2312llvm,04后端上
后端
后端由一套分析和转换趟组成,任务是生成代码,即把LLVM中间(IR)转换为目标代码(或汇编).
LLVM支持广泛目标:ARM,AArch64,Hexagon,MSP430,MIPS,NvidiaPTX,PowerPC,R600,SPARC,SystemZ,X86,和XCore.
所有这些后端共享一套,按通用API方法抽象后端任务的目标无关生成代码的一部分,即公共接口.
每个目标必须特化生成代码通用类,以实现目标相关行为.
这里,介绍LLVM后端的一般性质,对想编写新的后端,维护已有后端,或编写后端趟,都是很有用的.
概述
要经历多个步骤,才能转换LLVMIR为目标汇编代码.把IR转换为后端友好的指令,函数,全局变量的表示.随着程序经历各种后端变换,该表示越来越接近实际目标指令.
下面简略描述生成代码的各个阶段:
1,选指(InstructionSelection)过程,表示把内存中的IR转换为目标相关的SelectionDAG节点.
起初,该过程把三地址结构的LLVMIR转换为DAG有向无环图形式.
每个DAG可表示单个基本块的计算,即每个基本块关联不同的DAG.典型节点表示指令,而边代表它们的数据流依赖等.
可转换为DAG很重要,这样LLVM生成代码库,可运用基于树的模式匹配选指算法,经过一些调整,也能在DAG(而不仅是树)上工作.
该过程结束时,DAG已将它所有的LLVMIR节点转换为表示机器指令而不是LLVM指令的目标机器节点.
2,选指之后,就知道了,会使用哪些目标指令来计算每个基本块.
在SelectionDAG类中编码.然而,需要返回三地址表示,来决定基本块内部的指令顺序,因为DAG并不表明相互独立指令间的顺序.
第1个调度指令(InstructionScheduling),也叫前分配寄存器(RA)调度,排序指令来尽量指令级并行.
然后按MachineInstr三地址表示转换这些指令.
3,在分配寄存器(RegisterAllocation)前LLVMIR的寄存器集是无限的,它把无限引用的虚寄存器转换为有限的目标相关的寄存器集,不够时挤入(spill)到内存.
4,第2次调度指令,也叫后分配寄存器(RA)调度,此时.因此时在该点可获得真实寄存器信息,某些类型寄存器有额外风险和延迟,可用它来改进指令顺序.
5,发射代码(CodeEmission)阶段表示把指令从MachineInstr转换为MCInst实例.该新表示更适合汇编器和链接器,它有两个选择:输出汇编代码或输出(blob)二进制块到指定目标代码格式.
如此,整个后端流程用到了四种不同层次的指令表示:内存中的LLVMIR,SelectionDAG节点,MachineInstr,和MCInst.
使用后端工具
llc是后端主要工具.如果用前面的sum.bc位码,可用下面命令生成它的汇编代码:
$ llc sum.bc -o sum.s
或可用下面命令,生成目标代码:
$ llc sum.bc -filetype=obj -o sum.o
使用以上命令时,llc会试选择匹配sum.bc位码中指定目标三元组的一个后端.使用-march选项可覆盖它而选择指定后端.如,用下面命令生成MIPS目标代码:
$ llc -march=mips -filetype=obj sum.bc -o sum.o
如果运行llc-version命令,llc会显示所支持的-march选项的完整列表.注意,该列表和LLVM配置中用到的-enable-targets选项兼容.
注意,刚才确保让llc用不同后端为起初是为x86编译的位码生成代码.
因为C/C++语言有目标相关属性,所以相关性会在LLVMIR中体现.
因此,当位码目标三元组和运行llc -march的目标不匹配时,必须小心.可能导致ABI不匹配,坏程序行为,甚至导致生成代码失败.
然而一般,会成功生成代码,但更糟糕,它有微妙的bug.
为了理解IR的目标依赖.考虑程序分配了存储不同串的char指针的向量,你用通用的C语句
malloc(sizeof(char*)*n)
来为串向量分配内存.
如果给前端指定了目标,比如32位MIPS架构,它生成的代码会让malloc分配nx4字节的内存,因为在32位MIPS上每个指针是4字节.
然而,如果用llc编译该位码,并确保指定x86_64架构,它就生成了个坏程序.
运行时,会有潜在的段错误,因为x86_64架构的每个指针是8字节,这使得malloc分配的内存不够.
在x86_64上正确的malloc调用是分配nx8字节.
学习后端代码结构
在LLVM源码树的不同目录分散有后端实现.在lib目录和它的CodeGen,MC,TableGen,和Target子目录中,是生成代码背后的主要库:
1,CodeGen目录包含实现了所有通用生成代码算法的文件和头文件:选指,调度指令,分配寄存器,和需要的分析.
2,MC目录实现了汇编器(汇编解析器),松弛算法(反汇编器),和特定目标文件格式,如ELF,COFF,Macho等等低级功能.
3,TableGen目录包含TableGen工具,根据.td文件中的高级目标描述生成C++代码的完整实现.
4,在Target的子目录中实现各个目标,如包括多个.cpp,.h,和.td文件的Target/Mips目录.为不同目标实现类似功能的文件一般有相同名字.
如果编写新的后端,仅在Target目录中的一个子目录放置代码.如,用Sparc来阐明Target/Sparc子目录中的组织:
文件名 | 描述 |
|---|---|
SparcInstrInfo.td,SparcInstrFormats.td | 指令和格式定义 |
SparcRegisterInfo.td | 寄存器和寄存器类定义 |
SparcISelDAGToDAG.cpp | 择指 |
SparcISelLowering.cpp | 选择DAG节点降级 |
SparcTargetMachine.cpp | 目标相关属性(如数据布局和ABI)信息 |
Sparc.td | 定义计算机特征,CPU变体和扩展功能 |
SparcAsmPrinter.cpp | 发射汇编代码 |
SparcCallingConv.td | ABI定义调用约定 |
一般,后端都按此代码结构组织,因此开发者很容易地把一个后端具体问题映射到另一个后端中.如,你正在编写Sparc后端的SparcRegisterInfo.td寄存器信息文件,
并且想知道x86后端是如何实现它的,只需要查看Target/X86目录中的X86RegisterInfo.td文件.
了解后端库
llc的非共享代码是相当小的(见tools/llc/llc.cpp),如同其它LLVM工具,大部分都按可重用的库实现功能.
对llc,由生成代码库提供它的功能.这组库可分为目标相关和目标无关部分.在不同文件中,保存生成目标相关的库和目标无关的库,这样可链接期望的严格目标后端.
