机器学习深度学习面试笔记
机器学习&深度学习面试笔记
- 机器学习
- Q. 在线性回归中,如果自变量之间存在多重共线性,会导致什么问题?如何检测和处理多重共线性?
- Q. 什么是岭回归(Ridge Regression)和Lasso回归(Lasso Regression)?它们与普通线性回归之间的区别?
- Q. 逻辑回归与线性回归有什么区别?
- Q. 什么是逻辑回归的目标函数(损失函数)?
- Q. 如何处理多分类问题?
- Q. L1和L2正则化有什么区别?
- Q. 分类模型的评估指标:准确率、精准率、召回率、F1-Score、AP
- Q. 什么是ROC曲线和AUC值?它们用来评估逻辑回归模型的哪些性能?
- Q. ROC曲线和PR曲线的特点
- Q. 什么是决策树,它是如何工作的?简要描述其基本原理。
- Q. 决策树的构建过程中有哪些常用的划分准则?如何选择最佳划分准则?
- Q. 决策树的种类及差别
- Q. 在决策树中如何避免过拟合?
- Q. 决策树的剪枝方式有哪些?
- Q. 什么是随机森林,以及它是如何⼯作的?
- Q. 在随机森林中,袋外误差(Out-of-Bag Error)有什么作用,以及如何使用它来评估模型性能?
- Q. 随机森林如何评估特征的重要性?它们的计算方法是什么?
- Q. 随机森林的局限性
- Q. 什么是支持向量机?
- Q. 支持向量机如何应用在回归任务?
- Q. 在SVM中,如何处理⾮线性可分的数据?核函数(Kernel Function)的作用和常用类型。
- Q. SVM与逻辑回归(Logistic Regression)之间有哪些相似之处和差异?
- Q. 朴素贝叶斯是什么?它的基本原理是什么?
- Q. 什么是K近邻算法?
- Q. 什么是余弦距离,与欧氏距离有什么差别,有哪些方面的应用?
- Q. 什么是K均值聚类?它的主要目标是什么?
- Q. K均值聚类的优点和局限性是什么?
- Q. K均值聚类和层次聚类之间有哪些区别和相似之处?它们分别适用于什么类型的数据和应用场景?
- Q. 什么是集成学习,以及它的基本思想是什么?
- Q. 集成学习中的Bagging和Boosting有什么区别?
- Q. 对比Stacking和Blending两种融合方法的优劣势?
- Q. AdaBoost算法是如何改进弱分类器的性能的?它的基本原理是什么?
- Q. 什么是Gradient Boosting
- Q. 梯度提升与梯度下降的区别和联系是什么?
- Q. 基于Gradient Boosting的方法有哪些?(GDBT, XGBoost, LightGBM, CatBoost)
- Q. 什么是袋外误差(Out-of-Bag Error)和交叉验证(Cross-Validation)在集成学习中的作用?
- Q. 集成学习在哪些领域和任务中表现出色?它有什么局限性?
- Q. 图像训练数据不足怎么解决?
- Q. 常用的超参数调优方法有哪些?
- Q. RMSE的缺点
- Q. 在模型评估过程中有哪些主流方法,他们的优缺点是什么?
- 深度学习
- Q. BN和LN的区别
- Q. 梯度消失和梯度爆炸产生的原因和解决办法
- Q. RNN、LSTM和GRU的区别
- Q. 深度学习常用的优化算法
- Q. 什么是互信息?它如何用于特征选择和降维问题?
- Q. 归一化/标准化的作用
- Q. 特征选择和特征抽取的区别,以及它们在数据预处理中的作用
- Q. 什么是无监督学习?举例说明无监督学习任务
- Q. 常用的激活函数及优缺点
- Q. 正则化为什么可以提高模型泛化能力
机器学习
Q. 在线性回归中,如果自变量之间存在多重共线性,会导致什么问题?如何检测和处理多重共线性?
在线性回归中, 多重共线性是指⾃变量之间存在⾼度相关性或线性依赖关系的情况。
多重共线性可能会导致以下问题:
- 不稳定的估计:多重共线性会导致回归系数估计变得不稳定。这意味着⼩的数据变动或微⼩的变量选择变化都可能导致回归系数的⼤幅度变化,使得参数估计不可靠;
- 难以解释效果:多重共线性使得很难分离各⾃⾃变量对因变量的独⽴效应,因为它们之间的效应不再明确,这会降低模型的解释能⼒;
- 统计检验不准确:多重共线性会导致回归模型的统计检验不准确,如t检验和F检验,这可能会导致错误的结论,例如错误地认为某些⾃变量对因变量没有显著影响;
- 过度拟合:多重共线性可以导致过度拟合,因为模型可能会在⾃变量之间寻找微⼩的变化,从⽽试图解释由于共线性引起的噪声。
为了检测和处理多重共线性,可以采取以下⽅法:
- 相关系数分析:通过计算自变量之间的相关系数矩阵,可以初步了解⾃变量之间是否存在⾼度相关性,相关系数接近于1表示⾼度相关;
- 方差膨胀因子(VIF) : VIF⽤于衡量每个⾃变量与其他⾃变量的相关性程度。 VIF越⼤,表示共线性越严重。通常, VIF⼤于10或更⾼的⾃变量可能需要考虑去除或合并;
- 主成分分析(PCA) : PCA可以将相关的⾃变量合并成新的⽆关⾃变量,从⽽减少共线性的影响,但这会导致模型的解释变得更加复杂;
- 逐步回归:逐步回归⽅法允许逐渐添加或删除⾃变量,以找到最佳模型。在逐步回归中,会考虑每个⾃变量的贡献,从⽽减少共线性引起的问题;
- 合并自变量:如果多个⾃变量之间⾼度相关,可以考虑将它们合并成⼀个新的⾃变量或使⽤其平均值来代替,这样可以减少模型中的共线性。
处理多重共线性是线性回归建模中的⼀个重要挑战,因为它可以显著影响模型的可靠性和解释性。选择合适的⽅法来检测和处理多重共线性取决于数据和领域背景
Q. 什么是岭回归(Ridge Regression)和Lasso回归(Lasso Regression)?它们与普通线性回归之间的区别?
岭回归(Ridge Regression)是⼀种线性回归的正则化⽅法,⽤于处理多重共线性问题。它通过在目标函数中引⼊L2正则化项来限制模型的系数⼤⼩,以减⼩过拟合⻛险。
Lasso回归(Least Absolute Shrinkage and Selection Operator Regression)是⼀种线性回归的正则化⽅法,⽤于处理多重共线性问题并进⾏特征选择。它通过在⽬标函数中引⼊L1正则化项来约束模型的系数,并促使⼀些系数变为零,从⽽实现自动特征选择。
Q. 逻辑回归与线性回归有什么区别?
逻辑回归(Logistic Regression)与线性回归(Linear Regression)是两种不同的回归⽅法,主要⽤于不同类型的问题,具有不同的模型和目标。
它们之间的主要区别,这里通过概念和公式进⾏对比:
1.应用领域:
- 线性回归通常⽤于解决回归问题,其中⽬标是预测⼀个连续数值输出(如房价、销售量等)。线性回归试图建⽴⼀个线性关系,以最⼩化观测值与模型预测值之间的差异;
- 逻辑回归通常⽤于解决分类问题,其中⽬标是将输⼊数据分为两个或多个类别。逻辑回归使⽤Sigmoid函数将线性组合的输⼊映射到概率输出。
2.输出:
- 线性回归的输出是⼀个连续的数值,可以是任意实数;
- 逻辑回归的输出是⼀个介于0和1之间的概率值。
3.目标
- 线性回归的⽬标是找到⼀条最佳拟合线,以最⼩化实际观测值与预测值之间的误差平⽅和;
- 逻辑回归的⽬标是找到最佳参数,以最⼤化观测数据属于正类别或负类别的概率,从⽽能够进⾏分类。
Q. 什么是逻辑回归的目标函数(损失函数)?
逻辑回归的⽬标函数,通常也称为损失函数或代价函数,⽤于衡量模型的预测与实际观测值之间的差异。逻辑回归通常⽤于⼆分类问题,其⽬标是最⼤化观测数据属于正类别或负类别的概率,从⽽能够进⾏分类。逻辑回归的⽬标函数通常使⽤交叉熵损失函数(Cross-Entropy Loss Function)或对数损失函数(Log Loss Function),这两者通常是等价的。
这个损失函数的⽬标是最⼩化观测数据的负对数似然(negative log-likelihood),从⽽最⼤化观测数据属于正类别或负类别的概率。对于多分类问题,逻辑回归的损失函数可以使⽤多分类的交叉熵损失函数,如softmax交叉熵损失函数。通常采用梯度下降(Gradient Descent)或其变种来最⼩化损失函数并更新模型的参数(权重和截距)。
Q. 如何处理多分类问题?
核心方法包括三种,分别是OvO(one vs one)、OvR(one vs rest)和MvM(multi vs multi)。其中OvO具备性能优势,而MvM则具备判断效力优势。
- OVO的基本过程是将每个类别对应数据集单独拆分成一个子数据集,然后令其两两组合,再来进行模型训练;
- OVR的策略则是每次将一类的样例作为正例、其他所有数据作为反例来进行数据集拆分;
- MVM要求同时将若干类化为正类、其他类化为负类,并且要求多次划分,再进行集成。
还有一种Softmax回归方法,将多个类别之间的关系建模为⼀个多类别概率分布。它使⽤Softmax函数来将线性组合的输⼊映射到K个类别的概率分布,其中K是类别的数量。训练Softmax回归模型时,通常使⽤交叉熵损失函数。
Q. L1和L2正则化有什么区别?
L1正则化通过向损失函数添加参数的绝对值之和来惩罚模型中的⼤参数,从⽽促使⼀些参数变为零。
这实现了特征选择,可以使模型更加稀疏,剔除不重要的特征,提⾼模型的泛化能⼒。
L2正则化通过向损失函数添加参数的平⽅和来惩罚模型中的⼤参数,但不会使参数变为零,它只是压
缩参数的值。 L2正则化有助于减轻多重共线性问题,稳定模型的估计。
总的来说, L1和L2正则化都有助于控制模型的复杂度,防⽌过拟合。它们的主要区别在于:
- L1 正则化倾向于产⽣稀疏模型,即⼀些参数变为零,实现了特征选择;
- L2 正则化不会使参数变为零,⽽是对参数进⾏缩⼩,有助于减轻多重共线性问题。
Q. 分类模型的评估指标:准确率、精准率、召回率、F1-Score、AP

假设有以下混淆矩阵:

- 准确率(Accuracy) :预测正确的结果占总样本的百分比,(TP+TN)/(TP+TN+FP+FN)
- 精确率(Precision):所有被预测为正的样本中实际为正的样本的概率,强调降低误报率,TP/(TP+FP)
- 召回率(Recall):实际为正的样本中被预测为正样本的概率,强调“宁可错杀,不可放过”,TP/(TP+FN)
- F1-Score:平衡精确率和召回率,(2×Precision×Recall)/(Precision+Recall)
- AP(Average Precision):衡量模型在不同阈值下的精度变化。它计算了模型在不同召回率下的精确率,并取平均值,即:
AP = 平均精确率。
Q. 什么是ROC曲线和AUC值?它们用来评估逻辑回归模型的哪些性能?
ROC曲线是⼀种图形化⼯具,⽤于可视化⼆分类模型的性能。它以假正例率(False Positive Rate)(FP/(FP+TN))为横轴,以真正例率(True Positive Rate,也称为召回率)(TP/(TP+FN))为纵轴,绘制出模型在不同阈值下的性能表现。ROC曲线图中的每个点对应于不同的分类阈值,根据阈值的变化(从大到小),计算真正例率和假正例率,然后绘制出曲线。 ROC曲线越靠近左上⻆,模型性能越好。ROC曲线的优点是不受类别不平衡问题的影响,能够展示模型在各种不同阈值下的性能表现。

