亚马逊云科技:向量数据存储在生成式人工智能应用程序中的作用
生成式人工智能深受大众喜爱,并且由于具备回答问题、写故事、创作艺术品甚至生成代码的功能,推动了行业的转变,那么如何才能在自己的企业中充分地利用生成式人工智能等应运而生问题。许多客户已经积累了大量特定领域的数据(财务记录、健康记录、基因组数据、供应链等),这为他们提供了独特而有价值的视角,有助于他们深入探究自身的业务及更广泛的行业。对于生成式人工智能策略而言,这些专有数据可以带来优势,成为差异化因素。
同时,许多客户还注意到,在生成式人工智能应用程序中,向量数据存储或向量数据库的使用越来越普遍。他们想知道,这些解决方案如何适应他们围绕着生成式人工智能的整体数据战略。在这篇文章中,介绍了向量数据库在生成式人工智能应用程序中的作用,以及亚马逊云科技解决方案如何帮助您充分利用生成式人工智能的强大功能。
生成式人工智能应用程序
所有生成式人工智能应用程序的核心都是大型语言模型(LLM)。LLM是一种机器学习(ML)模型,利用大量的内容(例如可通过互联网访问的所有内容)进行训练。在利用海量可公开访问的数据训练之后,LLM被视为基础模型(FM)。这些模型可以针对各种使用场景进行调整和优化。Amazon SageMaker JumpStart提供各种预先训练的专有开源基础模型,可以在此基础上进行构建。这样的模型包括Stability AI的Text2Image(用于根据文本提示生成逼真的图像),以及Hugging Face的Text2Text Flan T-5(用于文本生成)。Amazon Bedrock是使用FM构建和扩展生成式人工智能应用程序的最简单方法。借助该服务,可以通过API访问AI21 Labs、Anthropic、Stability AI和Amazon Titan的模型。
尽管生成式人工智能应用程序单纯依赖FM就可以获得广泛的现实世界知识,但是,要想针对特定领域的主题或者专业化主题获得准确的结果,就需要对其进行定制。此外,互动内容越专业,出现幻觉(结果缺乏准确性,但看起来似乎非常正确)的频率就越高。那么,如何自定义生成式人工智能应用程序以实现领域专业化呢?
使用向量数据存储带来领域专业化
提示工程(也称为情境内学习)可能是最简单的一种方法,用于将生成式人工智能应用程序植根到特定领域的环境中并提高准确性。尽管这种技术无法完全消除幻觉,但是可以将语义含义范围缩小到您的特定领域。
就其内核而言,FM根据一组输入词元来推断出下一个词元。在这种情况下,词元是指任何具有语义含义的元素,例如文本生成中的单词或短语。提供的情境相关性越高,推断出的下一个词元与情境相关的可能性也就越大。查询FM时使用的提示应包含输入词元,以及尽可能多的情境相关数据。
情境数据通常来自内部数据库或数据湖,这是托管特定领域数据的系统。只需通过附加这些数据存储中的其他特定领域数据就可以扩充提示,但是向量数据存储可帮助您使用语义相关的输入来设计提示。此方法称为检索式增强生成(RAG,Retrieval Augmented Generation)。在实际应用中,可能会设计一个提示,使用与情境相关的个性化数据(例如用户个人资料信息)和具有相似语义的数据。
对于生成式人工智能的使用,特定领域数据必须编码为一组元素,每个元素在内部表示为向量。该向量包含跨一组维度(数字数组)的一组数值。下图演示的示例中,首先将情境数据转换为语义元素,然后再转换为向量。

这些数值用于在多维向量空间中,映射元素彼此之间的关系。当向量元素具有语义(它们表达了一种含义)时,邻近度就会成为情境关系的指标。以这种方式使用时,此类向量被称为嵌入。例如,在表示杂货或烹饪数据领域情境的多维空间中,“Cheese”的语义元素可以放在“Dairy”的语义元素附近。根据特定领域情境,语义元素可以是单词、短语、句子、段落、整个文档、图像或其他完全不同的东西。将特定领域的数据集拆分为有意义的元素,这些元素可以相互关联。例如,下图说明了在烹饪情境中简化的向量空间。
