爬虫持久化保存
## open方法- 方法名称及参数```markdown
**open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)****file** 文件的路径,需要带上文件名包括文件后缀(c:\\1.txt)**mode** 打开的方式(r,w,a,x,b,t,r+,w+,a+,U)**buffering** 缓冲的buffering大小, 0,就不会有寄存。1,寄存行。大于 1 的整数,寄存区的缓冲大小。负值,寄存区的缓冲大小为系统默认。**encoding** 文件的编码格式(utf-8,GBK等)
- 常用的文件打开方式
r 以只读方式打开文件。文件的指针会放在文件的开头。w 以写入方式打开文件。文件存在覆盖文件,文件不存在创建一个新文件。a 以追加方式打开文件。如果文件已存在,文件指针放在文件末尾。如果文件不存在,创建新文件并可写入。r+ 打开一个文件用于读写。文件指针会放在文件的开头w+ 打开一个文件用于读写。文件存在覆盖文件,文件不存在创建一个新文件。a+ 打开一个文件用于读写。如果文件已存在,文件指针放在文件末尾。如果文件不存在,创建新文件并可写入。记忆方法:记住r读,w写,a追加,每个模式后加入+号就变成可读写。
文件的读取及写入
- 读取文件
file.read([size]):读取文件(读取size个字节,默认读取全部)
file.readline()):读取一行
file.readlines():读取完整的文件,返回每一行所组成的列表
- 写入文件
file.write(str):将字符串写入文件
file.writelines(lines):将多行文本写入文件中,lines为字符串组成的列表或元组
爬虫数据持久化存储——csv文件
作用:将爬取的数据存放到本地的csv文件中
- 使用流程
1、导入模块
2、打开csv文件
3、初始化写入对象
4、写入数据(参数为列表)
import csv with open('film.csv','w') as f:writer = csv.writer(f)writer.writerow([])
- 示例:创建 test.csv 文件,在文件中写入数据
# 单行写入(writerow([]))
import csv
with open('test.csv','w',newline='') as f:writer = csv.writer(f)writer.writerow(['步惊云','36'])writer.writerow(['超哥哥','25'])# 多行写入(writerows([(),(),()]
import csv
with open('test.csv','w',newline='') as f:writer = csv.writer(f)writer.writerows([('聂风','36'),('秦霜','25'),('孔慈','30')])
爬虫数据处理:操作数据库模块——pymysql
pymysql介绍:
PyMySQL是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中是使用mysqldb
pymysql安装:
pip install pymysql -i https://pypi.douban.com/simple
pymysql基本使用
# 导入pymysql模块
import pymysql# 连接database
conn = pymysql.connect(host=“你的数据库地址”,user=“用户名”,password=“密码”,database=“数据库名”,charset=“utf8”)# 得到一个可以执行SQL语句的光标对象
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
# 得到一个可以执行SQL语句并且将结果作为字典返回的游标
#cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)# 定义要执行的SQL语句
sql = """
CREATE TABLE USER1 (
id INT auto_increment PRIMARY KEY ,
name CHAR(10) NOT NULL UNIQUE,
age TINYINT NOT NULL
)ENGINE=innodb DEFAULT CHARSET=utf8; #注意:charset='utf8' 不能写成utf-8
"""# 执行SQL语句
cursor.execute(sql)# 关闭光标对象
cursor.close()# 关闭数据库连接
conn.close()
增删改查操作
添加一条或多条数据
#假设已有某数据库xing,其中包含姓名及编号两个字段
import pymysqlconn = pymysql.connect(host='192.168.0.103',port=3306,user='root',password='123',database='xing',charset='utf8'
)
# 获取一个光标
cursor = conn.cursor()# 定义要执行的sql语句
sql = 'insert into userinfo(user,pwd) values(%s,%s);'
data = [('july', '147'),('june', '258'),('marin', '369')
]
# 拼接并执行sql语句
cursor.executemany(sql, data)# 涉及写操作要注意提交
conn.commit()# 关闭连接
cursor.close()
conn.close()
插入单条数据
import pymysql
conn =pymysql.connect(host ='192.168.0.103',port = 3306,user = 'root',password ='123',database ='xing',charset ='utf8'
)
cursor =conn.cursor() #获取一个光标
sql ='insert into userinfo (user,pwd) values (%s,%s);'name = 'wuli'
pwd = '123456789'
cursor.execute(sql, [name, pwd])
conn.commit()
cursor.close()
conn.close()
获取最新插入数据
import pymysql# 建立连接
