原理底层计划--HashMap
HashMap
之前写了“Java集合TreeMap红黑树一生只爱一次”,说到底还是太年轻了,Map其实在排序中应用比较少,一般追求的是速度,通过HashMap来获取速度。hashmap 调用object hashcode方法用于返回对象的哈希码,主要使用在哈希表中。
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable
HashMap继承AbstractMap 本质是key-value键值对,具有Map素有常用的方法put() get() remove()。
Cloneable意味着可以被克隆。
实现serializable接口的作用是就是可以把对象存到字节流,然后可以恢复。
当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。
get
hashmap常用的get方法,可以看到先hash话,然后获取
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;
}
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;
}
put
在Java 8中put这个方法的思路分为以下几步:
- 调用key的hashCode方法计算哈希值,并据此计算出数组下标index
- 如果发现当前的桶数组为null,则调用resize()方法进行初始化
- 如果没有发生哈希碰撞,则直接放到对应的桶中
- 如果发生哈希碰撞,且节点已经存在,就替换掉相应的value
- 如果发生哈希碰撞,且桶中存放的是树状结构,则挂载到树上
- 如果碰撞后为链表,添加到链表尾,如果链表长度超过TREEIFY_THRESHOLD默认是8,则将链表转换为树结构
- 数据put完成后,如果HashMap的总数超过threshold就要resize
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;
}
为什么非要使用红黑树呢?
这个选择是综合考虑的,既要put效率很高,同时也要get效率很高,红黑树就是其中一种。
二叉树也ok,红黑树是一种自平衡的二叉查找树
平衡二叉树可以有效的减少二叉树的深度,从而提高了查询的效率
除了之外,红黑树还具备
节点是红色或黑色;
根节点是黑色;
所有叶子都是黑色的空节点;
每个红色节点必须有两个黑色的子节点,也就是说从每个叶子到根的所有路径上,不能有两个连续的红色节点;
从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑色节点
红黑树的优势在于它是一个平衡二叉查找树,对于普通的二叉查找树(非平衡二叉查找树)在极端情况下可能会退化为链表的结构,再进行元素的添加、删除以及查询时,它的时间复杂度就会退化为 O(n)
红黑树的高度近似 log2n,它的添加、删除以及查询数据的时间复杂度为 O(logn)
红黑树时间复杂度比链表、二叉树小,这就是采用红黑树做hashMap底层原理,然后在treeMap里面就更经典了。
jdk1.7之前底层数据结构采用哈希+链表。但后来业务越来越追求速度,hash的目的是为了得到进行索引,有些hash冲突可能造成死循环,所以jdk1.8加上红黑树来解决明显可以提高效率。
但是要分情况在数组长度大于64,同时链表长度大于8的情况下,链表将转化为红黑树。当数据的长度退化成6时,红黑树转化为链表。数据长度没有那么长,就没必要采用红黑树,红黑树虽然提高了速度,但也提交了空间复杂度。数据长度大于8和数组长度大于64,采用红黑树。那为什么是6和8作为临近值呢,其实这个值不要死记,是官网进行压力测试的出来的结论。
为什么HashMap要扩容呢?
数组是固定的,但集合是动态的,可以扩容。
当hashmap越来越来多的元素塞进来之后,hashmap不得不扩容了,hashmap中元素个数超过160.75=12的时候,就把数组的大小扩展为216=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作。
所以我们提前预测知道hashmap容量,再稍微设置大些,这样可以减少性能的消耗的。
但是initialCapacity初始容量设置小了,会不会报错呢?
不会的,但是hashmap会自动扩容,同样也会走到上面过程,重新计算,消耗性能的操作。
提前预判,但是后来业务改变,需要那么大的容量,程序员应该即使更改,要不然就和不设置没有区别啦。
哈希 链表、红黑树 (来处理极端情况下的哈希碰撞)
数组+(链表或红黑树)Node类来存储Key、Value
hashMap什么时候扩容?
注意,是在put的时候才会扩容,在容量超过四分之三的时候就会扩容
hashMap的key可以为空吗
可以,Null值会作为key来存储
key重复了,会被覆盖吗?
