Python 之 NumPy 简介和创建数组
文章目录
- 一、NumPy 简介
- 1. 为什么要使用 NumPy
- 2. NumPy 数据类型
- 3. NumPy 数组属性
- 4. NumPy 的 ndarray 对象
- 二、numpy.array() 创建数组
- 1. 基础理论
- 2. 基础操作演示
- 3. numpy.array() 参数详解
- 三、numpy.arange() 生成区间数组
- 四、numpy.linspace() 创建等差数列
- 五、numpy.logspace() 创建等比数列
- 六、numpy.zeros() 创建全零数列
- 七、np.ones() 创建一数列
一、NumPy 简介
- NumPy(Numerical Python)是 Python 的一种开源的数值计算扩展。
- 这种工具可用来存储和处理大型矩阵,比 Python 自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
- 使用 NumPy 可以方便的使用数据、矩阵进行计算,包含线性代数、傅里叶变化、随机数生成等大量函数。
1. 为什么要使用 NumPy
- Numpy 是 Python 各种数据科学类库的基础库,比如:Scipy,Scikit-Learn、TensorFlow、pandas等。
- 对于同样的数值计算任务,使用 NumPy 比直接使用 Python 代码实现有如下优点:
- (1) 代码更简洁:NumPy 直接以数组、矩阵为粒度计算并且支撑大量的数学函数,而 python 需要用 for 循环从底层实现;
- (2) 性能更高效:NumPy 的数组存储效率和输入输出计算性能,比 Python 使用 List 或者嵌套 List 好很多。
- 这里有两点需要注意需要注意是,其一,Numpy 的数据存储和 Python 原生的 List 是不一样的。
- 其二,NumPy 的大部分代码都是 C 语言实现的,这是 Numpy 比纯 Python 代码高效的原因。
2. NumPy 数据类型
- NumPy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。
- 下表列举了常用 NumPy 基本类型:
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
- NumPy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。
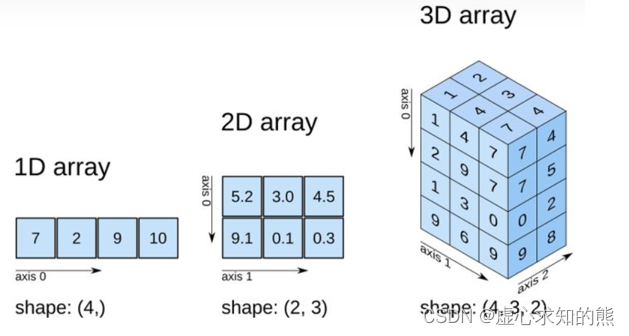
3. NumPy 数组属性
- NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
- 在 NumPy 中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。
- 比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
- 很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
- NumPy 的数组中比较重要 ndarray 对象属性有:
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray 元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
4. NumPy 的 ndarray 对象
- NumPy 定义了一个 n 维数组对象,简称 ndarray 对象,它是一个一系列相同类型元素组成的数组集合。数组中的每个元素都占有大小相同的内存块。
- ndarray 对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排列(行或列)。
二、numpy.array() 创建数组
1. 基础理论
- 基本的 ndarray 是使用 NumPy 中的数组函数创建的,如下所示:
numpy.array
- 它从任何暴露数组接口的对象,或从返回数组的任何方法创建一个 ndarray。
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
- 上面的构造器接受以下参数:
| 序号 | 参数 | 描述 |
|---|---|---|
| 1 | object | 表示一个数组序列。 |
| 2 | dtype | 可选参数,通过它可以更改数组的数据类型。 |
| 3 | copy | 可选参数,当数据源是ndarray时表示数组能否被复制,默认是 True。 |
| 4 | order | 可选参数,以哪种内存布局创建数组,有 3 个可选值,分别是 C(行序列)、F(列序列)、A(默认)。 |
| 5 | subok | 可选参数,类型为bool值,默认 False。为 True,使用object的内部数据类型;False:使用object数组的数据类型。 |
| 6 | ndmin | 可选参数,用于指定数组的维度。 |
2. 基础操作演示
- 在代码编写之前,我们需要线引入 NumPy。
