【Spring】八种常见Bean加载方式
🚩本文已收录至专栏:Spring家族学习
一.引入
(1) 概述
关于bean的加载方式,spring提供了各种各样的形式。因为spring管理bean整体上来说就是由spring维护对象的生命周期,所以bean的加载可以从大的方面划分成2种形式:
- 已知类通过(
类名.class)交给spring管理 - 已知类名通过(
类名字符串)并交给spring管理。
两种形式内部其实都一样,都是通过spring的BeanDefinition对象初始化spring的bean。
- bean的定义由前期xml配置逐步演化成注解配置,本质是一样的,都是通过反射机制加载类名后创建对象,对象就是spring管控的bean
- @Import注解可以指定加载某一个类作为spring管控的bean,如果被加载的类中还具有@Bean相关的定义,会被一同加载
- spring开放出了若干种可编程控制的bean的初始化方式,通过分支语句由固定的加载bean转成了可以选择bean是否加载或者选择加载哪一种bean
本文介绍八种常见的bean加载方式:
- xml
- xml+注解
- 注解
- @Import导入
- 使用register方法编程形式注册
- @Import导入实现ImportSelector接口的类
- @Import导入实现ImportBeanDefinitionRegistrar接口的类
- @Import导入实现BeanDefinitionRegistryPostProcessor接口的类
此外还介绍一些相关涉及知识
- @Bean定义FactoryBean接口
- @ImportResource
- @Configuration注解的proxyBeanMethods属性
(2) 环境搭建
在开始讲解之前,我们需要先介绍一下测试所用的环境。
- 创建Maven工程,可以选择导入如下Spring坐标用于测试
<dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.3.9</version></dependency>
<!-- 演示加载第三方bean--><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version></dependency>
- 创建一些用于后续示例演示的bean
二.八种加载方式
(1) XML方式
最初级的bean的加载方式其实可以直击spring管控bean的核心思想,就是提供类名,然后spring就可以管理了。所以第一种方式就是给出bean的类名,至于内部就是通过反射机制加载成class。
- 创建Spring的xml配置文件,通过其中的
<bean/>标签加载bean,我们可以在其中声明加载自己创建的bean,也可以加载第三方开发的bean。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><!--xml方式声明 自己 开发的bean--><bean class="com.guanzhi.bean.Cat"/><bean class="com.guanzhi.bean.Dog"/><!--xml方式声明 第三方 开发的bean--><bean class="com.alibaba.druid.pool.DruidDataSource"/></beans>
- 我们可以测试一下是否成功加载了这些bean
public class App {public static void main(String[] args) {// 加载配置文件ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");// 获取所有已加载bean的名称String[] names = ctx.getBeanDefinitionNames();// 打印查看for (String name : names) {System.out.println(name);}}
}
- 启动我们可以发现成功加载到了上述配置的三个bean

