R语言基础 | 安徽某高校《统计建模与R软件》期末复习
第一节 数字、字符与向量
1.1 向量的赋值
c<-(1,2,3,4,5)1.2 向量的运算
对于向量,我们可以直接对其作加(+),减(-),乘(*),除(/),乘方(^{}),整数除法(%/%),求余(%%)运算,其含义就是对向量的每一个元素进行运算。
1.3 向量运算函数
min(x) # 返回最小值max(x) # 返回最大值range(x) # 返回最小值和最大值which.min(x) # 返回最小值的下标which.max(x) # 返回最大值的下标sum(x) # 元素求和prod(x) # 元素连乘length(x) # 向量长度median(x) # 中位数mean(x) # 均值var(x) # 方差sd(x) # 标准差sort(x) # 排序order(x) # 返回排序后的索引1.4 逻辑向量
逻辑向量是一种用于存储逻辑(布尔)值的数据结构。逻辑向量可以包含两种可能的值:TRUE(真)和FALSE(假),用来表示逻辑条件的结果或逻辑操作的输出。
all(c(1,2,3)>2) # 返回FALSEall(c(1,2,3)>2) # 返回TRUEx <- c(1, 2, 3, 4, 5)
logical_vector <- ifelse(x > 3, TRUE, FALSE)
# logical_vector 包含 FALSE FALSE FALSE TRUE TRUE
1.5 生成有规律的序列
# 生成等差数列a:b# 等间隔函数s1<-seq(-5,5,by=2) # 生成间隔为2,从-5到5的等间隔序列# 重复函数rep()s1<-rep(x,times=3)1.6 缺失数值的操作
z<-c(1:3,NA) # 用NA表示缺失的数据is.na(z) # 逐个检测是否为缺失数据,TRUE则表示缺失z[is.na(z)]<-0 # 将缺失数据改成0is.nan() # 检测数据是否为NaNis.finite() # 检测数据是否有限(非NaN非无穷大) 补充:NA(Not Available)和NaN(Not a Number)是两个不同的概念,前者表示缺失值或不可用值,后者表示非有效数值,比如和
就是NaN。
1.7 字符型向量
字符型向量是R语言中的一种数据结构,用于存储文本数据或字符串。字符型向量可以包含任何文本字符,如字母、数字、符号等,并且可以包含不同长度的字符串。
k<-c("jerry","lin")paste()函数用于将多个元素(字符向量、数值、逻辑值等)组合成一个字符串,可以指定分隔符来连接这些元素。例如:
# 简单的连接字符型向量
fruits <- c("apple", "banana", "cherry")
result <- paste(fruits, collapse = ", ")
# result 包含 "apple, banana, cherry"# 使用不同的分隔符
numbers <- c(1, 2, 3, 4)
result <- paste(numbers, sep = "-")
# result 包含 "1-2-3-4"
result <- paste("x",numbers,sep = "-")
# result 包含 "x-1" "x-2" "x-3" "x-4"# 连接多个对象
name <- "John"
age <- 30
result <- paste("My name is", name, "and I am", age, "years old.")
# result 包含 "My name is John and I am 30 years old."
1.8 复数向量
# 创建一个复数
z <- complex(real = 3, imaginary = 4)# 计算实部
real_part <- Re(z)
cat("Real part:", real_part, "\n")# 计算虚部
imaginary_part <- Im(z)
cat("Imaginary part:", imaginary_part, "\n")# 计算模
modulus <- Mod(z)
cat("Modulus:", modulus, "\n")# 计算幅角(以弧度为单位)
argument <- Arg(z)
cat("Argument (in radians):", argument, "\n")
1.9 下标
1.9.1 下标的顺序访问
x<-(1,2,3)x[2] # 访问向量x的第二个元素1.9.2 下标的逻辑访问
x<-c(1,2,3)x[x<3] # 访问向量中所有小于3的元素1.9.3 下标的名称访问
# 创建一个有命名元素的向量
fruit_prices <- c(apple = 1.2, banana = 0.8, cherry = 2.5, orange = 1.0)# 访问向量的元素通过名字
apple_price <- fruit_prices["apple"]
# 也可以使用$符号来访问
banana_price <- fruit_prices$banana第二节 对象
2.1 对象的分类
可以将对象分为两类:单纯对象(atomic vectors)和复合对象(lists)。
- 单纯对象是R中的基本数据结构,它们包含具有相同数据类型的元素。
- R中常见的单纯对象类型包括:
- 向量(Vectors):包括数值向量、字符向量、逻辑向量、复数向量等,每个向量的元素都是相同的数据类型。
- 因子(Factors):用于表示分类数据,每个因子的元素属于一个有限的类别。
- 整数向量(Integer Vectors):包括整数类型的向量。
复合对象(Lists):
- 复合对象是R中的数据结构,它们可以包含不同数据类型的元素,因此被称为“复合”对象。
- 复合对象通常用于组织和存储各种数据类型的数据,可以包含向量、数据框、单纯对象、其他复合对象等。