# 注意默认都会给numpy包设置别名为np
import numpy as np
- NumPy 引入完成后,实现 array 创建数组。
- 在 array() 函数当中,括号内可以是列表、元组、数组、迭代对象,生成器等。
- 其中,列表和元组的整体相同,但是列表属于可变序列,它的元素可以随时修改或删除,元组是不可变序列,其中元素不可修改,只能整体替换。
- (1) 列表:
np.array([1,2,3,4,5])
#array([1, 2, 3, 4, 5])
- (2) 元组:
np.array((1,2,3,4,5))
#array([1, 2, 3, 4, 5])
- (3) 数组:
a = np.array([1,2,3,4,5]) #创建一个数组
np.array(a)
#array([1, 2, 3, 4, 5])
- (4) 迭代对象:
np.array(range(10))
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- (5) 生成器:
np.array([i**2 for i in range(10)])
#array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81])
- 当数组内的元素数据类型不相同时,那么数组内哪种数据类型存储的结果最大,就按哪种数据类型进行存储。
- 如下例子,在数组当中,包含整型,浮点型和字符串,其中字符串的数据类型存储结果最大,因此,数组内的所有元素均按字符串进行存储。
np.array([1,1.5,3,4.5,'5'])
#array(['1', '1.5', '3', '4.5', '5'], dtype='<U32')
- (1) 整型:
ar1 = np.array(range(10)) # 整型
ar1
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- (2) 浮点型(浮点型的数据存储大于整型的数据存储,因此全部转换为浮点型):
ar2 = np.array([1,2,3.14,4,5])
ar2
#array([1. , 2. , 3.14, 4. , 5. ])
- (3) 二维数组(嵌套序列(列表,元组均可)):
ar3 = np.array([[1,2,3],('a','b','c')])
ar3
#array([['1', '2', '3'],
# ['a', 'b', 'c']], dtype='<U11')
- (4) 当二维数组嵌套序列数量不一致:
ar4 = np.array([[1,2,3],('a','b','c','d')])
ar4
#array([list([1, 2, 3]), ('a', 'b', 'c', 'd')], dtype=object)
- 上述例子的秩是 1,可以通过 ar4.ndim 进行查看。
3. numpy.array() 参数详解
- (1) 设置 dtype 参数,默认自动识别。
a = np.array([1,2,3,4,5])
print(a)
# 设置数组元素类型
has_dtype_a = np.array([1,2,3,4,5],dtype='float')
has_dtype_a
#[1 2 3 4 5]
#array([1., 2., 3., 4., 5.])
- 如果将浮点型的数据,设置为整形,那么,数组内元素会自动舍弃尾数,转换为整型数据,具体输出如下所示。
np.array([1.1,2.5,3.8,4,5],dtype='int')
#array([1, 2, 3, 4, 5])
- (2) 设置 copy 参数,默认为 True。
- 我们设置 a 数组,然后,通过 a 数组复制得出 b 数组,此时,a 数组和 b 数组的地址不相同,创建了新的对象。
- 那么,对 a 数组和 b 数组的任意修改都不会影响另一个数组的元素。
a = np.array([1,2,3,4,5])
b = np.array(a)
print('a:', id(a), ' b:', id(b))
print('以上看出a和b的内存地址')
b[0] = 10
print(a)
#a: 2066732212352 b: 2066732213152
#以上看出a和b的内存地址
#[1 2 3 4 5]
- 当我们修改 b 数组的元素时,a 数组不会发生变化。
b[0] = 10
print('a:', a,' b:', b)
#a: [1 2 3 4 5] b: [10 2 3 4 5]
- 当设置 copy 参数为 Fasle 时,不会创建副本,两个变量会指向相同的内容地址,没有创建新的对象。
- 此时,由于 a 数组和 b 数组指向的是相同的内存地址,因此当修改 b 数组的元素时,a 数组对应的元素会发生变化。
a = np.array([1,2,3,4,5])
b = np.array(a, copy=False)
print('a:', id(a), ' b:', id(b))
print('以上看出a和b的内存地址')
b[0] = 10
print('a:',a,' b:',b)
#a: 2066732267520 b: 2066732267520
