Hadoop学习笔记(HDP)-Part.14 安装YARN+MR
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十四、安装YARN+MR
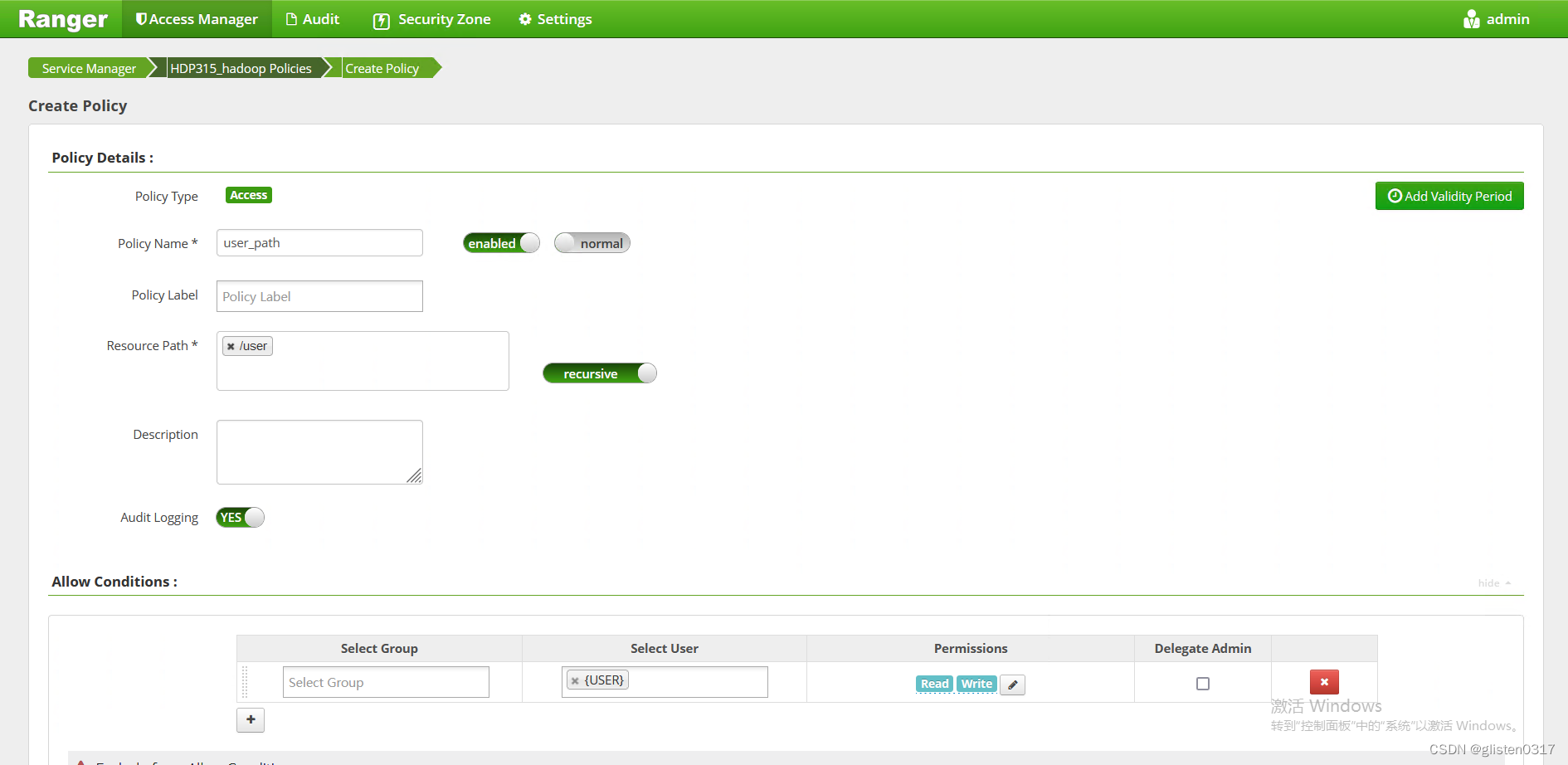
1.MR中间结果存储权限
使用Yarn提交MapReduce任务的时候,中间结果会保存在HDFS,/user/username/,如果/user目录下用户目录下不存在,则被创建,当MR执行结束之后,中间结果会被删除,目录保留。因此需要在Ranger中对/user的权限做策略。
2.安装服务
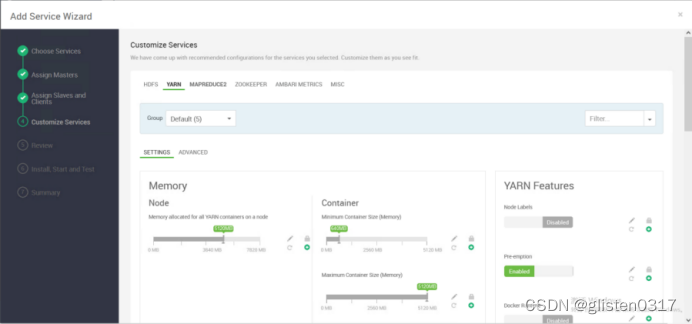
YARN的部分存储路径调整:
Node Manager
YARN NodeManager Local directories:/data01/hadoop/yarn/local
YARN NodeManager Log directories:/data01/hadoop/yarn/log
Application Timeline Server
yarn.timeline-service.leveldb-state-store.path:/data01/hadoop/yarn/timeline
yarn.timeline-service.leveldb-timeline-store.path:/data01/hadoop/yarn/timeline
Advanced yarn-hbase-env
is_hbase_system_service_launch:true
use_external_hbase:false
YARN可使用内置的HBase数据库,也可以使用外部;使用内置时,需要is_hbase_system_service_launch设置为true
Advanced ranger-yarn-security
Add YARN Authorization:取消勾选
该选项是禁用YARN本身的ACL权限控制,YARN队列的权限控制由RANGER统一管理
注:需要先对NameNode页面的认证取消了,否则ResourceManager修改后也不生效
MAPREDUCE2的部分存储路径调整:
Advanced mapred-site
mapreduce.jobhistory.recovery.store.leveldb.path:/data01/hadoop/mapreduce/jhs
Custom mapred-site
mapred.local.dir:/data01/hadoop/mapred
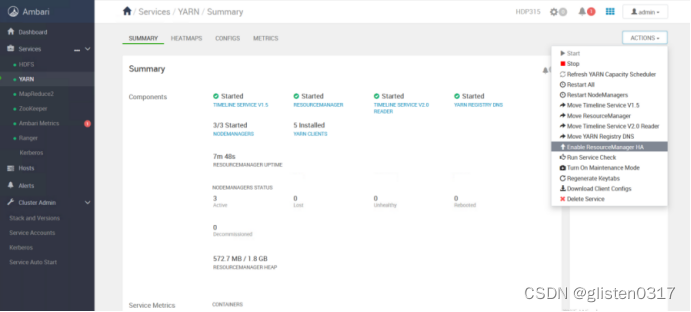
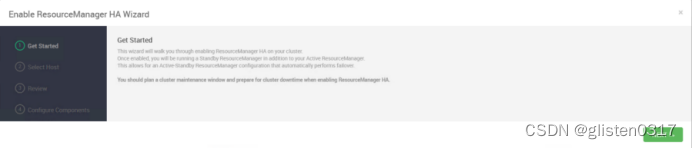
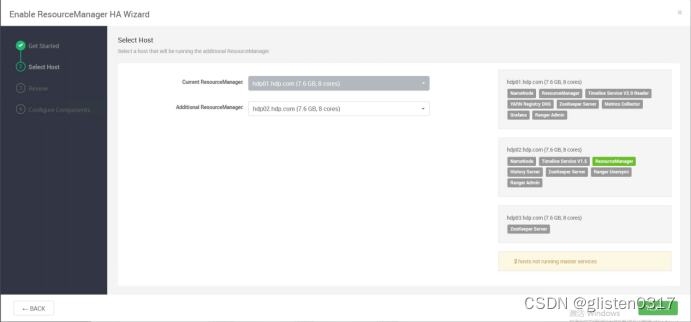
3.ResourceManager HA
(1)启用HA
在ACTIONS->Enable ResourceManager HA中配置
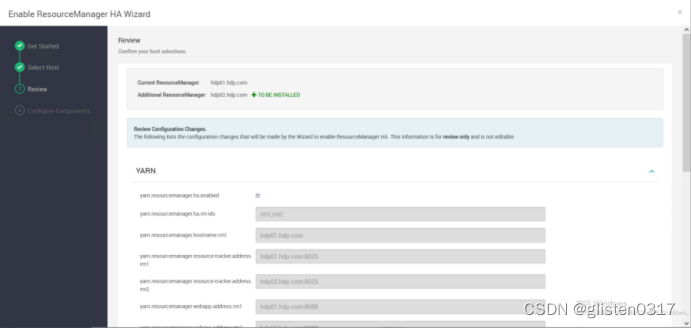
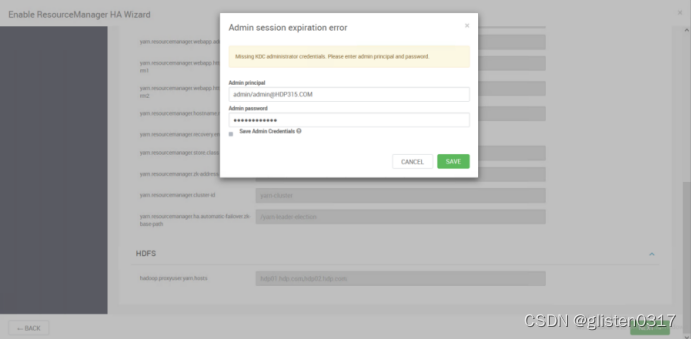
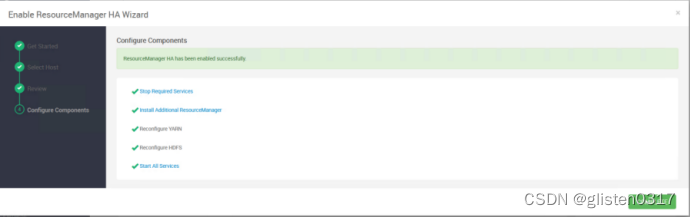
(2)确认配置文件
启用HA后,会在/etc/hadoop/conf/yarn-site.xml中出现如下关于HA的配置项
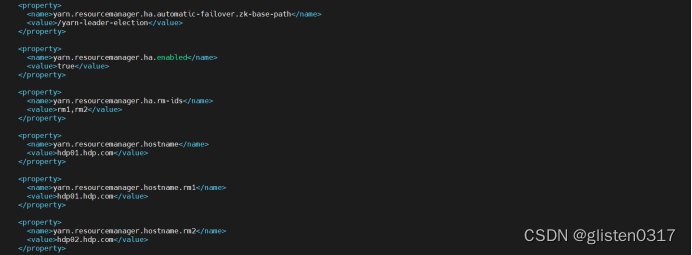
指定zk下对应的文件目录为/yarn-leader-election,对应的rm节点为hdp01.hdp.com和hdp02.hdp.com
在zookeeper中查看也同样生成了对应的文件目录

(3)确认YARN、MR2配置
①CPU资源调度
目前的CPU被划分为虚拟CPU,这里的虚拟CPU是yarn自己引入的概念,因为每个服务器的CPU计算能力不一样,有的机器可能是其他机器计算能力的两倍,然后可以通过多配置几个虚拟CPU弥补差异。在yarn中,CPU的相关配置如下:
yarn.nodemanager.resource.cpu-vcores
表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设置为与物理CPU核数数目相同。如果节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数。
yarn.scheduler.minimum-allocation-vcores
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
yarn.scheduler.maximum-allocation-vcores
单个任务可申请的最多虚拟CPU个数,默认是4。这里说的cpu个数都是说的虚拟cpu,默认的是1个物理cpu=2个虚拟cpu。
②Memory资源调度
yarn一般允许用户配置每个节点上可用的物理资源,注意,这里是"可用的",不是物理内存多少,就设置多少,因为一个服务器节点上会有若干的内存,一部分给yarn,一部分给hdfs,一部分给hbase。在yarn中,Memory相关的配置如下:
yarn.nodemanager.resource.memory-mb
设置该节点上yarn可使用的内存,默认为8G,如果节点内存资源不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般这个设置yarn的可用内存资源
yarn.scheduler.minimum-allocation-mb
单个任务可申请的最小的内存大小,默认是1G,当内存不够时,会自动按照一定大小累加内存。
yarn.scheduler.maximum-allocation-mb
单个任务最大申请物理内存量,默认为8291MB
③示例
以hdp03-05(8C、8G)为例,
yarn.nodemanager.resource.cpu-vcores 虚拟core
这个参数根据自己生产服务器决定,比如服务器很富裕,那就直接1:1,设置成8,如果服务器不是很富裕,那就直接成1:2,设置成8,本次设置为16
yarn.nodemanager.resource.memory-mb 总内存
生产上一般要预留15-20%的内存,那么可用内存就是8*0.8=6.4G,本次设置为6G
yarn.scheduler.minimum-allocation-mb 单任务最小内存
如果设置成500M,那6/0.5 = 12,就是最多可以跑12个container
如果设置成1G,那6/1 = 6,就是最多可以跑6个container
本次设置为1G
yarn.scheduler.minimum-allocation-vcores 单任务最少vcore
如果设置vcore = 1,那么16/1 = 16,就是最多可以跑16个container,如果设置成这个,根据上面内存分配的情况,最多只能跑6个container,vcore有点浪费
如果设置vcore = 2,那么16/2 = 8,就是最多可以跑8个container
yarn.scheduler.maximum-allocation-vcores 单任务最多vcore
一般就设置成4个,cloudera公司做过性能测试,如果cpu大于等于5之后,cpu利用率反而不是很好(固定经验值)
yarn.scheduler.maximum-allocation-mb 单任务最大内存
这个要根据实际业务设定,如果有大任务
4.测试
(1)创建租户并分配对应的资源队列
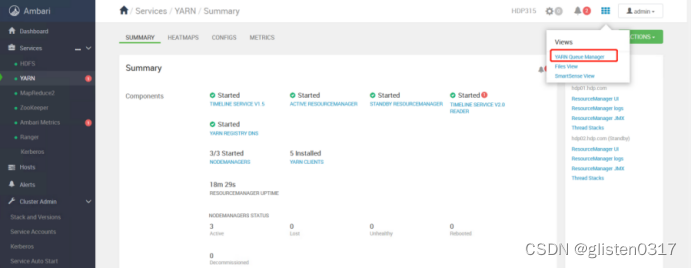
跳转至YARN Queue Manager页面,针对之前的租户tenant1和tenant2,新建资源队列,注意所有队列总和要为100%,否则会报错
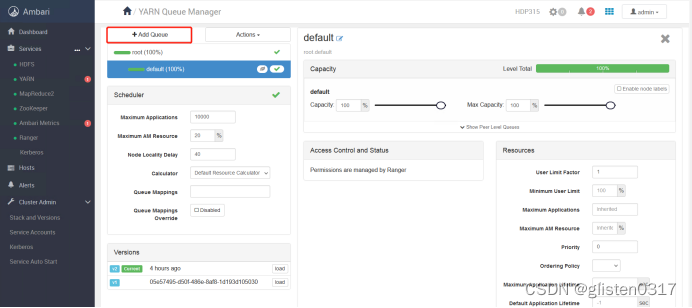
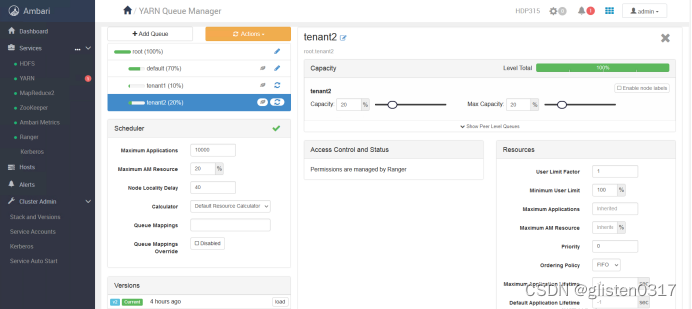
租户与队列资源关系绑定
[u | g] [username : groupname] [yarn队列的名字]
