科研学习|论文解读——融合类目偏好和数据场聚类的协同过滤推荐算法研究
论文链接(中国知网):
融合类目偏好和数据场聚类的协同过滤推荐算法研究 - 中国知网 (cnki.net)
摘要:[目的/意义]基于近邻用户的协同过滤推荐作为推荐系统应用最广泛的算法之一,受数据稀疏和计算可扩展问题影响,推荐效果不尽如人意。[方法/过程]针对上述问题,提出了一种改进的推荐算法(Category Preferred Data Filed Clustering based Collaborative Filtering Recommendation, CPDFC-CFR)。首先,该算法舍弃用户评分,利用评论情感构建用户—项目矩阵,以增强用户偏好表示能力。其次,该算法引入类目偏好和语义偏好的概念,利用类目偏好比对高维用户—项目矩阵进行降维,并在用户相似度计算中纳入评论情感偏好、项目类目偏好和语义偏好,以降低数据稀疏性。最后,该算法将数据场作为用户聚类的前置算法,把数据场输出(极大值点)作为K-means算法输入,以提升算法实时性和稳定性。[结果/结论]实验结果表明:(1)项目类目级别越低,CPDFC-CFR算法准确性(F-measure)和即时性(相似度计算次数和推荐耗时)越优;(2)与其它推荐算法相比,CPDFC-CFR算法能够有效提升推荐准确性和计算效率,对协同过滤推荐系统建设具有重要参考价值。
关键词:推荐系统;协同过滤;数据稀疏;计算可扩展;类目偏好;数据场聚类
Category Preferred Data Field Clustering based Collaborative Filtering Recommendation Algorithm Research
Abstract: [Purpose/Significance] Collaborative filtering recommendation based on nearest users, one of the most widely used algorithms in recommender systems, is affected by the issues of data sparsity and computational scalability, and the recommendation effect is unsatisfactory. [Method/Process] To address these issues, a category preferred data filed clustering based collaborative filtering recommendation algorithm(CPDFC-CFR) is proposed. First, the algorithm discards user ratings and uses comment sentiment to construct a user-item matrix to enhance the ability to express user preferences. Second, the algorithm introduces the concepts of category preference and semantic preference, reduces the dimensionality of the user-item matrix using category preferred ratio, and incorporates comment sentiment preference, category preference, and semantic preference in the user similarity calculation to reduce data sparsity. Finally, the algorithm uses the data field as the pre-algorithm for user clustering and uses its output (maximum point) as an input to the K-means algorithm to improve the real-time and stability performance of the algorithm. [Result/Conclusion] The findings indicated that: (1) the lower the item category level, the higher the accuracy (F-measure) and computational efficiency (number of similarity calculations and time-consuming of recommendation) of the CPDFC-CFR algorithm; (2) compared with other recommendation algorithms, CPDFC-CFR algorithm can effectively improve the recommendation accuracy and computational efficiency, which is an important reference value for the construction of collaborative filtering recommendation system.
Key words: recommendation system; collaborative filtering; data sparsity; computational scalability; category preferred; data field clustering.
1 引言
伴随信息通信技术的快速发展,数据呈指数式扩增,信息过载问题日益加剧[1]。为了帮助信息消费者从海量信息中获取有价值信息以及信息提供者提供高质量信息,推荐系统应运而生[2]。作为搜索引擎的重要补充,推荐系统能够通过分析用户历史数据,构建用户兴趣模型,对满足用户模糊的、不明确的信息需求具有重要意义,已被广泛应用于电子商务[3]、新闻传媒[4]、搜索引擎和文献信息获取[5]等诸多领域。
