C++数据结构:B树
目录
一. 常见的搜索结构
二. B树的概念
三. B树节点的插入和遍历
3.1 插入B树节点
3.2 B树遍历
四. B+树和B*树
4.1 B+树
4.2 B*树
五. B树索引原理
5.1 索引概述
5.2 MyISAM
5.3 InnoDB
六. 总结
一. 常见的搜索结构
表示1为在实际软件开发项目中,常用的查找结构和方法,包括顺序查找、二分查找、二叉搜索树、平衡二叉树、哈希表等,这几种查找方法和数据结构,都适合于内查找(将数据加载到内存中查找)。
| 搜索结构 | 数据要求 | 时间复杂度 |
|---|---|---|
| 顺序查找 | 无要求 | O(N) |
| 二分查找 | 顺序排序 | O(logN) |
| 二叉搜索树 | 无要求 | O(N) |
| 平衡二叉树 | 无要求 | O(logN) |
| 哈希表 | 无要求 | O(1) |
如果数据量极大,内存无法存放时,就需要将数据存储在磁盘当中,而CPU访问磁盘的速度要远远低于访问内存的速度,假设O(1)的时间复杂度下要执行2次访问,O(logN)的时间复杂度下要执行30次访问。如果对内存数据进行访问,因为访问内存速度相对较快,所有我们可以认为O(1)和O(logN)时间复杂度算法的性能是一致的。但是如果是对于磁盘上的数据的访问,由于磁盘数据访问的效率较低,因此O(1)和O(logN)差别会很大。
采用二叉搜索树检索磁盘数据的缺陷为:
- 二叉搜索树查找的时间复杂度为O(logN),磁盘IO效率低,O(logN)的时间复杂度相对于O(1)会很大程度上降低性能。
但是,哈希查找的时间复杂度是O(1),为什么哈希也不适用于对磁盘数据的检索呢?这是因为哈希的有这样的缺陷:
- 在极端情况下,哈希表中会产生大量的哈希冲突,查找的时间复杂度会接近O(N)。
- 虽然很多时候当哈希冲突达到一定数量时,在哈希散列中会由挂单链表改为挂红黑树,但红黑树查找的时间复杂度依旧是O(logN)。
为了解决平衡二叉树和哈希表无法很好的应对内存数据查找的情况,B树被创造和出来,B树适用于对磁盘中大量的数据进行检索,当然B树也能够在内存在查找数据,但效果就不如哈希和平衡二叉树。
由于B树/B+树适用于检索磁盘中大量数据的性质,经常被用于作为数据库的底层检索结构。
二. B树的概念
B树是一种适合外查找的平衡多叉树,一颗m阶的B树,是一颗m路的二叉搜索树,一颗B树要么为空树,要么满足如下几个条件:
- 根节点至少有两个孩子节点。
- 分支节点(非叶子节点)应当有K-1个键值和K个孩子节点,其中
,其中ceil为向上取整函数。
- 所有叶子节点都在同一层。
- 每个节点中的键值都是自小到大升序排序的,键值Key表示子树的阈值划分。
- 对于任意一个节点,孩子节点的数目总是比键值多一个。
图2.1就是一颗3阶B树,注意观察其根节点,两个键值为50和100,根节点的第一个孩子节点键值全部小于50,第二个孩子节点的键值位于(51,100)之间,第三个孩子节点键值大于100,这就是键值Key的阈值划分功能。
B树检索与二叉搜索树的检索类似,假设我们要在图2.1所示的B树中检索99,先从根节点开始找起,对比待查找的值和键值的大小,发现其位于(50,100)范围内,这样就向下遍历查找p2子树,在p2子树的键值中找到了键值99,检索完成。

三. B树节点的插入和遍历
3.1 插入B树节点
由于B树的插入操作过于抽象,因此直接上实例,在示例中讲解B树节点插入的具体操作。假设依次将std::vector<int> v = { 53,139,75,49,145,36,50,47,101}插入到3阶B树中。为了方便插入操作,我们在申请B树节点空间的时候,阶数为M,就为键值申请M个空间,为孩子节点申请M+1个空间,这样做的目的是方便插入时数据挪动,以及后面的分裂操作。
① 插入53
53是B树插入的第一个节点,因此直接将其插入到根节点的第一个键值位置处即可。如果3.1所示,插入53后,有一个B树根节点,这个根节点附带有两个孩子节点nullptr。这里的根节点也是叶子节点,注意B树插入新节点一定是向叶子节点插入的。
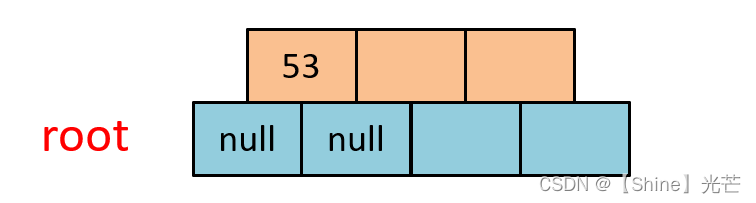
② 插入139
139大于53,且插入后根节点(叶子结点)中键值的数目不超过M-1,因此只需将139至于53的后面,并且带入null子节点即可。