本次绑定为
u:tenant1:tenant1,u:tenant2:tenant2
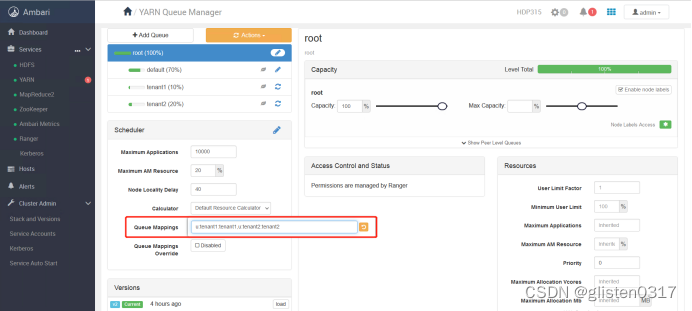
保存本次操作内容
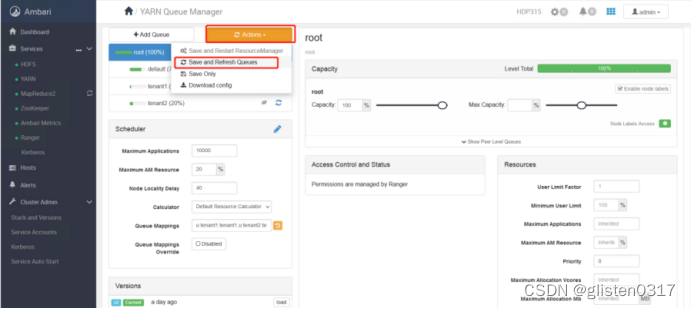
查看resourcemanager页面,可以看到已经更新出新的资源队列
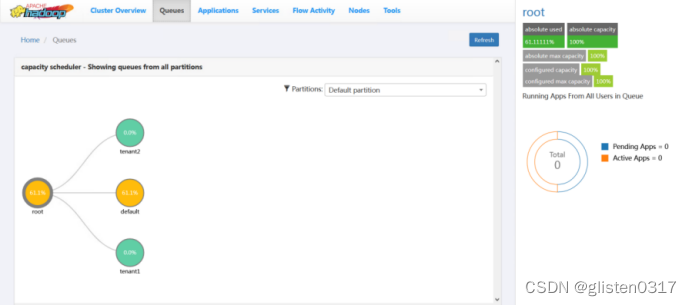
(2)队列使用权限
可使用官方提供的测试jar包
https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-examples
在OpenLDAP中创建账号ranger_yarn,重启UserSync服务后将账号同步至Ranger中,然后在kerberos中创建同样的账号(注:该测试jar包只能用账号ranger_yarn,队列offline)
kadmin.local
addprinc -randkey ranger_yarn
ktadd -kt /root/keytab/ranger_yarn.keytab ranger_yarn
在Yarn中创建队列及账号与队列的映射关系
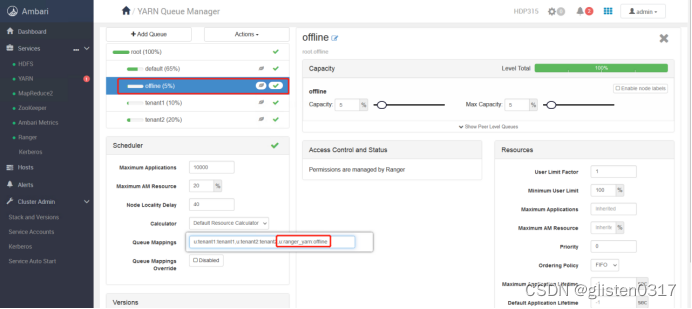
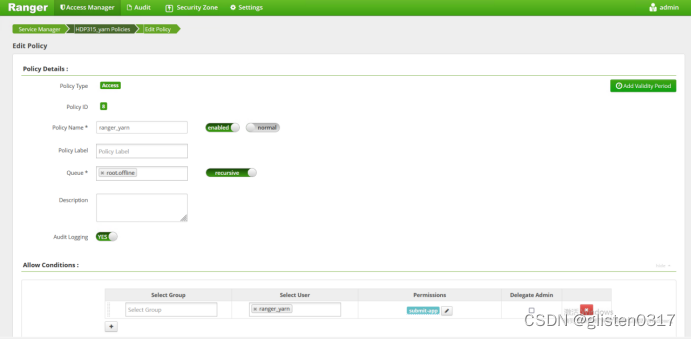
队列offline、账号ranger_yarn都准备好后,在Ranger上创建授权关系
① 计算圆周率
使用ranger_yarn登录,运行计算圆周率任务
kinit -kt /root/keytab/ranger_yarn.keytab ranger_yarn
hadoop jar /root/hadoop-mapreduce-examples-3.1.1.3.0.1.4-1.jar pi -Dmapred.job.queue.name=offline 10 50
hadoop jar是hadoop运行jar包命令
第一个参数pi:表示MapReduce程序执行圆周率计算
第二个参数:用于指定map阶段运行的任务次数,并发度,这是是10
第三个参数:用于指定每个map任务取样的个数,这里是50
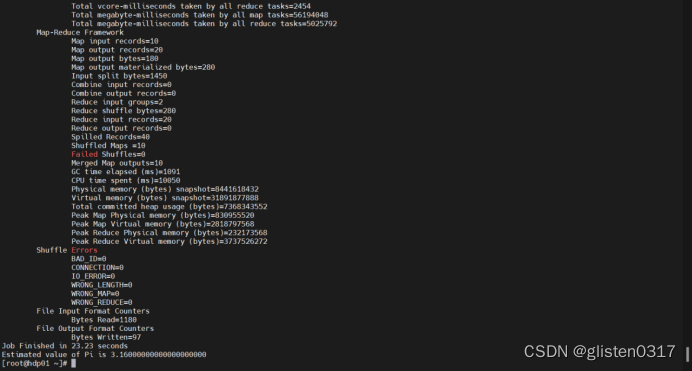
在Yarn中可查看Application的信息
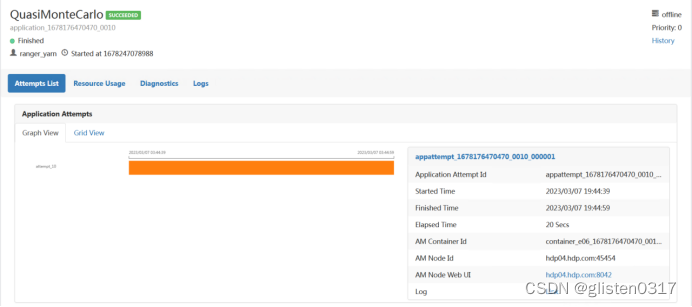
此时在运行jar包时指定队列为tenant1,执行报错,说明权限
② 单词词频统计
首先创建要统计词频的文件,并上传到hdfs上,提前做好对ranger_yarn的hdfs授权
kinit -kt /etc/security/keytabs/nn.service.keytab nn/hdp01.hdp.com@HDP315.COM
hdfs dfs -mkdir /testhdfs/ranger_yarn
kinit -kt /root/keytab/ranger_yarn.keytab ranger_yarn
hdfs dfs -put /root/wordcount_input /testhdfs/ranger_yarn
hdfs dfs -ls /testhdfs/ranger_yarn
运行词频统计jar包
kinit -kt /root/keytab/ranger_yarn.keytab ranger_yarn
hadoop jar /root/hadoop-mapreduce-examples-3.1.1.3.0.1.4-1.jar wordcount -Dmapred.job.queue.name=offline /testhdfs/ranger_yarn/wordcount_input /testhdfs/ranger_yarn/wordcount_output
第一个参数:wordcount表示执行单词统计
第二个参数:指定输入文件的路径
第三个参数:指定输出结果的路径(该路径不能已存在)
统计完成会在输出目录生成结果