如,配置LLVM时设置-enable-targets=x86,arm,这样llc就只会链接x86和ARM的后端库.
注意,所有的LLVM库都以libLLVM为前缀.在此省略该前缀.下面列举了一些目标无关生成代码的库:
1,AsmParser.a:包含解析汇编文本并实现汇编器的代码
2,AsmPrinter.a:包含打印汇编语言,并实现生成汇编文件后端的代码
3,CodeGen.a:包含生成代码算法
4,MC.a:包含MCInst类及其相关的类,并用来表示LLVM允许的最低级程序
5,MCDisassembler.a:实现了一个读取目标代码文件,并按MCInst对象解码字节的反汇编器
6,MCJIT.a:实现(即时)生成代码.
7,MCParser.a:包含MCAsmParser类的接口,用来解析汇编文本,执行部分汇编器工作
8,SelectionDAG.a:包含SelectionDAG及其相关的类
9,Target.a:包含可让目标无关算法请求其它库(目标相关部分)实现的目标相关功能的接口
另一方面,下面是目标相关的库:
1,<Target>AsmParser.a:包含AsmParser库的目标相关的部分,负责为目标机器实现汇编器
2,<Target>AsmPrinter.a:包含打印目标指令的功能,并让后端生成汇编语言文件
3,<Target>CodeGen.a:包括具体寄存器处理规则,选指和调度等后端目标相关功能的主体.
4,<Target>Desc.a:包含低级MC设施的目标机器信息,负责注册如MCCodeEmitter等目标相关的MC对象.
5,<Target>Disassembler.a:用目标相关的功能补充了MCDisassembler库,来建造可读字节并解码它们为MCInst目标指令的系统.
6,<Target>Info.a:负责在LLVM生成代码系统中注册目标,提供了让目标无关的生成代码库可访问目标相关功能的接口类.
在这些库名字中,用目标名替换<Target>,如,X86AsmParser.a是X86后端的解析库的名字.完整的LLVM安装在<LLVM_INSTALL_PATH>/lib目录中包含这些库.
学习LLVM后端,如何用TableGen
LLVM使用TableGen面向记录的语言,来描述多个编译器阶段用到的信息.如,在前端中,简单讨论了如何用TableGen文件(以.td为扩展名)描述前端的不同诊断信息.
最初,LLVM团队开发TableGen是为了帮助编写LLVM后端的.尽管生成代码库设计强调,要干净分离不同目标特性,
如,用不同的类表示指令的寄存器信息和其他,但是最终后端代码,不得不在多个不同文件中表示相同的某种机器特征.
问题是,不仅要编写后端代码,还在代码中引入了信息冗余,必须手工同步.
如,想修改后端如何处理寄存器,要修改代码中几处不同部分:在分配寄存器器中说明支持的寄存器类型;
在汇编打印器中说明如何打印该寄存器;在汇编解析器中说明,按汇编如何解析;及在反汇编器中,说明它要知道的寄存器编码方式.
这样,很难维护后端代码.
为此,创造了关于目标的TableGen中央信息库.
想法是:在单独位置声明机器的某种特性,如在<Target>InstrInfo.td中描述机器指令,然后TableGen后端用该信息库去具体实现,如生成自己写很烦的匹配模式选指算法等任务.
如今,用TableGen来描述各种目标相关信息,如指令格式,指令,寄存器,匹配模式DAG,选指匹配顺序,调用惯例,和目标CPU属性(支持的指令集架构(ISA)特征和处理器族)等.
注意,还在追求全自动为处理器生成后端,模拟器,和硬件综合描述文件.
典型方法是用类似TableGen的声明描述语言表示所有机器信息,然后用工具继承要求的各种软件(和硬件),并求值,测试处理器架构.
但这很难,和手写工具相比,自动生成工具质量很差.LLVMTableGen是辅助完成较小任务,但仍给你完整的控制权,让你用C++代码实现自定义逻辑.
语言
TableGen语言由创建记录的定义和类(class)组成.def定义用来根据class和multiclass关键字实例化记录.
由TableGen后端进一步处理这些记录,如为以下组件生成领域相关信息:生成代码,Clang诊断,Clang驱动选项,和静态解析器检查器.
因此,由后端给出记录所表示的实际意思,而记录仅保存信息.
如,假设想为1个架构定义ADD和SUB指令,而ADD有两种形式:所有操作数都是寄存器,一个操作数是寄存器一个是立即数.
SUB指令只有第1种形式.看下面insns.td文件的示例代码:
class Insn<bits <4> MajOpc, bit MinOpc> {bits<32> insnEncoding;let insnEncoding{15-12} = MajOpc;let insnEncoding{11} = MinOpc;
}
multiclass RegAndImmInsn<bits <4> opcode> {def rr : Insn<opcode, 0>;def ri : Insn<opcode, 1>;
}
def SUB : Insn<0x00, 0>;
defm ADD : RegAndImmInsn<0x01>;
Insn类表示一个普通指令,RegAndImmInsn表示另一种形式的指令.def SUB定义了SUB记录,而defm ADD定义了两个记录:ADDrr和ADDri.
用llvm-tblgen工具,可处理一个.td文件并检查结果记录:
$ llvm-tblgen -print-records insns.td
------------- Classes -----------------
class Insn<bits<4> Insn:MajOpc = {?,?,?,?}, bit Insn:MinOpc = ?> {bits<5> insnEncoding = { Insn:MinOpc, Insn:MajOpc{0},Insn:MajOpc{1}, Insn:MajOpc{2}, Insn:MajOpc{3} };string NAME = ;
}
------------- Defs -----------------
def ADDri { //Insn ribits<5> insnEncoding = { 1, 1, 0, 0, 0 };string NAME = "ADD";
}
def ADDrr { //Insn rrbits<5> insnEncoding = { 0, 1, 0, 0, 0 };string NAME = "ADD";
}
def SUB { //Insnbits<5> insnEncoding = { 0, 0, 0, 0, 0 };string NAME = ;
}
通过llvm-tblgen工具还可使用TableGen后端;输入llvm-tblgen -help,会列举所有后端选项.注意此例没有用LLVM相关的域,且未与后端工作.
TableGen更多信息
了解生成代码的.td文件
如前,生成代码广泛使用TableGen记录来表达目标相关信息.看看生成代码的TableGen文件.
目标属性
<Target>.td文件(如,X86.td)定义了所支持的ISA特性和处理器族.如,X86.td定义了AVX2扩展:
def FeatureAVX2 : SubtargetFeature<"avx2", "X86SSELevel", "AVX2", "Enable AVX2 instructions", [FeatureAVX]>;
def关键字从SubtargetFeature类类型定义了FeatureAVX2记录.最后参数是在定义中已包含的其它特性的一个列表.
