爬取豆瓣电影top250的电影名称(完整代码与解释)
在爬取豆瓣电影top250的电影名称之前,需要在安装两个第三方库requests和bs4,方法是在终端输入:
pip install requestspip install bs4
截几张关键性图片:


豆瓣top250电影网页
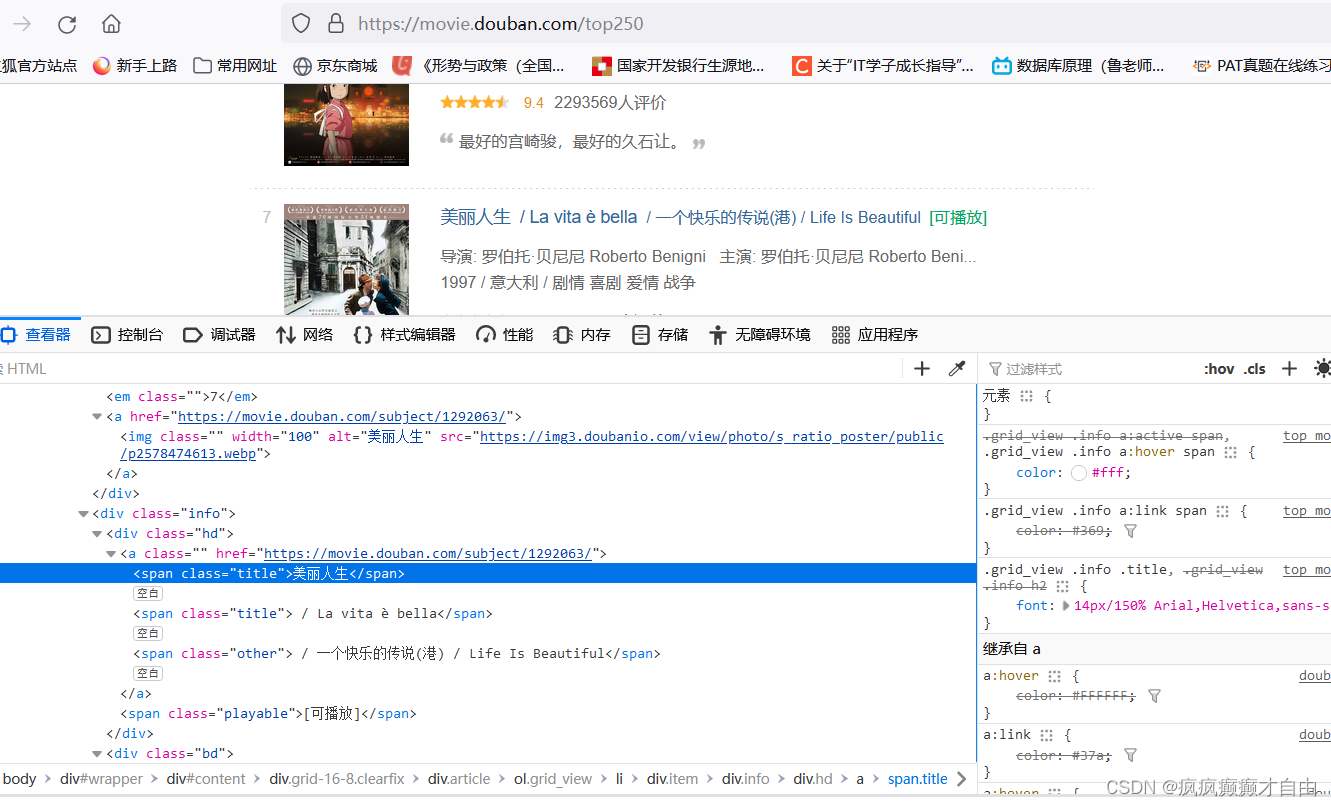
运行结果
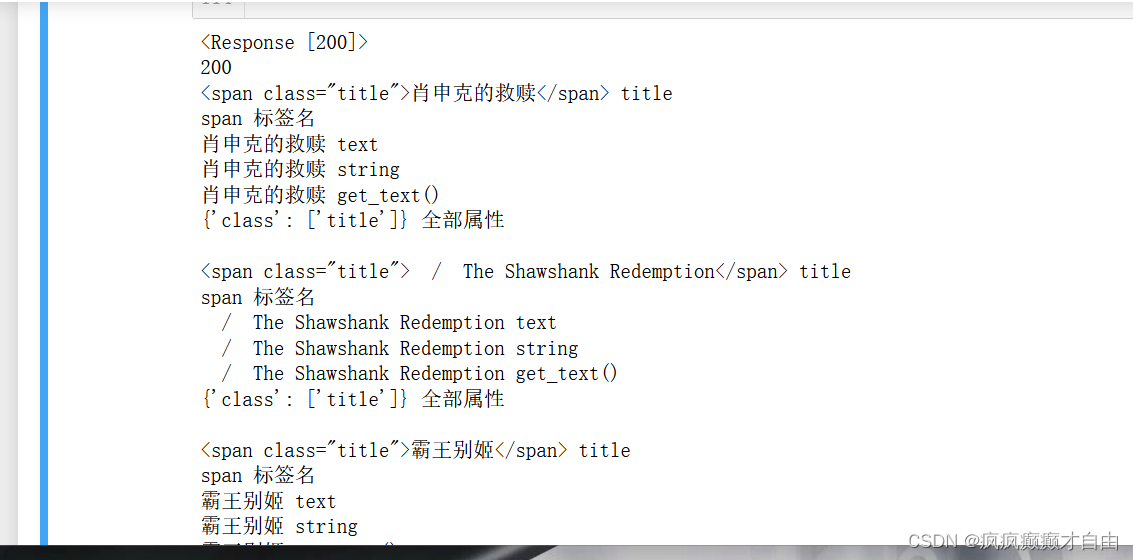
测试html文件标签的各个方法的作用:
# import requests# response = requests.get("https://movie.douban.com/top250")# print(response)import requests
#引入模块 requestsfrom bs4 import BeautifulSoup
# 从模块bs4中引入类 BeautifulSoup
# beautifulsoup4 是一个可以从HTML,XML文件中提取数据的库
# beautifulsoup:是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"
}# User-Agent:它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息,在做爬虫时加上此信息,
# 可以伪装成浏览器;如果不加很可能被识别出为爬虫# 由于豆瓣不对程序进行回应,故要伪装成浏览器进行请求,方法是在浏览器中随便打开一个网页,右击鼠标,点击
# 检查,出现页面后,刷新一下网页,随便点击一个请求报文,查看"User-Agent":后面的信息,并且复制该信息到
# headers中的"User-Agent":后,这就可以伪装成浏览器发送的请求response = requests.get(f"https://movie.douban.com/top250", headers = headers)# requests的get方法返回的是一个包含服务器资源的Response对象,包含了从服务器返回的所有的相关资源。
# response响应的属性:
# response.status_code 响应的状态码
# response.headers:响应头信息
# response.encoding 编码格式信息
# response.cookies cookies信息
# response.url 响应的url信息
# response.text 文本类型,通常是html文本
# response.content bytes型也就是二级制数据,如图片/视频/音频等print(response)
print(response.status_code)#print(response.text)html = response.text
soup = BeautifulSoup(html, "html.parser")
# soup=beautifulsoup(解析内容,解析器)
# 常用解析器:html.parser,lxml,Xml,html5lib# [BeautifulSoup默认支持Pythonl的标准HTML解析库,但是它也支持一些第三方的解析库:如图]
# (https://s2.51cto.com/images/blog/202104/05/d369a62192f243f59879d10173b68e86.png?x-oss-process=image/format,webp)all_titles = soup.find_all("span", attrs = {"class" : "title"})
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title";# 使用find和find_all方式
# find(name,attrs,recursive,text,**kwargs)
# 根据参数来找出对应的标签,但只返回第一个符合条件的结果。
# find_all(name, attrs, recursive, text, **kwargs)
# 根据参数来找出对应的标签,但只返回所有符合条件的结果。
# BeautifulSoup对象的find_all()方法返回的是一个由匹配的标签元素组成的列表。如果没有匹配的元素,返回一个空列表# 筛选条件参数介绍:
# name:为标签名,根据标签名来筛选标签
# attrs:为属性,根据属性键值对来筛选标签,赋值方式可以为:属性名=值,attrs={属性名:值}(但由于class是python关键字,需要使用class_)
# text:为文本内容,根据指定文本内容来筛选出标签,单独使用text作为筛选条件,只会返回text,所以一般与其他条件配合使用.
