pytorch01:概念、张量操作、线性回归与逻辑回归
目录
- 一、pytorch介绍
- 1.1pytorch简介
- 1.2发展历史
- 1.3pytorch优点
- 二、张量简介与创建
- 2.1什么是张量?
- 2.2Tensor与Variable
- 2.3张量的创建
- 2.3.1 直接创建torch.tensor()
- 2.3.2 从numpy创建tensor
- 2.4根据数值创建
- 2.4.1 torch.zeros()
- 2.4.2 torch.zeros_like()
- 2.4.3 torch.ones()和torch.ones_like()
- 2.4.4 torch.full()和torch.full_like()
- 2.4.5 torch.arange()
- 2.4.6 torch.linspace()
- 2.4.7 torch.logspace()
- 2.4.8 torch.eye()
- 2.5依概率分布创建张量
- 2.5.1 torch.normal()
- 2.5.2 torch.randn()和torch.randn_like()
- 2.5.3 torch.randint ()和torch.randint_like()
- 2.5.4 torch.randperm()
- 2.5.5 torch.bernoulli()
- 三、张量的操作
- 3.1 张量拼接与切分
- 3.1.1 torch.cat()
- 3.1.2 torch.stack()
- 3.1.3 torch.chunk()
- 3.1.4 torch.split()
- 3.2 张量索引
- 3.2.1 torch.index_select()
- 3.2.2 torch.masked_select()
- 3.3 张量变换
- 3.3.1 torch.reshape()
- 3.3.2 torch.transpose()
- 3.3.3 torch.t()
- 3.3.4 torch.squeeze()
- 3.3.5 torch.unsqueeze()
- 四、张量的运算
- torch.add()
- 五、线性回归
- 5.1线性回归概念
- 5.2 求解步骤
- 5.3线性回归代码实现
- 六、动态图机制
- 6.1计算图基本概念
- 6.2 计算图梯度求导
- 6.3 叶子结点
- 代码实现
- 查看叶子结点
- 查看梯度
- 查看梯度计算方法
- 6.4 动态图
- 6.4.1pytorch动态图
- 6.4.2TensorFlow静态图
- 七、逻辑回归
- 7.1 torch.autograd自动求导系统
- 7.1.1 torch.autograd.backward
- 7.1.2 torch.autograd.grad
- 7.1.3 自动求导系统注意事项
- 7.2逻辑回归
- 7.2.1 线性回归与对数回归的区别
- 7.2.2 逻辑回归代码实现
一、pytorch介绍
1.1pytorch简介
2017年1月,FAIR (FacebookAI Research) 发布PyTorch,PyTorch是在Torch基础上用python语言重新打造的一款深度学习框架,Torch 是采用Lua语言为接口的机器学习框架,但因Lua语言较为小众导致Torch知名度不高。
1.2发展历史
- 2017年1月正式发布PyTorch
- 2018年4月更新0.4.0版,支持Windows系统,caffe2正式并入PyTorch
- 2018年11月更新1.0稳定版,已GitHub 增长第二快的开源项目
- 2019年5月更新1.1.0版,支持TensorBoard,增强可视化功能
- 2019年8月更新1.2.0版,更新torchvision,torchaudio 和torchtext,增加更多功能
2014年10月至2018年02月arXiv论文中深度学习框架提及次数统计,PyTorch的增长速度与TensorFlow一致。

