探索 PyTorch 中的 torch.nn 模块**(1)
目录
引言
torch.nn使用和详解
Parameter
函数作用
使用技巧
使用方法和示例
UninitializedParameter
特点和用途
可进行的操作
使用示例
UninitializedBuffer
特点和用途
可进行的操作
使用示例
Module**(重点)
关键特性和功能
举例说明
torch.nn.Module 主要方法详解
add_module(name, module)
apply(fn)
bfloat16()
buffers(recurse=True)
children()
cpu()
cuda(device=None)
double()
eval()
extra_repr()
float()
forward(*input)
get_buffer(target)
get_parameter(target)
half()
load_state_dict(state_dict, strict=True, assign=False)
modules()
named_buffers(prefix='', recurse=True, remove_duplicate=True)
named_children()
named_modules(memo=None, prefix='', remove_duplicate=True)
named_parameters(prefix='', recurse=True, remove_duplicate=True)
parameters(recurse=True)
register_backward_hook(hook)
register_buffer(name, tensor, persistent=True)
register_forward_hook(hook)
register_forward_pre_hook(hook)
register_full_backward_hook(hook)
register_parameter(name, param)
state_dict()
to(*args, **kwargs)
train(mode=True)
type(dst_type)
zero_grad(set_to_none=True)
Sequential
主要特性
与 torch.nn.ModuleList 的区别
使用示例
append(module) 方法
ModuleList
主要特性
使用示例
ModuleList 的方法
ModuleDict
主要特性
使用示例
ModuleDict 的方法
ParameterList
主要特性
使用示例
ParameterList 的方法
ParameterDict
主要特性
使用示例
ParameterDict 的方法
总结
引言
在当今快速发展的人工智能领域,深度学习已成为其中最引人注目的技术之一。PyTorch 作为一种流行的深度学习框架,因其灵活性和易用性而受到广泛欢迎。在 PyTorch 的众多组件中,torch.nn 模块无疑是构建复杂深度学习模型的基石。本文将深入探讨 torch.nn 模块的功能、优势和使用技巧,旨在为读者提供一个清晰的理解和应用指南。torch.nn 提供了构建神经网络所需的所有基本构建块,包括各种类型的层(如卷积层、池化层、激活函数)、损失函数和容器。这些组件不仅是模块化和可重用的,而且也支持灵活的网络架构设计。通过本文,我们将逐一解析这些组件的特性和使用场景,并分享一些实用的技巧来优化网络性能。无论是新手还是有经验的开发者,都可以从中获得宝贵的见解,以更好地利用这个强大的模块来设计和实现高效的深度学习模型。
接下来的章节将从 torch.nn 的基础知识开始,逐步深入到更高级的主题,包括定制网络层、优化技巧和最佳实践。准备好,让我们开始这次深入浅出的 torch.nn 之旅吧!
torch.nn使用和详解
Parameter
torch.nn.parameter.Parameter 是 PyTorch 深度学习框架中的一个重要类,用于表示神经网络中的参数。这个类是 Tensor 的子类,它在与 Module(模块)一起使用时具有特殊属性。当 Parameter 被赋值为 Module 的属性时,它自动被添加到模块的参数列表中,并且会出现在例如 parameters() 迭代器中。这与普通的 Tensor 不同,因为 Tensor 赋值给模块时不会有这样的效果。
函数作用
- 目的:
Parameter主要用于将张量标记为模块的参数。这对于模型的训练和参数更新至关重要,因为只有被标记为Parameter的张量才会在模型训练时更新。 - 使用场景: 在构建自定义神经网络层或整个模型时,需要用到
Parameter来定义可训练的参数(如权重和偏置)。这些参数在训练过程中会通过反向传播进行优化。
使用技巧
- 参数初始化: 在定义模型的参数时,可以直接使用
Parameter类对其进行初始化,从而确保这些参数会被识别并在训练过程中更新。 - 控制梯度: 通过设置
requires_grad参数,可以控制特定参数是否需要在反向传播中计算梯度。这对于冻结模型的部分参数或进行特定的优化策略非常有用。
使用方法和示例
以下是 torch.nn.parameter.Parameter 的使用示例:
import torch
import torch.nn as nn# 定义一个自定义的线性层
class CustomLinearLayer(nn.Module):def __init__(self, in_features, out_features):super(CustomLinearLayer, self).__init__()# 定义权重为一个可训练的参数self.weight = nn.Parameter(torch.randn(out_features, in_features))# 定义偏置为一个可训练的参数self.bias = nn.Parameter(torch.randn(out_features))def forward(self, x):# 实现前向传播return torch.matmul(x, self.weight.t()) + self.bias# 创建一个自定义的线性层实例
layer = CustomLinearLayer(5, 3)
print(list(layer.parameters()))
在上述代码中,CustomLinearLayer 类中定义了两个 Parameter 对象:weight 和 bias。这些参数在模块被实例化时自动注册,并在训练过程中会被优化。通过打印 layer.parameters(),可以看到这些被注册的参数。
UninitializedParameter
torch.nn.parameter.UninitializedParameter 是 PyTorch 中的一个特殊类,用于表示尚未初始化的参数。这个类是 torch.nn.Parameter 的一个特殊情况,其主要特点是在创建时数据的形状(shape)还未知。
特点和用途
- 尚未初始化: 与常规的
torch.nn.Parameter不同,UninitializedParameter不持有任何数据。这意味着在初始化之前,试图访问某些属性(如它们的形状)会引发运行时错误。 - 灵活的初始化:
UninitializedParameter允许在模型定义阶段创建参数,而不必立即指定它们的大小或形状。这在某些情况下非常有用,例如,当参数的大小依赖于运行时才可知的因素时。
可进行的操作
- 更改数据类型: 可以更改
UninitializedParameter的数据类型。 - 移动到不同设备: 可以将
UninitializedParameter移动到不同的设备(例如从 CPU 移到 GPU)。 - 转换为常规参数: 可以将
UninitializedParameter转换为常规的torch.nn.Parameter,此时需要指定其形状和数据。
使用示例
在下面的示例中,将展示如何创建一个未初始化的参数,并在稍后将其转换为常规参数:
import torch
import torch.nn as nnclass CustomLayer(nn.Module):def __init__(self):super(CustomLayer, self).__init__()# 创建一个未初始化的参数self.uninitialized_param = nn.parameter.UninitializedParameter()def forward(self, x):# 在前向传播中使用参数前必须先初始化if isinstance(self.uninitialized_param, nn.parameter.UninitializedParameter):# 初始化参数self.uninitialized_param = nn.Parameter(torch.randn(x.size(1), x.size(1)))return torch.matmul(x, self.uninitialized_param.t())# 创建自定义层的实例
layer = CustomLayer()# 假设输入x
x = torch.randn(10, 5)# 使用自定义层
output = layer(x)
print(output)
在这个例子中,CustomLayer 在初始化时创建了一个 UninitializedParameter。在进行前向传播时,检查这个参数是否已初始化,如果没有,则对其进行初始化,并将其转换为常规的 Parameter。这种方式在处理动态大小的输入时特别有用。
UninitializedBuffer
torch.nn.parameter.UninitializedBuffer 是 PyTorch 中的一个特殊类,它代表一个尚未初始化的缓冲区。这个类是 torch.Tensor 的一个特殊情形,其主要特点是在创建时数据的形状(shape)还未知。
特点和用途
- 尚未初始化: 与常规的
torch.Tensor不同,UninitializedBuffer不持有任何数据。这意味着在初始化之前,尝试访问某些属性(如它们的形状)会引发运行时错误。 - 适用场景:
UninitializedBuffer适用于那些在模型定义阶段需要创建缓冲区,但其大小或形状取决于后来才可知的数据或配置的情况。
可进行的操作
- 更改数据类型: 可以更改
UninitializedBuffer的数据类型。 - 移动到不同设备: 可以将
UninitializedBuffer移动到不同的设备(例如从 CPU 移到 GPU)。 - 转换为常规张量: 可以将
UninitializedBuffer转换为常规的torch.Tensor,此时需要指定其形状和数据。
使用示例
在下面的示例中,将展示如何创建一个未初始化的缓冲区,并在稍后将其转换为常规张量:
import torch
import torch.nn as nnclass CustomLayer(nn.Module):def __init__(self):super(CustomLayer, self).__init__()# 创建一个未初始化的缓冲区self.uninitialized_buffer = nn.parameter.UninitializedBuffer()def forward(self, x):# 在前向传播中使用缓冲区前必须先初始化if isinstance(self.uninitialized_buffer, nn.parameter.UninitializedBuffer):# 初始化缓冲区self.uninitialized_buffer = torch.Tensor(x.size(0), x.size(1))# 在这里可以使用缓冲区进行计算或其他操作return x + self.uninitialized_buffer# 创建自定义层的实例
layer = CustomLayer()# 假设输入x
x = torch.randn(10, 5)# 使用自定义层
output = layer(x)
print(output)
在这个例子中,CustomLayer 在初始化时创建了一个 UninitializedBuffer。在进行前向传播时,检查这个缓冲区是否已初始化,如果没有,则对其进行初始化,并将其转换为常规的 Tensor。这种方法在动态处理数据大小时非常有用,特别是在需要临时存储数据但在模型定义阶段无法确定其大小的情况下。
Module**(重点)
torch.nn.Module 是 PyTorch 中用于构建所有神经网络模型的基类。几乎所有的 PyTorch 神经网络模型都是通过继承 torch.nn.Module 来构建的。这个类提供了模型需要的基本功能,如参数管理、模型保存和加载、设备转移(例如,从 CPU 到 GPU)等。
关键特性和功能
- 模块树结构:
Module可以包含其他Module,形成一个嵌套的树状结构。这允许用户以模块化的方式构建复杂的神经网络。 - 参数和缓冲区的管理:
Module自动管理其属性中的所有Parameter和Buffer对象。这包括注册参数、转移到不同设备、保存和加载模型状态等。 - 前向传播定义: 所有子类都应该覆盖
forward方法,以定义其在接收输入时的计算过程。
举例说明