因此,带AVX2的处理器包含所有AVX指令.
此外,还可定义包含它提供的ISA扩展和特性的处理器类型:
def : ProcessorModel<"corei7-avx", SandyBridgeModel, [FeatureAVX, FeatureCMPXCHG16B, ..., FeaturePCLMUL]>;
<Target>.td文件还包含了所有其它的.td文件,且是描述目标相关域信息的主文件.llvm-tblgen工具必须总是从它那获得目标的任意TableGen记录.
如,用下面命令,输出x86的一切记录:
$ cd <llvm_source>/lib/Target/X86
$ llvm-tblgen -print-records X86.td -I ../../../include
X86.td文件有TableGen用来生成X86GenSubtargetInfo.inc文件的部分信息,但不止,一般,不能从.td文件映射到.inc文件.
为此,考虑<Target>.td文件是个用TableGen的include指令包含了所有其它的.td文件的重要的顶层文件.
因此,生成C++代码时,TableGen总是解析所有后端.td文件,使你可自由地在任意的最合适位置放置记录.
即使X86.td包含了所有其它的后端.td文件,除了include指令,``内容也要同Subtargetx86子目标定义保持一致.
如果查看实现x86Subtarget类的X86Subtarget.cpp文件,会发现一个调用"#include"X86GenSubtargetInfo.inc"的C++预处理器指令,表明如何在普通的codebase中嵌入TableGen生成的C++代码.
该特别的include文件包含关联了串描述及其它相关的资源特征的处理器特征常量及处理器特性向量.
寄存器
在<Target>RegisterInfo.td文件中,定义寄存器和寄存器类.之后在定义指令中,寄存器类把指令操作数绑定到特定寄存器集合中.
如,X86RegisterInfo.td用下面语句定义了16位的寄存器:
let SubRegIndices = [sub_8bit, sub_8bit_hi], ... in {
def AX : X86Reg<"ax", 0, [AL,AH]>;
def DX : X86Reg<"dx", 2, [DL,DH]>;
def CX : X86Reg<"cx", 1, [CL,CH]>;
def BX : X86Reg<"bx", 3, [BL,BH]>;
...
此处let构建指令,用来定义额外的即{...}区域中的所有记录都有的SubRegIndices字段.
从X86Reg类继承16位寄存器的定义,为每个寄存器保存它的名字,数目,及8位子寄存器的列表.如下重新产生16位寄存器的寄存器类定义:
def GR16 : RegisterClass<"X86", [i16], 16,(add AX, CX, DX, ..., BX, BP, SP,R8W, R9W, ..., R15W, R12W, R13W)>;
GR16寄存器类,包含所有的16位寄存器和它们各自分配寄存器的优先顺序.在TableGen处理后,每个寄存器类的会得到RegClass后缀,如,GR16变成了GR16RegClass.
TableGen会生成寄存器和寄存器类的定义,来收集它们的相关信息,汇编器的二进制编码,和DWARF(Linux调试记录格式)信息.
可用llvm-tblgen查看TableGen生成的代码:
$ cd <llvm_source>/lib/Target/X86
$ llvm-tblgen -gen-register-info X86.td -I ../../../include
也可查看LLVM编译过程中生成的C++文件:
<LLVM_BUILD_DIR>/lib/Target/X86/X86GenRegisterInfo.inc
X86RegisterInfo.cpp包含来辅助定义X86RegisterInfo类,inc文件包含了寄存器的枚举,调试后端且不知道16表示什么寄存器时,它是一份有用的参考.
指令
分别在<Target>InstrFormats.td和<Target>InstInfo.td文件中定义指令格式和指令.指令格式包含按二进制格式写指令所必需的指令编码字段,而指令记录按单个记录表示一条指令.
可创建TableGen类用来继承指令记录的中间指令类,以找出公共特征,如相似数据处理指令的公共编码.
然而,每个指令或格式必须是在include/llvm/Target/Target.td中定义的指令的TableGen类的直接或间接子类.
它的字段显示了在指令记录中,TableGen后端期望找到的内容:
class Instruction {dag OutOperandList;dag InOperandList;string AsmString = "";list<dag> Pattern;list<Register> Uses = [];list<Register> Defs = [];list<Predicate> Predicates = [];bit isReturn = 0;bit isBranch = 0;
...
dag是个用来保存SelectionDAG节点的特殊TableGen类型.这些节点表示选指过程中的操作码,寄存器,或常量.代码中这些字段的意义:
1,OutOperandList字段存储结果节点,让后端确定代表指令输出的DAG节点.
如,在MIPS的ADD指令中,按(outs GP32Opnd:$rd)定义字段.此例中:
1,outs是个指示其子是输出操作数的特殊DAG节点
2,GPR32Opnd是MIPS特有的指示MIPS32位的通用寄存器实例的DAG节点
3,$rd是用来识别节点的任意寄存器名字.
2,InOperandList字段保存输入节点,如,在MIPSADD指令中,它是
(ins GPR32Opnd:$rs, GPR32Opnd:$rt)
3,AsmString字段表示指令汇编串,如,在MIPS的ADD指令中,它是"add$rd,$rs,$rt".
4,Pattern是选择指令时匹配模式的dag对象列表.如果匹配一个模式,选指会用该指令替换匹配节点.
如,在MIPS的ADD指令:
(set GPR32Opnd:$rd, (add GPR32Opnd:$rs, GPR32Opns:$rt))
模式中,[and]表示只有一个在类似LISP表示法的小括号间定义的dag元素列表的内容.
5,Uses和Defs记录在执行指令时,隐式使用和定义的寄存器列表.如,RISC处理器的return指令隐式使用返回地址寄存器,而call指令隐式定义返回地址寄存器.
6,Predicates字段,在选指试匹配指令前,存储要检查的前提列表.如果检查失败了,就没有匹配.如,一个前提可能说明,该指令只对特定子目标有效.
如果用选择了另一个子目标的目标三元组运行生成代码,该前提会求值为假,而该指令就不会匹配.
7,此外,其它还包括isReturn和isBranch字段,它们用指令行为信息增强生成代码.如,如果isBranch=1,则生成代码就知道该指令是分支指令,因此必须放在基本块尾.
