Milvus实战:构建QA系统及推荐系统
Milvus简介
全民AI的时代已经在趋势之中,各类应用层出不穷,而想要构建一个完善的AI应用/系统,底层存储是不可缺少的一个组件。
与传统数据库或大数据存储不同的是,这种场景下则需要选择向量数据库,是专门用来存储和查询向量的数据库,其存储的向量来自于对文本、语音、图像、视频等的向量化数据,向量数据库不仅能够完成基本的CRUD(添加、读取查询、更新、删除)等操作,还能够对向量数据进行更快速的相似性搜索。
Milvus是众多向量库中的之一,适用于多个场景,如Questions & Answering系统、推荐系统等,单节点 Milvus 可以在秒内完成十亿级的向量搜索,分布式架构亦能满足用户的水平扩展需求。
参考文档:
Milvus官网
为AI而生的数据库:Milvus详解及实战
实践之问答系统&推荐系统Mix-in
元数据定义
不论是问答还是推荐,它们对上层暴露的接口仅仅是predict(...)/search(...)/query(...),模式是相同的,因此可以共用一个基本的Schema,固定基本的字段即可。
public class MilvusMeta {@Getterprivate final RecommenderSchema defaultMetricsSchema;@Getterprivate final QASchema defaultQASchema;public interface Schema {String getCollectionName();CreateCollectionParam getCreateCollectionParam();CreateIndexParam getCreateIndexParam();}@AllArgsConstructorpublic abstract static class BasicSchema implements Schema {public static final String SEARCH_PARAM = "{\"nprobe\":10}"; // Paramspublic static final String INDEX_PARAM = "{\"nlist\":1024}"; // ExtraParampublic static final IndexType INDEX_TYPE_DEFAULT = IndexType.IVF_FLAT;public static final MetricType METRIC_TYPE_DEFAULT = MetricType.L2; // metric typepublic static final String INDEX_NAME_DEFAULT = "ivf_flat";public static final String PRIMARY_KEY_FIELD_NAME_DEFAULT = "id";public static final String PARTITION_KEY_FIELD_NAME_DEFAULT = "public";public static final String FIELD_NAME_DEFAULT = "embeddings";@Getterprotected final CreateCollectionParam createCollectionParam;@Getterprotected final CreateIndexParam createIndexParam;@Overridepublic String getCollectionName() {return createCollectionParam.getCollectionName();}}/*** This schema is designed for storing Zen metrics.* TODO: Add more fields/features to describe a metric.*/public static class RecommenderSchema extends BasicSchema {private RecommenderSchema(CreateCollectionParam collectionParam, CreateIndexParam indexParam) {super(collectionParam, indexParam);}public static RecommenderSchema create(ZenAiConfig.Storages.MilvusConf conf) {ZenAiConfig.Storages.Collection collection = conf.getActiveRecommenderCollection();return new RecommenderSchema(defaultCollectionParam(collection, collection.getEmbeddingsDimension()),MilvusUtil.createIndexParam(collection));}private static CreateCollectionParam defaultCollectionParam(ZenAiConfig.Storages.Collection collection,int dimension) {FieldType pkType = FieldType.newBuilder().withName(collection.getPrimaryKey()).withDataType(DataType.VarChar).withPrimaryKey(true).withMaxLength(100).withAutoID(false).build();// 被embedding的字段FieldType embeddedFieldType = FieldType.newBuilder().withName(collection.getEmbeddedFieldName()).withDataType(DataType.VarChar).withMaxLength(255).build();// embedding vector字段FieldType embeddingFieldType = FieldType.newBuilder().withName(collection.getFieldName()).withDataType(DataType.FloatVector).withDimension(dimension).build();// 指定分区键字段,每一个Collection都需要指定一个分区键,除了能够Hive/Spark那样切分数据外,还能够加速相似查询。// 虽然Milvus支持多种方案以切分数据,但从管理复杂度、查询效率上来看,一个Collection对应多个数据分区,是最佳的方案。FieldType partitionKeyType = FieldType.newBuilder().withName(collection.getPartitionKey()).withPartitionKey(true).withDataType(DataType.VarChar).withMaxLength(100).build();return CreateCollectionParam.newBuilder().withCollectionName(collection.getName()).withDescription(collection.getDescription())// .withShardsNum(2).addFieldType(pkType).addFieldType(embeddedFieldType).addFieldType(embeddingFieldType).addFieldType(partitionKeyType)// 开启动态字段添加功能.withEnableDynamicField(true).build();}}public static class QASchema extends BasicSchema {public static final String ANSWER_FIELD_NAME = "answer";public static final String SCORE_FIELD_NAME = "score";public static final float SCORE_MAX_DEFAULT = 5.0f;public static final float SCORE_MIN_DEFAULT = 0.0f;public static final String INTENTION_FIELD_NAME = "intention";public