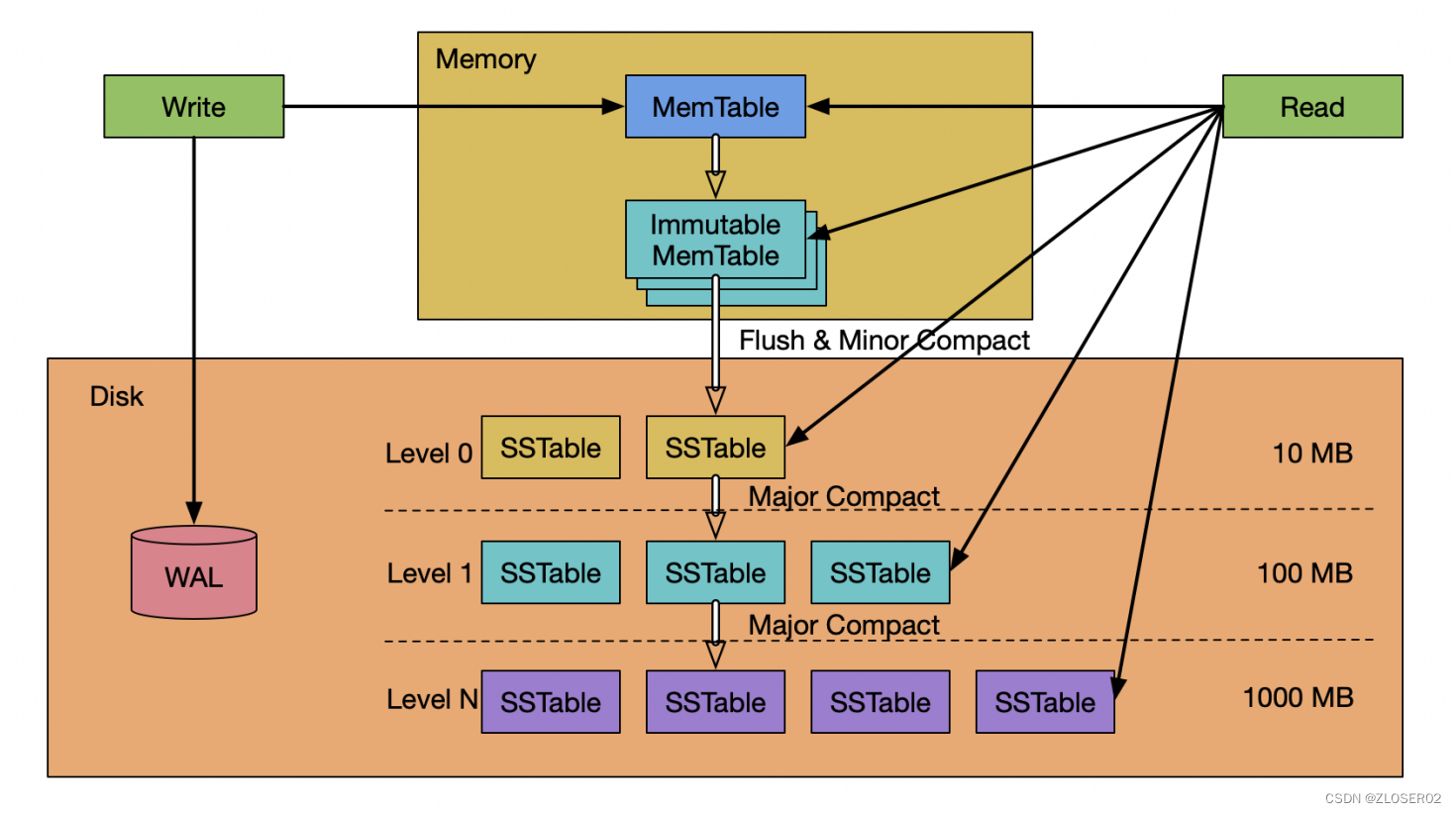
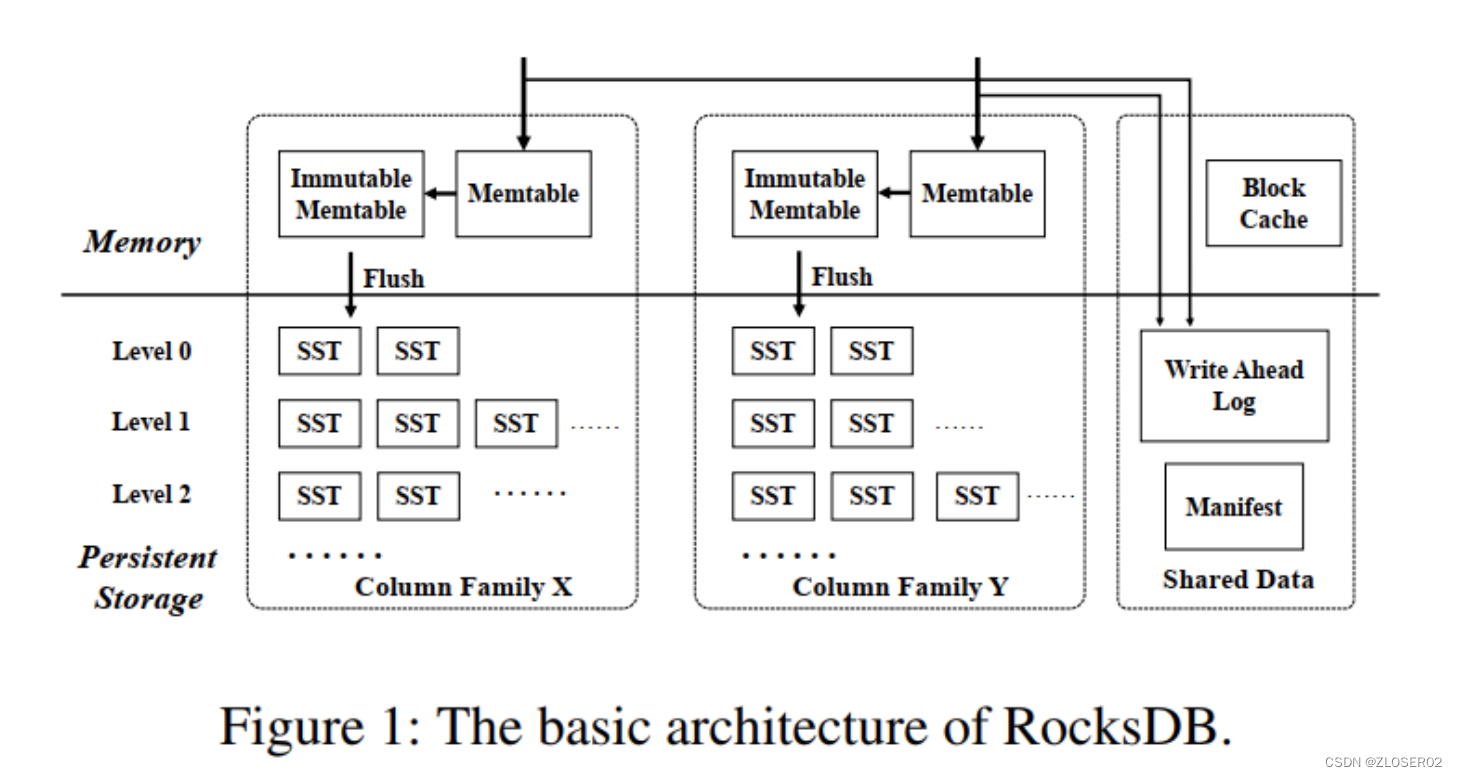
RocksDB 有三种基本的数据结构:memtable,sstfile 以及logfile。memtable 是一种内存数据结构——所有写入请求都会进入 memtable,然后选择性进入 logfile。logfile 是一个在存储上顺序写入的文件。当 memtable 被填满的时候,他会被刷到 sstfile 文件并存储起来,然后相关的 logfile 会在之后被安全地删除。sstfile 内的数据都是排序好的,以便于根据 key 快速搜索。 - RocksDB 是基于 LSM-Tree (log structured merge - tree) 实现;
LSM-Tree
- LSM-Tree 的核心思想是利用顺序写来提升写性能;LSM-Tree不是一种树状数据结构,仅仅是一种存储结构;**LSM-Tree 是为了写密集型的特定场景而提出的解决方案;**如日志系统、海量数据存储、数据分析;
- LO 层数据重复,文件间无序,文件内部有序;
- L1 ~ LN 每层数据没有重复,跨层可能有重复;文件间是有序
的;
关于访问速度
- 磁盘访问时间:寻道时间 + 旋转时间 + 传输时间;
寻道时间:8ms~12ms;
旋转时间:7200转/min(半周 4ms);
传输时间:50M/s(约0.3ms); - 磁盘随机 IO 磁盘顺序 IO 内存随机 IO 内存顺序 IO;
MemTable
- MemTable 是一个内存数据结构,他保存了落盘到 SST 文件前的数据。他**同时服务于读和写**——新的写入总是将数据插入到memtable,读取在查询 SST 文件前总是要查询 memtable,因为 memtable 里面的数据总是更新的。一旦一个 memtable 被写满,他会变成不可修改的,并被一个新的memtable 替换。一个后台线程会把这个 memtable 的内容落盘到一个 SST 文件,然后这个 memtable 就可以被销毁了。
- 默认的 memtable 实现是基于 skiplist (调表)的。
- 影响 memtable 大小的选项:
write_buffer_size: 一个 memtable 的大小;
db_write_buffer_size: 多个列族的 memtable 的大小总和;这可以用来管理memtable 使用的总内存数;
max_write_buffer_number: 内存中可以拥有刷盘到 SST 文件前的最大 memtable 数;

