数据结构--查找
目录
1. 查找的基本概念
2. 线性表的查找
3. 树表的查找
3.1 二叉排序树
3.1.1 定义:
3.1.2 存储结构:
3.1.3 二叉排序树的查找
3.1.4 二叉排序树的插入
3.1.5 二叉排序树删除
3.2 平衡二叉树(AVL
3.2.1 为什么要有平衡二叉树
3.2.2 定义
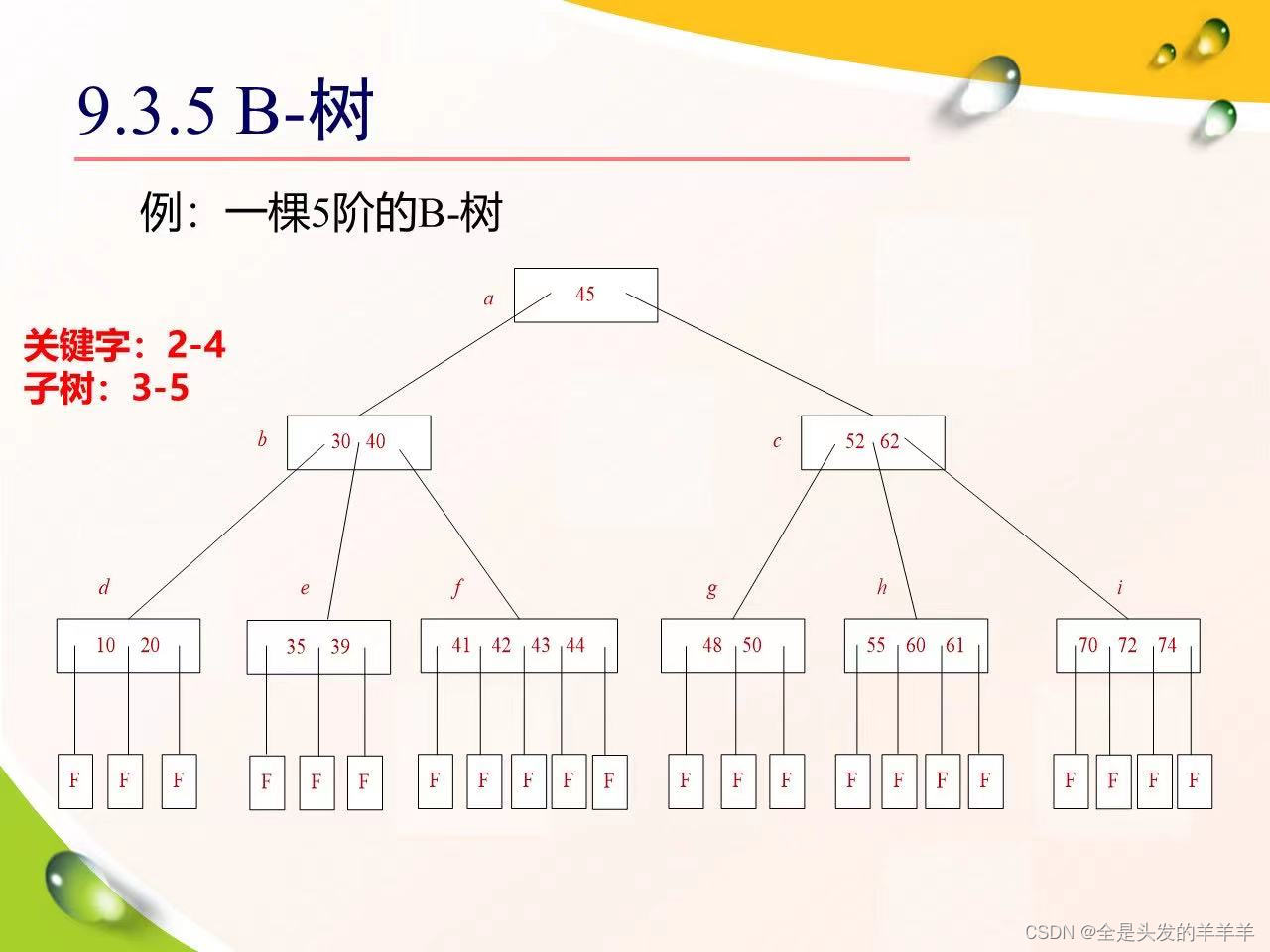
3.3 B-树
3.3.1 m阶的B-树的结构定义:
3.3.2 B-树的性质:
3.3.3 B-树的查找
3.3.4 B-树的插入
3.3.5 B-树的中序遍历
3.3.6 B-树的删除(存疑
3.4 B+树
3.5 红黑树
4. 哈希表的查找
4.1 哈希函数
4.2 哈希函数的构造方法
4.2.1 直接定址法
4.2.2 数字分析法
4.2.3 平方取中法
4.2.4 折叠法
编辑
4.2.5 除留余数法
4.3 哈希冲突
4.3.1 开放地址法
4.3.2 二次探测
4.3.3 双哈希
4.3.4 拉链法
4.4 哈希表的效率
1. 查找的基本概念
根据给定的值,在查找表中确定一个其关键字等于给定值的数据元素。
主关键字:
次关键字:
查找表分类
静态查找表(仅查询
动态查找表(有删除和插入
2. 线性表的查找
3. 树表的查找
3.1 二叉排序树
3.1.1 定义:
1. 就是若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
2. 若它的右子树不空,则右子树上所有节点的值均大于其根节点的值。
3. 其左右子树本身又各是一棵二叉排序树

