<蓝桥杯软件赛>零基础备赛20周--第9周--前缀和与差分
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集
20周的完整安排请点击:20周计划
每周发1个博客,共20周(读者可以按自己的进度选“正常”和“快进”两种计划)。
每周3次集中答疑,周三、周五、周日晚上,在QQ群上答疑:

文章目录
- 1. 前缀和概念
- 2. 前缀和例题
- 例1 基本应用
- 例2 基本应用
- 例3 异或的前缀和
- 例4 二维前缀和
- 3. 差分
- 4. 差分例题
- 例5 差分的基本应用
- 例6 差分的基本应用
第9周: 前缀和与差分
1. 前缀和概念
前缀和是一种操作简单但是非常有效的优化方法,能把计算复杂度为O(n)的区间计算优化为O(1)的端点计算。
前缀和是出题者喜欢考核的知识点,在算法竞赛中很常见,在蓝桥杯大赛中几乎必考。原因有两点:
一是简单,方便在很多场景下应用,与其他考点结合;
二是可以考核不同层次的能力,例如一道题用暴力法能通过30%的测试,用前缀和优化后能通过70%~100%的测试。
首先了解“前缀和”的概念。一个长度为n的数组a[1] ~ a[n],前缀和sum[i]等于a[1] ~ a[i]的和:
sum[i] = a[1] + a[2] + … + a[i]
利用递推,可以在O(n)时间内求得所有前缀和:
sum[i] = sum[i-1] + a[i]
如果预计算出前缀和,就能利用它快速计算出数组中任意一个区间a[i] ~ a[j]的和。即:
a[i] + a[i+1] + … + a[j-1] + a[j] = sum[j] - sum[i-1]
上式说明,复杂度为O(n)的区间求和计算,优化到了O(1)的前缀和计算。
2. 前缀和例题
前缀和是一种很简单的优化技巧,应用场合很多,在竞赛中极为常见。如果建模时发现有区间求和操作,可以考虑使用前缀和优化。
例1 基本应用
例题1 求和
题解:这是一道非常直白的前缀和题。为了说明前缀和的作用,下面用两种方法求解本题。
(1)通过30%的测试。直接按题意两两相乘然后求和,这是暴力法。
如果用C++编程,需要考虑S是否能用long long类型表示。若每个ai都是最大的1000,每两个相乘等于106,n个数两两相乘,共 n 2 / 2 = 20000 0 2 / 2 = 2 × 1 0 10 n^2/2 = 200000^2/2 = 2×10^{10} n2/2=2000002/2=2×1010次,和S约为 2 × 1 0 10 × 1 0 6 = 2 × 1 0 16 2×10^{10}×10^6 = 2×10^{16} 2×1010×106=2×1016。long long能表示的最大正整数远大于 2 × 1 0 16 2×10^{16} 2×1016,所以不需要用高精度处理大数。
#include<bits/stdc++.h>
using namespace std;
int main() {int n; cin >> n; // 读取nvector<int> a(n); //用vector定义数组a[]for (int i = 0; i < n; i++) cin >> a[i]; // 读取a[]int s = 0;for (int i = 0; i < n; i++) // 用两个for循环计算两两相乘,然后求和for (int j = i + 1; j < n; j++)s += a[i] * a[j];cout << s << endl;return 0;
}
下面分析代码的时间和空间效率。
1)时间复杂度。代码执行了多少步骤?花了多少时间?
代码第8、9行有2层for循环,循环次数是: n − 1 + n − 2 + . . . + 1 ≈ n 2 / 2 n-1 + n-2 + ... +1 ≈ n^2/2 n−1+n−2+...+1≈n2/2,计算复杂度为 O ( n 2 ) O(n^2) O(n2)。
对于30%的测试数据,n = 1000,循环次数$1000^2/2 = 50,000。计算时间远远小于题目的时间限制1s,能够通过测试。
对于100%的测试数据,n = 200000,循环次数$200000 2 / 2 = 2 × 1 0 10 2/2 = 2×10^{10} 2/2=2×1010。计算时间远大于题目的时间限制1s,超时不能通过测试。
2)空间复杂度,也就是程序占用的内存空间。对于100%的数据,若用数组int a[200000]存储数据,int是32位整数,占用4个字节,所以int a[200000]共使用了800K空间,远小于题目的空间限制256MB。
(2)通过100%测试。本题利用前缀和,能得到100%的分数。
把计算式子变换为:
S = ( a 1 + a 2 + . . . + a n − 1 ) × a n + ( a 1 + a 2 + . . . + a n − 2 ) × a n − 1 + ( a 1 + a 2 + . . . + a n − 3 ) × a n − 2 + . . . + ( a 1 + a 2 ) × a 3 + a 1 × a 2 S=(a_1+a_2 +...+a_{n-1})×a_n+(a_1+a_2 +...+a_{n-2})×a_{n-1}+(a_1+a_2+...+a_{n-3})×a_{n-2}+...+(a_1+a_2)×a_3+a_1×a_2 S=(a1+a2+...+an−1)×an+(a1+a2+...+an−2)×an−1+(a1+a2+...+an−3)×an−2+...+(a1+a2)×a3+a1×a2
其中括号内的部分是前缀和 s u m [ i ] = a 1 + a 2 + … + a i sum[i] = a_1+a_2+…+ a_i sum[i]=a1+a2+…+ai,把上式改为:
S = s u m [ n − 1 ] × a n + s u m [ n − 2 ] × a n − 1 + s u m [ n − 3 ] × a n − 2 + . . . + s u m [ 2 ] × a 3 + s u m [ 1 ] × a 2 S = sum[n-1] ×a_n + sum[n-2]×a_{n-1} + sum[n-3]×a_{n-2} + ... + sum[2]×a_3 + sum[1]×a_2 S=sum[n−1]×an+sum[n−2]×an−1+sum[n−3]×an−2+...+sum[2]×a3+sum[1]×a2
式子中用到的前缀和sum[1] ~ sum[n-1],用递推公式sum[i] = sum[i-1] + a[i]做一次for循环就能全部提前计算出来。
下面的C++代码第8行先预计算出前缀和sum[],然后利用sum[]求S。
#include<bits/stdc++.h>
using namespace std;
int main() {int n; cin >> n; //读nvector<int> a(n+1,0); //定义数组a[],并初始化为0for (int i=1; i<=n; i++) cin >> a[i]; // 读a[1]~a[n]vector<long long> sum(n+1, 0); //定义前缀和数组 sum[],并初始化为0for (int i=1; i<n; i++) sum[i]=a[i]+sum[i-1]; // 预计算前缀和sum[1]~sum[n-1]long long s = 0; for (int i=1; i<n; i++) s += sum[i]*a[i+1]; // 计算和scout << s << endl;return 0;
}
代码的计算量是多少?第8、10行各有一层for循环,分别计算n次,也就是两个O(n),合起来仍然是O(n)的。对于100%的数据,n = 200000,运行时间满足时间限制。
java代码
import java.util.Scanner;
