吴恩达深度学习L2W1作业1
初始化
欢迎来到“改善深度神经网络”的第一项作业。
训练神经网络需要指定权重的初始值,而一个好的初始化方法将有助于网络学习。
如果你完成了本系列的上一课程,则可能已经按照我们的说明完成了权重初始化。但是,如何为新的神经网络选择初始化?在本笔记本中,你能学习看到不同的初始化导致的不同结果。
好的初始化可以:
- 加快梯度下降、模型收敛
- 减小梯度下降收敛过程中训练(和泛化)出现误差的几率
首先,运行以下单元格以加载包和用于分类的二维数据集。
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
from init_utils import sigmoid, relu, compute_loss, forward_propagation, backward_propagation
from init_utils import update_parameters, predict, load_dataset, plot_decision_boundary, predict_dec%matplotlib inline
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'# load image dataset: blue/red dots in circles
train_X, train_Y, test_X, test_Y = load_dataset()
我们希望分类器将蓝点和红点分开。
1 神经网络模型
你将使用已经实现了的3层神经网络。 下面是你将尝试的初始化方法:
- 零初始化 :在输入参数中设置
initialization = "zeros"。 - 随机初始化 :在输入参数中设置
initialization = "random",这会将权重初始化为较大的随机值。 - He初始化 :在输入参数中设置
initialization = "he",这会根据He等人(2015)的论文将权重初始化为按比例缩放的随机值。
说明:请快速阅读并运行以下代码,在下一部分中,你将实现此model()调用的三种初始化方法。
def model(X, Y, learning_rate = 0.01, num_iterations = 15000, print_cost = True, initialization = "he"):"""Implements a three-layer neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.Arguments:X -- input data, of shape (2, number of examples)Y -- true "label" vector (containing 0 for red dots; 1 for blue dots), of shape (1, number of examples)learning_rate -- learning rate for gradient descent num_iterations -- number of iterations to run gradient descentprint_cost -- if True, print the cost every 1000 iterationsinitialization -- flag to choose which initialization to use ("zeros","random" or "he")Returns:parameters -- parameters learnt by the model"""grads = {}costs = [] # to keep track of the lossm = X.shape[1] # number of exampleslayers_dims = [X.shape[0], 10, 5, 1]# Initialize parameters dictionary.if initialization == "zeros":parameters = initialize_parameters_zeros(layers_dims)elif initialization == "random":parameters = initialize_parameters_random(layers_dims)elif initialization == "he":parameters = initialize_parameters_he(layers_dims)# Loop (gradient descent)for i in range(0, num_iterations):# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.a3, cache = forward_propagation(X, parameters)# Losscost = compute_loss(a3, Y)# Backward propagation.grads = backward_propagation(X, Y, cache)# Update parameters.parameters = update_parameters(parameters, grads, learning_rate)# Print the loss every 1000 iterationsif print_cost and i % 1000 == 0:print("Cost after iteration {}: {}".format(i, cost))costs.append(cost)# plot the lossplt.plot(costs)plt.ylabel('cost')plt.xlabel('iterations (per hundreds)')plt.title("Learning rate =" + str(learning_rate))plt.show()return parameters2 零初始化
在神经网络中有两种类型的参数要初始化:
- 权重矩阵
![]()
- 偏差向量
![]()
练习:实现以下函数以将所有参数初始化为零。 稍后你会看到此方法会报错,因为它无法“打破对称性”。总之先尝试一下,看看会发生什么。确保使用正确维度的np.zeros((..,..))。
# GRADED FUNCTION: initialize_parameters_zeros def initialize_parameters_zeros(layers_dims):"""Arguments:layer_dims -- python array (list) containing the size of each layer.Returns:parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])b1 -- bias vector of shape (layers_dims[1], 1)...WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])bL -- bias vector of shape (layers_dims[L], 1)"""parameters = {}L = len(layers_dims) # number of layers in the networkfor l in range(1, L):### START CODE HERE ### (≈ 2 lines of code)parameters['W'+str(l)]=np.zeros((layers_dims[l],layers_dims[l-1]))parameters['b'+str(l)]=np.zeros((layers_dims[l],1))### END CODE HERE ###return parameters
运行以下代码使用零初始化并迭代15,000次以训练模型。
parameters = model(train_X, train_Y, initialization = "zeros")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)


