Java并发简介(什么是并发)
文章目录
- 并发概念
- 并发和并行
- 同步和异步
- 阻塞和非阻塞
- 进程和线程
- 竞态条件和临界区
- 管程
- 并发的特点
- 提升资源利用率
- 程序响应更快
- 并发的问题
- 安全性问题
- 缓存导致的可见性问题
- 线程切换带来的原子性问题
- 编译优化带来的有序性问题
- 保证并发安全的思路
- 互斥同步(阻塞同步)
- 非阻塞同步
- 无同步
- 活跃性问题
- 死锁(Deadlock)
- 什么是死锁
- 避免死锁
- 活锁(Livelock)
- 什么是活锁
- 避免活锁
- 饥饿(Starvation)
- 什么是饥饿
- 解决饥饿
- 性能问题
- 上下文切换
- 什么是上下文切换?
- 减少上下文切换的方法
- 资源限制
- 什么是资源限制
- 资源限制引发的问题
- 如何解决资源限制的问题
- 小结
关键词:
进程、线程、安全性、活跃性、性能、死锁、饥饿、上下文切换摘要:并发编程并非 Java 语言所独有,而是一种成熟的编程范式,Java 只是用自己的方式实现了并发工作模型。学习 Java 并发编程,应该先熟悉并发的基本概念,然后进一步了解并发的特性以及其特性所面临的问题。掌握了这些,当学习 Java 并发工具时,才会明白它们各自是为了解决什么问题,为什么要这样设计。通过这样由点到面的学习方式,更容易融会贯通,将并发知识形成体系化。
并发概念
并发编程中有很多术语概念相近,容易让人混淆。本节内容通过对比分析,力求让读者清晰理解其概念以及差异。
并发和并行
并发和并行是最容易让新手费解的概念,那么如何理解二者呢?其最关键的差异在于:是否是同时发生:
- 并发:是指具备处理多个任务的能力,但不一定要同时。
- 并行:是指具备同时处理多个任务的能力。
下面是我见过最生动的说明,摘自 并发与并行的区别是什么?——知乎的高票答案:
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
同步和异步
- 同步:是指在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。
- 异步:则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
举例来说明:
- 同步就像是打电话:不挂电话,通话不会结束。
- 异步就像是发短信:发完短信后,就可以做其他事;当收到回复短信时,手机会通过铃声或振动来提醒。
阻塞和非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态:
- 阻塞:是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
- 非阻塞:是指在不能立刻得到结果之前,该调用不会阻塞当前线程。
举例来说明:
- 阻塞调用就像是打电话,通话不结束,不能放下。
- 非阻塞调用就像是发短信,发完短信后,就可以做其他事,短信来了,手机会提醒。
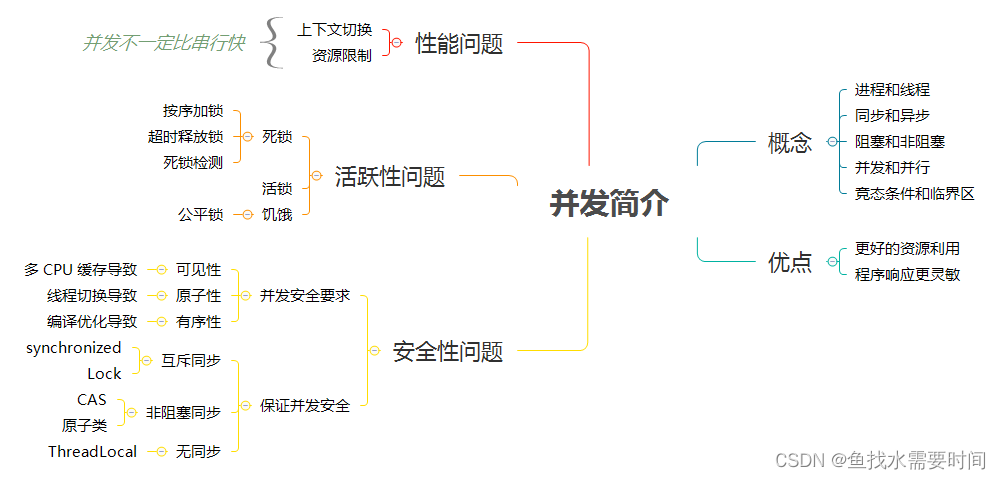
进程和线程
- 进程:进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动。进程是操作系统进行资源分配的基本单位。进程可视为一个正在运行的程序。
- 线程:线程是操作系统进行调度的基本单位。
进程和线程的差异:
- 一个程序至少有一个进程,一个进程至少有一个线程。
- 线程比进程划分更细,所以执行开销更小,并发性更高
- 进程是一个实体,拥有独立的资源;而同一个进程中的多个线程共享进程的资源。
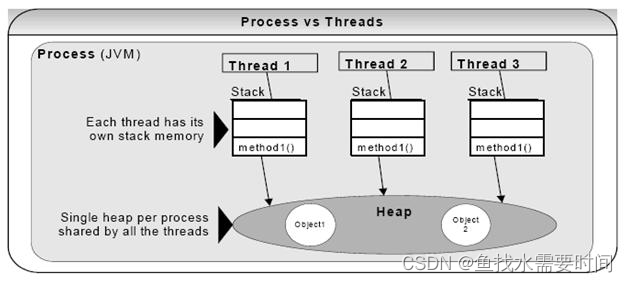
JVM 在单个进程中运行,JVM 中的线程共享属于该进程的堆。这就是为什么几个线程可以访问同一个对象。线程共享堆并拥有自己的堆栈空间。这是一个线程如何调用一个方法以及它的局部变量是如何保持线程安全的。但是堆不是线程安全的并且为了线程安全必须进行同步。