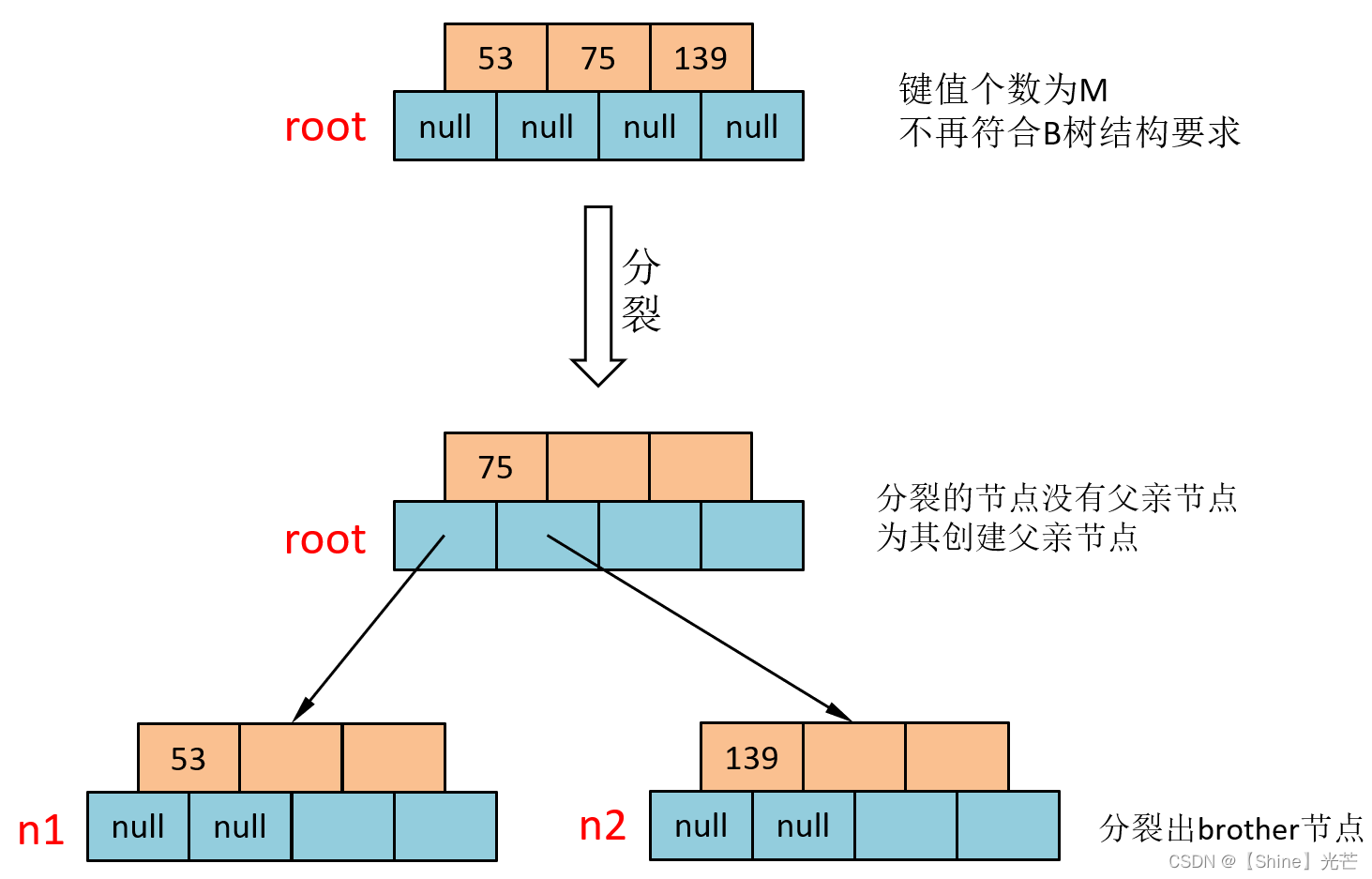
③ 插入75
75位于53和139之间,所以第一步要现将75插入到root节点的这两个值之间。但是,插入75后root节点就有了3个键值,这样就不符合B树的结构要求,需要进行分裂。
分裂操作的步骤为:
- 取中间位置mid = M/2下标处为分界线,创建一个兄弟节点brother,将下标位于[mid+1,M)的键值及其左右孩子都拷贝到brother节点中去(设下标为键值相同的孩子节点为左孩子,比键值下标大1的孩子节点称为右孩子)。
- 将mid处的键值交给其父亲节点,如果没有父亲节点节创建父亲节点,父亲节点的其中两个孩子节点就包含原先发生分裂的节点以及分裂出的节点brother。
④ 插入49
首先检索节点插入的位置,发现49小于根节点root的第一个键值,因此找到n1节点,n1节点为叶子节点可以执行插入操作,49小于第一个节点53,所以应当将53向后移动一位并将49设置为n1节点的第一个键值。

⑤ 插入145
首先检索插入数据的叶子节点,根节点只有一个键值75,145大于75,向n2节点查找,n2为叶子节点可以执行插入操作,将145插入到139后面,插入过后键值个数少于阶数M,不用分裂。

