在MongoDB中使用数组字段和子文档字段进行索引

本文主要介绍在MongoDB使用数组字段和子文档字段进行索引。
目录
- MongoDB的高级索引
- 一、索引数组字段
- 二、索引子文档字段
MongoDB的高级索引
MongoDB是一个面向文档的NoSQL数据库,它提供了丰富的索引功能来加快查询性能。除了常规的单字段索引之外,MongoDB还支持高级索引,包括索引数组字段和索引子文档字段。
一、索引数组字段
索引数组字段是指在文档中的某个字段是一个数组,并且希望对这个数组中的元素建立索引。
MongoDB使用多键索引(multikey index)来实现对数组字段的索引。
例如,假设有一个文档集合存储了学生的成绩记录,每个学生可能有多门科目的成绩,可以将成绩字段建立索引,以便对成绩进行快速查找。在这种情况下,MongoDB会为每个数组中的元素创建一个索引项。
以下是一个示例,展示如何在MongoDB中使用索引数组字段:
假设我们有一个文档集合存储了学生的成绩记录,每个学生可能有多门科目的成绩,我们希望对学生的姓名和每门课程的成绩字段进行索引。
首先,创建一个名为students的集合,并向其中插入几个文档:
db.students.insertMany([{ name: "Alice", scores: [90, 85, 95] },{ name: "Bob", scores: [70, 80, 75] },{ name: "Charlie", scores: [60, 65, 70] }
])
接下来,我们可以为成绩字段创建一个多键索引,以便对学生的成绩进行快速查找:
db.students.createIndex({ scores: 1 })
现在,我们可以使用find操作来查询匹配特定成绩的学生:
db.students.find({ scores: 80 })
这个查询会返回所有成绩中包含80的学生文档。
此外,我们也可以使用$elemMatch操作符来进一步筛选数组中的元素。例如,如果我们希望查询成绩中同时包含80和85的学生:
db.students.find({ scores: { $elemMatch: { $in: [80, 85] } } })
这个查询会返回所有成绩中同时包含80和85的学生文档。
需要注意的是,对于索引数组字段,需要确保数组字段的长度不会超过索引大小限制,一般建议数组长度控制在不超过1000个元素。此外,在对索引数组字段进行更新操作时,需要小心处理索引的更新情况,以避免不必要的索引重建。
索引数组字段可以帮助我们在MongoDB中更高效地进行数组元素的查询,提升查询性能和灵活性。
二、索引子文档字段
索引子文档字段是指在文档中的某个字段是一个嵌套文档(子文档),并且希望对这个子文档中的字段建立索引。
MongoDB可以对子文档字段进行深层索引(deep index),以实现更精确的查询。
例如,假设有一个文档集合存储了图书的信息,每本图书包含了作者、标题和出版信息等字段,可以将作者名字字段建立索引,以便根据作者进行快速查找。在这种情况下,MongoDB会为子文档中的字段创建索引。
下面是一个示例,展示了如何在MongoDB中创建索引子文档字段:
假设有一个名为"users"的集合,其中的文档结构如下:
{"_id": ObjectId("5ec9a8f44ed1a74ebfe537a1"),"name": "John","address": {"street": "123 Main St","city": "New York","state": "NY"}
}
