精度提升10个点!HD-Painter:无需训练的文本引导高分辨率图像修复方案!

基于文本到图像扩散模型的空前成功,在文本引导的图像修复方面取得了最新进展,取得了异常逼真和视觉上可靠的结果。然而,目前的文本到图像修复模型仍然存在显著的改进潜力,特别是在更好地与用户提示对齐和执行高分辨率修复方面。因此,在本文中,介绍了HD-Painter,这是一种完全无需训练的方法,能够准确地遵循提示并一致地扩展到高分辨率图像修复。
为此,本文设计了Prompt-Aware Introverted Attention(PAIntA)层,通过提示信息增强自注意力分数,从而实现更好的文本对齐生成。为了进一步提高提示的一致性,引入了Reweighting Attention Score Guidance(RASG)机制,将一种事后采样策略无缝集成到DDIM的一般形式中,以防止潜在分布偏移。此外,HD-Painter通过引入一种定制的用于修复的专门超分辨率技术,允许将图像的缺失区域补全到2K分辨率。
实验证明,HD-Painter在定性和定量上均优于现有的最先进方法,实现了61.4%的生成精度改进,而最先进方法为51.9%。
论文链接: https://arxiv.org/pdf/2312.14091
开源代码: https://github.com/Picsart-AI-Research/HD-Painter
引言
最近的扩散模型浪潮席卷全球,成为我们日常生活中越来越重要的一部分。在文本到图像模型取得空前成功之后,基于扩散的图像操作,如基于提示的编辑和变体、可控生成、对象级图像编辑、个性化和专业化图像合成、多模态等成为计算机视觉中的热门话题,引发了大量的应用。特别是,文本引导的图像补全或修复允许用户根据文本提示在给定图像的指定区域生成新内容(见下图1),从而产生了如修饰图像特定区域、替换或添加对象以及修改主题属性(如服装、颜色或情感)等用例。

预训练的文本到图像生成模型,如Stable Diffusion、Imagen和Dall-E 2,可以通过在后向扩散过程中将扩散的已知区域与生成的(去噪)未知区域混合来进行图像补全。尽管这种方法产生了协调一致且视觉上令人信服的补全效果,但在高扩散时间间隔中去噪时,它们在全局场景理解方面仍然存在不足。
为了解决这个问题,现有的方法修改了预训练的文本到图像模型,以获取额外的上下文信息,并专门为文本引导的图像补全进行微调。GLIDE和Stable Inpainting(在Stable Diffusion上微调的修复方法)将mask和mask图像作为额外通道连接到扩散UNet的输入,将新的卷积权重初始化为零。此外,为了获得更好的mask对齐,SmartBrush利用具有对象边界框和分割mask的实例感知训练。
尽管提到的方法产生了高质量的生成,具有令人印象深刻的多样性和逼真性,但我们注意到提示忽略的一个主要缺点,表现为两种情况:
(i) 背景支配:当未知区域使用背景补全而忽略提示时(例如下图4,第1、3行)