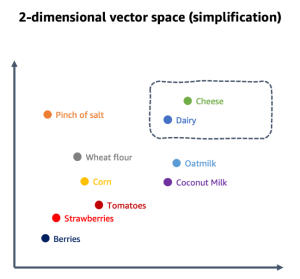
因此,要为提示生成相关的情境,需要查询数据库,并在向量空间中查找与输入密切相关的元素。借助向量数据存储系统,可以大规模存储和查询向量,并使用高效的最近邻查询算法以及合适的索引来改善数据检索。任何具有这些向量相关功能的数据库管理系统都可以是向量数据存储。许多常用的数据库系统都提供了这些向量功能以及其他功能。在具备向量功能的数据库中存储特定领域数据集,这种做法可以带来的一个好处是,向量将位于源数据附近。您可以使用其他元数据来扩充向量数据,而无需查询外部数据库,还可以简化数据处理管道。
为了快速开始使用向量数据存储,亚马逊云科技公布了Amazon OpenSearch无服务器的向量引擎。在正式发布后,该引擎会提供一个简单API,用于存储和查询数十亿个嵌入。此外,还有以下选项可用于满足更高级的向量数据存储需求:
-
Amazon Aurora PostgreSQL兼容版关系数据库,带有pgvector开源向量相似度搜索扩展插件
-
带有k-NN(k-最近邻)插件的Amazon OpenSearch Service(一种分布式搜索和分析服务),以及Amazon OpenSearch无服务器的向量引擎
-
Amazon Relational Database Service(Amazon RDS)for PostgreSQL关系数据库,带有pgvector扩展插件
嵌入应存储在靠近源数据的位置。因此,决定哪种选项适合您的因素包括:目前存储数据的位置以及对这些数据库技术的熟悉程度、向量维度的扩展、嵌入数量、性能需求。
为RAG使用向量数据存储
可以使用嵌入(向量)来提高生成式人工智能应用程序的准确性。下图展示了此数据流。
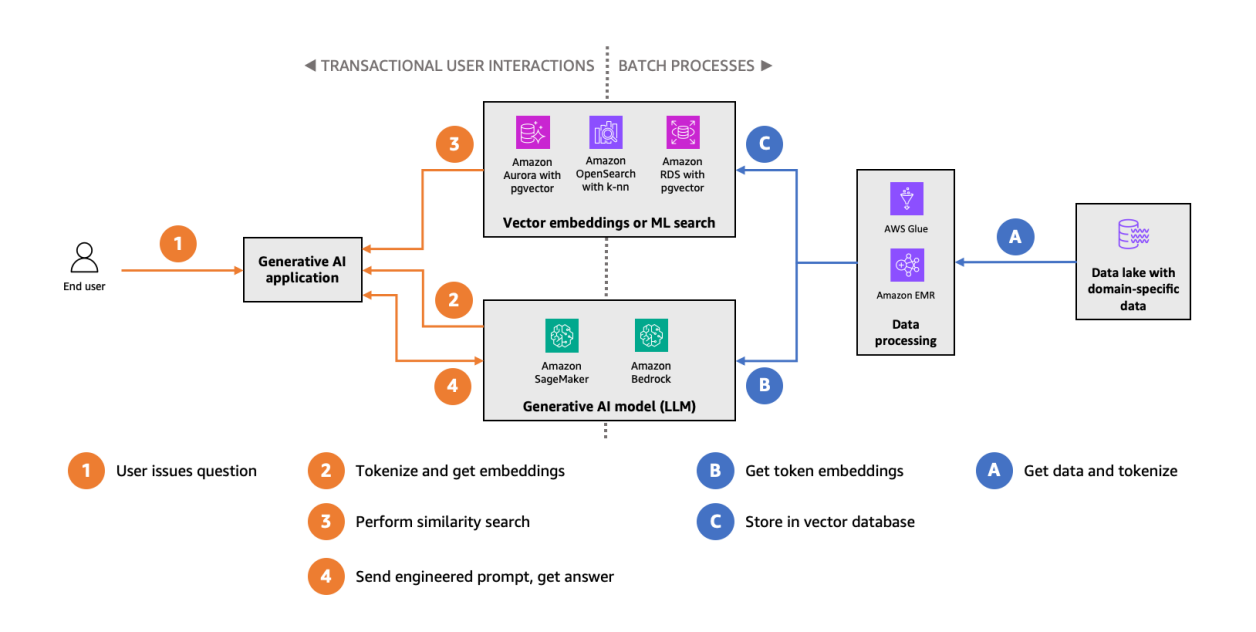
获取特定领域的数据集(上图的右侧,用蓝色表示),将其拆分为语义元素,然后使用FM计算这些语义元素的向量。然后,将这些向量存储在向量数据存储中,这样就能够执行相似度搜索。
在生成式人工智能应用程序(上图的左侧,用橙色表示)中,获取最终用户提出的问题,使用与数据集相同的算法将其拆分为语义元素(词元化),然后在向量数据存储中,查询输入元素在向量空间中的最近邻。借助存储,可以获得具有情境相似性的语义元素,然后将其添加到设计的提示中。此过程进一步使得LLM建立在特定领域情境之上,这样LLM更有可能输出准确且与情境相关的内容。
在向量数据存储中,在最终用户的关键路径上,使用并发读取查询执行相似度搜索。使用嵌入来填充向量数据存储以及保持更新数据更改的批处理过程,主要是对向量数据存储的数据写入。这种使用模式的各个方面以及前面提到的注意事项(例如熟悉度和规模)决定了哪种服务适合您:是Aurora PostgreSQL兼容数据库、OpenSearch Service、OpenSearch无服务器的向量引擎还是Amazon RDS for PostgreSQL。
向量数据存储注意事项
对于向量数据存储,本次介绍的使用模式还带来了一些独特而重要的注意事项。
使用的特定领域的数据量,以及用于将这些数据拆分为语义元素的过程,决定了向量数据存储需要支持的嵌入数量。特定领域的数据随着时间的推移不断增长和变化,向量数据存储也必须适应这种增长。在大规模使用时,这会影响索引效率和性能。特定领域的数据集产生数亿甚至数十亿个嵌入的情况并不少见。可以使用分词器来拆分数据,自然语言工具包(NLTK,Natural Language Toolkit)提供了多个可供使用的通用分词器。不过也可以使用其他工具。归根结底,合适的分词器取决于特定领域数据集中包含何种语义元素,如前所述,这可能是单词、短语、文本段落、整个文档或具有独立含义的任何数据细分。
