【Hadoop_04】HDFS的API操作与读写流程
- 1、HDFS的API操作
- 1.1 客户端环境准备
- 1.2 API创建文件夹
- 1.3 API上传
- 1.4 API参数的优先级
- 1.5 API文件夹下载
- 1.6 API文件删除
- 1.7 API文件更名和移动
- 1.8 API文件详情和查看
- 1.9 API文件和文件夹判断
- 2、HDFS的读写流程(面试重点)
- 2.1 HDFS写数据流程
- 2.2 网络拓扑-节点距离计算
- 2.3 机架感知(副本存储节点选择)
- 2.4 读数据流程
1、HDFS的API操作
1.1 客户端环境准备
- 首先要配置环境变量


- 其次在IDEA中创建一个Maven工程HdfsClientDemo,并导入相应的依赖坐标+日志添加
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.hamcrest</groupId><artifactId>hamcrest-core</artifactId><version>1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency></dependencies>
</project>
1.2 API创建文件夹
package com.wenxin.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;/*** @author Susie-Wen* @version 1.0* @description:客户端代码常用套路* 1、获取一个客户端对象* 2、执行相关的操作命令* 3、关闭资源* HDFS zookeeper* @date 2023/12/11 12:27*/
public class HdfsClient {private FileSystem fs;@Beforepublic void init() throws URISyntaxException, IOException, InterruptedException {// 连接的集群地址URI uri = new URI("hdfs://hadoop102:8020");// 用户String user = "root";// 创建一个配置文件Configuration configuration = new Configuration();// 1、获取到了客户端对象fs = FileSystem.get(uri, configuration, user);}@Afterpublic void close() throws IOException {// 3、关闭资源fs.close();}@Testpublic void testMkdir() throws IOException {// 2、创建一个文件夹fs.mkdirs(new Path("/xiyou/huaguoshan"));}
}上面这段代码把连接和关闭资源都进行了封装,更加方便。
@Before注解标识的方法 init() 是一个在测试方法执行之前会被调用的初始化方法。@After注解标识的方法 close() 是一个在测试方法执行之后会被调用的清理方法。
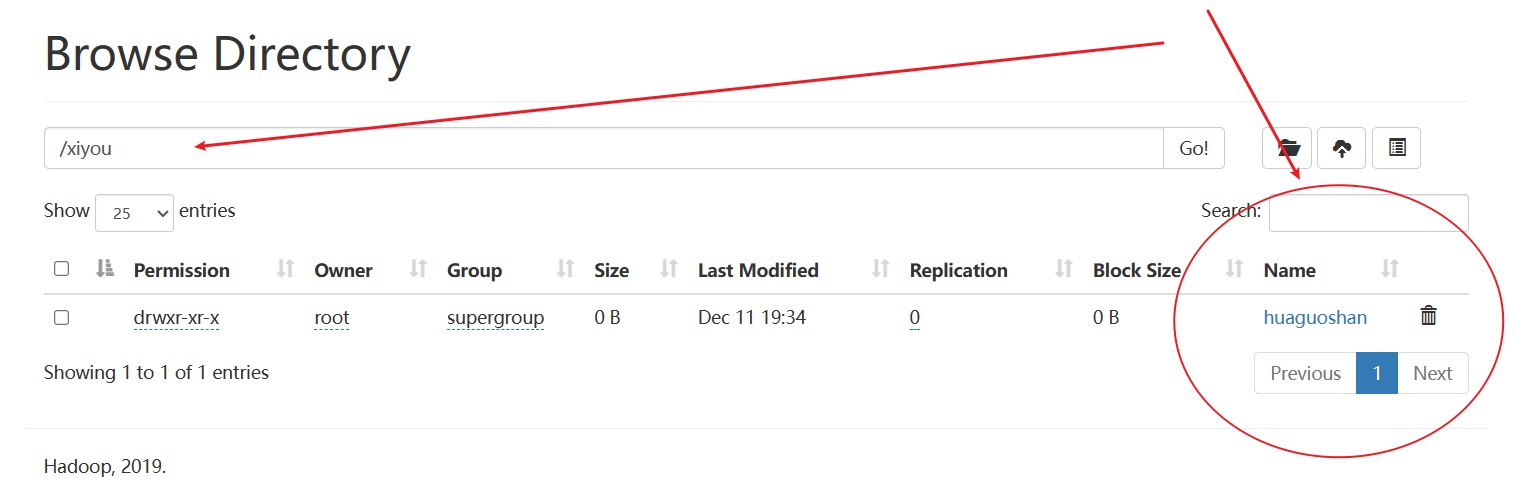
如下所示,确实创建了文件夹
1.3 API上传
接下来进行API上传操作:使用客户端远程访问HDFS,之后上传文件。
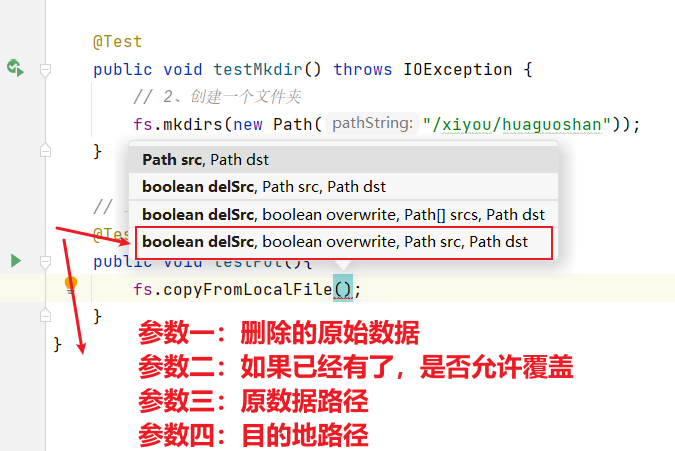
// 上传:客户端远程访问HDFS,之后上传文件@Testpublic void testPut() throws IOException {fs.copyFromLocalFile(false,false,new Path("E:\\VMWare\\Centos\\sunwukong.txt"),new Path("hdfs://hadoop102/xiyou/huaguoshan"));}
1.4 API参数的优先级
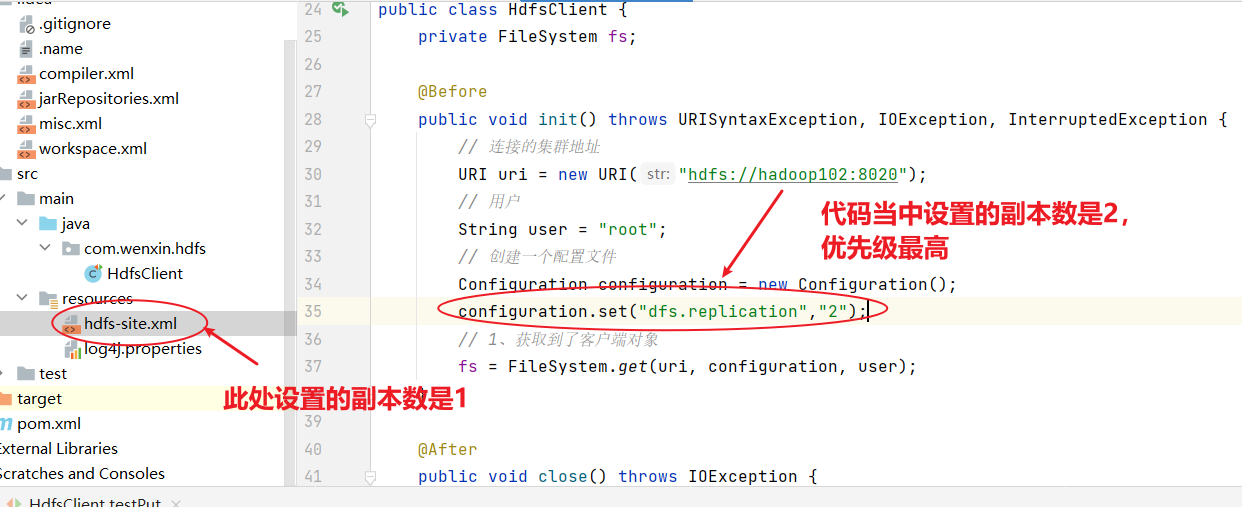
HDFS文件上传(测试参数优先级)
1)编写源代码
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {// 1 获取文件系统Configuration configuration = new Configuration();configuration.set("dfs.replication", "2");FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");// 2 上传文件fs.copyFromLocalFile(new Path("d:/sunwukong.txt"), new Path("/xiyou/huaguoshan"));// 3 关闭资源fs.close();
}2)将hdfs-site.xml拷贝到项目的resources资源目录下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的自定义配置(xxx-site.xml) >(4)服务器的默认配置(xxx-default.xml)
1.5 API文件夹下载
下载相当于从HDFS将文件下载到windows本地:
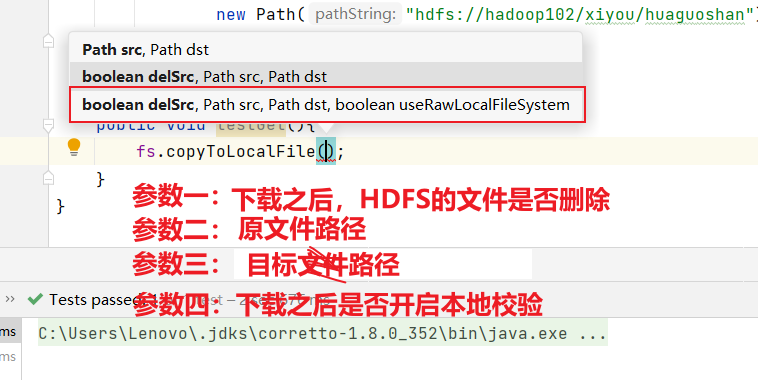
//下载:将文件从HDFS下载到windows当中public void testGet() throws IOException {fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou/huaguoshan"),new Path("E:\\VMWare\\"),false);}
- 如果参数四设置为true的话,就不会进行crc校验
1.6 API文件删除
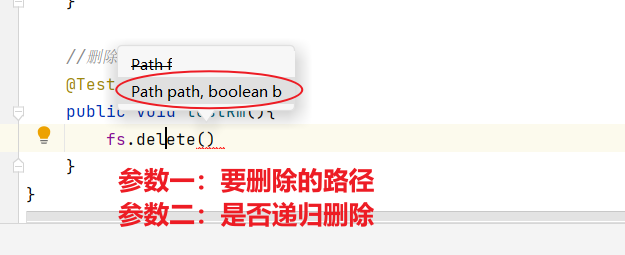
//删除@Testpublic void testRm() throws IOException {fs.delete(new Path("/xiyou/huaguoshan/sunwukong.txt"),false);}
- 除了删除文件之外,我们还可以删除空目录以及非空目录
- 多个文件如果是非递归删除的话,会报错
//删除@Testpublic void testRm() throws IOException {//1.删除文件fs.delete(new Path("/xiyou/huaguoshan/sunwukong.txt"),false);//2.删除空目录fs.delete(new Path("/xiyou"),false);//3.删除非空目录fs.delete(new Path("/xiyou/huaguoshan/"),false);}
1.7 API文件更名和移动