目前,推荐系统的常用推荐算法包括基于内容的推荐[6, 7]、基于知识的推荐[8]、协同过滤推荐和混合推荐[9, 10]。其中,基于内容的推荐利用项目固有的内容属性向用户产生推荐。基于知识的推荐利用用户的显示需求和项目领域知识产生推荐。混合推荐通过两种及以上推荐算法的组合为用户产生推荐。相比之下,协同过滤推荐利用用户和项目的交互评分为用户产生推荐,无需依赖项目的内容属性和领域知识,具有推荐项目类型多样、数据获取和技术复现难度小、个人信息安全性高等优势,成为众多推荐算法中最经典和最通用的一种推荐算法。协同过滤推荐包括基于模型的推荐和基于近邻的推荐[11-13]。基于模型的推荐通过算法模型(关联规则、回归、图等)预测为用户产生推荐。基于近邻的推荐通过用户或项目之间的近邻关系为用户产生推荐,分基于近邻用户的推荐和基于近邻项目的推荐两种。其中,基于近邻用户的协同过滤推荐(User-based Collaborative Filtering Recommendation, U-CFR)是最早为推荐系统开发的推荐算法之一[14]。
1.1 问题描述
准确、高效的推荐算法是推荐系统的核心,决定了推荐效果的优劣。对于U-CFR算法而言,数据稀疏和计算可扩展问题是最具挑战性的两个问题。为了说明这两个问题,我们对本研究采集的UserCats(10G)数据集进行了一些初步的实验与分析。
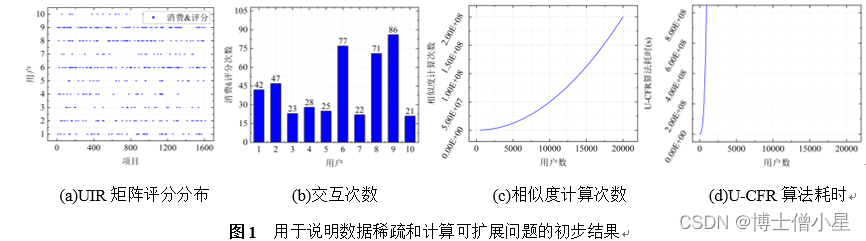
(1)评分数据稀疏。随机从UserCats数据集中抽取10名用户的历史数据,以研究数据稀疏问题。图1(a)和图1(b)分别绘制了10名用户的用户—项目评分矩阵(User-Item Rating, UIR)评分分布和交互次数,用户对项目进行消费且评分时记为一次交互。结果表明,多数用户仅对1612个项目中的小部分项目感兴趣[13],最高交互次数为86次(约为项目总量的5.33%),最低交互次数为21次(约为项目总量的1.30%),UIR矩阵稀疏度为97.25%,评分数据极为稀疏。
(2)计算可扩展性差。然后从相似度计算次数和推荐耗时两个方面研究算法的可扩展性。图1(c)显示随着用户数的增加,相似度计算次数呈指数式增长。类似的,从图1(d)中我们可以发现,U-CFR算法的耗时随用户数的增加也呈指数式上升,且变化率更大。结果表明,随着用户数的增加,相似度计算次数和推荐耗时呈指数式上升,U-CFR算法的计算可扩展性将显著下降[2]。
尽管近年来已在U-CFR算法的基础上提出了许多改进算法,例如:用于缓解数据稀疏的基于链接开源数据的推荐[15]和基于图随机游走的推荐[16]等,用于提升计算可扩展性的基于交替最小二乘的推荐[17]和基于划分聚类的推荐[2]等,但算法仍然受到数据稀疏和计算可扩展性问题的限制。一方面,现有缓解数据稀疏性的工作本质上是有限的,受附加数据获取成本、用户隐私保护和归纳偏差等问题制约,且忽视了离散有限评分(例如:5星离散评分)对用户真实偏好的表示能力。另一方面,相比数据稀疏,针对计算可扩展性问题的研究较为欠缺,且优化模型易受超参数和可解释性问题影响,性能波动较大。因此,对U-CFR算法的数据稀疏问题和计算可扩展问题的研究仍然是一个有价值且具有挑战性的任务。
1.2 研究贡献
受类目偏好、数据场聚类和评论情感挖掘启发,针对U-CFR算法存在的数据稀疏和计算可扩展性问题,本研究提出了一种融合类目偏好和数据场聚类的协同过滤推荐算法(Category Preferred Data Field Clustering based Collaborative Filtering Recommendation, CPDFC-CFR)。该算法首先基于评论情感构建UIS矩阵,并利用类目偏好比将高维情感矩阵映射为低维用户—类目偏好矩阵(User-Category Preference, UCP)。然后,利用数据场聚类对UCP矩阵中的用户进行分组,按同簇用户间的综合相似度大小确定目标用户最近邻域。最后,利用最近邻域用户的综合相似度和非共有情感值预测未知项目情感,按预测值大小为目标用户生成Top-n项目推荐列表。为了进一步验证算法性能,在两个真实的电商数据集上进行了对照实验,结果表明本研究所提CPDFC-CFR算法比U-CFR算法的系列改进算法在准确性和计算效率上有了较为显著的提升。
本文所提CPDFC-CFR算法的主要贡献如下:(1)增强了用户偏好的表示能力:该算法利用一种基于属性的无监督情感挖掘方法计算所得的评论情感代替用户评分,缓解了有限离散评分偏好表示能力有限的问题,且情感挖掘方法本身不受人工或机器标注情感标签的误差影响;(2)降低了数据稀疏性:该算法引入了类目偏好和用户语义的概念,并将其应用于用户聚类和相似度计算,缓解了稀疏数据对聚类和相似度计算效果的影响;(3)提高了计算效率和算法鲁棒性:该算法不仅利用划分聚类降低了用户相似度的计算次数,提高了推荐系统的实时性,而且将数据场作为划分聚类的前置算法,有效解决了随机初始聚类中心等对聚类效果的影响(例如:局部最优、反复迭代等),使算法结果更加稳定。
4 实验与分析
4.1 实验数据
本研究在遵循网站robots协议前提下,将在某知名电商平台上利用定向爬虫抓取的相关数据作为实验的原始数据集UserCats。该数据集由Categories、Comments和Products三个json文件组成,大小为10G,存储有585万用户与15万商品的交互数据,例如:用户昵称、产品标题、类目ID、店铺信息、评论、评分等。选择该数据集的原因有两个:第一,尽管用于U-CFR算法验证的开放数据集很多,如MovieLens、Netflix等,但项目类目、评论文本和用户昵称等数据不够完整;第二,电商领域是推荐系统应用最早的领域,也是一直以来推荐重点关注的领域,平台商品类目齐全且层次清晰,数据便于获取。
为确保实验可行性及有效性,本研究随机从UserCats中无放回抽取若干数据生成UserCats 1和UserCats 2两个实验数据集,并从中剔除未进行评论的用户、无任何评论的商品和有内容安全风险的商品[3]。其中,UserCats1数据集大小为109M,为740个用户和1006个商品的交互数据,有3个一级类目、5个二级类目和9个三级类目,评论情感稀疏度为96.34%。UserCats2数据集大小为108M,为854个用户与1373个商品的交互数据,有6个一级类目、9个二级类目和13个三级类目。综合考虑数据实时性和算法规模,采用PC离线方法进行实验[2](Windows 11, PyCharm 2021, Python 3.6, Inter(R) Core TM i7-8550U @ 200GHz,16G RAM)。数据集分训练集(80%)和测试集(20%)。实验数据集描述见表1。
