Spark集群部署与架构
在大数据时代,处理海量数据需要分布式计算框架。Apache Spark作为一种强大的大数据处理工具,可以在集群中高效运行,处理数十TB甚至PB级别的数据。本文将介绍如何构建和管理Spark集群,以满足大规模数据处理的需求。
Spark集群架构
Spark集群的核心组成部分包括Master节点、Worker节点和Driver程序。
Master节点
Master节点是Spark集群的控制中心,它负责协调和管理工作。Master节点的主要作用包括:
- 调度任务:Master节点决定将任务分配给哪些Worker节点,以便并行处理。
- 维护集群状态:Master节点跟踪Worker节点的健康状况,以便在节点故障时重新分配任务。
- 提供集群状态信息:通过Spark的Web界面可以查看集群的状态和性能指标。
Worker节点
Worker节点是集群中的工作马。它们负责执行Master节点分配的任务,具体来说,Worker节点的任务包括:
- 运行任务:Worker节点运行分布在集群中的任务,这些任务通常是由Driver程序提交的。
- 存储数据:Worker节点存储数据分区,以供任务处理。
Driver程序
Driver程序是Spark应用程序的入口点,它是用户提交的应用程序的主要控制器。Driver程序的主要作用包括:
- 定义应用程序的逻辑:Driver程序定义了应用程序的处理流程,包括数据处理、转换和分析。
- 协调任务:Driver程序与Master节点交互,请求任务分配给Worker节点。
- 收集和汇总结果:Driver程序负责收集各个Worker节点的处理结果并将最终结果返回给用户。
Spark集群部署
Spark可以以不同的模式部署,包括Standalone模式、YARN模式、Mesos模式和Kubernetes模式。每种模式都有其独特的优势和适用场景。
Standalone模式
在Standalone模式下,Spark自带了一个简单的集群管理器,适用于快速搭建和测试集群。以下是一个示例代码,演示如何在Standalone模式下启动Spark集群:
# 启动Master节点
./sbin/start-master.sh# 启动Worker节点
./sbin/start-worker.sh <master-url>
YARN模式
YARN是Hadoop的资源管理器,允许Spark作为一个应用程序运行在YARN集群上。
以下是一个示例代码,演示如何在YARN模式下提交Spark应用程序:
spark-submit --master yarn --deploy-mode cluster --class com.example.MyApp myApp.jar
Mesos模式
Mesos是一个通用的集群管理器,Spark可以作为Mesos的一个框架运行。
以下是一个示例代码,演示如何在Mesos模式下提交Spark应用程序:
spark-submit --master mesos://<mesos-master-url> --class com.example.MyApp myApp.jar
Kubernetes模式
