Token 和 N-Gram、Bag-of-Words 模型释义
ChatGPT(GPT-3.5)和其他大型语言模型(Pi、Claude、Bard 等)凭何火爆全球?这些语言模型的运作原理是什么?为什么它们在所训练的任务上表现如此出色?
虽然没有人可以给出完整的答案,但了解自然语言处理的一些基本概念有助于我们了解 LLM 内在工作原理。尤其是了解 Token 和 N-gram 对于理解几乎所有当前自回归和自编码模型都十分重要。本文为“「X」Embedding in NLP”的进阶版,将带大家详解 NLP 的核心基础!
01.Token 和 N-gram
在 C/C++ 的入门计算机科学课程中,通常很早就会教授字符串的概念。例如,C 语言中的字符串可以表示为以空字符终止的字符数组:
char my_str[128] = "Milvus";
在这个例子中,每个字符都可以被视为一个离散单位,将它们组合在一起就形成了有意义的文本——在这种情况下,my_str表示了世界上最广泛采用的向量数据库。
简单来说,这就是 N-gram 的定义:一系列字符(或下一段讨论的其他离散单位),当它们连在一起时,具有连贯的意义。在这个实例中,N 对应于字符串中的字符总数(在这个例子是 7)。
N-gram 的概念不必局限于单个字符——它们也可以扩展到单词。例如,下面的字符串是一个三元组(3-gram)的单词:
char my_str[128] = "Milvus vector database"
在上面的例子中,很明显my_str是由三个单词组成的,但一旦考虑到标点符号,情况就变得有些复杂:
char my_str[128] = "Milvus's architecture is unparalleled"
上面的字符串,严格来说,是四个单词,但第一个单词Milvus's是使用另一个单词Milvus作为基础的所有格名词。对于语言模型来说,将类似单词分割成离散的单位是有意义的,这样就可以保留额外的上下文:Milvus和's。这些被称为 Token,将句子分割成单词的基本方法称为标记化(Tokenization)。采用这种策略,上述字符串现在是一个由 5 个 Token 组成的 5-gram。
所有现代语言模型在数据转换之前都会进行某种形式的输入标记化。市面上有许多不同的标记器——例如,WordPiece 是一个流行的标记器,它被用在大多数 BERT 的变体中。在这个系列中我们没有过多深入标记器的细节——对于想要了解更多的人来说,可以查看 Huggingface的标记器总结
02.N-gram 模型
接下来,我们可以将注意力转向 N-gram 模型。简单来说,n-gram 模型是一种简单的概率语言模型,它输出一个特定 Token 在现有 Token 串之后出现的概率。例如,我们可以建模一个特定 Token 在句子或短语中跟随另一个Token(∣)的概率(p):
p(database∣vector)=0.1
上述声明表明,在这个特定的语言模型中,“vector”这个词跟在“database”这个词后面的概率为 10%。对于 N-gram 模型,这些模型总是通过查看输入文档语料库中的双词组的数量来计算,但在其他语言模型中,它们可以手动设置或从机器学习模型的输出中获取。
上面的例子是一个双词模型,但我们可以将其扩展到任意长度的序列。以下是一个三元组的例子:
p(database∣Milvus,vector)=0.9
这表明“database”这个词将以 90% 的概率跟在“Milvus vector”这两个 Token 之后。同样,我们可以写成:
p(chocolate∣Milvus,vector)=0.001
这表明在“Milvus vector”之后出现的词不太可能是“chocolate”(确切地说,概率为0.1%)。将这个应用到更长的序列上:
p(Milvus∣the,most,widely,adopted,vector,database,is)=0.999
接下来讨论一个可能更重要的问题:我们如何计算这些概率?简单而直接的答案是:我们计算文档或文档语料库中出现的次数。我将通过以下 3 个短语的例子来逐步解释(每个句子开头的代表特殊的句子开始标记)。为了清晰起见,我还在每个句子的结尾句号和前一个词之间增加了额外的空格:
-
<S>Milvus是最广泛采用的向量数据库。 -
<S>使用Milvus进行向量搜索。 -
<S>Milvus很棒。
列出以<S>、Milvus或vector开头的双词组:
some_bigrams = {these bigrams begin with <S>
("<S>", "Milvus"): 2,
("<S>", "vector"): 1,these bigrams begin with Milvus
("Milvus", "is"): 1,
("Milvus", "."): 1,
("Milvus", "rocks"): 1,these bigrams begin with vector
("vector", "database"): 1,
("vector", "search"): 1
}
根据这些出现的情况,可以通过对每个 Token 出现的总次数进行规范化来计算概率。例如:

类似:
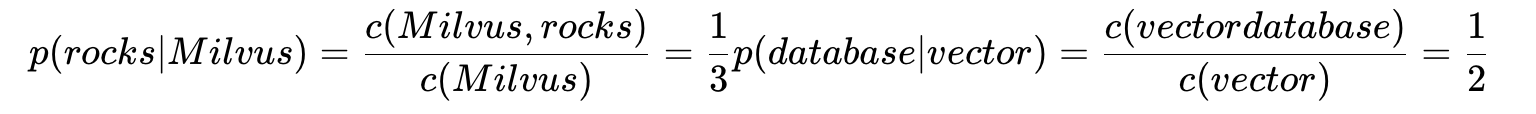
有了这些知识,我们就可以编写一些代码来构建一个双词模型。为了简单起见,我们假设所有输入文档中的每个 Token 都由一些空白字符分隔(回想一下前面的部分,现代标记器通常有更复杂的规则)。让我们从定义模型本身开始,即双词计数和 Token 计数:
from typing import Dict, Tuple
from collections import defaultdict
#keys correspond to tokensvalues are the number of occurences
token_counts = defaultdict(int)
#keys correspond to 2-tuples bigram pairsvalues are the number of occurences
bigram_counts = defaultdict(int)
def build_bigram_model(corpus):
"""Bigram model. """
#loop through all documents in the corpus
for doc in corpus:
prev = "<S>"
for word in doc.split():
#update token counts
token_counts[word] += 1
#update bigram counts
bigram = (prev, word)
bigram_counts[bigram] += 1
prev = word
#add a dummy end-of-sequence token so probabilities add to one
bigram_counts[(word, "</S>")] += 1
return (token_counts, bigram_counts)
def bigram_probability(bigram: Tuple[str]):
"""Computes the likelihood of the bigram from the corpus. """
return bigram_counts[bigram] / token_counts[bigram[0]]
然后,build_bigram_model会遍历整个文档语料库,先按空白字符分割每个文档,再存储双词组和 Token 计数。然后,我们可以调用bigram_probability函数,该函数查找相应的双词组计数和 Token 计数,并返回比率。
我们在 Milvus 的文档上测试这个模型,大家可以在此下载文档,并尝试上面的代码。
with open("README.md", "r") as f:
build_bigram_model([f.read()])
print(bigram_probability(("vector", "database")))
0.3333333333333333
03.词袋模型
除了 N-gram,另一个值得讨论的是词袋模型(BoW)。词袋模型将文档或文档语料库表示为一个无序的 Token 集合——从这个意义上说,它保持了每个 Token 出现的频率,但忽略了它们在每个文档中出现的顺序。因此,BoW 模型中的整个文档可以转换为稀疏向量,其中向量的每个条目对应于文档中特定单词出现的频率。在这里,我们将文档“Milvus 是最广泛采用的向量数据库。使用Milvus进行向量搜索很容易。”表示为一个 BoW稀疏向量:
limited vocabularybow_vector = [
0, # a
1, # adopted
0, # bag
0, # book
0, # coordinate
1, # database
1, # easy
0, # fantastic
0, # good
0, # great
2, # is
0, # juggle
2, # Milvus
1, # most
0, # never
0, # proof
0, # quotient
0, # ratio
0, # rectify
1, # search
1, # the
0, # undulate
2, # vector
1, # widely
1, # with
0, # yes
0, # zebra
]
这些稀疏向量随后可以用于各种 NLP 任务,如文本和情感分类。关于词袋模型的训练和推理学习可参考 Jason Brownlee的博客。
虽然词袋模型易于理解和使用,但它们有明显的局限性,即无法捕捉上下文或单个 Token 的语义含义,这意味着它们不适合用于最简单的任务之外的任何事情。
04.总结
在这篇文章中,我们讨论了自然语言处理的三个核心基础:标记化(Tokenization)、N-gram 和词袋模型。围绕 N-gram 的概念有助于后续了解关于自回归和自编码模型的训练方式。在下一个教程中,我们将分析“现代”NLP,即循环网络和文本 embedding。敬请期待!
本文由 mdnice 多平台发布
相关文章:
Token 和 N-Gram、Bag-of-Words 模型释义
ChatGPT(GPT-3.5)和其他大型语言模型(Pi、Claude、Bard 等)凭何火爆全球?这些语言模型的运作原理是什么?为什么它们在所训练的任务上表现如此出色? 虽然没有人可以给出完整的答案,但…...