3.1.2 存储结构:
typedef int DataType;
typedef struct BST_Node {DataType data;struct BST_Node *lchild, *rchild;
}BST_T, *BST_P;
void CreateBST(BST_P *T, int a[], int n)
{int i;for (i = 0; i < n; i++){Insert_BST(T, a[i]);}
}3.1.3 二叉排序树的查找
要在二叉树中找出查找最大最小元素是极简单的事情,从根节点一直往左走,直到无路可走就可得到最小值;从根节点一直往右走,直到无路可走,就可以得到最大值。
查找最小关键字:
BST_P SearchMin(BST_P root)
{if (root == NULL)return NULL;if (root->lchild == NULL)return root;else //一直往左孩子找,直到没有左孩子的结点 return SearchMin(root->lchild);
}查找最大关键字:
BST_P SearchMax(BST_P root)
{if (root == NULL)return NULL;if (root->rchild == NULL)return root;else //一直往右孩子找,直到没有右孩子的结点 return SearchMax(root->rchild);
}递归版查找(找到返回关键字的结点指针,没找到返回NULL):
BST_P Search_BST(BST_P root, DataType key)
{if (root == NULL)return NULL;if (key > root->data) //查找右子树 return Search_BST(root->rchild, key);else if (key < root->data) //查找左子树 return Search_BST(root->lchild, key);elsereturn root;
}非递归版查找:
BST_P Search_BST(BST_P root, DataType key)
{BST_P p = root;while (p) { if (p->data == key) return p;p = (key < p->data) ? p->lchild : p->rchild;}return NULL;
}3.1.4 二叉排序树的插入
插入新元素时,可以从根节点开始,遇键值较大者就向左,遇键值较小者就向右,一直到末端,就是插入点。
void Insert_BST(BST_P *root, DataType data)
{//初始化插入节点BST_P p = (BST_P)malloc(sizeof(struct BST_Node));if (!p) return;p->data = data;p->lchild = p->rchild = NULL;//空树时,直接作为根节点if (*root == NULL){*root = p;return;}//是否存在,已存在则返回,不插入if (Search_BST(root, data) != NULL) return; //进行插入,首先找到要插入的位置的父节点BST_P tnode = NULL, troot = *root;while (troot){ tnode = troot;troot = (data < troot->data) ? troot->lchild : troot->rchild;}if (data < tnode->data)tnode->lchild = p;elsetnode->rchild = p;
}3.1.5 二叉排序树删除
对于二叉排序树中的节点A,对它的删除分为两种情况:
1、如果A只有一个子节点,就直接将A的子节点连至A的父节点上,并将A删除;

2、如果A有两个子节点,我们就以右子树内的最小节点取代A,怎么得最小节点,前有有说。
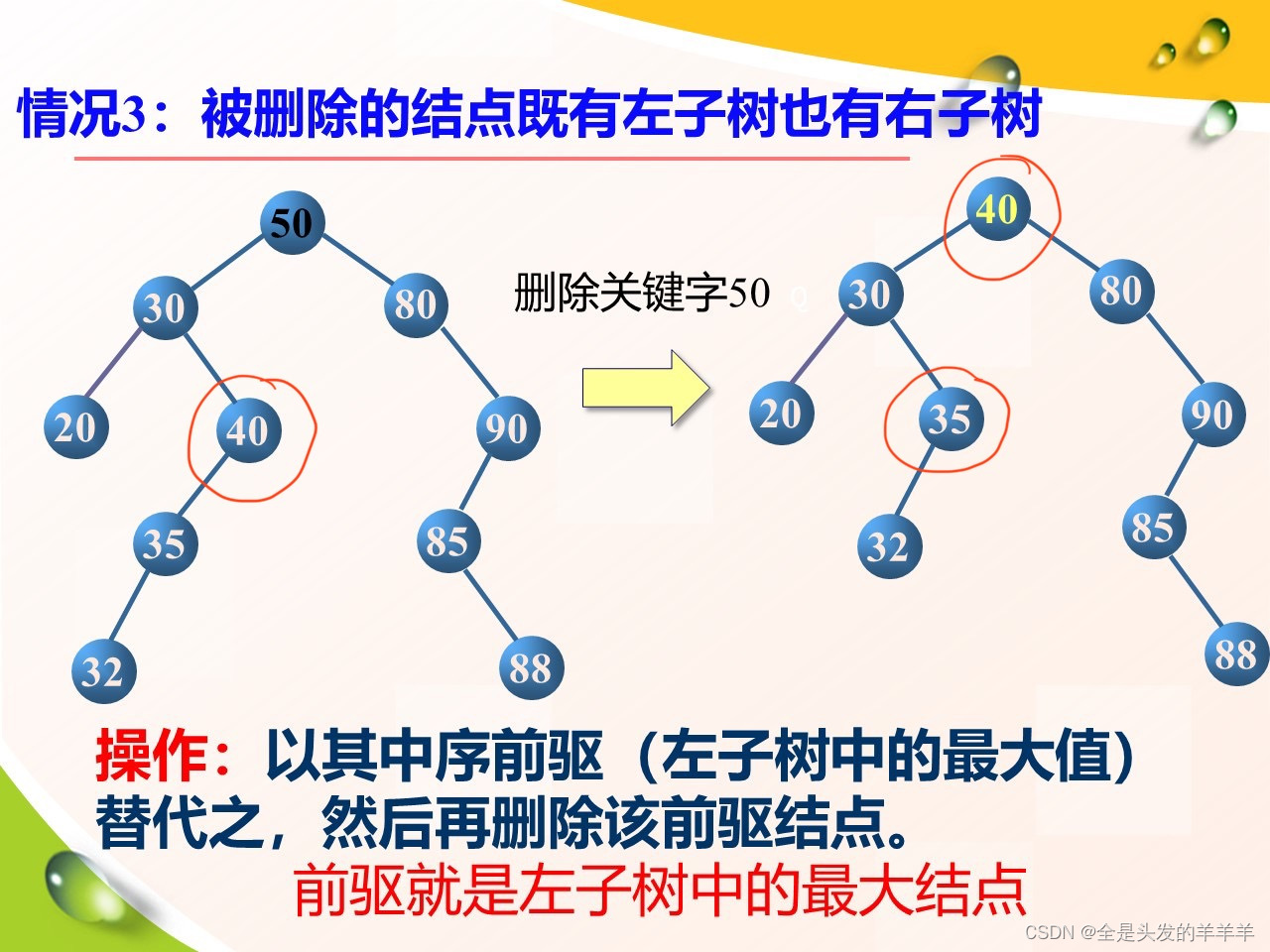
删除节点代码:
void DeleteBSTNode(BST_P *root, DataType data)
{BST_P p = *root, parent = NULL, s = NULL;if (!p) return;if (p->data == data) //找到要删除的节点了{/* It's a leaf node */if (!p->rchild && !p->lchild) *root = NULL;// 只有一个左节点else if (!p->rchild&&p->lchild) *root = p->lchild;// 只有一个右节点else if (!p->lchild&&p->rchild) *root = p->rchild;//左右节点都不空else {s = p->rchild;/* the s without left child */if (!s->lchild)s->lchild = p->lchild;/* the s have left child */else {/* find the smallest node in the left subtree of s */while (s->lchild) {/* record the parent node of s */parent = s;s = s->lchild;}parent->lchild = s->rchild;s->lchild = p->lchild;s->rchild = p->rchild;}*root = s;}free(p);}else if (data > p->data) //向右找DeleteBSTNode(&(p->rchild), data);else if (data < p->data) //向左找DeleteBSTNode(&(p->lchild), data);
}3.2 平衡二叉树(AVL
在AVL树中,任一节点对应的两棵子树的最大高度差为1,因此它也被称为高度平衡树。
3.2.1 为什么要有平衡二叉树
二叉搜索树一定程度上可以提高搜索效率,但是当原序列有序时,例如序列 A = {1,2,3,4,5,6},构造二叉搜索树如图 1.1。依据此序列构造的二叉搜索树为右斜树,同时二叉树退化成单链表,搜索效率降低为 O(n)。