下面代码块中,可见在SparcInstrInfo.td中的XNORrr指令的定义.它用到了(在SparcInstrFormats.td中定义的)F3_1格式,它包括了SPARCV8架构手册的F3格式的一部分:
def XNORrr : F3_1<2, 0b000111,(outs IntRegs:$dst), (ins IntRegs:$b, IntRegs:$c), "xnor $b, $c, $dst",[(set i32:$dst, (not (xor i32:$b, i32:$c)))]>;
该XNORrr指令有两个IntRegs(一个表示SPARC32位整数寄存器类的目标相关的DAG节点)源操作数和一个IntRegs结果,类似:
OutOperandList = (outs IntRegs:$dst)
InOperandList = (ins IntRegs:$b, IntRegs:$c)
AsmString汇编通过$记号引用指定的操作数:"xnor $b,$c,$dst".模式列表元素包含应该匹配到该指令的SelectionDAG节点.
如,每当not反转xor的结果位,且xor的两个操作数都是寄存器时,匹配XNORrr指令.
为了查看XNORrr指令记录字段,可用如下命令序列:
$ cd <llvm_sources>/lib/Target/Sparc
$ llvm-tblgen -print-records Sparc.td -I ../../../include | grep XNORrr -A 10
多个TableGen后端,用指令记录信息干活,从相同指令记录生成不同的.inc文件.这跟创建中心仓库,用它给后端各个部分生成代码的TablenGen的目标是一致的.
下面的每个文件是由不同的TableGen后端生成的:
1,<Target>GenDAGISel.inc:用指令记录中的模式字段信息来发射选择SelectionDAG数据结构的指令的代码.在<Target>ISelDAGtoDAG.cpp文件中包含它.
2,<Target>GenInstrInfo.inc:包含在其它描述指令的表中,列举目标所有指令的枚举.
在<Target>InstrInfo.cpp,<Target>InstrInfo.h,<Target>MCTargetDesc.cpp,和<Target>MCTargetDesc.h中包含.
然而,在包含TableGen生成文件,改变如何在每个环境中解析和使用前,每个文件会定义一组特定宏.
3,<Target>GenAsmWriter.inc:包含映射用来打印每个指令汇编的串的代码.在<Target>AsmPrinter.cpp文件中包含.
4,<Target>GenCodeEmitter.inc:包含为每条指令映射要输出的二进制代码,从而生成机器代码以填写目标文件的函数.在<Target>CodeEmitter.cpp中包含.
5,<Target>GenDisassemblerTables.inc:实现可解码字节序列并识别代表的目标指令的表和算法.用来实现反汇编工具,在<Target>Disassembler.cpp文件中包含它.
6,<Target>GenAsmMatcher.inc:实现目标指令的汇编器的解析器.在<Target>AsmParser.cpp文件中包含了它两次,每次都有一组不同预处理宏,从而改变解析方式.
理解选指
选指是转换LLVMIR为代表目标指令的SelectionDAG节点(SDNode)的过程.第一步是根据LLVMIR指令创建DAG,创建带IR操作节点的SelectionDAG对象.
接着,降级这些节点后,组合DAG,及标准化等过程,使它更易匹配目标指令.然后,选指用节点匹配模式方法来从DAG到DAG转换,转换SelectionDAG节点为代表目标指令的节点.
注意,选指是其中最耗时的后端趟.一项编译SPECCPU2006基准测试的函数的研究表明,在LLVM3.0中,以-O2运行llc工具,平均来说,选指趟几乎花去一半的时间.
SelectionDAG类
SelectionDAG类,用DAG表示每个基本块的计算,每个SDNode对应一个指令或操作数.
DAG的边通过use-def关系确保操作之间的顺序.如果B节点(如,add)连接到A节点(如,Constant<-10>),即A节点定义了一个值(32位的-10整数),而B节点使用它(用作加法).
因此,必须在B前执行A操作.黑色箭头表示指示数据流依赖的普通连线,如add示例.蓝色虚线箭头表示确保两条指令顺序的非数据流链,否则它们是不相关的,如,load和store指令,如果访问相同内存位置,则必须按原始程序顺序.
前面图中,CopyToReg操作,因为蓝色虚线箭头,必须在X86ISD::RET_FLAG之前.红色连线保证相邻节点必须结合在一起,即必须紧挨着执行,之间不能有其它指令.
如,因为红色连线,表明相同节点CopyToReg和X86ISD::RET_FLAG必须紧挨着调度.
根据它和它的用户的关系,每个节点可提供不同的值类型.值不必是具体的,也可能是个(token)抽象令牌.它可能有任意如下类型:
1,节点所提供的值可以是表示整数,浮点数,向量,或指针等具体值类型.从它的操作数计算新值的数据处理节点,就是一例.
类型可以是i32,i64,f32,v2f32(有两个f32元素的向量),和iPTR等.在LLVM示意图中,当另一个节点使用该值时,由普通黑色连线描绘生产者-消费者关系.
2,Other类型是表示链值(ch)的抽象令牌.在LLVM示意图中,另一节点使用一个Other类型的值时,按蓝色虚线打印连接两者的连线.
3,Glue类型表示组合.在LLVM示意图中,另一节点使用Glue类型值时,按红色来画连接两者的连线.
SelectionDAG对象有个表示基本块入口的EntryToken的特殊令牌,它通过消费首节点,提供Other类型的值,让链结的节点以它为起点.
SelectionDAG对象也可引用正好是按Other类型的值链编码关系的最后一条指令的后续节点的图的根节点.
在该阶段,可同时有目标无关和目标相关节点,这是执行预备步骤的结果,如负责准备选指DAG的降级和合法化.
然而,选指结束时,所有目标指令匹配的节点都会是目标相关的.前面,有如下目标无关的节点:CopyToReg,CopyFromReg,Register(%vreg0),add,和Constant.
此外,如下为已预处理且是目标相关的节点(尽管选指后仍可改变):TargetConstant,Register(%EAX),和X86ISD::REG_Flag.
可观察到下面的语义:
1,Register:可能引用虚或(目标相关的)物理的寄存器.
2,CopyFromReg:复制当前基本块域外定义的寄存器,示例中,它复制函数参数.
3,CopyToReg:不提供其它节点使用的具体值的,复制值到指定寄存器.
然而,该节点,要用不生成具体值的其它节点,产生一个要链接(Other类型)的链值.
如,为了使用写到EAX的值,X86ISD::RET_FLAG节点使用由Register(%EAX)提供的i32结果,且还消费由CopyToReg产生的链,这样确保用CopyToReg更新%EAX,因为该链会确保在X86ISD::RET_FLAG前调度CopyToReg.