【go语言实践】基础篇 - 流程控制
if语句 go里面if不需要括号将条件表达式包含起来,这与python也有点类似 if 条件表达式 { } if num > 18 {// ... } else if num > 20 {// ... } else {// ... }需要注意的是go支持在if的条件表达式中直接定义一个变量,变量的作用域只在if范围内…...

Linux:gdb的简单使用
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》《Linux》 文章目录 前言一、前置理解二、使用总结 前言 gdb是Linux中的调试代码的工具 一、前置理解 我们都知道要调试一份代码,这份代码的发布模式必须是debug。那你知道在li…...

NestJS的微服务实现
1.1 基本概念 微服务基本概念:微服务就是将一个项目拆分成多个服务。举个简单的例子:将网站的登录功能可以拆分出来做成一个服务。 微服务分为提供者和消费者,如上“登录服务”就是一个服务提供者,“网站服务器”就是一个服务消…...

Debian 终端Shell命令行长路径改为短路径
需要修改bashrc ~/.bashrc先备份一份 cp .bashrc bashrc.backup编辑bashrc vim ~/.bashrc可以看到bashrc内容为 # ~/.bashrc: executed by bash(1) for non-login shells. # see /usr/share/doc/bash/examples/startup-files (in the package bash-doc) # for examples# If…...

Ansible变量是什么?如何实现任务的循环?
Ansible 利用变量存储整个 Ansible 项目文件中可重复使用的值,从而可以简化项目的创建和维护,并减少错误的发生率。在定义Ansible变量时,通常有如下三种范围的变量: global范围:从命令行或Ansible配置中设置的变量&am…...

随机梯度下降的代码实现
在单变量线性回归的机器学习代码中,我们讨论了批量梯度下降代码的实现,本篇将进行随机梯度下降的代码实现,整体和批量梯度下降代码类似,仅梯度下降部分不同: import numpy as np import pandas as pd import matplotl…...

渐进推导中常用的一些结论
标题很帅 STAR-RIS Enhanced Joint Physical Layer Security and Covert Communications for Multi-antenna mmWave Systems文章末尾的一个推导。 lim M → ∞ ∥ Φ ( w k ⊗ Θ r ) Ω r w H g ∗ ∥ 2 2 M lim M → ∞ Tr ( g T Ω r w ( w k ⊗ Θ r ) H Φ H Φ…...