落盘策略
- Memtable 的大小在一次写入后超过 write_buffer_size。
- 所有列族中的 memtable 大小超过 db_write_buffer_size了,或者 write_buffer_manager 要求落盘。在这种场景,最大的 memtable 会被落盘;
- WAL 文件的总大小超过 max_total_wal_size。在这个场景,有着最老数据的 memtable 会被落盘,这样才允许携带有跟这个 memtable 相关数据的 WAL 文件被删除。
WAL
RocksDB 中的每个更新操作都会写到两个地方:
- 一个内存数据结构,名为 memtable (后面会被刷盘到SST文件)
- 写到磁盘上的 WAL 日志。在出现崩溃的时候,WAL 日志可以用于完整的恢复 memtable中的数据,以保证数据库能恢复到原来的状态。在默认配置的
情况下,RocksDB 通过在每次写操作后对 WAL 调用 fflush来保证一致性。
WAL 创建时机:
- db打开的时候;
- 一个列族落盘数据的时候;(新的创建、旧的延迟删除)
重要参数
- DBOptions::max_total_wal_size: 如果希望限制 WAL 的大小,RocksDB 使用 DBOptions::max_total_wal_size 作为列族落盘的触发器。一旦 WAL 超过这个大小,RocksDB 会开始强制列族落盘,以保证删除最老的 WAL 文件。这个配置在列族以不固定频率更新的时候非常有用。如果没有大小限制,如果这个WAL中有一些非常低频更新的列族的数据没有落盘,用户可能会需要保存非常老的WAL 文件。
- DBOptions::WAL_ttl_seconds , DBOptions::WAL_size_limit_MB:这两个选项影响 WAL 文件删除的时间。非0参数表示时间和硬盘空间的阈值,超过这个阀值,会触发删除归档的WAL文件。
Immutable MemTable
- Immutable MemTable 也是存储在内存中的数据,不过是**只读**的内存数据;
- 当 MemTable 写满后,会被置为只读状态,变成 ImmutableMemTable。然后会创建一块新的 MemTable 来提供写入操作;Immutable MemTable 将异步flush 到 SST 中;
SST
SST (Sorted String Table) 有序键值对集合;是 LSM-Tree 在磁盘中的数据结构;可以通过建立 key 的索引以及布隆过滤器来加快 key 的查询;LSM-Tree 会将所有的 DML 操作记录保存在内存中,继而批量顺序写到磁盘中;这与 B+ Tree 有很大不同,B+ Tree 的数据更新直接需要找到原数据所在页并修改对应值;而 LSM-Tree 是直接 append 的方式写到磁盘;虽然后面会通过合并的方式去除冗余无效的数据;
BlockCache
- 块缓存是 RocksDB 在内存中缓存数据以用于读取的地方。用户可以带上一个期望的空间大小,传一个 Cache 对象给 RocksDB实例。一个缓存对象可以在同一个进程的多个 RocksDB 实例之间共享,这允许用户控制总的缓存大小。块缓存存储未压缩过的块。用户也可以选择设置另一个块缓存,用来存储压缩后的块。读取的时候会先拉去未压缩的数据块的缓存,然后才拉取压缩数据块的缓存。在打开直接 IO 的时候压缩块缓存可以替代OS 的页缓存。
- RocksDB 里面有两种实现方式,分别叫做 LRUCache 和 ClockCache。两个类型的缓存都通过分片来减轻锁冲突。容量会被平均的分配到每个分片,分片间不共享空间。默认情况下,每个缓存会被分片到 64 个分片,每个分片至少有 512 B 空间。
- 用户可以选择将索引和过滤块缓存在 BlockCache 中;默认情况下,索引和过滤块都在 BlockCache 外面存储;
LRU 缓存
默认情况下,RocksDB 会使用 LRU 块缓存实现,空间为8MB。每个缓存分片都维护自己的 LRU 列表以及自己的查找哈希表。通过每个分片持有一个互斥锁来实现并发。不管是查找还是插入,都需要申请该分片的互斥锁。用户可以通过调用NewLRUCache 创建一个 LRU 缓存;
Clock缓存
- ClockCache 实现了CLOCK算法。每个clock缓存分片都维护一个缓存项的环形列表。一个clock指针遍历这个环形列表来找一个没有固定(unpinned block)的项进行驱逐,同时,如果在上一个扫描中他被使用过了,那么给予这个项两次机会来留在缓存里。tbb::concurrent_hash_map 被用来查找数据。
- 与 LRU 缓存比较,clock 缓存有更好的锁粒度。在 LRU 缓存下面,每个分片的互斥锁在读取的时候都需要上锁,因为他需要更新他的 LRU 列表。在一个 clock 缓存上查找数据不需要申请该分片的互斥锁,只需要搜索并行的哈希表就行了,所以有更好锁粒度。只有在插入的时候需要每个分片的锁。用 clock 缓存,在一定环境下,我们能看到读性能的增长;
写入流程
-
- 写入位于磁盘中的 WAL(Write Ahead Log)里。
-
- 写入memtable。
-
- 当大小达到一定阈值后,原有的memtable冻结变成immutable。后续的写入交接给新的memtable和WAL。
-
- 后台开启 Compaction 线程,开始将immutable落库变成一个L0 层的SSTable,写入成功后释放掉以前的 WAL。
-
- 若插入新的SSTable后,当前层(Li)的总文件大小超出了阈值,会从Li中挑选出一个文件,和Li+1层的重叠文件继续合并,直到所有层的大小都小于阈值。合并过程中,会保证L1以后,各SSTable的Key不重叠。
读取流程
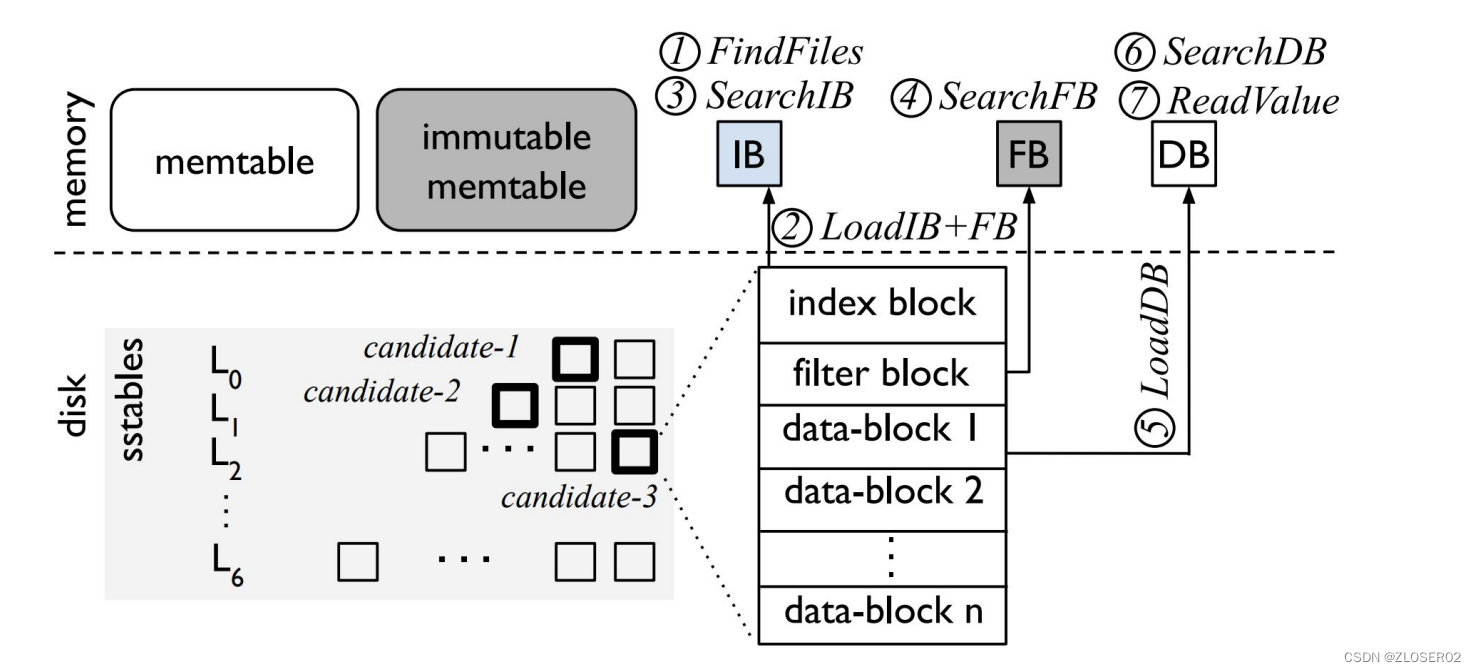