以下是一个基本的 torch.nn.Module 子类的示例:
import torch.nn as nn
import torch.nn.functional as Fclass SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.conv1 = nn.Conv2d(1, 20, 5)self.conv2 = nn.Conv2d(20, 20, 5)def forward(self, x):x = F.relu(self.conv1(x))return F.relu(self.conv2(x))model = SimpleModel()
在这个例子中,SimpleModel 继承了 torch.nn.Module。在其构造函数中,定义了两个卷积层 conv1 和 conv2,并在 forward 方法中定义了模型的前向传播逻辑。
torch.nn.Module 主要方法详解
add_module(name, module)
- 功能:向当前模块添加子模块。
- 参数:
name: 子模块的名称。- module: 要添加的子模块对象。
# 定义一个自定义模块
class CustomModule(nn.Module):def __init__(self):super(CustomModule, self).__init__()# 创建一个线性层linear = nn.Linear(10, 5)# 使用 add_module 添加线性层作为子模块self.add_module('linear', linear)
apply(fn)
- 功能:递归地将函数
fn应用于每个子模块及其自身。 - 参数:
fn: 要应用的函数,通常用于初始化参数。
# 定义一个初始化权重的函数
def init_weights(m):if type(m) == nn.Linear:nn.init.uniform_(m.weight)# 应用 init_weights 函数初始化模型的权重
model = CustomModule()
model.apply(init_weights)
bfloat16()
- 功能:将所有浮点参数和缓冲区转换为 bfloat16 数据类型。
- 注意:此方法就地修改模块。
# 将模型的参数和缓冲区转换为 bfloat16 数据类型
model.bfloat16()
buffers(recurse=True)
- 功能:返回一个迭代器,遍历模块的所有缓冲区。
- 参数:
recurse: 如果为 True,则遍历此模块及所有子模块的缓冲区。
# 遍历模型的所有缓冲区
for buf in model.buffers():print(buf.size())
children()
- 功能:返回一个迭代器,遍历模块的直接子模块。
# 遍历模型的直接子模块
for child in model.children():print(child)
cpu()
- 功能:将所有模型参数和缓冲区移动到 CPU。
# 将模型移动到 CPU
model.cpu()
cuda(device=None)
- 功能:将所有模型参数和缓冲区移动到 GPU。
- 参数:
device: 指定 GPU 设备。
# 将模型移动到 GPU
model.cuda()
double()
- 功能:将所有浮点参数和缓冲区转换为 double 数据类型。
# 将模型的参数和缓冲区转换为 double 数据类型
model.double()
eval()
- 功能:将模块设置为评估模式。
# 将模型设置为评估模式
model.eval()
extra_repr()
- 功能:设置模块的额外表示,用于自定义信息打印。
# 自定义模型的额外表示
class CustomModule(nn.Module):def __init__(self):super(CustomModule, self).__init__()def extra_repr(self):return '自定义信息'model = CustomModule()
print(model)
float()
- 功能:将所有浮点参数和缓冲区转换为 float 数据类型。
# 将模型的参数和缓冲区转换为 float 数据类型
model.float()
forward(*input)
- 功能:定义每次调用时的计算,所有子类必须覆盖此方法。
# 定义模型的前向传播
class CustomModule(nn.Module):def __init__(self):super(CustomModule, self).__init__()self.linear = nn.Linear(10, 5)def forward(self, x):return self.linear(x)model = CustomModule()
input = torch.randn(1, 10)
output = model(input)
get_buffer(target)
- 功能:根据目标名称返回对应的缓冲区。
# 获取特定名称的缓冲区
buffer = model.get_buffer('buffer_name')
get_parameter(target)
- 功能:根据目标名称返回对应的参数。
# 获取特定名称的参数
parameter = model.get_parameter('param_name')
half()
- 功能:将所有浮点参数和缓冲区转换为半精度 (half) 数据类型。
# 将模型的参数和缓冲区转换为半精度 (half) 数据类型
model.half()
load_state_dict(state_dict, strict=True, assign=False)
- 功能:从
state_dict中复制参数和缓冲区到此模块及其后代。 - 参数:
state_dict: 包含参数和持久缓冲区的字典。strict: 是否严格匹配state_dict和模块的键。
# 从 state_dict 加载模型状态
state_dict = {'linear.weight': torch.randn(5, 10), 'linear.bias': torch.randn(5)}
model.load_state_dict(state_dict, strict=False)
modules()
- 功能:返回一个迭代器,遍历网络中的所有模块。
# 遍历网络中的所有模块
for module in model.modules():print(module)
named_buffers(prefix='', recurse=True, remove_duplicate=True)
- 功能:返回一个迭代器,遍历模块的所有缓冲区,同时提供缓冲区的名称。
# 遍历模型的所有缓冲区,同时提供缓冲区的名称
for name, buf in model.named_buffers():print(f"Buffer name: {name}, Buffer: {buf}")
named_children()
- 功能:返回一个迭代器,遍历模块的直接子模块,同时提供子模块的名称。
# 遍历模型的直接子模块,同时提供子模块的名称
for name, child in model.named_children():print(f"Child name: {name}, Child module: {child}")
named_modules(memo=None, prefix='', remove_duplicate=True)
- 功能:返回一个迭代器,遍历网络中的所有模块,同时提供模块的名称。
# 遍历网络中的所有模块,同时提供模块的名称
for name, module in model.named_modules():print(f"Module name: {name}, Module: {module}")
named_parameters(prefix='', recurse=True, remove_duplicate=True)
- 功能:返回一个迭代器,遍历模块的所有参数,同时提供参数的名称。
# 遍历模型的所有参数,同时提供参数的名称
for name, param in model.named_parameters():print(f"Parameter name: {name}, Parameter: {param}")
parameters(recurse=True)
- 功能:返回一个迭代器,遍历模块的所有参数。
# 遍历模型的所有参数
for param in model.parameters():print(param)
register_backward_hook(hook)
- 功能:注册一个反向传播钩子。
# 注册一个反向传播钩子
def backward_hook(module, grad_input, grad_output):print(f"Backward hook in {module}")model.register_backward_hook(backward_hook)
register_buffer(name, tensor, persistent=True)
- 功能:向模块添加一个缓冲区。
# 向模块添加一个缓冲区
model.register_buffer('new_buffer', torch.randn(5))
register_forward_hook(hook)
- 功能:注册一个前向传播钩子。
# 注册一个前向传播钩子
def forward_hook(module, input, output):print(f"Forward hook in {module}")model.register_forward_hook(forward_hook)
register_forward_pre_hook(hook)
- 功能:注册一个前向传播预处理钩子。
# 注册一个前向传播钩子
def forward_hook(module, input, output):print(f"Forward hook in {module}")model.register_forward_hook(forward_hook)
register_full_backward_hook(hook)
- 功能:注册一个完整的反向传播钩子。
# 注册一个完整的反向传播钩子
def full_backward_hook(module, grad_input, grad_output):print(f"Full backward hook in {module}")model.register_full_backward_hook(full_backward_hook)
register_parameter(name, param)
- 功能:向模块添加一个参数。
# 向模块添加一个参数
param = nn.Parameter(torch.randn(5))
model.register_parameter('new_param', param)
state_dict()
- 功能:返回包含模块所有状态信息的字典。
# 获取模块所有状态信息的字典
state_dict = model.state_dict()
to(*args, **kwargs)
- 功能:移动和/或转换参数和缓冲区。
# 移动和/或转换参数和缓冲区
# 移动模型到 GPU 并转换为 double 类型
model.to('cuda', dtype=torch.double)
train(mode=True)
- 功能:将模块设置为训练模式。
# 将模块设置为训练模式
model.train()
type(dst_type)
- 功能:将所有参数和缓冲区转换为指定类型。
# 将所有参数和缓冲区转换为指定类型
model.type(torch.float32)
zero_grad(set_to_none=True)
- 功能:重置所有模型参数的梯度。
# 重置所有模型参数的梯度
model.zero_grad()
这些示例涵盖了 torch.nn.Module 类中的大多数主要方法,展示了如何在实际情况中使用它们。
Sequential
torch.nn.Sequential 是 PyTorch 中的一个容器模块,用于按顺序封装一系列子模块。它简化了模型的构建过程,使得将多个模块组合成一个单独的序列变得容易和直观。
主要特性
- 顺序处理:
Sequential按照它们在构造函数中传递的顺序,依次处理每个子模块。输入数据首先被传递到第一个模块,然后依次传递到每个后续模块。 - 容器作为单一模块:
Sequential允许将整个容器视为单一模块,对其进行的任何转换都适用于它存储的每个模块(每个模块都是Sequential的一个注册子模块)。
与 torch.nn.ModuleList 的区别
torch.nn.ModuleList 仅仅是一个存储子模块的列表,而 Sequential 中的层是级联连接的。在 ModuleList 中,层之间没有直接的数据流动关联,而在 Sequential 中,一个层的输出直接成为下一个层的输入。
使用示例
-
使用 Sequential 创建一个简单的模型:
model = nn.Sequential(nn.Conv2d(1, 20, 5),nn.ReLU(),nn.Conv2d(20, 64, 5),nn.ReLU())