public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int n = scanner.nextInt(); // 读nint[] a = new int[n+1]; // 定义数组a[],并初始化为0for (int i=1; i<=n; i++) a[i] = scanner.nextInt(); // 读取a[1]~a[n] long[] sum = new long[n+1]; // 定义前缀和数组 sum[],并初始化为0for (int i=1; i<n; i++) sum[i]=a[i]+sum[i-1]; // 预计算前缀和sum[1]~sum[n-1]long s = 0;for (int i=1; i<n; i++) s+=sum[i]*a[i+1]; // 计算和s System.out.println(s);}
}
python代码
n = int(input())
a = [0]+[int(i) for i in input().split()] #读入a[1]~a[n]。a[0]不用
sum = [0] * (n+1) #定义前缀和
sum[1] = 0
for i in range(1,n): sum[i] = a[i]+sum[i-1] #预计算前缀和sum[1]~sum[n-1]
s = 0
for i in range(1,n): s += sum[i]*a[i+1] #计算和s
print(s)
例2 基本应用
可获得的最小取值
第一步肯定是排序,例如从小到大排序,然后再进行两种操作。操作(1)在a[]的尾部选一个数,操作(2)在a[]的头部选2个数。
容易想到一种简单方法:每次在操作(1)和操作(2)中选较小的值。这是贪心法的思路。但是贪心法对吗?分析之后发现贪心法是错误的,例如{3, 1, 1, 1, 1, 1, 1},做k=3次操作,每次都按贪心法,做3次操作(2),结果是6。但是正确答案是做3次操作(1),结果是5。
回头重新考虑所有可能的情况。设操作(2)做p次,操作(1)做k-p次,求和:
∑ i = 1 2 p a i + ∑ i = n + p − k + 1 n a i \sum_{i=1}^{2p}a_i+\sum_{i={n+p-k+1}}^{n}a_i ∑i=12pai+∑i=n+p−k+1nai
为了找最小的和,需要把所有的p都试一遍。如果直接按上面的公式计算,那么验证一个p的计算量是O(n)的,验证所有的p,1≤p≤k,总计算量O(kn),超时。
容易发现公式的两个部分就是前缀和,分别等于sum[2p]、sum[n]-sum[n+p-k]。如果提前算出前缀和sum[],那么验证一个p的时间是O(1)的,验证所有p的总计算量是O(n)的。
下面是C++代码。注意sum[]需要用long long类型。
代码的计算复杂度,第10行sort()是O(nlogn),第13行是O(n),总复杂度为O(nlogn)。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 200010;
long long a[N],s[N]; //s[]是a[]的前缀和
int main(){int n, k; cin >> n >> k;for (int i = 1; i <= n; i++) scanf("%lld",&a[i]);sort(a + 1, a + 1 + n);for (int i = 1; i <= n; i++) s[i] = s[i-1]+ a[i];ll ans = 1e18;for (int p = 1; p <= k; p++)ans = min(s[n] - s[n+p-k] + s[2*p], ans);printf("%lld",ans);return 0;
}
java代码
import java.util.Arrays;
import java.util.Scanner;
public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int n = scanner.nextInt();int k = scanner.nextInt();long[] a = new long[n+1];for (int i = 1; i <= n; i++) a[i] = scanner.nextLong(); Arrays.sort(a, 1, n+1);long[] s = new long[n+1];for (int i = 1; i <= n; i++) s[i] = s[i-1] + a[i]; long ans = (long)1e18;for (int p = 1; p <= k; p++)ans = Math.min(s[n] - s[n+p-k] + s[2*p], ans); System.out.println(ans);}
}
Python代码
n, k = map(int, input().split())
b = list(map(int, input().split()))
a=[0] + sorted(b) # a[0]不用,从a[1]开始
s = [0] * (n+1)
for i in range(1, n+1): s[i] = s[i-1] + a[i]
ans = 10**18
for p in range(1, k+1):ans = min(s[n] - s[n+p-k] + s[2*p], ans)
print(ans)
例3 异或的前缀和
下面例题是前缀和在异或计算中的应用,也是常见的应用场景。
异或和之和
n个数 a 1 − a n a_1-a_n a1−an的异或和等于: a 1 ⊕ a 2 ⊕ . . . ⊕ a n a_1⊕a_2⊕...⊕a_n a1⊕a2⊕...⊕an。
(1)通过30%的测试。
本题的简单做法是直接按题意计算所有子段的异或和,然后加起来。
有多少个子段?
长度为1的子段异或和有n个: a 1 、 a 2 、 . . . 、 a n a_1、a_2、...、a_n a1、a2、...、an
长度为2的子段异或和有n-1个: a 1 ⊕ a 2 、 a 2 ⊕ a 3 、 . . . a n − 1 ⊕ a n a_1⊕a_2、a_2⊕a_3、...a_{n-1}⊕a_n a1⊕a2、a2⊕a3、...an−1⊕an
…
长度为n的子段异或和有1个: a 1 ⊕ a 2 ⊕ a 3 ⊕ . . . ⊕ a n − 1 ⊕ a n a_1⊕a_2⊕a_3⊕...⊕a_{n-1}⊕a_n a1⊕a2⊕a3⊕...⊕an−1⊕an
共 n 2 / 2 n^2/2 n2/2个子段。
下面代码第8、9行遍历所有的子段[L, R],第11行求[L,R]的字段和。共3重for循环,计算复杂度 O ( n 3 ) O(n^3) O(n3),只能通过30%的测试。
#include<bits/stdc++.h>
using namespace std;
int main(){int n; cin >> n;vector<int> a(n); //用vector定义数组a[]for (int i = 0; i < n; i++) cin >> a[i];long long ans=0; //注意这里用long longfor(int L=0;L<n;L++) //遍历所有区间[L,R]for(int R=L;R<n;R++){int sum=0;for(int i=L;i<=R;i++) sum^=a[i]; //子段和ans += sum; //累加所有子段和}cout<<ans;return 0;
}
(2)通过60%的测试。本题可以用前缀和优化。
记异或和 a 1 ⊕ a 2 ⊕ . . . ⊕ a i a_1⊕a_2⊕...⊕a_i a1⊕a2⊕...⊕ai的前缀和为:
s i = a 1 ⊕ a 2 ⊕ . . . ⊕ a i si=a_1⊕a_2⊕...⊕a_i si=a1⊕a2⊕...⊕ai
这里 s i s_i si是异或形式的前缀和。这样就把复杂度为O(n)的子段异或和计算 a 1 ⊕ a 2 ⊕ . . . ⊕ a i a_1⊕a_2⊕...⊕a_i a1⊕a2⊕...⊕ai,优化到了O(1)的求 s i s_i si的计算。
以包含 a 1 a1 a1的子段为例,这些子段的异或和相加,等于:
a 1 + a 1 ⊕ a 2 + . . . + a 1 ⊕ . . . ⊕ a i + . . . + a 1 ⊕ . . . ⊕ a n = s 1 + s 2 + . . . + s i + . . . + s n a_1+a_1⊕a_2+...+a_1⊕...⊕a_i+...+a_1⊕...⊕a_n = s_1+s_2+...+s_i+...+s_n a1+a1⊕a2+...+a1⊕...⊕ai+...+a1⊕...⊕an=s1+s2+...+si+...+sn
前缀和的计算用递推得到。普通前缀和的递推公式为 s [ i ] = s [ i − 1 ] + a [ i ] s[i] = s[i-1] + a[i] s[i]=s[i−1]+a[i],异或形式的前缀和递推公式为s[i] = s[i-1] ^ a[i],下面代码第11行用这个公式的简化形式求解了前缀和。
代码的计算复杂度是多少?第8行和第10行用两重循环遍历所有的子段,同时计算前缀和,计算复杂度是 O ( n 2 ) O(n^2) O(n2)的,可以通过60%的测试。
#include<bits/stdc++.h>
using namespace std;
int main(){int n; cin >> n;vector<int> a(n);for (int i = 0; i < n; i++) cin >> a[i];long long ans = 0;for (int L = 0; L < n; L++) {long sum = 0; //sum是包含a[L]的子段的前缀和for (int R = L ; R < n; R++) {sum ^= a[R]; //用递推求前缀和sumans += sum; //累加所有子段和}}cout << ans << endl;return 0;
}
(3)通过100%的测试。
本题有没有进一步的优化方法?这就需要仔细分析异或的性质了。根据异或的定义,有a⊕a = 0、0⊕a = a、0⊕0 = 0。推导子段 a i a j a_i ~ a_j ai aj的异或和:
a i ⊕ a i + 1 ⊕ . . . ⊕ a j − 1 ⊕ a j = ( a 1 ⊕ a 2 ⊕ . . . ⊕ a i − 1 ) ⊕ ( a 1 ⊕ a 2 ⊕ . . . ⊕ a j ) a_i⊕a_{i+1}⊕...⊕a_{j-1}⊕a_j = (a_1⊕a_2⊕...⊕a_{i-1}) ⊕ (a_1⊕a_2⊕...⊕a_j) ai⊕ai+1⊕...⊕aj−1⊕aj=(a1⊕a2⊕...⊕ai−1)⊕(a1⊕a2⊕...⊕aj)
记 s i = a 1 ⊕ a 2 ⊕ . . . ⊕ a i s_i = a_1⊕a_2⊕...⊕a_i si=a1⊕a2⊕...⊕ai,这是异或形式的前缀和。上式转化为:
a i ⊕ a i + 1 ⊕ . . . ⊕ a j − 1 ⊕ a j = s i − 1 ⊕ s j a_i⊕a_{i+1}⊕...⊕a_{j-1}⊕a_j = s_{i-1}⊕s_j ai⊕ai+1⊕...⊕aj−1⊕aj=si−1⊕sj
若 s i − 1 = s j s_{i-1} = s_j si−1=sj,则 s i − 1 ⊕ s j = 0 s_{i-1}⊕s_j = 0 si−1⊕sj=0;若 s i − 1 ≠ s j s_{i-1} ≠ s_j si−1=sj,则 s i − 1 ⊕ s j = 1 s_{i-1}⊕s_j =1 si−1⊕sj=1。题目要求所有子段异或和相加的结果,这等于判断所有的 s i , s j {s_i, s_j} si,sj组合,若 s i ≠ s j s_i ≠ s_j si=sj,则结果加1。
如何判断两个s是否相等?可以用位操作的技巧,如果它们的第k位不同,则两个s肯定不等。下面以 a 1 = 011 , a 2 = 010 a_1 = 011,a_2 = 010 a1=011,a2=010为例,分别计算第k位的异或和,并且相加:
k=0,第0位异或和, s 1 = 1 , s 2 = 1 ⊕ 0 = 1 , a n s 0 = a 1 + a 2 + a 1 ⊕ a 2 = s 1 + s 1 ⊕ s 2 + s 2 = 1 + 0 + 1 = 2 s_1=1,s_2=1⊕0=1,ans_0 = a_1+a_2+a_1⊕a_2 = s_1+s_1⊕s_2+s_2 = 1+0+1=2 s1=1,s2=1⊕0=1,ans0=a1+a2+a1⊕a2=s1+s1⊕s2+s2=1+0+1=2
k=1,第1位异或和, s 1 = 1 , s 2 = 1 ⊕ 1 = 0 , a n s 1 = a 1 + a 2 + a 1 ⊕ a 2 = s 1 + s 1 ⊕ s 2 + s 2 = 1 + 1 + 0 = 2 s_1=1,s_2=1⊕1=0,ans_1 = a_1+a_2+a_1⊕a_2 = s_1+s_1⊕s_2+s_2 = 1+1+0=2 s1=1,s2=1⊕1=0,ans1=a1+a2+a1⊕a2=s1+s1⊕s2+s2=1+1+0=2
k=2,第2位异或和, s 1 = 0 , s 2 = 0 ⊕ 0 = 0 , a n s 2 = a 1 + a 2 + a 1 ⊕ a 2 = s 1 + s 1 ⊕ s 2 + s 2 = 0 + 0 + 0 = 0 s_1=0,s_2=0⊕0=0,ans_2 = a_1+a_2+a_1⊕a_2 = s_1+s_1⊕s_2+s_2 = 0+0+0=0 s1=0,s2=0⊕0=0,ans2=a1+a2+a1⊕a2=s1+s1⊕s2+s2=0+0+0=0
最后计算答案: a n s = a n s 0 × 2 0 + a n s 1 × 2 1 + a n s 2 × 2 2 = 6 ans = ans_0 ×2^0+ ans_1×2^1 + ans_2×2^2 = 6 ans=ans0×20+ans1×21+ans2×22=6。
本题 0 ≤ A i ≤ 2 20 0≤A_i≤2^{20} 0≤Ai≤220,所有的前缀和s都不超过20位。代码第8行逐个计算20位的每一位,第11行for循环计算n个前缀和,总计算量约为20×n。
#include<bits/stdc++.h>
using namespace std;
int main() {int n; cin >> n;vector<int> a(n);for (int i = 0; i < n; i++) cin >> a[i];long long ans = 0;for(int k=0;k<=20;k++){ //所有a不超过20位int zero=1,one=0; //统计第k位的0和1的数量long long cnt=0,sum=0; //cnt用于统计第k位有多少对si⊕sj =1for(int i=0;i<n;i++){int v=(a[i]>>k)&1; //取a[i]的第k位sum ^= v; //对所有a[i]的第k位做异或得到sum,sum等于0或者1if(sum==0){ //前缀和为0zero++; //0的数量加1cnt += one; //这次sum=0,这个sum跟前面等于1的sum异或得1}else{ //前缀异或为1one++; //1的数量加1cnt += zero; //这次sum=1,这个sum跟前面等于0的sum异或得1}}ans += cnt*(1ll<<k); //第k位的异或和相加}cout<<ans;return 0;
}
java代码
import java.util.Scanner;
public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int n = scanner.nextInt();int[] a = new int[n];for (int i = 0; i < n; i++) a[i] = scanner.nextInt(); long ans = 0;for (int k = 0; k <= 20; k++) { // 所有a不超过20位int zero = 1, one = 0; // 统计第k位的0和1的数量long cnt = 0, sum = 0; //cnt用于统计第k位有多少对si⊕sj =1for (int i = 0; i < n; i++) {int v = (a[i] >> k) & 1; // 取a[i]的第k位sum ^= v; // 对所有a[i]的第k位做异或得到sum,sum等于0或者1if (sum == 0) { // 前缀和为0zero++; // 0的数量加1cnt += one; // 这次sum=0,这个sum跟前面等于1的sum异或得1} else { // 前缀异或为1one++; // 1的数量加1cnt += zero; // 这次sum=1,这个sum跟前面等于0的sum异或得1}}ans += cnt * (1L << k); // 第k位的异或和相加}System.out.println(ans);}
