Video anomaly detection with spatio-temporal dissociation 论文阅读
Video anomaly detection with spatio-temporal dissociation
- 摘要
- 1.介绍
- 2.相关工作
- 3. Methods
- 3.1. Overview
- 3.2. Spatial autoencoder
- 3.3. Motion autoencoder
- 3.4. Variance attention module
- 3.5. Clustering
- 3.6. The training objective function
- 4. Experiments
- 5. Conclusion
- 6阅读总结&&代码复现
文章信息:

发表于:Pattern Recognition(CCF A类)
原文链接:https://www.sciencedirect.com/science/article/pii/S0031320321003940
源代码:https://github.com/ChangYunPeng/VideoAnomalyDetection
摘要
视频中的异常检测仍然是一项具有挑战性的任务,主要由于异常的定义模糊不清以及真实视频数据中视觉场景的复杂性。
与以往利用重建或预测作为辅助任务来学习时间规律的方法不同,本研究探索了一种新颖的卷积自编码器架构,该架构能够分离时空表示,以分别捕捉空间和时间信息,因为异常事件通常在外观和/或运动行为方面与正常情况不同。具体而言,空间自编码器通过学习重构第一个个体帧(FIF)的输入来对外观特征空间中的正常性建模,而时间部分以前四个连续帧作为输入,并以RGB差异作为输出,以有效模拟光流的运动。外观和/或运动行为上的异常事件导致较大的重构误差。
为了提高对快速移动的异常值的检测性能,我们利用基于方差的注意力模块,并将其插入到运动自编码器中以突显移动较大的区域。
此外,我们提出了一种深度K均值聚类策略,强制空间和运动编码器提取紧凑的表示。对一些公开可用的数据集进行的广泛实验证明了我们的方法的有效性,达到了当前最先进的性能水平。
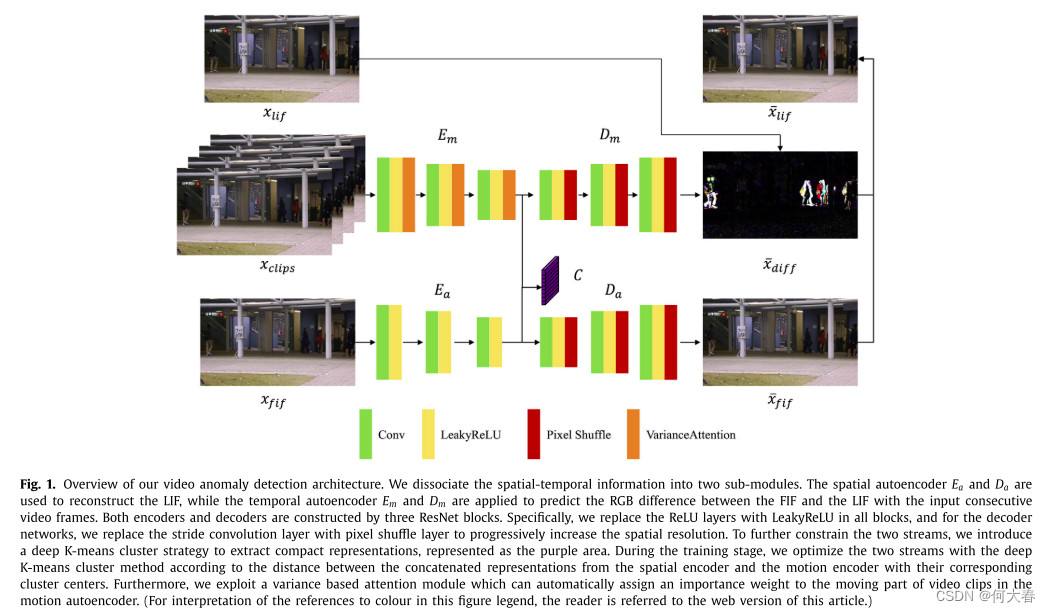
图1:我们的视频异常检测架构概述。我们将时空信息分解为两个子模块。空间自动编码器 E a E_a Ea和 D a D_a Da用于重建LIF,而时间自动编码器 E m E_m Em和 D m D_m Dm用于预测输入连续视频帧的FIF和LIF之间的RGB差。编码器和解码器都由三个ResNet块构成。具体来说,我们在所有块中用LeakyReLU替换ReLU层,对于解码器网络,我们用像素混洗层替换步长卷积层,以逐步提高空间分辨率。为了进一步约束这两个流,我们引入了一种深度K均值聚类策略来提取紧凑表示,表示为紫色区域。在训练阶段,我们根据空间编码器和运动编码器的级联表示与其对应的聚类中心之间的距离,使用深度K均值聚类方法对两个流进行优化。此外,我们开发了一个基于方差的注意力模块,该模块可以在运动自动编码器中自动为视频片段的运动部分分配重要性权重。(有关此图例中颜色参考的解释,读者可参考本文的网络版本。)
1.介绍
在这项工作中,我们将时空信息分解为两个子模块,以在空间和时间特征空间中同时学习规律。给定连续的视频帧,空间自编码器在**第一个个体帧(FIF)**上运行,而运动自编码器在前四个视频帧上运行。