网络安全等级保护V2.0测评指标
网络安全等级保护(等保V2.0)测评指标: 1、物理和环境安全 2、网络和通信安全 3、设备和计算安全 4、应用和数据安全 5、安全策略和管理制度 6、安全管理机构和人员 7、安全建设管理 8、安全运维管理 软件全文档获取:点我获取 1、物…...

java中list的addAll用法详细实例?
List 的 addAll() 方法用于将一个集合中的所有元素添加到另一个 List 中。下面是一个详细的实例,展示了 addAll() 方法的使用: java Copy code import java.util.ArrayList; import java.util.List; public class AddAllExample { public static v…...
关于学习计算机的心得与体会
也是隔了一周没有发文了,最近一直在准备期末考试,后来想了很久,学了这么久的计算机,这当中有些收获和失去想和各位正在和我一样在学习计算机的路上的老铁分享一下,希望可以作为你们碰到困难时的良药。先叠个甲…...
LLM之RAG理论(一)| CoN:腾讯提出笔记链(CHAIN-OF-NOTE)来提高检索增强模型(RAG)的透明度
论文地址:https://arxiv.org/pdf/2311.09210.pdf 检索增强语言模型(RALM)已成为自然语言处理中一种强大的新范式。通过将大型预训练语言模型与外部知识检索相结合,RALM可以减少事实错误和幻觉,同时注入最新知识。然而&…...
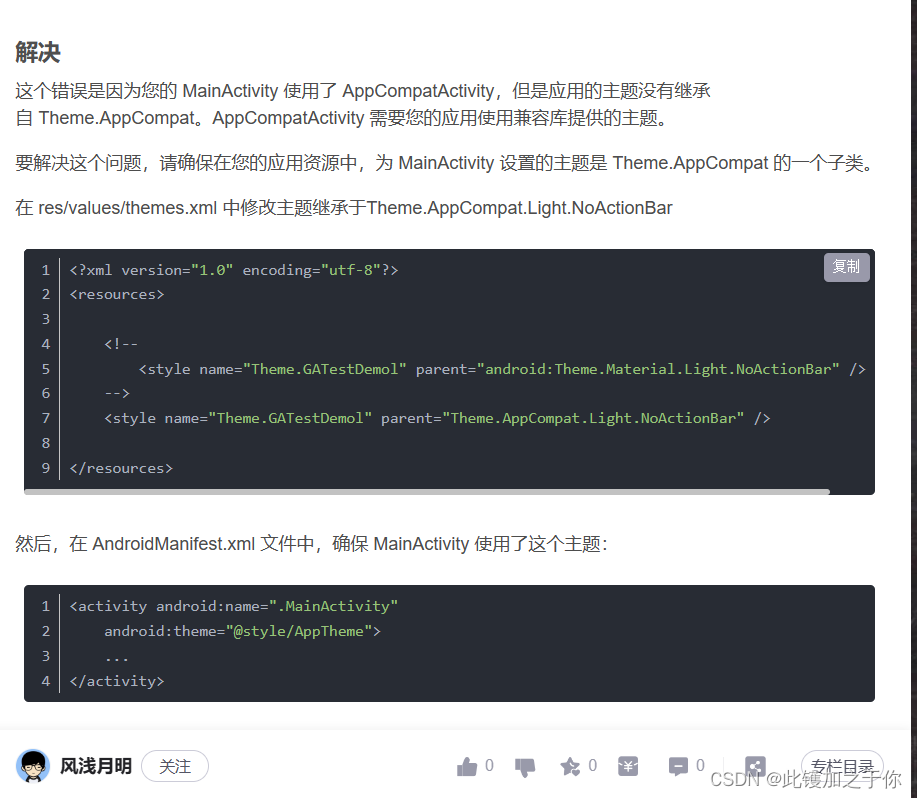
Android studio:打开应用程序闪退的问题2.0
目录 找到问题分析问题解决办法 找到问题 老生常谈,可能这东西真的很常见吧,在之前那篇文章中 linkhttp://t.csdnimg.cn/UJQNb 已经谈到了关于打开Androidstuidio开发的软件后明明没有报错却无法运行(具体表现为应用程序闪退的问题ÿ…...

Spring IoC如何存取Bean对象
小王学习录 IoC(Inversion of Control)1. 什么是IoC2. 什么是Spring IoC3. 什么是DI4. Spring IoC的作用 存储Bean对象1. 创建Bean2. 将Bean注册到Spring中. 取Bean对象.1. 获取Spring上下文信息使用ApplicationContext和BeanFactory的区别 2. 获取指定Bean对象 IoC(Inversion …...

