【Python百宝箱】时序之美:Python 时间序列探秘与创新
时光漫游:Python 时间序列分析全指南
前言
在数字化时代,时间序列数据扮演着关键的角色,从金融到气象再到生产制造。本文将引导你穿越Python丰富的时间序列分析工具,探索从基础统计到机器学习和深度学习的各个层面。无论你是初学者还是专业数据科学家,这里有一篇完整的指南等待你的探索。
欢迎订阅专栏:Python库百宝箱:解锁编程的神奇世界
文章目录
- 时光漫游:Python 时间序列分析全指南
- 前言
- 1. Prophet
- 1.1 概述
- 1.2 主要特点
- 1.3 应用场景
- 2. Statsmodels
- 2.1 概述
- 2.2 时间序列分析功能
- 2.2.1 ARIMA 模型
- 2.2.2 SARIMA 模型
- 3. Numpy
- 3.1 数组操作和数学函数
- 3.2 随机数生成
- 3.2.1 `numpy.random` 模块
- 4. Pandas
- 4.1 数据结构
- 4.1.1 Series
- 4.1.2 DataFrame
- 4.2 时间序列处理
- 4.2.1 时间索引
- 4.2.2 时期
- 5. Matplotlib
- 5.1 绘图基础
- 5.1.1 折线图
- 5.1.2 散点图
- 5.2 时间序列可视化
- 5.2.1 `matplotlib.dates` 模块
- 6. Seaborn
- 6.1 统计数据可视化
- 6.2 时间序列数据可视化
- 6.2.1 时间序列图
- 7. Scikit-learn
- 7.1 机器学习基础
- 7.2 时间序列预测与分类
- 7.2.1 时间序列预测模型
- 7.2.2 时间序列分类模型
- 8. TensorFlow
- 8.1 神经网络基础
- 8.2 时间序列预测与深度学习
- 8.2.1 LSTM 模型
- 8.2.2 GRU 模型
- 9. PyTorch
- 9.1 深度学习框架简介
- 9.2 时间序列深度学习模型
- 10. Scipy
- 10.1 科学计算库
- 10.2 信号处理与频谱分析
- 10.2.1 FFT(快速傅里叶变换)
- 10.2.2 滤波器设计
- 11. Plotly
- 11.1 交互式可视化
- 11.2 时间序列可视化
- 11.2.1 Plotly Express 库
- 12. Bokeh
- 12.1 互动式可视化工具
- 12.2 时间序列数据可视化
- 12.2.1 Bokeh 绘图基础
- 13. Prophet-ml
- 13.1 Prophet 模型的机器学习扩展
- 13.2 高级时间序列分析
- 13.2.1 季节性调整
- 13.2.2 节假日效应
- 14. XGBoost
- 14.1 梯度提升框架
- 14.2 时间序列预测中的 XGBoost
- 14.2.1 XGBoost 基础
- 14.2.2 XGBoost 在时间序列中的应用
- 总结
1. Prophet
1.1 概述
Facebook开源的Prophet是一款用于时间序列预测的工具。其设计初衷是简化时间序列分析的复杂性,使非专业人士能够轻松应用。Prophet能够处理缺失值、异常值,并支持多个季节性组件的建模。
1.2 主要特点
- 灵活性: Prophet能够处理多变量、不规则的假期效应,适用于多种业务场景。
- 自动调整: 自动调整参数,减轻用户的调参负担。
- 可解释性: 提供可解释的模型参数,方便用户理解预测结果。
1.3 应用场景
Prophet广泛应用于销售预测、股票价格预测等业务场景。以下是一个简单的Prophet使用示例:
from fbprophet import Prophet
import pandas as pd# 创建一个示例数据集
data = pd.DataFrame({'ds': pd.date_range(start='2023-01-01', periods=365),'y': range(1, 366)
})# 初始化Prophet模型
model = Prophet()# 拟合模型
model.fit(data)# 创建未来时间的数据框
future = model.make_future_dataframe(periods=30)# 预测未来数据
forecast = model.predict(future)# 绘制预测结果
fig = model.plot(forecast)
2. Statsmodels
2.1 概述
Statsmodels是一个强大的统计分析库,提供了丰富的时间序列分析工具。它包括了经典的统计模型,如ARIMA和SARIMA。
2.2 时间序列分析功能
2.2.1 ARIMA 模型
ARIMA(Autoregressive Integrated Moving Average)模型是一种常用于时间序列分析的模型,结合了自回归和移动平均的特性。以下是一个简单的ARIMA模型示例:
from statsmodels.tsa.arima.model import ARIMA
import numpy as np# 创建一个示例时间序列
np.random.seed(42)
data = np.cumsum(np.random.normal(size=100))# 拟合ARIMA模型
model = ARIMA(data, order=(1, 1, 1))
result = model.fit()# 打印模型摘要
print(result.summary())
2.2.2 SARIMA 模型
SARIMA(Seasonal Autoregressive Integrated Moving Average)模型在ARIMA的基础上引入了季节性成分。以下是一个简单的SARIMA模型示例:
from statsmodels.tsa.statespace.sarimax import SARIMAX# 创建一个示例时间序列
np.random.seed(42)
data = np.cumsum(np.random.normal(size=100))# 拟合SARIMA模型
model = SARIMAX(data, order=(1, 1, 1), seasonal_order=(0, 1, 1, 12))
result = model.fit()# 打印模型摘要
print(result.summary())
这样,文章将逐渐填充每个章节的内容,详细介绍每个库的特性和使用方法。
3. Numpy
3.1 数组操作和数学函数
Numpy是Python中用于科学计算的基础库之一,特别擅长处理数组操作和数学函数。以下是一个简单的Numpy示例:
import numpy as np# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])# 数组操作:加法
arr_plus_1 = arr + 1# 数学函数:平方
arr_squared = np.square(arr)# 打印结果
print("Original Array:", arr)
print("Array + 1:", arr_plus_1)
print("Array Squared:", arr_squared)
3.2 随机数生成
3.2.1 numpy.random 模块
numpy.random模块提供了生成随机数的功能。以下是一个简单的随机数生成示例:
import numpy as np# 生成服从正态分布的随机数
random_data = np.random.normal(loc=0, scale=1, size=100)# 打印前10个随机数
print("Random Data:", random_data[:10])
4. Pandas
4.1 数据结构
4.1.1 Series
Pandas中的Series是一种一维标记数组,可存储任意数据类型。以下是一个简单的Series示例:
import pandas as pd# 创建一个Series
series_data = pd.Series([1, 3, 5, np.nan, 6, 8])# 打印Series
print("Series Data:")
print(series_data)
4.1.2 DataFrame
DataFrame是Pandas中的二维表格数据结构。以下是一个简单的DataFrame示例:
import pandas as pd# 创建一个DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']
}
df = pd.DataFrame(data)# 打印DataFrame
print("DataFrame:")
print(df)
4.2 时间序列处理
4.2.1 时间索引
Pandas支持时间序列数据的处理,其中时间索引是关键。以下是一个简单的时间索引示例:
import pandas as pd# 创建一个时间序列
time_series_data = pd.Series([1, 2, 3, 4], index=pd.date_range('2023-01-01', periods=4))# 打印时间序列
print("Time Series Data:")
print(time_series_data)
4.2.2 时期
Pandas中的时期表示时间区间。以下是一个简单的时期示例:
import pandas as pd# 创建一个时期
period_data = pd.period_range('2023-01', periods=3, freq='M')# 打印时期