AUC是ROC曲线下⽅的⾯积,被称为"Area Under the ROC Curve"。 AUC值的范围通常在0.5和1之间,其中
0.5表示模型的性能等同于随机猜测, 1表示完美分类器。

Q. ROC曲线和PR曲线的特点
ROC曲线适用于评估分类器在不同分类阈值下的全面性能,对类别平衡的问题不敏感;而PR曲线更适用于评估分类器在类别不平衡情况下的性能,关注于正例的召回率和精确率之间的权衡。在实践中,根据具体的问题和需求,选择使用ROC曲线或PR曲线来评估模型的性能。
Q. 什么是决策树,它是如何工作的?简要描述其基本原理。
决策树(Decision Tree)是⼀种⽤于分类和回归问题的机器学习模型。它是⼀个树状结构,其中每个节点代表⼀个特征,每个分⽀代表⼀个特征值,每个叶⼦节点代表⼀个类别或回归值(该节点中所有训练样本的⽬标变量值的平均值)。决策树的基本原理是根据输⼊特征逐步分割数据集,以便最终能够根据特征的值来预测⽬标变量的类别或值。
基本⼯作原理:
- 根节点:开始时,整个数据集视为⼀个根节点。在根节点上,选择⼀个特征,将数据集分割成多个⼦集。选择的特征是基于某种度量标准,通常是根据信息增益(Entropy)、基尼不纯度(Gini Impurity)或均⽅误差(Mean Squared Error)等来进⾏选择;
- 分支节点:接下来,每个⼦集都被视为⼀个分⽀节点,并在分⽀节点上选择另⼀个特征,再次将数据集分割成更⼩的⼦集。这个过程递归地进⾏下去,直到达到某个停⽌条件,如达到最⼤深度、节点中的样本数⼩于阈值,或者节点的不纯度低于阈值;
- 叶子节点:当不再进⾏分割时,节点被标记为叶⼦节点,叶⼦节点中包含⼀个最终的类别标签(对于分类问题)或回归值(对于回归问题)。这个值是根据该节点上的数据集的主要类别(对于分类问题)或平均⽬标值(对于回归问题)来确定的;
- 预测:⼀旦构建了决策树,对新的未⻅样本进⾏预测时,从根节点开始根据特征的值遍历树的分⽀,直到达到叶⼦节点。然后,将叶⼦节点的类别标签或回归值作为预测结果。
决策树的优点包括易于理解和解释,能够处理数值和分类特征,对异常值不敏感。然⽽,它也容易过拟合,因此需要进⾏剪枝等正则化操作以提⾼泛化能⼒。