SelectionDAG细节,见llvm/include/llvm/CodeGen/SelectionDAG.h头文件.对节点结果类型,见llvm/include/llvm/CodeGen/ValueTypes.h头文件.
llvm/include/llvm/CodeGen/ISDOpcodes.h头文件定义了目标无关节点,而lib/Target/<Target>/<Target>ISelLowering.h头文件定义了目标相关节点.
降级
如果这是选指输入,为何在SelectionDAG中,已有一些目标相关节点?
为此,首先在下图中给出选指前步骤全局图,在左上角从LLVMIR步骤开始:
IR,1=>映射指令到SD节点,2=>SD节点=>组合1->标准化类型1
组合->合法化向量->合法化2=>组合=>合法化=>组合2=>选指
中间步骤中一堆降级.
首先,SelectionDAGBuilder实例(见SelectionDAGISel.cpp)访问每个函数,为每个基本块创建一个SelectionDAG对象.
在此时,一些特殊的IR指令如call和ret已要求目标相关语句,如,如何传递调用参数及如何从一个要转换为SelectionDAG节点的函数返回.
为此,第一次使用TargetLowering类中的算法.该类是每个目标都必须实现的抽象接口,且有大量所有后端可使用的共享功能.
为了实现该抽象接口,每个目标声明一个叫<Target>TargetLowering的TargetLowering的子类.每个目标还重载实现具体的目标无关高级节点应如何降级到更接近的机器级的方法.
如期,仅有小部分节点必须这样降级,而大部分在选指时就匹配和替换了其它节点.如,在sum.bc的SelectionDAG中,用X86TargetLowering::LowerReturn()方法(见lib/Target/X86/X86ISelLowering.cpp)降级IR的ret指令.
同时,生成了复制函数结果到EAX的X86ISD::RET_FLAG节点,按目标相关方式处理函数返回.
DAG结合与合法化
从SelectionDAGBuilder输出的SelectionDAG并不能直接选指,必须经历附加转换.在选指前执行的趟序列如下:
1,可获利时,DAG结合趟通过匹配一系列节点,并用简化结构替换它们,来优化次优化的SelectionDAG结构.
如,可把(add(RegisterX),(constant0))子图合并为(RegisterX).
类似,目标相关组合方法可识别节点模式,并根据是否可提高此目标选择指令的质量,决定是否合并和折叠它们.
可在lib/CodeGen/SelectionDAG/DAGCombiner.cpp文件中,找到LLVM通用的DAG结合的实现,在lib/Target/<Target_Name>/<Target>ISelLowering.cpp文件中找到目标相关的组合实现.
setTargetDAGCombine()方法,标记目标想要结合的节点.如,MIPS后端试结合加法:见lib/Target/Mips/MipsISelLowering.cpp中的setTargetDAGCombine(ISD::ADD)和performADDCombine().
注意,在每次合法化后运行DAG结合,来最小化SelectionDAG冗余.而且,DAG结合知道在趟链的何处运行,(如在合法化类型或向量后),可运用这些信息以更精确.
2,类型合法化趟,确保选指只需要处理目标天然支持的类型的合法类型.如,在只支持i32类型的目标上,i64操作数的加法是非法的.
此时,合法化类型,展开整数把i64操作数分为两个i32操作数,同时生成合适节点以操作它们.目标定义了每种类型所关联的寄存器,并显式声明了支持类型.
这样,必须检测并相应处理非法类型:可提升,展开,或软化标量类型,而可分解,标量化,或放宽向量类型,见llvm/include/llvm/Target/TargetLowering. h对每种情况的解释.
此外,目标还可设置自定义方法来合法化类型.两次运行合法化类型,第一次组合DAG后,及在合法化向量后.
3,有时,后端直接支持向量类型,即有个寄存器类,但是没有处理给定向量类型的具体操作.如,x86的SSE2支持v4i32向量类型.
然而,并没有x86指令支持v4i32类型的ISD::OR操作,而只有v2i64的.因此,向量合法化会为指令用合法类型来处理,提升或扩展.
目标还可自定义合法化.对前面提到的ISD::OR,会提升操作而使用v2i64类型.看一看下面的lib/Target/X86/X86ISelLowering.cpp的代码片:
setOperationAction(ISD::OR, v4i32, Promote);
AddPromotedToType (ISD::OR, v4i32, MVT::v2i64);
DAG合法化类似向量合法化,但是它用不支持类型(标量或向量)处理剩余的操作.它支持相同动作:提升,扩展,和自定义节点.
如,x86不支持以下三种:i8类型的有符号整数到浮点的转化操作(ISD::SINT_TO_FP),再请求合法化提升操作;
32位操作数的有符号除法,(ISD::SDIV),发起一个产生库调用处理该除法的扩展请求;f32操作数的浮点数绝对值,用自定义处理器生成有相同效果的等价代码.
x86以如下发起这些动作(见lib/Target/X86/X86ISelLowering.cpp):
setOperationAction(ISD::SINT_TO_FP, MVT::i8, Promote);
setOperationAction(ISD::SDIV, MVT::i32, Expand);
setOperationAction(ISD::FABS, MVT::f32, Custom);
DAG到DAG的选指
DAG到DAG选指目的,是用匹配模式转换目标无关节点为目标相关节点.选指算法是本地的,每次在SelectionDAG(基本块)的实例上工作.
如,后面给出了选指后最终的SelectionDAG结构.直到分配寄存器,CopyToReg,CopyFromReg,和Register节点不变.
选指过程甚至可能增加节点.选指之后,按X86指令ADD32ri8转换ISD::ADD节点,而X86ISD::RET_FLAG变为RET.
注意,在同一个DAG中并存有三个指令表示类型:通用的LLVMISD节点比如ISD::ADD,目标相关的<Target>ISD节点比如X86ISD::REG_FLAG,目标物理指令比如X86::ADD32ri8.