-
- FindFiles。从SST文件中查找,如果在 L0,那么每个文件都得读,因为 L0 不保证Key不重叠;如果在更深的层,那么Key保证不重叠,每层只需要读一个 SST 文件即可。L1 开始,每层可以在内存中维护一个 SST的有序区间索引,在索引上二分查找即可;
-
- LoadIB + FB。IB 和 FB 分别是 index block 和 filterblock 的缩写。index block是SST内部划分出的block的索引;filter block 则是一个布隆过滤器(Bloom Filter),可以快速排除 Key 不在的情况,因此首先加载这两个结构;
-
- SearchIB。二分查找 index block,找到对应的block;
-
- SearchFB。用布隆过滤器过滤,如果没有,则返回;
-
- LoadDB。则把这个block加载到内存;
-
- SearchDB。在这个block中继续二分查找;
-
- ReadValue。找到 Key后读数据,如果考虑 WiscKey KV分离的情况,还需要去 vLog 中读取;
LSM-Tree 三大问题
读放大
用来描述数据库必须物理读取的字节数相较于返回的字节数之比。和数据分层存放,读取操作也需要分层依次查找,直到找到对应数据;这个过程可能涉及多次 IO;在 range query 的时候,影响更大;
空间放大
用来描述磁盘上存储的数据字节数相较于数据库包含的逻辑字节数之比;所有的写入操作都是顺序写,而不是就地更新,无效数据不会马上被清理掉;
写放大
用来描述实际写入磁盘的数据大小和程序要求写入的数据大小之比;为了减小读放大和空间放大,RocksDB 采用后台线程合并数据的方式来解决;这些合并过程中会造成对同一条数据多次写入磁盘;
列族(column family)
RocksDB 的每个键值对都与唯一一个列族(column family)结合。如果没有指定 Column Family,键值对将会结合到“default” 列族。
列族提供了一种从逻辑上给数据库分片的方法。他的一些有趣的特性包括:
- 支持跨列族原子写。意味着你可以原子执行Write({cf1,key1,value1},{cf2,key2,value2}) 。
- 跨列族的一致性视图。
- 允许对不同的列族进行不同的配置
- 即时添加/删除列族。两个操作都是非常快的。
实现:
- 列族的主要实现思想是他们共享一个 WAL 日志,但是不共享memtable 和 table 文件。通过共享 WAL 文件实现了原子写。通过隔离 memtable 和 table 文件,我们可以独立配置每个列族并且快速删除它们。
- 每当一个单独的列族刷盘,我们创建一个新的 WAL 文件。所有列族的所有新的写入都会去到新的 WAL 文件。但是,我们还不能删除旧的 WAL,因为他还有一些对其他列族有用的数据。我们只能在所有的列族都把这个 WAL 里的数据刷盘了,才能删除这个 WAL 文件。这带来了一些有趣的实现细节以及一些有趣的调优需求。确保你的所有列族都会有规律地刷盘。另外,看一下Options::max_total_wal_size,通过配置他,过期的列族能自动被刷盘。
事务
当使用 TransactionDB 或者 OptimisticTransactionDB 的时候,RocksDB 将支持事务。事务带有简单的BEGIN/COMMIT/ROLLBACK API,并且允许应用并发地修改数据,具体的冲突检查,由 RocksDB 来处理。RocksDB 支持悲观
和乐观的并发控制。
注意,当通过 WriteBatch 写入多个 key 的时候,RocksDB 提供原子化操作。事务提供了一个方法,来保证他们只会在没有冲突的时候被提交。与WriteBatch 类似,只有当一个事务交,其他线程才能看到被修改的内容(读 committed)。
悲观事务(TransactionDB)
- 当使用 TransactionDB 的时候,所有正在修改的 RocksDB 里的 key 都会被上锁,让 RocksDB 执行冲突检测。如果一个 key发生锁冲突,操作会返回一个错误。当事务被提交,数据库保证这个事务是可以写入的。
- 一个 TransactionDB 在有大量并发工作压力的时候,相比OptimisticTransactionDB 有更好的表现。然而,由于非常过激的上锁策略,使用 TransactionDB 会有一定的性能损耗。
- TransactionDB 会在所有写操作的时候做冲突检查,包括不使用事务写入的时候。
乐观事务(OptimisticTransactionDB)
- 乐观事务提供轻量级的乐观并发控制,用来给那些多个事务间不会有高的竞争或者干涉的工作场景。
- 乐观事务在预备写的时候不使用任何锁。作为替代,他们把这个操作推迟到在提交的时候检查,是否有其他人修改了正在进行的事务。如果和另一个写入有冲突(或者他无法做决定),提交会返回错误,并且没有任何 key 都不会被写入。
- 乐观的并发控制在处理那些偶尔出现的写冲突非常有效。然而,对于那些大量事务对同一个 key 写入导致写冲突频繁发生的场景,却不是一个好主意。对于这些场景,使用TransactionDB 是更好的选择。OptimisticTransactionDB 在大量非事务写入,而少量事务写入的场景,会比 TransactionDB性能更好。
相关文章:
RocksDB实现原理
文章目录 简介编译安装RocksDB压缩库UbuntuCentos 基本接口高度分层架构LSM-Tree关于访问速度 MemTable落盘策略 WALRocksDB 中的每个更新操作都会写到两个地方:WAL 创建时机:重要参数 Immutable MemTableSSTBlockCacheLRU 缓存Clock缓存 写入流程读取流…...

