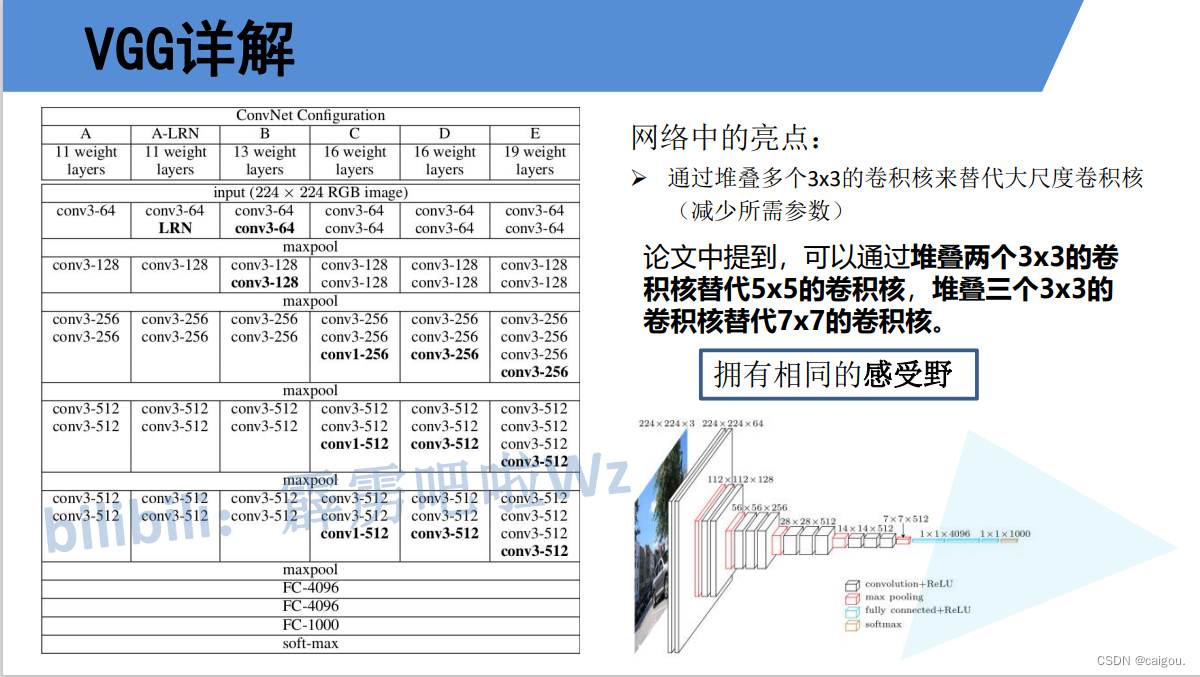
VGG(pytorch)
VGG:达到了传统串型结构深度的极限
学习VGG原理要了解CNN感受野的基础知识