hdfs dfs -cat /testhdfs/ranger_yarn/wordcount_output/part-r-00000

5.常用指令
(1)查看命令
yarn application -list
yarn application -list -appStates <ALL,NEW,NEW_SAVING,SUBMITTED,ACCEPTED,RUNNING,FINISHED,FAILED,KILLED>
(2)Kill命令
根据id杀死任务
yarn application -kill <application_id>
(3)查看日志
查询Application日志
yarn logs -applicationId <ApplicationId>
查询Container日志
yarn logs -applicationId -containerId <ApplicationId> -containerId <ContainerId>
(4)查看尝试运行的任务
查看尝试运行的任务
yarn applicationattempt -list<ApplicationId>
查看尝试运行任务的状态
yarn applicationattempt -status <ApplicationAttemptId>
(5)查看容器
列出所有Container
yarn container -list <ApplicationAttemptId>
打印Container状态
yarn container -status <ContainerId>
6.常见报错
(1)Timeline Service启动报错
启动时报错:
java.util.concurrent.ExecutionException: org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /atsv2-hbase-secure/hbaseid
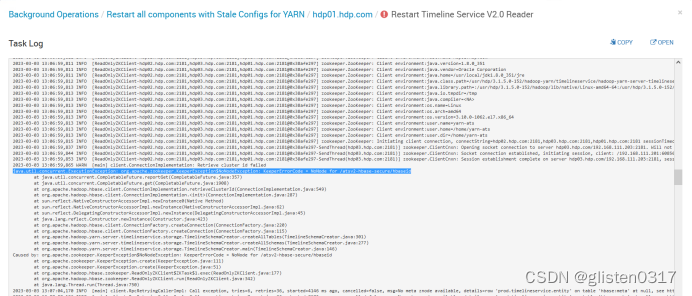
在Yarn中的CONFIGS->ADVANCED->Advanced yarn-hbase-env中,将is_hbase_system_service_launch启用
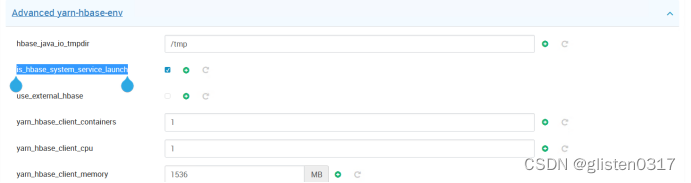
(2)History Server启动一会后报错
启动时无报错,等几分钟后报错并停止,在hdp02上查看日志,/var/log/hadoop-mapreduce/mapred/hadoop-mapred-historyserver-hdp02.log
报错信息为:
Error creating intermediate done directory: [hdfs://hdp315:8020/mr-history/tmp]
Permission denied: user=mapred, access=WRITE, inode="/mr-history"
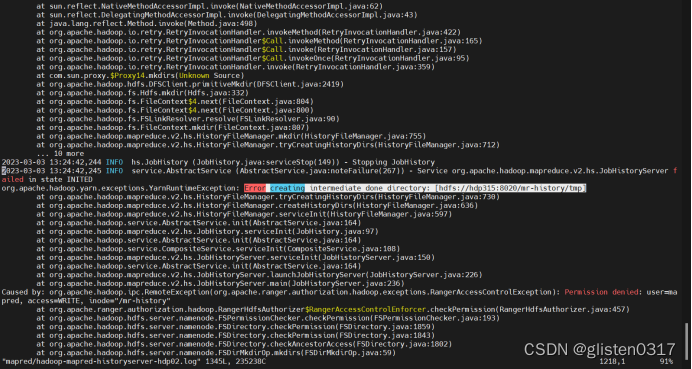
查看hdfs上的目录权限,确认权限归属无问题

原因是Ranger上取消了联合授权功能,在Ranger上没有对应的策略开放该目录,导致mapred用户无法访问对应的目录,开启联合授权功能后恢复。
(3)告警:ATS embedded HBase is NOT running on hdp01.hdp.com
告警信息:ATS embedded HBase is NOT running on hdp01.hdp.com
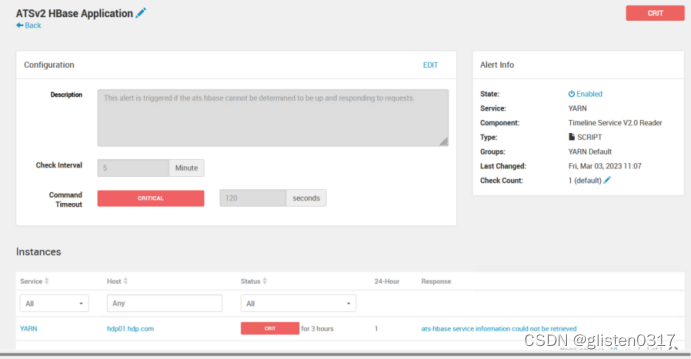
resourceMananger的JVM内存是1G,内存太小导致的,将ResourceManager中的Java heap size的JVM内存增加到了2048MB
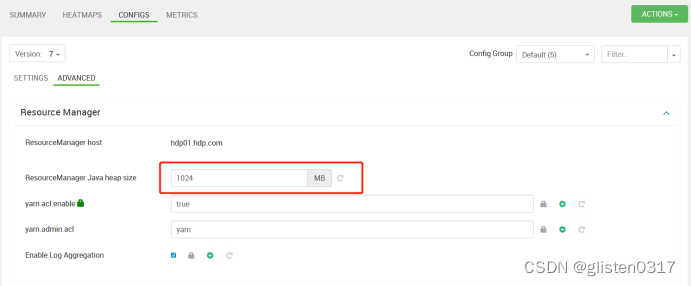
重启Yarn服务后告警消失
(4)提交任务后状态一直为ACCEPTED