}
Python代码
n = int(input())
a = [int(x) for x in input().split()]
ans = 0
for k in range(21): # 所有a不超过20位zero, one = 1, 0 # 统计第k位的0和1的数量cnt, sum = 0, 0 #cnt用于统计第k位有多少对si⊕sj =1for i in range(n):v = (a[i] >> k) & 1 # 取a[i]的第k位sum ^= v # 对所有a[i]的第k位做异或得到sum,sum等于0或者1if sum == 0: # 前缀和为0zero += 1 # 0的数量加1cnt += one # 这次sum=0,这个sum跟前面等于1的sum异或得1else: # 前缀异或为1one += 1 # 1的数量加1cnt += zero # 这次sum=1,这个sum跟前面等于0的sum异或得1ans += cnt * (1 << k) # 第k位的异或和相加
print(ans)
例4 二维前缀和
前面的例子都是一位数组上的前缀和,下面介绍二维数组上的前缀和。
例题:领地选择
概况题意:在n×m 的矩形中找一个边长为c的正方形,把正方形内所有坐标点的值相加,使价值最大。
简单的做法是枚举每个坐标,作为正方形左上角,然后算出边长c内所有地块的价值和,找到价值和最高的坐标。时间复杂度 O ( n × m × c 2 ) O(n×m×c^2) O(n×m×c2),能通过60%的测试。请读者练习。
本题是二维前缀和的直接应用。
一维前缀和定义在一维数组a[]上:sum[i] = a[1] + a[2] + … + a[i]
把一维数组a[]看成一条直线上的坐标,前缀和就是所有坐标值的和。

二维前缀和是一维前缀和的推广。设二维数组a[][]有1~n行,1~m列,二维前缀和:
sum[i][j] = a[1][1]+a[1][2]+a[1][3]+…+a[1][j]
+ a[2][1]+a[2][2]+a[2][3]+…+a[2][j]
+ …
+ a[i][1]+a[i][2]+a[i][3]+…+a[i][j]
把a[i][j]的(i,j)看成二维平面的坐标,那么sum[i][j]就是左下角坐标(1,1)和右上角坐标(i,j)围成的方形中所有坐标点的和。

二维前缀和sum[][]存在以下递推关系:
sum[i][j] = sum[i-1][j]+sum[i][j-1]-sum[i-1][j-1]+a[i][j]
根据这个递推关系,用两种for循环可以算出sum[][]。
对照上图理解这个公式,sum[i-1][j]是坐标(1,1) ~ (i-1, j)内所有的点,sum[i][j-1]是(1,1) ~ (i, j-1)内所有的点,两者相加,其中sum[i-1][j-1]被加了两次,所以要减去一次。
C++代码
#include<bits/stdc++.h>
using namespace std;
const int N=1005;
int a[N][N],s[N][N];
int main() {int n,m,c; cin>>n>>m>>c;for(int i=1;i<=n;i++)for(int j=1;j<=m;j++){cin >> a[i][j];s[i][j] = s[i-1][j]+s[i][j-1]-s[i-1][j-1]+a[i][j];}int Max = -1<<30, x, y;for(int x1=1;x1<=n-c+1;x1++)for(int y1=1;y1<=m-c+1;y1++){ //枚举所有坐标点int x2=x1+c-1,y2=y1+c-1; //正方形右下角坐标int ans = s[x2][y2]-s[x2][y1-1]-s[x1-1][y2]+s[x1-1][y1-1];if(ans > Max){Max = ans;x=x1, y=y1;}}cout<<x<<" "<<y<<"\n";return 0;
}
Java代码。sum[][]和a[][]可以共用,从而节省一半空间。
import java.util.Scanner;
public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int n = scanner.nextInt();int m = scanner.nextInt();int c = scanner.nextInt();int[][] a = new int[n + 1][m + 1];for (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {a[i][j] = scanner.nextInt();a[i][j] = a[i - 1][j] + a[i][j - 1] - a[i - 1][j - 1] + a[i][j];}}int Max = Integer.MIN_VALUE;int x = 0;int y = 0;for (int x1 = 1; x1 <= n - c + 1; x1++) {for (int y1 = 1; y1 <= m - c + 1; y1++) {int x2 = x1 + c - 1;int y2 = y1 + c - 1;int ans = a[x2][y2] - a[x2][y1 - 1] - a[x1 - 1][y2] + a[x1 - 1][y1 - 1];if (ans > Max) {Max = ans;x = x1;y = y1;}}}System.out.println(x + " " + y);}
}
Python代码
n, m , c = map(int, input().split())
a = []
a.append([0]*(m+1))
for i in range(0, n):a.append([int(k) for k in input().split()])a[i+1].insert(0, 0)
for i in range(1, n+1):for j in range(1, m+1):a[i][j] = a[i][j] + a[i-1][j] + a[i][j-1] - a[i-1][j-1]
Max = float('-inf')
for i in range(1, n+2-c):for j in range(1, m+2-c):ans = a[i+c-1][j+c-1] - a[i+c-1][j-1] - a[i-1][j+c-1] + a[i-1][j-1]if ans > Max:Max = ansx = iy = j
print(x, y)
3. 差分
前缀和的主要应用是差分:差分是前缀和的逆运算。
与一维数组a[]对应的差分数组d[]的定义:
d[k]=a[k]-a[k-1]
即原数组a[]的相邻元素的差。根据d[]的定义,可以推出:
a[k]=d[1]+d[2]+…+d[k]
即a[]是d[]的前缀和,所以“差分是前缀和的逆运算”。
为方便理解,把每个a[]看成直线上的坐标。每个d[]看成直线上的小线段,它的两端是相邻的a[]。这些小线段相加,就得到了从起点开始的长线段a[]。

差分是一种处理数据的巧妙而简单的方法,它应用于区间的修改和询问问题。把给定的数据元素集A分成很多区间,对这些区间做很多次操作,每次操作是对某个区间内的所有元素做相同的加减操作,若一个个地修改这个区间内的每个元素,非常耗时。引入“差分数组”,当修改某个区间时,只需要修改这个区间的“端点”,就能记录整个区间的修改,而对端点的修改非常容易,是O(1)复杂度的。当所有的修改操作结束后,再利用差分数组,计算出新的A。
为什么利用差分数组能提升修改的效率?
