urllib爬虫 应用实例(三)
目录
一、 ajax的get请求豆瓣电影第一页
二、ajax的get请求豆瓣电影前十页
三、ajax的post请求肯德基官网
一、 ajax的get请求豆瓣电影第一页
目标:获取豆瓣电影第一页的数据,并保存为json文件
设置url,检查 --> 网络 --> 全部 --> top_list --> 标头 --> 请求URL
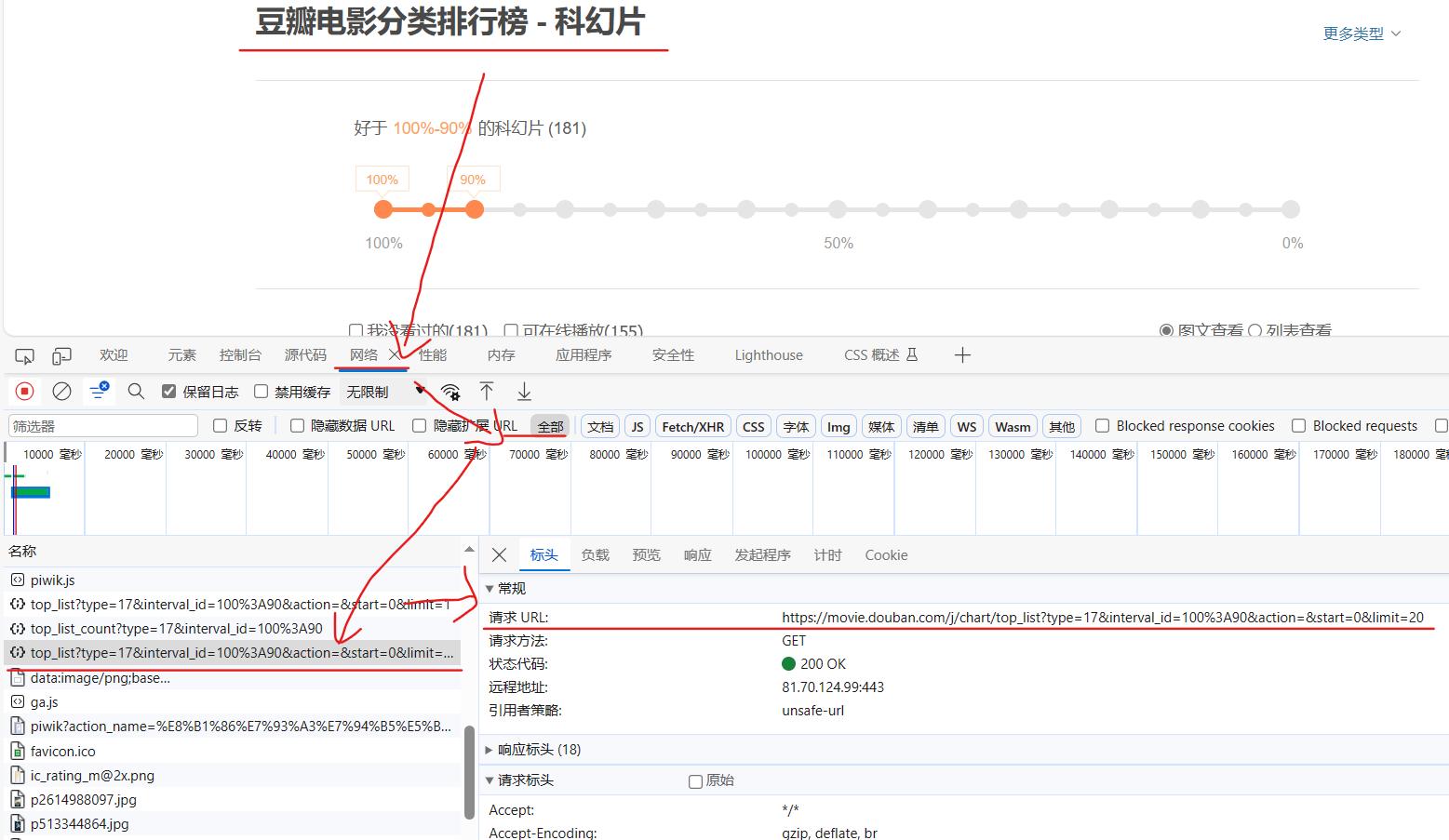
完整代码:
import urllib.request"""
# get请求
# 获取豆瓣电影第一页的数据,并保存为json文件
"""
url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}# 请求对象的定制
request = urllib.request.Request(url, headers=headers)# 获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)# 数据下载到本地
with open('douban.json','w', encoding='utf-8') as file:file.write(content)# import json
# with open('douban.json','w', encoding='utf-8') as file:
# json.dump(content, file, ensure_ascii=False)
"""
通常是因为默认情况下,json.dump() 使用的编码是 ASCII,不支持包含非ASCII字符(如中文)的文本。为了在 JSON 文件中包含中文字符,你可以指定 ensure_ascii=False 参数,以确保不将中文字符转换为 Unicode 转义序列。
"""
二、ajax的get请求豆瓣电影前十页
目标:下载豆瓣电影前十页的数据
知识点:问题的关键在于观察url的规律,然后迭代获取数据
1.设置url
找规律
点击top_list获取第一页的request url,复制url,点击清空,下拉滚动条,再次出现top_list时复制第二页的request url,重复操作,我们可以找到规律。

观察链接,可以看到page和start之间的关系
# url 规律
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=40&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=60&limit=20'# page 1 2 3 4
# start 0 20 40 602.定义请求对象定制的函数
def create_request(page):base_url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&'data={'start':(page-1)*20,'limit':20}data = urllib.parse.urlencode(data)url = base_url+dataheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}# 请求对象的定制request = urllib.request.Request(url, headers=headers)return request3.定义获取响应的数据的函数
def get_content(request):# 获取响应的数据response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return content4.定义下载函数
def down_load(content,page):with open('daouban_'+str(page)+'.json','w',encoding='utf-8') as file:file.write(content)5.调用这些函数,完成数据抓取
start_page = int(input("请输入起始页码"))
end_page = int(input("请输入结束的代码"))for page in range(start_page, end_page+1):# 请求对象的定制request = create_request(page)# 获取响应的数据content = get_content(request)# 下载down_load(content,page)print(f"done_{page}")完整代码
