【Hive_05】企业调优1(资源配置、explain、join优化)
- 1、 计算资源配置
- 1.1 Yarn资源配置
- 1.2 MapReduce资源配置
- 2、 Explain查看执行计划(重点)
- 2.1 Explain执行计划概述
- 2.2 基本语法
- 2.3 案例实操
- 3、分组聚合优化
- 3.1 优化说明
- (1)map-side 聚合相关的参数
- 3.2 优化案例
- 4、join优化
- 4.1 Join算法概述
- (1)Common Join
- (2)Map Join
- (3)Bucket Map Join
- (4)Sort Merge Bucket Map Join
- 4.2 使用说明
- (1)map join
- (2)map join案例
- (3)Bucket Map Join
- (4)Bucket Map Join案例
- (5) Sort Merge Bucket Map Join
- 关于调优,重要的是理解每一个优化手段的思路。理解优化需要配置的每个参数的实际作用。
1、 计算资源配置
计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
1.1 Yarn资源配置
1)Yarn配置说明
需要调整的Yarn参数均与CPU、内存等资源有关,核心配置参数如下
(1)yarn.nodemanager.resource.memory-mb
该参数的含义是,一个NodeManager节点分配给Container使用的内存。该参数的配置,取决于NodeManager所在节点的总内存容量和该节点运行的其他服务的数量。
考虑上述因素,此处可将该参数设置为64G,如下:
<property><name>yarn.nodemanager.resource.memory-mb</name><value>65536</value>
</property>
- 该参数默认使用8G内存去跑任务。
- 需要手动调整,一般给到总内存的1/2或者2/3。
(2)yarn.nodemanager.resource.cpu-vcores
该参数的含义是,一个NodeManager节点分配给Container使用的CPU核数。该参数的配置,同样取决于NodeManager所在节点的总CPU核数和该节点运行的其他服务。
考虑上述因素,此处可将该参数设置为16。
<property><name>yarn.nodemanager.resource.cpu-vcores</name><value>16</value>
</property>
(3)yarn.scheduler.maximum-allocation-mb
该参数的含义是,单个Container能够使用的最大内存。推荐配置如下:
<property><name>yarn.scheduler.maximum-allocation-mb</name><value>16384</value>
</property>
(4)yarn.scheduler.minimum-allocation-mb
该参数的含义是,单个Container能够使用的最小内存,推荐配置如下:
<property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value>
</property>
2)Yarn配置实操
(1)修改$HADOOP_HOME/etc/hadoop/yarn-site.xml文件
(2)修改如下参数
<property><name>yarn.nodemanager.resource.memory-mb</name><value>65536</value>
</property>
<property><name>yarn.nodemanager.resource.cpu-vcores</name><value>16</value>
</property>
<property><name>yarn.scheduler.maximum-allocation-mb</name><value>16384</value>
</property>
<property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value>
</property>
(3)分发该配置文件
(4)重启Yarn。
1.2 MapReduce资源配置
MapReduce资源配置主要包括Map Task的内存和CPU核数,以及Reduce Task的内存和CPU核数。核心配置参数如下:
1)mapreduce.map.memory.mb
该参数的含义是,单个Map Task申请的container容器内存大小,其默认值为1024。该值不能超出yarn.scheduler.maximum-allocation-mb和yarn.scheduler.minimum-allocation-mb规定的范围。
该参数需要根据不同的计算任务单独进行配置,在hive中,可直接使用如下方式为每个SQL语句单独进行配置:
set mapreduce.map.memory.mb=2048;
2)mapreduce.map.cpu.vcores
该参数的含义是,单个Map Task申请的container容器cpu核数,其默认值为1。该值一般无需调整。
3)mapreduce.reduce.memory.mb
该参数的含义是,单个Reduce Task申请的container容器内存大小,其默认值为1024。该值同样不能超出yarn.scheduler.maximum-allocation-mb和yarn.scheduler.minimum-allocation-mb规定的范围。
该参数需要根据不同的计算任务单独进行配置,在hive中,可直接使用如下方式为每个SQL语句单独进行配置:
set mapreduce.reduce.memory.mb=2048;
4)mapreduce.reduce.cpu.vcores
该参数的含义是,单个Reduce Task申请的container容器cpu核数,其默认值为1。该值一般无需调整。
2、 Explain查看执行计划(重点)
2.1 Explain执行计划概述
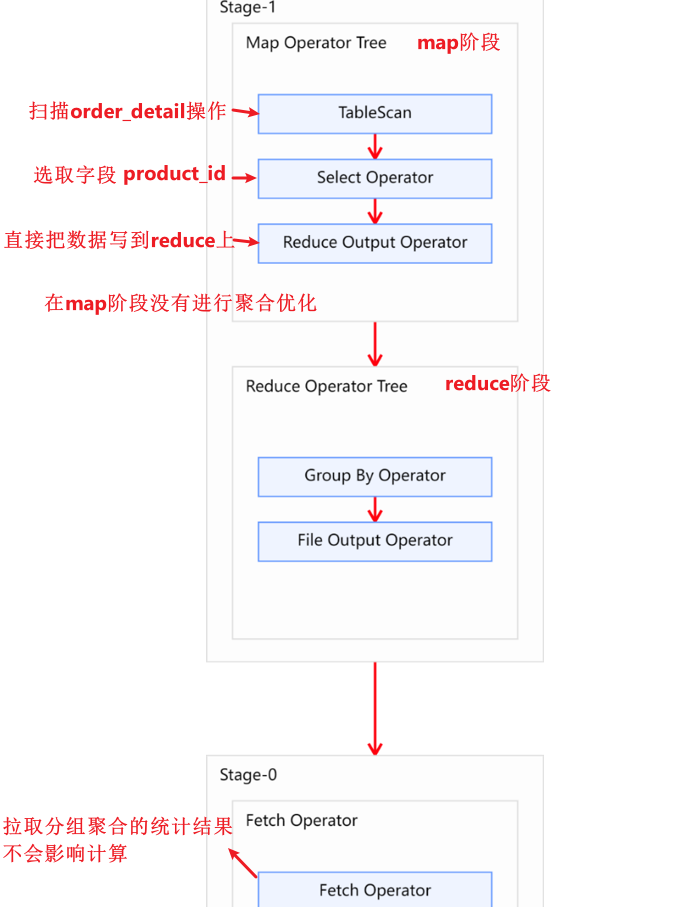
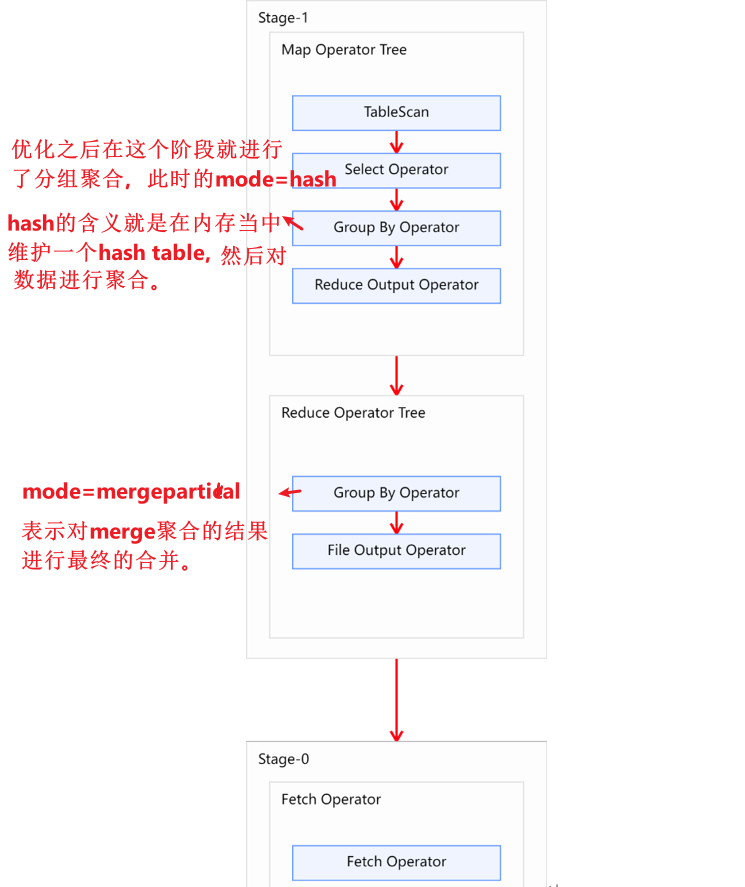
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。
- stage可以对应mr,也可以对应文件系统操作。因为不是所有的sql语句的底层都是mr。比如说load语句,底层就不是mr而是文件系统操作。
- 有些sql复杂,需要多个mr才能计算,这个时候对应的也就有多个stage,多个stage之间也是有依赖关系的。依赖关系也就表明了哪个mr先执行,哪个后面执行。
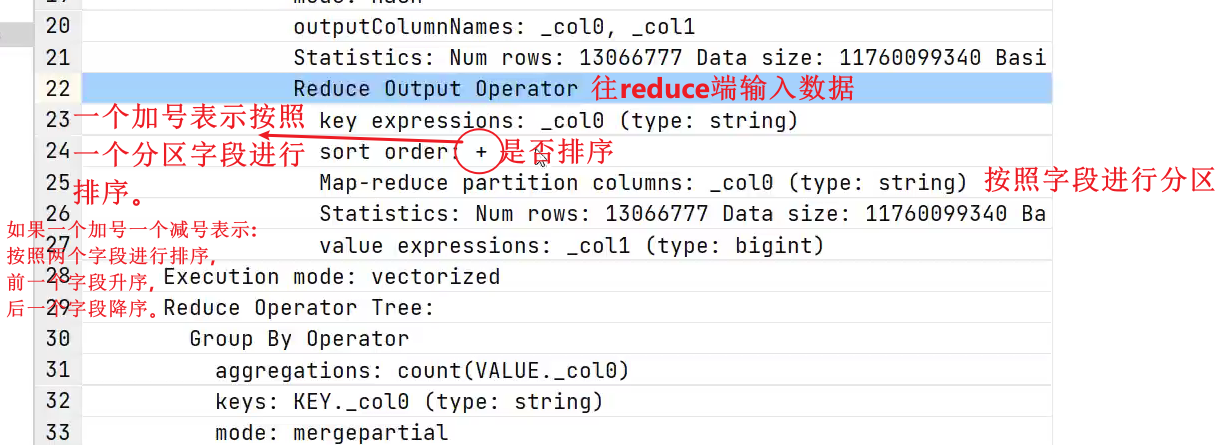
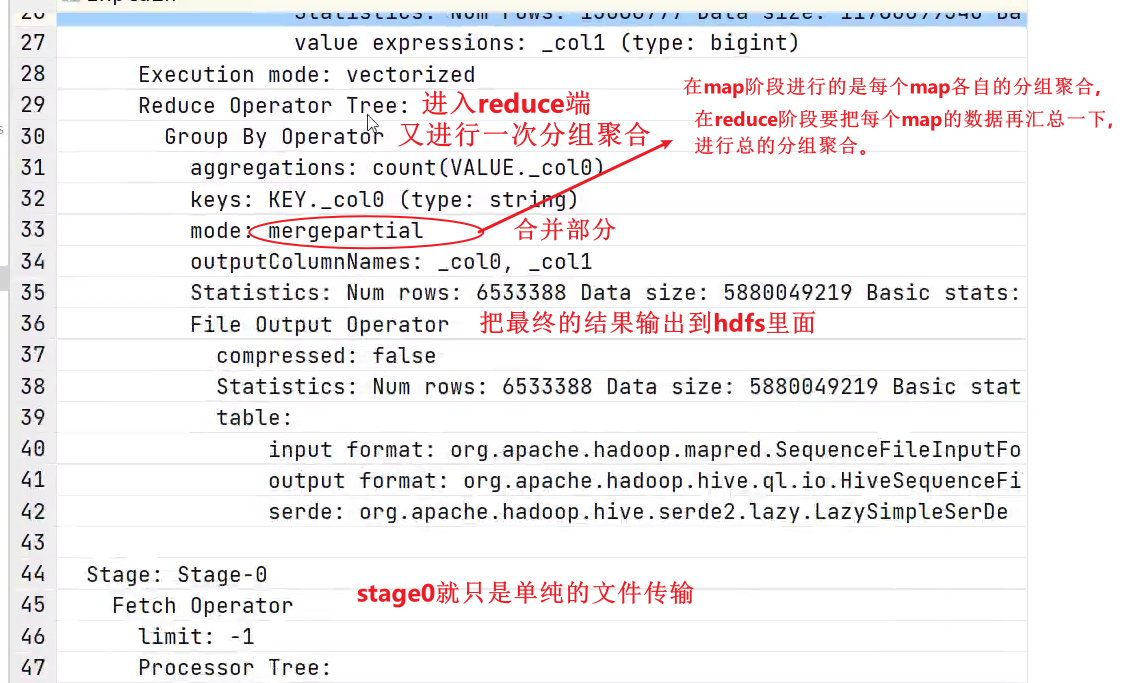
若某个Stage对应的一个MapReduce Job,其Map端和Reduce端的计算逻辑分别由Map Operator Tree和Reduce Operator Tree进行描述,Operator Tree由一系列的Operator组成,一个Operator代表在Map或Reduce阶段的一个单一的逻辑操作,例如TableScan Operator,Select Operator,Join Operator等。
下图是由一个执行计划绘制而成:
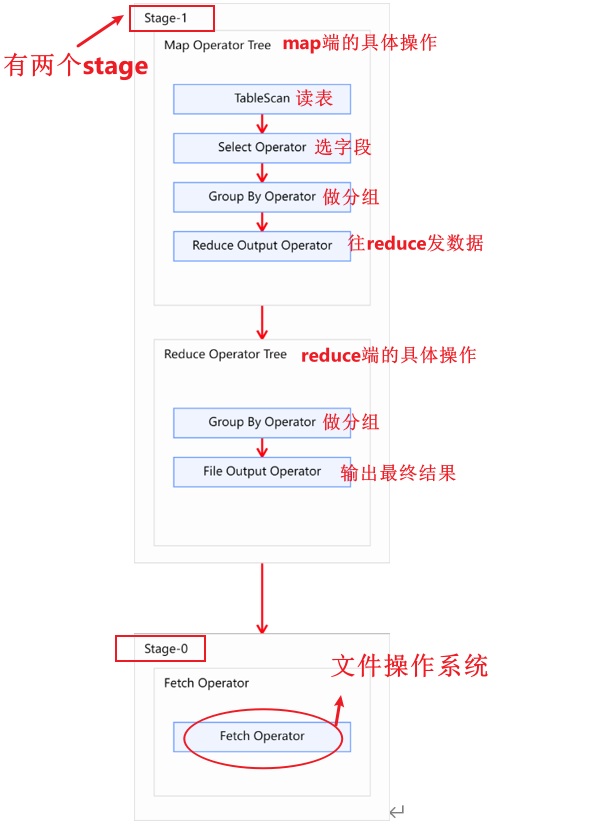
常见的Operator及其作用如下:
- TableScan:表扫描操作,通常map端第一个操作肯定是表扫描操作
- Select Operator:选取操作
- Group By Operator:分组聚合操作
- Reduce Output Operator:输出到 reduce 操作
- Filter Operator:过滤操作, 对应sql语句的where或者having
- Join Operator:join 操作
- File Output Operator:文件输出操作
- Fetch Operator 客户端获取数据操作,因为进行查询之后,会把数据写入到hdfs的临时表当中,通过fetch可以展示在终端。
2.2 基本语法
- 基本语法其实就是在sql的最前面加上explain
EXPLAIN [FORMATTED | EXTENDED | DEPENDENCY] query-sql
注:FORMATTED、EXTENDED、DEPENDENCY关键字为可选项,各自作用如下。
- FORMATTED:将执行计划以格式化的JSON字符串的形式输出
- EXTENDED:输出执行计划中的额外信息,通常是读写的文件名等信息
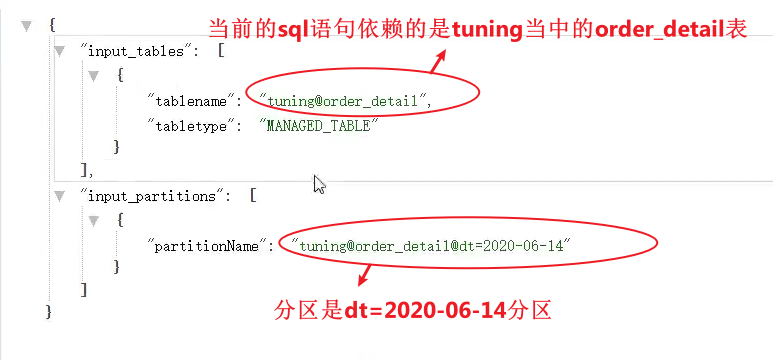
- DEPENDENCY:输出执行计划读取的表及分区
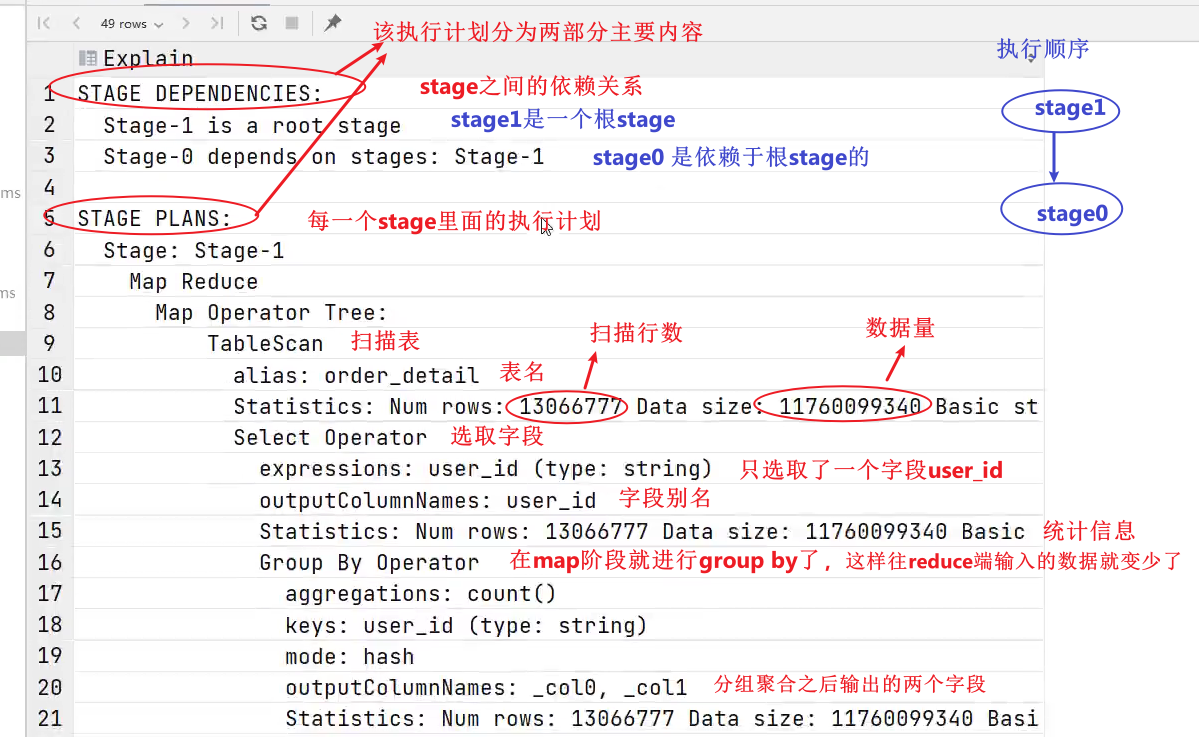
2.3 案例实操
hive (default)>
explain
selectuser_id,count(*)
from order_detail
group by user_id;
3、分组聚合优化
3.1 优化说明
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
- 聚合之后数据量不可能变大,但是有可能数据量不变。
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
(1)map-side 聚合相关的参数
1、启用map-side聚合
set hive.map.aggr=true;
- 该参数默认是开启的。
2、用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
- 如果hive.map.aggr.hash.min.reduction的值为1,则所有的数据不会判断,直接全部进行map端聚合。
3、用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
4、map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
3.2 优化案例
selectproduct_id,count(*)
from order_detail
group by product_id;
1、优化前(跑了46s)
set hive.map.aggr=false;
手动将该参数设置为false
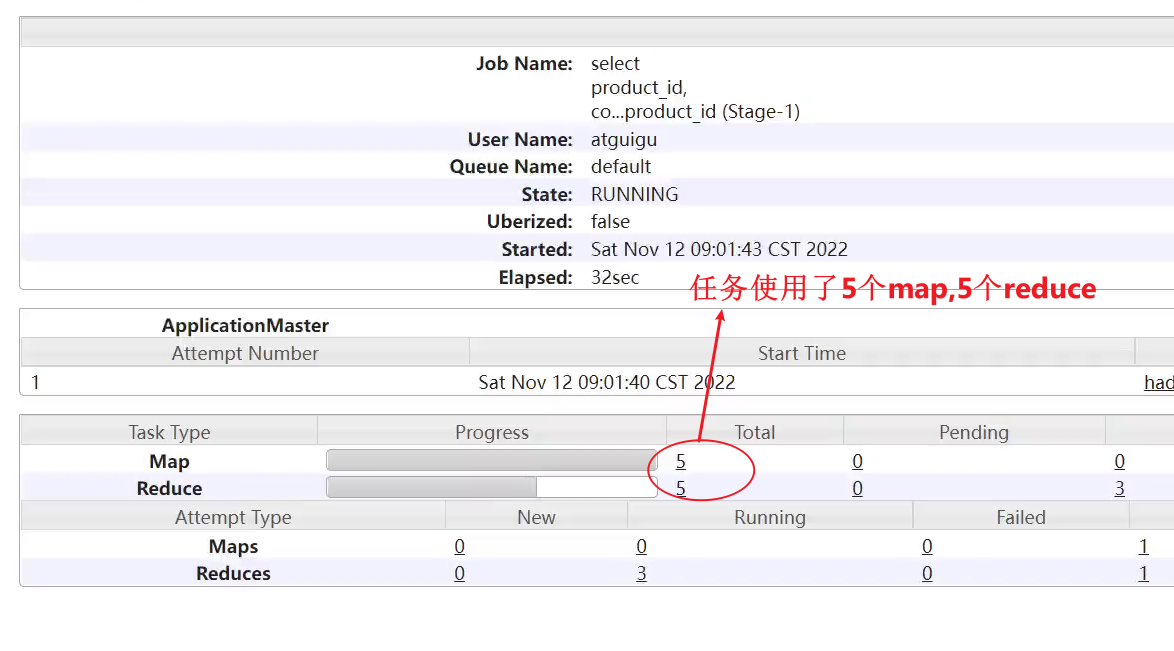
2、优化后(跑了46s)
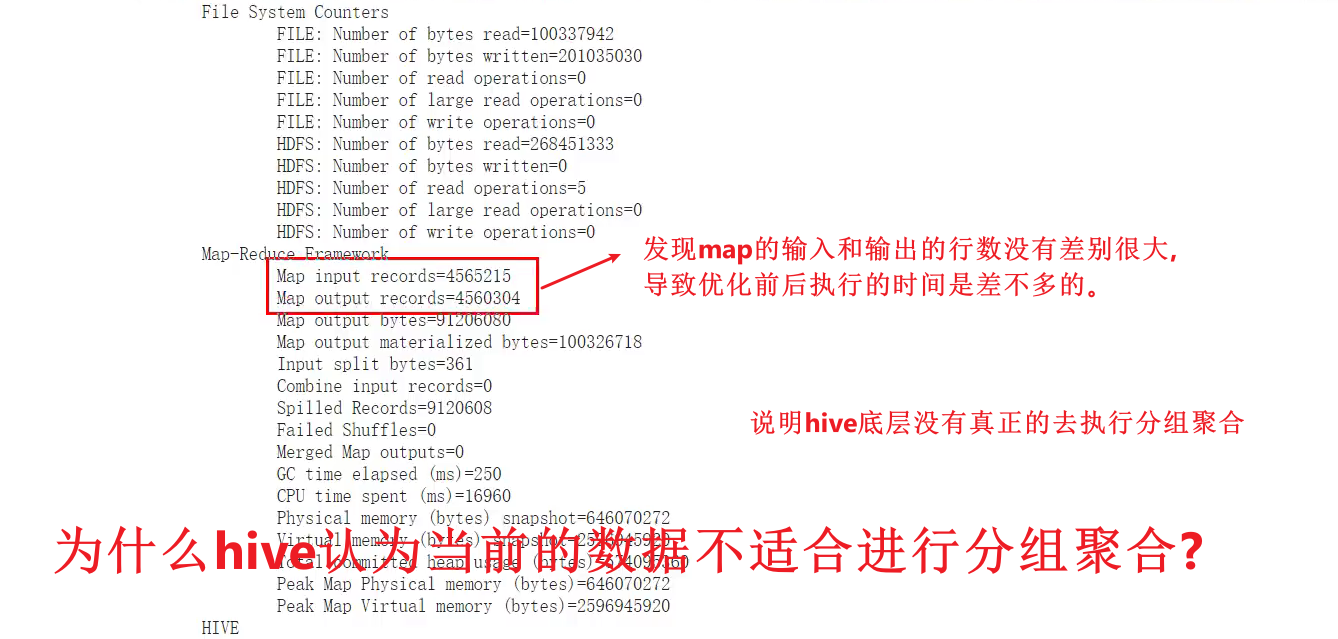
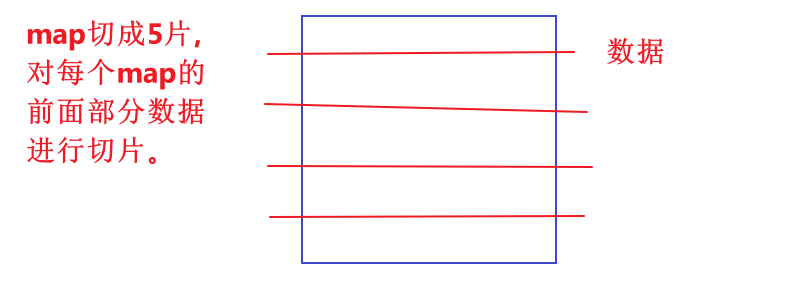
原因:和product_id的分组字段在这张表上的分布有关,因为hive在进行hive.groupby.mapaggr.checkinterval这个参数的校验时不是随机的去进行校验,只会对每个map的前面一部分数据进行判断。可能恰好前面的数据在进行分组聚合的时候,product_id的值都相同。
- 也就是hive判断是否适合分组聚合的不是很智能,这个时候我们可以让其强制进行分组聚合。
set hive.map.aggr.hash.min.reduction=1;
此时时间跑了32秒,比之前快了10秒。