Kubernetes是一种容器编排平台,允许Spark作为一个容器运行在Kubernetes集群中。
以下是一个示例代码,演示如何在Kubernetes模式下提交Spark应用程序:
spark-submit --master k8s://<kubernetes-master-url> --deploy-mode cluster --class com.example.MyApp myApp.jar
高可用性和容错性
Spark集群的高可用性和容错性是确保集群稳定运行的关键。Master节点的高可用性可以通过启用热备份来实现。Worker节点在执行任务时,会定期向Master节点汇报状态,如果一个Worker节点失败,Master节点会重新分配任务给其他健康的节点。
# 启用Master节点的热备份
./sbin/start-master.sh --ha
集群资源管理
集群资源管理是确保Spark应用程序高效运行的关键。您可以使用Spark的配置文件来设置资源分配,包括内存和CPU核心。
以下是一个示例配置:
spark.executor.memory 4g
spark.executor.cores 2
监控和调优
监控Spark集群的性能和资源使用情况是优化集群的关键。通过Spark的Web界面,可以实时查看任务的执行情况、资源使用和性能指标。另外,可以使用Spark的调优选项来优化应用程序的性能,例如调整内存分配、数据分区和并行度。
spark-submit --conf spark.driver.memory=2g --conf spark.executor.memory=4g --conf spark.default.parallelism=8 myApp.jar
部署生产环境
在将Spark部署到生产环境之前,需要考虑一些重要的因素,包括安全性、日志管理和备份策略。确保集群的安全性,限制对敏感数据的访问,设置访问控制和身份验证。另外,配置和管理日志以便在需要时进行故障排除和性能分析。定期备份集群数据,以防止数据丢失。
总结
本文深入研究了Apache Spark集群部署与架构,提供了详细的描述和示例代码来帮助读者更好地理解和掌握这些关键概念。了解如何构建、管理和优化Spark集群是大规模数据处理的必备技能。
相关文章:
Spark集群部署与架构
在大数据时代,处理海量数据需要分布式计算框架。Apache Spark作为一种强大的大数据处理工具,可以在集群中高效运行,处理数十TB甚至PB级别的数据。本文将介绍如何构建和管理Spark集群,以满足大规模数据处理的需求。 Spark集群架构…...
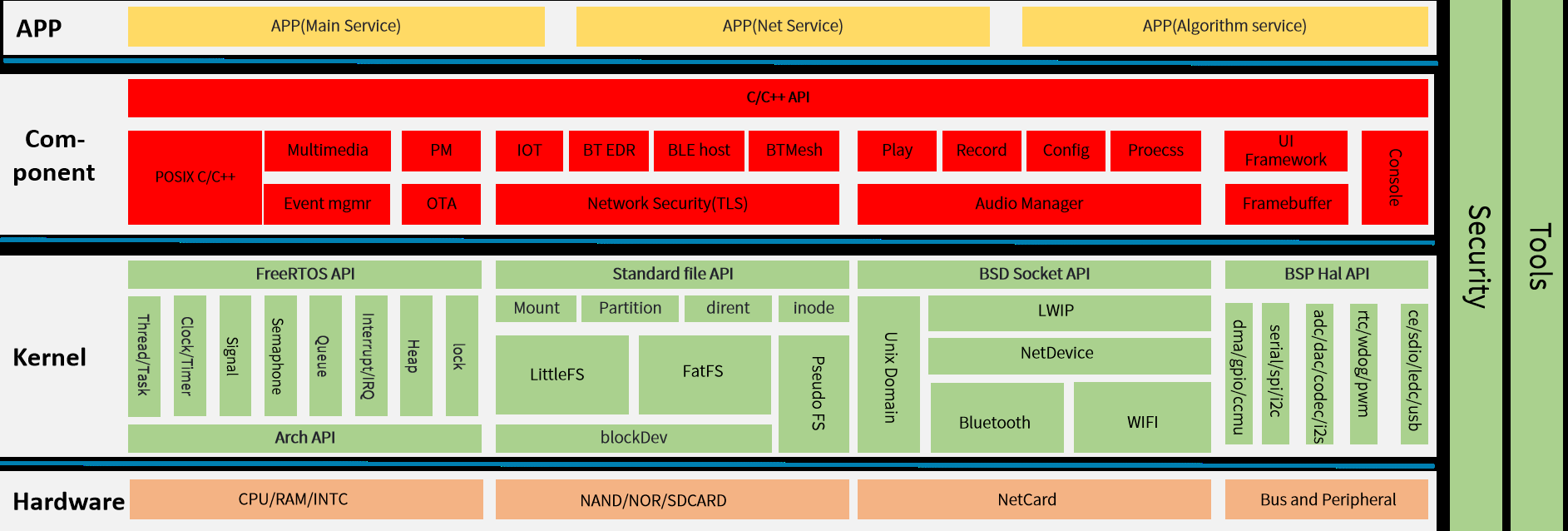
DshanMCU-R128s2 SDK 架构与目录结构
R128 S2 是全志提供的一款 M33(ARM)C906(RISCV-64)HIFI5(Xtensa) 三核异构 SoC,同时芯片内部 SIP 有 1M SRAM、8M LSPSRAM、8M HSPSRAM 以及 16M NORFLASH。 本文档作为 R128 FreeRTOS SDK 开发指南,旨在帮助软件开发工程师、技术支持工程师快速上手&am…...

