机器学习 | 贝叶斯方法
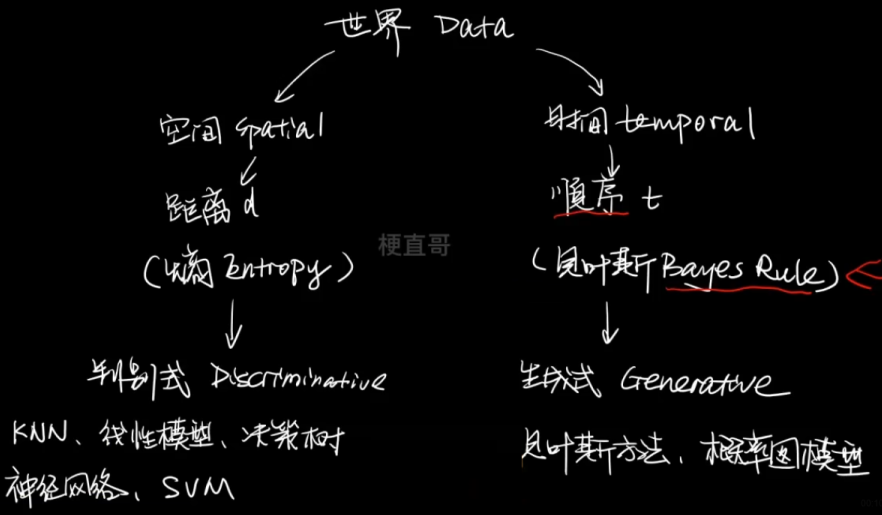
不同于KNN最近邻算法的空间思维,线性算法的线性思维,决策树算法的树状思维,神经网络的网状思维,SVM的升维思维。
贝叶斯方法强调的是 先后的因果思维。
监督式模型分为判别式模型和生成式模型。
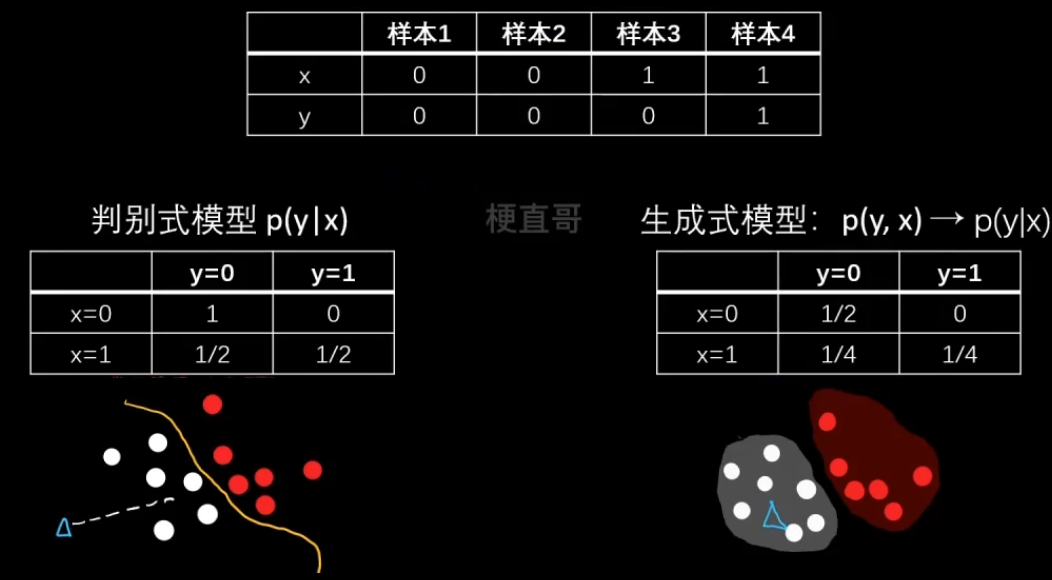
判别模型和生成模型的区别:
判别式模型:输入一个特征X可以直接得到一个y。
生成式模型:上来先学习一个联合概率分布 p(x,y),
再用他根据贝叶斯法则求条件概率密度分布。
—— 没有决策边界的存在
判别式数据对于数据分布特别复杂的情况,比如文本图像视频;
而生成式模型对于数据有部分特征缺失的情况下效果更好,
而且更容易添加数据的先验知识 p(x)
1、核心思想和原理
贝叶斯公式
建立了四个概率分布之间的关系,已知变量 X 和 未知变量(模型参数)w 之间的计算关系
假定 X 表示数据,W 表示模型的参数
Likelihood翻译成可能性或者是似然函数,最大似然估计指的就是这个