空间自编码器以单个帧外观的形式呈现有关视频中场景和对象的信息,而运动自编码器生成最后视频帧(LIF)和FIF之间的RGB差异,以获取运动信息。然后,我们将来自空间自编码器的重建结果与来自时态自编码器的RGB差异组合起来得到最终预测。
如图1所示,我们的两个子模块可以同时学习外观和运动规律。无论事件在外观特征空间还是运动特征空间中是否不规律,都将产生较大的重建误差。特别是,先前的研究[7,10,11]还利用了双流架构进行异常检测,其运动流主要通过生成或重建相应的光流来学习运动表示。然而,由于光流并非专门为异常检测而设计,因此光流可能不是学习规律的最佳选择[1,12]。此外,光流估计具有很高的计算成本。为了克服这些缺点,我们的运动自编码器以连续的视频帧作为输入,以它们的RGB差异作为输出来学习运动信息[13],其中RGB差异提示可以比光流更快地捕捉运动信息,并且运动自编码器的生成可以很容易地与空间自编码器的重建进行逐像素融合,以进一步帮助异常检测。值得注意的是,监控视频的大部分是静止的,异常值通常与快速移动具有很高的相关性,例如在地铁入口快速奔跑的行人和在人行道上快速驾驶的车辆。因此,我们利用基于方差的注意力模块来自动突出显示具有大运动的图像区域,并在运动编码器的每个块之后附加此注意力模块。此外,类似于先前的工作[14],该工作通过使用K均值算法[15]将正常训练样本聚类成k个簇,我们引入了一种深度K均值聚类策略来强制空间编码器和时态编码器获得更紧凑的数据表示。具体而言,我们使用K均值算法初始化我们的簇中心。
总的来说,我们的工作做出了以下贡献:
- 我们提出了一种新颖的自编码器架构,以分离时空表示,并在空间特征空间和运动特征空间中学习规律,从而检测视频中的异常事件。
- 我们设计了一个高效的运动自编码器,它以连续的视频帧作为输入,以RGB差异作为输出,以模仿光流的运动。所提出的方法比基于光流的运动表示学习方法更快,其平均运行时间为每秒32帧,使用一块GPU。
- 我们利用一个方差注意力模块,自动为视频剪辑的运动部分分配重要性权重,这有助于提高运动自编码器的性能。
- 我们探索了一种深度K均值聚类策略,以迫使自编码器网络生成紧凑的运动和外观描述符。由于簇仅在正常事件上进行训练,因此簇与异常表示之间的距离比正常模式之间的距离要大得多。重建误差和簇距离一起被用于评估异常情况。
2.相关工作
2.1. 基于自编码器的异常检测
由于现实数据的复杂性和有效标记数据的限制,异常事件检测任务通常在无监督设置下进行,其中训练集仅包含正常事件。大多数基于深度学习的方法使用自编码器[17–20]来提取特征表示,并采用基于重建或基于预测的方法来学习视频序列背后的正常性。基于重建的异常检测方法将给定的视频帧作为输入,通过提取高级特征表示学习以小的重建误差重构正常事件[1]。应用2D卷积自编码器来降低维度并学习时态规律[21–23]。使用相邻帧的时态一致性先验来训练自编码器网络[24]。引入了无标签监督,结合了约束学习和物理领域知识,共同解决了包括对象跟踪和行走人在内的三个计算机视觉任务[5]。使用编码器LSTM提取特征,并应用解码器LSTM进行重建,这种策略在顺序数据建模中被广泛使用。除了基于重建的方法,未来帧预测[3]是一种将异常视为不符合预期事件的替代深度学习方法。这些方法被训练以在正常训练数据集上基于其历史观察来预测未来帧,在测试阶段,通过将预测与期望进行比较来识别异常事件。我们还将自编码器作为骨干网络,并在正常数据集上对其进行训练,以提取通用因子。值得注意的是,我们同时结合了基于重建和基于预测的架构,通过同时重构输入的单个帧以捕捉外观特征,并预测未来帧与第一个输入帧之间的RGB差异来学习正常事件的运动模式。因此,在特征空间中包含不规则因素的异常样本无法准确重构。