(2) XML+注解方式
由于方式一种需要将spring管控的bean全部写在xml文件中,对于程序员来说非常不友好,所以就有了第二种方式。哪一个类要受到spring管控加载成bean,就在这个类的上面加一个注解,还可以顺带起一个bean的名字(id)。这里可以使用的注解有@Component以及三个衍生注解@Service、@Controller、@Repository。
- 例如我们可以在上述Cat类和Mouse类中加上注解
package com.guanzhi.bean;@Component("tom")
public class Cat {
}
package com.guanzhi.bean;@Service
public class Mouse {
}
当然,由于我们无法在第三方提供的技术源代码中去添加上述4个注解,因此当你需要加载第三方开发的bean的时候可以使用下列方式定义注解式的bean。将@Bean定义在一个方法上方,当前方法的返回值就可以交给spring管控,注意,这个方法所在的类一定要定义在@Configuration修饰的类中。
package com.guanzhi.config;@Configuration
public class DbConfig {@Beanpublic DruidDataSource dataSource(){DruidDataSource ds = new DruidDataSource();return ds;}
}
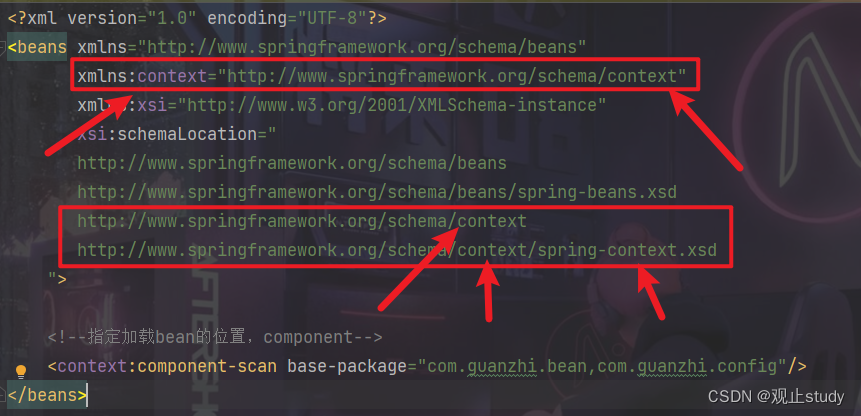
2. 仅仅如此还是不够,上面提供的只是bean的声明,spring并没有感知到这些东西。想让spring感知到这些声明,必须设置spring去检查这些类。我们可以通过下列xml配置设置spring去检查哪些包,发现定了对应注解,就将对应的类纳入spring管控范围,声明成bean。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:context="http://www.springframework.org/schema/context"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context.xsd"><!--指定扫描加载bean的位置--><context:component-scan base-package="com.guanzhi.bean,com.guanzhi.config"/>
</beans>
- 同样我们可以测试一下是否成功加载了这些bean
public class App {public static void main(String[] args) {// 加载配置文件ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");// 获取所有已加载bean的名称String[] names = ctx.getBeanDefinitionNames();// 打印查看for (String name : names) {System.out.println(name);}}
}
- 启动我们可以发现成功加载到了上述配置的三个bean

方式二声明bean的方式是目前企业中较为常见的bean的声明方式,但是也有缺点。方式一中,通过一个配置文件,你可以查阅当前spring环境中定义了多少个或者说多少种bean,但是方式二没有任何一个地方可以查阅整体信息,只有当程序运行起来才能感知到加载了多少个bean。
(3) 注解方式声明配置类
方式二已经完美的简化了bean的声明,以后再也不用写茫茫多的配置信息了。仔细观察xml配置文件,会发现这个文件中只剩了扫描包这句话,于是就有人提出,使用java类替换掉这种固定格式的配置,所以下面这种格式就出现了。
- 定义一个类并使用
@ComponentScan替代原始xml配置中的包扫描这个动作,其实功能基本相同。
@ComponentScan({"com.guanzhi.bean","com.guanzhi.config"})
public class SpringConfig {
}
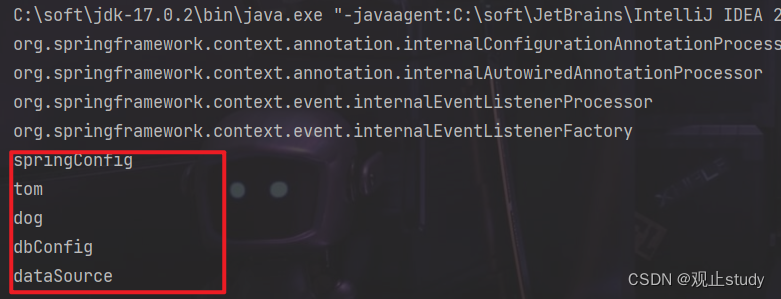
- 同样我们可以测试一下是否成功加载了这些bean
public class App {public static void main(String[] args) {// 加载配置文件ApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);// 获取所有已加载bean的名称String[] names = ctx.getBeanDefinitionNames();// 打印查看for (String name : names) {System.out.println(name);}}
}
- 启动我们可以发现成功加载了这些bean
(4) @Import注解注入
使用扫描的方式加载bean是企业级开发中常见的bean的加载方式,但是由于扫描的时候不仅可以加载到你要的东西,还有可能加载到各种各样的乱七八糟的东西。
有人就会奇怪,会有什么问题呢?比如你扫描了com.guanzhi.service包,后来因为业务需要,又扫描了com.guanzhi.dao包,你发现com.guanzhi包下面只有service和dao这两个包,这就简单了,直接扫描com.guanzhi就行了。但是万万没想到,十天后你加入了一个外部依赖包,里面也有com.guanzhi包,这下便加载了许多不需要的东西。
所以我们需要一种精准制导的加载方式,使用@Import注解就可以解决你的问题。它可以加载所有的一切,只需要在注解的参数中写上加载的类对应的.class即可。有人就会觉得,还要自己手写,多麻烦,不如扫描好用。 但是他可以指定加载啊,好的命名规范配合@ComponentScan可以解决很多问题,但是@Import注解拥有其重要的应用场景。有没有想过假如你要加载的bean没有使用@Component修饰呢?这下就无解了,而@Import就无需考虑这个问题。
@Import({Dog.class})
public class SpringConfig {
}
被导入的bean无需使用注解声明为bean
public class Dog {
}
此形式可以有效的降低源代码与Spring技术的耦合度,在spring技术底层及诸多框架的整合中大量使用
除了加载bean,还可以使用@Import注解加载配置类。其实本质上是一样的。
@Import(Dbconfig.class)
public class SpringConfig {
}
(5) 编程形式注册bean
前面介绍的加载bean的方式都是在容器启动阶段完成bean的加载,下面这种方式就比较特殊了,可以在容器初始化完成后手动加载bean。通过这种方式可以实现编程式控制bean的加载。
public class App {public static void main(String[] args) {AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);//上下文容器对象已经初始化完毕后,手工加载beanctx.register(Mouse.class);ctx.register(Dog.class);ctx.register(Cat.class);}
}
其实这种方式坑还是挺多的,比如容器中已经有了某种类型的bean,再加载会不会覆盖呢?这都是要思考和关注的问题。
public class App {public static void main(String[] args) {AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);//上下文容器对象已经初始化完毕后,手工加载beanctx.registerBean("tom", Cat.class,0);ctx.registerBean("tom", Cat.class,1);ctx.registerBean("tom", Cat.class,2);System.out.println(ctx.getBean(Cat.class));}
}
运行可以发现,后加载的覆盖了之前加载的