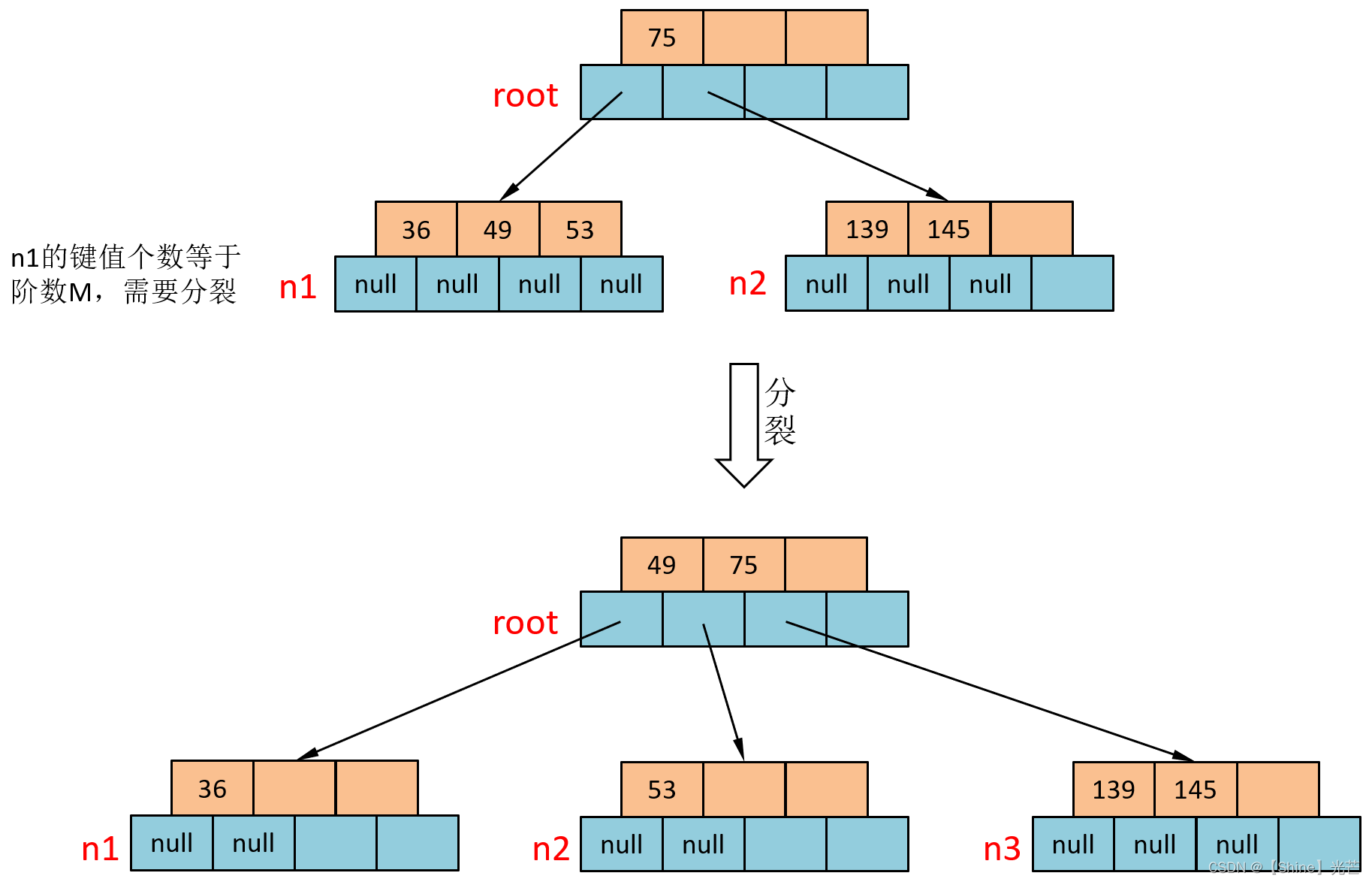
⑥ 插入36
查找36的插入位置应该为图3.5中的n1节点,将35插入n1后n1有3个键值需要进行分裂,兄弟节点取走53,49向上交给n1的父亲节点,分裂出的兄弟节点要作为root节点的一个孩子节点。
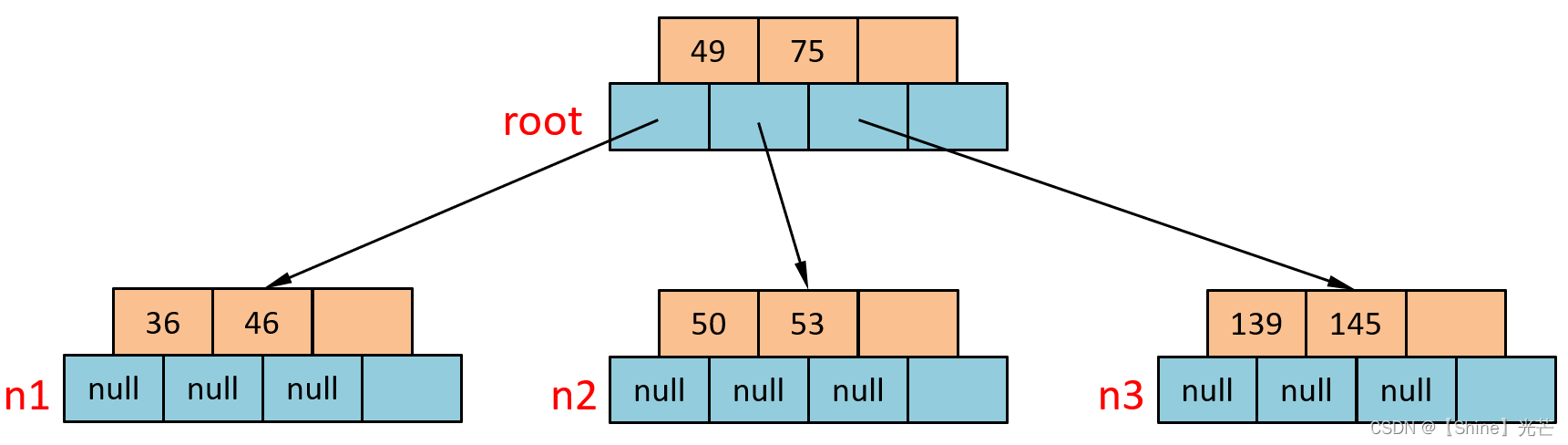
⑦ 插入50
直接找到n2节点,插入到键值53之前即可。

⑧ 插入47
插入到n1节点46的后面即可。
⑨ 插入101
先初步执行插入操作,即101插入到n3节点的第一个键值位置处,插入后n3节点的键值数量达到了阶数M,要执行分裂操作。然而分裂后将mid处键值交给父亲节点(root)管理后,root的键值数量也达到了阶数M,需要进一步分裂,更新root。