性能确实很差,损失也没有真正降低,该算法的性能甚至不如随机猜测。为什么呢?让我们看一下预测的详细信息和决策边界:
print ("predictions_train = " + str(predictions_train))
print ("predictions_test = " + str(predictions_test))
plt.title("Model with Zeros initialization")
axes = plt.gca()
axes.set_xlim([-1.5,1.5])
axes.set_ylim([-1.5,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
该模型预测的每个示例都为0。
通常,将所有权重初始化为零会导致网络无法打破对称性。 这意味着每一层中的每个神经元都将学习相同的东西,并且你不妨训练每一层的神经网络,且该网络的性能不如线性分类器,例如逻辑回归。
你应该记住:
- 权重
应该随机初始化以打破对称性。
- 将偏差
初始化为零是可以的。只要随机初始化了
3 随机初始化
为了打破对称性,让我们随机设置权重。 在随机初始化之后,每个神经元可以继续学习其输入的不同特征。 在本练习中,你将看到如果将权重随机初始化为非常大的值会发生什么。
练习:实现以下函数,将权重初始化为较大的随机值(按*10缩放),并将偏差设为0。 将 np.random.randn(..,..) * 10用于权重,将np.zeros((.., ..))用于偏差。我们使用固定的np.random.seed(..),以确保你的“随机”权重与我们的权重匹配。因此,如果运行几次代码后参数初始值始终相同,也请不要疑惑。
# GRADED FUNCTION: initialize_parameters_randomdef initialize_parameters_random(layers_dims):"""Arguments:layer_dims -- python array (list) containing the size of each layer.Returns:parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])b1 -- bias vector of shape (layers_dims[1], 1)...WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])bL -- bias vector of shape (layers_dims[L], 1)"""np.random.seed(3) # This seed makes sure your "random" numbers will be the as oursparameters = {}L = len(layers_dims) # integer representing the number of layersfor l in range(1, L):### START CODE HERE ### (≈ 2 lines of code)parameters['W'+str(l)]=np.random.randn(layers_dims[l],layers_dims[l-1])*10parameters['b'+str(l)]=np.zeros((layers_dims[l],1))### END CODE HERE ###return parameters 
运行以下代码使用随机初始化迭代15,000次以训练模型。
parameters = model(train_X, train_Y, initialization = "random")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)


因为数值舍入,你可能在0迭代之后看到损失为"inf",我们会在之后用更复杂的数字实现解决此问题。
总之,看起来你的对称性已打破,这会带来更好的结果。 相比之前,模型不再输出全0的结果了。

plt.title("Model with large random initialization")
axes = plt.gca()
axes.set_xlim([-1.5,1.5])
axes.set_ylim([-1.5,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
观察:
- 损失一开始很高是因为较大的随机权重值,对于某些数据,最后一层激活函数sigmoid输出的结果非常接近0或1,并且当该示例数据预测错误时,将导致非常高的损失。当log(a[3])=log(0)时,损失达到无穷大。
- 初始化不当会导致梯度消失/爆炸,同时也会减慢优化算法的速度。
- 训练较长时间的网络,将会看到更好的结果,但是使用太大的随机数进行初始化会降低优化速度。
总结:
- 将权重初始化为非常大的随机值效果不佳。
- 初始化为较小的随机值会更好。重要的问题是:这些随机值应为多小?让我们在下一部分中找到答案!
4 He初始化
最后,让我们尝试一下“He 初始化”,该名称以He等人的名字命名(类似于“Xavier初始化”,但Xavier初始化使用比例因子 sqrt(1./layers_dims[l-1])来表示权重,而He初始化使用
sqrt(2./layers_dims[l-1]))。
练习:实现以下函数,以He初始化来初始化参数。
提示:此函数类似于先前的initialize_parameters_random(...)。 唯一的不同是,无需将np.random.randn(..,..)乘以10,而是将其乘以![]() ,这是He初始化建议使用的ReLU激活层。
,这是He初始化建议使用的ReLU激活层。
# GRADED FUNCTION: initialize_parameters_hedef initialize_parameters_he(layers_dims):"""Arguments:layer_dims -- python array (list) containing the size of each layer.Returns:parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":W1 -- weight matrix of shape (layers_dims[1], layers_dims[0])b1 -- bias vector of shape (layers_dims[1], 1)...WL -- weight matrix of shape (layers_dims[L], layers_dims[L-1])bL -- bias vector of shape (layers_dims[L], 1)"""np.random.seed(3)parameters = {}L = len(layers_dims) - 1 # integer representing the number of layersfor l in range(1, L + 1):### START CODE HERE ### (≈ 2 lines of code)parameters['W'+str(l)]=np.random.randn(layers_dims[l],layers_dims[l-1])*np.sqrt(2./layers_dims[l-1])parameters['b'+str(l)]=np.zeros((layers_dims[l],1))### END CODE HERE ###return parameters
运行以下代码,使用He初始化并迭代15,000次以训练你的模型。
parameters = model(train_X, train_Y, initialization = "he")
print ("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print ("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)