以下图中 s 表示状态, o 表示观测。

参数估计
1、最大似然估计 MLE
2、最大后验估计 MAP
3、贝叶斯估计
2、朴素贝叶斯分类
我们知道分类问题是 给定特征 X,输出分类标记 y

那么朴素贝叶斯方法是如何由指定特征得到分类类别的呢?
2.1、举个栗子

能不能直接根据这些经验(上面的数据),来判断一个境外人员有没有得新冠呢?
—— 转换为数学语言即

比较难求的显然就是 Likelihood,所以朴素贝叶斯假设特征之间相互独立。

根据中心极限定理,频率就等于概率,虽然这里数据没有那么多,也一样可以这么算


2.2、朴素贝叶斯分类及其代码实现
- 逻辑简单,易于实现
- 效率高,时空开销小
- 条件独立假设不成立则分类效果一般
- 适用于特征相关性较小时
代码实现:
import numpy as npX = [[1,0,0,1],[0,1,0,0],[1,1,0,0],[0,1,2,0],[1,0,0,0],[1,0,0,0],[1,1,2,1],[0,1,1,0],[1,1,1,0],[0,0,2,0],[1,1,0,1],[1,1,0,1]]y = [0,0,1,1,0,0,1,1,1,1,0,0]t=[[0,0,0,1]]from sklearn.naive_bayes import BernoulliNBbnb = BernoulliNB()
bnb.fit(X,y)
bnb.predict_proba(t)array([[0.875, 0.125]])
2,3、朴素贝叶斯家族
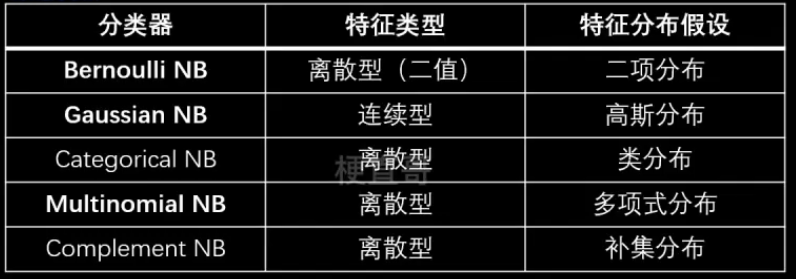
2.3.1、伯努利朴素贝叶斯与多项式朴素贝叶斯
伯努利分布(两点分布、0-1分布)
属于离散型概率分布
伯努利分布公式:
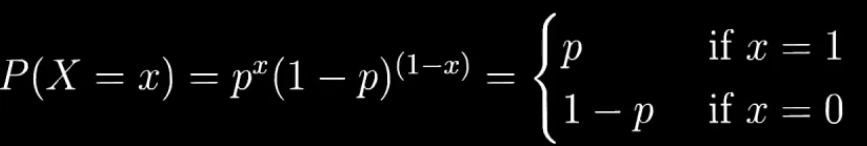
伯努利实验 —— 例如抛硬币。
二项式分布和多项式分布
二项式分布:伯努利实验重复n次。
n = 1的二项式分布就是伯努利分布。
多项式分布:抛硬币改为掷骰子。
伯努利朴素贝叶斯:每个特征都服从伯努利分布的一种贝叶斯分类器
适用于二分类离散变量。
特征的条件概率服从伯努利分布:
![]()
xi 表示第 i 哥特征维度,y 表示观测道德类别。
特征可选值大于两个时可用多项式分布。
2.3.2、 高斯朴素贝叶斯

