YOLOv5改进 | 2023主干篇 | 华为最新VanillaNet主干替换Backbone实现大幅度长点
一、本文介绍
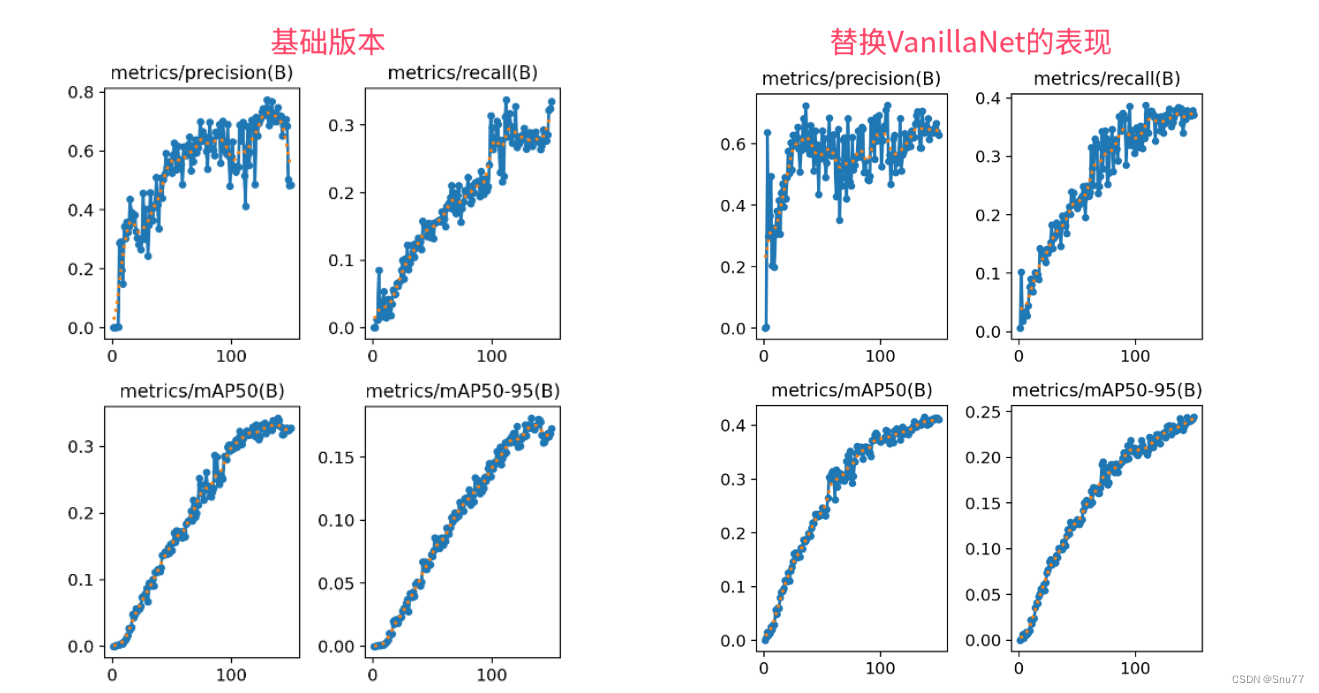
本文给大家来的改进机制是华为最新VanillaNet网络,其是今年最新推出的主干网络,VanillaNet是一种注重极简主义和效率的神经网络架构。它的设计简单,层数较少,避免了像深度架构和自注意力这样的复杂操作(需要注意的是该网络结构的通道数会被放大,GFLOPs的量会很高)。我将其替换整个YOLOv5的Backbone,在一些大目标和小目标检测上均有涨点,效果比上一篇RepViT的效果要好。我的实验数据集是一个包含1000张图片包含大中小的检测目标的数据集上(共有20+类别),下面我会附上基础版本和修改版本的训练对比图,同时我会手把手教你添加该网络结构。
推荐指数:⭐⭐⭐⭐⭐
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
训练结果对比图->
(有效性先用YOLOv8上的实验对比,后期会给大家补上)
目录
一、本文介绍
二、VanillaNet原理
2.2 VanillaNet的基本原理
2.2.1 深度训练策略
2.2.2 串联激活函数
三、VanillaNet的核心代码
四、手把手教你添加VanillaNet网络结构
修改一
修改二
修改三
修改四
修改五
修改五
修改六
修改七
五、VanillaNet的yaml文件
六、成功运行记录
七、本文总结
二、VanillaNet原理