在这个例子中,输入数据首先通过一个 Conv2d 层,然后是 ReLU 层,接着是第二个 Conv2d 层,最后是另一个 ReLU 层。
使用带有 OrderedDict 的 Sequential:
from collections import OrderedDictmodel = nn.Sequential(OrderedDict([('conv1', nn.Conv2d(1, 20, 5)),('relu1', nn.ReLU()),('conv2', nn.Conv2d(20, 64, 5)),('relu2', nn.ReLU())]))
使用 OrderedDict 允许为每个模块指定一个唯一的名称。这在需要引用特定层或在打印模型结构时提高了可读性。
append(module) 方法
- 功能: 将给定的模块添加到序列的末尾。
- 参数:
module(nn.Module): 要附加的模块。
- 返回类型:
Sequential
这种方式构建的模型可以简化前向传播的实现,使得模型的构建和理解更加直观。
ModuleList
torch.nn.ModuleList 是 PyTorch 中用于存储子模块的列表容器。它类似于 Python 的常规列表,但具有额外的功能,使其能够适当地注册其中包含的模块,并使它们对所有 Module 方法可见。
主要特性
- 列表式结构:
ModuleList提供了一个列表式的结构来保存模块,允许通过索引或迭代器访问这些模块。 - 模块注册: 它包含的模块会被正确注册,这意味着当调用诸如
.parameters()或.to(device)等Module方法时,这些子模块也会被考虑在内。
使用示例
class MyModule(nn.Module):def __init__(self):super().__init__()# 使用 ModuleList 创建一个线性层的列表self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])def forward(self, x):# ModuleList 可以作为迭代器,也可以使用索引访问for i, l in enumerate(self.linears):x = self.linears[i // 2](x) + l(x)return x
在这个例子中,MyModule 创建了一个 ModuleList,其中包含了 10 个 nn.Linear(10, 10) 层。在 forward 方法中,使用了两种不同的方式来访问和应用这些层。
ModuleList 的方法
-
append(module)- 功能:在列表末尾添加一个给定的模块。
- 参数:
module(nn.Module):要添加的模块。
-
extend(modules)- 功能:将来自 Python 可迭代对象的模块添加到列表的末尾。
- 参数:
modules(iterable):可迭代的模块对象。
-
insert(index, module)- 功能:在列表中给定索引之前插入一个模块。
- 参数:
index(int):插入的索引。module(nn.Module):要插入的模块。
ModuleList 提供了灵活的方式来管理子模块的集合,特别是当模型的某些部分是动态的或者模型结构中的层的数量在初始化时未知时非常有用。
ModuleDict
torch.nn.ModuleDict 是 PyTorch 中的一个容器模块,用于以字典形式保存子模块。它类似于 Python 的常规字典,但其包含的模块会被正确注册,并且对所有 Module 方法可见。
主要特性
- 字典式结构:
ModuleDict提供了一个字典式的结构来保存模块,允许通过键值对访问这些模块。 - 有序字典: 自 Python 3.6 起,
ModuleDict是一个有序字典,它会保留插入顺序和合并顺序。
使用示例
class MyModule(nn.Module):def __init__(self):super().__init__()# 使用 ModuleDict 创建一个由不同层组成的字典self.choices = nn.ModuleDict({'conv': nn.Conv2d(10, 10, 3),'pool': nn.MaxPool2d(3)})# 可以使用列表初始化 ModuleDictself.activations = nn.ModuleDict([['lrelu', nn.LeakyReLU()],['prelu', nn.PReLU()]])def forward(self, x, choice, act):# 通过键值访问 ModuleDict 中的模块x = self.choices[choice](x)x = self.activations[act](x)return x
在这个例子中,MyModule 创建了两个 ModuleDict,一个用于保存卷积层和池化层,另一个用于保存激活层。
ModuleDict 的方法
-
clear()- 功能:清除
ModuleDict中的所有项。
- 功能:清除
-
items()- 功能:返回
ModuleDict中的键/值对的迭代器。
- 功能:返回
-
keys()- 功能:返回
ModuleDict键的迭代器。
- 功能:返回
-
pop(key)- 功能:从
ModuleDict中移除键并返回其模块。 - 参数:
key(str):要从ModuleDict中弹出的键。
- 功能:从
-
update(modules)- 功能:用来自映射或迭代器的键值对更新
ModuleDict,覆盖现有的键。 - 参数:
modules(iterable):从字符串到模块的映射(字典),或键值对的迭代器。
- 功能:用来自映射或迭代器的键值对更新
-
values()- 功能:返回
ModuleDict中模块值的迭代器。
- 功能:返回
ModuleDict 提供了一个灵活的方式来管理具有特定键的子模块的集合。这在模型设计中特别有用,尤其是当模型的不同部分需要根据键动态选择时。
ParameterList
torch.nn.ParameterList 是 PyTorch 中的一个容器模块,用于按列表形式保存参数(Parameter 对象)。它类似于 Python 的常规列表,但其特殊之处在于其中包含的 Tensor 对象会被转换为 Parameter 对象,并正确注册,使得这些参数对所有 Module 方法可见。
主要特性
- 列表式结构:
ParameterList提供了一个列表式的结构来保存参数,允许通过索引或迭代器访问这些参数。 - 参数注册: 其中包含的
Tensor对象会被自动转换为Parameter对象,确保它们可以被 PyTorch 的优化器等模块正确处理。
使用示例
class MyModule(nn.Module):def __init__(self):super().__init__()# 使用 ParameterList 创建一个包含多个参数的列表self.params = nn.ParameterList([nn.Parameter(torch.randn(10, 10)) for i in range(10)])def forward(self, x):# ParameterList 可以作为迭代器,也可以使用索引访问for i, p in enumerate(self.params):x = self.params[i // 2].mm(x) + p.mm(x)return x
在这个例子中,MyModule 创建了一个 ParameterList,其中包含了 10 个形状为 10x10 的随机参数。在 forward 方法中,这些参数被用于矩阵乘法操作。
ParameterList 的方法
-
append(value)- 功能:在列表末尾添加一个给定的值(会被转换为
Parameter)。 - 参数:
value(Any):要添加的值。
- 功能:在列表末尾添加一个给定的值(会被转换为
-
extend(values)- 功能:将来自 Python 可迭代对象的值添加到列表的末尾(每个值都会被转换为
Parameter)。 - 参数:
values(iterable):要添加的值的可迭代对象。
- 功能:将来自 Python 可迭代对象的值添加到列表的末尾(每个值都会被转换为
ParameterList 提供了一种灵活的方式来管理模型中的参数集合,特别是当模型的某些部分参数数量动态变化时非常有用。通过使用 ParameterList,您可以确保模型的所有参数都正确注册,并且可以通过标准的 PyTorch 方法进行访问和优化。
ParameterDict
torch.nn.ParameterDict 是 PyTorch 中用于以字典形式保存参数(Parameter 对象)的容器模块。它类似于 Python 的常规字典,但其特殊之处在于其中包含的参数被正确注册,并对所有 Module 方法可见。
主要特性
- 字典式结构:
ParameterDict提供了一个字典式的结构来保存参数,允许通过键值对访问这些参数。 - 有序字典:
ParameterDict是一个有序字典,它保留插入顺序和合并顺序(对于OrderedDict或另一个ParameterDict)。
使用示例
class MyModule(nn.Module):def __init__(self):super().__init__()# 使用 ParameterDict 创建一个由不同参数组成的字典self.params = nn.ParameterDict({'left': nn.Parameter(torch.randn(5, 10)),'right': nn.Parameter(torch.randn(5, 10))})def forward(self, x, choice):# 通过键值访问 ParameterDict 中的参数x = self.params[choice].mm(x)return x
在这个例子中,MyModule 创建了一个 ParameterDict,其中包含了两个名为 'left' 和 'right' 的参数。在 forward 方法中,根据传入的 choice 键来选择相应的参数进行矩阵乘法操作。
ParameterDict 的方法
-
clear()- 功能:清除
ParameterDict中的所有项。
- 功能:清除
-
copy()- 功能:返回这个
ParameterDict实例的副本。
- 功能:返回这个
-
fromkeys(keys, default=None)- 功能:根据提供的键返回一个新的
ParameterDict。 - 参数:
keys(iterable, string):用于创建新ParameterDict的键。default(Parameter, 可选):为所有键设置的默认值。
- 功能:根据提供的键返回一个新的
-
get(key, default=None)- 功能:如果存在,返回与
key相关联的参数。否则,如果提供了default,则返回default;如果没有提供,则返回None。
- 功能:如果存在,返回与
-
items()- 功能:返回
ParameterDict键/值对的迭代器。
- 功能:返回
-
keys()- 功能:返回
ParameterDict键的迭代器。
- 功能:返回
-
pop(key)- 功能:从
ParameterDict中移除键并返回其参数。 - 参数:
key(str):要从ParameterDict中弹出的键。
- 功能:从
-
popitem()- 功能:从
ParameterDict中移除并返回最后插入的 (键, 参数) 对。
- 功能:从
-
setdefault(key, default=None)- 功能:如果
key在ParameterDict中,则返回其值。如果不是,插入key与参数default并返回default。default默认为None。
- 功能:如果
-
update(parameters)- 功能:用来自映射或迭代器的键值对更新
ParameterDict,覆盖现有的键。
- 功能:用来自映射或迭代器的键值对更新
-
values()- 功能:返回
ParameterDict中参数值的迭代器。
- 功能:返回
ParameterDict 提供了一种灵活的方式来管理模型中具有特定键的参数集合。这在模型设计中特别有用,尤其是当模型的不同部分需要根据键动态选择参数时。
总结
本文深入探索了 PyTorch 框架中的 torch.nn 模块,这是构建和实现高效深度学习模型的核心组件。我们详细介绍了 torch.nn 的关键类别和功能,包括 Parameter, Module, Sequential, ModuleList, ModuleDict, ParameterList 和 ParameterDict,为读者提供了一个全面的理解和应用指南。这篇博客仅仅是torch.nn的一部分功能,后续我这边会继续更新这个模块的其他相关功能。
相关文章:
)
探索 PyTorch 中的 torch.nn 模块**(1)
目录 引言 torch.nn使用和详解 Parameter 函数作用 使用技巧 使用方法和示例 UninitializedParameter 特点和用途 可进行的操作 使用示例 UninitializedBuffer 特点和用途 可进行的操作 使用示例 Module**(重点) 关键特性和功能 举例说…...