Q. 决策树的构建过程中有哪些常用的划分准则?如何选择最佳划分准则?
决策树的构建过程中常⽤的划分准则有三种:
- 信息增益(Information Gain):信息熵可以理解为表示给定随机变量的平均信息量。如果随机变量的分布接近均匀分布,每个取值的概率相等,那么每个取值所包含的信息量较大,信息熵越高表示不确定性越高。信息增益是⽤于分类问题的常⻅划分准则,它基于信息论的概念。在每个节点上,根据特征的取值将数据集分成多个⼦集,然后计算每个⼦集的熵(Entropy),然后计算信息增益,它是⽗节点熵与⼦节点熵之差。信息增益高表示使用该特征进行分裂后,整体熵的减少较大,即带来的信息量增加较多,因此该特征对于分类具有更大的贡献。在决策树算法中,选择信息增益最大的特征作为节点分裂的依据,以最大程度地减少不确定性,提高分类效果。信息增益的问题是它偏向于选择具有较多取值的特征。
- 基尼不纯度(Gini Impurity):基尼不纯度是另⼀种⽤于分类问题的划分准则。在每个节点上,根据特征的取值将数据集分成多个⼦集,然后计算每个⼦集的基尼不纯度,它表示从该⼦集中随机选择两个样本,它们的类别标签不⼀致的概率。基尼不纯度越低,表示⼦节点的纯度越⾼。选择基尼不纯度最低的特征作为划分特征。基尼不纯度相对于信息增益更加偏好选择取值较少的特征,因此在某些情况下,它可能会对多分类问题更有利;
- 均⽅误差(Mean Squared Error):均⽅误差是⽤于回归问题的划分准则。在每个节点上,根据特征的取值将数据集分成多个⼦集,然后计算每个⼦集中⽬标变量的均⽅误差。均⽅误差越低,表示⼦节点的⽬标变量值更接近于均值,模型对数据的拟合越好。
为了选择最佳特征和划分,决策树算法会尝试所有可能的特征和取值组合,并选择最优的划分⽅式,这个过程通常称为"贪心"⽅法。需要注意的是,在决策树构建过程中,还可以应⽤剪枝(pruning)等技术来避免过拟合,提⾼模型的泛化性能。选择合适的划分准则和适当的剪枝策略对于构建⾼性能的决策树模型⾮常重要。
Q. 决策树的种类及差别
决策树是一种常用的机器学习算法,用于分类和回归任务。根据不同的特性和应用场景,存在多种类型的决策树。以下是一些常见的决策树类型及其差异:
-
ID3(Iterative Dichotomiser 3):
ID3 是最早的决策树算法之一,用于分类问题。它基于信息增益(Information Gain)来选择最优的划分属性。ID3算法对于具有较少取值的属性有较好的表现,但对于具有大量取值的属性会受到偏好。 -
C4.5:
C4.5 是 ID3 的改进版本,也用于分类问题。相比于 ID3,C4.5引入了对连续属性的处理、处理缺失值、剪枝等改进。此外,C4.5使用基于信息增益比(Gain Ratio)来选择最优划分属性,以解决 ID3 中信息增益偏好的问题。 -
CART(Classification and Regression Trees):
CART 既可以用于分类问题,也可以用于回归问题。CART算法通过选择最优的划分属性和划分点来构建决策树。对于分类问题,CART使用基于基尼指数(Gini Index)的准则来选择最优划分属性;对于回归问题,CART使用平方误差最小化来选择最优划分属性。
ID3 和 C4.5 主要用于分类问题,它们构建的决策树用于对样本进行分类预测。CART 既可以用于分类问题,也可以用于回归问题。
ID3 和 C4.5 在处理连续属性时需要将其离散化成离散值,然后才能进行划分。CART 可以直接处理连续属性。CART通过选择最优的划分点将连续属性划分为两个子集。
ID3 和 C4.5 在构建决策树时对于缺失值的处理比较困难,通常会采用填充缺失值或忽略缺失值的方法。CART 可以自然地处理缺失值。在构建决策树时,CART能够考虑到缺失值并选择最优的划分属性。
Q. 在决策树中如何避免过拟合?
在决策树中避免过拟合的⽅法:
- 剪枝(Pruning):剪枝是⼀种减⼩树的复杂度的⽅法,它通过移除⼀些叶⼦节点或将⼀些⼦树替换为叶⼦节点来降低模型的复杂度。这有助于减少模型对训练数据的拟合程度,提⾼模型的泛化能⼒。剪枝的关键是确定何时停⽌分裂节点以及如何选择要剪枝的节点。常⽤的剪枝策略包括预剪枝和后剪枝。
- 限制树的深度(Max Depth):限制树的深度是⼀种简单⽽有效的⽅法,通过设置树的最⼤深度可以控制树的复杂度。树的深度过⼤会增加过拟合的⻛险,因此限制树的深度有助于提⾼模型的泛化性能。
- 增加最⼩样本数(Min Samples) :通过设置每个叶⼦节点的最⼩样本数,可以控制叶⼦节点的数量。增加最⼩样本数可以防⽌⽣成过于细分的叶⼦节点,从⽽减少模型的过拟合⻛险。
- 限制叶⼦节点的最⼩样本数(Min Samples per Leaf):与上⼀点类似,但是是限制每个叶⼦节点的最⼩样本数。这有助于确保叶⼦节点中的样本数量不会太少,从⽽减少过拟合。
- 降低信息增益阈值:信息增益⽤于选择划分特征,降低信息增益的阈值可以使模型更加保守,减少过度划分的可能性。
- 随机森林(Random Forest):随机森林是⼀种基于决策树的集成⽅法,通过随机选择特征⼦集和样本⼦集来构建多棵树,并将它们组合起来进⾏预测。随机森林通常能够降低过拟合⻛险,提⾼模型的泛化性能。
避免过拟合是决策树模型中的⼀个关键问题,需要根据具体问题和数据集选择适当的⽅法来控制模型的复杂度。通常,通过组合多种策略,可以有效地减轻过拟合问题,使决策树模型更加稳健。
Q. 决策树的剪枝方式有哪些?
决策树剪枝是一种用于减少决策树复杂度和提高泛化性能的技术。以下是常见的决策树剪枝方式:
1.预剪枝(Pre-pruning):
预剪枝是在构建决策树的过程中,在每个节点进行划分之前,通过一些预定的规则来判断是否进行划分。预剪枝的目标是在决策树过度拟合训练数据之前停止树的生长。常见的预剪枝策略包括:
- 最大深度限制:限制决策树的最大深度,防止过度拟合;
- 最小样本数限制:限制节点上的最小样本数,如果节点上的样本数小于阈值,则停止划分;
- 最小信息增益限制:如果划分后的信息增益小于阈值,则停止划分。
2.后剪枝(Post-pruning):
后剪枝是在决策树构建完成后,通过剪枝操作来减小决策树的复杂度。后剪枝的思想是通过剪掉一些节点或子树来减少过拟合。常见的后剪枝策略包括:
- 错误率剪枝:计算剪枝前后的错误率(训练集),如果剪枝后的错误率小于剪枝前,则进行剪枝操作;
- 基于验证集的剪枝:将数据集划分为训练集和验证集,通过验证集的性能来评估剪枝操作的效果,选择性能最好的剪枝。
预剪枝和后剪枝都是为了防止决策树过拟合训练数据,提高模型的泛化能力。预剪枝是在决策树构建的过程中进行剪枝操作,而后剪枝是在决策树构建完成后进行剪枝操作。选择合适的剪枝策略取决于具体的问题和数据特点。
Q. 什么是随机森林,以及它是如何⼯作的?
随机森林(Random Forest)是⼀种集成学习算法,⽤于解决分类和回归问题。它基于决策树(Decision Trees)构建,并通过组合多个决策树来提⾼模型的性能和稳定性。随机森林的主要思想是通过随机选择样本和特征来构建多棵决策树,然后综合它们的预测结果来进⾏分类或回归。
随机森林的⼯作原理:
- 随机选择样本:从训练数据集中随机选择⼀定数量的样本(有放回抽样),这个过程称为"Bootstrap"抽样。这意味着每棵决策树的训练数据都是随机抽取的,可能包含重复的样本;
- 随机选择特征:在每个决策树的节点上,随机选择⼀部分特征⼦集来进⾏分裂。这确保了每棵树都不会过度依赖于某些特征;
- 构建多棵决策树:根据以上两个步骤,构建多棵决策树。每棵树都会根据样本和特征的随机选择来学习数据的
不同⽅⾯; - 综合预测结果:对于分类问题,随机森林会采⽤多数投票的⽅式来确定最终的分类结果。对于回归问题,随机森林会取多棵树的平均预测值。
这种随机性和多棵树的组合使随机森林具有很强的泛化能⼒和抗过拟合能⼒,因此通常表现出⾊于单个决策树。
Q. 在随机森林中,袋外误差(Out-of-Bag Error)有什么作用,以及如何使用它来评估模型性能?
袋外误差是随机森林中⼀种重要的性能评估指标,主要有3⽅⾯作⽤:
- ⽆需额外验证集: OOB误差提供了⼀种在不使⽤额外验证集的情况下评估模型性能的⽅法。这对于⼩数据集或数据不⾜以划分出独⽴的验证集的情况⾮常有⽤;
- 评估模型泛化性能: OOB误差是⼀种对模型泛化性能的估计。它通过在训练过程中未被抽样到的数据(OOB样本)上进⾏评估来衡量模型的性能,这使得它可以提供⼀个较好的模型性能估计;
- 帮助选择超参数: OOB误差可以⽤于调整随机森林的超参数,例如树的数量、最⼤深度等。通过观察OOB误差在不同超参数设置下的变化,可以选择最佳的超参数配置。
Q. 随机森林如何评估特征的重要性?它们的计算方法是什么?
随机森林可以通过不同⽅法来评估特征的重要性,它们通常基于每个特征在模型中的使⽤频率和重要性来计算。
以下是评估随机森林中特征重要性的两种常⻅⽅法:
1.基于基尼不纯度或熵的特征重要性
在每棵决策树的构建过程中,随机森林可以测量每个特征对于减少不纯度(例如,基尼不纯度或熵)的贡献。这个贡献可以⽤来估计特征的重要性。
特征重要性的计算通常遵循以下步骤:
- 对于每个特征,在每次分裂节点时,测量该特征的分裂贡献,即通过该特征分裂后的不纯度减少程度。这可以通过基尼不纯度或熵的减少量来衡量;
- 对于每个特征,将所有分裂贡献的平均值或加权平均值汇总起来,以得到该特征的总体重要性得分;
- 最后,将所有特征的重要性得分标准化,使它们的总和等于1。
这种⽅法衡量了每个特征在模型中的贡献,对于减少不纯度的特征具有较⾼的重要性分数。
2.基于Out-of-Bag (OOB)误差的特征重要性
随机森林可以利⽤Out-of-Bag(OOB)样本来估计特征重要性。 OOB样本是在Bootstrap抽样过程中未被选择的样本。特征重要性的计算步骤如下:
- 对于每个特征,记录训练模型时使⽤该特征的树的OOB样本的预测误差;
- 对于每个特征,计算它对应的OOB误差的增加(或减少)。这是通过将特征的值随机排列来破坏特征与⽬标变量之间的关系,然后重新计算OOB误差来实现的;
- 特征重要性分数是通过⽐较原始OOB误差和破坏特征后的OOB误差来计算的。如果特征重要性分数增加了,那么该特征对模型的性能具有重要影响。
这两种⽅法都可以⽤来估计特征的相对重要性,但它们的计算⽅式略有不同。
Q. 随机森林的局限性
- 计算资源需求较⼤: 随机森林由多个决策树组成,因此需要较多的计算资源和内存来训练和存储模型,对于⼤规模数据集可能不太适⽤;
- 模型解释性较弱: 随机森林是集成模型,因此模型的解释性相对较弱,不如单⼀决策树直观;
- 可能不适⽤于稀疏数据: 随机森林通常对于稀疏数据的处理效果不如线性模型或其他模型;
- 随机性导致结果不确定: 随机森林的随机性机制导致不同运⾏时模型结果可能不完全⼀致,这在⼀些场景下可能不可接受;
- 对于平滑决策边界的问题表现较差: 随机森林的决策边界通常是锯⻮状的,不适⽤于对平滑决策边界的问题。
Q. 什么是支持向量机?
⽀持向量机(Support Vector Machine, SVM)是⼀种强⼤的监督学习算法,主要⽤于分类和回归问题。 SVM的核⼼思想是寻找⼀个最优的超平⾯或决策边界,以最⼤化不同类别数据点之间的间隔,并尽量避免误分类。
⽀持向量是训练数据中距离超平⾯最近的数据点。它们是⽤于定义分类间隔(Margin)的关键元素。分类间隔是指超平⾯与最近的⽀持向量之间的距离,SVM 的关键⽬标是找到⼀个超平⾯,使得分类间隔最⼤化。
SVM也可以应⽤于⾮线性分类问题,通过引⼊核函数来将数据映射到⾼维特征空间,从⽽在⾼维空间中找到线性可分的超平⾯。常⻅的核函数包括线性核、多项式核和径向基函数(RBF)核。
SVM的最优超平面是通过解决一个凸优化问题来获得的。优化问题的目标是在满足间隔最大化或分类误差最小化的约束条件下,找到一个能够将不同类别的样本点正确分开的超平面。这个优化问题可以通过使用拉格朗日乘子法和KKT条件来求解。
SVM使用的损失函数是基于间隔的合页损失函数(Hinge Loss)。合页损失函数的优化目标是最小化损失函数的总和,同时最大化间隔。在求解优化问题时,通常会引入正则化项,如 L2 正则化,以避免过拟合现象。
Q. 支持向量机如何应用在回归任务?
在回归任务中
- SVM回归的⽬标是找到⼀个超平⾯,使得数据点尽量接近超平⾯,同时在⼀定容忍度内;
- 在回归问题中, SVM的⽬标是最⼩化⼀个损失函数,损失函数衡量了数据点离超平⾯的距离以及容忍度的违规情况;
- 容忍度(Tolerance)是⼀个控制在训练期间允许数据点距离超平⾯的程度的参数。
Q. 在SVM中,如何处理⾮线性可分的数据?核函数(Kernel Function)的作用和常用类型。
在SVM中处理⾮线性可分的数据时,通常使⽤核函数(Kernel Function)来将数据映射到⼀个⾼维特征空间,使得数据在这个⾼维空间中变得线性可分。
核函数的作⽤是计算两个数据点之间的相似度或内积,⽽不需要显式地将数据映射到⾼维空间。以下是⼀些常⽤的核函数及其作⽤:
- 线性核函数(Linear Kernel):这是SVM的默认核函数,它在原始特征空间中计算数据点之间的线性关系,适⽤于线性可分的数据;
- 多项式核函数(Polynomial Kernel):多项式核函数通过引⼊多项式项将数据映射到⾼维空间,使其变得更容易分离。它有⼀个参数d,表示多项式的阶数;
- 高斯径向基核函数(Gaussian Radial Basis Function Kernel):⾼斯核函数通过计算数据点之间的相似度来将数据映射到⽆限维的⾼维空间。它有⼀个参数σ,控制了特征映射的“宽度”;
- Sigmoid核函数(Sigmoid Kernel):Sigmoid核函数将数据映射到⾼维空间,类似于神经⽹络的激活函数。它在某些特定应⽤中有⽤,但不如⾼斯核函数和多项式核函数常⽤。
Q. SVM与逻辑回归(Logistic Regression)之间有哪些相似之处和差异?
相似之处:
- ⽤途:SVM和逻辑回归都可以⽤于⼆元分类问题,也可以扩展到多类别分类;
- 线性模型:SVM和逻辑回归都是线性模型,它们尝试在特征空间中找到⼀个线性决策边界来分离不同类别的数据点。
差异:
- 损失函数:逻辑回归使⽤对数损失函数,⽽SVM使⽤合⻚损失函数(Hinge Loss)。这导致了它们在优化和预测时的不同⾏为。
- 决策边界:SVM的⽬标是找到离决策边界最近的数据点(⽀持向量),⽽逻辑回归的⽬标是找到最⼤似然估计下的决策边界。因此, SVM更加关注⽀持向量,⽽逻辑回归更加关注整体数据点的概率分布。
- 鲁棒性:SVM通常对异常值更加鲁棒,因为它最⼤化了离决策边界最近的数据点的间隔。逻辑回归对异常值更加敏感,因为它使⽤了对数损失函数。
- 参数调整:SVM的性能⾼度依赖于核函数的选择,⽽逻辑回归相对较少需要参数调整。
Q. 朴素贝叶斯是什么?它的基本原理是什么?
朴素⻉叶斯(Naive Bayes)是⼀种基于⻉叶斯定理的概率统计分类算法,常⽤于⽂本分类和多类别分类问题。它的基本原理是基于特征之间的条件独⽴性假设,因此称为"朴素"⻉叶斯。该算法通过计算给定类别的特征条件概率来进⾏分类。下⾯是朴素⻉叶斯的基本原理:
给定⼀个分类任务,我们希望找到⼀个类别标签(或类别的概率分布),使得给定特征数据集X的条件下,该类别标签的概率最⼤。

