【大数据】Hudi 核心知识点详解(一)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
- Hudi 核心知识点详解(一)
- Hudi 核心知识点详解(二)
Hudi 核心知识点详解(一)
- 1.数据湖与数据仓库的区别 ?
- 1.1 数据仓库
- 1.2 数据湖
- 1.3 两者的区别
- 2.Hudi 基础功能
- 2.1 Hudi 简介
- 2.2 Hudi 功能
- 2.3 Hudi 的特性
- 2.4 Hudi 的架构
- 2.5 湖仓一体架构
- 3.Hudi 数据管理
- 3.1 Hudi 表数据结构
- 3.1.1 .hoodie 文件
- 3.1.2 数据文件
- 3.2 数据存储概述
- 3.3 Metadata 元数据
- 3.4 Index 索引
- 索引策略
- 工作负载 1:对事实表
- 工作负载 2:对事件表
- 工作负载 3:随机更新 / 删除维度表
- 3.5 Data 数据
在 Flink 实时流中,经常会通过 Flink CDC 插件读取 Mysql 数据,然后写入 Hudi 中。所以在执行上述操作时,需要了解 Hudi 的基本概念以及操作原理,这样在近实时往 Hudi 中写数据时,遇到报错问题,才能及时处理。
接下来将从以下几方面全面阐述 Hudi 组件核心知识点。
- 数据湖与数据仓库的区别 ?
- Hudi 基础功能
- Hudi 数据管理
- Hudi 核心点解析
1.数据湖与数据仓库的区别 ?
1.1 数据仓库
-
数据仓库(英语:
Data Warehouse,简称:数仓、DW),是一个用于 存储、分析、报告 的数据系统。 -
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供 决策支持(
Decision Support)。

1.2 数据湖
-
数据湖(
Data Lake)和数据库、数据仓库一样,都是数据存储的设计模式,现在企业的数据仓库都会通过分层的方式将数据存储在文件夹、文件中。 -
数据湖是一个集中式数据存储库,用来存储大量的原始数据,使用平面架构来存储数据。
-
定义:一个以原始格式(通常是对象块或文件)存储数据的系统或存储库,通常是所有企业数据的单一存储。
-
数据湖可以包括来自关系数据库的结构化数据(行和列)、半结构化数据(CSV、日志、XML、JSON)、非结构化数据(电子邮件、文档、PDF)和二进制数据(图像、音频、视频)。
-
数据湖中数据,用于报告、可视化、高级分析和机器学习等任务。

1.3 两者的区别
-
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。
-
数据湖存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。
| 特性 | | |
|---|---|---|
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 设计在数据仓库实施之前(写入型 Schema) | 写入在分析时(读取型 Schema) |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI和可视化 | 机器学习、预测分析、数据发现和分析 |
数据湖并不能替代数据仓库,数据仓库在高效的报表和可视化分析中仍有优势。
2.Hudi 基础功能
2.1 Hudi 简介
Apache Hudi 由 Uber 开发并开源,该项目在 2016 年开始开发,并于 2017 年开源,2019 年 1 月进入 Apache 孵化器,且 2020 年 6 月称为 Apache 顶级项目,目前最新版本:0.10.1 版本。
Hudi 一开始支持 Spark 进行数据摄入(批量 Batch 和流式 Streaming),从 0.7.0 版本开始,逐渐与 Flink 整合,主要在于 Flink SQL 整合,还支持 Flink SQL CDC。

Hudi(Hadoop Upserts anD Incrementals 的缩写),是目前市面上流行的三大开源数据湖方案之一。
用于管理分布式文件系统 DFS 上大型分析数据集存储。
简单来说,Hudi 是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使 DFS 数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
2.2 Hudi 功能
- ✅ Hudi 是在大数据存储上的一个数据集,可以将 Change Logs 通过
upsert的方式合并进 Hudi。 - ✅ Hudi 对上可以暴露成一个普通 Hive 或 Spark 表,通过 API 或命令行可以获取到增量修改的信息,继续供下游消费。
- ✅ Hudi 保管修改历史,可以做时间旅行或回退。
- ✅ Hudi 内部有主键到文件级的索引,默认是记录到文件的布隆过滤器。