2.4、分类器效果对比
from sklearn.datasets import load_irisiris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)from sklearn.naive_bayes import BernoulliNB
nb = BernoulliNB()
nb.fit(X_train, y_train)
nb.score(X_test, y_test)0.23684210526315788
print(iris.DESCR).. _iris_dataset:Iris plants dataset --------------------**Data Set Characteristics:**:Number of Instances: 150 (50 in each of three classes):Number of Attributes: 4 numeric, predictive attributes and the class:Attribute Information:- sepal length in cm- sepal width in cm- petal length in cm- petal width in cm- class:- Iris-Setosa- Iris-Versicolour- Iris-Virginica:Summary Statistics:============== ==== ==== ======= ===== ====================Min Max Mean SD Class Correlation============== ==== ==== ======= ===== ====================sepal length: 4.3 7.9 5.84 0.83 0.7826sepal width: 2.0 4.4 3.05 0.43 -0.4194petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)============== ==== ==== ======= ===== ====================:Missing Attribute Values: None:Class Distribution: 33.3% for each of 3 classes.:Creator: R.A. Fisher:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov):Date: July, 1988The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken from Fisher's paper. Note that it's the same as in R, but not as in the UCI Machine Learning Repository, which has two wrong data points.This is perhaps the best known database to be found in the pattern recognition literature. Fisher's paper is a classic in the field and is referenced frequently to this day. (See Duda & Hart, for example.) The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. One class is linearly separable from the other 2; the latter are NOT linearly separable from each other... topic:: References- Fisher, R.A. "The use of multiple measurements in taxonomic problems"Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions toMathematical Statistics" (John Wiley, NY, 1950).- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New SystemStructure and Classification Rule for Recognition in Partially ExposedEnvironments". IEEE Transactions on Pattern Analysis and MachineIntelligence, Vol. PAMI-2, No. 1, 67-71.- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactionson Information Theory, May 1972, 431-433.- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS IIconceptual clustering system finds 3 classes in the data.- Many, many more ...
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB()
nb.fit(X_train, y_train)
nb.score(X_test, y_test)1.0
from sklearn.naive_bayes import CategoricalNB
nb = CategoricalNB()
nb.fit(X_train, y_train)
nb.score(X_test, y_test)0.8947368421052632
from sklearn.naive_bayes import MultinomialNB
nb = MultinomialNB()
nb.fit(X_train, y_train)
nb.score(X_test, y_test)0.5789473684210527
from sklearn.naive_bayes import ComplementNB
nb = ComplementNB()
nb.fit(X_train, y_train)
nb.score(X_test, y_test)0.5789473684210527
2.5、多项式朴素贝叶斯代码实现
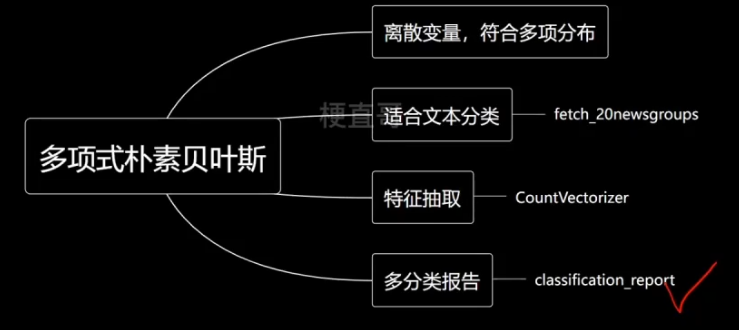
纯文本数据不能直接传入模型,需要进行特征抽取。
Chapter-10/10-6 多项式朴素贝叶斯代码实现.ipynb · 梗直哥/Machine-Learning - Gitee.com
3、优缺点和使用条件
朴素贝叶斯优点
过程简单速度快。
对多分类问题言样有效。
分布独立假设下效果好。
贝叶斯思想光芒万丈,先验打开“扇大门。(拓展 变分)
朴素贝叶斯缺点
条件独立假设在现实中往往很难保证。
只适用于简单比大小问题。
如果个别类别概率为0,则预测失败。(平滑技术解决)。
条件概率和先验分布计算复杂度较高,高维计算困难。
适用条件
文本分类/垃圾文本过滤/情感判别。
多分类实时预测。
推荐系统、与 协同过滤 一起。
复杂问题建模。