1.3pytorch优点
- 上手快: 掌握Numpy和基本深度学习概念即可上手
- 代码简洁灵活: 用nn.module封装使网络搭建更方便;基于动态图机制,更灵活
- Debug方便: 调试PyTorch就像调试 Python 代码一样简单
- 文档规范:https://pytorch.org/docs/可查各版本文档
- 资源多: arXiv中的新算法大多有PyTorch实现
- 开发者多:GitHub上贡献者(Contributors)已超过1100+
- 背靠大树: FaceBook维护开发
二、张量简介与创建
2.1什么是张量?
张量是一个多维数组,它是标量、向量、矩阵的高维拓展
在深度学习中,张量(tensor)是一个广泛使用的数学和计算工具,它是多维数组的泛化。以下是对深度学习中张量的一些解释:
1.数据结构: 张量是一个多维数组,可以是一个标量(0维张量,即一个数)、向量(1维张量,例如一行或一列数字)、矩阵(2维张量,例如一个表格或图像)、或者更高维度的数组。
2.Rank(秩): 张量的秩表示张量的维度数量。例如,标量的秩是0,向量的秩是1,矩阵的秩是2。通常,深度学习中的张量秩是可以很大的,因为神经网络中的数据通常是高维的。
3.形状: 张量的形状描述了它每个维度上的大小。例如,一个形状为 (3, 4) 的张量表示一个 3 行 4 列的矩阵。
4.类型: 张量可以包含不同类型的数据,例如整数、浮点数等。在深度学习中,通常使用浮点数张量。
5.操作: 张量上可以进行各种数学运算,如加法、减法、乘法等。这些操作是深度学习中神经网络的基础。
6.自动微分: 在深度学习中,张量通常与自动微分结合使用。自动微分是通过计算图和链式法则来计算梯度,用于训练神经网络。
7.存储和计算优化: 张量在内存中的存储方式通常是连续的,这有助于在硬件上进行高效的计算。深度学习框架使用张量来表示神经网络的参数和输入输出。
8.GPU 加速: 张量的并行性和规则结构使得深度学习中的许多计算可以受益于 GPU 的并行计算能力。因此,深度学习框架通常支持在 GPU 上进行张量操作。
在常见的深度学习框架(如 TensorFlow、PyTorch等)中,张量是核心数据结构,它们提供了丰富的操作和函数来处理张量,支持自动微分、梯度下降等算法,使得深度学习模型的实现更加方便和高效。

2.2Tensor与Variable
Variable是torch.autograd中的数据类型主要用于封装Tensor,进行自动求导
data: 被包装的Tensor
grad: data的梯度
grad fn: 创建Tensor的Function,是自动求导的关键
requires_grad: 指示是否需要梯度
is leaf: 指示是否是叶子结点 (张量)

2.3张量的创建
2.3.1 直接创建torch.tensor()
torch.tensor()
功能:从data创建tensor

• data: 数据, 可以是list, numpy
• dtype : 数据类型,默认与data的一致
• device : 所在设备, cuda/cpu
• requires_grad:是否需要梯度
• pin_memory:是否存于锁页内存
2.3.2 从numpy创建tensor
torch.from_numpy(ndarray)
注意事项: 从torch.from_numpy创建的tensor于原ndarray共享内存,当修改其中一个的数据,另外一个也将会被改动

2.4根据数值创建
2.4.1 torch.zeros()
功能:依size创建全0张量

• size: 张量的形状, 如(3, 3)、(3, 224,224)
• out : 输出的张量
• layout : 内存中布局形式, 有strided,sparse_coo等
• device : 所在设备, gpu/cpu
• requires_grad:是否需要梯度
2.4.2 torch.zeros_like()
功能:依input形状创建全0张量

• intput: 创建与input同形状的全0张量
• dtype : 数据类型
• layout : 内存中布局形式
2.4.3 torch.ones()和torch.ones_like()
功能:依input形状创建全1张量


• size: 张量的形状, 如(3, 3)、(3, 224,224)
• dtype : 数据类型
• layout : 内存中布局形式
• device : 所在设备, gpu/cpu
• requires_grad:是否需要梯度
2.4.4 torch.full()和torch.full_like()
功能:依input形状创建指定数据的张量

• size: 张量的形状, 如(3, 3)
• fill_value : 张量的值
2.4.5 torch.arange()
功能:创建等差的1维张量

注意事项:数值区间为[start, end)
• start : 数列起始值
• end : 数列“结束值”
• step: 数列公差,默认为1
2.4.6 torch.linspace()
功能:创建均分的1维张量

注意事项:数值区间为[start, end]
• start : 数列起始值
• end : 数列结束值
• steps: 数列长度
2.4.7 torch.logspace()
功能:创建对数均分的1维张量

注意事项:长度为steps, 底为base
• start : 数列起始值
• end : 数列结束值
• steps: 数列长度
• base : 对数函数的底,默认为10
2.4.8 torch.eye()
功能:创建单位对角矩阵( 2维张量)

注意事项:默认为方阵
• n: 矩阵行数
• m : 矩阵列数
2.5依概率分布创建张量
2.5.1 torch.normal()
功能:生成正态分布(高斯分布)

• mean : 均值
• std : 标准差
2.5.2 torch.randn()和torch.randn_like()
功能:生成标准正态分布
功能:在区间[0, 1)上,生成均匀分布