竞态条件和临界区
-
竞态条件(Race Condition):当两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件。
-
临界区(Critical Sections):导致竞态条件发生的代码区称作临界区。
管程
管程(Monitor),是指管理共享变量以及对共享变量的操作过程,让他们支持并发。
Java 采用的是管程技术,synchronized 关键字及 wait()、notify()、notifyAll() 这三个方法都是管程的组成部分。而管程和信号量是等价的,所谓等价指的是用管程能够实现信号量,也能用信号量实现管程。
并发的特点
技术在进步,CPU、内存、I/O 设备的性能也在不断提高。但是,始终存在一个核心矛盾:CPU、内存、I/O 设备存在速度差异。CPU 远快于内存,内存远快于 I/O 设备。
木桶短板理论告诉我们:一只木桶能装多少水,取决于最短的那块木板。同理,程序整体性能取决于最慢的操作(即 I/O 操作),所以单方面提高 CPU、内存的性能是无效的。

为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU 增加了缓存,以均衡与内存的速度差异;
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
其中,进程、线程使得计算机、程序有了并发处理任务的能力。
并发的优点在于:
- 提升资源利用率
- 程序响应更快
提升资源利用率
想象一下,一个应用程序需要从本地文件系统中读取和处理文件的情景。比方说,从磁盘读取一个文件需要 5 秒,处理一个文件需要 2 秒。处理两个文件则需要:
5秒读取文件A
2秒处理文件A
5秒读取文件B
2秒处理文件B
---------------------
总共需要14秒
从磁盘中读取文件的时候,大部分的 CPU 时间用于等待磁盘去读取数据。在这段时间里,CPU 非常的空闲。它可以做一些别的事情。通过改变操作的顺序,就能够更好的使用 CPU 资源。看下面的顺序:
5秒读取文件A
5秒读取文件B + 2秒处理文件A
2秒处理文件B
---------------------
总共需要12秒
CPU 等待第一个文件被读取完。然后开始读取第二个文件。当第二文件在被读取的时候,CPU 会去处理第一个文件。记住,在等待磁盘读取文件的时候,CPU 大 部分时间是空闲的。
总的说来,CPU 能够在等待 IO 的时候做一些其他的事情。这个不一定就是磁盘 IO。它也可以是网络的 IO,或者用户输入。通常情况下,网络和磁盘的 IO 比 CPU 和内存的 IO 慢的多。
程序响应更快
将一个单线程应用程序变成多线程应用程序的另一个常见的目的是实现一个响应更快的应用程序。设想一个服务器应用,它在某一个端口监听进来的请求。当一个请求到来时,它去处理这个请求,然后再返回去监听。
服务器的流程如下所述:
while(server is active) {listen for requestprocess request
}
如果一个请求需要占用大量的时间来处理,在这段时间内新的客户端就无法发送请求给服务端。只有服务器在监听的时候,请求才能被接收。另一种设计是,监听线程把请求传递给工作者线程(worker thread),然后立刻返回去监听。而工作者线程则能够处理这个请求并发送一个回复给客户端。这种设计如下所述:
while(server is active) {listen for requesthand request to worker thread
}
这种方式,服务端线程迅速地返回去监听。因此,更多的客户端能够发送请求给服务端。这个服务也变得响应更快。