3.2 B树遍历
B树是一种特殊的搜索树,如果按照中选遍历,那么理应得到升序的一组数据,B树遍历的方法与普通的二叉搜索树中序遍历并没有本质区别,区别在于M路遍历和双路遍历。图3.10为二叉搜索树的遍历流程图,遍历得到升序排序结果。

代码3.1:插入B树节点和前序遍历B树
#include <iostream>// B树节点,K为索引数据类型,M为最大阶数
template<class K, size_t M>
struct BTreeNode
{// 存储键值和孩子节点的一维数组// K _key[M - 1];// BTreeNode<K, M> _sub[M];// 为了方便后续的分裂和插入操作,多开辟一个空间K _key[M];BTreeNode<K, M>* _sub[M + 1];BTreeNode<K, M>* _parent; // 父亲节点size_t _n; // 键值个数// 构造函数BTreeNode(): _parent(nullptr), _n(0){// 键值全部清零,孩子节点全部为空for (size_t i = 0; i < M; ++i){_key[i] = K();_sub[i] = nullptr;}_sub[M] = nullptr;}
};template<class K, size_t M>
class BTree
{typedef BTreeNode<K, M> Node; // B树节点类型重定义
public:// 插入位置查找函数std::pair<Node*, int> Find(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){// 在本层中,查找大于key的键值,如果找到这样的键值或者走到了最后一个键值// 那么就到下一层去查找,如果找到与key相同的键值,那么就直接返回该位置对应pairsize_t i = 0;while (i < cur->_n){// 键值按照升序排序,逐个向后查找即可if (key > cur->_key[i]) {++i;}else if (key < cur->_key[i]){break;}else // 存在相等就直接返回{return std::make_pair(cur, i);}}parent = cur;cur = cur->_sub[i];}return std::make_pair(parent, -1);}// 在一个B树节点值插入新键值的函数void InsertKey(Node* parent, const K& key, Node* child){int end = parent->_n - 1;while (end >= 0){if (parent->_key[end] > key){// 将大于key的键值及其对应的右孩子节点全部向后移动一位parent->_key[end + 1] = parent->_key[end];parent->_sub[end + 2] = parent->_sub[end + 1];--end;}else{break;}}// 将新的key值插入到end+1位置处,并引入右孩子节点parent->_key[end + 1] = key;parent->_sub[end + 2] = child;++parent->_n;}// 新节点(键值)插入函数bool Insert(const K& key){// 特殊情况:当前B树根节点为空,插入的是第一个节点if (_root == nullptr){_root = new Node;_root->_key[0] = key;_root->_n++;return true;}// 查找要插入节点的位置std::pair<Node*, int> ret = Find(key);// 如果对应ret.second>=0,那说明key已经在B树中存在// B树不允许冗余,因此直接返回falseif (ret.second >= 0){return false;}Node* parent = ret.first;Node* child = nullptr;K newKey = key;// 向上插入,满足条件就分裂while (true){InsertKey(parent, newKey, child);if (parent->_n <= M - 1){return true;}else // 需要进行分裂操作{size_t mid = M / 2; // 中间节点// 将中间mid之后的键值全部交给新创建的brother节点Node* brother = new Node;size_t j = 0;for (size_t i = mid + 1; i < M; ++i){// 将key及其左孩子交给brother节点brother->_key[j] = parent->_key[i];brother->_sub[j] = parent->_sub[i];// 如果左孩子节点不为空,那么就要跟新其父亲为brotherif (parent->_sub[i] != nullptr){parent->_sub[i]->_parent = brother;}// 将parent节点中被挪走的key和sub清空parent->_key[i] = K();parent->_sub[i] = nullptr;++j;}// 将最后一个右孩子节点插入到brother节点中brother->_sub[j] = parent->_sub[M];if (parent->_sub[M] != nullptr){parent->_sub[M]->_parent = brother;}parent->_sub[M] = nullptr;// 更新键值个数,这里parent键值个数减去brother->_n + 1,+1是因为要把mid子节点交给父节点brother->_n = j;parent->_n -= (brother->_n + 1);K midKey = parent->_key[mid];parent->_key[mid] = K();if (parent == _root){_root = new Node;_root->_key[0] = midKey;_root->_sub[0] = parent;_root->_sub[1] = brother;parent->_parent = _root;brother->_parent = _root;_root->_n++;return true;}else{newKey = midKey;parent = parent->_parent;brother->_parent = parent;child = brother;}}}return true;}void _InOrder(Node* root){if (root == nullptr){return;}// 依次遍历每个节点的左孩子for (size_t i = 0; i < root->_n; ++i){_InOrder(root->_sub[i]);std::cout << root->_key[i] << " ";}// 遍历最后一个右孩子节点_InOrder(root->_sub[root->_n]);}// 中序函数void InOrder(){// 子函数_InOrder(_root);}private:Node* _root = nullptr;
};四. B+树和B*树
4.1 B+树
B+树是在B树上优化了的多路平衡搜索二叉树,相比于B树,B+树进行了以下几点优化:
- 每个节点的键值数量和孩子节点数量相同。
- 孩子节点指针p[i]指向的子B树键值范围位于 [ k[i], k[i+1] ) 之间。
- 所有存储了有效键值的节点都在叶子节点上。
- 所有叶子节点都被连接了起来。

B+树的节点插入,与B树类似,同样由于其过于抽象,本文以具体的实例来展示B+树节点插入的过程,假设要将std::vector<int> v = { 53,139,75,49,145,36,101 }插入到阶数M=3的B+树中去,插入的流程及操作如下:
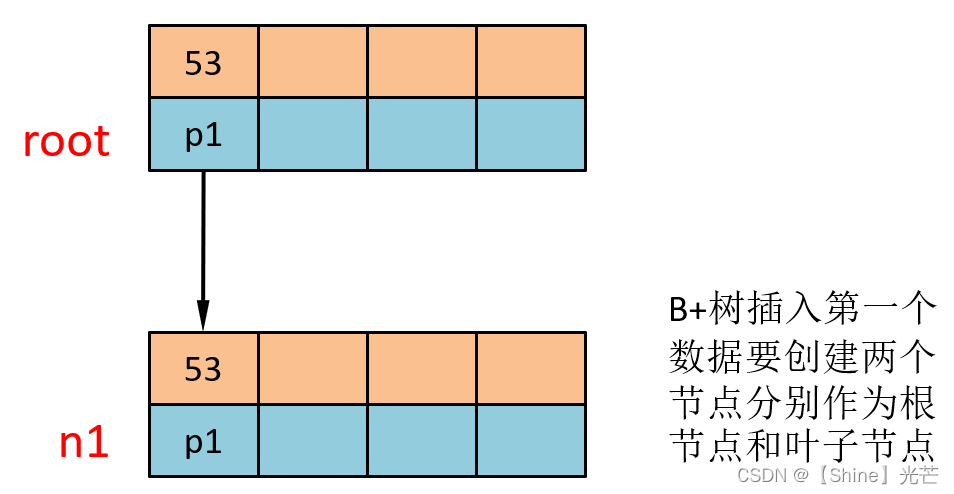
① 插入53
插入的第一个节点,首先创建两层B+树节点,一层为根节点,一层为叶子节点,在根节点和叶子节点的第一个键值位置处,插入元素53。和B树一样,如果阶数为M,就为键值和孩子节点都多开辟一个空间,以方便数据挪到和节点分裂。
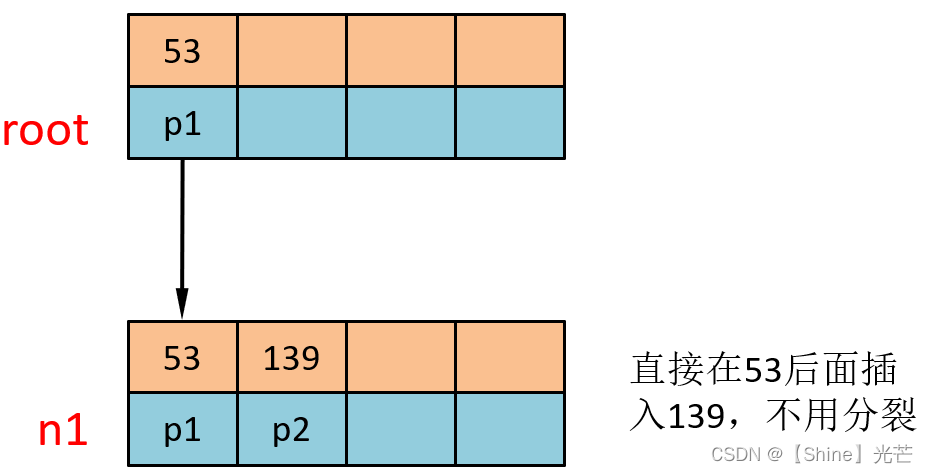
② 插入139
首先检索插入位置,发现139大于根节点中唯一一个键值53,因此向下遍历找到n1,将新数据插入到53后面,节点中键值个数尚未达到阶数,不需要分裂。
③ 插入75
检索到75应该插入子节点n1中,139向后挪一个单位,75插入到53和139之间,以保证键值升序。