主要可能的原因是分配给容器的内存过小导致,正常情况下需要适当调整分配内存,本次是因为总体内存量不大,而在分配queue:offline的时候,设置的资源大小为5%,导致无法正常运行,而是一直停留在分配资源阶段,重新分配队列资源大小后恢复。
(5)Timeline日志报错NoNode for /atsv2-hbase-secure/xxx
在timeline的日志中有如下报错
Caused by: java.io.IOException: org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /atsv2-hbase-secure/meta-region-serverat org.apache.hadoop.hbase.client.ConnectionImplementation.get(ConnectionImplementation.java:2002)at org.apache.hadoop.hbase.client.ConnectionImplementation.locateMeta(ConnectionImplementation.java:762)at org.apache.hadoop.hbase.client.ConnectionImplementation.locateRegion(ConnectionImplementation.java:729)at org.apache.hadoop.hbase.client.ConnectionImplementation.relocateRegion(ConnectionImplementation.java:707)at org.apache.hadoop.hbase.client.ConnectionImplementation.locateRegionInMeta(ConnectionImplementation.java:911)at org.apache.hadoop.hbase.client.ConnectionImplementation.locateRegion(ConnectionImplementation.java:732)at org.apache.hadoop.hbase.client.RpcRetryingCallerWithReadReplicas.getRegionLocations(RpcRetryingCallerWithReadReplicas.java:325)
说明zookeeper中没有对应的节点
登录到yarn-ats-habase用户,手工创建对应的节点
kinit -kt /etc/security/keytabs/yarn-ats.hbase-master.service.keytab yarn-ats-hbase/hdp01.hdp.com@HDP315.COM
/usr/hdp/3.1.5.0-152/zookeeper/bin/zkCli.sh -server hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181
create /atsv2-hbase-secure/meta-region-server yarn
create /atsv2-hbase-secure/hbaseid yarn
setAcl /atsv2-hbase-secure/meta-region-server sasl:yarn-ats-hbase:cdrwa,sasl:yarn:cdrwa
setAcl /atsv2-hbase-secure/hbaseid sasl:yarn-ats-hbase:cdrwa,sasl:yarn:cdrwa
ls /atsv2-hbase-secure
getAcl /atsv2-hbase-secure/meta-region-server
getAcl /atsv2-hbase-secure/hbaseid

重启timeline service,不再出现该报错。
相关文章:
Hadoop学习笔记(HDP)-Part.14 安装YARN+MR
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …...
