SQLAlchemy 第一篇
安装SQLAlchemy
pip install SQLAlchemy
查看当前版本
# 查看当前版本import sqlalchemyprint(sqlalchemy.__version__)2.0.23
创建数据库连接
此处我们以pymysql为mysql的数据库驱动
安装pymysql
pip install pymysql
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:root@localhost/test?charset=utf8mb4",echo=True,echo_pool=True,pool_size=20)
执行原生的sql语句
from sqlalchemy import textwith engine.connect() as conn:result = conn.execute(text("select 'Hello SQLAlchemy'"))print(result.all())
2023-12-14 10:18:36,836 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 10:18:36,837 INFO sqlalchemy.engine.Engine select 'Hello SQLAlchemy'
2023-12-14 10:18:36,838 INFO sqlalchemy.engine.Engine [generated in 0.00197s] {}
[('Hello SQLAlchemy',)]
2023-12-14 10:18:36,839 INFO sqlalchemy.engine.Engine ROLLBACK
创建表与执行插入语句
在下面的示例中,上下文管理器提供了数据库连接,并且还构建了事务内部的操作。Python DBAPI 的默认行为包括事务始终在进行中;当连接范围被释放时,会发出 ROLLBACK 来结束事务。事务不会自动提交;当我们想要提交数据时,我们通常需要调用Connection.commit()
with engine.connect() as conn:conn.execute(text("CREATE TABLE IF NOT EXISTS `user` (`id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4"))conn.execute(text("insert into user(name,age) values(:name,:age )"),[{"name":"cloud","age":18},{"name":"alex","age":19}])conn.commit()
2023-12-14 10:56:16,027 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 10:56:16,029 INFO sqlalchemy.engine.Engine CREATE TABLE IF NOT EXISTS `user` (`id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
2023-12-14 10:56:16,030 INFO sqlalchemy.engine.Engine [cached since 1825s ago] {}
2023-12-14 10:56:16,032 INFO sqlalchemy.engine.Engine insert into user(name,age) values(%(name)s,%(age)s )
2023-12-14 10:56:16,033 INFO sqlalchemy.engine.Engine [cached since 1825s ago] [{'name': 'cloud', 'age': 18}, {'name': 'alex', 'age': 19}]
2023-12-14 10:56:16,034 INFO sqlalchemy.engine.Engine COMMIT
隐式开启事务
使用engine.begin() 方法,可以隐式开启一个事务。并且执行正常后,会自动提交。如果有异常发送,则会回滚
with engine.begin() as conn:conn.execute(text("create table a(x int)"))2023-12-14 11:52:40,494 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 11:52:40,495 INFO sqlalchemy.engine.Engine create table a(x int)
2023-12-14 11:52:40,495 INFO sqlalchemy.engine.Engine [cached since 2032s ago] {}
2023-12-14 11:52:40,523 INFO sqlalchemy.engine.Engine COMMIT
with engine.begin() as conn:conn.execute(text("create table b(x int)"))conn.execute(text("insert into b(x) values(1)"))result = conn.execute(text("select * from b"))print(result.all())conn.execute(text("create table c(x intlong)"))
2023-12-14 11:55:44,902 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 11:55:44,904 INFO sqlalchemy.engine.Engine create table b(x int)
2023-12-14 11:55:44,905 INFO sqlalchemy.engine.Engine [cached since 1925s ago] {}
2023-12-14 11:55:44,932 INFO sqlalchemy.engine.Engine insert into b(x) values(1)
2023-12-14 11:55:44,932 INFO sqlalchemy.engine.Engine [generated in 0.00055s] {}
2023-12-14 11:55:44,934 INFO sqlalchemy.engine.Engine select * from b
2023-12-14 11:55:44,935 INFO sqlalchemy.engine.Engine [generated in 0.00116s] {}
[(1,)]