print("Period Data:")
print(period_data)
这样,文章将逐步填充每个章节的内容,详细介绍每个库的特性和使用方法。
5. Matplotlib
5.1 绘图基础
5.1.1 折线图
Matplotlib是Python中广泛使用的绘图库。以下是一个简单的折线图示例:
import matplotlib.pyplot as plt# 创建示例数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]# 绘制折线图
plt.plot(x, y, marker='o', linestyle='-')# 添加标签和标题
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Line Plot Example')# 显示图形
plt.show()
5.1.2 散点图
散点图是另一种常见的数据可视化方式。以下是一个简单的散点图示例:
import matplotlib.pyplot as plt# 创建示例数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]# 绘制散点图
plt.scatter(x, y, color='red', marker='o')# 添加标签和标题
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Scatter Plot Example')# 显示图形
plt.show()
5.2 时间序列可视化
5.2.1 matplotlib.dates 模块
Matplotlib中的matplotlib.dates模块提供了处理日期和时间的功能。以下是一个简单的时间序列可视化示例:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import pandas as pd# 创建示例时间序列数据
data = pd.DataFrame({'date': pd.date_range(start='2023-01-01', periods=365),'value': range(1, 366)
})# 绘制时间序列图
plt.plot(data['date'], data['value'])# 设置日期格式
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Value')
plt.title('Time Series Visualization')# 自动格式化日期
plt.gcf().autofmt_xdate()# 显示图形
plt.show()
6. Seaborn
6.1 统计数据可视化
Seaborn是基于Matplotlib的统计数据可视化库,能够创建各种吸引人的图形。以下是一个简单的Seaborn示例:
import seaborn as sns
import matplotlib.pyplot as plt# 创建示例数据
data = sns.load_dataset('tips')# 绘制箱线图
sns.boxplot(x='day', y='total_bill', data=data)# 添加标签和标题
plt.xlabel('Day')
plt.ylabel('Total Bill')
plt.title('Boxplot Example')# 显示图形
plt.show()
6.2 时间序列数据可视化
6.2.1 时间序列图
Seaborn同样支持时间序列数据的可视化。以下是一个简单的时间序列图示例:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd# 创建示例时间序列数据
data = pd.DataFrame({'date': pd.date_range(start='2023-01-01', periods=365),'value': range(1, 366)
})# 绘制时间序列图
sns.lineplot(x='date', y='value', data=data)# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Value')
plt.title('Time Series Visualization with Seaborn')# 显示图形
plt.show()
这样,文章将逐渐填充每个章节的内容,详细介绍每个库的特性和使用方法。
7. Scikit-learn
7.1 机器学习基础
Scikit-learn是一个用于机器学习的开源工具包,包含了多种机器学习算法和工具。以下是一个简单的线性回归模型示例:
from sklearn.linear_model import LinearRegression
import numpy as np# 创建示例数据
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5])# 初始化线性回归模型
model = LinearRegression()# 拟合模型
model.fit(X, y)# 打印模型参数
print("Coefficient:", model.coef_)
print("Intercept:", model.intercept_)
7.2 时间序列预测与分类
7.2.1 时间序列预测模型
Scikit-learn并不直接提供专门用于时间序列的模型,但可以使用其回归模型进行时间序列预测。
from sklearn.linear_model import LinearRegression
import numpy as np# 创建示例时间序列数据
X = np.array(range(1, 11)).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5, 7, 8, 9, 10, 12])# 初始化线性回归模型
model = LinearRegression()# 拟合模型
model.fit(X, y)# 预测未来数据
future_data = np.array(range(11, 16)).reshape(-1, 1)
predicted_values = model.predict(future_data)# 打印预测结果
print("Predicted Values:", predicted_values)
7.2.2 时间序列分类模型
对于时间序列的分类问题,可以使用Scikit-learn中的分类算法,如支持向量机(SVM)或决策树。
from sklearn.svm import SVC
import numpy as np# 创建示例时间序列数据
X = np.array(range(1, 11)).reshape(-1, 1)
y = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])# 初始化支持向量机分类器
model = SVC(kernel='linear')# 拟合模型
model.fit(X, y)# 预测未来数据
future_data = np.array(range(11, 16)).reshape(-1, 1)
predicted_labels = model.predict(future_data)# 打印预测结果
print("Predicted Labels:", predicted_labels)
8. TensorFlow
8.1 神经网络基础
TensorFlow是一个用于构建和训练深度学习模型的开源库。以下是一个简单的神经网络示例:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 创建示例数据
X = np.array(range(1, 11)).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5, 7, 8, 9, 10, 12])# 构建神经网络模型
model = Sequential([Dense(10, input_dim=1, activation='relu'),Dense(1, activation='linear')
])# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')# 训练模型
model.fit(X, y, epochs=100, verbose=0)# 预测未来数据
future_data = np.array(range(11, 16)).reshape(-1, 1)
predicted_values = model.predict(future_data)# 打印预测结果
print("Predicted Values:", predicted_values.flatten())
8.2 时间序列预测与深度学习
8.2.1 LSTM 模型
长短时记忆网络(LSTM)是一种常用于处理序列数据的深度学习模型。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense# 创建示例时间序列数据
X = np.array(range(1, 11)).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5, 7, 8, 9, 10, 12])# 构建LSTM模型