• size : 张量的形状
2.5.3 torch.randint ()和torch.randint_like()
功能:区间[low, high)生成整数均匀分布

• size : 张量的形状
2.5.4 torch.randperm()
功能:生成生成从0到n-1的随机排列

• n : 张量的长度
2.5.5 torch.bernoulli()
功能:以input为概率,生成伯努力分布(0-1分布,两点分布)

• input : 概率值
三、张量的操作
3.1 张量拼接与切分
3.1.1 torch.cat()
功能:将张量按维度dim进行拼接

• tensors: 张量序列
• dim : 要拼接的维度
3.1.2 torch.stack()
功能:在新创建的维度dim上进行拼接

• tensors:张量序列
• dim :要拼接的维度
3.1.3 torch.chunk()
功能:将张量按维度dim进行平均切分

返回值:张量列表
注意事项:若不能整除,最后一份张量小于其他张量
• input: 要切分的张量
• chunks : 要切分的份数
• dim : 要切分的维度
3.1.4 torch.split()
功能:将张量按维度dim进行切分

返回值:张量列表
• tensor: 要切分的张量
• split_size_or_sections : 为int时,表示每一份的长度;为list时,按list元素切分
• dim : 要切分的维度
3.2 张量索引
3.2.1 torch.index_select()
功能:在维度dim上,按index索引数据

返回值:依index索引数据拼接的张量
• input: 要索引的张量
• dim: 要索引的维度
• index : 要索引数据的序号
3.2.2 torch.masked_select()
功能:按mask中的True进行索引

返回值:一维张量
• input: 要索引的张量
• mask: 与input同形状的布尔类型张量
3.3 张量变换
3.3.1 torch.reshape()
功能:变换张量形状

注意事项:当张量在内存中是连续时,新张量与input共享数据内存
• input: 要变换的张量
• shape: 新张量的形状
3.3.2 torch.transpose()
功能:交换张量的两个维度

• input: 要变换的张量
• dim0: 要交换的维度
• dim1: 要交换的维度
3.3.3 torch.t()
功能:2维张量转置,对矩阵而言,等价于torch.transpose(input, 0, 1)

3.3.4 torch.squeeze()
功能:压缩长度为1的维度(轴)

• dim: 若为None,移除所有长度为1的轴;若指定维度,当且仅当该轴长度为1时,可以被移除;
3.3.5 torch.unsqueeze()
功能:依据dim扩展维度

• dim: 扩展的维度
四、张量的运算

torch.add()
功能:逐元素计算 input+alpha×other
• input: 第一个张量
• alpha: 乘项因子
• other: 第二个张量
五、线性回归
5.1线性回归概念

5.2 求解步骤

5.3线性回归代码实现
# -*- coding:utf-8 -*-import torch
import matplotlib.pyplot as plttorch.manual_seed(10)lr = 0.05 # 学习率# 创建训练数据
x = torch.rand(20, 1) * 10 # x data (tensor), shape=(20, 1)
y = 2 * x + (5 + torch.randn(20, 1)) # y data (tensor), shape=(20, 1)# 构建线性回归参数
w = torch.randn((1), requires_grad=True)
b = torch.zeros((1), requires_grad=True)for iteration in range(1000):# 前向传播 y=wx+bwx = torch.mul(w, x)y_pred = torch.add(wx, b)# 计算 MSE lossloss = (0.5 * (y - y_pred) ** 2).mean()# 损失反向传播来得到梯度gradloss.backward()# 更新参数b.data.sub_(lr * b.grad) # sub_:原地减法操作w.data.sub_(lr * w.grad)# 清零张量的梯度w.grad.zero_()b.grad.zero_()# 绘图if iteration % 20 == 0:plt.scatter(x.data.numpy(), y.data.numpy())plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)plt.text(2, 20, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})plt.xlim(1.5, 10)plt.ylim(8, 28)plt.title("Iteration: {}\nw: {} b: {}".format(iteration, w.data.numpy(), b.data.numpy()))plt.pause(0.5)# 设置一个终止条件,当loss小于1的时候停止更新if loss.data.numpy() < 1:break结果展示:


六、动态图机制
6.1计算图基本概念
计算图是用来描述运算的有向无环图计算图有两个主要元素:结点(Node)和边(Edge)结点表示数据,如向量,矩阵,张量边表示运算,如加减乘除卷积等用计算图表示:y = (x+ w) * (w+1);a = x + w ;b = w + 1 ;y = a * b

