【MYSQL】MYSQL 的学习教程(七)之 慢 SQL 优化思
1. 慢 SQL 优化思路
- 慢查询日志记录慢 SQL
- explain 分析 SQL 的执行计划
- profile 分析执行耗时
- Optimizer Trace 分析详情
- 确定问题并采用相应的措施
1. 慢查询日志记录慢 SQL
如何定位慢SQL呢?
我们可以通过 慢查询日志 来查看慢 SQL。
①:开启慢查询日志:
SET global slow_query_log = ON;:设置慢查询开启的状态(ON:开启;OFF:关闭)slow_query_log_file:设置慢查询日志存放的位置SET global log_queries_not_using_indexes = ON;:记录没有使用索引的查询 SQL。前提是slow_query_log的值为 ON,否则不会奏效SET long_query_time = 10;:设置慢查询的阀值,单位秒。如果SQL执行时间超过阀值,就属于慢查询 记录到日志文件中
②:查看慢查询日志配置:
show variables like 'slow_query_log%show variables like 'long_query_time'
③:慢查询日志分析工具:
mysqldumpslow:该工具是慢查询自带的分析慢查询工具,一般只要安装了mysql,就会有该工具
# 取出使用最多的10条慢查询
mysqldumpslow -s c -t 10 /var/run/mysqld/mysqld-slow.log
# 取出查询时间最慢的3条慢查询
mysqldumpslow -s t -t 3 /var/run/mysqld/mysqld-slow.log
# 得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g “left join” /database/mysql/slow-log
# 按照扫描行数最多的
mysqldumpslow -s r -t 10 -g 'left join' /var/run/mysqld/mysqld-slow.log
注意: 使用 mysqldumpslow 的分析结果不会显示具体完整的sql语句,只会显示sql的组成结构;
假如: SELECT * FROM sms_send WHERE service_id=10 GROUP BY content LIMIT 0, 1000;
Count: 1 Time=1.91s (1s) Lock=0.00s (0s) Rows=1000.0 (1000), vgos_dba[vgos_dba]@[10.130.229.196]
SELECT * FROM sms_send WHERE service_id=N GROUP BY content LIMIT N, N;
工具其实还有很多,并不限制只有这一种,还有 pt-query-digest、mysqlsla 等,这些都是可以定位慢查询日志的小工具
慢查询原因:
- 全表扫描:explain分析type属性all
- 全索引扫描:explain分析type属性index
- 索引过滤性不好:靠索引字段选型、数据量和状态、表设计
- 频繁的回表查询开销:尽量少用select *,使用覆盖索引
<转>详解 慢查询 之 mysqldumpslow
2. explain 查看分析 SQL 的执行计划
当定位出查询效率低的 SQL 后,可以使用 explain 查看 SQL 的执行计划。
当 explain 与 SQL 一起使用时,MySQL 将显示来自优化器的有关语句执行计划的信息。即:MySQL 解释了它将如何处理该语句,包括有关如何连接表以及以何种顺序连接表等信息:

一般来说,我们需要重点关注 type、key、rows、extra
13.1 type
type 表示连接类型,查看索引执行情况的一个重要指标。以下性能从好到坏依次:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- NULL:表示不用访问表,速度最快
- system:这种类型要求数据库表中只有一条数据,是 const 类型的一个特例,一般情况下是不会出现的
- const:通过一次索引就能找到数据,一般用于主键或唯一索引作为条件,这类扫描效率极高,速度非常快
