【Python百宝箱】贝叶斯统计的魅力:从PyMC3到ArviZ,探索数据背后的不确定性
标题:预测未来趋势的利器:深入贝叶斯统计和概率编程的世界
前言
贝叶斯统计和概率编程是一种强大的分析方法,可以帮助我们处理不确定性、建立灵活的模型以及进行参数估计和推断。本文将介绍几个常用的Python库,包括PyMC3、ArviZ以及其他一些贝叶斯统计和概率编程库,同时提供完整的代码示例和应用领域。
欢迎订阅专栏:Python库百宝箱:解锁编程的神奇世界
文章目录
- 标题:预测未来趋势的利器:深入贝叶斯统计和概率编程的世界
- 前言
- 1. PyMC3
- 1.1 概述
- 1.2 安装和环境配置
- 1.3 基本概念和术语
- 1.4 模型构建步骤
- 1.5 参数估计与推断
- 1.6 模型评估和对比
- 1.5 参数估计与推断
- 1.6 模型评估和对比
- 1.6.1 后验预测
- 1.6.2 WAIC和LOO
- 2. ArviZ
- 2.1 概述
- 2.2 安装和环境配置
- 2.3 数据可视化
- 2.3.1 样本后验分布可视化
- 2.3.2 参数估计结果可视化
- 2.4 统计分析
- 2.4.1 后验分布的摘要统计
- 2.4.2 参数比较和模型选择
- 2.5 后验预测
- 2.6 模型诊断和改进
- 2.6.1 轨迹可视化和收敛诊断
- 2.6.2 其他常用诊断方法
- 2.6.3 后验分析和模型诊断
- 2.6.3.1 后验分布可视化与解释
- 2.6.3.2 联合分布可视化
- 2.6.3.3 模型后验预测检验
- 2.6.3.4 后验效果量和置信区间计算
- 3. Edward
- 3.1 简介和特点
- 3.2 使用示例
- 3.3 变分推断
- 3.4 蒙特卡洛推断
- 3.5 模型评估与比较
- 3.6 Edward与其他概率编程工具的比较
- 4. BayesPy
- 4.1 概述和功能
- 4.2 应用案例
- 4.3 变分推断
- 4.4 蒙特卡洛推断
- 4.5 模型评估与比较
- 4.6 BayesPy与其他概率编程工具的比较
- 5 Stan
- 5.1 概述和特点
- 5.2 使用示例
- 5.3 高级功能
- 5.4 模型评估和比较
- 5.5 Stan与其他概率编程工具的比较
- 6 TensorFlow Probability
- 6.1 概述和特点
- 6.2 使用示例
- 6.3 高级功能
- 6.4 模型评估和比较
- 6.5 TensorFlow Probability与其他概率编程工具的比较
- 7 小结
- 总结
1. PyMC3
1.1 概述
PyMC3是一个用于贝叶斯统计建模和推断的强大Python库。它提供了丰富的概率分布和统计模型,以及使用马尔可夫链蒙特卡罗(MCMC)等技术进行参数估计和推断的功能。
1.2 安装和环境配置
要安装PyMC3,请运行以下命令:
!pip install pymc3
1.3 基本概念和术语
- 随机变量(Random Variable):表示未知的模型参数或结果的随机变量。
- 先验分布(Prior Distribution):代表对未知参数的先前知识或信念。
- 后验分布(Posterior Distribution):通过将观测数据与先验分布结合,利用贝叶斯定理得到的未知参数的分布。
- MCMC(Markov Chain Monte Carlo):一种采样方法,用于从后验分布中获取参数估计值。
1.4 模型构建步骤
下面是使用PyMC3构建模型的基本步骤:
- 定义数据。
- 定义未知参数的先验分布。
- 定义模型:使用先验分布和参数之间的关系描述数据生成过程。
- 使用观测数据运行推断算法以获得后验分布。
- 分析结果。
以下是一个简单的线性回归模型示例:
import pymc3 as pm
import numpy as np # 1. 定义数据
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([1, 2, 3, 4, 5, 6])# 2. 定义未知参数的先验分布
beta0_prior_mu = 0
beta0_prior_sd = 10
beta1_prior_mu = 0
beta1_prior_sd = 10# 3. 定义模型
with pm.Model() as model:beta0 = pm.Normal('beta0', mu=beta0_prior_mu, sd=beta0_prior_sd)beta1 = pm.Normal('beta1', mu=beta1_prior_mu, sd=beta1_prior_sd)sigma = pm.Uniform('sigma', lower=0, upper=10)y_pred = beta0 + beta1 * x# 4. 观测数据likelihood = pm.Normal('y', mu=y_pred, sd=sigma, observed=y)# 5. 运行推断算法trace = pm.sample(1000, tune=1000)# 分析结果
pm.summary(trace)
1.5 参数估计与推断
参数估计和推断是通过运行MCMC采样算法从后验分布中获得的。PyMC3提供了多种MCMC算法,如NUTS(No-U-Turn Sampler)和Metropolis-Hastings。
以下是一个使用NUTS算法进行参数估计和推断的示例:
with model:trace = pm.sample(1000, tune=1000, nuts_kwargs={'target_accept': 0.95})pm.summary(trace)
1.6 模型评估和对比
对于模型评估和对比,可以通过后验预测、WAIC(Widely Applicable Information Criterion)和LOO(Leave-One-Out)等方法来进行。
后验预测示例:
with model:post_pred = pm.sample_posterior_predictive(trace, samples=500)print(post_pred['y'].shape) # (500, 6)
WAIC和LOO示例:
waic = pm.waic(trace, model)
loo = pm.loo(trace, model)print(waic)
print(loo)
1.5 参数估计与推断
参数估计和推断是通过运行MCMC采样算法从后验分布中获得的。PyMC3提供了多种MCMC算法,如NUTS(No-U-Turn Sampler)和Metropolis-Hastings。
以下是一个使用Metropolis-Hastings算法进行参数估计和推断的示例:
with model:step = pm.Metropolis()trace = pm.sample(1000, tune=1000, step=step)pm.summary(trace)
在这个示例中,我们使用了Metropolis()作为采样步骤。通过逐步迭代改变参数值,并接受或拒绝新的参数值来探索参数空间。需要注意的是,与NUTS相比,Metropolis-Hastings算法可能更容易陷入局部极大值,因此需要谨慎选择采样步骤。
1.6 模型评估和对比
模型评估和对比是贝叶斯统计中重要的环节之一,它有助于判断模型的质量和性能,并选择最佳的模型。