# recursive:指定筛选是否递归,当为Falsel时,不会在子结点的后代结点中查找,只会查找子结点。cnt = 0;
for title in all_titles:print(title, "title")print(title.name, "标签名")print(title.text, "text")print(title.string, "string")print(title.get_text(), "get_text()")print(title.attrs, "全部属性")print("")title_string = title.stringcnt += 1if(cnt >= 3):break#由于all_titles 是find_all的返回内容,他是一个列表,列表中的每个元素就是html文件中的一行,就相当于一个标签# 一.使用标签名查找# 1)使用标签名来获取结点:
# Soup.标签名# 2)使用标签名来获取结点标签名(这个重点是name,主要用于非标签名式筛选时,获取结果的标签名):
# soup.标签.name# 3)使用标签名来获取结点属性:
# soup.标签.attrs(获取全部属性)
# soup.标签.attrs[属性名](获取指定属性)
# soup.标签[属性名](获取指定属性)
# soup.标签.get(属性名)# 二.使用标签名来获取结点的文本内容:
# soup.标签.text
# soup.标签.string
# soup.标签.get text()# if "/" not in title_string:
# print(title_string)# 由于我们只想要电影中文名,所以我们将不符合条件的字符串不打印出来,
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title",不难发现,就在中文电影名的下面有一个原版的
# 电影名,或者英文,或者其他国家的语言,但是我们不想要,再仔细观察会发现原版电影名前有一个字符 '/',而中文电影名没有字符'/';
# 所以可以用一个if 语句判断是否打印字符;二。爬取豆瓣电影top250的电影名称完整代码与解析:
解释全在代码中:
import requests
#引入模块 requests
# requests模块作用,发送http请求,获取响应数据from bs4 import BeautifulSoup
# 从模块bs4中引入类 BeautifulSoup
# beautifulsoup4 是一个可以从HTML,XML文件中提取数据的库
# beautifulsoup:是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"
}# User-Agent:它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息,在做爬虫时加上此信息,
# 可以伪装成浏览器;如果不加很可能被识别出为爬虫# 由于豆瓣不对程序进行回应,故要伪装成浏览器进行请求,方法是在浏览器中随便打开一个网页,右击鼠标,点击
# 检查,出现页面后,刷新一下网页,随便点击一个请求报文,查看"User-Agent":后面的信息,并且复制该信息到
# headers中的"User-Agent":后,这就可以伪装成浏览器发送的请求for start_num in range(0, 250, 25):response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers = headers)# 由于一个页面只展示25个电影,所以要爬取250个电影名字要爬取多个页面,用一个for循环结合range函数便可实现;if(start_num == 0):print(response.status_code, "status_code")print(response.headers, "headers")print(response.encoding, "encoding")print(response.cookies, "cookies")print(response.url, "url")# print(response.text, "text") #text 和 content信息太多,暂时不打印# print(response.content, "content")# requests的get方法返回的是一个包含服务器资源的Response对象,包含了从服务器返回的所有的相关资源。
