3易懂AI深度学习算法:长短期记忆网络(Long Short-Term Memory, LSTM)生成对抗网络 优化算法进化算法
继续写:https://blog.csdn.net/chenhao0568/article/details/134920391?spm=1001.2014.3001.5502
1.https://blog.csdn.net/chenhao0568/article/details/134931993?spm=1001.2014.3001.5502
2.https://blog.csdn.net/chenhao0568/article/details/134932800?spm=1001.2014.3001.5502
长短期记忆网络(Long Short-Term Memory, LSTM)
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),主要用于处理和预测序列数据中的长期依赖问题。LSTM网络在许多序列数据任务中表现出色,例如语言建模、语音识别和时间序列预测。
为了更好地理解LSTM,我们可以将其比作一部电视剧的编剧。在电视剧中,编剧需要记住过去的情节(长期记忆),同时还要考虑最近的发展(短期记忆),以决定接下来的剧情如何发展。同样,在处理序列数据时,LSTM网络需要记住长期的信息(比如整个对话的背景),同时也要处理最近的输入(比如最近几句话)。
LSTM的关键特点是其内部结构,主要包括三个门(门控单元):遗忘门、输入门和输出门。这些门控单元帮助网络决定何时更新记忆、何时忽略无关信息以及何时将记忆用于当前的输出。
-
遗忘门:决定哪些信息应该从单元状态中被遗忘。它通过一系列输入和先前的隐藏状态来查看信息,并输出一个0到1之间的值,其中1表示“完全保留”而0表示“完全忘记”。
-
输入门:决定哪些新的信息应该被添加到单元状态中。它包含一个sigmoid层和一个tanh层,sigmoid层决定哪些值需要更新,tanh层则创建一个新的候选值向量,这些值可能会被加入到状态中。
-
输出门:决定基于单元状态的下一个隐藏状态(即下一个输出)。隐藏状态包含了先前单元状态的信息,用于预测或决定下一步。
通过这种方式,LSTM能够在处理序列数据时保持对重要历史信息的记忆,同时忽略不相关的信息。这使得LSTM在处理长序列和需要理解长期依赖的任务中特别有效。
用python写个示例
当然可以。以下是一个使用Python中的Keras库来实现简单的LSTM网络的示例。这个例子中,我们将创建一个用于序列数据预测的小型LSTM模型。为了简化,我们会使用一个合成的时间序列数据。
首先,我们需要安装Keras和TensorFlow(如果你还没有安装的话)。你可以使用以下命令安装:
pip install tensorflow
然后,我们可以写一个简单的脚本来创建和训练我们的LSTM模型:
- 生成一些合成的时间序列数据。
- 创建一个LSTM模型。
- 训练模型并对其进行评估。
以下是完整的代码:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.optimizers import Adam# 生成合成数据
def generate_data(seq_length=100, num_samples=1000):x = np.array([np.linspace(0, (seq_length - 1)*0.1, seq_length) for _ in range(num_samples)])y = np.sin(x)return x, y# 创建LSTM模型
def create_lstm_model(input_shape):model = Sequential()model.add(LSTM(50, activation='relu', input_shape=input_shape))model.add(Dense(1))model.compile(optimizer=Adam(learning_rate=0.01), loss='mse')return model# 主程序
