ResNet论文阅读和简单实现
论文:https://arxiv.org/pdf/1512.03385.pdf
Deep Residual Learning for Image Recognition
本模块主要是阅读论文,会做简单的翻译(至少满足我自己能看明白)。
Introduction

由上图可见,在20层和56层的网络上训练的训练误差和测试误差的变化,可以看到层数加深不一定能带来性能上的提升,甚至更糟了。这就引出了文章的疑问(有些和直觉相反的结论):为什么不是层数约多,结果越好呢?文中给出的解释是:梯度消失/爆炸问题从一开始就阻碍了收敛,虽然这一问题已经通过normalized initialization和intermediate normalization layers在很大程度上得到了解决,这使得几十层的网络可以收敛,但是当层数逐渐增加,出现了“退化”问题(degradation)。这里的“退化”指的是,随着网络的加深,accuracy先逐渐升高到达饱和,然后迅速衰退。文中指出这一问题并非由过拟合导致(并不是模型过于复杂)。这一问题也说明了,我们并不能简单的认为通过堆叠层数来优化模型。

论文中通过引入一个deep residual learning框架(深度残差)。并不使用简单堆叠层数来获得一个满意的潜在映射,而是让这些层复合残差映射。
定义:
H(x):满意的潜在映射
F(x):堆叠的非线性层产生的映射,并且满足关系F(x) := H(x) - x
原始映射:F(x) + x
假设优化残差映射要比优化原始映射更容易。极端点来说,对于一个恒等映射,将残差推到0要比吧非线性层推到0更简单(不记得在哪里听到过,理论上,通过增加层数的方法来改善模型非常符合直觉,因为我们直觉上觉得可以无限的加y=x这样的变换,来无限制的增加层数。但是就像论文中描写的那样,我们并没有得到更高的准确度,而是出现了退化现象,这可能是因为DL太善于计算非线性了,反而没办法在线性上给一个比较好的表现,我觉得这是一个直觉上比较好的解释,故在此记录)。
F(x) + x这一形式在前馈神经网络中可以采用“shortcut connections”来实现。这里所谓的“shortcut connections”指的是跳过一层或多层。在本文中,这种连接仅仅是做“identity mapping”(恒等映射:在数学中,指一个函数将每个元素映射到其自身,即输入和输出相等的映射。),这一做法并不会增加额外的参数,也不会增加计算的复杂度(反正y=x也没什么影响,也没必要更新),这就使得整个网络仍然可以采用反向传播SGD进行end-to-end的训练。文章中提到,采用的152层的网络虽然比之前的VGG网络要深,但是实际上并没有那么复杂。
Deep Residual Learning
Residual Learning
在前面的定义中(H(x):满意的潜在映射)。让我们先把H(x)看做是由几个堆叠的层拟合的潜在映射(这里的几个不一定指的是整个网络),那么此时x表示的就是这些层中第一层的输入。假设多个非线性层可以逐渐逼近residual function(即H(x)- x,假设输入和输出的dimension相同,这里看起来有点autoencoder那个感觉)。因此,与其期待用堆叠的层去近似H(x),不如让这些层去拟合residual function F(x) := H(x) - x。尽管这两种形式都应该能够渐进地逼近所需的函数(如假设的那样),但学习的难易程度可能有所不同。
简单来说就是,不再直接的拟合函数,而是拟合残差函数,并且这么做的原因是这样更容易学。
如果添加的层可以构造为identity mapping(恒等映射),那么较深的模型的训练误差不应该大于较浅的模型。退化问题表明,在逼近多个非线性层的恒等映射时可能存在困难。使用residual方法之后,如果恒等映射是最优的,那么就可以简单的把多个非线性层的权重向0逼近,这就近似于恒等变换。
Identity Mapping by Shortcuts
对每个堆叠在一起的层(every few stacked layers)使用residual learning,构建出building block。将这个building block定义为:
y = F(x, {W_i}) + x
x, y:对应的堆叠在一起的层的输入和输出。
F(x, {W_i}):学到的residual mapping(我们最后想得到的是H(x),但是这里学到的是F(x, {W_i}),也就是H(x) - x,但是没有关系,我们最后输出的是F(x, {W_i}) + x,也就是H(x) - x + x,这种思路很像小时候做那种数列找规律求和,虽然直接算很难算,但是可以加上一项之后先算出来结果,最后再把加上来的项去掉)
在figure 2中,我们有两层,也就是,这里σ代表ReLU,为了简化,这里省略了bias。F+x采用shortcut connection和element-wise addition(简单来说就是直接拽过来加上,既然要拽过来直接加,那么一定要满足维度的一致)。这种方法既不引入额外的参数,也不增加计算复杂度。那么如果我们要改变输入输出的通道数时,可以执行一个线性投影:
F(x, {W_i})可以表示多层的卷积。
Network Architectures