# response响应的属性:
# response.status_code 响应的状态码
# response.headers:响应头信息
# response.encoding 编码格式信息
# response.cookies cookies信息
# response.url 响应的url信息
# response.text 文本类型,通常是html文本
# response.content bytes型也就是二级制数据,如图片/视频/音频等print(response , "这是什么")#response本身是Response对象,并包含返回状态码,Response对象含有从服务器返回的所有的相关资源。html = response.textsoup = BeautifulSoup(html, "html.parser")
# soup=beautifulsoup(解析内容,解析器)
# 常用解析器:html.parser,lxml,Xml,html5lib# [BeautifulSoup默认支持Pythonl的标准HTML解析库,但是它也支持一些第三方的解析库:如图]
# (https://s2.51cto.com/images/blog/202104/05/d369a62192f243f59879d10173b68e86.png?x-oss-process=image/format,webp)# all_titles = soup.find_all("span", attrs = {"class" : "title"})all_titles = soup.findAll("span", attrs = {"class" : "title"})
#这两句find函数都可行# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title";# 使用find和find_all方式
# find(name,attrs,recursive,text,**kwargs)
# 根据参数来找出对应的标签,但只返回第一个符合条件的结果。
# find_all(name, attrs, recursive, text, **kwargs)
# 根据参数来找出对应的标签,但只返回所有符合条件的结果。
# BeautifulSoup对象的find_all()方法返回的是一个由匹配的标签元素组成的列表。如果没有匹配的元素,返回一个空列表# 筛选条件参数介绍:
# name:为标签名,根据标签名来筛选标签
# attrs:为属性,根据属性键值对来筛选标签,赋值方式可以为:属性名=值,attrs={属性名:值}(但由于class是python关键字,需要使用class_)
# text:为文本内容,根据指定文本内容来筛选出标签,单独使用text作为筛选条件,只会返回text,所以一般与其他条件配合使用.
# recursive:指定筛选是否递归,当为Falsel时,不会在子结点的后代结点中查找,只会查找子结点。for title in all_titles:title_string = title.string # 提取为字符串#由于all_titles 是find_all的返回内容,他是一个列表,列表中的每个元素就是html文件中的一行,就相当于一个标签# 一.使用标签名查找# 1)使用标签名来获取结点:
# Soup.标签名# 2)使用标签名来获取结点标签名(这个重点是name,主要用于非标签名式筛选时,获取结果的标签名):
# soup.标签.name# 3)使用标签名来获取结点属性:
# soup.标签.attrs(获取全部属性)
# soup.标签.attrs[属性名](获取指定属性)
# soup.标签[属性名](获取指定属性)
# soup.标签.get(属性名)# 二.使用标签名来获取结点的文本内容:
# soup.标签.text
# soup.标签.string
# soup.标签.get text()if "/" not in title_string:print(title_string)# 由于我们只想要电影中文名,所以我们将不符合条件的字符串不打印出来,
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title",不难发现,就在中文电影名的下面有一个原版的
# 电影名,或者英文,或者其他国家的语言,但是我们不想要,再仔细观察会发现原版电影名前有一个字符 '/',而中文电影名没有字符'/';
# 所以可以用一个if 语句判断是否打印字符;参考文献:
爬虫基础篇_headers = {'user-agent': 'mozilla/5.0 (windows nt -CSDN博客
python爬虫之Beautifulsoup模块用法详解_51CTO博客_python爬虫模块
相关文章:
爬取豆瓣电影top250的电影名称(完整代码与解释)
在爬取豆瓣电影top250的电影名称之前,需要在安装两个第三方库requests和bs4,方法是在终端输入: pip install requestspip install bs4 截几张关键性图片: 豆瓣top250电影网页 运行结果 测试html文件标签的各个方法的作用…...