1.6.1 后验预测
后验预测是对未观测数据的预测,基于已观测数据和模型的后验分布。通过生成从后验分布中抽取的参数值,可以进行后验预测。
以下是一个后验预测的示例:
with model:post_pred = pm.sample_posterior_predictive(trace, samples=500)print(post_pred['y'].shape) # (500, 6)
在这个示例中,我们使用sample_posterior_predictive()函数从后验分布中生成了500组未观测数据的样本。这些样本可以用于评估模型的预测性能和对新数据的拟合程度。
1.6.2 WAIC和LOO
WAIC(Widely Applicable Information Criterion)和LOO(Leave-One-Out)是两种常用的模型比较方法,可用于评估不同模型的相对质量。
以下是一个计算WAIC和LOO的示例:
waic = pm.waic(trace, model)
loo = pm.loo(trace, model)print(waic)
print(loo)
通过计算模型的WAIC和LOO得分,我们可以比较不同模型的相对优劣。较低的WAIC和LOO得分表示更好的模型拟合和预测性能。
2. ArviZ
2.1 概述
ArviZ是一个用于可视化和诊断贝叶斯统计分析结果的Python库。它提供了丰富的数据可视化工具和统计分析方法,有助于理解和解释贝叶斯模型的结果。
2.2 安装和环境配置
要安装ArviZ,请运行以下命令:
!pip install arviz
2.3 数据可视化
2.3.1 样本后验分布可视化
以下是使用ArviZ可视化样本后验分布的示例:
import arviz as az# 假设已经获得了trace对象
az.plot_posterior(trace)
2.3.2 参数估计结果可视化
以下是使用ArviZ可视化参数估计结果的示例:
az.plot_trace(trace)
2.4 统计分析
2.4.1 后验分布的摘要统计
以下是使用ArviZ获取后验分布摘要统计的示例:
summary = az.summary(trace)
print(summary)
2.4.2 参数比较和模型选择
以下是使用ArviZ进行参数比较和模型选择的示例:
waic = az.waic(trace, model)
loo = az.loo(trace, model)print(waic)
print(loo)
2.5 后验预测
以下是使用ArviZ进行后验预测的示例:
post_pred = az.from_pymc3(trace=trace, model=model)
az.plot_ppc(post_pred)
2.6 模型诊断和改进
2.6.1 轨迹可视化和收敛诊断
以下是使用ArviZ进行轨迹可视化和收敛诊断的示例:
az.plot_trace(trace)
2.6.2 其他常用诊断方法
除了轨迹可视化,还可以使用其他诊断方法,如Gelman-Rubin收敛诊断、ESS(effective sample size)等。
2.6.3 后验分析和模型诊断
ArviZ提供了丰富的工具和方法,用于进行后验分析和对贝叶斯模型进行诊断。这些工具可以帮助我们检查模型的拟合情况、参数的影响以及模型假设的合理性。
2.6.3.1 后验分布可视化与解释
使用ArviZ,我们可以通过可视化来探索并解释参数的后验分布。
以下是一个绘制多个参数后验分布的示例:
az.plot_posterior(trace, var_names=['param1', 'param2'])
这将生成一个包含多个子图的图表,每个子图上显示了参数的后验分布。通过这种方式,我们可以一次性地观察多个参数的分布情况,并进行比较、解释和推断。
2.6.3.2 联合分布可视化
ArviZ还支持绘制参数之间的联合分布图,帮助我们理解参数之间的关系。
以下是一个绘制参数联合分布的示例:
az.plot_pair(trace, var_names=['param1', 'param2'])
这将生成一个散点图矩阵,其中每个散点图显示了两个参数之间的关系。通过观察这些联合分布图,我们可以了解参数之间是否存在相关性或依赖关系。
2.6.3.3 模型后验预测检验
通过使用ArviZ的sample_posterior_predictive()函数,我们可以生成从后验分布中抽取的数据样本,并将其与观测数据进行比较以进行模型后验预测检验。
以下是一个后验预测检验的示例代码:
with model:post_pred = pm.sample_posterior_predictive(trace, samples=1000)az.plot_ppc(az.from_pymc3(posterior_predictive=post_pred))
这将生成一个图表,显示了从后验分布中生成的模拟数据与观测数据之间的比较。通过这个可视化,我们可以评估模型的拟合程度以及对新数据的泛化能力。
2.6.3.4 后验效果量和置信区间计算
除了分析参数的后验分布外,我们还可以使用ArviZ计算后验效果量和置信区间来量化模型结果。
以下是一个计算后验效果量和置信区间的示例代码:
az.summary(trace, hdi_prob=0.95, eff_sample_size=True)
这将生成一个包含效果量、置信区间和有效样本量等信息的摘要统计表。通过这些统计信息,我们可以更准确地理解模型的效果和不确定性。
3. Edward
3.1 简介和特点
Edward是一个基于概率编程语言的高级API,用于构建概率模型并进行推断。它建立在TensorFlow之上,并提供了一种简洁而灵活的方式来定义概率模型和进行贝叶斯推断。
Edward的主要特点包括:
- 灵活性:Edward允许用户使用Python和TensorFlow的强大功能来定义复杂的概率模型。
- 可扩展性:Edward与TensorFlow紧密集成,可以利用TensorFlow的计算图和自动微分功能进行高效的推断。
- 丰富的推断方法:Edward支持多种推断方法,包括变分推断、蒙特卡洛推断和最大后验估计等。
- 易于使用:Edward提供了简单而直观的API,使得构建和推断概率模型变得容易上手。
3.2 使用示例
以下是使用Edward构建简单线性回归模型的示例:
import edward as ed
import tensorflow as tf# 定义数据
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([1, 2, 3, 4, 5, 6])# 定义模型
X = tf.placeholder(tf.float32, [None])
beta0 = ed.Normal(0.0, 1.0)
beta1 = ed.Normal(0.0, 1.0)
sigma = ed.HalfNormal(0.0, 1.0)
Y = ed.Normal(loc=beta0 + beta1 * X, scale=sigma)# 运行推断算法
inference = ed.MAP({}, data={X: x, Y: y})
inference.run()