static final String QUESTION_OCCURRENCE = "occurrence";public QASchema(CreateCollectionParam createCollectionParam, CreateIndexParam createIndexParam) {super(createCollectionParam, createIndexParam);}public static QASchema create(ZenAiConfig.Storages.MilvusConf conf) {ZenAiConfig.Storages.Collection collection = conf.getActiveQACollection();return new QASchema(defaultCollectionParam(collection, collection.getEmbeddingsDimension()),MilvusUtil.createIndexParam(collection));}private static CreateCollectionParam defaultCollectionParam(ZenAiConfig.Storages.Collection collection,int dimension) {FieldType pkType = FieldType.newBuilder().withName(collection.getPrimaryKey()).withDataType(DataType.VarChar).withPrimaryKey(true).withMaxLength(100).withAutoID(false).build();FieldType embeddedFieldType = FieldType.newBuilder().withName(collection.getEmbeddedFieldName()).withDataType(DataType.VarChar).withMaxLength(65535).build();FieldType embeddingFieldType = FieldType.newBuilder().withName(collection.getFieldName()).withDataType(DataType.FloatVector).withDimension(dimension).build();FieldType partitionKeyType = FieldType.newBuilder().withName(collection.getPartitionKey()).withPartitionKey(true).withDataType(DataType.VarChar).withMaxLength(100).build();return CreateCollectionParam.newBuilder().withCollectionName(collection.getName()).withDescription(collection.getDescription())// .withShardsNum(2).addFieldType(pkType).addFieldType(embeddedFieldType).addFieldType(embeddingFieldType).addFieldType(partitionKeyType).withEnableDynamicField(true) // enable to insert new fields without modifying the code.build();}}
Milvus可行的操作接口定义
public interface IMilvusOperations {ZenAiConfig.Storages.Collection getCollection();MilvusConnection.MultiStatus delete(Filter filter);MilvusConnection.MultiStatus create(MilvusMeta.Index index);MilvusConnection.MultiStatus drop(String index);MilvusConnection.MultiStatus insert(MilvusData.Dataset dataset);MilvusConnection.MultiStatus insertAndFlush(MilvusData.Dataset dataset);/*** Query records by filter on the specified partition, which works like a normal SQL engine.** @param partition which partition to query* @param filter boolean expression obeys the rules of Milvus* @param outputFields if empty, the result will contain all the fields, including the dynamic;* otherwise the result only contains the specified fields.* @return a nonnull instance, size of which is 0 if no matched records, otherwise is positive.*/MilvusData.BasicPredictData queryByPartition(String partition, Filter filter, List<String> outputFields);List<MilvusData.BasicPredictData> search(List<List<Float>> vectors, Filter filter, int topK,List<String> outputFields);}
抽象系统接口定义
/*** 每个系统可能有不同的embedding的实现,因此需要定义一个接口。*/
public interface IEmbedding {ImmutableList<List<Float>> getEmbeddings(List<String> messages);
}/*** 通用接口定义,供应用层使用,可以基于sentence返回Milvus相似性结果集。*/
public interface INlpSystem extends IMilvusOperations, IDataset, IEmbedding {default MilvusData.BasicPredictData predict(String sentence) {return predict(sentence, Filter.TRUE);}default MilvusData.BasicPredictData predict(String sentence, Filter filter) {return predict(sentence, filter, getCollection().getOutputFields());}default MilvusData.BasicPredictData predict(String sentence, Filter filter,List<String> outputFields) {ImmutableList<List<Float>> vectors = getEmbeddings(Lists.newArrayList(sentence));if (vectors.isEmpty()) {return MilvusData.BasicPredictData.EMPTY;}List<String> mergedOutputFields = Sets.union(ImmutableSet.copyOf(outputFields),ImmutableSet.copyOf(getCollection().getOutputFields())).immutableCopy().asList();List<MilvusData.BasicPredictData> res = search(vectors, filter, getCollection().getTopk(), mergedOutputFields);return res.isEmpty() ? MilvusData.BasicPredictData.EMPTY : res.get(0);}default