④ 插入49
首先查找可以插入49的叶子节点,检索到插入位置为第一个键值位置,因此要更新其父亲节点中对应位置的索引值,这样root的第一个键值就由53变为了49。同时,由于n1中的键值个数已经超过了阶数M,所以要对这个节点执行分裂操作。

B+树节点分裂操作:
- 创建兄弟节点brother,将分裂节点中后半部分键值挪动到brother中。
- 并将brother中首个键值插入到父亲节点中,将brother节点设为父节点的孩子节点。
⑤ 插入145
直接将145插入到节点n2中去,因为插入后键值数量未超过B树的阶数,不需要分裂。

⑥ 插入36
将36插入到n1的首个位置处,然后更新器父亲节点对应的键值。(B+树中向叶子节点的首个关键字位置插入数据,一定会更新父亲节点的索引)

⑦ 插入101
将101插入到n2的键值75和39之间,然后n2分裂。

4.2 B*树
相比于B+树,B*树要求每个分支节点的键值利用率达到,并且每一层节点又要存储指向其兄弟节点的指针,B*树相对于B+树,最大的优化就是节省了空间,能减少空间浪费。
五. B树索引原理
5.1 索引概述
索引,就是通过某些关键信息,让用户可以快速找到某些事物,例如通过目录,我们就可以快速检索到一本书中特定的内容所在的页码。B/B+最普遍的用途,就是做索引。
MySQL数据库官方给出的索引定义是:索引(index)是帮助MySQL高效获取数据的数据结构。
当数据量很大的时候,为了方便数据的管理、提高检索效率,通常会将数据保存至数据库。数据库不仅仅要存储数据,还要维护特定的数据结构和一些高效的搜索算法,以帮助用户快速引用到某些数据。这种实现快速查找的数据结构,就是索引。
MySQL是非常流行的开源关系型数据库,不仅免费,而且搜索效率较高,可靠性高,拥有灵活的插件式存储引擎,在MySQL中,索引是属于存储引擎范畴的概念,不同的存储引擎对索引的实现方式是不同的。索引是基于表的而不是基于数据库的。
5.2 MyISAM
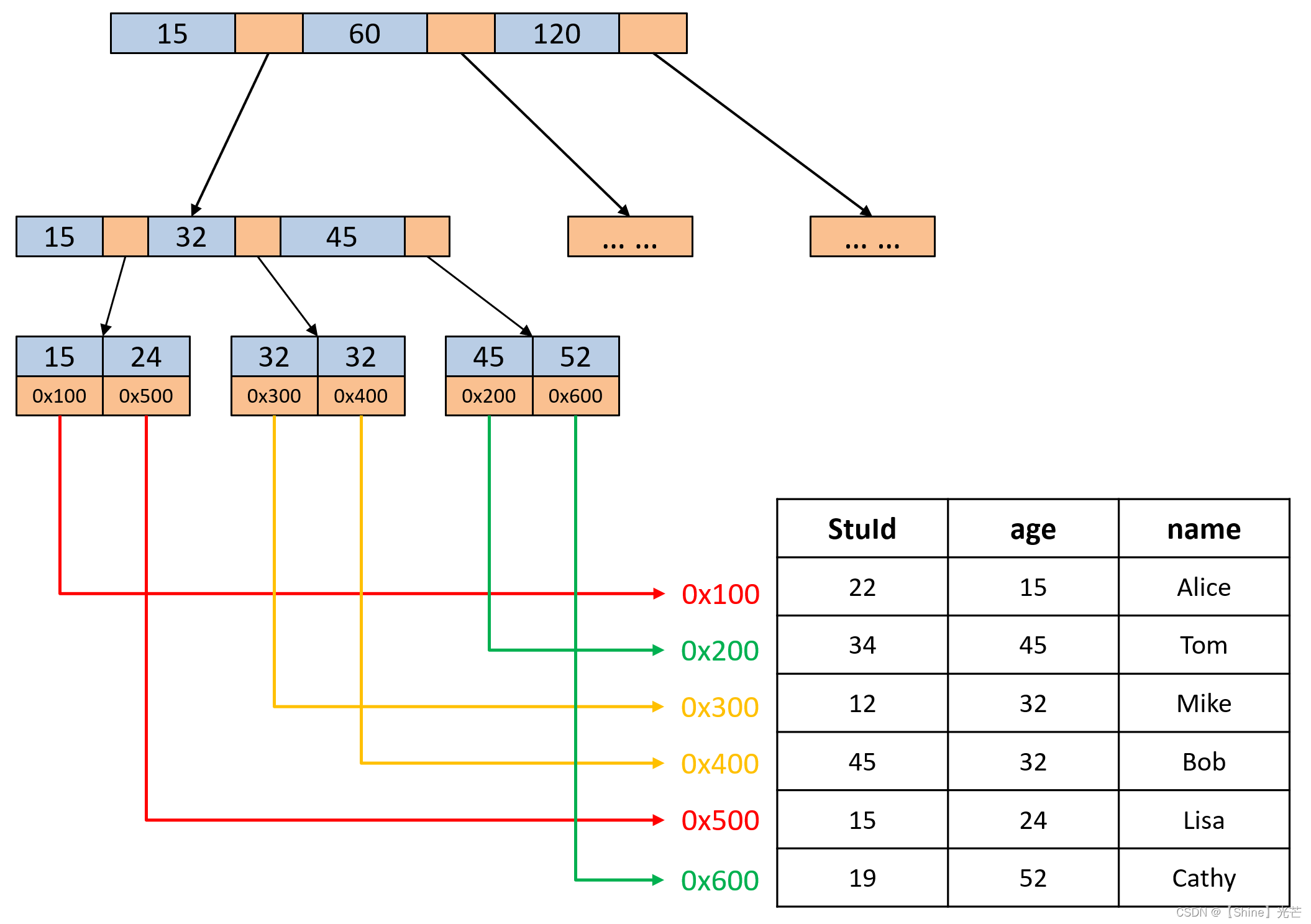