表1 实验数据集描述
| 名称 | 大小 | 评论数(λ) | 用户数(m) | 产品数(n) | 稀疏度 (1-λ/(m*n)) | 一级类目数 | 二级类目数 | 三级类目数 |
| UserCats1 | 109M | 27199 | 740 | 1006 | 0.9634 | 3 | 5 | 9 |
| UserCats2 | 108M | 24111 | 854 | 1373 | 0.9794 | 6 | 9 | 13 |
4.2 评价指标与对照算法
(1) 评价指标
实验使用两种类型的指标来评价算法性能:基于准确性指标的和基于即时性的指标。其中,基于准确性的指标为F-measure,该指标根据项目的Top-n推荐列表计算得出,综合考虑了精度和召回率,值越大推荐效果越好,相关定义参见文献[38]。基于即时性的指标为推荐耗时和相似度计算次数,评价的是算法计算效率。推荐耗时指整个推荐过程花费的时间,以秒为单位度量(实际数值取对数),值越大计算可扩展性越差。总相似度计算次数指为确定各用户最近邻域而需计算的相似度次数,值越大计算可扩展性越差。
鉴于推荐算法训练数据较大,进一步对相似度计算次数和推荐耗时进行了取对数操作,计算公式如下:

式中,y表示对数处理后的相似度计算次数或推荐耗时,U表示用户集合,xu表示为用户u生成推荐列表所需的相似度计算次数和推荐耗时。
(2) 对照算法
为全面验证CPDFC-CFR算法应对数据稀疏和计算可扩展性问题的有效性,本研究所选对照算法基本涵盖了现有研究提出的不同类型的U-CFR算法。下面,我们对本研究所选对照算法进行简要说明:
- POP(Popular Products):一种简单的非个性化基线算法,该算法按项目流行度的大小向各用户推荐相同的Top-n项目推荐列表。
- ALS(Alternating Least Squares)[17]:一种矩阵分解算法,该算法采用交替训练的方式获得一组用户和项目的嵌入,通过嵌入点积的形式近似原始的用户—项目矩阵。
- U-CFR(User-based Collaborative filtering Recommendation)[3]:一种简单的个性化基线算法,该算法基于用户相似度为目标用户推荐其近邻用户喜欢的项目。
- Km-CFR(K-means based Collaborative Filtering Recommendation)[3]:一种基于聚类的推荐算法,该算法在U-CFR基础上利用K-means算法减少用户相似度计算次数,提升算法推荐效率。
- CKm-CFR(Canopy-K-means based Collaborative Filtering Recommendation)[2]:一种基于聚类的推荐算法,该算法将Canopy作为K-means的前置算法,缓解了聚类数k对聚类效果的影响,在提升计算效率的同时也确保了结果的稳定性。
上述算法均适用于用户—项目矩阵,其中行表示用户,列表示项目,行列交点表示用户评分或用户评论情感。此外,还比较了CPDFC-CFR算法的三种中间算法,以比较算法不同计算单元的优化效果:
- U-CFR(UIS):与U-CFR算法相比,构建用户—项目矩阵利用的是用户评论情感。
- U-CFR(UIS+DF):与U-CFR(UIS)算法相比,在相似度计算前利用数据场聚类对用户进行了分组;
- U-CFR(UIS+SIM):与U-CFR(UIS)算法相比,Pearson相关系数替换为了综合相似度。
POP和ALS算法无用户相似度计算过程,研究仅比较了它们在推荐耗时上的计算效率表现。所有算法由Anaconda 3中implicit推荐算法库和sklearn、scipy等依赖库复现。
4.3 超参数选择
超参数是推荐算法开始学习过程之前人工设置值的参数。取最近邻个数N=10(总用户数的1%~2%[34])和项目推荐列表长度n=15(与Last.fm等平台的项目推荐长度相近[38]),通过对不同参数进行网格搜索来选择各算法的超参数,并以F-measure值大小作为最佳参数确定标准。实验结果取三折交叉验证结果的平均。各算法超参范围如下(POP除外):

4.4 实验结果分析
本节报告并讨论实验结果。首先探讨不同类目级别对CPDFC-CFR算法推荐准确性和计算效率的影响(4.4.1节),然后介绍CPDFC-CFR算法整体性能(4.4.2节),最后比较不同推荐算法的结果差异(4.4.3节)。
4.4.1 类目级别影响
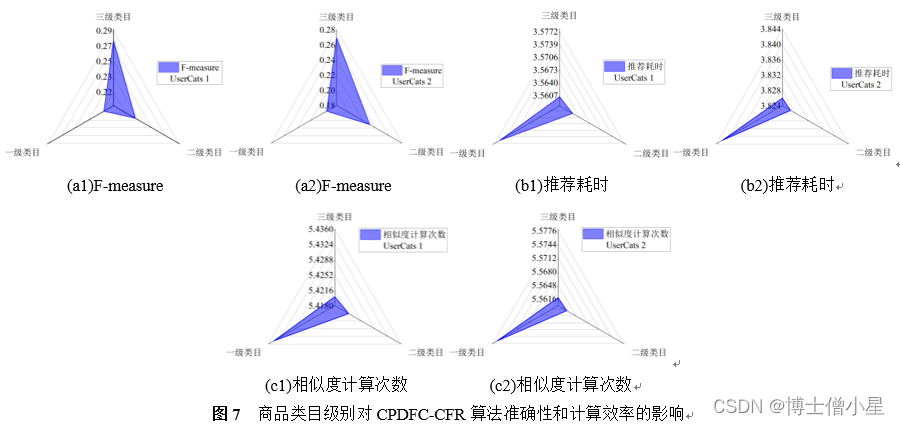
UserCats 1和UserCats 2中CPDFC-CFR算法在不同商品类目级别上的性能表现如图7所示。在准确性方面,商品类目级别越高,算法F-measure值越小。在计算效率方面,商品类目级别越高,算法推荐耗时越长,相似度计算次数越多。一个可能的原因是,随着商品类目级别的提升,UCP矩阵贡献的用户类目偏好信息粒度越来越大(图4(a1)和图4(a2)),弱化了用户之间的细微偏好差异,令数据场聚类效果下降,影响了算法计算效率和准确性。鉴于各评价指标值变化的拐点尚未出现,进一步降低商品类目级别(例如:细化三级类目的商品分类,构建四级商品类目),可能是一种提升CPDFC-CFR准确性和计算效率的有效途径。
4.4.2 总体性能分析
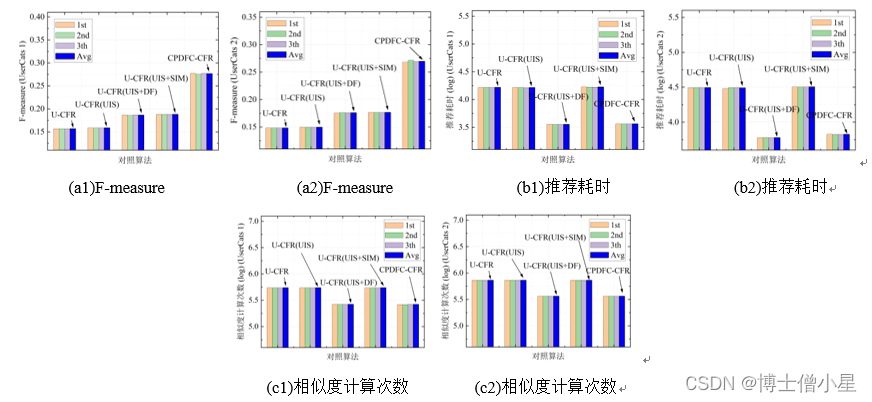
对照算法和本文所提算法及其中间算法在两个实验数据集中的F-measure、推荐耗时和相似度计算次数指标的三折及平均结果见图8。对比U-CFR和U-CFR(UIS)可知,利用评论情感构建的UIS矩阵能够为近邻协同过滤推荐算法提供比UIR矩阵更加接近用户真实喜好的向量表示。对比U-CFR(UIS)和U-CFR(UIS+DF)可知,利用数据场优化K-means算法的用户聚类效果是可行的,能够有效降低推荐算法的相似度计算次数和推荐耗时并提升准确性。对比U-CFR(UIS)和U-CFR(UIS+SIM)可知,尽管引入用户类目偏好信息(三级产品类目)和语义信息会令推荐耗时增加,但实验结果也基本证实了它们在缓解矩阵数据稀疏上的有效性。综合考虑上述优化思路的CPDFC-CFR算法在两个实验数据集中均取得了最高的F-measure、较少的推荐耗时和最低的相似度计算次数,与算法设计预期相符。
4.4.3 不同推荐算法比较