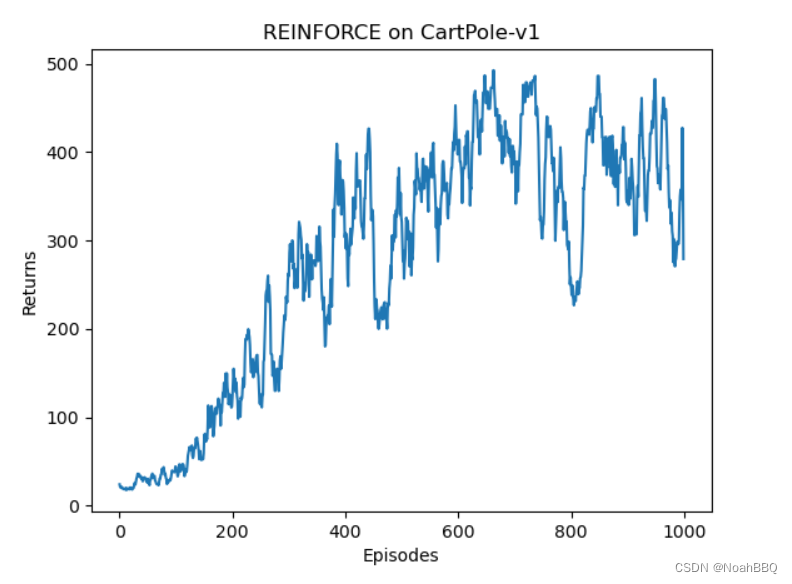
reinforce 跑 CartPole-v1
gym版本是0.26.1 CartPole-v1的详细信息,点链接里看就行了。 修改了下动手深度强化学习对应的代码。 然后这里 J ( θ ) J(\theta) J(θ)梯度上升更新的公式是用的不严谨的,这个和王树森书里讲的严谨公式有点区别。 代码 import gym import torch from …...
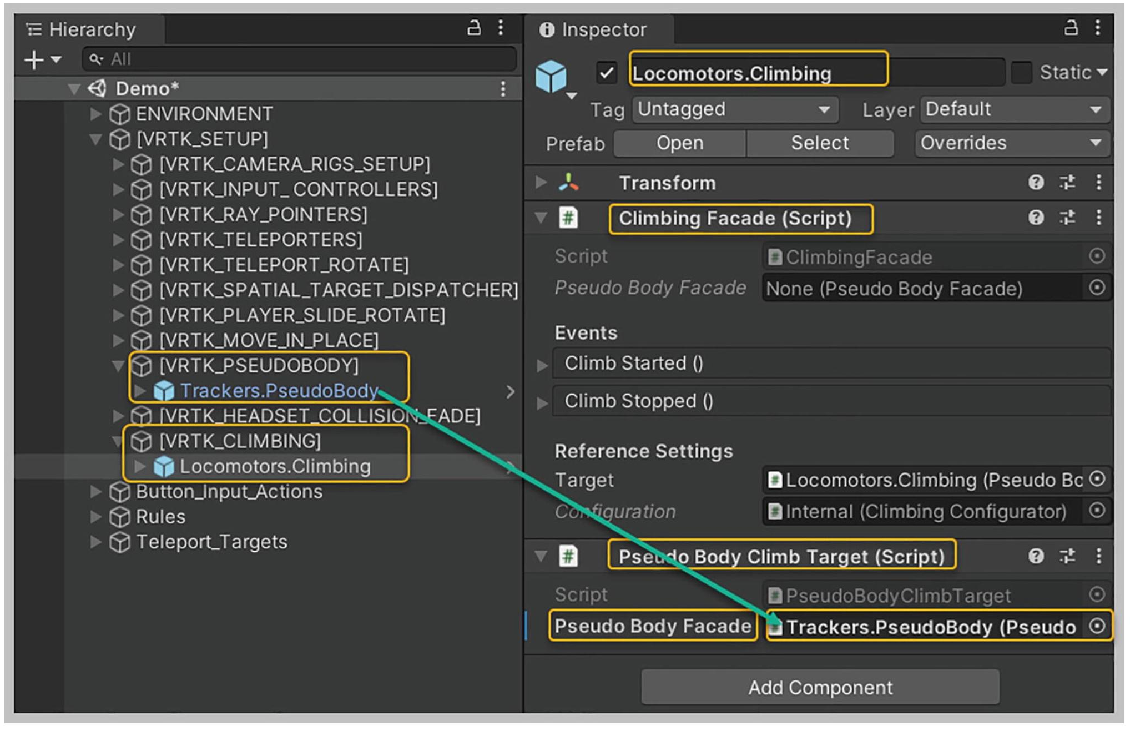
【VRTK】【VR开发】【Unity】13-攀爬
课程配套学习资源下载 https://download.csdn.net/download/weixin_41697242/88485426?spm=1001.2014.3001.5503 【概述】 VRTK提供两个预制件实现攀爬 Climbing Controller,用于控制Player的物理义体Climbable Interactable,用于设置可攀爬对象【设置Climbing Controller…...