- 按道理product_id只有100万数据,为什么这里map端输出的数据会大于100万?原因是因为触发了flush,也就是上面的第四个参数。例如,在flush之前已经有product_id=1的数据了,flush之后会重新用一个hash table,这样product_id可能就会输出多次了。
那么如果flush的次数多了,分组聚合的效果也不会很好,这个时候可以怎么办?
1、调整参数阈值。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
2、如果调整之后效果还是不明显,说明hive的总内存小,则可以调整下面这个参数:
set mapreduce.map.memory.mb=2048;
4、join优化
4.1 Join算法概述
Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等,下面对每种join算法做简要说明:
(1)Common Join
Common Join是Hive中最稳定的join算法,其通过一个MapReduce Job完成一个join操作。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。如下图所示:
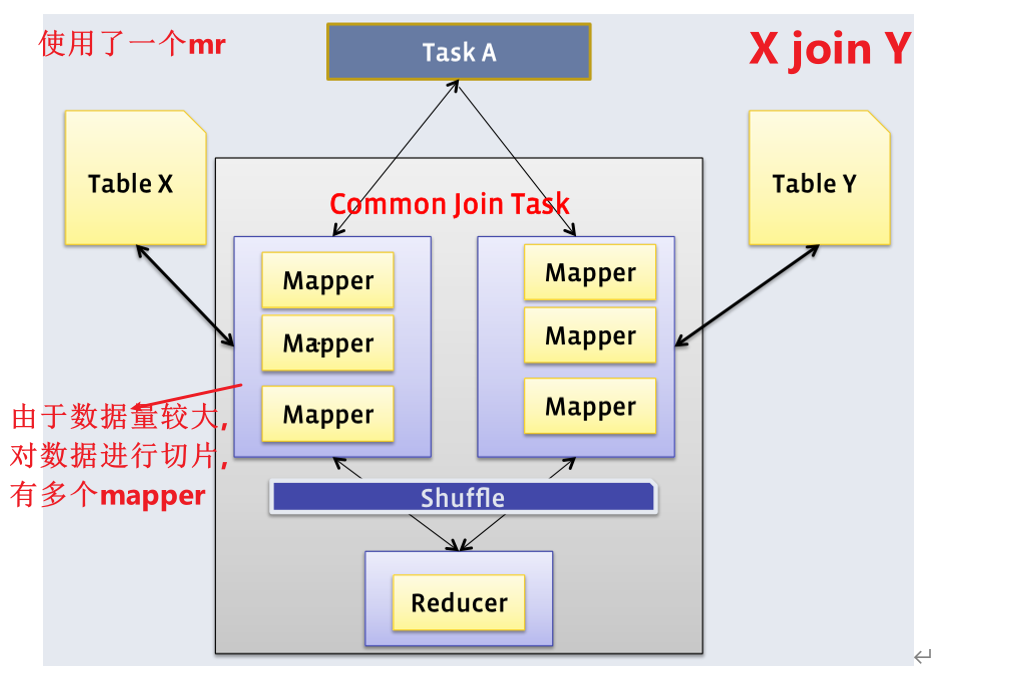
- 如果是A join B join C ,这种时候是使用1个MR还是2个MR呢?
- 如果join的字段都是相同的,这种时候没有必要使用两个MR,一个MR就够了,如下图所示。
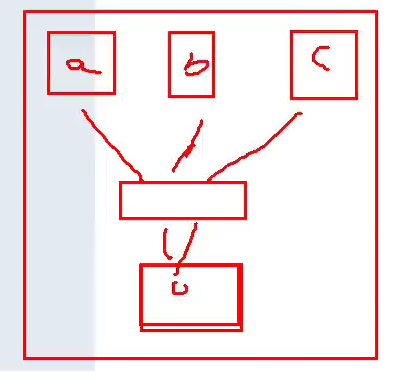
- 如果join的字段不相同,就不能使用一个MR,因为map分区的字段不同的。这种情况下只能A和B去进行common join,之后在对join之后的中间结果与C表进行另一个common join。
因此,sql语句中的join操作和执行计划中的Common Join任务并非一对一的关系,一个sql语句中的相邻的且关联字段相同的多个join操作可以合并为一个Common Join任务。
例如:
hive (default)>
select a.val, b.val, c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key1)
上述sql语句中两个join操作的关联字段均为b表的key1字段,则该语句中的两个join操作可由一个Common Join任务实现,也就是可通过一个Map Reduce任务实现。
hive (default)>
select a.val, b.val, c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key2)
上述sql语句中的两个join操作关联字段各不相同,则该语句的两个join操作需要各自通过一个Common Join任务实现,也就是通过两个Map Reduce任务实现。
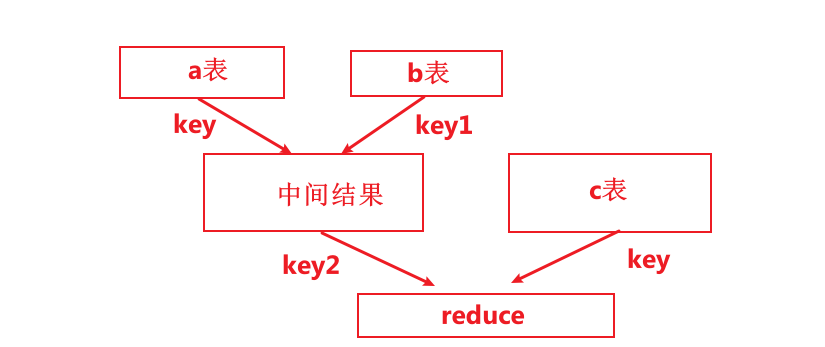
(2)Map Join
Map Join有两种触发方式,一种是用户在SQL语句中增加hint提示,另外一种是Hive优化器根据参与join表的数据量大小,自动触发。
Map Join算法可以通过两个只有map阶段的Job完成一个join操作。其适用场景为大表join小表。若某join操作满足要求,则第一个job会读取小表数据,将其制作为hash table,并上传至Hadoop 分布式缓存(本质上是上传至HDFS)。第二个job会先从分布式缓存中读取小表数据,并缓存在Map Task 的内存中,然后扫描大表数据,这样在map端即可完成关联操作。如下图所示:
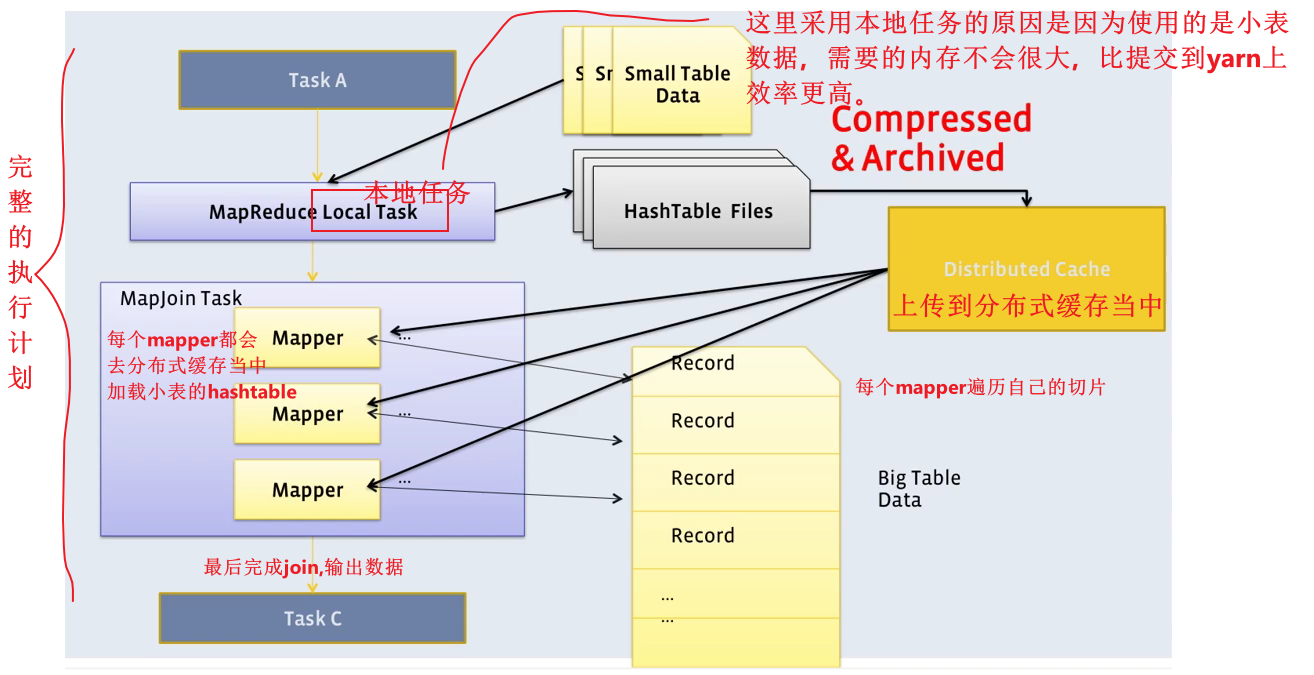
- 在map阶段完成join,比在reduce阶段完成join的效率要更高,因为这样可以省去shuffle的时间。
- map join核心的点在于:要将小表的数据都缓存到mapper的内存里面,所以map join有瓶颈:不能适用于大表join大表的情况。
- 但是并不是所有的join都能在map阶段完成,适用场景是:大表join小表。
(3)Bucket Map Join
Bucket Map Join是对Map Join算法的改进,其打破了Map Join只适用于大表join小表的限制,可用于大表join大表的场景。
Bucket Map Join的核心思想是:【要满足下面几个条件】
1、参与join的表均为分桶表
2、关联字段为分桶字段
3、其中一张表的分桶数量是另外一张表分桶数量的整数倍
满足上面三个条件则能保证参与join的两张表的分桶之间具有明确的关联关系,就可以在两表的分桶间进行Map Join操作了。
这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶即可。其原理如图所示:
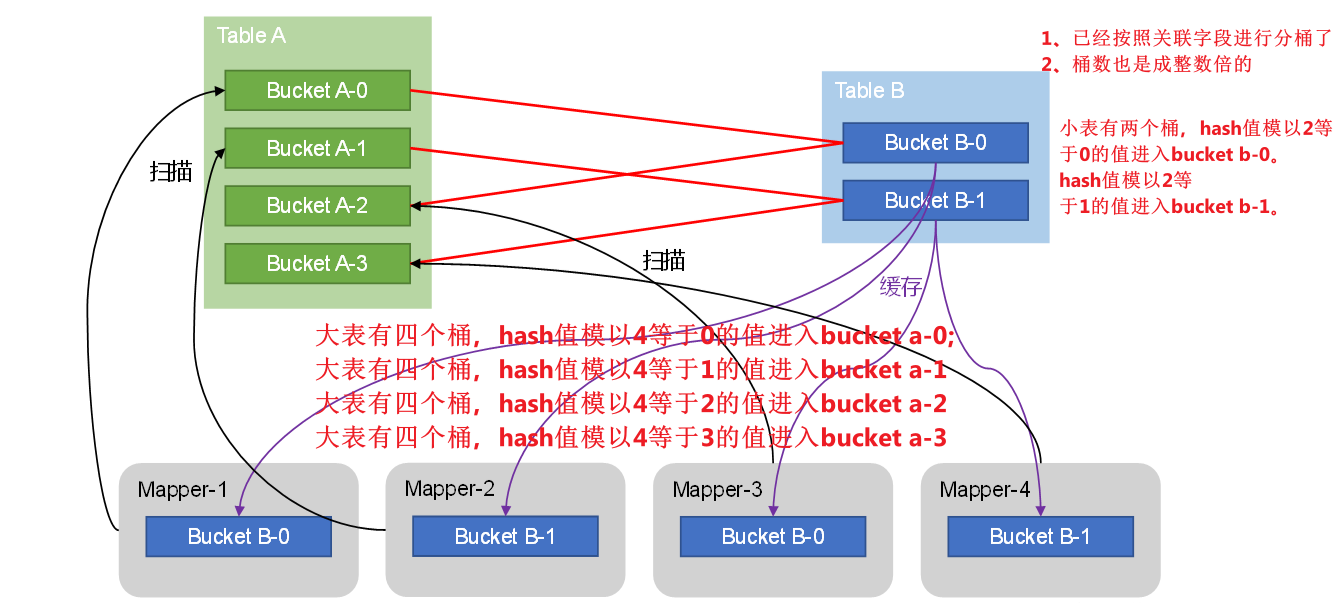
- bucket map join和map join的核心原理是一致的,同样是分两个阶段去做,第一个阶段也是要由本地任务去读取相对来说小一点的表的数据,这里读B的数据,之后制作hash表。这里hash表是根据分桶的数据操作的。
- 有几个桶就会有几个mapper。
(4)Sort Merge Bucket Map Join
Sort Merge Bucket Map Join(简称SMB Map Join)基于Bucket Map Join。SMB Map Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。
SMB Map Join同Bucket Join一样,同样是利用两表各分桶之间的关联关系,在分桶之间进行join操作,不同的是,分桶之间的join操作的实现原理。Bucket Map Join,两个分桶之间的join实现原理为Hash Join算法;而SMB Map Join,两个分桶之间的join实现原理为Sort Merge Join算法。
Hash Join和Sort Merge Join均为关系型数据库中常见的Join实现算法。Hash Join的原理相对简单,就是对参与join的一张表构建hash table,然后扫描另外一张表,然后进行逐行匹配。Sort Merge Join需要在两张按照关联字段排好序的表中进行,其原理如图所示:
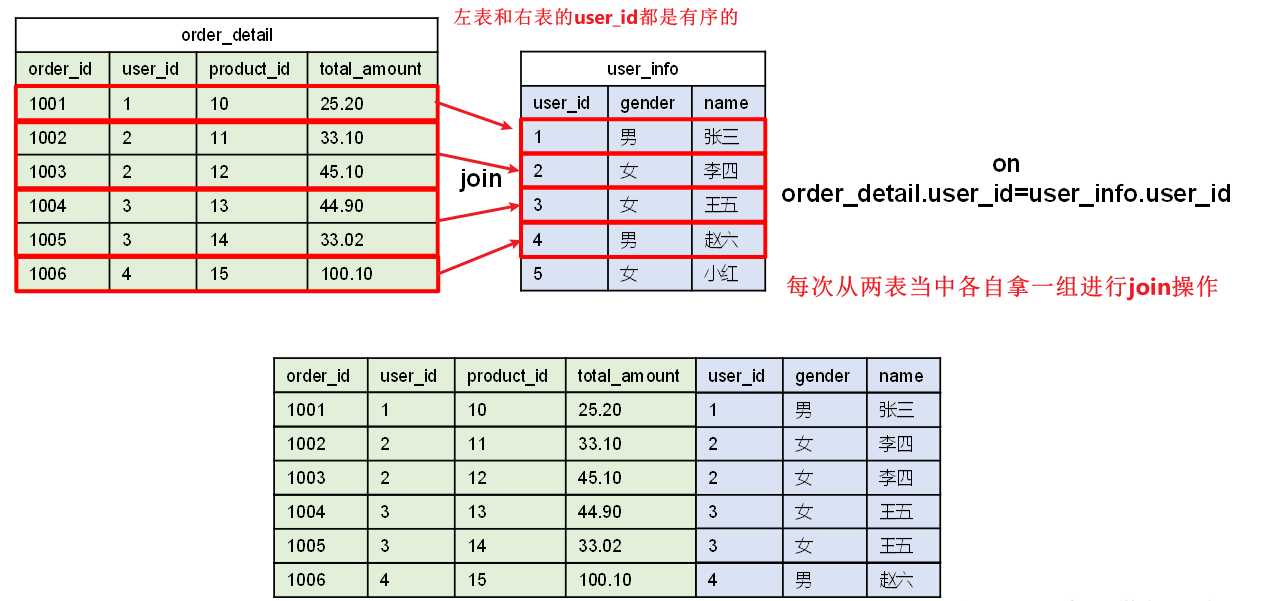
SMB Map Join与Bucket Map Join相比的优势是什么?
1、不需要在制作hash表,分桶在匹配的时候也不需要使用hash表。
2、对内存的要求更低,不需要将桶在放到第二个join的内存当中,因为桶内的数据已经有序了。
- Hive中的SMB Map Join就是对两个分桶的数据按照上述思路进行Join操作。可以看出,SMB Map Join与Bucket Map Join相比,在进行Join操作时,Map端是无需对整个Bucket构建hash table,也无需在Map端缓存整个Bucket数据的,每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可。
4.2 使用说明
(1)map join
Map Join有两种触发方式,一种是用户在SQL语句中增加hint提示,另外一种是Hive优化器根据参与join表的数据量大小,自动触发。
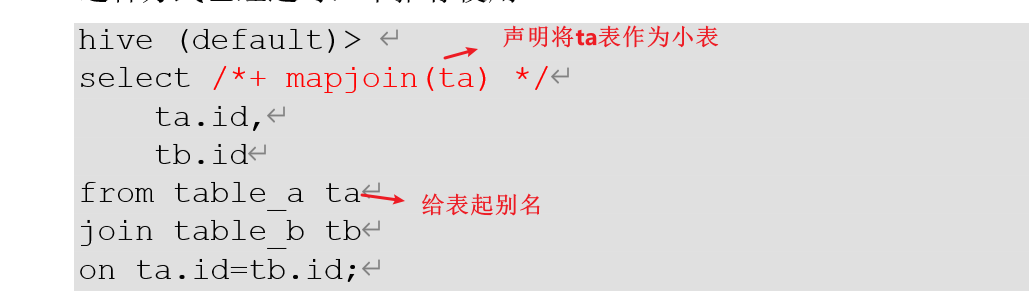
1)Hint提示
用户可通过如下方式,指定通过map join算法,并且ta将作为map join中的小表。这种方式已经过时,不推荐使用。
hive (default)>
select /*+ mapjoin(ta) */ta.id,tb.id
from table_a ta
join table_b tb
on ta.id=tb.id;
2)自动触发
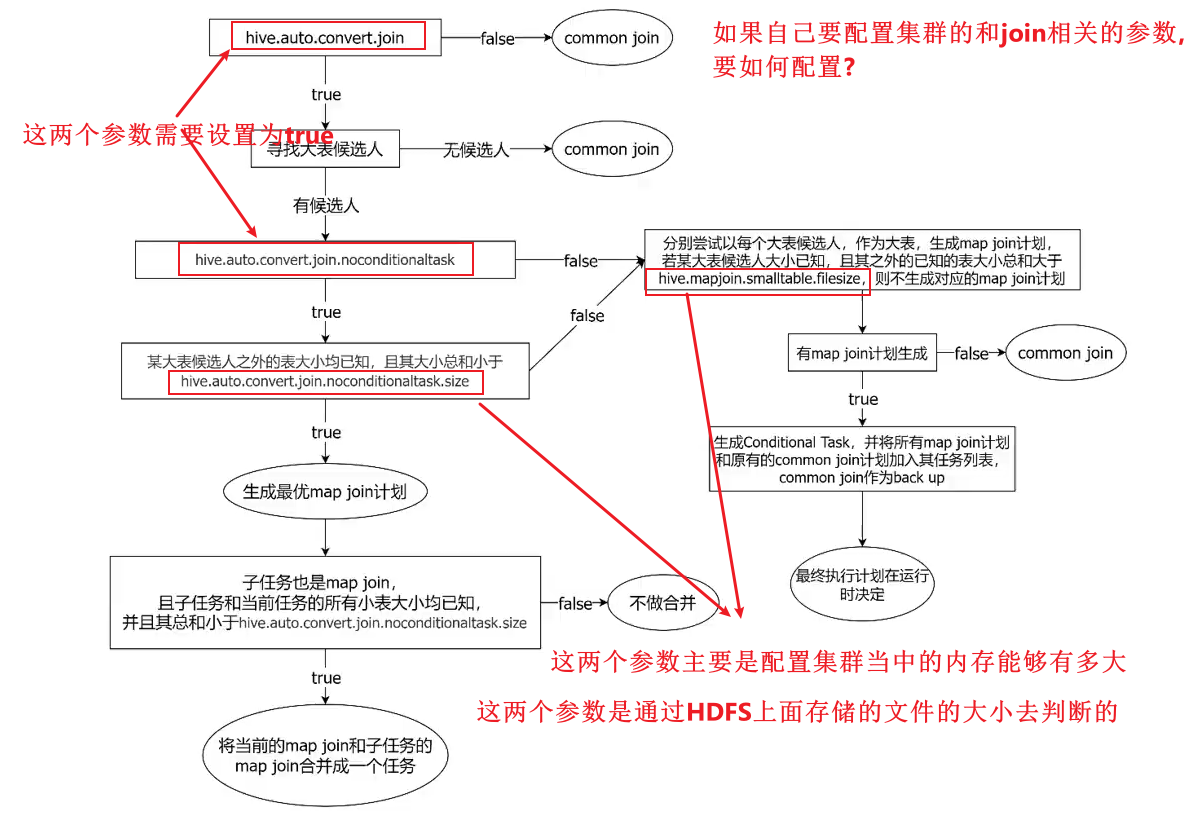
Hive在编译SQL语句阶段,起初所有的join操作均采用Common Join算法实现。
之后在物理优化阶段,Hive会根据每个Common Join任务所需表的大小判断该Common Join任务是否能够转换为Map Join任务,若满足要求,便将Common Join任务自动转换为Map Join任务。
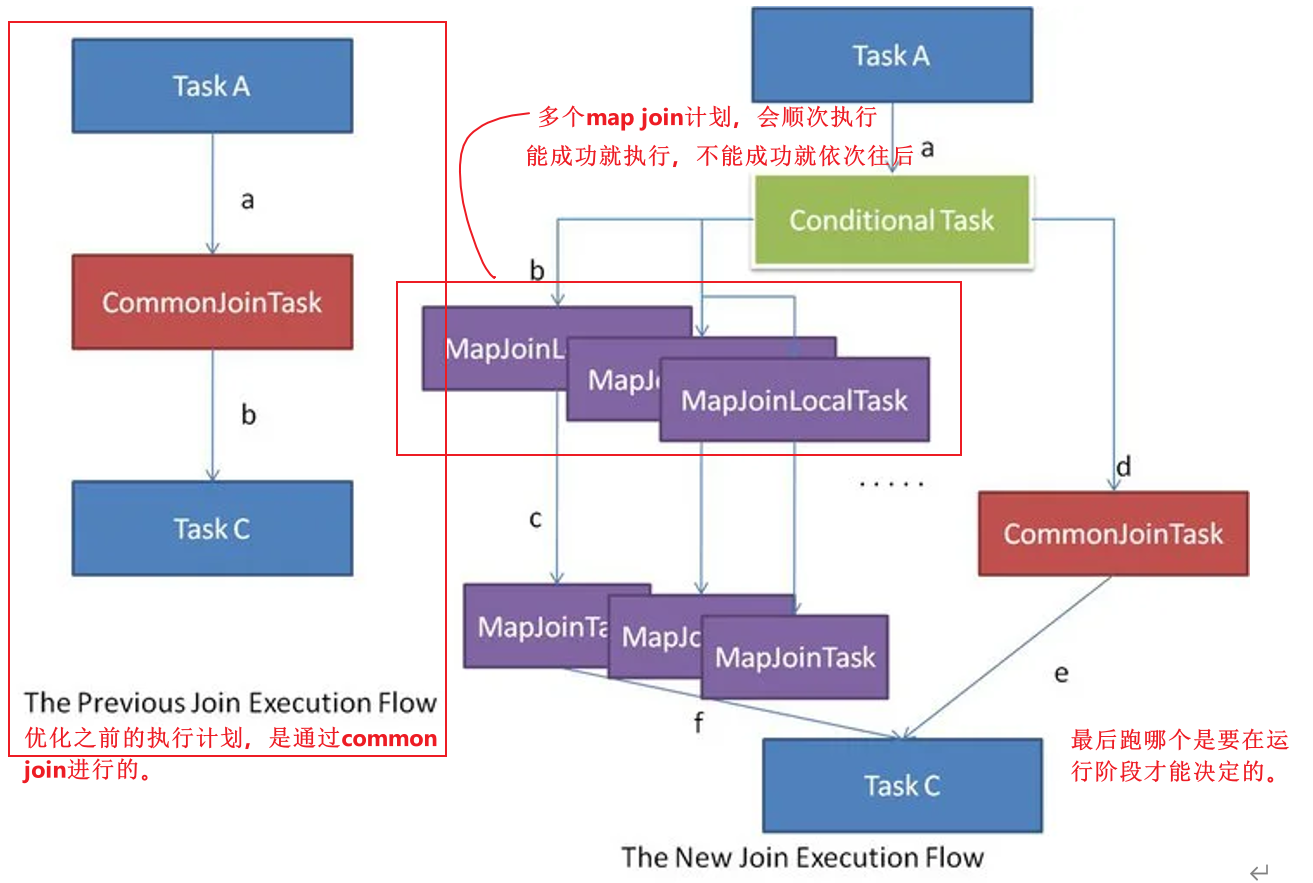
但有些Common Join任务所需的表大小,在SQL的编译阶段是未知的(例如对子查询进行join操作),所以这种Common Join任务是否能转换成Map Join任务在编译阶是无法确定的。
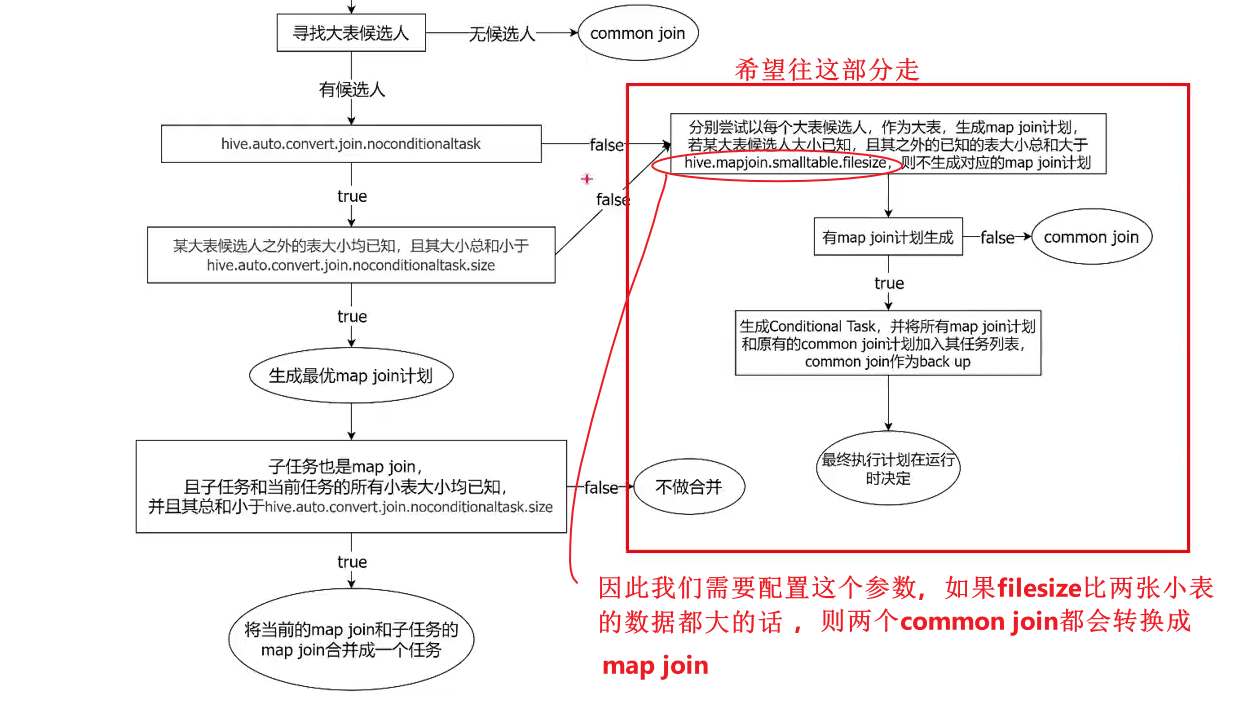
针对这种情况,Hive会在编译阶段生成一个条件任务(Conditional Task),其下会包含一个计划列表,计划列表中包含转换后的Map Join任务以及原有的Common Join任务。