(6) 导入实现ImportSelector接口的类
在方式五中,我们感受了bean的加载可以进行编程化的控制,添加if语句就可以实现bean的加载控制了。但是毕竟是在容器初始化后实现bean的加载控制,那是否可以在容器初始化过程中进行控制呢?答案是必须的。实现ImportSelector接口的类可以设置加载的bean的全路径类名,记得一点,只要能编程就能判定,能判定意味着可以控制程序的运行走向,进而控制一切。
public class MyImportSelector implements ImportSelector { @Overridepublic String[] selectImports(AnnotationMetadata metadata) {// 各种条件的判定,判定完毕后,决定是否装载指定的bean// 判断是否满足xx条件,满足则加载xx,否则xxboolean flag = metadata.hasAnnotation("org.springframework.context.annotation.Configuration");if(flag){return new String[]{"com.guanzhi.bean.Dog"};}return new String[]{"com.guanzhi.bean.Cat"};}
}在配置类中导入
//@Configuration
@Import(MyImportSelector.class)
public class SpringConfig {
}
编写测试类
public class App {public static void main(String[] args) {ApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);String[] names = ctx.getBeanDefinitionNames();for (String name : names) {System.out.println(name);}System.out.println("----------------------");}
}
运行可以发现,根据MyImportSelector中的判断条件,如果在SpringConfig加上Configuration注解得打印com.guanzhi.bean.Cat,否则打印com.guanzhi.bean.Dog。如此我们便实现了Bean的动态加载。
(7) 导入实现ImportBeanDefinitionRegistrar接口的类
方式六中提供了给定类全路径类名控制bean加载的形式,如果对spring的bean的加载原理比较熟悉的小伙伴知道,其实bean的加载不是一个简简单单的对象,spring中定义了一个叫做BeanDefinition的东西,它才是控制bean初始化加载的核心。BeanDefinition接口中给出了若干种方法,可以控制bean的相关属性。说个最简单的,创建的对象是单例还是非单例,在BeanDefinition中定义了scope属性就可以控制这个。
如果你感觉方式六没有给你开放出足够的对bean的控制操作,那么方式七你值得拥有。我们可以通过定义一个类,然后实现ImportBeanDefinitionRegistrar接口的方式定义bean,并且还可以让你对bean的初始化进行更加细粒度的控制.