另一个需要考虑的重要因素是嵌入向量的维数。不同的FM生成具有不同维数的向量。例如,all-MiniLM-L6-v2模型生成的向量有384个维度,而Falcon-40B向量有8192个维度。向量的维度越大,它所能表示的情境就越丰富,直至达到某个临界点。最终会看到收益递减和查询延迟增加。这最终会导致维数灾难(对象似乎稀疏分布且不相似)。要执行语义相似度搜索,通常需要具有密集维数的向量,但您可能需要减小嵌入维度,以便数据库能够高效地处理此类搜索。
另一个考虑因素是否需要精确相似的搜索结果。向量数据存储中的索引功能可显著加快相似度搜索的速度,但它们也会使用近似最近邻(ANN,Approximate Nearest Neighbor)算法来生成结果。ANN算法以性能和内存效率换取准确性。这些算法无法保证每次都返回最近邻。
最后要考虑的是数据治理。特定领域数据集可能包含高度敏感的数据,例如个人数据或知识产权。在向量数据存储接近现有特定领域数据集的情况下,可以将访问权限、质量和安全控制扩展到向量数据存储,从而简化操作。在许多情况下,无法在不影响数据的语义含义的情况下剥离此类敏感数据,这随之会降低准确性。因此,对于创建、存储和查询嵌入的系统,了解和控制流经其中的数据流非常重要。
使用Aurora PostgreSQL或Amazon RDS for PostgreSQL及pgvector
Pgvector是一款开源的PostgreSQL扩展插件,由社区提供支持,可用于Aurora PostgreSQL和Amazon RDS for PostgreSQL。该扩展插件对PostgreSQL进行扩展,提供了名为vector的向量数据类型,三个用于相似度搜索的查询运算符(Euclidian、负内积和余弦距离),以及ivfflat(倒向文件和存储向量)索引机制,使向量可以更快地执行近似距离搜索。尽管可以存储最多1.6万个维度的向量,但只能对2000个维度进行索引以提高相似度搜索性能。实际上,客户倾向于使用具有较少维度的嵌入。使用Amazon SageMaker和pgvector在PostgreSQL中构建人工智能驱动的搜索一文深入研究了这个扩展插件,是一个不错的资源。
如果已经在关系数据库(尤其是PostgreSQL)上进行了大量投入,并且在该领域拥有丰富的专业知识,那么应该考虑为向量数据存储使用Aurora PostgreSQL与pgvector扩展插件。此外,高度结构化的特定领域数据集本质上也更适合使用关系数据库。如果需要使用特定社区版本的PostgreSQL,Amazon RDS for PostgreSQL也是一个不错的选择。相似度搜索查询(读取)同样可以水平扩展,但需要遵循单个数据库集群中Aurora支持的最大只读副本数(15),以及复制链中Amazon RDS支持的最大只读副本数(15)。
Aurora PostgreSQL还支持Amazon Aurora Serverless v2,这是一种按需自动扩展配置,可以根据负载自动调整数据库实例的计算和内存容量。此配置简化了操作,因为在大多数使用场景中,不再需要针对峰值进行预置或执行复杂的容量规划。
借助Amazon Aurora机器学习(Aurora ML)功能,可以通过SQL函数调用托管在Amazon SageMaker中的机器学习模型。可以使用该功能来调用FM,直接从数据库生成嵌入。可以将这些调用打包到存储过程中,也可以将它们与其他PostgreSQL功能集成,这样向量化过程就可以完全从应用程序中抽象出来。借助Aurora ML内置的批处理功能,甚至可能无需从Aurora导出初始数据集,即可对其进行转换来创建初始向量集。
将OpenSearch Service与k-NN插件和OpenSearch无服务器
的向量引擎结合使用
k-NN插件使用自定义knn_vector数据类型,扩展OpenSearch这一开源的分布式搜索和分析套件,使您能够将嵌入存储在OpenSearch索引中。该插件还提供了三种执行k最近邻相似度搜索的方法:近似k-NN、Script Score k-NN(准确)和无痛扩展(准确)。OpenSearch包括非度量空间库(NMSLIB,Non-Metric Space Library)和Facebook AI Research的FAISS库。您可以使用不同的距离搜索算法来找到最适合需求的算法。这个插件也可以在OpenSearch Service中使用。Amazon OpenSearch Service的向量数据库功能说明一文是很好的资源,可使用其来深入了解这些功能。