- 列表(List)是R中最常见的复合对象类型,它允许你创建包含不同类型的元素的数据结构。
2.2 对象的基本属性
对象具有两个基本属性:类型(Mode)属性和长度(Length)属性。这些属性对于操作和分析数据非常重要。可以使用不同的函数来检测对象的类型和长度,以便更好地理解和操作数据。
对象类型(Mode)属性:
- 你可以使用
mode()函数来获取对象的类型属性。 - 也可以使用
is.*()函数系列来检测对象的类型,这些函数返回逻辑值(TRUE或FALSE),用于判断对象是否属于特定类型。 - 例如,
is.numeric()检测对象是否为数值类型,is.character()检测对象是否为字符类型,is.data.frame()检测对象是否为数据框等。
对象长度(Length)属性:
- 你可以使用
length()函数来获取对象的长度属性,它告诉你对象中包含的元素数量。 - 对于复合对象,比如列表或数据框,
length()返回的是元素的数量,而不是元素的总数。
2.3 强制类型转换
你可以使用 as. 开头的一系列函数来进行类型转换,以将一个对象强制转换为另一种数据类型。这些函数通常用于将对象从一种数据类型转换为另一种,以满足特定的计算或分析需求。例如:
x <- "123"
x_numeric <- as.numeric(x)y <- 5.7
y_integer <- as.integer(y)z <- 123
z_character <- as.character(z)a <- 0
a_logical <- as.logical(a)b <- c("red", "green", "blue", "red")
b_factor <- as.factor(b)2.4 attributes和attr函数
你可以使用 attributes(object) 函数来获取对象 object 的各个特殊属性组成的列表,但这个列表通常不包括固有属性 mode 和 length。这个函数可以用于检查对象的附加信息和属性。
# 创建一个向量并为其添加特殊属性
x <- c(1, 2, 3, 4, 5)
attr(x, "description") <- "This is a numeric vector"# 获取对象的特殊属性
attr_list <- attributes(x)
print(attr_list)
在这个示例中,我们首先创建了一个名为 x 的数值向量,并使用 attr() 函数为它添加了一个特殊属性 "description"。然后,我们使用 attributes() 函数来获取 x 的特殊属性列表。
2.5 自动伸长和强制压缩
在R语言中,允许对超出对象长度的下标进行赋值,这个特性通常被称为"自动伸长"。当你使用超出对象长度的下标进行赋值时,R会自动扩展对象的长度,并将未赋值的元素初始化为缺失值(NA)。这可以方便地向对象添加新元素或修改现有元素。我们也可以通过直接修改length值对对象进行压缩。例如:
# 创建一个向量
x <- c(1, 2, 3)# 使用超出对象长度的下标赋值(自动伸长)
x[5] <- 6
# 现在向量x变为 1 2 3 NA 6# 缩短对象长度
x <- x[1:3]
# 向量x变为 1 2 3# 直接给长度赋值
length(x) <- 2
# 向量x变为 1 2
2.6 class属性
在R语言中,可以使用特殊的class属性来支持面向对象的编程风格,这允许你定义自己的对象类,并为这些类定义不同的方法。通过给对象设置不同的class属性,你可以使通用函数(如print()、plot()等)根据对象的类别执行不同的操作,实现多态性。
第三节 因子
3.1 变量的类别
3.1.1 区间变量
区间变量是一种连续的数值变量,可以进行各种数学运算,如求和、平均值、差值等。
它们可以用数值来表示,并且数值之间具有加减乘除的意义。
区间变量通常表示一定范围内的度量,如温度、年龄等。
3.1.2 名义变量
名义变量是一种离散的变量,可以用数值或字符型值来表示,但具体数值没有数学运算的意义。
名义变量主要用于分类或计数,用来表示不同的类别或类别之间的差异。
例子包括性别、省份、职业等。
3.1.3 有序变量
有序变量是一种离散的变量,可以用数值或字符型值来表示,但具有顺序或排序的含义。
虽然有序变量的数值有意义,但仅限于表示它们的相对顺序,而不支持加减乘除等数学运算。
有序变量通常用于表示等级、名次、满意度等具有明显排序关系的情况,如班级、名次等。
3.2 factor、levels、table函数
sex<-c("M","F","M","M","F")sexf<-factor(sex) # 创建因子sexl<-levels(sexf) # 得到因子的水平,即不同的类别标签sext<-table(sexf) # 统计频数3.3 apply和tapply函数
3.3.1 apply函数
apply函数用于在矩阵或数组的行或列上执行函数操作。它可以对数据的行或列进行操作,而不仅仅是单一的向量。apply函数的语法为:apply(X, MARGIN, FUN),其中:X是要操作的矩阵或数组。MARGIN指定了要操作的维度,通常为1表示行,2表示列,或者其他维度的索引。FUN是要应用的函数,通常是自定义的或内置的R函数。
示例:
# 创建一个矩阵
mat <- matrix(1:12, nrow = 3, ncol = 4)# 使用apply函数计算每列的和
col_sums <- apply(mat, 2, sum)
3.3.2 tapply函数
tapply函数用于按照一个或多个因子变量对数据进行拆分(分组),然后在每个分组上应用一个函数,并将结果整合成一个列表或向量。tapply函数的语法为:tapply(X, INDEX, FUN),其中:X是要操作的数据向量。INDEX是一个或多个因子变量,用于定义数据的分组。FUN是要应用于每个分组的函数。
示例:
# 创建一个数据框
df <- data.frame(gender = c("M", "F", "M", "F", "M"),score = c(80, 85, 78, 92, 88)