plt.title("Model with He initialization")
axes = plt.gca()
axes.set_xlim([-1.5,1.5])
axes.set_ylim([-1.5,1.5])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
观察:
- 使用He初始化的模型可以在少量迭代中很好地分离蓝色点和红色点。
5 总结
我们已经学习了三种不同类型的初始化方法。对于相同的迭代次数和超参数,三种结果比较为:
| Model | 测试准确率 | 评价 |
|---|---|---|
| 零初始化的3层NN | 50% | 未能打破对称性 |
| 随机初始化的3层NN | 83% | 权重太大 |
| He初始化的3层NN | 99% | 推荐方法 |
此作业中应记住的内容:
- 不同的初始化会导致不同的结果
- 随机初始化用于打破对称性,并确保不同的隐藏单元可以学习不同的东西
- 不要初始化为太大的值
- 初始化对于带有ReLU激活的网络非常有效。
相关文章:
吴恩达深度学习L2W1作业1
初始化 欢迎来到“改善深度神经网络”的第一项作业。 训练神经网络需要指定权重的初始值,而一个好的初始化方法将有助于网络学习。 如果你完成了本系列的上一课程,则可能已经按照我们的说明完成了权重初始化。但是,如何为新的神经网络选择…...
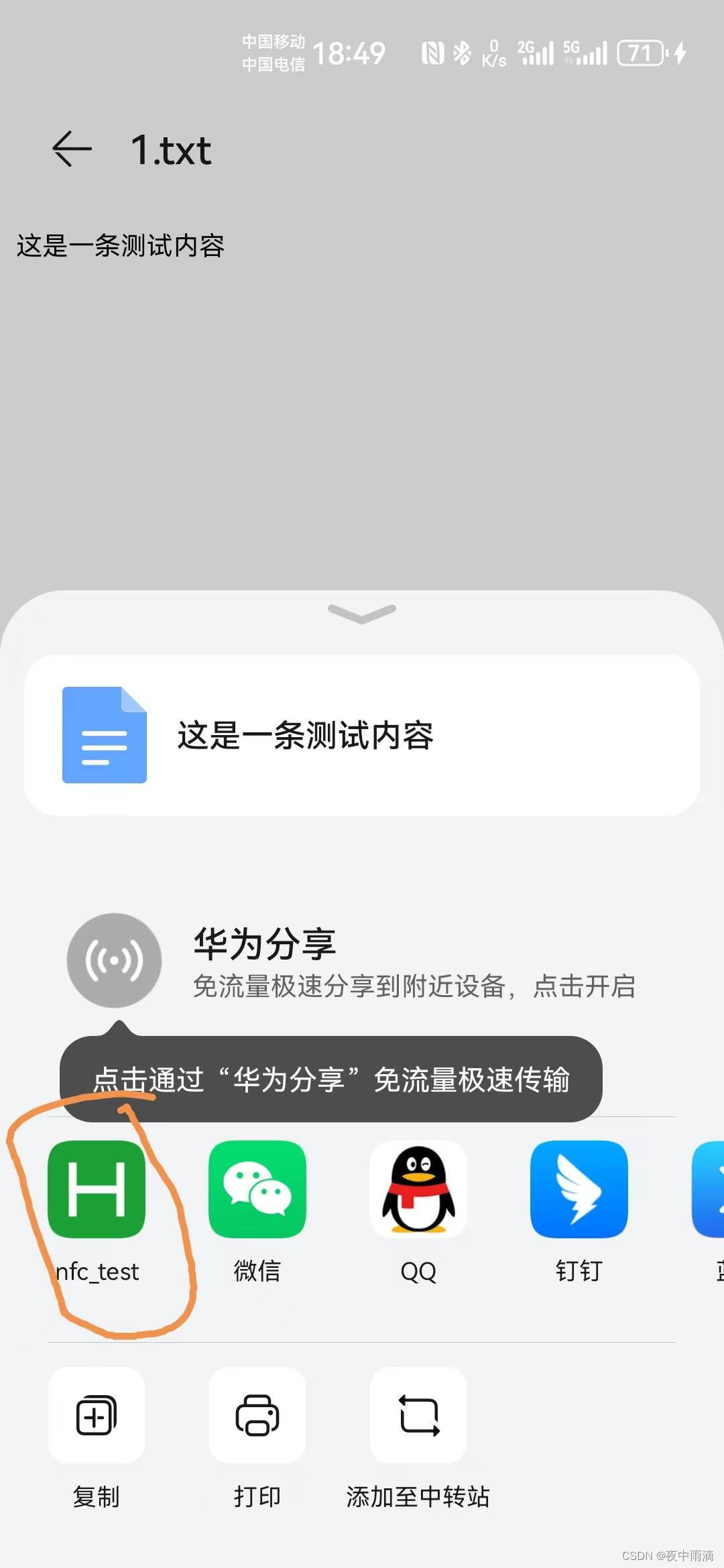
uniapp原生插件之安卓app添加到其他应用打开原生插件
插件介绍 安卓app添加到其他应用打开原生插件,接收分享的文本和文件,支持获取和清空剪切板内容 插件地址 安卓app添加到其他应用打开原生插件,支持获取剪切板内容 - DCloud 插件市场 超级福利 uniapp 插件购买超级福利 详细使用文档 u…...