该方法忽略了特征相关性,且不适用于回归问题。
Q. 什么是K近邻算法?
K近邻(K-Nearest Neighbors,简称KNN)算法是⼀种基本的机器学习算法,常⽤于分类和回归问题。⼯作原理很简单,概括为以下步骤:
- 训练阶段:在训练阶段,算法会存储所有的训练样本数据及其所属的类别或标签;
- 测试阶段:在测试阶段,对于待分类或回归的样本,算法会找出与该样本最近的K个训练样本;
- 分类:对于分类问题, KNN算法使⽤这K个最近的训练样本中最常⻅的类别来预测待分类样本的类别。例如,如果K=3,这三个最近的训练样本分别属于类别A、 B、 B,那么待分类样本将被预测为类别B;
- 回归:对于回归问题, KNN算法使⽤这K个最近的训练样本的平均值或加权平均值来预测待回归样本的输出。例如,如果K=3,这三个最近的训练样本的⽬标值分别为5、 6、 7,那么待回归样本的输出将被预测为它们的平均值或加权平均值。
计算距离的方法通常有欧⽒距离、曼哈顿距离等。KNN算法需要计算新样本与所有训练样本之间的距离,随着训练集的规模增加,计算成本会显著增加。
Q. 什么是余弦距离,与欧氏距离有什么差别,有哪些方面的应用?
余弦距离(Cosine Distance)是衡量两个向量之间的相似性的一种度量方法。它衡量的是两个向量之间的夹角的余弦值,而不仅仅是向量之间的欧氏距离。与欧氏距离相比,余弦距离的主要差别在于它不考虑向量的大小和绝对位置,而更关注向量之间的方向和夹角。欧氏距离衡量的是两个向量之间的直线距离,而余弦距离衡量的是两个向量之间的夹角的余弦值。
余弦距离具有以下特点:
-
范围在0到1之间:余弦距离的取值范围在0到1之间,其中0表示两个向量之间完全不相似,1表示两个向量之间完全相似;
-
不受向量大小的影响:余弦距离只关注向量之间的方向,而不考虑其长度或绝对位置。因此,它对于不同大小的向量具有鲁棒性;
-
对稀疏向量适用:余弦距离在处理高维稀疏向量时效果较好,因为它只关注向量之间的方向,而不考虑零元素的影响。
应用方面,余弦距离在许多领域有广泛的应用,包括但不限于以下几个方面:
- 文本相似性度量:在文本挖掘和自然语言处理中,可以使用余弦距离来度量文本之间的相似性,例如计算文档、句子或单词的相似性;
- 图像检索:在图像处理和计算机视觉中,可以使用余弦距离来比较图像特征向量的相似性,从而进行图像检索和相似图像推荐;
- 推荐系统:在协同过滤推荐系统中,可以使用余弦距离来度量用户之间的兴趣相似性,从而为用户推荐相似的项目或用户;
- 聚类分析:在聚类算法中,可以使用余弦距离来度量样本之间的相似性,例如在文本聚类和社交网络分析中;
- 信息检索:在信息检索系统中,可以使用余弦距离来计算查询和文档之间的相关性,从而进行文档排序和搜索结果的排名。
总结而言,余弦距离是一种度量向量相似性的有效方法,特别适用于处理高维稀疏数据和度量向量之间的方向关系。它在文本处理、图像处理、推荐系统和聚类分析等领域中具有广泛的应用。
Q. 什么是K均值聚类?它的主要目标是什么?
K均值聚类(K-means clustering)是⼀种常⽤的⽆监督学习算法,⽤于将数据集划分为K个不同的簇。该算法通过最⼩化簇内样本之间的平⽅误差和最⼤化簇间的距离来确定簇的位置。K均值聚类的步骤如下:
- 随机选择K个初始质⼼作为簇的中⼼点;
- 对每个样本计算其与各个质⼼之间的距离,并将样本分配给与其最近的质⼼所代表的簇;
- 更新每个簇的质⼼为该簇的所有样本的平均值;
- 重复步骤2和3,直到质⼼不再变化或达到预定义的停⽌条件。
Q. K均值聚类的优点和局限性是什么?
K均值聚类是一种常用的无监督学习算法,用于将数据集划分为K个不同的簇。它具有以下优点和缺点:
优点:
- 简单而有效:K均值聚类是一种简单而直观的算法,易于实现和理解。它的计算复杂度相对较低,适用于大规模数据集;
- 可扩展性:K均值聚类可以轻松地扩展到大规模数据集,因为它的计算复杂度是线性的;
- 聚类结果可解释性强:K均值聚类的结果相对容易解释,每个簇都由其质心(簇中心)和对应的数据点组成。
缺点:
- 需要指定簇的数量:K均值聚类需要预先指定聚类的数量K,但在实际应用中,我们通常无法事先确定最佳的簇数。选择不合适的K值可能导致聚类结果不准确;
- 对初始质心敏感:K均值聚类对初始质心的选择非常敏感。不同的初始质心可能导致不同的聚类结果。这意味着算法可能会陷入局部最小值,并且无法找到全局最优解;
- 受异常值和噪声影响:K均值聚类对异常值和噪声数据非常敏感。异常值可能会导致质心偏离正常聚类,而噪声数据可能会形成自己的簇;
- 仅适用于凸形簇:K均值聚类假设簇是凸形的,这意味着它无法很好地处理非凸形簇、嵌套簇或具有复杂形状的簇;
- 不适用于处理数据不平衡的情况:如果数据集的各个簇的大小差异很大,K均值聚类可能无法准确地捕捉到小簇中的数据点。
Q. K均值聚类和层次聚类之间有哪些区别和相似之处?它们分别适用于什么类型的数据和应用场景?
区别:
- ⽅法:
K均值聚类: K均值聚类是⼀种划分聚类⽅法,它将数据划分为K个不重叠的簇,每个数据点属于其中⼀个簇。该算法通过迭代更新簇的中⼼点和重新分配数据点来实现聚类。
层次聚类:层次聚类是⼀种层次性聚类⽅法,它创建⼀个层次结构的簇,从单个数据点开始,逐渐合并为越来越⼤的簇,最终形成⼀个包含所有数据点的单⼀簇或树状结构。 - 簇的数⽬:
K均值聚类需要事先指定簇的数量K。
层次聚类不需要指定簇的数量,它⽣成⼀个层次性的聚类结构,可以根据需要在不同层次上选择聚类。 - 结果表示:
K均值聚类的结果是每个数据点属于哪个簇的分配。
层次聚类的结果可以以树状结构(树状图或树状热图)的形式表示,也可以通过剪枝来获得不同数量的簇。
相似之处:
4. 距离度量: K均值聚类和层次聚类都使⽤距离度量来度量数据点之间的相似性或距离,例如欧⽒距离、曼哈顿距离等。
5. ⽆监督学习: 它们都是⽆监督学习⽅法,不需要事先标记的类别信息。
适⽤场景:
6. K均值聚类适⽤于:数据点分布近似均匀,簇的形状⼤致相似,簇内的数据点具有相似的⼤⼩和⽅差。你事先知道要分成多少个簇。对计算资源要求有限的情况,因为K均值计算较快。
7. 层次聚类适⽤于:数据点的分布具有层次性或嵌套结构,可以使⽤不同的聚类级别。不确定需要分成多少个簇,希望通过可视化和剪枝选择聚类数。对计算资源要求相对较⾼,因为构建层次结构可能需要更多的计算资源。

K均值聚类更适⽤于简单的聚类问题,⽽层次聚类更适⽤于复杂的聚类问题,尤其是当你希望获得层次性聚类结果时。选择哪种⽅法应该取决于数据的特性以及问题的需求。
Q. 什么是集成学习,以及它的基本思想是什么?
集成学习(Ensemble Learning)是⼀种机器学习⽅法,其基本思想是通过组合多个学习算法或模型的预测来提⾼整体性能和泛化能⼒。它的核⼼思想是通过汇总多个模型的意⻅,以减⼩单个模型的偏差和⽅差,从⽽提⾼模型的鲁棒性和准确性。
Q. 集成学习中的Bagging和Boosting有什么区别?
Bagging(Bootstrap Aggregating):
- ⼯作原理: Bagging通过随机有放回地从训练数据集中抽取多个⼦样本(Bootstrap样本),然后使⽤这些⼦样本来训练多个基本模型,每个基本模型都是在不同的数据⼦集上训练的;
- 模型训练:每个基本模型都独⽴地学习训练数据的不同⼦集,因此它们之间相对独⽴,可以并⾏训练。这些模型通常使⽤相同的学习算法;
- 集成策略: Bagging的集成策略是通过平均(对于回归问题)或投票(对于分类问题)来集成基本模型的预测结果,以获得最终的集成模型。
Boosting:
4. ⼯作原理: Boosting通过迭代地训练⼀系列基本模型,每个基本模型都试图修正前⼀个模型的错误。它会给每个样本分配⼀个权重,使前⼀个模型错误分类的样本在下⼀轮训练中获得更⾼的权重。
5. 模型训练: Boosting的基本模型是依次训练的,每个模型都在前⼀个模型的基础上进⾏学习,尝试减⼩前⼀个模型的错误。
6. 集成策略: Boosting的集成策略是通过加权平均基本模型的预测结果来获得最终的集成模型。权重通常是根据模型性能分配的,性能更好的模型通常有更⾼的权重。
总之, Bagging的基本思想是通过并⾏训练多个相对独⽴的基本模型,然后将它们的预测结果平均化,以减⼩⽅差;⽽Boosting的基本思想是通过迭代训练⼀系列基本模型,每个模型都试图纠正前⼀个模型的错误,以提⾼整体性能。 Boosting通常在模型性能上更强⼤,但也更容易过拟合。

Q. 对比Stacking和Blending两种融合方法的优劣势?
Stacking(堆叠)方法:
- 数据划分:将原始训练数据划分为多个不相交的子集,通常是将数据划分为K个折(K-fold);
- 基本学习器训练:对于每个子集,使用不同的基本学习算法或模型进行训练,得到K个不同的基本学习器;
- 基本学习器预测:对于每个基本学习器,使用剩余的未使用子集进行预测,并将预测结果保存下来;
- 元学习器训练:将预测结果作为新的特征输入,再加上相应的标签,训练一个元学习器(也称为组合器或者元分类器)进行最终的预测;
- 元学习器预测:使用测试数据集对元学习器进行预测。

Blending(混合)方法:
- 数据划分:将原始训练数据划分为两个不相交的部分,通常是将数据划分为训练集和验证集;
- 基本学习器训练:使用训练集训练多个不同的基本学习器,得到多个基本学习器;
- 基本学习器预测:对于每个基本学习器,使用验证集进行预测,并将预测结果保存下来;
- 元学习器训练:将预测结果作为新的特征输入,再加上相应的标签,训练一个元学习器进行最终的预测;
- 元学习器预测:使用测试数据集对元学习器进行预测。
主要差别:
- 数据划分方式:Stacking将数据划分为多个折,每个折都用于基本学习器的训练和预测;而Blending只划分为训练集和验证集,验证集用于基本学习器的预测;
- 预测数据来源:Stacking中,基本学习器的预测结果来自于剩余的未使用子集;而Blending中,基本学习器的预测结果来自于验证集;
- 元学习器的训练数据:Stacking中,元学习器的训练数据是基本学习器的预测结果和相应的标签;Blending中,元学习器的训练数据是基本学习器的预测结果和验证集的标签;
- 预测阶段:在预测阶段,Stacking使用元学习器对测试集进行预测;Blending也使用元学习器对测试集进行预测。
总的来说,Stacking和Blending的差异在于数据划分方式、基本学习器预测数据来源和元学习器的训练数据。Stacking使用K-fold交叉验证来训练基本学习器并生成预测数据,而Blending只使用训练集和验证集来训练基本学习器并生成预测数据。
Q. AdaBoost算法是如何改进弱分类器的性能的?它的基本原理是什么?
AdaBoost(Adaptive Boosting)是⼀种集成学习⽅法,旨在通过组合多个弱分类器来提⾼整体性能。它的基本原理是通过逐步改进训练样本的权重分布,使得难以分类的样本逐渐得到更多的关注。下⾯是AdaBoost算法的基本原理:
- 初始化样本权重:开始时,将每个训练样本的权重初始化为相等值,通常为1/n,其中n是样本数量;
- 迭代训练弱分类器:对于每次迭代, AdaBoost选择⼀个弱分类器并进⾏训练。弱分类器的选择通常基于其分类误差率,即它在当前样本权重下的分类准确度。分类误差率较低的弱分类器将具有更⼤的权重;
- 更新样本权重:根据弱分类器的分类结果,更新每个训练样本的权重。被错误分类的样本将获得更⾼的权重,⽽正确分类的样本则获得较低的权重。这样⼀来,被错误分类的样本将在后续的迭代中得到更多的关注;
- 组合弱分类器:根据弱分类器的分类准确度,给予每个弱分类器⼀个权重。分类准确度较⾼的弱分类器将获得更⾼的权重;
- 集成强分类器:将所有加权的弱分类器组合成⼀个强分类器。在预测过程中,每个弱分类器的输出结果会根据其权重进⾏加权求和,得到最终的预测结果。
通过这种迭代的⽅式, AdaBoost能够逐步提⾼整体分类准确度。它善于处理复杂问题,尤其适⽤于⼆元分类任务。弱分类器可以是任何具有略优于随机猜测性能的分类器,如决策树桩(仅有⼀个分裂节点的决策树)。
Q. 什么是Gradient Boosting
梯度提升方法(Gradient Boosting)是一种集成学习算法,通过串行训练一系列弱学习器(通常是决策树),逐步减小损失函数的梯度来提升整体模型的性能。
梯度提升方法的基本原理是以迭代的方式构建一个强大的预测模型,每一轮迭代都会训练一个新的弱学习器,并将其加入到模型中,以减小之前模型的预测误差。在每一轮迭代中,梯度提升方法会计算损失函数相对于当前模型的负梯度,然后用这个负梯度拟合一个新的弱学习器,使得新学习器能够更好地拟合损失函数的残差。
具体来说,梯度提升方法的步骤如下:
- 初始化模型,通常使用一个常数作为初始预测值。
- 对于每一轮迭代:
a. 计算损失函数相对于当前模型的负梯度(残差)。
b. 使用当前模型拟合这个负梯度,得到一个新的弱学习器。
c. 更新模型,将新的弱学习器加入到模型中。 - 重复步骤2,直到达到预设的迭代次数或满足停止条件。
梯度提升方法的一个重要特点是可以通过优化不同的损失函数来适应不同的问题,比如平方损失函数用于回归问题,交叉熵损失函数用于分类问题。另外,梯度提升方法还可以通过正则化技术(如学习率、子采样)来提高模型的泛化能力,防止过拟合。
Q. 梯度提升与梯度下降的区别和联系是什么?
两者都是在每一轮迭代中,利用损失函数相对于模型的负梯度方向的信息来对当前模型进行更新,只不过在梯度下降中,模型是以参数化形式表示,从而模型的更新等价于参数的更新。而在梯度提升中,模型并不需要进行参数化表示,而是直接定义在函数空间中,从而大大扩展了可以使用的模型种类。