在此二叉搜索树中查找元素 6 需要查找 6 次。
二叉搜索树的查找效率取决于树的高度,因此保持树的高度最小,即可保证树的查找效率。同样的序列 A,将其改为图 1.2 的方式存储,查找元素 6 时只需比较 3 次,查找效率提升一倍。

可以看出当节点数目一定,保持树的左右两端保持平衡,树的查找效率最高。
这种左右子树的高度相差不超过 1 的树为平衡二叉树。
3.2.2 定义
1. 可以是空树。
2. 假如不是空树,任何一个结点的左子树与右子树都是平衡二叉树,并且高度之差的绝对值不超过 1。
平衡因子
定义:某节点的左子树与右子树的高度(深度)差即为该节点的平衡因子(BF,Balance Factor),平衡二叉树中不存在平衡因子大于 1 的节点。在一棵平衡二叉树中,节点的平衡因子只能取 0 、1 或者 -1 ,分别对应着左右子树等高,左子树比较高,右子树比较高。
结点的平衡因子=结点左子树的高度-结点右子树的高度

如果在一棵AVL树中插入一个新结点后造成失衡,必须立刻重新调整树的结构,使之恢复平衡
调整的基本思想
·在构造二叉排序树的过程中,每插入一个结点,首先检查是否因插入而破坏了树的平衡性
·若失衡,则找出最小的平衡子树,在保持二叉排序树特性的前提下,调整最小平衡子树使之成为新的平衡子树
最小失衡子树:在新插入的结点向上查找,以第一个平衡因子的绝对值超过 1 的结点为根的子树称为最小不平衡子树。
也就是说,一棵失衡的树,是有可能有多棵子树同时失衡的。而这个时候,我们只要调整最小的不平衡子树,就能够将不平衡的树调整为平衡的树。
3个结点
平衡二叉树的失衡调整主要是通过旋转最小失衡子树来实现的。根据旋转的方向有两种处理方式,左旋 与 右旋 。
旋转的目的就是减少高度,通过降低整棵树的高度来平衡。哪边的树高,就把那边的树向上旋转。