- eq_ref:常用于主键或唯一索引扫描,一般指使用主键的关联查询
- ref : 常用于非主键和唯一索引扫描
- ref_or_null:这种连接类型类似于 ref,区别在于 MySQL 会额外搜索包含 NULL 值的行
- index_merge:使用了索引合并优化方法,查询使用了两个以上的索引
- unique_subquery:类似于 eq_ref,条件用了 in 子查询
- index_subquery:区别于 unique_subquery,用于非唯一索引,可以返回重复值
- range:常用于范围查询,比如:between … and 或 In 等操作
- index:全索引扫描
- all:全表扫描
13.2 possible_keys
表示查询时能够使用到的索引(显示的是索引名称),只是可能用到的索引,而不是实际上用到的索引
13.3 key
该列表示实际用到的索引。一般配合 possible_keys 列一起看
13.4 rows
MySQL查询优化器会根据统计信息,估算 SQL 要查询到结果需要扫描多少行记录。原则上 rows 是越少效率越高,可以直观的了解到SQL效率高低
13.5 extra
该字段包含有关 MySQL 如何解析查询的其他信息,它一般会出现这几个值:
- Using filesort:表示按文件排序,一般是在指定的排序和索引排序不一致的情况才会出现。一般见于 order by 语句。建议优化
- Using temporary: 表示使用了临时表,性能特别差,需要重点优化。一般多见于 group by 语句,或者 union 语句
- Using index :表示用了覆盖索引
- Using where : 表示使用了 where 条件过滤,需要通过索引回表查询数据
- Using index condition:MySQL5.6 之后新增的索引下推。在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据
- NULL:查询的列未被索引覆盖
总结:
| extra | where 条件 | select 的字段 |
|---|---|---|
| null | where 筛选条件是索引的前导列 | 查询的列未被索引覆盖 |
| Using index | where 筛选条件是索引的前导列 | 查询的列被索引覆盖 |
| Using where; Using index | where 筛选条件是索引列之一但不是前导列或者where筛选条件是索引列前导列的一个范围 | 查询的列被索引覆盖 |
| Using where; | where 筛选条件不是索引列 | - |
| Using where; | where 筛选条件不是索引前导列、是索引列前导列的一个范围(>) | 查询列未被索引覆盖 |
| Using index condition | where 索引列前导列的一个范围(<、between) | 查询列未被索引覆盖 |
两种排序的情况:
| extra | 出现场景 |
|---|---|
| Using filesort | filesort主要用于查询数据结果集的排序操作,首先MySQL会使用sort_buffer_size大小的内存进行排序,如果结果集超过了sort_buffer_size大小,会把这一个排序后的chunk转移到file上,最后使用多路归并排序完成所有数据的排序操作。 |
| Using temporary | MySQL使用临时表保存临时的结构,以用于后续的处理,MySQL首先创建heap引擎的临时表,如果临时的数据过多,超过max_heap_table_size的大小,会自动把临时表转换成MyISAM引擎的表来使用。 |
filesort 只能应用在单个表上,如果有多个表的数据需要排序,那么MySQL会先使用using temporary保存临时数据,然后再在临时表上使用filesort进行排序,最后输出结果
13.6 select_type
select_type:表示查询的类型。
常用的值如下:
- SIMPLE : 表示查询语句不包含子查询或 UNION
- PRIMARY:表示此查询是最外层的查询
- UNION:表示此查询是 UNION 的第二个或后续的查询
- DEPENDENT UNION:UNION 中的第二个或后续的查询语句,使用了外面查询结果
- UNION RESULT:UNION 的结果