tidb 集成 flyway 报错 denied to user for table global_variables
报错内容: Caused by: java.sql.SQLException: connection disabled at com.alibaba.druid.pool.DruidPooledConnection.checkStateInternal(DruidPooledConnection.java:1181) at com.alibaba.druid.pool.DruidPooledConnection.checkState(DruidPooledConnection.jav…...

很实用的ChatGPT网站—在线编程模块增补篇
很实用的ChatGPT网站(http://chat-zh.com/)——增补篇 今天介绍一个好兄弟开发的ChatGPT网站,网址[http://chat-zh.com/]。这个网站功能模块很多,包含生活、学习、医疗、法律、经济等很多方面。今天跟大家分享一下,新…...

A股风格因子看板 (2024.01第01期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴 露等。 今日为该因子跟踪第1期,指数组合数据截止日2024-12-01,要点如下 近1年A股风格因子检验统…...

基于gamma矫正的照片亮度调整(python和opencv实现)
import cv2 import numpy as npdef adjust_gamma(image, gamma1.0):invGamma 1.0 / gammatable np.array([((i / 255.0) ** invGamma) * 255 for i in np.arange(0, 256)]).astype("uint8")return cv2.LUT(image, table)# 读取图像 original cv2.imread("tes…...

LeetCode-Java(29)
29. 两数相除 结果肯定落在dividend上,于是对这个区间每一个数进行二分查找,判断方法就是 while (l < r) {long mid l r 1 >> 1;if (mul(mid, y) < x) {l mid;} else {r mid - 1;}} 其中mul是一个要定义的快速乘法。 完整代码如下 …...