2.3 Hudi 的特性
Apache Hudi 使得用户能在 Hadoop 兼容的存储之上存储大量数据,同时它还提供两种原语,不仅可以 批处理,还可以在数据湖上进行 流处理。
1️⃣ Update / Delete 记录:Hudi 使用细粒度的文件 / 记录级别索引来支持 Update / Delete 记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
2️⃣ 变更流:Hudi 对获取数据变更提供了一流的支持:可以从给定的 时间点 获取给定表中已 updated / inserted / deleted 的所有记录的增量流,并解锁新的查询姿势(类别)。
- ✅ Apache Hudi 本身不存储数据,仅仅管理数据。
- ✅ Apache Hudi 也不分析数据,需要使用计算分析引擎,查询和保存数据,比如 Spark 或 Flink。
- ✅ 使用 Hudi 时,加载
jar包,底层调用 API,所以需要依据使用大数据框架版本,编译 Hudi 源码,获取对应依赖jar包。

2.4 Hudi 的架构

- ✅ 通过 DeltaStreammer、Flink、Spark 等工具,将数据摄取到数据湖存储,可使用 HDFS 作为数据湖的数据存储。
- ✅ 基于 HDFS 可以构建 Hudi 的数据湖。
- ✅ Hudi 提供统一的访问 Spark 数据源和 Flink 数据源。
- ✅ 外部通过不同引擎,如:Spark、Flink、Presto、Hive、Impala、Aliyun DLA、AWS Redshit 访问接口。

2.5 湖仓一体架构
Hudi 对于 Flink 友好支持以后,可以使用 Flink + Hudi 构建实时湖仓一体架构,数据的时效性可以到分钟级,能很好的满足业务准实时数仓的需求。
通过湖仓一体、流批一体,准实时场景下做到了:数据同源、同计算引擎、同存储、同计算口径。

3.Hudi 数据管理
3.1 Hudi 表数据结构
Hudi 表的数据文件,可以使用操作系统的文件系统存储,也可以使用 HDFS 这种分布式的文件系统存储。为了后续分析性能和数据的可靠性,一般使用 HDFS 进行存储。以 HDFS 存储来看,一个 Hudi 表的存储文件分为两类。

.hoodie文件:由于 CRUD 的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响 HDFS 的性能,Hudi 设计了一套文件合并机制。.hoodie文件夹中存放了对应的 文件合并操作 相关的日志文件。amricas和asia相关的路径是 实际的数据文件,按分区存储,分区的路径key是可以指定的。
3.1.1 .hoodie 文件
Hudi 把随着时间流逝,对表的一系列 CRUD 操作叫做 Timeline,Timeline 中某一次的操作,叫做 Instant。
Hudi 的核心是维护 Timeline 在不同时间对表执行的所有操作,Instant 这有助于提供表的即时视图,同时还有效地支持按到达顺序检索数据。Hudi Instant 由以下组件组成:
Instant Action:记录本次操作是一次操作类型,数据提交(COMMITS),还是 文件合并(COMPACTION),或者是 文件清理(CLEANS)。Instant Time:本次操作发生的时间,通常是时间戳(例如:20190117010349),它按照动作开始时间的顺序单调递增。State:操作的状态,发起(REQUESTED),进行中(INFLIGHT),还是 已完成(COMPLETED)。
.hoodie 文件夹中存放对应操作的状态记录:

3.1.2 数据文件
Hudi 真实的数据文件使用 Parquet 文件格式存储。

其中包含一个 metadata 元数据文件和数据文件 parquet 列式存储。
Hudi 为了实现数据的 CRUD,需要能够唯一标识一条记录,Hudi 将把数据集中的 唯一字段(record key)+ 数据所在分区(partition Path)联合起来当做 数据的唯一键。
3.2 数据存储概述
Hudi 数据集的 组织目录结构 与 Hive 表示非常相似,一份数据集对应这一个根目录。数据集被 打散为多个分区,分区字段以文件夹形式存在,该文件夹包含该分区的所有文件。

在根目录下,每个分区都有唯一的分区路径,每个分区数据存储在多个文件中。
每个文件都有唯一的 fileId 和生成文件的 commit 标识。如果发生更新操作时,多个文件共享相同的 fileId,但会有不同的 commit。
3.3 Metadata 元数据
以 时间轴(Timeline)的形式将数据集上的各项操作元数据维护起来,以支持数据集的瞬态视图,这部分元数据存储于根目录下的元数据目录。一共有三种类型的元数据:
- Commits:一个单独的
commit包含对数据集之上一批数据的一次原子写入操作的相关信息。我们用单调递增的时间戳来标识commits,标定的是一次写入操作的开始。 - Cleans:用于清除数据集中不再被查询所用到的旧版本文件的后台活动。
- Compactions:用于协调 Hudi 内部的数据结构差异的后台活动。例如,将更新操作由基于行存的日志文件归集到列存数据上。