桌面应用也是同样如此。如果你点击一个按钮开始运行一个耗时的任务,这个线程既要执行任务又要更新窗口和按钮,那么在任务执行的过程中,这个应用程序看起来好像没有反应一样。相反,任务可以传递给工作者线程(worker thread)。当工作者线程在繁忙地处理任务的时候,窗口线程可以自由地响应其他用户的请求。当工作者线程完成任务的时候,它发送信号给窗口线程。窗口线程便可以更新应用程序窗口,并显示任务的结果。对用户而言,这种具有工作者线程设计的程序显得响应速度更快。
并发的问题
任何事物都有利弊,并发也不例外。
我们知道了并发带来的好处:提升资源利用率、程序响应更快,同时也要认识到并发带来的问题,主要有:
- 安全性问题
- 活跃性问题
- 性能问题
安全性问题
并发最重要的问题是并发安全问题。
并发安全:是指保证程序的正确性,使得并发处理结果符合预期。
并发安全需要保证几个基本特性:
- 可见性 - 是一个线程修改了某个共享变量,其状态能够立即被其他线程知晓,通常被解释为将线程本地状态反映到主内存上,
volatile就是负责保证可见性的。 - 原子性 - 简单说就是相关操作不会中途被其他线程干扰,一般通过同步机制(加锁:
sychronized、Lock)实现。 - 有序性 - 是保证线程内串行语义,避免指令重排等。
缓存导致的可见性问题
一个线程对共享变量的修改,另外一个线程能够立刻看到,称为 可见性。
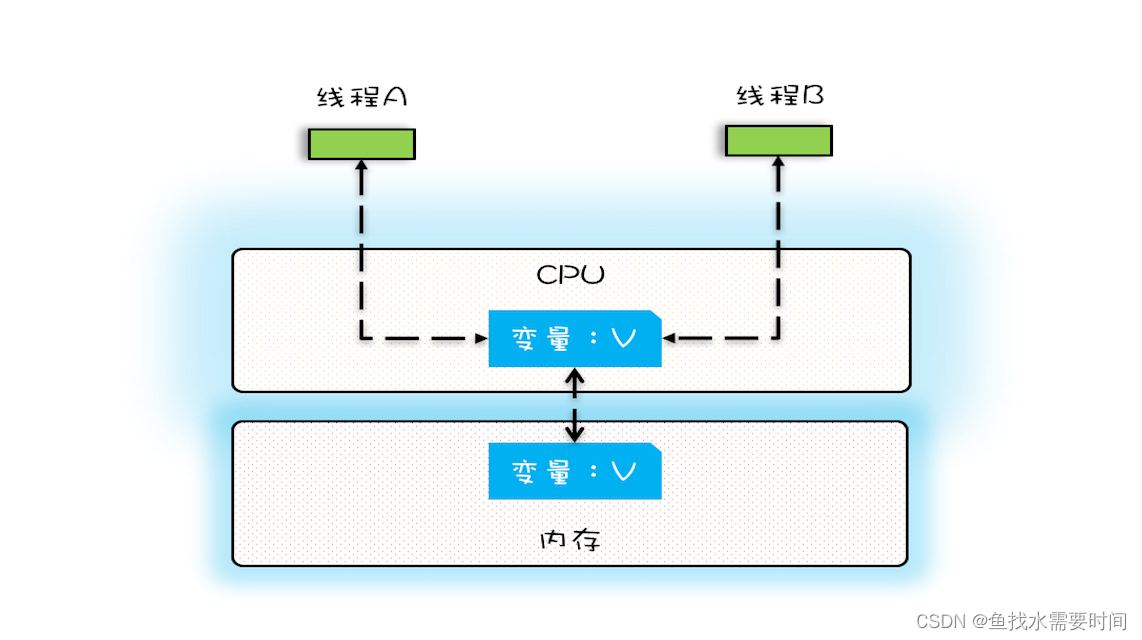
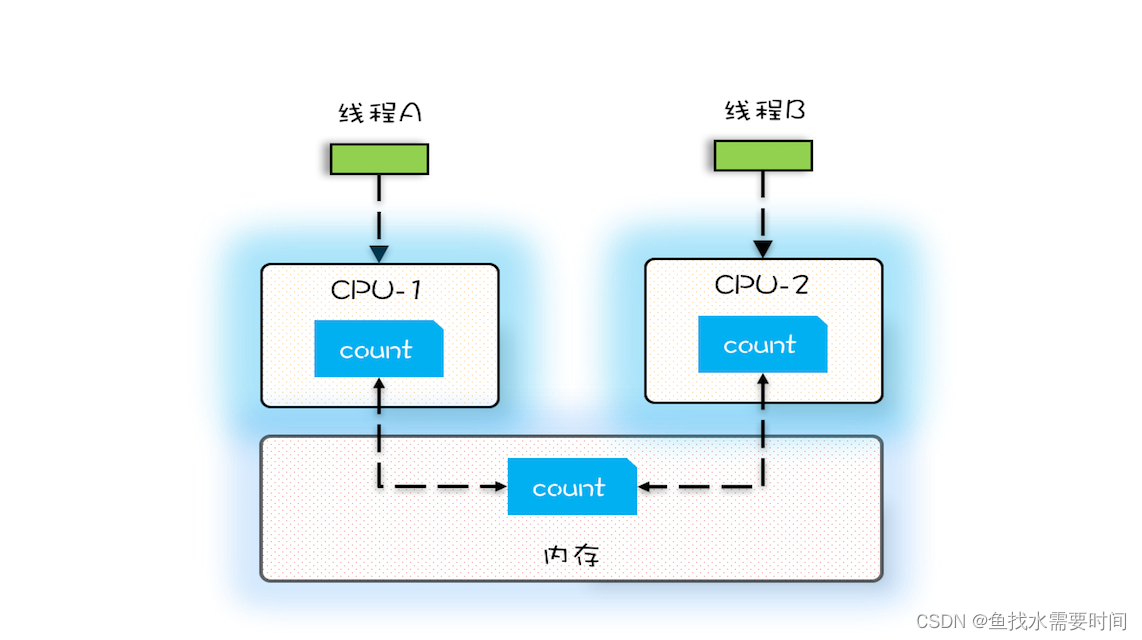
在单核时代,所有的线程都是在一颗 CPU 上执行,CPU 缓存与内存的数据一致性容易解决。因为所有线程都是操作同一个 CPU 的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的。例如在下面的图中,线程 A 和线程 B 都是操作同一个 CPU 里面的缓存,所以线程 A 更新了变量 V 的值,那么线程 B 之后再访问变量 V,得到的一定是 V 的最新值(线程 A 写过的值)。
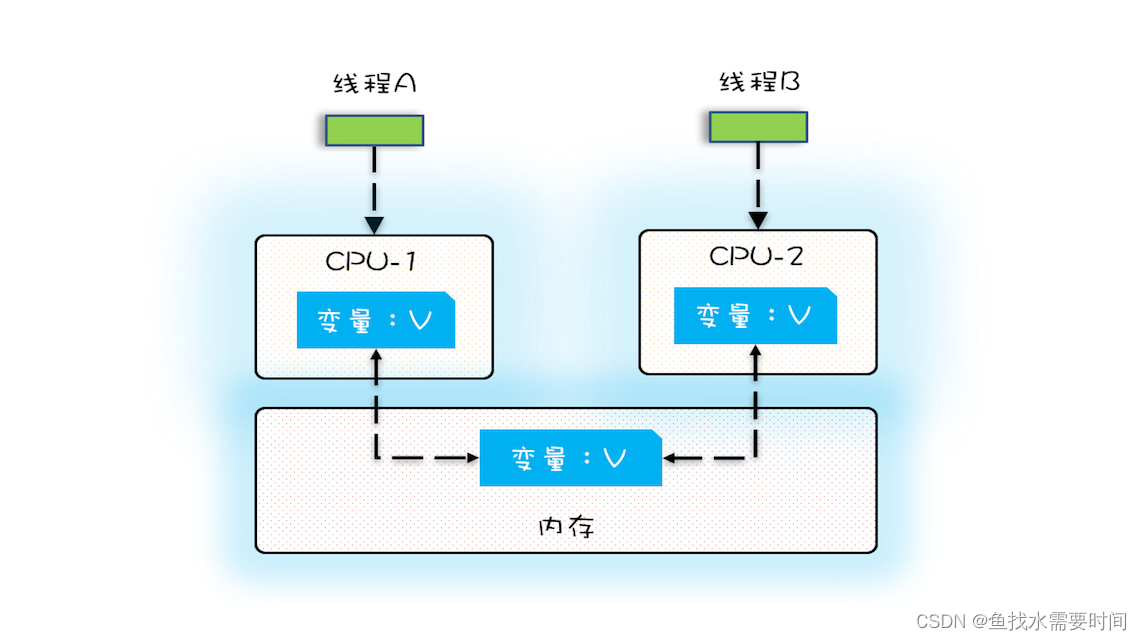
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。比如下图中,线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,很明显,这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。
【示例】线程不安全的示例
下面我们再用一段代码来验证一下多核场景下的可见性问题。下面的代码,每执行一次 add10K() 方法,都会循环 10000 次 count+=1 操作。在 calc() 方法中我们创建了两个线程,每个线程调用一次 add10K() 方法,我们来想一想执行 calc() 方法得到的结果应该是多少呢?
public class Test {private long count = 0;private void add10K() {int idx = 0;while(idx++ < 10000) {count += 1;}}public static long calc() {final Test test = new Test();// 创建两个线程,执行 add() 操作Thread th1 = new Thread(()->{test.add10K();});Thread th2 = new Thread(()->{test.add10K();});// 启动两个线程th1.start();th2.start();// 等待两个线程执行结束th1.join();th2.join();return count;}
}
直觉告诉我们应该是 20000,因为在单线程里调用两次 add10K() 方法,count 的值就是 20000,但实际上 calc() 的执行结果是个 10000 到 20000 之间的随机数。为什么呢?
