Zookeeper在分布式命名服务中的实践
Java学习+面试指南:https://javaxiaobear.cn
命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的顺序维护能力,来为分布式系统中的资源命名。
哪些应用场景需要用到分布式命名服务呢?典型的有:
-
分布式API目录
-
分布式节点命名
-
分布式ID生成器
1、分布式API目录
为分布式系统中各种API接口服务的名称、链接地址,提供类似JNDI(Java命名和目录接口)中的文件系统的功能。借助于ZooKeeper的树形分层结构就能提供分布式的API调用功能。
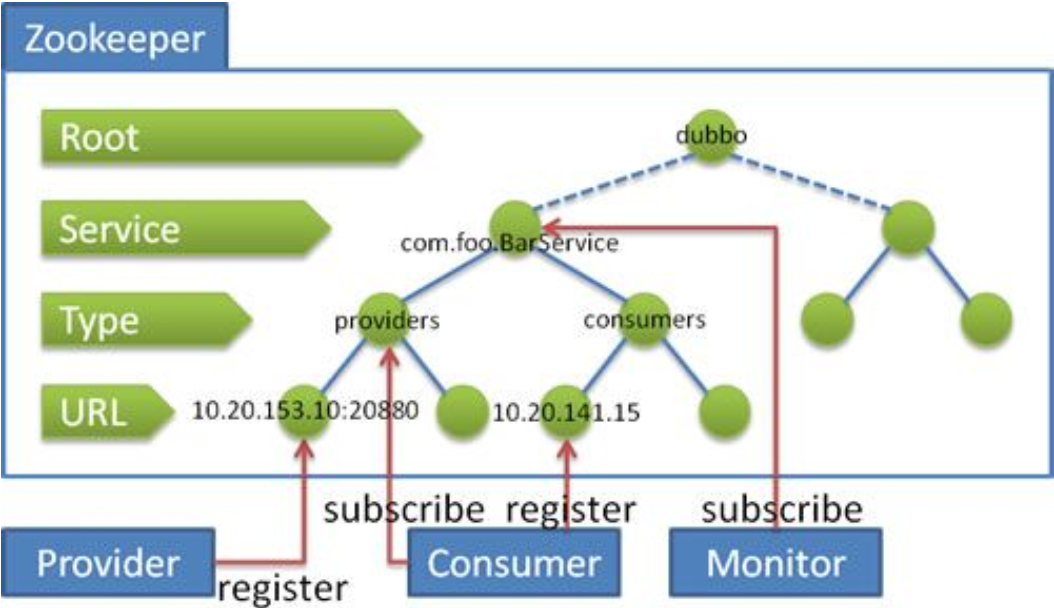
著名的Dubbo分布式框架就是应用了ZooKeeper的分布式的JNDI功能。在Dubbo中,使用ZooKeeper维护的全局服务接口API的地址列表。大致的思路为:
-
服务提供者(Service Provider)在启动的时候,向ZooKeeper上的指定节点/dubbo/${serviceName}/providers写入自己的API地址,这个操作就相当于服务的公开。
-
服务消费者(Consumer)启动的时候,订阅节点/dubbo/{serviceName}/providers下的服务提供者的URL地址,获得所有服务提供者的API。
2、分布式节点命名
一个分布式系统通常会由很多的节点组成,节点的数量不是固定的,而是不断动态变化的。比如说,当业务不断膨胀和流量洪峰到来时,大量的节点可能会动态加入到集群中。而一旦流量洪峰过去了,就需要下线大量的节点。再比如说,由于机器或者网络的原因,一些节点会主动离开集群。
如何为大量的动态节点命名呢?一种简单的办法是可以通过配置文件,手动为每一个节点命名。但是,如果节点数据量太大,或者说变动频繁,手动命名则是不现实的,这就需要用到分布式节点的命名服务。
可用于生成集群节点的编号的方案:
(1)使用数据库的自增ID特性,用数据表存储机器的MAC地址或者IP来维护。
(2)使用ZooKeeper持久顺序节点的顺序特性来维护节点的NodeId编号。
在第2种方案中,集群节点命名服务的基本流程是:
-
启动节点服务,连接ZooKeeper,检查命名服务根节点是否存在,如果不存在,就创建系统的根节点。
-
在根节点下创建一个临时顺序ZNode节点,取回ZNode的编号把它作为分布式系统中节点的NODEID。
-
如果临时节点太多,可以根据需要删除临时顺序ZNode节点。
3、分布式ID生成器
在分布式系统中,分布式ID生成器的使用场景非常之多:
-
大量的数据记录,需要分布式ID。
-
大量的系统消息,需要分布式ID。
-
大量的请求日志,如restful的操作记录,需要唯一标识,以便进行后续的用户行为分析和调用链路分析。
-
分布式节点的命名服务,往往也需要分布式ID。
-
。。。
传统的数据库自增主键已经不能满足需求。在分布式系统环境中,迫切需要一种全新的唯一ID系统,这种系统需要满足以下需求:
(1)全局唯一:不能出现重复ID。
(2)高可用:ID生成系统是基础系统,被许多关键系统调用,一旦宕机,就会造成严重影响。
有哪些分布式的ID生成器方案呢?大致如下:
- Java的UUID。
- 分布式缓存Redis生成ID:利用Redis的原子操作INCR和INCRBY,生成全局唯一的ID。
- Twitter的SnowFlake算法。
- ZooKeeper生成ID:利用ZooKeeper的顺序节点,生成全局唯一的ID。
- MongoDb的ObjectId:MongoDB是一个分布式的非结构化NoSQL数据库,每插入一条记录会自动生成全局唯一的一个“_id”字段值,它是一个12字节的字符串,可以作为分布式系统中全局唯一的ID。
前面我写过一篇关于分布式ID的设计与实现,关于其他的实现可参考这篇哈
1、基于Zookeeper实现分布式ID生成器
在ZooKeeper节点的四种类型中,其中有以下两种类型具备自动编号的能力
-
PERSISTENT_SEQUENTIAL持久化顺序节点。