3.4 Index 索引
Hudi 维护着一个索引,以支持在记录 key 存在情况下,将新记录的 key 快速映射到对应的 fileId。
- Bloom filter:存储于数据文件页脚。默认选项,不依赖外部系统实现。数据和索引始终保持一致。
- Apache HBase:可高效查找一小批
key。在索引标记期间,此选项可能快几秒钟。

索引策略
工作负载 1:对事实表
许多公司将大量事务数据存储在 NoSQL 数据存储中。例如,拼车情况下的行程表、股票买卖、电子商务网站中的订单。这些表通常会随着对最新数据的随机更新而不断增长,而长尾更新会针对较旧的数据,这可能是由于交易在以后结算 / 数据更正所致。换句话说,大多数更新进入最新的分区,很少有更新进入较旧的分区。

对于这样的工作负载,BLOOM 索引表现良好,因为索引查找 将基于大小合适的布隆过滤器修剪大量数据文件。此外,如果可以构造键,以使它们具有一定的顺序,则要比较的文件数量会通过范围修剪进一步减少。
Hudi 使用所有文件键范围构建一个区间树,并有效地过滤掉更新 / 删除记录中与任何键范围不匹配的文件。
为了有效地将传入的记录键与布隆过滤器进行比较,即最小数量的布隆过滤器读取和跨执行程序的统一工作分配,Hudi 利用输入记录的缓存并采用可以使用统计信息消除数据偏差的自定义分区器。有时,如果布隆过滤器误报率很高,它可能会增加混洗的数据量以执行查找。
Hudi 支持动态布隆过滤器(使用启用 hoodie.bloom.index.filter.type=DYNAMIC_V0),它根据存储在给定文件中的记录数调整其大小,以提供配置的误报率。
工作负载 2:对事件表
事件流无处不在。来自 Apache Kafka 或类似消息总线的事件通常是事实表大小的 10 − 100 10-100 10−100 倍,并且通常将 时间(事件的到达时间 / 处理时间)视为一等公民。
例如,物联网事件流、点击流数据、广告印象 等。插入和更新仅跨越最后几个分区,因为这些大多是仅附加数据。鉴于可以在端到端管道中的任何位置引入重复事件,因此在存储到数据湖之前进行重复数据删除是一项常见要求。

一般来说,这是一个非常具有挑战性的问题,需要以较低的成本解决。虽然,我们甚至可以使用键值存储来使用 HBASE 索引执行重复数据删除,但索引存储成本会随着事件的数量线性增长,因此可能会非常昂贵。
实际上,BLOOM 带有范围修剪的索引是这里的最佳解决方案。人们可以利用时间通常是一等公民这一事实并构造一个键,event_ts + event_id 例如插入的记录具有单调递增的键。即使在最新的表分区中,也可以通过修剪大量文件来产生巨大的回报。
工作负载 3:随机更新 / 删除维度表
这些类型的表格通常包含高维数据并保存参考数据,例如 用户资料、商家信息。这些是高保真表,其中更新通常很小,但也分布在许多分区和数据文件中,数据集从旧到新。通常,这些表也是未分区的,因为也没有对这些表进行分区的好方法。

如前所述,BLOOM 如果无法通过比较范围 / 过滤器来删除大量文件,则索引可能不会产生好处。在这样的随机写入工作负载中,更新最终会触及表中的大多数文件,因此布隆过滤器通常会根据一些传入的更新指示所有文件的真阳性。因此,我们最终会比较范围 / 过滤器,只是为了最终检查所有文件的传入更新。
SIMPLE 索引将更适合,因为它不进行任何基于预先修剪的操作,而是直接与每个数据文件中感兴趣的字段连接 。HBASE 如果操作开销是可接受的,并且可以为这些表提供更好的查找时间,则可以使用索引。
在使用全局索引时,用户还应该考虑设置 hoodie.bloom.index.update.partition.path=true 或 hoodie.simple.index.update.partition.path=true 处理分区路径值可能因更新而改变的情况,例如用户表按家乡分区;用户搬迁到不同的城市。这些表也是 Merge-On-Read 表类型的绝佳候选者。
3.5 Data 数据
Hudi 以两种不同的存储格式存储所有摄取的数据,用户可选择满足下列条件的任意数据格式:
- 读优化的列存格式(
ROFormat):缺省值为Apache Parquet。 - 写优化的行存格式(
WOFormat):缺省值为Apache Avro。

相关文章:
【大数据】Hudi 核心知识点详解(一)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 &#x…...
windows上抓包出现大包未分片以及关闭tso方法
wireshark抓包中会有大数据包(未分片包)和ip校验和不对的包,问题根因在目前很多电脑网卡支持TSO和将校验和计算到网卡上,导致抓出数据包未分片 详细文章看: https://www.cnblogs.com/charlieroro/p/11363336.html 目前很多网卡已…...