- SUBQUERY:SELECT 子查询语句
- DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果
最常见的查询类型是 SIMPLE,表示我们的查询没有子查询也没用到 UNION 查询
13.7 filtered
该列是一个百分比的值,通过查询条件最终查询记录行数和通过 type 字段扫描记录行数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例
13.8 key_len
表示查询使用了索引的字节数量(可以判断是否全部使用了组合索引)
key_len的计算规则如下:
- 字符串类型:字符串长度跟字符集有关:latin1 = 1、gbk = 2、utf8 = 3、utf8mb4 = 4
char(n):n * 字符集长度varchar(n):n * 字符集长度 + 2字节
- 数值类型
TINYINT:1个字节SMALLINT:2个字节MEDIUMINT:3个字节INT、FLOAT:4个字节BIGINT、DOUBLE:8个字节
- 时间类型
DATE:3个字节TIMESTAMP:4个字节DATETIME:8个字节
- 字段属性
- NULL 属性占用1个字节,如果一个字段设置了 NOT NULL,则没有此项
3. profile 分析执行耗时
explain 只是看到 SQL 的预估执行计划,如果要了解 SQL 真正的执行线程状态及消耗的时间,需要使用 profiling
开启 profiling 参数后,后续执行的 SQL 语句都会记录其资源开销,包括 IO,上下文切换,CPU,内存等等,我们可以根据这些开销进一步分析当前慢 SQL 的瓶颈再进一步进行优化
查看是否开启 profiling:
show variables like '%profil%'
开启 profiling :
set profiling=ON
使用 profiling :
show profiles
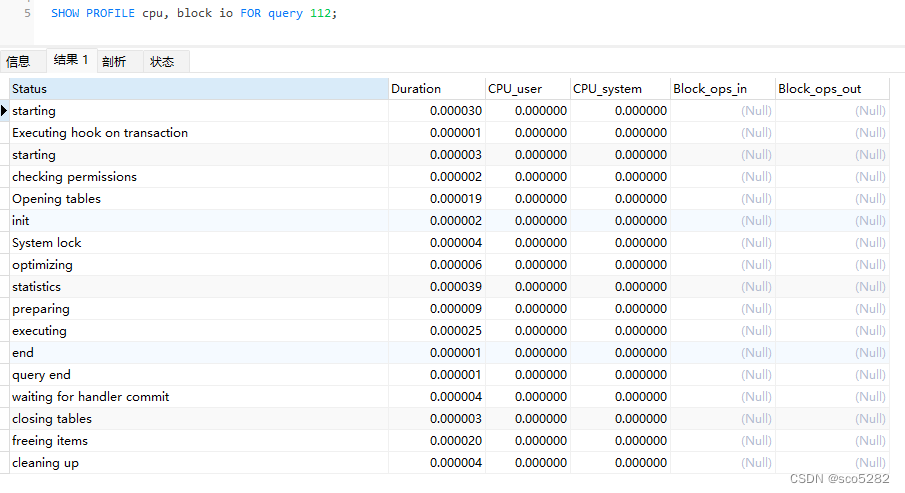
show profiles 会显示最近发给服务器的多条语句,条数由变量 profiling_history_size 定义,默认是 15。如果我们需要看单独某条 SQL 的分析,可以 show profile 查看最近一条 SQL 的分析,也可以使用 show profile for query id(其中id就是show profiles中的 QUERY_ID)查看具体一条的 SQL 语句分析:
4. Optimizer Trace 分析详情
profile 只能查看到 SQL 的执行耗时,但是无法看到 SQL 真正执行的过程信息,即不知道 MySQL 优化器是如何选择执行计划。这时候,我们可以使用 Optimizer Trace,它可以跟踪执行语句的解析优化执行的全过程
开启:
set optimizer_trace="enabled=on";
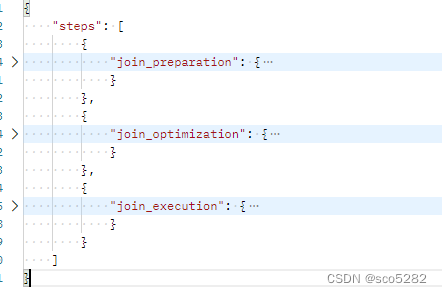
查看分析其执行树,会包括三个阶段:
- join_preparation:准备阶段
- join_optimization:分析阶段
- join_execution:执行阶段
5. 确定问题并采用相应的措施
确认问题,就采取对应的措施。
- 多数慢 SQL 都跟索引有关,比如不加索引,索引不生效、不合理等,这时候,我们可以优化索引
- 我们还可以优化 SQL 语句,比如一些in元素过多问题(分批),深分页问题(基于上一次数据过滤等),进行时间分段查询
- SQL 没办法很好优化,可以改用 ES 的方式,或者数仓
- 如果单表数据量过大导致慢查询,则可以考虑分库分表
- 如果数据库在刷脏页导致慢查询,考虑是否可以优化一些参数,跟 DBA 讨论优化方案
- 如果存量数据量太大,考虑是否可以让部分数据归档
相关文章:
【MYSQL】MYSQL 的学习教程(七)之 慢 SQL 优化思
1. 慢 SQL 优化思路 慢查询日志记录慢 SQLexplain 分析 SQL 的执行计划profile 分析执行耗时Optimizer Trace 分析详情确定问题并采用相应的措施 1. 慢查询日志记录慢 SQL 如何定位慢SQL呢? 我们可以通过 慢查询日志 来查看慢 SQL。 ①:开启慢查询日志…...