【WPF.NET开发】预览事件
本文内容 先决条件预览标记为“已处理”的事件通过控件解决事件禁止问题 预览事件,也称为隧道事件,是从应用程序根元素向下遍历元素树到引发事件的元素的路由事件。 引发事件的元素在事件数据中报告为Source 。 并非所有事件场景都支持或需要预览事件。…...
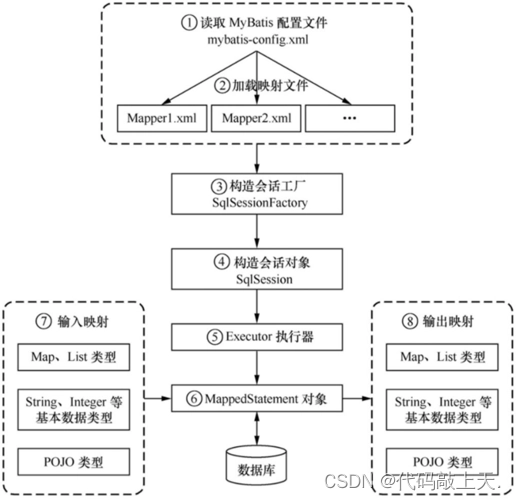
JDBC->SpringJDBC->Mybatis封装JDBC
一、JDBC介绍 Java数据库连接,(Java Database Connectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法。JDBC也是Sun Microsystems的商标。我们…...