参考
Machine-Learning: 《机器学习必修课:经典算法与Python实战》配套代码 - Gitee.com
相关文章:
机器学习 | 贝叶斯方法
不同于KNN最近邻算法的空间思维,线性算法的线性思维,决策树算法的树状思维,神经网络的网状思维,SVM的升维思维。 贝叶斯方法强调的是 先后的因果思维。 监督式模型分为判别式模型和生成式模型。 判别模型和生成模型的区别…...
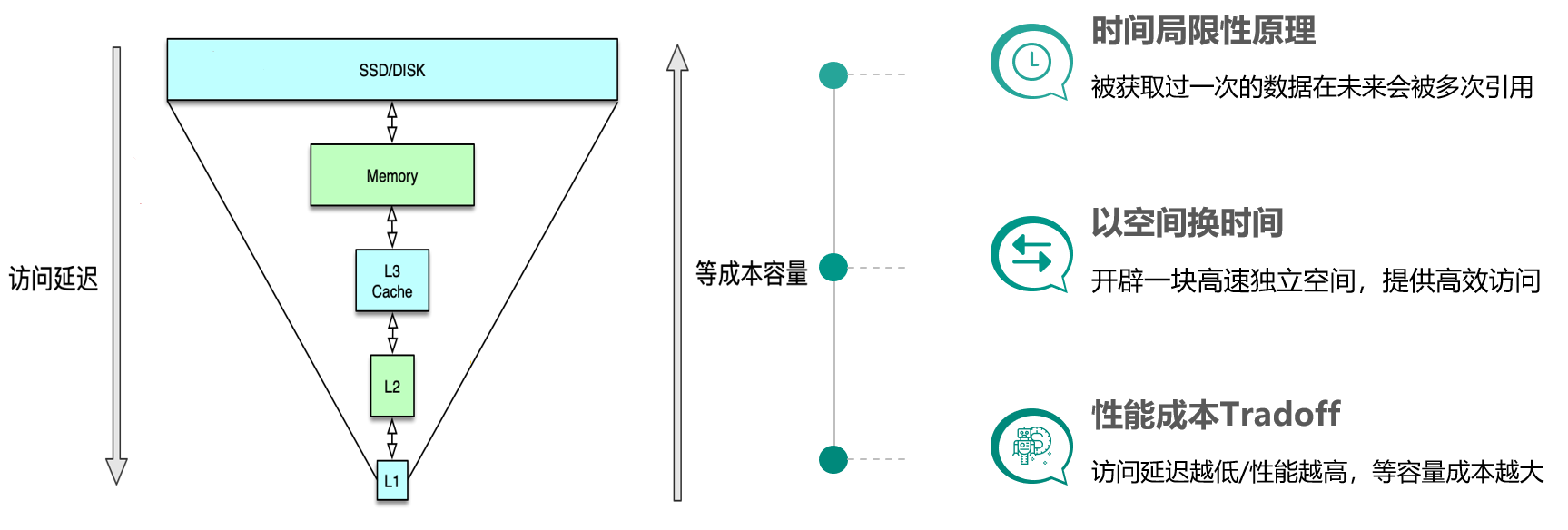
缓存的定义及重要知识点
文章目录 缓存的意义缓存的定义缓存原理缓存的基本思想缓存的优势缓存的代价 缓存的重要知识点 缓存的意义 在互联网高访问量的前提下,缓存的使用,是提升系统性能、改善用户体验的唯一解决之道。 缓存的定义 缓存最初的含义,是指用于加速 …...
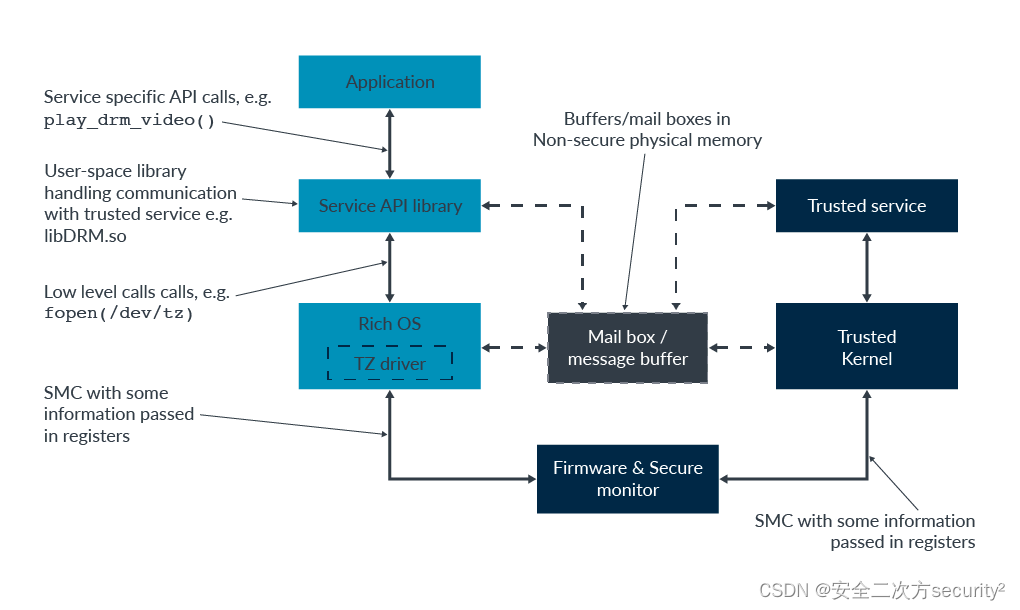
TrustZone之顶层软件架构