Q. 基于Gradient Boosting的方法有哪些?(GDBT, XGBoost, LightGBM, CatBoost)
-
梯度提升树(Gradient Boosting Trees):梯度提升树是最早和最经典的基于Gradient Boosting的方法之一。它使用决策树作为弱学习器,通过迭代地拟合损失函数的负梯度来逐步提升模型性能。每一棵树都是在之前所有树的预测值的基础上构建的,以减小模型的残差。梯度提升树的核心思想是通过不断添加树来逼近真实的梯度值,从而逐步减小模型的偏差和方差。
-
XGBoost(eXtreme Gradient Boosting):XGBoost是梯度提升树的一种优化实现,它在梯度提升树的基础上引入了一些创新的技术,如自定义损失函数、正则化项、列抽样等,以提高模型的性能和泛化能力。XGBoost的主要原理是通过近似的贪婪算法来构建树模型,同时利用二阶梯度信息进行分裂点的选择,从而更准确地拟合目标函数。
-
LightGBM(Light Gradient Boosting Machine):LightGBM是另一种基于梯度提升树的算法,它在XGBoost的基础上进行了改进。LightGBM采用了基于直方图的决策树算法,通过对特征值进行离散化处理,以加快训练速度。此外,LightGBM还引入了互斥特征捆绑技术和直方图偏差修正方法,以进一步提高性能。
-
CatBoost(Categorical Boosting):CatBoost是一种专门针对具有类别特征的数据集的梯度提升方法,无需手动进行特征编码。它通过使用特殊的处理技术来处理类别特征,并利用对称树和排序算法来提高模型性能。CatBoost还具有自动处理缺失值和稀疏数据的能力,并且支持多种损失函数和评估指标。
Q. 什么是袋外误差(Out-of-Bag Error)和交叉验证(Cross-Validation)在集成学习中的作用?
袋外误差(Out-of-Bag Error)和交叉验证(Cross-Validation)是⽤于评估集成学习模型性能和选择最佳参数的重要⼯具。
- 袋外误差:在基于⾃助采样(Bootstrap)的集成学习⽅法中,每个基础学习器在构建过程中只使⽤了部分训练样本。因此,未被选中的样本可以⽤于评估模型性能,这些样本称为袋外样本。袋外误差衡量了模型在未⻅过的样本上的预测能⼒。通过计算基础学习器在袋外样本上的误差平均值,可以得到整个集成模型的袋外误差估计。袋外误差提供了⼀种⽆偏估计集成模型的泛化性能的⽅法,可以帮助评估模型的准确度。
- 交叉验证:交叉验证是⼀种常⽤的模型选择和参数调优⽅法,可⽤于选择最佳的基础学习器、确定集成模型的规模或权重等。它包括将训练数据集划分为多个互斥的⼦集(通常称为折),然后在其中⼀部分作为验证集,其余部分作为训练集。重复进⾏交叉验证,并评估模型在各个验证集上的性能。最常⽤的交叉验证⽅法是k折交叉验证,其中将数据集划分为k个⼦集,每次选择⼀个作为验证集,剩余k-1个作为训练集。通过对各个验证集的性能进⾏平均或加权平均,可以得到对模型性能的估计。交叉验证可以帮助选择最佳的基础学习器、调整模型参数、评估模型性能,并避免了对单个训练/验证集的过度依赖。
袋外误差和交叉验证都是集成学习中常⽤的评估⼿段,它们提供了⼀种⽆偏估计模型性能的⽅法,有助于选择合适的模型和优化集成模型的参数。
Q. 集成学习在哪些领域和任务中表现出色?它有什么局限性?
集成学习在许多领域和任务中都表现出⾊,特别适⽤于以下情况:
- 分类问题:集成学习在分类问题中表现出⾊,尤其是在处理复杂的、⾼维度的数据集时。它能够通过组合多个弱分类器来提⾼整体分类准确度;
- ⼤规模数据集:当有⼤量数据可⽤时,集成学习能够有效地利⽤这些数据,从⽽提⾼模型的泛化性能;
- 不平衡数据集:当数据集中的类别分布不均衡时,集成学习可以通过调整样本权重或基础学习器的权重来处理这种情况,并提⾼少数类别的分类准确度;
- 噪声数据:集成学习对于噪声数据具有鲁棒性,通过组合多个基础学习器的输出,可以降低噪声对最终预测结果的影响。
然⽽,集成学习也有⼀些局限性:
- 训练时间:由于需要构建和训练多个基础学习器,集成学习的训练时间通常⽐单个基础学习器更⻓;
- 内存消耗:将多个基础学习器组合成集成模型需要占⽤更多的内存空间;
- 解释性:当集成模型的复杂度增加时,模型的解释性会降低。这是由于集成模型通常由多个基础学习器组成,并且其预测结果可能更难以解释;
- ⾼度依赖基础学习器:集成学习的性能取决于所选择的基础学习器。如果基础学习器性能较差,整个集成模型的性能可能⽆法达到期望;
- 过拟合⻛险:在构建过程中,集成学习可能⾯临过拟合问题。当集成模型过于复杂或基础学习器过度拟合训练数据时,模型在未⻅过的数据上的泛化性能可能下降。
尽管存在⼀些局限性,但集成学习仍然是⼀种强⼤的机器学习技术,在很多实际应⽤中取得了显著的成功。
Q. 图像训练数据不足怎么解决?
当图像训练数据不足时,可以考虑以下方法来解决这个问题:
-
数据增强(Data Augmentation):通过应用各种图像处理技术,如旋转、平移、缩放、翻转、剪切、亮度调整等,对现有数据进行扩充,生成更多的训练样本。这可以帮助模型更好地泛化,并且减少过拟合的风险;
-
迁移学习(Transfer Learning):使用预训练的模型作为初始模型,然后在较小的数据集上进行微调。预训练模型通常在大规模数据集上进行训练,因此具有良好的特征提取能力。通过在这个基础上微调模型参数,可以在较小的数据集上获得较好的性能;
-
数据合成(Data Synthesis):如果无法获得足够的真实数据,可以考虑使用合成数据来增加训练样本。例如,使用生成对抗网络(GAN)生成类似真实图像的合成数据。这种方法可能需要一些领域专业知识,以确保生成的数据与真实数据具有相似的特征;
-
联合训练(Joint Training):如果存在其他相关任务的数据集,可以将这些数据集与目标任务的数据集进行联合训练。通过联合训练,模型可以共享和学习其他任务中学到的特征,从而提高目标任务的性能。
需要根据具体情况选择合适的方法。组合使用多种方法可以进一步提高模型的性能,并使其在数据不足的情况下也能取得较好的效果。
Q. 常用的超参数调优方法有哪些?
常用的超参数调优方法包括网格搜索(Grid Search)、随机搜索(Random Search)、贝叶斯优化(Bayesian Optimization)、进化算法(Evolutionary Algorithms)等。
1.网格搜索(Grid Search):
网格搜索是一种简单直观的超参数调优方法,通过穷举搜索给定的超参数组合来找到最佳组合。它将超参数的可能取值组成一个网格,然后在这个网格上进行模型的训练和评估,并找出具有最佳性能的超参数组合。
优点:
- 直观易用:网格搜索的原理简单,易于理解和实现;
- 全面搜索:网格搜索遍历了给定超参数取值的所有组合,因此可以找到在给定搜索空间内的最佳超参数组合。
缺点:
- 计算开销大:当超参数的数量和取值范围增加时,网格搜索的计算开销会呈指数级增长,尤其是在大规模数据集和复杂模型上。
2.随机搜索(Random Search):
随机搜索与网格搜索类似,但是它在给定的超参数空间中随机采样一组超参数组合进行模型训练和评估。相比于网格搜索,随机搜索不需要遍历所有可能的组合,因此具有更低的计算开销。
优点:
- 计算效率高:相比于网格搜索,随机搜索的计算开销较小,尤其是在超参数空间较大时;
- 可能找到非常好的超参数组合:随机搜索具有一定的随机性,有机会在搜索空间中找到隐藏的最佳超参数组合。
缺点:
- 不保证找到全局最佳解:由于随机性的存在,随机搜索不能保证找到全局最佳超参数组合,可能会在搜索空间中漏掉一些优秀的组合。
3.贝叶斯优化(Bayesian Optimization):
贝叶斯优化通过建立模型来估计超参数和模型性能之间的关系,并根据这个模型选择下一个要尝试的超参数组合。它使用贝叶斯推断来更新模型,并通过选择最有希望的超参数进行迭代优化。
优点:
- 高效的参数搜索:贝叶斯优化通过利用模型的预测来选择下一个要尝试的超参数组合,从而有效地利用了之前的尝试结果,减少了搜索空间;
- 自适应:贝叶斯优化可以自适应地调整搜索空间,根据之前的结果调整超参数的搜索范围和分布。
缺点:
- 对于大规模数据集和复杂模型,贝叶斯优化的计算开销可能较大。
- 对于某些问题和搜索空间,贝叶斯优化可能需要更多的迭代次数才能找到最佳超参数组合。
4.进化算法(Evolutionary Algorithms):
进化算法使用生物进化的概念,如遗传算法、粒子群优化等,通过模拟进化过程来搜索超参数空间。它通过不断迭代地生成新的超参数组合,并根据预定义的适应度函数来评估和选择优秀的超参数组合。
优点:
- 并行搜索:进化算法可以并行地搜索超参数空间,在每一代中生成多个超参数组合进行评估,从而加快搜索速度;
- 适用性广泛:进化算法适用于各种问题和搜索空间,不受超参数类型和范围的限制。
缺点:
- 调优结果高度依赖于算法参数:进化算法的性能受到算法参数的影响,需要进行合适的参数设置;
- 计算开销大:进化算法的计算开销较大,尤其是在大规模数据集和复杂模型上。
Q. RMSE的缺点
RMSE由于有一个平方项,导致其对离群点非常敏感。可以换更鲁棒的评价指标,比如平均绝对百分比误差(MAPE)。
Q. 在模型评估过程中有哪些主流方法,他们的优缺点是什么?
在模型评估过程中,常见的主流方法包括交叉验证(Cross-Validation)、留出法(Holdout Method)、自助法(Bootstrap Method)。
1.交叉验证(Cross-Validation):
交叉验证是一种常用的模型评估方法,它将数据集划分为训练集和验证集,并多次重复这个过程以获得稳定的评估结果。常见的交叉验证方法包括k折交叉验证(k-fold Cross-Validation)和分层k折交叉验证(Stratified k-fold Cross-Validation)。
优点:
- 充分利用数据:交叉验证可以最大程度地利用给定的数据进行模型评估,因为它在多个数据集划分上进行评估;
- 可靠性高:通过多次重复划分和评估,交叉验证可以提供相对可靠的评估结果;
缺点:
- 计算开销较大:交叉验证需要多次训练模型和评估,因此在计算上比留出法和自助法要更昂贵;
- 不适用于大数据集:对于大规模数据集,交叉验证可能会消耗大量的计算资源;
- 不适用于小数据集:样本划分导致训练数据减少,影响训练效果。
2.留出法(Holdout Method):
留出法是将数据集划分为训练集和测试集两个部分,其中训练集用于模型的训练,测试集用于模型的评估。
优点:
- 计算效率高:相对于交叉验证和自助法,留出法只需要进行一次训练和评估,因此计算开销较小;
- 适用于大数据集:留出法对于大规模数据集是一种较为实用的评估方法。
缺点:
- 数据利用效率低:留出法将一部分数据作为测试集,因此留给模型训练的数据较少,可能导致评估结果的方差较大;
- 对数据分布敏感:如果训练集和测试集的数据分布有较大差异,留出法可能会导致评估结果不准确。
3.自助法(Bootstrap Method):
自助法是一种通过有放回地从原始数据集中抽样来创建新的训练集的方法。每次抽样后,该样本被放回,使得样本在新训练集中的选择概率相等。
优点:
- 数据利用效率高:自助法通过有放回地抽样,可以充分利用原始数据集,使得大约有63.2%的样本出现在新的训练集中;
- 适用于小样本数据集:对于样本较少的数据集,自助法可以提供相对可靠的评估结果;
缺点:
- 产生冗余样本:由于有放回地抽样,自助法会产生与原始数据集大小相当的冗余样本,这可能导致训练集中包含重复的样本;
- 计算开销较大:由于每次抽样都会生成一个新的训练集,自助法需要进行多次训练和评估,因此计算开销较大;
总结而言,不同的模型评估方法具有各自的优点和缺点。交叉验证提供了相对可靠的评估结果,但计算开销较大;留出法计算效率高,但数据利用率较低;自助法适用于小样本数据集,但产生冗余样本;
深度学习
Q. BN和LN的区别
Batch Normalization(BN)是在每个特征上单独做标准化。假设我们有10行3列的数据,即batchsize = 10,每一行数据有三个特征,假设这三个特征是身高、体重、年龄,那么BN是针对每一列(特征)进行缩放。相反Layer Normalization(LN)是在每个样本上做标准化,即针对每一行(样本)进行缩放。
BN是为了克服神经网络加深导致难以训练而诞生的,随着神经网络深度加深,训练起来就会越来越困难,收敛速度回很慢,常常会导致梯度弥散问题(Vanishing Gradient Problem)。BN一般用在非线性映射(激活函数)之前,让每一层的输入有一个稳定的分布会有利于网络的训练。
BN的优点:
- 加大搜索的步长,加快收敛的速度;
- 更容易跳出局部最小值;
- 破坏原来的数据分布,一定程度上缓解了过拟合;
- 提高梯度流动,BN通过将数据归一化到均值为0、方差为1的分布,有助于缓解梯度消失和爆炸的问题,使得梯度能够更好地传播。
BN的缺点:
- BN是在batch size样本上各个维度做标准化的,所以size越大肯定越能得出合理的μ和σ来做标准化,因此BN比较依赖size的大小;
- BN需要计算每个批次的均值和方差,增加了计算的复杂性。
然而在NLP领域中LN更合适,这是因为BN的操作方向是对每个位置的词在batch维度进行操作。但语言文本的复杂性是很高的,任何一个词都有可能放在初始位置,而且每个句子长度不一,且词序可能并不影响我们对句子的理解。而BN是针对每个位置进行缩放,这不符合NLP的规律。而LN则是针对一句话进行缩放的,且LN一般用在第三维度,如[batchsize, seq_len, dims]中的dims,一般为词向量的维度,或者是RNN的输出维度等等,这一维度各个特征的量纲应该相同,因此也不会遇到上面因为特征的量纲不同而导致的缩放问题。
LN的优点:
- LN是每个样本内部做标准化,跟size没关系,不受其影响;
- LN对网络深度的变化比较鲁棒,适用于较深的网络结构;
LN的缺点:
- 比较容易受到输入维度的影响,LN是在特征维度上进行归一化的,因此对于输入维度较大的情况,可能会受到特征之间关系的影响。
BN 和 LN 都可以比较好的抑制梯度消失和梯度爆炸的情况。BN不适合RNN、transformer等序列网络,不适合文本长度不定和batchsize较小的情况,适合于CV中的CNN等网络;而LN适合用于NLP中的RNN、transformer等网络,因为sequence的长度可能是不一致的。