- 包括文件名称的修改,文件的移动和更名以及目录的更名
//文件的更名和移动@Testpublic void testMove() throws IOException {//1.文件名称的修改fs.rename(new Path("/input/word.txt"),new Path("/input/ss.txt"));//2.文件的移动和更名:从input目录移动到根目录下并修改姓名fs.rename(new Path("/input/ss.txt"),new Path("/wenxin.txt"));//3.目录的更名fs.rename(new Path("/input"),new Path("/output"));}
1.8 API文件详情和查看
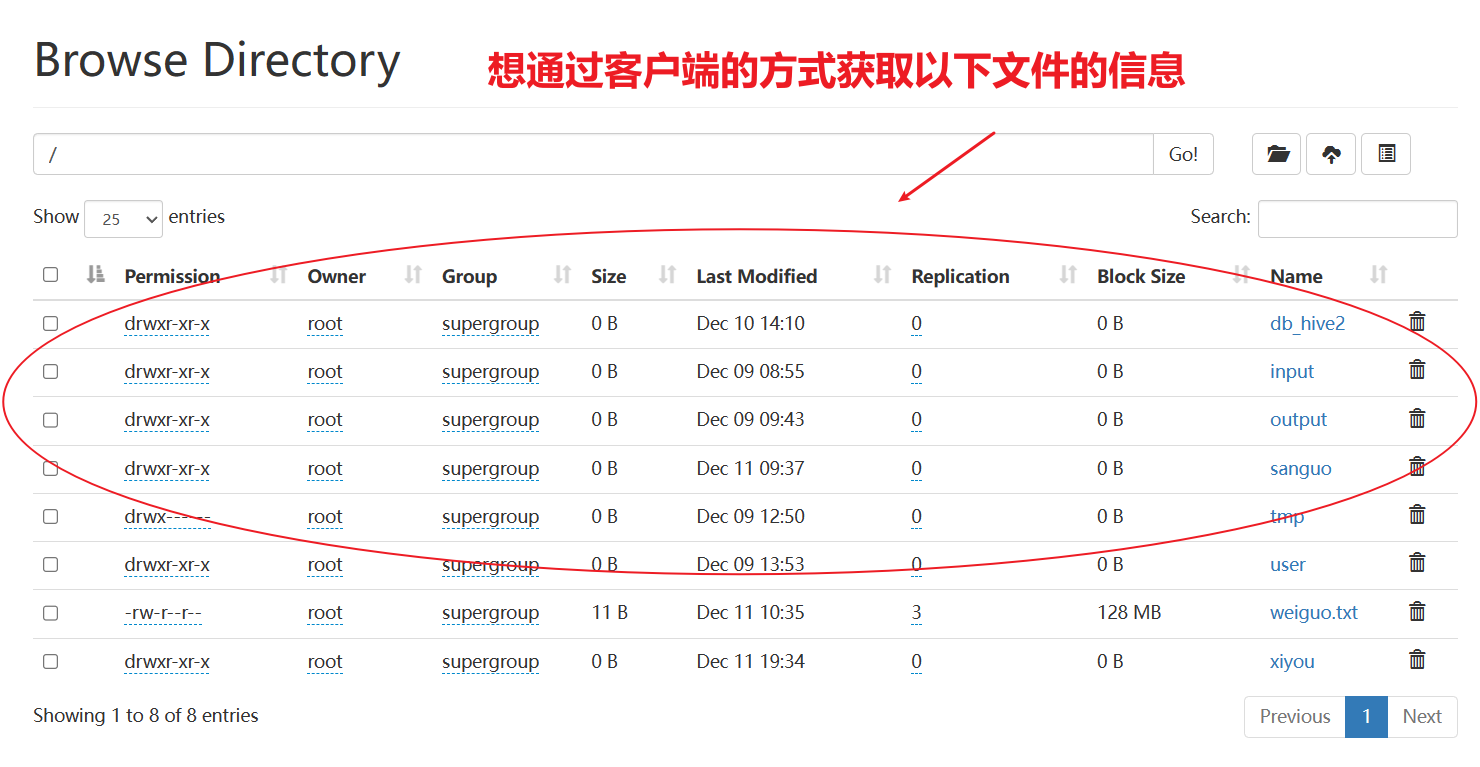