在处理器中的TrustZone和系统架构中,我们探讨了硬件中的TrustZone支持,包括Arm处理器和更广泛的内存系统。本主题关注TrustZone系统中发现的软件架构。 一、顶层软件架构 下图显示了启用TrustZone的系统的典型软件栈: 【注意】:为简单起见,该图不包括管理程序,尽管它们可…...
SpringBoot Whitelabel Error Page 报错--【已解决】
springboot 报错信息如下 这个报错页面就是个404 ,代表你访问的url 没有对应的的requestmapping 其实没啥影响的一个问题,但是看到Error 就是不爽,改了他丫的 解决方法如下 一、调整application.properties配置【治标不治本】 server.err…...
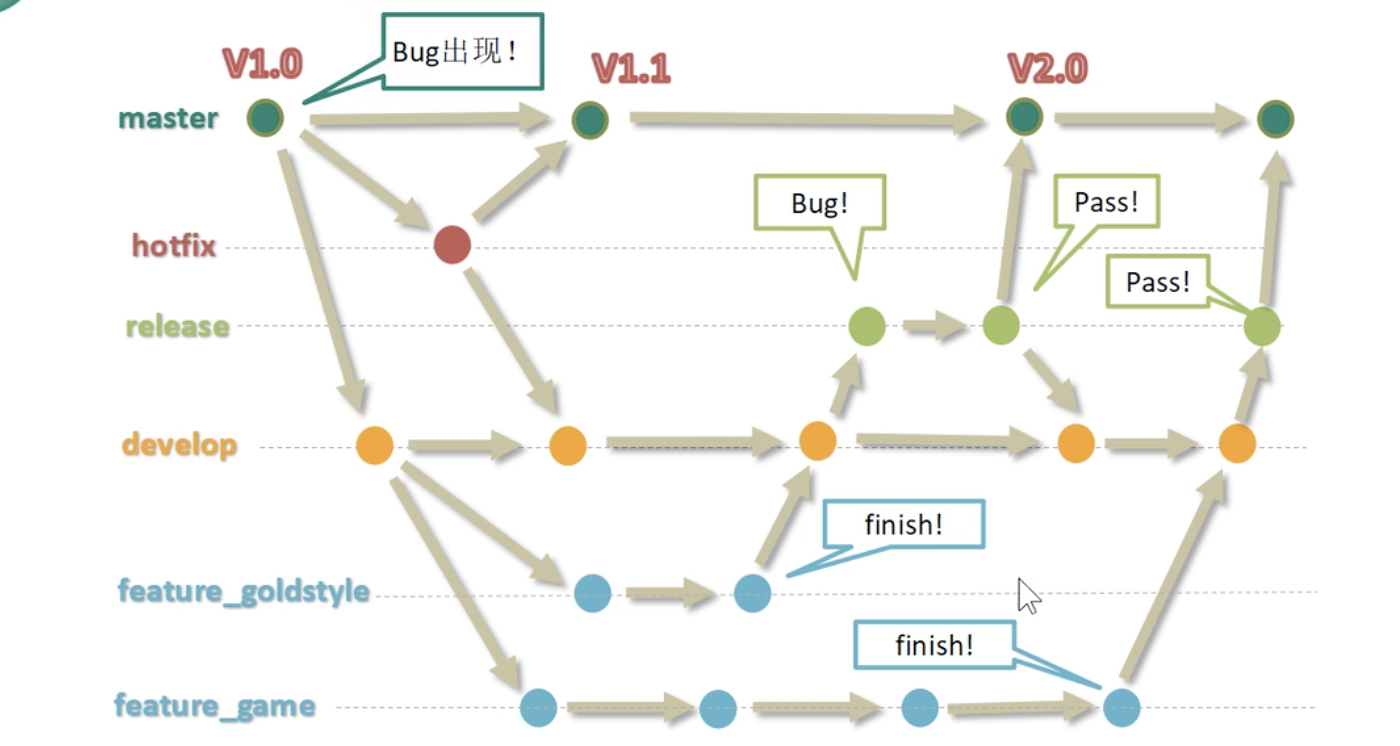
02.Git常用基本操作
一、基本配置 (1)打开Git Bash (2)配置姓名和邮箱 git config --global user.name "Your Name" git config --global user.email "Your email" 因为Git是分布式版本控制工具,所以每个用户都需要…...