在这个示例中,我们首先定义了输入数据 x 和目标数据 y。然后,我们使用Edward创建了一个简单的线性回归模型,其中我们对系数 beta0、beta1 和噪声 sigma 分别假设了先验分布。接下来,我们使用最大后验估计(MAP)方法进行参数估计,通过将数据和模型传递给 ed.MAP() 对象,并调用其 run() 方法来执行推断。
通过Edward的灵活API和丰富的推断方法,我们可以构建更复杂的概率模型并进行更全面的贝叶斯推断分析。
3.3 变分推断
Edward支持使用变分推断进行贝叶斯推断。变分推断是一种近似推断方法,旨在寻找与真实后验分布最接近的分布。它通过最小化两个分布之间的差异度量来实现。
以下是使用Edward进行变分推断的示例:
import edward as ed
import tensorflow as tf# 定义数据
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([1, 2, 3, 4, 5, 6])# 定义模型
X = tf.placeholder(tf.float32, [None])
beta0 = ed.Normal(0.0, 1.0)
beta1 = ed.Normal(0.0, 1.0)
sigma = ed.HalfNormal(0.0, 1.0)
Y = ed.Normal(loc=beta0 + beta1 * X, scale=sigma)# 定义变分推断
qbeta0 = ed.Normal(loc=tf.Variable(0.0), scale=tf.Variable(1.0))
qbeta1 = ed.Normal(loc=tf.Variable(0.0), scale=tf.Variable(1.0))
qsigma = ed.HalfNormal(scale=tf.Variable(1.0))inference = ed.KLqp({beta0: qbeta0, beta1: qbeta1, sigma: qsigma}, data={X: x, Y: y})
inference.run()
在这个示例中,我们使用Edward的KLqp类来定义变分推断。我们通过将模型参数和变分参数进行匹配,并使用输入数据 x 和 y 来执行推断。最后,我们调用 run() 方法来运行变分推断。
3.4 蒙特卡洛推断
Edward还支持使用蒙特卡洛推断进行贝叶斯推断。蒙特卡洛推断是一种基于随机采样的推断方法,通过从潜在的后验分布中抽取样本来近似求解。
以下是使用Edward进行蒙特卡洛推断的示例:
import edward as ed
import tensorflow as tf# 定义数据
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([1, 2, 3, 4, 5, 6])# 定义模型
X = tf.placeholder(tf.float32, [None])
beta0 = ed.Normal(0.0, 1.0)
beta1 = ed.Normal(0.0, 1.0)
sigma = ed.HalfNormal(0.0, 1.0)
Y = ed.Normal(loc=beta0 + beta1 * X, scale=sigma)# 运行蒙特卡洛推断
n_samples = 1000
inference = ed.MonteCarlo({}, data={X: x, Y: y})
inference.run(n_samples=n_samples)
在这个示例中,我们使用Edward的MonteCarlo类来定义蒙特卡洛推断。我们通过将模型参数传递给 run() 方法,并指定抽样次数来运行蒙特卡洛推断。
通过变分推断和蒙特卡洛推断,Edward提供了灵活且强大的工具来进行贝叶斯推断,并帮助我们理解和解释概率模型的结果。
3.5 模型评估与比较
Edward提供了多种方法用于评估和比较概率模型的性能。这些方法可以帮助我们判断模型的拟合程度、预测能力和参数估计的准确性。
一种常用的评估方法是使用对数似然函数(Log Likelihood),它衡量观测数据在给定模型下的概率。对数似然函数越高,模型对观测数据的拟合程度就越好。在Edward中,我们可以通过调用inference.compute_ll()方法来计算对数似然函数的估计值。
另一种评估方法是使用后验预测分布(Posterior Predictive Distribution),它可以用来生成新的伪数据,并与真实观测数据进行比较。如果后验预测分布能够产生与真实数据相似的模式,那么模型具有良好的预测能力。Edward提供了通过ed.ppc()函数进行后验预测检验的功能。
除了单个模型的评估,Edward还支持模型之间的比较。一种常见的比较方法是使用交叉验证(Cross Validation)。交叉验证将数据集划分为训练集和测试集,在训练集上进行参数估计,在测试集上进行预测并计算性能指标。Edward提供了用于实现交叉验证的功能,例如ed.evaluate()函数。
通过这些评估和比较方法,我们可以全面地了解概率模型的性能和适用性,并作出相应的改进和调整。
3.6 Edward与其他概率编程工具的比较
Edward是一个强大的概率编程工具,但也存在其他类似的工具可供选择。下面是Edward与其他概率编程工具的简要比较:
-
Pyro:Pyro是另一个基于概率编程语言的工具,它建立在PyTorch上。与Edward类似,Pyro提供了定义概率模型、进行推断和进行模型评估的功能。不同之处在于,Pyro更加注重灵活性和交互性,同时提供了更多高级的推断算法和模型构建工具。
-
Stan:Stan是一种专门用于贝叶斯统计建模的概率编程语言。与Edward和Pyro不同,Stan使用自己独特的建模语言,提供了一种声明式的方式来定义概率模型。Stan拥有丰富的推断算法,并具有高效的后端引擎。与Edward相比,Stan更适合处理中等规模的统计模型,尤其是需要高精度参数估计的情况。
-
PyMC3:PyMC3是一个基于Python的概率编程库,用于构建贝叶斯统计模型。PyMC3使用了类似Edward的变分推断和蒙特卡洛推断方法,并提供了方便的API来定义模型、进行推断和评估。与Edward相比,PyMC3在模型定义和推断方法上的风格略有不同,用户可以根据自己的偏好选择适合的工具。
这些概率编程工具都有各自的优点和特点,选择合适的工具取决于具体的需求和任务。Edward作为一个灵活而强大的工具,在构建概率模型、进行推断和模型评估方面提供了丰富的功能和简洁的API,使得贝叶斯推断变得更加容易和高效。
4. BayesPy
4.1 概述和功能
BayesPy是一个用于概率编程和贝叶斯推断的Python库。它提供了一组用于构建概率模型的高级API,并支持多种推断算法。
BayesPy的主要功能包括:
- 灵活的概率建模:BayesPy允许用户使用Python来定义复杂的概率模型,并支持多种常见的概率分布和节点类型。
- 丰富的推断算法:BayesPy提供了多种推断算法,包括变分推断、蒙特卡洛推断和期望传递等,用于近似计算后验分布。
- 易于使用的API:BayesPy提供了简洁而直观的API,使得构建和推断概率模型变得容易上手。
4.2 应用案例
以下是使用BayesPy进行简单线性回归模型的示例:
from bayespy.nodes import Gaussian # 定义数据