public class MyRegistrar implements ImportBeanDefinitionRegistrar {@Overridepublic void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) {BeanDefinition beanDefinition = BeanDefinitionBuilder.rootBeanDefinition(Dog.class).getBeanDefinition();registry.registerBeanDefinition("dog",beanDefinition);}
}
在配置类中导入
@Import(MyRegistrar.class)
public class SpringConfig {
}
测试
public class App {public static void main(String[] args) {ApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);String[] names = ctx.getBeanDefinitionNames();for (String name : names) {System.out.println(name);}}
}(8) 导入实现BeanDefinitionRegistryPostProcessor接口的类
上述七种方式都是在容器初始化过程中进行bean的加载或者声明,但是这里有一个bug。这么多种方式,它们之间如果有冲突怎么办?谁能有最终裁定权?这是个好问题,当某种类型的bean被接二连三的使用各种方式加载后,在你对所有加载方式的加载顺序没有完全理解清晰之前,你还真不知道最后谁说了算。
BeanDefinitionRegistryPostProcessor,看名字知道,BeanDefinition意思是bean定义,Registry注册的意思,Post后置,Processor处理器,全称bean定义后处理器,在所有bean注册都加载完后,它是最后一个运行的,实现对容器中bean的最终裁定.
public class MyPostProcessor implements BeanDefinitionRegistryPostProcessor {@Overridepublic void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {BeanDefinition beanDefinition = BeanDefinitionBuilder.rootBeanDefinition(Dog.class).getBeanDefinition();registry.registerBeanDefinition("Dog",beanDefinition);}
}使用与上述一致
三.相关补充
(1) FactroyBean接口
spring提供了一个接口FactoryBean,也可以用于声明bean,只不过实现了FactoryBean接口的类造出来的对象不是当前类的对象,而是FactoryBean接口泛型指定类型的对象。如下列,造出来的bean并不是DogFactoryBean,而是Dog。这有什么用呢?它可以帮助我们在对象初始化前做一些事情。
// 创建一个类实现FactoryBean接口
public class DogFactoryBean implements FactoryBean<Dog> {@Overridepublic Dog getObject() throws Exception {Dog dog = new Dog();// 扩展要做的其他事情.....return dog;}@Overridepublic Class<?> getObjectType() {return Dog.class;}// 是否为单例@Overridepublic boolean isSingleton() {return true;}
}
有人说,注释中的代码写入Dog的构造方法不就行了吗?干嘛这么费劲转一圈,还写个类,还要实现接口,多麻烦啊。还真不一样,你可以理解为Dog是一个抽象后剥离的特别干净的模型,但是实际使用的时候必须进行一系列的初始化动作。只不过根据情况不同,初始化动作不同而已。如果写入Dog,或许初始化动作A当前并不能满足你的需要,这个时候你就要做一个DogB的方案了。如此,你就要做两个Dog类。而使用FactoryBean接口就可以完美解决这个问题。
通常实现了FactoryBean接口的类使用@Bean的形式进行加载,当然也可以使用@Component去声明DogFactoryBean,只要被扫描加载到即可。
@ComponentScan({"com.guanzhi.bean","com.guanzhi.config"})
public class SpringConfig {@Beanpublic DogFactoryBean dog(){return new DogFactoryBean();}
}
(2) 注解导入XML配置的bean
由于早起开发的系统大部分都是采用xml的形式配置bean,现在的企业级开发基本上不用这种模式了。但是如果你特别幸运,需要基于之前的系统进行二次开发,这就尴尬了。新开发的用注解格式,之前开发的是xml格式。这个时候可不是让你选择用哪种模式的,而是两种要同时使用。spring提供了一个注解可以解决这个问题,@ImportResource,在配置类上直接写上要被融合的xml配置文件名即可,算的上一种兼容性解决方案。
@Configuration
@ComponentScan("com.guanzhi")
@ImportResource("applicationContext.xml")
public class SpringConfig {
}
(3) proxyBeanMethods属性
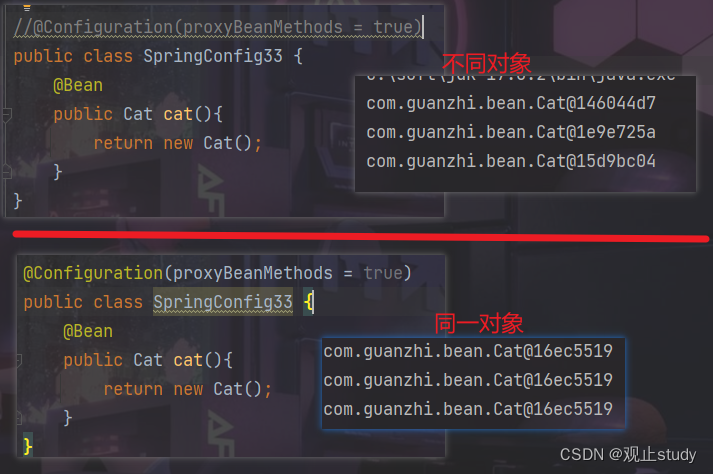
前面的例子中用到了@Configuration这个注解,它可以保障配置类中使用方法创建的bean的唯一性,使我们得到的对象是从容器中获取的而不是重新创建的。只需为@Configuration注解设置proxyBeanMethods属性值为true即可,由于此属性默认值为true,所以很少看见明确书写的,除非想放弃此功能。
@Configuration(proxyBeanMethods = true)
public class SpringConfig {@Beanpublic Cat cat(){return new Cat();}
}
下面通过容器再调用上面的cat方法时,得到的就是同一个对象了。注意,必须使用spring容器对象调用此方法才有保持bean唯一性的特性。此特性在很多底层源码中有应用,在MQ中也应用了此特性。
public class App {public static void main(String[] args) {ApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);SpringConfig springConfig = ctx.getBean("springConfig", SpringConfig.class);System.out.println(springConfig.cat());System.out.println(springConfig.cat());System.out.println(springConfig.cat());}
}
相关文章:
【Spring】八种常见Bean加载方式
🚩本文已收录至专栏:Spring家族学习 一.引入 (1) 概述 关于bean的加载方式,spring提供了各种各样的形式。因为spring管理bean整体上来说就是由spring维护对象的生命周期,所以bean的加载可以从大的方面划分成2种形式ÿ…...