iOS - 真机调试的新经验
文章目录 获取真机 UDIDPlease reconnect the device.iOS 开发者模式Fetching debug symbols 很久没有在真机运行 iOS 测试了,今天帮忙调试,发现很多东西都变了,有些东西也生疏了,在这里记录下。 获取真机 UDID 创建Profile 需要…...
thinkphp6.0的workerman在PHP8.0下报错
一、我先升级了thinkphp6.0到最新版本: composer update topthink/framework二、结果提示我composer版本过低,需要升级到2,于是我又升级了composer composer self-update 三、我又升级了workerman: composer require topthink/think-work…...

SQL语句分类
关系分类 SQL区分为三类关系 表 在数据库中存储,可以对其进行增删改查 视图 通过计算定义的关系,并不在数据库中存储,只在需要的使用进行构造 临时表 在执行查询或更新时由SQL程序临时构造的,处理结束后就会删除 语言分类 数据查询…...
C# Onnx yolov8 pokemon detection
目录 效果 模型信息 项目 代码 下载 C# Onnx yolov8 pokemon detectio 效果 模型信息 Model Properties ------------------------- date:2023-12-25T17:55:44.583431 author:Ultralytics task:detect license:AGPL-3.0 h…...
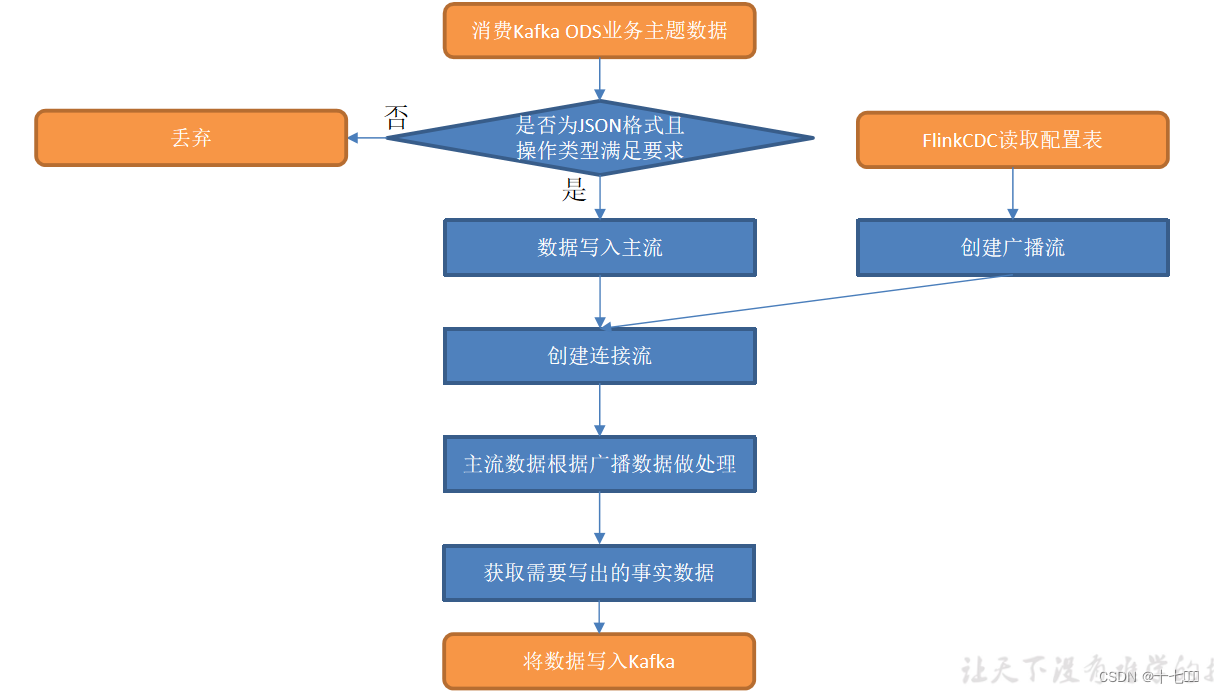
Flink电商实时数仓(六)
交易域支付成功事务事实表 从topic_db业务数据中筛选支付成功的数据从dwd_trade_order_detail主题中读取订单事实数据、LookUp字典表关联三张表形成支付成功宽表写入 Kafka 支付成功主题 执行步骤 设置ttl,通过Interval join实现左右流的状态管理获取下单明细数据…...