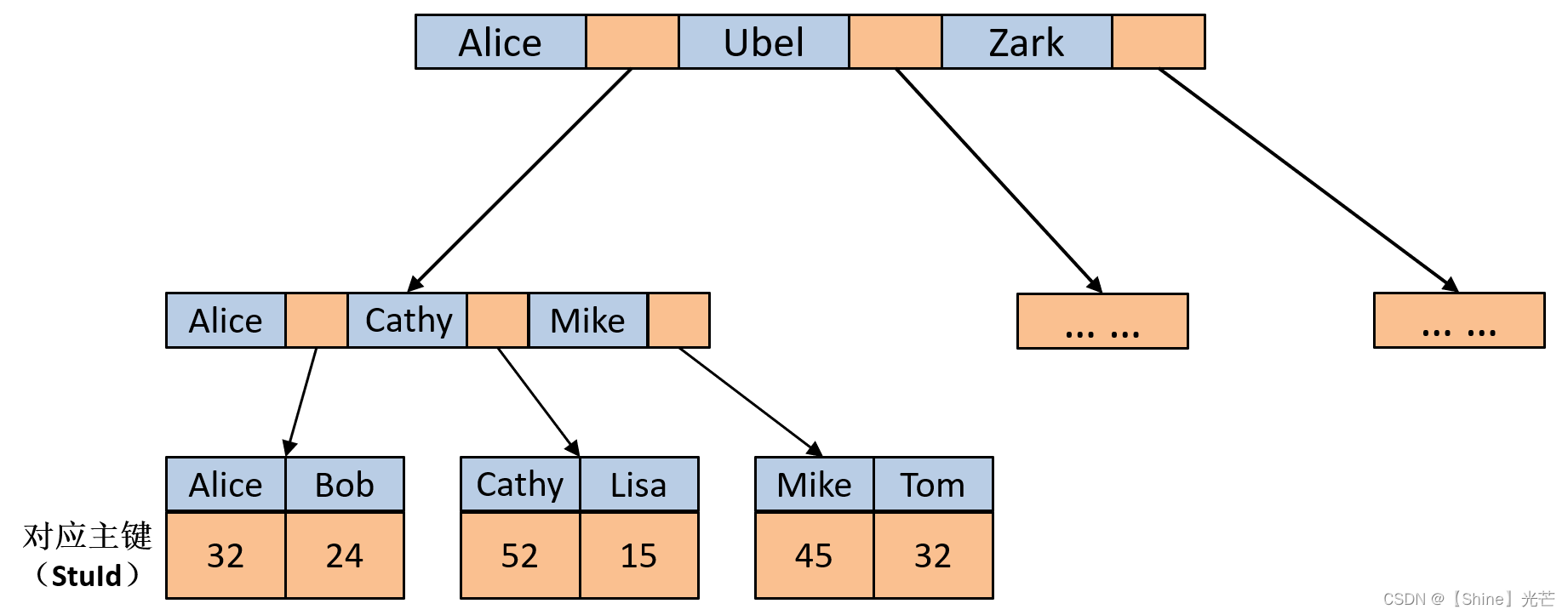
在早期的MySQL数据库中,所使用的搜索引擎都是MyISAM,这种搜索引擎不支持事务,支持全文索引,其使用的数据结构是B+树。在MyISAM搜索引擎中,叶子节点中的data域存储的是数据在磁盘中的地址,而不是数据本身。如图5.1所示的学生信息管理数据库,要记录学生的学号(StuId)、年龄(age)以及姓名,B+树用于检索,图5.1中选取的主键为StuId。
在绝大部分数据库中,一般要求加入到数据库中的数据要有一个主键,并且主键是不允许出现重复的。就以图5.1所示的学生信息管理系统为例,选取学号能保证每个学生之间的学号不重复,而姓名和年龄则不可避免的出现重复,那么就应当选取学号作为主键。如果没有一个合适的参数作为主键,那么可以采用自增主键,自增主键实际就是一个常数,第一次插入的数据常数1为主键,第二次插入的数据常数2为主键,以此类推。

以图如果用户通过主键索引查找数据库中的相关信息,那么就会对B树进行检索,直到检索到叶子节点发现匹配项或者确认数据库中没有对应主键即可。如果使用非主键(未建立辅助索引)的参数进行检索,那么进行的操作是全表扫描查找匹配项。
对于MySQL数据库,我们处理使用主键建立主索引之外,还可以建立辅助索引,主索引不允许出现重复项,而辅助索引允许出现重复项,如图5.2所示,就是通过学生年龄age建立的学生数据库的辅助索引。
5.3 InnoDB
现在高版本的MySQL数据库,全部采用InnoDB为搜索引擎,InnoDB是面向在线事务处理的应用,支持B+树索引、哈希索引、全文索引等。但是,InnoDB使用B+树支持索引的实现方式与MyISAM却有着很大的不同。
InnoDB文件本身就是索引文件的一部分。在InnoDB的中,B+树的叶子节点要存放表的全部数据,数据库中的数据,要按照主键从小到大的顺序排列起来。如图5.3所示,InnoDB的叶子节点中要包含所有的数据记录,这种索引叫做聚集索引。由于InnoDB数据文件本身要按照主键来聚集,因此InnoDB必须有主键,而MyISAM则可以没有主键。