腾讯云导入导出镜像官方文档
制作与导出 Linux 镜像 https://cloud.tencent.com/document/product/213/17814 制作与导出 Windows 镜像 https://cloud.tencent.com/document/product/213/17815 云服务器 导出镜像-操作指南-文档中心-腾讯云 (tencent.com) 轻量应用服务器 管理共享镜像-操作指…...

keras 深度学习框架实现 手写数字识别
阅读本文之前,请先参考--------win10搭建keras深度学习框架 安装运行环境 阅读本文之前,请先参考--------keras人工智能框架 MNIST 数据集 随机展示 查看训练图片 完整代码如下图: 在sublimeText中 使用ctrlB运行代码,结果如…...

SELinux策略语法以及示例策略
首发公号:Rand_cs 本文来讲述 SELinux 策略常用的语法,然后解读一下 SELinux 这个项目中给出的示例策略 安全上下文 首先来看一下安全上下文的格式: user : role : type : level每一个主体和客体都有一个安全上下文,通常也称安…...
电路笔记 :自激振荡电路笔记 电弧打火机
三极管相关 三极管的形象描述 二极管 简单求解(理想) 优先导通(理想) 恒压降 稳压管(二极管plus) 基础工作模块 理想稳压管的工作特性 晶体管之三极管(“两个二极管的组合” ) 电弧打火机电路 1.闭合开…...
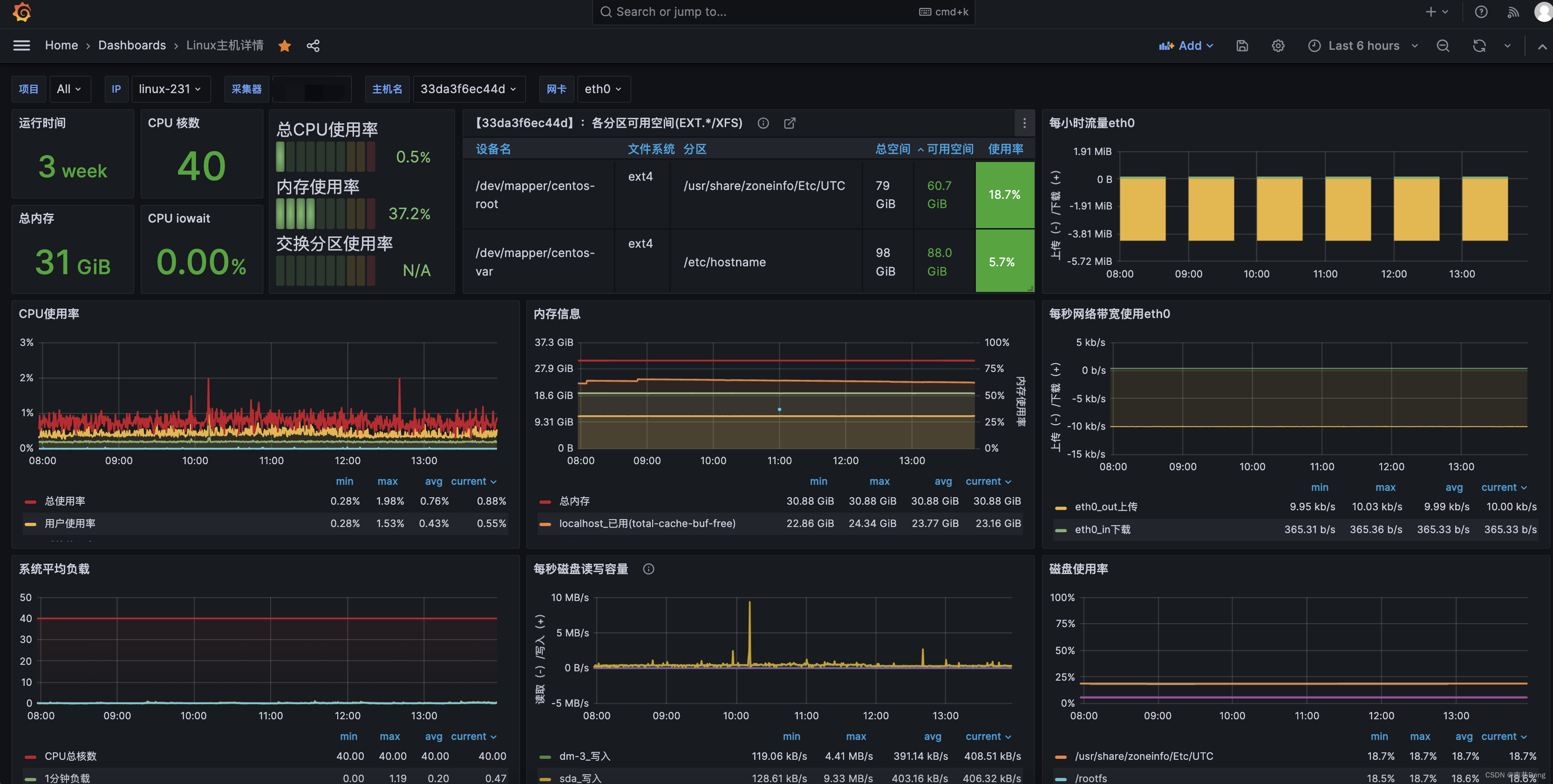
prometheus grafana linux服务器监控
文章目录 前传node-exporter安装配置promethues监控node节点grafana操作查看监控:外传 前传 prometheus grafana的安装使用:https://nanxiang.blog.csdn.net/article/details/135384541 本文说下监控nginx,prometheus grafana linux 安装配…...