第五回:样式色彩秀芳华
import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np第五回详细介绍matplotlib中样式和颜色的使用,绘图样式和颜色是丰富可视化图表的重要手段,因此熟练掌握本章可以让可视化图表变得更美观,突出重点和凸显艺术性。…...

关于@Test单元测试
1、关于doReturndoReturn(new Test()).when(testService).updateStatusByLock(any(), any());在单元测试里这个方法可以执行到这里之间跳过不去执行,返回你想要的返回值2、关于givengiven(user.getName(any())).willReturn("张三");在单元测试里这个方法 …...

【项目实战】WebFlux整合r2dbc-mysql实战
一、背景 Webflux虽然是响应式的,但是没办法,JDBC是基于阻塞IO实现的,所以无法真正的威力发挥不出来。 但是,Webflux一旦整合了R2DBC之后,那么它将不再受限于数据库连接了,真正打通了响应式应用的任督二脉,性能才被释放。 当然,除了Spring推出的R2DBC协议,还有Orac…...

go版本分布式锁redsync使用教程
redsync使用教程前言redsync结构Pool结构Mutex结构acquire加锁操作release解锁操作redsync包的使用前言 在编程语言中锁可以理解为一个变量,该变量在同一时刻只能有一个线程拥有,以便保护共享数据在同一时刻只有一个线程去操作。对于高可用的分布式锁应…...

大数据之Hudi数据湖_大数据治理_简介_发展历史_特性_应用场景---大数据之Hudi数据湖工作笔记0001
支持hive spark flink 美国公司开发的~ 都在使用,这些企业都在用 支持hadoop的,更新,插入,删除 和数据增量处理 支持流式数据处理. hive是离线数仓 hive不支持事物 insert overwrite 底层后来通过这种方式支持了事物 insert overwrite处理数据很低效,因为更新是基于覆盖实现…...