MilvusData.BasicPredictData predictByPartition(String partition, String sentence) {return predictByPartition(partition, sentence, Filter.TRUE, getCollection().getOutputFields());}default MilvusData.BasicPredictData predictByPartition(String partition, String sentence,Filter filter, List<String> outputFields) {ImmutableList<List<Float>> vectors = getEmbeddings(Lists.newArrayList(sentence));if (vectors.isEmpty()) {return MilvusData.BasicPredictData.EMPTY;}List<String> mergedOutputFields = Sets.union(ImmutableSet.copyOf(outputFields),ImmutableSet.copyOf(getCollection().getOutputFields())).immutableCopy().asList();return searchByPartition(partition, vectors.get(0), filter, mergedOutputFields);}}/*** Q & A系统接口。*/
public interface IQuestionAnswering extends INlpSystem {
}/*** 推荐系统接口。*/
public interface IRecommender extends INlpSystem, ISyncer {
}
插入数据集定义
以列式格式构建插入Milvus的数据集,需要注意的是,Milvus JAVA SDK 2.3.1版本并不支持列式导致dynamic fields,因此我对源码进行了改造,以支持列式插入动态字段。
这个问题,已经反馈给了社区,并且已经在v2.3.2版本中支持。
public interface MilvusData {interface BasicData {/*** Return a list view of the splitted data, to avoid copy.*/BasicData[] split(int splitSize);/*** Return a view of the range [start, end) data, to avoid copy.*/BasicData subData(int groupId, int start, int end);int size();}interface EmbeddingsProducer extends Function<List<String>, ImmutableList<List<Float>>> {}@Getter@Setter@AllArgsConstructor@NoArgsConstructorclass Dataset {private List<BasicInsertData> inserts;}abstract class GroupedBasicData implements BasicData {@Getterprivate final int groupId;@Getter@Setter@Accessors(chain = true)private GroupedBasicData parent;protected GroupedBasicData(int groupId) {this.groupId = groupId;}/*** Split the data into more more sub-dataset.** @param groups the number of expected groups* @return an array of sub-dataset views from the original dataset*/public abstract BasicData[] grouped(int groups);/*** 每一个切分或是extract的子数据集,都应该拥有一个可以唯一标识它的ID*/public String fullGroupId() {if (parent == null) {return String.valueOf(groupId);}return parent.fullGroupId() + "-" + groupId;}}@Getterabstract class PartitionedBasicData<T> extends GroupedBasicData {// 每一个系统都需要指定一个分区键,因此为了能够最小化存储,这里使用一个变量// 保存整个数据集应该插入private final T partition;protected PartitionedBasicData(T partition, int groupId) {super(groupId);this.partition = partition;}public abstract List<T> getPartitions();}/*** 以列式的形式构建插入数据集,并完成数据导入到Milvus。* Milvus*/class BasicInsertData extends PartitionedBasicData<String> {private final String collection;private final ImmutableList<String> ids;private final ImmutableList<String> embeddingsInput;private final Supplier<ImmutableList<List<Float>>> vectorsSupplier;private final EmbeddingsProducer embeddingsProducer;private ImmutableMap<String, List<?>> dynamicFields;private final AtomicBoolean vectorsInitialized = new AtomicBoolean(false);
}
结果集定义
public interface MilvusData {/*** 一个通用的数据集,可以保存search/query的结果,行式数据结构。*/@Getterclass BasicPredictData extends GroupedBasicData {@Getter@Builder@AllArgsConstructorpublic static class Row {@JsonPropertyprivate String id;private String embeddingsInput;@JsonPropertyprivate Map<String, Object> extensions;@JsonPropertyprivate float distance;@JsonIgnoreprivate List<Float> vector;public <T> T getAs(String key, Class<T> clazz) {return getAs(key, clazz, null);}public <T> T getAs(String key, Class<T> clazz, T defaultValue) {return clazz.cast(extensions.getOrDefault(key, defaultValue));}}}
}
数据插入实例:列式插入
这个代码示例展示了如何构建列式数据集,并将其插入Milvus的流程。
注意到这里特别演示了使用了多线程并行 插入的功能,其原因有二:
- 一个批次的数据集过大,Milvus无法一次快速且稳定地完成插入动作,因此需要将原始数据集进行分组,例如这里分成3个组;
- 通常LLM(Large language Model)的一次API调用,只能支持生成16个向量数组,因此这里又对每一个分组后的子数据集进行横向切分,产生多个Batch,每个Batch包含一条记录。
@Test