-
EPHEMERAL_SEQUENTIAL临时顺序节点。
ZooKeeper的每一个节点都会为它的第一级子节点维护一份顺序编号,会记录每个子节点创建的先后顺序,这个顺序编号是分布式同步的,也是全局唯一的。
可以通过创建ZooKeeper的临时顺序节点的方法,生成全局唯一的ID
/*** @author 小熊学Java* @version 1.0* @description: TODO* @date 2023/12/17 21:08*/
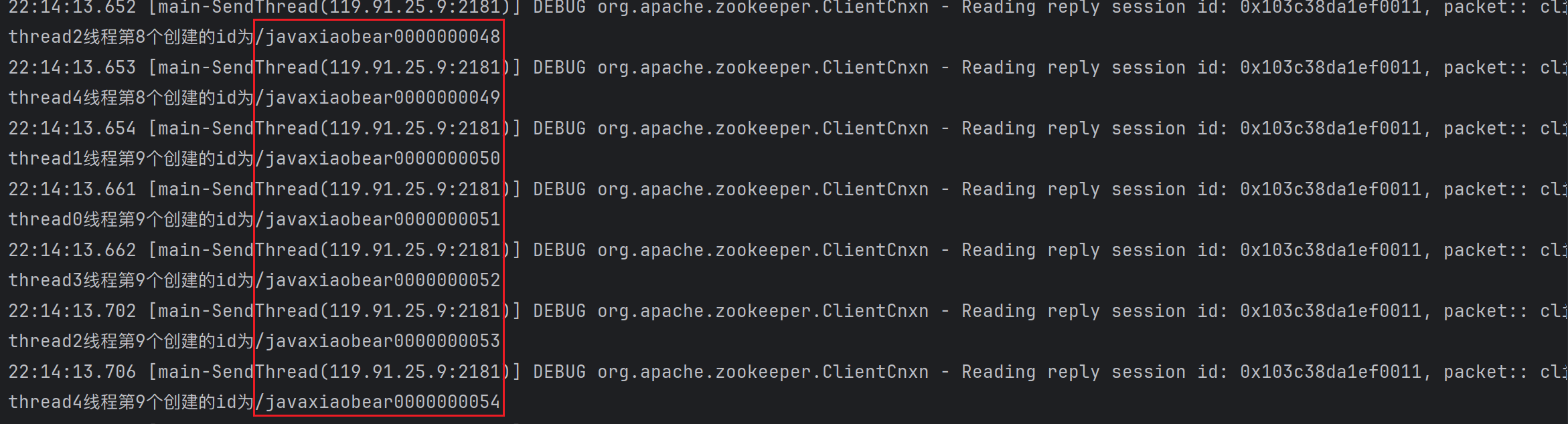
public class IDMaker {private static final String ZOOKEEPER_ADDRESS = "ip:2181";private static final int SESSION_TIMEOUT = 3000;public CuratorFramework client;public IDMaker() {// 重试策略RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);client = CuratorFrameworkFactory.newClient(ZOOKEEPER_ADDRESS, retryPolicy);client.start();}/*** 根据路径创建* @param path* @return* @throws Exception*/public String createSeqNode(String path) throws Exception{return client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);}public String createId(String path) throws Exception{String seqNode = createSeqNode(path);if (!StringUtils.isBlank(seqNode)){//获取末尾的序号int i = seqNode.lastIndexOf(path);if (i > 0){i += path.length();return i <= seqNode.length() ? seqNode.substring(i) : "";}}return seqNode;}public static void main(String[] args) throws InterruptedException {IDMaker idMaker = new IDMaker();String nodePath = "/javaxiaobear";for(int i=0;i<5;i++){new Thread(()->{for (int j=0;j<10;j++){String id = null;try {id = idMaker.createId(nodePath);System.out.println(Thread.currentThread().getName() + "线程第" + j + "个创建的id为"+ id);} catch (Exception e) {e.printStackTrace();}}},"thread"+i).start();}Thread.sleep(Integer.MAX_VALUE);}
}
执行结果
2、基于Zookeeper实现SnowFlakeID算法
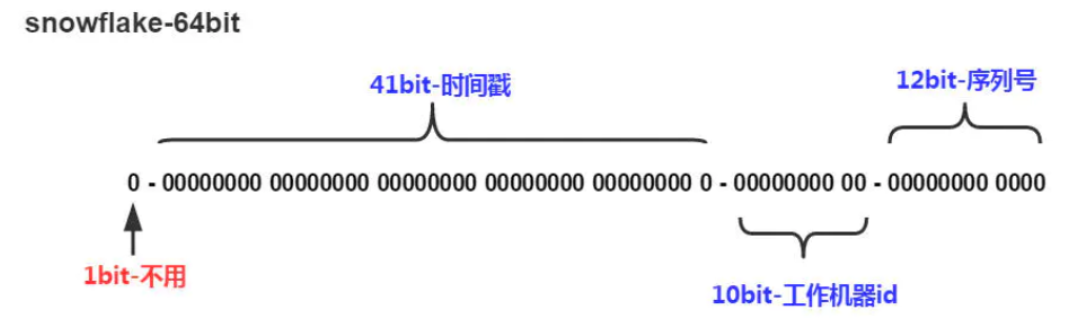
Twitter(推特)的SnowFlake算法是一种著名的分布式服务器用户ID生成算法。SnowFlake算法所生成的ID是一个64bit的长整型数字,如图10-2所示。这个64bit被划分成四个部分,其中后面三个部分分别表示时间戳、工作机器ID、序列号。
SnowFlakeID的四个部分,具体介绍如下:
(1)第一位 占用1 bit,其值始终是0,没有实际作用。