def main():# 生成数据x, y = generate_data()x = x.reshape((x.shape[0], x.shape[1], 1)) # 重塑为LSTM需要的形状# 创建并编译模型model = create_lstm_model((x.shape[1], 1))# 训练模型model.fit(x, y, epochs=20, batch_size=32, verbose=1)# 评估模型(这里我们简单地用训练数据评估)loss = model.evaluate(x, y)print("Model Loss:", loss)if __name__ == "__main__":main()
这个脚本首先生成一个基于正弦函数的时间序列数据,然后创建一个包含一个LSTM层和一个密集层的模型。之后,它使用这些数据训练模型,并评估模型的性能。这只是一个简单的示例,实际应用中可能需要更复杂的数据处理和模型结构调整。
生成对抗网络(Generative Adversarial Networks, GANs)
生成对抗网络(GANs)是一种深度学习模型,主要用于生成数据。它由两个部分组成:生成器(Generator)和鉴别器(Discriminator)。
想象一下,生成器就像是一个艺术家,它试图创造看起来真实的作品。鉴别器则像是一个艺术评论家,它的任务是判断作品是真实的还是生成器创造的假作品。
在训练过程中,生成器不断尝试创造越来越逼真的数据(比如图片),而鉴别器则不断学习如何更好地区分真实数据和生成器创造的数据。这个过程就像是一场博弈,最终目标是让生成器能够创造出鉴别器也难以区分的高质量数据。
举个例子,如果我们用GANs来生成图片,生成器最开始可能生成的是一些难以辨认的图像。但随着训练的进行,它学会如何创造越来越真实的图片,比如逼真的人脸或风景画。同时,鉴别器也在学习如何更精准地分辨真假图片。这个过程就像是一个学习和适应的游戏。
用python写个示例
创建一个简单的生成对抗网络(GAN)示例需要使用深度学习库,比如TensorFlow或PyTorch。这里我将使用TensorFlow来演示如何构建一个基本的GAN模型。这个示例将展示如何构建和训练一个生成器(Generator)和一个鉴别器(Discriminator)来生成手写数字图片(类似于MNIST数据集中的图片)。
首先,确保您的环境中已安装TensorFlow。如果未安装,可以通过运行pip install tensorflow来安装。
接下来是构建和训练GAN模型的代码:
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Reshape
from tensorflow.keras import Sequential
import matplotlib.pyplot as plt
import numpy as np# 加载MNIST数据集
(X_train, _), (_, _) = tf.keras.datasets.mnist.load_data()
X_train = X_train / 255.0 # 归一化# 创建生成器
generator = Sequential([Dense(128, activation='relu', input_shape=(100,)),Dense(784, activation='sigmoid'),Reshape((28, 28))
])# 创建鉴别器
discriminator = Sequential([Flatten(input_shape=(28, 28)),Dense(128, activation='relu'),Dense(1, activation='sigmoid')
])# 编译鉴别器
discriminator.compile(loss='binary_crossentropy', optimizer='adam')
discriminator.trainable = False# 创建和编译GAN模型