model = Sequential([LSTM(50, activation='relu', input_shape=(1, 1)),Dense(1)
])# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')# 将输入数据调整为LSTM的输入形状
X_lstm = X.reshape((X.shape[0], 1, 1))# 训练模型
model.fit(X_lstm, y, epochs=100, verbose=0)# 调整未来数据形状并预测
future_data = np.array(range(11, 16)).reshape(-1, 1, 1)
predicted_values = model.predict(future_data)# 打印预测结果
print("Predicted Values:", predicted_values.flatten())
8.2.2 GRU 模型
门控循环单元(GRU)是另一种处理序列数据的深度学习模型。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense# 创建示例时间序列数据
X = np.array(range(1, 11)).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5, 7, 8, 9, 10, 12])# 构建GRU模型
model = Sequential([GRU(50, activation='relu', input_shape=(1, 1)),Dense(1)
])# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')# 将输入数据调整为GRU的输入形状
X_gru = X.reshape((X.shape[0], 1, 1))# 训练模型
model.fit(X_gru, y, epochs=100, verbose=0)# 调整未来数据形状并预测
future_data = np.array(range(11, 16)).reshape(-1, 1, 1)
predicted_values = model.predict(future_data)# 打印预测结果
print("Predicted Values:", predicted_values.flatten())
9. PyTorch
9.1 深度学习框架简介
PyTorch是另一个流行的深度学习框架,具有动态计算图的优势。以下是一个简单的PyTorch示例:
import torch
import torch.nn as nn
import numpy as np# 创建示例数据
X = torch.tensor(np.array(range(1, 11)).reshape(-1, 1), dtype=torch.float32)
y = torch.tensor(np.array([2, 4, 5, 4, 5, 7, 8, 9, 10, 12]), dtype=torch.float32)# 构建神经网络模型
model = nn.Sequential(nn.Linear(1, 10),nn.ReLU(),nn.Linear(10, 1)
)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)# 训练模型
for epoch in range(100):# 前向传播predictions = model(X)# 计算损失loss = criterion(predictions, y.view(-1, 1))# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 预测未来数据
future_data = torch.tensor(np.array(range(11, 16)).reshape(-1, 1), dtype=torch.float32)
predicted_values = model(future_data)# 打印预测结果
print("Predicted Values:", predicted_values.detach().numpy().flatten())
9.2 时间序列深度学习模型
PyTorch同样可以用于构建和训练深度学习模型来处理时间序列数据。以下是一个使用LSTM模型的时间序列预测示例:
import torch
import torch.nn as nn
import numpy as np# 创建示例时间序列数据
X = torch.tensor(np.array(range(1, 11)).reshape(-1, 1), dtype=torch.float32)
y = torch.tensor(np.array([2, 4, 5, 4, 5, 7, 8, 9, 10, 12]), dtype=torch.float32)# 将输入数据调整为LSTM的输入形状
X_lstm = X.view(-1, 1, 1)# 构建LSTM模型
model = nn.Sequential(nn.LSTM(1, 50, batch_first=True),nn.Linear(50, 1)
)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)# 训练模型
for epoch in range(100):# 前向传播predictions, _ = model(X_lstm)# 计算损失loss = criterion(predictions[:, -1, :], y.view(-1, 1))# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 调整未来数据形状并预测
future_data = torch.tensor(np.array(range(11, 16)).reshape(-1, 1), dtype=torch.float32)
future_data_lstm = future_data.view(-1, 1, 1)
predicted_values, _ = model(future_data_lstm)# 打印预测结果
print("Predicted Values:", predicted_values.detach().numpy().flatten())
10. Scipy
10.1 科学计算库
Scipy是一个建立在Numpy基础上的科学计算库,提供了许多用于科学和工程的模块。以下是一个简单的Scipy示例:
import scipy.stats as stats
import numpy as np# 创建示例数据
data = np.array([1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5])# 计算均值和标准差
mean_value = np.mean(data)
std_dev = np.std(data)# 计算正态分布的概率密度函数
pdf_values = stats.norm.pdf(data, loc=mean_value, scale=std_dev)# 打印结果
print("Mean:", mean_value)
print("Standard Deviation:", std_dev)
print("PDF Values:", pdf_values)
10.2 信号处理与频谱分析
10.2.1 FFT(快速傅里叶变换)
快速傅里叶变换是一种频谱分析方法,用于将信号从时域转换到频域。
from scipy.fft import fft
import numpy as np
import matplotlib.pyplot as plt# 创建示例信号
fs = 1000 # 采样频率
t = np.linspace(0, 1, fs, endpoint=False) # 时间向量
freq = 5 # 信号频率
signal = np.sin(2 * np.pi * freq * t)# 进行快速傅里叶变换
fft_result = fft(signal)# 计算频率轴
freq_axis = np.fft.fftfreq(len(fft_result), 1/fs)# 绘制频谱图
plt.plot(freq_axis, np.abs(fft_result))
plt.xlabel('Frequency (Hz)')
plt.ylabel('Amplitude')
plt.title('FFT Example')# 显示图形
plt.show()
10.2.2 滤波器设计
Scipy提供了滤波器设计的功能,以下是一个简单的滤波器设计示例:
from scipy import signal
import matplotlib.pyplot as plt# 设计一个低通Butterworth滤波器
order = 4 # 滤波器阶数
cutoff_frequency = 100 # 截止频率b, a = signal.butter(order, cutoff_frequency, btype='low', analog=False, fs=1000)# 频率响应
w, h = signal.freqz(b, a, worN=8000)
plt.plot(0.5 * 1000 * w / np.pi, np.abs(h), 'b')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Gain')