import urllib.request
import urllib.parse
# url 规律
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=0&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=40&limit=20'
'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=60&limit=20'# page 1 2 3 4
# start 0 20 40 60# 全部工作:下载豆瓣电影前十页的数据
# 请求对象的定制
# 获取响应的数据
# 下载数据def create_request(page):base_url = 'https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&'data={'start':(page-1)*20,'limit':20}data = urllib.parse.urlencode(data)url = base_url+dataheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}# 请求对象的定制request = urllib.request.Request(url, headers=headers)return requestdef get_content(request):# 获取响应的数据response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentdef down_load(content,page):with open('daouban_'+str(page)+'.json','w',encoding='utf-8') as file:file.write(content)start_page = int(input("请输入起始页码"))
end_page = int(input("请输入结束的代码"))for page in range(start_page, end_page+1):# 请求对象的定制request = create_request(page)# 获取响应的数据content = get_content(request)# 下载down_load(content,page)print(f"done_{page}")
三、ajax的post请求肯德基官网
目标:查询肯德基某地区餐厅前十页的信息
1.设置url
进入肯德基官网,点击餐厅查询,右键检查
网络 --> 名称 --> 标头 --> 请求URL
然后点击清空(左上角的 ∅),点击第二页,再次获取链接信息及负载中的表单数据,找规律

可以找到如下规律
pageIndex就是页码
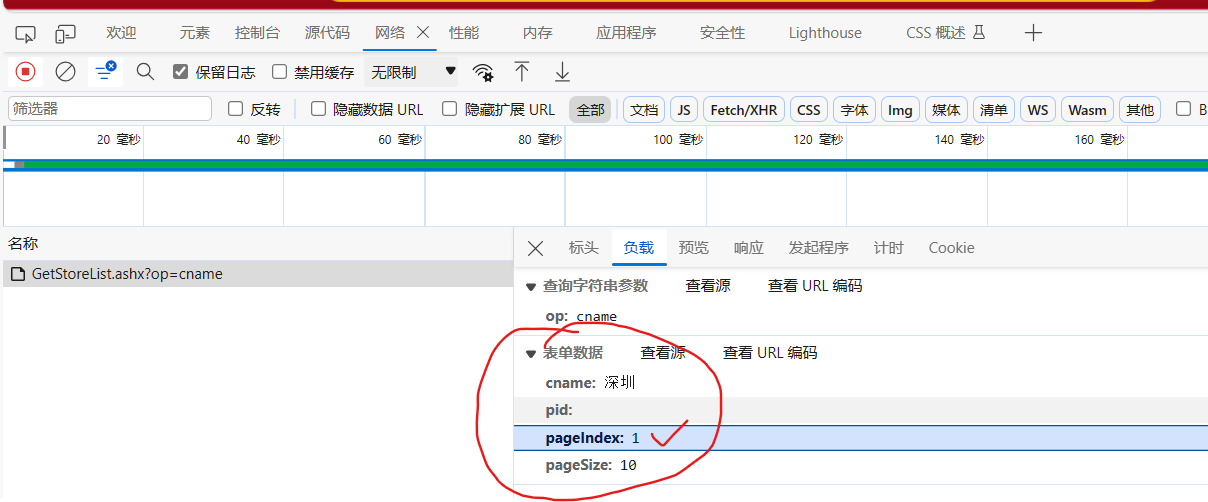
# 第1页
# cname: 深圳
# pid:
# pageIndex: 1
# pageSize: 10# 第2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 深圳
# pid:
# pageIndex: 2
# pageSize: 102.定义请求对象地址的函数
def create_request(page):base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'data={'cname': '深圳','pid': '','pageIndex': page,'pageSize': '10'}data = urllib.parse.urlencode(data).encode('utf-8')headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}request = urllib.request.Request(base_url, data, headers)return request3.获取网页源码
def get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return content4.下载