)# 使用tapply函数按性别分组计算平均分
avg_score_by_gender <- tapply(df$score, df$gender, mean)
3.4 gl函数
gl()函数是用于创建因子的函数,特别适用于生成重复的因子水平:
gl(n, k, labels = NULL, length = n * k, ordered = FALSE)
n:一个正整数,表示每个水平要重复的次数。k:一个正整数,表示总的水平数。labels:一个字符向量,包含了水平的标签。如果未指定,将使用默认标签。length:生成的因子向量的长度。ordered:一个逻辑值,表示生成的因子是否应该是有序的,默认为FALSE。
第四节 多维数组和矩阵
4.1 数组和矩阵的生成
4.1.1 向量直接生成
向量只有定义了维数向量(dim属性)后才能被看作是数组,⽐如:
z<-1:12dim(z)<-c(3,4)注意:矩阵的元素是按列存放的。
4.1.2 array函数
array() 函数是R语言中用于创建多维数组的函数。多维数组是一种数据结构,可以存储多个维度的数据。array() 函数允许你指定数据、维度和维度名称,以便创建具有特定结构的数组。
data <- c(1, 2, 3, 4, 5, 6)
# 创建一个二维数组,并指定维度和维度名称
arr <- array(data, dim = c(2, 3), dimnames = list(c("Row1", "Row2"), c("Col1", "Col2", "Col3")))
data:要存储在数组中的数据,通常是一个向量或矩阵。dim:一个整数向量,指定了数组的维度,它定义了数组的形状和结构。dimnames:一个包含行和列名称的列表,用于指定数组的维度名称。
4.1.3 matrix函数
matrix(data, nrow = , ncol = , byrow = FALSE, dimnames = NULL)data:用于填充矩阵的数据,可以是向量或其他可转换为矩阵的数据结构。nrow:矩阵的行数。ncol:矩阵的列数。byrow:一个逻辑值,用于指定数据填充矩阵的方式。如果为TRUE,则按行填充;如果为FALSE(默认值),则按列填充。dimnames:一个包含行名和列名的列表,用于指定矩阵的行名和列名。
4.2 数组的下标
数组与向量⼀样,可以对数组中的某些元素进⾏访问,或进⾏运算:
# 选择下标为(1, 2, 1)的元素
a[1, 2, 1]# 选择下标为(1, 2, 1)和(1, 3, 1)的元素
a[1, 2:3, 1]# 选择所有第一维下标为1的元素
a[1,,]# 选择整个数组(返回整个数组的副本)
a[]# 对数组的数据向量取子集,选择从第三个元素到第十个元素
a[3:10]
4.3 矩阵的运算
# 转置运算
t(A)# 求方阵的行列式
det(A)# 计算向量x和y的内积
x %*% y# 计算向量x和y的内积(另一种方式)
crossprod(x, y)# 计算向量x和y的外积
x %o% y# 计算向量x和y的外积(等价于x %*% t(y))
tcrossprod(x, y)# 获取矩阵A的对角线元素(若A为向量,则创建对角阵)
diag(A)# 解线性方程组Ax=b
solve(A, b)# 求矩阵A的特征值和特征向量
eigen(A)# 求矩阵A的秩
rank(A)# 对矩阵A进行奇异值分解
svd(A)# 对矩阵A进行QR分解
qr(A)
第五节 列表与数据框
5.1 列表
列表是一种复合数据结构,可以包含多种不同类型的数据,包括向量、矩阵、数据框、函数等。列表的主要特点如下:
-
多类型元素:列表可以包含不同数据类型的元素,因此它是一种松散结构,允许在同一个列表中存储不同类型的数据。
-
使用列表索引:列表的元素可以使用索引来访问,每个元素可以有一个名称(标签)或使用数字索引进行访问。
-
创建列表:可以使用
list()函数来创建列表。例如,通过以下方式创建一个包含不同类型元素的列表:my_list <- list(a = 1, b = "text", c = c(1, 2, 3))
这将创建一个名为 my_list 的列表,其中包含了整数、字符和数值向量等不同类型的元素。
-
访问列表元素:可以使用
$运算符或[[ ]]来访问列表的元素。例如,要访问列表中的元素可以使用以下方式:使用$运算符:my_list$a或my_list$b;使用[[ ]]运算符:my_list[["c"]]。
5.2 数据框
数据框是一种二维数据结构,类似于表格或电子表格,它是R中最常用的数据结构之一。数据框的主要特点如下:
-
二维结构:数据框包含行和列,可以看作是一个二维表格,其中每一列可以包含不同数据类型的数据,但每一列的数据类型必须一致。
-
列名和行名:数据框的列(变量)有名称,可以通过列名来访问数据。同时,数据框的行可以有行名,也可以通过行名来访问数据。
-
创建数据框:可以使用
data.frame()函数来创建数据框。例如,通过以下方式创建一个包含不同类型数据的数据框:my_df <- data.frame(ID = 1:3, Name = c("Alice", "Bob", "Charlie"))这将创建一个名为
my_df的数据框,其中包含了整数和字符数据类型的列("ID" 和 "Name")。 -
访问数据框元素:可以使用
$运算符或[ ]来访问数据框的列或元素。例如,要访问数据框中的列,可以使用以下方式:使用$运算符:my_df$Name;使用[ ]运算符:my_df[1, 2]。
(个人总结,如有谬误或需要改进之处欢迎联系作者)
相关文章:
R语言基础 | 安徽某高校《统计建模与R软件》期末复习
第一节 数字、字符与向量 1.1 向量的赋值 c<-(1,2,3,4,5) 1.2 向量的运算 对于向量,我们可以直接对其作加(),减(-),乘(*),除(/)…...