有哪些有用的工作技巧?
有效沟通免去麻烦 说起职场的工作技巧,首先不得不提的便是有效沟通。高效的职场沟通不仅能显著提高工作效率,通过清晰准确地传递信息,减少误解和错误,还能促进团队间的紧密合作,建立起相互信任和理解的环境。在面临挑…...
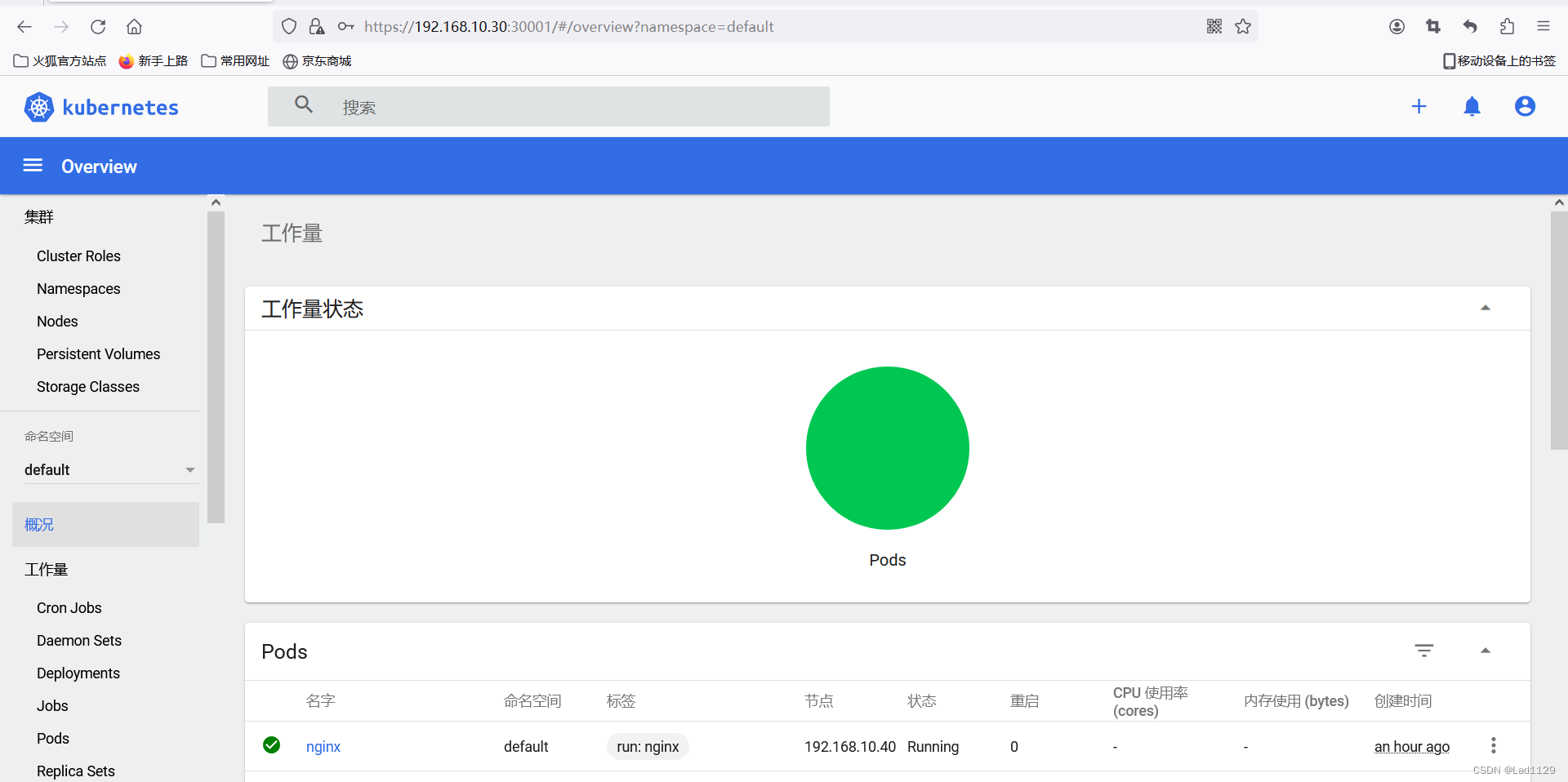
k8s的网络类型
部署 CNI 网络组件 部署 flannel K8S 中 Pod 网络通信: Pod 内容器与容器之间的通信 在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享同一个网络命名空间, 相当于它们在同一台机器上一样,可以用 localho…...