卷积层大多具有3×3滤波器,并遵循两个简单的设计规则:(i)对于相同的输出特征图大小,各层具有相同数量的滤波器;(ii)如果特征图大小减半,则滤波器的数量增加一倍,以保持每层的时间复杂度。我们通过步长为2的卷积层直接执行下采样。网络以一个全局平均池化层和一个带有softmax的1000路全连接层结束。图3(中)加权层总数为34层。

对中间的plain network,增加shortcut connections,就能改成residual版本。当输入输出维度相同时,可以直接使用identity shortcut(Eqn.(1))(y = F(x, {W_i}) + x)
当维度增加时(图3中的虚线快捷方式),我们考虑两个方案:
(A)快捷方式仍然执行恒等映射,为增加维度填充额外的0。这个方案不引入额外的参数;
(B) 中的投影shortcut用于匹配维度(通过1×1卷积完成)。
对于这两个方案,当快捷键跨越两个大小的特征映射时,它们的步幅为2。
Implementation
从图像或其水平翻转中随机采样224×224裁剪,并减去每像素平均值。使用中的标准颜色增强。在每次卷积之后和激活之前采用批归一化(BN)。初始化权重,并从头开始训练所有的plain/residual网络。使用SGD的小批量大小为256。学习率从0.1开始,当误差趋于平稳时除以10,模型的训练次数可达60 × 104次。
Experiments
Deeper Bottleneck Architectures

对于每个残差函数F,我们使用3层而不是2层的(图5)。这三层是1×1, 3×3和1×1卷积,其中1×1层负责减少然后增加(恢复)维度,使3×3层成为输入/输出维度较小的瓶颈。图5给出了一个例子,其中两种设计具有相似的时间复杂度。无参数标识快捷方式对于瓶颈体系结构尤其重要。如果将图5(右)中的标识快捷方式替换为投影,可以看出,由于shortcut连接到两个高维端点,时间复杂度和模型尺寸都增加了一倍。
关于论文的理解
卷积后特征图尺寸变化:H_out = (H_in + 2P - K) / S + 1
转载神经网络学习小记录20——ResNet50模型的复现详解_resnet50复现-CSDN博客末尾的resnet50结构图