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([1, 2, 3, 4, 5, 6])# 定义模型
beta0 = Gaussian(0, 10)
beta1 = Gaussian(0, 10)
sigma = Gaussian(0, 10)
Y = Gaussian(beta0 + beta1 * x, sigma)# 运行推断算法
Y.observe(y)
Q = VB(Y, beta0, beta1, sigma)
Q.update(repeat=1000)
在这个示例中,我们首先定义了输入数据 x 和目标数据 y。然后,使用BayesPy创建了一个简单的线性回归模型。我们定义了系数 beta0、beta1 和噪声 sigma 的先验分布,并将它们作为高斯节点添加到模型中。接下来,我们观测到目标变量 Y 的值,使用 observe() 方法将实际观测数据 y 绑定到变量 Y 上。最后,我们选择变分贝叶斯(Variational Bayes)作为推断算法,并使用 update() 方法运行推断过程。
通过BayesPy的灵活API和丰富的推断算法,我们可以构建更复杂的概率模型并进行更全面的贝叶斯推断分析。
4.3 变分推断
BayesPy支持使用变分推断进行贝叶斯推断。变分推断是一种近似推断方法,旨在寻找与真实后验分布最接近的分布。它通过最小化两个分布之间的差异度量来实现。
以下是使用BayesPy进行变分推断的示例:
from bayespy.nodes import Gaussian, Gamma# 定义数据
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([1, 2, 3, 4, 5, 6])# 定义模型
beta0 = Gaussian(0, 10)
beta1 = Gaussian(0, 10)
sigma = Gamma(1e-3, 1e-3)
Y = Gaussian(beta0 + beta1 * x, sigma)# 运行变分推断
Y.observe(y)
Q = VB(Y, beta0, beta1, sigma)
Q.update(repeat=1000)
在这个示例中,我们使用BayesPy的Gaussian()和Gamma()节点来定义模型的先验分布。我们观测到目标变量 Y 的值,并使用变分贝叶斯(VB)作为推断算法来计算后验分布。
4.4 蒙特卡洛推断
BayesPy还支持使用蒙特卡洛推断进行贝叶斯推断。蒙特卡洛推断是一种基于随机采样的推断方法,通过从潜在的后验分布中抽取样本来近似求解。
以下是使用BayesPy进行蒙特卡洛推断的示例:
from bayespy.nodes import Gaussian, Gamma# 定义数据
x = np.array([0, 1, 2, 3, 4, 5])
y = np.array([1, 2, 3, 4, 5, 6])# 定义模型
beta0 = Gaussian(0, 10)
beta1 = Gaussian(0, 10)
sigma = Gamma(1e-3, 1e-3)
Y = Gaussian(beta0 + beta1 * x, sigma)# 运行蒙特卡洛推断
Y.observe(y)
Q = MC(Y, beta0, beta1, sigma)
Q.update(repeat=1000)
在这个示例中,我们使用BayesPy的Gaussian()和Gamma()节点来定义模型的先验分布。我们观测到目标变量 Y 的值,并使用蒙特卡洛(MC)作为推断算法来计算后验分布。
通过变分推断和蒙特卡洛推断,BayesPy提供了灵活且强大的工具来进行贝叶斯推断,并帮助我们理解和解释概率模型的结果。
4.5 模型评估与比较
BayesPy提供了多种方法用于评估和比较概率模型的性能。这些方法可以帮助我们判断模型的拟合程度、预测能力和参数估计的准确性。
一种常用的评估方法是使用对数似然函数(Log Likelihood),它衡量观测数据在给定模型下的概率。对数似然函数越高,模型对观测数据的拟合程度就越好。在BayesPy中,我们可以通过调用Q.log_likelihood()方法来计算对数似然函数的估计值。
另一种评估方法是使用后验预测分布(Posterior Predictive Distribution),它可以用来生成新的伪数据,并与真实观测数据进行比较。如果后验预测分布能够产生与真实数据相似的模式,那么模型具有良好的预测能力。BayesPy提供了通过Y.random()方法进行后验预测检验的功能。
除了单个模型的评估,BayesPy还支持模型之间的比较。一种常见的比较方法是使用信息准则,例如贝叶斯信息准则(Bayesian Information Criterion,BIC)或赤池信息准则(Akaike Information Criterion,AIC)。BayesPy提供了计算BIC和AIC的函数。
通过这些评估和比较方法,我们可以全面地了解概率模型的性能和适用性,并作出相应的改进和调整。
4.6 BayesPy与其他概率编程工具的比较
BayesPy是一个强大的概率编程工具,但也存在其他类似的工具可供选择。下面是BayesPy与其他概率编程工具的简要比较:
-
Edward:Edward是一个基于TensorFlow的概率编程库,提供了灵活而高效的方法来定义概率模型和进行贝叶斯推断。与BayesPy相比,Edward更注重深度学习和神经网络模型的建模与推断。
-
Pyro:Pyro是一个基于PyTorch的概率编程库,用于构建概率模型并进行推断。与BayesPy相比,Pyro更注重灵活性和交互性,提供了更多高级的推断算法和模型构建工具。
-
Stan:Stan是一种专门用于贝叶斯统计建模的概率编程语言。与BayesPy相比,Stan使用了自己独特的建模语言,并提供了一种声明式的方式来定义概率模型。Stan拥有丰富的推断算法,并具有高效的后端引擎。
这些概率编程工具都有各自的优点和特点,选择合适的工具取决于具体的需求和任务。BayesPy作为一个灵活而强大的工具,在构建概率模型、进行推断和模型评估方面提供了丰富的功能和简洁的API,使得贝叶斯推断变得更加容易和高效。
5 Stan
5.1 概述和特点
Stan是一种用于贝叶斯推断的概率编程语言和库。它提供了一个声明性建模语言,可以定义概率模型,并通过高性能的MCMC(Markov Chain Monte Carlo)算法进行推断。
Stan的主要特点包括:
- 灵活的建模语言:Stan使用一种简洁而强大的声明性建模语言,允许用户描述复杂的概率模型。
- 高性能的推断引擎:Stan使用基于梯度的HMC(Hamiltonian Monte Carlo)算法,具有快速收敛和高效采样的优势。
- 丰富的分布和函数库:Stan提供了广泛的概率分布和数学函数,方便用户构建各种类型的概率模型。
- 可扩展性:Stan可以处理大规模数据集和复杂模型,支持并行计算和分布式计算。
- 多语言支持:Stan不仅支持自身的编程语言,还提供了Python、R和其他语言的接口。
5.2 使用示例
以下是使用Stan进行简单线性回归模型的示例:
data {int<lower=0> N; // 数据点数量vector[N] x; // 输入变量vector[N] y; // 目标变量