深度神经网络下的风格迁移模型(C#)
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 这个是C#版本的,这里就只放出代码。VB.Net版本请参看 深度神经网络下的风格迁移模型-CSDN博客 斯坦福大学李飞飞团队的…...
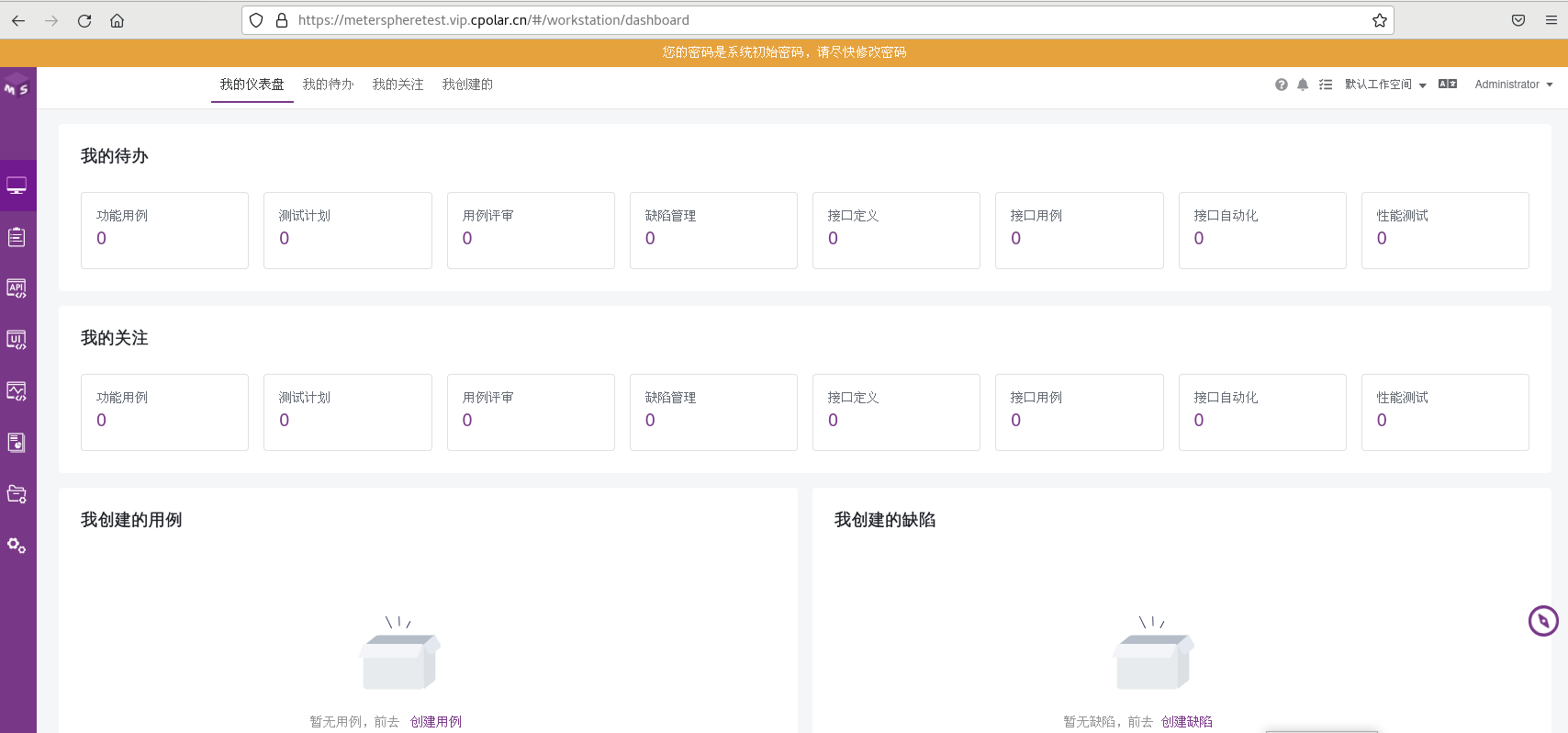
Linux部署MeterSphere结合内网穿透实现远程访问服务管理界面
文章目录 前言1. 安装MeterSphere2. 本地访问MeterSphere3. 安装 cpolar内网穿透软件4. 配置MeterSphere公网访问地址5. 公网远程访问MeterSphere6. 固定MeterSphere公网地址 前言 MeterSphere 是一站式开源持续测试平台, 涵盖测试跟踪、接口测试、UI 测试和性能测试等功能&am…...