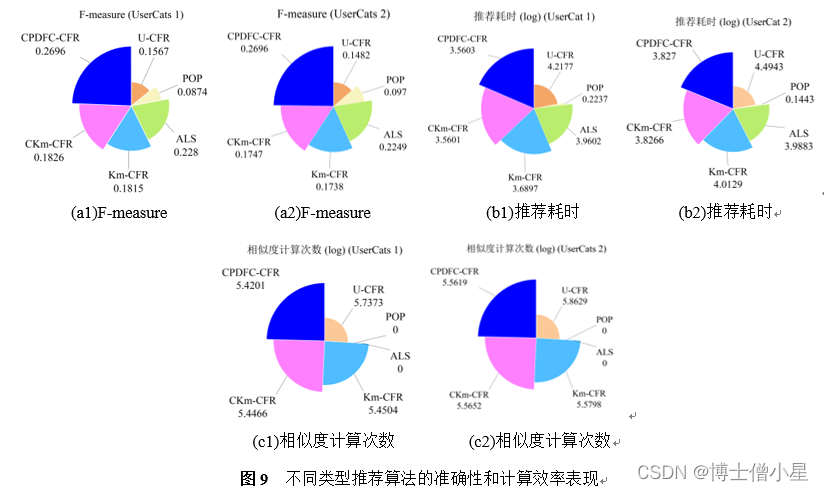
UserCats 1和UserCats 2数据集中不同类型推荐算法的性能如图9所示(三折交叉验证均值)。总体而言,两个数据集中本文所提CPDFC-CFR算法均取得了整体上的最优性能(最高的准确性和较高的计算效率)。在准确性方面,交替训练ALS的F-measure值要高于Km-CFR和CKm-CFR等基于传统聚类的协同过滤推荐算法。POP表现最差,因为其基于产品流行度向所有用户推荐相同的商品列表。在计算效率方面,U-CFR耗时最长,POP耗时最短,ALS因无需反复计算相似度耗时较短。受超参数影响,Km-CFR的相似度计算次数和推荐耗时高于CKm-CFR和CPDFC-CFR。此外,从图中数据可知,无论那种类型推荐算法,UserCats 1(稀疏度96.34%)中的结果都优于UserCats 2(稀疏度97.94%),这表明数据稀疏性对推荐性能有较大影响。
5 结 语
5.1 结论
伴随信息过载,推荐成为信息消费者获取个性化信息以及信息提供者提供高质量信息的重要方式。受用户评分失真、附加数据完整性和安全性差以及超参数(例如:随机初始聚类中心)等问题影响,现有针对基于近邻用户的协同过滤推荐算法数据稀疏和计算可扩展性(计算效率)问题的相关研究仍存在进一步优化的空间。为此,本文提出了一种融合类目偏好和数据场聚类的协同过滤推荐算法(Category Preferred Data Field Clustering based Collaborative Filtering Recommendation, CPDFC-CFR)。该算法首先通过评论情感构建用户—项目矩阵,并利用类目偏好比降低矩阵维度;然后,通过数据场聚类对用户进行分组,缩小最近邻域检索范围,减少相似度计算次数;最后,计算同簇中由评论情感、类目偏好和用户语义共同构成的用户相似度,同时预测UIS矩阵缺失评分,产生Top-n个性化项目推荐列表。为进一步验证算法性能,本研究在电商领域的两个真实数据集上进行了对照实验,结果表明,CPDFC-CFR算法比对照算法和U-CFR算法的系列改进算法在准确性和计算效率上有了较为明显的提升(UserCats1数据集上F-measure=27.65%,推荐耗时=3633.50秒,相似度计算次数=263096次;UserCats2数据集上F-measure=26.96%,推荐耗时=6698.18秒,相似度计算次数=364658次),整体性能最优。
5.2 局限与未来工作
本研究的不足之处在于:第一,受数据采集成本限制,研究仅在电商场景中对算法准确性和计算效率进行了验证,实验数据的多样性上可能存在一定疏漏,导致研究结果的可靠性和算法的可推广性有待进一步提升。未来工作可能会采集不同场景下的数据集,例如:新闻传媒、金融理财、研发等,在不同数据量级和不同稀疏度等组合条件下验证算法性能;第二,虽然研究未发现类目级别与算法准确性和计算效率之间的均衡点,但却可以看出一定的规律,即:随着类目级别的降低,算法准确性和计算效率逐渐上升(图8)。未来的工作可能会尝试利用深度学习或人工方式细化类目分类,找到类目级别与算法准确性和计算效率的均衡点,进一步提升算法推荐效果。
相关文章:
科研学习|论文解读——融合类目偏好和数据场聚类的协同过滤推荐算法研究
论文链接(中国知网): 融合类目偏好和数据场聚类的协同过滤推荐算法研究 - 中国知网 (cnki.net) 摘要:[目的/意义]基于近邻用户的协同过滤推荐作为推荐系统应用最广泛的算法之一,受数据稀疏和计算可扩展问题影响&#x…...

算法学习系列(十五):最小堆、堆排序
目录 引言一、最小堆概念二、堆排序模板(最小堆)三、模拟堆 引言 这个堆排序的话,考的还挺多的,主要是构建最小堆,并且在很多情况下某些东西还用得着它来优化,比如说迪杰斯特拉算法可以用最小堆优化&#…...

HCIA-Datacom题库(自己整理分类的)——OSPF协议多选
ospf的hello报文功能是 邻居发现 同步路由器的LSDB 更新LSA信息 维持邻居关系 下列关于OSPF区域描述正确的是 在配置OSPF区域正确必须给路由器的loopback接配置IP地址 所有的网络都应在区域0中宣告 骨干区域的编号不能为2 区域的编号范围是从0.0.0.0到255.255.255.255…...

elasticsearch-hadoop.jar 6.8版本编译异常
## 背景 重新编译 elasticsearch-hadoop 包; GitHub - elastic/elasticsearch-hadoop at 6.8 编译 7.17 版本时很正常,注意设置下环境变量就好,JAVA8_HOME/.... 编译 6.8 版本时(要求jdk8 / jdk9),出现…...
)
面试经典150题(50-53)
leetcode 150道题 计划花两个月时候刷完,今天(第二十二天)完成了4道(50-53)150: 50.(141. 环形链表)题目描述: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个…...

Jetpack Compose中使用Android View
使用AndroidView创建日历 Composable fun AndroidViewPage() {AndroidView(factory {CalendarView(it)},modifier Modifier.fillMaxWidth(),update {it.setOnDateChangeListener { view, year, month, day ->Toast.makeText(view.context, "${year}年${month 1}月$…...
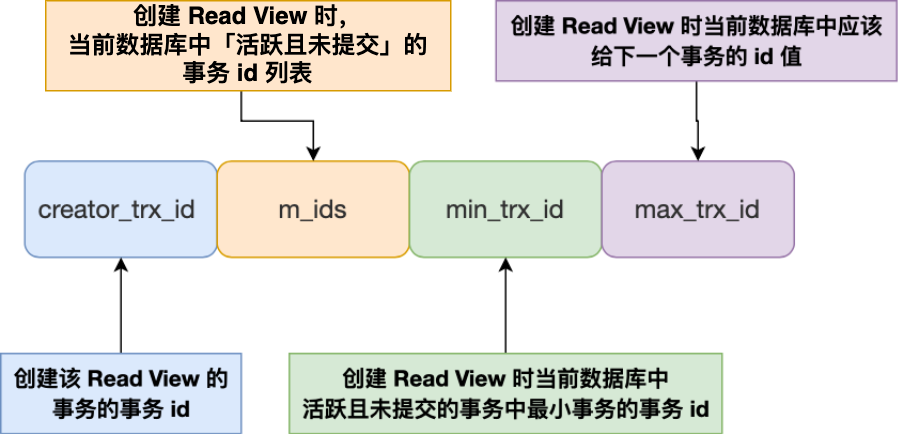
《MySQL》事务篇
事务特性 ACID Atomicity原子性:事务中的操作要么全部完成,要么全部失败。 Consistency一致性:事务操作前后,数据满足完整性约束。 Isolation隔离性:允许并发执行事务,每个事务都有自己的数据空间&…...

高阶组件和高阶函数是什么
高阶组件和高阶函数都是在函数式编程中常见的概念。 高阶组件(Higher-Order Component, HOC)是一种函数,接受一个组件作为参数,并返回一个新的组件。它可以用来增强现有的组件,给它添加额外的功能或属性。高阶组件在R…...