(ii) 附近对象支配:当已知区域对象根据视觉上下文可能性传播到未知区域,而不是根据给定提示时(例如上面图4,第5、6行)。
也许两个问题的出现是因为普通的扩散修复缺乏准确解释文本提示或将其与已知区域的上下文信息相结合的能力。为了解决上述问题,本文引入了Prompt-Aware Introverted Attention(PAIntA)块,无需任何训练或微调即可增强自注意力分数。PAIntA根据给定的文本条件提高自注意力分数,目的是减小来自图像已知区域的非提示相关信息的影响,同时增加与提示对齐的已知像素的贡献。
为了进一步提高生成结果的文本对齐性,本文通过利用交叉注意力分数应用事后引导机制。然而,诸如[6, 7]等开创性工作使用的一般事后引导机制可能由于后向扩散方程中的附加梯度项引起的梯度漂移而导致生成质量下降(参考后面的方程4)。为此,本文提出了Reweighting Attention Score Guidance(RASG),这是一种事后机制,可以将梯度分量无缝集成到DDIM过程的一般形式中。这使得能够同时引导采样朝着更与提示对齐的潜在值并保持它们在其训练域内,从而产生视觉上令人信服的修复结果。
通过PAIntA和RASG的组合,本文的方法在解决提示忽略问题上具有显著优势,超越了当前的最先进方法。此外,PAIntA和RASG都是即插即用的组件,因此可以添加到任何扩散基修复模型之上,以缓解上述问题。此外,通过利用高分辨率扩散模型和迭代混合技术,作者设计了一种简单而有效的pipeline,用于2048×2048分辨率的修复。
总结一下,本文的主要贡献如下:
• 引入了Prompt-Aware Introverted Attention(PAIntA)层,以缓解文本引导的图像修复中背景和附近对象支配的提示忽略问题。
• 为了进一步提高生成结果的文本对齐性,提出了Reweighting Attention Score Guidance(RASG)策略,它能够在进行事后引导采样时防止分布外漂移。
• 本文设计的文本引导图像补全的流程是完全无需训练的,并在定量和定性上明显优于当前的最先进方法。此外,通过简单而有效的修复专用超分辨率框架的额外帮助,实现了高分辨率(高达2048×2048)的图像修复。
相关工作
图像修复
图像修复是以视觉合理的方式填补图像中缺失区域的任务。早期的深度学习方法,如[20, 42, 43],引入了从已知区域传播深度特征的机制。随后的研究[31, 40, 46, 47]利用类似StyleGAN-v2的解码器和判别式训练来更好地生成图像细节。
引入扩散模型后,修复任务也从中受益。特别是文本引导的图像修复方法出现了。给定一个预训练的文本到图像扩散模型,在采样过程中用已知区域的噪声版本替换潜在的unmasked区域。然而,正如[22]所指出的,这会导致生成质量差,因为去噪网络只看到已知区域的噪声版本。因此,他们提出通过将去噪模型调整为文本引导的图像修复,通过将去噪模型调整为unmasked区域和生成的随机mask的串联来进行微调。在训练中加入对象mask预测以获得更好的mask对齐。在这项工作中,本文提出了一种无需训练的方法,利用了可插拔组件PAIntA和RASG,并改善了文本提示对齐。此外,该方法允许对高分辨率图像进行修复(高达2048×2048)。
修复专用架构块