2.2. 具有两个流网络的视频任务
为了充分利用视频任务中的空间和时间信息,[25]首次利用了双流网络,即RGB流和光流流,其中通过后期融合将两个流组合用于动作分类[26]。提出了一个带有两个网络分支的时空注意力模块,用于活动识别[8]。共同模拟人群模式的外观和动态,并在建模复杂动态场景中证明了双流架构的有效性。由于异常事件可以通过外观或运动来检测,[7]引入了用于视频异常检测的双流架构。此外,图像补丁和由光流表示的动态运动被用作两个独立网络的输入,分别捕获外观表示和运动表示,然后通过后期融合将这两个流的异常分数进行组合以进行最终评估[11]。利用两个生成器网络学习人群行为的正常模式,其中一个生成器网络接受输入帧以生成光流图像,而另一个生成器网络从光流中重构帧[10]。使用两个处理流,第一个自编码器学习正常事件中的常见空间外观结构,第二个流学习由光流表示的相应运动特征。除了直接以视频帧和光流为输入的方法外,MPEDRNN [27]提取2D人体骨骼轨迹并将这些轨迹馈送到编码器中,然后通过两个交互分支同时重构输入和预测未来,其中每个分支由带有RNN的编码器-解码器组成,以检测监控视频中的异常人类相关事件。然而,对于这些方法,获取光流[28]或轨迹是时间成本较高的。相比之下,我们利用RGB差异策略替代光流来模拟运动信息,这更加高效。具体而言,在训练阶段,我们堆叠除LIF外的所有其他帧,并使用2D CNN作为时态自编码器的骨干来处理连续的视频帧。通过强制运动编码器学习紧凑的运动表示并产生RGB差异,运动自编码器可以有效地学习时态规律和运动一致性。
2.3. 数据表示和数据聚类
许多异常检测方法[29-33]旨在在正常事件中找到“紧凑的描述”。最近,一些基于自动编码器的方法将特征学习和聚类结合在一起[34]。联合训练CNN自动编码器和多项式逻辑回归模型到自动编码器潜在空间。类似地,[35]交替表示学习和聚类,其中使用小批量k-Means作为聚类组件[36]。提出了一种深度嵌入式聚类(DEC)方法,该方法联合更新从预训练的自动编码器初始化的聚类中心和数据点表示。DEC使用经过优化的软分配,通过Kullback-Leibler发散损失来匹配更严格的分配。IDEC[37]和ST-GCAE[38]随后被提出作为DEC[14]的改进。提出了一种基于将训练样本聚类为正态性聚类的监督分类方法[39]。通过将各种模式的正常数据记录到存储器中的各个项目中,利用存储器模块进行异常检测。基于这种架构,并受到[40]思想的启发,我们引入了一个深度K-means聚类,以迫使自动编码器网络生成用于视频异常检测的紧凑特征表示。在训练阶段,我们通过最小化数据表示和聚类中心之间的距离来训练我们的深度K-means聚类。因此,每个聚类中心可以被视为训练数据集中的正常时空模式。在推理阶段,正态样本的表示将更紧密地映射到聚类中心。
3. Methods
3.1. Overview
主要有4个点
3.2. Spatial autoencoder
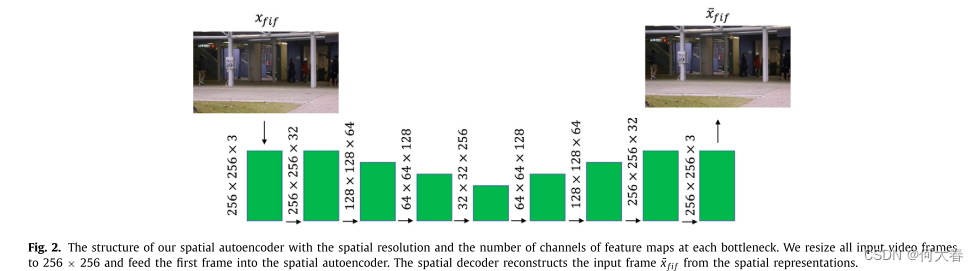
这是空间autoencoder,主要是重构视频序列的第一帧,用于重构视频的静态表示(理解为空间信息)。
输入为 x f i f x_{fif} xfif(视频序列第一帧),通过编码器 E a E_a Ea得到描述 Z a Z_a Za, Z a Z_a Za再经过解码器 D a D_a Da得到 x ^ f i f \widehat{x}_{fif} x fif,如下面公式所示:

这里有个loss,是输入输出的均方误差:

3.3. Motion autoencoder
Motion autoencoder的结构如图所示:
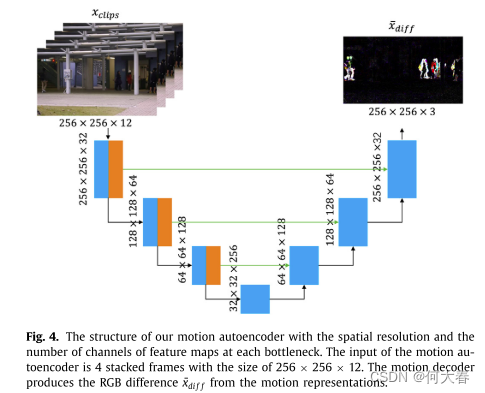
输入4张图片,Motion autoencoder的输出为第5帧和第1帧的RGB差异,通过这种方式来表示运动差异,得到运动上的重构。
如公式所示:


过编码器 E m E_m Em得到特征描述 Z m Z_m Zm, Z m Z_m Zm再经过解码器 D m D_m Dm得到 x ^ d i f f \widehat{x}_{diff} x diff。
其中 x ^ d i f f \widehat{x}_{diff} x diff为第5帧和第1帧的RGB差异。
这里的损失函数定义为:
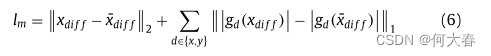
由两部分组成,前半部分是 x ^ d i f f \widehat{x}_{diff} x diff与 x d i f f x_{diff} xdiff的均方误差,后半部分是梯度损失。
3.4. Variance attention module
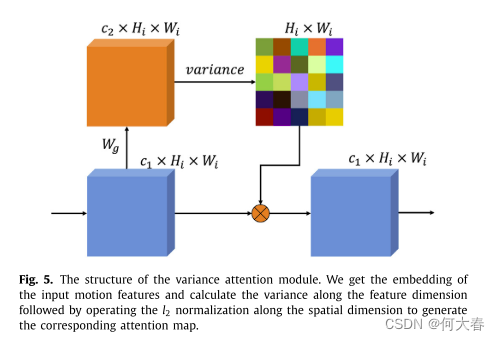
方差注意力模块如上图所示,个人感觉论文里写的不太好理解,去源码上看了一下主要就是以下步骤:
- 对输入进行一次卷积操作:
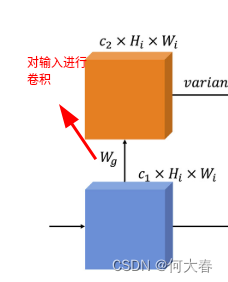
得到图中黄色的特征图,对应公式如下:其中 W g W_g Wg表示卷积, z m i z_m^i zmi表示输入。
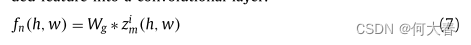
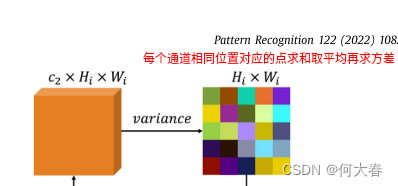
- 对每个通道相同位置对应的点求方差,得到通道的空间注意力权重
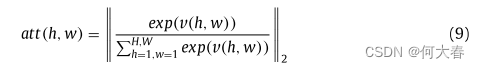
- 最后将注意力和原始输入相乘:
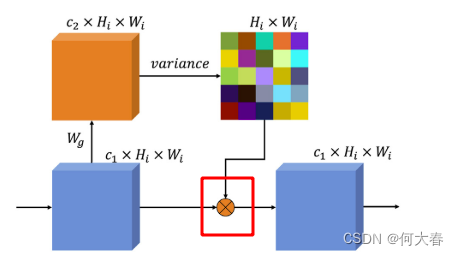
3.5. Clustering
对聚类的知识了解较少,只能理解为将两个编码器的输出进行聚类,能得到更好的正常表示。
3.6. The training objective function
损失函数有3个
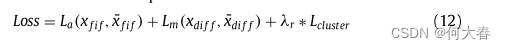
分别是静态损失,动态损失和聚类的损失。
4. Experiments
评价指标采用AUC:
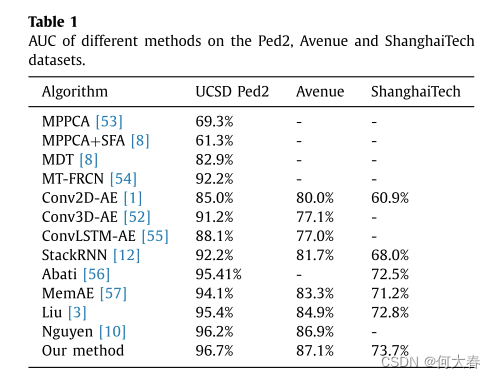
5. Conclusion
在本文中,我们提出了一种新的自动编码器架构,将时空信息分解为两个子模块,以学习空间和时间特征空间中的规律性,并在正常事件中生成紧凑的描述。具体地,
空间自动编码器对第一单独帧(FIF)进行操作,并通过重构输入来提取空间空间中的规则性。
时间自动编码器对连续的视频帧进行处理,通过构造RGB差来学习时间规律。根据捕获的时间规律性和运动一致性,时间自动编码器可以学习预测RGB残差,该残差包含用于异常检测的有用运动信息,非常有效。
此外,我们设计了一个方差注意力模块来突出框架的运动部分。此外,为了有效地学习空间和运动特征空间中的正规性,并获得更紧凑的数据表示,我们通过深度Kmeans聚类方法最小化级联表示与聚类中心之间的距离。我们将空间自动编码器和运动自动编码器的结果相结合,以获得最后一个单独帧(LIF)的预测,并将预测与像素级的聚类距离相融合,以评估异常。在三个具有代表性的数据集上进行的大量实验表明,我们的方法达到了最先进的性能。