会的
HashMap扩容为什么总是2的次幂?
HashMap扩容主要是给数组扩容的,因为数组长度不可变,而链表是可变长度的。从HashMap的源码中可以看到HashMap在扩容时选择了位运算,向集合中添加元素时,会使用(n - 1) & hash的计算方法来得出该元素在集合中的位置。只有当对应位置的数据都为1时,运算结果也为1,当HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞
当HashMap的容量是16时,它的二进制是10000,(n-1)的二进制是01111
JDk1.7HashMap扩容死循环问题
HashMap是一个线程不安全的容器,在最坏的情况下,所有元素都定位到同一个位置,形成一个长长的链表,这样get一个值时,最坏情况需要遍历所有节点,性能变成了O(n)。
JDK1.7中HashMap采用头插法拉链表,所谓头插法,即在每次都在链表头部(即桶中)插入最后添加的数据。
死循环问题只会出现在多线程的情况下。
假设在原来的链表中,A节点指向了B节点。
在线程1进行扩容时,由于使用了头插法,链表中B节点指向了A节点。
在线程2进行扩容时,由于使用了头插法,链表中A节点又指向了B节点。
在线程n进行扩容时,
这就容易出现问题了。在并发扩容结束后,可能导致A节点指向了B节点,B节点指向了A节点,链表中便有了环
死循环解决方案:
1)、使用线程安全的ConcurrentHashMap替代HashMap,个人推荐使用此方案。
2)、使用线程安全的容器Hashtable替代,但它性能较低,不建议使用。
3)、使用synchronized或Lock加锁之后,再进行操作,相当于多线程排队执行,也会影响性能,不建议使用。
为了解决JDK1.7死循环问题,JDK1.8引入了红黑树
即在数组长度大于64,同时链表长度大于8的情况下,链表将转化为红黑树。同时使用尾插法。当数据的长度退化成6时,红黑树转化为链表。
从JDK1.8开始,在HashMap里面定义了一个常量TREEIFY_THRESHOLD,默认为8。当链表中的节点数量大于TREEIFY_THRESHOLD时,链表将会考虑改为红黑树
使用线程安全如Concurrenthashmap、HashTable
为什么线程不安全?
1、put的时候导致的多线程数据不一致。
这个问题比较好想象,比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的桶索引和线程B要插入的记录计算出来的桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2、另外一个比较明显的线程不安全的问题是HashMap的get操作可能因为resize而引起死循环(cpu100%)
HashMap的扩容机制就是重新申请一个容量是当前的2倍的桶数组,然后将原先的记录逐个重新映射到新的桶里面,然后将原先的桶逐个置为null使得引用失效。HashMap之所以线程不安全,就是resize这里出的问题。
相关文章:

原理底层计划--HashMap
HashMap 之前写了“Java集合TreeMap红黑树一生只爱一次”,说到底还是太年轻了,Map其实在排序中应用比较少,一般追求的是速度,通过HashMap来获取速度。hashmap 调用object hashcode方法用于返回对象的哈希码,主要使用在…...

win10 设备管理器中的黄色感叹号(华硕)
目录一、前言二、原因三、方案四、操作一、前言 打开设备管理器,我们可以看到自己设备的信息,但是在重装系统后,你总会在不经意间发现。咦,怎么多了几个感叹号??? 由于我已经解决该问题&#…...

新产品上市推广不是“铺货”上架
只有不断推出新产品的企业才能走得长远,但现实中往往有很多企业投入了大量人力、物力、财力研发的新产品却在推广的过程中屡屡受挫。那么,为什么适合市场的新产品会在市场营销推广的过程中夭折呢?小马识途营销顾问分析有如下几点:…...

MATLAB训练神经网络小结
MATLAB训练神经网络小结1、一个典型例子1.1 可视化神经网络1.2 指定某一层的激活函数1.3 训练神经网络时使用L1正则化1.4返回训练过程中的参数1.5 查看训练好的权重系数1.6 如何使用早停法来防止过拟合1、一个典型例子 例如输入特征为10维,想训练一个10x20x10x1的三…...