早期的深度学习方法设计了用于更好/更高效图像修复的特殊层。特别地,[17, 20, 44]引入了特殊的卷积层,处理图像的已知区域,以有效地提取对视觉上合理的图像补全有用的信息。[42]引入了上下文注意力层,减少了用于高质量修复的all to all自注意力的不必要的繁重计算。在这项工作中,本文提出了Prompt-Aware Introverted Attention(PAIntA)层,专门设计用于文本引导的图像修复。它旨在减少(增加)已知区域中与提示不相关(相关)的信息,以获得更好的文本对齐修复生成。
扩散过程中的事后引导
事后引导方法是反向扩散采样技术,其将下一步的潜在预测引导到特定的目标函数最小化。当生成具有额外约束的视觉内容时,这样的方法似乎非常有帮助。特别是[6]引入了分类器引导,旨在生成特定类别的图像。稍后,[22]引入了CLIP引导,利用CLIP作为一种开放词汇分类方法。LDM进一步将该概念扩展到通过任何图像到图像翻译方法引导扩散采样过程,特别是引导低分辨率训练模型生成两倍或更大的图像。[4]通过最大化多次迭代优化过程中的最大交叉注意力分数来引导图像生成,从而获得更好的文本对齐结果。[7]甚至更进一步,通过利用交叉注意力分数进行对象位置、大小、形状和外观引导。所有提到的事后引导方法都通过梯度术语(见公式6)改变潜在的生成过程,有时会导致图像质量下降。为此,本文提出了Reweighting Attention Score Guidance(RASG)机制,允许在保持扩散潜在域的同时进行任何目标函数的事后引导。具体对于修复任务,为了缓解提示被忽略的问题,利用基于交叉注意力的开放词汇分割属性的引导目标函数。
方法
本文首先制定文本引导的图像补全问题,然后介绍扩散模型,特别是 Stable Diffusion和 Stable Inpainting。然后,讨论该方法及其组件的概述。随后,详细介绍的Prompt-Aware Introverted Attention(PAIntA)块和 Reweighting Attention Score Guidance(RASG)机制。最后,介绍特定于修复的超分辨率技术。
设 I ∈ 为 RGB 图像,M ∈ 为二进制mask,表示在图像 I 中希望用文本提示 τ 进行修复的区域。文本引导的图像修复的目标是输出一个图像 ,使得 在区域 M 中包含由提示 τ 描述的对象,而在 M 之外,它与 I 相符,即 。
Stable Diffusion 和 Stable Inpainting
Stable Diffusion(SD)是一个扩散模型,其在自编码器 D(E(·)) 的潜在空间中运行(VQ-GAN 或 VQ-VAE),其中 表示编码器,D 表示相应的解码器。具体而言,设 I ∈ 为图像,,考虑具有超参数 {} ⊂[0,1] 的以下正向扩散过程

其中 是在给定 的条件下 的条件密度,{} 是一个马尔可夫链。这里 T 足够大,使得可以假设 ∼ N(0,1)。然后,SD 学习到一个反向过程(类似地,{} 是一个马尔可夫链)
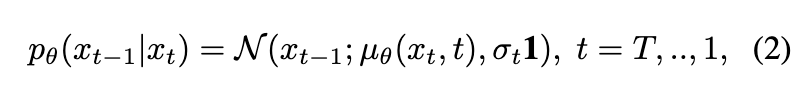
并且有一组超参数 {},允许从标准高斯噪声 生成信号 。其中, 由被建模为神经网络的预测噪声 定义(参见[12]):。然后返回 。
从主要的 DDIM 原理,即 [34] 中的定理 1,可以推导出以下论断。
「论断 1」 在训练了扩散反向过程(方程2)之后,可以应用以下由 {} 参数化的 DDIM 采样过程生成高质量图像:
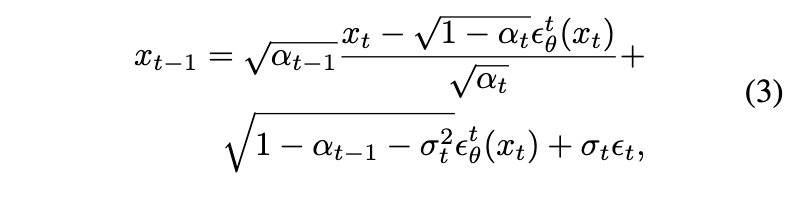
这里, 可以是任意参数。通常(例如,在下面描述的 SD 或 Stable Inpainting 中),取 = 0 以获得确定性过程:

在文本到图像合成中,SD 使用文本提示 τ 来引导这些过程。因此,函数 ,由类似 UNet 的结构([28])建模,也通过其交叉注意力层对 τ 进行条件化。为简单起见,有时我们在写作 时省略 τ。
如前所述,稳定扩散可以被修改和微调以进行文本引导的图像修复。为此,[27]将由编码器 E 获得的mask图像 = I ⊙ (1 − M) 的特征和(降采样的)二进制mask M 的特征与潜变量 连接,并将生成的张量馈送到 UNet 中,以获得估计的噪声 ,其中 down 是降采样操作,以匹配潜在变量 的形状。新增的卷积滤波器使用零进行初始化,而 UNet 的其余部分来自稳定扩散的预训练checkpoint。通过随机对图像进行mask处理,并优化模型以基于来自 LAION-5B ([32]) 数据集的图像说明重建它们来进行训练。得到的模型显示了视觉上合理的图像修复,将其称为 Stable Inpainting。
HD-Painter: Overview
本文的方法概览如下图2所示。所提出的流程由两个阶段组成:首先在分辨率 H/4 × W/4 上进行文本引导的图像修复,然后对生成的内容进行 ×4 超分辨率处理。
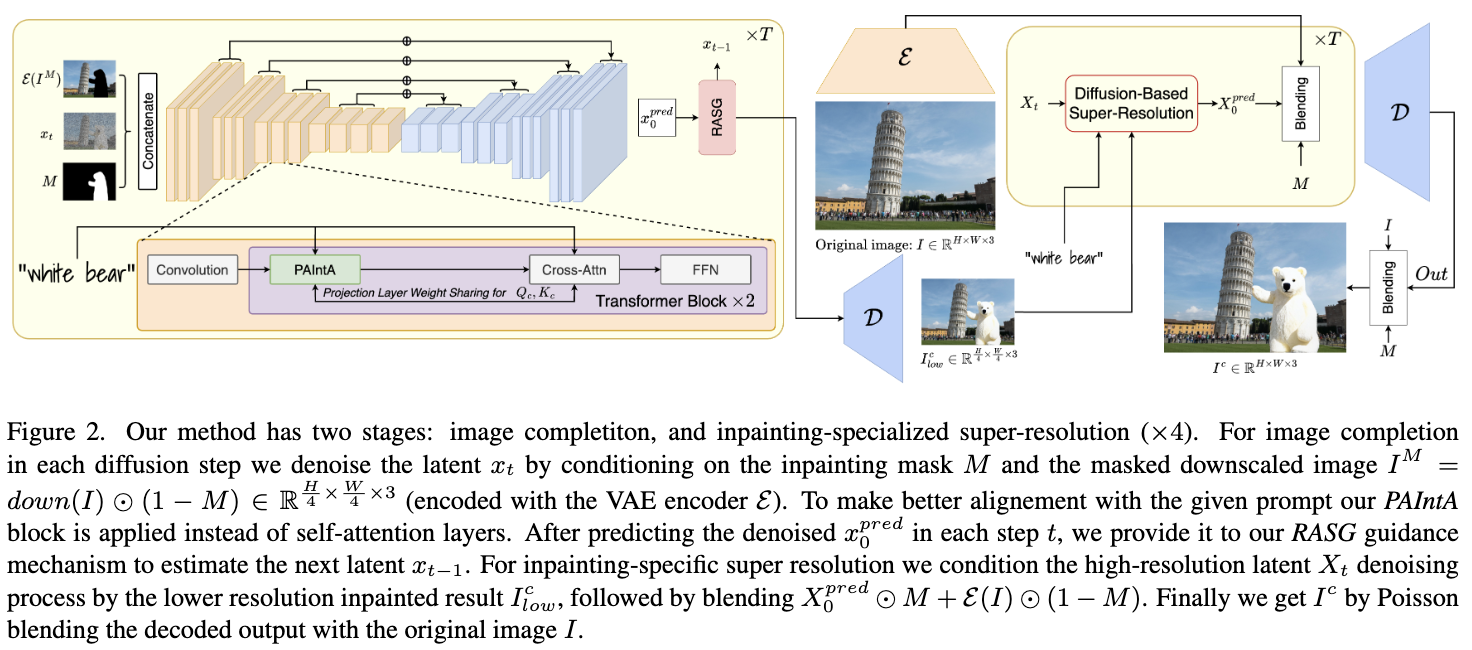
为了根据给定的提示 τ 补全缺失的区域 M,我们使用预训练的图像修复扩散模型(例如 Stable Inpainting),将自注意力层替换为 PAIntA 层,并通过应用RASG 机制执行扩散反向过程。在获取最终估计的潜在变量 后,对其进行解码,得到修复的图像 。
为了对原始尺寸的图像 I ∈ 进行修复,使用来自[27]的超分辨率稳定扩散。从 ∼ N(0,1) 开始应用 SD 的扩散反向过程,并在每一步中将去噪后的 与原始图像的编码 (I) 在由mask (1−M) ∈{0,1} 指示的已知区域进行混合,并通过 公式4推导出下一个潜在变量 。在最后一步之后,通过 D() 对潜变量进行解码,并与 I 一起使用泊松融合([23]),以避免边缘伪影。
Prompt-Aware Introverted Attention (PAIntA)
实验中,注意到现有方法,如 Stable Inpainting,往往忽略用户提供的提示,更依赖于修复区域周围的视觉上下文。在介绍中,我们根据用户体验将这个问题分为两类:背景主导和附近对象主导。确实,例如在图4的第1、3、4行中,现有解决方案(除了 BLD)都用背景填充了区域,并且在第5、6行中,它们更倾向于继续是动物和汽车,而不是生成船和火焰。假设视觉上下文主导提示的问题归因于自注意力层的无提示、仅空间特性。为了缓解这个问题,引入了自注意力的插件替代方案,Prompt-Aware Introverted Attention(PAIntA,见图3 (a)),它利用修复mask M 和交叉注意力矩阵来控制未知区域中的自注意力输出。下面将详细讨论 PAIntA。
让 X ∈ 为 PAIntA 的输入张量。与自注意力类似,PAIntA 首先应用投影层来获取分别表示为 的query、key和value,其中 ,并且相似性矩阵 。然后,通过调整对修复区域产生影响的已知像素的注意力分数,我们减轻了已知区域对未知区域的过于强烈影响。具体来说,利用提示 τ,PAIntA 定义了一个新的相似性矩阵。