Q. 梯度消失和梯度爆炸产生的原因和解决办法
当前神经网络依靠反向传播来更新参数,反向传播算法可以说是梯度下降在链式法则中的应用,而链式法则是一个连乘的形式,所以当层数越深的时候,梯度将以指数形式传播。梯度消失问题和梯度爆炸问题一般随着网络层数的增加会变得越来越明显。在根据损失函数计算的误差通过梯度反向传播的方式对深度网络权值进行更新时,得到的梯度值接近0或特别大,也就是梯度消失或爆炸。梯度消失或梯度爆炸在本质原理上其实是一样的。
【梯度消失】产生的原因有:一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid。当梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层时,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习。
【梯度爆炸】一般出现在深层网络和权值初始化值太大的情况下。在深层神经网络或循环神经网络中,误差的梯度可在更新中累积相乘。如果网络层之间的梯度值大于 1.0,那么重复相乘会导致梯度呈指数级增长,梯度变的非常大,然后导致网络权重的大幅更新,并因此使网络变得不稳定。
解决办法:
- 梯度剪裁:通过设置一个阈值,限制梯度的最大值,防止梯度超过阈值,用于解决梯度爆炸问题;
- 权重正则化:正则化主要是通过对网络权重做正则来限制过拟合。如果发生梯度爆炸,那么权值就会变的非常大,反过来,通过正则化项来限制权重的大小,也可以在一定程度上防止梯度爆炸的发生;
- 激活函数:选择ReLU等梯度大部分落在常数上的激活函数,ReLU函数的导数在正数部分是恒等于1的,因此在深层网络中使用ReLU激活函数就不会导致梯度消失和爆炸的问题;
- Batch Normalization:BN就是通过对每一层的输出规范为均值和方差一致的方法,消除了权重参数放大缩小带来的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区;
- 残差结构:残差网络反向传播时,错误信号可以不经过任何中间权重矩阵变换直接传播到低层,一定程度上可以缓解梯度弥散问题。计算梯度时因为有“1”的存在,高层的梯度可以直接传递到低层,有效防止了梯度消失的情况;
- LSTM的“门”结构:LSTM的结构设计可以改善RNN中的梯度消失的问题,主要原因在于LSTM内部复杂的“门”,记忆细胞允许梯度在时间上保持更长的路径,而门控机制允许选择性地更新和传递信息,从而改善了梯度的传播和稳定性。
Q. RNN、LSTM和GRU的区别
RNN(循环神经网络),LSTM(长短期记忆网络)和GRU(门控循环单元)是用于处理序列数据的神经网络模型,它们在结构和功能上有一些区别:
RNN(循环神经网络):
- RNN是最基本的循环神经网络模型,通过在网络中引入循环连接,使得网络可以处理序列数据;
- RNN的隐藏状态在每个时间步被更新,并传递到下一个时间步,以捕捉序列中的上下文信息;
- 然而,标准RNN存在梯度消失和梯度爆炸的问题,难以处理长期依赖关系。
LSTM(长短期记忆网络):
- LSTM是一种特殊类型的循环神经网络,旨在解决RNN中的梯度消失和梯度爆炸问题;
- LSTM引入了记忆细胞(memory cell)和门控机制(如遗忘门、输入门和输出门)来控制信息的流动和存储。记忆细胞允许梯度在时间上保持更长的路径,而门控机制允许选择性地遗忘、更新和输出信息,减轻梯度消失和梯度爆炸的问题。
GRU(门控循环单元):
- GRU是LSTM的一种简化变体,旨在减少LSTM的复杂性并降低计算成本;
- GRU合并了LSTM中的遗忘门和输入门,只使用了一个更新门和一个复位门;更新门决定了过去信息和当前输入的权重,复位门决定了如何将过去信息与当前输入相结合;
- GRU的参数比LSTM更少,计算效率更高,但在某些情况下可能性能稍逊于LSTM。
总的来说,LSTM和GRU是对标准RNN进行改进的模型,解决了梯度消失和梯度爆炸的问题。LSTM通过引入记忆细胞和门控机制,而GRU通过合并门控单元来简化网络结构。选择使用哪种模型取决于具体的任务需求和性能要求。

Q. 深度学习常用的优化算法
- 梯度下降(Gradient Descent):是最基本的优化算法之一,通过计算目标函数的梯度,并沿着负梯度方向更新参数值,以逐步逼近最优解;

- 随机梯度下降法(Stochastic Gradient Descent,SGD):是梯度下降算法的一种变体,每次迭代只使用一个样本或一小批样本计算梯度和更新参数,以降低计算成本和内存需求。但是该方法会导致准确度下降,由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛,此外可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势;
- Mini-Batch SGD(Mini-Batch Stochastic Gradient Descent):是梯度下降算法的一种变体,它在每次迭代中使用一小批(mini-batch)的样本来计算梯度和更新参数。相比于传统的梯度下降算法和随机梯度下降算法,Mini-Batch SGD综合了两者的优点,既减少了计算成本,又保持了一定的随机性;
- AdaGrad(Adaptive Gradient):是梯度下降法的改进算法,其优点是可以自适应学习率。该优化算法在较为平缓处学习速率大,有比较高的学习效率,在陡峭处学习率小,在一定程度上可以避免越过极小值点。但是AdaGrad算法过于依赖之前的梯度,在梯度突然变化无法快速响应;