由于OpenSearch的分布式特性,对于具有大量嵌入的向量数据存储库来说,这是一个很好的选择。索引可以水平扩展,这样就可以处理更多的吞吐量,用于存储嵌入和执行相似度搜索。对于想要更深入地控制执行搜索所用的方法和算法的客户而言,这也是一个很好的选择。搜索引擎专为低延迟、高吞吐量的查询而设计,为此在事务行为上进行了权衡。
OpenSearch无服务器是一种按需的无服务器配置,消除了预置、配置和调整OpenSearch域的操作复杂性。只需先创建索引集合,然后就可以开始填充索引数据。新公布的OpenSearch无服务器的向量引擎作为一种新的向量集合类型提供,同时还包括了搜索和时间序列集合。该引擎提供了一种简便的方法,可以着手使用向量相似度搜索。这为Amazon Bedrock提供了易于操作的配对方法,无需机器学习或向量技术方面的高级专业知识,即可将提示工程集成到生成式人工智能应用程序中。借助向量引擎,可以在单个API调用中轻松查询向量嵌入、元数据和描述性文本,从而获得更准确的搜索结果,同时降低应用程序堆栈的复杂性。
在带有k-NN插件的OpenSearch中,向量在使用nmslib和faiss引擎时最多支持1.6万个维度,在使用Lucene引擎时最多支持1024个维度。Lucene提供OpenSearch的核心搜索和分析功能,以及向量搜索。OpenSearch使用自定义的REST API执行大多数操作,包括相似度搜索。它在与OpenSearch索引交互时实现了更好的灵活性,同时可以重复利用现有的构建分布式Web应用程序的技能。
如果需要将语义相似度搜索与关键字搜索使用场景相结合,OpenSearch也是一个很好的选择。生成式人工智能应用程序的提示工程涉及情境数据的检索和RAG。例如,客户支持座席应用程序可以提供以前具有相同关键字的支持案例,以及具有相似语义的支持案例,以此来构建提示,这样推荐的解决方案就会基于合适的情境。
通过Neural Search插件(实验版本),可以将机器学习语言模型直接集成到OpenSearch工作流中。使用此插件,OpenSearch会自动为在摄取和搜索期间提供的文本创建向量。然后,它会无缝地将向量用于搜索查询。这可以简化RAG中使用的相似度搜索任务。
此外,如果偏好特定领域数据上的完全托管式的语义搜索体验,则应考虑使用Amazon Kendra。该服务提供了开箱即用的语义搜索功能,具备先进的文档和段落排名功能,消除了管理文本提取、段落拆分、获取嵌入和管理向量数据存储的开销。可以使用Amazon Kendra来满足语义搜索需求,并将结果打包到设计的提示中,从而以最少的操作开销最大限度地发挥RAG的优势。使用Amazon Kendra、LangChain和大型语言模型,在企业数据上快速构建高精度的生成式人工智能应用程序一文更深入地探讨了这个使用场景。
最后,LangChain支持带有pgvector的Aurora PostgreSQL和Amazon RDS for PostgreSQL、OpenSearch无服务器的向量引擎以及带有k-NN的OpenSearch Service。LangChain是一个流行的Python框架,可基于LLM开发具备数据感知能力的代理式应用程序。
小结
嵌入应在靠近特定领域数据集的位置存储和管理。这样一来,就可以将嵌入数据与其他元数据组合,而无需使用额外的外部数据来源。同样,数据不是静态的,而是会随着时间的推移发生变化,将嵌入存储在靠近源数据的位置可以简化数据管道,从而使嵌入保持最新状态。