model.py
import torch.nn as nn
import torch# official pretrain weights
model_urls = {'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth','vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth','vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth','vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}class VGG(nn.Module):def __init__(self, features, num_classes=1000, init_weights=False):super(VGG, self).__init__()#features参数是特征层模型,传入这个参数直接使用构造的特征层模型self.features = featuresself.classifier = nn.Sequential(nn.Linear(512*7*7, 4096),nn.ReLU(True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(p=0.5),nn.Linear(4096, num_classes))if init_weights:self._initialize_weights()def forward(self, x):# N x 3 x 224 x 224x = self.features(x)# N x 512 x 7 x 7x = torch.flatten(x, start_dim=1)# N x 512*7*7x = self.classifier(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')nn.init.xavier_uniform_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)# nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)def make_features(cfg: list):layers = []in_channels = 3#传入参数cfg是一个列表,遍历参数列表构造VGG特征层for v in cfg:if v == "M":layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)layers += [conv2d, nn.ReLU(True)]in_channels = vreturn nn.Sequential(*layers)#特征层函数返回一个nn.Sequential(*layers),#这段代码中的 return nn.Sequential(*layers) 使用了 nn.Sequential 类来创建一个神经网络模型。# 在这里,layers 是一个可迭代对象,包含了神经网络模型的各个层或模块。#这段代码的作用是封装一个神经网络模型,该模型按照 layers 中层或模块的顺序连接起来,并作为 nn.Sequential 对象返回。cfgs = {'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}#在函数定义中的 **kwargs 是一个特殊的参数形式,它允许函数接受任意数量的关键字参数(keyword arguments)。
# 这个参数形式使用了双星号 ** 来表示。
#在上述代码中,**kwargs 的作用是允许函数 vgg() 接受额外的关键字参数,并将这些参数收集到 kwargs 字典中
#如vgg(model_name="vgg16", num_classes=10, pretrained=True) pretrained就是一个**kwargs参数
def vgg(model_name="vgg16", **kwargs):assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)cfg = cfgs[model_name]model = VGG(make_features(cfg), **kwargs)return model
train.py
import os
import sys
import jsonimport torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdmfrom model import vggdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root pathimage_path = os.path.join(data_root, "data_set", "flower_data") # flower data set pathassert os.path.exists(image_path), "{} path does not exist.".format(image_path)train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),transform=data_transform["train"])train_num = len(train_dataset)# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}flower_list = train_dataset.class_to_idxcla_dict = dict((val, key) for key, val in flower_list.items())# write dict into json filejson_str = json.dumps(cla_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)batch_size = 32nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))#定义一个数据加载器用于迭代提取数据train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=nw)validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),transform=data_transform["val"])val_num = len(validate_dataset)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=batch_size, shuffle=False,num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,val_num))# test_data_iter = iter(validate_loader)# test_image, test_label = test_data_iter.next()model_name = "vgg16"net = vgg(model_name=model_name, num_classes=5, init_weights=True)net.to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0001)epochs = 30best_acc = 0.0save_path = './{}Net.pth'.format(model_name)train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = net(val_images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_numprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()
这里由于训练时间太长,运行了19个epoch中断。结果如下
using cuda:0 device.
Using 8 dataloader workers every process
using 3306 images for training, 364 images for validation.
train epoch[1/30] loss:1.542: 100%|██████████| 104/104 [08:39<00:00, 4.99s/it]
100%|██████████| 12/12 [01:13<00:00, 6.15s/it]
[epoch 1] train_loss: 1.605 val_accuracy: 0.245
train epoch[2/30] loss:1.399: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.12s/it]
[epoch 2] train_loss: 1.476 val_accuracy: 0.401
train epoch[3/30] loss:1.310: 100%|██████████| 104/104 [08:34<00:00, 4.94s/it]
100%|██████████| 12/12 [01:18<00:00, 6.53s/it]
[epoch 3] train_loss: 1.293 val_accuracy: 0.456
train epoch[4/30] loss:0.958: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.11s/it]
[epoch 4] train_loss: 1.185 val_accuracy: 0.519
train epoch[5/30] loss:1.327: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.11s/it]
[epoch 5] train_loss: 1.135 val_accuracy: 0.527
train epoch[6/30] loss:1.209: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.12s/it]
[epoch 6] train_loss: 1.077 val_accuracy: 0.571
train epoch[7/30] loss:0.725: 100%|██████████| 104/104 [1:25:27<00:00, 49.30s/it]
100%|██████████| 12/12 [01:21<00:00, 6.82s/it]
[epoch 7] train_loss: 1.051 val_accuracy: 0.596
train epoch[8/30] loss:1.146: 100%|██████████| 104/104 [08:50<00:00, 5.10s/it]
100%|██████████| 12/12 [01:27<00:00, 7.31s/it]
[epoch 8] train_loss: 1.008 val_accuracy: 0.615
train epoch[9/30] loss:1.381: 100%|██████████| 104/104 [08:48<00:00, 5.08s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 9] train_loss: 0.995 val_accuracy: 0.640
train epoch[10/30] loss:0.466: 100%|██████████| 104/104 [08:34<00:00, 4.95s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 10] train_loss: 0.966 val_accuracy: 0.673
train epoch[11/30] loss:0.867: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.13s/it]
[epoch 11] train_loss: 0.926 val_accuracy: 0.659
train epoch[12/30] loss:0.804: 100%|██████████| 104/104 [08:34<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 12] train_loss: 0.916 val_accuracy: 0.665
train epoch[13/30] loss:0.377: 100%|██████████| 104/104 [08:35<00:00, 4.96s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 13] train_loss: 0.879 val_accuracy: 0.648
train epoch[14/30] loss:0.588: 100%|██████████| 104/104 [08:35<00:00, 4.95s/it]
100%|██████████| 12/12 [01:13<00:00, 6.16s/it]
[epoch 14] train_loss: 0.841 val_accuracy: 0.676
train epoch[15/30] loss:0.725: 100%|██████████| 104/104 [08:35<00:00, 4.96s/it]
100%|██████████| 12/12 [01:13<00:00, 6.13s/it]
[epoch 15] train_loss: 0.830 val_accuracy: 0.687
train epoch[16/30] loss:0.977: 100%|██████████| 104/104 [08:35<00:00, 4.96s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 16] train_loss: 0.811 val_accuracy: 0.720
train epoch[17/30] loss:0.923: 100%|██████████| 104/104 [08:34<00:00, 4.95s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 17] train_loss: 0.796 val_accuracy: 0.703
train epoch[18/30] loss:1.150: 100%|██████████| 104/104 [08:34<00:00, 4.95s/it]
100%|██████████| 12/12 [01:13<00:00, 6.15s/it]
[epoch 18] train_loss: 0.794 val_accuracy: 0.720
train epoch[19/30] loss:0.866: 19%|█▉ | 20/104 [01:54<07:59, 5.71s/it]predict.py
import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom model import GoogLeNetdef main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")data_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load imageimg_path = "../tulip.jpg"assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path)plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)# read class_indictjson_path = './class_indices.json'assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)with open(json_path, "r") as f:class_indict = json.load(f)# create modelmodel = GoogLeNet(num_classes=5, aux_logits=False).to(device)# load model weightsweights_path = "./googleNet.pth"assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path, map_location=device),strict=False)model.eval()with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],predict[predict_cla].numpy())plt.title(print_res)for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))plt.show()if __name__ == '__main__':main()
预测结果
class: daisy prob: 0.00207
class: dandelion prob: 0.00144
class: roses prob: 0.101
class: sunflowers prob: 0.00535
class: tulips prob: 0.89
相关文章:
VGG(pytorch)
VGG:达到了传统串型结构深度的极限 学习VGG原理要了解CNN感受野的基础知识 model.py import torch.nn as nn import torch# official pretrain weights model_urls {vgg11: https://download.pytorch.org/models/vgg11-bbd30ac9.pth,vgg13: https://download.pytorch.org/mo…...