把区间[L, R]内每个元素a[]加上v,只需要把对应的d[]做以下操作:
(1)把d[L]加上v: d[L] += v
(2)把d[R+1]减去v:d[R+1] -= v
利用d[],能精确地实现只修改区间内元素的目的,而不会修改区间外的a[]值。根据前缀和a[x] = d[1] + d[2] + … + d[x],有:
(1)1 ≤ x < L,前缀和a[x]不变;
(2)L ≤ x ≤ R,前缀和a[x]增加了v;
(3)R < x ≤ N,前缀和a[x]不变,因为被d[R+1]中减去的v抵消了。
每次操作只需要修改区间[L, R]的两个端点的d[]值,复杂度是O(1)的。经过这种操作后,原来直接在a[]上做的复杂度为O(n)的区间修改操作,就变成了在d[]上做的复杂度为O(1)的端点操作。完成区间修改并得到d[]后,最后用d[]计算a[],复杂度是O(n)的。m次区间修改和1次查询,总复杂度为O(m + n),比暴力法的O(mn)好多了。
数据A可以是一维的线性数组a[]、二维矩阵a[][]、三维立体a[][][]。相应地,定义一维差分数组D[]、二维差分数组D[][]、三维差分数组D[][][]。
4. 差分例题
例5 差分的基本应用
重新排序
本题的m个查询可以统一处理,读入m个查询后,每个a[i]被查询了多少次就知道了。用cnt[i]记录a[i]被查询的次数,cnt[i]*a[i]就是a[i]对总和的贡献。
下面分别给出70%和100%的两种解法。
(1)通过70%的测试。
先计算出cnt[],然后第15行算出原数组上的总和ans1。
然后计算新数组上的总和。显然,把查询次数最多的数分给最大的数,对总和的贡献最大。对a[]和cnt[]排序,把最大的a[n]与最大的cnt[n]相乘、次大的a[n-1]与次大的cnt[n-1]相乘,等等。代码第18行算出新数组上的总和ans2。
代码的主要计算量是第10行的while和第12行的for,复杂度O(mn),只能通过70%的测试。
注意,如果把下面第9行的long long改成int,那么只能通过30%。
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+3;
int a[N],cnt[N]; //a[]:读入数组;cnt[i]:第i个数被加的次数
int main(){int n; scanf("%d", &n);for(int i=1;i<=n;i++) scanf("%d", &a[i]);int m; scanf("%d", &m);long long ans1=0,ans2=0; //ans1: 原区间和; ans2: 新区间和while(m--){int L,R; scanf("%d%d", &L, &R);for(int i=L;i<=R;i++)cnt[i]++; //第i个数被加了一次,累计一共加了多少次
}
for(int i=1; i<=n; i++) ans1+=(long long)a[i]*cnt[i]; //在原数组上求区间和sort(a+1,a+1+n);sort(cnt+1,cnt+1+n);for(int i=1;i<=n;i++) ans2+=(long long)a[i]*cnt[i];printf("%lld\n", ans2-ans1); //注意 %lld不要写成 %dreturn 0;
}
(2)通过100%的测试。本题是差分优化的直接应用。
前面提到,70%的代码效率低的原因是第12行的for循环计算cnt[]。根据差分的应用场景,每次查询的[L, R]就是对a[L]~a[R]中的所有数累加次数加1,也就是对cnt[L]~cnt[R]中的所有cnt[]加1。那么对cnt[]使用差分数组d[]即可。
C++代码。代码第12行用差分数组d[]记录cnt[]的变化,第15行用d[]恢复得到cnt[]。其他部分和前面的70%代码一样。
代码的计算复杂度,10行的while只有O(n),最耗时的是第17、18行的排序,复杂度O(nlogn),能通过100%的测试。
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5+3;
int a[N],d[N],cnt[N];
int main() {int n; scanf("%d", &n);for(int i=1;i<=n;i++) scanf("%d", &a[i]);int m; scanf("%d", &m);long long ans1=0,ans2=0;while(m--){int L,R; scanf("%d%d", &L, &R);d[L]++; d[R+1]--;}cnt[0] = d[0];for(int i=1; i<=n; i++) cnt[i] = cnt[i-1]+d[i]; //用差分数组d[]求cnt[]for(int i=1; i<=n; i++) ans1 += (long long)a[i] * cnt[i];sort(a+1,a+1+n);sort(cnt+1,cnt+1+n);for(int i=1; i<=n; i++) ans2 += (long long)a[i] * cnt[i];printf("%lld\n", ans2-ans1);return 0;
}
java代码
import java.util.*;public class Main {public static void main(String[] args) {Scanner scanner = new Scanner(System.in);int N = 100003;int[] a = new int[N];int[] d = new int[N];int[] cnt = new int[N]; int n = scanner.nextInt();for (int i = 1; i <= n; i++) a[i] = scanner.nextInt(); int m = scanner.nextInt();long ans1 = 0, ans2 = 0;while (m-- > 0) {int L = scanner.nextInt();int R = scanner.nextInt();d[L]++;d[R+1]--;} cnt[0] = d[0];for (int i = 1; i <= n; i++) cnt[i] = cnt[i-1] + d[i]; for (int i = 1; i <= n; i++) ans1 += (long) a[i] * cnt[i]; Arrays.sort(a, 1, n+1);Arrays.sort(cnt, 1, n+1); for (int i = 1; i <= n; i++) ans2 += (long) a[i] * cnt[i]; System.out.println(ans2 - ans1);scanner.close();}
}
Python代码
N = 100003
a = [0] * N
d = [0] * N
cnt = [0] * N
n = int(input())
a[1:n+1] = map(int, input().split())
m = int(input())
ans1 = 0
ans2 = 0
for _ in range(m):L, R = map(int, input().split())d[L] += 1d[R+1] -= 1
cnt[0] = d[0]
for i in range(1, n+1): cnt[i] = cnt[i-1] + d[i]
for i in range(1, n+1): ans1 += a[i] * cnt[i]
a[1:n+1] = sorted(a[1:n+1])
cnt[1:n+1] = sorted(cnt[1:n+1])
for i in range(1, n+1): ans2 += a[i] * cnt[i]
print(ans2 - ans1)
例6 差分的基本应用
推箱子
题解 https://blog.csdn.net/weixin_43914593/article/details/131730112
相关文章:
<蓝桥杯软件赛>零基础备赛20周--第9周--前缀和与差分
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集 20周的完整安排请点击:20周计划 每周发1个博客,共20周(读者可以按…...

LeetCode-2487. 从链表中移除节点【栈 递归 链表 单调栈】
LeetCode-2487. 从链表中移除节点【栈 递归 链表 单调栈】 题目描述:解题思路一:可以将链表转为数组,然后从后往前遍历,遇到大于等于当前元素的就入栈,最终栈里面的元素即是最终的答案。解题思路二:递归&am…...

Redisson分布式锁原理分析
1.Redisson实现分布式锁 在分布式系统中,涉及到多个实例对同一资源加锁的情况,传统的synchronized、ReentrantLock等单进程加锁的API就不再适用,此时就需要使用分布式锁来保证多服务之间加锁的安全性。 常见的分布式锁的实现方式有ÿ…...
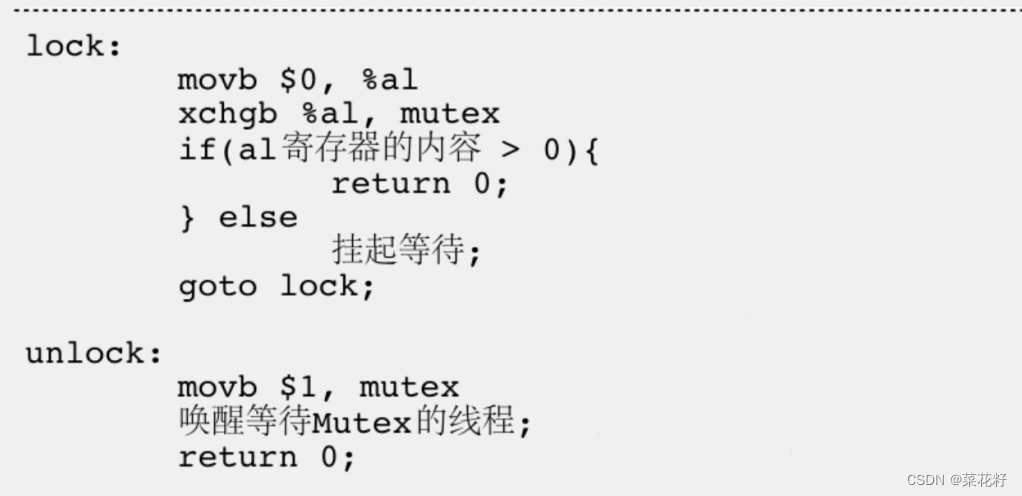
【Linux】:线程(二)互斥
互斥与同步 一.线程的局部存储二.线程的分离三.互斥1.一些概念2.上锁3.锁的原理4.死锁 一.线程的局部存储 例子 可以看到全局变量是所有线程共享的,如果我们想要每个线程都单独访问g_val怎么办呢?其实我们可以在它前面加上__thread修饰。 这就相当于把g…...

vscode报错Pylance client: couldn‘t create connection to server.
问题描述: 一打开vscode,右下角就弹报错,Pylance client: couldn’t create connection to server.,让我打开output,打开后似乎是在说连不上server 因为连不上server,所以我的python代码没法解析࿰…...

智能优化算法应用:基于萤火虫算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于萤火虫算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于萤火虫算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.萤火虫算法4.实验参数设定5.算法结果6.参考文…...