#以上看出a和b的内存地址
#a: [10 2 3 4 5] b: [10 2 3 4 5]
- (3) ndmin 用于指定数组的维度。
- 将一维数组转换为二维数组。
a = np.array([1,2,3])
print(a)
a = np.array([1,2,3], ndmin=2)
a
#[1 2 3]
#array([[1, 2, 3]])
- (4) subok 参数,类型为 bool 值,默认 False。为 True 时,使用 object 的内部数据类型;False:使用 object 数组的数据类型。
- 首先,创建一个 a 矩阵,然后输出 a 矩阵的数据类型,便于后面的比较。
- 其次,通过 a 矩阵生成 at 和 af 两个数组,at 数组的 subok 参数设置为 True,at 数组的 subok 参数不设置,即默认为 False。
- 最后,输出 at 数组和 af 数组的数据类型,用于比较观察。
a = np.mat([1,2,3,4])
print(type(a))
at = np.array(a,subok=True)
af = np.array(a)
print('at,subok为True:',type(at))
print('af,subok为False:',type(af))
print(id(at),id(a))
#<class 'numpy.matrix'>
#at,subok为True: <class 'numpy.matrix'>
#af,subok为False: <class 'numpy.ndarray'>
#2066738151720 2066738151608
- 书写代码时需要注意的内容:
- 先定义一个 a 数组。
a = np.array([2,4,3,1])
- 在定义 b 数组时,如果想复制 a 数组,有如下几种方案:
- (1) 使用 np.array()。
- (2) 使用数组的 copy() 方法。
b = np.array(a)
print('b = np.array(a):',id(b),id(a))
c = a.copy()
print('c = a.copy():',id(c),id(a))
#b = np.array(a): 2066731363744 2066731901216
#c = a.copy(): 2066732267520 2066731901216
- 注意不能直接使用 = 号复制,直接使用 = 号,会使 2 个变量指向相同的内存地址。
三、numpy.arange() 生成区间数组
- 根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
numpy.arange(start, stop, step, dtype)
- 其参数含义如下:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 起始值,默认为 0 |
| 2 | stop | 终止值(不包含) |
| 3 | step | 步长,默认为 1 |
| 4 | dtype | 返回 ndarray 的数据类型,如果没有提供,则会使用输入数据的类型。 |
- 如果只有一个参数,那么起始值就是 0,终止值就是那个参数,步长就是 1。
- 如果有两个参数,那么,第一个参数就是起始值,第二个参数就是终止值。
np.arange(10)
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- 可以使用浮点型数值。
np.arange(3.1)
#array([0., 1., 2., 3.])
- 返回浮点型的,也可以指定类型。
x = np.arange(5, dtype = float)
x
#array([0., 1., 2., 3., 4.])
- 设置了起始值、终止值及步长:
- (1) 起始值是 10,终止值是 20,步长是 2。
np.arange(10,20,2)
#array([10, 12, 14, 16, 18])
- (1) 起始值是 0,终止值是 20,步长是 3。
ar2 = np.arange(0,20,3)
print(ar2)
ar3 = np.arange(20,step=3) #指定传参
ar3
#[ 0 3 6 9 12 15 18]
#array([ 0, 3, 6, 9, 12, 15, 18])
- 如果数组太大而无法打印,NumPy 会自动跳过数组的中心部分,并只打印边角。
np.arange(10000)
#array([ 0, 1, 2, ..., 9997, 9998, 9999])
四、numpy.linspace() 创建等差数列
- 返回在间隔 [开始,停止] 上计算的 num 个均匀间隔的样本。数组是一个等差数列构成。
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
- 其参数含义如下:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 必填项,序列的起始值, |