同时针对之前论文中的结构图,要说明的是,有部分内容上面的结构图和论文都没有直接说明,比如conv1_x中需要加padding,否则(224-7)/2+1是没办法成112的,这里padding=3,conv2_x中stride=1,其他stride=2(比如56->28,(56-1)/2+1=28)
注意,在每一个小的block里面有些直接计算发现数字不对的,都是加了padding。
比如,conv2_x里面3×3那个就加了padding=1
代码实现
1
参考:https://www.youtube.com/watch?v=DkNIBBBvcPs
import torch
import torch.nn as nnclass block(nn.Module):def __init__(self, inchannels, out_channels, identity_downsample=None, stride=1):super(block, self).__init__()# 每一个resnet的block的输入和输出的通道数的比值都是1/4,也就是说通道数扩大了4倍self.expension = 4self.conv1 = nn.Conv2d(inchannels, outchannels, kernel_size=1, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(outchannels, outchannels, kernel_size=3, stride=stride, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.conv3 = nn.Conv2d(outchannels, outchannels*self.expansion, kernel_size=1, stride=1, padding=0)self.bn3 = nn.BatchNorm2d(out_channels*self.expansion)self.relu = nn.ReLU()self.identity_downsample = identity_downsampledef forward(self, x):identity = xx = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.conv2(x)x = self.bn2(x)x = self.relu(x)x = self.conv3(x)x = self.bn3(x)if self.identity_downsample is not None:identity = self.identity_downsample(identity)# 方案A or 方案Bx += identityx = self.relu(x)return xclass ResNet(nn.Module):def __init__(self, block, layers, image_channels, num_classes):super(ResNet, self).__init__()# 在res50中block的堆叠是3 4 6 3# conv1_x# 刚刚输入的时候channel是3,在这里conv一下转成64self.in_channels = 64self.conv1 = nn.Conv2d(image_channels, 64, kernel_size=7, stride=2, padding=3)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU()# conv2_xself.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 理论上我们在这里就可以开始一层一层写了,比如:# self.layer1 = ...# self.layer2 = ...# 直接定义一个函数替我们写self.layer1 = self._make_layer(block, layer[0], out_channel=64, stride=1)self.layer2 = self._make_layer(block, layer[1], out_channel=128, stride=2)self.layer3 = self._make_layer(block, layer[2], out_channel=256, stride=2)self.layer4 = self._make_layer(block, layer[3], out_channel=512, stride=2)self.avgpool = nn.AdaptiveAvgPool2d((1,1))self.fc = nn.Linear(512*4, num_classes)def forward(self, x):x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = x.reshape(x.shape[0], -1)x = self.fc(x)return xdef _make_layer(self, block, num_residual_block, out_channels, stride):identity_downsample = Nonelayers = []# 如果不能直接相加(channel数量变化了)# 比如说conv2_x中的第一个block,输入64输出256,这种显然没办法把64硬加到256上if stride != 1 or self.inchannels != out_channels*4:identity_downsample = nn.Sequential(nn.Conv2(self.in_channels, out_channels*4, kernel_size=1,stride=1),nn.BatchNorm2d(out_channels*4))layers.append(block(self.inchannels, out_channels, identity_downsample, stride))self.inchannels = out_channels*4for i in range(num_residual_block-1):layers.append(block(self.in_channels, out_channels))return nn.Sequential(*layers)def ResNet50(img_channels, num_classes=1000):return ResNet(block, [3,4,6,3], img_channels, num_classes)
2
神经网络学习小记录20——ResNet50模型的复现详解_resnet50复现-CSDN博客
https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
ResNet50 with PyTorch | Kaggle
GitHub - JayPatwardhan/ResNet-PyTorch: Basic implementation of ResNet 50, 101, 152 in PyTorch
3
Writing ResNet from Scratch in PyTorch
与1中的类似,引用如下:
class ResidualBlock(nn.Module):def __init__(self, in_channels, out_channels, stride = 1, downsample = None):super(ResidualBlock, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size = 3, stride = stride, padding = 1),nn.BatchNorm2d(out_channels),nn.ReLU())self.conv2 = nn.Sequential(nn.Conv2d(out_channels, out_channels, kernel_size = 3, stride = 1, padding = 1),nn.BatchNorm2d(out_channels))self.downsample = downsampleself.relu = nn.ReLU()self.out_channels = out_channelsdef forward(self, x):residual = xout = self.conv1(x)out = self.conv2(out)if self.downsample:residual = self.downsample(x)out += residualout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, layers, num_classes = 10):super(ResNet, self).__init__()self.inplanes = 64self.conv1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size = 7, stride = 2, padding = 3),nn.BatchNorm2d(64),nn.ReLU())self.maxpool = nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 1)self.layer0 = self._make_layer(block, 64, layers[0], stride = 1)self.layer1 = self._make_layer(block, 128, layers[1], stride = 2)self.layer2 = self._make_layer(block, 256, layers[2], stride = 2)self.layer3 = self._make_layer(block, 512, layers[3], stride = 2)self.avgpool = nn.AvgPool2d(7, stride=1)self.fc = nn.Linear(512, num_classes)def _make_layer(self, block, planes, blocks, stride=1):downsample = Noneif stride != 1 or self.inplanes != planes:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes, kernel_size=1, stride=stride),nn.BatchNorm2d(planes),)layers = []layers.append(block(self.inplanes, planes, stride, downsample))self.inplanes = planesfor i in range(1, blocks):layers.append(block(self.inplanes, planes))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.maxpool(x)x = self.layer0(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc(x)return xnum_classes = 10
num_epochs = 20
batch_size = 16
learning_rate = 0.01model = ResNet(ResidualBlock, [3, 4, 6, 3]).to(device)# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay = 0.001, momentum = 0.9) # Train the model
total_step = len(train_loader)Layers in PyTorch
Now coming to the different types of layers available in PyTorch that are useful to us:
nn.Conv2d: These are the convolutional layers that accepts the number of input and output channels as arguments, along with kernel size for the filter. It also accepts any strides or padding if we want to apply thosenn.BatchNorm2d: This applies batch normalization to the output from the convolutional layernn.ReLU: This is a type of activation function applied to various outputs in the networknn.MaxPool2d: This applies max pooling to the output with the kernel size givennn.Dropout: This is used to apply dropout to the output with a given probabilitynn.Linear: This is basically a fully connected layernn.Sequential: This is technically not a type of layer but it helps in combining different operations that are part of the same step
看起来和之前的resnet50不太一样的原因是这里是34层的。