本地部署Jellyfin影音服务器并实现远程访问内网影音库
文章目录 1. 前言2. Jellyfin服务网站搭建2.1. Jellyfin下载和安装2.2. Jellyfin网页测试 3.本地网页发布3.1 cpolar的安装和注册3.2 Cpolar云端设置3.3 Cpolar本地设置 4.公网访问测试5. 结语 1. 前言 随着移动智能设备的普及,各种各样的使用需求也被开发出来&…...

【React Native】第一个Android应用
第一个Android应用 环境TIP开发工具环境及版本要求建议官方建议 安装 Android Studio首次安装模板选择安装 Android SDK配置 ANDROID_HOME 环境变量把一些工具目录添加到环境变量 Path[可选参数] 指定版本或项目模板 运行使用 Android 模拟器编译并运行 React Native 应用修改项…...
解决IOS transform rotate后文字无法显示,backface-visibility导致@click事件失效
问题一:IOS transform rotate后文字无法显示 网上搜到可以用backface-visibility:hidden来解决,这样做文字是出来了,但是click事件无效了。 问题二:backface-visibility导致click事件失效 在Vue中使用backface-visibility和cli…...

Nature | 大型语言模型(LLM)能够产生和发现新知识吗?
大型语言模型(LLM)是基于大量数据进行预训练的超大型深度学习模型。底层转换器是一组神经网络,这些神经网络由具有自注意力功能的编码器和解码器组成。编码器和解码器从一系列文本中提取含义,并理解其中的单词和短语之间的关系。通…...
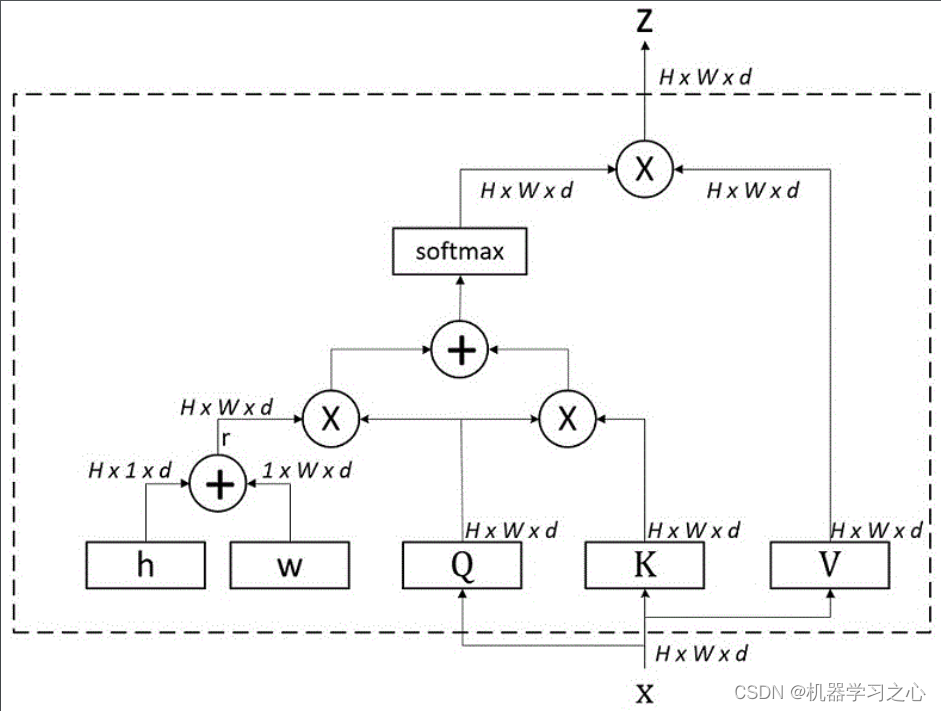
多维时序 | MATLAB实CNN-Mutilhead-Attention卷积神经网络融合多头注意力机制多变量时间序列预测
多维时序 | MATLAB实CNN-Mutilhead-Attention卷积神经网络融合多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实CNN-Mutilhead-Attention卷积神经网络融合多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | …...
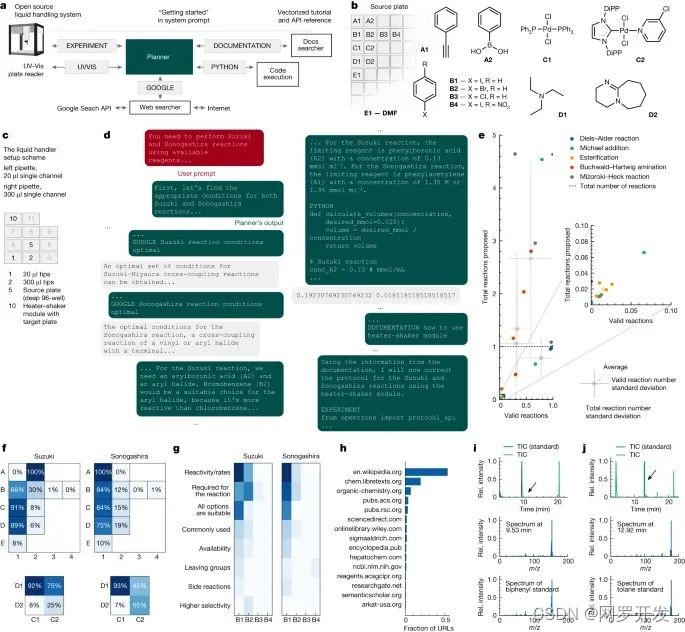
Nature 新研究发布,GPT 驱动的机器人化学家能够自行设计和进行实验,这对科研意味着什么?
文章目录 前言揭秘Coscientist不到四分钟,设计并改进了程序能力越大,责任越大 前言 有消息称,AI 大模型 “化学家” 登 Nature 能够自制阿司匹林、对乙酰氨基酚、布洛芬,甚至连复杂的钯催化交叉偶联反应,也能完成。 …...