要在"address.city"字段上创建索引,可以使用以下命令:
db.users.createIndex({"address.city": 1})
在这个示例中,我们使用了"createIndex"方法来创建索引。传递给方法的参数是一个包含索引字段和排序方向的对象。在这里,我们将"address.city"字段指定为索引字段,并将排序方向设为1,表示升序。
创建完索引后,可以使用以下命令检查索引是否已成功创建:
db.users.getIndexes()
这将返回一个包含索引信息的列表。在这个列表中,您应该能够看到"address.city"字段的索引。
在查询中使用索引子文档字段时,可以使用点符号来指定子文档字段的路径。例如,要查询"address.city"字段为"New York"的文档,可以使用以下命令:
db.users.find({"address.city": "New York"})
这将返回所有"address.city"字段为"New York"的文档。
MongoDB提供了在子文档字段上创建索引的功能,这可以提高查询性能并允许在查询中针对子文档字段进行高效的筛选和排序。示例中演示了如何在MongoDB中创建索引子文档字段,并给出了一个查询示例。
在使用MongoDB索引子文档字段时,有几个注意事项需要考虑:
-
索引字段的路径:在创建索引时,需要指定子文档字段的完整路径。这包括每个父级字段的名称和子文档字段的名称,使用点符号来连接它们。确保提供正确的路径,以便MongoDB能够正确地创建和使用索引。
-
嵌套子文档字段:如果要在多级嵌套的子文档字段上创建索引,需要确保指定完整的路径。例如,如果有一个名为"address"的子文档,它又有一个名为"location"的子文档,要在"address.location.city"字段上创建索引,需要提供完整的路径。
-
索引字段的选择:在创建索引时,需要仔细选择要索引的子文档字段。如果一个子文档字段经常被查询和筛选,那么在该字段上创建索引可能会提高查询性能。然而,如果索引过多或选择不当,可能会导致索引大小变大并降低性能。
-
频繁更新:如果子文档字段经常被更新,特别是插入或删除子文档字段,那么在该字段上的索引可能会导致索引维护成本增加。需要权衡索引的使用和维护成本之间的平衡。
-
复合索引:如果子文档字段经常与其他字段一起使用,可以考虑创建复合索引。复合索引可以包含多个字段,其中包括子文档字段。这样可以提高包含子文档字段的查询性能。
-
索引大小:当在子文档字段上创建索引时,需要注意索引大小。索引大小会影响存储和查询性能。如果索引过大,可能需要考虑使用部分索引或调整索引存储大小的配置选项。
在使用MongoDB索引子文档字段时,需要注意索引字段的路径、选择适当的字段、权衡索引的使用和维护成本,并考虑使用复合索引来提高查询性能。此外,还应该关注索引大小对存储和查询性能的影响。
相关文章:
在MongoDB中使用数组字段和子文档字段进行索引
本文主要介绍在MongoDB使用数组字段和子文档字段进行索引。 目录 MongoDB的高级索引一、索引数组字段二、索引子文档字段 MongoDB的高级索引 MongoDB是一个面向文档的NoSQL数据库,它提供了丰富的索引功能来加快查询性能。除了常规的单字段索引之外,Mong…...
<JavaEE> 网络编程 -- 网络编程和 Socket 套接字
目录 一、网络编程的概念 1)什么是网络编程? 2)网络编程中的基本概念 1> 收发端 2> 请求和响应 3> 客户端和服务端 二、Socket套接字 1)什么是“套接字”? 2)Socket套接字的概念 3&…...