因此这里没有313这样的结构了。但是本质上是一样的。
————————————————————————————
一些题外话,虽然在很多地方看到说resnet已经是很老的模型了,但是相比于之前的CNN方法而言,在方法上确实是非常厉害的创新,虽然现在似乎CNN已经被调侃的像上世纪的产物了orz。似乎现在已经是transformer的天下了……
相关文章:
ResNet论文阅读和简单实现
论文:https://arxiv.org/pdf/1512.03385.pdf Deep Residual Learning for Image Recognition 本模块主要是阅读论文,会做简单的翻译(至少满足我自己能看明白)。 Introduction 由上图可见,在20层和56层的网络上训练的…...
QT上位机开发(数据库sqlite编程)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 编写软件的时候,如果用户的数据比较少,那么用json保存是非常方便的。但是一旦数据量大了之后,建议还是用数据库…...

在ARMv8中aarch64与aarch32切换
需求描述 在项目调试过程中,由于内存或磁盘空间不足需要将系统从aarch64切换到aarch32的运行状态去执行,接下来记录cortexA53的调试过程。 相关寄存器描述 ARM64: SPSR_EL3 N (Negative):表示运算结果的最高位,用于指示运算结果是否为负数。 Z (Zero):表示运算结果是否…...

拧巴的 tcp
本来想说说 tcp fastopen(tfo),但没什么意义,看 rfc7413 好了,还是 tcp 的惯常套路,引入一个新特性,解决了某个问题,带来一些新问题,然后就是各种 tradeoff,哪里适用哪里不适用。久而…...

java servlet 学生管理系统myeclipse开发oracle数据库BS模式java编程网
一、源码特点 java servlet 学生管理系统是一套完善的web设计系统,对理解JSP java编程开发语言有帮助servletbeandao (mvc模式开发),系统具有完整的源代码和数据库,开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为Oracle 10g…...

使用buildx构建多架构镜像
使用buildx构建多架构镜像 1. 前置条件 docker 19.03以上版本 ubuntu 22.04 2. 安装相关组件 2.1 安装docker sudo apt-get updatesudo apt-get install \apt-transport-https \ca-certificates \curl \gnupg-agent \software-properties-commoncurl -fsSL https://mirrors.…...