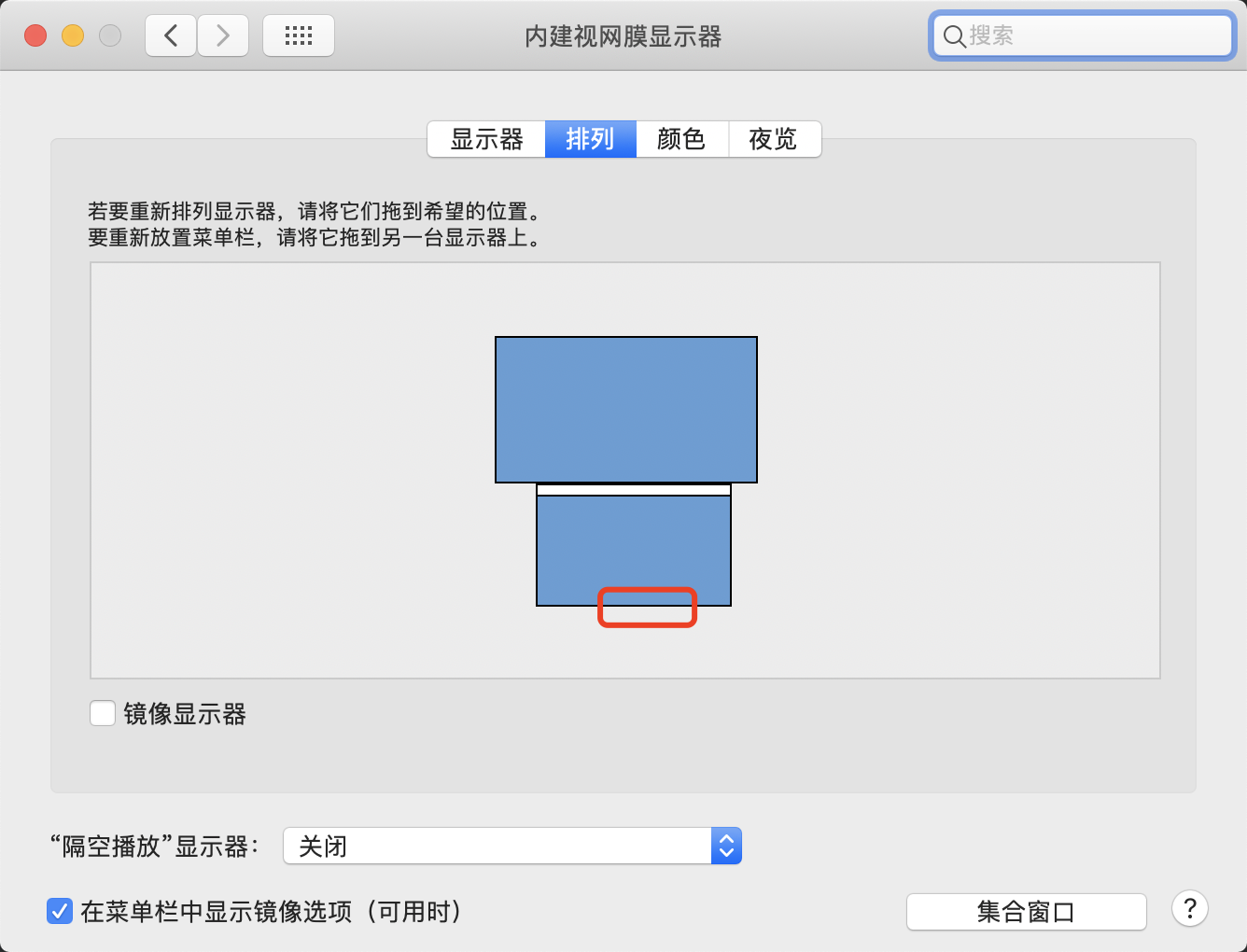
MacOS多屏状态栏位置不固定,程序坞不小心跑到副屏
目录 方式一:通过系统设置方式二:鼠标切换 MacOS多屏状态栏位置不固定,程序坞不小心跑到副屏 方式一:通过系统设置 先切换到左边 再切换到底部 就能回到主屏了 方式二:鼠标切换 我的两个屏幕放置位置如下 鼠标在…...
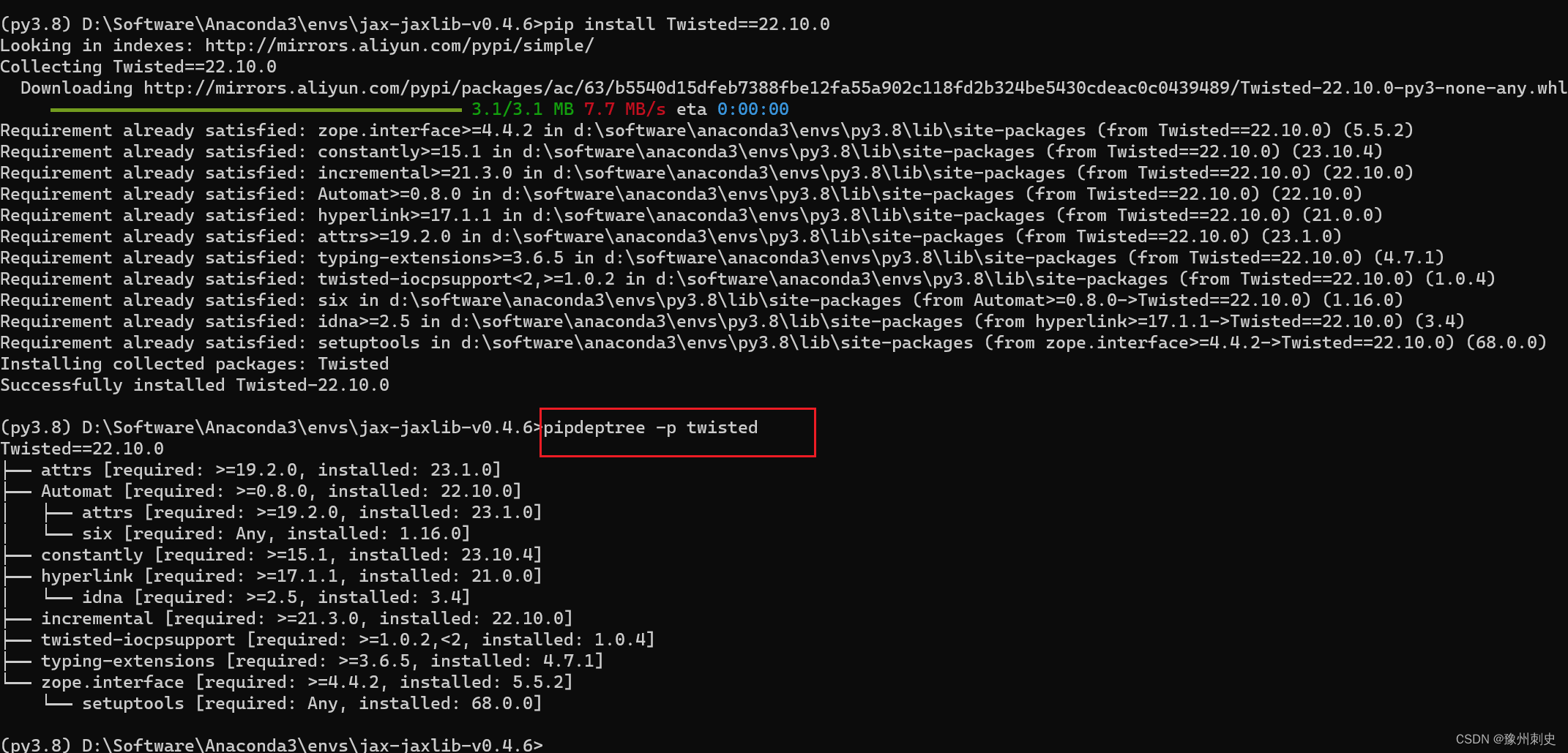
Python:pipdeptree 语法介绍
相信大家在按照一些包的时候经常会碰到版本不兼容,但是又不知道版本之间的依赖关系,今天给大家介绍一个工具:pipdeptree pipdeptree 是一个 Python 包,用于查看已安装的 pip 包及其依赖关系。它以树形结构展示包之间的依赖关系&am…...