【5G PHY】NR参考信号功率和小区总传输功率的计算
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…...

k8s学习 — 各知识点快捷入口
k8s学习 — 各知识点快捷入口 k8s学习 — 第一章 核心概念 k8s学习 — 第一章 核心概念 命名空间 实践: k8s学习 — (实践)第二章 搭建k8s集群k8s学习 — (实践)第三章 深入Podk8s学习 — (实践࿰…...

【Python】Python 批量转换PDF到Excel
PDF是面向展示和打印使用的,并未考虑编辑使用,所以缺少了很多编辑属性且非常难修改PDF里面的数据。当您需要分析或修改PDF文档数据时,可以将PDF保存为Excel工作簿,实现轻松编辑数据的需求。PDF转Excel,技术关键就是提取…...

Python并行计算和分布式任务全面指南
更多Python学习内容:ipengtao.com 大家好,我是彭涛,今天为大家分享 Python并行计算和分布式任务全面指南。全文2900字,阅读大约8分钟 并发编程是现代软件开发中不可或缺的一部分,它允许程序同时执行多个任务࿰…...

微信小程序promise封装
一. 在utils文件夹内创建一个request.js 写以下封装的 wx.request() 方法 const baseURL https:// 域名 ; //公用总路径地址 export const request (params) > { //暴露出去一个函数,并且接收一个外部传入的参数let dataObj params.data || {}; //…...

hash长度扩展攻击
作为一个信息安全的人,打各个学校的CTF比赛是比较重要的! 最近一个朋友发了道题目过来,发现有道题目比较有意思,这里跟大家分享下 这串代码的大致意思是: 这段代码首先引入了一个名为"flag.php"的文件&am…...
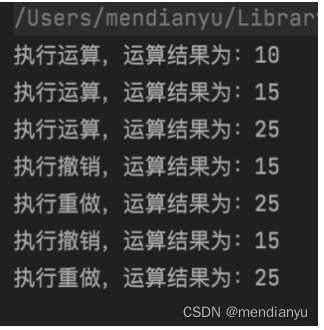
设计模式--命令模式
实验16:命令模式 本次实验属于模仿型实验,通过本次实验学生将掌握以下内容: 1、理解命令模式的动机,掌握该模式的结构; 2、能够利用命令模式解决实际问题。 [实验任务]:多次撤销和重复的命令模式 某系…...

单例模式的七种写法
为什么使用单例? 避免重复创建对象,节省内存,方便管理;一般我们在工具类中频繁使用单例模式; 1.饿汉式(静态常量)-[可用] /*** 饿汉式(静态常量)*/ public class Singleton1 {private static final Singleton1 INSTANCE new Singleton1();private Singleton1(){}…...
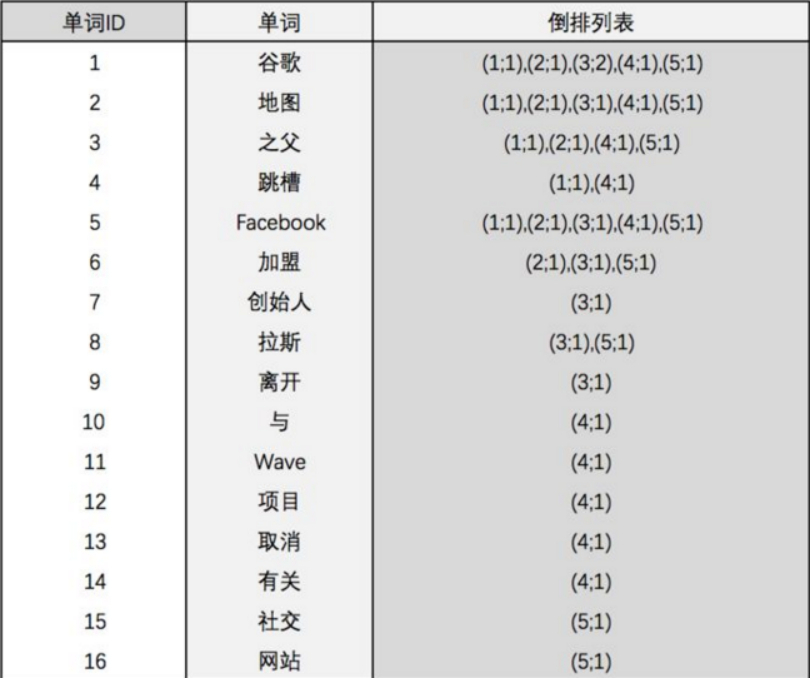
ElasticSearch入门介绍和实战
目录 1.ElasticSearch简介 1.1 ElasticSearch(简称ES) 1.2 ElasticSearch与Lucene的关系 1.3 哪些公司在使用Elasticsearch 1.4 ES vs Solr比较 1.4.1 ES vs Solr 检索速度 2. Lucene全文检索框架 2.1 什么是全文检索 2.2 分词原理之倒排索引…...