scala编码
1、Scala高级语言 Scala简介 Scala是一门类Java的多范式语言,它整合了面向对象编程和函数式编程的最佳特性。具体来讲Scala运行于Java虚拟机(JVM)之上,井且兼容现有的Java程序,同样具有跨平台、可移植性好、方便的垃圾回收等特性…...

智慧路灯杆如何实现雪天道路安全监测
随着北方区域连续发生暴雪、寒潮、大风等气象变化,北方多地产生暴雪和低温雨雪冰冻灾害风险,冬季雨雪天气深度影响人们出行生活,也持续增加道路交通风险。 智慧路灯杆是现代城市不可或缺的智能基础设施,凭借搭载智慧照明、环境监测…...
C语言指针基础题(二)
目录 例题一题目解析及答案 例题二题目解析及答案 例题三题目解析及答案 例题四题目解析及答案 例题五题目解析及答案 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 🥸🥸…...
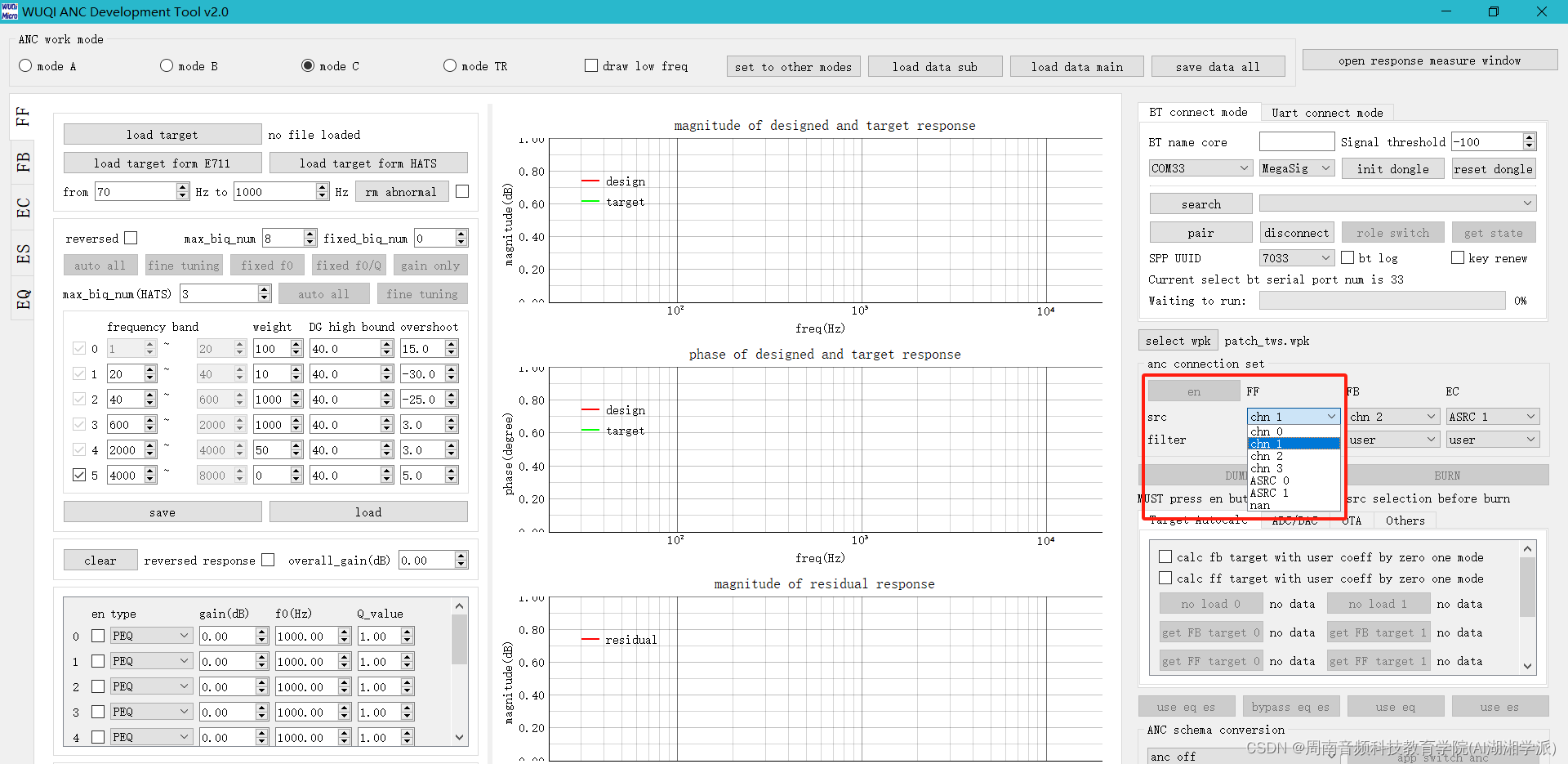
物奇平台MIC配置与音频通路关系
物奇平台MIC配置与音频通路关系 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,群赠送语音信号处理降噪算法,蓝牙耳机音频,DSP音频项目核心开发资料, 1 255代表无效&am…...
外包干了3年,技术退步太明显了。。。。。
先说一下自己的情况,本科生生,18年通过校招进入武汉某软件公司,干了差不多3年的功能测试,今年国庆,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能…...