conn = pymysql.connect(host="192.168.0.103",port=3306,user="root",password="123",database="xing",charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "insert into userinfo (user, pwd) values (%s, %s);"
name = "wuli"
pwd = "123456789"
# 并执行SQL语句
cursor.execute(sql, [name, pwd])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接# 获取最新的那一条数据的ID
last_id = cursor.lastrowid
print("最后一条数据的ID是:", last_id)cursor.close()
conn.close()
删除操作
import pymysql# 建立连接
conn = pymysql.connect(host="192.168.0.103",port=3306,user="root",password="123",database="xing",charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "delete from userinfo where user=%s;"
name = "june"
# 拼接并执行SQL语句
cursor.execute(sql, [name])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接cursor.close()
conn.close()
更新数据
import pymysql# 建立连接
conn = pymysql.connect(host="192.168.0.103",port=3306,user="root",password="123",database="xing",charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "delete from userinfo where user=%s;"
name = "june"
# 拼接并执行SQL语句
cursor.execute(sql, [name])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接cursor.close()
conn.close()
查询数据
# 可以获取指定数量的数据
cursor.fetchmany(3)
# 光标按绝对位置移动1
cursor.scroll(1, mode="absolute")
# 光标按照相对位置(当前位置)移动1
cursor.scroll(1, mode="relative"
爬虫数据持久化存储——写入MySQL
- 在数据库中建库建表
# 连接到mysql数据库
mysql -h127.0.0.1 -uroot -p123456
# 建库建表
create database maoyandb charset utf8;
use maoyandb;
create table filmtab(
name varchar(100),
star varchar(300),
time varchar(50)
)charset=utf8;
- 回顾pymysql基本使用
一般方法:import pymysql# 创建2个对象
db = pymysql.connect('localhost','root','123456','maoyandb',charset='utf8')
cursor = db.cursor()# 执行SQL命令并提交到数据库执行
# execute()方法第二个参数为列表传参补位
ins = 'insert into filmtab values(%s,%s,%s)'
cursor.execute(ins,['霸王别姬','张国荣','1993'])
db.commit()# 关闭
cursor.close()
db.close()
- 来试试高效的executemany()方法?
import pymysql# 创建2个对象
db = pymysql.connect('192.168.153.137','tiger','123456','maoyandb',charset='utf8')
cursor = db.cursor()# 抓取的数据
film_list = [('月光宝盒','周星驰','1994'),('大圣娶亲','周星驰','1994')]# 执行SQL命令并提交到数据库执行
# execute()方法第二个参数为列表传参补位
cursor.executemany('insert into filmtab values(%s,%s,%s)',film_list)
db.commit()# 关闭
cursor.close()
db.close()
相关文章:

爬虫持久化保存
## open方法- 方法名称及参数markdown **open(file, moder, bufferingNone, encodingNone, errorsNone, newlineNone, closefdTrue)****file** 文件的路径,需要带上文件名包括文件后缀(c:\\1.txt)**mode** 打开的方式(r,w,a,x,b,t…...
统一大语言模型和知识图谱:如何解决医学大模型-问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
统一大语言模型和知识图谱:如何解决医学大模型问诊不充分、检查不准确、诊断不完整、治疗方案不全面? 医学大模型问题如何使用知识图谱加强和补足专业能力?大模型结构知识图谱增强大模型的方法 医学大模型问题 问诊。偏离主诉和没抓住核心。…...

读写分离之同步延迟测试
背景 读写分离是快速提高数据库性能的手段,主库只负责写入,从库负责查询。但在性能得到提升的同时,编程的复杂度就会提升。由其碰到主从同步延迟的情况,在数据写入后,在从库无法读取到最新数据,会对业务逻…...

SpringBoot+OCR 实现PDF 内容识别
一、SpringBootOCR对pdf文件内容识别提取 1、在 Spring Boot 中,您可以结合 OCR(Optical Character Recognition)库来实现对 PDF 文件内容的识别和提取。 一种常用的 OCR 库是 Tesseract,而 pdf2image 是一个用于将 PDF 转换为图…...