射频功率放大器基于纵向导波的杆状构件腐蚀诊断方法的研究
实验名称:基于纵向导波的杆状构件腐蚀诊断方法研究方向:无损探伤测试设备:信号号发生器、安泰ATA-8202功率放大器、数据采集卡、直流电源、超声探头、钢杆、前置放大器。实验过程:图:试验装置试验装置如图3.2所示。监测…...
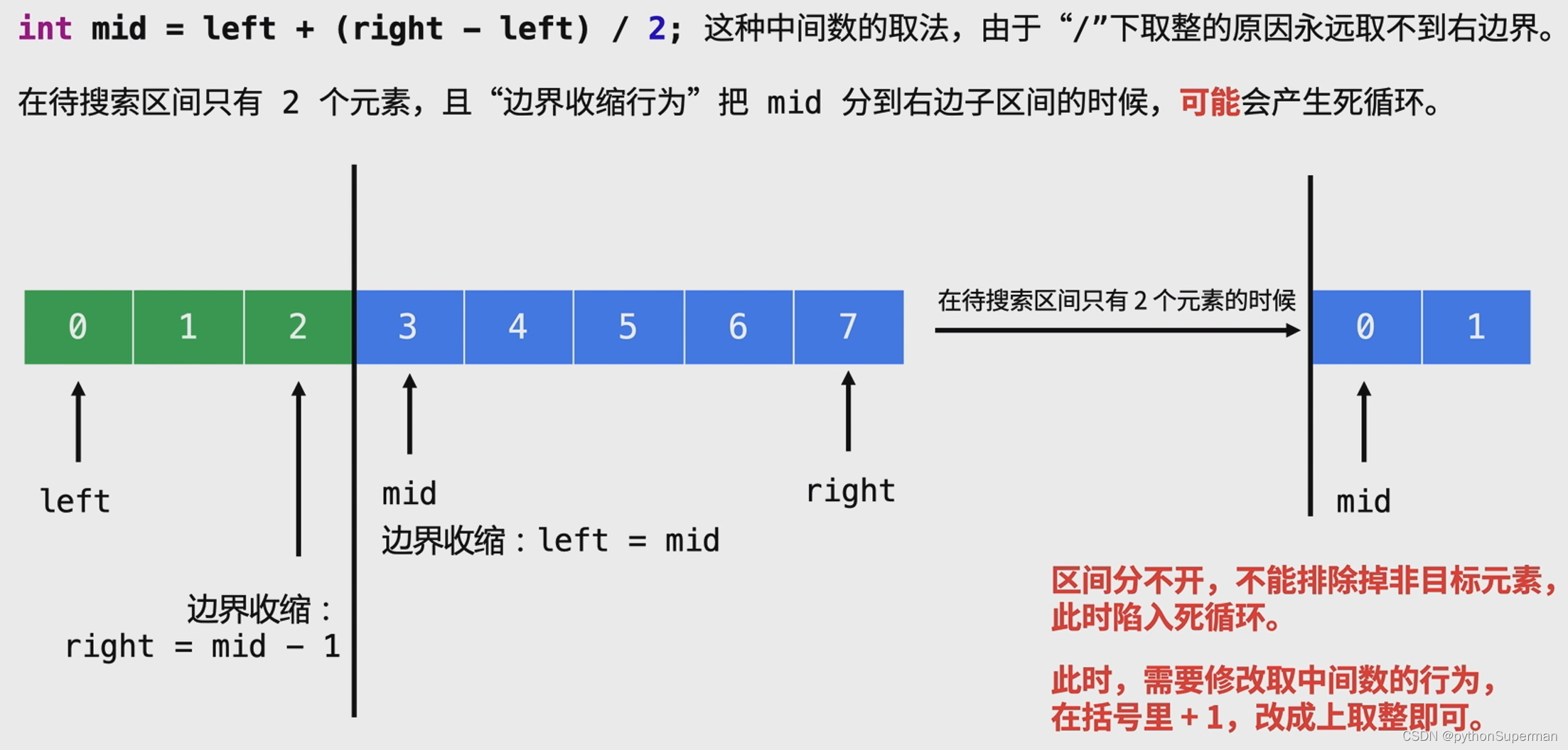
Leedcode 二分查找 理解1
一个up的理解 一、二分查找基础例题 力扣https://leetcode.cn/problems/binary-search/ 二、二分查找模板问题 带搜索区间分为3个部分: 1、[mid],直接返回 2、[left,mid-1],设置边界right mid - 1 3、[mid1,right]&#x…...