阶段十-java新特性
JDK9新特性 1.模块化系统 jar包结构的变化 jar -》model -》package -》class 通过不同的模块进行开发 每个模块都有自己的模块配置文件module-info.java 2.JShell JDK9自带的命令行开发,在进行简单的代码调试时可以直接编译使用 可以定义变量,方法&…...

win10重装系统历程
win10系统更新出问题了,重置系统卡死,遂决定重装。 微软官方工具制作U盘启动盘, 进行到分区时,一冲动把盘都格式化了, 后面了解到,即便进不了系统也有办法备份数据的... 进行到安装时,提示W…...
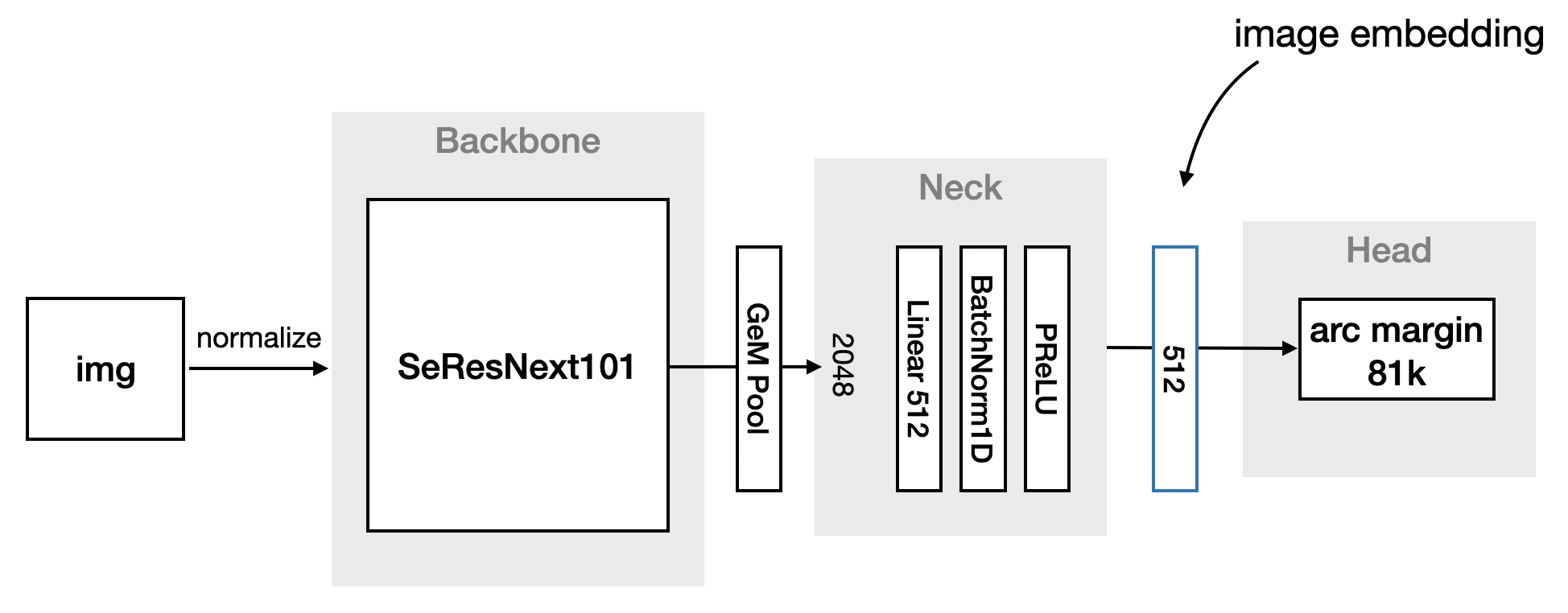
【知识积累】深度度量学习综述
原文指路:https://hav4ik.github.io/articles/deep-metric-learning-survey Problem