平衡二叉排序树的构造
在插入过程中,采用平衡旋转技术
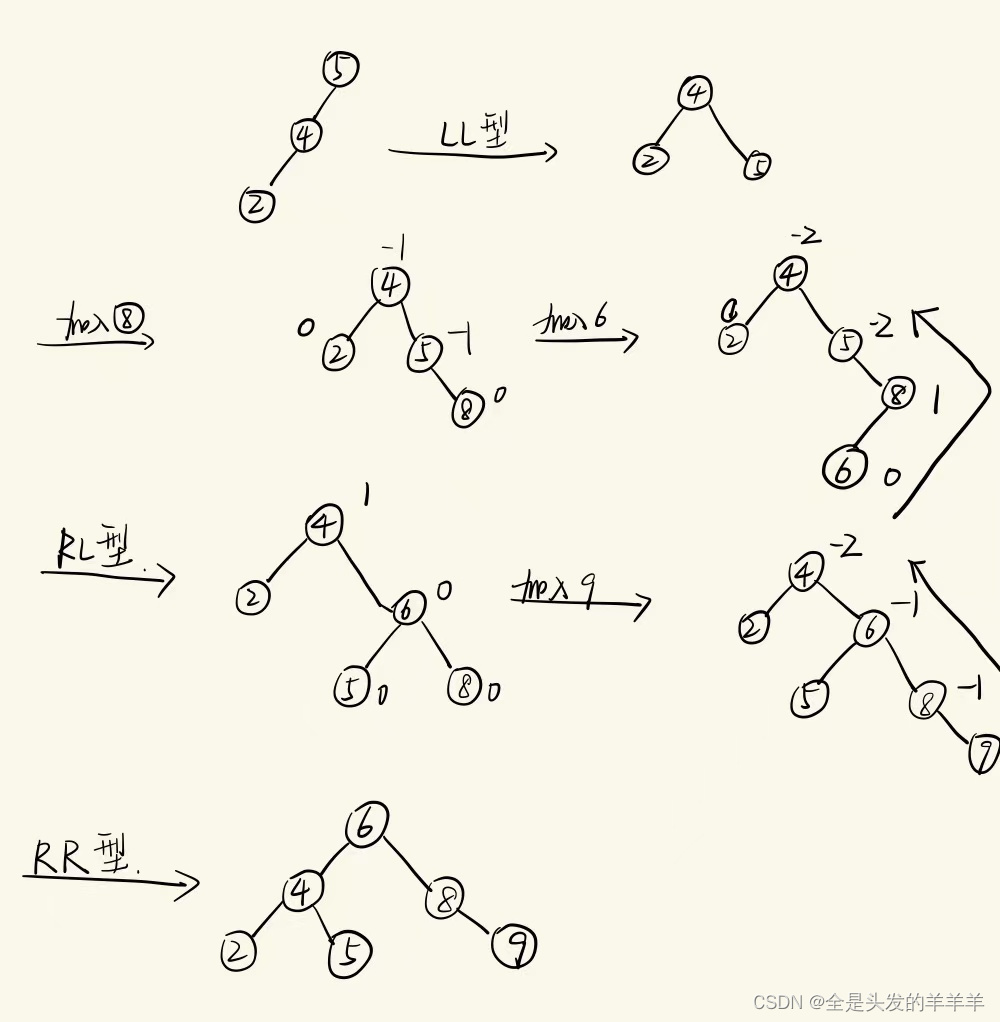
例题1
设有关键码序列{5 ,4 , 2, 8, 6, 9}构造平衡树
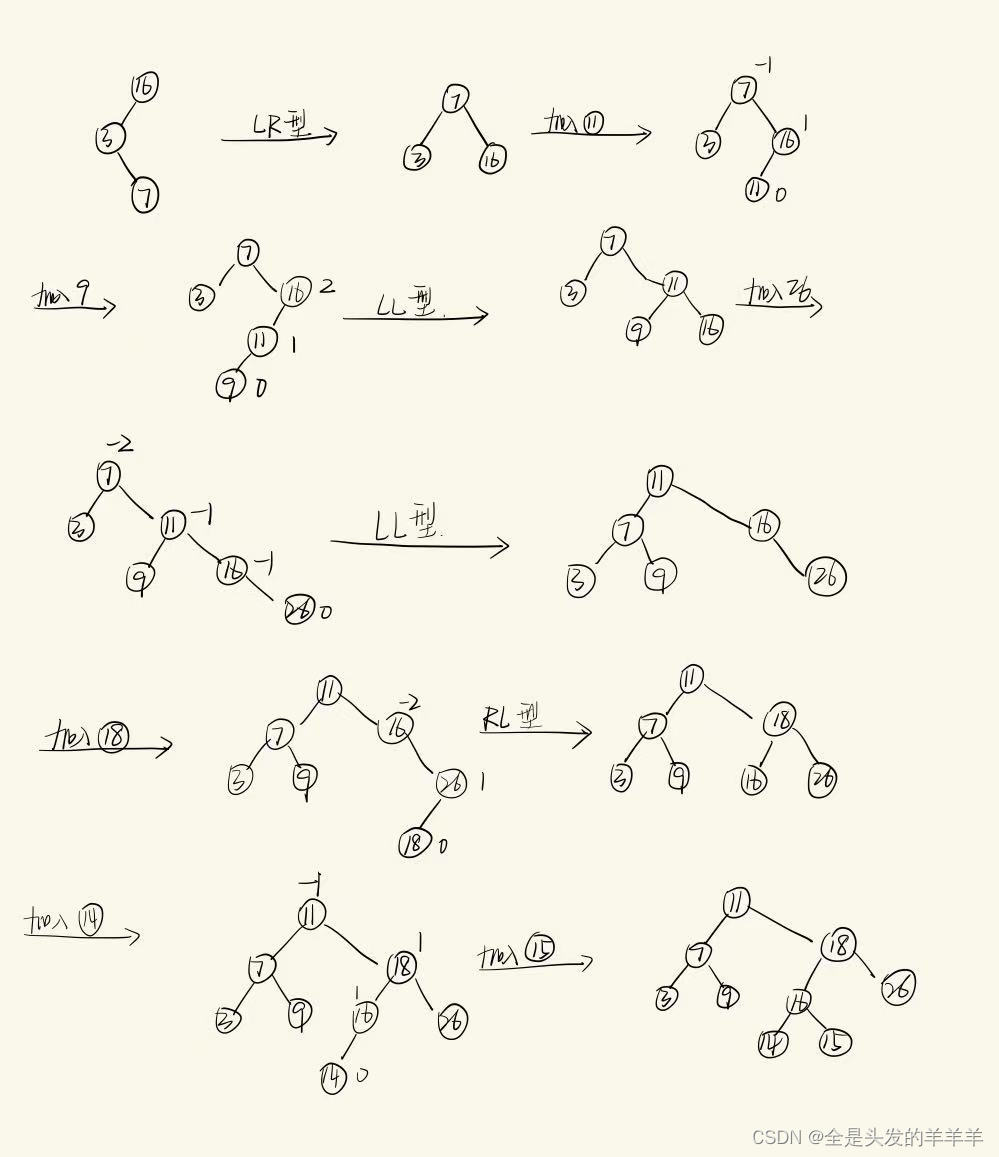
例题2
设有关键码序列{16 ,3 ,7 ,11 ,9 ,26 ,18 ,14 ,15 }构造平衡树
3.3 B-树
是一种平衡的多分树
3.3.1 m阶的B-树的结构定义:
1. 树的每个结点至多有m棵子树
2. 若根结点不是叶子结点,则至少有两棵子树
3. 除根结点之外的所有非终端结点至少有m/2 棵子树
4. 一个包含 个关键字的结点有
+1 个孩子;
5. 所有叶子结点都出现在同一层次,不含任何信息
6. 一个结点中的所有关键字升序排列,两个关键字 1 和
2 之间的孩子结点的所有关键字 key 在 (
1,
2) 的范围之内。
3.3.2 B-树的性质:
1. 树高平衡,所有叶结点都在同一层
2. 关键字没有重复,父结点中的关键字是其子结点的分界
3. B-树把值接近的相关记录放在同一个磁盘页中,从而利用了访问局部性原理
4. B-树保证树至少有一定比例的结点是满的

3.3.3 B-树的查找

查找的时间取决于两个因素:
1. 给定关键字所在结点的层次
2. 结点中关键字的个数
3.3.4 B-树的插入
插入操作案例

我们以在上图中插入关键字 I 为例进行说明。其中最小度 t = 2 ,一个结点最多可存储 2t - 1 = 3 个结点。
第一步:访问根结点,发现插入关键字 I 小于 P , 但根结点未满,不分裂,直接访问其第一个孩子结点。

第二步:访问结点 P 的第一个孩子结点 [C、G、L] ,发现第一个孩子结点已满,将第一个孩子结点分裂为两个:

第三步:将结点 I 插入到结点 L 的第一个左孩子当中,发现 L 的第一个左孩子 [H、J、K] 已满,则将其分裂为两个。

第四步:将结点 I 插入到结点 J 的第一个孩子当中,发现 L 的第一个孩子结点 [H] 未满且为叶子结点,则将 I 直接插入。

3.3.5 B-树的中序遍历
B-树的中序遍历与二叉树的中序遍历也很相似,我们从最左边的孩子结点开始,递归地打印最左边的孩子结点,然后对剩余的孩子和关键字重复相同的过程。最后,递归打印最右边的孩子.
对于这个图的中序遍历结果为:

3.3.6 B-树的删除(存疑
B-树的删除操作相比于插入操作更为复杂,如果仅仅只是删除叶子结点中的关键字,也非常简单,但是如果删除的是内部节点的,就不得不对结点的孩子进行重新排列。
与 B-树的插入操作类似,我们必须确保删除操作不违背 B-树的特性。正如插入操作中每一个结点所包含的关键字的个数不能超过 2t -1 一样,删除操作要保证每一个结点包含的关键字的个数不少于 t -1 个(除根结点允许包含比 t -1 少的关键字的个数。
接下来一一横扫删除操作中可能出现的所有情况。
初始的 B-树 如图所示,其中 m=3 每一个结点最多可包含 5 个关键字,至少包含 2个关键字(根结点除外)。
1. 待删除的关键字 k 在结点 x 中,且 x 是叶子结点,删除关键字k
删除 B-树中的关键字 F

2. 待删除的关键字 k 在结点 x 中,且 x 是内部结点,分一下三种情况
情况一: 如果位于结点 x 中的关键字 k 之前的第一个孩子结点 y 至少有 t 个关键字,则在孩子结点 y 中找到 k 的前驱结点 0 ,递归地删除关键字
0 ,并将结点 x 中的关键字 k 替换为
0 .
删除 B-树中的关键字 G ,G 的前一个孩子结点 y 为 [D、E、F] ,包含 3个关键字,满足情况一,关键字 G 的直接前驱为关键 F ,删除 F ,然后将 G 替换为 F .