(2)时间戳 占用41 bit,精确到毫秒,总共可以容纳约69年的时间。
(3)工作机器id占用10 bit,最多可以容纳1024个节点。
(4)序列号 占用12 bit。这个值在同一毫秒同一节点上从0开始不断累加,最多可以累加到4095。
在工作节点达到1024顶配的场景下,SnowFlake算法在同一毫秒最多可以生成的ID数量为: 1024 * 4096 =4194304,在绝大多数并发场景下都是够用的。
SnowFlake算法的优点:
-
生成ID时不依赖于数据库,完全在内存生成,高性能和高可用性。
-
容量大,每秒可生成几百万个ID。
-
ID呈趋势递增,后续插入数据库的索引树时,性能较高。
SnowFlake算法的缺点:
-
依赖于系统时钟的一致性,如果某台机器的系统时钟回拨了,有可能造成ID冲突,或者ID乱序。
-
在启动之前,如果这台机器的系统时间回拨过,那么有可能出现ID重复的危险。
基于zookeeper实现雪花算法:
public class SnowflakeIdGenerator {/*** 单例*/public static SnowflakeIdGenerator instance =new SnowflakeIdGenerator();/*** 初始化单例** @param workerId 节点Id,最大8091* @return the 单例*/public synchronized void init(long workerId) {if (workerId > MAX_WORKER_ID) {// zk分配的workerId过大throw new IllegalArgumentException("woker Id wrong: " + workerId);}instance.workerId = workerId;}private SnowflakeIdGenerator() {}/*** 开始使用该算法的时间为: 2017-01-01 00:00:00*/private static final long START_TIME = 1483200000000L;/*** worker id 的bit数,最多支持8192个节点*/private static final int WORKER_ID_BITS = 13;/*** 序列号,支持单节点最高每毫秒的最大ID数1024*/private final static int SEQUENCE_BITS = 10;/*** 最大的 worker id ,8091* -1 的补码(二进制全1)右移13位, 然后取反*/private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);/*** 最大的序列号,1023* -1 的补码(二进制全1)右移10位, 然后取反*/private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);/*** worker 节点编号的移位*/private final static long WORKER_ID_SHIFT = SEQUENCE_BITS;/*** 时间戳的移位*/private final static long TIMESTAMP_LEFT_SHIFT = WORKER_ID_BITS + SEQUENCE_BITS;/*** 该项目的worker 节点 id*/private long workerId;/*** 上次生成ID的时间戳*/private long lastTimestamp = -1L;/*** 当前毫秒生成的序列*/private long sequence = 0L;/*** Next id long.