Setting of Supervised Metric Learning 深度度量学习是一组旨在衡量数据样本之间相似性的技术。 Contrastive Approaches 对比方法的主要思想是设计一个损失函数,直…...
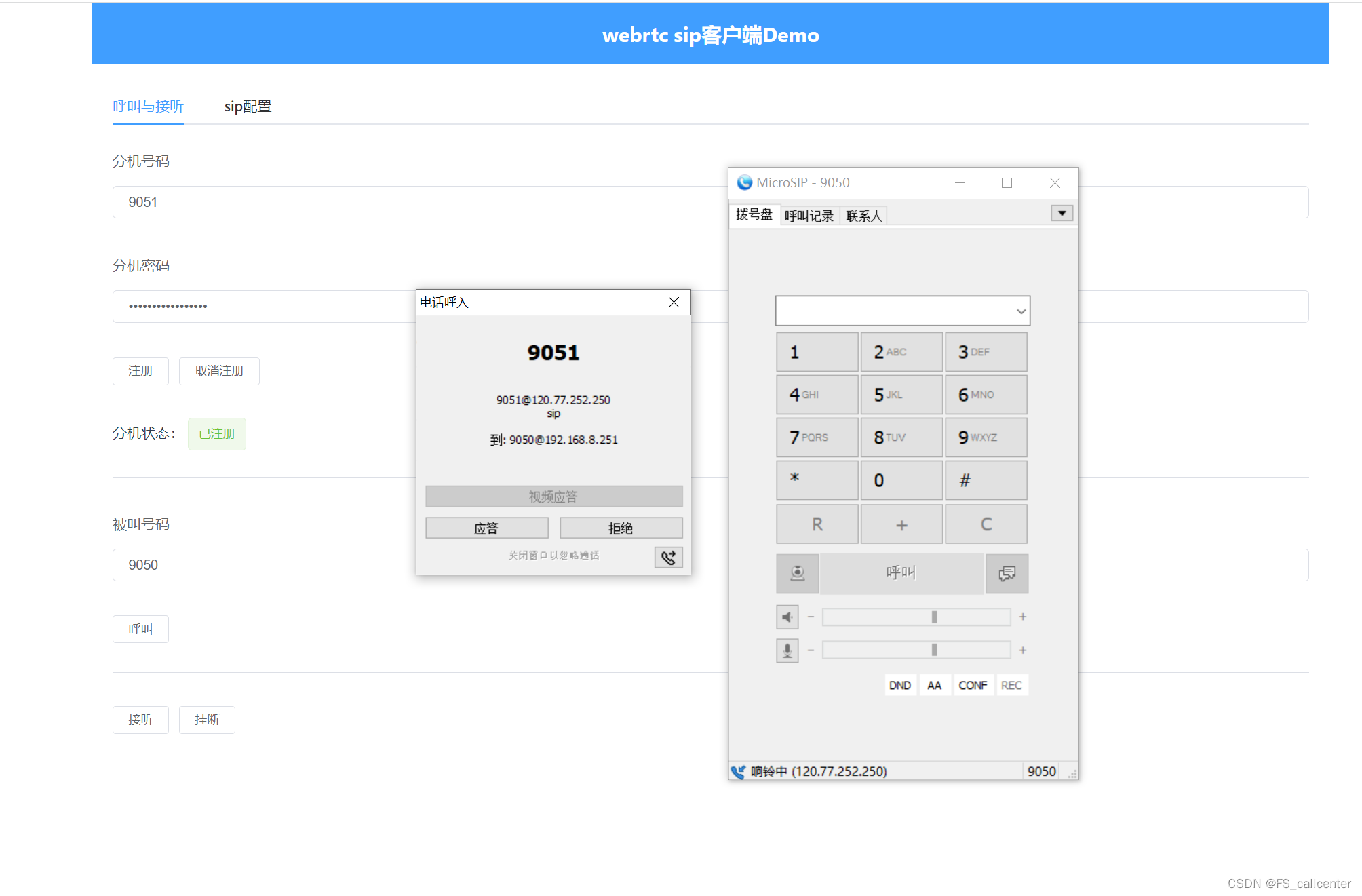
webrtc网之sip转webrtc
OpenSIP是一个开源的SIP(Session Initiation Protocol)服务器,它提供了一个可扩展的基础架构,用于建立、终止和管理VoIP(Voice over IP)通信会话。SIP是一种通信协议,用于建立、修改和终止多媒体…...
【Spring】依赖注入之属性注入详解
前言: 我们在进行web开发时,基本上一个接口对应一个实现类,比如IOrderService接口对应一个OrderServiceImpl实现类,给OrderServiceImpl标注Service注解后,Spring在启动时就会将其注册成bean进行统一管理。在Co…...