查看文件名称、权限、长度、块信息
//获取文件详情信息@Testpublic void fileDetail() throws IOException {//1.获取所有文件信息RemoteIterator<LocatedFileStatus> listFiles=fs.listFiles(new Path("/"), true);//2.遍历文件while(listFiles.hasNext()){LocatedFileStatus fileStatus=listFiles.next();System.out.println("====="+fileStatus.getPath()+"=====");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getPath());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockLocations());System.out.println(fileStatus.getPath().getName());}}
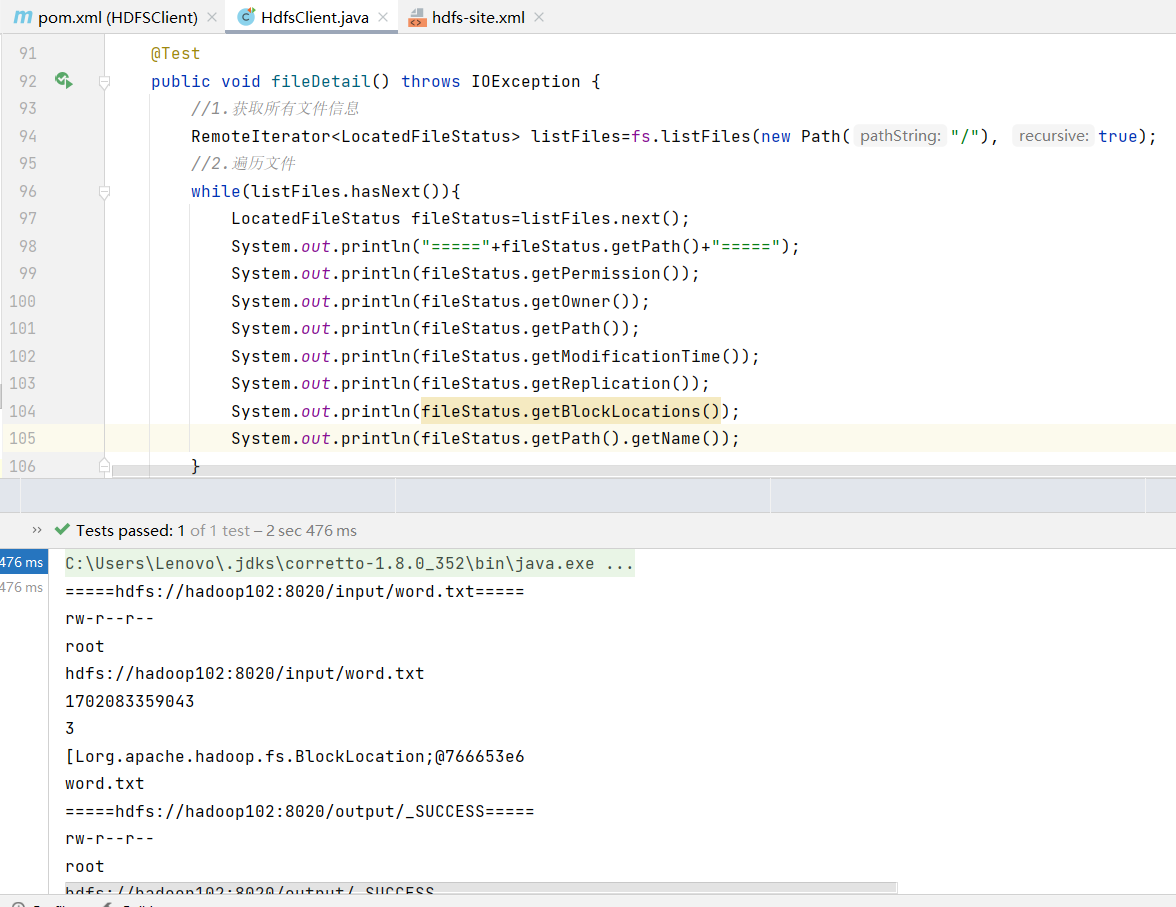
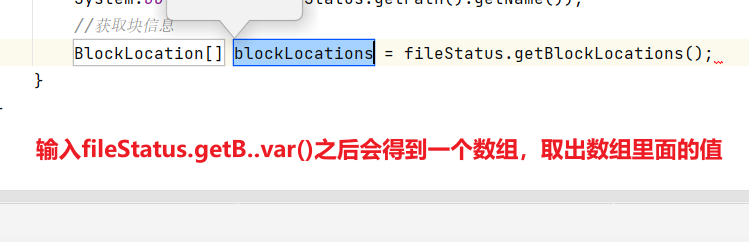
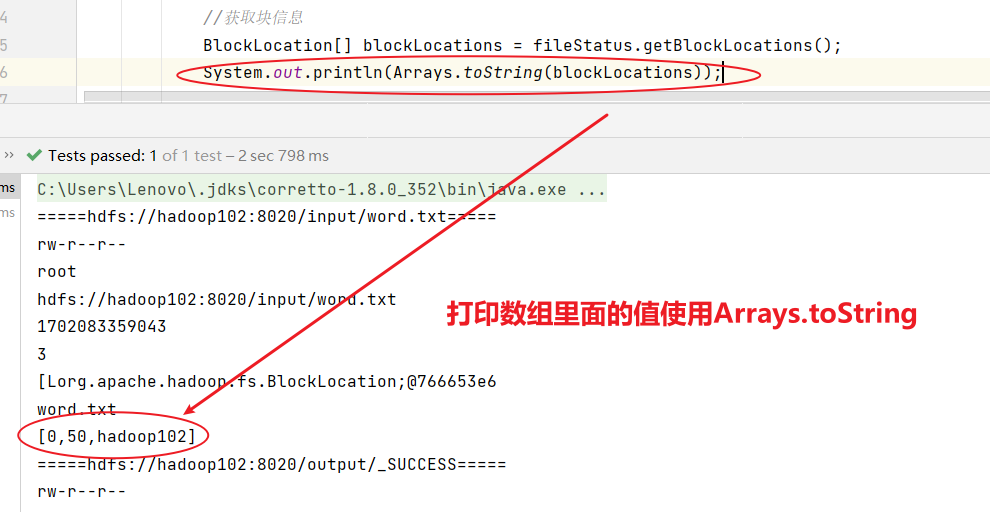
//获取文件详情信息@Testpublic void fileDetail() throws IOException {//1.获取所有文件信息RemoteIterator<LocatedFileStatus> listFiles=fs.listFiles(new Path("/"), true);//2.遍历文件while(listFiles.hasNext()){LocatedFileStatus fileStatus=listFiles.next();System.out.println("====="+fileStatus.getPath()+"=====");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getPath());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockLocations());System.out.println(fileStatus.getPath().getName());//获取块信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println(Arrays.toString(blockLocations));}}
1.9 API文件和文件夹判断
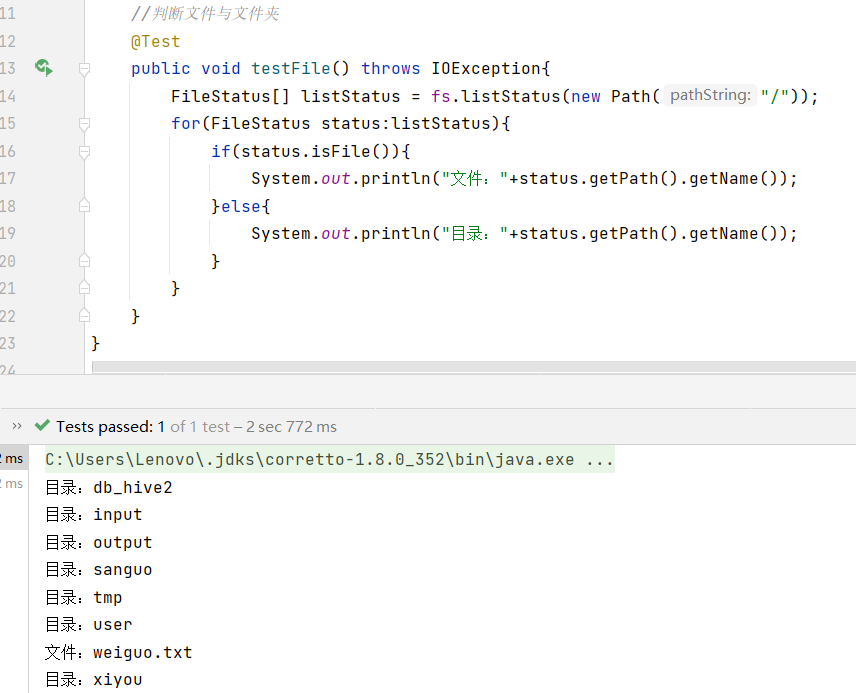
判断根目录那个是文件,那个是文件夹