InnoDB建立B+树辅助索引,叶子节点的数据域中记录的并不是数据数据文件本身的内容,而是对应的主键,如图5.4所示,在InnoDB索引方式下,建立对于name的辅助索引,叶子结点数据域就存储了对应的StdId(学号),使用辅助索引检索时,先拿到对应的主键,再通过主索引查找内容,这样就相当于要检索两次。
六. 总结
- 常见的搜索结构有哈希、二分、顺序查找、平衡二叉树等,这些数据结构和算法都只适用于内查找。
- 对于海量数据,内存中无法容纳,应当使用B树/B+树来进行检索,B/B+树是高效的外查找专用数据结构。
- MySQL数据库的检索主要是通过B+树来进行的,有MyISAM和InnoDB两种检索方式,MyISAM的B+树的叶子节点的数据域中存储的是数据文件在磁盘中的地址,InnoDB的B+树的叶子节点中数据域存放的是数据文件本身。
- B+树做外查找时,B+树本身存储在磁盘中。
相关文章:
C++数据结构:B树
目录 一. 常见的搜索结构 二. B树的概念 三. B树节点的插入和遍历 3.1 插入B树节点 3.2 B树遍历 四. B树和B*树 4.1 B树 4.2 B*树 五. B树索引原理 5.1 索引概述 5.2 MyISAM 5.3 InnoDB 六. 总结 一. 常见的搜索结构 表示1为在实际软件开发项目中,常用…...

【07】ES6:对象的扩展
一、对象字面量语法扩展 1、属性简写 当属性名称和属性值的变量名称相同时,可以省略冒号的变量名称。 const foo barconst baz { foo } // 等同于 const baz { foo: foo }baz // { foo: bar }function f(x, y) {return { x, y } } // 等同于 function f(x, y)…...
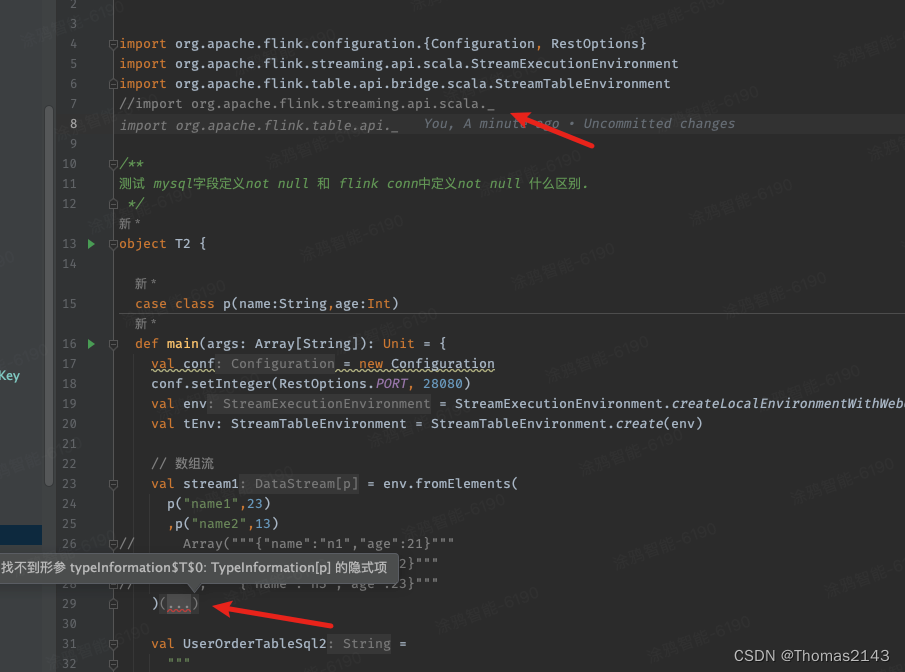
flink找不到隐式项
增加 import org.apache.flink.streaming.api.scala._ 即可...

【网络编程】-- 04 UDP
网络编程 6 UDP 6.1 初识Tomcat 服务端 自定义 STomcat S 客户端 自定义 C浏览器 B 6.2 UDP 6.2.1 udp实现发送消息 接收端: package com.duo.lesson03;import java.net.DatagramPacket; import java.net.DatagramSocket; import java.net.SocketExceptio…...

【脚本】图片-音视频-压缩文件处理
音视频处理 一,图片操作1,转换图片格式2,多张图片合成视频 二,音频操作1,转换音频格式2,分割音频为多段3,合成多段音频 三,视频操作1,转换视频格式2,提取视频…...

跨品牌的手机要怎样相互投屏?iPhone和iPad怎么相互投屏?
选择买不同品牌的手机是基于品牌声誉、产品特点、价格和性价比等多个因素的综合考虑。每个人的需求和偏好不同,选择适合自己的手机品牌是一个个人化的决策。 一些品牌可能更加注重摄影功能,而其他品牌可能更加注重性能和速度。选择不同品牌的手机可以根据…...
图像特征提取-角点
角点特征 大多数人都玩过拼图游戏。首先拿到完整图像的碎片,然后把这些碎片以正确的方式排列起来从而重建这幅图像。如果把拼图游戏的原理写成计算机程序,那计算机就也会玩拼图游戏了。 在拼图时,我们要寻找一些唯一的特征,这些…...
N26:构建无缝体验的平台工程之路-Part 2
在第一部分,我们介绍了 N26 团队为达成 “在 Day 1 实现轻松部署” 的目标而设定的战略规划和开发人员体验图,在这一部分,我们将带您了解该团队如何构建最简可行平台以及该平台如何运作。 01 计划构建最简可行平台 我们通…...

【Hadoop-Distcp】通过Distcp的方式进行两个HDFS集群间的数据迁移
【Hadoop-Distcp】通过Distcp的方式进行两个HDFS集群间的数据迁移 1)Distcp 工具简介及参数说明2)Shell 脚本 1)Distcp 工具简介及参数说明 【Hadoop-Distcp】工具简介及参数说明 2)Shell 脚本 应用场景: 两个实时集…...
【Linux】使用Bash和GNU Parallel并行解压缩文件
介绍 在本教程中,我们将学习如何使用Bash脚本和GNU Parallel实现高效并行解压缩多个文件。这种方法在处理大量文件时可以显著加快提取过程。 先决条件 确保系统上已安装以下内容: BashGNU Parallel 你可以使用以下命令在不同Linux系统上安装它们&am…...