plt.title('Butterworth Lowpass Filter Frequency Response')
plt.show()
11. Plotly
11.1 交互式可视化
Plotly是一个用于创建交互式图形的库,支持多种图表类型。以下是一个简单的Plotly示例:
import plotly.express as px
import pandas as pd# 创建示例数据
data = pd.DataFrame({'x': [1, 2, 3, 4, 5],'y': [2, 4, 5, 4, 5],'category': ['A', 'A', 'B', 'B', 'B']
})# 绘制交互式散点图
fig = px.scatter(data, x='x', y='y', color='category', title='Interactive Scatter Plot')
fig.show()
11.2 时间序列可视化
11.2.1 Plotly Express 库
Plotly Express是Plotly的高级接口,能够轻松创建时间序列图。
import plotly.express as px
import pandas as pd# 创建示例时间序列数据
data = pd.DataFrame({'date': pd.date_range(start='2023-01-01', periods=365),'value': range(1, 366)
})# 绘制时间序列图
fig = px.line(data, x='date', y='value', title='Time Series Visualization with Plotly Express')
fig.show()
12. Bokeh
12.1 互动式可视化工具
Bokeh是一个用于创建交互式可视化的库,支持多种图表类型。以下是一个简单的Bokeh示例:
from bokeh.plotting import figure, show
from bokeh.models import ColumnDataSource
import pandas as pd# 创建示例数据
data = pd.DataFrame({'x': [1, 2, 3, 4, 5],'y': [2, 4, 5, 4, 5],'color': ['red', 'blue', 'green', 'red', 'blue']
})# 创建Bokeh的ColumnDataSource
source = ColumnDataSource(data)# 绘制散点图
p = figure(title='Interactive Scatter Plot with Bokeh', tools='pan,box_zoom,reset', x_axis_label='X-axis', y_axis_label='Y-axis')
p.scatter('x', 'y', source=source, size=10, color='color')# 显示图形
show(p)
12.2 时间序列数据可视化
12.2.1 Bokeh 绘图基础
Bokeh同样支持时间序列数据的可视化。以下是一个简单的时间序列图示例:
from bokeh.plotting import figure, show
from bokeh.models import ColumnDataSource
import pandas as pd# 创建示例时间序列数据
data = pd.DataFrame({'date': pd.date_range(start='2023-01-01', periods=365),'value': range(1, 366)
})# 创建Bokeh的ColumnDataSource
source = ColumnDataSource(data)# 绘制时间序列图
p = figure(title='Time Series Visualization with Bokeh', x_axis_label='Date', y_axis_label='Value', x_axis_type='datetime')
p.line('date', 'value', source=source, line_width=2)# 显示图形
show(p)
13. Prophet-ml
13.1 Prophet 模型的机器学习扩展
Prophet-ml是基于Prophet模型的机器学习扩展,支持更灵活的模型调整和集成学习方法。
13.2 高级时间序列分析
13.2.1 季节性调整
Prophet-ml支持对时间序列数据进行季节性调整,以更准确地捕捉季节性趋势。
13.2.2 节假日效应
通过Prophet-ml的节假日效应功能,用户可以更好地建模和预测在特定节假日期间可能发生的异常情况。
14. XGBoost
14.1 梯度提升框架
XGBoost是一个用于梯度提升的框架,支持分布式计算和优化技巧。
14.2 时间序列预测中的 XGBoost
14.2.1 XGBoost 基础
XGBoost可以应用于时间序列预测问题,以下是一个简单的XGBoost示例:
import xgboost as xgb
import numpy as np# 创建示例数据
X = np.array(range(1, 11)).reshape(-1, 1)
y = np.array([2, 4, 5, 4, 5, 7, 8, 9, 10, 12])# 初始化XGBoost回归模型
model = xgb.XGBRegressor(objective ='reg:squarederror', colsample_bytree = 0.3, learning_rate = 0.1, max_depth = 5, alpha = 10, n_estimators = 10)# 拟合模型
model.fit(X, y)# 预测未来数据
future_data = np.array(range(11, 16)).reshape(-1, 1)
predicted_values = model.predict(future_data)# 打印预测结果
print("Predicted Values:", predicted_values)
14.2.2 XGBoost 在时间序列中的应用
XGBoost在时间序列问题中可以通过调整参数、使用滞后特征(lag features)和引入时间相关的特征来优化性能。以下是一个更细致的XGBoost时间序列预测示例:
import xgboost as xgb
import pandas as pd
import numpy as np# 创建示例时间序列数据
data = pd.DataFrame({'date': pd.date_range(start='2023-01-01', periods=10),'value': [2, 4, 5, 4, 5, 7, 8, 9, 10, 12]
})# 添加滞后特征
for i in range(1, 4):data[f'value_lag_{i}'] = data['value'].shift(i)# 添加时间特征
data['month'] = data['date'].dt.month
data['day'] = data['date'].dt.day
data['day_of_week'] = data['date'].dt.dayofweek# 将数据拆分为训练集和测试集
train_data = data.iloc[:-2, :]
test_data = data.iloc[-2:, :]# 提取特征和目标变量
X_train = train_data.drop(['date', 'value'], axis=1)
y_train = train_data['value']
X_test = test_data.drop(['date', 'value'], axis=1)# 初始化XGBoost回归模型
model = xgb.XGBRegressor(objective ='reg:squarederror', colsample_bytree = 0.3, learning_rate = 0.1, max_depth = 5, alpha = 10, n_estimators = 10)# 拟合模型
model.fit(X_train, y_train)# 预测未来数据
predicted_values = model.predict(X_test)# 打印预测结果
print("Predicted Values:", predicted_values)
这样,你可以调整XGBoost模型的参数,尝试不同的特征工程方法,以获得更好的时间序列预测效果。
总结
时间序列分析是数据科学领域中不可或缺的一环,而Python生态系统提供了丰富的工具和库来应对这一挑战。从最简单的统计模型到复杂的深度学习算法,本文旨在为读者提供全方位的视角,让他们能够灵活应对不同领域的时间序列数据分析任务。通过学习本文,读者将不仅仅了解这些库的使用方法,还能够选择最适合自己需求的方法。
相关文章:

【Python百宝箱】时序之美:Python 时间序列探秘与创新
时光漫游:Python 时间序列分析全指南 前言 在数字化时代,时间序列数据扮演着关键的角色,从金融到气象再到生产制造。本文将引导你穿越Python丰富的时间序列分析工具,探索从基础统计到机器学习和深度学习的各个层面。无论你是初学…...