mysql 链接超时的几个参数详解
mysql5.7版本中,先查看超时设置参数,我们这里只关注需要的超时参数,并不是全都讲解 show variables like %timeout%; connect_timeout 指的是连接过程中握手的超时时间,在5.0.52以后默认为10秒,之前版本默认是5秒,主…...
[架构之路-259]:目标系统 - 设计方法 - 软件工程 - 软件设计 - 架构设计 - 面向服务的架构SOA与微服务架构(以服务为最小的构建单位)
目录 前言: 二、软件架构层面的复用 三、什么是面向服务的架构SOA 3.1 什么是面向服务的架构 3.2 面向服务架构的案例 3.3 云服务:everything is service一切皆服务 四、什么是微服务架构 4.1 什么是微服务架构 4.2 微服务架构的案例 五、企业…...
7z压缩成jar包
比如我们要改下jar包中的某个文件,或者更换一下,那么就要先解压。解压后是这样的 弄好后,使用7z进行压缩,7z默认是标准压缩,会把BOOT-INF\lib 目录下的jar包也进行一次压缩,这会导致java -jar 会报 jar包相…...

python-缩进式编码+算术运算符+定义与赋值代码示例
文章目录 一、缩进式编码二、算术运算符三、定义与赋值关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品Python学习书籍四、Python工具包项目源码合集①Python工具包②Python实战案例③Python小游戏源码五、面试资料六、Python兼职渠道 一、…...