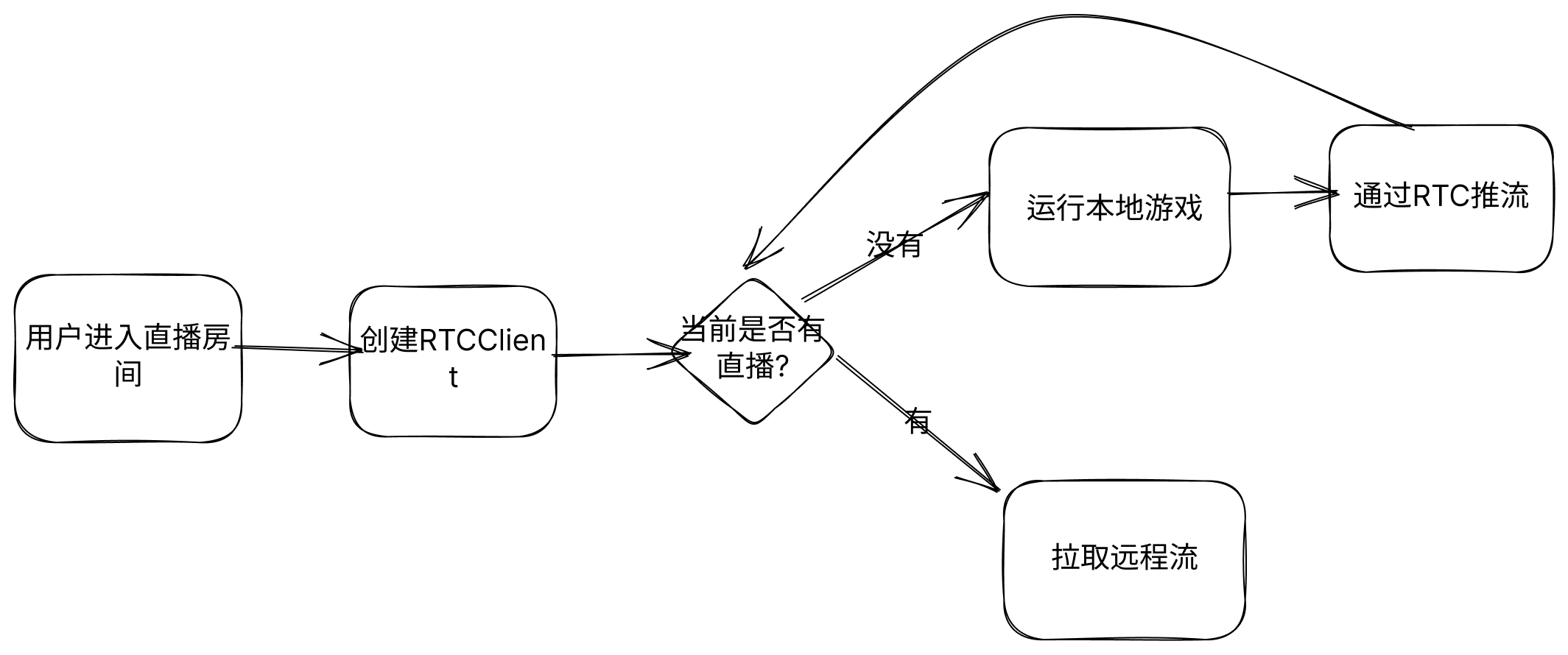
实战:一天开发一款内置游戏直播的国产版Discord应用【附源码】
游戏直播是Discord产品的核心功能之一,本教程教大家如何1天内开发一款内置游戏直播的国产版Discord应用,用户不仅可以通过IM聊天,也可以进行语聊,看游戏直播,甚至自己进行游戏直播,无任何实时音视频底层技术…...