| 2 | stop | 必填项,序列的终止值,如果 endpoint 为 True,该值包含于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为 True 时,数列中包含 stop 值,反之不包含,默认是 True。 |
| 5 | retstep | 如果为 True 时,生成的数组中会显示间距,反之不显示。 |
| 6 | dtype | ndarray 的数据类型 |
- 以下例子用到三个参数,设置起始点为 1 ,终止点为 10,数列个数为 10。
a = np.linspace(1,10,10)
a
#array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
- 如果,我们将 endpoint 设置为 False,就不会包含 10,此时,默认步长是 50。
a = np.linspace(1,10,endpoint=False)
a
#array([1. , 1.18, 1.36, 1.54, 1.72, 1.9 , 2.08, 2.26, 2.44, 2.62, 2.8 ,
# 2.98, 3.16, 3.34, 3.52, 3.7 , 3.88, 4.06, 4.24, 4.42, 4.6 , 4.78,
# 4.96, 5.14, 5.32, 5.5 , 5.68, 5.86, 6.04, 6.22, 6.4 , 6.58, 6.76,
# 6.94, 7.12, 7.3 , 7.48, 7.66, 7.84, 8.02, 8.2 , 8.38, 8.56, 8.74,
# 8.92, 9.1 , 9.28, 9.46, 9.64, 9.82])
- 以下实例用到三个参数,设置起始位置为 2.0,终点为 3.0,数列个数为 5。
ar1 = np.linspace(2.0, 3.0, num=5)
ar1
#array([2. , 2.25, 2.5 , 2.75, 3. ])
- 将参数 endpoint 设置为 False 时,不包含终止值,
ar1 = np.linspace(2.0, 3.0, num=5, endpoint=False)
ar1
#array([2. , 2.2, 2.4, 2.6, 2.8])
- 设置 retstep 显示计算后的步长。
ar1 = np.linspace(2.0,3.0,num=5, retstep=True)
print(ar1)
type(ar1)
#(array([2. , 2.25, 2.5 , 2.75, 3. ]), 0.25)
#tuple
- 将 endpoint 设置为 False,不包含终止值,再设置 retstep 显示计算后的步长。
ar1 = np.linspace(2.0,3.0,num=5,endpoint=False,retstep=True)
ar1
#(array([2. , 2.2, 2.4, 2.6, 2.8]), 0.2)
- 等差数列在线性回归经常作为样本集,例如:生成 x_data,值为 [0, 100] 之间 500 个等差数列数据集合作为样本特征,根据目标线性方程 y=3×x+2y=3×x+2y=3×x+2,生成相应的标签集合 y_data。
x_data = np.linspace(0,100,500)
x_data
五、numpy.logspace() 创建等比数列
- 返回在间隔 [开始,停止] 上计算的 num 个均匀间隔的样本。数组是一个等比数列构成。
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
- 其参数含义如下:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | start | 必填项,序列的起始值, |
| 2 | stop | 必填项,序列的终止值,如果endpoint为true,该值包含于数列中 |
| 3 | num | 要生成的等步长的样本数量,默认为50 |
| 4 | endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True。 |
| 5 | base | 对数 log 的底数 |
| 6 | dtype | ndarray 的数据类型 |
a = np.logspace(0,9,10,base=2)
a
#array([ 1., 2., 4., 8., 16., 32., 64., 128., 256., 512.])
- 上述代码可以理解为 202^{0}20 到 292^{9}29。
- np.logspace(A,B,C,base=D) 中的参数分别是如下含义:
- A:生成数组的起始值为 D 的 A 次方。
- B:生成数组的结束值为 D 的 B 次方。
- C:总共生成 C 个数。
- D:指数型数组的底数为 D,当省略 base=D 时,默认底数为 10。
- 我们先使用前 3 个参数,将 [1,5] 均匀分成 3 个数,得到 {1,3,5},然后利用第 4 个参数 base=2(默认是 10)使用指数函数可以得到最终输出结果 {212^{1}21,232^{3}23,252^{5}25}。
np.logspace(1,5,3,base=2)
#array([ 2., 8., 32.])