2023-12-14 11:55:44,936 INFO sqlalchemy.engine.Engine create table c(x intlong)
2023-12-14 11:55:44,937 INFO sqlalchemy.engine.Engine [cached since 177.2s ago] {}
2023-12-14 11:55:44,938 INFO sqlalchemy.engine.Engine ROLLBACK---------------------------------------------------------------------------ProgrammingError Traceback (most recent call last)File ~/pythonProjects/SQLAlchemy-v2.0-tutorial/venv/lib/python3.11/site-
ProgrammingError: (pymysql.err.ProgrammingError) (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'intlong)' at line 1")
[SQL: create table c(x intlong)]
(Background on this error at: https://sqlalche.me/e/20/f405)
获取行
with engine.connect() as conn:result = conn.execute(text("select * from user"))print("查询结果是:")for row in result:print(row)
2023-12-14 10:56:19,065 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 10:56:19,066 INFO sqlalchemy.engine.Engine select * from user
2023-12-14 10:56:19,067 INFO sqlalchemy.engine.Engine [cached since 1765s ago] {}
查询结果是:
(1, 'cloud', 18)
(2, 'alex', 19)
2023-12-14 10:56:19,069 INFO sqlalchemy.engine.Engine ROLLBACK
绑定参数
with engine.connect() as conn:result = conn.execute(text("select * from user where name=:name"),{"name":"cloud"})print(result.all())
2023-12-14 10:56:23,113 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 10:56:23,114 INFO sqlalchemy.engine.Engine select * from user where name=%(name)s
2023-12-14 10:56:23,116 INFO sqlalchemy.engine.Engine [cached since 35.77s ago] {'name': 'cloud'}
[(1, 'cloud', 18)]
2023-12-14 10:56:23,118 INFO sqlalchemy.engine.Engine ROLLBACK
绑定多个参数
with engine.connect() as conn:result = conn.execute(text("select * from user where name=:name and age=:age"),{"name":"cloud","age":18})for row in result:print(row)2023-12-14 11:11:57,727 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 11:11:57,728 INFO sqlalchemy.engine.Engine select * from user where name=%(name)s and age=%(age)s
2023-12-14 11:11:57,729 INFO sqlalchemy.engine.Engine [cached since 877.5s ago] {'name': 'cloud', 'age': 18}
(1, 'cloud', 18)
2023-12-14 11:11:57,731 INFO sqlalchemy.engine.Engine ROLLBACK
元组分配
with engine.connect() as conn:result = conn.execute(text("select id,name,age from user"))for id,name,age in result:print(f"id:{id},name:{name},age:{age}")2023-12-14 11:13:30,871 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 11:13:30,872 INFO sqlalchemy.engine.Engine select id,name,age from user
2023-12-14 11:13:30,872 INFO sqlalchemy.engine.Engine [generated in 0.00153s] {}
id:1,name:cloud,age:18
id:2,name:alex,age:19
2023-12-14 11:13:30,874 INFO sqlalchemy.engine.Engine ROLLBACK
## 通过索引访问
with engine.connect() as conn:result = conn.execute(text("select id,name,age from user"))for row in result:print(row[0],row[1],row[2])
2023-12-14 11:16:50,814 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-12-14 11:16:50,815 INFO sqlalchemy.engine.Engine select id,name,age from user
2023-12-14 11:16:50,816 INFO sqlalchemy.engine.Engine [cached since 199.9s ago] {}
1 cloud 18
2 alex 19
2023-12-14 11:16:50,818 INFO sqlalchemy.engine.Engine ROLLBACK
相关文章:

SQLAlchemy 第一篇
安装SQLAlchemy pip install SQLAlchemy查看当前版本 # 查看当前版本import sqlalchemyprint(sqlalchemy.__version__)2.0.23创建数据库连接 此处我们以pymysql为mysql的数据库驱动 安装pymysql pip install pymysqlfrom sqlalchemy import create_engine engine create_…...

Node.js模块化的基本概念和分类及使用方法
1.模块概念 模块:指解决一个复杂问题的时候,自顶向下逐层把系统划分成若干模块的过程。对于整个系统来讲,模块是可以组合、分解和更换的单元。 在编辑领域中的模块,就是遵守固定的规则,把一个大文件拆成独立并且相互…...
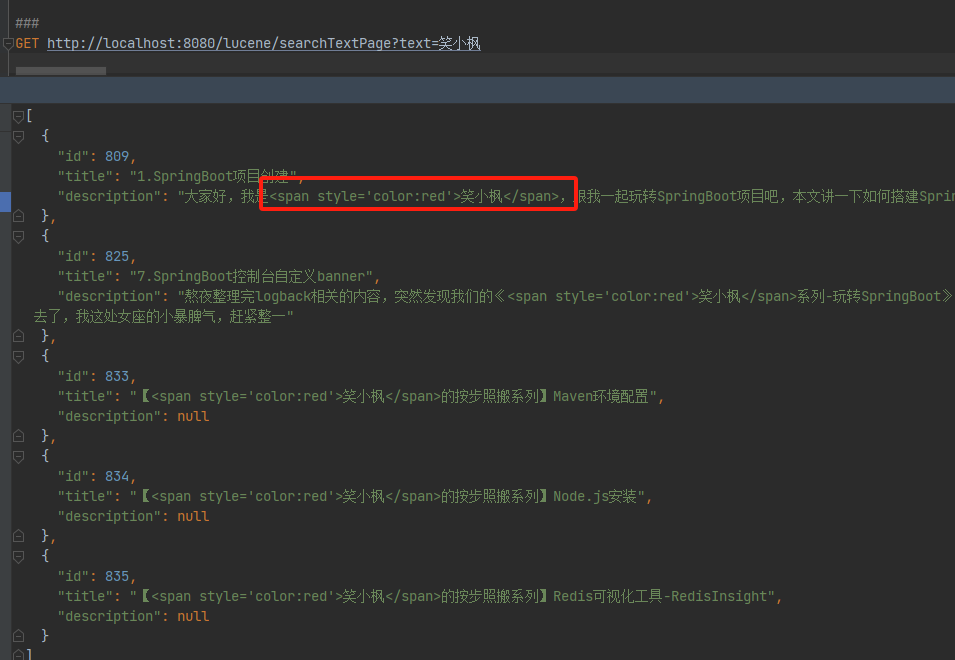
SpringBoot整合Lucene实现全文检索【详细步骤】【附源码】
笑小枫的专属目录 1. 项目背景2. 什么是Lucene3. 引入依赖,配置索引3.1 引入Lucene依赖和分词器依赖3.2 表结构和数据准备3.3 创建索引3.4 修改索引3.5删除索引 4. 数据检索4.1 基础搜索4.2 一个关键词,在多个字段里面搜索4.3 搜索结果高亮显示4.4 分页检…...

基于ssm生活缴费系统及相关安全技术的设计与实现论文
摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为人们提供服务。针对生活缴费信息管理混乱,出错率高,信息安全性差…...
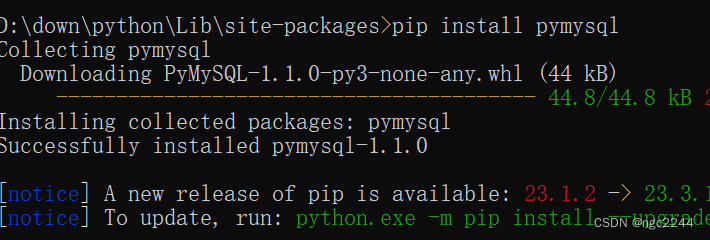
VS的python没有pandas(VS连接mysql数据库)
import pandas as pd from sqlalchemy import create_engine# 初始化数据库连接 engine create_engine(mysqlpymysql://root:556localhost:3306/仓库)sql_chaSELECT * FROM 库房 print(sql_cha) df_read pd.read_sql_query(sql_cha, engine); print(df_read);VS连接mysql如上…...