Go和Java实现抽象工厂模式
Go和Java实现抽象工厂模式 本文通过简单数据库操作案例来说明抽象工厂模式的使用,使用Go语言和Java语言实现。 1、抽象工厂模式 抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创 建型模式,它…...

深入理解Java虚拟机---内存分配
深入理解Java虚拟机---内存分配 GC日志内存分配与回收策略对象优先在Eden分配大对象直接进入老年代长期存活的对象将进入老年代动态对象年龄判定空间分配担保 GC日志 以下两段典型的GC日志: 33.125: [GC [DefNew: 3324K->152K(3712K), 0.0025925 secs] 3324K-&…...

计算机网络2
OSI参考模型七层: 1.应用层 2.表示层 3.会话层 4.传输层 5.网络层 6.数据链路层 7.物理层 TCP/IP模型 5层参考模型...

jenkins-Generic Webhook Trigger指定分支构建
文章目录 1 需求分析1.1 关键词 : 2、webhooks 是什么?3、配置步骤3.1 github 里需要的仓库配置:3.2 jenkins 的主要配置3.3 option filter配置用于匹配目标分支 实现指定分支构建 1 需求分析 一个项目一般会开多个分支进行开发,测试&#x…...

源码解析8-QSS原理-案例-Qt的qss特殊设置多个子控件的颜色与伪状态
Qt源码解析 索引 源码解析8-QSS原理-案例-Qt的qss特殊设置多个子控件的颜色与伪状态 有些时候我们想特殊设置QSS,比如某一类标题栏目,某一个窗口中的颜色。 重要的是我们需要同时设置多个特殊的按钮等。 统一设置所有 单一按钮全局设置 QPushButton…...
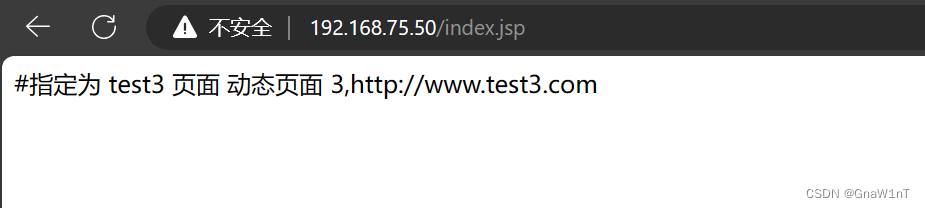
Nginx+Tomcat实现负载均衡和动静分离
目录 前瞻 动静分离和负载均衡原理 实现方法 实验(七层代理) 部署Nginx负载均衡服务器(192.168.75.50:80) 部署第一台Tomcat应用服务器(192.168.75.60:8080) 多实例部署第二台Tomcat应用服务器(192.168.75.70:80…...
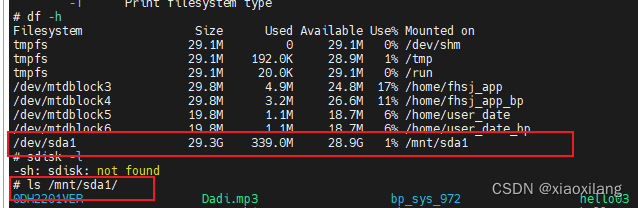
linux系统的u盘/mmc/sd卡等的支持热插拔和自动挂载行为
1.了解mdev mdev是busybox自带的一个简化版的udev。udev是从Linux 2.6 内核系列开始的设备文件系统(DevFS)的替代品,是 Linux 内核的设备管理器。总的来说,它取代了 devfs 和 hotplug,负责管理 /dev 中的设备节点。同时…...