- RMSProp(Root Mean Square Propagation):为了解决Adagrad的问题,在AdaGrad的基础上添加了衰减速率参数。也就是说在当前梯度与之前梯度之间添加了权重,如果当前梯度的权重较大,那么响应速度也就更快;

- AdaDelta:AdaDelta是对RMSprop的改进,它消除了学习率的设置,并引入了一个适应性学习率的更新规则,使得学习率的调整更加平滑。AdaDelta的主要目标是解决学习率衰减的问题,使得学习率的调整更加平滑,不需要手动设置学习率;
- 动量优化(Momentum):用于加速模型的收敛和减少震荡,避免陷入局部最优。它引入了一种动量项,通过累积过去梯度的指数加权平均,并将其与当前的梯度相结合,以更新模型参数。Momentum的作用是在参数更新时增加一个惯性项,这样可以使得参数在梯度方向上累积动量,从而加速收敛过程。其实vi就是之前所有的gradient的加权总和,越久远的gradient对现在产生的影响越小;

- Adam(Adaptive Moment Estimation):结合了Momentum和RMSprop的优点。它使用了动量项和自适应学习率,并且能够在训练初期迅速收敛,同时在后期能够更精确地调整参数。

Q. 什么是互信息?它如何用于特征选择和降维问题?
互信息(Mutual Information)是⼀种⽤于度量两个随机变量之间的相关性或依赖关系的概念。互信息衡量了⼀个随机变量中的信息对另⼀个随机变量的预测能力,即⼀个随机变量中的信息是否提供了关于另⼀个随机变量的额外信息。

其中, 是p(x,y)联合概率分布,p(x)和p(y)分别是边缘概率分布。互信息可以⽤于特征选择和降维问题:
- 特征选择:互信息可⽤于评估⼀个特征与⽬标变量之间的相关性。通过计算每个特征与⽬标变量的互信息,可以选择具有⾼互信息值的特征作为重要的特征进⾏建模和预测;
- 降维:在降维问题中,互信息可⽤于度量原始特征与新⽣成的降维特征之间的相关性。通过选择具有⾼互信息值的特征或特征组合,可以保留最具信息量的特征,从⽽实现维度的减少。
注意,互信息在计算特征之间的相关性时不考虑它们的线性关系。在某些情况下,互信息可能⽆法捕捉到⾮线性相关性。因此,在实际应⽤中,需要结合其他⽅法和技术来综合考虑特征选择和降维的需求。

Q. 归一化/标准化的作用
- 消除特征之间的量纲差异:不同的特征往往具有不同的数值范围,归一化或标准化可以使得特征之间的数值范围统一,避免由于数值范围差异带来的偏差;
- 提高模型收敛速度:归一化或标准化可以加快模型的收敛速度,尤其是对于使用基于梯度的优化算法(如梯度下降)的模型。这是因为特征值的范围统一可以使得更新的步长更加一致和稳定;
- 有效地利用特征信息:归一化或标准化可以确保特征的分布形状和方差尽可能一致,这有助于避免某些特征对模型的影响过大,从而更好地利用特征信息;
- 提⾼特征的可解释性:在某些情况下,归⼀化或标准化可以提⾼特征的可解释性,使得不同特征的权重
更容易⽐较
⼀般来说,如果特征值的分布范围未知,或者特征值分布接近正态分布,标准化是⼀个不错的选择。如果特征有已知的上下界或者需要将特征映射到⼀定范围内,那么归⼀化可能更合适。有时候,也可以同时使⽤两者,根据具体情况对不同特征进⾏不同的处理。
Q. 特征选择和特征抽取的区别,以及它们在数据预处理中的作用
特征选择(Feature Selection):
- 特征选择是从原始特征集合中选择⼀部分重要的特征,保留它们,⽽丢弃不相关或冗余的特征;
- 特征选择的⽬的是降低维度、减少计算成本、提⾼模型的解释性、减少过拟合的⻛险,并且可能改善模型的性能;
- 特征选择⽅法包括过滤⽅法、包装⽅法和嵌⼊⽅法等。过滤⽅法独⽴于模型,基于统计或信息论等度量进⾏特征选择,如相关性、互信息等。包装⽅法通过模型的性能来评估特征的重要性,例如递归特征消除(Recursive Feature Elimination, RFE)。嵌⼊⽅法将特征选择与模型训练过程结合在⼀起,例如L1正则化的线性回归。
特征抽取(Feature Extraction):
- 特征抽取是通过将原始特征转换为新的特征集合来降低维度。这些新特征通常是原始特征的线性或⾮线性组合;
- 特征抽取的⽬的是发现数据中的潜在结构、减少冗余信息、降低维度、提⾼模型性能,并且可以⽤于降维和可视化;
- 常⻅的特征抽取技术包括主成分分析(Principal Component Analysis,PCA)和独⽴成分分析(Independent Component Analysis,ICA),以及⾮线性降维技术如t-SNE(t-Distributed Stochastic Neighbor Embedding)等。
区别:
- 主要区别在于特征选择保留了原始特征,⽽特征抽取创建了新的特征。特征选择是从现有特征中挑选出最有价值的特征,⽽特征抽取是通过线性或⾮线性变换创建新的特征;
- 特征选择通常更容易解释,因为它仅仅是选择原始特征中的⼀个⼦集,⽽特征抽取可能创建的新特征不直接对应原始特征;
- 特征选择更适⽤于数据维度较低,⽽特征抽取通常⽤于⾼维数据或在需要减少冗余信息的情况下。
在实际应⽤中,选择特征选择还是特征抽取取决于问题的性质、数据的维度和机器学习模型的要求。在某些情况下,这两种⽅法也可以结合使⽤,先进⾏特征抽取,然后再进⾏特征选择,以达到更好的特征⼯程效果。
Q. 什么是无监督学习?举例说明无监督学习任务
⽆监督学习(Unsupervised Learning)是机器学习的⼀种分⽀,其特点是在训练数据中没有明确的标签或⽬标输出。在⽆监督学习中,模型的任务是从数据中发现隐藏的结构、模式或关系,⽽不需要预先知道⽬标变量或标签。⽆监督学习任务通常可以分为两类:
- 聚类(Clustering):聚类任务的⽬标是将数据分成不同的组或簇,使得同⼀组内的数据点相似,⽽不同组之间的数据点差异较⼤;
- 降维(Dimensionality Reduction):降维任务的⽬标是减少数据的维度,保留尽可能多的信息,同时降低冗余性。降维可以帮助简化数据,减少噪声,并提⾼计算效率。
⽆监督学习通常⽤于发现数据的内在结构和关联,因此在数据挖掘、特征⼯程和可视化等领域有⼴泛的应⽤。与监督学习不同,⽆监督学习不需要事先标记的训练数据,因此更适⽤于探索性分析和数据探索。
Q. 常用的激活函数及优缺点
常用的激活函数有以下几种:
Sigmoid函数:
- 优点:Sigmoid函数将输入映射到0到1之间的连续输出,适用于二分类问题和输出概率的情况。
- 缺点:Sigmoid函数存在梯度饱和问题,当输入较大或较小时,梯度接近于0,导致反向传播时梯度消失的问题;输出不是以0为中心,可能导致神经元的输出偏移。
双曲正切函数(Tanh函数):
- 优点:Tanh函数将输入映射到-1到1之间的连续输出,相比于Sigmoid函数,Tanh函数的输出以0为中心,更适用于神经网络的隐藏层。
- 缺点:Tanh函数同样存在梯度饱和问题,当输入较大或较小时,梯度接近于0,导致反向传播时梯度消失的问题。
ReLU函数:
- 优点:ReLU函数将负数映射为0,正数保持不变,解决了Sigmoid和Tanh函数的梯度饱和问题,使得神经网络的训练更加快速和稳定;计算简单,减少了计算复杂性。
- 缺点:ReLU函数存在一个问题称为“神经元死亡”,当输入小于0时,梯度为0,导致该神经元无法更新权重,因此在训练过程中可能会出现某些神经元始终不被激活的情况。
Leaky ReLU函数:
- 优点:Leaky ReLU函数在负数部分引入一个小的斜率,解决了ReLU函数的“神经元死亡”问题,允许负数部分有小的梯度,使得神经元在训练过程中能够更新权重。
- 缺点:Leaky ReLU函数在实践中并没有被广泛证明比ReLU函数效果更好,斜率的选择可能会影响模型的性能。
Softmax函数:
- 优点:Softmax函数常用于多分类问题,将输入映射到0到1之间的概率分布,并且所有类别的概率之和为1。
- 缺点:Softmax函数的输出受到输入中最大值的影响,当输入较大时,Softmax函数的输出梯度接近于0,可能导致梯度消失的问题。
每种激活函数都有其适用的场景和局限性,选择适合特定任务和网络结构的激活函数是神经网络设计中的重要考虑因素。
Q. 正则化为什么可以提高模型泛化能力
正则化可以增加模型的泛化能力,主要基于以下两个原因:
-
减少过拟合:正则化通过限制模型的复杂性,防止模型对训练数据的过拟合。过拟合指的是模型过度拟合训练数据,导致在新的未见过的数据上表现不佳。正则化方法(如L1正则化、L2正则化)通过在损失函数中引入正则化项,惩罚模型的复杂性,使得模型倾向于选择简单的解决方案。这样可以防止模型过于依赖于训练数据中的噪声或不相关的特征,从而提高在新数据上的泛化能力。
-
特征选择和权重衰减:正则化方法可以促使模型选择重要的特征并减少对不相关或冗余特征的依赖。例如,L1正则化倾向于产生稀疏权重向量,将一些特征的权重推向零,相当于进行特征选择,只保留对目标变量有更强预测能力的特征。而L2正则化通过权重衰减减小权重的幅度,使得每个特征对模型的影响更加均衡。这样可以提高模型对特征的鲁棒性,减少对特定样本的过度敏感性,进而提高泛化能力。
通过正则化方法,模型能够在学习过程中在准确性和复杂性之间进行权衡,更好地适应未见过的数据。正则化可以看作是一种对模型的约束,帮助模型学习到更一般化的规律,减少对训练数据的过度拟合,从而提高模型的泛化能力。
相关文章:
机器学习深度学习面试笔记
机器学习&深度学习面试笔记 机器学习Q. 在线性回归中,如果自变量之间存在多重共线性,会导致什么问题?如何检测和处理多重共线性?Q. 什么是岭回归(Ridge Regression)和Lasso回归(Lasso Regression)?它们与普通线性回…...
安卓和Android是两种不同的操作系统?
实际上,安卓和Android并不是同一种操作系统! Android是由Google开发并维护更新的一款操作系统,目前仅能运行在Pixel手机上。 Google Pixel 与 iPhone手机:哪个更好?Google Pixel 与 Apple iPhone哪个手机才是性价比最…...
Java学习——设计模式——结构型模式2
文章目录 结构型模式装饰者模式桥接模式外观模式组合模式享元模式 结构型模式 结构型模式主要涉及如何组合各种对象以便获得更好、更灵活的结构。虽然面向对象的继承机制提供了最基本的子类扩展父类的功能,但结构型模式不仅仅简单地使用继承,而更多地通过…...