def download(content, page):with open ('kfc_'+str(page)+'.json','w',encoding='utf-8') as file:file.write(content)5.调用函数
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page+1):# 请求对象定制response = create_request(page)# 获取网页源码content = get_content(response)# 下载1download(content, page)完整代码:
import urllib.request
import urllib.parse# 第1页
# cname: 深圳
# pid:
# pageIndex: 1
# pageSize: 10# 第2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 深圳
# pid:
# pageIndex: 2
# pageSize: 10def create_request(page):base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'data={'cname': '深圳','pid': '','pageIndex': page,'pageSize': '10'}data = urllib.parse.urlencode(data).encode('utf-8')headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"}request = urllib.request.Request(base_url, data, headers)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentdef download(content, page):with open ('kfc_'+str(page)+'.json','w',encoding='utf-8') as file:file.write(content)start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page+1):# 请求对象定制response = create_request(page)# 获取网页源码content = get_content(response)# 下载1download(content, page)参考
尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)
相关文章:
urllib爬虫 应用实例(三)
目录 一、 ajax的get请求豆瓣电影第一页 二、ajax的get请求豆瓣电影前十页 三、ajax的post请求肯德基官网 一、 ajax的get请求豆瓣电影第一页 目标:获取豆瓣电影第一页的数据,并保存为json文件 设置url,检查 --> 网络 --> 全部 -…...

【数据挖掘】国科大苏桂平老师数据库新技术课程作业 —— 第三次作业
part 1 设计一个学籍管理小系统。系统包含以下信息: 学号、学生姓名、性别、出生日、学生所在系名、学生所在系号、课程名、课程号、课程类型(必修、选修、任选)、学分、任课教师姓名、教师编号、教师职称、教师所属系名、系号、学生所选课…...
TP5上传图片压缩尺寸
图片上传,最简单的就是, 方法一: 修改上传限制,不让上传大于多少多少的图片 改一下size即可,默认单位是B换算成M还需要除以两次1024 方法二: 对上传的图片进行缩放,此办法网上找了不少的代码…...

使用 Tailwind CSS 完成导航栏效果
使用 Tailwind CSS 完成导航栏效果 本文将向您介绍如何使用 Tailwind CSS 创建一个漂亮的导航栏。通过逐步演示和示例代码,您将学习如何使用 Tailwind CSS 的类来设计和定制导航栏的样式。 准备工作 在开始之前,请确保已经安装了 Tailwind CSS。如果没…...
docker容器配置MySQL与远程连接设置(纯步骤)
以下为ubuntu20.04环境,默认已安装docker,没安装的网上随便找个教程就好了 拉去mysql镜像 docker pull mysql这样是默认拉取最新的版本latest 这样是指定版本拉取 docker pull mysql:5.7查看已安装的mysql镜像 docker images通过镜像生成容器 docke…...