gan = Sequential([generator, discriminator])
gan.compile(loss='binary_crossentropy', optimizer='adam')# 训练GAN
epochs = 100
batch_size = 32
for epoch in range(epochs):for _ in range(batch_size):# 随机噪声noise = np.random.normal(0, 1, (batch_size, 100))# 生成图片generated_images = generator.predict(noise)# 真实图片real_images = X_train[np.random.randint(0, X_train.shape[0], batch_size)]# 标签real_y = np.ones((batch_size, 1))fake_y = np.zeros((batch_size, 1))# 训练鉴别器discriminator.trainable = Trued_loss_real = discriminator.train_on_batch(real_images, real_y)d_loss_fake = discriminator.train_on_batch(generated_images, fake_y)d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)# 训练生成器noise = np.random.normal(0, 1, (batch_size, 100))discriminator.trainable = Falseg_loss = gan.train_on_batch(noise, real_y)# 每个epoch结束时打印损失print(f'Epoch {epoch + 1}/{epochs}, Discriminator Loss: {d_loss}, Generator Loss: {g_loss}')# 生成一些图片以查看结果
noise = np.random.normal(0, 1, (10, 100))
generated_images = generator.predict(noise)
plt.figure(figsize=(10, 10))
for i in range(generated_images.shape[0]):plt.subplot(2, 5, i+1)plt.imshow(generated_images[i], cmap='gray')plt.axis('off')
plt.tight_layout()
plt.show()
这个代码首先加载MNIST数据集,然后定义了生成器和鉴别器的结构。生成器的目标是从随机噪声中生成手写数字图片,而鉴别器则试图区分真实图片和生成器生成的图片。接着,代码中定义了训练循环,其中交替地训练鉴别器和生成器。最后,代码生成了一些图片以展示训练后生成器的效果。
梯度下降(Gradient Descent)
梯度下降(Gradient Descent)是一种用于优化算法的方法,广泛应用于机器学习和深度学习中。我们可以用一个生活中的比喻来理解它:想象你站在山上,目标是要走到山谷的最低点。但是,由于浓雾的遮挡,你看不到整座山,只能感觉到脚下地面的倾斜程度。
梯度下降就像是你决定沿着脚下最陡峭的方向(这就是“梯度”)往下走,希望这样能更快地到达山谷底部。在机器学习中,这座山就代表了一个损失函数(Loss Function),这个函数描述了当前模型预测值与实际值之间的误差。山谷的最低点,即损失函数的最小值,对应于模型的最佳参数。
梯度下降法的步骤大致如下:
-
选择起始点:这就好比选择一个山上的起始位置。在机器学习中,这通常是随机选择模型参数的初始值。
-
计算梯度:梯度是损失函数在当前位置的斜率,指示了误差下降最快的方向。这就像是感觉脚下的地面,判断哪个方向最陡。
-