《元宇宙2086》团队发布AI创作的元宇宙之歌
《元宇宙2086》团队发布AI创作的元宇宙之歌 数字科技领域著名IP——《元宇宙2086》的团队发布AI创作的《元宇宙之歌》,歌词是AI与人共同完成,作曲、混音、人声合成全部由AI完成并且演唱,歌曲描绘了未来的元宇宙世界。 “踏入元宇宙的奇境&am…...

【数据结构】数组实现队列(详细版)
目录 队列的定义 普通顺序队列的劣势——与链队列相比 顺序队列实现方法: 一、动态增长队列 1、初始化队列 2、元素入队 3、判断队列是否为空 4、元素出队 5、获取队首元素 6、获取队尾元素 7、获取队列元素个数 8、销毁队列 总结: 动态增长队列…...
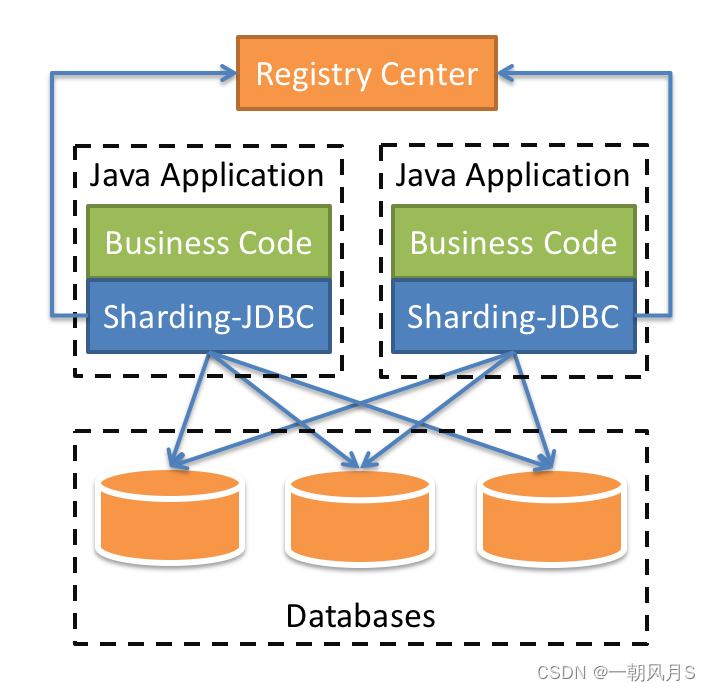
Sharding-JDBC快速使用【笔记】
1 引言 最近在使用Sharding-JDBC实现项目中数据分片、读写分离需求,参考官方文档(Sharding官方文档)感觉内容庞杂不够有条理,重复内容比较多;现结合项目应用整理笔记如下供大家参考和自己回忆使用; 在…...