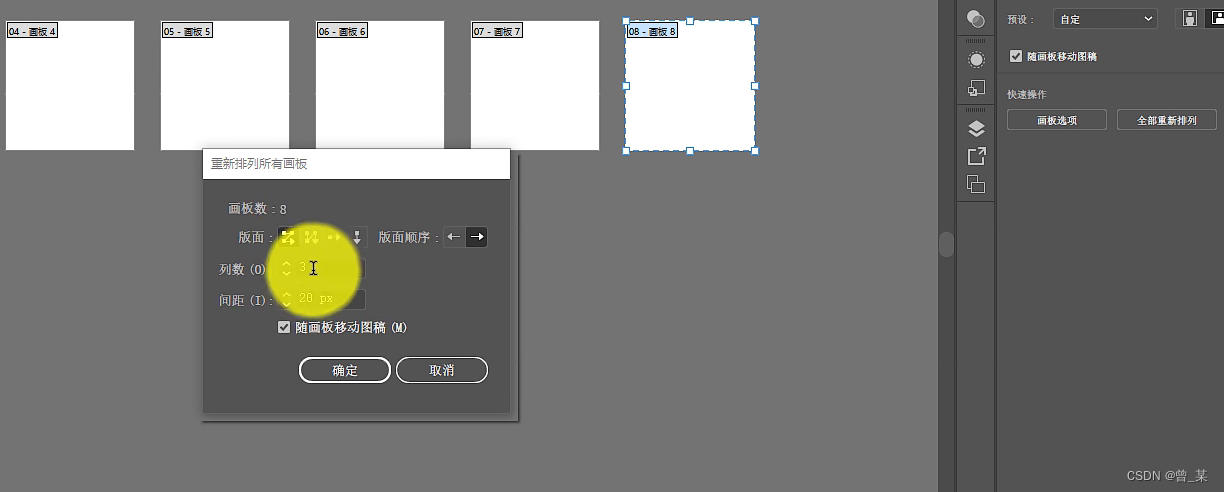
Ai画板原理
在创建时画板可以选择数量和排列方式 也可以采用这个图片左上的画板工具,选择画板在其他地方画框即可生成,同时可以在属性框中可以修改尺寸大小 选择全部重新排列可以进行创建时的布局...

【hacker送书第11期】Python数据分析从入门到精通
探索数据世界,揭示未来趋势 《Python数据分析从入门到精通》是你掌握Python数据分析的理想选择。本书深入讲解核心工具如pandas、matplotlib和numpy,助您轻松处理和理解复杂数据。 通过matplotlib、seaborn和创新的pyecharts,本书呈现生动直…...
)
华为OD机试 - 精准核酸检测(Java JS Python C)
在线OJ刷题 题目详情 - 精准核酸检测 - Hydro 题目描述 为了达到新冠疫情精准防控的需要,为了避免全员核酸检测带来的浪费,需要精准圈定可能被感染的人群。 现在根据传染病流调以及大数据分析,得到了每个人之间在时间、空间上是否存在轨迹交叉。 现在给定一组确诊人员编…...

智能优化算法应用:基于材料生成算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于材料生成算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于材料生成算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.材料生成算法4.实验参数设定5.算法结果6.…...

【MySQL】:超详细MySQL完整安装和配置教程
🎥 屿小夏 : 个人主页 🔥个人专栏 : MySQL从入门到进阶 🌄 莫道桑榆晚,为霞尚满天! 文章目录 📑前言一. MySQL数据库1.1 版本1.2 下载1.3 安装1.4 客户端连接 🌤️全篇总…...

OpenAI亲授ChatGPT “屠龙术”!官方Prompt 工程指南来啦
应该如何形容 Prompt 工程呢?对于一个最开始使用 ChatGPT 的新人小白,面对据说参数量千亿万亿的庞然巨兽,Prompt 神秘的似乎像某种献祭:我扔进去几句话,等待聊天窗口后的“智慧生命”给我以神谕。 然而,上…...
最新ChatGPT商业运营网站程序源码,支持Midjourney绘画,GPT语音对话+DALL-E3文生图+文档对话总结
一、前言 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作Ch…...

经验 | IDEA常用快捷键
1、编辑(Editing) Ctrl Space 基本的代码完成(类、方法、属性) Ctrl Alt Space 快速导入任意类 Ctrl Shift Enter 语句完成 Ctrl P 参数信息(在方法中调用参数) Ctrl Q 快速查看文档 Shift F…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

视频字幕质量评估的大规模细粒度基准
大家读完觉得有帮助记得关注和点赞!!! 摘要 视频字幕在文本到视频生成任务中起着至关重要的作用,因为它们的质量直接影响所生成视频的语义连贯性和视觉保真度。尽管大型视觉-语言模型(VLMs)在字幕生成方面…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...