更新位置:根据梯度和一个称为“学习率”的参数,更新你的位置。学习率决定了你每一步走多远。太大可能会越过最低点,太小则下降得很慢。
-
重复步骤:重复计算梯度和更新位置,直到找到一个“足够好”的最低点,或者达到预设的迭代次数。
梯度下降法的关键在于学习率的选择和梯度的准确计算。如果学习率太大,可能会错过最低点;如果太小,则可能需要很长时间才能到达最低点。同时,由于只能根据当前位置的梯度信息来决策,因此有时可能会陷入局部最低点,而不是全局最低点。
用python写个示例
当然可以。让我们以一个简单的例子来展示梯度下降的过程:假设有一个函数 ( f(x) = x^2 ),我们想要找到使这个函数最小化的 ( x ) 值。很显然,这个函数的最小值在 ( x = 0 ) 处,但我们将使用梯度下降法来找到这个点。
首先,我们需要计算函数的梯度,即 ( f’(x) = 2x )。然后,我们将从一个随机点开始,比如 ( x = 10 ),并使用梯度下降法来更新 ( x ) 的值,直到找到最小值。
我将编写一个Python脚本来演示这个过程。我们将设置一个学习率,例如 0.1,然后迭代地更新 ( x ) 的值。
通过梯度下降法,我们从起始点 ( x = 10 ) 开始,经过 100 次迭代后,得到的 ( x ) 的值接近于 0(大约是 ( 2.04 \times 10^{-9} )),这与我们预期的最小化点 ( x = 0 ) 非常接近。这个结果展示了梯度下降法在寻找函数最小值时的有效性。在每次迭代中,我们根据函数的梯度(斜率)来更新 ( x ) 的值,并逐渐接近最小值点。
进化算法(Evolutionary Algorithms)
进化算法是一种模仿生物进化过程的算法,用于解决优化和搜索问题。就像自然选择中最适应环境的生物能够生存下来一样,进化算法通过迭代过程优化解决方案。这个过程包括选择、交叉(或称为杂交)、变异和遗传这几个步骤。
让我们用一个简单的例子来理解进化算法的基本原理:假设你正在尝试创建一个可以走得很远的小机器人。你有很多不同设计的小机器人,但你不知道哪一个最好。
-
初始化:首先,你随机创建一群小机器人(这就是“种群”)。
-
评估:然后,你测试每个机器人走多远(这就是“适应度”评估)。
-
选择:选择表现最好的一些机器人。这就像自然界中生存竞争,表现好的有更多机会“繁衍”。
-
交叉:将这些表现好的机器人的“特性”组合起来,创造新一代机器人。这就像生物的杂交,后代会继承父代的特性。
-
变异:在新一代中引入一些小的随机改变。这就像生物进化中的突变,有助于探索新的可能性。
-
迭代:重复这个过程多次。每一代机器人都会根据其走路的能力被评估,选择,杂交,然后再变异。
随着时间的推移,你会发现整体的机器人性能在提高,因为不断有更适应的机器人被创造出来。这就是进化算法的基本思想:通过模拟自然选择和遗传原理来不断优化解决方案。
用python写个示例
当然可以。让我们以一个简单的例子来演示进化算法:我们将尝试优化一个函数,使其输出尽可能接近目标值。我们的目标是找到一个数字,当将其平方时,结果尽可能接近某个给定的目标值(比如42)。
在这个例子中,我们将使用一个非常基础的进化算法流程:
- 初始化:生成一个随机数列表(种群)。
- 评估:计算每个数字平方后与目标值的差距(适应度)。
- 选择:选择表现最好(即与目标值差距最小)的数字。
- 交叉和变异:结合和修改选择出的数字以创建新的数字。
- 迭代:重复这个过程,直到找到足够接近目标值的解。
现在,我将用Python编写这个示例的代码。
经过25代的进化,我们找到了一个相当接近目标值42的解。这个最佳个体的值约为-6.842,其平方与42的差距仅为0.353。
这个简单的进化算法示例展示了如何通过初始化一个随机种群、计算适应度、选择最佳个体、进行交叉和变异,以及迭代这些步骤来逐步优化解决方案。当然,实际应用中的进化算法可能会更加复杂和精细,包括更高级的选择、交叉和变异策略,以及对不同类型问题的特定调整。
相关文章:
生成对抗网络 优化算法进化算法)
3易懂AI深度学习算法:长短期记忆网络(Long Short-Term Memory, LSTM)生成对抗网络 优化算法进化算法