6.2 计算图梯度求导

求导流程如下:

6.3 叶子结点
叶子结点:用户创建的结点称为叶子结点,如X 与 W;在torch中有如下图属性,is_leaf: 指示张量是否为叶子结点。
grad_fn: 记录创建该张量时所用的方法(函数)
当x,w使用torch方法创建之后,该属性会保留grad属性,a、b、y都是通过x,w计算得到的,在反向传播之后就会释放梯度,减少内存开销。


代码实现
查看叶子结点
import torchw = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x) # retain_grad()
b = torch.add(w, 1)
y = torch.mul(a, b)y.backward()
print(w.grad)# 查看叶子结点
print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)输出结果:
tensor([5.])
is_leaf:True True False False False
查看梯度
# -*- coding:utf-8 -*-import torchw = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x) # retain_grad()
a.retain_grad()b = torch.add(w, 1)
b.retain_grad()
y = torch.mul(a, b)y.backward()
print(w.grad)
print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)输出结果:
tensor([5.])
gradient:tensor([5.]) tensor([2.]) tensor([2.]) tensor([3.]) None
注意:a,b,y非叶子结点,所以反向传播之后会清除梯度,所以使用a.grad方法结果是none,需要在中间使用a.retain_grad()方法将a的梯度保留下来。
查看梯度计算方法
import torchw = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x) # retain_grad()
# a.retain_grad()b = torch.add(w, 1)
# b.retain_grad()
y = torch.mul(a, b)y.backward()
print(w.grad)
# 查看 grad_fn
print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)输出结果:
tensor([5.])
grad_fn:None None <AddBackward0 object at 0x00000217F70B1330> <AddBackward0 object at 0x00000217F70B1300> <MulBackward0 object at 0x00000217F70B13F0>
从上面结果可以看出,a和b的梯度计算使用的是加法,y梯度使用的是乘法。
6.4 动态图
为什么近几年TensorFlow逐渐被淘汰了,因为TensorFlow使用的任然是静态图,先搭建网络后进行运算,这样会导致效率低下;

6.4.1pytorch动态图

6.4.2TensorFlow静态图

七、逻辑回归
7.1 torch.autograd自动求导系统
7.1.1 torch.autograd.backward
功能:自动求取梯度

• tensors: 用于求导的张量,如 loss
• retain_graph : 保存计算图
• create_graph : 创建导数计算图,用于高阶
求导
• grad_tensors:多梯度权重
7.1.2 torch.autograd.grad
功能:求取梯度

• outputs: 用于求导的张量,如 loss
• inputs : 需要梯度的张量
• create_graph : 创建导数计算图,用于高阶
求导
• retain_graph : 保存计算图
• grad_outputs:多梯度权重
7.1.3 自动求导系统注意事项
- 梯度不自动清零
- 依赖于叶子结点的结点,requires_grad默认为True
- 叶子结点不可执行in-place
7.2逻辑回归
逻辑回归是线性的二分类模型,模型表达式和函数图像如下:

线性回归是分析自变量x与因变量y(标量)之间关系的方法
逻辑回归是分析自变量x与因变量y(概率)之间关系的方法
7.2.1 线性回归与对数回归的区别

7.2.2 逻辑回归代码实现

# -*- coding: utf-8 -*-import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as nptorch.manual_seed(10)# ============================ step 1/5 生成数据 ============================
sample_nums = 100
mean_value = 1.7
bias = 1
n_data = torch.ones(sample_nums, 2)
x0 = torch.normal(mean_value * n_data, 1) + bias # 类别0 数据 shape=(100, 2)
y0 = torch.zeros(sample_nums) # 类别0 标签 shape=(100, 1)
x1 = torch.normal(-mean_value * n_data, 1) + bias # 类别1 数据 shape=(100, 2)
y1 = torch.ones(sample_nums) # 类别1 标签 shape=(100, 1)
train_x = torch.cat((x0, x1), 0) # 在0维进行拼接
train_y = torch.cat((y0, y1), 0)# ============================ step 2/5 选择模型 ============================
class LR(nn.Module):def __init__(self):super(LR, self).__init__()self.features = nn.Linear(2, 1)self.sigmoid = nn.Sigmoid()def forward(self, x):x = self.features(x)x = self.sigmoid(x)return xlr_net = LR() # 实例化逻辑回归模型# ============================ step 3/5 选择损失函数 ============================
loss_fn = nn.BCELoss() # 二分类交叉熵损失函数# ============================ step 4/5 选择优化器 ============================
lr = 0.01 # 学习率
optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)# ============================ step 5/5 模型训练 ============================
for iteration in range(1000):# 前向传播y_pred = lr_net(train_x)# 计算 lossloss = loss_fn(y_pred.squeeze(), train_y)# 反向传播loss.backward()# 更新参数optimizer.step()# 清空梯度optimizer.zero_grad()# 绘图if iteration % 20 == 0:mask = y_pred.ge(0.5).float().squeeze() # 以0.5为阈值进行分类correct = (mask == train_y).sum() # 计算正确预测的样本个数acc = correct.item() / train_y.size(0) # 计算分类准确率plt.scatter(x0.data.numpy()[:, 0], x0.data.numpy()[:, 1], c='r', label='class 0')plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c='b', label='class 1')w0, w1 = lr_net.features.weight[0]w0, w1 = float(w0.item()), float(w1.item())plot_b = float(lr_net.features.bias[0].item())plot_x = np.arange(-6, 6, 0.1)plot_y = (-w0 * plot_x - plot_b) / w1plt.xlim(-5, 7)plt.ylim(-7, 7)plt.plot(plot_x, plot_y)plt.text(-5, 5, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})plt.title("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}".format(iteration, w0, w1, plot_b, acc))plt.legend()plt.show()plt.pause(0.5)if acc > 0.99:break运行结果:380次迭代之后准确率达到99.5%

相关文章:
pytorch01:概念、张量操作、线性回归与逻辑回归
目录 一、pytorch介绍1.1pytorch简介1.2发展历史1.3pytorch优点 二、张量简介与创建2.1什么是张量?2.2Tensor与Variable2.3张量的创建2.3.1 直接创建torch.tensor()2.3.2 从numpy创建tensor 2.4根据数值创建2.4.1 torch.zeros()2.4.2 torch.zeros_like()2.4.3 torch…...

storyBook play学习
场景 在官方给出的案例中, Page.stories.js import { within, userEvent } from storybook/testing-library import MyPage from ./Page.vueexport default {title: Example/Page,component: MyPage,parameters: {// More on how to position stories at: https:/…...
Android Matrix画布Canvas旋转Rotate,Kotlin
Android Matrix画布Canvas旋转Rotate,Kotlin private fun f1() {val originBmp BitmapFactory.decodeResource(resources, R.mipmap.pic).copy(Bitmap.Config.ARGB_8888, true)val newBmp Bitmap.createBitmap(originBmp.width, originBmp.height, Bitmap.Config.…...
私有部署ELK,搭建自己的日志中心(三)-- Logstash的安装与使用
一、部署ELK 上文把采集端filebeat如何使用介绍完,现在随着数据的链路,继续~~ 同样,使用docker-compose部署: version: "3" services:elasticsearch:container_name: elasticsearchimage: elastic/elasticsearch:7.9…...

2023就这样过去了,2024会更好吗?
2023年,不是很好 2023年是疫情后的第一年,疫情过去了,大家都有大多的希望,希望经济可以恢复,希望信心可以恢复,但是整体都是远远低于预期的。年初的一片热潮,年中的一片哀嚎,年底基…...

SpringBoot加载配置的6种方式
从配置文件中获取属性应该是SpringBoot开发中最为常用的功能之一,简单回顾一下这六种的使用方式: 说明Environment对象Environment是springboot核心的环境配置接口,它提供了简单的方法来访问应用程序属性,包括系统属性、操作系统…...
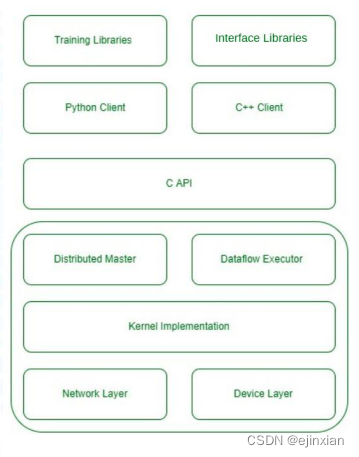
大语言模型(LLM)训练平台与工具
LLM 是利用深度学习和大数据训练的人工智能系统,专门 设计来理解、生成和回应自然语言。 大模型训练平台和工具提供了强大且灵活的基础设施,使得开发和训练复杂的语言模型变得可行且高效。 平台和工具提供了先进的算法、预训练模型和优化技术,…...