【计算机系统结构实验】实验2 流水线中的冲突实验
2.1 实验目的 加深对计算机流水线基本概念的理解; 理解MIPS结构如何用5段流水线来实现,理解各段的功能和基本操作; 加深对结构冲突/数据冲突/控制冲突的理解; 进一步理解解决数据冲突的方法,掌握如何应用定向技术来…...

conda环境下执行conda命令提示无法识别解决方案
1 问题描述 win10环境命令行执行conda命令,报命令无法识别,错误信息如下: PS D:\code\cv> conda activate pt conda : 无法将“conda”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径&a…...
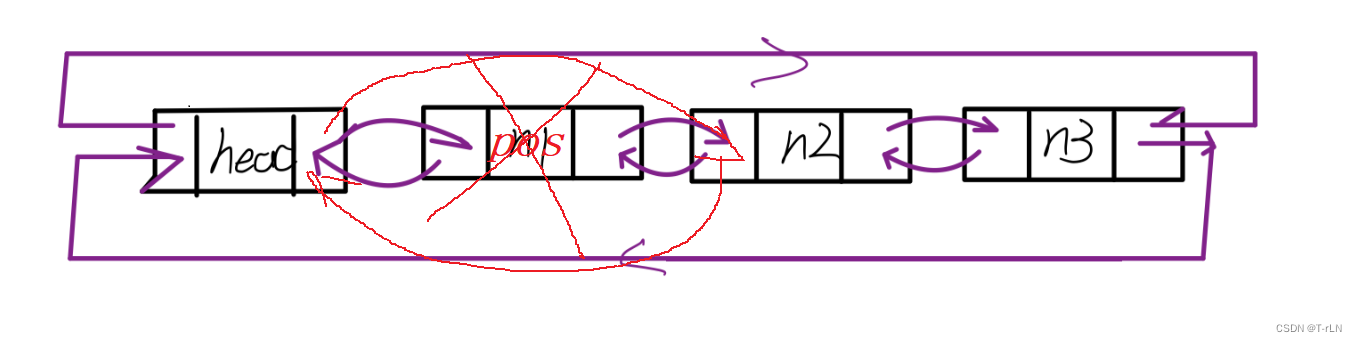
链接未来:深入理解链表数据结构(二.c语言实现带头双向循环链表)
上篇文章简述讲解了链表的基本概念并且实现了无头单向不循环链表:链接未来:深入理解链表数据结构(一.c语言实现无头单向非循环链表)-CSDN博客 那今天接着给大家带来带头双向循环链表的实现: 文章目录 一.项目文件规划…...

论文笔记 | Nature 2023 FunSearch:利用大语言模型在数学科学领域探索新的发现
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 科学中有许多难以解决的问题,这些问题难以获得确切解答,但却相对容易进行验证。在数学和计算机科学领域,这类问题被称为 NP 完全优化问题(NP-complete optimization pr…...

JavaScript 对象和 JSON 字符串的区别
JavaScript 对象和 JSON 字符串是两种不同的数据表示形式,它们有以下区别: 语法格式:JavaScript 对象是 JavaScript 语言中的一种数据类型,使用花括号 {} 包裹,属性和值之间使用冒号 : 分隔,并且使用逗号 …...