APM性能分享观看有感
应用性能监控是什么 应用 ios,app,pc 性能 performance用户体验,注重快:流畅,稳:崩溃,省:资源占用省 监控那些性能 一,快: 1.启动监控:冷启…...

免费好用的API接口攻略
台风信息查询:提供西北太平洋及南海地区过去两年及当前年份所有编号台风的信息查询,包括台风实时位置、过去路径、预报路径及登陆信息等要素。短信验证码:可用于登录、注册、找回密码、支付认证等等应用场景。支持三大运营商,3秒可…...

五、C#笔记
/// <summary> /// 第八章:理解值和引用 /// </summary> namespace Chapter8 { class Program { static void Main(string[] args) { //8.1复制值类型的变量和类 int i 42; int copyi i…...
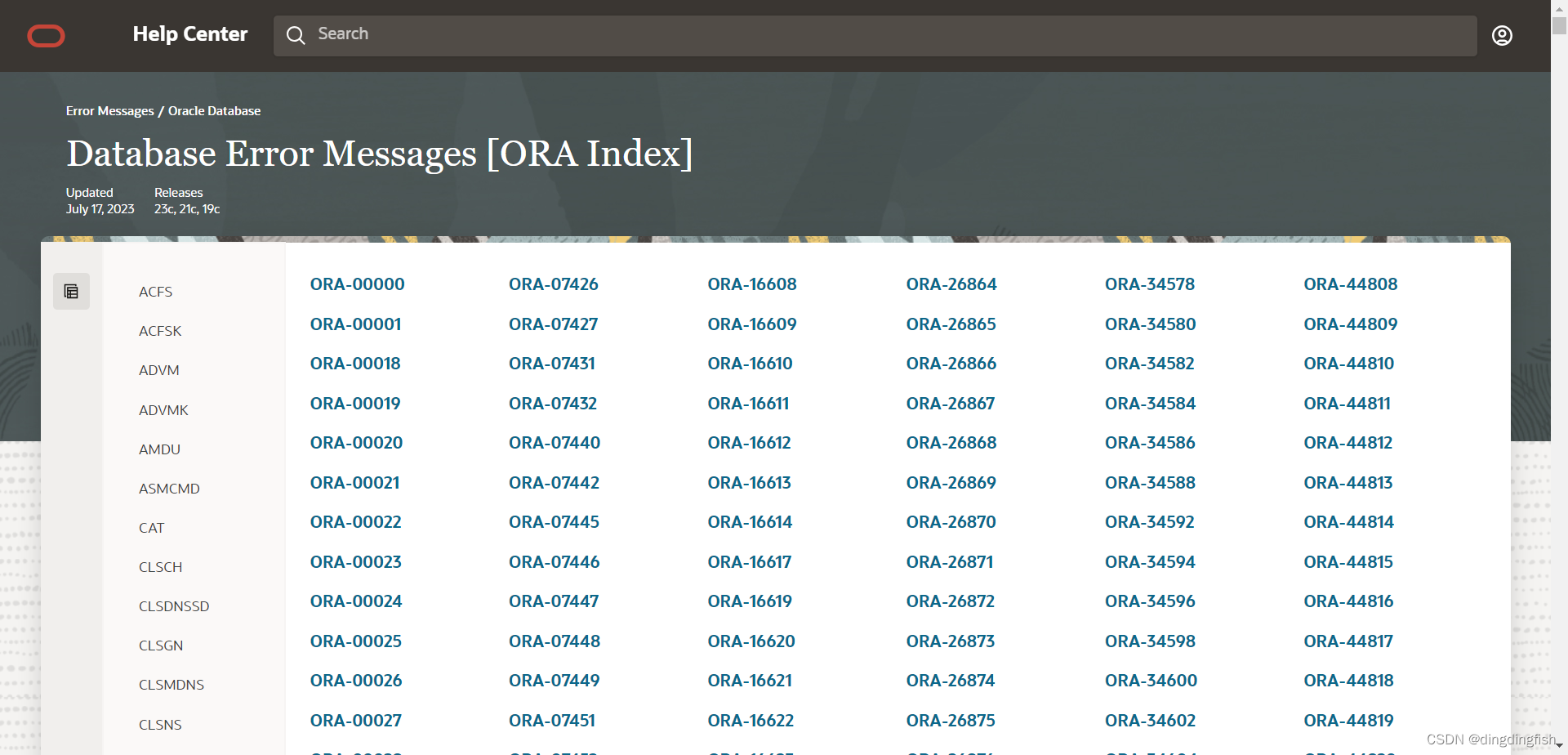
Oracle的错误信息帮助:Error Help
今天看手册时,发现上面有个提示: Error messages are now available in Error Help. 点击 View Error Help,显示如下,其实就是oerr命令的图形化版本: 点击Database Error Message Index,以下界面等同于命令…...
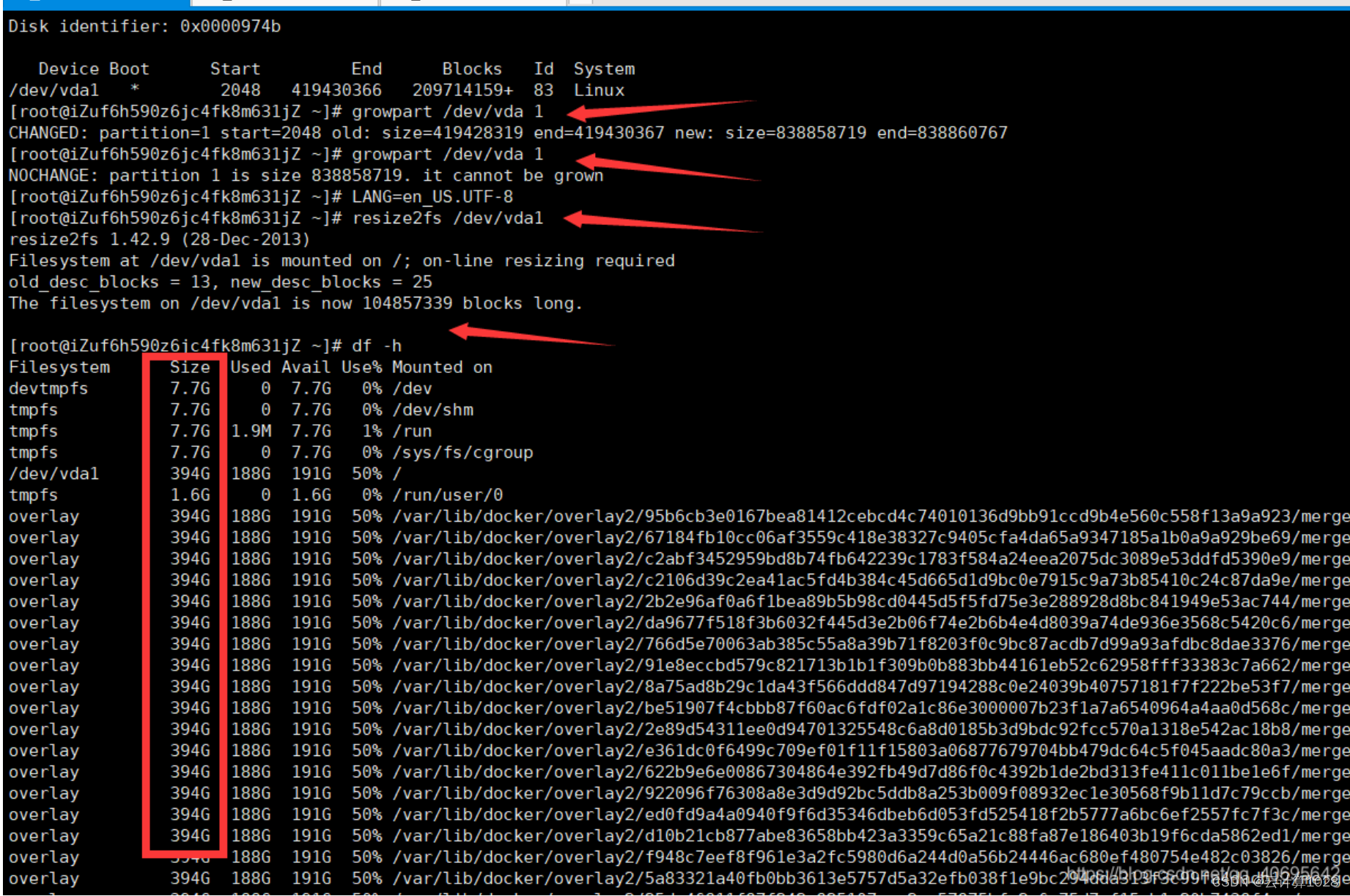
阿里云磁盘在线扩容
我们从阿里云的控制面板中给硬盘扩容后结果发现我们的磁盘空间并没有改变 注意:本次操作是针对CentOS 7的 #使用df -h并没有发现我们的磁盘空间增加 #使用fdisk -l发现确实还有部分空间 运行df -h命令查看云盘分区大小。 以下示例返回分区…...
OpenCV图像相似性比对算法