docker配置buildx插件
一、介绍 Docker buildx是docker的一个插件 支持Moby BuildKit的所有特性 可以跨CPU架构编译镜像 可以在多节点编译镜像 二、前提 使用 buildx 作为 docker CLI 插件需要使用 Docker 19.03 或更新版本。 三、配置步骤 1)客户端:在客户端的配置文…...

mysql 空间函数
ST_GeomFromText:将文本表示的几何对象转换为几何对象。 SELECT ST_GeomFromText(POINT(1 1)); ST_AsText:将几何对象转换为文本表示。 SELECT ST_AsText(ST_GeomFromText(POINT(1 1))); ST_Contains:判断一个几何对象是否包含另一个几何对象…...
vscode调试 反汇编c/c++ 查看汇编代码gdb/lldb
先看下流程! 先看下流程! 有问题请留言! 文章目录 必备F5开启调试左侧侧边栏->确保打开回调栈右键函数栈->查看反汇编 方法二:手动输入命令查看 必备 使用c/c 插件,这应该是必备的。 F5开启调试 左侧侧边栏-&…...
)
总结项目中oauth2模块的配置流程及实际业务oauth2认证记录(Spring Security)
文章目录 简单示例添加oauth2的依赖配置认证服务器配置资源服务器配置安全使用http或者curl命令测试 实际业务中工具类(记录):认证服务器资源服务器、配置安全用户验证登录控制层配置文件application.yml 项目中用过的spring security&#x…...

传感器原理与应用复习
测量与误差 传感器原理与应用复习—测量概述与测量误差 传感器特性与应变式传感器 传感器原理与应用复习–传感器基本特性与应变式传感器 电感式传感器 传感器原理与应用复习–电感式传感器 电容式与电压式传感器 传感器原理与应用复习–电容式与压电式传感器 电磁式与…...
)
蓝桥杯python比赛历届真题99道经典练习题 (8-12)
【程序8】 题目:输出9*9口诀。 1.程序分析:分行与列考虑,共9行9列,i控制行,j控制列。 2.程序源代码: #include "stdio.h" main() {int i,j,result;printf("\n");for (i=1;i<10;i++){ for(j=1;j<10;j++){result=i*j;printf("%d*%d=%-3…...

八个理由:从java8升级到Java17
目录 前言 1. 局部变量类型推断 2.switch表达式 3.文本块 4.Records 5.模式匹配instanceof 6. 密封类 7. HttpClient 8.性能和内存管理能力提高 前言 从Java 8 到 Java 20,Java 已经走过了漫长的道路,自 Java 8 以来,Java 生态系统…...

使用poi将pptx文件转为图片详解
目录 项目需求 后端接口实现 1、引入poi依赖 2、代码编写 1、controller 2、service层 测试出现的bug 小结 项目需求 前端需要上传pptx文件,后端保存为图片,并将图片地址保存数据库,最后大屏展示时显示之前上传的pptx的图片。需求看上…...
【微服务】springboot整合skywalking使用详解
目录 一、前言 二、SkyWalking介绍 2.1 SkyWalking是什么 2.2 SkyWalking核心功能 2.3 SkyWalking整体架构 2.4 SkyWalking主要工作流程 三、为什么选择SkyWalking 3.1 业务背景 3.2 常见监控工具对比 3.3 为什么选择SkyWalking 3.3.1 代码侵入性极低 3.3.2 功能丰…...

electron——查看electron的版本(代码片段)
electron——查看electron的版本(代码片段)1.使用命令行: npm ls electron 操作如下: 2.在软件内使用代码,如下: console.log(process) console.log(process.versions.electron) process 里包含很多信息: process详…...

【Electron】富文本编辑器之文本粘贴
由于这个问题导致,从其他地方复制来的内容 粘贴发送之后都会多一个 换行 在发送的时候如果直接,发送innerHTML 就 可以解决 Electron h5 Andriod 都没问题,但是 公司的 IOS 端 不支持,且不提供支持(做不了。ÿ…...

