人工智能|网络爬虫——用Python爬取电影数据并可视化分析
一、获取数据
1.技术工具
IDE编辑器:vscode
发送请求:requests
解析工具:xpath
def Get_Detail(Details_Url):Detail_Url = Base_Url + Details_UrlOne_Detail = requests.get(url=Detail_Url, headers=Headers)One_Detail_Html = One_Detail.content.decode('gbk')Detail_Html = etree.HTML(One_Detail_Html)Detail_Content = Detail_Html.xpath("//div[@id='Zoom']//text()")Video_Name_CN,Video_Name,Video_Address,Video_Type,Video_language,Video_Date,Video_Number,Video_Time,Video_Daoyan,Video_Yanyuan_list = None,None,None,None,None,None,None,None,None,Nonefor index, info in enumerate(Detail_Content):if info.startswith('◎译 名'):Video_Name_CN = info.replace('◎译 名', '').strip()if info.startswith('◎片 名'):Video_Name = info.replace('◎片 名', '').strip()if info.startswith('◎产 地'):Video_Address = info.replace('◎产 地', '').strip()if info.startswith('◎类 别'):Video_Type = info.replace('◎类 别', '').strip()if info.startswith('◎语 言'):Video_language = info.replace('◎语 言', '').strip()if info.startswith('◎上映日期'):Video_Date = info.replace('◎上映日期', '').strip()if info.startswith('◎豆瓣评分'):Video_Number = info.replace('◎豆瓣评分', '').strip()if info.startswith('◎片 长'):Video_Time = info.replace('◎片 长', '').strip()if info.startswith('◎导 演'):Video_Daoyan = info.replace('◎导 演', '').strip()if info.startswith('◎主 演'):Video_Yanyuan_list = []Video_Yanyuan = info.replace('◎主 演', '').strip()Video_Yanyuan_list.append(Video_Yanyuan)for x in range(index + 1, len(Detail_Content)):actor = Detail_Content[x].strip()if actor.startswith("◎"):breakVideo_Yanyuan_list.append(actor)print(Video_Name_CN,Video_Date,Video_Time)f.flush()try:csvwriter.writerow((Video_Name_CN,Video_Name,Video_Address,Video_Type,Video_language,Video_Date,Video_Number,Video_Time,Video_Daoyan,Video_Yanyuan_list))except:pass保存数据:csv
if __name__ == '__main__':with open('movies.csv','a',encoding='utf-8',newline='')as f:csvwriter = csv.writer(f)csvwriter.writerow(('Video_Name_CN','Video_Name','Video_Address','Video_Type','Video_language','Video_Date','Video_Number','Video_Time','Video_Daoyan','Video_Yanyuan_list'))spider(117)2.爬取目标
本次爬取的目标网站是阳光电影网https://www.ygdy8.net,用到技术为requests+xpath。主要获取的目标是2016年-2023年之间的电影数据。
3.字段信息
获取的字段信息有电影译名、片名、产地、类别、语言、上映时间、豆瓣评分、片长、导演、主演等,具体说明如下:

 二、数据预处理
二、数据预处理
技术工具:jupyter notebook
1.加载数据
首先使用pandas读取刚用爬虫获取的电影数据

2.异常值处理
这里处理的异常值包括缺失值和重复值
首先查看原数据各字段的缺失情况

从结果中可以发现缺失数据还蛮多的,这里就为了方便统一删除处理,同时也对重复数据进行删除

可以发现经过处理后的数据还剩1711条。
3.字段处理
由于爬取的原始数据中各个字段信息都很乱,出现很多“/”“,”之类的,这里统一进行处理,主要使用到pandas中的apply()函数,同时由于我们分析的数2016-2023年的电影数据,除此之外的进行删除处理
# 数据预处理
data['Video_Name_CN'] = data['Video_Name_CN'].apply(lambda x:x.split('/')[0]) # 处理Video_Name_CN
data['Video_Name'] = data['Video_Name'].apply(lambda x:x.split('/')[0]) # 处理Video_Name
data['Video_Address'] = data['Video_Address'].apply(lambda x:x.split('/')[0]) # 处理Video_Address
data['Video_Address'] = data['Video_Address'].apply(lambda x:x.split(',')[0].strip())
data['Video_language'] = data['Video_language'].apply(lambda x:x.split('/')[0])
data['Video_language'] = data['Video_language'].apply(lambda x:x.split(',')[0])
data['Video_Date'] = data['Video_Date'].apply(lambda x:x.split('(')[0].strip())
data['year'] = data['Video_Date'].apply(lambda x:x.split('-')[0])
data['Video_Number'] = data['Video_Number'].apply(lambda x:x.split('/')[0].strip())
data['Video_Number'] = pd.to_numeric(data['Video_Number'],errors='coerce')
data['Video_Time'] = data['Video_Time'].apply(lambda x:x.split('分钟')[0])
data['Video_Time'] = pd.to_numeric(data['Video_Time'],errors='coerce')
data['Video_Daoyan'] = data['Video_Daoyan'].apply(lambda x:x.split()[0])
data.drop(index=data[data['year']=='2013'].index,inplace=True)
data.drop(index=data[data['year']=='2014'].index,inplace=True)
data.drop(index=data[data['year']=='2015'].index,inplace=True)
data.dropna(inplace=True)
data.head()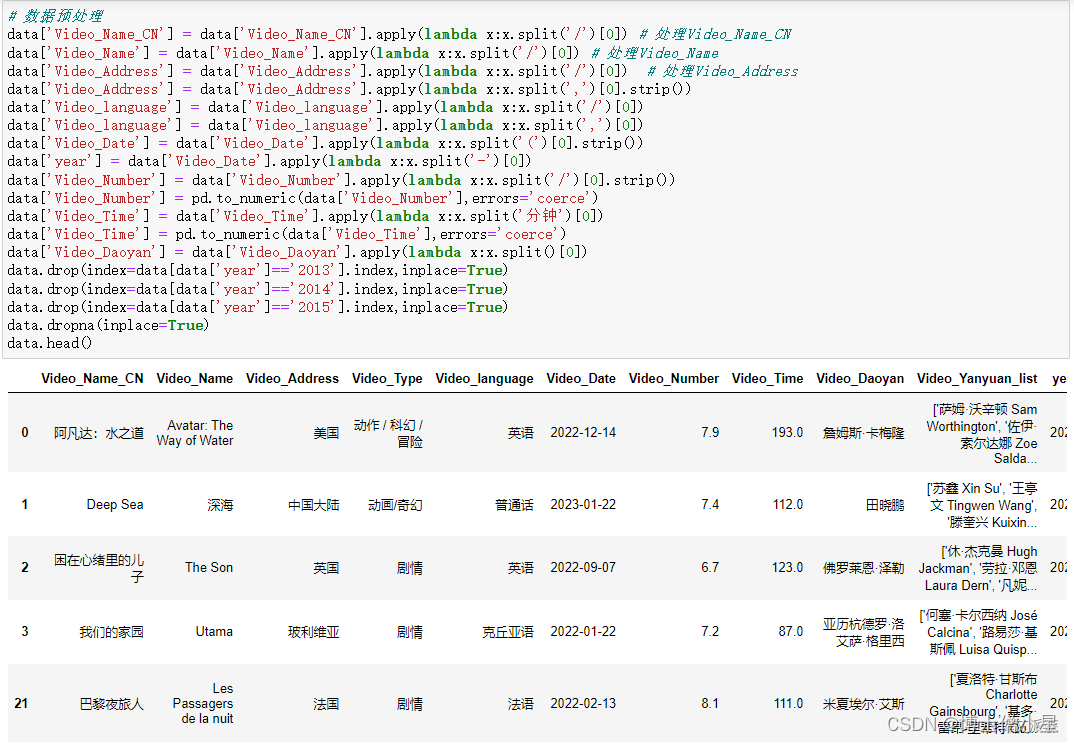
三、数据可视化
1.导入可视化库
本次可视化主要用到matplotlib、seaborn、pyecharts等第三方库
import matplotlib.pylab as plt
import seaborn as sns
from pyecharts.charts import *
from pyecharts.faker import Faker
from pyecharts import options as opts
from pyecharts.globals import ThemeType
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示2.分析各个国家发布的电影数量占比
# 分析各个国家发布的电影数量占比
df2 = data.groupby('Video_Address').size().sort_values(ascending=False).head(10)
a1 = Pie(init_opts=opts.InitOpts(theme = ThemeType.LIGHT))
a1.add(series_name='电影数量',data_pair=[list(z) for z in zip(df2.index.tolist(),df2.values.tolist())],radius='70%',)
a1.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item'))
a1.render_notebook()3.发布电影数量最高Top5导演
# 发布电影数量最高Top5导演
a2 = Bar(init_opts=opts.InitOpts(theme = ThemeType.DARK))
a2.add_xaxis(data['Video_Daoyan'].value_counts().head().index.tolist())