)
6-tornado配置文件的使用(命令行解析、文件设置)
tornado.options options 可以让服务运行前提前设置参数,而常见的2种设置参数方式为:1. 命令行设置 2. 文件设置命令行解析 使用tornado.options.define前定义,通常在模块的顶层。 然后,可以将这些选项作为以下属性的属性进行访…...
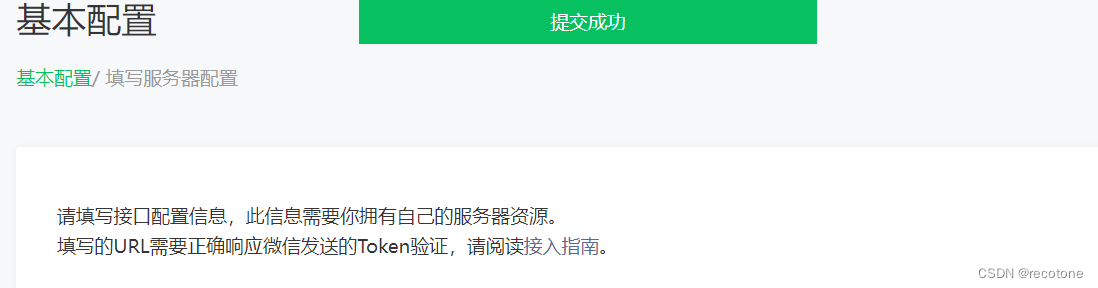
k8s ingress service endpoints 解决微信服务器验证问题(内网穿透)
最近公司要搞微信公众号开发,想用自己公司内网的电脑调试,但涉及到微信服务器地址(URL)验证的问题(内网穿透),查了网上一堆文章有推荐ngrok的,但被微信墙了;有推荐sunny-ngrok的,免费…...