ts中的keyof 关键字
const getVal <T,K extends keyof T>(obj:T,key:K) : T[K]>{return obj[key]; }使用了 keyof 关键字。keyof 是 TypeScript 的一个特性,它返回一个字符串字面量类型,表示对象类型的所有属性键的联合类型。 这段代码定义了一个泛型函数 gatVal&…...

Head First Design Patterns - 装饰者模式
什么是装饰者模式 装饰者模式动态地将额外责任附加到对象上。对于拓展功能,装饰者提供子类化的弹性替代方案。 --《Head First Design Patterns》中的定义 为什么会有装饰者模式 根据上述定义,简单来说,装饰者模式就是对原有的类,…...
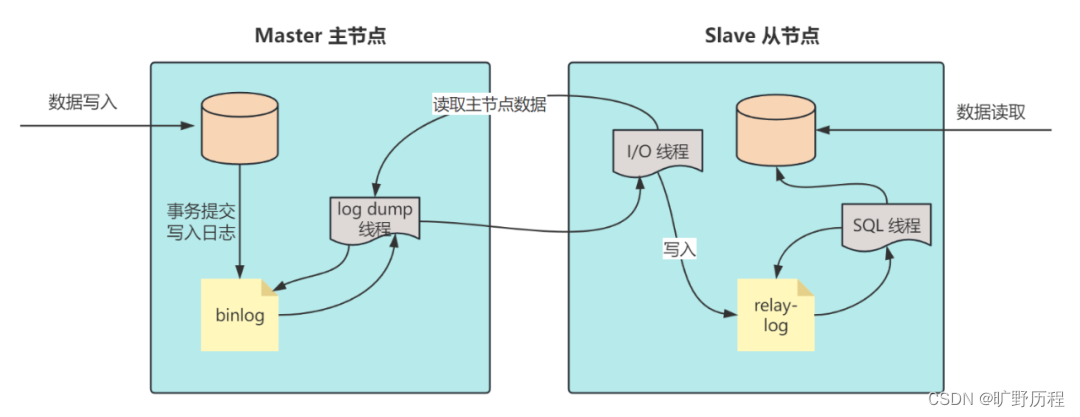
MySQL 执行过程
MySQL 的执行流程也确实是一个复杂的过程,它涉及多个组件的协同工作,故而在面试或者工作的过程中很容易陷入迷惑和误区。 MySQL 执行过程 本篇将以 MySQL 常见的 InnoDB 存储引擎为例,为大家详细介绍 SQL 语句的执行流程。从连接器开始&…...
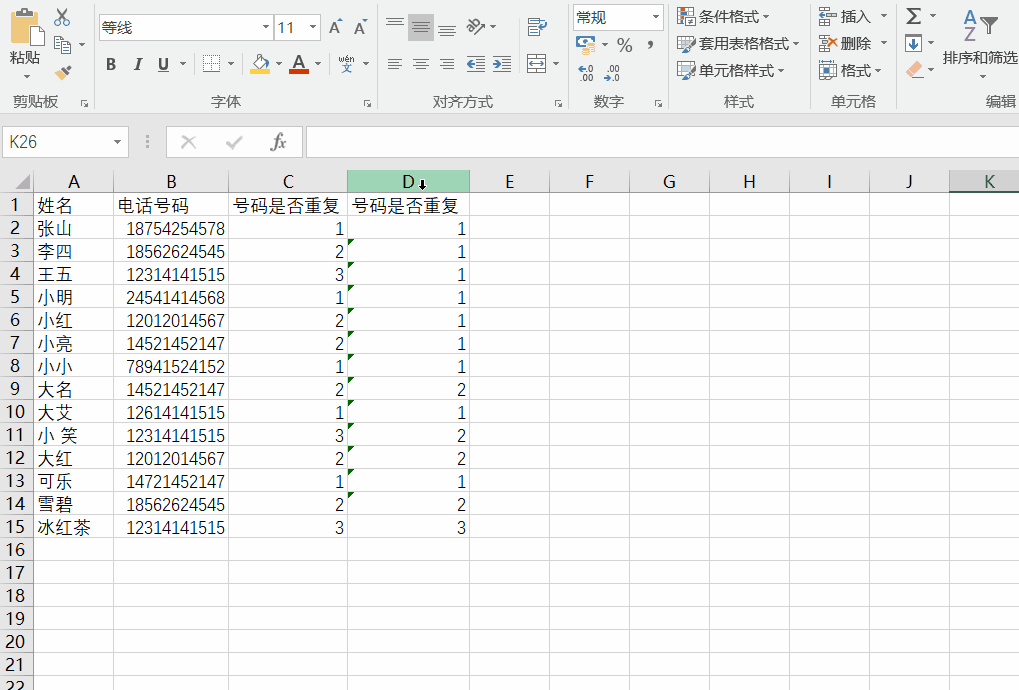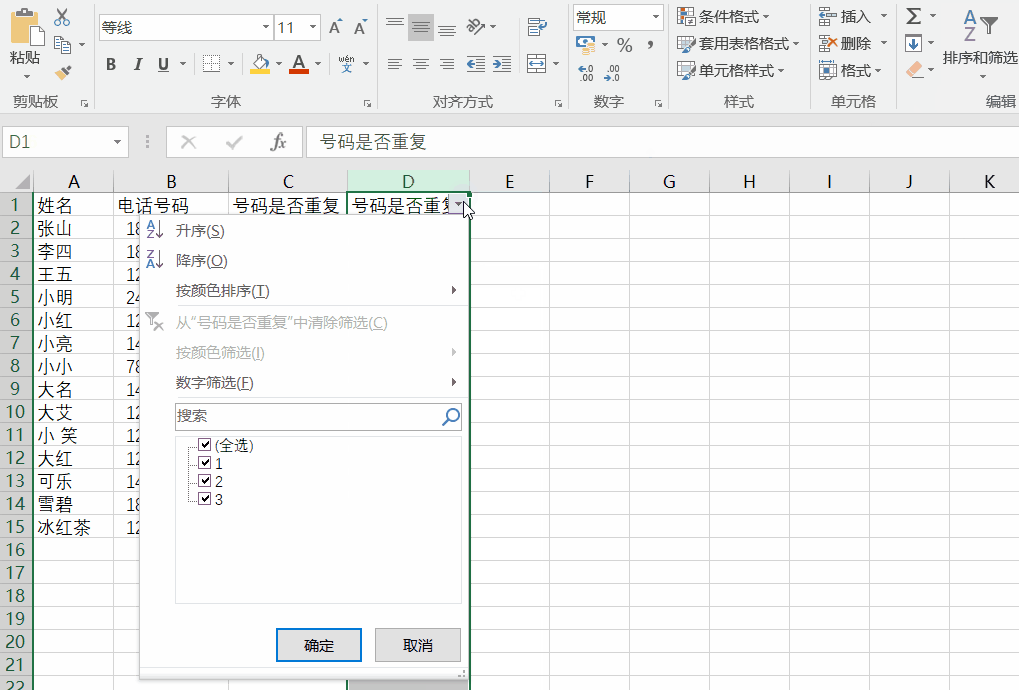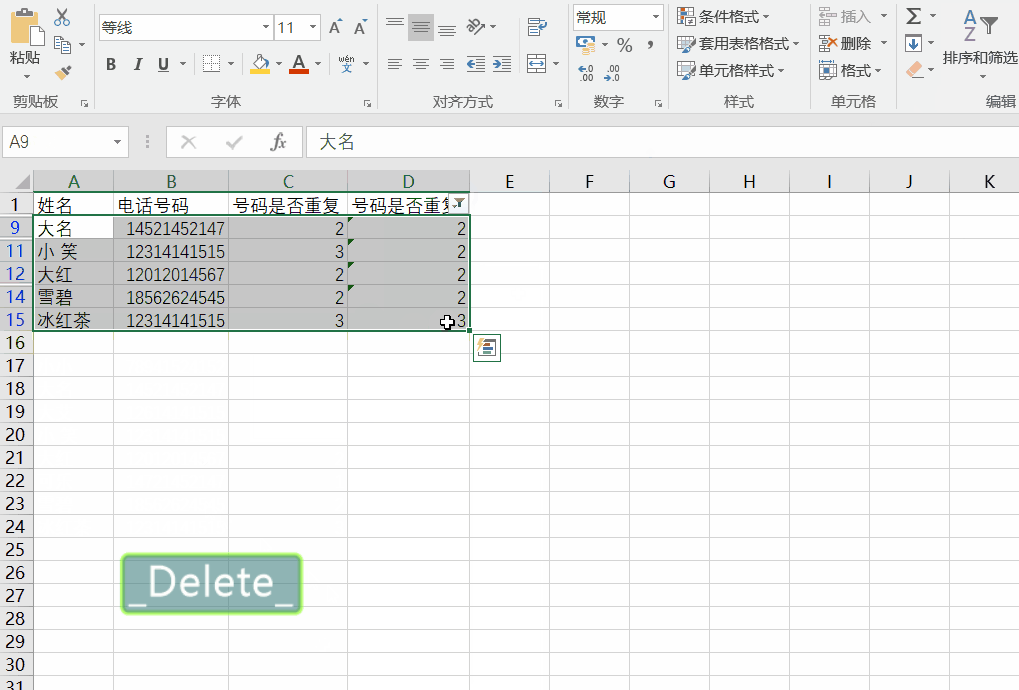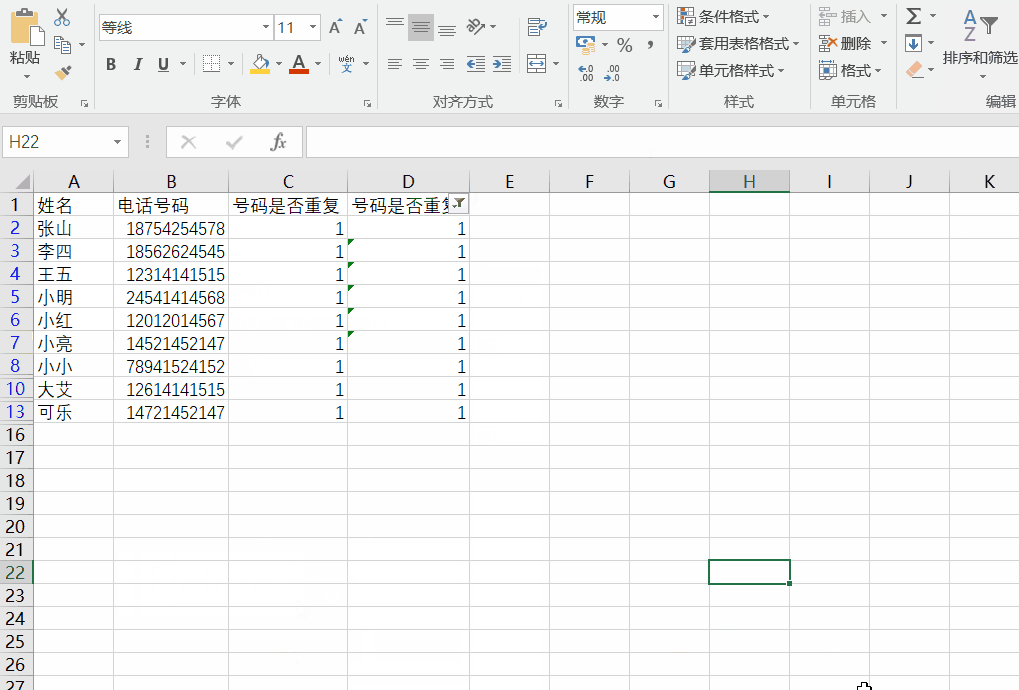
判断电话号码是否重复-excel
有时候重复的数据不需要或者很烦人,就需要采取措施,希望以下的方法能帮到你。 1.判断是否重复 方法一: 1)针对第一个单元格输入等号,以及公式countif(查找记录数的范围,需要查找的单元格) 2…...
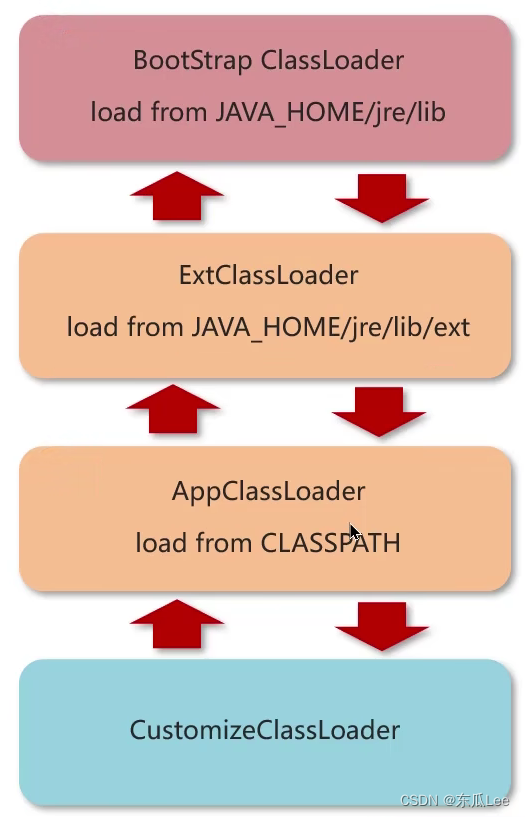
【Java开发岗面试】八股文—Java虚拟机(JVM)
声明: 背景:本人为24届双非硕校招生,已经完整经历了一次秋招,拿到了三个offer。本专题旨在分享自己的一些Java开发岗面试经验(主要是校招),包括我自己总结的八股文、算法、项目介绍、HR面和面试…...
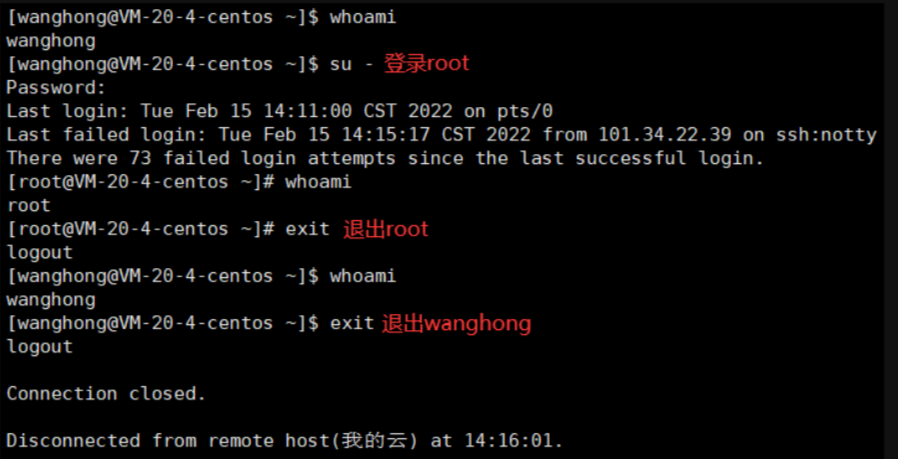
【Linux】Linux 下基本指令 -- 详解
无论是什么命令,用于什么用途,在 Linux 中,命令有其通用的格式: command [-options] [parameter] command:命令本身。-options:[可选,非必填]命令的一些选项,可以通过选项控制命令的…...