【FPGA】分享一些FPGA视频图像处理相关的书籍
在做FPGA工程师的这些年,买过好多书,也看过好多书,分享一下。 后续会慢慢的补充书评。 【FPGA】分享一些FPGA入门学习的书籍【FPGA】分享一些FPGA协同MATLAB开发的书籍 【FPGA】分享一些FPGA视频图像处理相关的书籍 【FPGA】分享一些FPGA高速…...
)
AUTOSAR从入门到精通-车载以太网(四)
目录 前言 原理 车载以太网发展历史 为何选择车载以太网...

MySQL报错:1054 - Unknown column ‘xx‘ in ‘field list的解决方法
我在操作MySQL遇到1054报错,报错内容:1054 - Unknown column Cindy in field list,下面演示解决方法,非常简单。 根据箭头指示,Cindy对应的应该是VARCHAR文本数字类型,字符串要用引号,所以解决方…...
:40+个依赖子模块之ActionBarShadow)
【Android 13】使用Android Studio调试系统应用之Settings移植(四):40+个依赖子模块之ActionBarShadow
文章目录 一、篇头二、系列文章2.1 Android 13 系列文章2.2 Android 9 系列文章2.3 Android 11 系列文章三、子模块AS移植3.1 AS创建目标3.2 创建ActionBarShadow(1)使用VS Code打开org_settings/SettingsLib目录(2)ActionBarShadow的Manifest.xml(3)ActionBarShadow的An…...
nosql-redis整合测试
nosql-redis整合测试 1、创建项目并导入redis2、配置redis3、写测试类4、在redis中创建key5、访问80826、在集成测试中测试方法 1、创建项目并导入redis 2、配置redis 3、写测试类 4、在redis中创建key 5、访问8082 6、在集成测试中测试方法 package com.example.boot3.redis;…...

智能化中的控制与自动化中的控制不同
智能化中的控制相对于自动化中的控制更加灵活、智能、综合和学习能力强。智能化控制系统能够根据实际情况进行自主决策和优化,适用范围更广,效果更好。 首先,智能化控制系统能够根据外部环境的变化和实时数据的反馈来自主调整和优化控制策略&…...