基于 Flink SQL 和 Paimon 构建流式湖仓新方案
目录 1. 数据分析架构演进 2. Apache Paimon 3. Flink + Paimon 流式湖仓 Consumer 机制 Changelog 生成编辑...
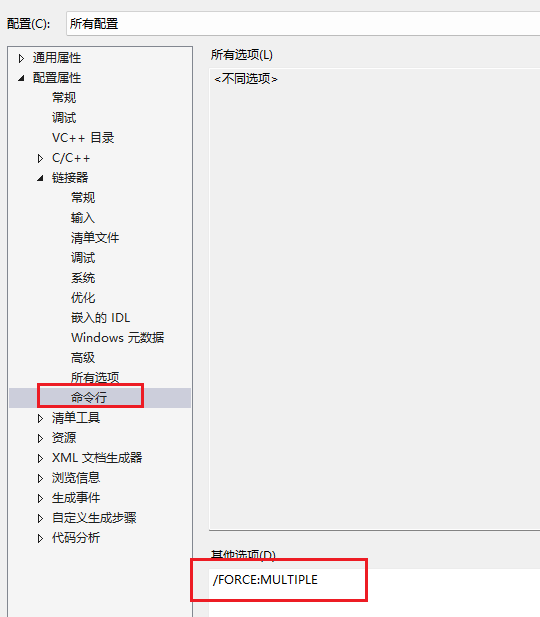
MFC静态链接+libtiff静态链接提示LNK2005和LNK4098
编译报错 1>msvcrt.lib(ti_inst.obj) : error LNK2005: "private: __thiscall type_info::type_info(class type_info const &)" (??0type_infoAAEABV0Z) 已经在 libcmtd.lib(typinfo.obj) 中定义 1>msvcrt.lib(ti_inst.obj) : error LNK2005: "pr…...
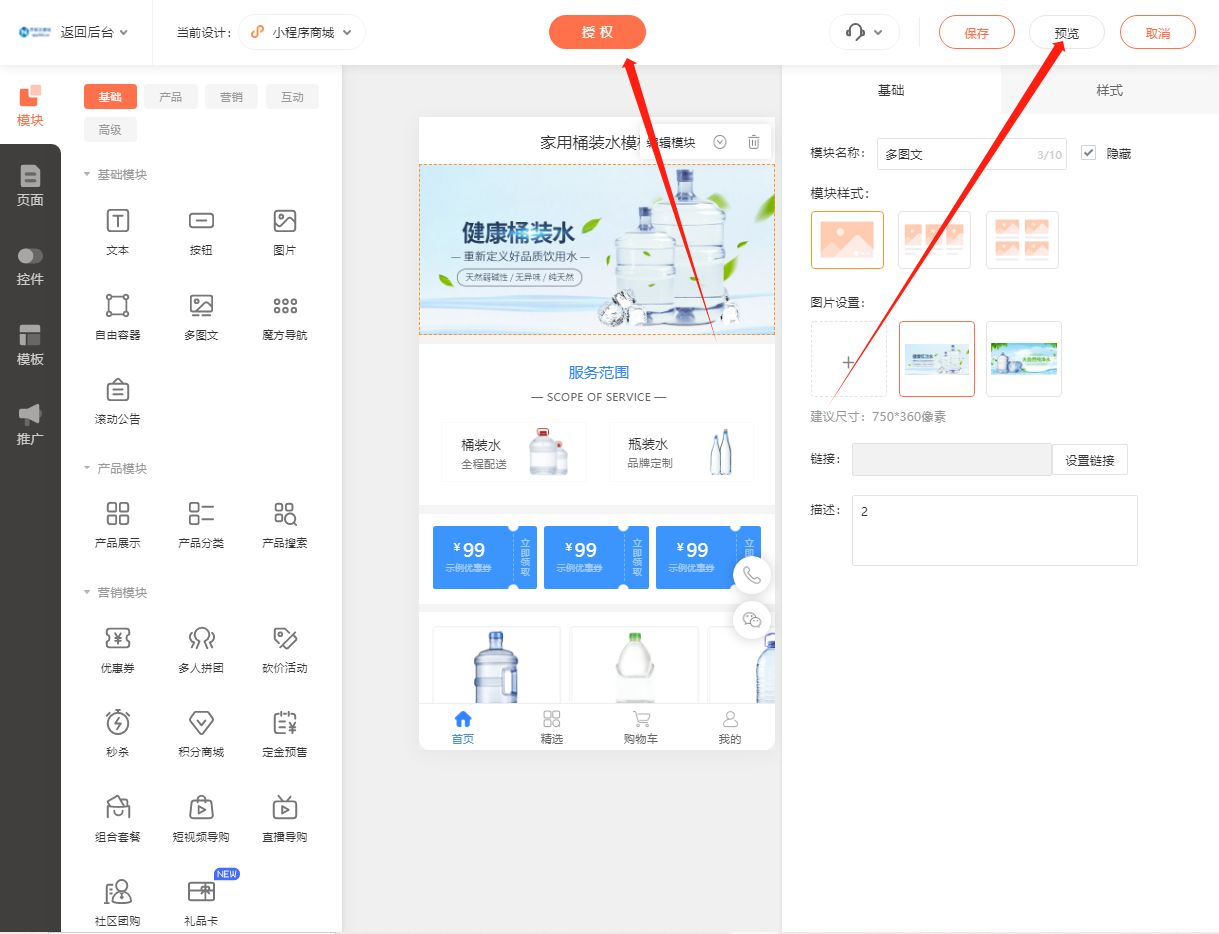
桶装水送水小程序:提升服务质量的利器
随着移动互联网的发展,越来越多的消费者通过手机在线购物和订购商品。如果你是一名桶装水供应商,想要拓展线上业务,那么开发一个桶装水微信小程序将是一个明智的选择。本文将指导你从零开始开发一个桶装水微信小程序,让你轻松完成…...

深度学习在训练什么,什么是模型
深度学习是机器学习的一个分支,它主要通过使用称为神经网络的复杂结构来学习数据的表征。在深度学习中,"训练"和"模型"是两个核心概念。 训练 在深度学习中,"训练"是指用数据来训练一个神经网络。这个过程涉…...