6阅读总结&&代码复现
- 将空间和运动信息结合起来重构正常序列,时间编码器用于重构一帧,运动编码器用于重构最后一帧和第一帧的RGB差,用于代表运动信息,或者叫时间信息;
- 引入Kmeans聚类算法将空间和运动信息绑定;
- 设计了一个方差注意力模块。
复现结果如下图在ped2在数据集,和作者差了两个点:

相关文章:
Video anomaly detection with spatio-temporal dissociation 论文阅读
Video anomaly detection with spatio-temporal dissociation 摘要1.介绍2.相关工作3. Methods3.1. Overview3.2. Spatial autoencoder3.3. Motion autoencoder3.4. Variance attention module3.5. Clustering3.6. The training objective function 4. Experiments5. Conclusio…...

svn 安装
安装系统 ubuntu 22 安装命令: sudo apt-get install subversion 创建第一个工程: 创建版本库、项目 1、先创建svn根目录文件夹 sudo mkdir /home/svn 2、创建项目的目录文件夹 sudo mkdir /home/svn/demo_0 svnadmin create /home/svn/demo_0 配置&a…...
slurm 23.11.0集群 debian 11.5 安装
slurm 23.11.0集群 debian 11.5 安装 用途 Slurm(Simple Linux Utility for Resource Management, http://slurm.schedmd.com/ )是开源的、具有容错性和高度可扩展的Linux集群超级计算系统资源管理和作业调度系统。超级计算系统可利用Slurm对资源和作业进行管理&a…...
ffmpeg可以做什么
用途 FFmpeg是一个功能强大的多媒体处理工具,可以处理音频和视频文件。它是一个开源项目,可在各种操作系统上运行,包括Linux、Windows和Mac OS X等。以下是FFmpeg可以做的一些主要任务: 转换媒体格式:可将一个媒体格式…...
一种缩小数据之间差距的算法
先上代码: /** * 缩小数据之间的差距,但是大小关系不变的方法* param {Array} features */function minMaxData(data) {for (let i 0; i < data.length; i) {const f data[i];const x f[1];const yf[2];//此处5根据实际情况设置const y2 Math.pow(…...
【Axure RP9】动态面板使用------案例:包括轮播图和多方式登入及左侧菜单栏案例
目录 一 动态面板简介 1.1 动态面板是什么 二 轮播图 2.1 轮播图是什么 2.2 轮播图应用场景 2.3 制作实播图 三 多方式登入 3.1多方式登入是什么 3.3 多方式登入实现 四 左侧菜单栏 4.1左侧菜单栏是什么 4.2 左侧菜单栏实现 一 动态面板简介 1.1 动态面板是什么…...