- 这个条件任务会包含所有可能的map join任务。
- 原有的Common Join任务是作为一个后备任务的。
最终具体采用哪个计划,是在运行时决定的。大致思路如下图所示:
- 在表已知大小的情况下,就不需要使用这个conditional task了。
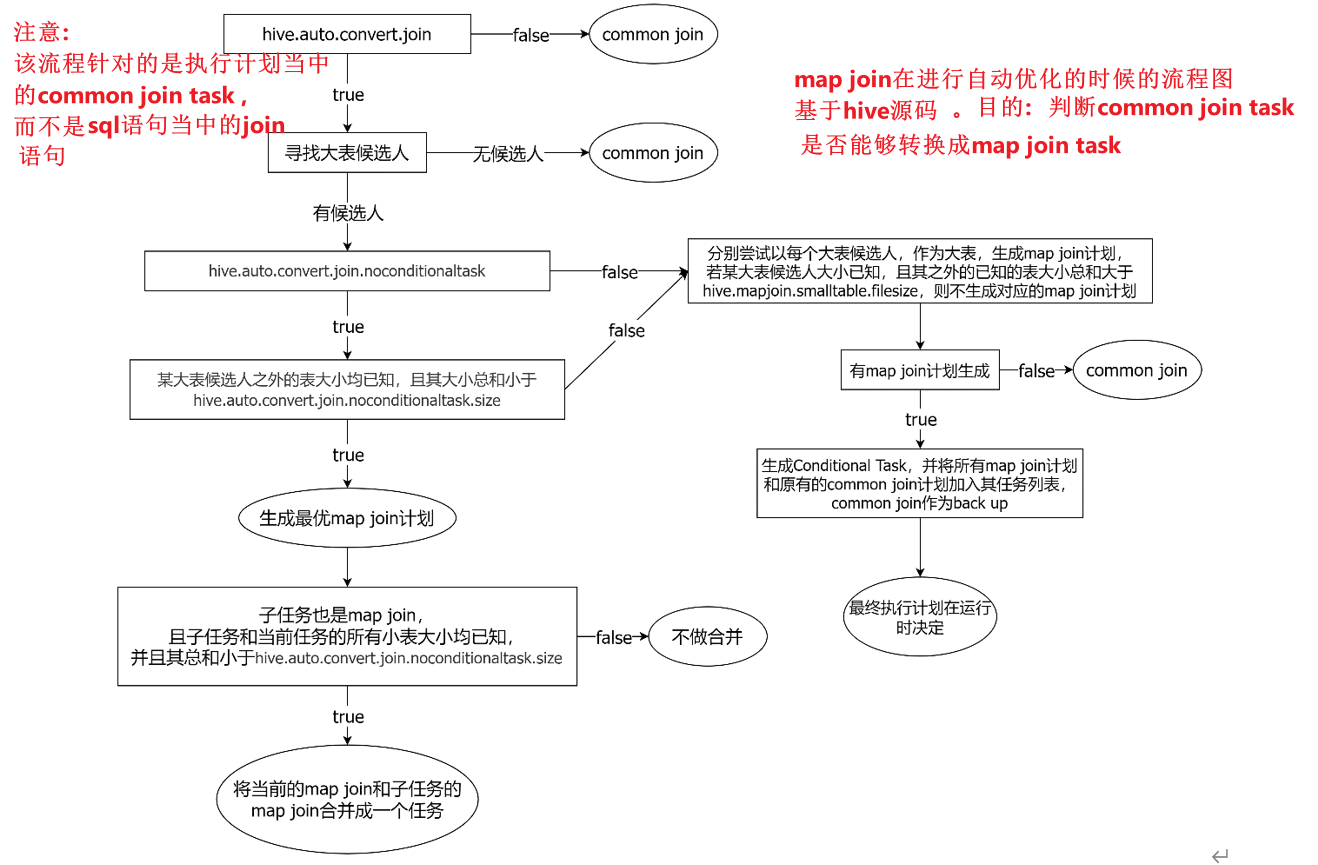
假设现在是a表 join b表
寻找大表候选人阶段:
1、如果是left join,则大表候选人为a表。
2、如果是inner join,则大表候选人为a表和b表。
3、如果是right join,则大表候选人为b表。
4、如果是full join,则这种情况下无法进行map join。因为这时候必须保证返回a和b的全部数据。但是map join的原理是缓存大表,遍历小表,因此无法做到。
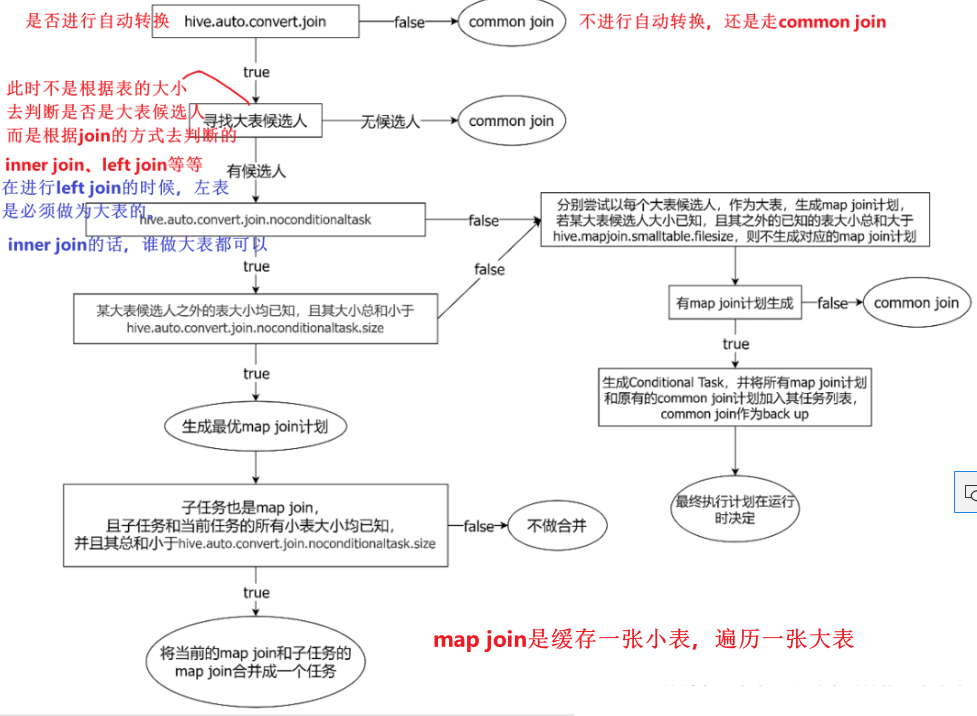
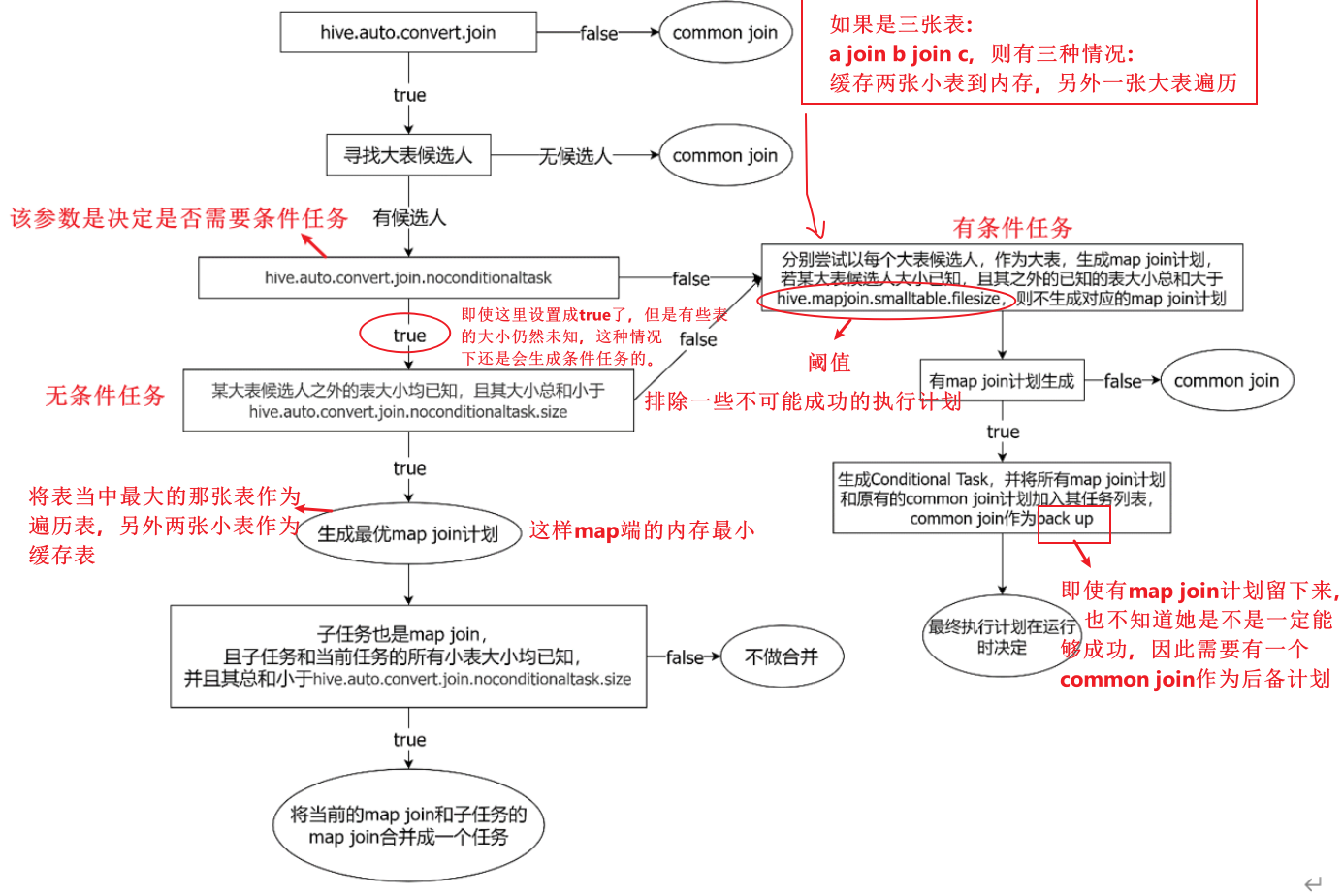
图中涉及到的参数如下:
1、启动Map Join自动转换
set hive.auto.convert.join=true;
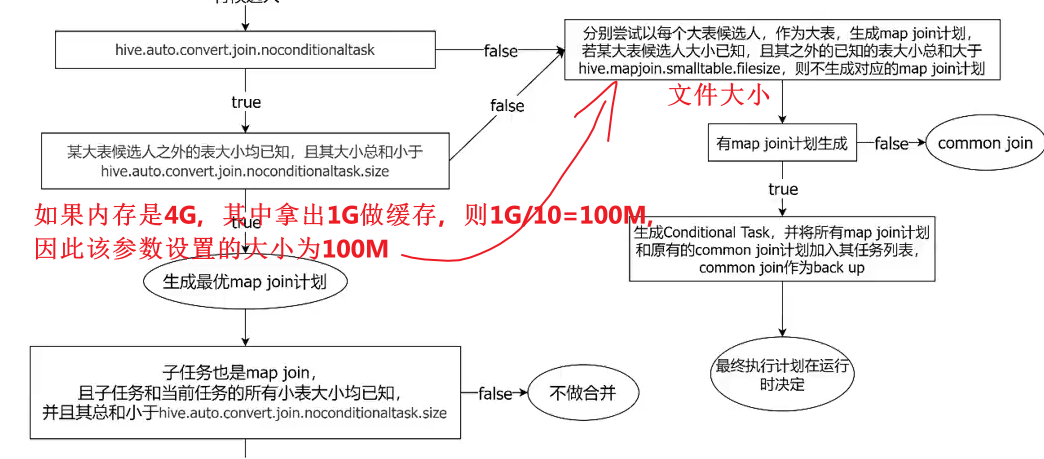
2、一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的已知大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
3、开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
4、无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;
(2)map join案例
(1)首先查看下面的sql语句优化前是如何执行的。