//判断文件与文件夹@Testpublic void testFile() throws IOException{FileStatus[] listStatus = fs.listStatus(new Path("/"));for(FileStatus status:listStatus){if(status.isFile()){System.out.println("文件:"+status.getPath().getName());}else{System.out.println("目录:"+status.getPath().getName());}}}
2、HDFS的读写流程(面试重点)
2.1 HDFS写数据流程
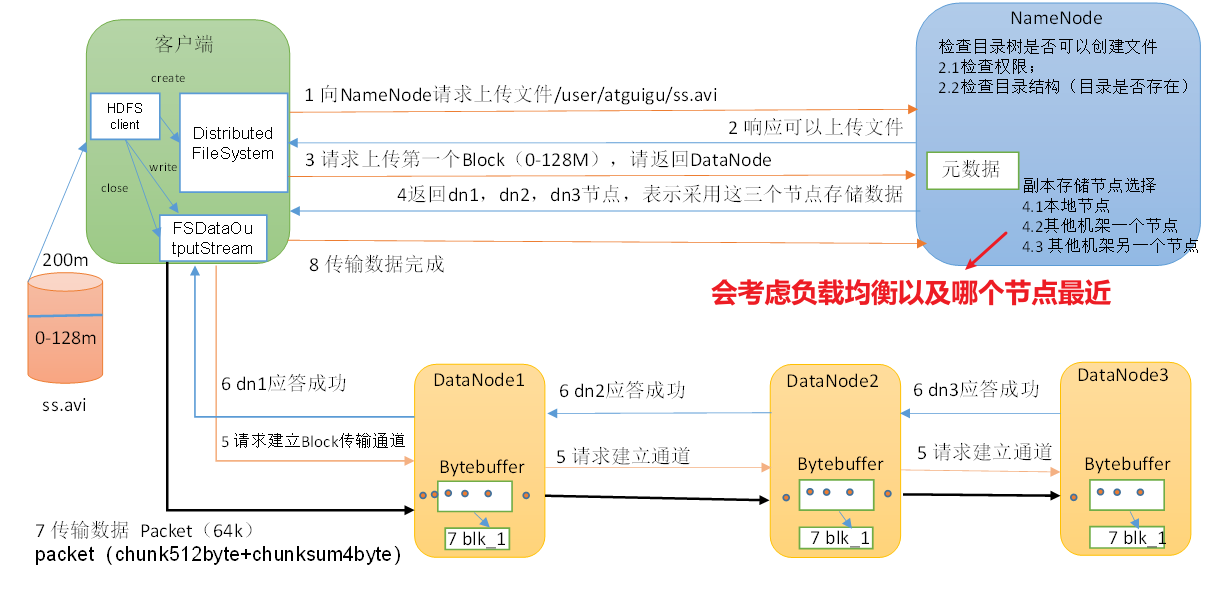 (1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
2.2 网络拓扑-节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
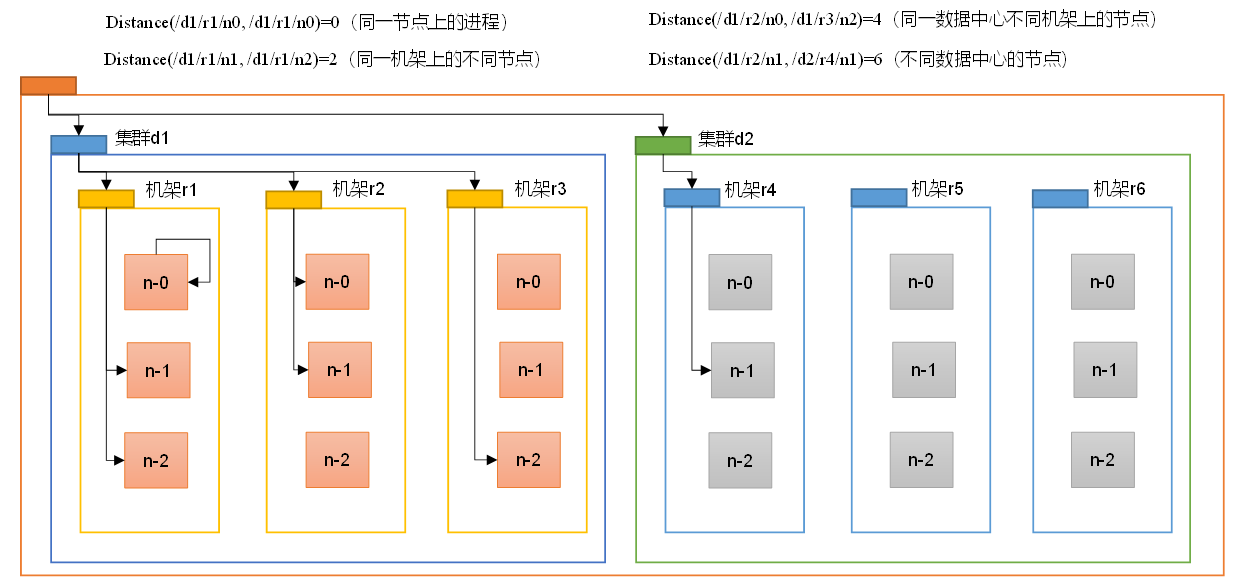
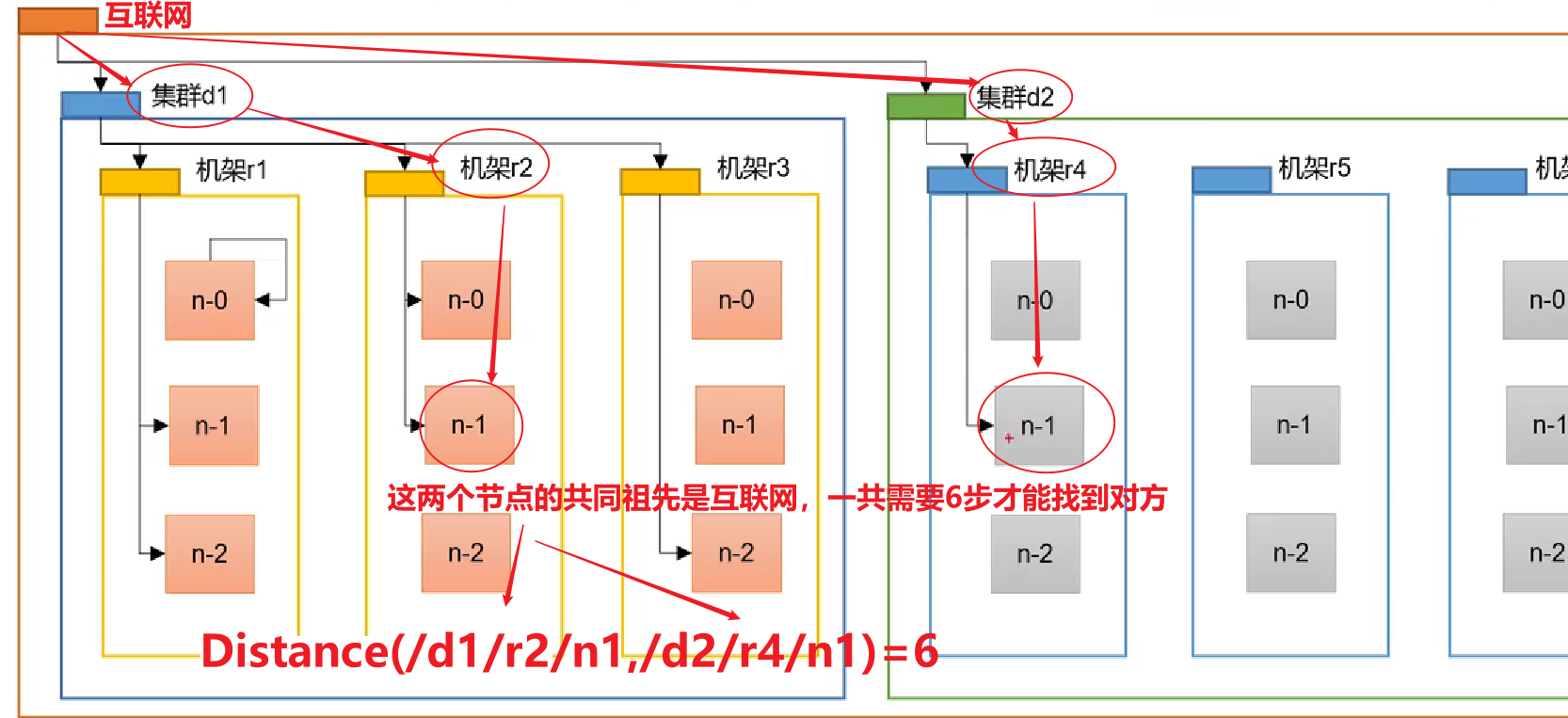
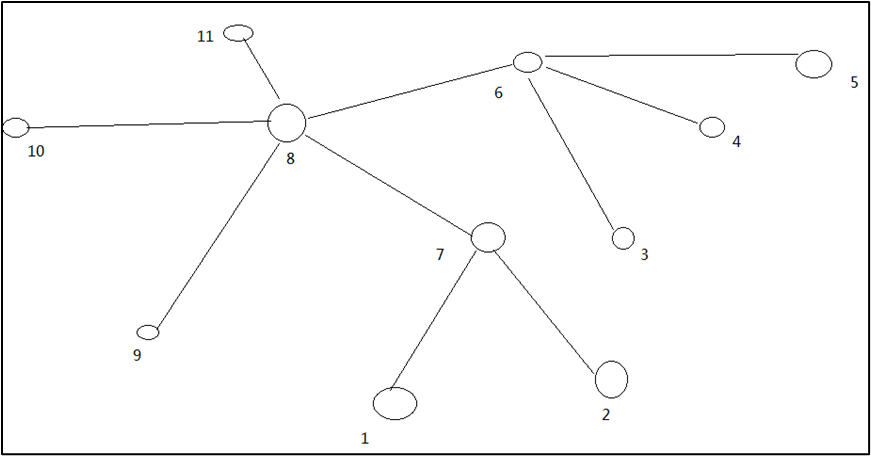
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
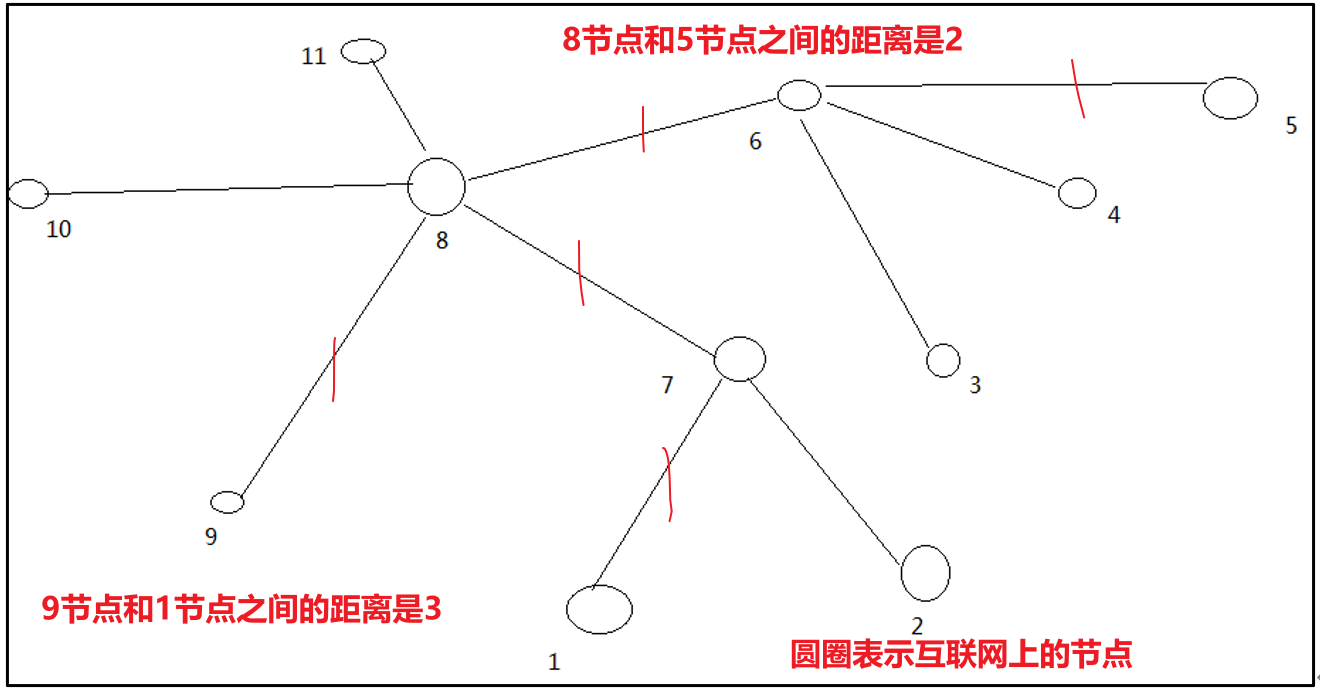
算一算每两个节点之间的距离:
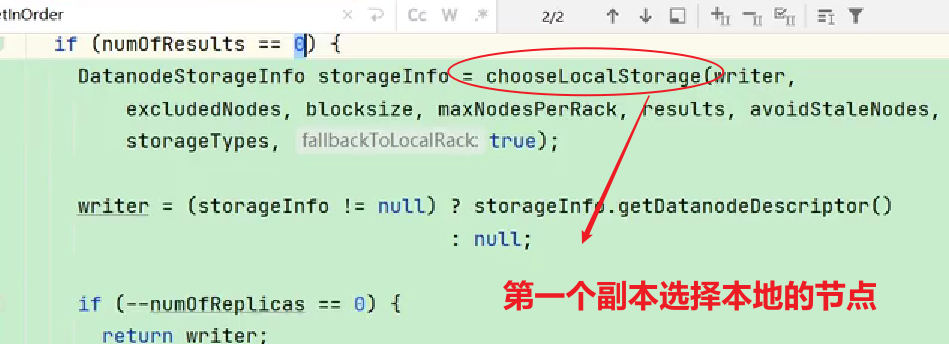
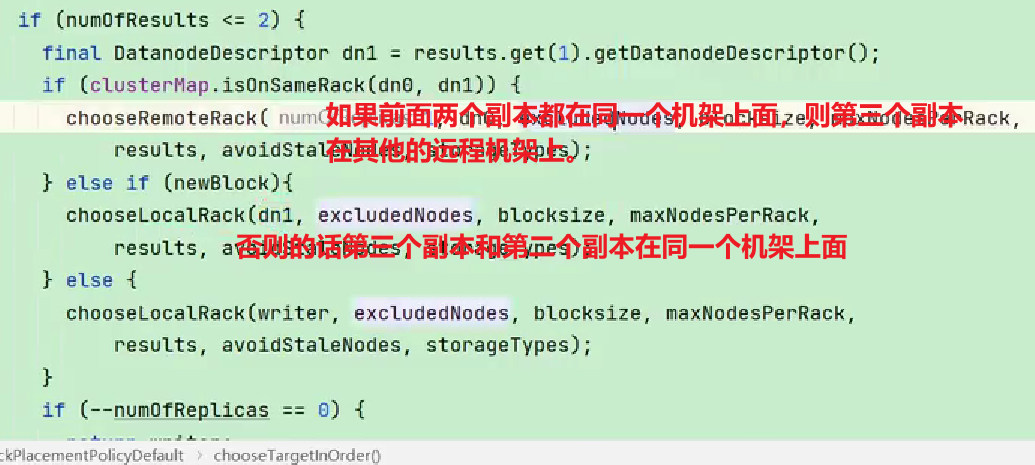
2.3 机架感知(副本存储节点选择)
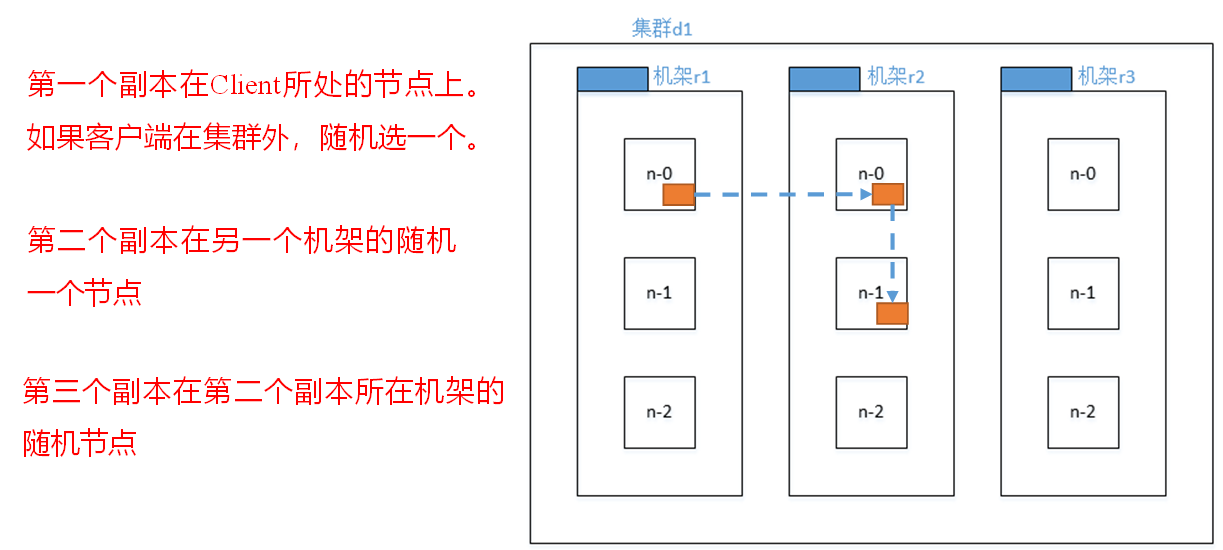
官方说明:
对于常见情况,当副本为3时,HDFS的放置策略是,如果编写器在datanode上,则将一个副本放在本地计算机上,否则放在随机datanode上,另一个副本放在不同(远程)机架中的节点上,最后一个放在同一远程机架中的不同节点上。此策略减少了机架间的写入流量,从而总体上提高了写入性能。机架故障的几率远小于节点故障的几率;该策略不影响数据可靠性和可用性保证。但是,它确实减少了读取数据时使用的聚合网络带宽,因为一个数据块只放在两个不同的机架中,而不是三个。使用此策略,文件的副本不会均匀分布在机架上。三分之一的副本位于一个节点上,三分之二的副本位于一个机架上,另外三分之一的副本均匀分布在其余机架上。该策略提高了写入性能,而不影响数据可靠性或读取性能。
- 第一个副本考虑的是节点距离最近,上传速度最快。
- 第二个节点保证数据的可靠性。
- 第三个节点在保证数据可靠性的前提下兼顾效率。
查看源码:
Crtl + n 查找BlockPlacementPolicyDefault,在该类中查找chooseTargetInOrder方法。