其中 显示第 j 个特征标记(像素)与给定的文本提示 τ 的对齐情况。
使用跨注意力空间文本相似性矩阵 定义 {},其中 是相应交叉注意层的query和key张量,l 是提示 τ 的token数。具体而言,我们考虑提示 τ 的 CLIP 文本embedding,并分离与 τ 的单词和文本结束 (EOT) token对应的embedding(实质上,我们只是忽略 SOT token和空token embedding),并用 ind(τ) ⊂ {1,2,...,l} 表示所选索引的集合。我们包含 EOT,因为(与 SOT 相反)它包含有关提示 τ 的信息,根据 CLIP 文本编码器的体系结构。对于每个第 j 个像素,我们通过将其与从 ind(τ) 索引的embedding的相似性分数相加来定义其与提示 τ 的相似性,即 。此外,我们发现将分数 cj 进行标准化是有益的,即 = clip(,其中 clip 是在 [0,1] 之间的夹紧操作。
请注意,在纯粹的 SD 中,跨注意力层在自注意力层之后,因此在 PAIntA 中,为了获得query和key张量 ,借用了下一个跨注意模块的投影层权重(见前面图2)。最后,通过与输入的残差连接获得 PAIntA 层的输出:Out = X + SoftMax()·。
由于 RASG 机制依赖于跨注意力层的开放词汇分割属性,为了进一步增强生成与提示 τ 的对齐,采用了一种事后采样引导机制 [6],其目标函数 利用了跨注意层的开放词汇分割属性。具体而言,在每个步骤之后,使用以下更新规则预测噪声 之后: ← ,其中 s 是控制引导量的超参数。然而,正如 [4] 也指出的那样,纯粹的事后引导可能会使扩散潜在 的域发生变化,导致图像质量降低。确实,根据(确定性的)DDIM 过程(公式 4),在用 替换 后,我们得到:
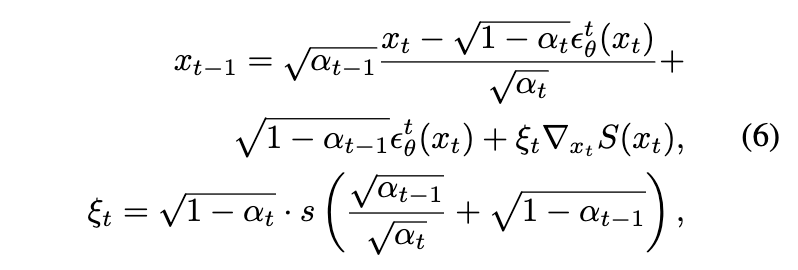
因此,在公式 4中,我们得到了额外的项 S(),它可能会改变 的原始分布。
为此,引入了 Reweighting Attention Score Guidance (RASG) 策略,它利用了通用的 DDIM 后向过程(公式 3)并引入了一个梯度重新加权机制,从而实现了潜在域的保留。具体而言,根据论断 1,通过 公式4 或 公式 3 得到的 将在所需的域内(见下图 3)。
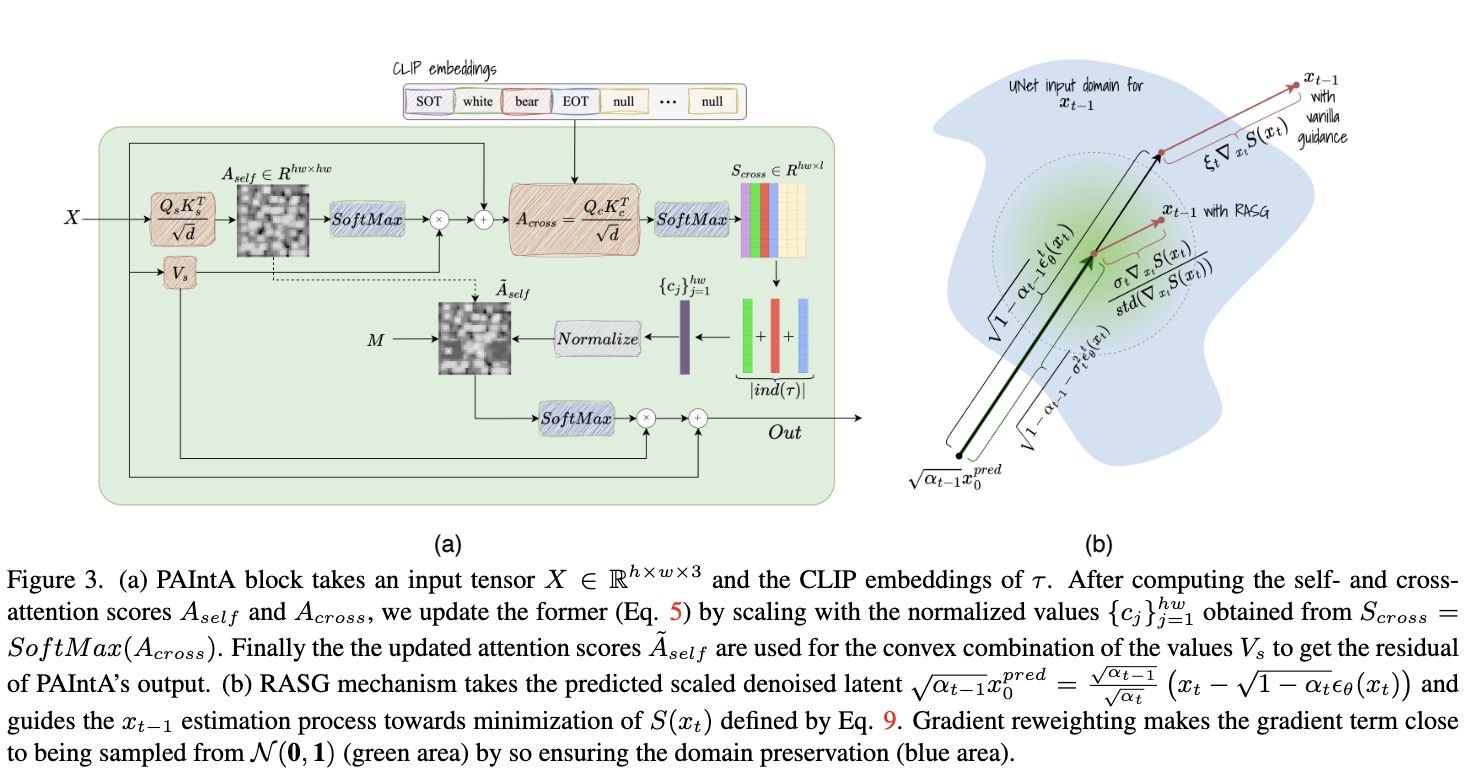
因此,如果在 公式 3 中用梯度 S() 的重新缩放版本(使其更接近从 N(0,1) 中抽样)替换随机分量 ,将保持 在所需的域内,并同时引导其采样朝向 最小化。梯度 S() 的重新缩放是通过将其除以其标准差来补全的(为了保持方向不变,不改变均值,更多讨论见附录)。因此,RASG 采样由以下公式完成:

现在定义函数 S()。首先,考虑所有输出分辨率为 H/32 × W/32 的交叉注意力映射 ,其中 m 是这些交叉注意力层的数量,l 是token embedding的数量。然后,对于每个 k ∈ ind(τ) ⊂ {1, ..., l},对注意力映射进行平均并重塑为 H/32 × W/32:

使用后处理引导和 S(),目标是在由二进制mask M ∈ {0,1}H×W 确定的未知区域中最大化注意力分数,因此我们采用 和 M 之间的二进制交叉熵的平均值(这里的 M 是使用 NN 插值下采样的,σ 是 sigmoid 函数):

这里讨论了高分辨率修复方法,利用预训练的基于扩散的超分辨率模型。利用来自已知区域的细粒度信息来放大修复区域(见图2)。回想一下,I ∈ 是要修复的原始高分辨率图像,E 是 VQ-GAN [8] 的编码器。考虑 并取标准高斯噪声 。然后,通过使用专门用于放大的 SD 模型并在低分辨率修复图像 上进行条件化,在 上应用反向扩散过程(公式 4)。在每个扩散步骤之后,使用 M 将估计的去噪潜在 = 与 混合。

并使用新的 (通过 公式 4)。在最后一个扩散步骤之后, 被解码并与原始图像 I 混合(Poisson 混合)。值得注意的是,我们的混合方法受到开创性的工作 [1, 33] 的启发,这些工作将 与正向扩散的噪声潜在的混合。相比之下,我们将 的高频成分与去噪预测 进行混合,允许无噪声的图像细节在所有扩散步骤中从已知区域传播到缺失区域。
实验
实现细节
代码基于 Stable Diffusion 2.0 的公共 GitHub 仓库,链接为 https://github.com/Stability-AI/stablediffusion,其中还包括我们用作图像补全和补全专用超分辨率基线的 Stable Inpainting 2.0 和 Stable Super-Resolution 2.0 的预训练模型。PAIntA 用于替换 H/32 × W/32 和 H/16 × W/16 分辨率上的自注意力层。对于 RASG,仅选择 H/32 ×W/32 分辨率的交叉注意力相似矩阵,因为我们注意到当还采取更精细的分辨率时,没有进一步的改进(原因是通过交叉注意力层进行的分割在很大程度上独立于层输入分辨率),而且扩散过程显著减慢。对于超参数 {},我们选择 ,其中 η = 0.25。
实验设置
在这里,与现有的最先进方法进行比较,如 GLIDE 、Stable Inpainting、NUWA-LIP 和 Blended Latent Diffusion (BLD) 。在 MSCOCO 2017 的验证集中随机选择了 10000 个(图像、mask、提示)三元组进行方法的评估,其中提示被选择为所选实例mask的标签。注意到,当给 Stable Inpainting 一个精确的形状mask时,它倾向于忽略提示,而是根据形状进行图像修复。为了防止这种情况发生,使用对象分割mask的凸包,并相应地计算指标。
使用 MSCOCO 的一个预训练实例检测模型进行 CLIP 分数的评估。在生成图像的裁剪区域上运行它,由于裁剪中可能包含多个对象,如果提示标签在检测到的对象列表中,将其视为正例。最后,使用 PickScore作为文本对齐和视觉保真度的综合度量。在设置中,与其他方法的结果之间应用 PickScore,并计算它何时对我们有优势的百分比。
定量和定性分析
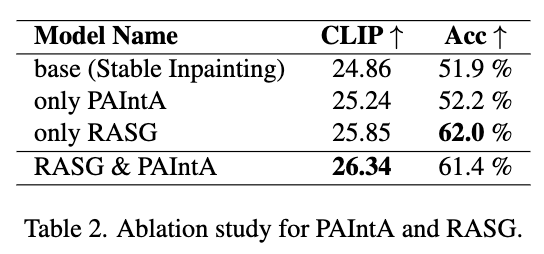
下表1显示了我们的方法在所有三个指标上均大幅优于竞争对手。

特别是我们在所有竞争对手的基础上将 CLIP 分数提高了 1.5 分以上,并将生成准确率(Acc)提高到了 61.4%,而其他最先进方法为 51.9%。此外,PickScore 的比较显示了我们在整体质量方面的优势。还进行了用户研究,证明了我们在提示对齐和整体质量方面明显优于竞争对手的最先进方法。由于篇幅限制,将用户研究的详细信息放在补充材料中。
前面图4中的示例演示了我们的方法与其他最先进方法之间的定性比较。在许多情况下,基线方法要么生成背景(图 4,行 1、2、3、4),要么在忽略提示的情况下重建已知区域对象的缺失区域(图 4,行 5、6),而我们的方法由于 PAIntA 和 RASG 的结合,成功生成了目标对象。请注意,BLD 生成的所需对象比其他竞争对手更多,然而生成的质量较差。同样,Stable Inpainting 有时会生成对象,但获取提示对齐的频率较低(请参阅附录)。此外,图 1 展示了我们的修复专用超分辨率在利用已知区域细节进行生成区域放大方面的有效性。我们在附录中展示了更多的结果,以及与用于修复后放大的 Stable Super-Resolution 方法作为方法进行比较。
消融研究
在下表2中,展示了 PAIntA 和 RASG 单独对模型在数量上提供了实质性的改进。还在补充材料中对它们的每一个进行了更多的讨论,包括通过可视化演示它们的影响的深入分析。
结论
本文介绍了一种无需训练的文本引导高分辨率图像修复方法,解决了常见的提示忽略问题:背景和附近对象的支配。本文的贡献,即 Prompt-Aware Introverted Attention (PAIntA) 层和 Reweighting Attention Score Guidance (RASG) 机制,有效地缓解了上述问题,使我们的方法在定性和定量上均超越了现有的最先进方法。此外,独特的修复专用超分辨率技术在高分辨率图像中提供了无缝补全,使我们的方法在区别于现有解决方案的同时得以突显。





参考文献
[1] HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models
更多精彩内容,请关注公众号:AI生成未来

相关文章:
精度提升10个点!HD-Painter:无需训练的文本引导高分辨率图像修复方案!
基于文本到图像扩散模型的空前成功,在文本引导的图像修复方面取得了最新进展,取得了异常逼真和视觉上可靠的结果。然而,目前的文本到图像修复模型仍然存在显著的改进潜力,特别是在更好地与用户提示对齐和执行高分辨率修复方面。因…...
javaweb初体验
javaweb初体验 文章目录 javaweb初体验前言一、流程:1.创建Maven的父工程2.创建Maven,Webapp的子工程3.在pom.xml文件中添加依赖(父工程与子工程共用)4.写一个helloservlet类实现httpservlet接口,重写doget,…...