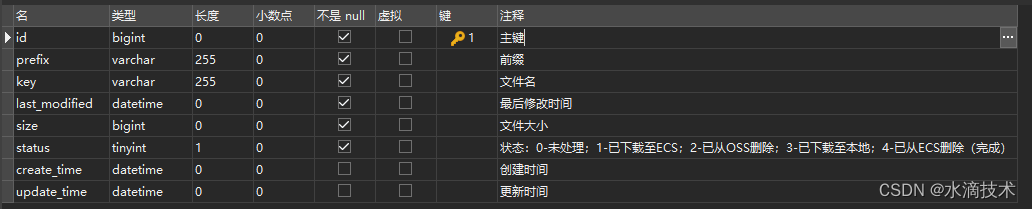
使用Python将OSS文件免费下载到本地:项目分析和准备工作
大家好,我是水滴~~ 本文将介绍如何使用Python编程语言将OSS(对象存储服务)中的文件免费下载到本地计算机。我们先进行项目分析和准备工作,为后续的编码及实施提供基础。 《Python入门核心技术》专栏总目录・点这里 文章目录 1. 前…...
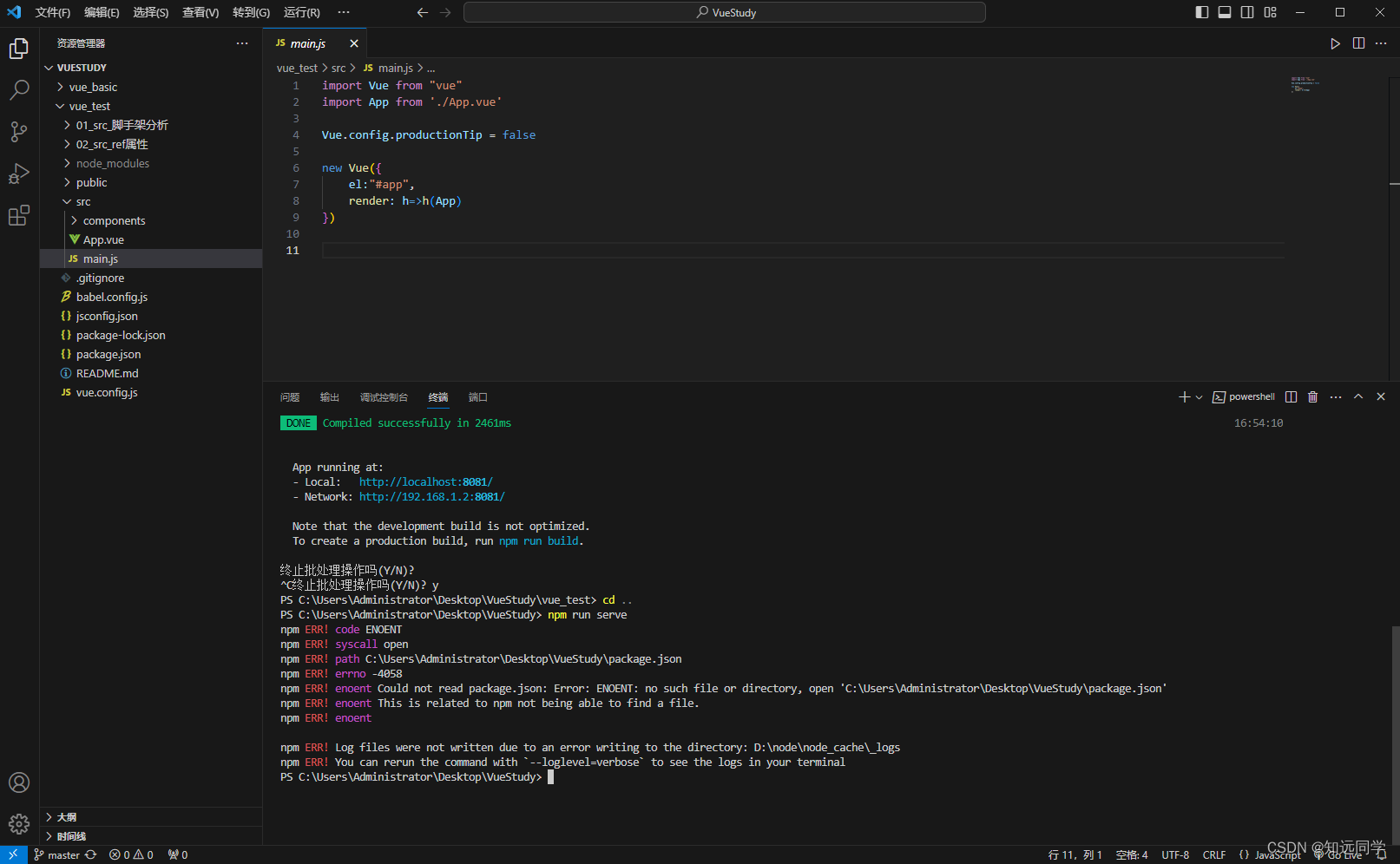
从Gitee克隆项目、启动方法
从gitee克隆VUE项目到本地后,不能直接运行,需要进行npm install安装node_modules文件夹里面的内容,因为在git上传的时候,一般都会过滤到node_modules中的依赖文件。 安装依赖以后,启动通过npm run serve启动项目出错。…...