- 取得 1 到 2 之间 10 个常用对数。
np.logspace(1.0,2.0,num=10)
#array([ 10. , 12.91549665, 16.68100537, 21.5443469 ,
# 27.82559402, 35.93813664, 46.41588834, 59.94842503,
# 77.42636827, 100. ])
- 上述实际上是 10110^{1}101 到 10210^{2}102。
六、numpy.zeros() 创建全零数列
- 创建指定大小的数组,数组元素以 0 来填充。
numpy.zeros(shape, dtype = float, order = 'C')
- 其参数含义如下:
| 序号 | 参数 | 描述说明 |
|---|---|---|
| 1 | shape | 数组形状 |
| 2 | dtype | 数据类型,可选 |
- 默认的数据类型是浮点数。
np.zeros(5)
#array([0., 0., 0., 0., 0.])
- 将数据类型设置为整型。
np.zeros((5,), dtype = 'int')
array([0, 0, 0, 0, 0])
- 生成一个 2 行 2 列的全 0 数组。
np.zeros((2,2))
#array([[0., 0.],
# [0., 0.]])
- 使用 zeros_like 可以返回具有与给定数组相同的形状和类型的零数组。
ar1 = np.array([[1,2,3],[4,5,6]])
np.zeros_like(ar1)
#array([[0, 0, 0],
# [0, 0, 0]])
七、np.ones() 创建一数列
- 生成元素全部是 1 的数列。
ar5 = np.ones(9)
ar6 = np.ones((2,3,4))
ar7 = np.ones_like(ar3)
print('ar5:',ar5)
print('ar6:',ar6)
print('ar7:',ar7)
#ar5: [1. 1. 1. 1. 1. 1. 1. 1. 1.]
#ar6: [[[1. 1. 1. 1.]
# [1. 1. 1. 1.]
# [1. 1. 1. 1.]]
#
# [[1. 1. 1. 1.]
# [1. 1. 1. 1.]
# [1. 1. 1. 1.]]]
#ar7: [1 1 1 1 1 1 1]
相关文章:
Python 之 NumPy 简介和创建数组
文章目录一、NumPy 简介1. 为什么要使用 NumPy2. NumPy 数据类型3. NumPy 数组属性4. NumPy 的 ndarray 对象二、numpy.array() 创建数组1. 基础理论2. 基础操作演示3. numpy.array() 参数详解三、numpy.arange() 生成区间数组四、numpy.linspace() 创建等差数列五、numpy.logs…...
与六年测试工程师促膝长谈,他分享的这些让我对软件测试工作有了全新的认知~
不知不觉已经从事软件测试六年了,2016年毕业到进入外包公司外包给微软做软件测试, 到现在加入著名的外企。六年的时间过得真快。长期的测试工作也让我对软件测试有了比较深入的认识。但是我至今还是一个底层的测试人员,我的看法都比较狭隘&am…...

裕太微在科创板上市:市值约186亿元,哈勃科技和小米基金为股东
2月10日,裕太微电子股份有限公司(下称“裕太微”,SH:688515)在上海证券交易所上市。本次上市,裕太微的发行价为92元/股,发行2000万股,发行市盈率不适用,发行后总股本8000万股。 根据…...

毕业后5年,我终于变成了月薪13000的软件测试工程师
我用了近2个月的时间转行,在今年1月底顺利入职了一家北京的互联网公司,从事的是软件测试的工作。 和大家看到的一样,我求职的时间花费的比较短,求职过程非常顺利,面试了一周就拿到了3家offer,3家offer的薪…...

实践指南|如何在 Jina 中使用 OpenTelemetry 进行应用程序的监控和跟踪
随着软件和云技术的普及,越来越多的企业开始采用微服务架构、容器化、多云部署和持续部署模式,这增加了因系统失败而给运维/ SRE / DevOps 团队带来的压力,从而增加了开发团队和他们之间的摩擦,因为开发团队总是想尽快部署新功能&…...
MySQL 创建数据表
在创建数据库之后,接下来就要在数据库中创建数据表。所谓创建数据表,指的是在已经创建的数据库中建立新表。 创建数据表的过程是规定数据列的属性的过程,同时也是实施数据完整性(包括实体完整性、引用完整性和域完整性)…...

