【论文极速读】LVM,视觉大模型的GPT时刻?
前言
这一周,LVM在arxiv上刚挂出不久,就被众多自媒体宣传为『视觉大模型的GPT时刻』,笔者抱着强烈的好奇心,在繁忙工作之余对原文进行了拜读,特此笔记并留下读后感,希望对诸位读者有所帮助。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇ \nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用(https://www.zhihu.com/column/c_1265262560611299328)
微信公众号:机器学习杂货铺3号店
LVM(Large Vision Models) [1] 自本月1号挂到arxiv以来,引发了众多自媒体的追捧,不乏称之为『视觉大模型的GPT时刻』的盛赞,也有不少大V对此表示持怀疑态度,这一周一直吃瓜的笔者也非常好奇,想一睹其视觉大模型的GPT风采,于是在工作之余抽空简单翻阅了下,总得来说还是受益匪浅的。
LVM的整体思想比较直白,既然NLP领域中,基于自回归的大模型(如GPT、LLaMA等)已经取得令人瞩目的成功,何不将视觉的预训练任务也统一到自回归中,也许就能产生和GPT一般的『智能』呢?考虑到NLP中,最小处理单元是token(下文翻译为『令牌』,tokenization则翻译为『令牌化』),我们不能以图片的像素级别去进行自回归,何不将图片也进行『令牌化』呢?将图片也转换成一个个令牌吧!那么我们就可以用NLP原生的预训练任务,比如自回归任务进行预训练了,如Fig 1.所示,将图片令牌化到若干个令牌后,就将视觉预训练任务转化为了『文本』预训练任务,作者将这样一个通过视觉令牌构成的句子,称之为Visual Sentence,也蕴含着将视觉任务文本化的意味?

那么如何将图像进行令牌化呢?在之前的一些工作,比如VQ-VAE、VQ-GAN中曾经对图像令牌化有所考虑,读者可在笔者之前的博文[2]中简单参考其思路,同时,在BEiT v2 [3] 中也有对VQ-VAE的一些改进(引入更语义的信息),在本篇工作中,作者采用了VQ-GAN对图片进行令牌化,笔者觉得是由于LVM后续还需要对视觉令牌进行解码,生成图像(见Fig 1的decoder部分),采用VQ-GAN能提供更好的图像生成能力,向量量化的简易示意图可参考Fig 2.所示。
作者在本工作中的一个最大贡献,就是收集了一套大规模的用于LVM预训练的数据集,其中图像数据形式各种各样,来自于各种公开数据集,包括:
- 图片:一般的图片,如LAION数据集。
- 视频序列:将视频抽帧作为图片序列,此处视频类型各种各样,包括一般的视频,3D物体旋转的视频,CAD模型旋转产生不同视角的图片序列等等。
- 带有标注的图片:比如物体识别,语义分割等图片,可能包含有包围框、语义分割、图片风格转换、着色等标注在图片上。
- 带有标注的视频:如带有视频的分割标注等。
该数据集是一个纯图片数据集,没有任何配对的文本数据,具体数据收集的细节请见论文,此处不累述,作者将这个数据集命名为UVD-V1(Unified Vision Dataset),其中包含了50个公开数据集的数据,在将每张图片大小resize到256*256后,通过VQ-GAN将每个图片转化为了256个令牌后(码表大小8192),产生了4200亿个令牌(420B)。此时,每张图片/视频序列都可以描述为一个视觉短句,如
[BOS] V1, V2, V3, …, Vn [EOS]
通过自回归的方式,采用交叉熵损失去建模下一个令牌出现的概率,即是:
L v l m = ∑ i log P ( V i ∣ V 1 , ⋯ , V i − 1 ; Θ ) \mathcal{L}_{vlm} = \sum_{i} \log P(V_{i}|V_{1},\cdots,V_{i-1};\Theta) Lvlm=i∑logP(Vi∣V1,⋯,Vi−1;Θ)
这就是所谓视觉任务语言模型化,因此作者也采用了LLM的开源模型LLaMA作为底座模型建模,大致的模型建模和数据构建部分就简单介绍到这里,里面很多细节问题也不在此处讨论,笔者主要关注了下论文的实验和效果展示部分。

在实验部分,作者通过控制变量法,探讨了一些基础的模型超参数下的模型基础表现,如输入长度、模型大小、数据集消融等等的影响,具体可见原论文,笔者不进行累述,笔者主要想对论文中的图像提示词(prompt)和生成结果进行讨论。作者通过图像提示词的方式,对诸多传统的CV任务,如人体关键点检测、物体检测、视频帧预测、inpainting、去雨乃至是基础推理能力进行了研究,如Fig 3.就展示了通过提供一个视频序列的前15帧,对接续4帧进行预测的能力,能看到预测的接续4帧从视觉上看会较为趋同,但是也有一些模型『推理能力』的痕迹在里面,比如最后一个骑摩托的生成结果,有明显的从近到远离去的变化。