Java实现pdf文件合并
在maven项目中引入以下依赖包 <dependencies><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-examples</artifactId><version>3.0.1</version></dependency><dependency><groupId>co…...
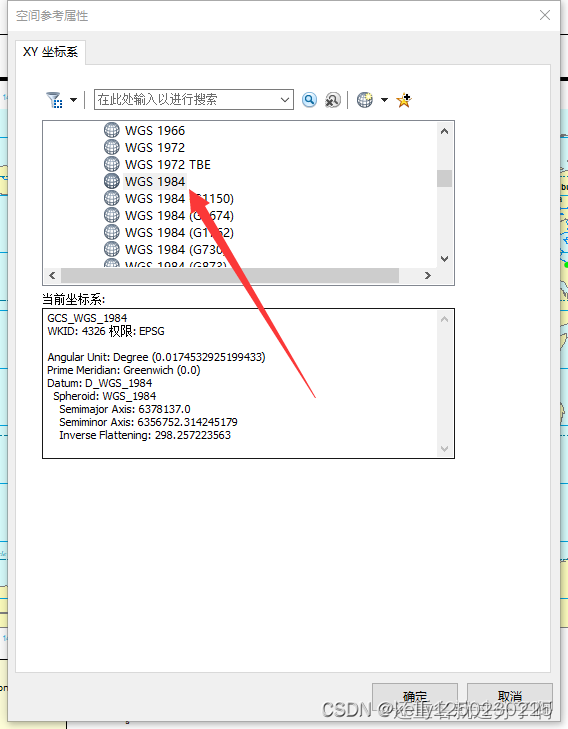
ArcGIS导入excel中的经纬度信息,绘制矢量
1.首先整理坐标信息 2.其次转成2003格式的excel文件 3.导入arcgis,点击右键添加excel数据 4.显示xy数据 5.显示经度和纬度信息 6:点击【地理坐标系】->【World】->【WGS 1984】->【确定】 7.投影带的确定方式: 因为自己一直…...
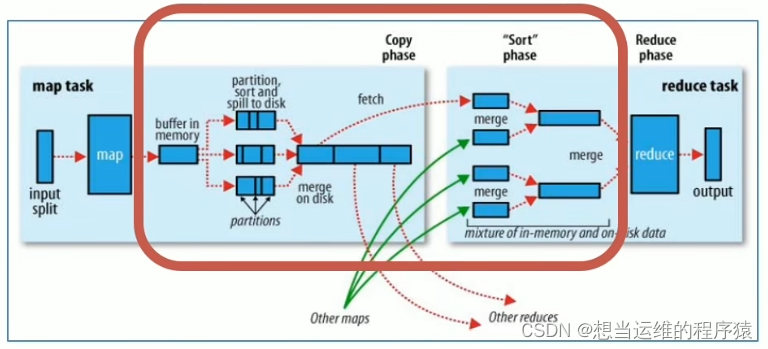
【Hadoop】
Hadoop是一个开源的分布式离线数据处理框架,底层是用Java语言编写的,包含了HDFS、MapReduce、Yarn三大部分。 组件配置文件启动进程备注Hadoop HDFS需修改需启动 NameNode(NN)作为主节点 DataNode(DN)作为从节点 SecondaryNameNode(SNN)主节点辅助分…...
GitHub帐户管理更改电子邮件
登录到您的 GitHub 帐户: 前往 GitHub 网站并使用您的凭据登录。 访问个人设置: 单击右上角的您的头像,然后选择“Settings”(设置)。 选择电子邮件选项卡: 在左侧边栏中选择“Emails”(电子邮…...

InsCode实践分享
一、背景介绍 随着社交媒体的普及,越来越多的品牌和商家开始关注如何利用社交媒体平台来提高品牌知名度和销售额。其中,Instagram作为一个以图片和视频为主要内容的社交媒体平台,已经成为了很多品牌和商家进行营销的重要渠道。InsCode是Inst…...

大一C语言作业 12.14
1.A A:将pa指向的元素赋值给x,即x a[0] B:将a数组第二个元素的值赋给x,即x a[1] C:将pa指向的下一个元素的值赋给x,即x a[1] D:将a数组第二个元素的值赋给x,即x a[1] 2. 6 2 3 …...

微服务技术 RabbitMQ SpringAMQP P61-P76
B站学习视频https://www.bilibili.com/video/BV1LQ4y127n4?p61&vd_source8665d6da33d4e2277ca40f03210fe53a 文档资料: 链接:https://pan.baidu.com/s/1P_Ag1BYiPaF52EI19A0YRw?pwdd03r 提取码:d03r 一 初始MQ 1. 同步通讯 2. 异步通讯 3. MQ常…...
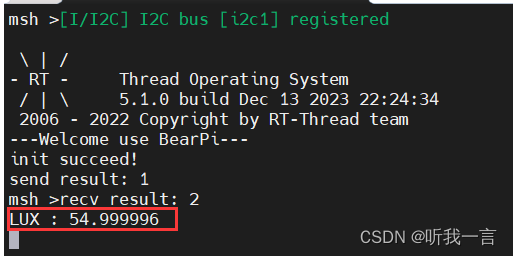
BearPi Std 板从入门到放弃 - 先天神魂篇(3)(RT-Thread I2C设备 读取光照强度BH1750)
简介 使用BearPi IOT Std开发板及其扩展板E53_SC1, SC1上有I2C1 的光照强度传感器BH1750 和 EEPROM AT24C02, 本次主要就是读取光照强度; 主板: 主芯片: STM32L431RCT6LED : PC13 \ 推挽输出\ 高电平点亮串口: Usart1I2C使用 : I2C1E53_SC1扩展板 : LE…...