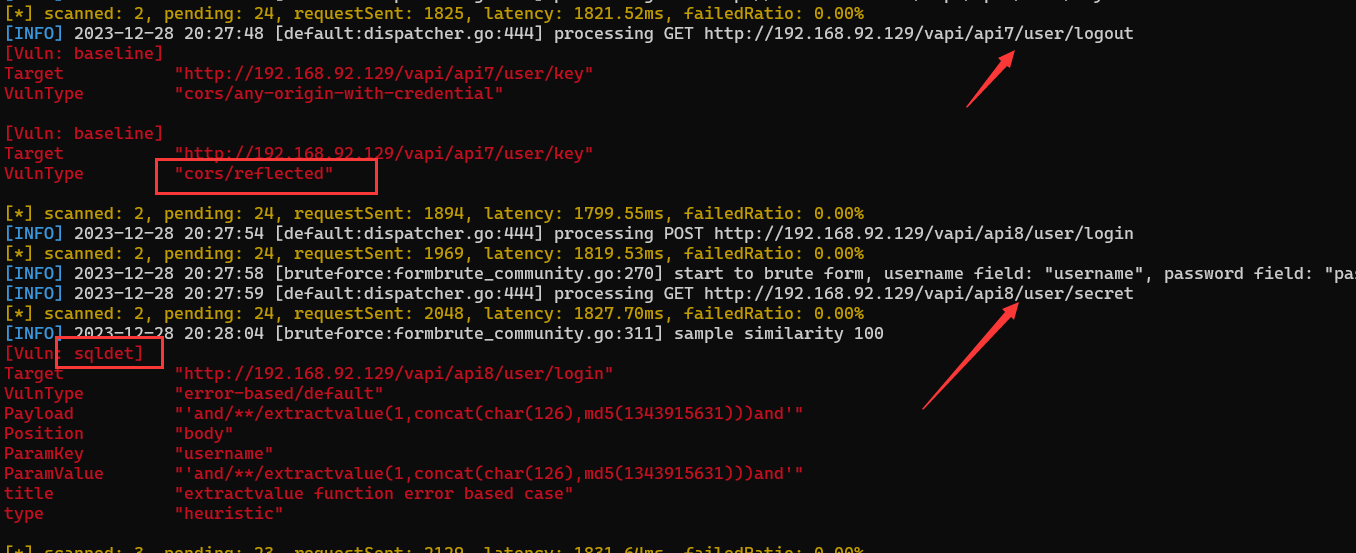
初步认识API安全
一、认识API 1. 什么是API API(应用程序接口):是一种软件中介,它允许两个不相关的应用程序相互通信。它就像一座桥梁,从一个程序接收请求或消息,然后将其传递给另一个程序,翻译消息并根据 API 的程序设计执行协议。A…...
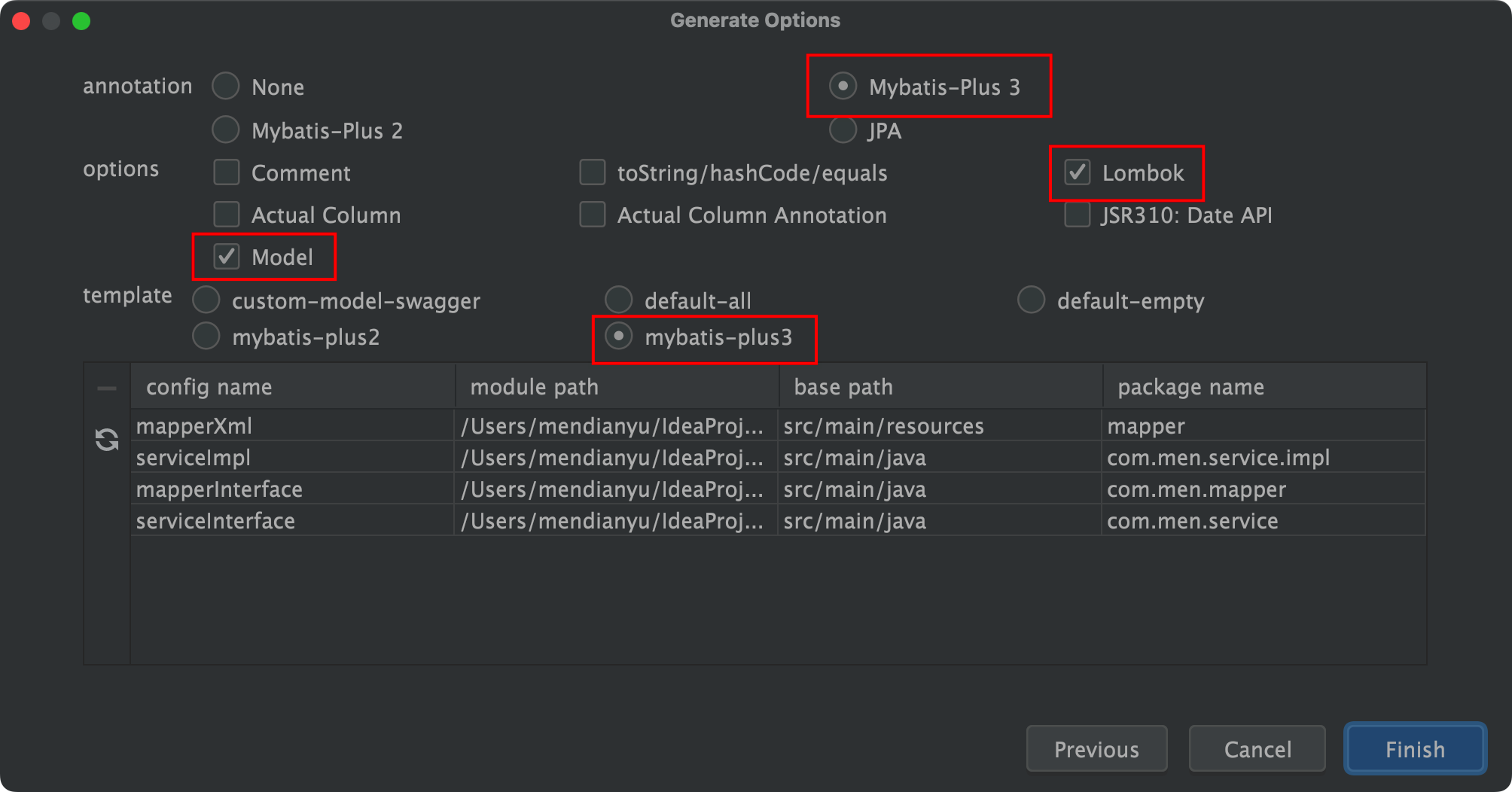
MybatisX逆向工程方法
官方文档链接:MybatisX快速开发插件 | MyBatis-Plus (baomidou.com) 使用MybatisX可以快速生成mapper文件,实体类和service及实现 效果 方法:首先下载mybatisX插件 然后创建数据库信息 然后选中表,右键,点击Mybatis…...

每日一题:LeetCode-LCR 179. 查找总价格为目标值的两个商品
每日一题系列(day 16) 前言: 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🌈 🔎…...