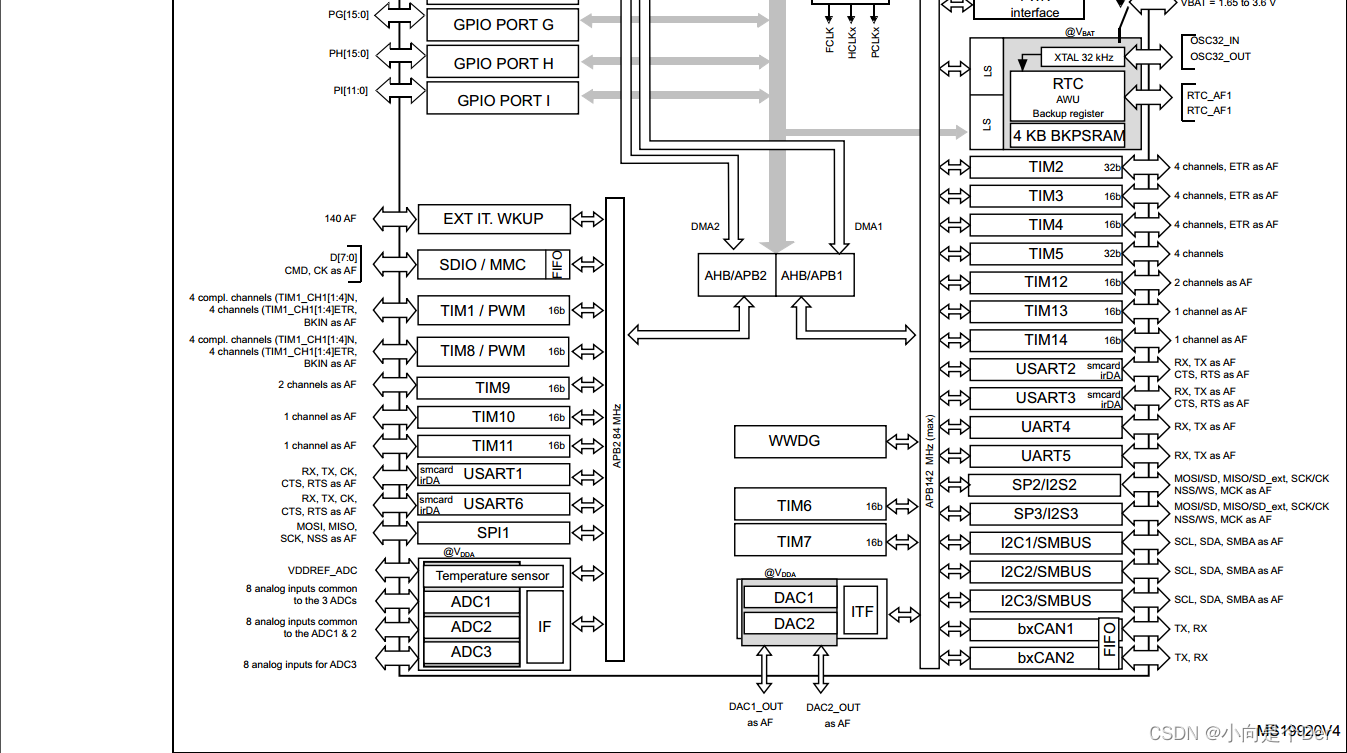
嵌入式学习笔记——基于Cortex-M的单片机介绍
基于Cortex-M的单片机介绍前言生产厂商及其产品线ARM单片机的产品线命名规则留个作业习单片机的资料准备STM32开发所需手册1.芯片的数据手册作业2前言 本文继续接着上一篇中关于Cortex-M的介绍,来记录一些关于ARM系单片机的知识。 生产厂商及其产品线 芯片厂商在…...
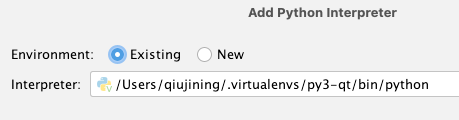
Python 虚拟环境的使用
PyCharm 创建的虚拟环境与使用 workon 命令创建的虚拟环境在本质上没有区别,它们都是 Python 的虚拟环境。 使用 PyCharm 创建工程时,使用可以使用曾经工程的虚拟环境,或者新建一个虚拟环境来安装 Python 的库,又或者使用 workon…...

招生咨询|浙江大学MPA项目2023年招生问答与通知
问:报考浙江大学MPA的基本流程是怎么样的? 答:第一阶段为网上报名与确认。MPA考生须参加全国管理类联考,网上报名时间一般为10月初开始、10月下旬截止,错过网上报名时间后不能补报。确认时间一般为11月上旬,…...