黑盒测试中关键截图如何打点
黑盒测试中关键截图如何打点Android黑盒测试过程中如何进行有效的打点是我们经常遇到的问题,我们一般会在脚本内部进行数据打点,也可以使用其他进程录屏或截图。那我们如何选取合适的方式进行打点记录呢?下图是对常用打点方式的统计ÿ…...

画图之C4架构图idea和vscode环境搭建篇
VS Code 下C4-PlantUML安装 安装VS Code 直接官网下载安装即可,过程略去。 安装PlantUML插件 在VS Code的Extensions窗口中搜索PlantUML,安装PlantUML插件。 配置VS Code代码片段 安装完PlantUML之后,为了提高效率,我们最好安装PlantUML相关的代码片段。 打开VS Cod…...

安卓小练习-校园闲置交易APP(SQLite+SimpleCursorAdapter适配器)
环境: SDK:34 JDK:20.0.2 编写工具:Android Studio 2022.3.1 整体效果(视频演示): 小练习-闲置社区APP演示视频-CSDN直播 部分效果截图: 整体工作流程: 1.用户登录&…...

Pycharm 如何更改成中文版| Python循环语句| for 和 else 的搭配使用
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

智合同是怎么审合同的?
#智合同#审合同#AI#深度学习#自然语言处理#知识图谱 智合同采用深度学习、自然语言处理、知识图谱等人工智能技术,为企业提供专业的合同相关的智能服务。其服务包含:合同智能审查、合同要素智能提取、合同版本对比、合同智能起草、文本一致性对比、广告…...
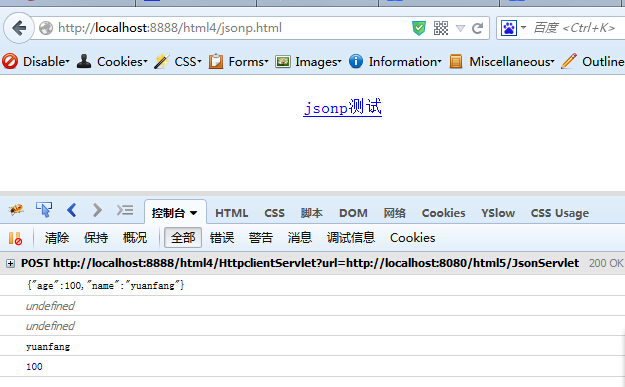
使用Httpclient来替代客户端的jsonp跨域解决方案
最近接手一个项目,新项目需要调用老项目的接口,但是老项目和新项目不再同一个域名下,所以必须进行跨域调用了,但是老项目又不能进行任何修改,所以jsonp也无法解决了,于是想到了使用了Httpclient来进行服务端…...
测试工具Jmeter:设置中文界面
首先我们打开Jmeter所在的文件,进入bin目录,打开Jmeter.properties: 打开后找到languageen: 改为zh_CN: 保存关闭,然后再打开Jmeter: 英文并不会显得高级,能做到高效的性能测试才是高级的。...
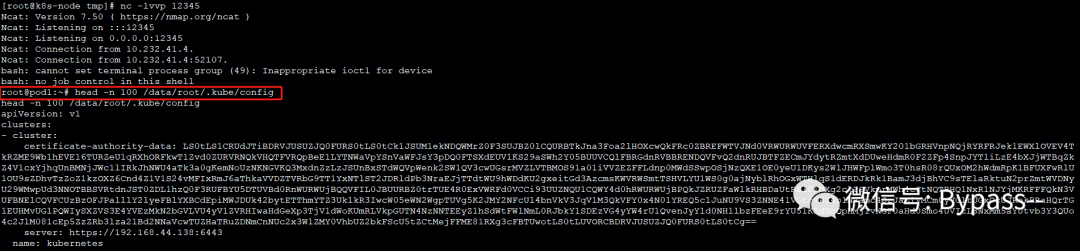
K8s攻击案例:RBAC配置不当导致集群接管
01、概述 Service Account本质是服务账号,是Pod连接K8s集群的凭证。在默认情况下,系统会为创建的Pod提供一个默认的Service Account,用户也可以自定义Service Account,与Service Account关联的凭证会自动挂载到Pod的文件系统中。 …...
运行hive的beelin2时候going to print operations logs printed operations logs
运行hive的beelin2时候going to print operations logs printed operations logs 检查HiveServer2的配置文件hive-site.xml,确保以下属性被正确设置: <property><name>hive.async.log.enabled</name><value>false</value>…...