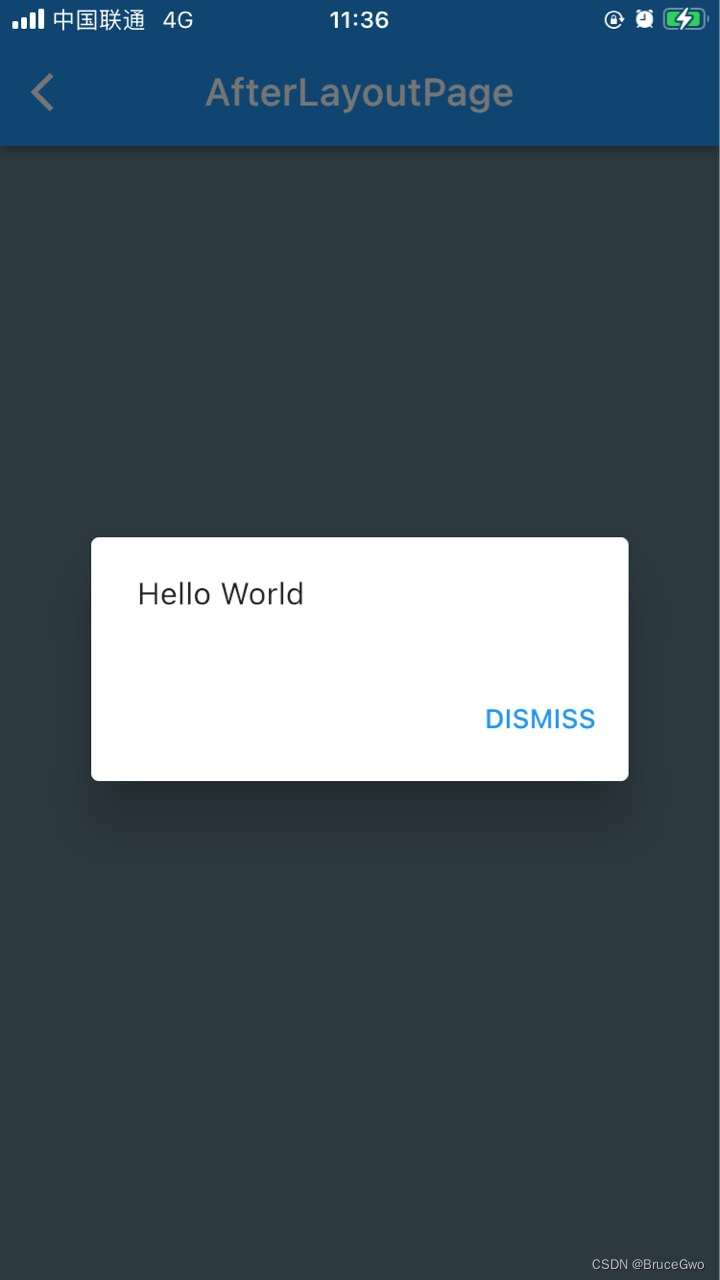
flutter开发实战-第一帧布局完成回调实现
flutter开发实战-第一帧布局完成回调实现 在开发中,我们有时候需要在第一帧布局完成后调用一些相关的方法。这里记录一下是实现过程。 Flutter中有多种不同的Binding,每种Binding都负责不同的功能。下面是Flutter中常见的Binding: 这里简单…...
Windows11编译VTM源码生成Visual Studio 工程
VTM介绍 VTM作为H266/VVC标准的官方参考软件,一直用作H266/VVC标准的研究和迭代。关于H2666/VVC标准的介绍、代码、提案、文档等,可以参考H266/VVC编码标准介绍。 官方代码地址: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM&…...
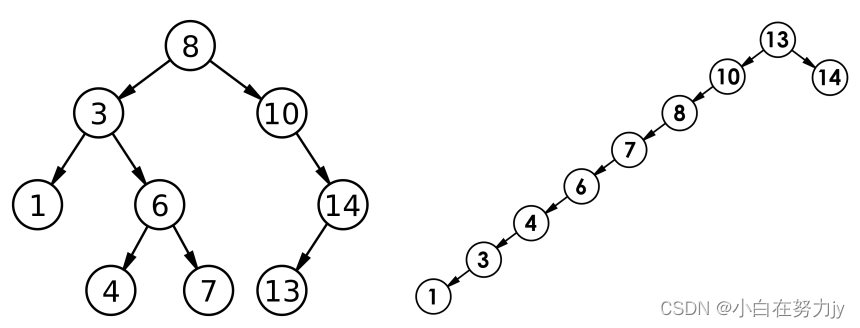
[数据结构进阶 C++] 二叉搜索树(BinarySearchTree)的模拟实现
文章目录 1、二叉搜索树1.1 二叉搜索数的概念1.2 二叉搜索树的操作1.2.1 二叉搜索树的查找1.2.2 二叉搜索树的插入1.2.3 二叉搜索树的删除 2、二叉搜索树的应用2.1 K模型2.2 KV模型 3、二叉搜索树的性能分析4、K模型与KV模型完整代码4.1 二叉搜索树的模拟实现(K模型…...
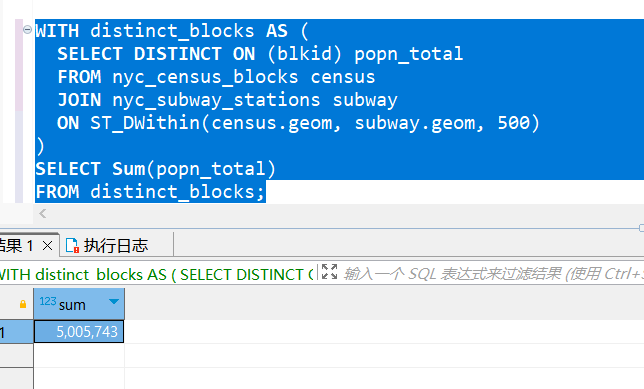
PostGIS学习教程十四:更多的空间连接
PostGIS学习教程十四:更多的空间连接 在上一节中,我们看到了ST_Centroid(geometry)和ST_Union([geometry])函数,以及一些简单的示例。在本节中,我们将用它们做一些更详细的事情。 提示:写完文章后,目录可以…...
【爬虫软件】孔夫子二手书采集
项目演示 孔网爬取图书信息 目录结构 [ |-- api-ms-win-core-synch-l1-2-0.dll, |-- api-ms-win-core-sysinfo-l1-1-0.dll, |-- api-ms-win-core-timezone-l1-1-0.dll, |-- api-ms-win-core-util-l1-1-0.dll, |-- api-ms-win-crt-conio-l1-1-0.dll, |-- api…...