我们假设线程 A 和线程 B 同时开始执行,那么第一次都会将 count=0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。这就是缓存的可见性问题。
循环 10000 次 count+=1 操作如果改为循环 1 亿次,你会发现效果更明显,最终 count 的值接近 1 亿,而不是 2 亿。如果循环 10000 次,count 的值接近 20000,原因是两个线程不是同时启动的,有一个时差。
线程切换带来的原子性问题
由于 IO 太慢,早期的操作系统就发明了多进程,操作系统允许某个进程执行一小段时间(称为 时间片)。
在一个时间片内,如果一个进程进行一个 IO 操作,例如读个文件,这个时候该进程可以把自己标记为“休眠状态”并出让 CPU 的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得 CPU 的使用权了。
这里的进程在等待 IO 时之所以会释放 CPU 使用权,是为了让 CPU 在这段等待时间里可以做别的事情,这样一来 CPU 的使用率就上来了;此外,如果这时有另外一个进程也读文件,读文件的操作就会排队,磁盘驱动在完成一个进程的读操作后,发现有排队的任务,就会立即启动下一个读操作,这样 IO 的使用率也上来了。
早期的操作系统基于进程来调度 CPU,不同进程间是不共享内存空间的,所以进程要做任务切换就要切换内存映射地址,而一个进程创建的所有线程,都是共享一个内存空间的,所以线程做任务切换成本就很低了。现代的操作系统都基于更轻量的线程来调度,现在我们提到的“任务切换”都是指“线程切换”。
Java 并发程序都是基于多线程的,自然也会涉及到任务切换,也许你想不到,任务切换竟然也是并发编程里诡异 Bug 的源头之一。任务切换的时机大多数是在时间片结束的时候,我们现在基本都使用高级语言编程,高级语言里一条语句往往需要多条 CPU 指令完成,例如上面代码中的 count += 1,至少需要三条 CPU 指令。
- 指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执行 +1 操作;
- 指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
操作系统做任务切换,可以发生在任何一条CPU 指令执行完,是的,是 CPU 指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设 count=0,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。
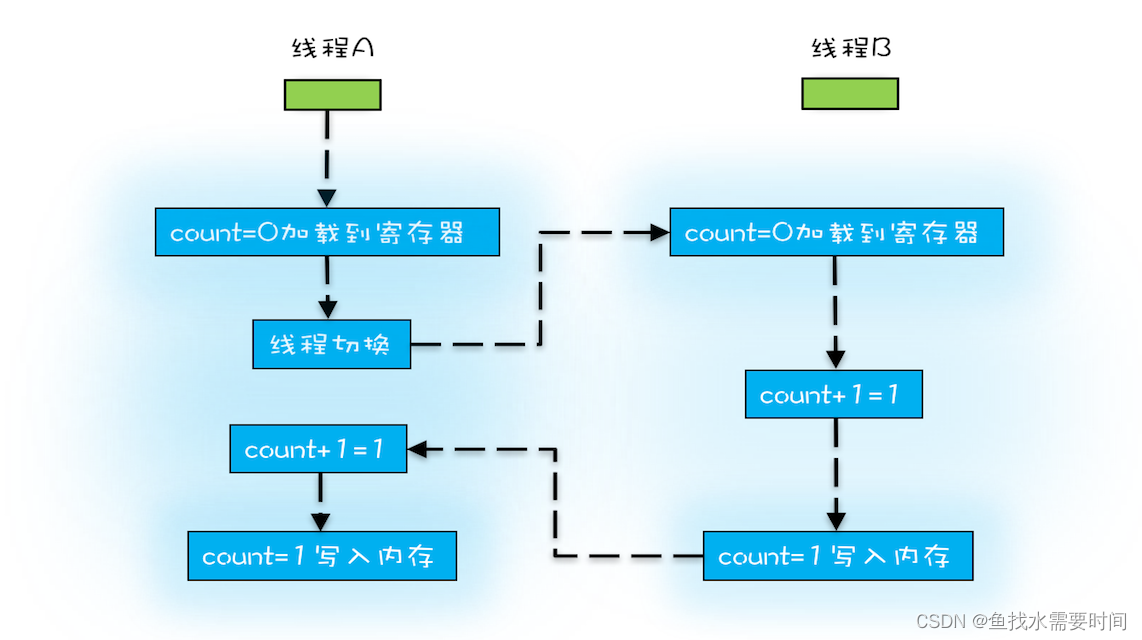
我们潜意识里面觉得 count+=1 这个操作是一个不可分割的整体,就像一个原子一样,线程的切换可以发生在 count+=1 之前,也可以发生在 count+=1 之后,但就是不会发生在中间。我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。CPU 能保证的原子操作是 CPU 指令级别的,而不是高级语言的操作符,这是违背我们直觉的地方。因此,很多时候我们需要在高级语言层面保证操作的原子性。
编译优化带来的有序性问题
那并发编程里还有没有其他有违直觉容易导致诡异 Bug 的技术呢?有的,就是有序性。顾名思义,有序性指的是程序按照代码的先后顺序执行。编译器为了优化性能,有时候会改变程序中语句的先后顺序,例如程序中:“a=6; b=7;”编译器优化后可能变成“b=7; a=6;”,在这个例子中,编译器调整了语句的顺序,但是不影响程序的最终结果。不过有时候编译器及解释器的优化可能导致意想不到的 Bug。
在 Java 领域一个经典的案例就是利用双重检查创建单例对象,例如下面的代码:在获取实例 getInstance() 的方法中,我们首先判断 instance 是否为空,如果为空,则锁定 Singleton.class 并再次检查 instance 是否为空,如果还为空则创建 Singleton 的一个实例。
public class Singleton {static Singleton instance;static Singleton getInstance(){if (instance == null) {synchronized(Singleton.class) {if (instance == null)instance = new Singleton();}}return instance;}
}
假设有两个线程 A、B 同时调用 getInstance() 方法,他们会同时发现 instance == null ,于是同时对 Singleton.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);线程 A 会创建一个 Singleton 实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 Singleton 实例了,所以线程 B 不会再创建一个 Singleton 实例。
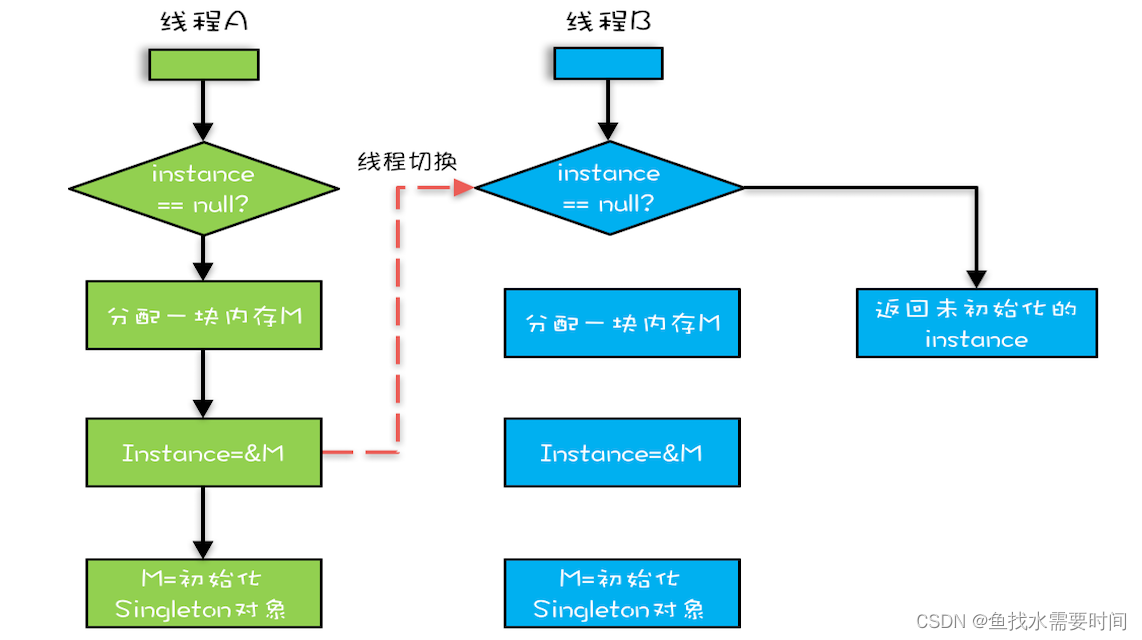
这看上去一切都很完美,无懈可击,但实际上这个 getInstance() 方法并不完美。问题出在哪里呢?出在 new 操作上,我们以为的 new 操作应该是:
- 分配一块内存 M;
- 在内存 M 上初始化 Singleton 对象;
- 然后 M 的地址赋值给 instance 变量。
但是实际上优化后的执行路径却是这样的:
- 分配一块内存 M;
- 将 M 的地址赋值给 instance 变量;
- 最后在内存 M 上初始化 Singleton 对象。
优化后会导致什么问题呢?我们假设线程 A 先执行 getInstance() 方法,当执行完指令 2 时恰好发生了线程切换,切换到了线程 B 上;如果此时线程 B 也执行 getInstance() 方法,那么线程 B 在执行第一个判断时会发现 instance != null ,所以直接返回 instance,而此时的 instance 是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。
保证并发安全的思路
互斥同步(阻塞同步)
互斥同步是最常见的并发正确性保障手段。
同步是指在多线程并发访问共享数据时,保证共享数据在同一时刻只能被一个线程访问。
互斥是实现同步的一种手段。临界区(Critical Sections)、互斥量(Mutex)和信号量(Semaphore)都是主要的互斥实现方式。
最典型的案例是使用 synchronized 或 Lock 。
互斥同步最主要的问题是线程阻塞和唤醒所带来的性能问题,互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
非阻塞同步
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略:先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
为什么说乐观锁需要 硬件指令集的发展 才能进行?因为需要操作和冲突检测这两个步骤具备原子性。而这点是由硬件来完成,如果再使用互斥同步来保证就失去意义了。
这类乐观锁指令常见的有:
- 测试并设置(Test-and-Set)
- 获取并增加(Fetch-and-Increment)
- 交换(Swap)
- 比较并交换(CAS)
- 加载链接、条件存储(Load-linked / Store-Conditional)
Java 典型应用场景:J.U.C 包中的原子类(基于 Unsafe 类的 CAS 操作)
无同步
要保证线程安全,不一定非要进行同步。同步只是保证共享数据争用时的正确性,如果一个方法本来就不涉及共享数据,那么自然无须同步。
Java 中的 无同步方案 有:
- 可重入代码 - 也叫纯代码。如果一个方法,它的 返回结果是可以预测的,即只要输入了相同的数据,就能返回相同的结果,那它就满足可重入性,当然也是线程安全的。
- 线程本地存储 - 使用
ThreadLocal为共享变量在每个线程中都创建了一个本地副本,这个副本只能被当前线程访问,其他线程无法访问,那么自然是线程安全的。
活跃性问题
死锁(Deadlock)
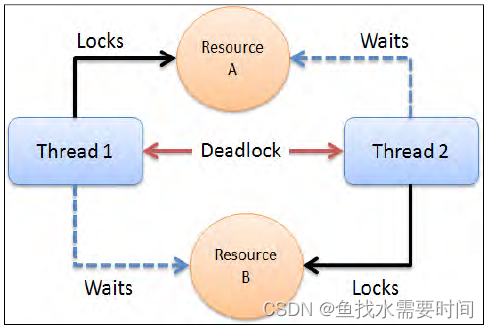
什么是死锁
多个线程互相等待对方释放锁。
死锁是当线程进入无限期等待状态时发生的情况,因为所请求的锁被另一个线程持有,而另一个线程又等待第一个线程持有的另一个锁。
避免死锁
(1)按序加锁
当多个线程需要相同的一些锁,但是按照不同的顺序加锁,死锁就很容易发生。
如果能确保所有的线程都是按照相同的顺序获得锁,那么死锁就不会发生。
按照顺序加锁是一种有效的死锁预防机制。但是,这种方式需要你事先知道所有可能会用到的锁(注:并对这些锁做适当的排序),但总有些时候是无法预知的。
(2)超时释放锁
另外一个可以避免死锁的方法是在尝试获取锁的时候加一个超时时间,这也就意味着在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求。若一个线程没有在给定的时限内成功获得所有需要的锁,则会进行回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。这段随机的等待时间让其它线程有机会尝试获取相同的这些锁,并且让该应用在没有获得锁的时候可以继续运行(注:加锁超时后可以先继续运行干点其它事情,再回头来重复之前加锁的逻辑)。
(3)死锁检测
死锁检测是一个更好的死锁预防机制,它主要是针对那些不可能实现按序加锁并且锁超时也不可行的场景。
每当一个线程获得了锁,会在线程和锁相关的数据结构中(map、graph 等等)将其记下。除此之外,每当有线程请求锁,也需要记录在这个数据结构中。
当一个线程请求锁失败时,这个线程可以遍历锁的关系图看看是否有死锁发生。
如果检测出死锁,有两种处理手段:
- 释放所有锁,回退,并且等待一段随机的时间后重试。这个和简单的加锁超时类似,不一样的是只有死锁已经发生了才回退,而不会是因为加锁的请求超时了。虽然有回退和等待,但是如果有大量的线程竞争同一批锁,它们还是会重复地死锁(注:原因同超时类似,不能从根本上减轻竞争)。
- 一个更好的方案是给这些线程设置优先级,让一个(或几个)线程回退,剩下的线程就像没发生死锁一样继续保持着它们需要的锁。如果赋予这些线程的优先级是固定不变的,同一批线程总是会拥有更高的优先级。为避免这个问题,可以在死锁发生的时候设置随机的优先级。
活锁(Livelock)
什么是活锁
活锁是一个递归的情况,两个或更多的线程会不断重复一个特定的代码逻辑。预期的逻辑通常为其他线程提供机会继续支持’this’线程。