背景 在做图像处理或者计算机视觉相关的项目的时候,很多时候需要我们对当前获得的图像和上一次的图像做相似性比对,从而找出当前图像针对上一次的图像的差异性和变化点,这需要用到OpenCV中的一些图像相似性和差异性的比对算法,在O…...
)
RedHat8.1安装mysql5.6(GLIBC方式)
安装包下载链接下载链接 https://dev.mysql.com/downloads/file/?id492142 [rootlocalhost ~]# ls //查看压缩包 anaconda-ks.cfg Desktop Documents Downloads initial-setup-ks.cfg Music mysql-5.6.47-linux-glibc2.12-x86_64.tar.gz Pictures Public Templates…...

数据结构之插入排序
目录 前言 插入排序 直接插入排序 插入排序的时间复杂度 希尔排序 前言 在日常生活中,我们不经意间会遇到很多排序的场景,比如在某宝,某东上买东西,我们可以自己自定义价格是由高到低还是由低到高,再比如在王者某…...

2023年江西省“振兴杯”网络信息行业(信息安全测试员)职业技能竞赛 Write UP
文章目录 一、2023csy-web1二、2023csy-web2三、2023csy-web3四、2023csy-web4五、2023csy-misc1六、2023csy-misc2七、2023csy-crypto1八、2023csy-re1 一、2023csy-web1 该题提供一个web靶场,《伟大的挑战者》,分值:5分 web页面一直在播放c…...

【5G PHY】5G NR 如何计算资源块的数量?
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…...