情况二: y 所包含的关键字少于 t 个关键字,则检查结点 x 中关键字 k 的后一个孩子结点 z 包含的关键字的个数,如果 z 包含的关键字的个数至少为 t 个,则在 z 中找到关键字 k 的直接后继0 ,然后删除
0 ,并将关键 k 替换为
0 .
删除 B-树中的关键字 C , y 中包含的关键字的个数为 2 个,小于 t = 3 ,结点 [C、G、L] 中的 关键字 C 的后一个孩子 z 为 [D、E、F] 包含 3 个关键字,关键字 C 的直接后继为 D ,删除 D ,然后将 C 替换为 D .

情况三:如果 y 和 z 都只包含 t -1 个关键字,合并关键字 k 和所有 z 中的关键字到 结点 y 中,结点 x 将失去关键字 k 和孩子结点 z,y 此时包含 2t -1 个关键字,释放结点 z 的空间并递归地从结点 y 中删除关键字 k.
为了说明这种情况,我们将用下图进行说明。

删除关键字 C , 结点 y 包含 2 个关键字 ,结点 z 包含 2 个关键字,均等于 t - 1 = 2 个, 合并关键字 C 和结点 z 中的所有关键字到结点 y 当中:

此时结点 y 为叶子结点,直接删除关键字 C

3. 如果关键字 k 不在当前在内部结点 x 中,则确定必包含 k 的子树的根结点 x.c(i) (如果 k 确实在 B-树中)。如果 x.c(i) 只有 t - 1 个关键字,必须执行下面两种情况进行处理:
首先我们得确认什么是当前内部结点 x ,什么是 x.c(i) ,如下图所示, P 现在不是根结点,而是完整 B-树的一个子树的根结点:

情况二:如果 x.c(i) 及 x.c(i) 的所有相邻兄弟都只包含 t - 1 个关键字,则将 x.c(i) 与 一个兄弟合并,即将 x 的一个关键字移动至新合并的结点,使之成为该结点的中间关键字,将合并后的结点作为新的 x 结点 .
情况二上面的图标明了相应的 x 及 x.c(i) ,我们以删除关键字 D 为例,此时当前内部结点 x 不包含关键字 D , 确定是第三种情况,我们可以确认关键 D 一定在结点 x 的第一个孩子结点所在的子树中,结点 x 的第一个孩子结点所在子树的跟结点为 x.c(i) 即 [G、L] . 其中 结点 [G、L] 及其相邻的兄弟结点 [T、W] 都只包含 2 个结点(即 t - 1) ,则将 [G、L] 与 [T、W] 合并,并将结点 x 当中仅有的关键字 P 合并到新结点中;然后将合并后的结点作为新的 x 结点,递归删除关键字 D ,发现D 此时在叶子结点 y 中,直接删除,就是 1. 的情况。(此时清晰了很多)

情况一:x.c(i) 仅包含 t - 1 个关键字且 x.c(i) 的一个兄弟结点包含至少 t 个关键字,则将 x 的某一个关键字下移到 x.c(i) 中,将 x.c(i) 的相邻的左兄弟或右兄弟结点中的一个关键字上移到 x 当中,将该兄弟结点中相应的孩子指针移到 x.c(i) 中,使得 x.c(i) 增加一个额外的关键字。(一头雾水)
为了去掉 “一头雾水“,我们在上面情况二删除后的结果上继续进行说明:

)
我们以删除结点 [A、B] 中的结点 B 为例,上图中 x.c(i) 包含 2 个关键字,即 t - 1 个关键字, x.c(i) 的一个兄弟结点 [H、J、K] 包含 3 个关键字(满足至少 t 个关键字的要求),则将兄弟结点 [H、J、K] 中的关键字 H 向上移动到 x 中, 将 x 中的关键字 C 下移到 x.c(i) 中;删除关键字 B .

3.4 B+树
B+树是B-树的一种变形,是在叶子结点存储信息的树
定义:
1. 根结点至少有两棵子树,最多有m棵子树
2. 每个结点(除根外),至少有[m/2]棵子树,最多有m棵子树
3. 有n棵子树的结点包含n个关键字
4. 所有叶子结点在同一层,并包含了所有关键字,按关键字从小到大顺序链接
5. 所有非终端结点可以作为叶结点的索引,结点中仅包含其子树中最大(或最小)的关键字
3.5 红黑树
一种高效的自平衡(不是绝对平衡)二叉排序树
性质:
1.结点时红色或者黑色的
2. 根结点时黑色的
3. 叶子结点都为黑色,且都为空
4. 红色结点的父节点和子节点都为黑色(不存在两个连续的红色结点
5. 从任一结点到叶子结点的所有路径都包含相同数量的黑色结点
4. 哈希表的查找
参考图文并茂详解数据结构之哈希表 - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/144296454
哈希表也叫散列表,哈希表是一种数据结构,它提供了快速的插入操作和查找操作,无论哈希表总中有多少条数据,插入和查找的时间复杂度都是为O(1),因为哈希表的查找速度非常快,所以在很多程序中都有使用哈希表,例如拼音检查器。
4.1 哈希函数
哈希函数的作用是帮我们把非int的「键」或者「关键字」转化成int,可以用来做数组的下标。

static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}哈希函数不管怎么实现,都应该满足下面三个基本条件:
- 散列函数计算得到的散列值是一个非负整数
- 如果 key1 = key2,那 hash(key1) == hash(key2)
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)
第一点:因为数组的下标是从0开始,所以哈希函数生成的哈希值也应该是非负数
第二点:同一个key生成的哈希值应该是一样的,因为我们需要通过key查找哈希表中的数据
第三点:看起来非常合理,但是两个不一样的值通过哈希函数之后可能才生相同的值,因为我们把巨大的空间转出成较小的数组空间时,不能保证每个数字都映射到数组空白处。所以这里就会才生冲突,在哈希表中我们称之为哈希冲突
4.2 哈希函数的构造方法
4.2.1 直接定址法
取关键字或关键字的某个线性函数值为哈希地址:H(key) = key 或 H(key) = a·key + b
其中a和b为常数,这种哈希函数叫做自身函数。
注意:由于直接定址所得地址集合和关键字集合的大小相同。因此,对于不同的关键字不会发生冲突。但实际中能使用这种哈希函数的情况很少。
4.2.2 数字分析法
根据关键码在各个位上的分布情况,选取分布比较均匀的若干位组成散列地址