带有pgvector的Aurora PostgreSQL和Amazon RDS for PostgreSQL,OpenSearch无服务器的向量引擎以及带有k-NN插件的OpenSearch Service,是满足向量数据存储需求的理想选择,但哪种解决方案最为适合最终将取决于使用场景和优先事项。如果选择的数据库没有向量功能,这篇文章中讨论的选项涵盖了熟悉的SQL和NoSQL范围,而且很容易上手,没有太多的操作开销。无论选择哪个选项,向量数据存储解决方案都需要维持由应用程序调度的并发吞吐量。使用完整的嵌入集合大规模验证解决方案,以确保相似度搜索响应延迟符合预期要求。
同时,可以将提示工程与SageMaker JumpStart和Amazon Bedrock提供的基础模型结合使用,以便能够构建创新的生成式人工智能解决方案,且无需投资于大量的机器学习技能即可让客户满意。
相关文章:
亚马逊云科技:向量数据存储在生成式人工智能应用程序中的作用
生成式人工智能深受大众喜爱,并且由于具备回答问题、写故事、创作艺术品甚至生成代码的功能,推动了行业的转变,那么如何才能在自己的企业中充分地利用生成式人工智能等应运而生问题。许多客户已经积累了大量特定领域的数据(财务记…...

小程序面试总结
简单描述下微信小程序的相关文件类型 微信小程序主要涉及以下几种文件类型: JSON 文件(.json): 用于描述小程序的配置信息,比如全局配置、页面路径、窗口样式等。WXML 文件(.wxml):…...

mac 安装anaconda和lightgbm
1.mac安装anaconda 要去[官网](Free Download | Anaconda)下载安装包 不要去清华大学的anaconda的安装包列表去下载安装包,清华的版本太老了, 老到连conda install 安装lightgbm都不只支持 2.安装好anaconda 后, 能用conda install xxx 的尽量不用pip 用pip install light…...
Flink 有状态流式处理
传统批次处理方法 【1】持续收取数据(kafka等),以window时间作为划分,划分一个一个的批次档案(按照时间或者大小等); 【2】周期性执行批次运算(Spark/Stom等);…...

LeetCode //C - 1071. Greatest Common Divisor of Strings
1071. Greatest Common Divisor of Strings For two strings s and t, we say “t divides s” if and only if s t … t (i.e., t is concatenated with itself one or more times). Given two strings str1 and str2, return the largest string x such that x divides …...
智能优化算法应用:基于群居蜘蛛算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于群居蜘蛛算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于群居蜘蛛算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.群居蜘蛛算法4.实验参数设定5.算法结果6.…...

AtCoder Beginner Contest 332
E - Lucky bag(简单状态压缩dp) 题目链接 题意:给你n个物品,m个福袋,让你将这n个物品用m个福袋打包(福袋可以为空),让分完之后的总方差最小,输出最小方差。 思路:其实由题目的数据…...

华为OD试题二(文件目录大小、相对开音节、找最小数)
1. 文件目录大小 题目描述: 一个文件目录的数据格式为:目录id,本目录中文件大小,(子目录id 列表)。其中目录id全局唯一,取值范围[1,200],本目录中文件大小范 围[1,1000],子目录id列表个数[0,10…...