论文地址: 官方论文地址
代码地址: 官方代码地址

2.2 VanillaNet的基本原理
VanillaNet是一种注重极简主义和效率的神经网络架构。它的设计简单,层数较少,避免了像深度架构和自注意力这样的复杂操作。VanillaNet的关键特性包括深度训练策略,最初使用激活函数训练两个卷积层,随后这个激活函数逐渐简化为恒等映射,允许层合并。此外,VanillaNet还使用并行堆叠的激活函数来提高非线性,从而提升简单网络的性能。
VanillaNet的原理包括以下几个关键点:
1. 深度训练策略:初始阶段采用两个卷积层和一个激活函数进行训练,随着训练进程,激活函数逐渐转化为恒等映射,允许这些层合并,从而减少推断时间。
2. 串联激活函数:VanillaNet引入了并行堆叠激活函数来增强非线性,这对于简单网络的性能至关重要。
下面为大家展示了VanillaNet-6模型的架构:
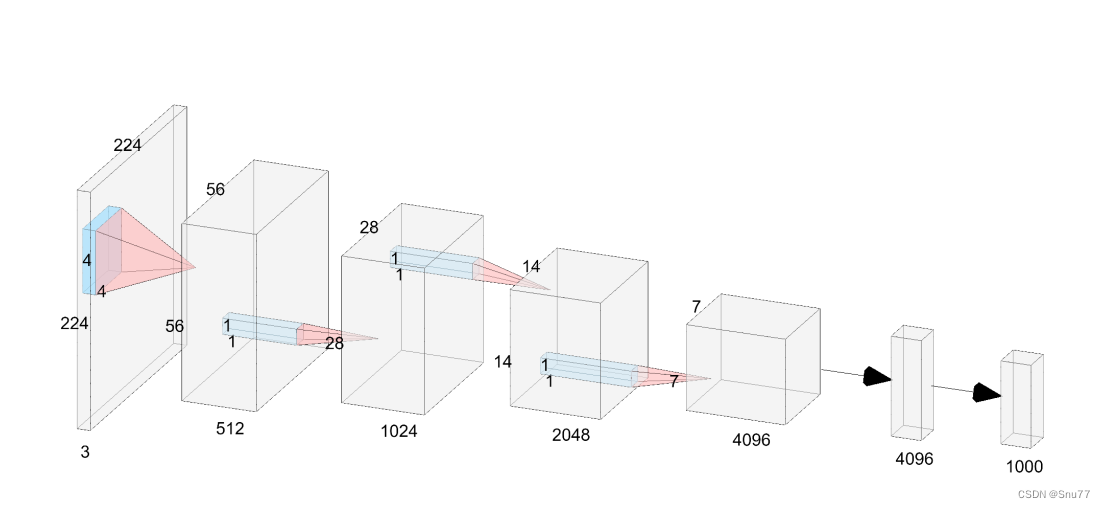
它仅由6个卷积层构成。输入特征的尺寸会在每个阶段降低,而通道数则会翻倍,这一设计借鉴了如AlexNet和VGGNet这类经典神经网络的设计理念。通过这种方式,VanillaNet-6模型能够以较低的计算成本处理图像数据,同时通过增加通道数来保持足够的特征表达能力。
2.2.1 深度训练策略
深度训练策略是指在神经网络训练初期采用比标准配置更多的层和更复杂的结构,这通过增加模型的非线性和表示能力来提高训练效果。(这是一种现在比较流行的网络设计方式,在训练的时候使用复杂的结构,推理的时候使用简单的结构)。训练的后期,这些额外层会通过技术手段合并或简化,以减少模型的复杂性和提高推理时的效率。
这种策略允许在初期利用深层结构的强大能力,在不牺牲推理速度的前提下,随着训练的进行,逐步优化模型结构,最终达到一个既能保持良好性能又能高效运行的平衡点。这样做的目的是在保持推理效率的同时,利用深度结构在训练过程中提供的额外能力。
2.2.2 串联激活函数
串联激活函数是指在一个神经网络的相同层或连续层中使用多个激活函数,这样可以增强网络处理非线性问题的能力。传统的神经网络可能只在每个卷积层后使用一个激活函数,而串联激活函数的做法是将多个激活函数按序排列,每个函数的输出成为下一个函数的输入。这种串联可以创建更复杂的函数映射,从而允许模型捕捉到更丰富的数据表示和特征。
三、VanillaNet的核心代码
下面的代码是整个VanillaNet的核心代码,其中有个版本,对应的GFLOPs也不相同,使用方式看章节四。
# Copyright (C) 2023. Huawei Technologies Co., Ltd. All rights reserved.# This program is free software; you can redistribute it and/or modify it under the terms of the MIT License.# This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the MIT License for more details.import torch
import torch.nn as nn
from timm.layers import weight_init__all__ = ['vanillanet_5', 'vanillanet_6', 'vanillanet_7', 'vanillanet_8', 'vanillanet_9', 'vanillanet_10','vanillanet_11', 'vanillanet_12', 'vanillanet_13', 'vanillanet_13_x1_5', 'vanillanet_13_x1_5_ada_pool']class activation(nn.ReLU):def __init__(self, dim, act_num=3, deploy=False):super(activation, self).__init__()self.deploy = deployself.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num * 2 + 1, act_num * 2 + 1))self.bias = Noneself.bn = nn.BatchNorm2d(dim, eps=1e-6)self.dim = dimself.act_num = act_numweight_init.trunc_normal_(self.weight, std=.02)def forward(self, x):if self.deploy:return torch.nn.functional.conv2d(super(activation, self).forward(x),self.weight, self.bias, padding=(self.act_num * 2 + 1) // 2, groups=self.dim)else:return self.bn(torch.nn.functional.conv2d(super(activation, self).forward(x),self.weight, padding=self.act_num, groups=self.dim))def _fuse_bn_tensor(self, weight, bn):kernel = weightrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta + (0 - running_mean) * gamma / stddef switch_to_deploy(self):if not self.deploy:kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)self.weight.data = kernelself.bias = torch.nn.Parameter(torch.zeros(self.dim))self.bias.data = biasself.__delattr__('bn')self.deploy = Trueclass Block(nn.Module):def __init__(self, dim, dim_out, act_num=3, stride=2, deploy=False, ada_pool=None):super().__init__()self.act_learn = 1self.deploy = deployif self.deploy:self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)else:self.conv1 = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=1),nn.BatchNorm2d(dim, eps=1e-6),)self.conv2 = nn.Sequential(nn.Conv2d(dim, dim_out, kernel_size=1),nn.BatchNorm2d(dim_out, eps=1e-6))if not ada_pool:self.pool = nn.Identity() if stride == 1 else nn.MaxPool2d(stride)else:self.pool = nn.Identity() if stride == 1 else nn.AdaptiveMaxPool2d((ada_pool, ada_pool))self.act = activation(dim_out, act_num)def forward(self, x):if self.deploy:x = self.conv(x)else:x = self.conv1(x)x = torch.nn.functional.leaky_relu(x, self.act_learn)x = self.conv2(x)x = self.pool(x)x = self.act(x)return xdef _fuse_bn_tensor(self, conv, bn):kernel = conv.weightbias = conv.biasrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta + (bias - running_mean) * gamma / stddef switch_to_deploy(self):if not self.deploy:kernel, bias = self._fuse_bn_tensor(self.conv1[0], self.conv1[1])self.conv1[0].weight.data = kernelself.conv1[0].bias.data = bias# kernel, bias = self.conv2[0].weight.data, self.conv2[0].bias.datakernel, bias = self._fuse_bn_tensor(self.conv2[0], self.conv2[1])self.conv = self.conv2[0]self.conv.weight.data = torch.matmul(kernel.transpose(1, 3),self.conv1[0].weight.data.squeeze(3).squeeze(2)).transpose(1, 3)self.conv.bias.data = bias + (self.conv1[0].bias.data.view(1, -1, 1, 1) * kernel).sum(3).sum(2).sum(1)self.__delattr__('conv1')self.__delattr__('conv2')self.act.switch_to_deploy()self.deploy = Trueclass VanillaNet(nn.Module):def __init__(self, in_chans=3, num_classes=1000, dims=[96, 192, 384, 768],drop_rate=0, act_num=3, strides=[2, 2, 2, 1], deploy=False, ada_pool=None, **kwargs):super().