4.2.3 平方取中法
取关键字平方后的中间几位为哈希地址。(适用于不知道全部关键字的情况
通过平方扩大差别,另外中间几位与乘数的每一位相关,由此产生的散列地址较为均匀。这是一种较常用的构造哈希函数的方法。
将一组关键字(0100,0110,1010,1001,0111)
平方后得(0010000,0012100,1020100,1002001,0012321)
若取表长为1000,则可取中间的三位数作为散列地址集:(100,121,201,020,123)
4.2.4 折叠法

4.2.5 除留余数法
取关键字被数p除后所得余数为哈希地址:H(key) = key mod p (p ≤ m)。
注意:这是一种最简单,也最常用的构造哈希函数的方法。它不仅可以对关键字直接取模(mod),也可在折迭、平方取中等运算之后取模。值得注意的是,在使用除留余数法时,对p的选择很重要。一般情况下可以选p为小于或等于表长(最好接近表长)的质数或不包含小于20的质因素的合数
4.3 哈希冲突
哈希冲突是不可避免的,我们常用解决哈希冲突的方法有两种「开放地址法」和「链表法」
4.3.1 开放地址法
在开放地址法中,若数据不能直接存放在哈希函数计算出来的数组下标时,就需要寻找其他位置来存放。在开放地址法中有三种方式来寻找其他的位置,分别是「线性探测」、「二次探测」、「再哈希法」
4.3.1.1 线性探测的插入
在线性探测哈希表中,数据的插入是线性的查找空白单元,例如我们将数88经过哈希函数后得到的数组下标是16,但是在数组下标为16的地方已经存在元素,那么就找17,17还存在元素就找18,一直往下找,直到找到空白地方存放元素。我们来看下面这张图

我们向哈希表中添加一个元素钱多多,钱多多经过哈希函数后得到的数组下标为0,但是在0的位置已经有张三了,所以下标往前移,直到下标4才为空,所以就将元素钱多多添加到数组下标为4的地方。
4.3.1.2 线性探测的查找
线性探测哈希表的查找过程有点儿类似插入过程。我们通过散列函数求出要查找元素的键值对应的散列值,然后比较数组中下标为散列值的元素和要查找的元素。如果相等,则说明就是我们要找的元素;否则就顺序往后依次查找。如果遍历到数组中的空闲位置,还没有找到,就说明要查找的元素并没有在哈希表中。
4.3.1.3 线性探测的删除
线性探测哈希表的删除相对来说比较复杂一点,我们不能简单的把这一项数据删除,让它变成空
线性探测哈希表在查找的时候,一旦我们通过线性探测方法,找到一个空闲位置,我们就可以认定哈希表中不存在这个数据。但是,如果这个空闲位置是我们后来删除的,就会导致原来的查找算法失效。本来存在的数据,会被认定为不存在。
因此我们需要一个特殊的数据来顶替这个被删除的数据,因为我们的学生学号都是正数,所以我们用学号等于-1来代表被删除的数据。

这样会带来一个问题,如何在线性探测哈希表中做了多次操作,会导致哈希表中充满了学号为-1的数据项,使的哈希表的效率下降,所以很多哈希表中没有提供删除操作,即使提供了删除操作的,也尽量少使用删除函数。
4.3.2 二次探测
在线性探测哈希表中,数据会发生聚集,一旦聚集形成,它就会变的越来越大,那些哈希函数后落在聚集范围内的数据项,都需要一步一步往后移动,并且插入到聚集的后面,因此聚集变的越大,聚集增长的越快。
二次探测是防止聚集产生的一种尝试,思想是探测相隔较远的单元,而不是和原始位置相邻的单元。在线性探测中,如果哈希函数得到的原始下标是x,线性探测就是x+1,x+2,x+3......,以此类推,而在二次探测中,探测过程是x+1,x+4,x+9,x+16,x+25......,以此类推,到原始距离的步数平方,为了方便理解,我们来看下面这张图

还是使用线性探测中的例子,在线性探测中,我们从原始探测位置每次往后推一位,最后找到空位置,在线性探测中我们找到钱多多的存储位置需要经过4步。在二次探测中,每次是原始距离步数的平方,所以我们只需要两次就找到钱多多的存储位置。
二次探测的问题
二次探测消除了线性探测的聚集问题,这种聚集问题叫做原始聚集,然而,二次探测也产生了新的聚集问题,之所以会产生新的聚集问题,是因为所有映射到同一位置的关键字在寻找空位时,探测的位置都是一样的。
比如讲1、11、21、31、41依次插入到哈希表中,它们映射的位置都是1,那么11需要以一为步长探测,21需要以四为步长探测,31需要为九为步长探测,41需要以十六为步长探测,只要有一项映射到1的位置,就需要更长的步长来探测,这个现象叫做二次聚集。
二次聚集不是一个严重的问题,因为二次探测不怎么使用,这里我就不贴出二次探测的源码,因为「双哈希」是一种更加好的解决办法。
4.3.3 双哈希
双哈希是为了消除原始聚集和二次聚集问题,不管是线性探测还是二次探测,每次的探测步长都是固定的。双哈希是除了第一个哈希函数外再增加一个哈希函数用来根据关键字生成探测步长,这样即使第一个哈希函数映射到了数组的同一下标,但是探测步长不一样,这样就能够解决聚集的问题。
第二个哈希函数必须具备如下特点
- 和第一个哈希函数不一样
- 不能输出为0,因为步长为0,每次探测都是指向同一个位置,将进入死循环,经过试验得出
stepSize = constant-(key%constant);形式的哈希函数效果非常好,constant是一个质数并且小于数组容量
我们将上面的添加改变成双哈希探测,示意图如下:

双哈希的哈希表写起来来线性探测差不多,就是把探测步长通过「关键字」来生成
为什么双哈希需要哈希表的容量是一个质数?
假设我们哈希表的容量为15,某个「关键字」经过双哈希函数后得到的数组下标为0,步长为5。那么这个探测过程是0,5,10,0,5,10,一直只会尝试这三个位置,永远找不到空白位置来存放,最终会导致崩溃。
如果我们哈希表的大小为13,某个「关键字」经过双哈希函数后得到的数组下标为0,步长为5。那么这个探测过程是0,5,10,2,7,12,4,9,1,6,11,3。会查找到哈希表中的每一个位置。
使用开放地址法,不管使用那种策略都会有各种问题,开放地址法不怎么使用,在开放地址法中使用较多的是双哈希策略。
4.3.4 拉链法
开放地址法中,通过在哈希表中再寻找一个空位解决冲突的问题,还有一种更加常用的办法是使用「拉链法」来解决哈希冲突。「拉链法」相对简单很多,「拉链法」是每个数组对应一条链表。当某项关键字通过哈希后落到哈希表中的某个位置,把该条数据添加到链表中,其他同样映射到这个位置的数据项也只需要添加到链表中,并不需要在原始数组中寻找空位来存储。下图是「拉链法」的示意图。