继续写:https://blog.csdn.net/chenhao0568/article/details/134920391?spm1001.2014.3001.5502 1.https://blog.csdn.net/chenhao0568/article/details/134931993?spm1001.2014.3001.5502 2.https://blog.csdn.net/chenhao0568/article/details/134932800?spm10…...
云计算 云原生
一、引言 云计算需要终端把信息上传到服务器,服务器处理后再返回给终端。在之前人手一台手机的情况下,云计算还是能handle得过来的。但是随着物联网的发展,什么东西都要联网,那数据可就多了去了,服务器处理不过来&…...

深拷贝、浅拷贝 react的“不可变值”
知识获取源–晨哥(现实中的人 嘿嘿) react中如果你想让一个值始终不变 或者说其他操作不影响该值 它只是作用初始化的时候 使用了浅拷贝–改变了初始值 会改变初始值(selectList1) 都指向同一个地址 const selectList1 { title: 大大, value: 1 };con…...

赛宁网安多领域亮相第三届网络空间内生安全发展大会
2023年12月8日,第三届网络空间内生安全发展大会在宁开幕。两院院士、杰出专家学者和知名企业家相聚南京,围绕数字经济新生态、网络安全新范式进行广泛研讨,为筑牢数字安全底座贡献智慧和力量。 大会围绕“一会、一赛、一展”举办了丰富多彩的…...
)
LintCode 123 · Word Search (DFS字符处理经典题!)
123 Word Search Algorithms Medium Description Given a 2D board and a string word, find if the string word exists in the grid. The string word can be constructed from letters of sequentially adjacent cell, where “adjacent” cells are those horizontally o…...
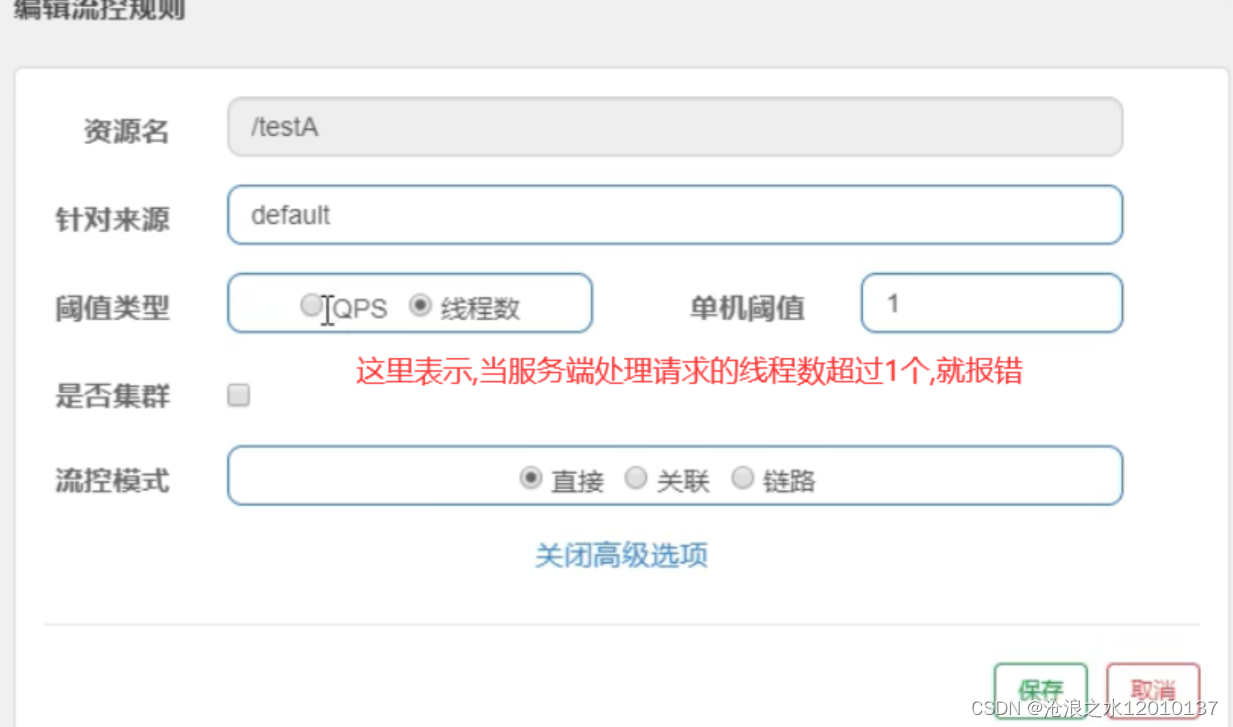
SpringCloud面试题——Sentinel
一:什么是Sentinel? Sentinel是一个面向分布式架构的轻量级服务保护框架,实现服务降级、服务熔断、服务限流等功能 二:什么是服务降级? 比如当某个服务繁忙,不能让客户端的请求一直等待,应该立刻返回给客户端一个备…...

【精选】 VulnHub (超详细解题过程)
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~ ✨主攻领域:【渗透领域】【应急响应】 【python】 【VulnHub靶场复现】【面试分析】 🎉点赞➕评论➕收藏…...
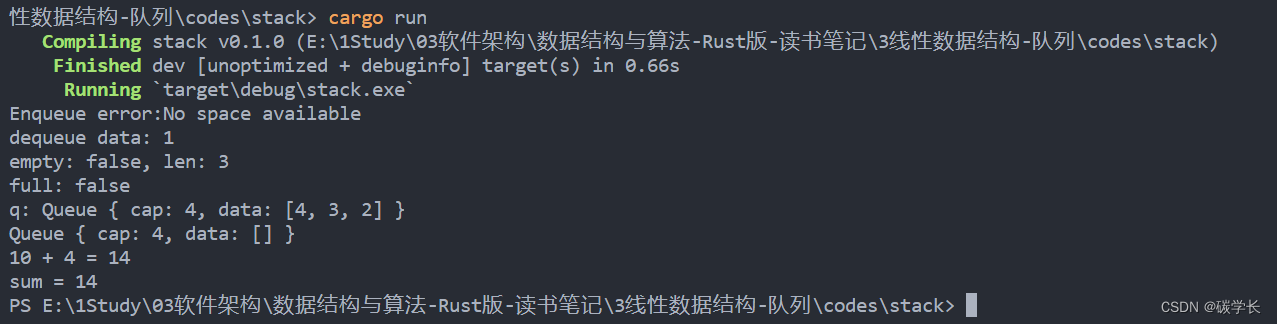
数据结构与算法-Rust 版读书笔记-2线性数据结构-队列
数据结构与算法-Rust 版读书笔记-2线性数据结构-队列 1、队列:先进先出 队列是项的有序集合,其中,添加新项的一端称为队尾,移除项的另一端称为队首。一个元素在从队尾进入队列后,就会一直向队首移动,直到…...

Android Kotlin Viewbinding封装
目录 Viewbinding配置 Activity封装 Activity使用 Fragment封装 Fragment使用 Dialog封装 Dialog使用 Viewbinding配置 android { viewBinding { enabled true } } Activity封装 import android.os.Bundle import android.view.LayoutInflater import androidx.ap…...