- 可以看到这是多表join,并且关联的字段是不同的。字段不同,因此是两个common join task。
不进行优化,所以下面这个参数需要关闭,下面这个参数是自动进行map join优化的子开关。
set hive.auto.convert.join=false;
使用explain查看执行计划
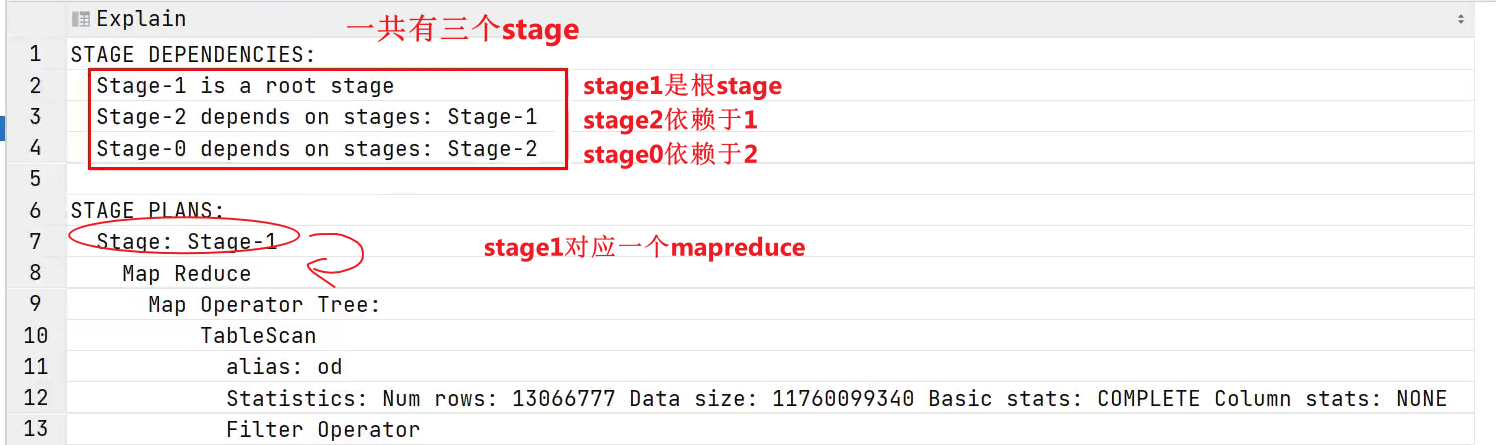
- stage1做了什么?
stage1的第一个tablescan
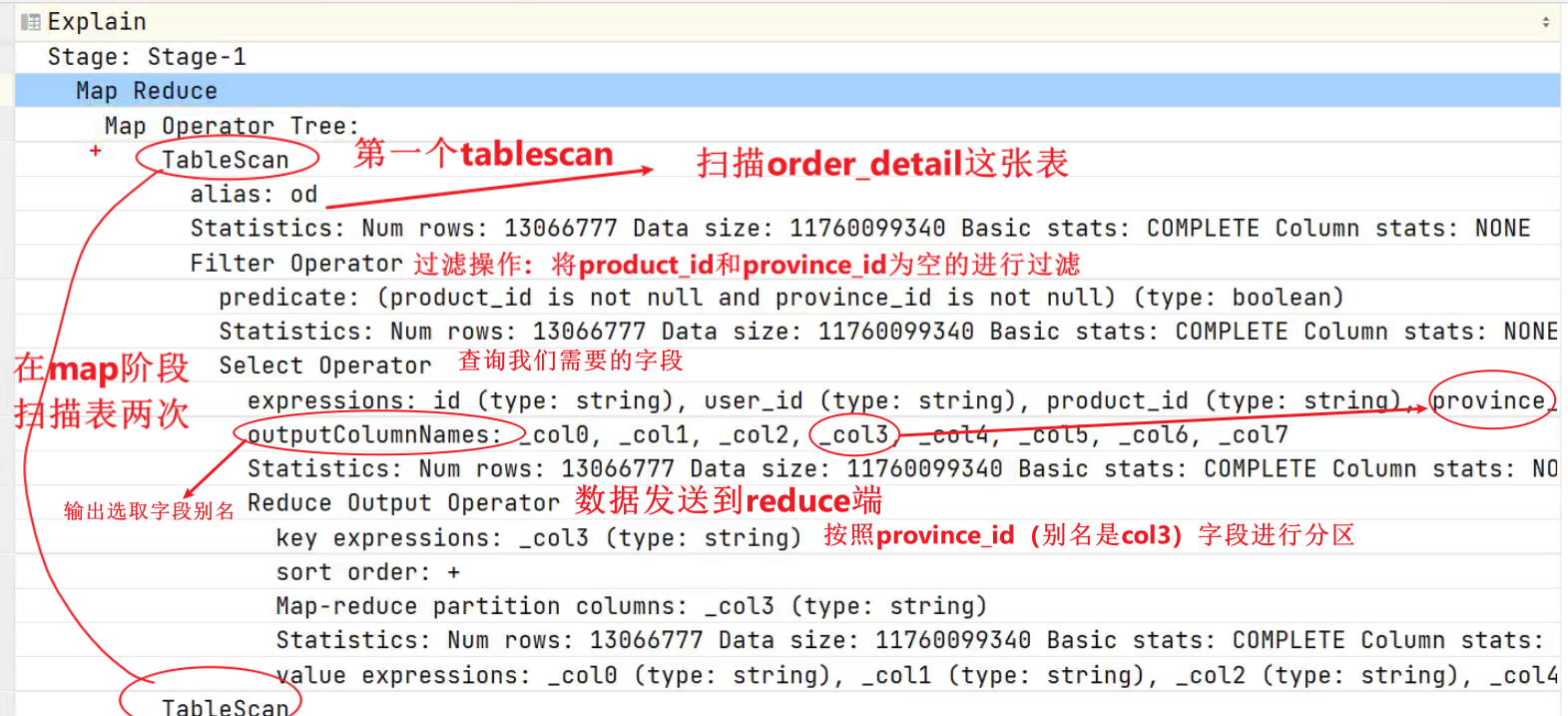
stage1的第二个tablescan
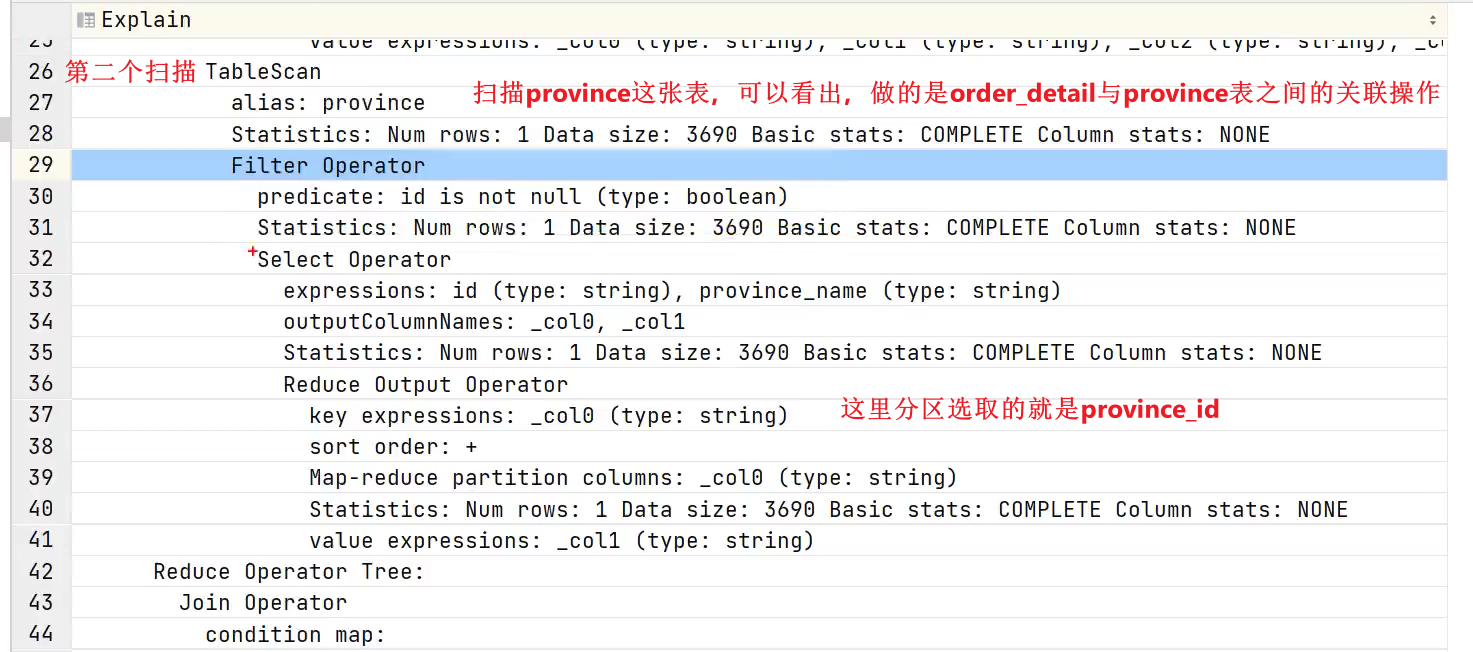
stage1的reduce阶段
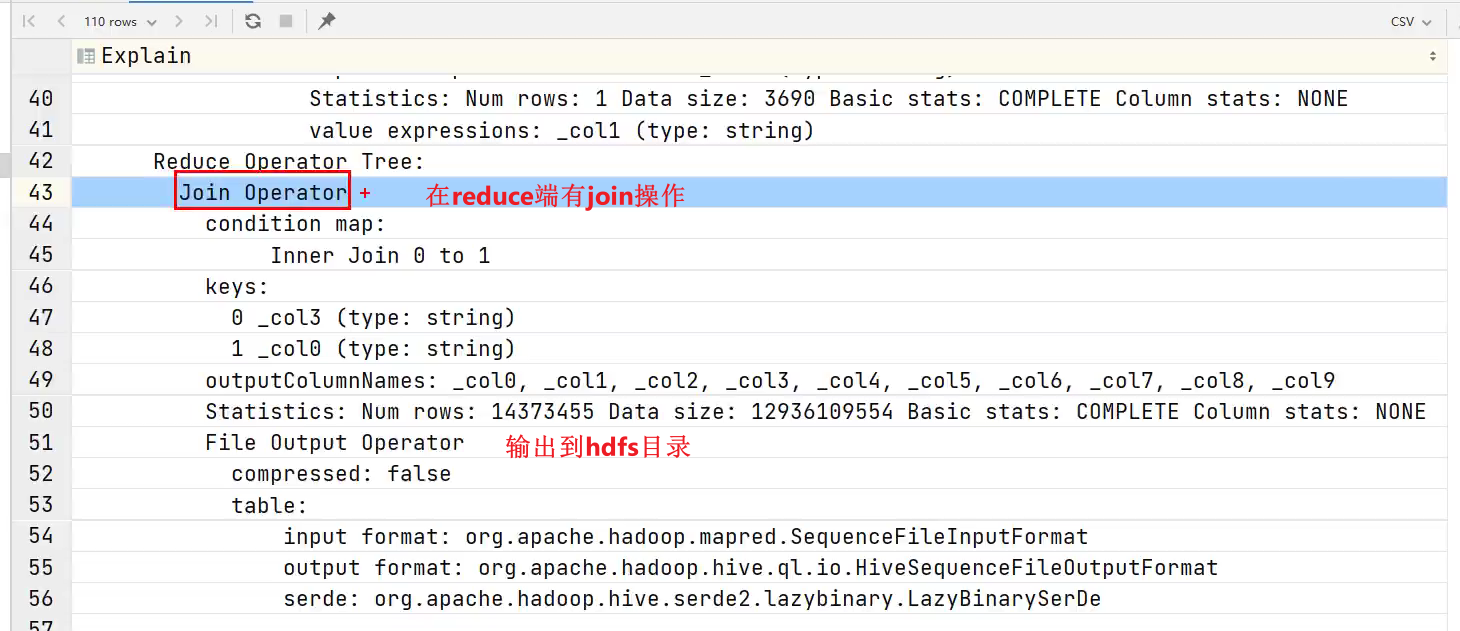
- stage2做了什么?
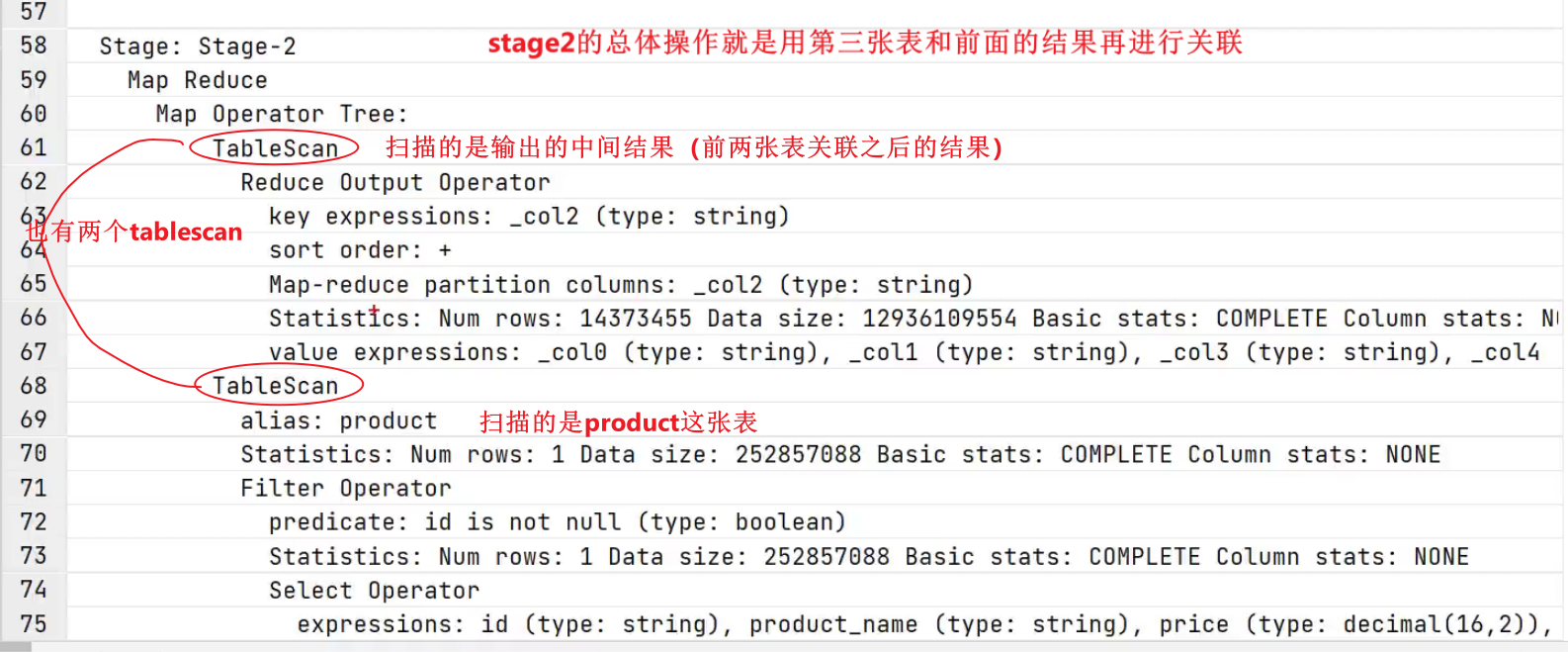
经过上面的分析发现:
我们自己写的sql语句的多表join的顺序,和真正执行计划当中表的join顺序是不同的。hive会选取最小代价的方式进行多表join。
(2)优化思路
- 进行优化的时候,必须考虑表的大小,不能脱离表的大小去考虑优化思路。
经分析,参与join的三张表,数据量如下
| 表名 | 大小 |
|---|---|
| order_detail | 1176009934(约1122M)【大表】 |
| product_info | 25285707(约24M)【小表】 |
| province_info | 369(约0.36K)【小表】 |
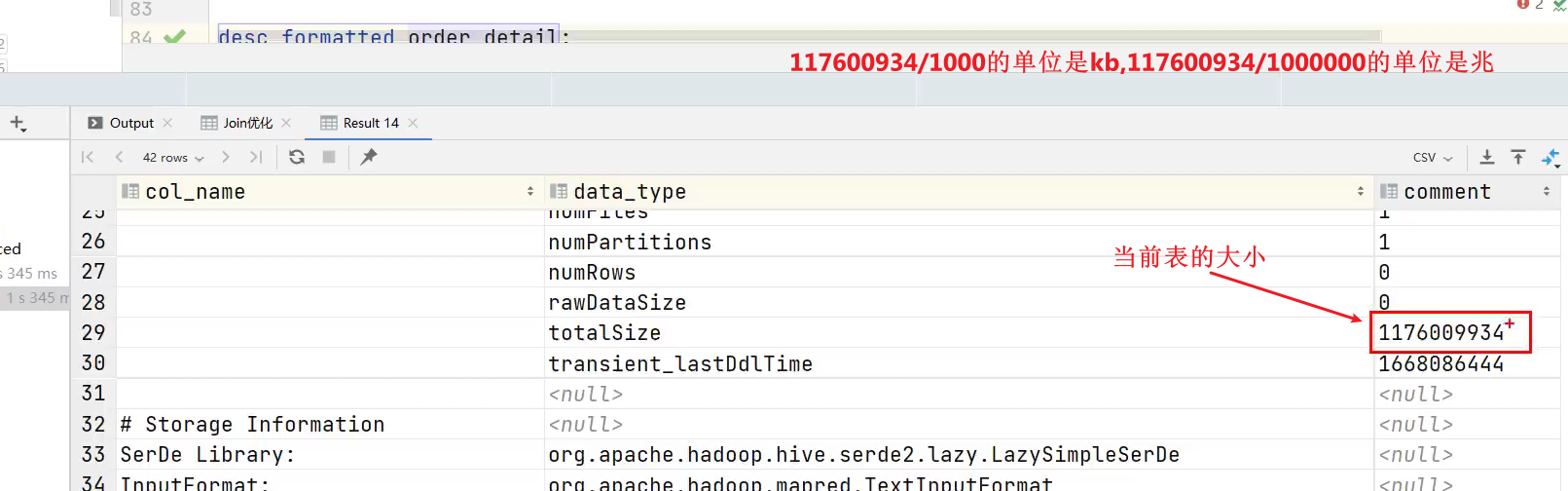
注:可使用如下语句获取表/分区的大小信息
hive (default)>
desc formatted table_name partition(partition_col='partition');
通过partition(partition_col=‘partition’),这个参数,则只会打印’partition这个分区的信息了。
三张表中,product_info和province_info数据量较小,可考虑将其作为小表,进行Map Join优化。
根据前文Common Join任务转Map Join任务的判断逻辑图,可得出以下优化方案:
方案一:(9min41s)
启用Map Join自动转换。
hive (default)>
set hive.auto.convert.join=true;
不使用无条件转Map Join,因此会产生条件任务。
hive (default)>
set hive.auto.convert.join.noconditionaltask=false;
调整hive.mapjoin.smalltable.filesize参数,使其大于等于product_info。这样的话可以保证product_info表和province_info表都放到内存里面。
hive (default)>
set hive.mapjoin.smalltable.filesize=25285707;
这样可保证将两个Common Join operator均可转为Map Join operator,并保留Common Join作为后备计划,保证计算任务的稳定。
调整优化参数之后再次查看执行计划:
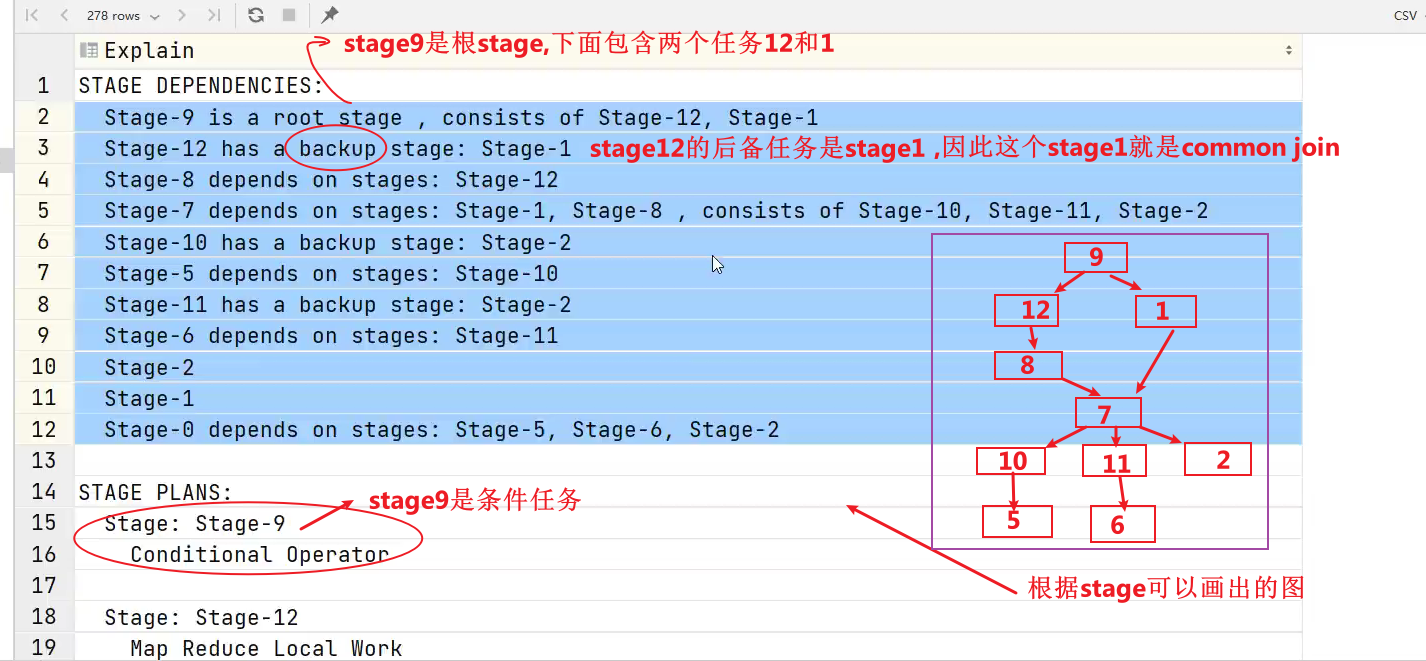
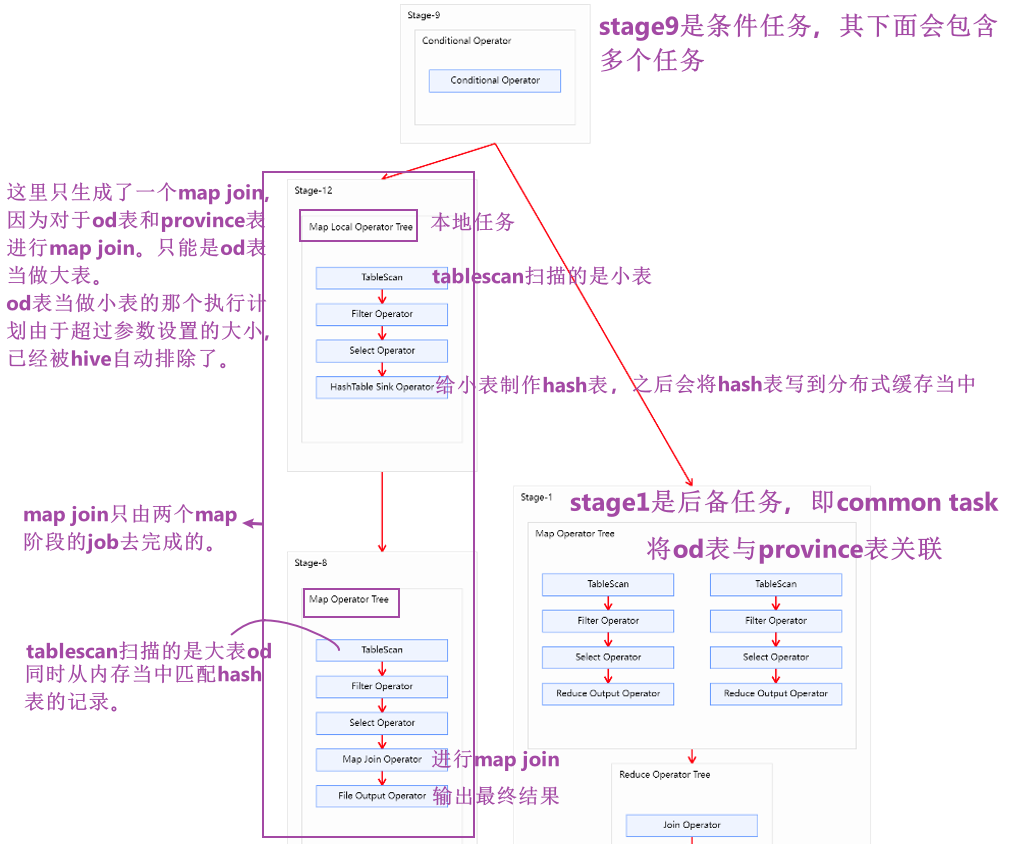
- stage5和stage6是将第三张表和中间结果各自当成大表,生成的执行任务。
将流程图放大如下所示:
方案二:(4min52s)
启用Map Join自动转换。
hive (default)>
set hive.auto.convert.join=true;
使用无条件转Map Join。也就是不需要条件任务了。因为我们三张表的大小都知道了,就不需要了。
hive (default)>
set hive.auto.convert.join.noconditionaltask=true;
没有条件任务之后,就不用再调整hive.mapjoin.smalltable.filesize参数了,而要调整
调整hive.auto.convert.join.noconditionaltask.size参数,使其大于等于product_info和province_info之和。
hive (default)>
set hive.auto.convert.join.noconditionaltask.size=25286076;
这样可直接将两个Common Join operator转为两个Map Join operator,并且由于两个Map Join operator的小表大小之和小于等于hive.auto.convert.join.noconditionaltask.size,故两个Map Join operator任务可合并为同一个。这个方案计算效率最高,但需要的内存也是最多的。
方案二的执行计划如下图所示,相比于方案一要简洁很多。
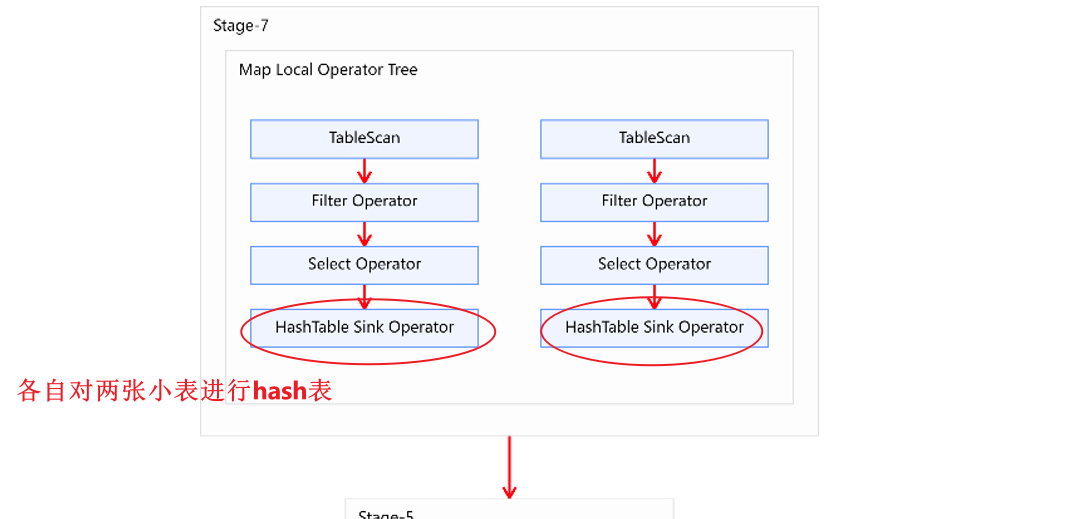
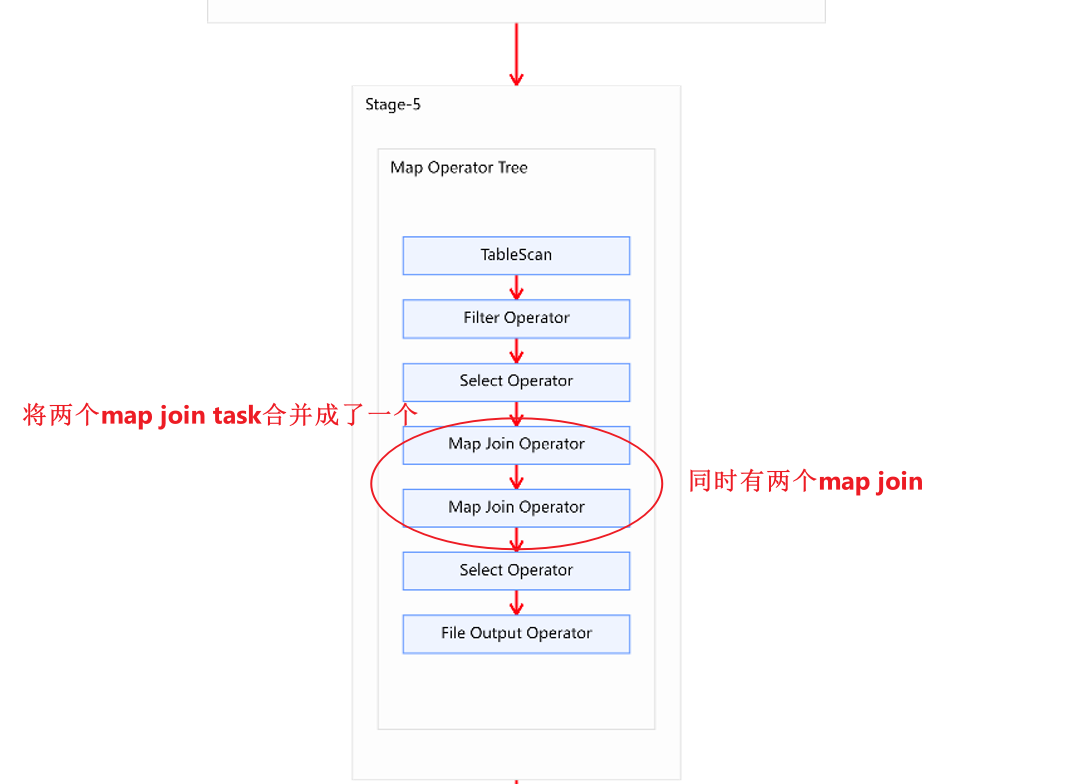
- 分析:为什么方案二比方案一更快
方案一虽然两个都是map join,但是没有进行合并。方案二不要条件任务,并且在内存充足的情况下,可以将两个map join进行合并,
方案三:(时间和方案一差不多)
启用Map Join自动转换。
hive (default)>
set hive.auto.convert.join=true;
使用无条件转Map Join。
hive (default)>
set hive.auto.convert.join.noconditionaltask=true;
调整hive.auto.convert.join.noconditionaltask.size参数,使其等于product_info。
hive (default)>
set hive.auto.convert.join.noconditionaltask.size=25285707;
这样可直接将两个Common Join operator转为Map Join operator,但不会将两个Map Join的任务合并。该方案计算效率比方案二低,但需要的内存也更少。
- 需要注意的是,文件在磁盘当中占用的空间,和加载到内存当中占用空间的大小是不同的。例如:数据从文件当中加载到内存当中需要有一个解序列化的过程,解序列化之后数据会变大的,除此之外,数据来到内存当中,可能会封装成对象,也会有一些额外的开销。这种情况下文件的大小是远小于加载到内存当中的大小的。大小一般是10倍的差距。也就是如果文件是1G的话,内存当中会是10G。
(3)Bucket Map Join
在MR当中,Bucket Map Join不支持自动转换,发须通过用户在SQL语句中提供如下Hint提示,并配置如下相关参数,方可使用。
1)Hint提示
hive (default)>
select /*+ mapjoin(ta) */ta.id,tb.id
from table_a ta
join table_b tb on ta.id=tb.id;
2)相关参数
1、关闭cbo优化,cbo会导致hint信息被忽略