什么是Maven ??? (以及关于依赖,中央仓库,国内源)
文章目录 什么是 Maven创建第一个 Maven 项目依赖管理Maven 的仓库Maven 如何设置国内源 什么是 Maven Maven :用于构建和管理任何基于java的项目的工具。**说白了就是管理 Java项目 的工具。**我们希望我们已经创建了一些东西,可以使Java开发人员的日常…...

c++期末考题笔试来咯
最后一道大题题目再现 写一个person类,有姓名,性别,年龄。然后在此基础上派生出教师类和学生类。教师类增加了以下数据:工号,职称,工资。学生类增加了以下数据成员:学号,专业&#…...
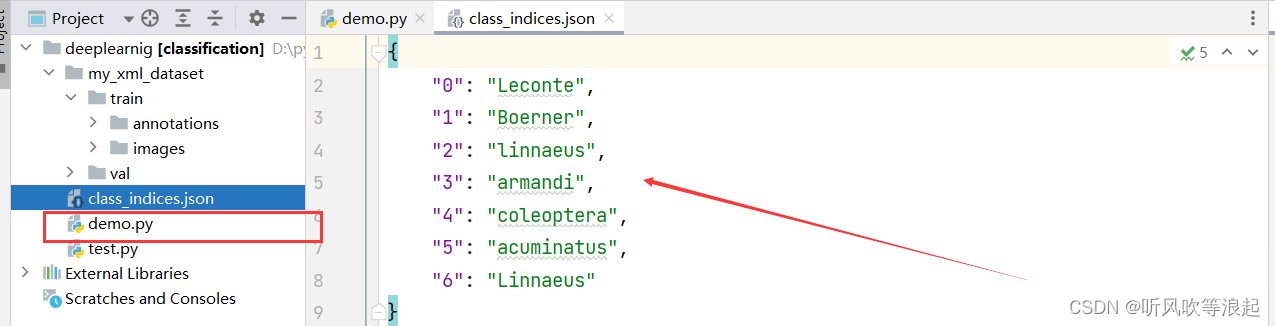
目标检测篇:如何根据xml标注文件生成类别classes的json文件
1. 介绍 之前在做目标检测任务的时候,发现很多的数据集仅有数据(只有图片标注的xml文件),没有关于类别的json文件,为了以后方便使用,这里记录一下 一般来说,yolo标注的数据集,只有第一个是数字类别&#x…...
spring见解2基于注解的IOC配置
3.基于注解的IOC配置 学习基于注解的IOC配置,大家脑海里首先得有一个认知,即注解配置和xml配置要实现的功能都是一样的,都是要降低程序间的耦合。只是配置的形式不一样。 3.1.创建工程 3.1.1.pom.xml <?xml version"1.0" en…...
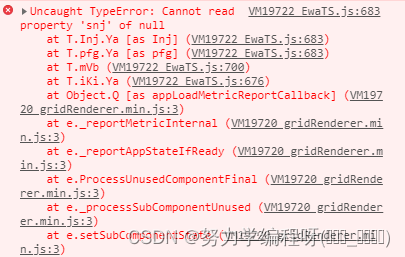
Uncaught TypeError: Cannot read property ‘snj‘ of null
项目场景: 项目相关背景: 调试项目时,控制台出现红色报错信息 问题描述 问题: 调试项目时,控制台出现如下所示的报错信息: Uncaught TypeError: Cannot read property snj of nullat T.Inj.Ya [as Inj…...
Jenkins基础教程
目录 第一章、快速了解Jenkins1.1)Jenkins中一些概念介绍1.2)Jenkins和maven用途上的区别1.3)为什么使用Jenkins1.4)学习过程中的疑问 第二章、安装Jenkins2.1)安装之前的准备2.2)Windows中Jenkins下载安装…...

嵌入式C语言--WatchDog最全概念
嵌入式C语言–WatchDog最全概念 嵌入式C语言--WatchDog最全概念 嵌入式C语言--WatchDog最全概念一. 什么是Watchdog1)什么是“被狗咬”2)什么是喂狗 二. 基本思想三. 作用四. 监视目标1) 监视一个进程2)监视一个操作系统 五. 系统初始化时关闭…...

数据结构【树篇】(二)
数据结构【树篇】(二) 文章目录 数据结构【树篇】(二)前言为什么突然想学算法了?为什么选择码蹄集作为刷题软件? 目录树(一)、树的存储(二)、树和森林的遍历——并查集(三)、并查集的优化 结语 前言 为什么突然想学算法了…...

2024上海城博会|上海国际城市与建筑博览会-官 网
2024上海城博会|上海国际城市与建筑博览会 时间:2024年10月30日-11月1日 地点:上海世博展览馆 主办单位:联合国人居署 上海市住房和城乡建设管理委员会 协办单位:上海世界城市日事务协调中心 展会介绍 上海国际城市与建筑博览…...

Dockerfile - 基于 SpringBoot 项目自定义镜像(项目上线全过程)
目录 一、Dockerfile 自定义项目镜像 1.1、创建 SpringBoot 项目并编写 1.2、打包项目(jar) 1.3、编写 Dockerfile 文件,构建镜像 1.4、运行镜像并测试 一、Dockerfile 自定义项目镜像 1.1、创建 SpringBoot 项目并编写 a)简…...

论文查重降重写成大白话可以吗
大家好,今天来聊聊论文查重降重写成大白话可以吗,希望能给大家提供一点参考。 以下是针对论文重复率高的情况,提供一些修改建议和技巧,可以借助此类工具: 论文查重降重:用大白话解析 一、引言 写论文是每个…...

【WPF.NET开发】WPF中的命令
本文内容 什么是命令WPF 中的简单命令示例WPF 命令中的四个主要概念命令库创建自定义命令 命令是 Windows Presentation Foundation (WPF) 中的一种输入机制,与设备输入相比,它提供的输入处理更侧重于语义级别。 示例命令如许多应用程序均具有的“复制…...
怎么将epub转换成txt文件?
怎么将epub转换成txt文件?在当前时代,各种各样的电子书是很多人都喜欢接触并阅读的,但很少有人知道电子书格式的不同,其中就包括epub和txt格式,这两种格式虽然都可以展示文本但能达到的效果完全不一样,在某…...

Java单词排序
【问题描述】 编写一个程序,从一个文件中读入单词(即:以空格分隔的字符串),并对单词进行排序,删除重复出现的单词,然后将结果输出到另一个文件中。 【输入形式】从一个文件sort.in中读入单词。 …...

Moonsong Labs与Web3演变
作者:Derek Yoo 创建Moonsong Labs的理由 我们创建了Moonsong Labs,其使命是创建推动Web3采用的软件基础设施协议。我们的动力来自这样一个观念,即Web3使人类相互交往更加透明、高效和公正。这无疑是一个值得努力实现的目标,但更…...

流媒体学习之路(WebRTC)——GCC分析(4)
流媒体学习之路(WebRTC)——GCC分析(4) —— 我正在的github给大家开发一个用于做实验的项目 —— github.com/qw225967/Bifrost目标:可以让大家熟悉各类Qos能力、带宽估计能力,提供每个环节关键参数调节接口并实现一个json全配置…...
)
k8s持久化存储(NFS-StorageClass)
一、StatefulSet由以下几个部分组成: 用于定义网络标志(DNS domain)的Headless Service用于创建PersistentVolumes的volumeClaimTemplates定义具体应用的StatefulSet 二、StatefulSet 特点 StatefulSet 适用于有以下某个或多个需求的应用&a…...

Staticcheck终极指南:10个技巧提升Go代码质量与性能
Staticcheck终极指南:10个技巧提升Go代码质量与性能 【免费下载链接】go-tools Staticcheck - The advanced Go linter 项目地址: https://gitcode.com/gh_mirrors/go/go-tools Staticcheck是Go语言生态中一款强大的静态代码分析工具,它能够帮助开…...

VideoAgentTrek-ScreenFilter模型解释性研究:可视化AI决策过程增强信任
VideoAgentTrek-ScreenFilter模型解释性研究:可视化AI决策过程增强信任 你有没有遇到过这种情况?一个AI模型告诉你某段视频不合适,但你完全不明白它为什么这么判断。是画面里某个不起眼的角落触发了规则,还是模型“误解”了视频内…...
)
STM32+BME680实战:5分钟搞定气体传感器校准(附EEPROM存储技巧)
STM32BME680实战:5分钟搞定气体传感器校准(附EEPROM存储技巧) 在智能家居和便携式空气质量监测领域,BME680作为博世推出的四合一环境传感器,凭借其紧凑尺寸和多功能检测能力成为开发者首选。但实际应用中,长…...

图吧工具箱:一站式硬件检测与优化解决方案
1. 图吧工具箱:硬件玩家的瑞士军刀 第一次装机时,我盯着主板上密密麻麻的接口发懵。商家信誓旦旦保证是i7处理器,但系统属性里显示的型号总觉得不对劲。直到朋友推荐了图吧工具箱,用CPU-Z一查才发现是ES工程样品——这个188MB的绿…...

OBS与现代直播软件的对比:技术演进和设计思想分析 [特殊字符]
OBS与现代直播软件的对比:技术演进和设计思想分析 🎥 【免费下载链接】OBS Open Broadcaster Software (Deprecated: See OBS Studio repository instead) 项目地址: https://gitcode.com/gh_mirrors/ob/OBS Open Broadcaster Software࿰…...

liburing性能优化终极指南:如何实现零拷贝和极致吞吐量
liburing性能优化终极指南:如何实现零拷贝和极致吞吐量 【免费下载链接】liburing 项目地址: https://gitcode.com/gh_mirrors/li/liburing liburing是Linux系统中一款强大的异步I/O框架,它通过内核级接口提供高效的I/O操作能力,帮助…...

105【SV】SystemVerilog Interview Questions Set 6
📘 SystemVerilog 面试题集 6 —— 验证工程师的“知识锦囊” 在芯片验证面试中,除了基本概念,面试官更关注你解决实际问题的能力。今天,我们继续解析第六组面试题,涵盖随机化、队列、类继承、竞争避免等实用技巧。每个…...

特斯拉、英伟达、谷歌都在布局:人形机器人核心技术解析与未来应用场景
人形机器人技术全景:从核心模块到商业落地的深度拆解 当特斯拉Optimus在2023年展示折叠衬衫的能力时,很多人第一次意识到人形机器人已经离我们如此之近。不同于传统工业机械臂的单一功能,人形机器人正在突破技术边界,向通用化、智…...
)
Python turtle库实战:5分钟教你画一棵动态圣诞树(附完整源码)
Python turtle库创意编程:从圣诞树到动态艺术画的进阶指南 当第一次看到屏幕上由代码生成的图案缓缓展开时,那种创造力的爆发感令人难忘。Python的turtle库正是这样一个神奇的工具箱——它用最直观的方式将编程逻辑转化为视觉艺术。不同于枯燥的语法练习…...
,Keil单片机编程软件软件仿真+硬件仿真)
单片机编程软件很简单(七),Keil单片机编程软件软件仿真+硬件仿真
单片机编程软件的重要性不言而喻,对于单片机编程软件,大家或多或少有所接触。在往期单片机编程软件文章中,小编介绍过IAR单片机编程软件、Keil单片机编程软件。在本文中,小编将再次基于Keil软件,介绍这款单片机编程软件…...