** @return the nextId*/public Long nextId() {return generateId();}/*** 生成唯一id的具体实现*/private synchronized long generateId() {long current = System.currentTimeMillis();if (current < lastTimestamp) {// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,出现问题返回-1return -1;}if (current == lastTimestamp) {// 如果当前生成id的时间还是上次的时间,那么对sequence序列号进行+1sequence = (sequence + 1) & MAX_SEQUENCE;if (sequence == MAX_SEQUENCE) {// 当前毫秒生成的序列数已经大于最大值,那么阻塞到下一个毫秒再获取新的时间戳current = this.nextMs(lastTimestamp);}} else {// 当前的时间戳已经是下一个毫秒sequence = 0L;}// 更新上次生成id的时间戳lastTimestamp = current;// 进行移位操作生成int64的唯一ID//时间戳右移动23位long time = (current - START_TIME) << TIMESTAMP_LEFT_SHIFT;//workerId 右移动10位long workerId = this.workerId << WORKER_ID_SHIFT;return time | workerId | sequence;}/*** 阻塞到下一个毫秒*/private long nextMs(long timeStamp) {long current = System.currentTimeMillis();while (current <= timeStamp) {current = System.currentTimeMillis();}return current;}
}

相关文章:
Zookeeper在分布式命名服务中的实践
Java学习面试指南:https://javaxiaobear.cn 命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的顺序维护能力,来为分布式系统中的资源命名。 哪些应用场景需要用到分布式命名服务呢࿱…...
说说 Spring Boot 实现接口幂等性有哪几种方案?
一、什么是幂等性 幂等是一个数学与计算机学概念,在数学中某一元运算为幂等时,其作用在任一元素两次后会和其作用一次的结果相同。 在计算机中编程中,一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数或幂等…...
Dash中的callback的使用 多input 6
代码说明 import plotly.express as pxmport plotly.express as px用于导入plotly.express模块并给它起一个别名px。这样在后续的代码中,你可以使用px来代替plotly.express,使代码更加简洁。 plotly.express是Plotly的一个子模块,用于快速创…...
)
平方矩阵()
平方矩阵1 平方矩阵2 曼哈顿距离 #include<iostream> #include<algorithm> #include<cstdio> #include<cstring>using namespace std;const int N 110;int n; int a[N][N];int main() {while(cin >> n, n){for (int i 0; i < n; i )fo…...
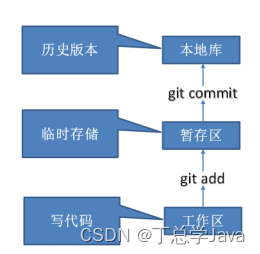
git基本命令
1、安装 介绍 安装 配置 2、git基本命令 2.1 基本操作 #1、查看空目录的git状态 $ git status fatal: not a git repository (or any of the parent directories): .git#2、初始化本地仓库:创建一个git的目录管理当前项目的所有文件版本 $ git init Initializ…...