接下来是通过提供few-shot visual prompt,以<原图, 目标图>的形式喂给LVM进行预测的任务,如Fig 4.所示,在多种传统CV任务上都有着不俗的表现。考虑到数据集中有着3D渲染的多视角数据,作者还探索了LVM建模3D旋转的能力(用以证明LVM具有一定的三维视觉理解能力?),如Fig 5.所示,通过提供一系列将同一个3D物体进行某个方向旋转的visual prompt,LVM可以对接续的4帧进行预测。


在Fig 6.中,作者还报告了LVM对多种CV任务的组合能力,比如提供的visual prompt是3D旋转和关键点追踪两个CV任务的复合体,从生成接续的3帧来看也能得到合理的结果,表征了LVM似乎能对多种CV任务进行组合,即便这些组合在原始训练数据中可能不曾出现。



与此同时,想要成为视觉领域的GPT,那么除了基础的CV能力之外,其逻辑推理能力也不能落下,作者提供了几个visual prompt,给读者稍微一些遐想。如Fig 7,LVM对一些规律性的CV问题,比如图片内物体递增、光照变化、尺度放缩等有所感知。如Fig 8.所示,LVM能对一些找规律的题目进行一些感知。GPT有着诸多体现『智能』的表现,如
- 强大的逻辑推理能力
- 代码理解和生成能力
- 分步思考,思维链能力
- 类人的理解能力,包括一些幽默感、反讽、情绪理解等能力
- 世界知识:包括事实性知识 (factual knowledge) 和常识 (commonsense)
- …
其中的逻辑推理能力,可以说是最接近我们通常理解的『智能』的能力,我们之前展示的LVM能力,是否足以证实LVM具有和GPT一般的逻辑推理能力呢?
笔者认为似乎论据仍然不足,首先从论文提供的数据中,能看出推理能力的是Fig 8中展示的几何图形找规律任务,但是我们是从结果上的正确与否确定的,我们是否能『探知』到LVM的思考过程呢?完全没有看到,如下图所示,不像LLM能够通过自我反省的方式,让它吐出推理的过程,进而判断是否具有逻辑推理能力,以及模型推理能力的强弱。在LVM中我们只能通过给定一些具有逻辑性的视觉任务(而且还是人类认为具有逻辑性的题目,也许LVM会通过其他信号去拟合,而不是通过『逻辑推理』的方式?),通过直接输出的结果进行检测,正如笔者所说,这个方式并不是一个合适的探知推理能力的方法。此外,笔者认为推理能力依赖一些世界知识,比如实体识别能力,实体解释能力等,从文章中似乎没有看出明显的体现?LVM是否可以解释什么是苹果?什么是梨子?苹果和梨子之前有什么共同点和差异?这些能力没法从现在的LVM中看到。目前的视觉提示词的方式,似乎不容易从中探知LVM的世界知识能力?
笔者认为单纯的视觉大模型很难建模完整的逻辑推理能力(当然也不是不可能,毕竟人类以视觉识别文本,文本完全可以渲染成图片作为LVM输入,从而LVM变为通用的多模态GPT,但是我们为什么要舍弃文本呢?),逻辑推理能力依赖一些世界知识和语义,脱离了文本很难建模,并且文本作为表达需求和可以作为自我解释的手段,也是一个通用AGI模型不能舍弃的。因此笔者对LVM的评价是:一个很不错和有启发的工作,但是称之为视觉大模型的GPT时刻似乎不妥,称之为AGI更是有捧杀之意了。
当然,对于笔者来说这篇工作还有更多值得思考的,比如作者采用了视觉令牌化作为模型的直接输入进行建模这块,笔者就深表赞同。笔者在工作中也尝试以各种角度落地多模态技术,无论是从工业界遇到的问题,还是学术界研究的角度来看,视觉令牌化都是一个非常值得探索的技术。之前笔者在项目实践中觉得视觉令牌化应该是对视觉语义的提取,会失去不少视觉细节信息,但是从Fig 4来看,似乎LVM对很多偏向low-level的视觉任务都有不错的表现(包括未展示的de-rain任务),这些low-level的任务对视觉的细粒度信息应该还是有所需要的,因此这一点比较刷新作者的认识,笔者猜想可能是由于采用了VQ-GAN技术导致的视觉令牌中可以携带更多细粒度的视觉信息?毕竟在实践中,视觉词表是一个偏向于利用率不充分的存在,也许采用了VQ-GAN技术后可以更加充分利用词表,进而对细粒度有所感知。当然,这些都是笔者的一些随性猜想罢了,希望抛砖引玉得到各位读者的指教。