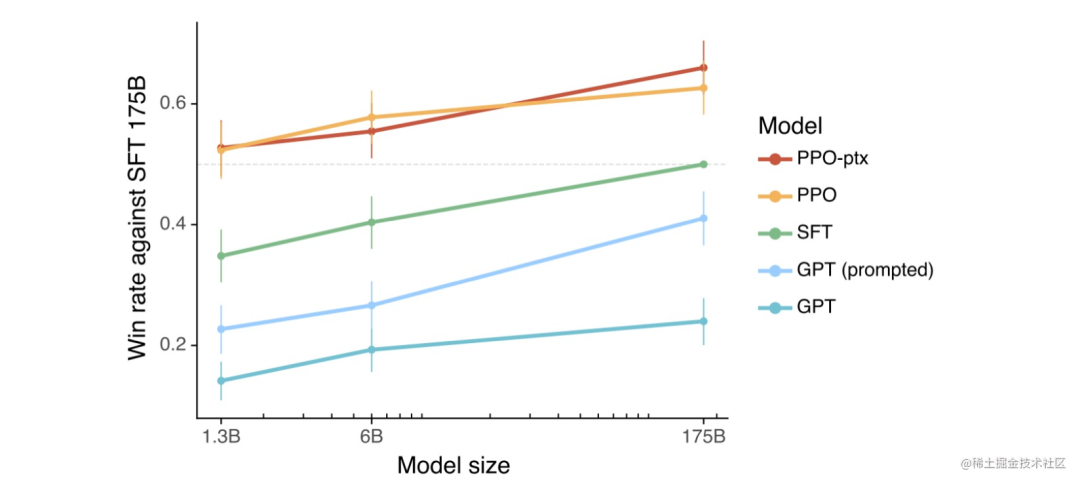
不用再找了,这是大模型实践最全的总结
随着ChatGPT的迅速出圈,加速了大模型时代的变革。对于以Transformer、MOE结构为代表的大模型来说,传统的单机单卡训练模式肯定不能满足上千(万)亿级参数的模型训练,这时候我们就需要解决内存墙和通信墙等一系列问题&am…...

QT 记录
qml 移动窗口会闪烁 int main(int argc, char *argv[]) {QCoreApplication::setAttribute(Qt::AA_UseOpenGLES);//orQCoreApplication::setAttribute(Qt::AA_UseSoftwareOpenGL); }window 拉取qml程序依赖文件 打开QT自带的命令窗口,转到exe程序目录: …...
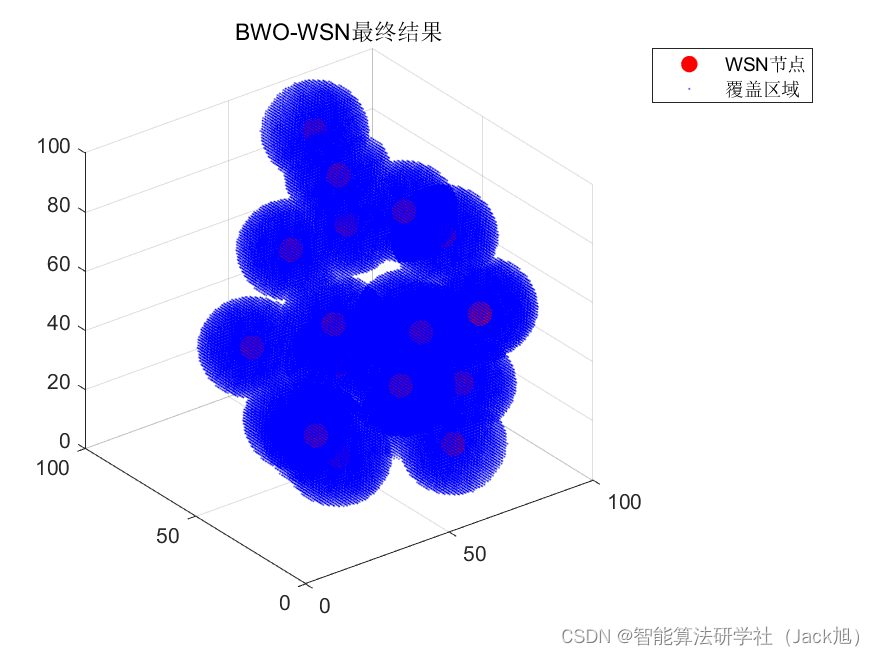
智能优化算法应用:基于黑寡妇算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于黑寡妇算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于黑寡妇算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.黑寡妇算法4.实验参数设定5.算法结果6.参考文…...