【开源】基于Vue.js的实验室耗材管理系统
文末获取源码,项目编号: S 081 。 \color{red}{文末获取源码,项目编号:S081。} 文末获取源码,项目编号:S081。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 耗材档案模块2.2 耗材入库模块2.3 耗…...
Datawhale聪明办法学Python(task2Getting Started)
一、课程基本结构 课程开源地址:课程简介 - 聪明办法学 Python 第二版 章节结构: Chapter 0 安装 InstallationChapter 1 启航 Getting StartedChapter 2 数据类型和操作 Data Types and OperatorsChapter 3 变量与函数 Variables and FunctionsChapte…...
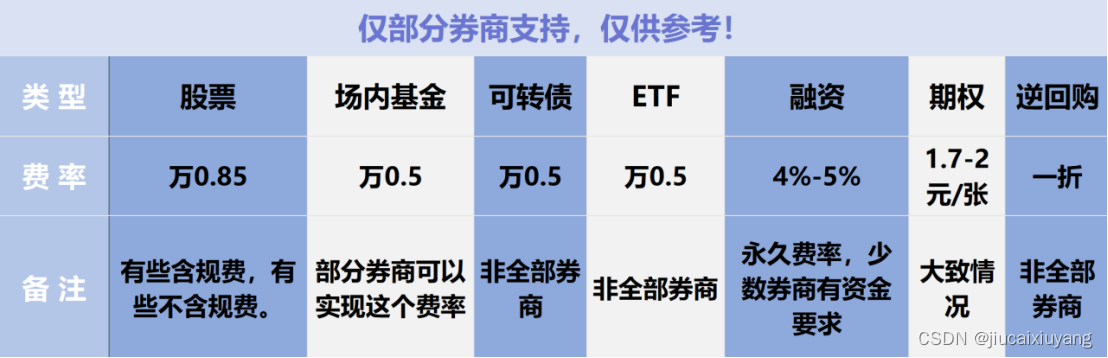
量化交易怎么操作?量化软件怎么选择比较好?(散户福利,建议收藏)
一:量化的具体操作步骤是什么呢?1. 数据获取:索取和收集金融市场数据。 2. 策略制定:制定数量交易策略,这包括制定投资目标、建立交易规则和风险控制机制等,这个过程需要不断优化和更新。 3. 编写算法&am…...
什么是 AWS IAM?如何使用 IAM 数据库身份验证连接到 Amazon RDS(上)
驾驭云服务的安全环境可能很复杂,但 AWS IAM 为安全访问管理提供了强大的框架。在本文中,我们将探讨什么是 AWS Identity and Access Management (IAM) 以及它如何增强安全性。我们还将提供有关使用 IAM 连接到 Amazon Relational Database Service (RDS…...
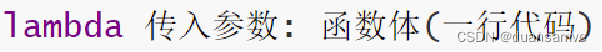
Python从入门到精通七:Python函数进阶