)
华为OD机试真题-求幸存数之和-2023年OD统一考试(C卷)
题目描述: 给一个正整数列 nums,一个跳数 jump,及幸存数量 left。运算过程为:从索引为0的位置开始向后跳,中间跳过 J 个数字,命中索引为J1的数字,该数被敲出,并从该点起跳ÿ…...
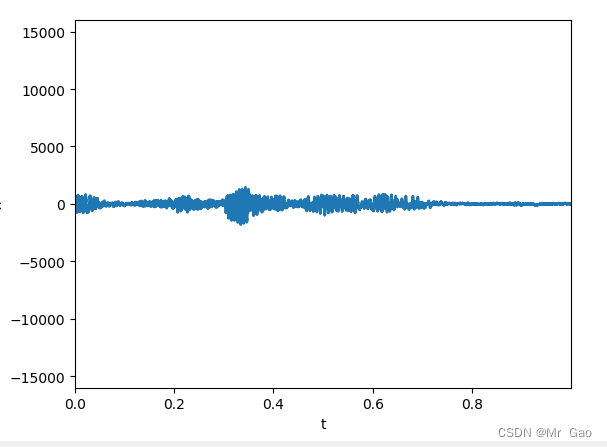
python pyaudio实时读取音频数据并展示波形图
python pyaudio实时读取音频数据并展示波形图 下面代码可以驱动电脑接受声音数据,并实时展示音波图: import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation import pyaudio import wave import os import op…...
【算法系列篇】递归、搜索和回溯(二)
文章目录 前言1. 两两交换链表中的节点1.1 题目要求1.2 做题思路1.3 代码实现 2. Pow(X,N)2.1 题目要求2.2 做题思路2.3 代码实现 3. 计算布尔二叉树的值3.1 题目要求3.2 做题思路3.3 代码实现 4. 求根节点到叶结点数字之和4.1 题目要求4.2 做题思路4.3 代码实现 前言 前面为大…...

Ubuntu下安装SDL
源码下载地址(SDL version 2.0.14):https://www.libsdl.org/release/SDL2-2.0.14.tar.gz 将源码包拷贝到系统里 使用命令解压 tar -zxvf SDL2-2.0.14.tar.gz 解压得到文件夹 SDL2-2.0.14 进入文件夹 执行命令 ./configure 执行命令 make…...

创建vue项目:vue脚手架安装、vue-cli安装,vue ui界面创建vue工程(vue2/vue3),安装vue、搭建vue项目开发环境(保姆级教程二)
今天讲解 Windows 如何利用脚手架创建 vue 工程,以及 vue ui 图形化界面搭建 vue 开发环境,这是这个系列的第二章,有什么问题请留言,请点赞收藏!!! 文章目录 1、安装vue-cli脚手架2、vue ui创建…...
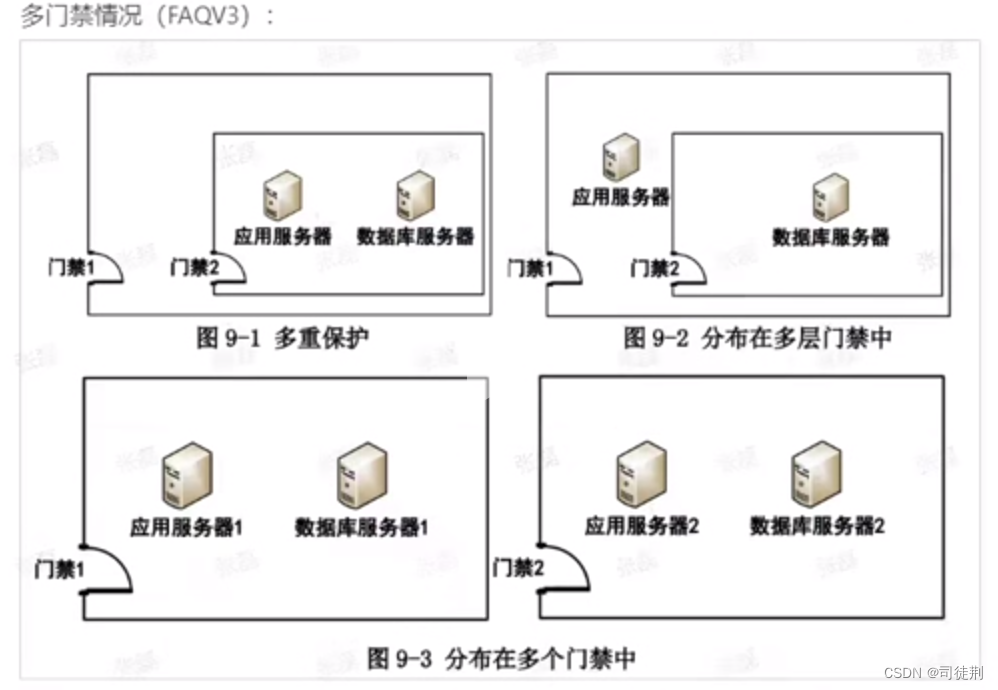
【3】密评-物理和环境安全测评
0x01 依据 GB/T 39786 -2021《信息安全技术 信息系统密码应用基本要求》针对等保三级系统要求: 物理和环境层面: a)宜采用密码技术进行物理访问身份鉴别,保证重要区域进入人员身份的真实性; b)宜采用密码技术保证电子门…...

笨爸爸工房,我们在校园|“小鲁班”,铸未来
为了响应国家号召,将劳动教育课程真正实现融入校园生活,笨爸爸工房已与洛阳市西下池小学、洛阳市第一实验小学西工校区、洛阳市西工区第二实验小学、洛阳第二外国语学校(兰溪校区)、洛阳市睿源幼儿园,这4所学校及1家幼…...

RPC 集群,gRPC 广播和组播
一、集群抽象:cluster 它是指我们在调用远程的时候,尝试解决: 1、failover:即引入重试功能,但是重试的时候会换一个新节点 2、failfast: 立刻失败,不需要重试 3、广播:将请求发送到所有的节点上 4、组…...