postgresql-effective_cache_size参数详解
在 PostgreSQL 中,effective_cache_size 是一个配置参数,用于告诉查询规划器关于系统中可用缓存的估计信息。这个参数并不表示实际的内存量,而是用于告诉 PostgreSQL 查询规划器系统中可用的磁盘缓存和操作系统级别的文件系统缓存的大小。它用…...

CUDA锁页内存的使用
1.定义指针变量 float *host_Weights; // 锁页内存 float *dev_Weights; // 设备端内存2.分配内存 cudaHostAlloc((void**)&host_Weights, numInputs * sizeof(float), cudaHostAllocDefault); // 用锁页内存,可以有效加快数据传递速度 cudaMalloc((vo…...

python常见代码用法
1.result [[]] * n 和 result [[] for _ in range(n)] 辨析 n 3 result [[]] * nprint(result) # 输出:[[], # [], # []]print(result[0] is result[1] is result[2]) # 输出:True* 运算符进行复制,这些空列表实际…...

MTU TCP-MSS(转载)
MTU MTU 最大传输单元(Maximum Transmission Unit,MTU)用来通知对方所能接受数据服务单元的最大尺寸,说明发送方能够接受的有效载荷大小。 是包或帧的最大长度,一般以字节记。如果MTU过大,在碰到路由器时…...
 高级篇 20 -- SNOOPer 使用介绍】)
【ARM Trace32(劳特巴赫) 高级篇 20 -- SNOOPer 使用介绍】
请阅读【Trace32 ARM 专栏导读】 文章目录 Trace32 SNOOPer 介绍SNOOPer 主要功能:SNOOPer 使用场景SNOOPer.ERRORSTOPSNOOPer.ModeSNOOPer.PCSNOOPer.RateSNOOPer.SELectSNOOPer.SIZESNOOPer.TDelaySNOOPer.TOutSNOOPer.TValueSNOOPer PC 采样Trace32 SNOOPer 介绍 在 Laut…...

MySQL笔记-第11章_数据处理之增删改
视频链接:【MySQL数据库入门到大牛,mysql安装到优化,百科全书级,全网天花板】 文章目录 第11章_数据处理之增删改1. 插入数据1.1 实际问题1.2 方式1:VALUES的方式添加1.3 方式2:将查询结果插入到表中 2. 更…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...
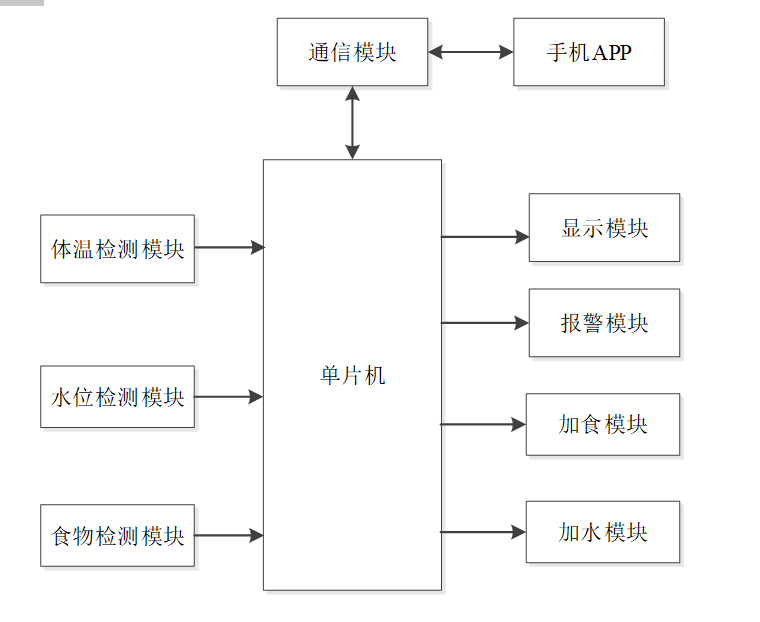
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...
之(六) ——通用对象池总结(核心))
怎么开发一个网络协议模块(C语言框架)之(六) ——通用对象池总结(核心)
+---------------------------+ | operEntryTbl[] | ← 操作对象池 (对象数组) +---------------------------+ | 0 | 1 | 2 | ... | N-1 | +---------------------------+↓ 初始化时全部加入 +------------------------+ +-------------------------+ | …...

命令行关闭Windows防火墙
命令行关闭Windows防火墙 引言一、防火墙:被低估的"智能安检员"二、优先尝试!90%问题无需关闭防火墙方案1:程序白名单(解决软件误拦截)方案2:开放特定端口(解决网游/开发端口不通)三、命令行极速关闭方案方法一:PowerShell(推荐Win10/11)方法二:CMD命令…...

【版本控制】GitHub Desktop 入门教程与开源协作全流程解析
目录 0 引言1 GitHub Desktop 入门教程1.1 安装与基础配置1.2 核心功能使用指南仓库管理日常开发流程分支管理 2 GitHub 开源协作流程详解2.1 Fork & Pull Request 模型2.2 完整协作流程步骤步骤 1: Fork(创建个人副本)步骤 2: Clone(克隆…...