}parameters {real beta0; // 截距real beta1; // 斜率real<lower=0> sigma; // 噪声标准差
}model {y ~ normal(beta0 + beta1 * x, sigma); // 观测模型
}
在这个示例中,我们首先定义了数据部分,包括数据点数量 N、输入变量 x 和目标变量 y。然后,我们定义了参数部分,包括截距 beta0、斜率 beta1 和噪声标准差 sigma。最后,我们使用观测模型语句 y ~ normal(beta0 + beta1 * x, sigma) 定义了观测数据和模型之间的关系。
要在Stan中运行这个模型,可以使用Stan的Python接口:
import pystan# 定义数据
data = {'N': len(x), 'x': x, 'y': y}# 编译和运行模型
model = pystan.StanModel(file='linear_regression.stan')
fit = model.sampling(data=data)
通过使用Stan的Python接口,我们可以将数据传递给模型,编译并运行模型。然后,我们可以从结果中获取参数的后验分布和其他统计信息,以进行进一步的分析和推断。
5.3 高级功能
除了基本的贝叶斯推断功能之外,Stan还提供了一些高级功能,例如:
- 后验预测检验:Stan可以生成从后验分布中抽取的数据样本,用于模型的后验预测检验。
- 优化和最大似然估计:Stan还支持通过最大似然估计来拟合模型,并进行参数优化。
- 贝叶斯模型比较:Stan提供了模型比较方法,如WAIC(Widely Applicable Information Criterion)和LOO(Leave-One-Out Cross-Validation),用于评估和选择不同的贝叶斯模型。
通过这些高级功能,Stan使得贝叶斯建模和推断变得更加灵活和全面。
5.4 模型评估和比较
Stan提供了多种方法来评估和比较概率模型的性能。以下是一些常用的方法:
-
对数似然函数(Log Likelihood):Stan可以计算给定模型下观测数据的对数似然函数值,该值越高表示模型对观测数据的拟合程度越好。
-
后验预测检验(Posterior Predictive Checks):Stan可以生成从后验分布中抽取的伪数据,并与真实观测数据进行比较。这可以帮助我们评估模型的预测能力和拟合程度。
-
信息准则(Information Criteria):Stan支持计算信息准则,如WAIC和LOO,用于模型比较。这些准则考虑了模型的复杂性和拟合优度,以选择最合适的模型。
-
参数诊断和收敛诊断:Stan提供了各种诊断工具,用于检查参数的估计质量和MCMC算法的收敛性。这包括Gelman-Rubin诊断、效率诊断和自相关诊断等。
通过这些评估和比较方法,我们可以全面地了解概率模型的性能和适应性,并作出相应的改进和调整。
5.5 Stan与其他概率编程工具的比较
Stan是一个强大的概率编程工具,但也存在其他类似的工具可供选择。以下是Stan与其他概率编程工具的简要比较:
-
Edward:Edward是一个基于TensorFlow的概率编程库,提供了灵活而高效的方法来定义概率模型和进行贝叶斯推断。与Stan相比,Edward更注重深度学习和神经网络模型的建模与推断。
-
Pyro:Pyro是一个基于PyTorch的概率编程库,用于构建概率模型并进行推断。与Stan相比,Pyro更注重灵活性和交互性,提供了更多高级的推断算法和模型构建工具。
-
BayesPy:BayesPy是一个用于概率编程和贝叶斯推断的Python库,提供了一组高级API和多种推断算法。与Stan相比,BayesPy更注重灵活的建模语言和直观的API。
这些概率编程工具都有各自的优点和特点,选择合适的工具取决于具体的需求和任务。Stan作为一个灵活且高性能的工具,在建模语言、推断引擎和扩展性方面提供了全面的功能,并且在统计推断和贝叶斯建模领域有着广泛的应用。
6 TensorFlow Probability
6.1 概述和特点
TensorFlow Probability(TFP)是一个基于TensorFlow的概率编程库,用于构建概率模型、进行贝叶斯推断和深度生成模型。
TensorFlow Probability的主要特点包括:
- 紧密集成的TensorFlow:TFP建立在TensorFlow之上,利用TensorFlow的自动微分和计算图功能,提供了高效的概率推断和训练。
- 丰富的概率分布和推断算法:TFP提供了广泛的概率分布和推断算法,包括变分推断、蒙特卡洛推断和海森估计等,在处理各种复杂问题时具有很大的灵活性。
- 可组合的模型表示:TFP使用TensorFlow的静态图表示,使得模型可以轻松地与其他TensorFlow代码集成,并支持模块化和可组合的建模方式。
- 高性能的GPU加速:由于建立在TensorFlow之上,TFP可以利用TensorFlow的GPU加速功能,处理大规模数据和复杂模型。
6.2 使用示例
以下是使用TensorFlow Probability进行简单线性回归模型的示例:
import tensorflow as tf
import tensorflow_probability as tfp # 定义数据
x = np.array([0, 1, 2, 3, 4, 5], dtype=np.float32)
y = np.array([1, 2, 3, 4, 5, 6], dtype=np.float32)# 定义模型
model = tfp.glm.GLM(model=tfp.glm.Normal(),name='linear_regression',x_offset=None,feature_names=['x'],response_dtype=tf.float32)# 运行推断算法
results = model.fit(x=x[:, tf.newaxis], y=y, num_steps=1000)# 获取后验分布参数
beta0_posterior_samples = results.parameters['linear_regression/mean/b']
beta1_posterior_samples = results.parameters['linear_regression/mean/w']
sigma_posterior_samples = results.parameters['linear_regression/scale']
在这个示例中,我们首先定义了输入数据 x 和目标数据 y。然后,使用TFP的GLM(Generalized Linear Model)类构建了一个线性回归模型,并指定了使用正态分布作为观测模型。接下来,我们通过调用 fit() 方法运行推断算法,并传递输入和目标数据。最后,我们可以从结果中获取参数的后验分布样本,以进行进一步的分析和预测。
通过TensorFlow Probability的丰富功能和紧密集成的TensorFlow,我们可以更灵活地构建复杂的概率模型,并进行高效的贝叶斯推断。
6.3 高级功能
除了基本的贝叶斯推断功能之外,TensorFlow Probability还提供了一些高级功能,例如:
- 深度生成模型:TFP支持构建深度生成模型,如变分自编码器(Variational Autoencoders)和生成对抗网络(Generative Adversarial Networks),用于生成新样本和进行无监督学习。
- 可微分推断算法:TFP提供了各种可微分推断算法,如变分推断和重参数化梯度估计,使得模型可以通过自动微分进行训练和优化。
- 结构化概率模型:TFP支持构建结构化概率模型,如图模型和马尔可夫随机场,以表示变量之间的相关关系和条件依赖性。
通过这些高级功能,TFP扩展了概率编程的能力,并提供了更多灵活性和表达能力,适用于各种领域和问题。
6.4 模型评估和比较
TensorFlow Probability提供了多种方法来评估和比较概率模型的性能。以下是一些常用的方法:
-
对数似然函数(Log Likelihood):TFP可以计算给定模型下观测数据的对数似然函数值,该值越高表示模型对观测数据的拟合程度越好。
-
后验预测分布(Posterior Predictive Distribution):TFP可以从后验分布中抽取样本,生成伪数据,并与真实观测数据进行比较。这可以帮助我们评估模型的预测能力和拟合程度。
-
信息准则(Information Criteria):TFP支持计算信息准则,如WAIC和LOO,用于模型比较。这些准则考虑了模型的复杂性和拟合优度,以选择最合适的模型。
-
参数诊断和收敛诊断:TFP提供了各种诊断工具,用于检查参数的估计质量和MCMC算法的收敛性。这包括Gelman-Rubin诊断、效率诊断和自相关诊断等。
通过这些评估和比较方法,我们可以全面地了解概率模型的性能和适应性,并作出相应的改进和调整。
6.5 TensorFlow Probability与其他概率编程工具的比较
TensorFlow Probability是一个功能强大的概率编程工具,但也存在其他类似的工具可供选择。以下是TensorFlow Probability与其他概率编程工具的简要比较:
-
Edward:Edward是一个基于TensorFlow的概率编程库,提供了灵活而高效的方法来定义概率模型和进行贝叶斯推断。与TensorFlow Probability相比,Edward更注重灵活性和直观性,提供了更多高级的推断算法和模型构建工具。
-
Pyro:Pyro是一个基于PyTorch的概率编程库,用于构建概率模型并进行推断。与TensorFlow Probability相比,Pyro更注重灵活性和交互性,提供了更多高级的推断算法和模型构建工具。
-
Stan:Stan是一种专门用于贝叶斯统计建模的概率编程语言。与TensorFlow Probability相比,Stan使用了自己独特的建模语言,并提供了一种声明式的方式来定义概率模型。Stan拥有丰富的推断算法,并具有高效的后端引擎。
这些概率编程工具都有各自的优点和特点,选择合适的工具取决于具体的需求和任务。TensorFlow Probability作为一个紧密集成的TensorFlow扩展,提供了丰富的概率分布、推断算法和深度生成模型,以及高性能的GPU加速,使得贝叶斯推断和深度学习更加易于使用和高效。
7 小结
本章介绍了几个常用的贝叶斯统计和概率编程库,包括Edward、BayesPy、Stan和TensorFlow Probability。这些工具提供了灵活且强大的工具来构建概率模型、进行贝叶斯推断,并帮助我们理解和分析数据。
Edward是一个基于概率编程语言的高级API,使用Python和TensorFlow进行模型构建和推断。它提供了灵活性、可扩展性和丰富的推断方法。
BayesPy是一个Python库,用于概率编程和贝叶斯推断。它提供了灵活的建模语言和多种推断算法。
Stan是一种概率编程语言和库,通过声明性建模语言和高性能的MCMC算法实现贝叶斯推断。
TensorFlow Probability是一个基于TensorFlow的概率编程库,紧密集成了TensorFlow的功能,提供了丰富的概率分布和推断算法。
通过了解这些工具和方法,您可以根据自己的需求选择适合的贝叶斯统计工具,并在实践中取得更好的结果。
总结
贝叶斯统计和概率编程是一种强大的统计分析方法,能够处理不确定性、灵活建模并提供可解释性。本文介绍了PyMC3和ArviZ这两个常用的Python库,在构建贝叶斯模型、运行推断算法和结果分析方面提供了详细的指导和示例代码。此外,我们还介绍了其他贝叶斯统计和概率编程库的特点和应用领域。贝叶斯统计和概率编程在数据分析、机器学习、金融风险评估、医学研究等领域具有广泛的应用前景,并且随着技术的进步和方法的改进,它们将在未来发挥更重要的作用。
相关文章:

【Python百宝箱】贝叶斯统计的魅力:从PyMC3到ArviZ,探索数据背后的不确定性
标题:预测未来趋势的利器:深入贝叶斯统计和概率编程的世界 前言 贝叶斯统计和概率编程是一种强大的分析方法,可以帮助我们处理不确定性、建立灵活的模型以及进行参数估计和推断。本文将介绍几个常用的Python库,包括PyMC3、ArviZ…...

Knowledge Graph知识图谱—8. Web Ontology Language (OWL)
8. Web Ontology Language (OWL) 在RDFs不可能实现: Property cardinalities, Functional properties, Class disjointness, we cannot produce contradictions, circumvent the Non Unique Naming Assumption, circumvent the Open World Assumption 8.1 OWL Tr…...

排序算法——冒泡排序
排序算法是计算机科学中最基本的概念之一。在众多排序算法中,冒泡排序因其实现简单而被广泛学习。尽管它不是最高效的排序方法,但对于理解基本的排序概念非常有用。本文将深入探讨冒泡排序的原理、实现、优缺点以及应用场景。 1. 冒泡排序原理 冒泡排序…...
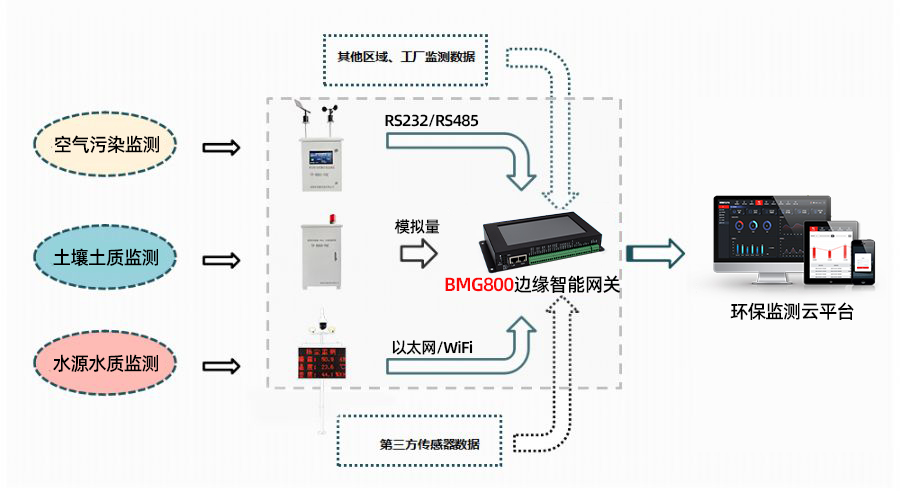
边缘智能网关如何应对环境污染难题
随着我国工业化、城镇化的深入推进,包括大气污染在内的环境污染防治压力继续加大。为应对环境污染防治难题,佰马综合边缘计算、物联网、智能感知等技术,基于边缘智能网关打造环境污染实时监测、预警及智能干预方案,可应用于大气保…...

uniapp定时器的应用
1、初始化定时器 data(){return{timer: null, //定时器} } 2、定时器的使用 定时器分两种,setInterval和setTimeout。 二者的区别: setInterval函数会无限执行下去,除非调用clearInterval函数来停止它。setTimeout函数只执行一次&#x…...

Docker中安装Oracle10g和oracle增删改查
Docker中安装Oracle 10g 一、Docker中安装Oracle 10安装步骤二、连接数据库登录三 oracle数据库的增删改查及联表查询的相关操作oracle数据库,创建students数据表,创建100万条数据增删改查 一、Docker中安装Oracle 10安装步骤 Docker中安装Oracle 10g 1.下载镜像 docker pull …...