P8736 [蓝桥杯 2020 国 B] 游园安排
题目描述 L \mathrm{L} L 星球游乐园非常有趣,吸引着各个星球的游客前来游玩。小蓝是 L \mathrm{L} L 星球 游乐园的管理员。 为了更好的管理游乐园,游乐园要求所有的游客提前预约,小蓝能看到系统上所有预约游客的名字。每个游客的名字由一…...
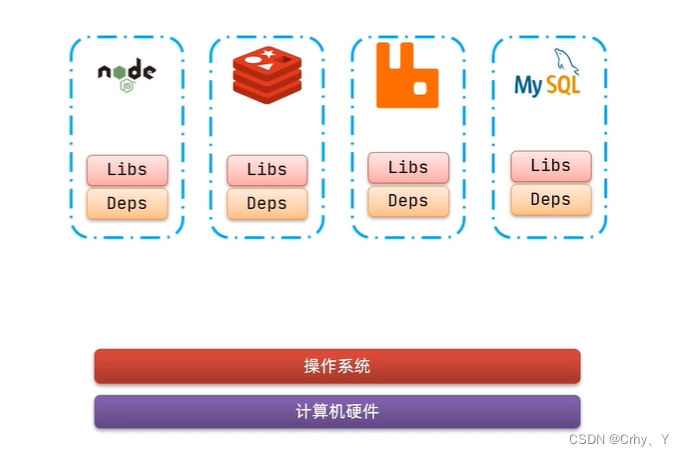
初识Docker-什么是docker
Docker是一个快速交付应用、运行应用的技术 目录 一、Docker 二、运用场景 一、什么是Docker?它的作用是什么? Docker如何解决大型项目依赖关系复杂,不同组件依赖的兼容性问题? Docker允许开发中将应用、依赖、函数库、配置一起打包&…...

maven的pom.xml设置本地仓库
配置 在Maven项目中,您可以在pom.xml文件中配置本地仓库的路径。在pom.xml文件中,您可以添加以下配置来指定本地仓库的路径: <project>...<repositories><repository><id>local-repo</id><url>file://…...

Qt获取屏幕DPI缩放比
获取屏幕缩放比 网上很多代码是用 logicalDotsPerInch 除以 96 来获取屏幕缩放比: // Windows 除以 96,macOS 除以 72 qreal factor window->screen()->logicalDotsPerInch() / 96.0; 当使能了缩放适配后,logicalDotsPerInch 值就不…...

Spring MVC控制层框架
三、Spring MVC控制层框架 目录 一、SpringMVC简介和体验 1. 介绍2. 主要作用3. 核心组件和调用流程理解4. 快速体验 二、SpringMVC接收数据 1. 访问路径设置2. 接收参数(重点) 2.1 param 和 json参数比较2.2 param参数接收2.3 路径 参数接收2.4 json参…...
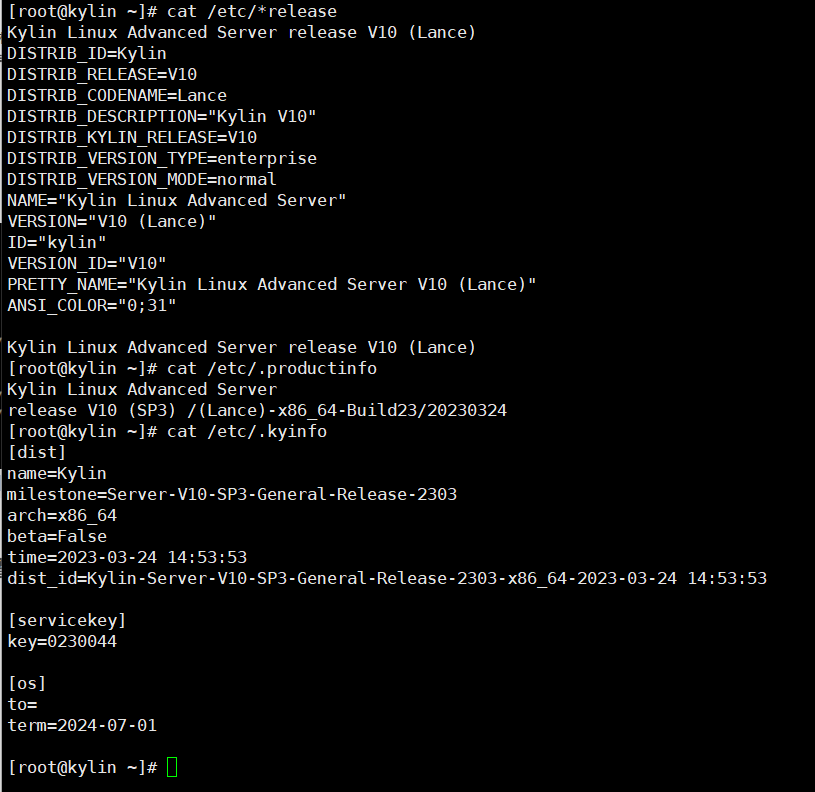
vmware安装银河麒麟V10高级服务器操作系统
vmware安装银河麒麟V10高级服务器操作系统 1、下载银河麒麟V10镜像2、VMware安装银河麒麟V10高级服务器操作系统2.1、新建虚拟机2.2、安装虚拟机 3、配置银河麒麟V10高级服务器操作系统3.1、安装vmware tools3.2、配置静态IP地址 和 dns3.3、查看磁盘分区3.4、查看系统版本 1、…...

掌握Jenknis基础概念
目录 任务(Jobs) 构建(Builds) 触发器(Triggers) 构建环境(Build Environment): 插件(Plugins): 参数化构建(Paramet…...