a2.add_yaxis('电影数量',data['Video_Daoyan'].value_counts().head().values.tolist())
a2.set_series_opts(itemstyle_opts=opts.ItemStyleOpts(color='#B87333'))
a2.set_series_opts(label_opts=opts.LabelOpts(position="top"))
a2.render_notebook()4.分析电影平均评分最高的前十名国家
# 分析电影平均评分最高的前十名国家
data.groupby('Video_Address').mean()['Video_Number'].sort_values(ascending=False).head(10).plot(kind='barh')
plt.show()5.分析哪种语言最受欢迎
# 分析哪种语言最受欢迎
from pyecharts.charts import WordCloud
import collections
result_list = []
for i in data['Video_language'].values:word_list = str(i).split('/')for j in word_list:result_list.append(j)
result_list
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
wc = WordCloud()
wc.add('',word_counts_top)
wc.render_notebook()6.分析哪种类型电影最受欢迎
# 分析哪种类型电影最受欢迎
from pyecharts.charts import WordCloud
import collections
result_list = []
for i in data['Video_Type'].values:word_list = str(i).split('/')for j in word_list:result_list.append(j)
result_list
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
wc = WordCloud()
wc.add('',word_counts_top)
wc.render_notebook()7.分析各种类型电影的比例
# 分析各种类型电影的比例
word_counts_top = word_counts.most_common(10)
a3 = Pie(init_opts=opts.InitOpts(theme = ThemeType.MACARONS))
a3.add(series_name='类型',data_pair=word_counts_top,rosetype='radius',radius='60%',)
a3.set_global_opts(title_opts=opts.TitleOpts(title="各种类型电影的比例",pos_left='center',pos_top=50))
a3.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item',formatter='{a} <br/>{b}:{c} ({d}%)'))
a3.render_notebook()8.分析电影片长的分布
# 分析电影片长的分布
sns.displot(data['Video_Time'],kde=True)
plt.show()9.分析片长和评分的关系
# 分析片长和评分的关系
plt.scatter(data['Video_Time'],data['Video_Number'])
plt.title('片长和评分的关系',fontsize=15)
plt.xlabel('片长',fontsize=15)
plt.ylabel('评分',fontsize=15)
plt.show()10.统计 2016 年到至今的产出的电影总数量
# 统计 2016 年到至今的产出的电影总数量
df1 = data.groupby('year').size()
line = Line()
line.add_xaxis(xaxis_data=df1.index.to_list())
line.add_yaxis('',y_axis=df1.values.tolist(),is_smooth = True)
line.set_global_opts(xaxis_opts=opts.AxisOpts(splitline_opts = opts.SplitLineOpts(is_show=True)))
line.render_notebook()四、总结
本次实验通过使用爬虫获取2016年-2023年的电影数据,并可视化分析的得出以下结论:
1.2016年-2019年电影数量逐渐增大,2019年达到最大值,从2020年开始迅速逐年下降。
2.发布电影数量最多的国家是中国和美国。
3.电影类型最多的剧情片。
4.电影片长呈正态分布,且片长和评分呈正相关关系。
相关文章:
人工智能|网络爬虫——用Python爬取电影数据并可视化分析
一、获取数据 1.技术工具 IDE编辑器:vscode 发送请求:requests 解析工具:xpath def Get_Detail(Details_Url):Detail_Url Base_Url Details_UrlOne_Detail requests.get(urlDetail_Url, headersHeaders)One_Detail_Html One_Detail.cont…...