函数多返回值 学习目标: 知道函数如何返回多个返回值 问: 如果一个函数如些两个return (如下所示),程序如何执行? 答:只执行了第一个return,原因是因为return可以退出当前函数,导致return下方的代码不执…...
uniapp踩坑之项目:使用过滤器将时间格式化为特定格式
利用filters过滤器对数据直接进行格式化,注意:与method、onLoad、data同层级 <template><div><!-- orderInfo.time的数据为:2023-12-12 12:10:23 --><p>{{ orderInfo.time | formatDate }}</p> <!-- 2023-1…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...
的打车小程序)
基于鸿蒙(HarmonyOS5)的打车小程序
1. 开发环境准备 安装DevEco Studio (鸿蒙官方IDE)配置HarmonyOS SDK申请开发者账号和必要的API密钥 2. 项目结构设计 ├── entry │ ├── src │ │ ├── main │ │ │ ├── ets │ │ │ │ ├── pages │ │ │ │ │ ├── H…...
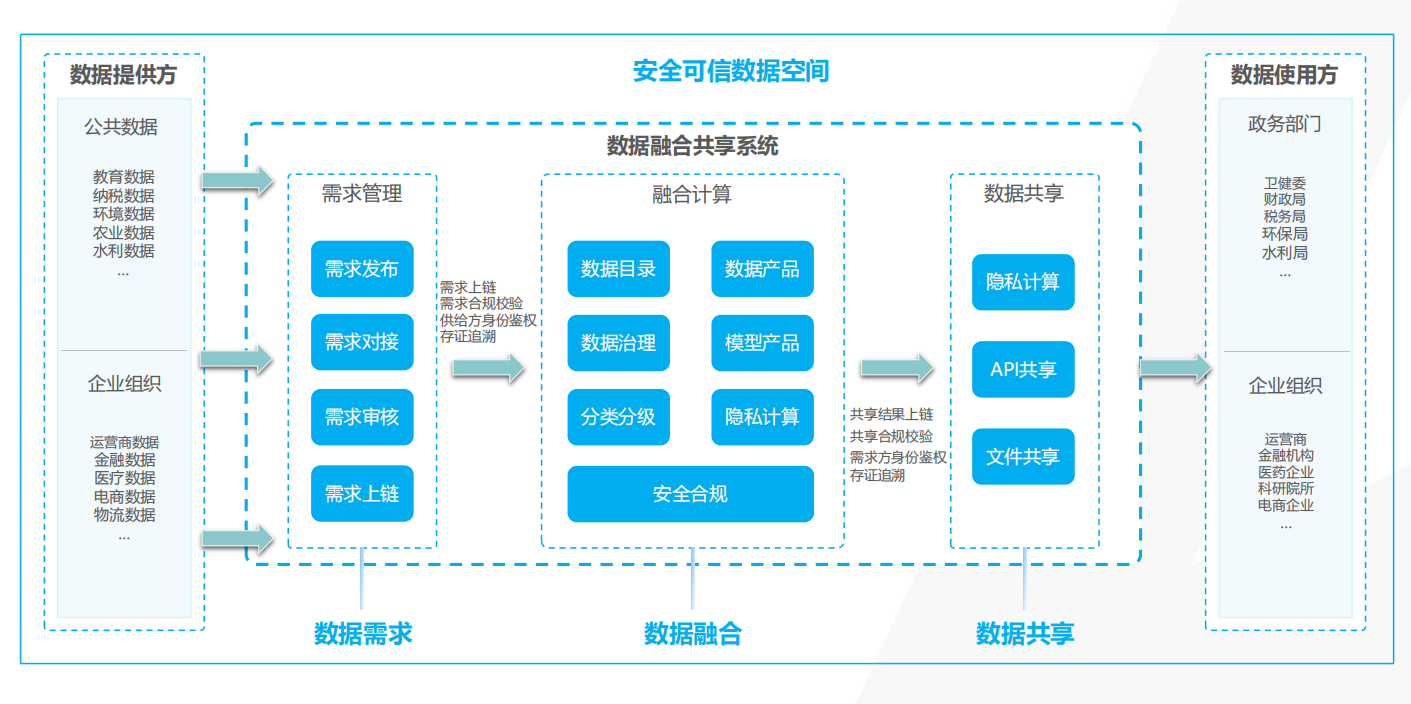
热烈祝贺埃文科技正式加入可信数据空间发展联盟
2025年4月29日,在福州举办的第八届数字中国建设峰会“可信数据空间分论坛”上,可信数据空间发展联盟正式宣告成立。国家数据局党组书记、局长刘烈宏出席并致辞,强调该联盟是推进全国一体化数据市场建设的关键抓手。 郑州埃文科技有限公司&am…...

C++--string的模拟实现
一,引言 string的模拟实现是只对string对象中给的主要功能经行模拟实现,其目的是加强对string的底层了解,以便于在以后的学习或者工作中更加熟练的使用string。本文中的代码仅供参考并不唯一。 二,默认成员函数 string主要有三个成员变量,…...