MyBatis见解4
10.MyBatis的动态SQL 10.5.trim标签 trim标签可以代替where标签、set标签 mapper //修改public void updateByUser2(User user);<update id"updateByUser2" parameterType"User">update user<!-- 增加SET前缀,忽略,后缀…...
Linux操作系统——进程(三) 进程优先级
进程优先级 首先呢,我们知道一个进程呢(或者也可以叫做一个任务),它呢有时候要在CPU的运行队列中排队,要么有时候阻塞的时候呢又要在设备的等待队列中排队,其实我们排队的本质就是:确认优先级。…...

插入排序详解(C语言)
前言 插入排序是一种简单直观的排序算法,在小规模数据排序或部分有序的情况下插入排序的表现十分良好,今天我将带大家学习插入排序的使用。let’s go ! ! ! 插入排序 插入排序的基本思想是将待排序的序列分为已排序和未排序两部分。初始时,…...
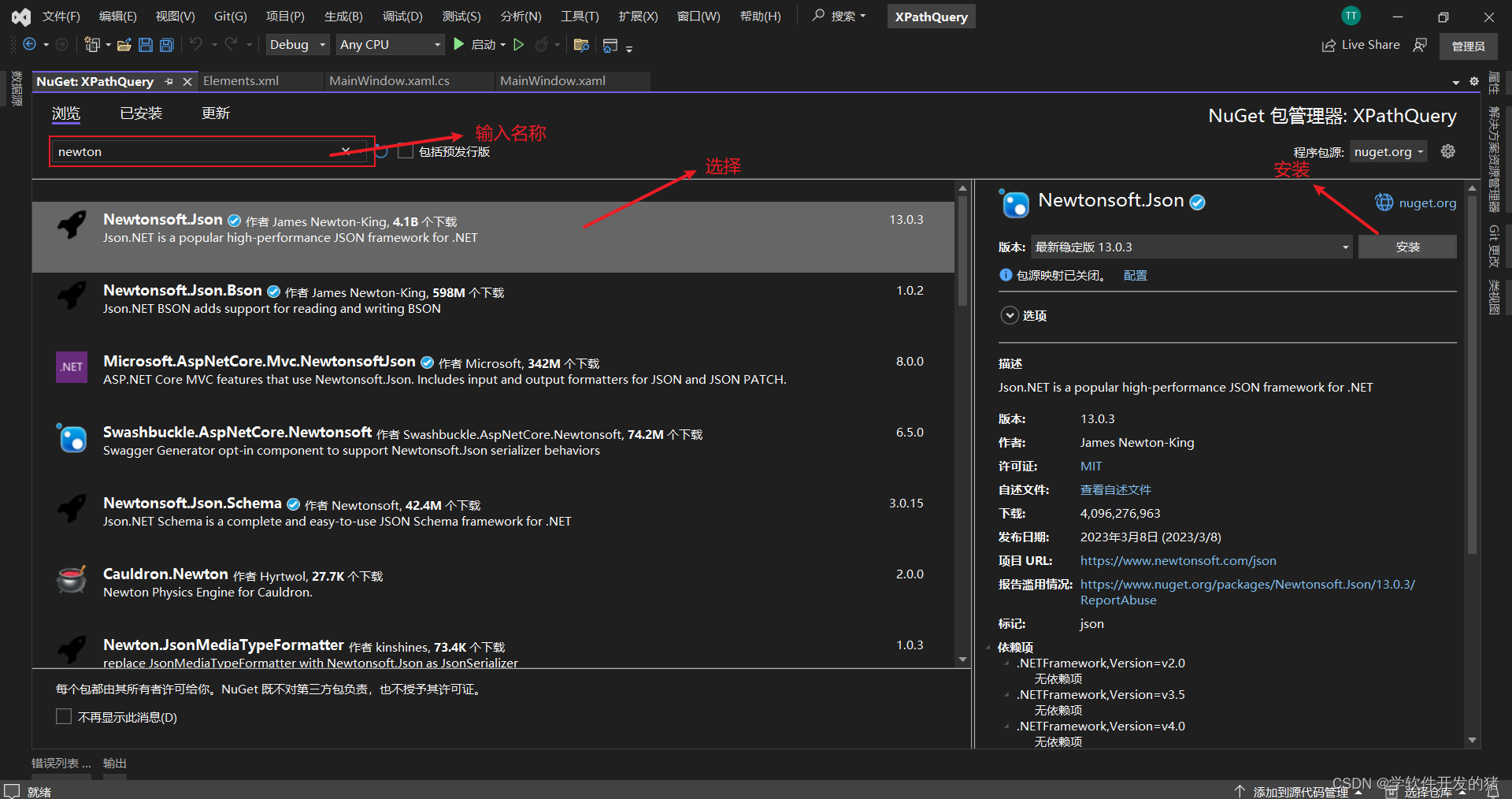
Json和Xml
一、前言 学习心得:C# 入门经典第8版书中的第21章《Json和Xml》 二、Xml的介绍 Xml的含义: 可标记性语言,它将数据以一种特别简单文本格式储存。让所有人和几乎所有的计算机都能理解。 XML文件示例: <?xml version"1.…...