GPU性能实时监测的实用工具
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
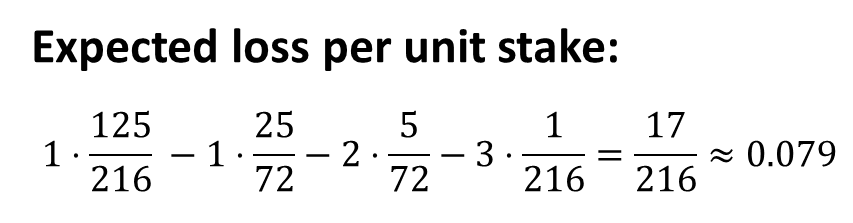
概率论中的 50 个具有挑战性的问题 [第 6 部分]:Chuck-a-Luck
一、说明 我最近对与概率有关的问题产生了兴趣。我偶然读到了弗雷德里克莫斯特勒(Frederick Mosteller)的《概率论中的五十个具有挑战性的问题与解决方案》)一书。我认为创建一个系列来讨论这些可能作为面试问题出现的迷人问题会很有趣。每篇…...

windows搭建MySQL主从补充说明
这3种情况是在HA切换时,由于是异步复制,且sync_binlog0,会造成一小部分binlog没接收完导致同步报错。 第一种:在master上删除一条记录,而slave上找不到。 第二种:主键重复。在slave已经有该记录ÿ…...

Python:GUI Tkinter
GUI编程 GUI编程(Graphical User Interface Programming)指的是用于创建图形用户界面的程序设计。这种界面采用图形方式显示信息,让用户可以通过图形化的方式与程序进行交互,而不是仅仅通过文本命令。GUI编程使得软件更加直观易用…...

制作一个可以离线安装的Visual Studio安装包
须知 前提条件,需要电脑可以正常上网且网速还行,硬盘可以空间容量足够大,怎么判断容量够用?由组件数量的多少来决定。Visual Studio 频道和发布节奏 https://learn.microsoft.com/zh-cn/visualstudio/productinfo/release-rhythm…...
机器学习——决策树(三)
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。 1、案例一 决策树用于是否赖床问题。 采用决策树进行分类,要经过数据采集、特征向量化、模型训练和决策树可视化4个步骤。 赖床数据链接:https://pan…...
模型量化之AWQ和GPTQ
什么是模型量化 模型量化(Model Quantization)是一种通过减少模型参数表示的位数来降低模型计算和存储开销的技术。一般来说,模型参数在深度学习模型中以浮点数(例如32位浮点数)的形式存储,而模型量化可以…...
一个简单的 HTTP 请求和响应服务——httpbin
拉取镜像 docker pull kennethreitz/httpbin:latest 查看本地是否存在存在镜像 docker images | grep kennethreitz/httpbin:latest 创建 deployment,指定镜像 apiVersion: apps/v1 kind: Deployment metadata:labels:app: httpbinname: mm-httpbinnamespace: mm-…...
赛题第3套)
2024黑龙江省职业院校技能大赛暨国赛选拔赛应用软件系统开发赛项(高职组)赛题第3套
2024黑龙江省职业院校技能大赛暨国赛选拔赛 应用软件系统开发赛项(高职组) 赛题第3套 目录: 需要竞赛源码资料可以私信博主。 竞赛说明 模块一:系统需求分析 任务1:制造执行MES—质量管理—来料检验(…...

云原生Kubernetes系列 | Kubernetes Secret及ConfigMap
云原生Kubernetes系列 | Kubernetes Secret及Configmap 1. Secret及Configmap使用背景简介2. Secret2.1. Secret创建方式2.1.1. 命令行方式2.1.2. 文件方式2.1.3. 变量方式2.1.4. YAML文件方式2.2. Secret使用方式2.2.1. 用于传递配置文件2.2.3. 用于传递变量3. ConfigMap1. Se…...

dev express 15.2图表绘制性能问题
dev express 15.2 绘制曲线 前端代码 <dxc:ChartControl Grid.Row"1"><dxc:XYDiagram2D EnableAxisXNavigation"True"><dxc:LineSeries2D x:Name"series" CrosshairLabelPattern"{}{A} : {V:F2}"/></dxc:XYDi…...