【哈希数组】697. 数组的度
697. 数组的度 解题思路 首先创建一个IndexMap 键表示元素 值表示一个列表List list存储该元素在数组的所有索引之后再次创建一个map1 针对上面的List 键表示列表的长度 值表示索引的差值遍历indexmap 将所有的list的长度 和 索引的差值存储遍历map1 找到最大的key 那么这个Ke…...

GO语言工具函数库--Lancet
支持300常用功能的开源GO语言工具函数库–Lancet lancet(柳叶刀)是一个全面、高效、可复用的go语言工具函数库。lancet受到了java apache common包和lodash.js的启发。 特性 全面、高效、可复用300常用go工具函数,支持string、slice、dateti…...

3分钟完成Windows Defender永久禁用:开源控制工具终极指南
3分钟完成Windows Defender永久禁用:开源控制工具终极指南 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-control …...

Total Uninstall:强力卸载软件解决程序残留与顽固卸载难题
你是否曾经从控制面板卸载了一个软件,却发现它的文件夹还留在Program Files里?右键删除时提示“正在使用”;或者打开注册表编辑器,搜索软件名称,发现成百上千条残留项。这些残留不仅占用磁盘空间,还可能拖慢…...

AI写论文别担心!4款AI论文写作利器,轻松应对论文创作挑战
你是不是也在为撰写期刊论文、毕业论文或职称论文而感到无从下手呢?在写论文时,面对浩如烟海的文献资料,仿佛在大海中寻找针,繁杂的格式要求更是让人无从着手,反复的修改不断消耗着你的耐心,写作效率低下令…...
)
新手避坑指南:用PHPStudy在Windows上快速搭建Pikachu靶场(附常见错误解决)
新手避坑指南:用PHPStudy在Windows上快速搭建Pikachu靶场(附常见错误解决) 在网络安全学习的过程中,搭建本地靶场环境是每个初学者必须掌握的技能。Pikachu靶场作为一个专为Web安全学习设计的漏洞演示平台,包含了SQL注…...
(项目源码+数据集+模型权重+UI界面+python+深度学习+远程环境部署))
YOLOv26篮球运动员检测系统:9类关键目标识别(附mAP 86.5%实测)(项目源码+数据集+模型权重+UI界面+python+深度学习+远程环境部署)
摘要 本文基于YOLO26目标检测算法,构建了一套面向篮球比赛场景的多类别目标检测系统。该系统能够自动识别篮球比赛视频中的9类关键目标:篮球(Ball)、篮筐(Hoop)、比赛节数(Period)、运动员(Player)、裁判(Ref)、进攻计时器(Shot Clock)、队名(Team Name…...

把 memory_order 从 seq_cst 改成 acquire/release,QPS 涨了 40%——但下一行代码差点就是数据竞争
看这段代码: std::atomic<bool> ready{false}; int data = 0;// 线程 A:生产者 void producer()...

Dubbo 超时机制与集群容错机制详解:防止雪崩的利器
Dubbo 超时机制与集群容错机制详解:防止雪崩的利器 一、引言 在分布式系统中,服务间的远程调用充满不确定性——网络延迟、服务端GC停顿、瞬间流量洪峰等都可能导致调用失败或响应缓慢。如果没有合理的保护机制,一个服务的不稳定会像多米诺骨…...

保姆级教程:在全志A40i的Linux 3.10内核上配置RTL8188FU WiFi并测试网速
全志A40i嵌入式系统RTL8188FU无线网卡深度配置与性能调优指南 当你在全志A40i平台上第一次插入那块小小的USB无线网卡时,可能不会想到这个看似简单的动作背后隐藏着多少技术细节。作为一款广泛应用于工业控制、智能家居等领域的嵌入式处理器,全志A40i搭…...

nomic-embed-text-v2-moe实战教程:嵌入向量持久化到FAISS/Chroma向量库
nomic-embed-text-v2-moe实战教程:嵌入向量持久化到FAISS/Chroma向量库 你是不是遇到过这样的问题:手头有一堆文档、文章或者产品描述,想快速找到和某个问题最相关的内容,却只能靠手动搜索关键词,效率低下还容易遗漏&…...

浅学线性回归与逻辑回归
1.什么是线性回归和逻辑回归 线性回归是一种用于建模连续目标变量与一个或多个自变量之间线性关系的统计方法,它的基本形式为y theta0 theta1*x theta2 * x*x .......。其中,我们会假设自变量与因变量存在线性关系,自变量之间相关性较低。 线性回归…...