Qt std :: bad_alloc
文章目录摘要问题出现原因第一种 请求内存多余系统可提供内存第二种 地址空间过于分散,无法满足大块连续内存的请求第三种 堆管理数据结构损坏稍微总结下没想到还能更新参考关键字: std、 bad、 alloc、 OOM、 异常退出摘要 今天又是被BUG统治的一天&a…...

《设计模式》装饰者模式
《设计模式》装饰者模式 装饰者模式(Decorator Pattern)是一种结构型设计模式,它允许在不改变现有对象结构的情况下,动态地添加行为或责任到对象上。在装饰者模式中,有一个抽象组件(Component)…...
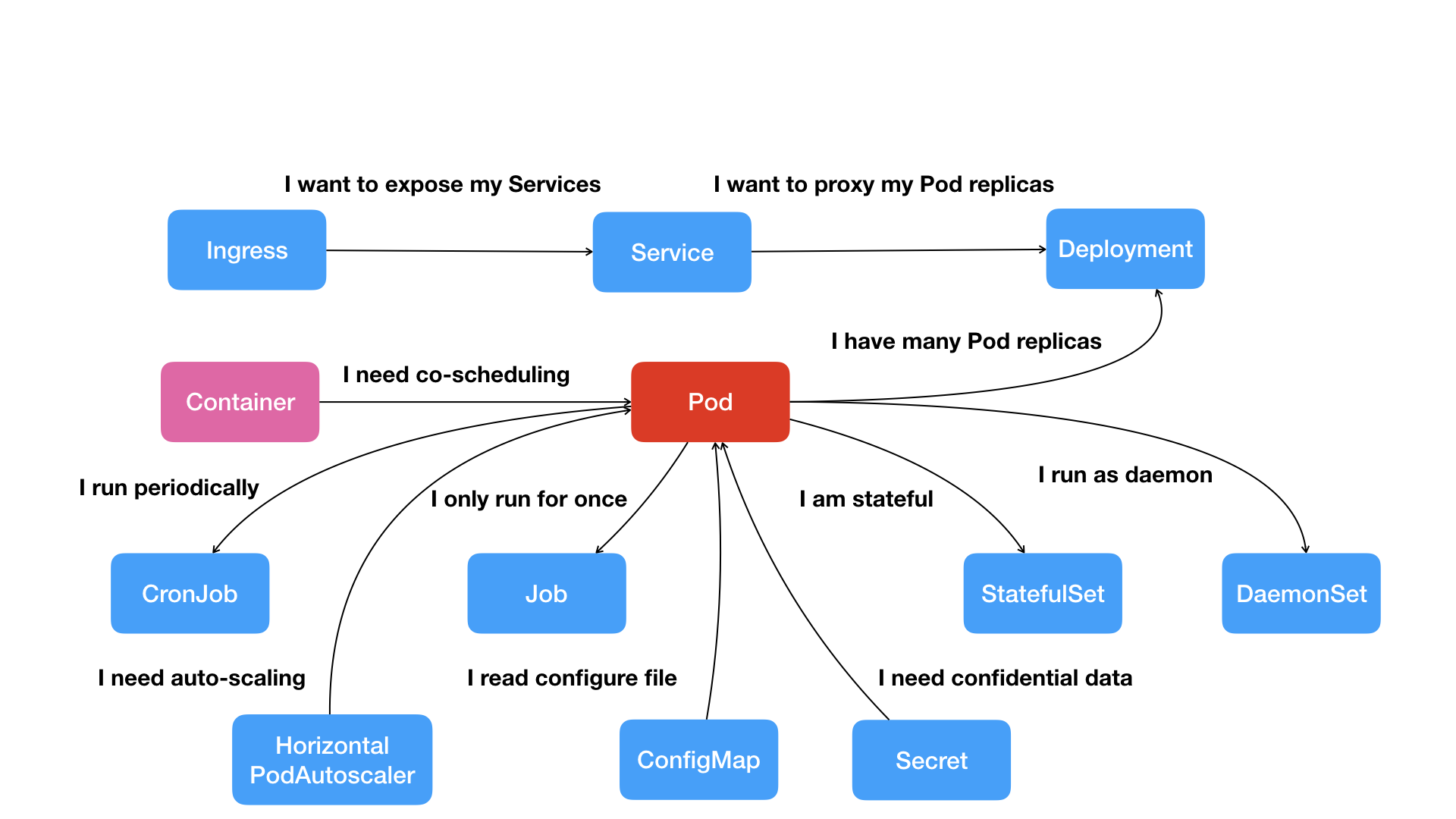
一文说清Kubernetes的本质
文章目录Kubernetes解决了什么问题?Kubernetes的全局架构Kubernetes的设计思想Kubernetes的核心功能Kubernetes如何启动一个容器化任务?Kubernetes解决了什么问题? 编排?调度?容器云?还是集群管理…...