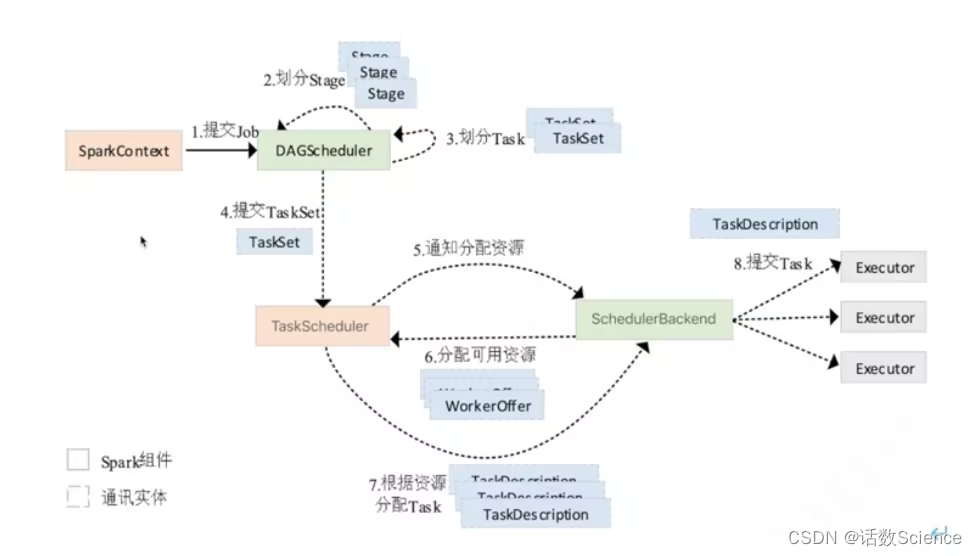
【Spark精讲】Spark作业执行原理
基本流程 用户编写的Spark应用程序最开始都要初始化SparkContext。 用户编写的应用程序中,每执行一个action操作,就会触发一个job的执行,一个应用程序中可能会生成多个job执行。一个job如果存在宽依赖,会将shuffle前后划分成两个…...
Docker容器:Centos7搭建Docker镜像私服harbor
目录 1、安装docker 1.1、前置条件 1.2、查看当前操作系统的内核版本 1.3、卸载旧版本(可选) 1.4、安装需要的软件包 1.5、设置yum安装源 1.6、查看docker可用版本 1.7、安装docker 1.8、开启docker服务 1.9、安装阿里云镜像加速器 1.10、设置docker开机自启 2、安…...

ClickHouse安装和部署
ClickHouse安装过程: ClickHouse支持运行在主流64位CPU架构(X86、AArch和PowerPC)的Linux操作 系统之上,可以通过源码编译、预编译压缩包、Docker镜像和RPM等多种方法进行安装。由于篇幅有限,本节着重讲解离线RPM的安…...

Spring Cloud Gateway中对admin端点进行认证
前言 我们被扫了一个漏洞,SpringBoot Actuator 未授权访问,漏洞描述是这样的: Actuator 是 springboot 提供的用来对应用系统进行自省和监控的功能模块,借助于 Actuator 开发者可以很方便地对应用系统某些监控指标进行查看、统计…...

2. 如何通过公网IP端口映射访问到设备的vmware虚拟机的ubuntu服务器
文章目录 1. 主机设备是Windows 11系统2. 安装vmware虚拟机3. 创建ubuntu虚拟机(据说CentOS 7 明年就不维护了,就不用这个版本的linux了)4. 安装nginx服务:默认端口805. 安装ssh服务:默认端口226. 设置主机 -> ubuntu的端口映射7. 设置路由…...