mac苹果笔记本电脑如何强力删除卸载app软件?
苹果电脑怎样删除app?不是把app移到废纸篓就行了吗,十分简单呢! 其实不然,因为在Mac电脑上,删除应用程序只是删除了应用程序的主要组件。大多数时候,系统会有一个相当长的目录,包含所有与应用程…...

net6中使用MongoDB
目录 一、MongoDB是什么? 二、使用步骤 1.安装驱动 2.设置连接字符串、配置类 3.建立实体类 4.服务层 5.在Program添加服务 6.在Controller注入服务 总结 一、MongoDB是什么? MongoDB 是一个开源的、可扩展的、跨平台的、面向文档的非关系型数据库&…...

vue中yarn install超时问题
囚笼中的网络固然可以稳定局势,不让猴子们得以随时醒悟!给你吃的你就好好吃,不要有其他的翻然醒悟的时刻。无论如何,愚蠢的活着也是一种幸福,听着那些耐心寻味的统计幸福指数,我们不由的幸福的一批。。 最…...

vue3 引入 markdown编辑器
参考文档 安装依赖 pnpm install mavon-editor // "mavon-editor": "3.0.1",markdown 编辑器 <mavon-editor></mavon-editor>新增文本 <mavon-editor ref"editorRef" v-model"articleModel.text" codeStyle"…...

算法----K 和数对的最大数目
题目 给你一个整数数组 nums 和一个整数 k 。 每一步操作中,你需要从数组中选出和为 k 的两个整数,并将它们移出数组。 返回你可以对数组执行的最大操作数。 示例 1: 输入:nums [1,2,3,4], k 5 输出:2 解释&…...
RocketMQ-源码架构
源码环境搭建 1、主要功能模块 RocketMQ官方Git仓库地址:GitHub - apache/rocketmq: Apache RocketMQ is a cloud native messaging and streaming platform, making it simple to build event-driven applications. RocketMQ的官方网站下载:下载 | R…...
14-1、IO流
14-1、IO流 lO流打开和关闭lO流打开模式lO流对象的状态 非格式化IO二进制IO读取二进制数据获取读长度写入二进制数据 读写指针 和 随机访问设置读/写指针位置获取读/写指针位置 字符串流 lO流打开和关闭 通过构造函数打开I/O流 其中filename表示文件路径,mode表示打…...

每日一道算法题 1
借鉴文章:Java-敏感字段加密 - 哔哩哔哩 题目描述 给定一个由多个命令字组成的命令字符串; 1、字符串长度小于等于127字节,只包含大小写字母,数字,下划线和偶数个双引号 2、命令字之间以一个或多个下划线_进行分割…...

【网络奇缘】- 计算机网络|深入学习物理层|网络安全
🌈个人主页: Aileen_0v0🔥系列专栏: 一见倾心,再见倾城 --- 计算机网络~💫个人格言:"没有罗马,那就自己创造罗马~" 回顾链接:http://t.csdnimg.cn/ZvPOS 这篇文章是关于深入学习原理参考模型-物理层的相关知识点&…...

❀expect命令运用于bash❀
目录 ❀expect命令运用于bash❀ expect使用原理 expet使用场景 常用的expect命令选项 Expect脚本的结尾 常用的expect命令选参数 Expect执行方式 单一分支语法 多分支模式语法第一种 多分支模式语法第二种 在shell 中嵌套expect Shell Here Document(内…...

2023年团体程序设计天梯赛——总决赛题
F-L1-1 最好的文档 有一位软件工程师说过一句很有道理的话:“Good code is its own best documentation.”(好代码本身就是最好的文档)。本题就请你直接在屏幕上输出这句话。 输入格式: 本题没有输入。 输出格式: 在一…...