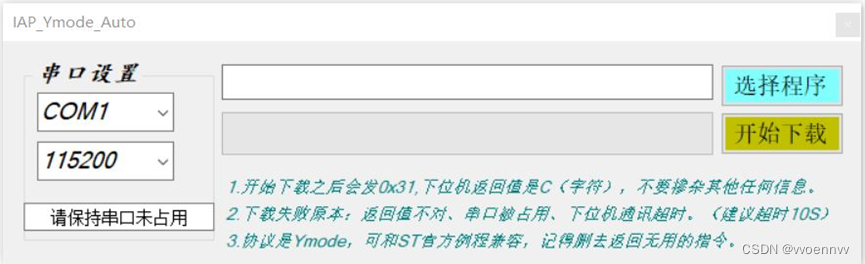
STM32 支持IAP的bootloader开发,使用串口通过Ymodem协议传输固件
资料下载: https://download.csdn.net/download/vvoennvv/88658447 一、概述 关于IAP的原理和Ymodem协议,本文不做任何论述,本文只论述bootloader如何使用串口通过Ymodem协议接收升级程序并进行IAP升级,以及bootloader和主程序两个工程的配置…...

【SVN】centos7搭建svn--亲测能通
centos7.6搭建svn 1 知识小课堂1.1 CentOS1.2 SVN 2 搭建过程2.1 前期准备2.2 通过yum命令安装svnserve2.3 创建版本库目录2.4 创建svn版本库2.5 配置修改2.5 防火墙配置2.6 启动或关闭svn服务器2.6.1 进程守护2.6.2 检测svn端口3690是否已经监听:2.6.3 关闭SVN 2.7…...

MY FILE SERVER: 1
下载地址 https://download.vulnhub.com/myfileserver/My_file_server_1.ova 首先我们需要发现ip 我的kali是59.162所以167就是靶机的 然后我们拿nmap扫一下端口 nmap -sV -p- 192.168.59.167 扫完发现有七个端口开放 按照习惯先看80 没看到有啥有用信息,用nikto扫一下 nik…...
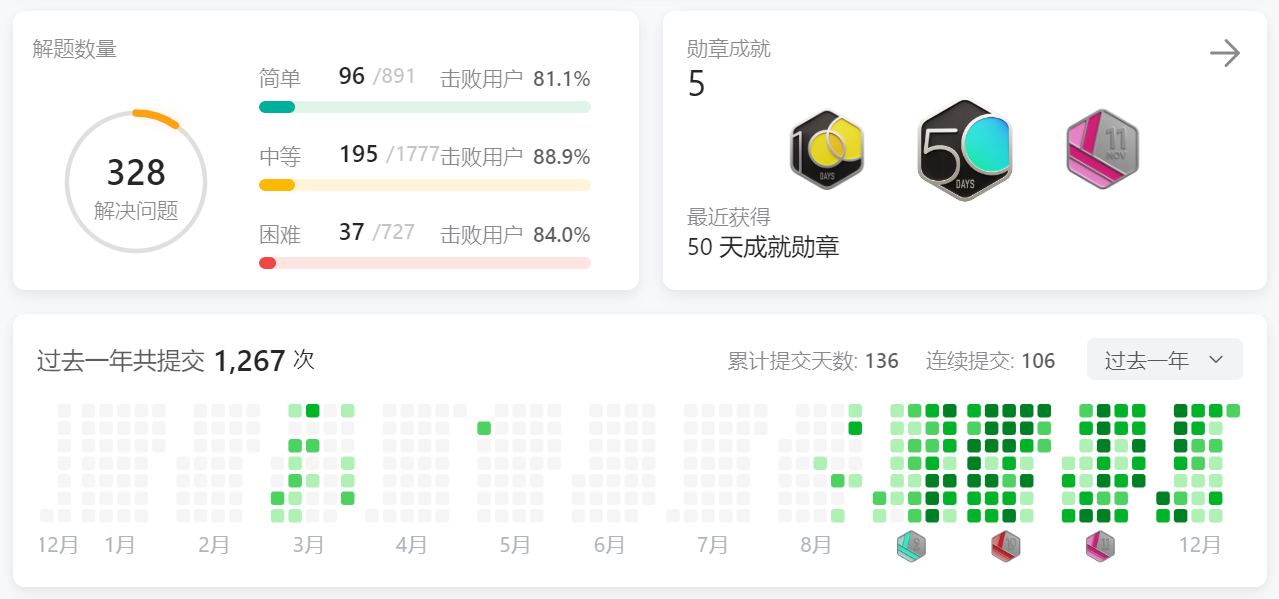
Day70力扣打卡
打卡记录 收集足够苹果的最小花园周长(找规律 二分) 链接 class Solution:def minimumPerimeter(self, neededApples: int) -> int:l, r 1, 10 ** 5while l < r:mid (l r) >> 1if 2 * (2 * (mid ** 3) 3 * (mid ** 2) mid) > nee…...