set hive.cbo.enable=false;
2、map join hint默认会被忽略(因为已经过时),需将如下参数设置为false
set hive.ignore.mapjoin.hint=false;
3、启用bucket map join优化功能
set hive.optimize.bucketmapjoin = true;
(4)Bucket Map Join案例
1)示例SQL
hive (default)>
select*
from(select*from order_detailwhere dt='2020-06-14'
)od
join(select*from payment_detailwhere dt='2020-06-14'
)pd
on od.id=pd.order_detail_id;
2)优化前
上述SQL语句共有两张表一次join操作,故优化前的执行计划应包含一个Common Join任务,通过一个MapReduce Job实现。执行计划如下图所示:
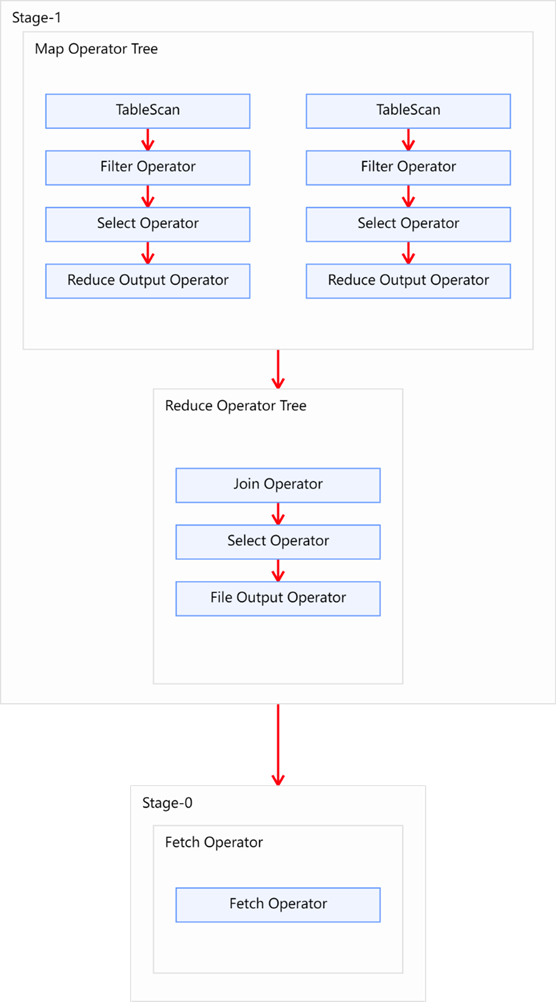
- 上面的图使用的是common join
3)优化思路
经分析,参与join的两张表,数据量如下。
| 表名 | 大小 |
|---|---|
| order_detail | 1176009934(约1122M) |
| payment_detail | 334198480(约319M) |
- 这里的大小是在底层文件的大小,而不是在内存当中的大小。
如果此时使用map join将payment_detail当成小表的话,按照之前的规律,319M*10大于3G,在内存当中需要占用3G多才能缓存小表的Hash表。
因此这个使用考虑使用bucket map join。首先确保这两张表是分桶表,分桶个数成倍数,且两张表的分桶字段需要相同。
首先需要依据源表创建两个分桶表,order_detail建议分16个bucket,payment_detail建议分8个bucket,注意分桶个数的倍数关系以及分桶字段。
–订单表
hive (default)>
drop table if exists order_detail_bucketed;
create table order_detail_bucketed(id string comment '订单id',user_id string comment '用户id',product_id string comment '商品id',province_id string comment '省份id',create_time string comment '下单时间',product_num int comment '商品件数',total_amount decimal(16, 2) comment '下单金额'
)
clustered by (id) into 16 buckets
row format delimited fields terminated by '\t';
–支付表
hive (default)>
drop table if exists payment_detail_bucketed;
create table payment_detail_bucketed(id string comment '支付id',order_detail_id string comment '订单明细id',user_id string comment '用户id',payment_time string comment '支付时间',total_amount decimal(16, 2) comment '支付金额'
)
clustered by (order_detail_id) into 8 buckets
row format delimited fields terminated by '\t';
然后向两个分桶表导入数据。
订单表:
hive (default)>
insert overwrite table order_detail_bucketed
selectid,user_id,product_id,province_id,create_time,product_num,total_amount
from order_detail
where dt='2020-06-14';
分桶表:
hive (default)>
insert overwrite table payment_detail_bucketed
selectid,order_detail_id,user_id,payment_time,total_amount
from payment_detail
where dt='2020-06-14';
然后设置以下参数:
1、关闭cbo优化,cbo会导致hint信息被忽略,需将如下参数修改为false
set hive.cbo.enable=false;
2、map join hint默认会被忽略(因为已经过时),需将如下参数修改为false
set hive.ignore.mapjoin.hint=false;
3、启用bucket map join优化功能,默认不启用,需将如下参数修改为true
set hive.optimize.bucketmapjoin = true;
最后在重写SQL语句,如下:
hive (default)>
select /*+ mapjoin(pd) */*
from order_detail_bucketed od
join payment_detail_bucketed pd on od.id = pd.order_detail_id;
优化后的执行计划如图所示:
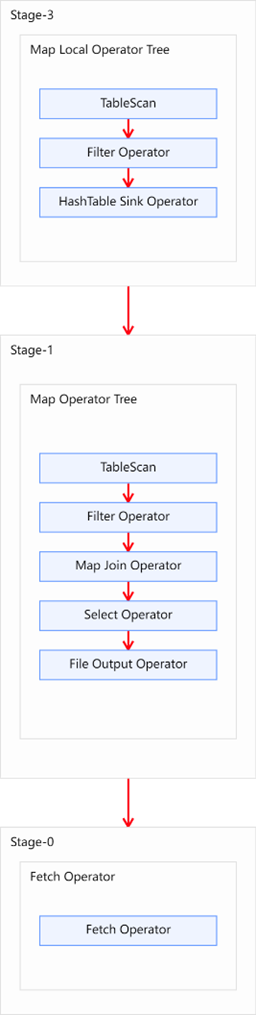
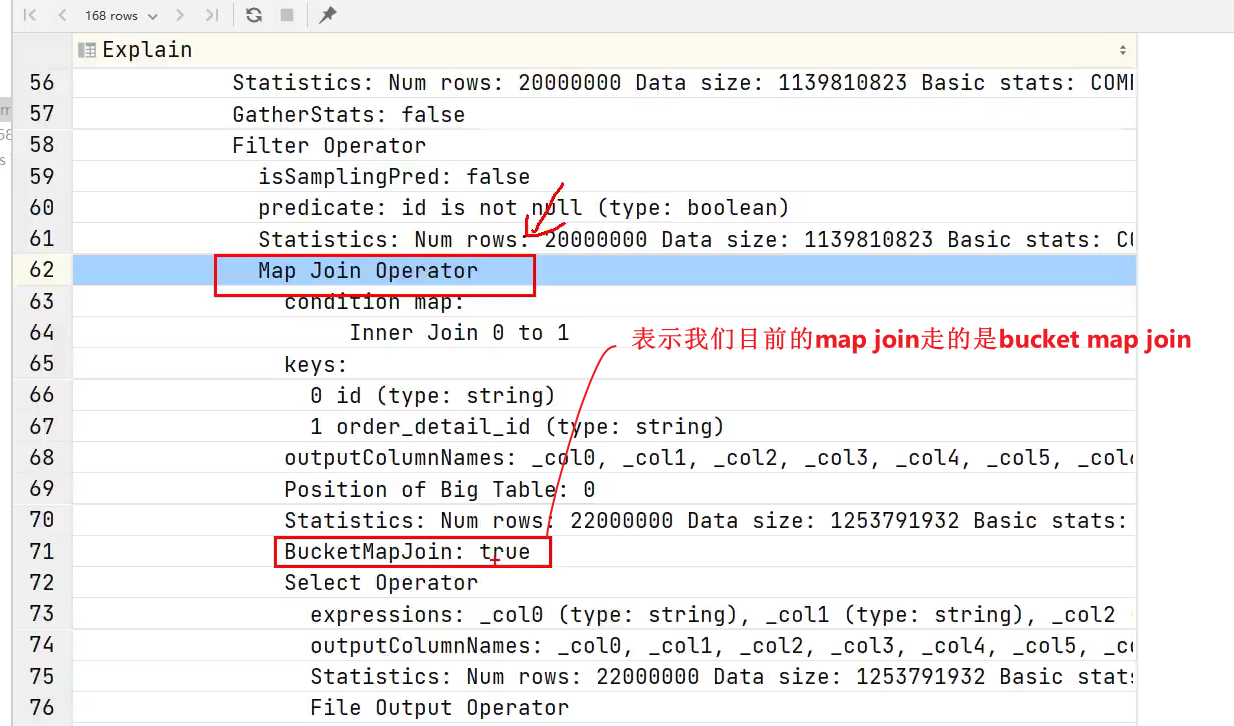
- 上面的图使用的是map join
(5) Sort Merge Bucket Map Join
Sort Merge Bucket Map Join有两种触发方式,包括Hint提示和自动转换。Hint提示已过时,不推荐使用。
下面是自动转换的相关参数:
1、启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
2、使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
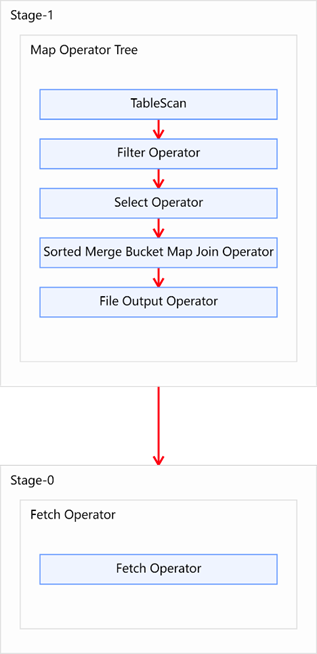
使用和上一个案例相同的数据(分桶之后多加了一个桶内有序),得到的结果如下图所示:
相关文章:
【Hive_05】企业调优1(资源配置、explain、join优化)
1、 计算资源配置1.1 Yarn资源配置1.2 MapReduce资源配置 2、 Explain查看执行计划(重点)2.1 Explain执行计划概述2.2 基本语法2.3 案例实操 3、分组聚合优化3.1 优化说明(1)map-side 聚合相关的参数 3.2 优化案例 4、join优化4.1…...
synchronized
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:JavaEE 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 synchronized 1. 特性1.1 互斥1.2 可重入 …...