void testSyncCollections() throws ExecutionException, InterruptedException {ExecutorService executorService = Executors.newFixedThreadPool(2);// 一组唯一值,用于区别每一条数据记录ImmutableList<String> ids = ImmutableList.of("1", "2", "3", "4", "5");// 一组指标名,这些指标就是待检索的合法指标集。ImmutableList<String> metrics = ImmutableList.of("m1", "m2", "m3", "m4", "m5");// 生成一组包含5个向量的列表,对应于每一个指标名ImmutableList<List<Float>> vectors = generateVectors(5, TEST_COLLECTION_DIMENSION);// 构建插入数据集MilvusData.BasicInsertData data = new MilvusData.BasicInsertData(config.getStorages().getMilvusConf().getActiveRecommenderCollection().getName(), ids, metrics,//这里使用Java中的Provider接口,提供执行插入数据任务时,对指标名列表向量化,由于这里事先生成了向量数组,因此直接从索引构建数据messages -> messages.stream().map(metrics::indexOf).map(vectors::get).collect(toImmutableList()));ImmutableList<Double> randoms = ImmutableList.of(1.0d, 2.0d, 3.0d, 4.0d, 5.0d);// 添加动态字段及相应的数据data.updateDynamicFields(ImmutableMap.of("random", randoms));// 构建并行插入数据任务// 3 groups: ([1, 2]), ([3, 4]), ([5])// 1 batche: ([1],[2]),([3],[4]),([5])CompletableFuture<Integer>[] futures = milvusService.syncMetrics(data, 3, 1, executorService);assertEquals(3, futures.length);CompletableFuture.allOf(futures).join();assertEquals(2, futures[0].get());assertEquals(2, futures[1].get());assertEquals(1, futures[2].get());
}
相似性检索实例:指标推荐
用户输入一个指标(Metric)名,或是包含指标名的语句,可以通过Milvus的Search接口,找到最相近的TOP K指标,前提是需要对输入指标名进行向量化,然后以此向量来r从Milvus库中既存的指标集中计算找到最相似的。
@Testvoid testLookingForMetric() {int topK = config..getMilvusConf().getActiveRecommenderCollection().getTopk();Optional<MilvusData.BasicPredictData> metrics = milvusService.getActiveRecommenderSys().map(system -> system.predict("销售总额"));assertTrue(metrics.isPresent());assertEquals(metrics.get().getRows().size(), topK);metrics = milvusService.getActiveRecommenderSys().map(system -> system.predict("销售总额", lt("random", 0f)));assertFalse(metrics.isPresent());}
相似性检索实例:问答
用户输入一段描述,可以通过Milvus提供的Search接口,找到历史相关的问题,并返回与此问题相关的上下文,并辅助回答AI模型回答用户的当前问题。
@Testvoid testSearchWithSimilarityOfMultiVectors() {ImmutableList<String> testQuestions = ImmutableList.of("用柱形图展示2019年12月的总销售额", "用拆线图展示2020年12月的总净利润");ImmutableList<String> testIds = testQuestions.stream().map(DefaultQuestionAnswering::encodeQuestion).collect(ImmutableList.toImmutableList());IEmbedding embeddingSvc = aiService.getMilvusService().get().getActiveQuestionAnswering().get();DefaultQuestionAnswering.QAInsertData insertData = system.getInsertDataBuilder().ids(testIds).questions(testQuestions).answers(ImmutableList.of("很好", "不错"))// 用户对于此问题返回结果的评价.scores(ImmutableList.of(1.0f, 1.0f))// 定义embeddings生成器,在插入时才会计算embeddings.embeddingsProducer(questions -> {ImmutableList<List<Float>> qvectors = embeddingSvc.getEmbeddings(questions);ImmutableList<List<Float>> mvectors = embeddingSvc.getEmbeddings(ImmutableList.of("总销售额", "总净利润"));return ImmutableList.of(merge(qvectors.get(0), mvectors.get(0)), merge(qvectors.get(1), mvectors.get(1)));}).build();system.insert(new MilvusData.Dataset(ImmutableList.of(insertData)));// Case 1:// 用柱形图展示2019年12月的总销售额: 52.0181// 用拆线图展示2020年12月的总净利润: 147.0664verifySearch(system, "用拆线图展示2020年12月的总销售额", "总销售额", 0, "销售额", this::merge);// Case 2:// 用柱形图展示2019年12月的总销售额: 313.70105// 用拆线图展示2020年12月的总净利润: 181.3783verifySearch(system, "今年5月的净利润详情", "净利润", 0, "利润", this::merge);// Case 3:// 用柱形图展示2019年12月的总销售额: 160.30568// 用拆线图展示2020年12月的总净利润: 357.7008verifySearch(system, "今年5月的销售额详情", "销售额", 0, "销售额", this::merge);}
总结
Milvus对上层提供了与传统数据库相似的接口,以管理Milvus数据,同时提供了带有过滤功能的数据检索接口,使得上层应用能够很方便地利用传统数据库思维,来设计 和实现自己的系统。
但在使用中也感受到一些局限性或可能提升的点:
- 库中的一行记录只能对应一个embedding vector:只能使用相同模型生成的vector才能更好地检索向量,如果想一处持编码的文本对应多个vectors是不可能的,用户不得不创建新的Collection存储相同文本的不同向量。
- 用户显示Flush/Load Collection:每一次更新数据集,客户端必须要显示地load collection的操作,才能将新的数据加载到Server结点的内存中,同时第一次加载Collection必须是全量。
- 粗糙的表达式字符串:对于API接口的使用,缺少便利的表达式类定义,只能传递字符串,很容易出错,只能在运行时才知道哪些出错了。
- 缓存特性的支持:通常Milvus被用作Cache角色被引入系统中,但Milvus缺少一些缓存特性,如过期自动清理、partial dataset的load/unload功能等。
相关文章:

Milvus实战:构建QA系统及推荐系统
Milvus简介 全民AI的时代已经在趋势之中,各类应用层出不穷,而想要构建一个完善的AI应用/系统,底层存储是不可缺少的一个组件。 与传统数据库或大数据存储不同的是,这种场景下则需要选择向量数据库,是专门用来存储和查…...
使用Docker部署Nexus Maven私有仓库并结合Cpolar实现远程访问
文章目录 1. Docker安装Nexus2. 本地访问Nexus3. Linux安装Cpolar4. 配置Nexus界面公网地址5. 远程访问 Nexus界面6. 固定Nexus公网地址7. 固定地址访问Nexus Nexus是一个仓库管理工具,用于管理和组织软件构建过程中的依赖项和构件。它与Maven密切相关,可…...

GEE-Sentinel-2月度时间序列数据合成并导出
系列文章目录 第一章:时间序列数据合成 文章目录 系列文章目录前言时间序列数据合成总结 前言 利用每个月可获取植被指数数据取均值,合成月度平均植被指数,然后将12个月中的数据合成一个12波段的时间数据合成数据。 时间序列数据合成 代码…...

【深度学习】语言模型与注意力机制以及Bert实战指引之二
文章目录 前言 前言 这一篇是bert实战的完结篇,准备中。...
计算机网络 网络层下 | IPv6 路由选择协议,P多播,虚拟专用网络VPN,MPLS多协议标签
文章目录 5 IPv65.1 组成5.2 IPv6地址5.3 从IPv4向IPv6过渡5.3.1 双协议栈5.3.2 隧道技术 6 因特网的路由选择协议6.1 内部网关协议RIP6.2 内部网关协议 OSPF基本特点 6.3 外部网关协议 BGP6.3.1 路由选择 6.4 路由器组成6.4.1 基本了解6.4.2 结构 7 IP多播7.1 硬件多播7.2 IP多…...
【MATLAB第83期】基于MATLAB的LSTM代理模型的SOBOL全局敏感性运用
【MATLAB第83期】基于MATLAB的LSTM代理模型的SOBOL全局敏感性运用 引言 在前面几期,介绍了敏感性分析法,本期来介绍lstm作为代理模型的sobol全局敏感性分析模型。 【MATLAB第31期】基于MATLAB的降维/全局敏感性分析/特征排序/数据处理回归问题MATLAB代…...
求奇数的和 C语言xdoj147
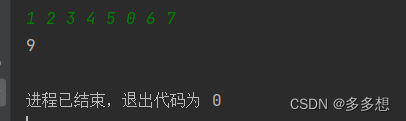
题目描述:计算给定一组整数中奇数的和,直到遇到0时结束。 输入格式:共一行,输入一组整数,以空格分隔 输出格式:输出一个整数 示例: 输入:1 2 3 4 5 0 6 7 输出:9 #inclu…...