Eureka注册及使用
一、Eureka的作用 Eureka是一个服务注册与发现的工具,主要用于微服务架构中的服务发现和负载均衡。其主要作用包括: 服务提供者将自己注册到Eureka Server上,包括服务的地址和端口等信息。服务消费者从Eureka Server上获取服务提供者的地址…...
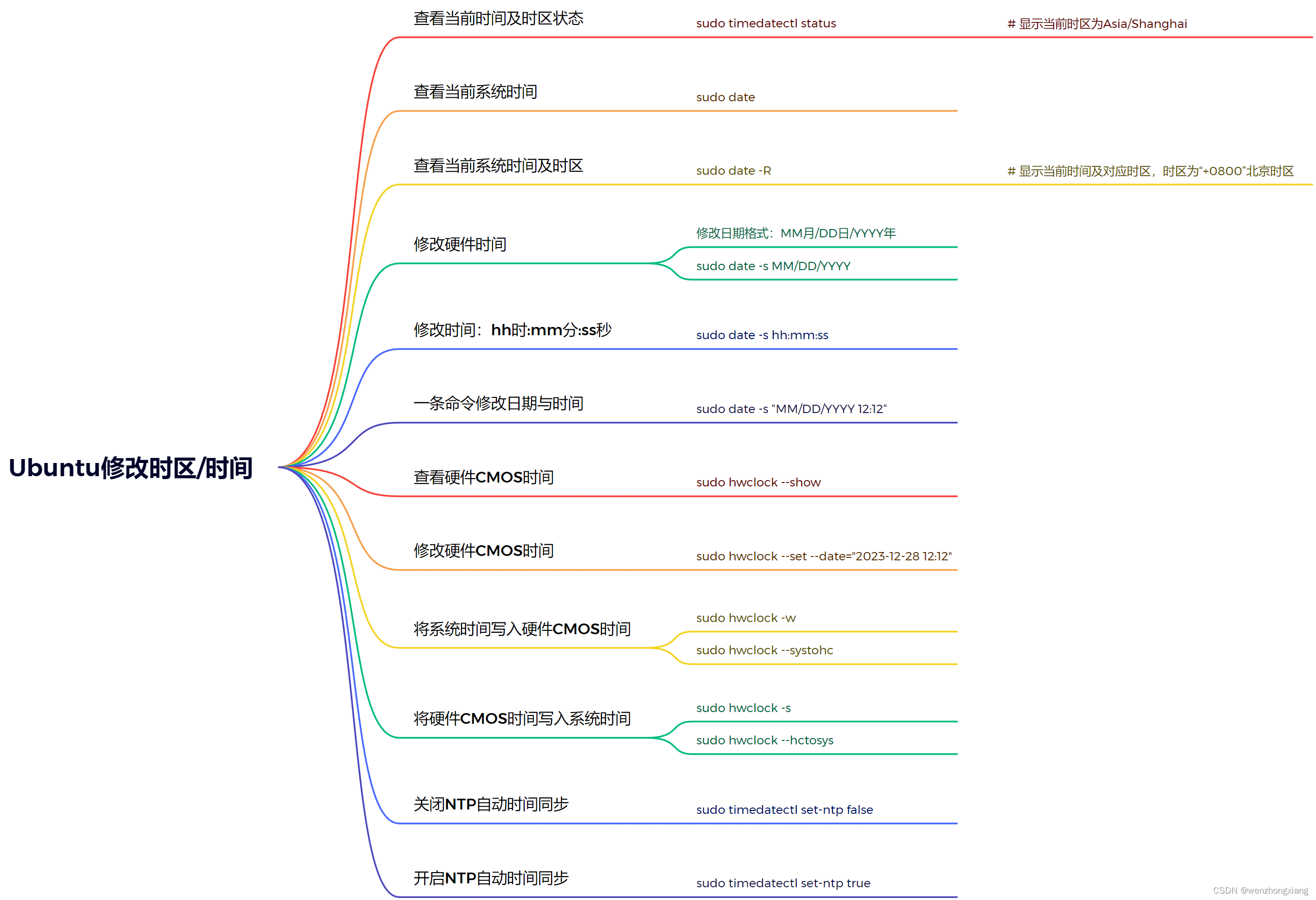
Ubuntu之修改时区/时间
1、查看当前时间及时区状态 sudo timedatectl status # 显示当前时区为Asia/Shanghai 2、查看当前系统时间 sudo date 3、查看当前系统时间及时区 sudo date -R # 显示当前时间及对应时区,时区为“0800”北京时区 4、修改硬件时间 修改日期格式:…...
)
4、内存泄漏检测(多线程)
4、内存泄漏多线程 多线程下使用Valgrind 工具的memcheck检查. 安装 sudo apt install valgrind使用 valgrind --toolmemcheck --leak-checkfull ./app_main 指令效果如下所示. wqwq-Virtual-Machine:~/work/test_zlog/build$ valgrind --toolmemcheck --leak-checkfull .…...