T天池SQL训练营(五)-窗口函数等
–天池龙珠计划SQL训练营 5.1窗口函数 5.1.1窗口函数概念及基本的使用方法 窗口函数也称为OLAP函数。OLAP 是OnLine AnalyticalProcessing 的简称,意思是对数据库数据进行实时分析处理。 为了便于理解,称之为窗口函数。常规的SELECT语句都是对整张表进…...

道可云元宇宙每日资讯|上海市区块链关键技术攻关专项项目立项清单公布
道可云元宇宙每日简报(2023年12月11日)讯,今日元宇宙新鲜事有: 上海市2023年度区块链关键技术攻关专项项目立项清单公布 据上海市科学技术委员会近日发布通知,上海市2023年度“科技创新行动计划”区块链关键技术攻关…...

大语言模型有什么意义?亚马逊训练自己的大语言模型有什么用?
近年来,大语言模型的崭露头角引起了广泛的关注,成为科技领域的一项重要突破。而在这个领域的巅峰之上,亚马逊云科技一直致力于推动人工智能的发展。那么,作为一家全球科技巨头,亚马逊为何会如此注重大语言模型的研发与…...
RabbitMQ-学习笔记(初识 RabbitMQ)
本篇文章学习于 bilibili黑马 的视频 (狗头保命) 同步通讯 & 异步通讯 (RabbitMQ 的前置知识) 同步通讯:类似打电话,只有对方接受了你发起的请求,双方才能进行通讯, 同一时刻你只能跟一个人打视频电话。异步通讯:类似发信息,…...

SQL Update语句
SQL Update语句 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! SQL Update语句:数据库操作高招解析 数据库是我们搭建查券返利机器人的重要组成部分&…...

C语言-WIN32API介绍
Windows API 从第一个32位的Windows开始就出现了,就叫做Win32API.它是一个纯C的函数库,就和C标准库一样,使你可以写Windows应用程序过去很多Windows程序是用这个方式做出来的 main()? main()成为C语言的入口函数其实和C语言本身无关&…...

TFIDF、BM25、编辑距离、倒排索引
TFIDF TF刻画了词语t对某篇文档的重要性,IDF刻画了词语t对整个文档集的重要性...
MySQL之DML语句
文章目录 DML语句创建表添加表字段**插入数据**查询数据更新数据替换数据删除数据清除表数据删除表 DML语句 数据操作语言DML(Data Manipulation Langua) 是SQL语言的一个分类,用于对表的数据进行增,删,改,…...

kubernetes集群常用指令
目录 1.1 基础控制指令 1.2 命令实践 1.3 备注 1.1 基础控制指令 # 查看对应资源: 状态 $ kubectl get <SOURCE_NAME> -n <NAMESPACE> -o wide # 查看对应资源: 事件信息 $ kubectl describe <SOURCE_NAME> <SOURCE_NAME_RANDOM_ID> -n <NAMES…...

PyQt6 QTreeView树视图
锋哥原创的PyQt6视频教程: 2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili QTreeView类,它是树控件的基类,使用时,必须为其提供一个模型来与之配合。 QTreeView类的常用方法: 方法…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...
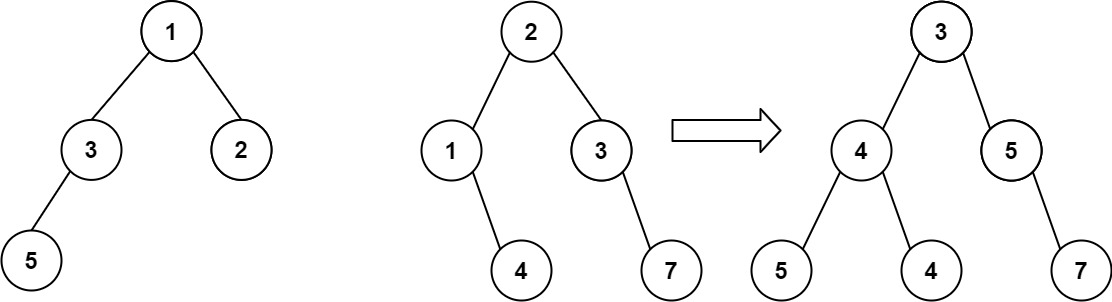
算法打卡第18天
从中序与后序遍历序列构造二叉树 (力扣106题) 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入:inorder [9,3,15,20,7…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...

Pydantic + Function Calling的结合
1、Pydantic Pydantic 是一个 Python 库,用于数据验证和设置管理,通过 Python 类型注解强制执行数据类型。它广泛用于 API 开发(如 FastAPI)、配置管理和数据解析,核心功能包括: 数据验证:通过…...
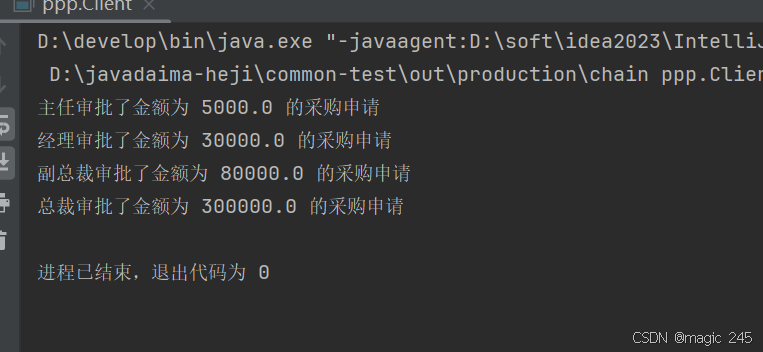
Java设计模式:责任链模式
一、什么是责任链模式? 责任链模式(Chain of Responsibility Pattern) 是一种 行为型设计模式,它通过将请求沿着一条处理链传递,直到某个对象处理它为止。这种模式的核心思想是 解耦请求的发送者和接收者,…...