想象这样一个例子:两个人在狭窄的走廊里相遇,二者都很礼貌,试图移到旁边让对方先通过。但是他们最终在没有取得任何进展的情况下左右摇摆,因为他们都在同一时间向相同的方向移动。
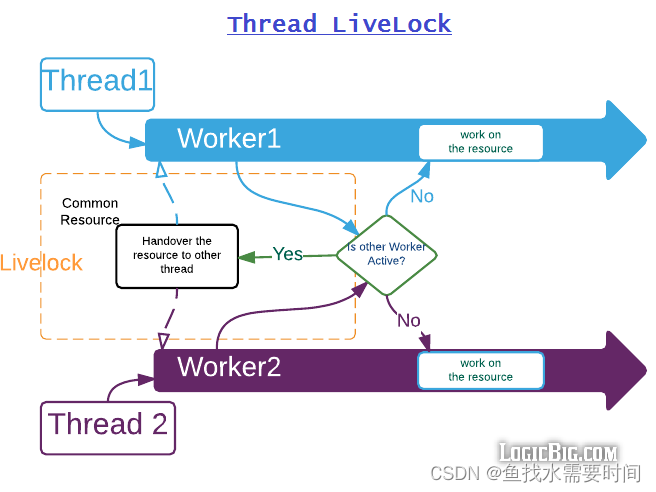
如图所示:两个线程想要通过一个 Worker 对象访问共享公共资源的情况,但是当他们看到另一个 Worker(在另一个线程上调用)也是“活动的”时,它们会尝试将该资源交给其他工作者并等待为它完成。如果最初我们让两名工作人员都活跃起来,他们将会面临活锁问题。
避免活锁
解决“活锁”的方案很简单,谦让时,尝试等待一个随机的时间就可以了。由于等待的时间是随机的,所以同时相撞后再次相撞的概率就很低了。“等待一个随机时间”的方案虽然很简单,却非常有效,Raft 这样知名的分布式一致性算法中也用到了它。
饥饿(Starvation)
什么是饥饿
- 高优先级线程吞噬所有的低优先级线程的 CPU 时间。
- 线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之前持续地对该同步块进行访问。
- 线程在等待一个本身(在其上调用
wait())也处于永久等待完成的对象,因为其他线程总是被持续地获得唤醒。
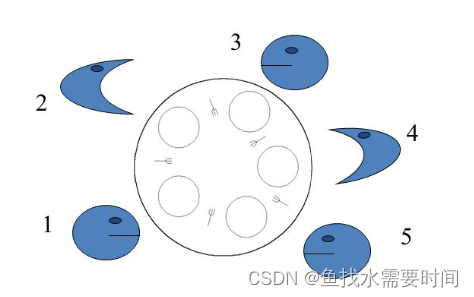
饥饿问题最经典的例子就是哲学家问题。如图所示:有五个哲学家用餐,每个人要获得两把叉子才可以就餐。当 2、4 就餐时,1、3、5 永远无法就餐,只能看着盘中的美食饥饿的等待着。
解决饥饿
Java 不可能实现 100% 的公平性,我们依然可以通过同步结构在线程间实现公平性的提高。
有三种方案:
- 保证资源充足
- 公平地分配资源
- 避免持有锁的线程长时间执行
这三个方案中,方案一和方案三的适用场景比较有限,因为很多场景下,资源的稀缺性是没办法解决的,持有锁的线程执行的时间也很难缩短。倒是方案二的适用场景相对来说更多一些。
那如何公平地分配资源呢?在并发编程里,主要是使用公平锁。所谓公平锁,是一种先来后到的方案,线程的等待是有顺序的,排在等待队列前面的线程会优先获得资源。
性能问题
并发执行一定比串行执行快吗?线程越多执行越快吗?
答案是:并发不一定比串行快。因为有创建线程和线程上下文切换的开销。
上下文切换
什么是上下文切换?
当 CPU 从执行一个线程切换到执行另一个线程时,CPU 需要保存当前线程的本地数据,程序指针等状态,并加载下一个要执行的线程的本地数据,程序指针等。这个开关被称为“上下文切换”。
减少上下文切换的方法
- 无锁并发编程 - 多线程竞争锁时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,如将数据的 ID 按照 Hash 算法取模分段,不同的线程处理不同段的数据。
- CAS 算法 - Java 的
Atomic包使用 CAS 算法来更新数据,而不需要加锁。 - 使用最少线程 - 避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这样会造成大量线程都处于等待状态。
- 使用协程 - 在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
资源限制
什么是资源限制
资源限制是指在进行并发编程时,程序的执行速度受限于计算机硬件资源或软件资源。
资源限制引发的问题
在并发编程中,将代码执行速度加快的原则是将代码中串行执行的部分变成并发执行,但是如果将某段串行的代码并发执行,因为受限于资源,仍然在串行执行,这时候程序不仅不会加快执行,反而会更慢,因为增加了上下文切换和资源调度的时间。
如何解决资源限制的问题
在资源限制情况下进行并发编程,根据不同的资源限制调整程序的并发度。
- 对于硬件资源限制,可以考虑使用集群并行执行程序。
- 对于软件资源限制,可以考虑使用资源池将资源复用。
小结
并发编程可以总结为三个核心问题:分工、同步、互斥。
- 分工:是指如何高效地拆解任务并分配给线程。
- 同步:是指线程之间如何协作。
- 互斥:是指保证同一时刻只允许一个线程访问共享资源。
相关文章:
Java并发简介(什么是并发)
文章目录并发概念并发和并行同步和异步阻塞和非阻塞进程和线程竞态条件和临界区管程并发的特点提升资源利用率程序响应更快并发的问题安全性问题缓存导致的可见性问题线程切换带来的原子性问题编译优化带来的有序性问题保证并发安全的思路互斥同步(阻塞同步…...

团队API管理工具-YAPI
团队API管理工具-YAPI 推荐一款接口管理平台,操作简单、界面友好、功能丰富、支持markdown语法、可使用Postman导入、Swagger同步数据展示、LDAP、权限管理等功能。 YApi是高效、易用、功能强大的api管理平台,旨在为开发、产品、测试人员提供更优雅的接…...

学习记录 --- Pytorch优化器
文章目录参考文献什么是优化器optimizer的定义optimizer的属性defaultsstateparam_groupsoptimizer的方法zero_grad()step()add_param_group()state_dict()、load_state_dict()优化一个网络同时优化多个网络当成一个网络优化当成多个网络优化只优化网络的某些指定的层调整学习率…...