__init__()self.deploy = deployif self.deploy:self.stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),activation(dims[0], act_num))else:self.stem1 = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),nn.BatchNorm2d(dims[0], eps=1e-6),)self.stem2 = nn.Sequential(nn.Conv2d(dims[0], dims[0], kernel_size=1, stride=1),nn.BatchNorm2d(dims[0], eps=1e-6),activation(dims[0], act_num))self.act_learn = 1self.stages = nn.ModuleList()for i in range(len(strides)):if not ada_pool:stage = Block(dim=dims[i], dim_out=dims[i + 1], act_num=act_num, stride=strides[i], deploy=deploy)else:stage = Block(dim=dims[i], dim_out=dims[i + 1], act_num=act_num, stride=strides[i], deploy=deploy,ada_pool=ada_pool[i])self.stages.append(stage)self.depth = len(strides)self.apply(self._init_weights)self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):weight_init.trunc_normal_(m.weight, std=.02)nn.init.constant_(m.bias, 0)def change_act(self, m):for i in range(self.depth):self.stages[i].act_learn = mself.act_learn = mdef forward(self, x):results = []if self.deploy:x = self.stem(x)else:x = self.stem1(x)x = torch.nn.functional.leaky_relu(x, self.act_learn)x = self.stem2(x)results.append(x)for i in range(self.depth):x = self.stages[i](x)results.append(x)return resultsdef _fuse_bn_tensor(self, conv, bn):kernel = conv.weightbias = conv.biasrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta + (bias - running_mean) * gamma / stddef switch_to_deploy(self):if not self.deploy:self.stem2[2].switch_to_deploy()kernel, bias = self._fuse_bn_tensor(self.stem1[0], self.stem1[1])self.stem1[0].weight.data = kernelself.stem1[0].bias.data = biaskernel, bias = self._fuse_bn_tensor(self.stem2[0], self.stem2[1])self.stem1[0].weight.data = torch.einsum('oi,icjk->ocjk', kernel.squeeze(3).squeeze(2),self.stem1[0].weight.data)self.stem1[0].bias.data = bias + (self.stem1[0].bias.data.view(1, -1, 1, 1) * kernel).sum(3).sum(2).sum(1)self.stem = torch.nn.Sequential(*[self.stem1[0], self.stem2[2]])self.__delattr__('stem1')self.__delattr__('stem2')for i in range(self.depth):self.stages[i].switch_to_deploy()self.deploy = Truedef vanillanet_5(pretrained=False,in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 256*4, 512*4, 1024*4], strides=[2,2,2], **kwargs)return modeldef vanillanet_6(pretrained=False,in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 256*4, 512*4, 1024*4, 1024*4], strides=[2,2,2,1], **kwargs)return modeldef vanillanet_7(pretrained=False,in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 1024*4, 1024*4], strides=[1,2,2,2,1], **kwargs)return modeldef vanillanet_8(pretrained=False, in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 512*4, 1024*4, 1024*4], strides=[1,2,2,1,2,1], **kwargs)return modeldef vanillanet_9(pretrained=False, in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 1024*4, 1024*4], strides=[1,2,2,1,1,2,1], **kwargs)return modeldef vanillanet_10(pretrained=False, in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 512*4, 1024*4, 1024*4],strides=[1,2,2,1,1,1,2,1],**kwargs)return modeldef vanillanet_11(pretrained=False, in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 512*4, 512*4, 1024*4, 1024*4],strides=[1,2,2,1,1,1,1,2,1],**kwargs)return modeldef vanillanet_12(pretrained=False, in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 512*4, 512*4, 512*4, 1024*4, 1024*4],strides=[1,2,2,1,1,1,1,1,2,1],**kwargs)return modeldef vanillanet_13(pretrained=False, in_22k=False, **kwargs):model = VanillaNet(dims=[128*4, 128*4, 256*4, 512*4, 512*4, 512*4, 512*4, 512*4, 512*4, 512*4, 1024*4, 1024*4],strides=[1,2,2,1,1,1,1,1,1,2,1],**kwargs)return modeldef vanillanet_13_x1_5(pretrained=False, in_22k=False, **kwargs):model = VanillaNet(dims=[128*6, 128*6, 256*6, 512*6, 512*6, 512*6, 512*6, 512*6, 512*6, 512*6, 1024*6, 1024*6],strides=[1,2,2,1,1,1,1,1,1,2,1],**kwargs)return modeldef vanillanet_13_x1_5_ada_pool(pretrained=False, in_22k=False, **kwargs):model = VanillaNet(dims=[128*6, 128*6, 256*6, 512*6, 512*6, 512*6, 512*6, 512*6, 512*6, 512*6, 1024*6, 1024*6],strides=[1,2,2,1,1,1,1,1,1,2,1],ada_pool=[0,38,19,0,0,0,0,0,0,10,0],**kwargs)return model四、手把手教你添加VanillaNet网络结构
这个主干的网络结构添加起来算是所有的改进机制里最麻烦的了,因为有一些网略结构可以用yaml文件搭建出来,有一些网络结构其中的一些细节根本没有办法用yaml文件去搭建,用yaml文件去搭建会损失一些细节部分(而且一个网络结构设计很多细节的结构修改方式都不一样,一个一个去修改大家难免会出错),所以这里让网络直接返回整个网络,然后修改部分 yolo代码以后就都以这种形式添加了,以后我提出的网络模型基本上都会通过这种方式修改,我也会进行一些模型细节改进。创新出新的网络结构大家直接拿来用就可以的。下面开始添加教程->
(同时每一个后面都有代码,大家拿来复制粘贴替换即可,但是要看好了不要复制粘贴替换多了)
修改一
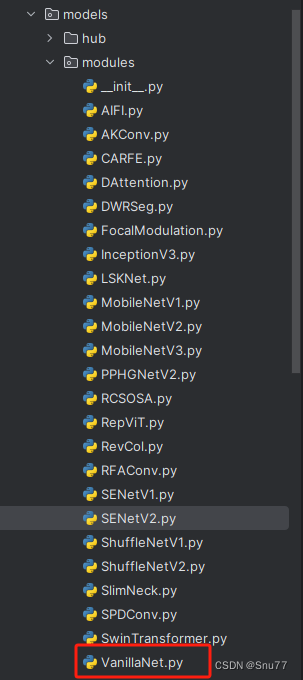
我们复制网络结构代码到“yolov5-master/models”目录下创建一个目录,我这里的名字是modules(如果将文件放在models下面随着改进机制越来越多不太好区分,所以创建一个文件目录将改进机制全部放在里面) ,然后创建一个py文件将代码复制粘贴到里面我这里起的名字是VanillaNet。
修改二
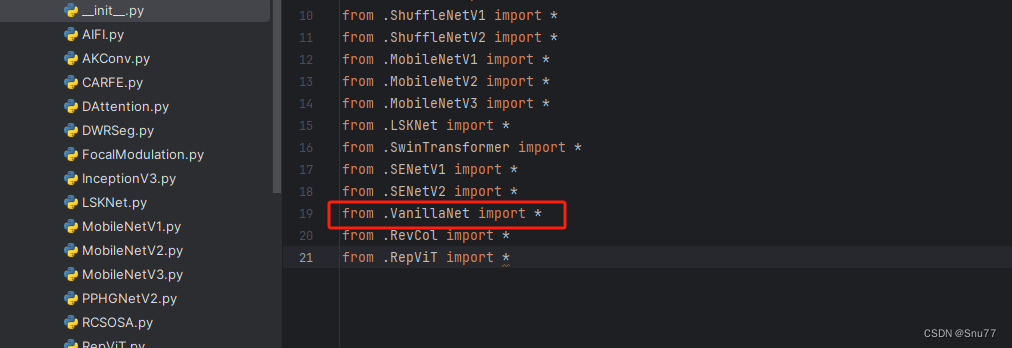
然后我们在我们创建的目录里面创建一个初始化文件'__init__.py',然后在里面导入我们同级目录的所有改进机制
修改三
我们找到如下文件'models/yolo.py'在开头里面导入我们的模块,这里需要注意要将代码放在common导入的文件上面,否则有一些模块会使用我们modules里面的,可能同名导致报错,这里如果你使用多个我的改进机制填写一个即可,不用重复添加。
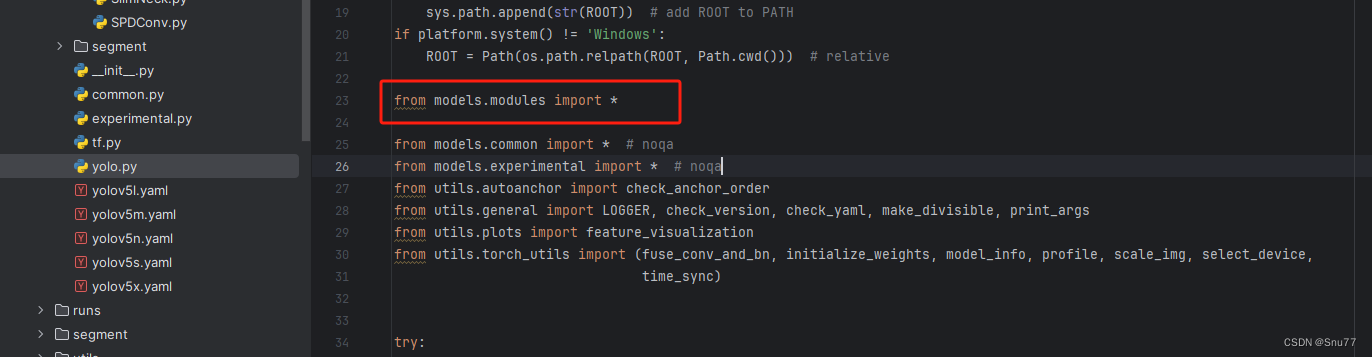
修改四
添加如下两行代码,根据行数找相似的代码进行添加