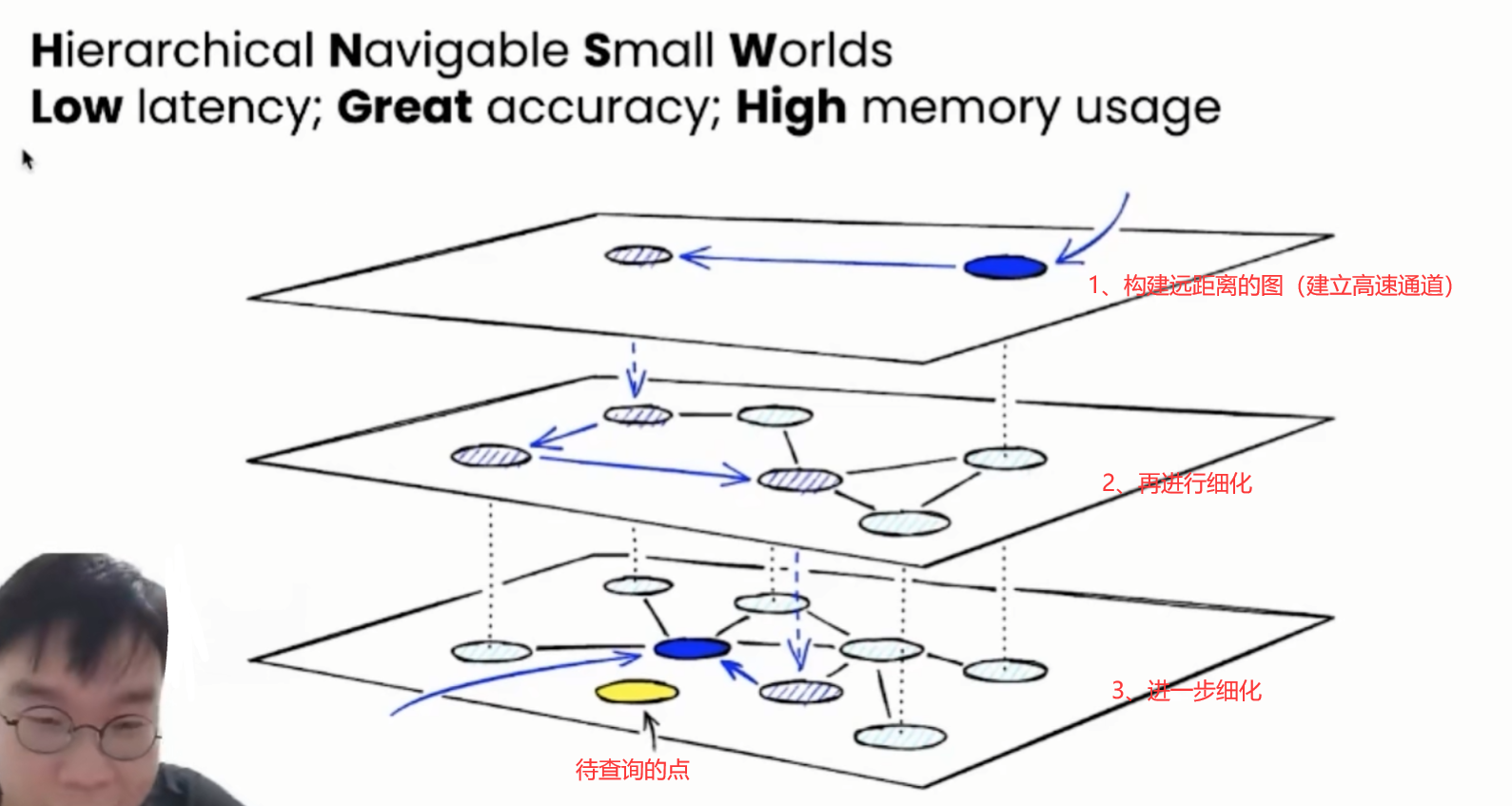
推荐算法:HNSW【推荐出与用户搜索的类似的/用户感兴趣的商品】
HNSW算法概述 HNSW(Hierarchical Navigable Small Word)算法算是目前推荐领域里面常用的ANN(Approximate Nearest Neighbor)算法了。其目的就是在极大量的候选集当中如何快速地找到一个query最近邻的k个元素。 要找到一个query的…...
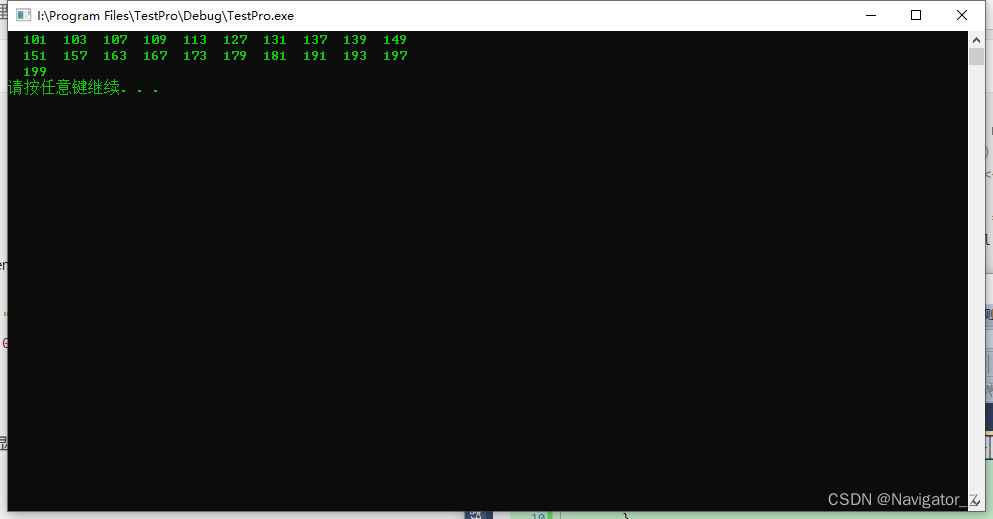
C++ //例3.14 找出100~200间的全部素数。
C程序设计 (第三版) 谭浩强 例3.14 例3.14 找出100~200间的全部素数。 IDE工具:VS2010 Note: 使用不同的IDE工具可能有部分差异。 代码块 方法:使用函数的模块化设计 #include <iostream> #include <iomanip> #i…...
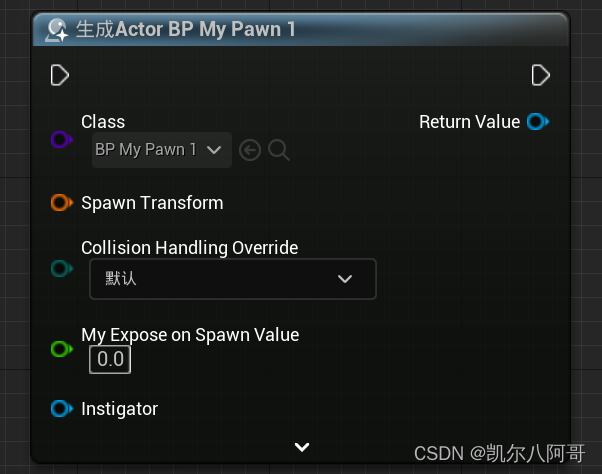
虚幻学习笔记11—C++结构体、枚举与蓝图的通信
一、前言 结构体的定义和枚举类似,枚举的定义有两种方式。区别是结构体必须以“F”开头命名,而枚举不用。 额外再讲了一下蓝图生成时暴露变量的方法。 二、实现 2.1、结构体 1、定义结构体 代码如下,注意这个定义的代码一定要在“UCLASS()”…...