手写爬虫框架
前言 参照了Scrapy、Feapder的设计模式,实现的一个轻量级爬虫框架(目前约200行代码) 源码地址 https://gitee.com/markadc/pader 项目持续更新中…...
基于Kettle和帆软Finereport的血缘解析
一、背景: 用户经常会针对数据存在质量的存疑,反馈数据不准。开发人员排查数据质量问题步骤:首先和业务人员对接了解是哪里数据不准确,要定位是哪张报表,然后查看报表后面数据来源,然后一路排查数仓。往往定…...
光盘)
给qemu虚机更换(Windows PE)光盘
1. 背景 qemu虚机里运行windows。如果遇到虚机windows启动故障,甚至连安全模式也故障时,可以尝试更换另一个光驱里的光盘为pe光盘。 2. 步骤 2.1. 找出VDI虚机所在的计算节点 ssh登录之,virsh list获得虚机id,例如 391 1255…...

python 神经网络归纳
CNN卷积神经网络 一个卷积神经网络主要由以下5层组成: 数据输入层/ Input layer卷积计算层/ CONV layerReLU激励层 / ReLU layer池化层 / Pooling layer全连接层 / FC layer 1. 数据输入层 该层要做的处理主要是对原始图像数据进行预处理,其中包括&…...

Python高级语法与正则表达式
Python提供了 with 语句的写法,既简单又安全。 文件操作的时候使用with语句可以自动调用关闭文件操作,即使出现异常也会自动关闭文件操作。 # 1、以写的方式打开文件 with open(1.txt, w) as f:# 2、读取文件内容f.write(hello world) 生成器的创建方…...

【洛谷算法题】P4414-[COCI2006-2007#2] ABC【入门2分支结构】Java题解
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P4414-[COCI2006-2007#2] ABC【入门2分支结构】Java题解🌏题目描述&a…...

Python如何将图片转换成字符
PIL(Python Image Library)库是Python平台上一个功能强大的图像处理标准库,支持图像的存储、显示和处理,几乎可以处理所有图片格式,如图像的压缩、裁剪、叠加、添加文字等等。 安装PIL库:pip install pillow from PIL import Image ascii_cha…...
国家开放大学形成性考核 统一资料 参考试题
试卷代号:1174 水工钢筋混凝土结构(本)参考试题 一、选择题(每小题2分,共20分,在所列备选项中,选1项正确的或最好的作为答案,将选项号填入各题的括号中) 1.钢筋混凝土结…...
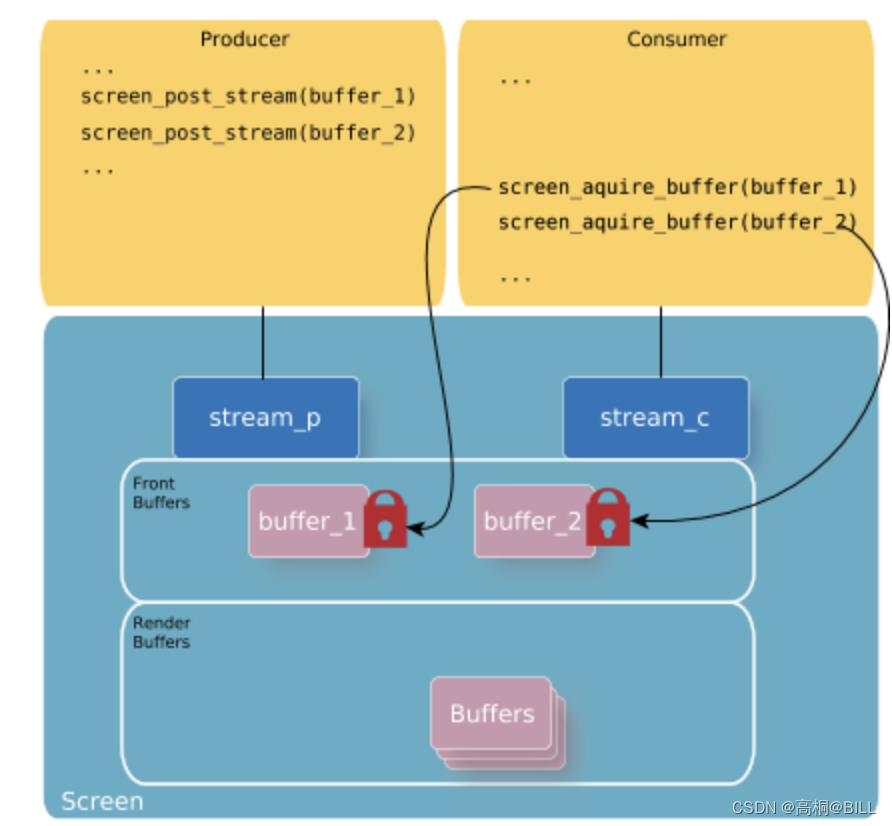
4.7 【共享源】流的生产者(二)
七,模式 流的模式决定了Screen如何使前台缓冲区可用。生产者通过调用screen_set_stream_property_iv()并设置SCREEN_PROPERTY_MODE属性来设置模式。有效模式如下: 7.1 SCREEN_STREAM_MODE_DEFAULT 如果生产者应用程序没有在流上明确设置 SCREEN_PROPERTY_MODE 属性,则 Sc…...