2.4 读数据流程
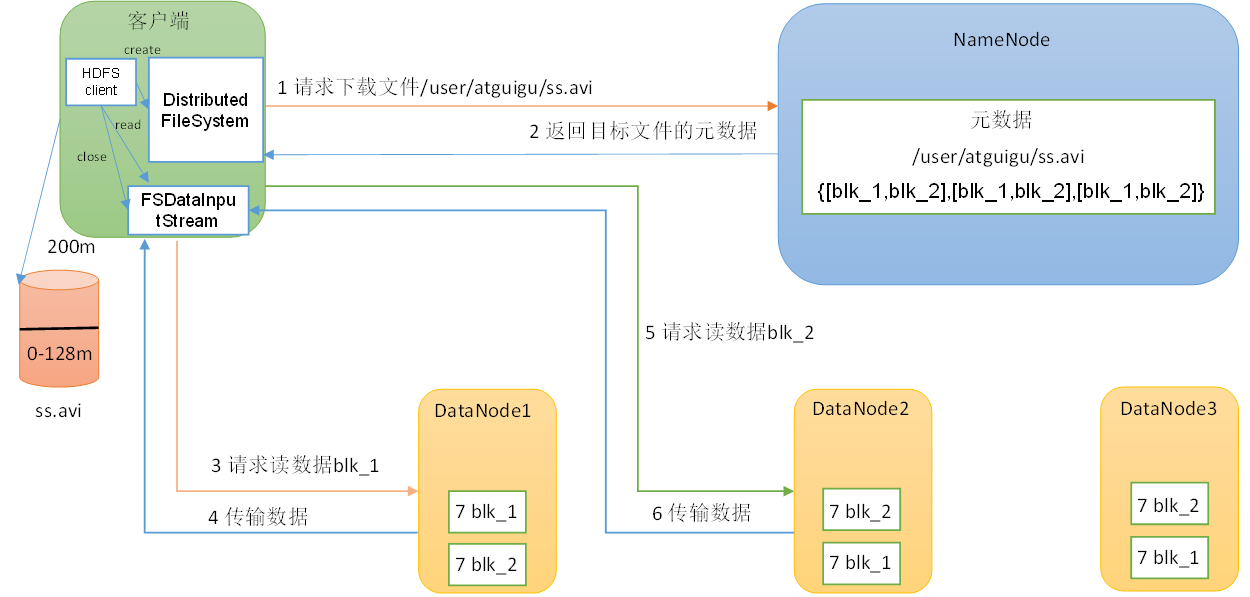
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。【DistributedFileSystem是分布式文件系统对象】
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。【除了考虑节点最近之外,还会考虑当前节点的负载能力】
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
- 这里读取数据采用的是串行读取,而不是并行读取。
相关文章:
【Hadoop_04】HDFS的API操作与读写流程
1、HDFS的API操作1.1 客户端环境准备1.2 API创建文件夹1.3 API上传1.4 API参数的优先级1.5 API文件夹下载1.6 API文件删除1.7 API文件更名和移动1.8 API文件详情和查看1.9 API文件和文件夹判断 2、HDFS的读写流程(面试重点)2.1 HDFS写数据流程2.2 网络拓…...