中文分词演进(查词典,hmm标注,无监督统计)新词发现
查词典和字标注 目前中文分词主要有两种思路:查词典和字标注。 首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。 查词典的方法…...

Docker容器数据卷
一、概念 1.定义 卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过Union File System提供一些用于持续存储或共享数据的特性。 卷的设计目的就是数据的持久化,完全独…...
chatGPT 国内版,嵌入midjourney AI创作工具
聊天GPT国内入口,免切网直达,可直接多语言对话,操作简单,无需复杂注册,智能高效,即刻使用.可以用作个人助理,学习助理,智能创作、新媒体文案创作、智能创作等各种应用场景! 地址: https://ai.wboat.cn/...

Yum仓库架构解析与搭建实践
1.Yum仓库搭建 1.1本地Yum仓库图解 1.2Linux本地仓库搭建 配置本地光盘镜像仓库 1)挂载 [roothadoop101 ~]# mount -t iso996 /dev/cdrom/mnt 2)查看 [rooothadoop101 ~] # df -h | |grep -i mnt /dev/sr0 4.6G 4.4G 3…...
ElementPlus中的分页逻辑与实现
ElementPlus中的分页逻辑与实现 分页是web开发中必不可少的组件,element团队提供了简洁美观的分页组件,配合table数据可以实现即插即用的分页效果。分页的实现可以分成两种,一是前端分页,二是后端分页。这两种分页分别适用于不同…...
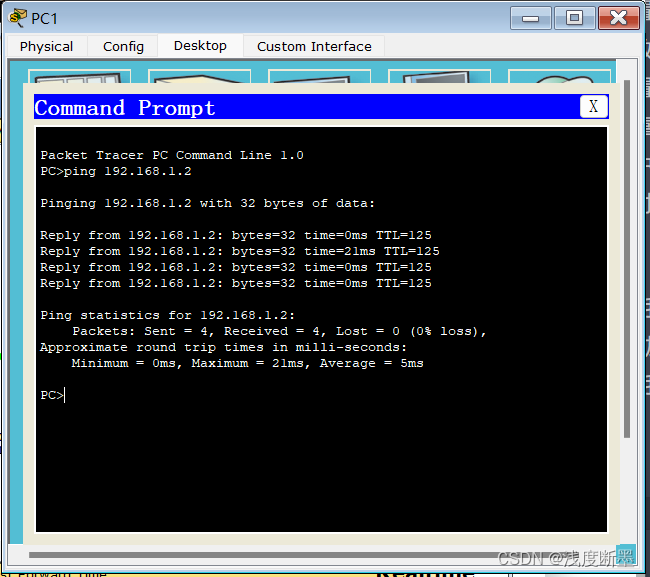
实验01:静态路由配置实验
1.实验目的: 本次实验的主要目的是了解静态路由的配置和实现原理,熟悉路由器的基本操作,掌握在网络中进行静态路由配置的方法和技巧。 2.实验内容: 搭建网络拓扑,包括三台路由器和两台PC。配置路由器的IP地址和路由…...

C#中简单的继承和多态
今天我们来聊一聊继承,说实话今天也是我第一次接触。 继承的概念是什么呢?就是一个类可以继承另一个类的属性和方法(成员) 继承是面向对象编程中的一个非常重要的特性。 好了,废话不多说,下面切入正题&a…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

Kubernetes 网络模型深度解析:Pod IP 与 Service 的负载均衡机制,Service到底是什么?
Pod IP 的本质与特性 Pod IP 的定位 纯端点地址:Pod IP 是分配给 Pod 网络命名空间的真实 IP 地址(如 10.244.1.2)无特殊名称:在 Kubernetes 中,它通常被称为 “Pod IP” 或 “容器 IP”生命周期:与 Pod …...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...

用鸿蒙HarmonyOS5实现中国象棋小游戏的过程
下面是一个基于鸿蒙OS (HarmonyOS) 的中国象棋小游戏的实现代码。这个实现使用Java语言和鸿蒙的Ability框架。 1. 项目结构 /src/main/java/com/example/chinesechess/├── MainAbilitySlice.java // 主界面逻辑├── ChessView.java // 游戏视图和逻辑├──…...