Flink State 状态后端分析
flink状态实现分析 state * State* |* -------------------InternalKvState* | |* MergingState |* | |* …...

和年薪30W的阿里测开工程师聊过后,才知道我的工作就是打杂的...
前几天和一个朋友聊面试,他说上个月同时拿到了腾讯和阿里的offer,最后选择了阿里。 阿里内部将员工一共分为了14个等级,P6是资深工程师,P7是技术专家。 其中P6和P7就是一个分水岭了,P6是最接近P7的不持股员工&#x…...

C#开发的OpenRA的界面布局数据加载
C#开发的OpenRA的界面布局数据加载 当显示完成加载界面之后,就是进行其它内容处理。 因为后面内容的加载会比较长时间,所以首先显示加载界面是一种非常友好的方法。 因此在软件设计里,尽可能先显示界面,让用户先看到程序正在运行, 然后再处理时间长的加载。如果不这样做,…...

并查集结构
文章目录并查集特点构建过程查找两个元素是否是同一集合优化查找领头元素设置两个元素为同一集合构建结构应用场景并行计算集合问题并查集特点 对于使用并查集构建的结构,可以使得查询两个元素是否在同一集合,以及合并集合的操作无限接近O(1) 构建过程…...

全国CSM敏捷教练认证将于2023年3月25-26开班,报名从速!
CSM,即Certified Scrum Master,是Scrum联盟发起的Scrum认证。 CSM可以帮助团队正确使用Scrum,从而提高项目整体成功的可能性。 CSM深刻理解Scrum的价值观、实践以及Scrum框架。 CSM是“服务型领导”,帮助Scrum团队一起紧密合作。 …...
JavaEE进阶第六课:SpringBoot ⽇志⽂件
上篇文章介绍了SpringBoot配置文件,这篇文章我们将会介绍SpringBoot ⽇志⽂件 荔枝1.日志有什么用2.自定义日志输出2.1获取程序日志对象2.2使用相关方法输出日志2.3日志级别2.3.1日志级别的作用2.3.2日志级别如何设置2.4日志格式3.持久化日志4.更简单的日志输出4.1使…...

外置MOS管平均电流型LED降压恒流驱动器
产品描述 AP5125 是一款外围电路简单的 Buck 型平均电 流检测模式的 LED 恒流驱动器,适用于 8-100V 电压 范围的非隔离式大功率恒流 LED 驱动领域。芯片采用 固定频率 140kHz 的 PWM 工作模式, 利用平均电 流检测模式,因此具有优异的负载调整…...

python+pytest接口自动化(6)-请求参数格式的确定
我们在做接口测试之前,先需要根据接口文档或抓包接口数据,搞清楚被测接口的详细内容,其中就包含请求参数的编码格式,从而使用对应的参数格式发送请求。例如某个接口规定的请求主体的编码方式为 application/json,那么在…...

开发手册——一、编程规约_3.代码格式
这篇文章主要梳理了在java的实际开发过程中的编程规范问题。本篇文章主要借鉴于《阿里巴巴java开发手册终极版》 下面我们一起来看一下吧。 1. 【强制】大括号的使用约定。如果是大括号内为空,则简洁地写成{}即可,不需要换行;如果是非空代码…...
)
十七、Django-restframework之序列化器(二)
1. 序列化器 REST framework提供了一个serializer类,它可以非常方便的序列化模型实例和查询集为JSON或者其他内容形式。它还提供反序列化,允许在验证传入数据后将解析的数据转换回复杂类型。 2. 定义序列化器 在crm应用目录下创建serializers.py文件&a…...
python GUI图形化编程-----wxpython
一、python gui(图形化)模块介绍: Tkinter :是python最简单的图形化模块,总共只有14种组建 Pyqt :是python最复杂也是使用最广泛的图形化 Wx :是python当中居中的一个图形化,学习结构很清晰 Pywin :是pyth…...

【Python 】yyyy-MM-dd HH:mm:ss 时间格式 时间戳 全面解读超详细
时间格式 时间格式(协议)描述gg时期或纪元。y不包含纪元的年份。不具有前导零。yy不包含纪元的年份。具有前导零。yyyy包含纪元的四位数的年份。M月份数字。一位数的月份没有前导零。MM月份数字。一位数的月份有一个前导零。MMM月份的缩写名称,在AbbreviatedMonthN…...
【C++】C++11 异常
目录 1. C语言传统的处理错误的方式 2. C异常概念 3. 异常的使用 3.1. 异常的抛出和捕获 3.2. 在函数调用链中异常栈展开匹配原则 3.3. 异常的重新抛出 3.4. 异常安全 3.5. 异常规范 4.自定义异常体系 5. C标准库的异常体系 6. 异常的优缺点 6.1. C异常的优点&…...
关于Thread.start()后的困惑、imap
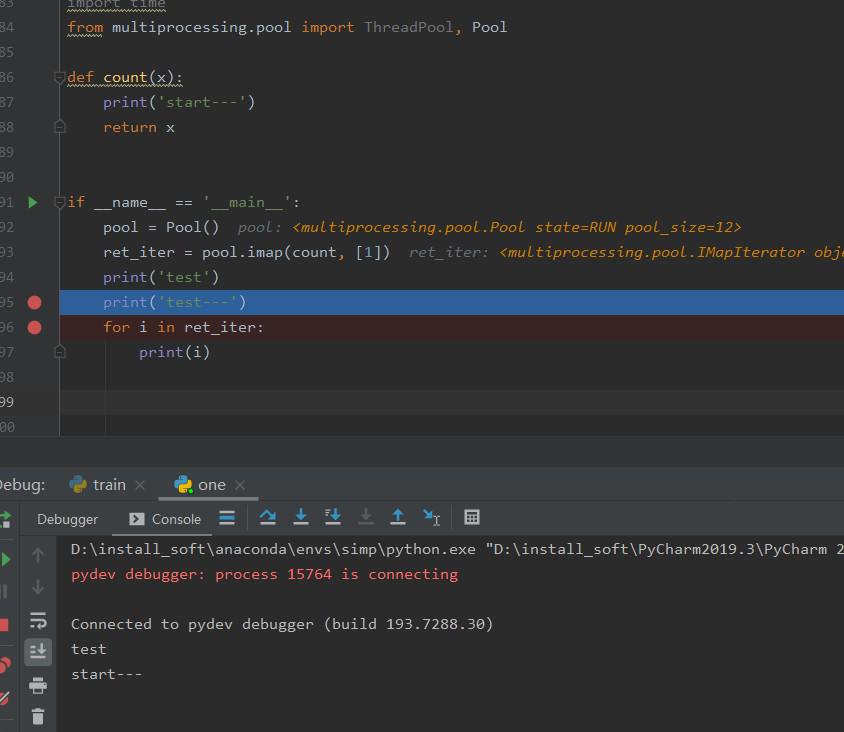
在for循环中,接着开thread,开完就start,当时有个困惑,就是比如开的一个thread的这个start执行完,但是这个for循环还没执行完,那程序会跑到for循环的后面逻辑吗?比如下面13行for循环开始开第一个…...