go-zero开发入门之网关往rpc服务传递数据
go-zero 的网关往 rpc 服务传递数据时,可以使用 headers,但需要注意前缀规则,否则会发现数据传递不过去,或者对方取不到数据。 go-zero 的网关对服务的调用使用了第三方库 grpcurl,入口函数为 InvokeRPC: …...
Word插件-好用的插件-批量插入图片-大珩助手
现有100张图片,需要批量插入word中,并在word中以每页6张图片的形式呈现,请问怎样做? 使用word大珩助手,多媒体-插入图片,根据图片的长宽,选择连续图片、一行2个图或一行3个图,可一次…...
小程序域名SSL证书能用免费的吗?
众所周知,目前小程序要求域名强制使用https协议,否则无法上线。但是对于大多数开发者来说,为每一个小程序都使用上付费的SSL证书,也是一笔不小的支出。那么小程序能使用免费的SSL证书吗? 答案是肯定的。目前市面上可选…...

selenium自动化(中)
显式等待与隐式等待 简介 在实际工作中等待机制可以保证代码的稳定性,保证代码不会受网速、电脑性能等条件的约束。 等待就是当运行代码时,如果页面的渲染速度跟不上代码的运行速度,就需要人为的去限制代码执行的速度。 在做 Web 自动化时…...

uniapp app将base64保存到相册,uniapp app将文件流保存到相册
如果是文件流可以先转base64详情见>uniapp 显示文件流图片-CSDN博客 onDown(){let base64 this.qrcodeUrl ; // base64地址const bitmap new plus.nativeObj.Bitmap("test");bitmap.loadBase64Data(base64, function() {const url "_doc/" new Dat…...
Navicat 技术指引 | 适用于 GaussDB 分布式的服务器对象的创建/设计
Navicat Premium(16.3.3 Windows版或以上)正式支持 GaussDB 分布式数据库。GaussDB分布式模式更适合对系统可用性和数据处理能力要求较高的场景。Navicat 工具不仅提供可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结构…...
五、HotSpot细节实现
一、并发标记与三色标记 问题:三色标记到底发生在什么阶段,替代了什么。并发标记 1、并发标记( Concurrent Marking) 从 GC Root 开始对堆中对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象,这阶段耗…...
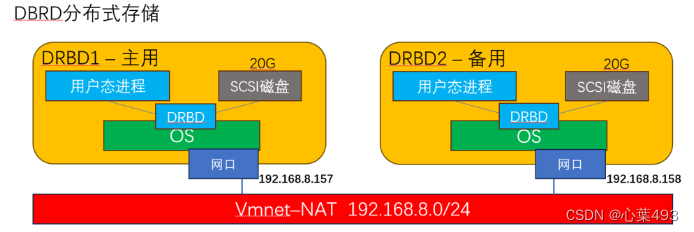
DRBD分布式存储实验
DRBD DRBD的全称为:Distributed Replicated Block Device (DRBD) 分布式块设备复制 与心跳连接结合使用,构建高可用性(HA)的集群。 实现方式是通过网络来镜像(mirror)整个设备。它允许用户在远程机器上建立一个本地块设备的实时镜像。DRBD负责接收数据…...