Leetcode 2454. 下一个更大元素 IV
Leetcode 2454. 下一个更大元素 IV题目 给你一个下标从 0 开始的非负整数数组 nums 。对于 nums 中每一个整数,你必须找到对应元素的 第二大 整数。如果 nums[j] 满足以下条件,那么我们称它为 nums[i] 的 第二大 整数: j >nums[j] > nu…...

浏览器全屏按键同f11效果
模拟键f11 // for IE,这里和fullScreen相同,模拟按下F11键退出全屏 let wscript new ActiveXObject(WScript.Shell) if (wscript ! null) {wscript.SendKeys({F11}) }同f11键效果生效全屏函数 //判断是否是全屏状态 var isFull Math.abs(window.scree…...
CentOS 7.9 安装 k8s(详细教程)
🍿安装步骤 🍚安装前准备事项🍚安装docker🍚删除docker🍚安装yum工具🍚设置docker镜像源🍚安装指定版本docker🍚设置开启自启🍚阿里云镜像加速 🍚准备环境&am…...
区块链的可拓展性研究【05】闪电网络
1.闪电网络:闪电网络是一种基于比特币区块链的 Layer2 扩容方案,它通过建立一个双向支付通道网络,实现了快速、低成本的小额支付。闪电网络的交易速度非常快,可以达到每秒数万笔交易,而且交易费用非常低,几…...
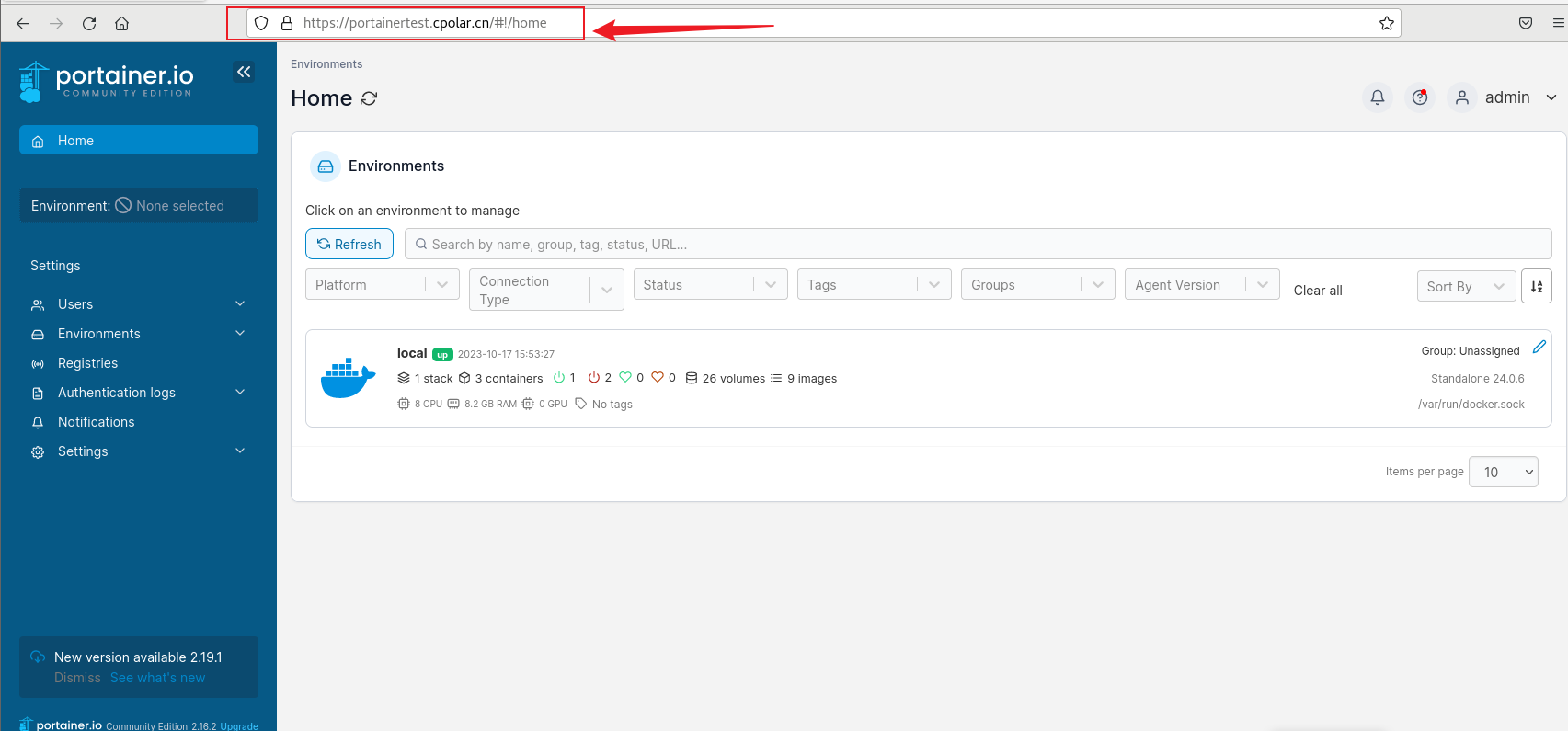
如何部署Portainer容器管理工具+cpolar内网穿透实现公网访问管理界面
文章目录 前言1. 部署Portainer2. 本地访问Portainer3. Linux 安装cpolar4. 配置Portainer 公网访问地址5. 公网远程访问Portainer6. 固定Portainer公网地址 前言 本文主要介绍如何本地安装Portainer并结合内网穿透工具实现任意浏览器远程访问管理界面。Portainer 是一个轻量级…...
Linux——Samba文件共享服务配置
SMB/CIFS协议 SMB协议(Server Message Block 又称Common Internet File System(CIFS)) 是由微软开发的网络传输协议,用来实现网络共享文件系统、打印机等资源。 SMB协议有多个版本和不同的兼容性。 SMBv1/CIFS: 也称为SMB1或CIFS。最初由Micr…...