celery/schedules.py源码精读
BaseSchedule类 基础调度类,它定义了一些调度任务的基本属性和方法。以下是该类的主要部分的解释: __init__(self, nowfun: Callable | None None, app: Celery | None None):初始化方法,接受两个可选参数,nowfun表…...
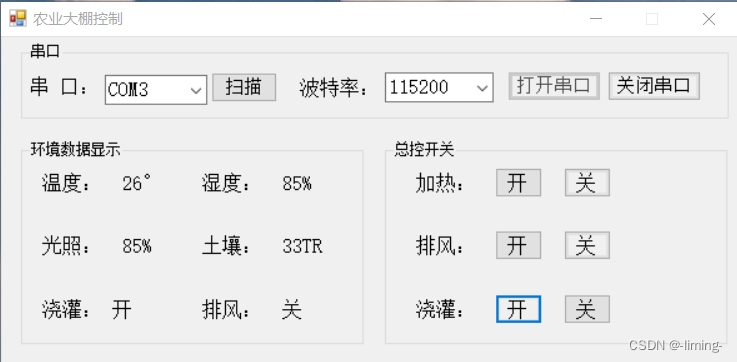
单片机上位机(串口通讯C#)
一、简介 用C#编写了几个单片机上位机模板。可定制!!! 二、效果图...