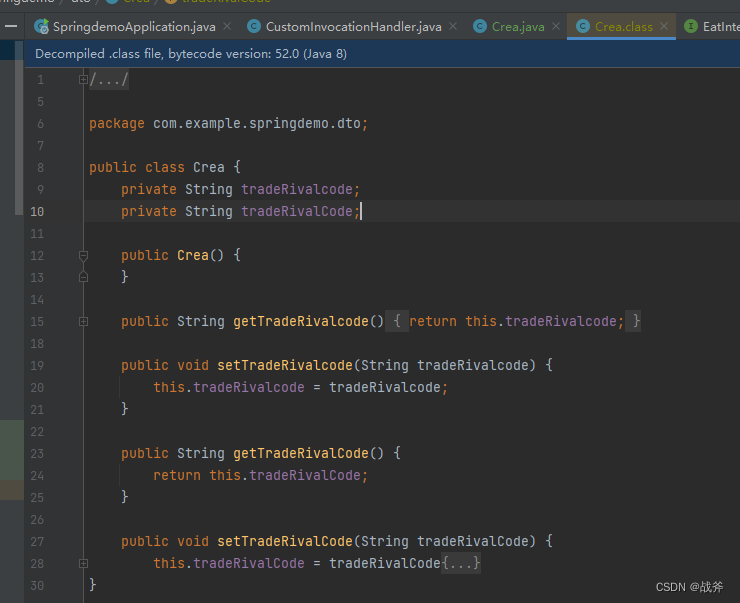
【问题处理】—— lombok 的 @Data 大小写区分不敏感
问题描述 今天在项目本地编译的时候,发现有个很奇怪的问题,一直提示某位置找不到符号, 但是实际在Idea中显示确实正常的,一开始以为又是IDEA的故障,所以重启了IDEA,并执行了mvn clean然后重新编译。但是问…...

跟着我学Python基础篇:08.集合和字典
往期文章 跟着我学Python基础篇:01.初露端倪 跟着我学Python基础篇:02.数字与字符串编程 跟着我学Python基础篇:03.选择结构 跟着我学Python基础篇:04.循环 跟着我学Python基础篇:05.函数 跟着我学Python基础篇&#…...
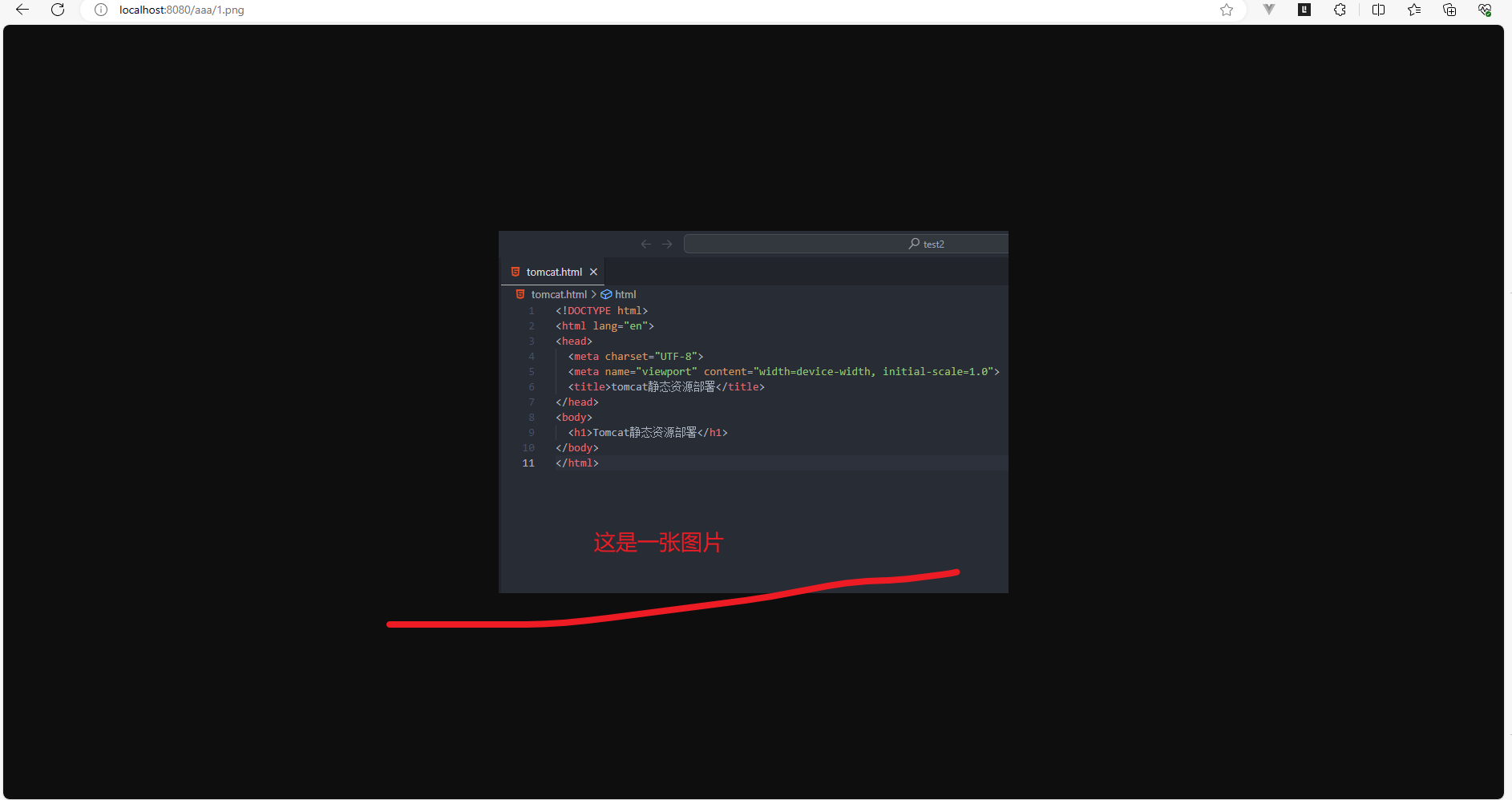
Tomcat部署(图片和HTML等)静态资源时遇到的问题
文章目录 Tomcat部署静态资源问题图中HTML代码启动Tomcat后先确认Tomcat是否启动成功 Tomcat部署静态资源问题 今天,有人突然跟我提到,使用nginx部署静态资源,如图片。可以直接通过url地址访问,为什么他的Tomcat不能通过这样的方…...

在接触新的游戏引擎的时候,如何能快速地熟悉并开发出一款新游戏?
引言 大家好,今天分享点个人经验。 有一定编程经验或者游戏开发经验的小伙伴,在接触新的游戏引擎的时候,如何能快速地熟悉并开发出一款新游戏? 利用现成开发框架。 1.什么是开发框架? 开发框架,顾名思…...