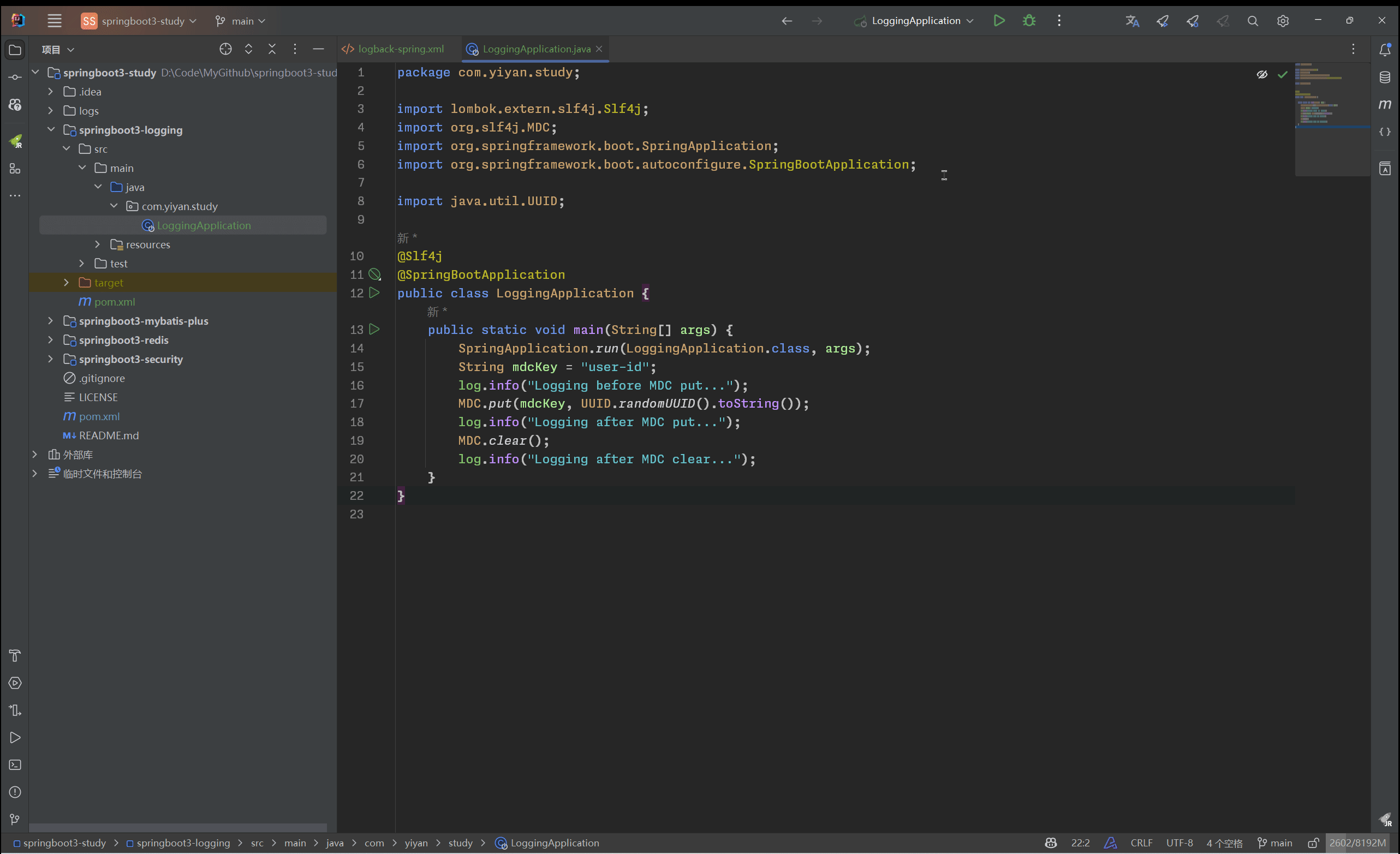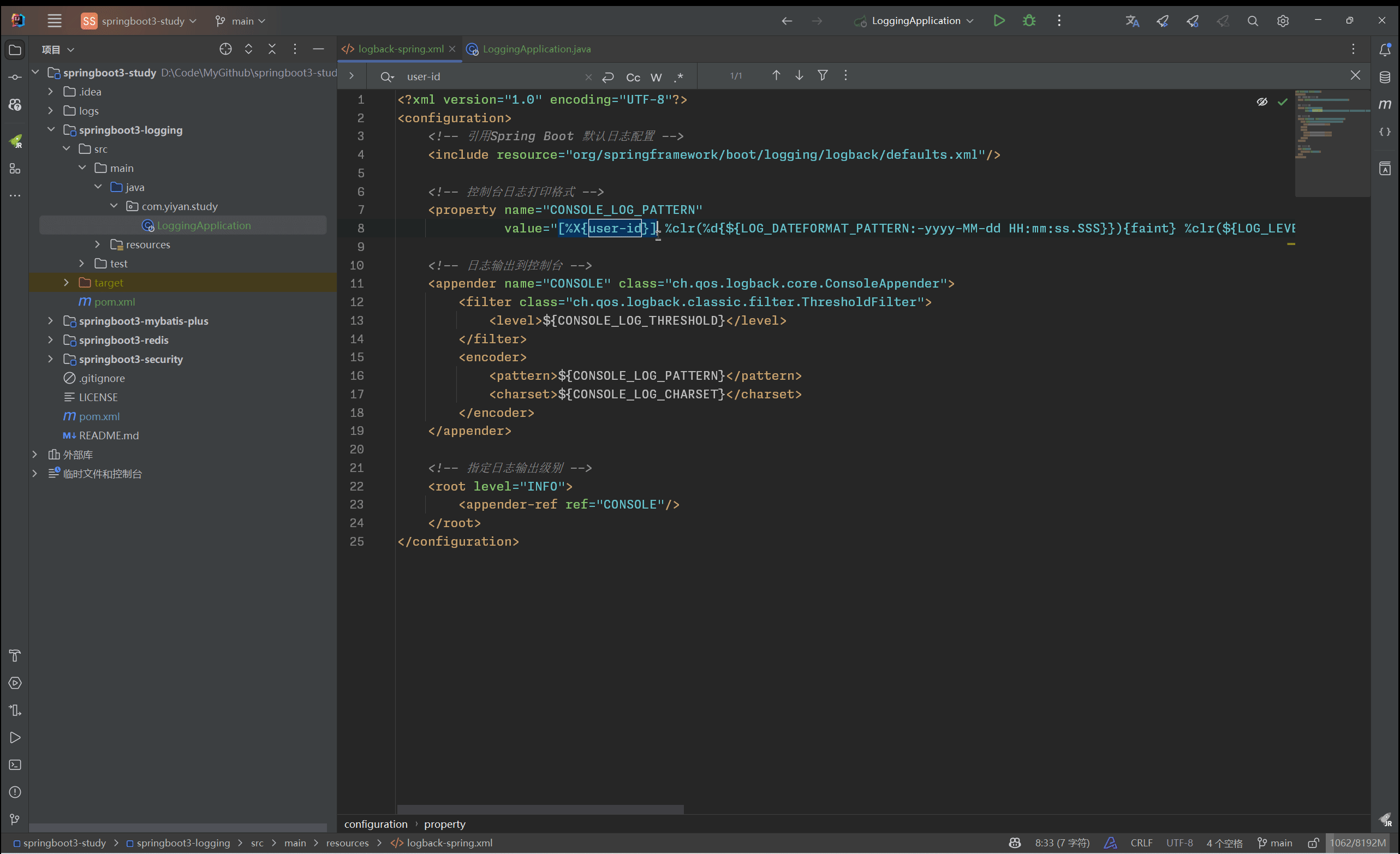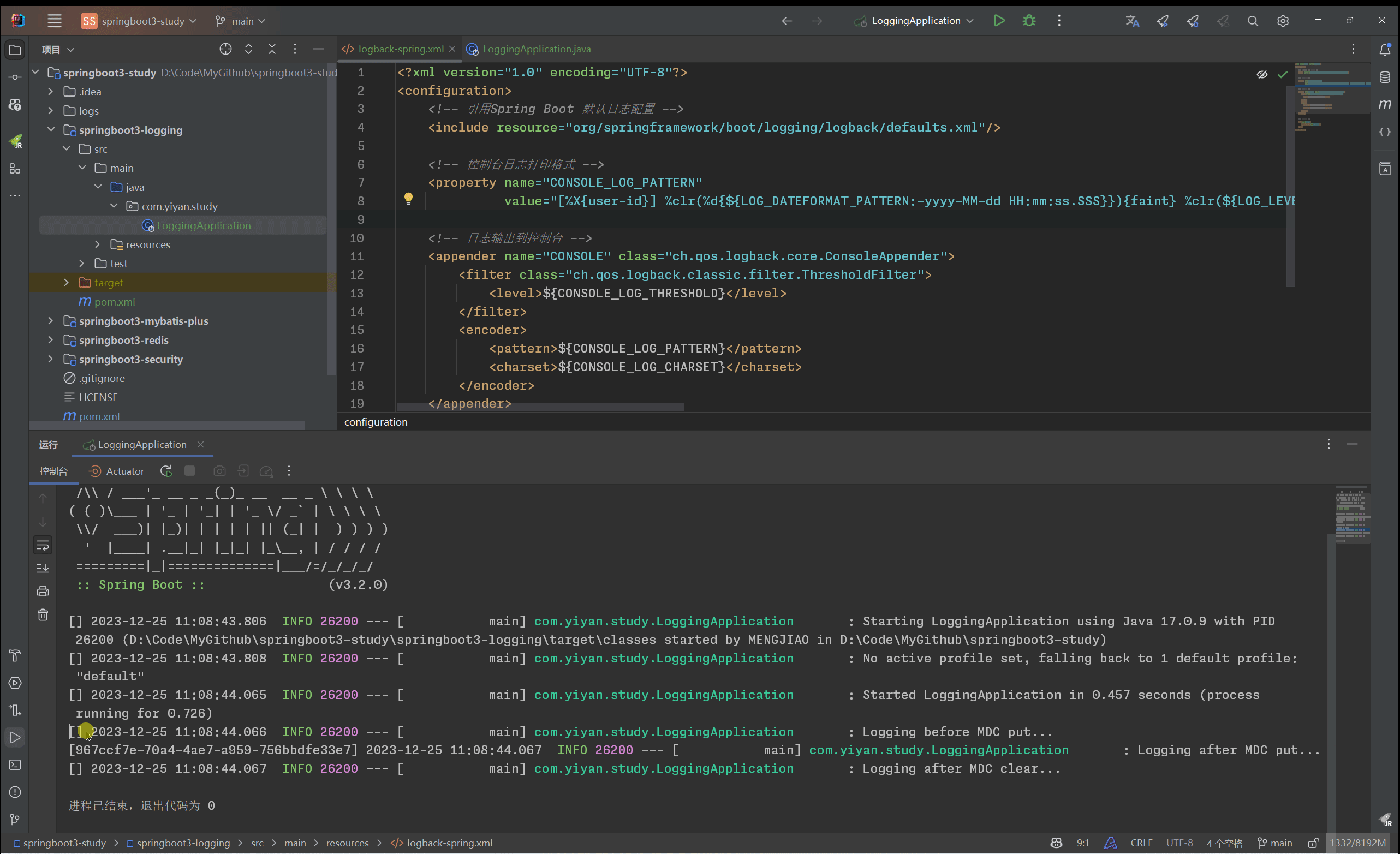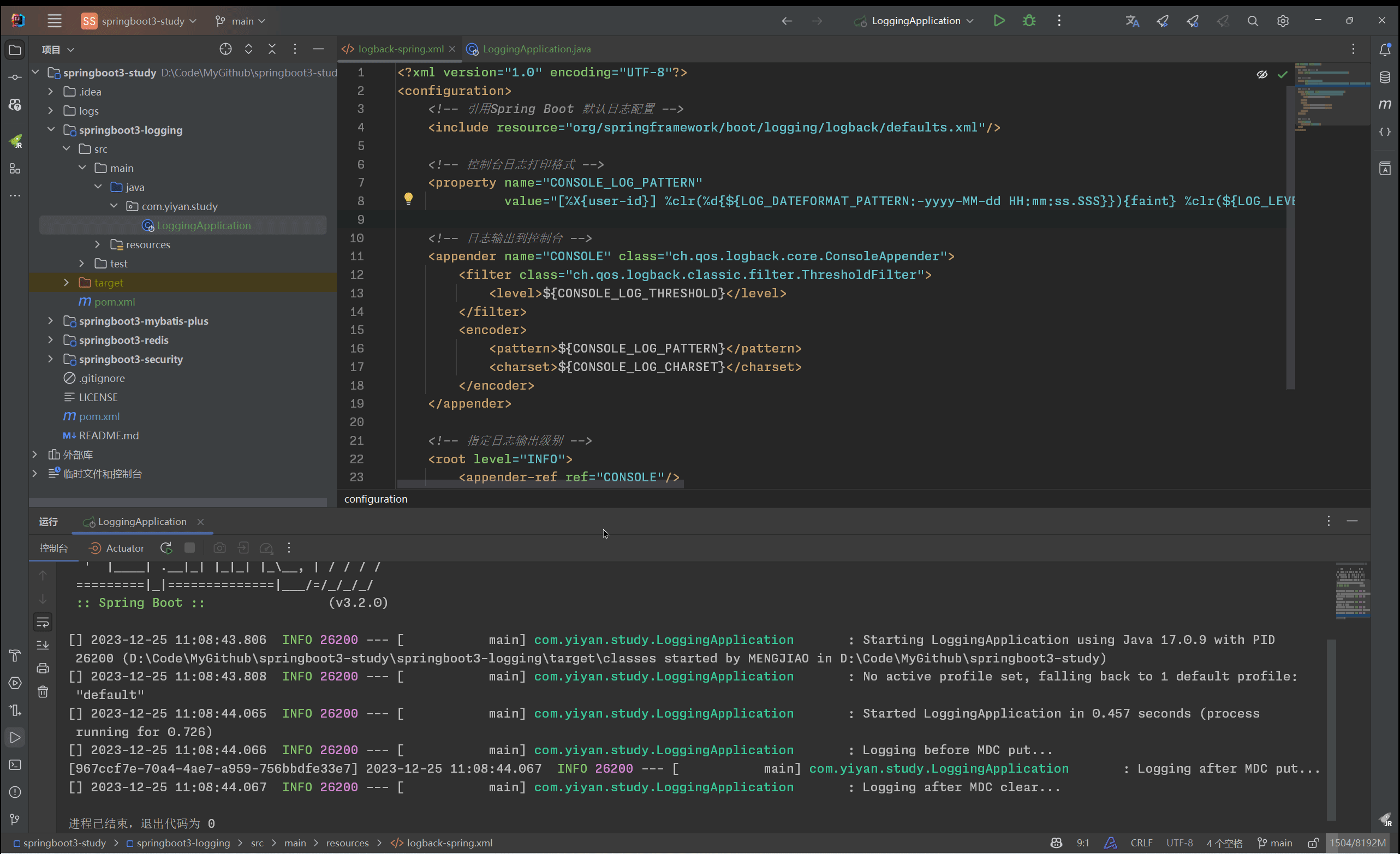
SpringBoot 3.2.0 基于Logback定制日志框架
依赖版本 JDK 17 Spring Boot 3.2.0 工程源码:Gitee 日志门面和日志实现 日志门面(如Slf4j)就是一个标准,同JDBC一样来制定“规则”,把不同的日志系统的实现进行了具体的抽象化,只提供了统一的日志使用接…...