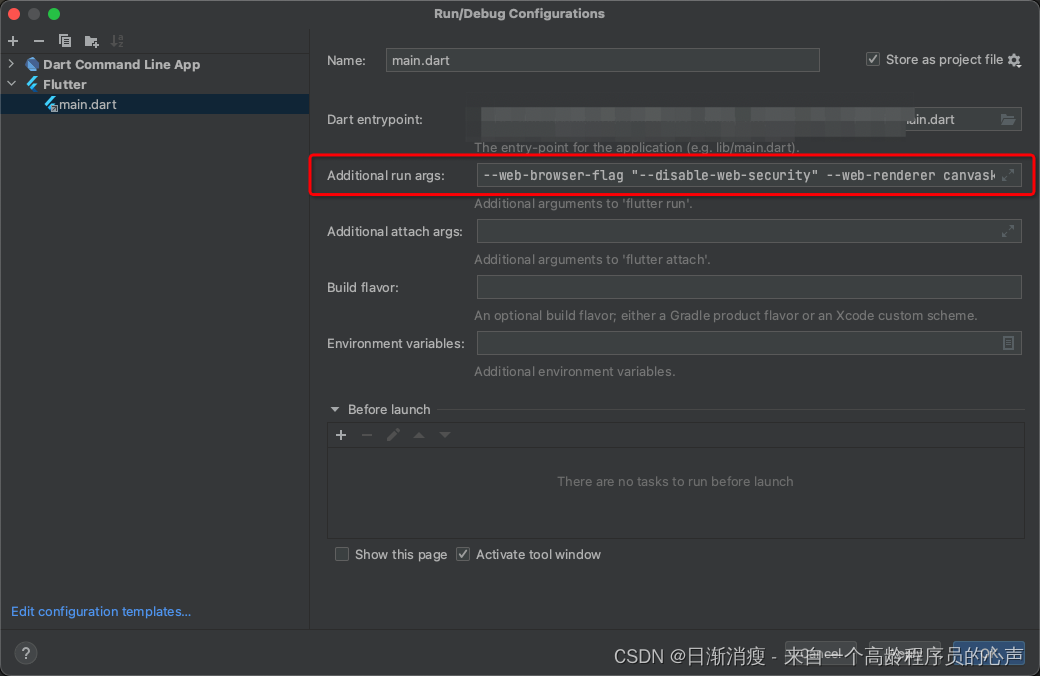
Flutter:web项目跨域问题解决
前后端解决系列 文章目录 一、Flutter web客户端解决本地环境调试跨域问题二、Flutter web客户端解决线上环境跨域问题 一、Flutter web客户端解决本地环境调试跨域问题 就一句命令【--web-browser-flag "--disable-web-security"】,用来屏蔽浏览器域名请…...
--A2L文件生成的方法)
汽车标定技术(十二)--A2L文件生成的方法
目录 1.工具生成 1.1 CANape/ASAP2 Studio 1.2 ASAP2ToolKit 1.3 Matlab/Simulink 2.手写A2L要点 3.小结 A2L文件的制作一直以来是一个很少有人关注的方向,不管是标定工程师还是Slave协议栈的开...

《PySpark大数据分析实战》-03.了解Hive
📋 博主简介 💖 作者简介:大家好,我是wux_labs。😜 热衷于各种主流技术,热爱数据科学、机器学习、云计算、人工智能。 通过了TiDB数据库专员(PCTA)、TiDB数据库专家(PCTP…...