相关文章:

2312llvm,04后端上
后端 后端由一套分析和转换趟组成,任务是生成代码,即把LLVM中间(IR)转换为目标代码(或汇编). LLVM支持广泛目标:ARM,AArch64,Hexagon,MSP430,MIPS,NvidiaPTX,PowerPC,R600,SPARC,SystemZ,X86,和XCore. 所有这些后端共享一套,按通用API方法抽象后端任务的目标无关生成代码的一部…...
springboot学习笔记(五)
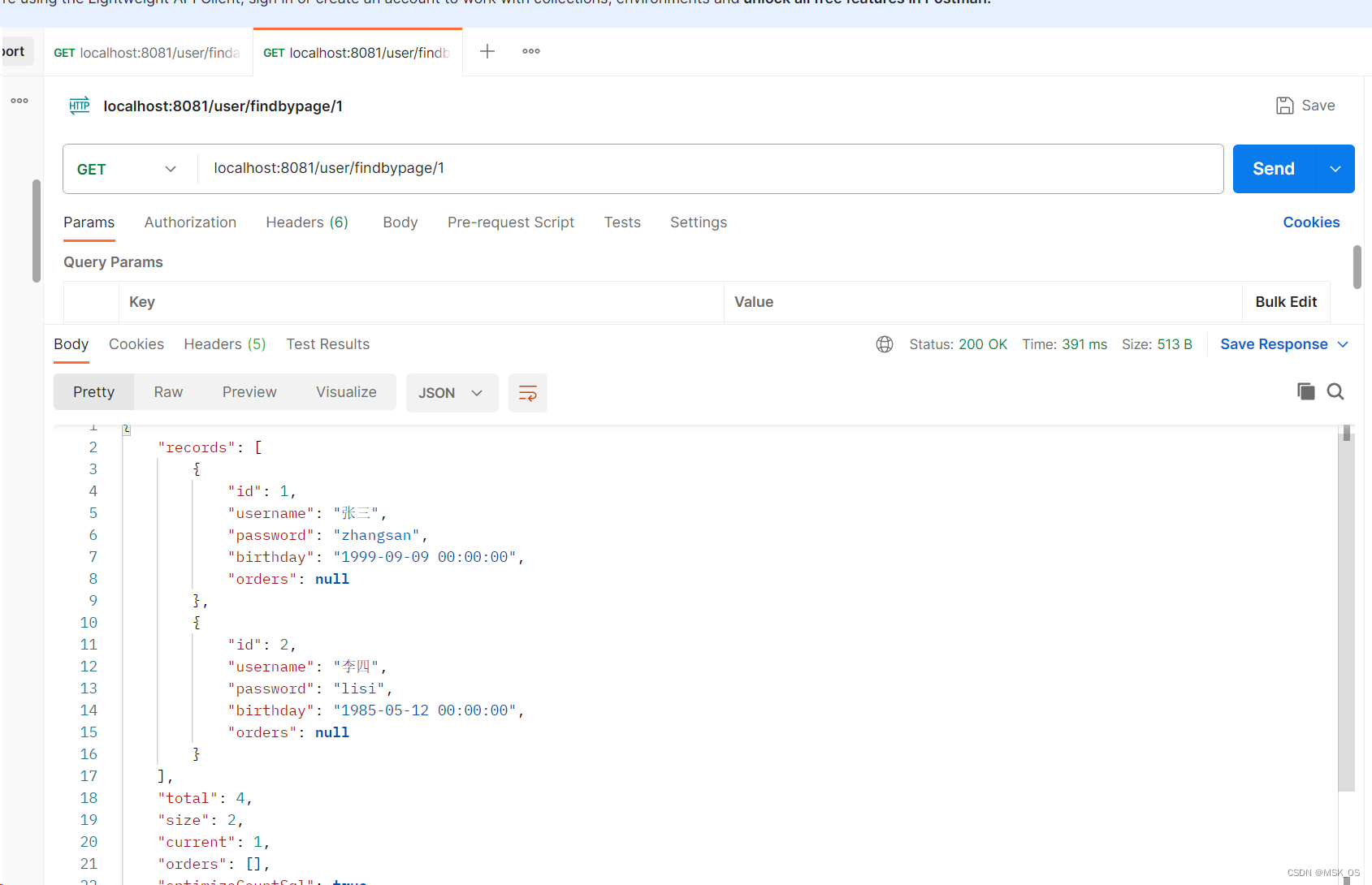
MybatisPlus进阶 1.MybatisPlus一对多查询 2.分页查询 1.MybatisPlus一对多查询 场景:我有一个表,里面填写的是用户的个人信息(姓名,生日,密码,用户ID)。我还有一个表填写的订单信息&#x…...

文件上传——后端
文件上传流程: 创建阿里云OSS(对象存储服务)的bucket 登录阿里云,并完成实名认证,地址:https://www.aliyun.com/. 可以通过搜索,进入以下页面: 点击立即使用后: 点击…...
虾皮开通:如何在虾皮上开通跨境电商店铺
在当今的数字时代,跨境电商已经成为了全球贸易的一种重要形式。虾皮(Shopee)作为东南亚市场份额第一的跨境电商平台,为卖家提供了广阔的销售机会。如果您想在虾皮上开通店铺,以下是一些步骤和注意事项供您参考。 先给…...

C语言—每日选择题—Day60
明天更新解析 第一题 1. 下列for循环的循环体执行次数为() for(int i 10, j 1; i j 0; i, --j) A:0 B:1 C:无限 D:以上都不对 答案及解析 A for循环的判断条件是 i j 0;赋值语句做判断条件…...
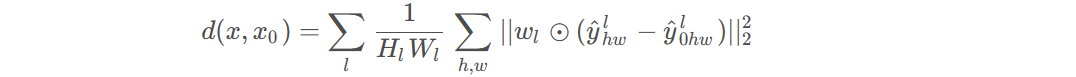
【3D生成与重建】SSDNeRF:单阶段Diffusion NeRF的三维生成和重建
系列文章目录 题目:Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction 论文:https://arxiv.org/pdf/2304.06714.pdf 任务:无条件3D生成(如从噪音中,生成不同的车等)、…...