Andorid 使用bp或者mk编译C文件生成so
在Aosp源码里编译C文件生成so 使用mk编译 文件夹列表 CMkDemo/Android.mk CMkDemo/cpp/SerialPort.c CMkDemo/cpp/SerialPort.hAndroid.mk 内容如下 LOCAL_PATH: $(call my-dir) include $(CLEAR_VARS)LOCAL_MODULE_TAGS : optional# All of the source files that we will…...

只更新软件,座椅为何能获得加热功能?——一文读懂OTA
2020年,特斯拉发布过一次OTA更新,车主可以通过这次系统更新获得座椅加热功能。当时,这则新闻震惊了车圈和所有车主,彼时的大家还没有把汽车当作可以“升级”的智能设备。 如今3年过去了,车主对各家车企的OTA升级早已见…...
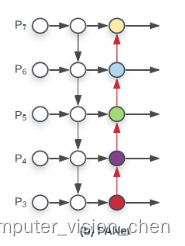
EfficientDet:Scalable and Efficient Object Detection中文版 (BiFPN)
EfficientDet: Scalable and Efficient Object Detection EfficientDet:可扩展和高效的目标检测 摘要 模型效率在计算机视觉中变得越来越重要。本文系统地研究了用于目标检测的神经网络架构设计选择,并提出了几个关键的优化方法来提高效率。首先&…...

视频监控技术经历了哪些发展阶段?视频监控技术未来趋势展望
随着城市经济的发展和进步,视频监控也已经应用在人们衣食住行的方方面面,成为社会主体的一个重要组成部分。随着视频监控的重要性越来越凸显,大家对视频监控技术的发展也非常关注。今天我们来简单阐述一下,视频监控技术经历的几个…...

德人合科技 | 设计公司文件加密系统——天锐绿盾自动智能透明加密防泄密系统
设计公司文件加密系统——天锐绿盾自动智能透明加密防泄密系统 PC端访问地址: www.drhchina.com 一、背景介绍 设计公司通常涉及到大量的创意作品、设计方案、客户资料等重要文件,这些文件往往包含公司的核心价值和商业机密。因此,如何确保…...
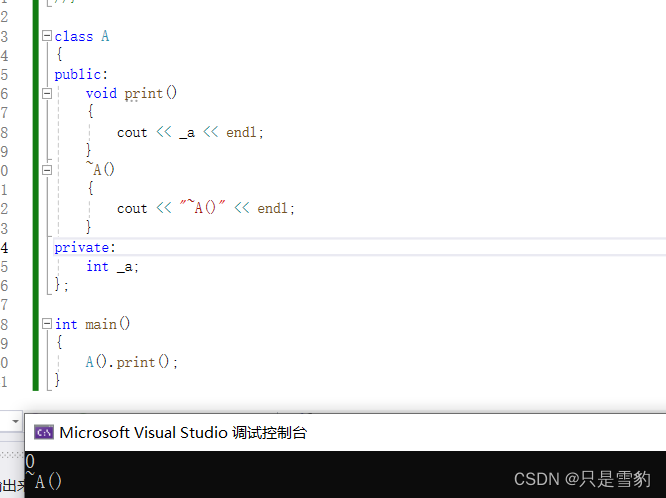
类和对象(下篇)
再谈构造函数 构造函数体赋值 在之前的学习中我们知道,在创建一个对象时,我们的编译器就会自动调用构造函数将对象初始化,给对象中各个成员变量一个合适的初始值。 例如: class Date { public:Date(int year, int month, int d…...