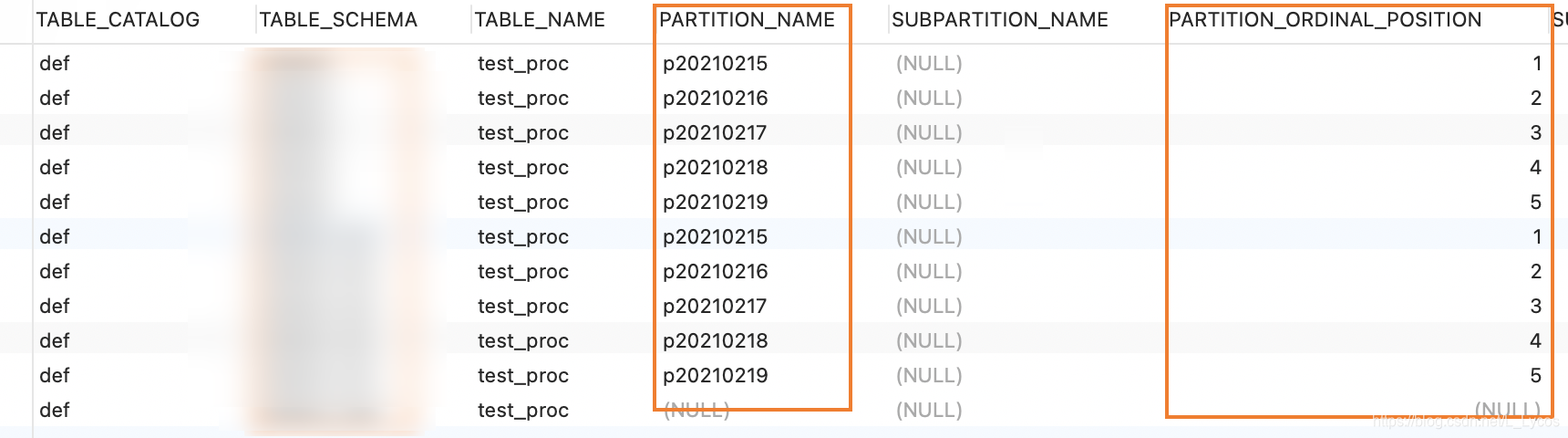
经验分享|MySQL分区实战(RANGE)
概述 分区概述 在 MySQL 中, InnoDB存储引擎长期以来一直支持表空间的概念。在 MySQL 8.0 中,同一个分区表的所有分区必须使用相同的存储引擎。但是,也可以为同一 MySQL 服务器甚至同一数据库中的不同分区表使用不同的存储引擎。 通俗地讲…...
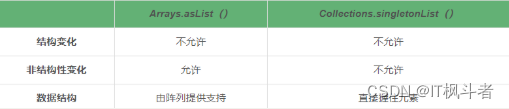
Arrays.asList() 和 Collections.singletonList()
Arrays.asList() 和 Collections.singletonList() 概述 List 是我们使用Java时常用的集合类型。众所周知,我们可以轻松地在一行中初始化列表。例如,当我们想要初始化一个只有一个元素的List时,我们可以使用Arrays.asList(&#…...
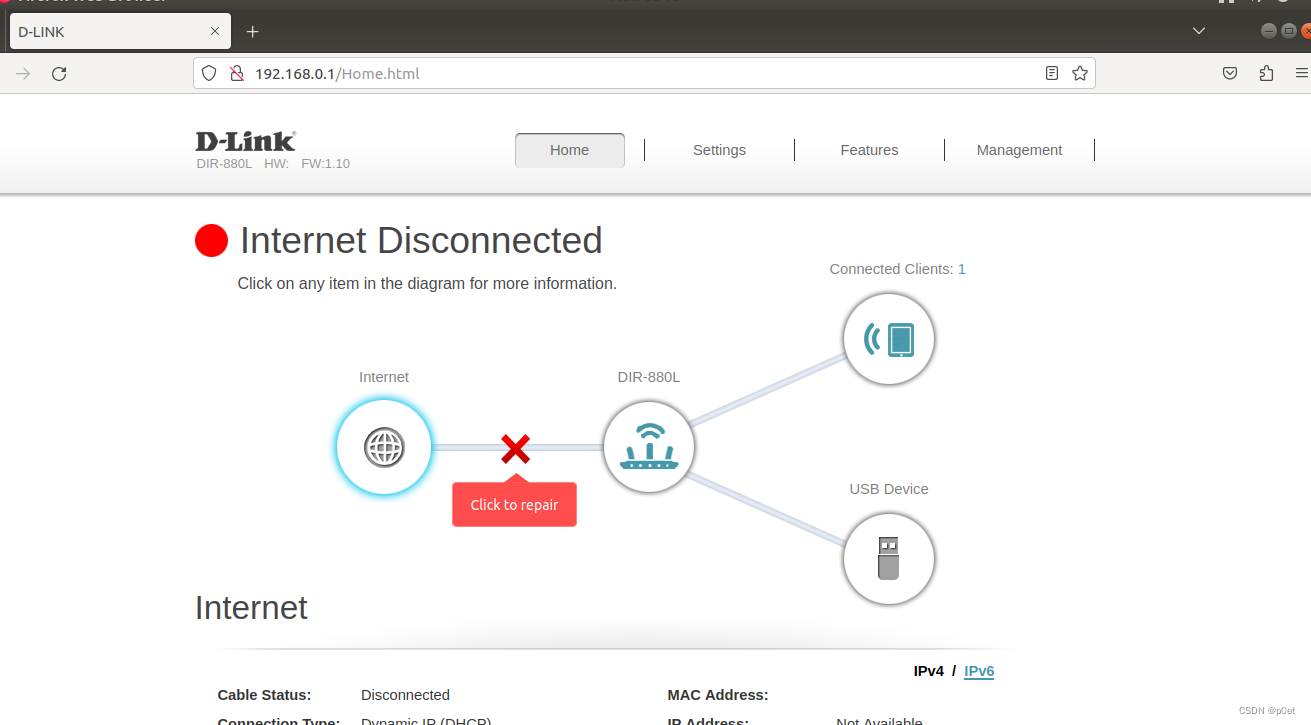
Firmware Analysis Plus (Fap)固件模拟安装教程(最新)
最近在搞IoT的研究,但是难在设备比较难弄,只有固件,而没有设备,买吧,又太费钱,不划算。好在有很多项目可以在模拟环境中运行固件。但是几乎没有一个平台能够模拟所有硬件设备。IoT产品的架构也不尽相同。 …...

使用包、Crate 和模块管理项目(上)
目录 1、包和Crate 2、定义模块来控制作用域与私有性 2.1 在模块中对相关代码进行分组 3、引用模块项目的路径 3.1 使用 pub 关键字暴露路径 二进制和库 crate 包的最佳实践 3.2 super 开始的相对路径 3.3 创建公有的结构体和枚举 Rust 有许多功能可以让你管理代码的组…...