初识Flask
摆上中文版官方文档网站:https://flask.github.net.cn/quickstart.html 开启实验之路~~~~~~~~~~~~~ from flask import Flaskapp Flask(__name__) # 使用修饰器告诉flask触发函数的URL,绑定URL,后面的函数用于返回用户在浏览器上看到的内容…...

JeecgBoot jmreport/queryFieldBySql RCE漏洞复现
0x01 产品简介 Jeecg Boot(或者称为 Jeecg-Boot)是一款基于代码生成器的开源企业级快速开发平台,专注于开发后台管理系统、企业信息管理系统(MIS)等应用。它提供了一系列工具和模板,帮助开发者快速构建和部署现代化的 Web 应用程序。 0x02 漏洞概述 Jeecg Boot jmrepo…...
机器学习---模型评估
1、混淆矩阵 对以上混淆矩阵的解释: P:样本数据中的正例数。 N:样本数据中的负例数。 Y:通过模型预测出来的正例数。 N:通过模型预测出来的负例数。 True Positives:真阳性,表示实际是正样本预测成正样…...
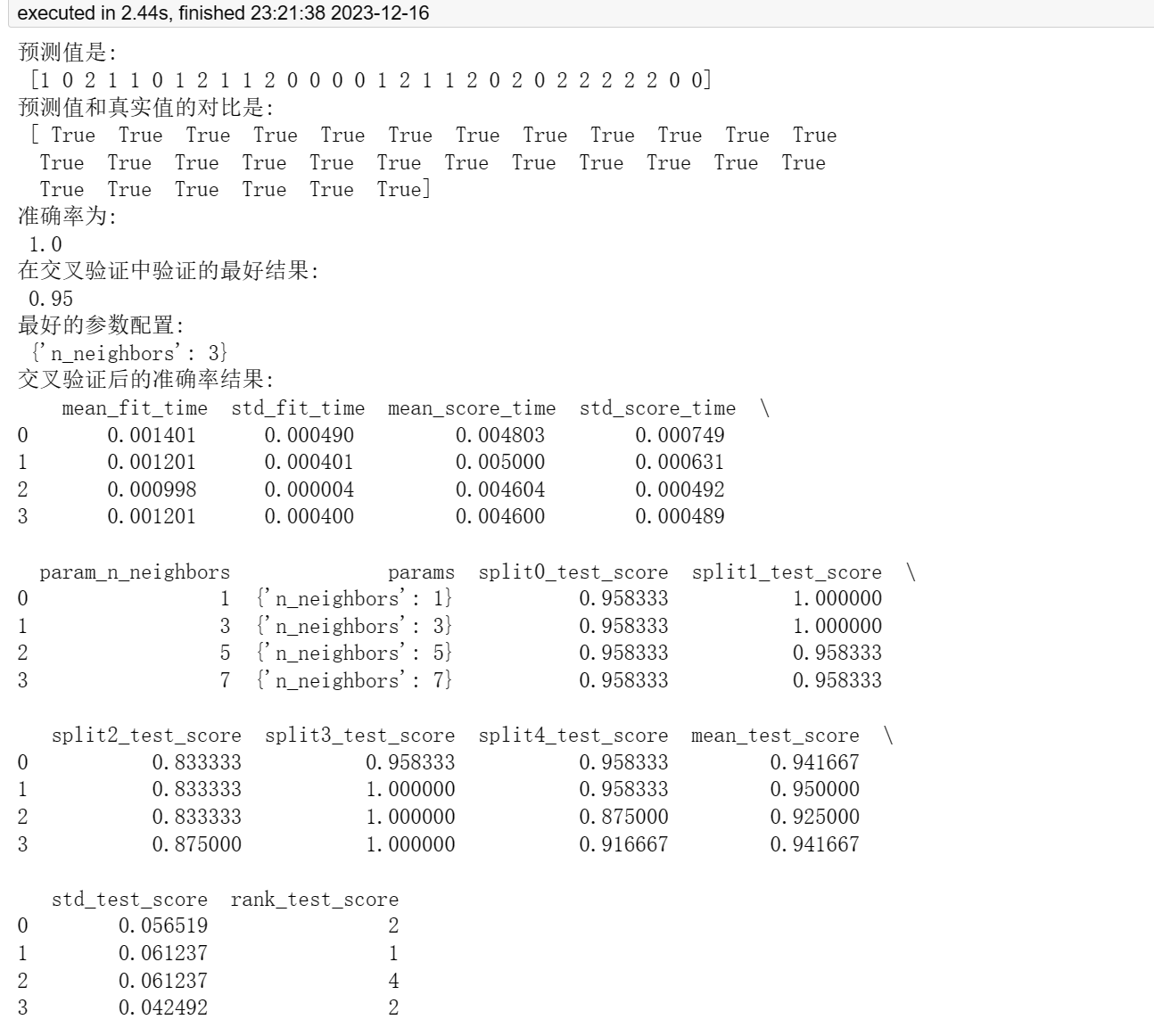
【机器学习】应用KNN实现鸢尾花种类预测
目录 前言 一、K最近邻(KNN)介绍 二、鸢尾花数据集介绍 三、鸢尾花数据集可视化 四、鸢尾花数据分析 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Fil…...