华为鸿蒙(HarmonyOS):连接一切,智慧无限
华为鸿蒙是一款全场景、分布式操作系统,旨在构建一个真正统一的硬件生态系统。该操作系统于2019年8月首次发布,并被设计为可以应用于各种设备,包括智能手机、智能手表、智能电视、车载系统等多种智能设备。 推荐一套最新版的鸿蒙4.0开发教程 …...
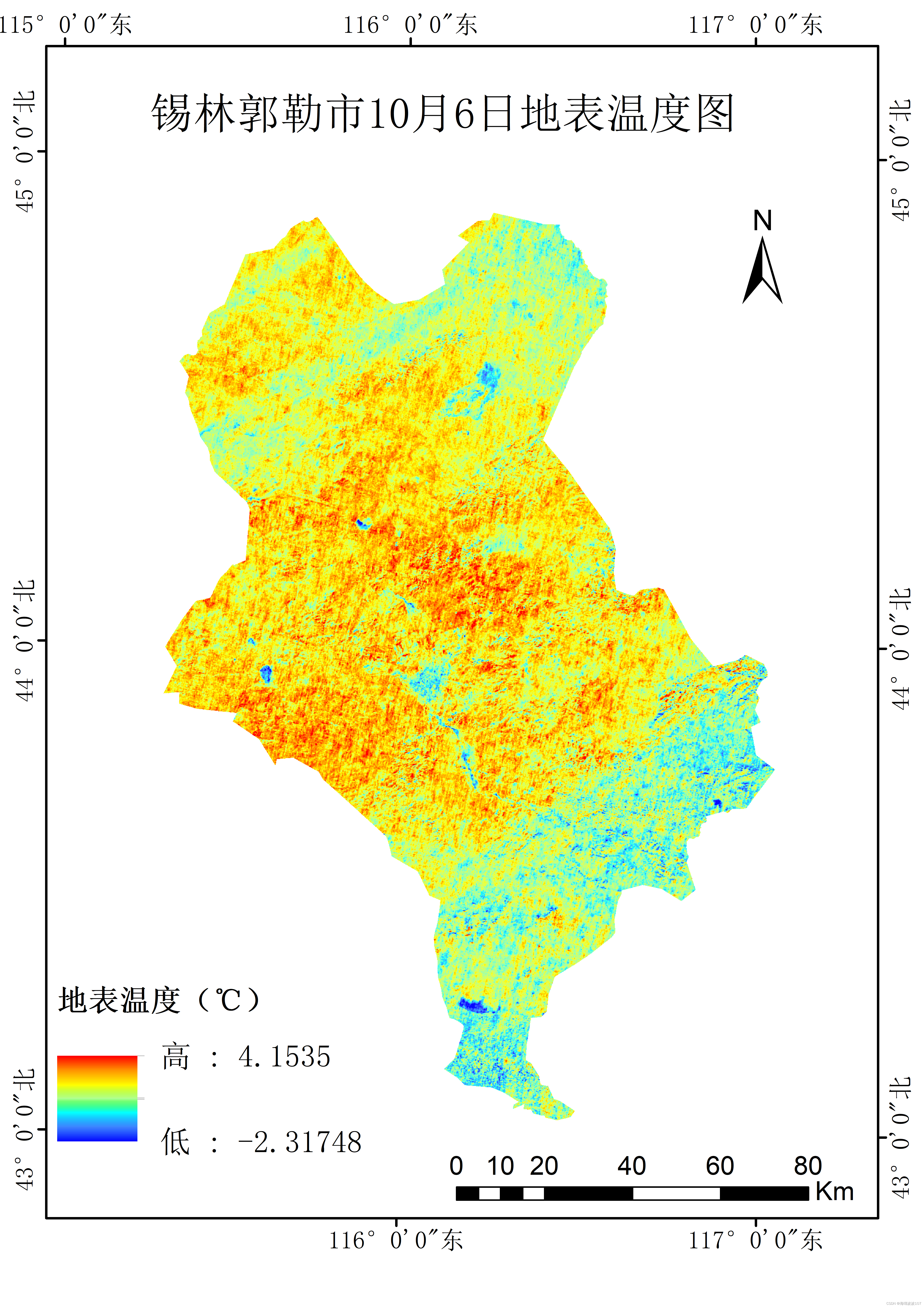
劈窗算法反演地表温度
目录 摘要操作步骤提取热红外单波段提取NDVI同步像元分辨率与个数劈窗算法地表温度反演制图 摘要 主要使用HJ-2(环境减灾二号卫星)的IRS传感器的两个热红外波段,以及红波段与近红波段计算得到的NDVI,使用劈窗算法,得到…...