自动驾驶右向辅助功能规范
目 录 Contents 目录 1. 介绍 Introduction. 8 1.1 此文档的范围和目的 Scope and Purpose of This Document 8 1.2 参考文档References. 9 1.3 文档的维护 Maintenance of the Document 10 1.4 缩略词Abbreviations. 10 1.5 文档概述Document Overview.. 11 1.6 功能…...

ASF-YOLO开源 | SSFF融合+TPE编码+CPAM注意力,精度提升!
目录 摘要 1 Introduction 2 Related work 2.1 Cell instance segmentation 2.2 Improved YOLO for instance segmentation 3 The proposed ASF-YOLO model 3.1 Overall architecture 3.2 Scale sequence feature fusion module 3.3 Triple feature encoding module …...

Mac 如何删除文件及文件夹?可以尝试使用终端进行删除
MacOS 是 Mac 电脑采用的操作系统,你知道 Mac 如何删除文件吗?除了直接将文件或者文件夹拖入废纸篓之外,我们还可以采用终端命令的办法去删除文件,本文为大家总结了 Mac 删除文件方法。 为何使用命令行删除文件 在使用 Mac 电脑…...
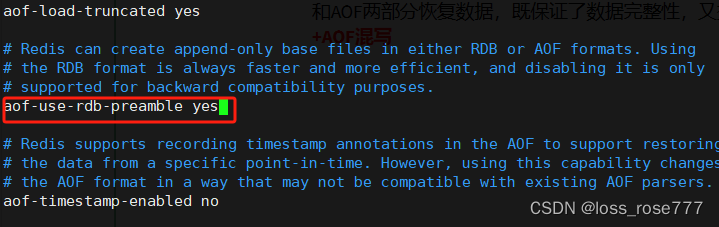
最新Redis7持久化(权威出版)
首先我们要知道什么是持久化:持久化是指将数据保存到磁盘上,以确保在Redis服务器重启时数据不会丢失。 Redis支持两种主要的持久化方式:RDB持久化和AOF持久化 下面让我依次给你介绍一下: RDB持久化 作用 这是将Redis数据保存…...

Redis权限管理体系(一):客户端名及用户名
在Redis6之前的版本中,因安全认证的主要方式是使用Redis实例的密码进行基础控制,而无法按照不同的应用来源配置不同账号以及更细粒度的操作权限控制来管理。本文先从client list中的信息入手,逐步了解Redis的客户端名设置、用户设置及权限控制…...