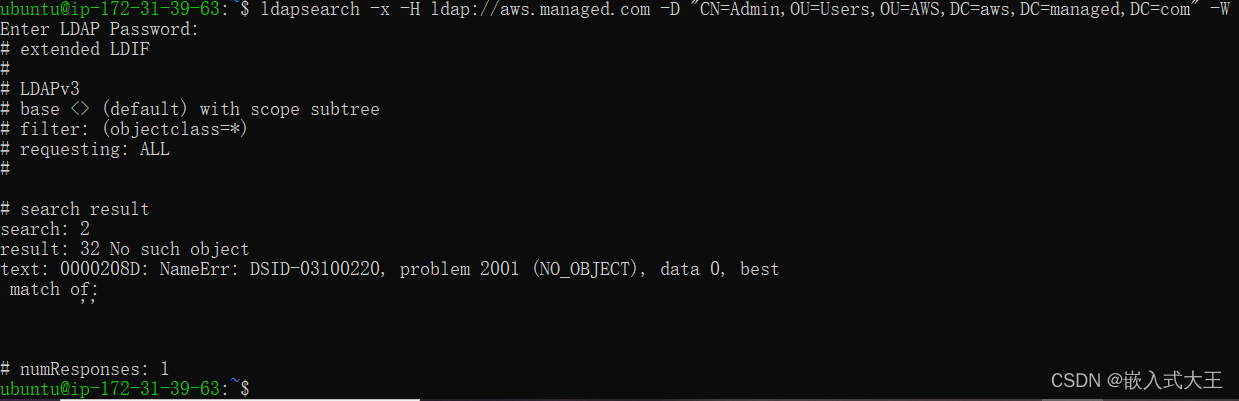
AWS 知识二:AWS同一个VPC下的ubuntu实例通过ldapsearch命令查询目录用户信息
前言: 前提:需要完成我的AWS 知识一创建一个成功运行的目录。 主要两个重要:1.本地windows如何通过SSH的方式连接到Ubuntu实例 2.ldapsearch命令的构成 一 ,启动一个新的Ubuntu实例 1.创建一个ubuntu实例 具体创建实例步骤我就不…...
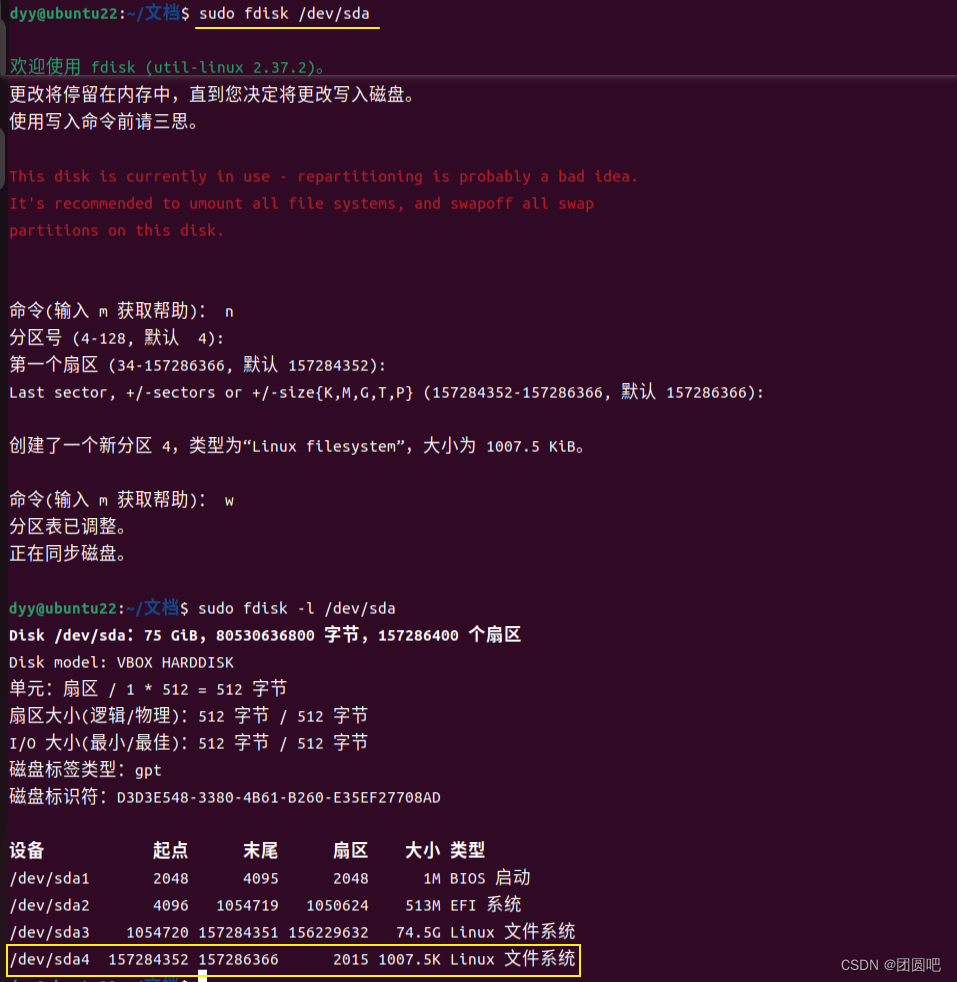
Ubuntu 常用命令之 fdisk 命令用法介绍
📑Linux/Ubuntu 常用命令归类整理 fdisk 是一个用于处理磁盘分区的命令行工具,它在 Linux 系统中广泛使用。fdisk 命令可以创建、删除、更改、复制和显示硬盘分区,以及更改硬盘的分区 ID。 fdisk 命令的常用参数如下 -l:列出所…...

论文中公式怎么降重 papergpt
大家好,今天来聊聊论文中公式怎么降重,希望能给大家提供一点参考。 以下是针对论文重复率高的情况,提供一些修改建议和技巧,可以借助此类工具: 论文中公式怎么降重 一、引言 在论文撰写过程中,公式是表达学…...
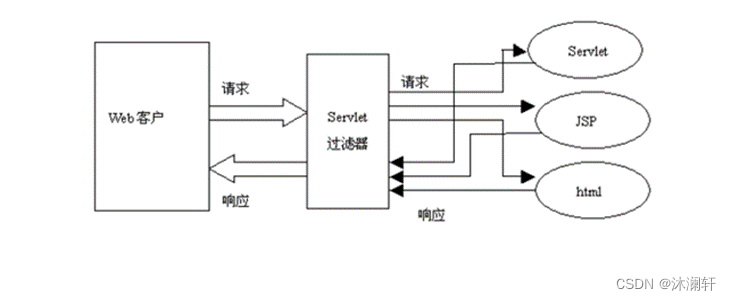
27. 过滤器
Filter(过滤器)简介 Filter 的基本功能是对 Servlet 容器调用 Servlet 的过程进行拦截,从而在 Servlet 进行响应处理的前后实现一些特殊的功能。在 Servlet API 中定义了三个接口类来开供开发人员编写 Filter 程序:Filter, FilterChain, FilterConfigFi…...