从 MySQL 到 DolphinDB,Debezium + Kafka 数据同步实战
Debezium 是一个开源的分布式平台,用于实时捕获和发布数据库更改事件。它可以将关系型数据库(如 MySQL、PostgreSQL、Oracle 等)的变更事件转化为可观察的流数据,以供其他应用程序实时消费和处理。本文中我们将采用 Debezium 与 K…...

六.聚合函数
聚合函数 1.什么是聚合函数1.1AVG和SUM函数1.2MIN和MAX函数1.3COUNT函数 2.GROUP BY2.1基本使用2.2使用多个列分组2.3GROUP BY中使用WITH ROLLUP 3.HAVING3.1基本使用3.2WHERE和HAVING的区别 4.SELECT的执行过程4.1查询的结构4.2SELECT执行顺序4.3SQL执行原理 1.什么是聚合函数…...

Eclipse_03_如何加快index速度
1. ini配置文件 -Xms:是最小堆内存大小,也是初始堆内存大小,因为堆内存大小可以根据使用情况进行扩容,所以初始值最小,随着扩容慢慢变大。 -Xmx:是最大堆内存大小,随着堆内存的使用率越来越高&a…...

scrapy的入门和使用
scrapy的入门使用 学习目标: 掌握 scrapy的安装应用 创建scrapy的项目应用 创建scrapy爬虫应用 运行scrapy爬虫应用 scrapy定位以及提取数据或属性值的方法掌握 response响应对象的常用属性 1 安装scrapy 命令: sudo apt-get install scrapy 或者&#x…...

yolov5单目测距+速度测量+目标跟踪(算法介绍和代码)
要在YOLOv5中添加测距和测速功能,您需要了解以下两个部分的原理: 单目测距算法 单目测距是使用单个摄像头来估计场景中物体的距离。常见的单目测距算法包括基于视差的方法(如立体匹配)和基于深度学习的方法(如神经网…...

flink 读取 apache paimon表,查看source的延迟时间 消费堆积情况
paimon source查看消费的数据延迟了多久 如果没有延迟 则显示0 官方文档 Metrics | Apache Paimon...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...
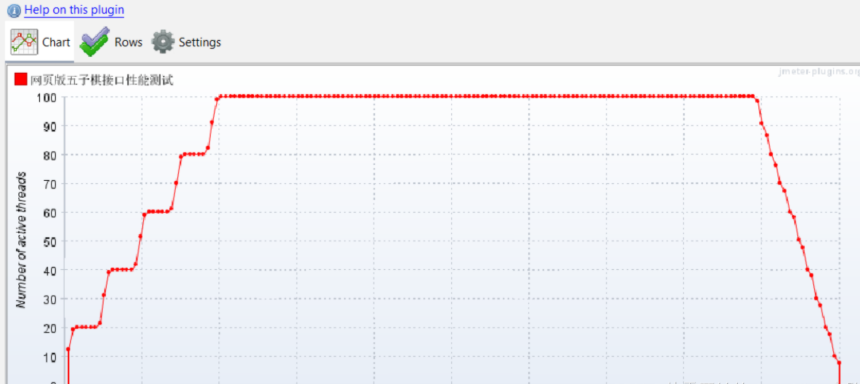
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...
 ----- Python的类与对象)
Python学习(8) ----- Python的类与对象
Python 中的类(Class)与对象(Object)是面向对象编程(OOP)的核心。我们可以通过“类是模板,对象是实例”来理解它们的关系。 🧱 一句话理解: 类就像“图纸”,对…...