什么是网站劫持
网站劫持是一种网络安全威胁,它通过非法访问或篡改网站的内容来获取机密信息或者破坏计算机系统。如果您遇到了网站劫持问题,建议您立即联系相关的安全机构或者技术支持团队,以获得更专业的帮助和解决方案。...
LeNet
概念 代码 model import torch.nn as nn import torch.nn.functional as Fclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__() # super()继承父类的构造函数self.conv1 nn.Conv2d(3, 16, 5)self.pool1 nn.MaxPool2d(2, 2)self.conv2 nn.Conv2d(16…...
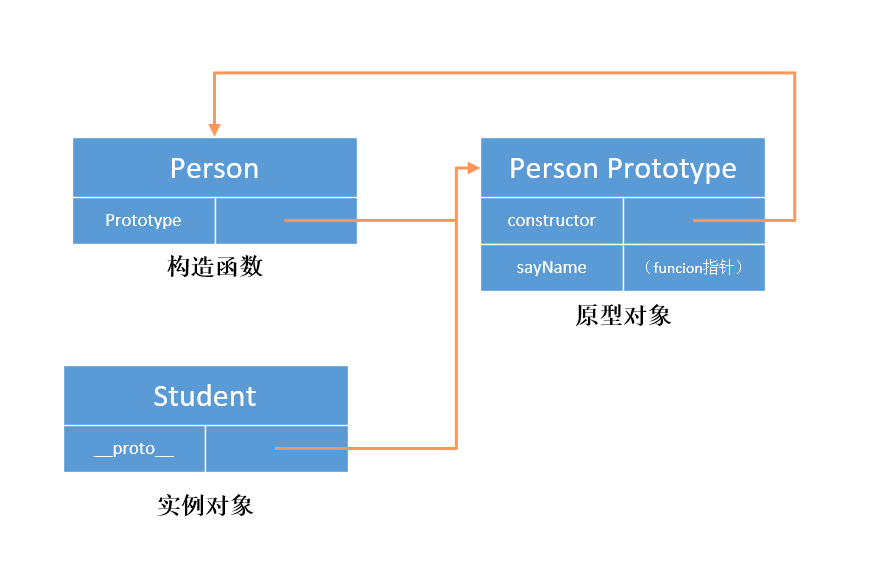
JavaScript 简单理解原型和创建实例时 new 操作符的执行操作
function Person(){// 构造函数// 当函数创建,prototype 属性指向一个原型对象时,在默认情况下,// 这个原型对象将会获得一个 constructor 属性,这个属性是一个指针,指向 prototype 所在的函数对象。 } // 为原型对象添…...
生成对抗网络——研讨会
时隔一年,再跟着李沐大师学习了GAN之后,仍旧没能在离散优化中实现通用的应用,实在惭愧,借着组内研讨会的机会,再队GAN的前世今生做一个简单的综述。 GAN产生的背景 目前与GAN相关的应用 去reddit社区的机器学习板块…...