在使用tcp长连接时,是否还需要再引入重发机制?
一 什么是tcp长连接? 在TCP(Transmission Control Protocol)中,长连接是指在通信过程中保持连接状态的一种方式,相对于短连接而言。长连接通常用于需要频繁通信的场景,以减少连接建立和断开的开销。在长连接…...
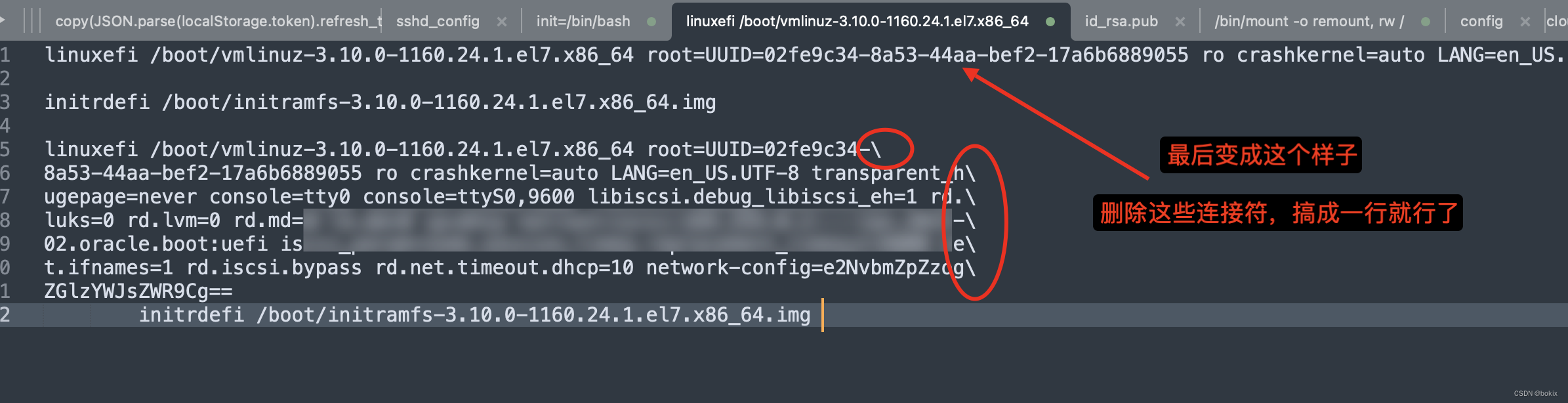
记一次Oracle Cloud计算实例ssh恢复过程
#ssh秘钥丢失# , #Oracle Cloud# 。 电脑上的ssh秘钥文件不知道什么时候丢失了,直到用的时候才发现没有了,这下可好,Oracle Cloud的计算实例连不上了,这个实例只能通过ssh连接上去: 以下是解决步骤&#x…...