Vue在页面上添加水印
第一步:在自己的项目里创建一个js文件;如图所示我在在watermark文件中创建了一个名为waterMark.js文件。 waterMark.js /** 水印添加方法 */ let setWatermark (str1, str2) > {let id 1.23452384164.123412415if (document.getElementById(id) …...
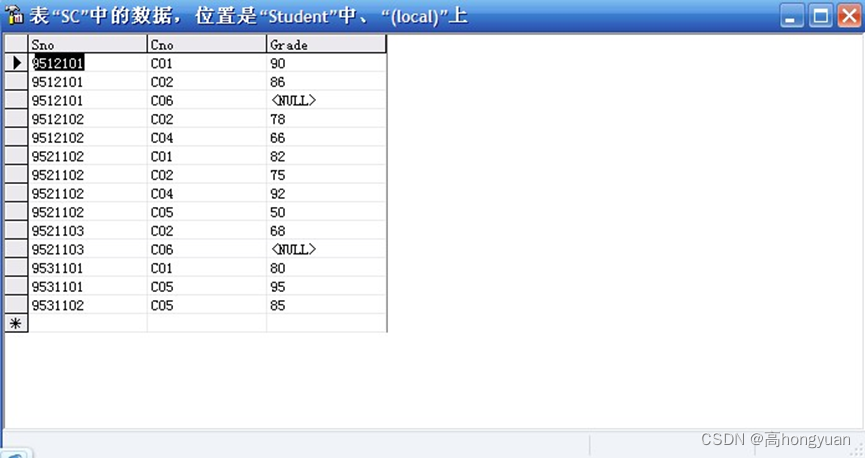
SQL server 数据库练习题及答案(练习2)
使用你的名字创建一个数据库 创建表: 数据库中有三张表,分别为student,course,SC(即学生表,课程表,选课表) 问题: --1.分别查询学生表和学生修课表中的全部数据。--2.查询成绩在70到80分之间…...