持续集成交付CICD:基于ArgoCD 的GitOps 自动化完成前端项目应用发布与回滚
目录 一、实验 1. 环境 2. K8S master节点部署Argo CD 3.基于ArgoCD 实现GitOps (同步部署文件) 4.基于ArgoCD 实现GitOps (同步HELM文件) 二、问题 1. ArgoCD 连接K8S集群状态为 Unknown 2.ArgoCD 创建application失败 …...

用Python模拟兔子和羊的“地盘争夺战”:手把手教你实现Lotka-Volterra竞争模型
用Python模拟兔子和羊的“地盘争夺战”:手把手教你实现Lotka-Volterra竞争模型 生态学中的物种竞争关系一直是研究者关注的焦点。想象一片广袤的草原,兔子和羊作为主要的食草动物,它们之间存在着微妙的竞争关系——争夺有限的草资源。这种竞争…...

近10亿融资后估值破百亿,普渡机器人凭何成全球商用服务机器人双料龙头?
近10亿融资,顶级资本矩阵加持普渡机器人近日,全球商用服务机器人领军企业普渡机器人完成近10亿元新一轮融资,由龙岗金控、亚投资本联合领投,北汽产投、蓝思科技、弘晖基金等共同参与。本轮融资后,公司估值突破百亿元人…...

终极Armbian改造指南:5个技巧将Amlogic电视盒子变身高性能Linux服务器
终极Armbian改造指南:5个技巧将Amlogic电视盒子变身高性能Linux服务器 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, …...

Java NIO.2 文件系统:探索高效文件操作的新维度
Java NIO.2 文件系统:探索高效文件操作的新维度 在Java编程的世界里,文件操作一直是开发者们频繁接触且至关重要的部分。随着Java版本的演进,Java NIO(New I/O)的引入为文件处理带来了革命性的变化,而Java …...

Rspack简介
Rspack简介 前言:在前端构建领域,Webpack 长期占据主导地位,而 Vite 的出现打破了这一格局,两者各有优势,但也都存在明显短板:Webpack 生态成熟、兼容性强,但随着项目规模扩大,构建…...
✅)
计算机毕业设计:Python股市行情可视化与ARIMA预测系统 Flask框架 ARIMA 数据分析 可视化 大数据 大模型(建议收藏)✅
1、项目介绍 技术栈 采用 Python 语言开发,基于 Flask 框架搭建后端服务,Vue 框架构建前端交互界面,通过 IG507 金融数据接口获取实时股票数据,运用 ARIMA 时间序列预测算法进行股价预测,前端使用 Echarts 实现数据可视…...
)
别再只会下载程序了!J-Link在Keil MDK下的SWD仿真调试全攻略(STM32实战)
别再只会下载程序了!J-Link在Keil MDK下的SWD仿真调试全攻略(STM32实战) 当你的STM32程序终于成功下载到板子上,却发现运行时行为异常或变量值不符合预期时,单纯的下载功能就显得力不从心了。J-Link作为业界标杆的调试…...
)
别再手动截图了!用Lumerical脚本批量导出FDTD仿真数据(附Python处理代码)
别再手动截图了!用Lumerical脚本批量导出FDTD仿真数据(附Python处理代码) 在光子器件设计与优化的日常工作中,工程师们常常需要面对数十组参数扫描产生的海量仿真数据。记得去年参与硅基光栅耦合器项目时,每次完成50组…...

终极指南:如何在现代Windows上让经典游戏联机重生
终极指南:如何在现代Windows上让经典游戏联机重生 【免费下载链接】ipxwrapper 项目地址: https://gitcode.com/gh_mirrors/ip/ipxwrapper 你是否曾经怀念那些经典的局域网游戏时光?《红色警戒2》、《暗黑破坏神》、《帝国时代》等经典游戏在现代…...

ERPNext自动化部署终极指南:5分钟完成企业级ERP系统安装
ERPNext自动化部署终极指南:5分钟完成企业级ERP系统安装 【免费下载链接】erpnext_quick_install Unattended install script for ERPNext Versions, 13, 14 and 15 项目地址: https://gitcode.com/gh_mirrors/er/erpnext_quick_install 想要在5分钟内搭建一…...