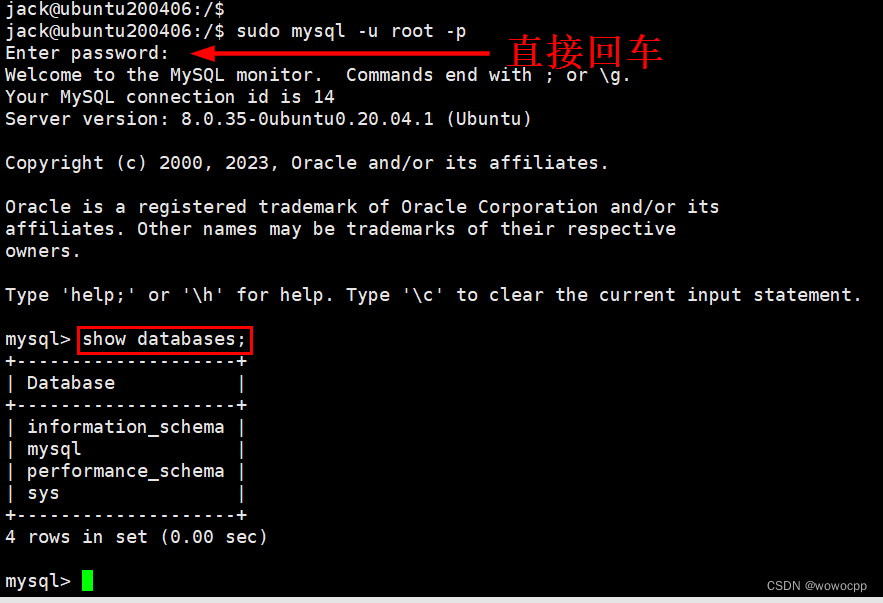
Ubuntu 20.04 安装 mysql8 LTS
Ubuntu 20.04 安装 mysql8 LTS sudo apt-get update sudo apt-get install mysql-server -y mysql --version mysql Ver 8.0.35-0ubuntu0.20.04.1 for Linux on x86_64 ((Ubuntu)) Ubuntu20.04 是自带了 MySQL8. 几版本的,低于 20.04 则默认安装是 MySQL5.7.33…...

蓝桥杯:货物摆放
小蓝有一个超大的仓库,可以摆放很多货物。 现在,小蓝有 n 箱货物要摆放在仓库,每箱货物都是规则的正方体。小蓝规定了长、宽、高三个互相垂直的方向,每箱货物的边都必须严格平行于长、宽、高。 小蓝希望所有的货物最终摆成一个大…...
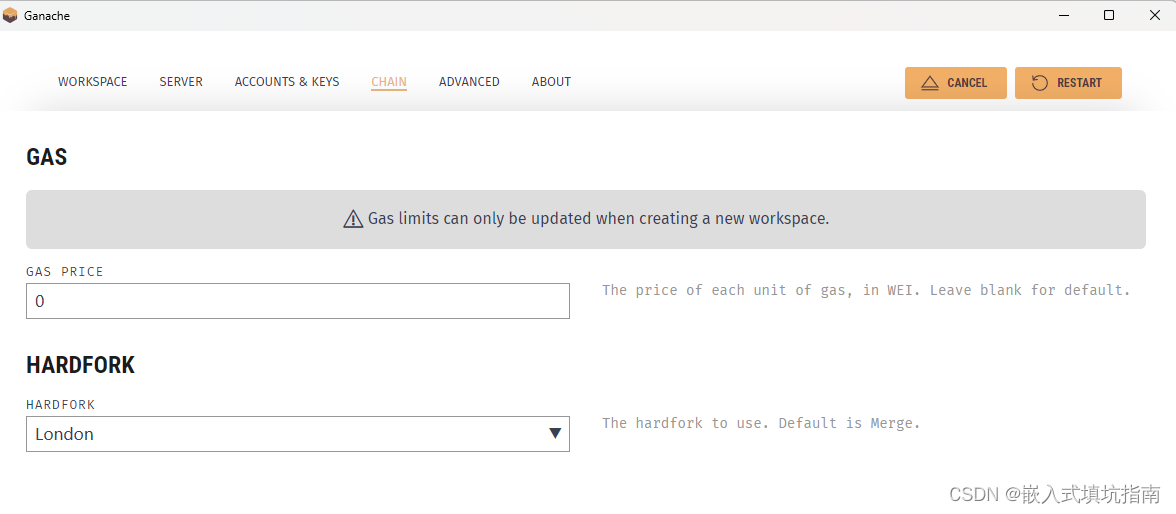
ganache部署智能合约报错VM Exception while processing transaction: invalid opcode
这是因为编译的字节码不正确,ganache和remix编译时需要选择相同的evm version 如下图所示: remix: ganache: 确保两者都选择london或者其他evm,只要确保EVM一致就可以正确编译并部署, 不会再出现VM Exception while processing…...

金融银行业更适合申请哪种SSL证书?
在当今数字化时代,金融行业的重要性日益增加。越来越多的金融交易和敏感信息在线进行,金融银行机构必须采取必要的措施来保护客户数据的安全。SSL证书作为一种重要的安全技术工具,可以帮助金融银行机构加密数据传输,验证网站身份&…...