解决oracle.sql.TIMESTAMP序列化转换失败问题 及 J2EE13Compliant原理
目录 报错现象报错内容处理方法Oracle驱动源码总结 报错现象 oracle表中存在TIMESTAMP类型的列时,jdbc查出来做序列化时报错 报错内容 org.springframework.web.util.NestedServletException: Request processing failed; nested exception is org.springframewo…...
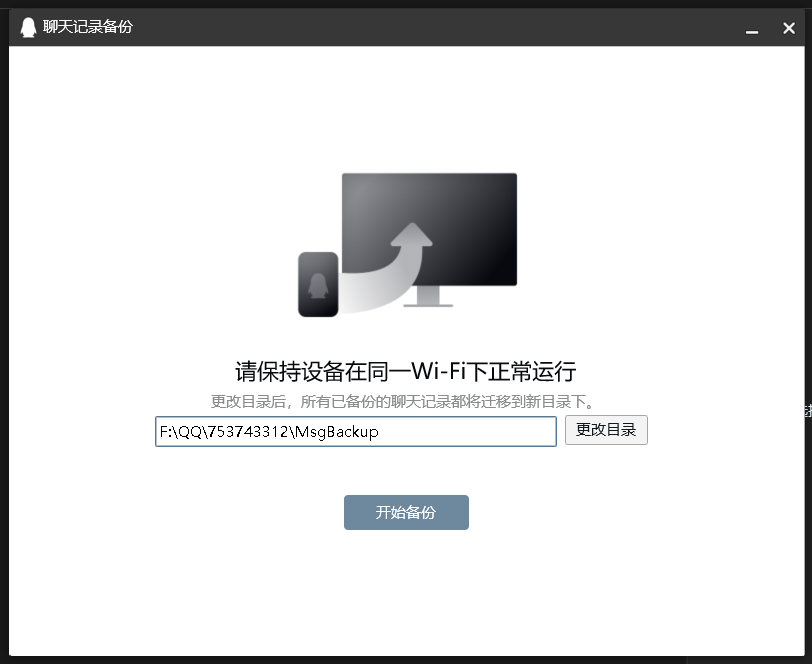
QQ2023备份
需要修改的路径(共3处) 这三处路径中,只有一处是需要修改的 QQPC端-主菜单-设置-基本设置-文件管理 点击上面的“”自定义“”,然后修改路径即可 修改路径后提示 然后等一会才会关干净QQ的相关进程,关闭后才会有自动…...
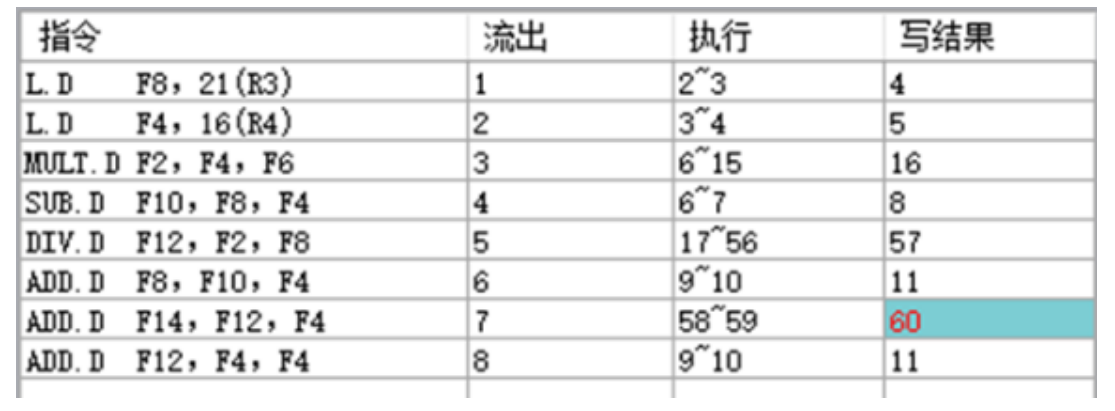
HNU计算机结构体系-实验2:CPU动态指令调度Tomasulo
文章目录 实验2 CPU动态指令调度Tomasulo一、实验目的二、实验说明三、实验内容问题1:问题2:问题3:问题4:问题5: 四、思考题问题1:问题2: 五、实验总结 实验2 CPU动态指令调度Tomasulo 一、实验…...