Reference
[1]. Bai, Yutong, et al. “Sequential Modeling Enables Scalable Learning for Large Vision Models.” arXiv preprint arXiv:2312.00785 (2023).
[2]. https://blog.csdn.net/LoseInVain/article/details/129224424,【论文极速读】VQ-VAE:一种稀疏表征学习方法
[3]. Peng, Zhiliang, Li Dong, Hangbo Bao, Qixiang Ye, and Furu Wei. “Beit v2: Masked image modeling with vector-quantized visual tokenizers.” arXiv preprint arXiv:2208.06366 (2022)
相关文章:
【论文极速读】LVM,视觉大模型的GPT时刻?
【论文极速读】LVM,视觉大模型的GPT时刻? FesianXu 20231210 at Baidu Search Team 前言 这一周,LVM在arxiv上刚挂出不久,就被众多自媒体宣传为『视觉大模型的GPT时刻』,笔者抱着强烈的好奇心,在繁忙工作之…...

TS基础语法
前言: 因为在写前端的时候,发现很多UI组件的语法都已经开始使用TS语法,不学习TS根本看不到懂,所以简单的学一下TS语法。为了看UI组件的简单代码,不至于一脸懵。 一、安装node 对于windows来讲,node版本高…...

【基于NLP的微博情感分析:从数据爬取到情感洞察】
基于NLP的微博情感分析:从数据爬取到情感洞察 背景数据集技术选型功能实现创新点 今天我将分享一个基于NLP的微博情感分析项目,通过Python技术、NLP模型和Flask框架,对微博数据进行清洗、分词、可视化,并利用NLP和贝叶斯进行情感分…...

Ubuntu 18.04使用Qemu和GDB搭建运行内核的环境
安装busybox 参考博客: 使用GDBQEMU调试Linux内核环境搭建 一文教你如何使用GDBQemu调试Linux内核 ubuntu22.04搭建qemu环境测试内核 交叉编译busybox 编译busybox出现Library m is needed, can’t exclude it (yet)的解释 S3C2440 制作最新busybox文件系统 https:…...

GEE——利用Landsat系列数据集进行1984-2023EVI指数趋势分析
简介: 利用Landsat系列数据集进行1984-2023EVI指数趋势分析其主要目的是进行长时序的分析,这里我们选用EVI指数,然后进行了4个月的分析,查看其最后的线性趋势以及分布状况。 EVI指数: EVI指数(Enhanced Vegetation Index,增强型植被指数)是一种反映植被生长状态的遥…...
JAVA安全之Spring参数绑定漏洞CVE-2022-22965
前言 在介绍这个漏洞前,介绍下在spring下的参数绑定 在Spring框架中,参数绑定是一种常见的操作,用于将HTTP请求的参数值绑定到Controller方法的参数上。下面是一些示例,展示了如何在Spring中进行参数绑定: 示例1&am…...

辨析旅行商问题(TSP)与车辆路径问题(VRP)
目录 前言旅行商问题 (TSP)问题介绍数学模型符号定义问题输入约束条件目标函数问题输出 解的空间解空间大小计算解释 车辆路径问题 (VRP)问题介绍TSP到VRP的过渡数学模型符号定义问题输入约束条件优化目标问题输出 解空间特殊情况一般情况 TSP 与 VRP 对比 前言 计划是通过本文…...

2024年JAVA招聘行情如何?
大家都在说Java求职不好找,是真的吗?我们来看看数据。 数据支持:根据TIOBE 5月份的编程语言排行榜,Java仍然是前三名之一。这意味着,Java在开发领域仍然占据重要地位。 而在中国的IT市场中,Java仍然是主要…...
【合集】SpringBoot——Spring,SpringBoot,SpringCloud相关的博客文章合集
前言 本篇博客是spring相关的博客文章合集,内容涵盖Spring,SpringBoot,SpringCloud相关的知识,包括了基础的内容,比如核心容器,springMVC,Data Access;也包括Spring进阶的相关知识&…...

yolov5 获取漏检图片脚本
yolov5 获取漏检图片脚本 获取样本分数在0.05到0.38直接的样本。 # YOLOv5 by Ultralytics, GPL-3.0 licenseimport argparse import json import os import sys import time from pathlib import Pathimport cv2 import numpy as np import torch import torch.backends.cud…...
Unity之OpenXR+XR Interaction Toolkit接入微软VR设备Windows Mixed Reality
前言 Windows Mixed Reality 是 Microsoft 用于增强和虚拟现实体验的VR设备,如下图所示: 在国内,它的使用率很低,一把都是国外使用,所以适配起来是相当费劲。 这台VR设备只能用于串流Windows,启动后,会自动连接Window的Mixed Reality程序,然后打开微软的增强现实门户…...