Crow:run的流程4 准备接收http请求
完成tcp的accept后,下一步需要接收tcp的数据,同时完成http的分析 class Connection { public:void start(){adaptor_.start([this](const asio::error_code& ec) {if (!ec){start_deadline();parser_.clear();do_read();}else{CROW_LOG_ERROR << "Could not …...
Springboot集成RabbitMq一
0、知识点 1、创建项目-生产者 默认官方start.spring.io已不支持自动生成低版本jkd的Spring项目,自定义用阿里云的starter即可:https://start.aliyun.com 2、创建配置类 package com.wym.rabbitmqprovider.utils;import org.springframework.amqp.core.…...

零知识证明(zk-SNARK)- groth16(一)
全称为 Zero-Knowledge Succinct Non-Interactive Argument of Knowledge,简洁非交互式零知识证明,简洁性使得运行该协议时,即便 statement 非常大,它的 proof 大小也仅有几百个bytes,并且验证一个 proof 的时间可以达…...

Spring java和go并发的实现策略
Spring Java框架和Go框架在处理并发请求时采用了不同的策略。 1. Spring Java框架: Spring框架基于Java语言,通常使用线程池来处理并发请求。具体来说,Spring框架中的Servlet容器(如Tomcat、Jetty等)会使用线程池来管…...

第二十五章 JDBC 和数据库连接池
一、JDBC 概述(P821) 1. 基本介绍 (1)JDBC 为访问不同的数据库提供了统一的接口,为使用者屏蔽了细节问题。 (2)Java 程序员使用 JDBC,可以连接任何提供了 JDBC 驱动程序的数据库系统…...
Baumer工业相机堡盟工业相机如何通过NEOAPI SDK设置相机的固定帧率(C++)
Baumer工业相机堡盟工业相机如何通过NEOAPI SDK设置相机的固定帧率(C) Baumer工业相机Baumer工业相机的固定帧率功能的技术背景CameraExplorer如何查看相机固定帧率功能在NEOAPI SDK里通过函数设置相机固定帧率 Baumer工业相机通过NEOAPI SDK设置相机固定…...

基于Java课堂签到系统
基于Java课堂签到系统 功能需求 1、用户登录:学生需要使用学号或手机号等唯一标识登录系统。 2、签到功能:在课堂开始时,学生可以通过系统进行签到,以证明出席。 3、签出功能:在课堂结束时,学生可以通过…...

springboot整合webservice使用总结
因为做的项目中用到了webservice,所以在此总结一下。 一、webservice简介 Web Service也叫XML Web Service, WebService是一种可以接收从Internet或者Intranet上的其它系统中传递过来的请求,轻量级的独立的通讯技术。是通过SOAP在Web上提供的软件服务,使…...

MySQL中的索引之分类,原理,作用,优缺点和执行计划
索引 索引的作用:加速查找 例如: 300w条数据的表中查询,无索引需要700s, 利用索引可能只需要1s用索引的时机是,数据量巨大,并且搜索快速 索引为什么能实现加速查找 基于索引的内部存储结构索引底层基于 BTree 的数据结构存储的在…...

如何做好档案数字化前的鉴定工作
要做好档案数字化前的鉴定工作,可以按照以下步骤进行: 1. 确定鉴定目标:明确要鉴定的档案的内容、数量和性质,确定鉴定的范围和目标。 2. 进行档案清点:对档案进行全面清点和登记,包括数量、种类、状况等信…...