「拉链法」解决哈希冲突代码比较简单,但是代码比较多,因为需要维护一个链表的操作,我们这里采用有序链表,有序链表不能加快成功的查找,但是可以减少不成功的查找时间,因为只要有一项比查找值大,就说明没有我们需要查找的值,删除时间跟查找时间一样,有序链表能够缩短删除时间。但是有序链表增加了插入时间,我们需要在有序链表中找到正确的插入位置。


4.4 哈希表的效率
在哈希表中执行插入和搜索操作都可以达到O(1)的时间复杂度,在没有哈希冲突的情况下,只需要使用一次哈希函数就可以插入一个新数据项或者查找到一个已经存在的数据项。
如果发生哈希冲突,插入和查找的时间跟探测长度成正比关系,探测长度取决于装载因子,装载因子是用来表示空位的多少
参考图解:什么是B树?(心中有 B 树,做人要虚心)一文读懂B-树 - 知乎 (zhihu.com)
相关文章:
数据结构--查找
目录 1. 查找的基本概念 2. 线性表的查找 3. 树表的查找 3.1 二叉排序树 3.1.1 定义: 3.1.2 存储结构: 3.1.3 二叉排序树的查找 3.1.4 二叉排序树的插入 3.1.5 二叉排序树删除 3.2 平衡二叉树(AVL 3.2.1 为什么要有平衡二叉树 3.2.2 定义 3.3 B-树 3.3.1…...
IntelliJ IDEA Apache Dubbo,IDEA 官方插件正式发布!
作者:刘军 最受欢迎的 Java 集成开发环境 IntelliJ IDEA 与开源微服务框架 Apache Dubbo 社区强强合作,给广大微服务开发者带来了福音。与 IntelliJ IDEA 2023.2 版本一起,Jetbrains 官方发布了一款全新插件 - Apache Dubbo in Spring Frame…...
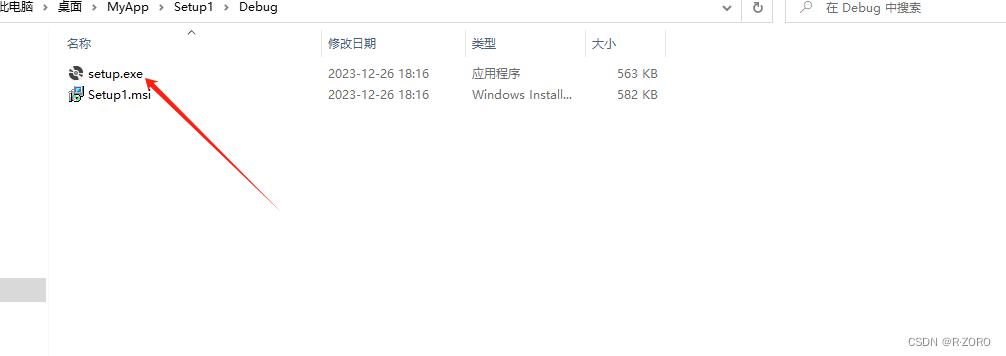
使用Visual Studio 2022 winform项目打包成安装程序.exe
winform项目打包 1.安装扩展插件 Microsoft Visual Studio Installer Projects 20222.在解决方案上新建一个setup project 项目3.新建成功如下图,之后添加你的winform程序生成之后的debug下的文件4.在Application Folder上点击右键->Add->项目输出->主输出…...
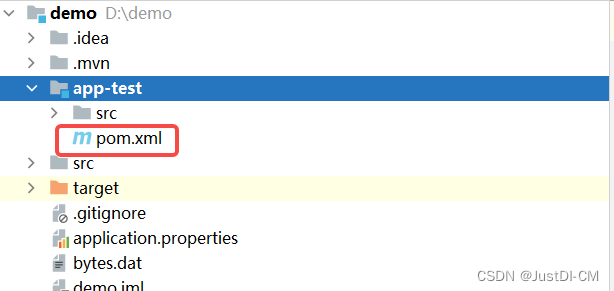
报错-idea pom.xml 有一条灰色横线
1. 背景 打开 idea 更新代码,发现有个 module 的 pom.xml 有一条灰色横线,导致这个 module 没有加载成功。 2. 原因 1) 可能本地 Remove 了这个 module 2)本地删除了这个 module ,又从远端拉取了回来 3)…...
openmediavault(OMV) (19)云相册(3)mt-photos
简介 MT Photos是一款为Nas用户量身打造的照片管理系统。通过AI技术,自动将您的照片整理、分类,包括但不限于时间、地点、人物、照片类型。可以在任何支持Docker的系统中运行它。详情可查看mtmt.tech官网,mt-photos是付费订阅使用的,也可以一次性付费永久使用,具体使用mt…...
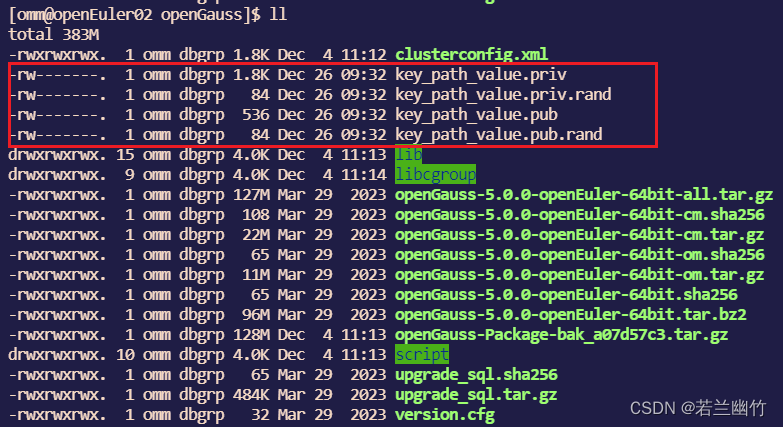
基于openGauss5.0.0全密态数据库等值查询小案例
基于openGauss5.0.0全密态数据库等值查询小案例 一、全密态数据库简介二、环境说明三、测试步骤四、使用约束 一、全密态数据库简介 价值体现: 密态数据库意在解决数据全生命周期的隐私保护问题,使得系统无论在何种业务场景和环境下,数据在传…...