在接口实现类中,加不加@Override的区别
最近的软件构造实验经常需要设计接口,我们知道Override注解是告诉编译器,下面的方法是重写父类的方法,那么单纯实现接口的方法需不需要加Override呢? 定义一个类实现接口,使用idea时,声明implements之后会…...
优质全套SpringMVC教程
三、SpringMVC 在SSM整合中,MyBatis担任的角色是持久层框架,它能帮我们访问数据库,操作数据库 Spring能利用它的两大核心IOC、AOP整合框架 1、SpringMVC简介 1.1、什么是MVC MVC是一种软件架构的思想(不是设计模式-思想就是我们…...
微信小程序---使用npm包安装Vant组件库
在小程序项目中,安装Vant 组件库主要分为如下3步: 注意:如果你的文件中不存在pakage.json,请初始化一下包管理器 npm init -y 1.通过 npm 安装(建议指定版本为1.3.3) 通过npm npm i vant/weapp1.3.3 -S --production 通过y…...

GPT-4V被超越?SEED-Bench多模态大模型测评基准更新
📖 技术报告 SEED-Bench-1:https://arxiv.org/abs/2307.16125 SEED-Bench-2:https://arxiv.org/abs/2311.17092 🤗 测评数据 SEED-Bench-1:https://huggingface.co/datasets/AILab-CVC/SEED-Bench SEED-Bench-2&…...

数据库_mongoDB
1 介绍 MongoDB 是一种 NoSQL 数据库,它将每个数据存储为一个文档,这里的文档类似于 JSON/BSON 对象,具体数据结构由键值(key/value)对组成。字段值可以包含其他文档,数组及文档数组。其数据结构非常松散&…...

Layui实现自定义的table列悬停事件并气泡提示信息
1、概要 使用layui组件实现table的指定列悬停时提示信息,因为layui组件中没有鼠标悬停事件支持,所以需要结合js原生事件来实现这个功能,并结合layui的tips和列的templte属性气泡提示实现效果。 2、效果图 3、代码案例 <!DOCTYPE html&g…...
Tomcat从认识安装到详细使用
文章目录 一.什么是Tomact?二.Tomcat的安装1.下载安装包2.一键下载3.打开Tomcat进行测试4.解决Tomcat中文服务器乱码 三.Tomcat基本使用1.启动与关闭Tomcat2.Tomcat部署项目与浏览器访问项目 四.Tomcat操作中的常见问题1.启动Tomcat后,启动窗口一闪而过?…...
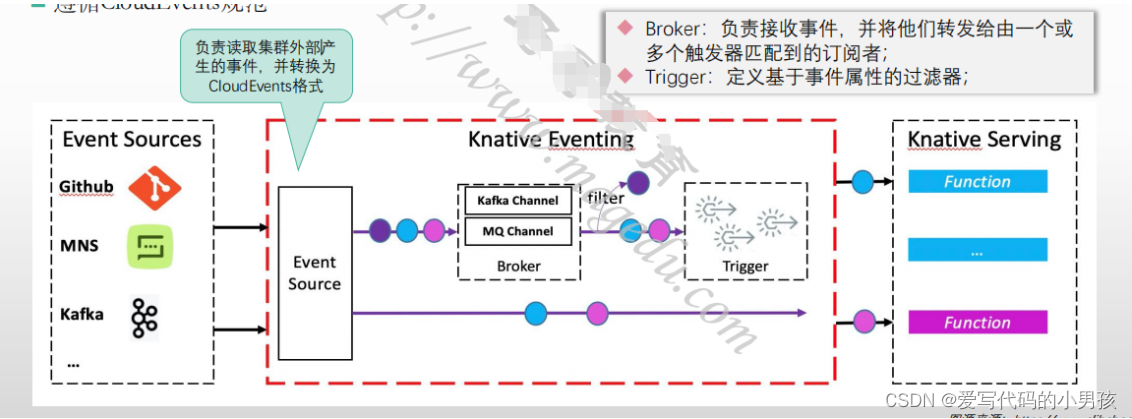
07-Eventing及实践
1 Knative Eventing的相关组件 Knative Eventing具有四个最基本的组件:Sources、Brokers、Triggers 和 Sinks 事件会从Source发送至SinkSink是能够接收传入的事件可寻址(Addressable)或可调用(Callable)资源 Knative S…...