ACL和NAT
目录 一.ACL 1.概念 2.原理 3.应用 4.种类 5.通配符 1.命令 2.区别 3.例题 4.应用原则 6.实验 1.实验目的 2.实验拓扑 3.实验步骤 7.实验拓展 1.实验目的 2.实验步骤 3.测试 二.NAT 1.基本理论 2.作用 3.分类 静态nat 动态nat NATPT NAT Sever Easy-IP…...

MX6ULL学习笔记(十二)Linux 自带的 LED 灯
前言 前面我们都是自己编写 LED 灯驱动,其实像 LED 灯这样非常基础的设备驱动,Linux 内 核已经集成了。Linux 内核的 LED 灯驱动采用 platform 框架,因此我们只需要按照要求在设备 树文件中添加相应的 LED 节点即可,本章我们就来学…...

Qt容器QToolBox工具箱
# QToolBox QToolBox是Qt框架中的一个窗口容器类,常用的几个函数有: setCurrentIndex(int index):设置当前显示的页面索引。可以通过调用该函数,将指定索引的页面设置为当前显示的页面。 addItem(QWidget * widget, const QString & text):向QToolBox中添加一个页面…...

华为实训课笔记
华为实训 12/1312/14 12/13 ping 基于ICMP协议,用来进行可达性测试 ping 目的IP地址/设备域名(主机名) 如果能收到 reply 回复,则表示双方可以正常通信 <Huawei> 用户视图,只能做查询和一些简单的资源调用&…...
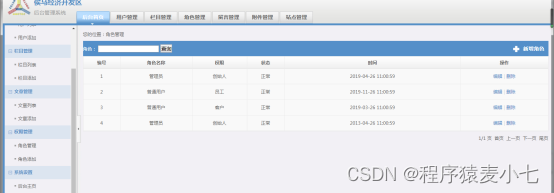
基于java 的经济开发区管理系统设计与实现(源码+调试)
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。今天给大家介绍一篇基于java 的经济开发区管…...

外包干了3个月,技术退步明显。。。
先说一下自己的情况,本科生生,19年通过校招进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测…...
详细教程 - 从零开发 Vue 鸿蒙harmonyOS应用 第一节
关于使用Vue开发鸿蒙应用的教程,我这篇之前的博客还不够完整和详细。那么这次我会尝试写一个更加完整和逐步的指南,从环境准备,到目录结构,再到关键代码讲解,以及调试和发布等,希望可以让大家详实地掌握这个过程。 一、准备工作 下载安装 DevEco Studio 下载地址:…...