修改五
找到七百多行大概把具体看图片,按照图片来修改就行,添加红框内的部分,注意没有()只是函数名,我这里只添加了部分的版本,大家有兴趣这个VanillaNet还有更多的版本可以添加,看我给的代码函数头即可。
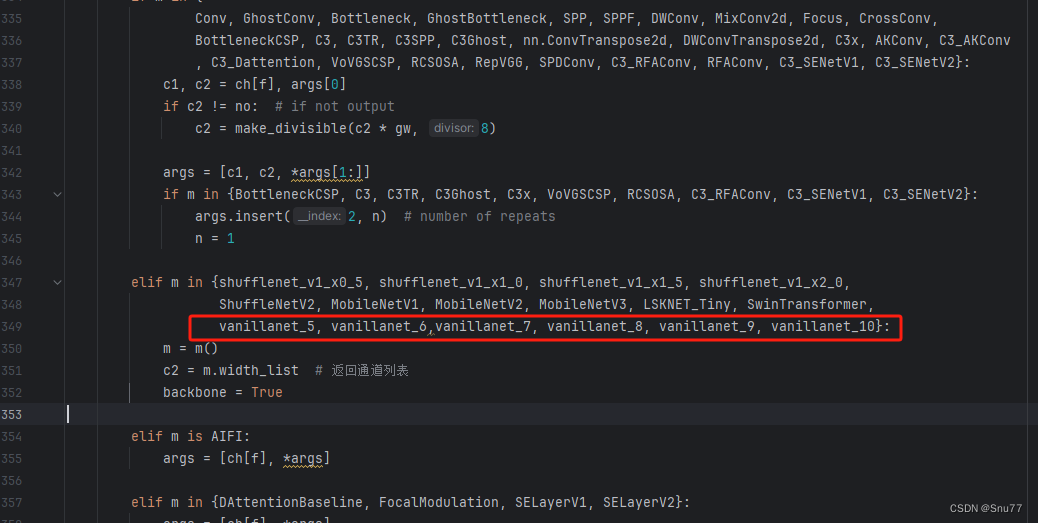
elif m in {自行添加对应的模型即可,下面都是一样的}:m = m()c2 = m.width_list # 返回通道列表backbone = True修改五
下面的两个红框内都是需要改动的。
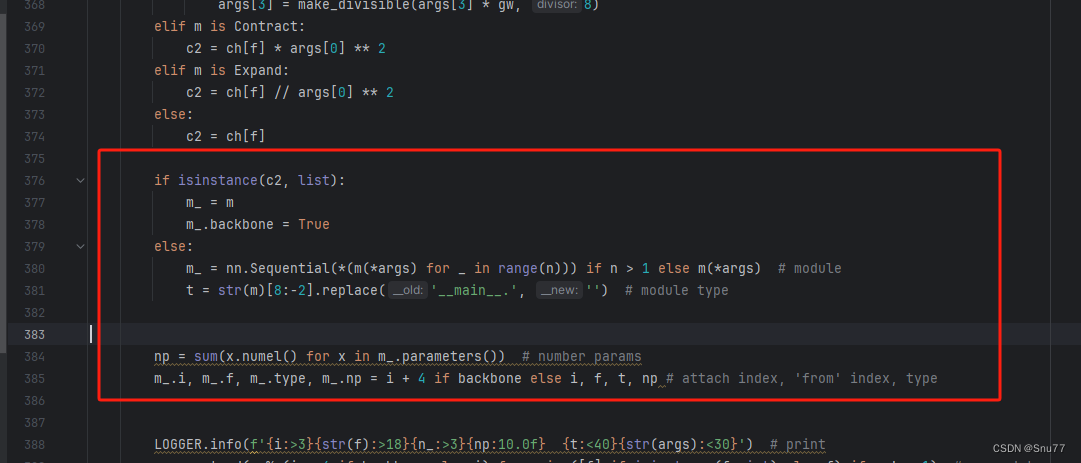
if isinstance(c2, list):m_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i + 4 if backbone else i, f, t, np # attach index, 'from' index, type修改六
如下的也需要修改,全部按照我的来。
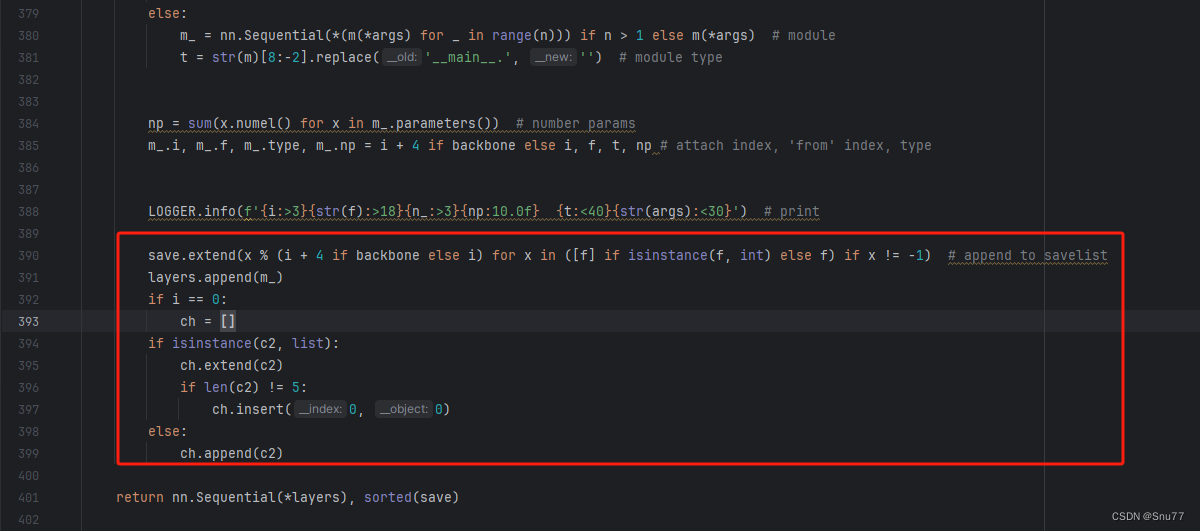
代码如下把原先的代码替换了即可。
save.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)if len(c2) != 5:ch.insert(0, 0)else:ch.append(c2)修改七
修改七和前面的都不太一样,需要修改前向传播中的一个部分, 已经离开了parse_model方法了。
可以在图片中开代码行数,没有离开task.py文件都是同一个文件。 同时这个部分有好几个前向传播都很相似,大家不要看错了,是70多行左右的!!!,同时我后面提供了代码,大家直接复制粘贴即可,有时间我针对这里会出一个视频。
找到如下的代码,这里不太好找,我给大家上传一个原始的样子。
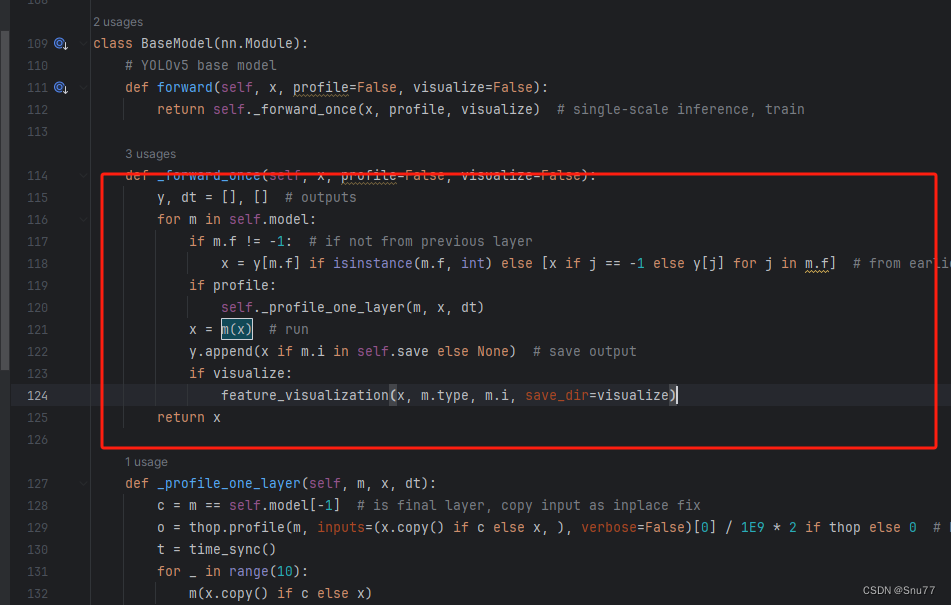
然后我们用后面的代码进行替换,替换完之后的样子如下->
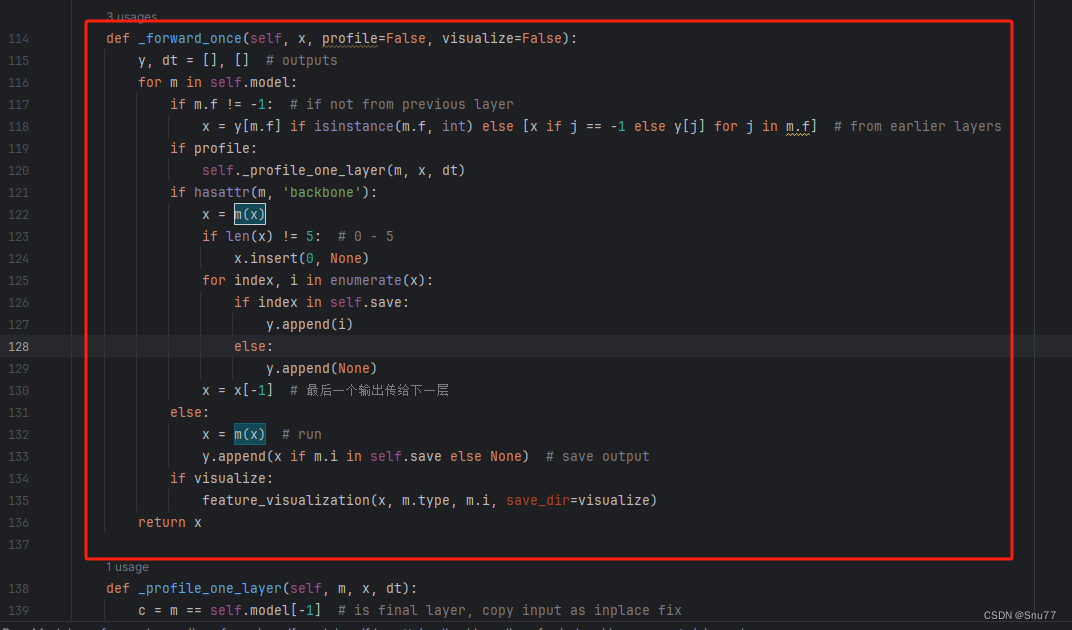
代码如下->
def _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)if len(x) != 5: # 0 - 5x.insert(0, None)for index, i in enumerate(x):if index in self.save:y.append(i)else:y.append(None)x = x[-1] # 最后一个输出传给下一层else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x到这里就完成了修改部分,但是这里面细节很多,大家千万要注意不要替换多余的代码,导致报错,也不要拉下任何一部,都会导致运行失败,而且报错很难排查!!!