minicube搭建golang容器服务
引言 最近在自己电脑上搭建一个小型k8s环境,以学习云原生相关内容。这里我主要分为三部分记录: 容器及容器编排理论环境安装相关rpcx服务实战 还在调试中,先总结整理下,这里后续补充上我的github工程链接。 一、容器及容器编排理…...
图片批量处理:图片批量缩放,高效调整尺寸的技巧
在数字媒体时代,图片处理已是日常生活和工作中不可或缺的一部分。有时候要批量处理图片,如缩放图片尺寸,以满足不同的应用需求。现在一起来看看办公提效式具如何高效的将图片批量处理方法,快速、准确地批量调整图片尺寸操作。 下…...

直接插入排序【从0-1学数据结构】
文章目录 💗 直接插入排序Java代码C代码JavaScript代码稳定性时间复杂度空间复杂度 我们先来学习 直接插入排序, 直接排序算是所有排序中最简单的了,代码也非常好实现,尽管直接插入排序很简单,但是我们依旧不可以上来就直接写代码,一定要分析之后才开始写,这样可以提…...

C++/CLI——1简介
C/CLI——1简介 如果你是.net程序员,不免会用到C/C写的库。对于简单的调用,可以直接使用DllImport来完成就可以,详情可参考C#调用C/C从零深入讲解。但是对于复杂的C类和对象,尤其是类似于OCC的大型C项目,DllImport可能…...
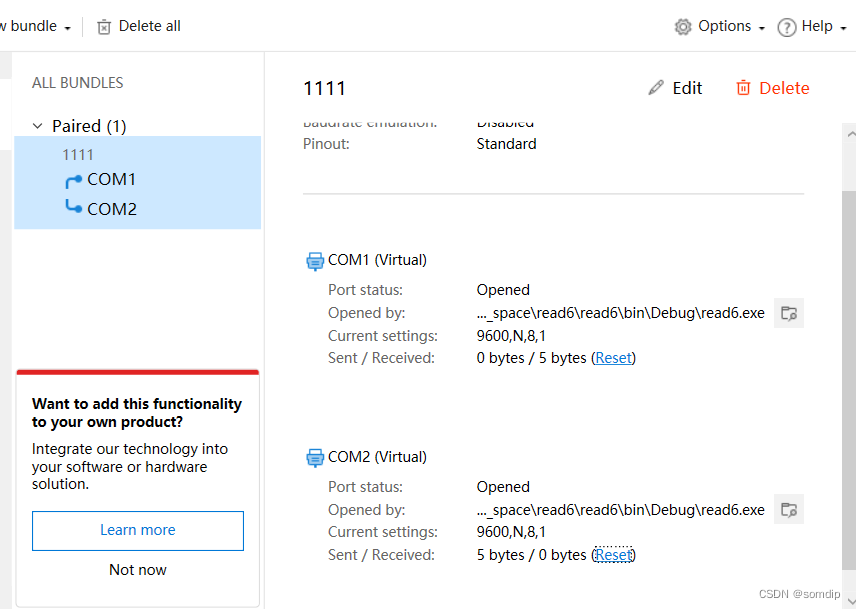
C#实现串口通讯
1、官网下载Launch Virtual Serial Port Driver Virtual Serial Port Driver - create and emulate virtual COM port,开个虚拟串口: Pair模式(一对,成双成对的意思,就是COM1向COM2传或者COM2向COM1,好比两台机器的CO…...
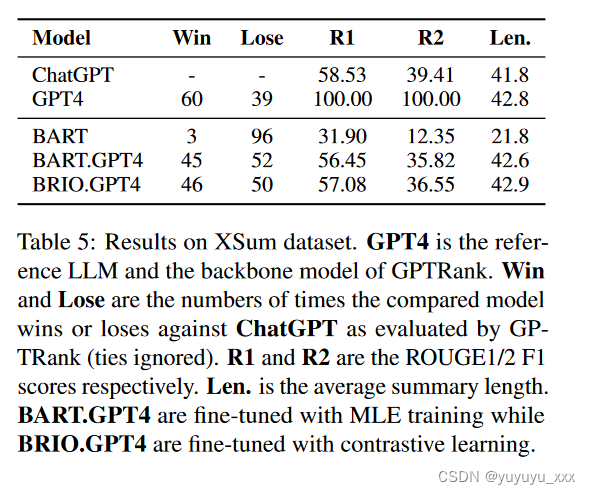
NLP论文阅读记录 - 以大语言模型为参考学习总结
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作2.1文本生成模型的训练方法2.2 基于LLM的自动评估2.3 LLM 蒸馏和基于 LLM 的数据增强 三.本文方法3.1 Summarize as Large Language Models3.1.1 前提3.1.2 大型语言模型作为参考具有…...

前端---资源路径
当我们使用img标签显示图片的时候,需要指定图片的资源路径,比如: <img src"images/logo.png">这里的src属性就是设置图片的资源路径的,资源路径可以分为相对路径和绝对路径。 1. 相对路径 从当前操作 html 的文档所在目录算…...