【告别篇】大家好,再见了,我转行了,在筹备创业
前言 相信大家也一直看到我的博客没有更新过了,我其实很久没有打开过博客了,也就意味着我很长一段时间都在停滞不前,没有了学习的动力。 现在我上来是想跟大家告个别 : 很多粉丝宝宝的私信我看了,但是没有回…...

Java——岛屿数量
题目链接 leetcode在线oj题——岛屿数量 题目描述 给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相…...

《代码整洁之道》笔记
1章:专业人士要有专业人士素养,要有责任心,编写代码尽可能完善没有bug,有bug也要勇于承担。坚持学习,坚持练习,保证自己的专业技能。谦虚,相互学习,与顾客达成一致2章:说…...
个人网站如何集成QQ快捷登录功能?
目录 一、网站集成QQ快捷登录的好处 二、网站接入QQ快捷登录具体步骤 (1)登录到QQ互联官网 (2)进行个人开发者认证 (3)创建网站应用 (4)填写网站资料 三、如何在本地开发环境…...
从工厂打螺丝到月薪18k测试工程师,我该满足吗?
以前我比较喜欢小米那句“永远相信美好的事情即将发生”,后来发现如果不努力不可能有美好的事情发生!01高中毕业进厂5年,创业经商多次战败,为了生计辗转奔波高中毕业后我就进了工厂,第一份工作是做模具加工。从500元一…...

【相关分析-高阶绘图】MATLAB实现皮尔逊相关分析-散点直方图
虽然皮尔逊相关分析很常见,但如何更好的展现相关性、散点分布、柱状分布,以提升研究结果的美感和冲击感呢?本文拟通过MATLAB绘制包含散点分布、柱状分布、线性展示的散点直方图,有助于审稿人眼前一亮。 1、Pearson相关系数原理 Pearson相关系数(Pearson Correlation Co…...

Spark性能优化二 Shuffle机制分析
(一) 什么情况下发生shuffle 在MapReduce框架中,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。在整个shuffle过程中,…...
软测入门(四)Appium-APP移动测试基础
Appium 用来测试手机程序。 测试方面: 功能测试安装卸载测试升级测试兼容测试 Android系统版本不同分辨率不同网络 网络切换、中断测试使用中来电话、短信横竖屏切换 环境搭建 Java安装(查资料)Android SDK安装,配置 HOME和P…...

华为OD机试用Python实现 -【集五福】 |老题且简单
华为OD机试题 最近更新的博客华为 OD 机试 300 题大纲集五福题目描述输入描述输出描述示例一输入输出示例二输入输出代码编写思路Python 代码最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典...

Typro使用以及安装教程来啦
Typora是一款轻便简洁的Markdown编辑器,支持即时渲染技术,这也是与其他Markdown编辑器最显著的区别。即时渲染使得你写Markdown就想是写Word文档一样流畅自如,不像其他编辑器的有编辑栏和显示栏。今天为大家分享下有关Typroa的安装以及使用&a…...

武汉凯迪正大KD305系列智能数字绝缘电阻测试仪
一、概述 KD305系列智能数字绝缘电阻测试仪采用嵌入式工业单片机实时操作系统,数字模拟指针与数字段码显示结合,该系列表具有多种电压输出等级(500V、1000V、2500V、5000V、10000V)、容量大、抗干扰强、模拟指针与数字同步显示、交…...

如何使用码匠连接 Redis
目录 在码匠中集成 Redis 在码匠中使用 Redis 关于码匠 Redis 是由 Salvatore Sanfilippo 用 C 语言开发的一款开源的、高性能的键值对存储数据库,它采用 BSD 协议,为了适应不同场景下的存储需求,提供了多种键值数据类型。到目前为止&…...