很难排查!!!
五、VanillaNet的yaml文件
复制如下yaml文件进行运行!!!
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32backbone:# [from, number, module, args][[-1, 1, vanillanet_5, []], # 0-4-P1/[-1, 1, SPPF, [1024, 5]], # 5]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 3], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 9[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 2], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 13 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 9], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 16 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 5], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 19 (P5/32-large)[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]六、成功运行记录
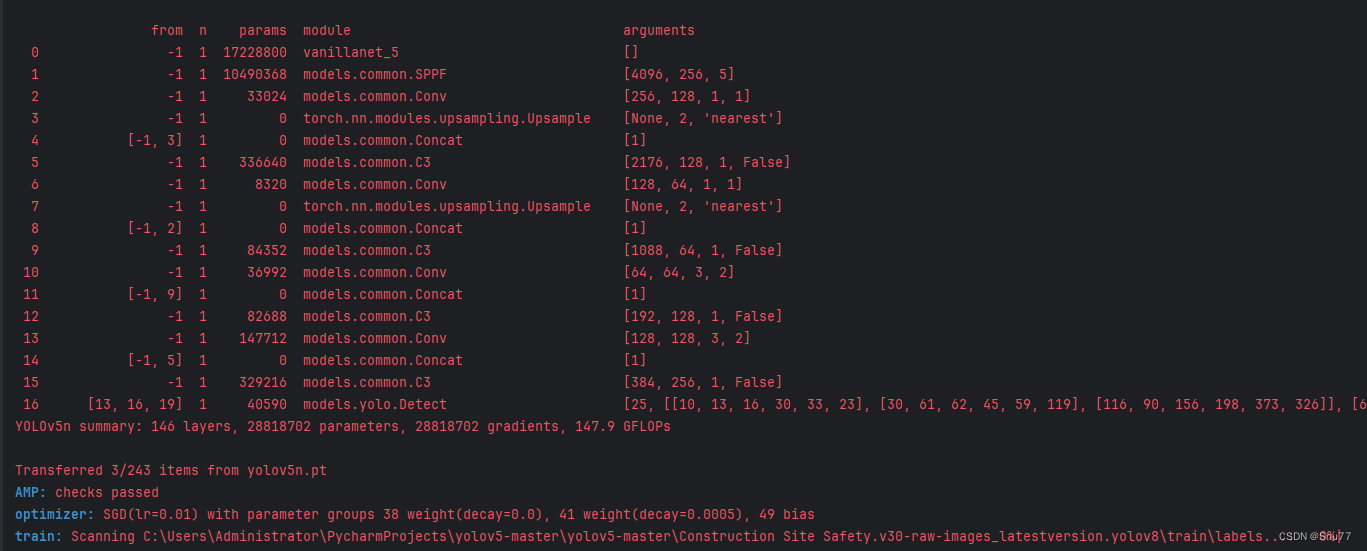
下面是成功运行的截图,已经完成了有1个epochs的训练,图片太大截不全第2个epochs了。
七、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分97分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新