go的结构体作为返回值
结构体有两种方式作为返回值 结构体结构体指针 代码 package mainimport ("fmt" )type SS struct {Name stringAge int }func getInfo() (*SS) {var ac SS{}ac.Age 1return &ac }func getInfo1() (aa *SS) {aa.Age 1return }func getInfo2() (SS) {var ac…...
谷歌地图问题)
uniapp的subnvue苹果适配(ios)谷歌地图问题
谷歌地图,google地图,调整宽度。这个适配花了点时间,苹果IOS宽度一直无效失灵,赶紧记录分享,很坑。可能所有的ios的subnvue适配都这样。看了网上很多方法无效,最终找到试出答案。 pages.json的配置宽度无效…...

项目实战之RabbitMQ重试机制进行消息补偿通知
🧑💻作者名称:DaenCode 🎤作者简介:啥技术都喜欢捣鼓捣鼓,喜欢分享技术、经验、生活。 😎人生感悟:尝尽人生百味,方知世间冷暖。 文章目录 🌟架构图&#x…...

MySQL之数据库的创建指令
创建数据库 #创建数据库指令: CREATE DATABASE hsp_db1 #创建名字为关键字的数据库,为规避关键字,可以使用反引号 CREATE DATABASE CREATE#删除数据库指令: DROP DATABASE hsp_db1 DROP DATABASE CREATE如果不指定在这里插入代码片…...
编写)
[网络安全]批处理(脚本)编写
Windows DOS命令Linux 一.作用: 自上而下成批次处理每一条命令,直到执行到最后一条 二.如何创建批处理: 扩展名:.bat创建办法:新建一个记事本,把扩展名改为 .bat 三.编辑方法: 右击 -编辑 1).一行一个命令 四.批处理命令: pause 暂停 (及时后面有命令,也不执行)echo …...
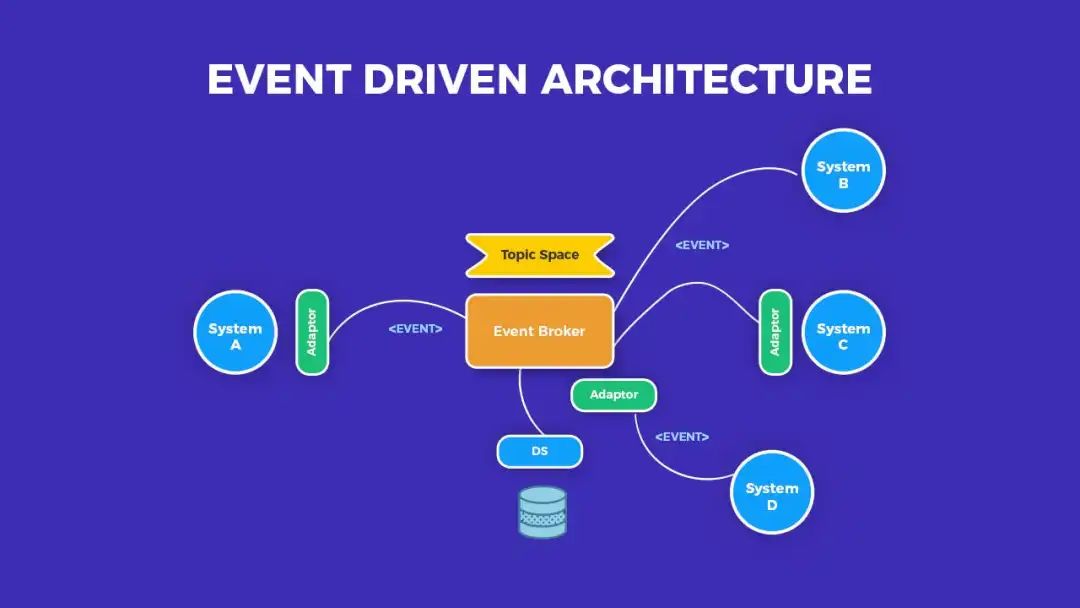
事件驱动架构 vs. RESTful架构:通信模式对比与选择
1. 通信风格 事件驱动架构(EDA) 是一种异步通信风格,组件之间通过产生和消费事件进行通信。 事件是表示系统中重大变化或事件的消息,并分发给感兴趣的组件。这种通信模型允许系统的不同部分之间进行解耦和动态交互。 组件充当事件…...

代码随想录算法训练营第五十二天| 300 最长递增子序列 674 最长连续递增子序列 718 最长重复子数组
目录 300 最长递增子序列 674 最长连续递增子序列 718 最长重复子数组 300 最长递增子序列 class Solution { public:int lengthOfLIS(vector<int>& nums) {vector<int>dp(nums.size(),1);//以i结尾的最长递增子序列的长度for(int i 0;i < nums.size()…...
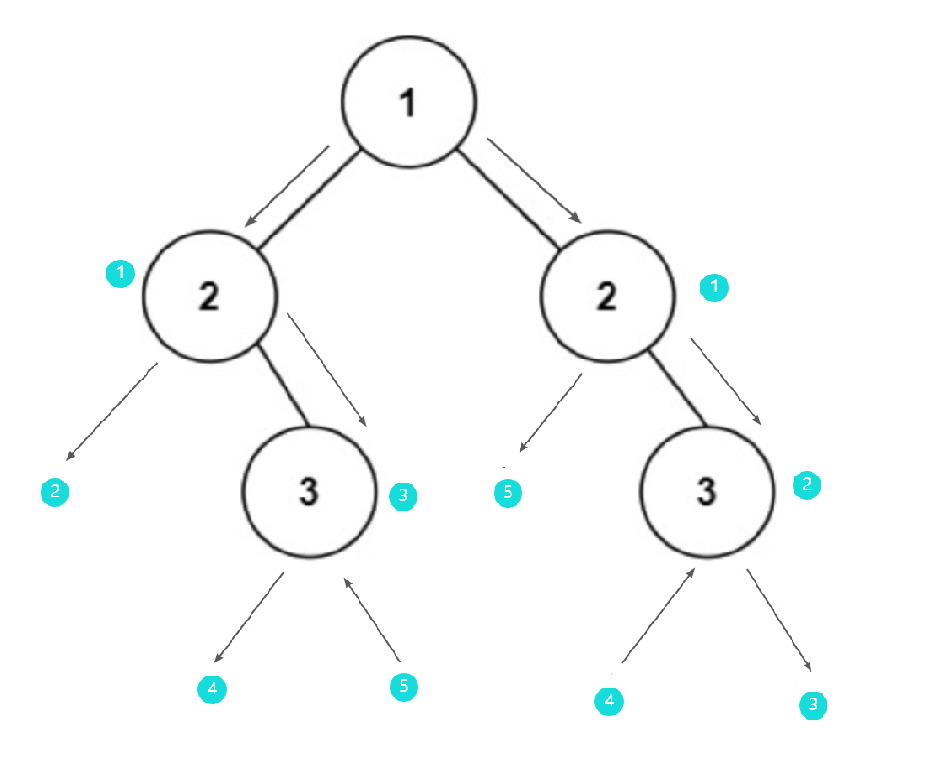
leetcode 101.对称二叉树
学习这部分还是要多画图,多思考 101.对称二叉树 题目 给你一个二叉树的根节点 root , 检查它是否轴对称。 题目链接 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 文字 和 画图 分析 明确结束条件和继续递归条件 判断是否对称…...