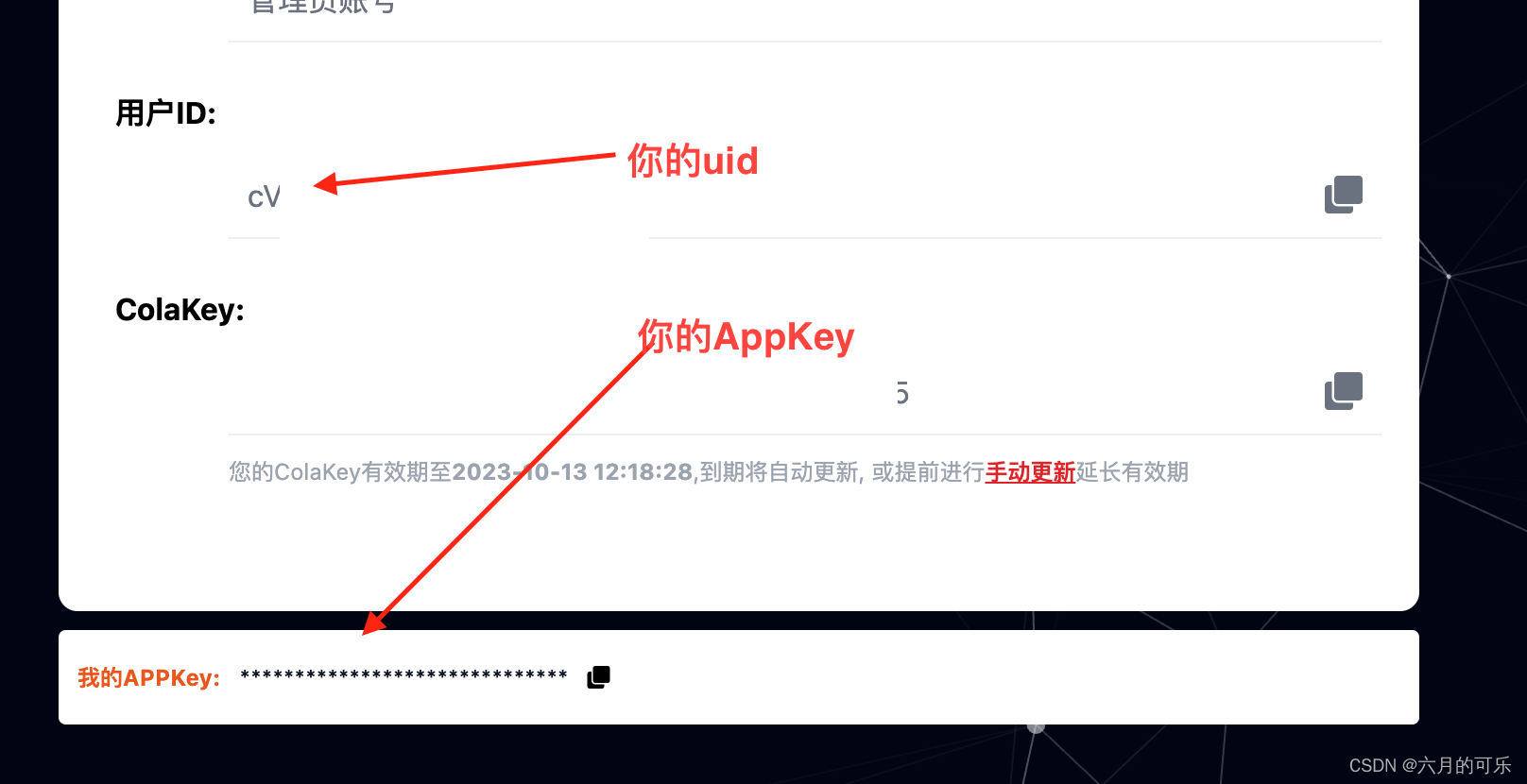
文心一言API(高级版)使用
文心一言API高级版使用 一、百度文心一言API(高级版)二、使用步骤1、接口2、请求参数3、请求参数示例4、接口 返回示例 三、 如何获取appKey和uid1、申请appKey:2、获取appKey和uid 四、重要说明 一、百度文心一言API(高级版) 基于百度文心一言语言大模型的智能文本对话AI机器…...