信息发布小程序【源码好优多】
简介 信息发布小程序,实现数据与小程序数据同步共享,通过简单的配置就能搭建自己的小程序。,基于微信小程序开发的小程序。 这个框架比较简单就是用微信原生开发技术进行实现的,可以用于信息展示等相关信息。其中目前APP比较多&am…...

创新型中小企业申报流程
据工业和信息化部《优质中小企业梯度培育管理暂行办法》(工信部企业〔2022〕63号)和省《优质中小企业梯度培育管理实施细则》(鲁工信发〔2022〕8号,以下简称《细则》),现就做好2022年山东省创新型中小企业评…...
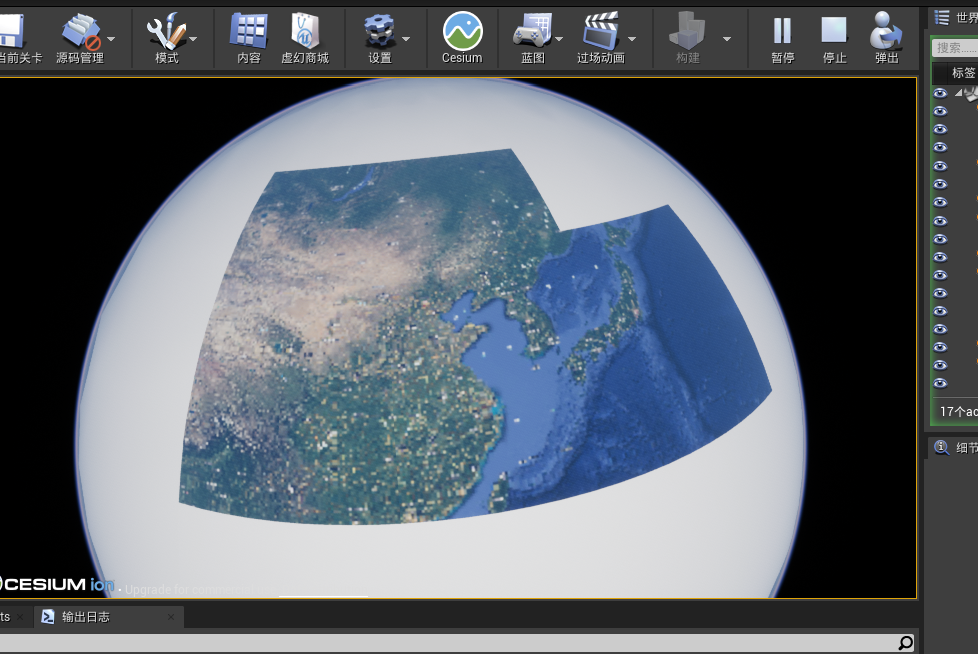
【UE4 Cesium】加载离线地图
主体思路:先使用水经注软件下载瓦片数据,再使用Python转换瓦片数据格式(TMS),使用Nginx发布网络服务,最后将网络服务加载到UE中。步骤:使用水经注下载瓦片数据,这里下载的是全球七级…...