相关文章:
YOLOv5改进 | 2023主干篇 | 华为最新VanillaNet主干替换Backbone实现大幅度长点
一、本文介绍 本文给大家来的改进机制是华为最新VanillaNet网络,其是今年最新推出的主干网络,VanillaNet是一种注重极简主义和效率的神经网络架构。它的设计简单,层数较少,避免了像深度架构和自注意力这样的复杂操作(需要注意的是…...
爬虫工作量由小到大的思维转变---<第三十三章 Scrapy Redis 23年8月5日后会遇到的bug)>
前言: 收到回复评论说,按照我之前文章写的: 爬虫工作量由小到大的思维转变---<第三十一章 Scrapy Redis 初启动/conn说明书)>-CSDN博客 在启动scrapy-redis后,往redis丢入url网址的时候遇到: TypeError: ExecutionEngine.crawl() got an unexpected …...

PostgreSQL | 概念 | 什么是OLTPOLAP?
什么是OLTP&OLAP? 大白话理解:业务系统都可以称作OLTP,基于业务系统产生的数据进行数据分析和决策的都可以称为OLAP。 OLTP OLTP( Online Transaction Processing)在线事务处理系统 用途: 用于支持日…...
2023年成都市中等职业学校学生技能大赛“网络搭建及应用”赛项竞赛样卷
2023年成都市中等职业学校学生技能大赛 “网络搭建及应用”赛项竞赛样卷 (总分1000分) 目录 2023年成都市中等职业学校学生技能大赛 “网络搭建及应用”赛项竞赛样卷 网络建设与调试项目(500分) 服务器搭建与运维项目(…...