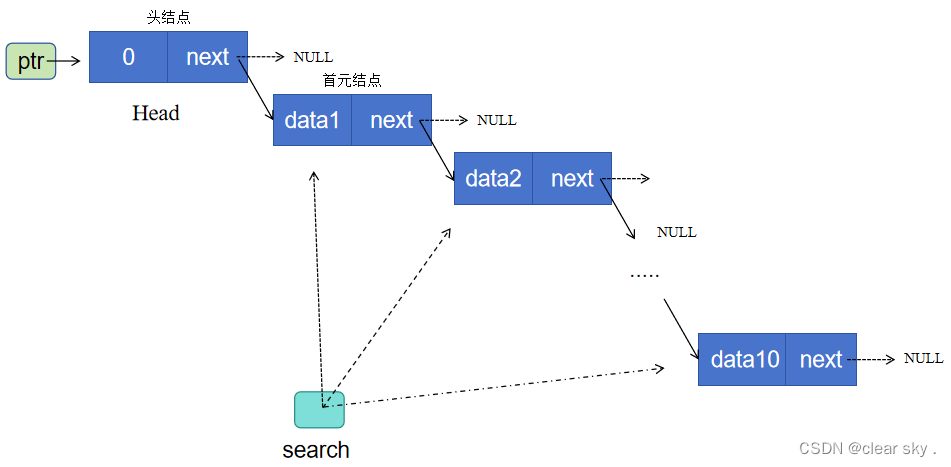
单链表的创建,插入及删除(更新ing)
1.单链表创建 ptr为头指针,指向头结点地址,即该指针变量的值为头结点地址; mov为一个辅助指针,用于将链表尾节点的指针域next指向新增节点的地址. search为一个辅助指针,用于遍历链表各节点地址,打印各节…...
C#/WPF 播放音频文件
C#播放音频文件的方式: 播放系统事件声音使用System.Media.SoundPlayer播放wav使用MCI Command String多媒体设备程序接口播放mp3,wav,avi等使用WindowsMediaPlayer的COM组件来播放(可视化)使用DirectX播放音频文件使用Speech播放(朗读器&am…...
如何使用宝塔面板+Discuz+cpolar内网穿透工具搭建可远程访问论坛服务
文章目录 前言1.安装基础环境2.一键部署Discuz3.安装cpolar工具4.配置域名访问Discuz5.固定域名公网地址6.配置Discuz论坛 前言 Crossday Discuz! Board(以下简称 Discuz!)是一套通用的社区论坛软件系统,用户可以在不需要任何编程的基础上&a…...
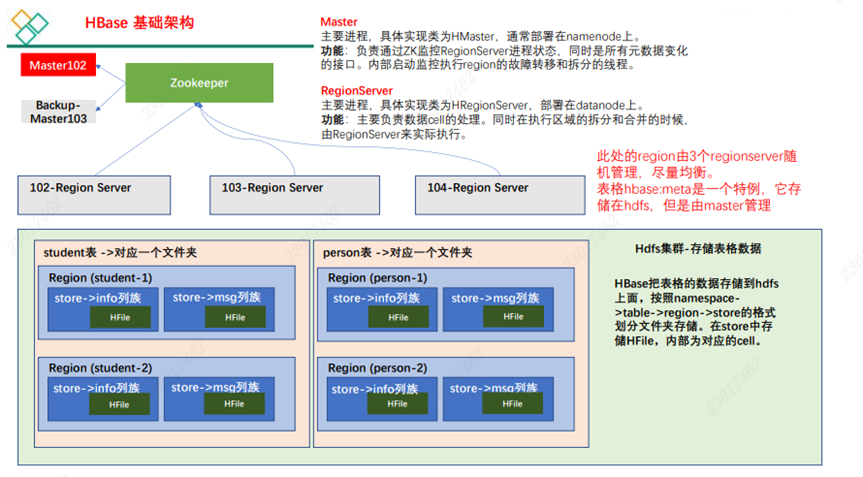
【HBase】——简介
1 HBase 定义 Apache HBase™ 是以 hdfs 为数据存储的,一种分布式、可扩展的 NoSQL 数据库。 2 HBase 数据模型 • HBase 的设计理念依据 Google 的 BigTable 论文,论文中对于数据模型的首句介绍。 Bigtable 是一个稀疏的、分布式的、持久的多维排序 m…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...