全链路压力测试:解析其主要特点
随着信息技术的飞速发展和云计算的普及,全链路压力测试作为一种关键的质量保障手段,在软件开发和系统部署中扮演着至关重要的角色。全链路压力测试以模拟真实生产环境的压力和负载,对整个业务流程进行全面测试,具有以下主要特点&a…...

算法基础之约数个数
约数个数 核心思想: 用哈希表存每个质因数的指数 然后套公式 #include <iostream>#include <algorithm>#include <unordered_map>#include <vector>using namespace std;const int N 110 , mod 1e9 7;typedef long long LL; //long l…...
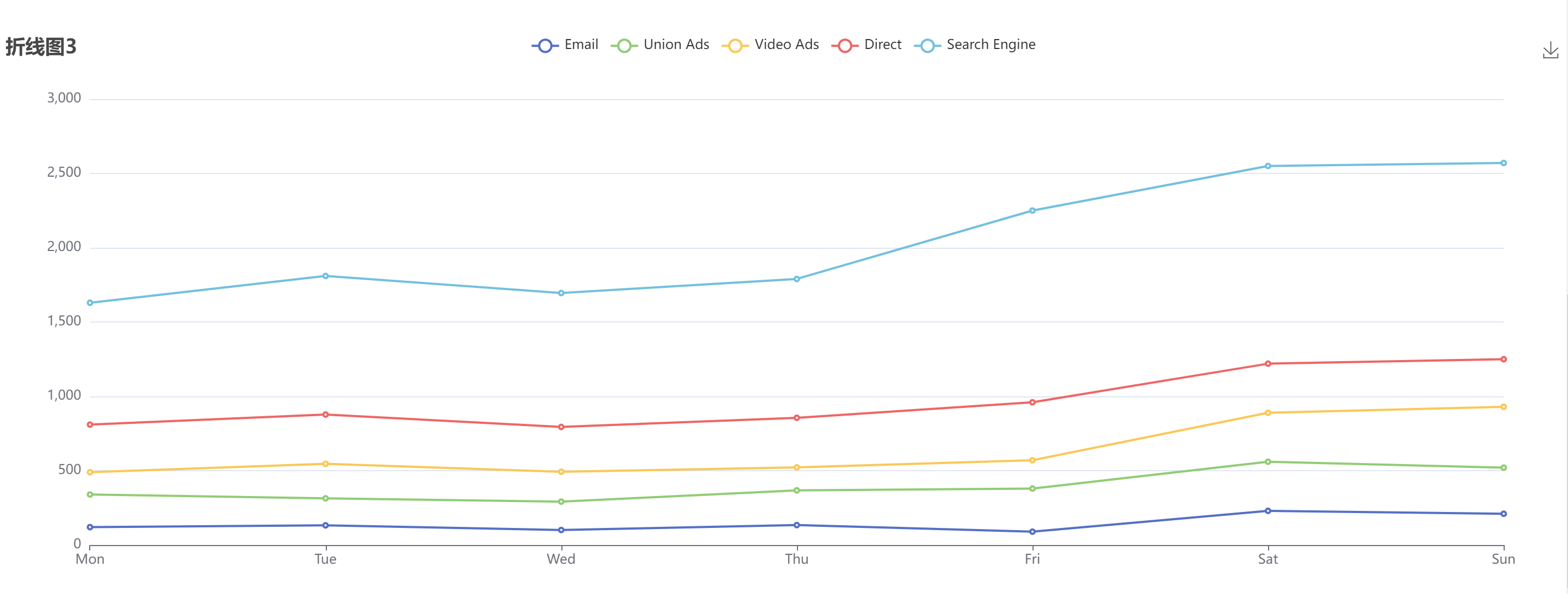
【ECharts】折线图
文章目录 折线图1折线图2折线图3示例 参考: Echarts官网 Echarts 配置项 折线图1 带X轴、Y轴标记线,其中X轴是’category’ 类目轴,适用于离散的类目数据。 let myChart echarts.init(this.$refs.line_chart2); let yList [400, 500, 6…...
java jdbc连接池
什么是连接池: Java JDBC连接池是一个管理和分配数据库连接的工具。在Java应用程序中,连接到数据库是一个耗时且资源密集的操作,而连接池可以通过创建一组预先初始化的数据库连接,然后将其保持在连接池中,并按需分配给…...
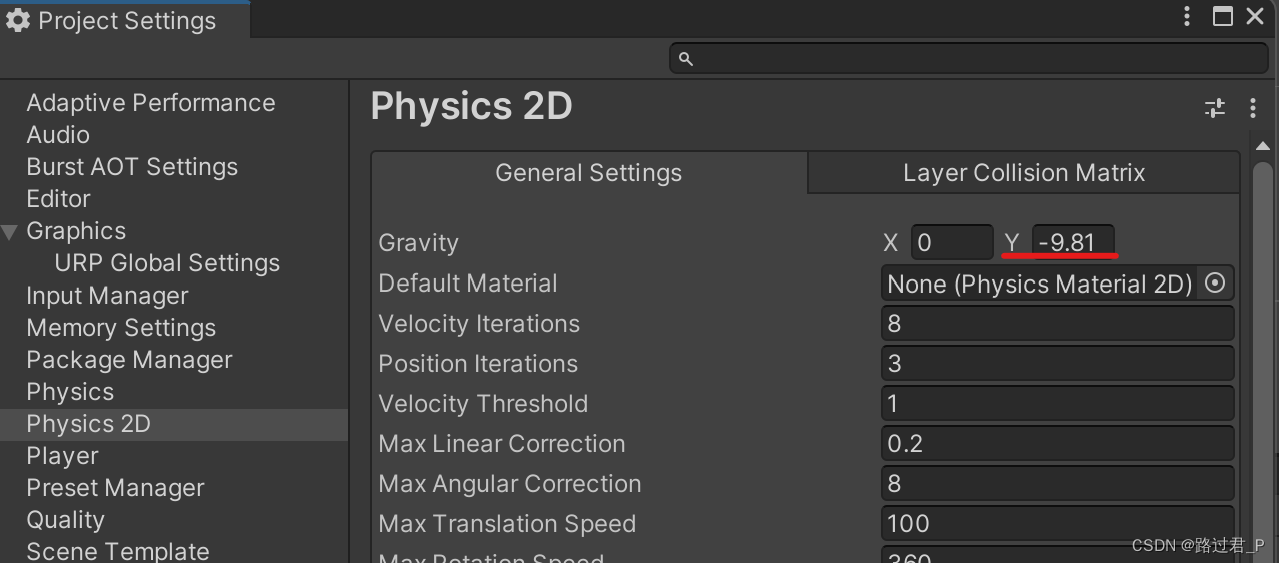
unity2d 关闭全局重力
UNITY2D项目默认存在Y轴方向重力,创建俯视角2D场景时可通过以下配置关闭 Edit > Project Settings > Physics 2D > General Settings > Gravity 设置Y0...
大数据时代,如何基于机密虚拟化技术构建数据安全的“基石”
云布道师 2023 年 10 月 31 日-11 月 2 日,2023 云栖大会在中国杭州云栖小镇举行,阿里云弹性计算产品专家唐湘华、阿里云高级安全专家刘煜堃、蚂蚁集团高级技术专家肖俊贤三位嘉宾在【云服务器 & 计算服务】专场中共同带来题为《大数据时代…...