计网 - TCP四次挥手原理全曝光:深度解析与实战演示
文章目录 Pre导图过程分析抓包实战第一次挥手 【FIN ACK】第二次挥手 【ACK】第三次挥手 【FINACK】第四次挥手 【ACK】 小结 Pre 计网 - 传输层协议 TCP:TCP 为什么握手是 3 次、挥手是 4 次? 计网 - TCP三次握手原理全曝光:深度解析与实战…...

个人养老金知多少?
个人养老金政策你了解吗?税优政策你知道吗?你会计算能退多少税吗?… 点这里看一看...
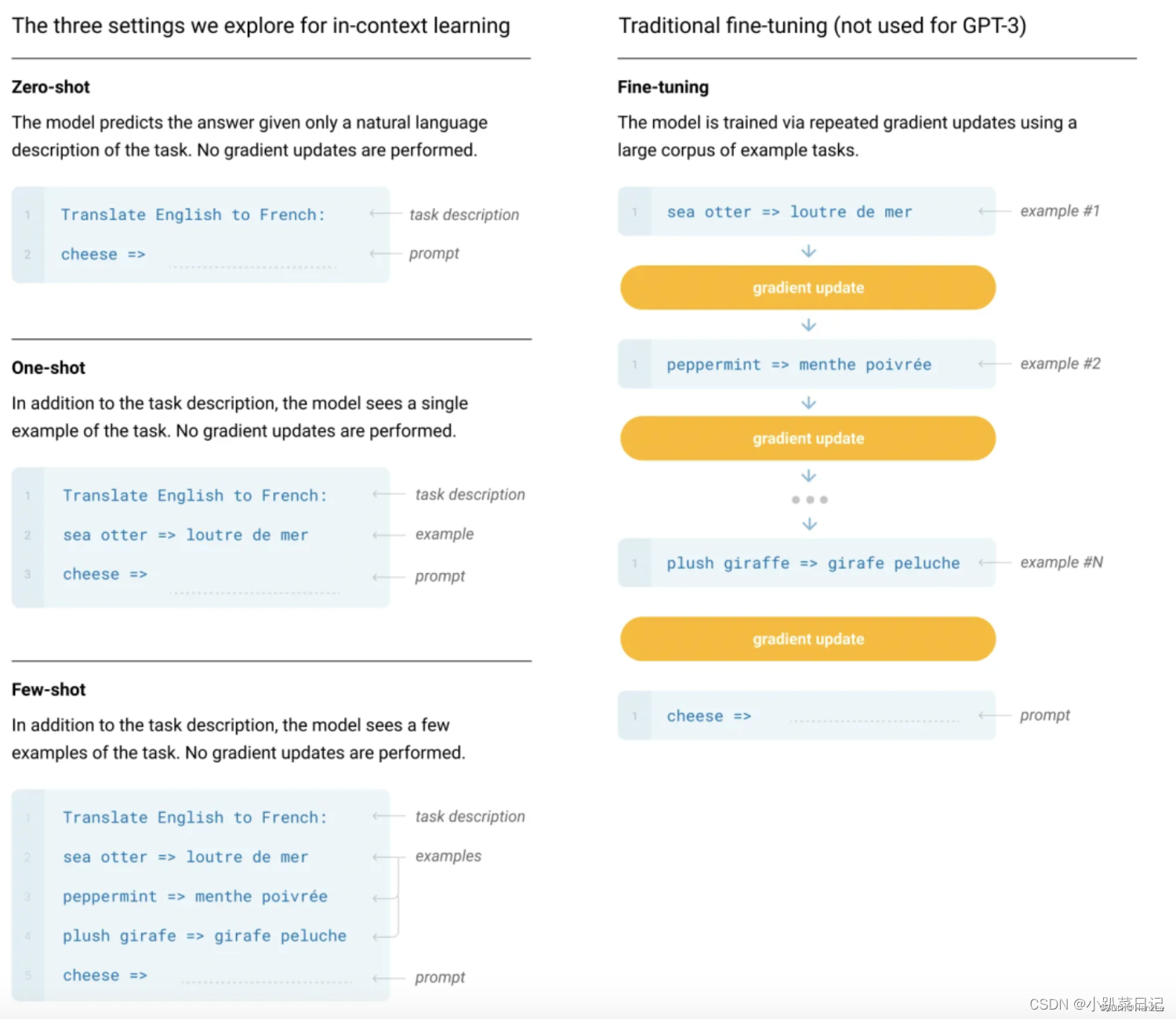
gpt3、gpt2与gpt1区别
参考:深度学习:GPT1、GPT2、GPT-3_HanZee的博客-CSDN博客 Zero-shot Learning / One-shot Learning-CSDN博客 Zero-shot(零次学习)简介-CSDN博客 GPT1、GPT2、GPT3、InstructGPT-CSDN博客 目录 gpt2与gpt1区别: gp…...
PyQt6 QDateEdit日期控件
锋哥原创的PyQt6视频教程: 2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~共计39条视频,包括:2024版 PyQt6 Python桌面开发 视频教程(无废话…...
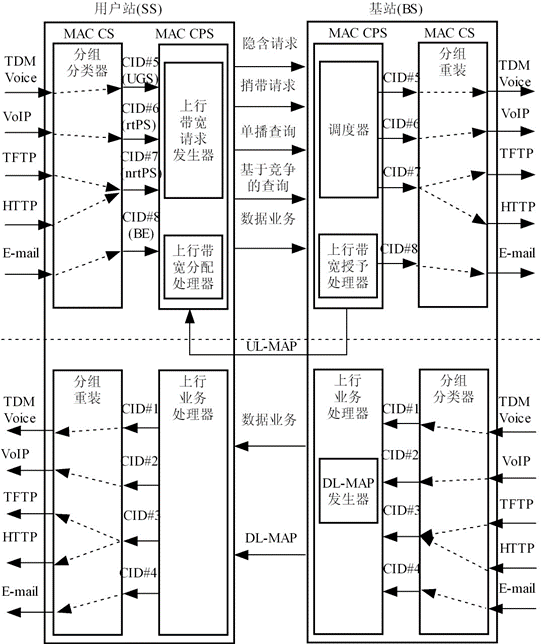
【无线网络技术】——无线城域网(学习笔记)
📖 前言:无线城域网(WMAN)是指在地域上覆盖城市及其郊区范围的分布节点之间传输信息的本地分配无线网络。能实现语音、数据、图像、多媒体、IP等多业务的接入服务。其覆盖范围的典型值为3~5km,点到点链路的覆盖可以高达…...
RK3568平台 OTA升级原理
一.前言 在迅速变化和发展的物联网市场,新的产品需求不断涌现,因此对于智能硬件设备的更新需求就变得空前高涨,设备不再像传统设备一样一经出售就不再变更。为了快速响应市场需求,一个技术变得极为重要,即OTA空中下载…...

mysql迁移步骤
MySQL迁移是指将MySQL数据库从一台服务器迁移到另一台服务器。这可能是因为您需要升级服务器、增加存储空间、提高性能或改变数据库架构。 以下是MySQL迁移的一般步骤: 以上是MySQL迁移的一般步骤,具体步骤可能因您的环境和需求而有所不同。在进行迁移之…...

计算机网络应用层(期末、考研)
计算机网络总复习链接🔗 目录 DNS域名服务器域名解析过程分类递归查询(给根域名服务器造成的负载过大,实际中几乎不用)迭代查询 域名缓存(了解即可)完整域名解析过程采用UDP服务 FTP控制连接与数据连接 电…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...