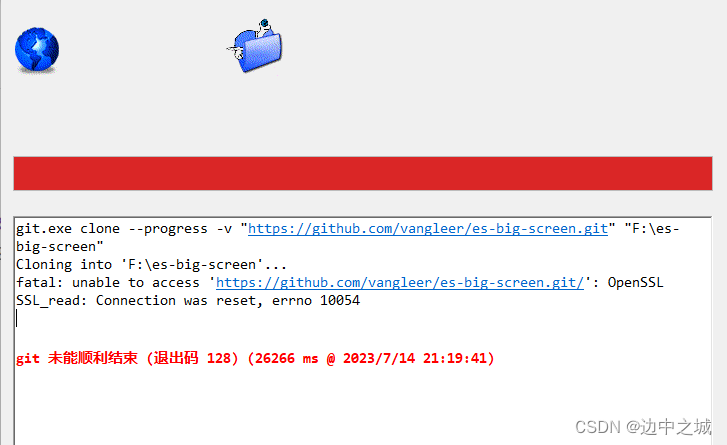
OpenSSL SSL_read: Connection was reset, errno 10054
fatal: unable to access ‘https://github.com/vangleer/es-big-screen.git/’: OpenSSL SSL_read: Connection was reset, errno 10054 解决方法:git config --global http.sslVerify “false” 参考链接: https://github.com/Kong/insomnia/issues/2…...
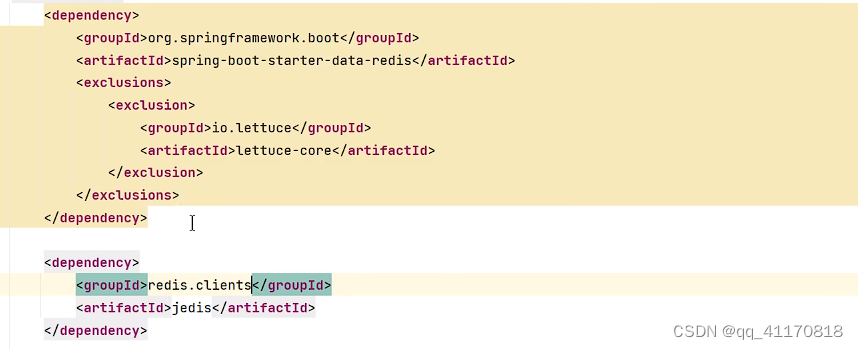
【springboot】整合redis和定制化
1.前提条件:docker安装好了redis,确定redis可以访问 可选软件: 2.测试代码 (1)redis依赖 org.springframework.boot spring-boot-starter-data-redis (2)配置redis (3) 注入 Resource StringRedisTemplate stringRedisTemplate; 这里如果用Autowi…...

HarmonyOS鸿蒙操作系统架构开发
什么是HarmonyOS鸿蒙操作系统? HarmonyOS是华为公司开发的一种全场景分布式操作系统。它可以在各种智能设备(如手机、电视、汽车、智能穿戴设备等)上运行,具有高效、安全、低延迟等优势。 目录 HarmonyOS 一、HarmonyOS 与其他操…...
共创共赢|美创科技获江苏移动2023DICT生态合作“产品共创奖”
12月6日,以“5G江山蓝 算网融百业 数智创未来”为主题的中国移动江苏公司2023DICT合作伙伴大会在南京成功举办。来自行业领军企业、科研院所等DICT产业核心力量的百余家单位代表参加本次大会,共话数实融合新趋势,共拓合作发展新空间。 作为生…...
)
深度学习——第3章 Python程序设计语言(3.5 Python类和对象)
3.5 Python类和对象 目录 1. 面向对象的基本概念 2. 类和对象的关系 3. 类的声明 4. 对象的创建和使用 5. 类对象属性 6. 类对象方法 7. 面向对象的三个基本特征 8. 综合案例:汉诺塔图形化移动 1.1 面向对象的基本概念 1.1.1 对象(object&#x…...

【原创】【一类问题的通法】【真题+李6卷6+李4卷4(+李6卷5)分析】合同矩阵A B有PTAP=B,求可逆阵P的策略
【铺垫】二次型做的变换与相应二次型矩阵的对应:二次型f(x1,x2,x3)xTAx,g(y1,y2,y3)yTBy ①若f在可逆变换xPy下化为g,即P为可逆阵,有P…...

代码随想录算法训练营第六十天 | 84.柱状图中最大的矩形
84.柱状图中最大的矩形 题目链接:84. 柱状图中最大的矩形 本题与接雨水相近。按列来看,是要找到每一个柱子左右第一个比它矮的柱子,即对于该柱子来说所能组成的最大面积,将每个柱子所能得到的最大面积进行对比最终得到最大矩形。 …...
C#结合JavaScript实现多文件上传
目录 需求 引入 关键代码 操作界面 JavaScript包程序 服务端 ashx 程序 服务端上传后处理程序 小结 需求 在许多应用场景里,多文件上传是一项比较实用的功能。实际应用中,多文件上传可以考虑如下需求: 1、对上传文件的类型、大小…...
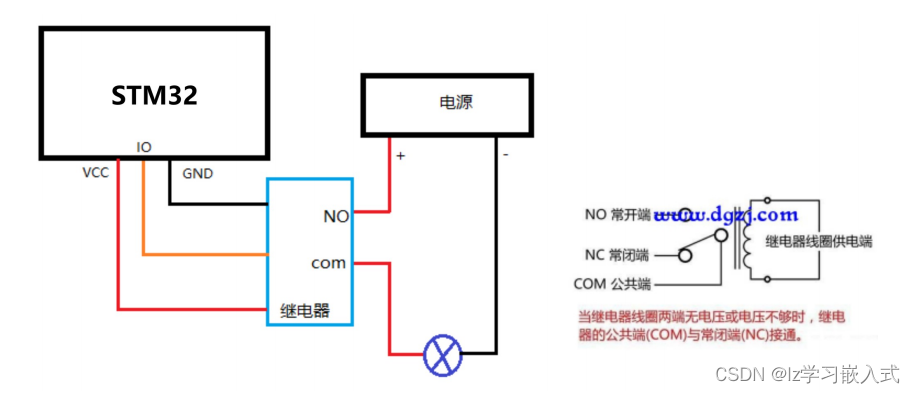
STM32——继电器
继电器工作原理 单片机供电 VCC GND 接单片机, VCC 需要接 3.3V , 5V 不行! 最大负载电路交流 250V/10A ,直流 30V/10A 引脚 IN 接收到 低电平 时,开关闭合。...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...