pytorch04:网络模型创建
目录 一、模型创建过程1.1 以LeNet网络为例1.2 LeNet结构1.3 nn.Module 二、网络层容器(Containers)2.1 nn.Sequential2.1.1 常规方法实现2.1.2 OrderedDict方法实现 2.2 nn.ModuleList2.3 nn.ModuleDict2.4 三种容器构建总结 三、AlexNet网络构建 一、模型创建过程 1.1 以LeNe…...
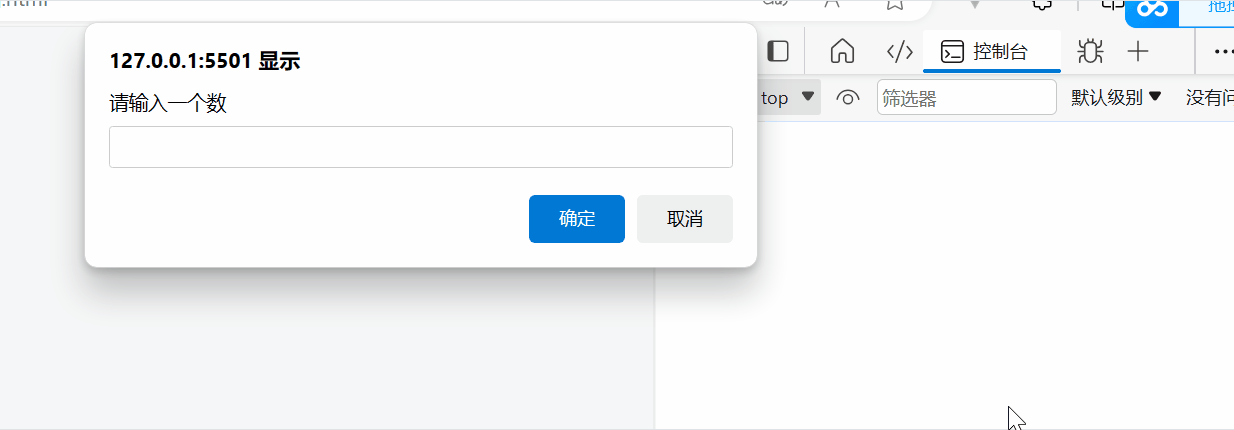