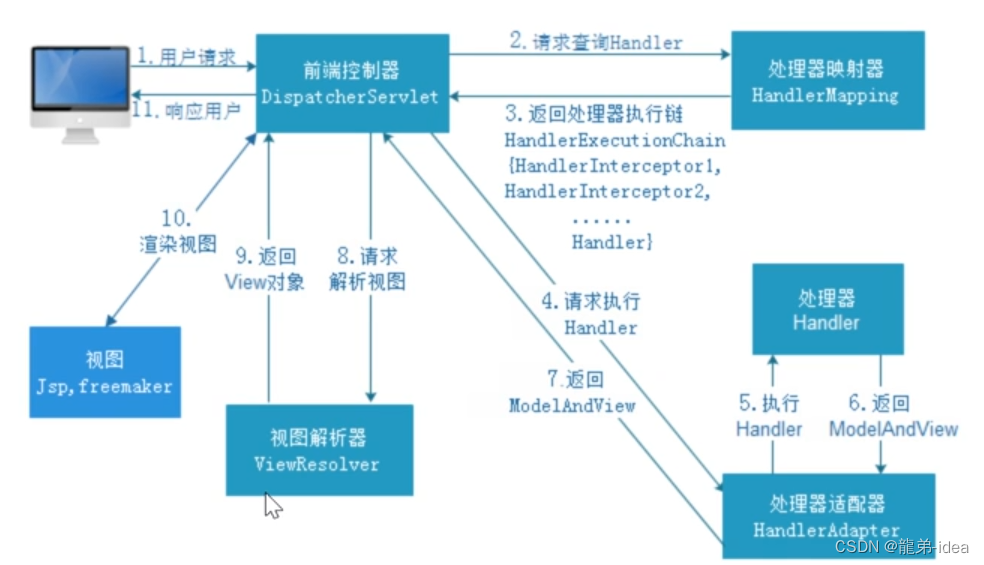
Spring面试题
目录 Spring、Springmvc、Springboot的区别是什么 SpringMVC工作流程是什么 SpringMVC的九大组件有哪些 Spring的核心是什么 spring的事务传播机制是什么 Spring框架中的单例Bean是线程安全的么 spring框架中使用了哪些设计模式及应用场景 spring事务的隔离级别有哪些?…...
动态网站开发讲课笔记03:HTTP协议
文章目录零、本节学习目标一、HTTP概述(一)HTTP的概念1、HTTP的概念2、HTTP协议的特点(1)C/S模式(2)简单快速(3)灵活(4)无状态(二)HTT…...

2023年天津财经大学珠江学院专升本专业课考试题型
天津财经大学珠江学院关于2023年高职升本科专业课考试时间及题型一、专业课考试 (一)时间安排 2023年天津财经大学珠江学院高职升本科专业课考试定于2023年3月25日14:00-17:00进行,凡报考工商管理、旅游管理、税收学专业的考生&am…...

五方面提高销售流程管理的CRM系统
销售充满了不确定性,面对不同的客户,销售人员需要采用不同的销售策略。也正因为这种不确定性,规范的销售流程对企业尤为重要,它会让销售工作更加有效,快速地实现成交。下面小编给您推荐个不错的CRM销售流程管理系统。 …...

AutoCAD通过handle id选择实体
获得实体的handle id。注意是handle id 不是id,方法有2种:方法(a):通过ArxDeg插件(ObjectARX附带的源码编译得到:\samples\database\ARXDBG)查找:此handle id本来就是16进…...