Angular进阶之六:Progressive rendering
简介 Progressive Rendering 是一种提高 Web 应用性能的方法,允许页面在加载过程中逐步呈现,以提高用户体验。在本文中,我们将探讨如何在 Angular 中通过自定义指令实现 Progressive Rendering,特别是处理从服务器获取大量数据的…...

机器人中的数值优化之线性共轭梯度法
欢迎大家关注我的B站: 偷吃薯片的Zheng同学的个人空间-偷吃薯片的Zheng同学个人主页-哔哩哔哩视频 (bilibili.com) 本文ppt来自深蓝学院《机器人中的数值优化》 目录 1.无约束优化方法对比 2.Hessian-vec product 3.线性共轭梯度方法的步长编辑 4.共轭梯度…...

嵌入式Linux C语言介绍
目录 一.前言 二.C语言的特点 一.前言 开发工具通常依赖于操作系统提供的各种功能和服务。许多开发工具都基于操作系统的API(应用程序接口)进行开发,这些API提供了文件处理、网络通信、图形界面等核心功能。没有操作系统的支持,…...

基于Java电影院票票务系统
基于Java电影院票票务系统 功能需求 1、用户登录与注册:用户可以通过系统注册账号并登录系统,方便进行购票和管理个人信息。 2、个人信息管理:用户可以查看和修改个人信息,包括姓名、联系方式等。 3、影片信息查询:…...

HarmonyOS应用开发实战—开箱即用的登录页面3【ArkTS】
文章目录 一.HarmonyOS应用开发实战—开箱即用的登录页面2【ArkTS】【鸿蒙专栏-31】1.1 项目背景1.2 ArkTS详解二.HarmonyOS应用开发实战—开箱即用的登录页面3【ArkTS】2.1 ArkTS页面源码2.2 代码解析2.3 心得一.HarmonyOS应用开发实战—开箱即用的登录页面2【ArkTS】【鸿蒙专…...

Unity坦克大战开发全流程——1)需求分析
实践项目:需求分析 该游戏共有三个主要部分:UI、数据储存、核心游戏逻辑,下面我们将从开始场景、游戏场景、结束场景三个角度切入进行分析。...