一文详解网络安全事件的防护与响应
网络安全事件的发生,往往意味着一家企业的生产经营活动受到影响,甚至数据资产遭到泄露。日益复杂的威胁形势使现代企业面临更大的网络安全风险。因此,企业必须提前准备好响应网络安全事件的措施,并制定流程清晰、目标明确的事件响…...

vue directive 注册局部指令
注册局部指令 vue directive 在注册局部指令时,是通过在组件 options 选项中设置 directives 属性。如下: directives: {focus: {// 指令的定义inserted: function (el) {el.focus()}} }在模板中的任何元素上都可以使用新的 v-focus propertyÿ…...
LC-70-爬楼梯
原题链接:爬楼梯 个人解法 思路: 动态规划 状态表示:f[i]表示走到第n阶台阶有几种方法 状态转移:f[i] f[i -1] f[i - 2] 这实际上就是斐波那契数列,通过转移可以看到,我们只用了三个变量,故…...

Scratch少儿编程案例-可爱的简约贪吃蛇
专栏分享 点击跳转=>Unity3D特效百例点击跳转=>案例项目实战源码点击跳转=>游戏脚本-辅助自动化点击跳转=>Android控件全解手册点击跳转=>Scratch编程案例👉关于作者...

编译 Android 时如何指定输出目录?
文章目录0. 导读1. 指定 Android 编译输出目录2. 指定 Android dist 编译输出目录3. 指定 Android 模块编译输出目录4. Android 源码中编译相关的文档0. 导读 偶尔会有朋友问编译 Android 时如何指定输出目录? 这里有两种情况: 一是如何将 Android 默认的输出目…...

CF1574C Slay the Dragon 题解
CF1574C Slay the Dragon 题解题目链接字面描述题面翻译题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1提示代码实现题目 链接 https://www.luogu.com.cn/problem/CF1574C 字面描述 题面翻译 给定长度为 nnn 的序列 aaa,mmm 次询问,每次询…...
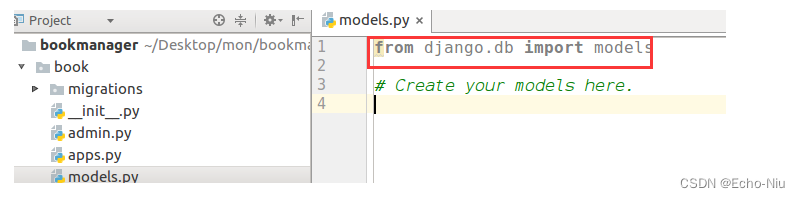
创建Django项目
创建Django项目 步骤 创建Django项目 django-admin startproject name 创建子应用 python manager.py startapp name创建工程 在使用Flask框架时,项目工程目录的组织与创建是需要我们自己手动创建完成的。 在django中,项目工程目录可以借助django提供…...
CUDA中的统一内存
文章目录1. Unified Memory Introduction1.1. System Requirements1.2. Simplifying GPU Programming1.3. Data Migration and Coherency1.4. GPU Memory Oversubscription1.5. Multi-GPU1.6. System Allocator1.7. Hardware Coherency1.8. Access Counters2. Programming Mode…...

利用机器学习(mediapipe)进行人脸468点的3D坐标检测--视频实时检测
上期文章,我们分享了人脸468点的3D坐标检测的图片检测代码实现过程,我们我们介绍一下如何在实时视频中,进行人脸468点的坐标检测。 import cv2 import mediapipe as mp mp_drawing = mp.solutions.drawing_utils mp_face_mesh = mp.solutions.face_mesh face_mesh = mp_fac…...
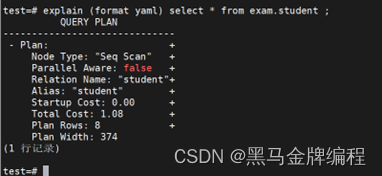
事务基础知识与执行计划
事务基础知识 数据库事务的概念 数据库事务是什么? 事务是一组原子性的SQL操作。事务由事务开始与事务结束之间执行的全部数据库操作组成。A(原子性)、(C一致性)、I(隔离性)、D(持久…...