智慧城市是什么?为什么要建智慧城市?
智慧城市是一个通过现代科技手段推动城市管理和服务创新的概念。 具体来说,它利用信息技术和创新概念,将城市的各个系统和服务集成起来,以提升城市运行效率、优化城市管理和服务,改善市民的生活质量。 为什么要建智慧城市呢&…...
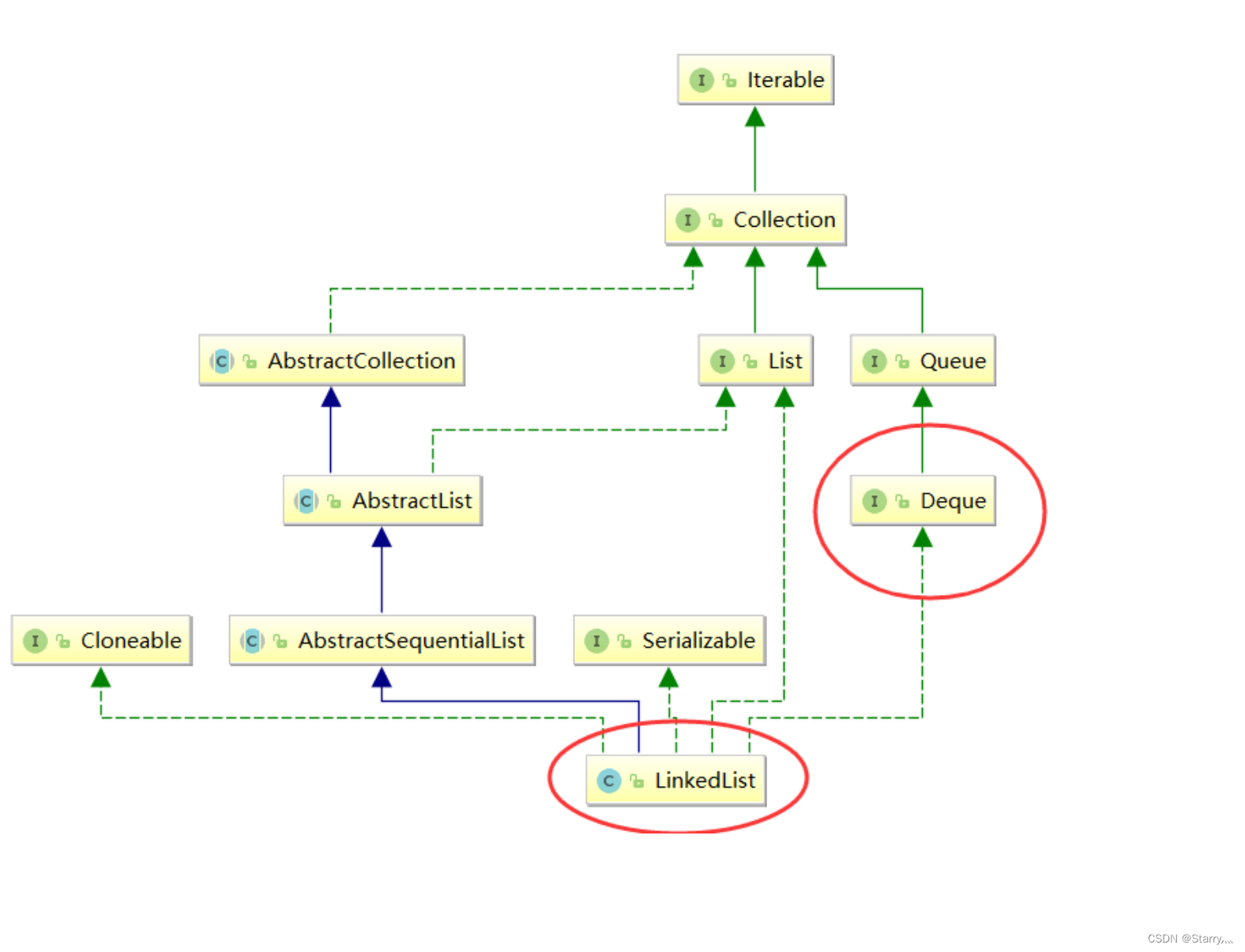
数据结构线性表-栈和队列的实现
1. 栈(Stack) 1.1 概念 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈 顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。 …...

SKMemory:构建AI记忆宫殿,实现跨会话连续性与情感感知
1. 项目概述:SKMemory,一个为AI打造的“记忆宫殿” 如果你和我一样,长期在AI Agent开发的第一线折腾,肯定遇到过这个让人头疼的问题:每次对话重启,Agent就像得了“健忘症”,之前聊过的关键信息、…...

大模型时代智能答案评估系统Bot Scanner解析
1. 大模型时代的答案搜索引擎:Bot Scanner深度解析在AI大模型爆发的今天,我们正面临一个前所未有的困境:当ChatGPT、Claude、Llama等模型同时回答同一个问题时,究竟该相信哪个答案?这就像在20家航空公司中手动比价&…...

如何高效获取百度文库文档:专业自动化工具完整指南
如何高效获取百度文库文档:专业自动化工具完整指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 在学术研究、工作汇报和资料收集过程中,百度文库作为中文文档资源平台&a…...

终极指南:如何3步绕过Cursor API限制,实现无限免费使用Pro功能
终极指南:如何3步绕过Cursor API限制,实现无限免费使用Pro功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: You…...

URP 与 Built-in 渲染管线SubShader Pass 执行机制全解
01渲染管线总览:Built-in vs URP/HDRPUnity 渲染管线历史上经历了两个重要时代。早期的 Built-in Render Pipeline(内置管线,也称 Legacy Pipeline)是随 Unity 3/4/5 时代共同成长的"老一代"渲染架构,功能齐…...

DLSS Swapper:游戏DLSS版本管理与性能优化全攻略
DLSS Swapper:游戏DLSS版本管理与性能优化全攻略 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 对于追求极致游戏体验的PC玩家来说,DLSS(深度学习超级采样)技术已成为现…...

手把手调出‘漂亮’的失真波形:电赛E题中三极管截止、饱和与交越失真的仿真与实战调整
手把手调出‘漂亮’的失真波形:电赛E题中三极管截止、饱和与交越失真的仿真与实战调整 在电子设计竞赛的实战环节,失真波形的设计与调试往往是区分普通作品与优秀作品的关键。许多参赛者在面对"双向失真波形"这类题目时,常常陷入理…...
)
保姆级教程:在uni-app中集成FFmpeg 7.1播放RTSP流(Android原生插件实战)
在uni-app中集成FFmpeg 7.1实现RTSP流播放的完整指南 跨平台开发中处理实时视频流一直是技术难点,尤其是RTSP协议的视频流播放。本文将手把手带你完成从FFmpeg编译到uni-app插件集成的全流程,解决Android平台下RTSP播放的痛点问题。 1. 环境准备与FFmp…...

手把手调试UEFI文本模式:用OVMF和QEMU探索GraphicsConsoleDxe支持的行列数
深入解析UEFI文本模式:从像素到字符的转换机制 在UEFI固件开发领域,图形显示系统的调试一直是工程师们面临的核心挑战之一。当我们在OVMF模拟环境中看到清晰的命令行界面时,背后实际上经历了一系列复杂的像素到字符的转换过程。本文将带您深…...

离散制造业生产流程优化,AI落地实操步骤详解:从传统自动化到企业级智能体的技术范式跃迁
在2026年的工业版图中,离散制造业正处于一场前所未有的范式转移中心。随着“多品种、小批量、定制化”需求成为市场常态,传统的以固定规则驱动的自动化体系已难以应对生产流程中的高频波动。AI技术,尤其是企业级智能体(Enterprise…...