为你自己学laravel - 15 - model的更新和删除
为你自己学laravel。 model的部分。 这一次讲解的是model当中怎么从数据库当中更新数据和删除数据。 先从数据库当中抓出来资料。 当然我们是使用php artisan tinker进入到终端机。 我们的做法是想要将available这个栏位修改成为true。 第一种更新方法 上面我们就是修改了对…...

列举mfc140u.dll丢失的解决方法,常见的mfc140u.dll问题
在使用电脑的过程中,有时会遇到mfc140u.dll文件丢失的问题,导致一些应用程序无法正常启动。本文将介绍mfc140u.dll丢失的常见原因,并提供相应的解决办法。同时,还会列举一些与mfc140u.dll丢失相关的常见问题和解答。 第一部分&…...

智能优化算法应用:基于野狗算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于野狗算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于野狗算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.野狗算法4.实验参数设定5.算法结果6.参考文献7.MA…...
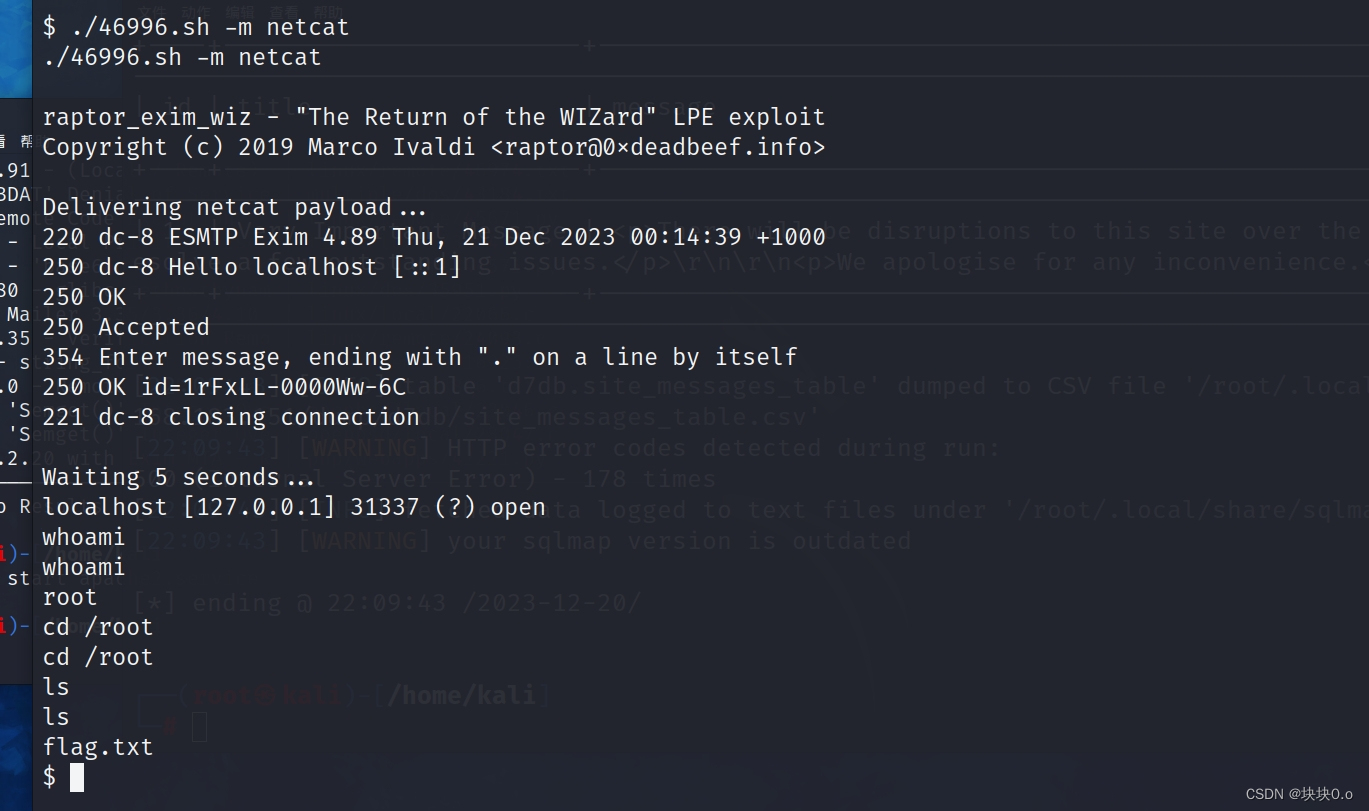
DC-8靶场
目录 DC-8靶场链接: 首先进行主机发现: sqlmap得到账号密码: 反弹shell: exim4提权: Flag: DC-8靶场链接: https://www.five86.com/downloads/DC-8.zip 下载后解压会有一个DC-8.ova文件…...
SQL Server 安装教程
安装数据库 1、启动SQL Server2014安装程序,运行setup.exe文件,打开”SQL Server安装中心“对话框,单击左侧 的导航区域中的”安装“选项卡。 2、选择”全新SQL Server独立安装或向现有安装添加功能“,启动SQL Server2014安装向导…...
快猫视频模板源码定制开发 苹果CMS 可打包成双端APP
苹果CMS快猫视频网站模板源码,可用于开发双端APP,后台支持自定义参数,包括会员升级页面、视频、演员、专题、收藏和会员系统等完整模块。还可以直接指定某个分类下的视频为免费专区,具备完善的卡密支付体系,无需人工管…...
【C++】理解string类的核心理念(实现一个自己的string类)
目录 一、引言 二、自我实现 1.成员变量的读写 2.构造与析构 3.迭代器 4.插入字符或字符串 尾插 中间插入 5.删除字符或子字符串 6.查找字符或子串 7.获取子串 三、完整代码 四、补充 一、引言 实现自己的 string 类是学习 C 语言和面向对象编程的一个好方法。通过…...