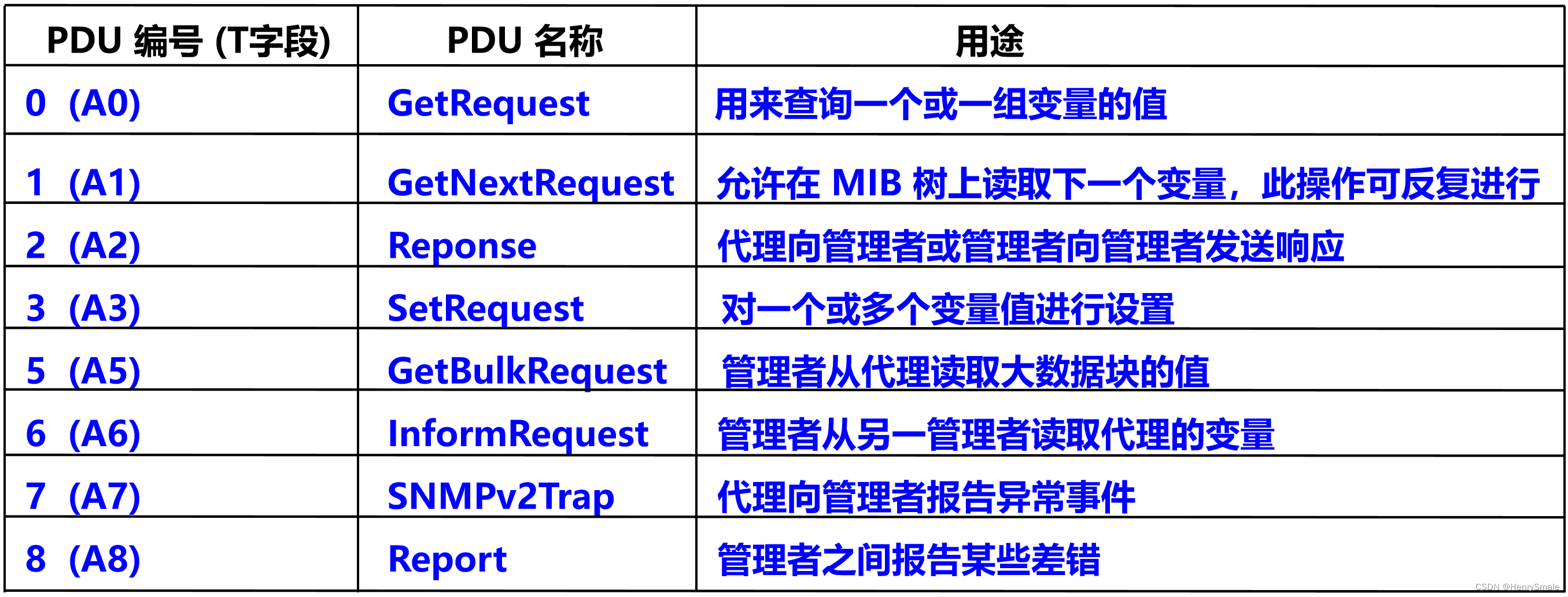
计算机网络:应用层
0 本节主要内容 问题描述 解决思路 1 问题描述 不同的网络服务: DNS:用来把人们使用的机器名字(域名)转换为 IP 地址;DHCP:允许一台计算机加入网络和获取 IP 地址,而不用手工配置࿱…...
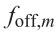
现代雷达车载应用——第3章 MIMO雷达技术 3.2节 汽车MIMO雷达波形正交策略
经典著作,值得一读,英文原版下载链接【免费】ModernRadarforAutomotiveApplications资源-CSDN文库。 3.2 汽车MIMO雷达波形正交策略 基于MIMO雷达技术的汽车雷达虚拟阵列合成依赖于不同天线发射信号的可分离性。当不同天线的发射信号正交时&#x…...

Unresolved plugin: ‘org.apache.maven.plugins‘解决报错
新建springboot项目报Unresolved plugin: ‘org.apache.maven.plugins:maven-surefire-plugin:3.1.2’ 缺什么插件 引入什么插件的依赖就行 <dependency><groupId>org.apache.maven.plugins</groupId><artifactId>maven-install-plugin</artifact…...

阿里云林立翔:基于阿里云 GPU 的 AIGC 小规模训练优化方案
云布道师 本篇文章围绕生成式 AI 技术栈、生成式 AI 微调训练和性能分析、ECS GPU 实例为生成式 AI 提供算力保障、应用场景案例等相关话题展开。 生成式 AI 技术栈介绍 1、生成式 AI 爆发的历程 在 2022 年的下半年,业界迎来了生成式 AI 的全面爆发,…...
从0开始学Git指令
从0开始学Git指令 因为网上的git文章优劣难评,大部分没有实操展示,所以打算自己从头整理一份完整的git实战教程,希望对大家能够起到帮助! 初始化一个Git仓库,使用git init命令。 添加文件到Git仓库,分两步…...

B039-SpringMVC基础
目录 SpringMVC简介复习servletSpringMVC入门导包配置前端控制器编写处理器实现Contoller接口普通类加注解(常用) 路径问题获取参数的方式过滤器简介自定义过滤器配置框架提供的过滤器 springMVC向页面传值的三种方式视图解析器springMVC的转发和重定向 SpringMVC简介 1.Sprin…...
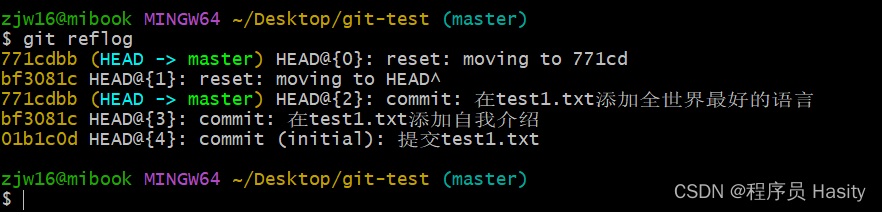
Tomcat报404问题解决方案大全(包括tomcat可以正常运行但是报404)
文章目录 Tomcat报404问题解决方案大全(包括tomcat可以正常运行但是报404)1、正确的运行页面2、报错404问题分类解决2.1、Tomcat未配置环境变量2.2、IIs访问权限问题2.3、端口占用问题2.4、文件缺少问题解决办法: Tomcat报404问题解决方案大全(包括tomcat可以正常运…...

debian10安装配置vim+gtags
sudo apt install global gtags --version gtags //生成gtag gtags-cscope //查看gtags gtags与leaderf配合使用 参考: 【VIM】【LeaderF】【Gtags】打造全定制化的IDE开发环境! - 知乎...

vue跳转方式
Vue的页面跳转有两种方式,第一种是标签内跳转,第二种是编程式路由导航 1. <router-link to/Demo><button>点击跳转1</button> </router-link>2.router.push("/Demo");一、标签内通过 router-link跳转 通常用于点击 …...

基于ssm+jsp学生综合测评管理系统源码和论文
网络的广泛应用给生活带来了十分的便利。所以把学生综合测评管理与现在网络相结合,利用java技术建设学生综合测评管理系统,实现学生综合测评的信息化。则对于进一步提高学生综合测评管理发展,丰富学生综合测评管理经验能起到不少的促进作用。…...