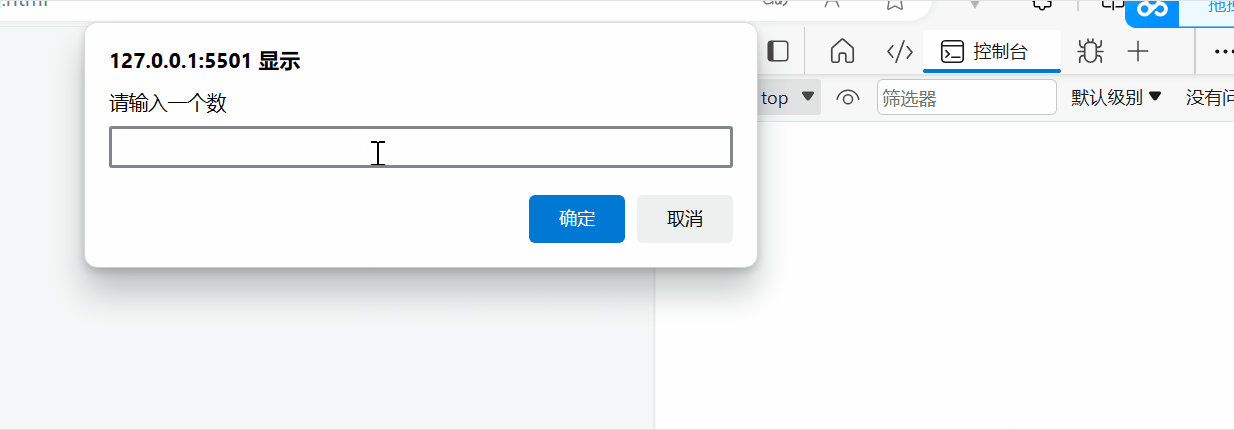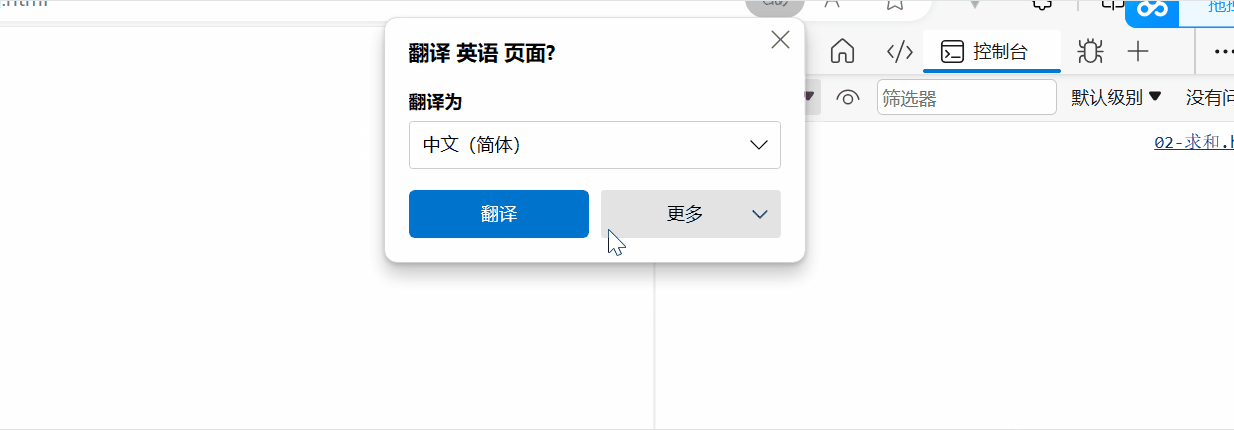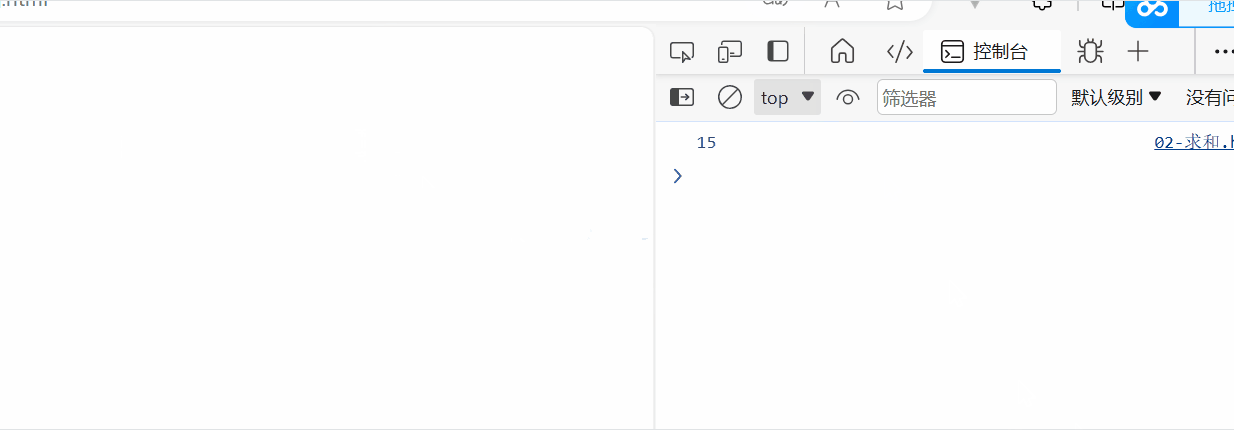
用js让用户输入一个数累加和
需求:用户输入一个数, 计算 1 到这个数的和。 比如 用户输入的是 5, 则计算 1~5 之间的累加和 并且输出到控制台 <body><script>let numprompt(请输入一个数)let sum0for(let i1;i<num;i){sumi}console.log(sum)</script…...