【本人新书】《OpenCV应用开发:入门、进阶与工程化实践》
写作初心 OpenCV作为开源的计算机视觉框架已经有超过20年的发展历程,OpenCV4是OpenCV目前为止最重要的里程碑版本。OpenCV4不仅包含了传统图像处理、图像分析、特征提取等模块的各种主流算法算子,还包含了深度学习模型部署与加速支持模块,兼…...

【Linux系统编程】进度条的编写
目录 一,进度条的必备知识 1,缓冲区的粗略介绍 2,回车与换行 二,进度条的初步制作 1,进度条的初步矿建 2,进度条的版本一 3,进度条的版本二 一,进度条的必备知识 1ÿ…...

互斥锁的原理
互斥锁(Mutex,全称Mutual Exclusion)是一种同步机制,用于确保在任意时刻,只有一个线程可以访问共享资源,从而防止数据竞争和不一致性。互斥锁的基本思想是在进入临界区之前,先获取锁;…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...
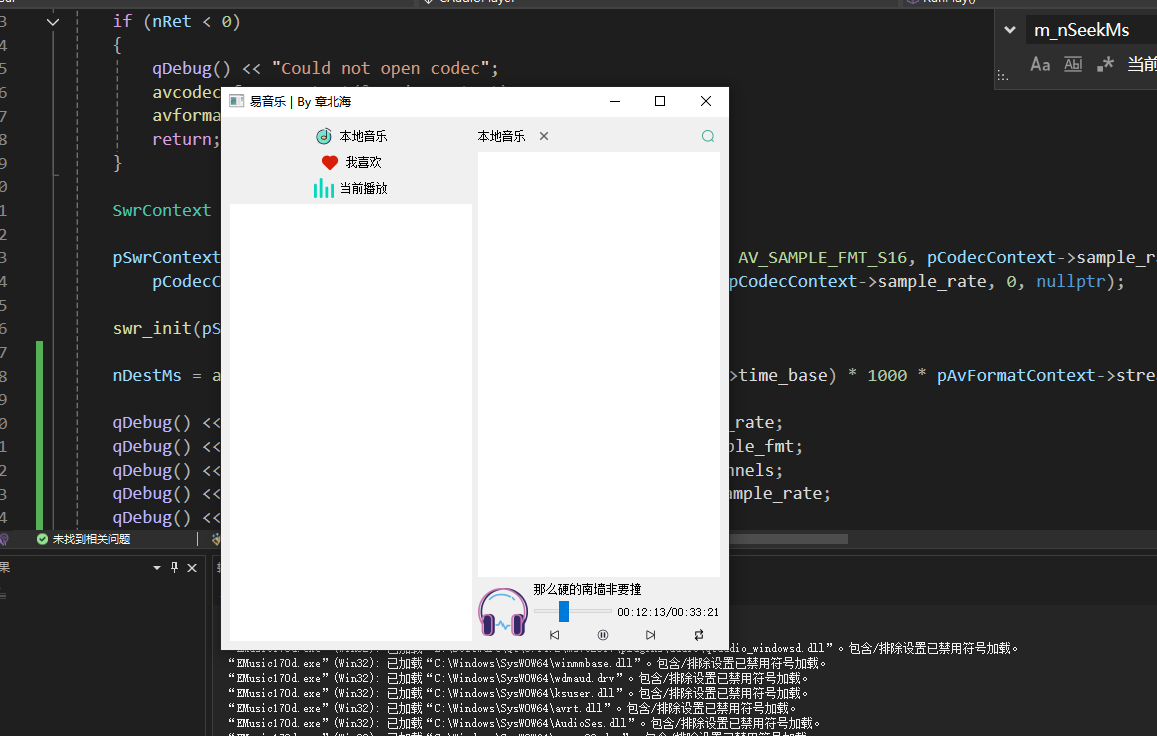
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...
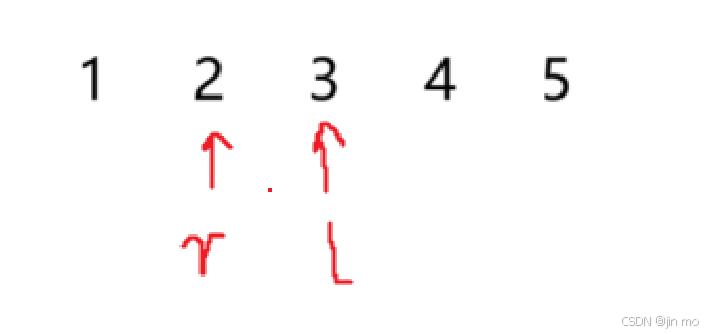
leetcode_69.x的平方根
题目如下 : 看到题 ,我们最原始的想法就是暴力解决: for(long long i 0;i<INT_MAX;i){if(i*ix){return i;}else if((i*i>x)&&((i-1)*(i-1)<x)){return i-1;}}我们直接开始遍历,我们是整数的平方根,所以我们分两…...

软件工程教学评价
王海林老师您好。 您的《软件工程》课程成功地将宏观的理论与具体的实践相结合。上半学期的理论教学中,您通过丰富的实例,将“高内聚低耦合”、SOLID原则等抽象概念解释得十分透彻,让这些理论不再是停留在纸面的名词,而是可以指导…...
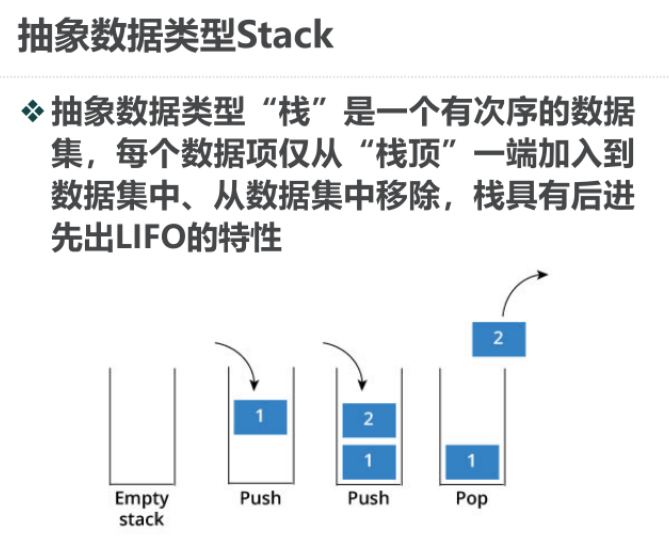
Python[数据结构及算法 --- 栈]
一.栈的概念 在 Python 中,栈(Stack)是一种 “ 后进先出(LIFO)”的数据结构,仅允许在栈顶进行插入(push)和删除(pop)操作。 二.栈的抽象数据类型 1.抽象数…...
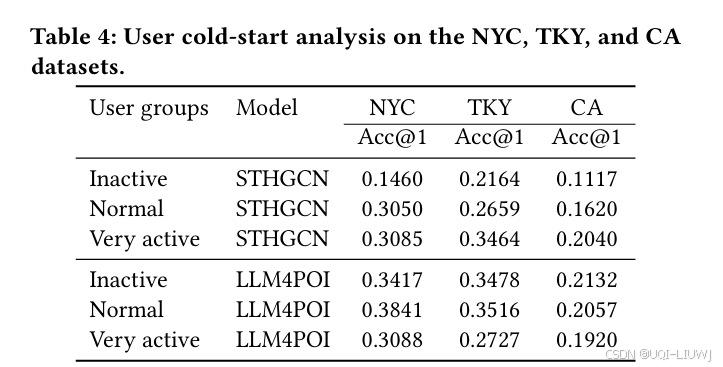
论文笔记:Large Language Models for Next Point-of-Interest Recommendation
SIGIR 2024 1 intro 传统的基于数值的POI推荐方法在处理上下文信息时存在两个主要限制 需要将异构的LBSN数据转换为数字,这可能导致上下文信息的固有含义丢失仅依赖于统计和人为设计来理解上下文信息,缺乏对上下文信息提供的语义概念的理解 ——>使用…...