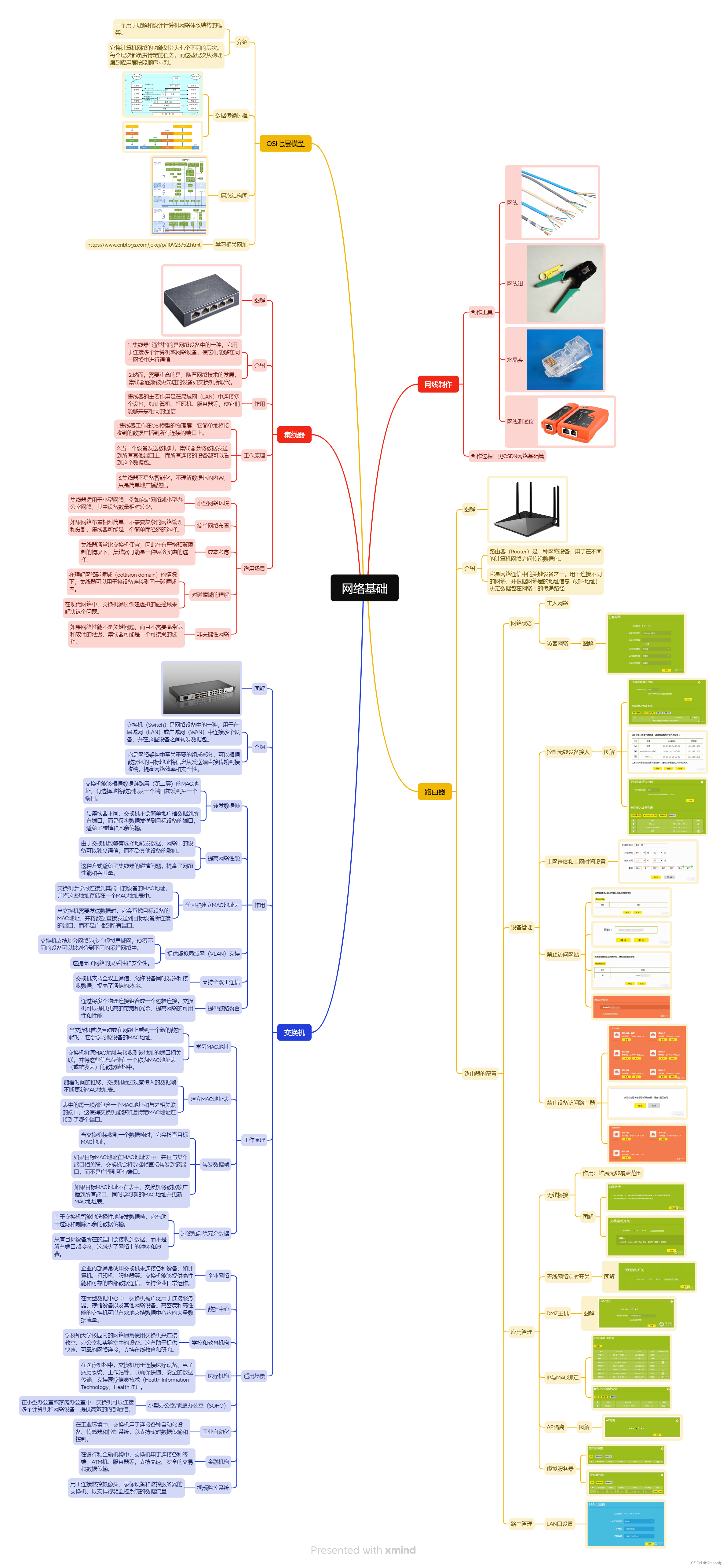
网络基础篇【网线的制作,OSI七层模型,集线器和交换机的介绍,路由器的介绍与设置】
目录 一、网线制作 1.1 工具介绍 1.1.1网线 1.1.2 网线钳 1.1.3 水晶头 1.1.4 网线测试仪 二、OSI七层模型 2.1 简介 2.2 OSI模型层次介绍 2.2.1 结构图 2.2.2 数据传输过程 2.3 相关网站 二、集线器 2.1 介绍 2.2 适用场景 三、交换机 3.1 介绍 3.2 适用场景…...
使用说明)
CSRF检测工具(XSRF检测工具)使用说明
目录 检查类型 测试单个端点 抓取网站 添加Cookie 自定义用户代理...
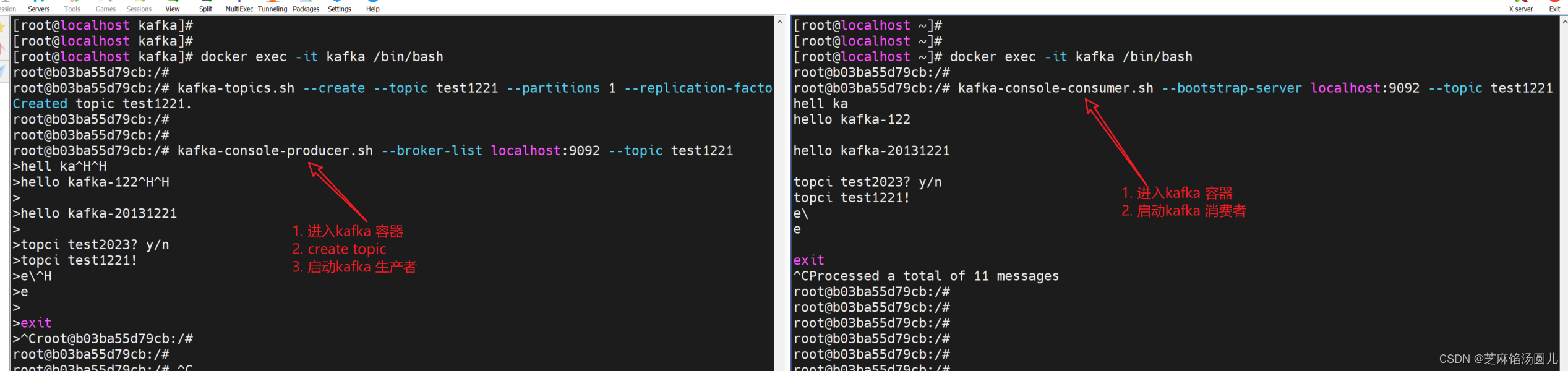
docker 部署kafka
随笔记录 目录 1. 安装zookeeper 2. 安装Kafka 2.1 拉取kafka image 2.2 查询本地docker images 2.3 查看本地 容器(docker container) 2.3.1 查看本地已启动的 docker container 2.3.2 查看所有容器的列表,包括已停止的容器。 2.3.…...

Android 架构 - 组件化
一、概念 组件化是对单个功能进行开发,使得功能可以复用。将多个功能组合起来就是一个业务模块,因此去除了模块间的耦合,使得按业务划分的模块成了可单独运行的业务组件。(一定程度上的独立,还是依附于整个项目中&…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...