【小聆送书第二期】人工智能时代AIGC重塑教育
🌈个人主页:聆风吟 🔥系列专栏:网络奇遇记、数据结构 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋正文📝活动参与规则 参与活动方式文末详见。 📋正文 AI正迅猛地…...

中国移动公网IP申请过程
一、动机 由于从事互联网行业10年,一直从事移动端(前端)开发工作,未曾深入了解过后端技术,以至于工作10年也不算进入互联网的门。 所以准备在自己家用设备上搭建各种场景的服务器(云服务对个人来说成本偏…...
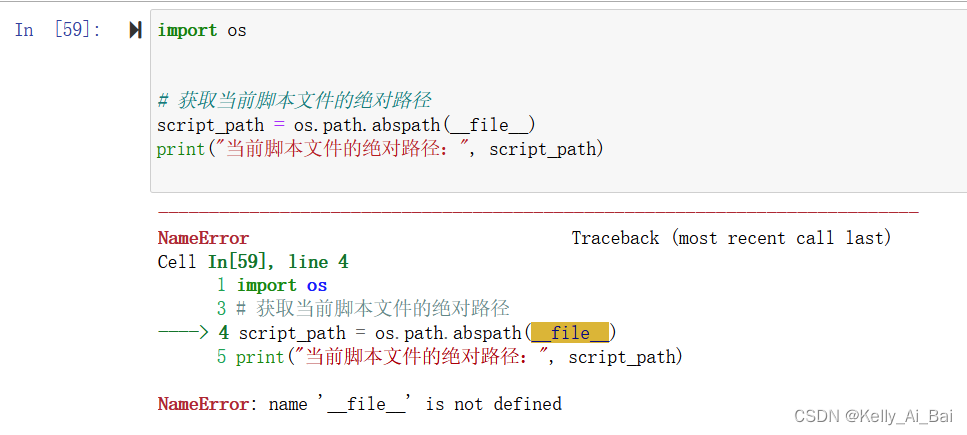
动态获取绝对路径
在Python中,可以使用 os模块 来获取当前工作目录的路径,并使用 os.path.join()函数 将相对路径与当前工作目录结合起来,形成一个动态获取的绝对路径 以下是一个简单的例子: import os# 获取当前工作目录的路径 current_director…...

pytorch中的归一化:BatchNorm、LayerNorm 和 GroupNorm
1 归一化概述 训练深度神经网络是一项具有挑战性的任务。 多年来,研究人员提出了不同的方法来加速和稳定学习过程。 归一化是一种被证明在这方面非常有效的技术。 1.1 为什么要归一化 数据的归一化操作是数据处理的一项基础性工作,在一些实际问题中&am…...
--顺序消息)
RocketMq源码分析(九)--顺序消息
文章目录 一、顺序消息二、顺序消息消费过程1、消息队列负载2、消息拉取3、消息消费4、消息进度存储 三、总结 一、顺序消息 RocketMq在同一个队列中可以保证消息被顺序消费,所以如果要做到消息顺序消费,可以将消费主题(topic)设置…...
Windows下nginx的启动,重启,关闭等功能bat脚本
echo off rem 提供Windows下nginx的启动,重启,关闭功能echo begincls ::ngxin 所在的盘符 set NGINX_PATHG:::nginx 所在目录 set NGINX_DIRG:\projects\nginx-1.24.0\ color 0a TITLE Nginx 管理程序增强版CLSecho. echo. ** Nginx 管理程序 *** echo.…...
之间的区别)
Python 字典:dic = {} 和 dic = defaultdict(list)之间的区别
d defaultdict(list) 和 d {} 在Python中代表了两种不同类型的字典初始化方式,它们之间有几个关键的区别: 1、类型 d defaultdict(list):这里使用的是 collections 模块中的 defaultdict 类。它是一个字典的子类,提供了一个默…...

绘图 Seaborn 10个示例
绘图 Seaborn 是什么安装使用显示中文及负号散点图箱线图小提琴图堆叠柱状图分面绘图分类散点图热力图成对关系图线图直方图 是什么 Seaborn 是一个Python数据可视化库,它基于Matplotlib。Seaborn提供了高级的绘图接口,可以用来绘制各种统计图形…...
airserver mac 7.27官方破解版2024最新安装激活图文教程
airserver mac 7.27官方破解版是一款好用的airplay投屏工具,可以轻松将ios荧幕镜像(airplay)至mac上,在mac平台上实现视频、音频、幻灯片等文件资源的接收及投放演示操作,解决iphone或ipad的屏幕录像问题,满…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

BLEU评分:机器翻译质量评估的黄金标准
BLEU评分:机器翻译质量评估的黄金标准 1. 引言 在自然语言处理(NLP)领域,衡量一个机器翻译模型的性能至关重要。BLEU (Bilingual Evaluation Understudy) 作为一种自动化评估指标,自2002年由IBM的Kishore Papineni等人提出以来,…...