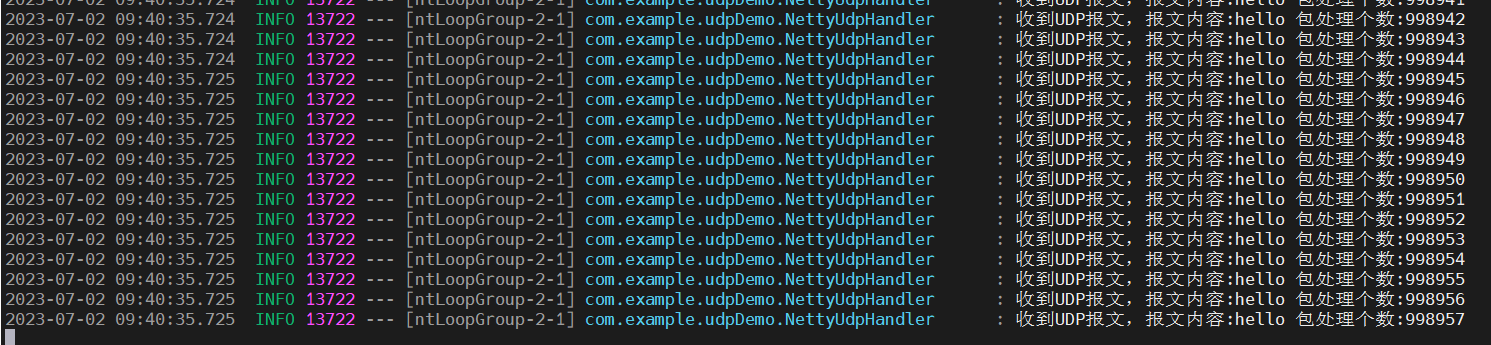
Linux下Netty实现高性能UDP服务
前言 近期笔者基于Netty接收UDP报文进行业务数据统计的功能,因为Netty默认情况下处理UDP收包只能由一个线程负责,无法像TCP协议那种基于主从reactor模型实现多线程监听端口,所以笔者查阅网上资料查看是否有什么方式可以接收UDP收包的性能瓶颈…...
Ubuntu 22.04 Tesla V100s显卡驱动,CUDA,cuDNN,MiniCONDA3 环境的安装
今天来将由《蓝创精英团队》带来一个Ubuntu 显卡环境的安装,主要是想记录下来,方便以后快捷使用。 主要的基础环境 显卡驱动 (nvidia-smi)CUDA (nvidia-smi 可查看具体版本)cuDNN (cuda 深度学习加速库)Conda python环境管理(Miniconda3) Nvidia 驱动…...
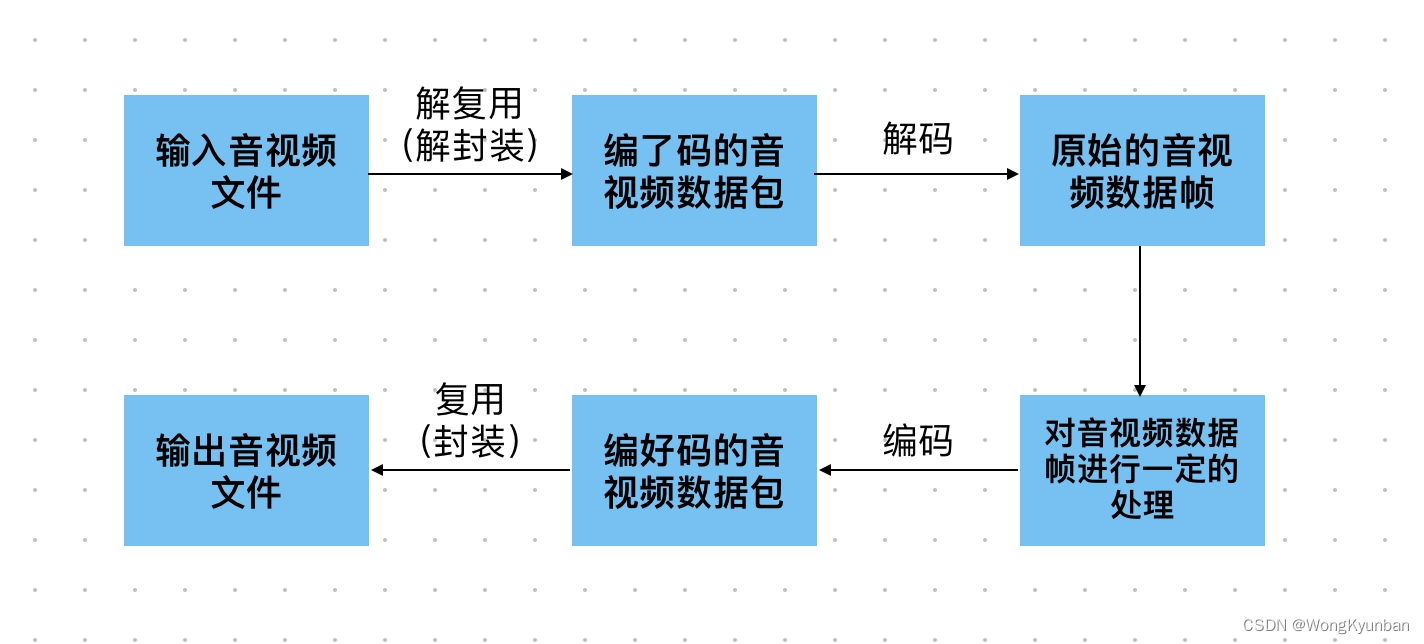
FFmpeg转码流程和常见概念
视频格式:mkv,flv,mov,wmv,avi,mp4,m3u8,ts等等 FFmpeg的转码工具,它的处理流程是这样的: 从输入源获得原始的音视频数据,解封装得到压缩封装的音…...