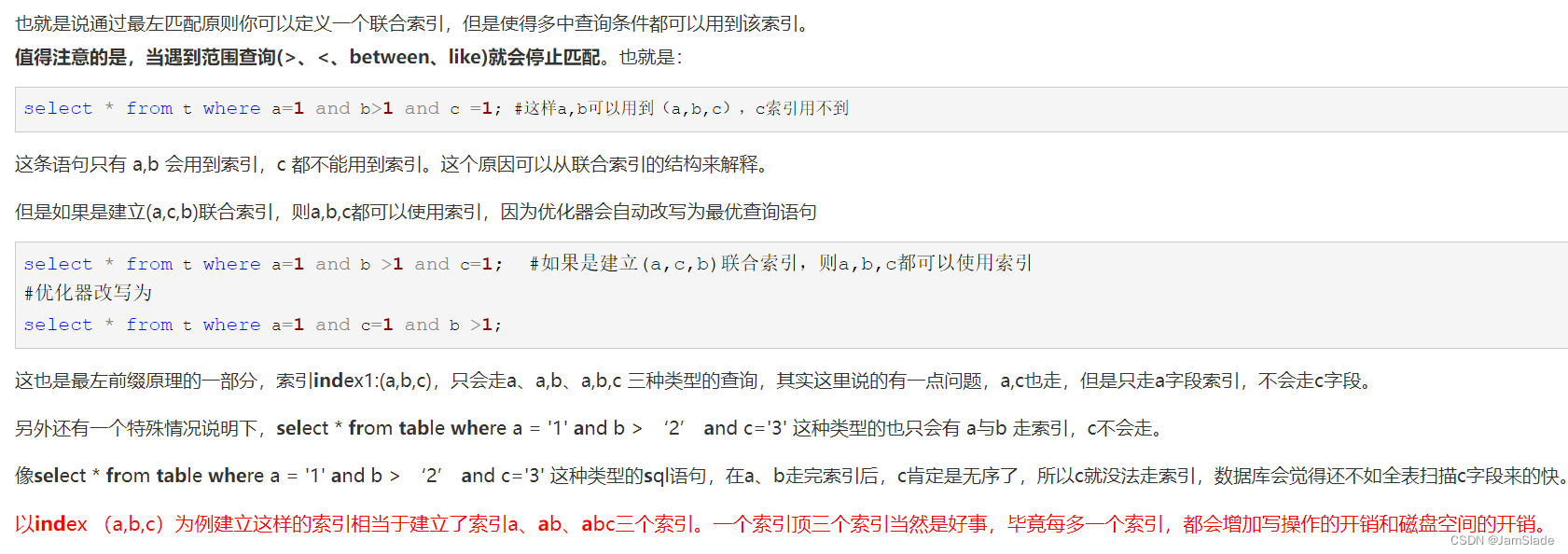
数据库实践LAB大纲 06 INDEX
索引 索引是一个列表 —— 若干列集合和这些值的记录在数据表存储位置的物理地址 作用 加快检索速度唯一性索引 —— 保障数据唯一性加速表的连接分组和排序进行检索的时候 —— 减少时间消耗 一般建立原则 经常查询的数据主键外键连接字段排序字段少涉及、重复值多的字段…...

网络安全实验室6.解密关
6.解密关 1.以管理员身份登录系统 url:http://lab1.xseclab.com/password1_dc178aa12e73cfc184676a4100e07dac/index.php 进入网站点击忘记密码的链接,进入到重置密码的模块 输入aaa,点击抓包,发送到重放模块go 查看返回的链接…...