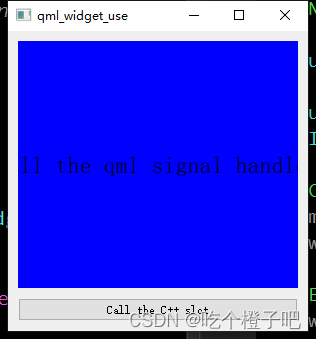
qml学习之qwidget与qml结合使用并调用信号槽交互
学习qml系列之一说明: 学习qml系列之qwiget和qml信号槽的交互使用,并在qwidget中显示qml界面 在qml中发送信号到qwidget里 在qwidget里发送信号给qml 在qwidget里面调用qml界面方式 方式一:使用QQuickView 这个是Qt5.0中提供的一个类&…...
)
【 华为OD机试 2023】 组装新的数组(C++ Java JavaScript Python)
文章目录 题目描述输入描述输出描述备注用例题目解析C++JavaScriptJavaPython题目描述 给你一个整数M和数组N,N中的元素为连续整数,要求根据N中的元素组装成新的数组R,组装规则: R中元素总和加起来等于MR中的元素可以从N中重复选取R中的元素最多只能有1个不在N中,且比N中…...
)
【洛谷 P2089】烤鸡(循环枚举)
烤鸡 题目背景 猪猪 Hanke 得到了一只鸡。 题目描述 猪猪 Hanke 特别喜欢吃烤鸡(本是同畜牲,相煎何太急!)Hanke 吃鸡很特别,为什么特别呢?因为他有 101010 种配料(芥末、孜然等)…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...

起重机起升机构的安全装置有哪些?
起重机起升机构的安全装置是保障吊装作业安全的关键部件,主要用于防止超载、失控、断绳等危险情况。以下是常见的安全装置及其功能和原理: 一、超载保护装置(核心安全装置) 1. 起重量限制器 功能:实时监测起升载荷&a…...
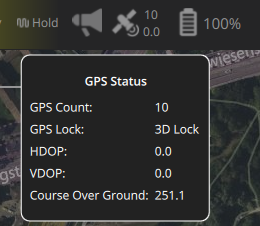
【PX4飞控】mavros gps相关话题分析,经纬度海拔获取方法,卫星数锁定状态获取方法
使用 ROS1-Noetic 和 mavros v1.20.1, 携带经纬度海拔的话题主要有三个: /mavros/global_position/raw/fix/mavros/gpsstatus/gps1/raw/mavros/global_position/global 查看 mavros 源码,来分析他们的发布过程。发现前两个话题都对应了同一…...
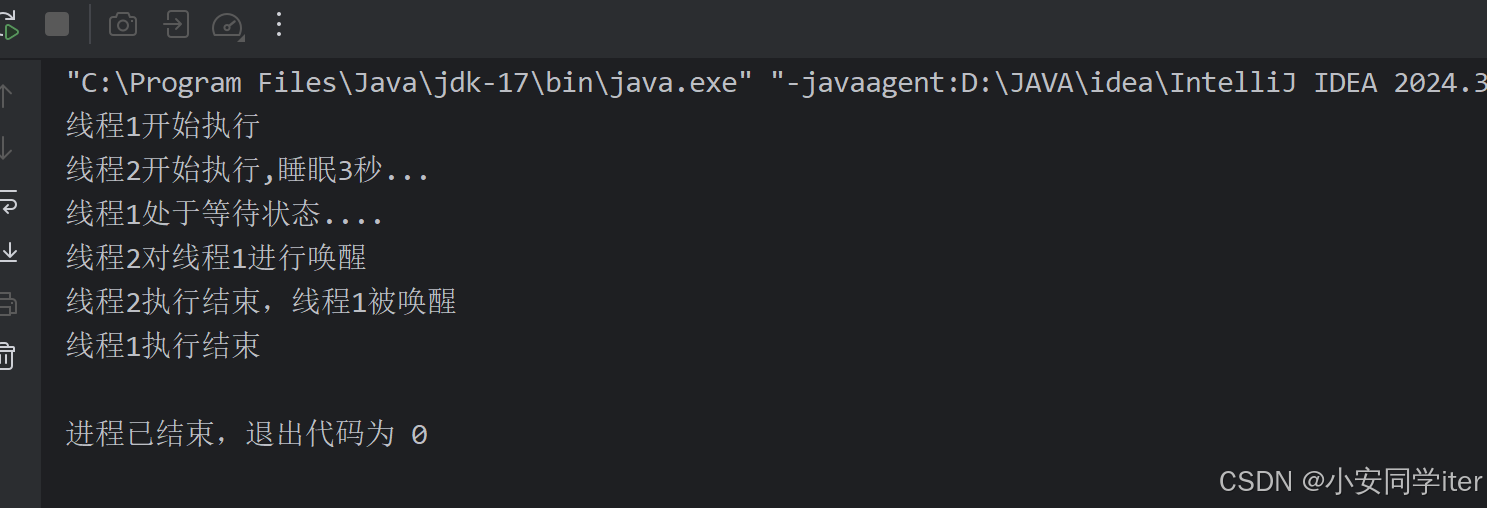
JUC并发编程(二)Monitor/自旋/轻量级/锁膨胀/wait/notify/锁消除
目录 一 基础 1 概念 2 卖票问题 3 转账问题 二 锁机制与优化策略 0 Monitor 1 轻量级锁 2 锁膨胀 3 自旋 4 偏向锁 5 锁消除 6 wait /notify 7 sleep与wait的对比 8 join原理 一 基础 1 概念 临界区 一段代码块内如果存在对共享资源的多线程读写操作…...

day51 python CBAM注意力
目录 一、CBAM 模块简介 二、CBAM 模块的实现 (一)通道注意力模块 (二)空间注意力模块 (三)CBAM 模块的组合 三、CBAM 模块的特性 四、CBAM 模块在 CNN 中的应用 一、CBAM 模块简介 在之前的探索中…...