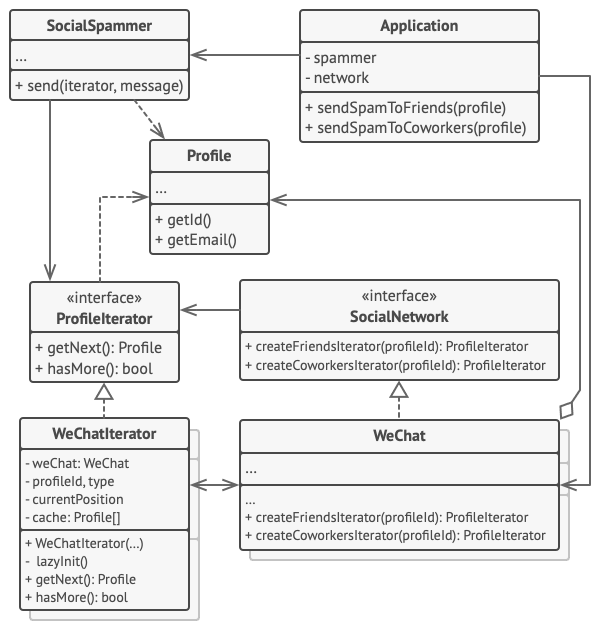
3. 行为模式 - 迭代器模式
亦称: Iterator 意图 迭代器模式是一种行为设计模式, 让你能在不暴露集合底层表现形式 (列表、 栈和树等) 的情况下遍历集合中所有的元素。 问题 集合是编程中最常使用的数据类型之一。 尽管如此, 集合只是一组对象的…...

rsync文件同步
场景:主要是用来发布文件。 一、rsync服务器端架设 1、安装 wget https://download.samba.org/pub/rsync/src/rsync-3.0.6.tar.gz tar -zxvf rsync-3.0.6.tar.gz ./configure --prefix/usr/local/rsync make make install 2、配置 2.1、配置rsyncd.conf 不存在…...

docker 安装mysql 8.0.35
1.拉取镜像 docker pull mysql:8.0.35 2.创建相关挂载目录与文件 mkdir -p /opt/mysql8/conf mkdir -p /opt/mysql8/data mkdir -p /opt/mysql8/logs 或者:mkdir -p /opt/mysql8/{data,conf,logs,mysqld,mysql-files} 文件与文件夹授权:chmod -R 775 /opt/mysql8/* 3.运…...

力扣labuladong一刷day46天并查集
力扣labuladong一刷day46天并查集 文章目录 力扣labuladong一刷day46天并查集一、323. 无向图中连通分量的数目二、130. 被围绕的区域三、990. 等式方程的可满足性 一、323. 无向图中连通分量的数目 题目链接:https://leetcode.cn/problems/number-of-connected-co…...
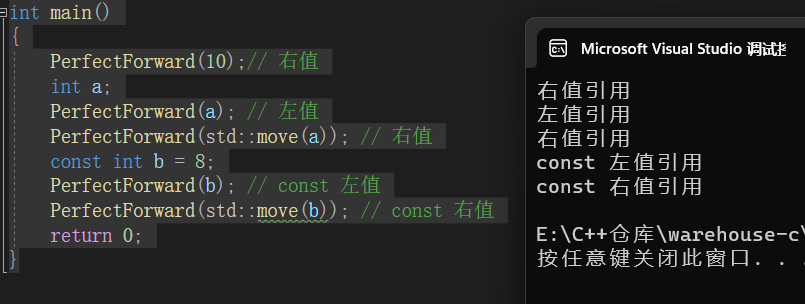
C++11(上):新特性讲解
C11新特性讲解 前言1.列表初始化1.1{ }初始化1.2std::initializer_list 2.类型推导2.1 auto2.2 typeid2.3 decltype 3.范围for4.STL的变化4.1新容器4.2容器的新方法 5.右值引用和移动语义5.1 左值引用和右值引用5.2 左值引用与右值引用比较5.3 右值引用的使用场景5.4 右值、左值…...