踩坑记录-安装nuxt3报错:Error: Failed to download template from registry: fetch failed;
报错复现 安装nuxt3报错:Error: Failed to download template from registry: fetch failednpx nuxi init nuxt-demo 初始化nuxt 项目 报错 Error: Failed to download template from registry: fetch faile 解决方法 配置hosts Mac电脑:/etc/hostswin电…...
-Spark非常用及重要特性)
大数据学习(31)-Spark非常用及重要特性
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…...

Ubuntu 22.04 开机卡在/dev/sda3: clean的磁盘空间分析与扩容实战
1. 问题现象与初步诊断 当你兴冲冲地按下Ubuntu 22.04的开机键,却看到屏幕卡在/dev/sda3: clean这个神秘提示时,那种感觉就像开车时突然遇到路障——明明昨天还能正常使用,今天怎么就罢工了?这种情况我遇到过不止一次,…...

NsEmuTools:开源模拟器管理工具的质量保障与工程实践
NsEmuTools:开源模拟器管理工具的质量保障与工程实践 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 在开源项目的生命周期中,如何在快速迭代与代码质量之间找到平…...

Phi-4-Reasoning-Vision开源模型:Phi-4-reasoning-vision-15B双卡推理镜像详解
Phi-4-Reasoning-Vision开源模型:Phi-4-reasoning-vision-15B双卡推理镜像详解 1. 项目概述 Phi-4-Reasoning-Vision是基于微软Phi-4-reasoning-vision-15B多模态大模型开发的高性能推理工具,专为双卡RTX 4090环境优化设计。这个工具严格遵循官方SYSTE…...

HP-Socket技术演讲视频描述撰写指南:关键词与吸引力
HP-Socket技术演讲视频描述撰写指南:关键词与吸引力 【免费下载链接】HP-Socket High Performance TCP/UDP/HTTP Communication Component 项目地址: https://gitcode.com/gh_mirrors/hp/HP-Socket HP-Socket是一款高性能跨平台网络通信框架,专为…...

Vision-Agents:构建下一代实时视觉AI代理的终极指南
Vision-Agents:构建下一代实时视觉AI代理的终极指南 【免费下载链接】Vision-Agents Open Vision Agents by Stream. Build Vision Agents quickly with any model or video provider. Uses Streams edge network for ultra-low latency. 项目地址: https://gitco…...

Qwen3-0.6B-FP8快速上手:无需CUDA环境的CPU友好型大模型对话工具指南
Qwen3-0.6B-FP8快速上手:无需CUDA环境的CPU友好型大模型对话工具指南 想体验大模型对话,但被动辄几十GB的模型和昂贵的显卡劝退?今天给大家介绍一个“小钢炮”——Qwen3-0.6B-FP8对话工具。它只有6亿参数,经过FP8量化后体积小巧&…...

AI 大模型落地系列|Eino 组件核心篇:ChatTemplate 为什么不是字符串拼接
声明:本文数据源于官方文档与官方实现,重点参考 ChatTemplate 使用说明。 为什么很多人学 Eino 后,写 Prompt 时还是把 ChatTemplate 用成了字符串拼接?1. ChatTemplate 是什么,不是什么2. 接口虽短,但起的…...

SpeedyStepper Forked:嵌入式步进电机硬实时控制库解析
1. SpeedyStepper Forked:面向嵌入式实时控制的高性能步进电机驱动库深度解析1.1 库定位与工程价值SpeedyStepper Forked 是一个专为嵌入式平台(尤其是基于Arduino生态的MCU)设计的轻量级、高精度步进电机运动控制库。其核心目标并非提供图形…...

Skytraq NavIC库:Arduino平台的GNSS驱动与区域增强开发指南
1. Skytraq NavIC 库概述Skytraq NavIC 库是一个面向 Arduino 平台的完整 GNSS 驱动框架,专为基于 Skytraq 芯片组(如 SGR-03、SGR-05、SGR-07 系列)的高精度定位模块设计。该库不仅全面支持全球主流卫星导航系统,更深度适配印度区…...

HBuilderX + 极光推送踩坑实录:免费版为啥息屏收不到通知?手把手教你配置与避坑
HBuilderX与极光推送免费版避坑指南:破解息屏通知失效难题 早上八点,你的咖啡还没喝完,测试组的消息就炸开了锅——"昨晚推送的版本在息屏状态下根本收不到通知!"作为使用HBuilderX开发跨平台应用的团队,这个…...