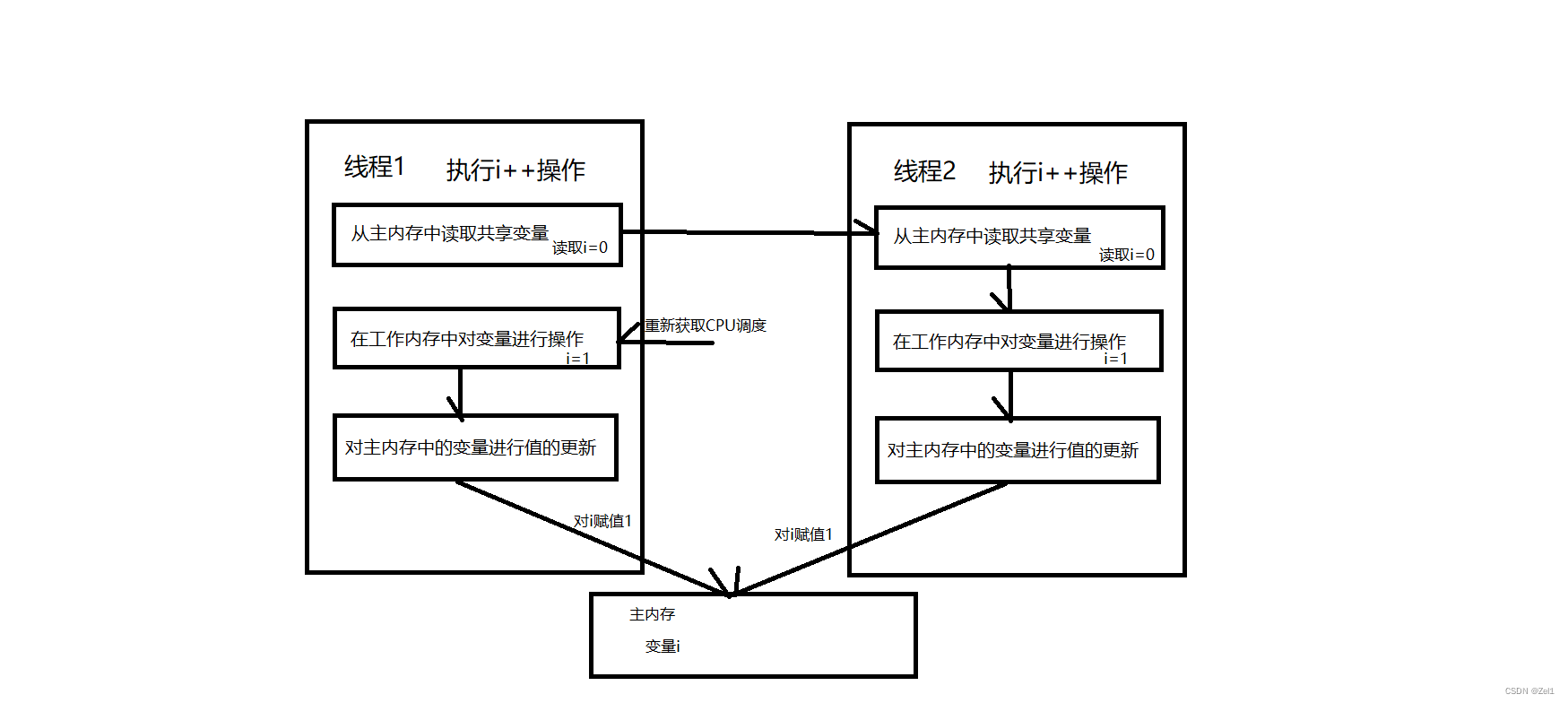
了解并发编程
并发与并行的概念: 并发:一段时间内(假设只有一个CPU)执行多个线程,多个线程时按顺序执行 并行:同个时间点上,多个线程同时执行(多个CPU) 什么是并发编程? 在现代互联网的应用中,会出现多个请求同时对共享资源的访问情况,例如在买票,秒杀与抢购的场景中 此时就会出现线程安…...

(C语言)程序环境和预处理
问:1. 什么是C语言的源代码?2. 由于计算机只认识什么?因此它只能接收与执行什么?也就是什么?3. 在ANSI C的任何一种实现中,存在哪两个不同的环境?在这两种环境里面分别干什么事情?4.…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

Spring AI 入门:Java 开发者的生成式 AI 实践之路
一、Spring AI 简介 在人工智能技术快速迭代的今天,Spring AI 作为 Spring 生态系统的新生力量,正在成为 Java 开发者拥抱生成式 AI 的最佳选择。该框架通过模块化设计实现了与主流 AI 服务(如 OpenAI、Anthropic)的无缝对接&…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...