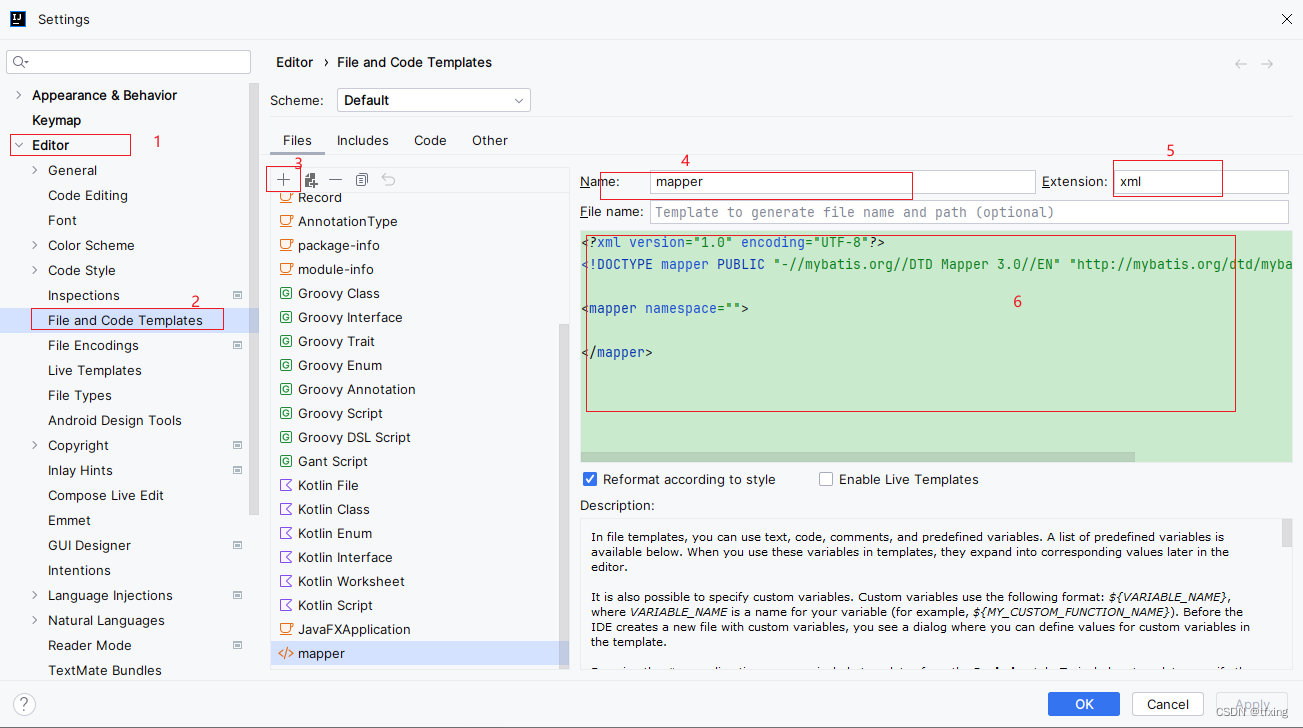
将mapper.xml保存为idea的文件模板
将mapper.xml保存为idea的文件模板 在idea的File and Code Templates中将需要使用模板的内容添加为模板文件。 那么接下来请看图,跟着步骤操作吧。 mapper.xml文件内容 <?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE mapper P…...

LabVIEW在横向辅助驾驶系统开发中的应用
LabVIEW在横向辅助驾驶系统开发中的应用 随着横向辅助驾驶技术的快速发展,越来越多的研究致力于提高该系统的效率和安全性。项目针对先进驾驶辅助系统(ADAS)中的横向辅助驾驶进行深入研究。在这项研究中,LabVIEW作为一个强大的系…...
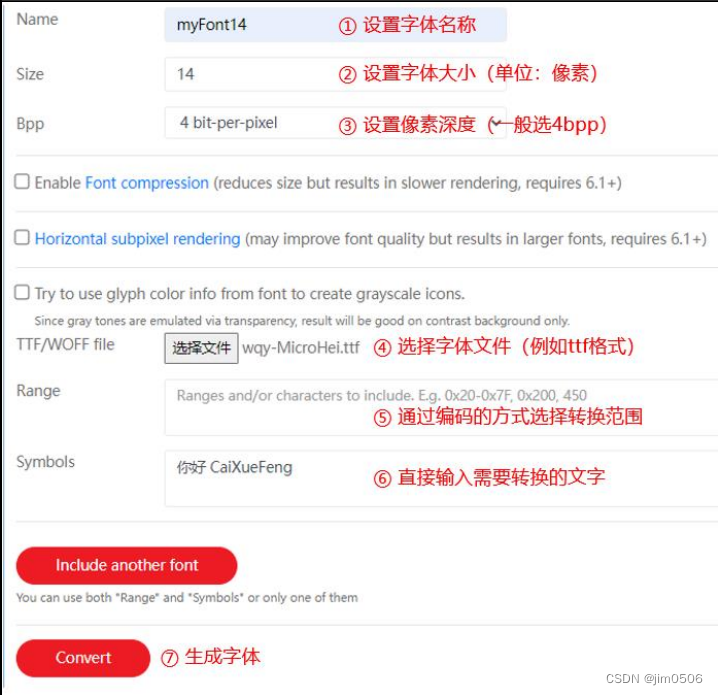
STM32移植LVGL图形库
1、问题1:中文字符keil编译错误 解决方法:在KEIL中Options for Target Flash -> C/C -> Misc Controls添加“--localeenglish”。 问题2:LVGL中显示中文字符 使用 LVGL 官方的在线字体转换工具: Online font converter -…...

迪文屏开发保姆级教程5—表盘时钟和文本RTC显示
这篇文章要讲啥事呢? 本篇文章主要介绍了在DGBUS平台上使用表盘时钟和文本时钟RTC显示功能的方法。 文哥悄悄话: 官方开发指南PDF:(不方便下载的私聊我发给你) https://download.csdn.net/download/qq_21370051/8864…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

Linux nano命令的基本使用
参考资料 GNU nanoを使いこなすnano基础 目录 一. 简介二. 文件打开2.1 普通方式打开文件2.2 只读方式打开文件 三. 文件查看3.1 打开文件时,显示行号3.2 翻页查看 四. 文件编辑4.1 Ctrl K 复制 和 Ctrl U 粘贴4.2 Alt/Esc U 撤回 五. 文件保存与退出5.1 Ctrl …...