总结MySQL 的一些知识点:MySQL 排序
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

Linux中经常使用的相关命令
查看硬盘存储容量使用情况: df -lh 列出 /bin 目录中的 5 个最大文件: ls -lSh /bin | head -5 删除文件和文件夹 在Linux中,要删除文件的命令是rm。你可以使用以下命令来删除一个文件: rm file_name如果要删除多个文件,可…...

2022-2023年度广东省职业院校学生专业技能大赛“软件测试”赛项性能测试题目-Jmeter
性能测试-JM 1、脚本添加: 脚本文件名称:SuppAndComp,测试计划名称:SuppAndComp。测试计划下添加两个线程组: (1)线程组一操作内容:系统管理员登录、进行新增供应商操作。 线程组名称SuppAdd。具体要求如下: 登录操作存放到仅一次控制器中,供应商名称前4位为固定…...
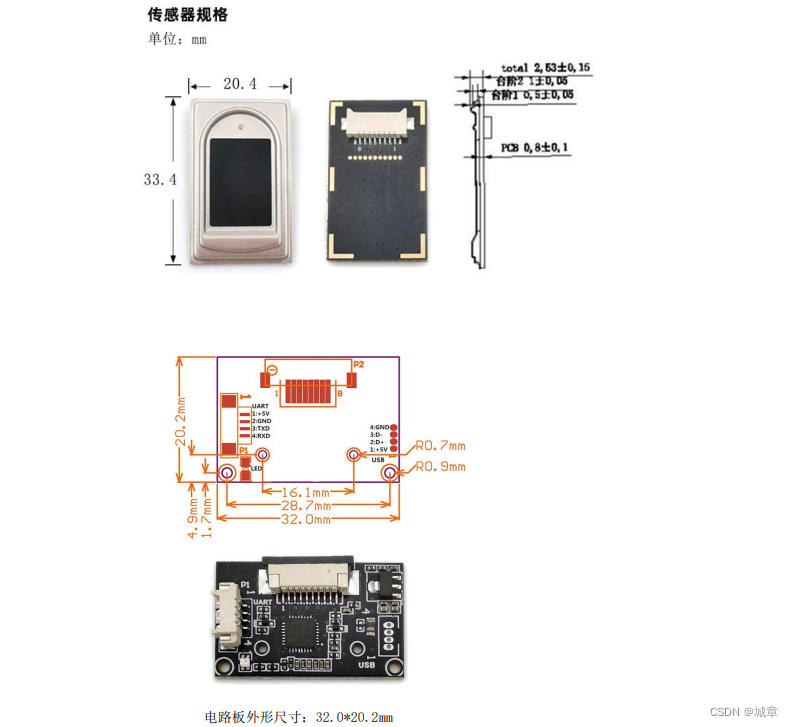
R304S 指纹识别模块的硬件接口说明
一.外部接口尺寸图 二.串行通讯 R304S 指纹模块通讯接口定义: 引脚号名称定义描述15V电源输入电源正输入端 DC 4.2--6V2GND电源和信号地电源和信号地3TXD数据发送串行数据输出,TTL 逻辑电平4RXD数据接收串行数据输入,TTL 逻辑电平 三.USB通…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...