【android开发-19】android中内容提供者contentProvider用法讲解
1,内容URI 在Android系统中,Content URI是一种用于唯一标识和访问应用程序中的数据的方法。它由Android系统提供,通过Content Provider来实现数据的共享和访问。 Content URI使用特定的格式来标识数据,通常以"content://&qu…...
)
浅谈排序——快速排序(最常用的排序)
快速排序(Quick Sort)是一种常见的排序算法,由英国计算机科学家东尼霍尔(Tony Hoare)在1960年发明。这是一种分治算法,基本思想是通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所…...

Springboot项目实现简单的文件服务器,实现文件上传+图片及文件回显
文章目录 写在前面一、配置1、application.properties2、webMvc配置3、查看效果 二、文件上传 写在前面 平常工作中的项目,上传的文件一般都会传到对象存储云服务中。当接手一个小项目,如何自己动手搭建一个文件服务器,实现图片、文件的回显…...

5V低压步进电机驱动芯片GC6150,应用于摄像机,机器人 医疗器械等产品中。具有低噪声、低振动的特点
GC6150是双通道5V低压步进电机驱动器,具有低噪声、低振动的特点,特别适用于相机变焦对焦系统、万向架、摇头机等精度、低噪声STM控制系统,该芯片为每个通道集成了一个256微步的驱动器。通过SPI & T2C接口,客户可以方使地调整驱…...
3D Web轻量引擎HOOPS Communicator如何实现对大模型的渲染支持?
除了读取轻松外,HOOPS Communicator对超大模型的支持效果也非常好,它可以支持30GB的包含70万个零件和3.5亿个三角面的Catia装配模型! 那么它是如何来实现对大模型的支持呢? 我们将从以下几个方面与大家分享:最低帧率…...
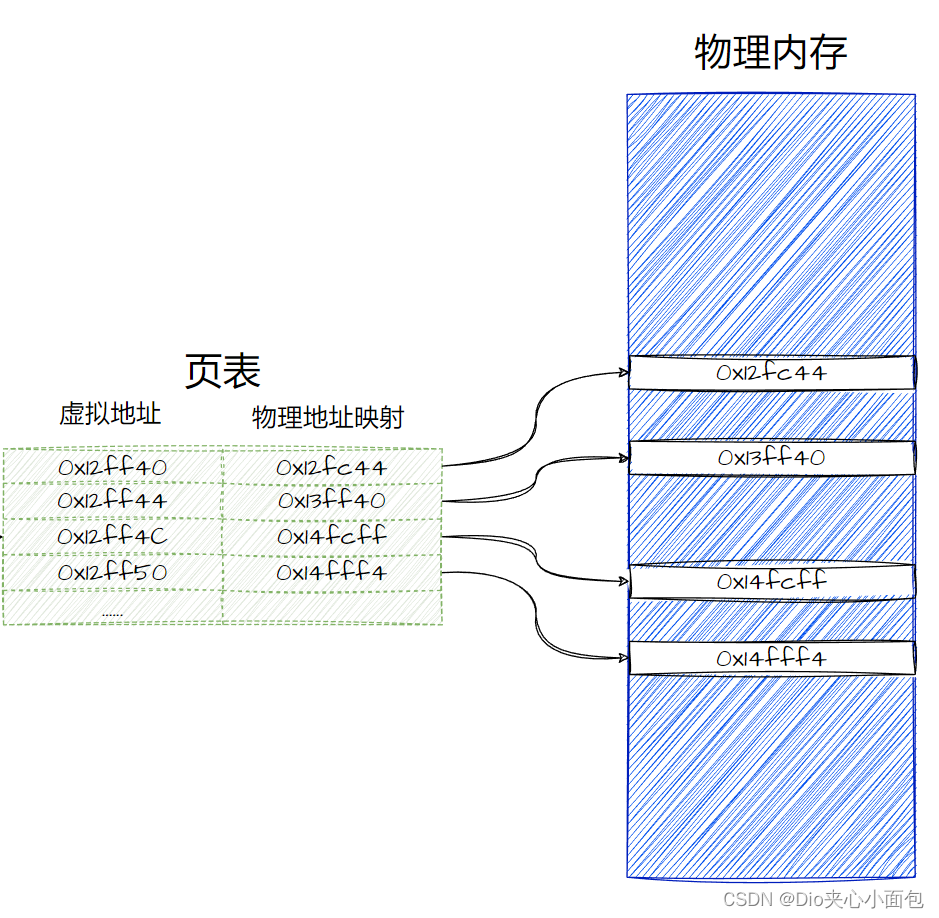
『 Linux 』进程地址空间概念
文章目录 🫙 前言🫙 进程地址空间是什么🫙 写时拷贝🫙 可执行程序中的虚拟地址🫙 物理地址分布方式 🫙 前言 在c/C中存在一种内存的概念; 一般来说一个内存的空间分布包括栈区,堆区,代码段等等; 且内存是…...

PySpark大数据处理详细教程
欢迎各位数据爱好者!今天,我很高兴与您分享我的最新博客,专注于探索 PySpark DataFrame 的强大功能。无论您是刚入门的数据分析师,还是寻求深入了解大数据技术的专业人士,这里都有丰富的知识和实用的技巧等着您。让我们…...
ts非基础类型(对象))
三(五)ts非基础类型(对象)
在ts里面定义对象的方式也有很多。 普通定义 let obj1:{} {} // obj1.name fufu 报错,只能定义为空对象且不能修改 // 但是可以在赋初始值的时候直接添加属性,这是ts在类型推断时,它会宽容地匹配对象的结构。 let obj2:{} {name: fufu}…...
HeartBeat监控Redis状态
目录 一、概述 二、 安装部署 三、配置 四、启动服务 五、查看数据 一、概述 使用heartbeat可以实现在kibana界面对redis服务存活状态进行观察,如有必要,也可在服务宕机后立即向相关人员发送邮件通知 二、 安装部署 参照文章:HeartBeat监…...

FairGuard无缝兼容小米澎湃OS、ColorOS 14 、鸿蒙4!
随着移动互联网时代的发展,各大手机厂商为打造生态系统、构建自身的技术壁垒,纷纷投身自研操作系统。 而对于一款游戏安全产品,在不同操作系统下,是否能够无缝兼容并且提供稳定的、高强度的加密保护,成了行业的一大痛…...
【Copilot】Edge浏览器的copilot消失了怎么办
这种原因,可能是因为你的ip地址的不在这个服务的允许范围内。你需要重新使用之前出现copilot的ip地址,然后退出edge的账号,重新登录一遍,最后重启edge,就能够使得copilot侧边栏重新出现了。...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...