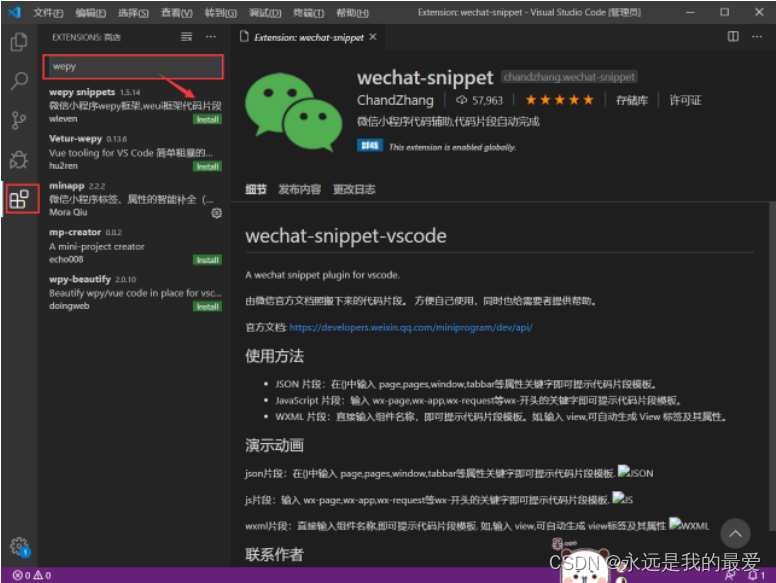
VSCode 常用的快捷键和技巧系列(2)
一、如何让VSCode工程树显示图标 第一步:安装 快捷键 CtrlP ,输入 ext install vscode-icons ,然后点击安装插件 第二步:配置 安装成功后,点击Reload重新加载。 然后配置,当前图标使用VsCode-Icons Go…...
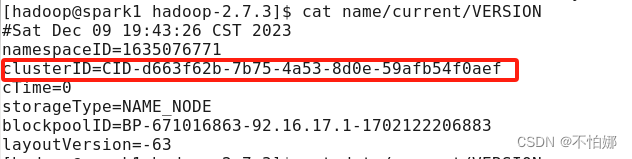
【Hadoop】执行start-dfs.sh启动hadoop集群时,datenode没有启动怎么办
执行start-dfs.sh后,datenode没有启动,很大一部分原因是因为在第一次格式化dfs后又重新执行了格式化命令(hdfs namenode -format),这时主节点namenode的clusterID会重新生成,而从节点datanode的clusterID 保持不变。 在…...
计算机网络(四)
九、网络安全 (一)什么是网络安全? A、网络安全状况 分布式反射攻击逐渐成为拒绝攻击的重要形式 涉及重要行业和政府部门的高危漏洞事件增多。 基础应用和通用软硬件漏洞风险凸显(“心脏出血”,“破壳”等&#x…...
非递归实现的快速排序
目录 序列文章 前言 学前补充 非递归快速排序 注意事项(重要) 实现步骤 代码实现 时空复杂度 快速排序的特性 栈的相关代码 序列文章 非递归实现的快速排序:http://t.csdnimg.cn/UEcL6 快速排序的挖坑法与双指针法:ht…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...