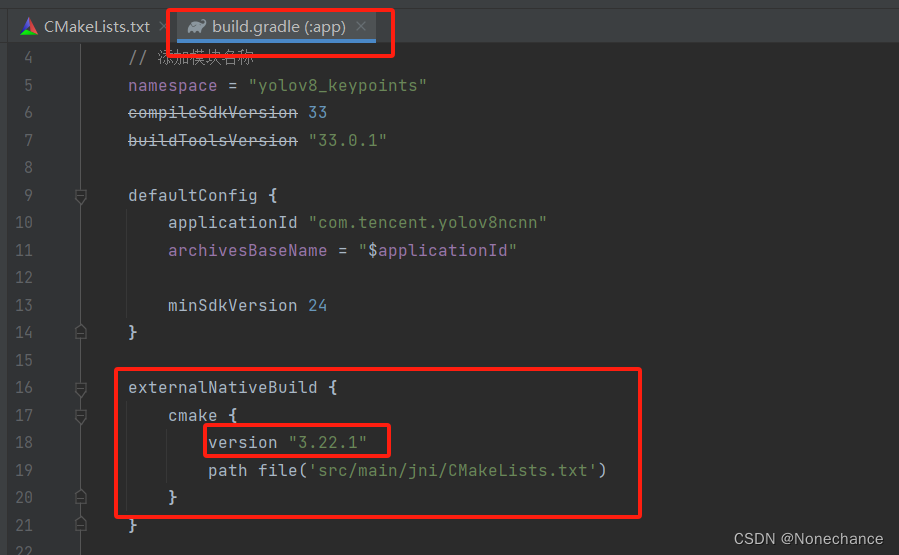
配置android sudio出现的错误
导入demo工程,配置过程参考: AndroidStudio导入项目的正确方式,修改gradle配置 错误:Namespace not specified. Specify a namespace in the module’s build file. 并定位在下图位置: 原因:Android 大括号…...

【初阶C++】前言
C前言 1. 什么是C2. C发展史3. C的重要性4. 如何学习C 1. 什么是C C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, …...
MAC IDEA Maven Springboot
在mac中,使用idea进行maven项目构建 环境配置如何运行maven项目1.直接在IDEA中运行2.使用jar打包后执行 如何搭建spring boot1.添加依赖2.创建入口类3.创建控制器4. 运行5.其他 环境配置 官网安装IDEA使用IDEA的创建新项目选择创建MAEVEN项目测试IDEA的MAVEN路径是…...

Angular13无法在浏览器debug
前言 本文将介绍如何解决在Angular 13中无法在浏览器中进行调试的问题,并提供了一种解决方法。 发生场景 根据项目需求,升级至Angular 13后,发现无法在浏览器中进行调试。 问题原因 无法进行调试的原因是,当使用Angular 13的…...
:视频编码的演进)
H.264与H.265(HEVC):视频编码的演进
目录 H.264的发展历程 1. 标准发布 2. 广泛应用 3. 专业化应用 H.265的出现...
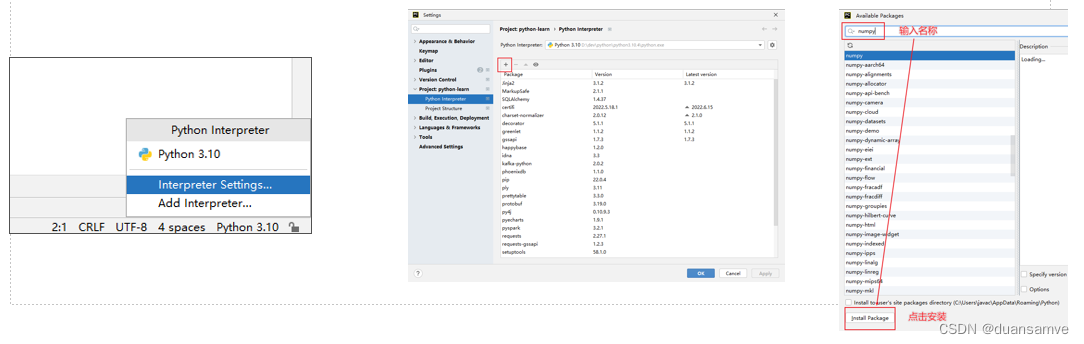
Python从入门到精通九:Python异常、模块与包
了解异常 什么是异常 当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”, 也就是我们常说的BUG bug单词的诞生 早期计算机采用大量继电器工作,马克二型计算机就是这样的。 19…...
无需公网IP联机Minecraft,我的世界服务器本地搭建教程
目录 前言 1.Mcsmanager安装 2.创建Minecraft服务器 3.本地测试联机 4. 内网穿透 4.1 安装cpolar内网穿透 4.2 创建隧道映射内网端口 5.远程联机测试 6. 配置固定远程联机端口地址 6.1 保留一个固定TCP地址 6.2 配置固定TCP地址 7. 使用固定公网地址远程联机 8.总…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...