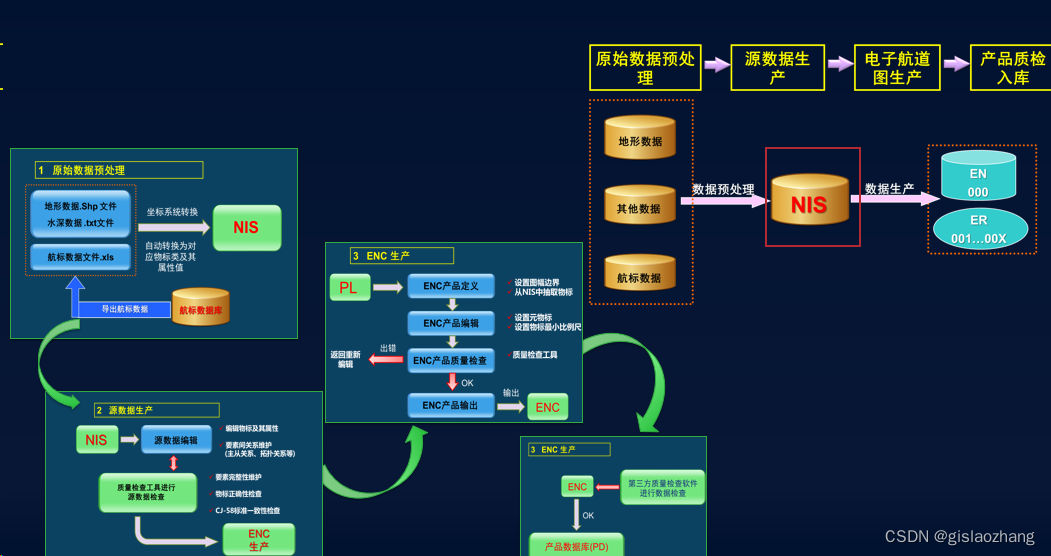
【01】GeoScene生产海图或者电子航道图
1.1 什么是电子海图制图模块 GeoScene海事模块是一个用于管理和制作符合国际水文组织(IHO)S-100系列标准和S-57标准的海事数据的系统。提供了S-100和S-57工具,用于加载基于S-100的要素目录、创建基于S-57传输结构的数据、输入数据、符号化数…...

TWS蓝牙耳机的船运模式
TWS蓝牙耳机的船运模式 是否需要申请加入数字音频系统研究开发交流答疑群(课题组)?可加我微信hezkz17, 本群提供音频技术答疑服务,+群赠送语音信号处理降噪算法,蓝牙耳机音频,DSP音频项目核心开发资料, TWS蓝牙耳机的船运模式是指在将耳机从一个地方运送到另一个地方时,…...

Vue系列之指令 v-html
文章の目录 1、v-html指令2、基本用法写在最后 1、v-html指令 v-html 指令类似于 v-text 指令,它与 v-text 区别在于 v-text 输出的是纯文本,浏览器不会对其再进行html解析,但v-html会将其当html标签解析后输出,类似于 JavaScrip…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...