这次终于选对了!降AI率软件深度测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

立知-lychee-rerank-mm效果展示:汽车配置单与实拍图一致性验证
立知-lychee-rerank-mm效果展示:汽车配置单与实拍图一致性验证 1. 引言:多模态重排序的实用价值 在日常工作和生活中,我们经常遇到这样的场景:看到一份产品配置单,但不确定实际产品是否真的符合描述;或者…...

OpenClaw多模型切换指南:ollama-QwQ-32B与本地小模型协同工作
OpenClaw多模型切换指南:ollama-QwQ-32B与本地小模型协同工作 1. 为什么需要多模型协同 去年冬天,当我第一次尝试用OpenClaw自动整理电脑里堆积如山的论文时,发现一个尴尬的问题:简单的文件分类任务消耗了过多token。每次让大模…...

成本对比实测:OpenClaw本地部署Qwen3.5-9B比API节省40%
成本对比实测:OpenClaw本地部署Qwen3.5-9B比API节省40% 1. 为什么我要做这个测试 上个月我给自己定了个目标:用OpenClaw实现个人知识库的自动化更新。这个任务需要每天抓取20篇行业文章,提取关键信息,整理成结构化笔记。最初我直…...

具身智能:千亿赛道崛起、多元场景落地与数据标注协同发展
2025被称为“具身智能元年”! “具身智能” 也首次被写入中国《政府工作报告》,纳入国家战略规划,各地密集出台专项政策布局赛道。 数据标注作为具身智能涌现的核心基石,也同步完成了从劳动密集型向高技术专业化的范式升级。 具…...

基于人工电场搜索智能优化算法的水库发电和供水优化调度
基于人工电场搜索智能优化算法的水库发电和供水优化调度; 代码为MATLAB编写,可直接运行; 含有实例数据,点击即可运行,替换成自己数据点击即可出结果,如图。在水库管理中,实现发电和供水的优化调…...

档案宝 档案管理系统怎么样?为什么企业选择他?
在当今信息化高速发展的时代,企业档案管理已经从传统的纸质化时代迈向了数字化、智能化的新阶段。随着企业规模的不断扩大和业务类型的日益复杂,档案管理面临着前所未有的挑战:档案数量激增、查找困难、存储空间紧张、安全隐患突出等问题严重…...

ESP32 IDF环境下DHT11温湿度读取避坑指南:从时序图到数据拼接的完整解析
ESP32 IDF环境下DHT11温湿度读取避坑指南:从时序图到数据拼接的完整解析 在物联网设备开发中,温湿度传感器是最基础也最常用的环境感知元件之一。DHT11作为一款低成本、单总线数字输出的温湿度传感器,被广泛应用于各类嵌入式项目中。然而&…...

GB28181协议实战:WVP开源项目+ZLM流媒体服务联调配置详解
GB28181协议实战:WVP开源项目ZLM流媒体服务联调配置详解 在视频监控领域,GB28181协议作为国家标准协议,已经成为设备互联互通的重要基础。而将WVP(Web Video Platform)开源项目与ZLM(ZLMediaKit)…...

三菱/安川伺服电机调试笔记:零点与原点参数设置的5个易错点
三菱/安川伺服电机调试实战:零点与原点参数设置的5个致命陷阱 伺服电机调试过程中,零点与原点的参数设置就像给精密机械赋予"空间感知"能力。三菱J4系列和安川Σ-7作为工业自动化领域的标杆产品,其调试逻辑看似简单,实则…...