【Kotlin】
Lambda 就是一小段可以作为参数传递的代码。 因为正常情况下,我们向某个函数传参时只能传入变量,而借助Lambda 却允许传入一小段代码。 Lambda 表达式的语法结构: {参数名1: 参数类型, 参数名2: 参数类型 -> 函数体}首先,最外…...

JavaDay17
创建不可变集合 import java.util.Iterator; import java.util.List;public class Test {public static void main(String[] args) {/*创建不可变的List集合* "张三" "李四" "王五" "赵六*///一旦创建之后 是无法进行修改的 在下面的代码…...
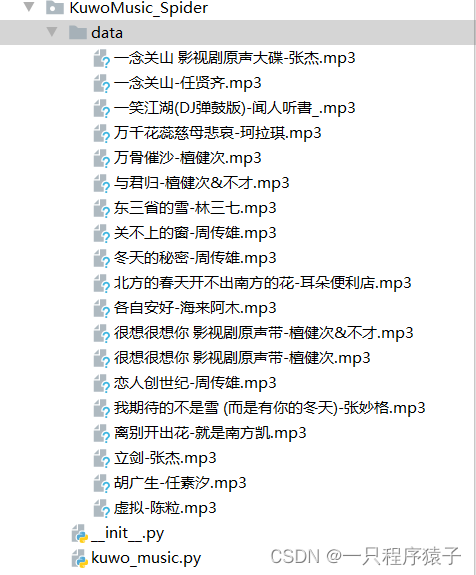
Python爬取酷我音乐
🎈 博主:一只程序猿子 🎈 博客主页:一只程序猿子 博客主页 🎈 个人介绍:爱好(bushi)编程! 🎈 创作不易:喜欢的话麻烦您点个👍和⭐! 🎈…...
)
项目实战第四十七讲:易宝支付对接详解(保姆级教程)
易宝支付对接(保姆级教程) 为了实现项目的支付需求,公司选择了易宝支付进行对接,本文是项目实战第四十七讲,详解易宝支付对接。 文章目录 易宝支付对接(保姆级教程)1、需求背景2、流程图3、技术方案4、相关接口4.1、入驻相关(商户入网)4.2、账户相关接口(充值、提现、…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...