【2024考研】心情记录
今天是12.26日。距离24考研已经过去了2天,自认为缓过来了,故写下这篇文章。 25日早上简单过了一下答案,但实在是记不住答案了,不知道是我的脑子抵触还是怎的,像一块灰色的布遮住了我的记忆,羞于打开&#x…...
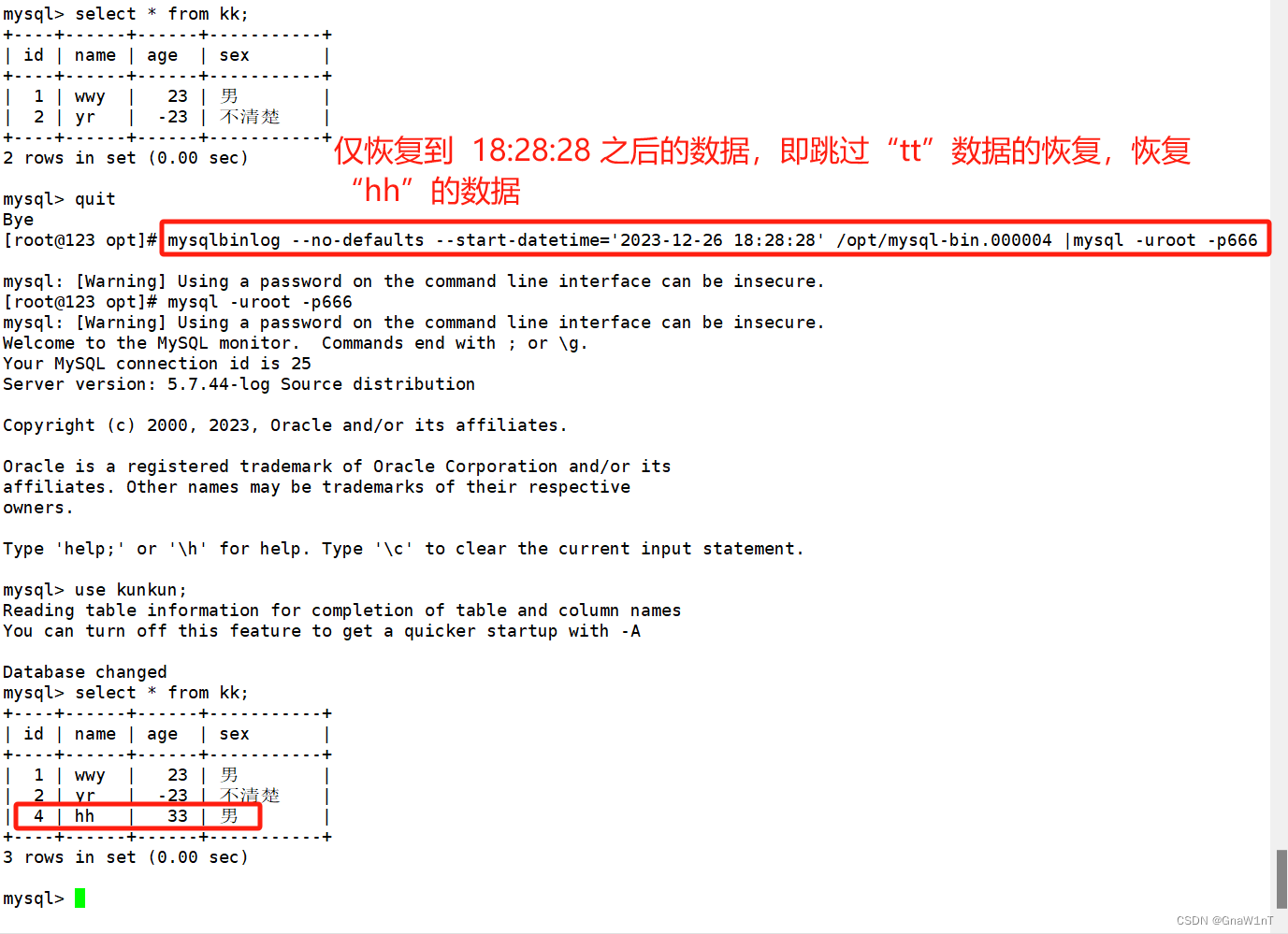
MySQL数据库日志管理和数据的备份及恢复
目录 MySQL日志管理 数据库备份的重要性 数据库备份的分类 从物理与逻辑的角度 从数据库的备份策略角度 常见的备份方法 物理冷备 专用备份工具mysqldump或mysqlhotcopy 启用二进制日志进行增量备份 第三方工具备份 MySQL完全备份与恢复 MySQL完全备份 物理冷备份与…...
)
node-schedule nodejs定时提醒(并判断段是否是工作日)
概述 工作中有个需求:在特定的时间发送一些消息,也就是说比如在每天的7点发送消息:该起床了。一开始我想用定时器每分钟每分钟的去查当前时间,但好像有点蠢,然后我找到了这个包 使用方法 安装 npm install node-sc…...

LeetCode 75| 前缀和
目录 1732 找到最高海拔 724 找到数组的中心下标 1732 找到最高海拔 class Solution { public:int largestAltitude(vector<int>& gain) {int res 0;int sum 0;for(int num : gain){sum num;res max(res,sum);}return res;} }; 时间复杂度O(n) 空间复杂度O(…...
, HSpider)
智能,轻量,高效的爬虫工具 (爬虫宝第一代), HSpider
场景 之前玩爬虫宝一时爽,但是我很快发现了一个致命的问题。就是chat3.5 有时候误判,Claude2 是遇到大一点的html就无法解析,chat4 Api没有申请下来,chat3.5 误判这个可以纠正,但是每次爬取花费的钱都是2刀以上&#…...
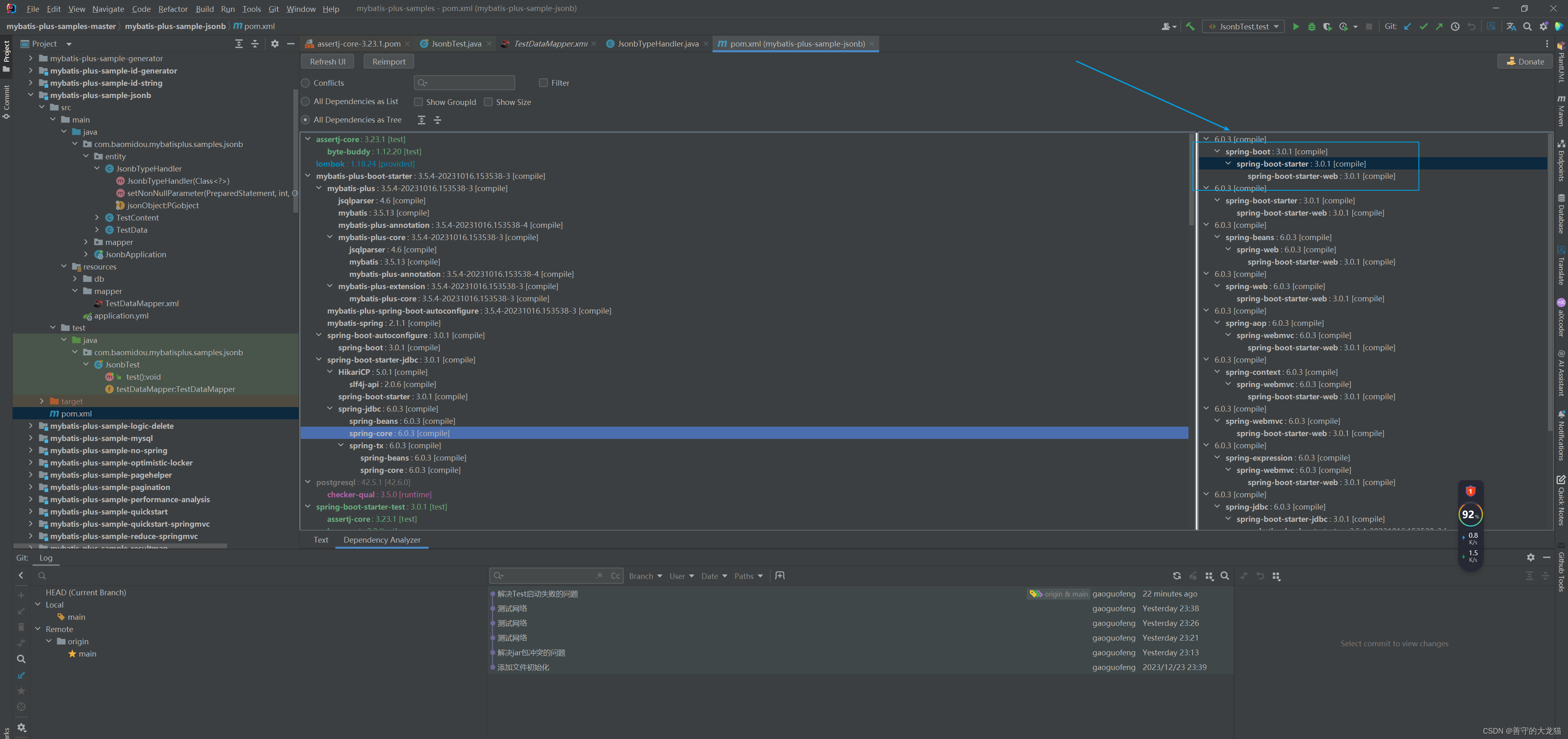
IDEA Maven Helper插件 解决jar冲突
Jar包冲突报错 程序抛出java.lang.ClassNotFoundException异常; 程序抛出java.lang.NoSuchMethodError异常; 程序抛出java.lang.NoClassDefFoundError异常; 程序抛出java.lang.LinkageError异常等;Maven Jar包管理机制 在Maven项…...
)
装饰 Web3 项目的用户交互界面(Web3项目二实战之四)
用户交互界面是Web3项目必不可少的,毕竟,Web3项目最终是面向用户的,所以,Web3项目总得需要一个优美的UI界面,已达到用户在视觉上精彩盛宴。 诚然,一个Web3项目若到了用户交互界面,大体上,这个Web3项目也将告一段落了。 没错,Web3第二个项目,也将终结于本篇,顺势拉开…...

【数据库系统概论】第3章-关系数据库标准语言SQL(3)
文章目录 3.5 数据更新3.5.1 插入数据3.5.2 修改数据3.5.3 删除数据 3.6 空值的处理3.7 视图3.7.1 建立视图3.7.2 查询视图3.7.3 更新视图3.7.4 视图的作用 3.5 数据更新 3.5.1 插入数据 注意:插入数据时要满足表或者列的约束条件,否则插入失败&#x…...
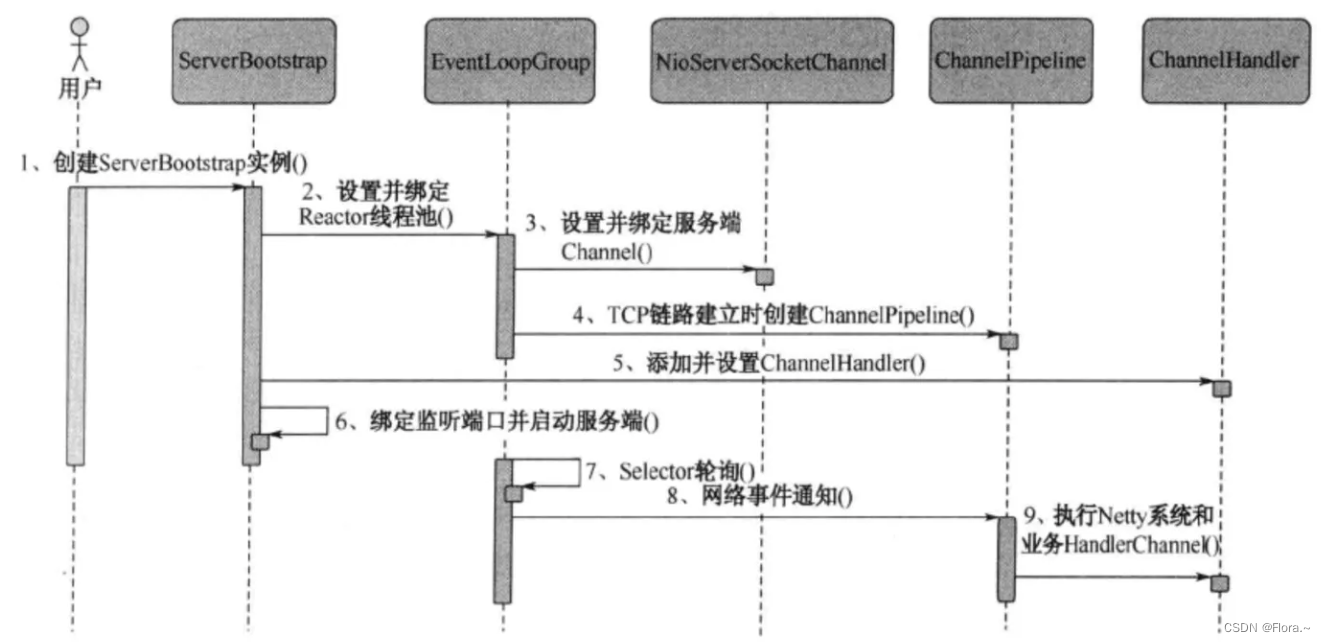
理解io/nio/netty
一、io io即input/output,输入和输出 1.1 分类 输入流、输出流(按数据流向) 字节流(InputStream/OutputStream(细分File/Buffered))、字符流(Reader/Writer(细分File/Buffered/pu…...

电赛小车避坑指南:从2011到2024,那些年我们踩过的传感器和通信模块的‘坑’
电赛小车避坑指南:从2011到2024,那些年我们踩过的传感器和通信模块的"坑" 参加全国大学生电子设计竞赛的同学们都知道,小车控制类赛题一直是热门选项。从2011年的双车自主超车到2024年的自动行驶小车,这些题目看似简单&…...

低成本自动化方案:OpenClaw+Qwen3-32B替代SaaS API调用实测
低成本自动化方案:OpenClawQwen3-32B替代SaaS API调用实测 1. 为什么选择本地AI自动化方案 去年我在处理海外客户邮件时,每月需要支付近200美元的SaaS服务费。这些费用主要消耗在邮件分类、摘要生成和自动回复等基础功能上。当我发现OpenClaw框架可以对…...

为什么操作 UI 必须加 `lcd_mutex` 互斥锁?不用会怎样?
1. 先给结论(你必须记住) LVGL 所有界面操作(创建文字、按钮、刷新屏幕)都不是线程安全的。 意思是: 绝对不能有两个线程同时操作 LVGL 界面! 线程A:LVGL 主线程(一直在刷新屏幕&…...
 接口设计)
图床项目(二) 接口设计
接口设计 1 . muduo 网络模型 该模型相较于普通的reactor模型复杂一点,其中包括mainReactor 和 多个 subReactor ,其中每一个 subReactor对应一个线程。 其中 mainReactor 负责处理新连接 , 并将连接均匀分配给 subReactor ,后续…...

CasRel开源大模型部署教程:一键拉取镜像+5分钟完成SPO推理
CasRel开源大模型部署教程:一键拉取镜像5分钟完成SPO推理 1. 什么是CasRel关系抽取模型 如果你需要从大段文字中自动找出"谁做了什么"、"谁是什么"这样的信息,CasRel模型就是你的得力助手。这个模型专门用来从文本中提取主体-谓语…...

3分钟搞定网易云音乐加密文件:NCMD解密工具终极指南
3分钟搞定网易云音乐加密文件:NCMD解密工具终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐的NCM加密文件无法在其他播放器播放而烦恼吗?今天我要为你介绍一款简单高效的音频解密神器…...

零成本实现3D模型跨平台迁移:Blender到Unreal Engine的无缝解决方案
零成本实现3D模型跨平台迁移:Blender到Unreal Engine的无缝解决方案 【免费下载链接】bl_datasmith Blender addon to export UE4 Datasmith format 项目地址: https://gitcode.com/gh_mirrors/bl/bl_datasmith 你是否曾遇到这样的困境:在Blender…...

从移位相加到硬件实现:FPGA二进制乘法器的设计精髓
1. 从纸笔计算到硬件逻辑:二进制乘法的本质 记得第一次学二进制乘法时,我拿着铅笔在纸上画了半天移位相加的步骤。比如计算11011011,就像小学生列竖式一样,先写下110111101,然后11011左移一位变成11010,接着…...

ChatTTS 安装与部署实战:从零搭建到性能调优
最近在做一个语音合成的项目,选型时看中了 ChatTTS,它开源的特性、不错的音质和可控性很吸引人。但在实际动手安装和部署时,发现从个人电脑跑起来到服务器上稳定服务,中间有不少坑。今天就把我这一路从零搭建到性能调优的实战经验…...

效率直接起飞!盘点2026年全网顶尖的AI论文工具
一天写完毕业论文在2026年已不再是天方夜谭。2026年最炸裂的AI论文工具,实测提速效果惊人,覆盖选题构思、文献整理、内容生成、格式排版全流程,让你高效搞定论文,告别熬夜赶工。 一、全流程王者:一站式搞定论文全链路&…...