R语言对医学中的自然语言(NLP)进行机器学习处理(1)
什么是自然语言(NLP),就是网络中的一些书面文本。对于医疗方面,例如医疗记录、病人反馈、医生业绩评估和社交媒体评论,可以成为帮助临床决策和提高质量的丰富数据来源。如互联网上有基于文本的数据(例如,对医疗保健提供者的社交媒体评论),这些数据我们可…...

什么是CI/CD?如何在PHP项目中实施CI/CD?
CI/CD(持续集成/持续交付或持续部署)是一种软件开发和交付方法,它旨在通过自动化和持续集成来提高开发速度和交付质量。以下是CI/CD的基本概念和如何在PHP项目中实施它的一般步骤: 持续集成(Continuous Integration -…...
:容器指令、生命周期、资源限制、容器化支持、常用命令)
玩转Docker(四):容器指令、生命周期、资源限制、容器化支持、常用命令
文章目录 一、容器指令1.运行2.启动/停止/重启3.暂停/恢复4.删除 二、生命周期三、资源限制1.内存限额2.CPU限额3.磁盘读写带宽限额 四、cgroup和namespace五、常用命令 一、容器指令 1.运行 按用途容器大致可分为两类:服务类容器和工具类的容器。 服务类容器&am…...
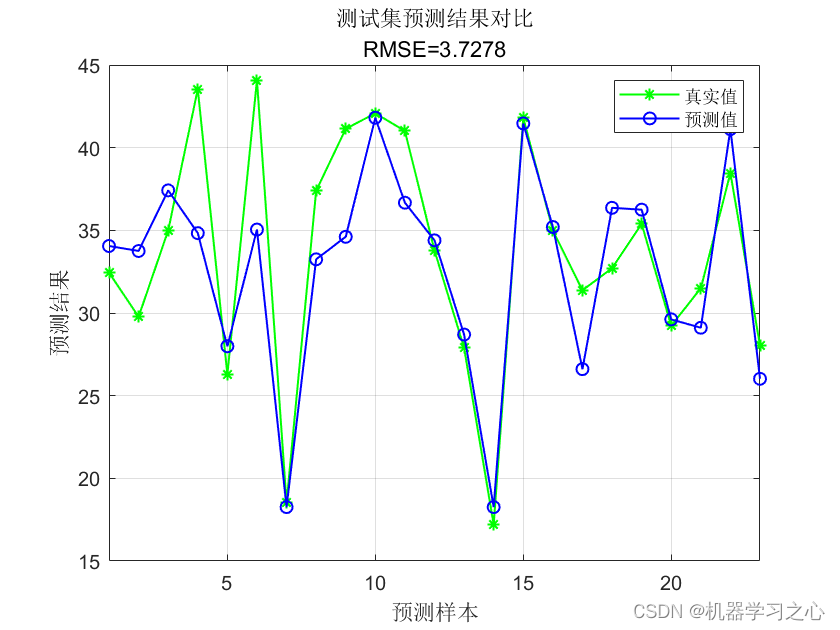
回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图)
回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图) 目录 回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图)效果…...

Qt/C++视频监控安卓版/多通道显示视频画面/录像存储/视频播放安卓版/ffmpeg安卓
一、前言 随着监控行业的发展,越来越多的用户场景是需要在手机上查看监控,而之前主要的监控系统都是在PC端,毕竟PC端屏幕大,能够看到的画面多,解码性能也强劲。早期的手机估计性能弱鸡,而现在的手机性能不…...

【docker】容器使用(Nginx 示例)
查看 Docker 客户端命令选项 docker上面这三张图都是 常用命令: run 从映像创建并运行新容器exec 在运行的容器中执行命令ps 列出容器build 从Dockerfile构建映像pull 从注册表下载图像push 将图像上载到注册表…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...