K8S 工具收集
杂货铺,我不用 K8S,把见过的常用工具放在这里,后面学的时候再来找 名称描述官网Pixie查看 k8s 的工具。集群性能、网络状态、pod 状态、热点图等HomeKubernetes Dashboard基于 Web 的 Kubernetes 集群用户界面。GithubGardenerSAP 开源的 K8…...
自动化测试之读取配置文件
前言: 在日常自动化测试开发工作中,经常要使用配置文件,进行环境配置,或进行数据驱动等。我们常常把这些文件放置在 resources 目录下,然后通过 getResource、ClassLoader.getResource 和 getResourceAsStream() 等方法…...
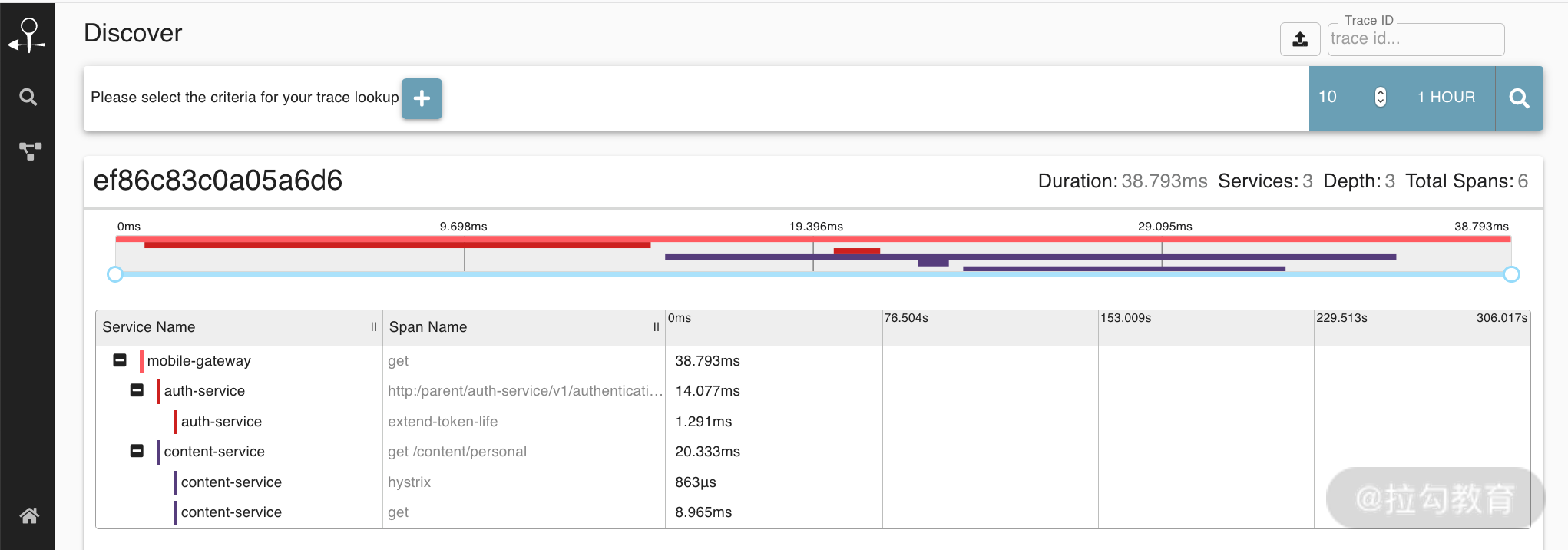
如何实现分布式调用跟踪?
分布式服务拆分以后,系统变得日趋复杂,业务的调用链也越来越长,如何快速定位线上故障,就需要依赖分布式调用跟踪技术。下面我们一起来看下分布式调用链相关的实现。 为什么需要分布式调用跟踪 随着分布式服务架构的流行…...
)
接口的性能优化(从前端、后端、数据库三个角度分析)
接口的性能优化(前端、后端、数据库) 主要通过三方面进行优化 前端后端数据库 前端优化 接口拆分 不要搞一个大而全的接口,要区分核心与非核心的接口,不然核心接口就会被非核心接口拖累 或者一个接口中大部分返回都很快&…...

区块链扩容问题研究【06】
1.Plasma:Plasma 是一种基于以太坊区块链的 Layer2 扩容方案,它通过建立一个分层结构的区块链网络,将大量的交易放到子链上进行处理,从而提高了以太坊的吞吐量。Plasma 还可以通过智能合约实现跨链交易,使得不同的区块…...

英语论文写作常用词汇积累
baseline:比较算法好坏中作为“参照物”而存在,在比较中作为基线;目的是比较提出算法的性能或者用以彰显所提出的算法的优势; benchmark:评价算法好坏的一种规则和标准。是目前的模型能做到的比较好的效果;…...

redis集群(cluster)笔记
1. 定义: 由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序…...

css 元素前后添加图标(::before 和 ::after 的妙用)
<template><div class"container"><div class"label">猜你喜欢</div></div> </template><style lang"scss" scoped> .label {display: flex;&::before,&::after {content: "";widt…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...