python练习2【题解///考点列出///错题改正】
一、单选题 【文件】 *1.【单选题】 ——文件:读取方法 下列哪个选项可以从文件中读取任意字节的内容?(C )A A.read() B.readline() C.readlines() D.以上全部 A\B\C三种方法都是可以读取文件中任意的字节内容的࿰…...
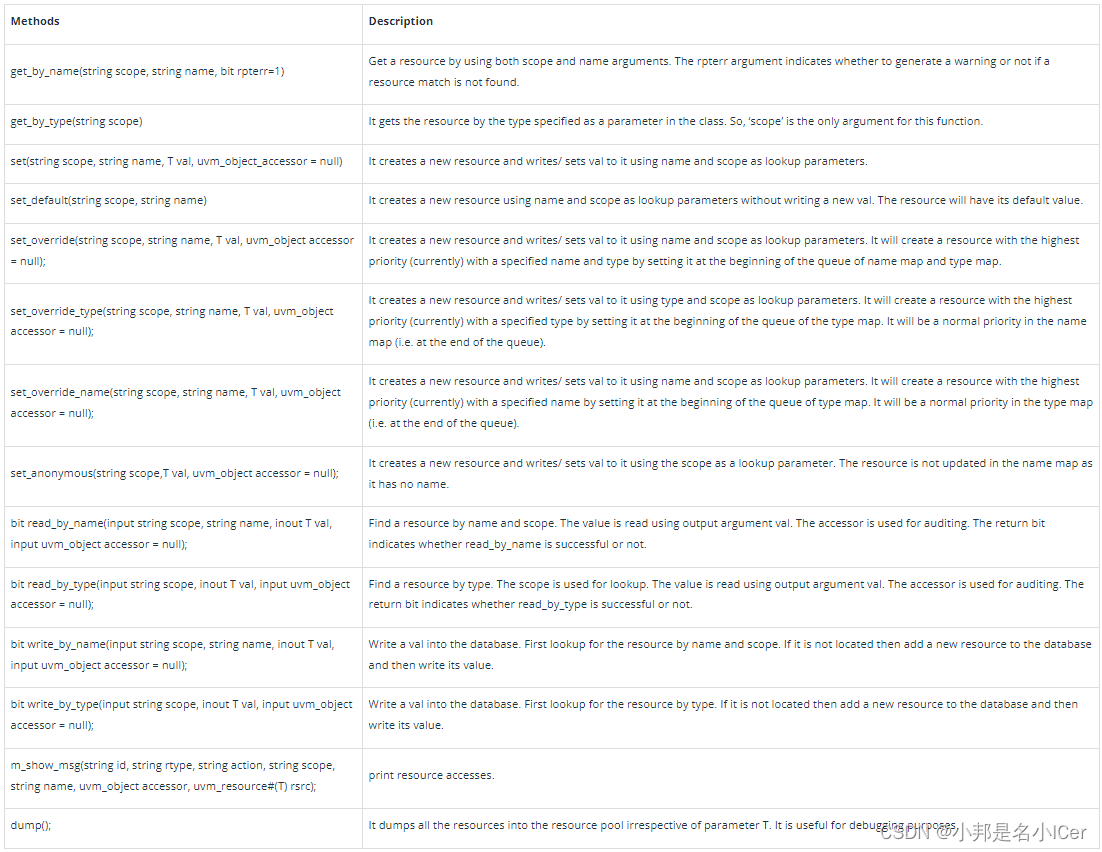
7.2 uvm_resource_db in UVM
uvm_resource_db是一个类型参数化 type-parameterized的类,它是资源数据库顶部的一个方便层(convenience layer)。这个便利层简化了对低级数据库的访问,并且没有添加新功能。因此,uvm_resource_db不是从uvm_resource类派生的。以下uvm_resour…...
)
洛谷——P3879 [TJOI2010] 阅读理解(STL:hash+set,c++)
文章目录 一、题目[TJOI2010] 阅读理解题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1 提示 二、题解基本思路:代码 一、题目 [TJOI2010] 阅读理解 题目描述 英语老师留了 N N N 篇阅读理解作业,但是每篇英文短文都有很多生词需要查字典&am…...
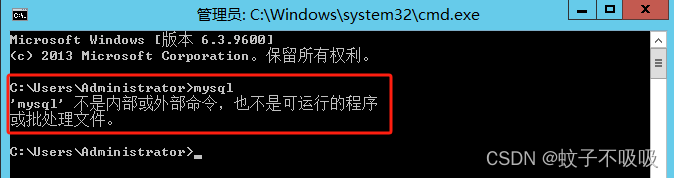
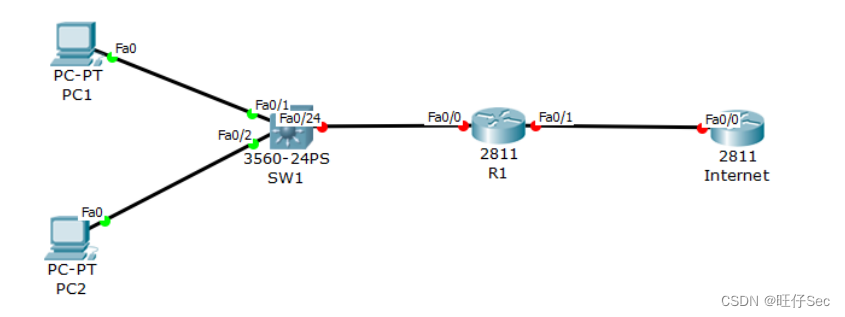
Windows/Linux环境登入mysql、mysqldump命令等多方式解决方案之简易记录
Windows/Linux环境登入mysql、mysqldump命令等多方式解决方案之简易记录 之前发布过Window方式,这次结合以上主题,完善下Linux相关登入方式过程,纯属做个记录,有需要的朋友可以做个学习参考。 一、Windows环境提示“‘mysql’ 不是内部或外部命令,也不是可运行的程序或批…...

【基础】【Python网络爬虫】【13.免费代理与付费代理】(附大量案例代码)(建议收藏)
Python网络爬虫基础 一、免费代理1. 什么是代理IP2. 代理IP的类型3. 代理IP的作用4. 免费代理的潜在风险5. 免费代理网站 二、付费代理1. 找付费代理服务站点2. 生成获取代理的api接口3. python获取代理请求接口示例数据返回示例 4. 解决请求速率5. 品易代理使用注意事项代理添…...

【 YOLOv5】目标检测 YOLOv5 开源代码项目调试与讲解实战(3)-训练yolov5模型(本地)
训练yolov5模型(本地) 训练文件 train.py训练如下图 一些参数的设置weights:对于weight参数,可以往Default参数中填入的参数有 cfg:(缩写)cfg参数可以选择的网络模型 data对于data hyp 超参数epochs 训练多…...
fastApi 项目部署
方式一,Uvicorn部署 Run a Server Manually - Uvicorn - FastAPI 1,linux服务器安装 python>3.8 2,安装 uvicorn : pip install "uvicorn[standard]" 3,上传项目到服务器 main.py from typing imp…...

python操作mysql数据库
说明:这里仅仅为了演示python操作MySQL数据库,真实环境中,最好把CURD分别封装为对应的方法。并将这些方法在类中封装,体现python面向对象的特征。python链接MySQL数据库 建表 create database mydb; use mydb; create table EMP…...
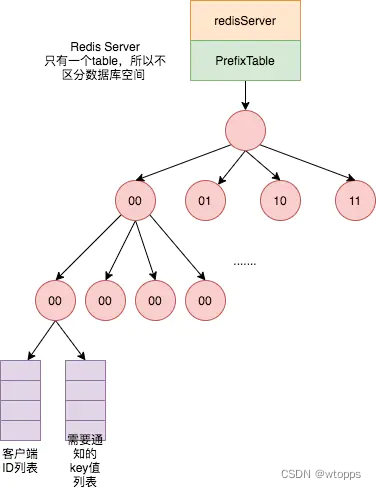
Redis6.0 Client-Side缓存是什么
前言 Redis在其6.0版本中加入了Client-side caching的支持,开启该功能后,Redis可以将指定的key-value缓存在客户端侧,这样当客户端发起请求时,如果客户端侧存在缓存,则无需请求Redis Server端。 Why Client-side Cac…...
Leetcode—1572.矩阵对角线元素的和【简单】
2023每日刷题(七十三) Leetcode—1572.矩阵对角线元素的和 实现代码 class Solution { public:int diagonalSum(vector<vector<int>>& mat) {int n mat.size();if(n 1) {return mat[0][0];}int sum 0;int i 0, j n - 1;while(i &…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...