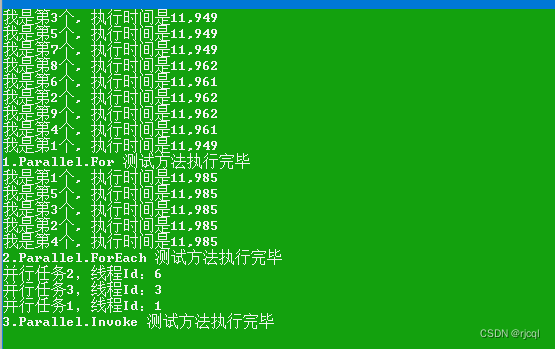
C# 任务并行类库Parallel调用示例
写在前面 Task Parallel Library 是微软.NET框架基础类库(BCL)中的一个,主要目的是为了简化并行编程,可以实现在不同的处理器上并行处理不同任务,以提升运行效率。Parallel常用的方法有For/ForEach/Invoke三个静态方法…...

2024年江苏省职业院校技能大赛信息安全管理与评估 第二阶段学生组(样卷)
2024年江苏省职业院校技能大赛信息安全管理与评估 第二阶段学生组(样卷) 竞赛项目赛题 本文件为信息安全管理与评估项目竞赛-第二阶段样题,内容包括:网络安全事件响应、数字取证调查、应用程序安全。 本次比赛时间为180分钟。 …...

飞天使-linux操作的一些技巧与知识点3
http工作原理 http1.0 协议 使用的是短连接,建立一次tcp连接,发起一次http的请求,结束,tcp断开 http1.1 协议使用的是长连接,建立一次tcp的连接,发起多次http的请求,结束,tcp断开ngi…...

Appium获取toast方法封装
一、前置说明 toast消失的很快,并且通过uiautomatorviewer也不能获取到它的定位信息,如下图: 二、操作步骤 toast的class name值为android.widget.Toast,虽然toast消失的很快,但是它终究是在Dom结构中出现过&…...

Google Guava简析
Google Guava 是Google开源的一个Java类库,对基本类库做了扩充。感觉最大的价值点在于其 集合类、Cache和String工具类。 github项目地址:GitHub - google/guava: Google core libraries for Java github文档地址:Home google/guava Wiki …...
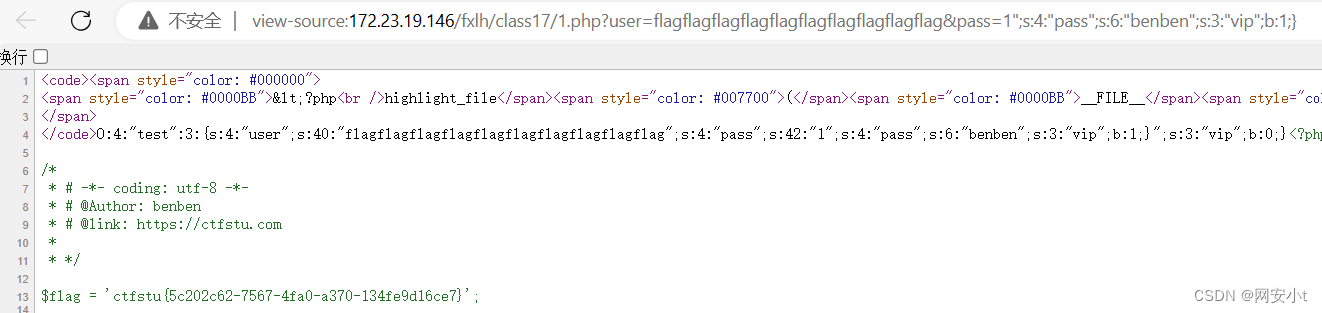
反序列化漏洞详解(二)
目录 pop链前置知识,魔术方法触发规则 pop构造链解释(开始烧脑了) 字符串逃逸基础 字符减少 字符串逃逸基础 字符增加 实例获取flag 字符串增多逃逸 字符串减少逃逸 延续反序列化漏洞(一)的内容 pop链前置知识,魔术方法触…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...