做一个wiki页面是体验HTML语义的好方法
HTML语义:如何运用语义类标签来呈现Wiki网页 在上一篇文章中,我花了大量的篇幅和你解释了正确使用语义类标签的好处和一些场景。那么,哪些场景适合用到语义类标签呢,又如何运用语义类标签呢? 不知道你还记不记得在大…...
金融CRM有用吗?金融行业CRM有哪些功能
市场形式波诡云谲,金融行业也面临着资源体系分散、竞争力后继不足、未知风险无法规避等问题。金融企业该如何解决这些问题,或许可以了解一下CRM管理系统,和其提供的金融行业CRM解决方案。 金融行业是银行业、保险业、信托业、证券业和租赁业…...

@XmlAccessorType+@XmlElement完美解决Java类到XML映射问题
前言: 最近项目在做静态代码扫描的时候,出现Java类中成员变量命名的问题,开头字母必须小写,但是这个类成员是对接其他公司的字段,对方提供的请求格式是XML,必须将Java类转化为XML的格式,而且这…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...
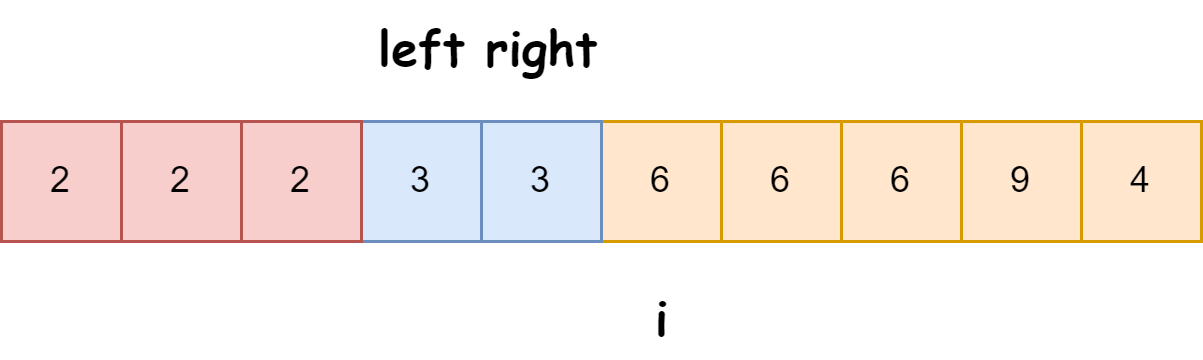
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...

【深尚想】TPS54618CQRTERQ1汽车级同步降压转换器电源芯片全面解析
1. 元器件定义与技术特点 TPS54618CQRTERQ1 是德州仪器(TI)推出的一款 汽车级同步降压转换器(DC-DC开关稳压器),属于高性能电源管理芯片。核心特性包括: 输入电压范围:2.95V–6V,输…...
深入解析光敏传感技术:嵌入式仿真平台如何重塑电子工程教学
一、光敏传感技术的物理本质与系统级实现挑战 光敏电阻作为经典的光电传感器件,其工作原理根植于半导体材料的光电导效应。当入射光子能量超过材料带隙宽度时,价带电子受激发跃迁至导带,形成电子-空穴对,导致材料电导率显著提升。…...
解决MybatisPlus使用Druid1.2.11连接池查询PG数据库报Merge sql error的一种办法
目录 前言 一、问题重现 1、环境说明 2、重现步骤 3、错误信息 二、关于LATERAL 1、Lateral作用场景 2、在四至场景中使用 三、问题解决之道 1、源码追踪 2、关闭sql合并 3、改写处理SQL 四、总结 前言 在博客:【写在创作纪念日】基于SpringBoot和PostG…...
)
【系统架构设计师-2025上半年真题】综合知识-参考答案及部分详解(回忆版)
更多内容请见: 备考系统架构设计师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20~21题】【第…...

多模态大语言模型arxiv论文略读(110)
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving ➡️ 论文标题:CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving ➡️ 论文作者:Hidehisa Arai, Keita Miwa, Kento Sasaki, Yu Yamaguchi, …...
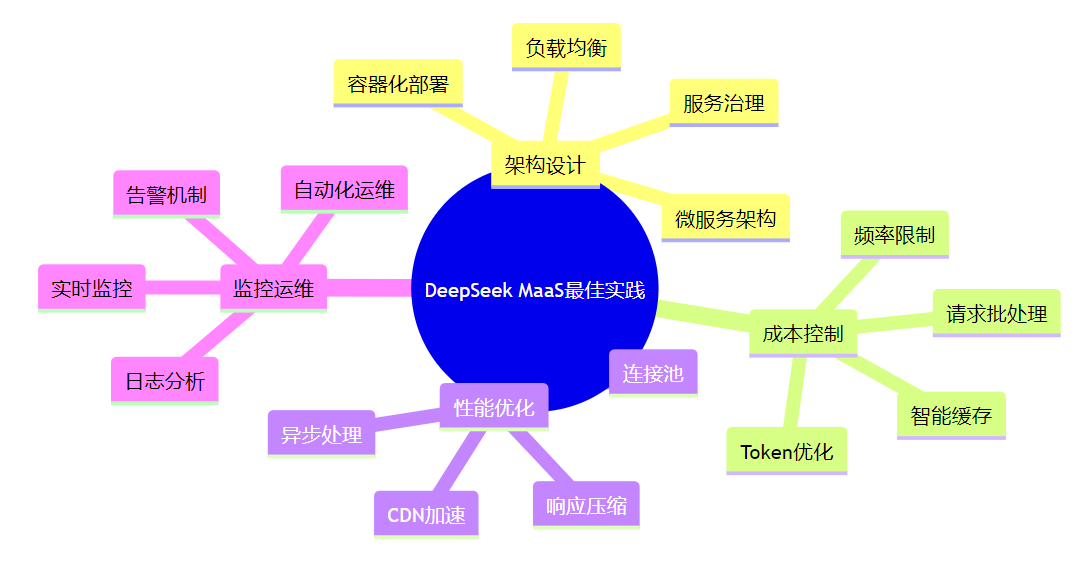
华为云Flexus+DeepSeek征文 | MaaS平台避坑指南:DeepSeek商用服务开通与成本控制
作者简介 我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。 目录 作者简介 前言 一、技术架构概览 1.1 整体架构设…...