微软发布安卓版Copilot,可免费使用GPT-4、DALL-E 3
12月27日,微软的Copilot助手,可在谷歌应用商店下载。目前,只有安卓版,ios还无法使用。 Copilot是一款类ChatGPT助手支持中文,可生成文本/代码/图片、分析图片、总结内容等,二者的功能几乎没太大差别。 值…...

【STM32】程序在SRAM中运行
程序在RAM中运行 1、配置内存分配。 2、修改跳转文件 FUNC void Setup(void) { SP _RDWORD(0x20000000); PC _RDWORD(0x20000004); } LOAD RAM\Obj\Project.axf INCREMENTAL Setup(); 3、修改下载ROM地址和RAM地址; 中断向量表映射 中断向量表映射到SRA…...

docker 部署mysql
docker pull mysql:5.7.25 docker run \ --name mysql \ -e MYSQL_ROOT_PASSWORD123456 \ -p 3306:3306 \ -v /soft/mysql/conf:/etc/mysql \ -v /soft/mysql/data:/var/lib/mysql \-d \mysql:5.7.25安装好之后可以用命令行进入查看 docker exec -it mysql mysql -u root -p密…...

科荣AIO ReportServlet存在目录遍历漏洞
文章目录 产品简介漏洞概述指纹识别漏洞利用修复建议 产品简介 科荣AIO是一款企业管理软件,提供企业一体化管理解决方案。它整合了ERP(如进销存、财务管理)、OA(办公自动化)、CRM(客户关系管理)…...
Ubuntu Desktop 22.04 桌面主题配置
Ubuntu Desktop 22.04 桌面主题配置 使用这么久 Ubuntu Desktop,本着不折腾的原则,简单介绍下自己的桌面主题配置。 安装 tweaks 安装 GNOME Shell 安装 GNOME theme安装 gnome-tweaks & chrome-gnome-shell sudo apt update # 安装 gnome-tweaks…...
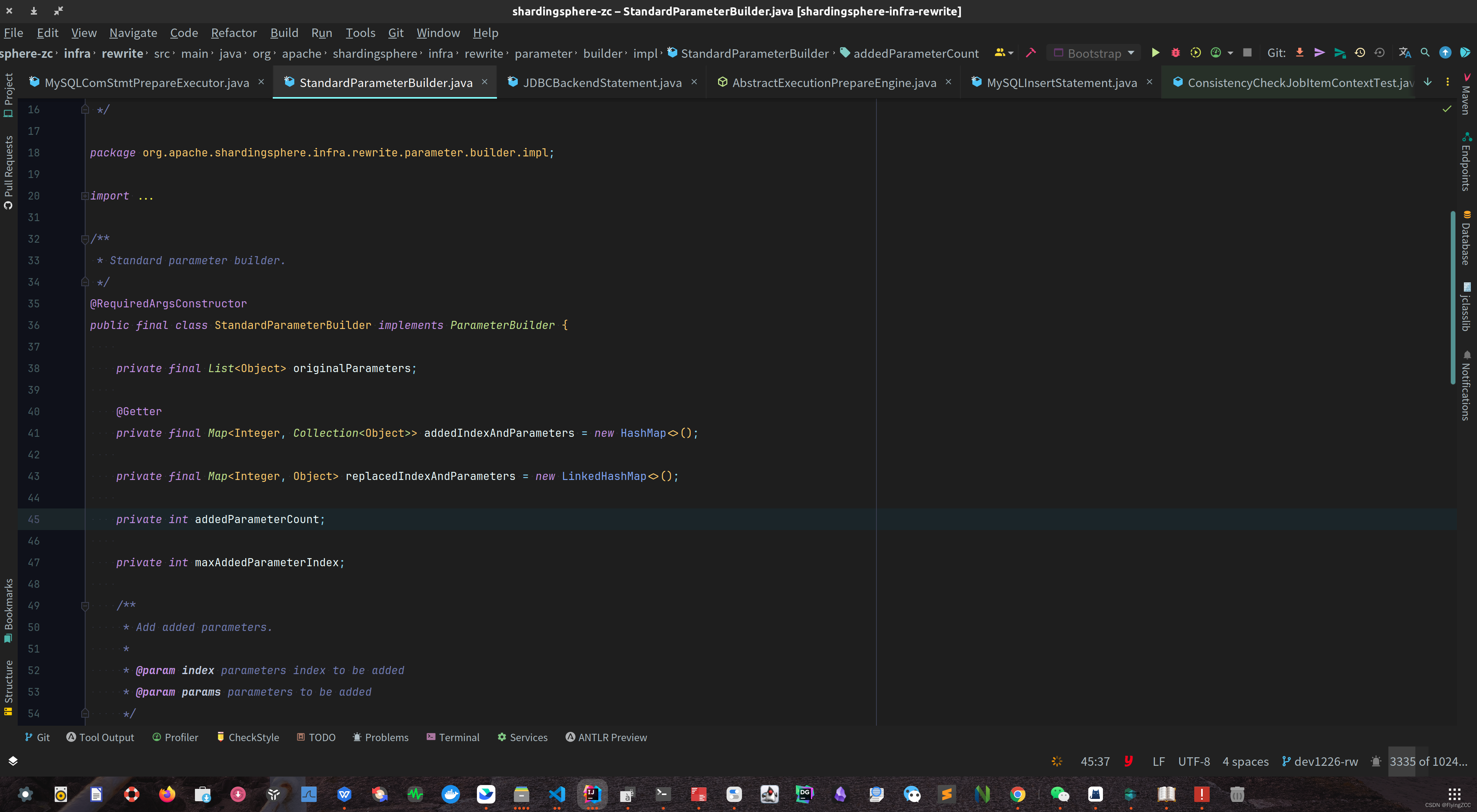
SuperMap iServer发布的ArcGIS REST 地图服务如何通过ArcGIS API进行要素查询
作者:yx 前言 前面我们介绍了SuperMap iServer发布的ArcGIS REST 地图服务如何通过ArcGIS API加载,这里呢我们再来看看如何进行要素查询呢? 一、服务发布 SuperMap iServer发布的ArcGIS REST 地图服务如何通过ArcGIS API加载已经介绍如何发…...
H5向微信小程序发送信息(小程序web-view打开H5)
引入weixin-js-sdk npm i weixin-js-sdk 页面引入 // 引入wxjsimport wx from "weixin-js-sdk"; 点击触发方法 methods: {goweap(id){console.log(wx);// H5传递数据 (navigateBack)wx.miniProgram.navigateBack({delta: 1});wx.min…...
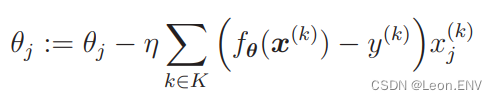
白话机器学习的数学-1-回归
1、设置问题 投入的广告费越多,广告的点击量就越高,进而带来访问数的增加。 2、定义模型 定义一个函数:一次函数 y ax b (a 是斜率、b 是截距) 定义函数: 3、最小二乘法 例子: 用随便确定的参…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...