Oracle中varchar2和nvarchar2的区别
Oracle中的varchar2和nvarchar2都是可变长度的字符数据类型,这意味着它们能够根据实际存储的数据长度来动态调整占用的空间。但它们之间有以下主要区别: 1. 字符编码和存储: - VARCHAR2:存储的是字节字符串,对字符…...

linux环境下从一个服务器复制文件到另一个服务器
在Linux中使用scp命令可以将文件或目录从一台服务器复制到另外一台服务器。 # 从源服务器复制文件到目标服务器 scp /path/to/source_file usernamedestination:/path/to/destination_directory # 从源服务器复制目录及其内容到目标服务器 scp -r /path/to/source_directory us…...

JSoup 爬虫遇到的 404 错误解决方案
在网络爬虫开发中,使用JSoup进行数据抓取是一种常见的方式。然而,当我们尝试使用JSoup来爬虫抓取腾讯新闻网站时,可能会遇到404错误。这种情况可能是由于网站的反面爬虫机制检测到了我们的爬虫行为,从而拒绝了我们的请求。 假设我…...

Vue.set 方法原理
function set(target, key, value) {// 判断是否是数组,并且 key 是一个有效的索引值if (Array.isArray(target) && isValidArrayIndex(key)) {target.length Math.max(target.length, key)target.splice(key, 1, value)return value}// 判断 key 是否已经…...

CentOS 7的新特性
CentOS 7在发布时相较于CentOS 6引入了许多重要的变化和优化。以下是一些主要的改进和新特性: 系统初始化程序:CentOS 7使用了systemd作为其初始化系统,取代了之前版本的init系统。systemd提供了更快的启动时间和更好的管理服务。 内核更新&…...

Vue 模板编译原理
Vue 模板编译原理是指将 Vue 的模板转换为渲染函数的过程。在 Vue 中,模板被定义为 HTML 代码片段或者在 .vue 单文件组件中定义。当 Vue 实例化时,会将模板编译为渲染函数,该函数可以根据组件的状态生成虚拟 DOM 并更新视图。 Vue 的模板编…...
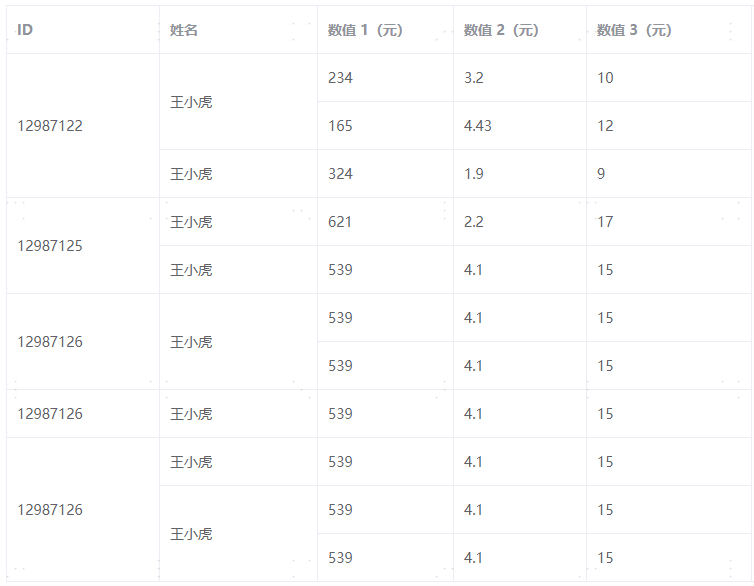
ElementUI的Table组件行合并上手指南
ElementUI的Table组件行合并 ,示例用官网vue3版的文档 <el-table :data"tableData" :span-method"objectSpanMethod" border style"width: 100%; margin-top: 20px"><el-table-column prop"id" label"ID&qu…...

【ES6】Class继承-super关键字
目录 一、前言二、ES6与ES5继承机制区别三、super作为函数1、构造函数this1)、首先要明确this指向①、普通函数②、箭头函数③、注意事项 2)、其次要明确new操作符做了哪些事情 2、super()的用法及注意点1)、用法2)、注意点 四、s…...

做亚马逊测评不知道怎么找客户?这才是亚马逊测评的正确打开方式!
如今的跨境电商内卷严重,花费大量资金做广告推广的效果却微乎其微,这也是亚马逊测评迅速崛起的最根本原因。做亚马逊测评是近年来兴起的一种方式,许多卖家都需要大量的测评来提高自己的产品排名和信誉度。很多兄弟最近来问龙哥亚马逊测评怎么…...

传感器基础:传感器使用与编程使用(三)
目录 常用传感器讲解九--雨滴传感器具体讲解电路连接代码实现 常用传感器讲解十--光传感器根据亮度安排灯具体讲解电路连接代码实现 常用传感器讲解七--light cup(KY-008)具体讲解电路连接代码实现 常用传感器讲解十二--倾斜开关传感器(KY-02…...

深入浅出:分布式、CAP 和 BASE 理论(荣耀典藏版)
大家好,我是月夜枫,一个漂泊江湖多年的 985 非科班程序员,曾混迹于国企、互联网大厂和创业公司的后台开发攻城狮。 在计算机科学领域,分布式系统是一门极具挑战性的研究方向,也是互联网应用中必不可少的优化实践&…...
vue3+elementPlus:el-drawer新增修改弹窗复用
在el-drawer的属性里设置:title属性,和重置函数 //html<!-- 弹窗 --><el-drawerv-model"drawer":title"title":size"505":direction"direction":before-close"handleClose"><el-formlabel-posit…...

使用Docker快速安装grafana
Docker 提供了一个轻量级、易于部署的容器化解决方案,让您能够方便地在不同环境中运行应用程序。以下是在 Docker 中安装 Grafana 的基本步骤: 文章目录 使用Docker快速安装grafana如何使用Grafana步骤 1:连接数据源步骤 2:创建仪…...
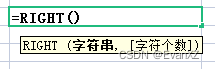
excel 函数技巧
1:模糊查询 LOOKUP(1,0/FIND(F1062,Sheet1!C$2:Sheet1!C$9135),Sheet1!B$2:Sheet1!B$9135) 函数含义:寻找F列1062行和sheet1中的C2行到C9135行进行模糊查询,返回该行对应的B2行到B9135行的结果。未查到返回结果0 函数公式: LO…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...