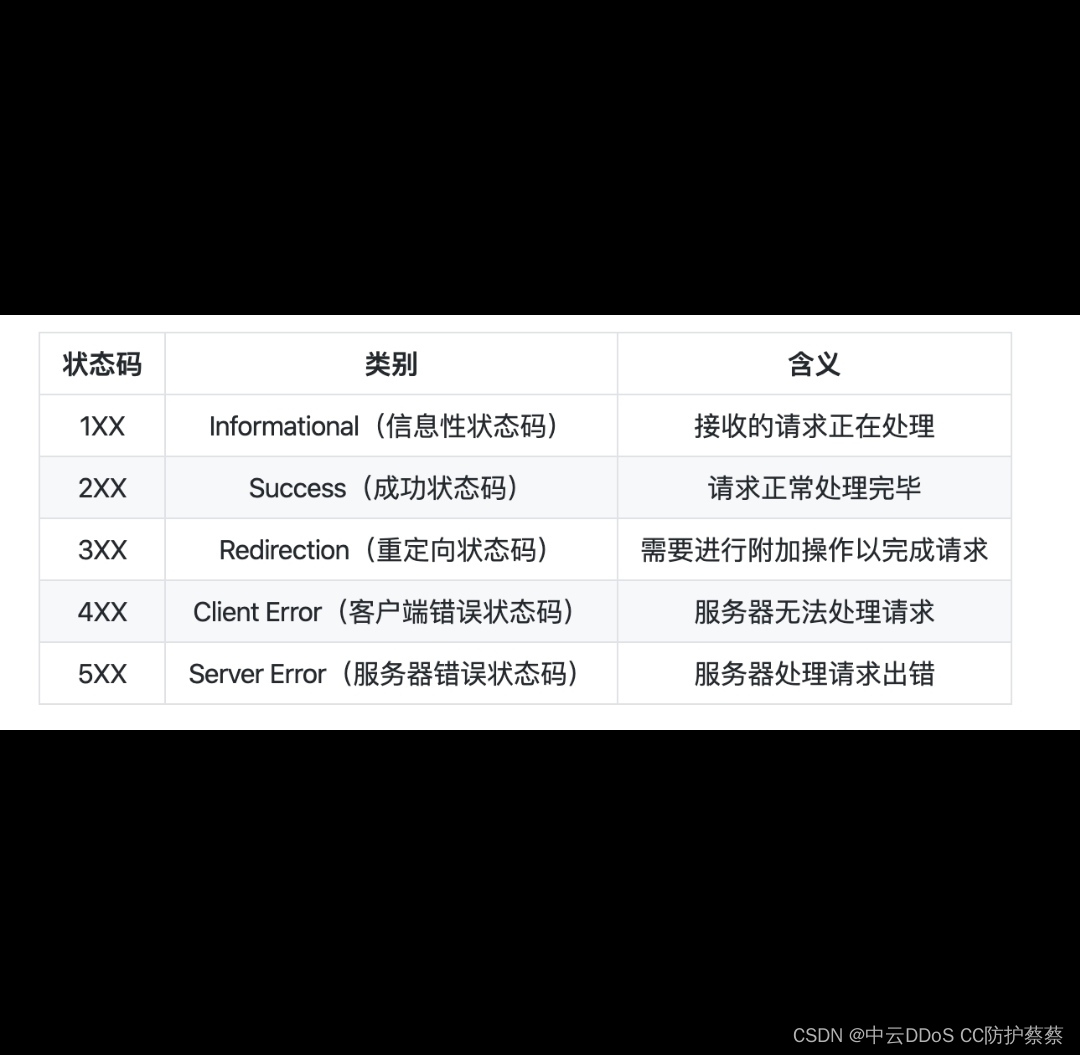
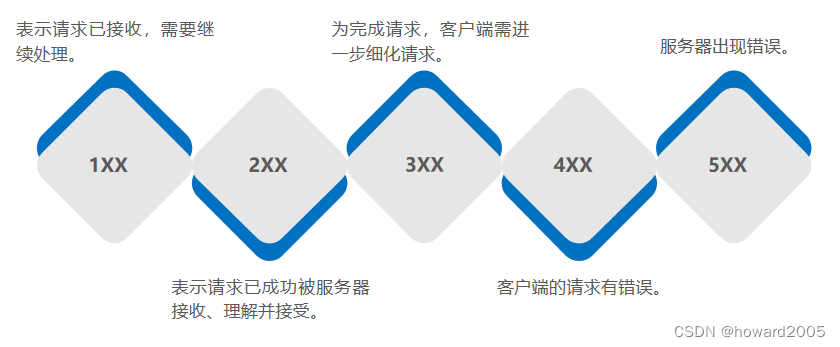
页面状态码的含义
使用互联网产品或服务的过程中,会遇到网页报错的情况, 比如404、505等,具体这些数字有什么含义呢?本文基本涵盖了99%的报错情况,可供大家查询使用。 状态码的定义 状态码一般是由3位数字和原因短语组成的(…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...