流量录制回放工具在自动化测试领域应用探索
引言: 随着中国农业银行技术架构的日益更迭与业务场景的不断创新,测试工作正在面临数据构造繁琐、案例维护成本较高且质量参差不齐等诸多问题与挑战,主要体现在以下四方面: 一是在系统架构升级与代码重构时,大量原始接…...

【高数定积分求解旋转体体积】 —— (上)高等数学|定积分|柱壳法|学习技巧
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:"没有罗马,那就自己创造罗马~" 目录 Shell method Setting up the Integral 例题 Example 1: Example 2: Example 3: Example …...
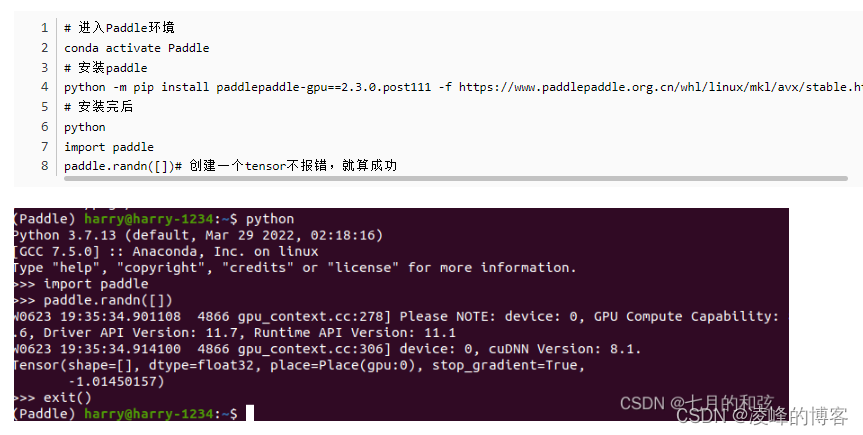
Ubuntu20.04 及深度学习环境anaconda、cuda、cudnn、pytorch、paddle2.3安装记录
学习目标: Ubuntu20.04下装好torch、paddle深度学习环境。 选择的版本环境是 :最新的nvidia驱动、cuda 11.1 、cudnn v8.1.1,下面会说为啥这么选。 学习内容: 1. Ubuntu20.04仓库换源 本节参考Ubuntu 20.04 Linux更换源教程 2…...

场景切割CVPr2022 SceneSegmentation
目录 算法介绍 无监督训练原理 源码地址: lstm模块 bilstm opencv场景分割 加阈值:...

Spring Cloud Feign作为HTTP客户端调用远程HTTP服务
如果你的项目使用了SpringCloud微服务技术,那么你就可以使用Feign来作为http客户端来调用远程的http服务。当然,如果你不想使用Feign作为http客户端,也可以使用比如JDK原生的URLConnection、Apache的Http Client、Netty的异步HTTP Client或者Spring的RestTemplate。 那么,为…...

[node] Node.js的文件系统
[node] Node.js的文件系统 文件系统的使用异步和同步input.txt示例 常用方法打开文件语法示例 获取文件信息语法示例 写入文件语法示例 读取文件语法示例 关闭文件语法示例 截取文件语法示例 删除文件语法示例 创建目录语法示例 读取目录语法示例 删除目录语法示例 文件模块方法…...
【Linux系统基础】(2)在Linux上部署MySQL、RabbitMQ、ElasticSearch、Zookeeper、Kafka、NoSQL等各类软件
实战章节:在Linux上部署各类软件 前言 为什么学习各类软件在Linux上的部署 在前面,我们学习了许多的Linux命令和高级技巧,这些知识点比较零散,同学们跟随着课程的内容进行练习虽然可以基础掌握这些命令和技巧的使用,…...

CJson 使用 - 解析Object结构
简介 准备在开发板中使用json结构传送数据, 选用了cJson, 现在看下cJson的使用吧步骤 下载 git clone https://github.com/DaveGamble/cJSON 或者直接压缩包下载也行, 毕竟国内有时候下载不下来Qt 中使用cJson 在下载的cJson 目录中加入cJson.pri, 内容如下 INCLUDEPATH …...

MySQL8主主搭建
-- mysql8 主主搭建 mysql-8.0.35-linux-glibc2.12-x86_64.tar.xz 主1 : 192.168.2.160 主2 : 192.168.2.161 --解压mysql-8.0.35-linux-glibc2.12-x86_64.tar.xz为mysql8 -- 初始化mysql8 (略) -- 参数192.168.2.160 [root…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...