2024年01月数据库流行度最新排名
点击查看最新数据库流行度最新排名(每月更新) 2024年01月数据库流行度最新排名 TOP DB顶级数据库索引是通过分析在谷歌上搜索数据库名称的频率来创建的 一个数据库被搜索的次数越多,这个数据库就被认为越受欢迎。这是一个领先指标。原始数…...
Stable Diffusion API入门:简明教程
Stable Diffusion 是一个先进的深度学习模型,用于创造和修改图像。这个模型能够基于文本描述来生成图像,让机器理解和实现用户的创意。使用这项技术的关键在于掌握其 API,通过编程来操控图像生成的过程。 在探索 Stable Diffusion API 的世界…...

数据结构--二叉搜索树的实现
目录 1.二叉搜索树的概念 2.二叉搜索树的操作 二叉搜索树的插入 中序遍历(常用于排序) 二叉搜索树的查找 二叉搜索树的删除 完整二叉树代码: 二叉搜索树的应用 key/value搜索模型整体代码 1.二叉搜索树的概念 二叉搜索树又称二叉排序树,它或者是一…...

《微信小程序开发从入门到实战》学习六十八
6.6 网络API 6.6.1 网络API 使用wx.request接口可以发起网络请求。该接口接受一个Object参,参数支持属性如下所示: url(必填):开发者服务器地址 data:请求的参数,类型为string/object/ArrayBuffer header…...

阿里是如何去“O”的?
大家好,我是老猫,猫头鹰的“猫”。 今天我们来聊聊数据库这个话题。 2009年,阿里提出“去IOE化”的概念,这在当时看起来是天方夜谭,但目前来看可以说是"轻舟已过万重山"。 IOE是传统IT三大件,…...

蓝桥杯备赛 day 1 —— 递归 、递归、枚举算法(C/C++,零基础,配图)
目录 🌈前言 📁 枚举的概念 📁递归的概念 例题: 1. 递归实现指数型枚举 2. 递归实现排列型枚举 3. 递归实现组合型枚举 📁 递推的概念 例题: 斐波那契数列 📁习题 1. 带分数 2. 反硬币 3. 费解的…...
)
【Warp+Claude】任务完成自动通知(macOS + Warp 版)
本篇是macOS 适配版,针对 Warp 终端用户优化。 在 Warp 里让 Claude 跑任务,切到其他应用做自己的事。任务完成时 terminal-notifier 自动弹出 macOS 原生通知,你不需要盯着终端等。 一、环境说明 系统:macOS终端:…...

5分钟掌握Bonjour零配置网络发现技术:让设备自动找到彼此的终极指南
5分钟掌握Bonjour零配置网络发现技术:让设备自动找到彼此的终极指南 【免费下载链接】bonjour A Bonjour/Zeroconf protocol implementation in JavaScript 项目地址: https://gitcode.com/gh_mirrors/bo/bonjour 在当今智能家居与物联网飞速发展的时代&…...

衡山派开发板镜像烧录实战:使用AiBurn工具从编译到上电的完整指南
衡山派开发板镜像烧录实战:使用AiBurn工具从编译到上电的完整指南 最近有不少刚拿到衡山派(HSPI)开发板的朋友问我,编译好的系统镜像该怎么烧录到板子里?是像STM32那样用J-Link吗?其实衡山派有自己的一套方…...

Requestly代理插件:前端开发中的高效调试利器
1. Requestly代理插件:前端调试的瑞士军刀 第一次接触Requestly是在三年前的一个紧急项目里,当时需要模拟支付接口的各种异常状态。同事推荐说"试试这个小插件,比Charles简单十倍",结果真的只用5分钟就搞定了所有测试场…...

树莓派上快速搭建OpenCV开发环境的完整指南
1. 为什么选择树莓派OpenCV组合 树莓派这个信用卡大小的微型电脑,配上OpenCV这个强大的计算机视觉库,简直就是创客们的梦幻组合。我最早接触这个搭配是在做一个智能门禁项目时,当时需要实时识别人脸,试了几种方案后发现树莓派4BOp…...

5个维度解析Unity游戏马赛克移除技术:从问题诊断到跨场景应用
5个维度解析Unity游戏马赛克移除技术:从问题诊断到跨场景应用 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUnityDem…...

PHP面试中的Redis与Memcached选型:PHP-Interview-Best-Practices-in-China对比分析
PHP面试中的Redis与Memcached选型:PHP-Interview-Best-Practices-in-China对比分析 【免费下载链接】PHP-Interview-Best-Practices-in-China 项目地址: https://gitcode.com/gh_mirrors/ph/PHP-Interview-Best-Practices-in-China 在PHP开发领域࿰…...

Rackstack常见问题解决:打印、组装和使用中的技巧与窍门
Rackstack常见问题解决:打印、组装和使用中的技巧与窍门 【免费下载链接】rackstack A modular 3d-printable mini rack system. 项目地址: https://gitcode.com/gh_mirrors/ra/rackstack Rackstack是一款模块化3D打印迷你机架系统,为电子设备提供…...
)
避坑指南:YOLOv8模型部署微信小程序常见问题解决方案(阿里云服务器实战)
YOLOv8模型部署微信小程序全链路避坑实战 第一次把YOLOv8模型部署到微信小程序时,我踩遍了所有能想到的坑——从Docker镜像构建失败到小程序图片传输超时,从服务器性能瓶颈到域名备案的各种奇葩问题。这篇文章将分享我在阿里云服务器上部署YOLOv8模型的全…...

从原理到实战:闭环BUCK电源的稳定性设计与性能调优
1. 闭环BUCK电源的工作原理与核心挑战 我第一次接触BUCK电路是在十年前设计车载充电器的时候。当时被这个看似简单却暗藏玄机的电路折腾得不轻——明明按照教科书上的公式计算了电感电容值,实际测试时却总是出现输出电压振荡。后来才明白,闭环BUCK电源就…...