java练习题之多态练习
1:关于多态描述错误的是(D) A. 父类型的引用指向不同的子类对象 B. 用引用调用方法,只能调用引用中声明的方法 C. 如果子类覆盖了父类中方法,则调用子类覆盖后的方法 D. 子类对象类型会随着引用类型的改变而改变 2:class Supe…...
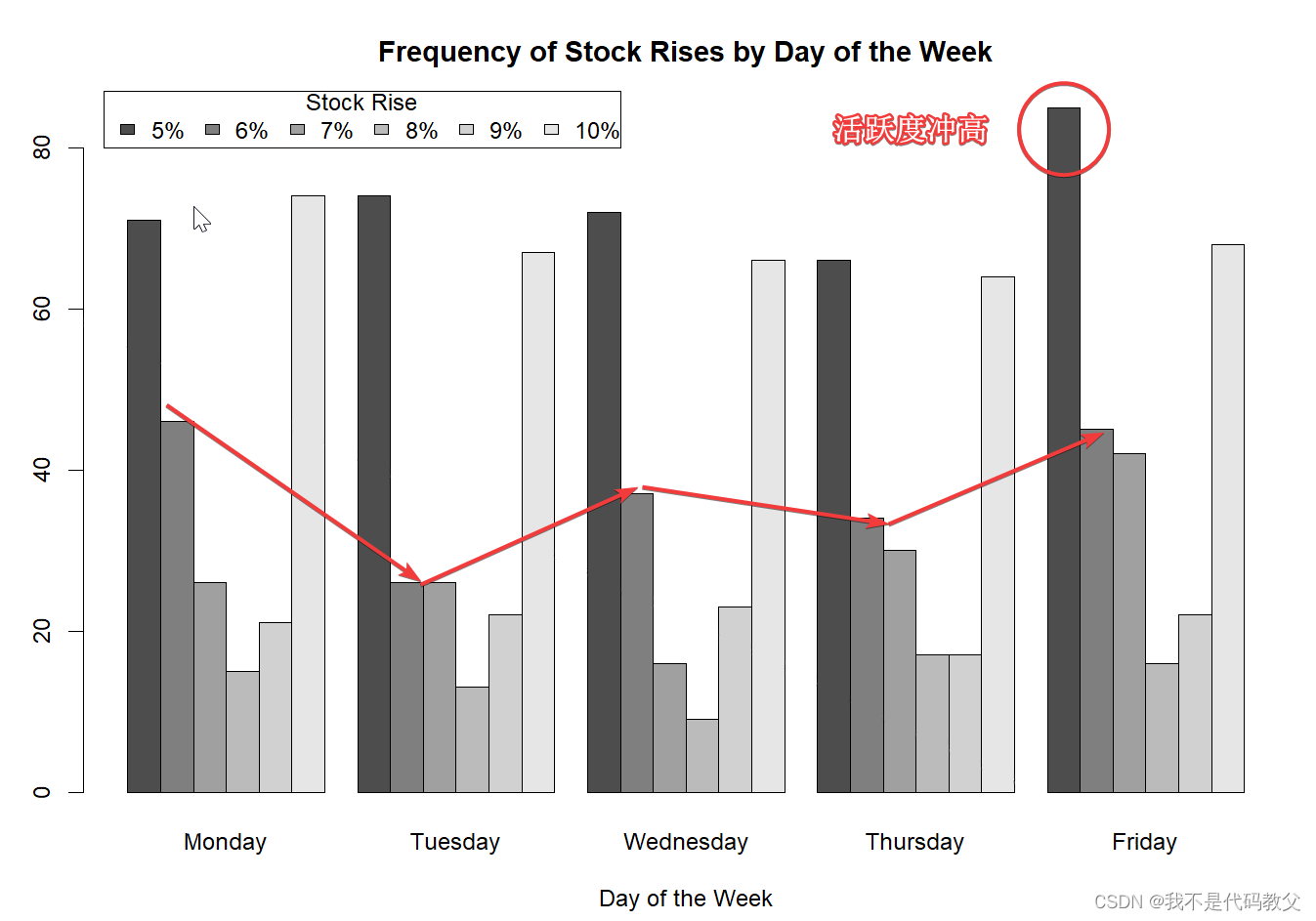
[原创][R语言]股票分析实战[4]:周级别涨幅趋势的相关性
[简介] 常用网名: 猪头三 出生日期: 1981.XX.XX QQ联系: 643439947 个人网站: 80x86汇编小站 https://www.x86asm.org 编程生涯: 2001年~至今[共22年] 职业生涯: 20年 开发语言: C/C、80x86ASM、PHP、Perl、Objective-C、Object Pascal、C#、Python 开发工具: Visual Studio、D…...
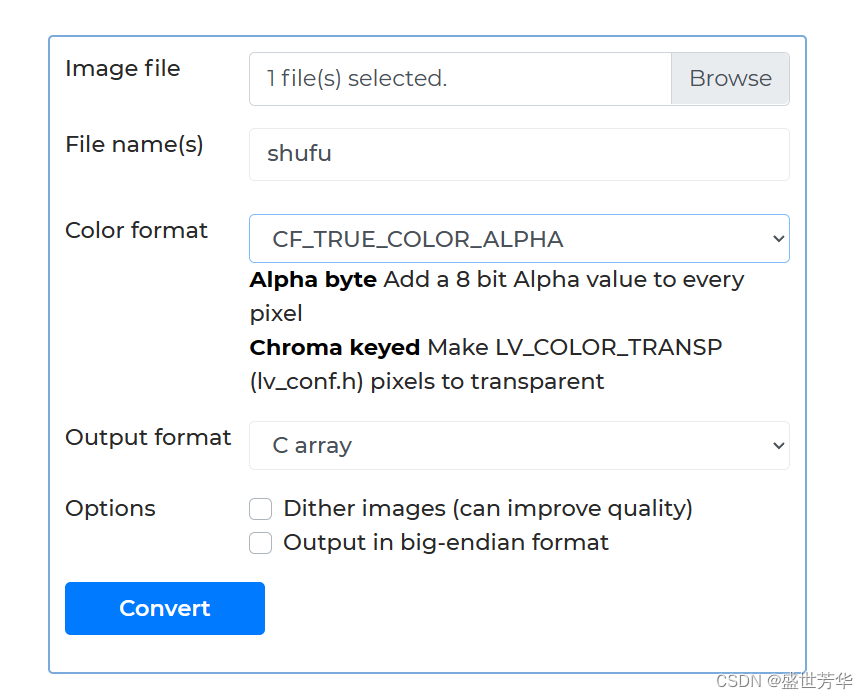
esp32使用lvgl,给图片取模显示图片
使用LVGL官方工具。 https://lvgl.io/tools/imageconverter 上传图片,如果想要透明效果,那么选择 输出格式C array,点击Convert进行转换。 下载.c文件放置到工程下使用即可。...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...