文章目录汇总
文章目录1. 编程语言1.1 C 语言1.2 Capl 编程1.3 Python 编程2. 工具使用手册2.1 编辑器2.1.1 Vscode02.1.2 PyCharm2.1.3 Notepad2.2 版本管控2.2.1 Git2.2.2 Svn2.2.3 Source tree2.3 软件开发2.3.1 ISOLAR2.3.2 EB2.3.3 PLS UDE2.3.4 Beyond Compare2.4 软件调试2.4.1 CANoe…...

Ollama本地模型全攻略:从下载到Python调用,手把手教你玩转千问2
Ollama本地模型全攻略:从下载到Python调用,手把手教你玩转千问2 在人工智能技术快速发展的今天,本地运行大型语言模型已成为许多开发者和技术爱好者的新选择。Ollama作为一个轻量级的本地模型运行工具,让用户能够轻松下载和管理各…...
)
从科研到消费级:EEG技术如何通过Muse头环走进日常生活(含最新Muse S Athena评测)
从实验室到客厅:EEG技术如何通过消费级设备重塑健康生活 站在多伦多大学实验室的走廊里,我盯着墙上那张泛黄的脑电图记录纸——那是上世纪70年代一台重达半吨的EEG设备输出的结果。如今,同样的脑电波监测技术,已经被装进重量不到1…...

互联网产品经理利器:MiniCPM-V-2_6快速生成PRD与用户画像
互联网产品经理利器:MiniCPM-V-2_6快速生成PRD与用户画像 作为一名在互联网行业摸爬滚打多年的产品人,我深知产品策划初期的痛苦。面对一个模糊的想法,要从零开始梳理需求、分析用户、撰写文档,这个过程往往耗时耗力,…...

Windows系统下非Docker方式快速搭建Ollama与Open WebUI大模型运行环境
1. 环境准备:Windows系统的基础配置 在Windows系统上搭建大模型运行环境,首先需要确保你的电脑满足基本硬件要求。根据我的实测经验,至少需要16GB内存才能流畅运行Llama3这类8B参数的模型。如果打算尝试更大的模型(如70B版本&…...

Python 3.15多解释器隔离配置终极对照表:CPython 3.14 vs 3.15 vs 3.15.1-beta2,12项关键行为变更速查
第一章:Python 3.15多解释器隔离配置的演进背景与核心定位Python 3.15 引入的多解释器(PEP 684)增强支持,标志着 CPython 运行时在并发模型上的范式跃迁。此前,GIL(全局解释器锁)将整个进程绑定…...

3步搭建本地智能图像检索工具:千万级图库秒级搜索实战指南
3步搭建本地智能图像检索工具:千万级图库秒级搜索实战指南 【免费下载链接】ImageSearch 基于.NET8的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 在数字内容爆炸的时代&…...
)
别再傻等通知了!一个浏览器脚本帮你自动抢到AutoDL的GPU(附完整代码)
深度学习开发者必备:AutoDL GPU资源实时监控与自动抢占方案 在深度学习模型训练和推理过程中,GPU资源的重要性不言而喻。然而,对于许多独立开发者、学生和研究团队来说,获取稳定的GPU计算资源始终是个挑战。AutoDL作为国内领先的G…...

MusePublic开发者实测:Windows平台CUDA 12.1兼容性完整报告
MusePublic开发者实测:Windows平台CUDA 12.1兼容性完整报告 最近在Windows上折腾AI绘画工具的朋友,可能都绕不开一个头疼的问题:CUDA版本。新模型、新框架层出不穷,但CUDA版本不匹配,轻则报错,重则直接无法…...

Ruoyi-vue-plus多租户权限管理避坑指南:7个常见问题及解决方案
Ruoyi-vue-plus多租户权限管理实战:7个关键问题与深度解决方案 在SaaS系统开发领域,多租户架构已成为企业级应用的标准配置。作为国内流行的快速开发框架,Ruoyi-vue-plus提供了完善的多租户解决方案,但在实际落地过程中࿰…...