【数据库设计和SQL基础语法】--查询数据--排序
一、排序数据 1.1 ORDER BY子句 单列排序 单列排序是通过使用 ORDER BY 子句对查询结果按照单个列进行排序。以下是单列排序的一些示例: 升序排序(默认): SELECT column1, column2, ... FROM your_table_name ORDER BY column_t…...
【sqli靶场】第六关和第七关通关思路
目录 前言 一、sqli靶场第六关 1.1 判断注入类型 1.2 观察报错 1.3 使用extractvalue函数报错 1.4 爆出数据库中的表名 二、sqli靶场第七关 1.1 判断注入类型 1.2 判断数据表中的字段数 1.3 提示 1.4 构造poc爆库名 1.5 构造poc爆表名 1.6 构造poc爆字段名 1.7 构造poc获取账…...
c语言快速排序(霍尔法、挖坑法、双指针法)图文详解
快速排序介绍: 快速排序是一种非常常用的排序方法,它在1962由C. A. R. Hoare(霍尔)提的一种二叉树结构的交换排序方法,故因此它又被称为霍尔划分,它基于分治的思想,所以整体思路是递归进行的。 …...

【mysql】锁的类型有哪些呢?
0 回答 根据数据的访问级别来区分: mysql锁分为共享锁和排他锁,也叫做读锁和写锁。读锁是共享的,可以通过lock in share mode实现,这时候只能读不能写。写锁是排他的,它会阻塞其他的写锁和读锁。 从颗粒度来区分&am…...

uniapp 显示文件流图片
如果是需要将文件流保存到相册,可以先转base64.详情见>uniapp app将base64保存到相册,uniapp app将文件流保存到相册-CSDN博客 uni.request({url: "www.baidu.com",data: {},header: {content-type:application/json,Authorization: "token"…...
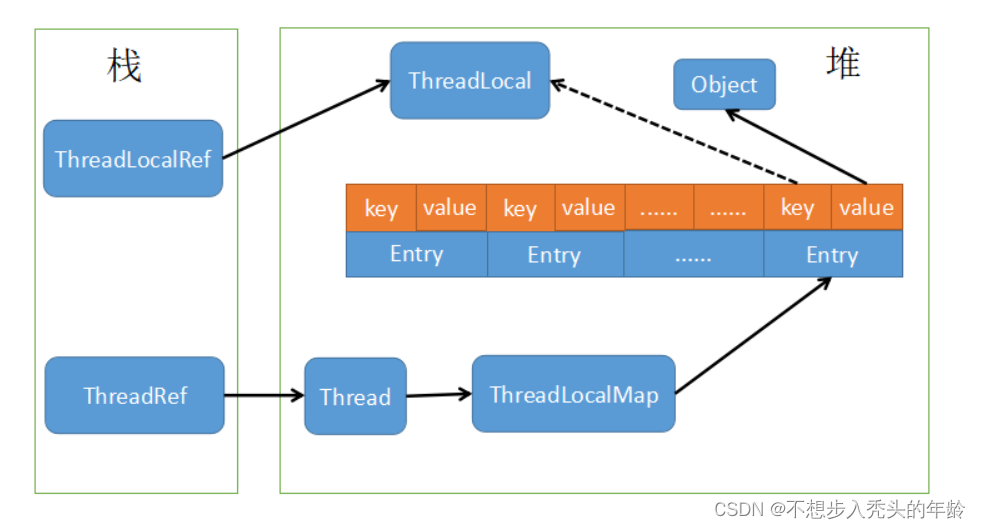
多线程------ThreadLocal详解
目录 1. 什么是 ThreadLocal? 2. 如何使用 ThreadLocal? 3. ThreadLocal 的作用 4. ThreadLocal 的应用场景 5. ThreadLocal 的注意事项 我的其他博客 ThreadLocal 是 Java 中一个很有用的类,它提供了线程局部变量的支持。线程局部变量…...
:随机数、密码、时间戳、日期和时间(格式化与解析)、时区、本地时间)
【C++】POCO学习总结(十六):随机数、密码、时间戳、日期和时间(格式化与解析)、时区、本地时间
【C】郭老二博文之:C目录 1、Poco::Random 随机数 1.1 说明 POCO包括一个伪随机数生成器(PRNG),使用非线性加性反馈算法,具有256位状态信息和长达269的周期。 PRNG可以生成31位的伪随机数。 它可以生成UInt32, char, bool, float和double…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...