计算机网络【Google的TCP BBR拥塞控制算法深度解析】
Google的TCP BBR拥塞控制算法深度解析
宏观背景下的BBR
慢启动、拥塞避免、快速重传、快速恢复:

说实话,这些机制完美适应了1980年代的网络特征,低带宽,浅缓存队列,美好持续到了2000年代。
随后互联网大爆发,多媒体应用特别是图片,音视频类的应用促使带宽必须猛增,而摩尔定律促使存储设施趋于廉价而路由器队列缓存猛增,这便是BBR诞生的背景。

正文之前,给出本文的图例:
BBR的组成
bbr算法实际上非常简单,在实现上它由5部分组成:

BBR(Bottleneck Bandwidth and Round-trip time)拥塞控制算法是由Google开发的一种现代化的TCP拥塞控制算法。与传统的TCP拥塞控制算法(如TCP Cubic)相比,BBR采用了不同的工作原理和算法策略。
BBR拥塞控制算法具有以下几个显著的优势:
- 高带宽利用率:BBR算法通过准确估算网络的瓶颈带宽,能够充分利用可用的带宽资源。相比传统的拥塞控制算法,如TCP Cubic,它能够更有效地利用网络带宽,提供更高的吞吐量。
- 低延迟:BBR算法通过实时测量往返时间(RTT)和带宽来调整发送速率,以最小化网络延迟。它能够更快地适应网络变化,并通过动态的发送速率控制来减少排队延迟,从而提供更低的端到端延迟。
- 公平性:BBR算法采用了公平共享带宽的策略,以避免某些连接占据过多的带宽,导致其他连接的性能下降。它能够在网络负载较高的情况下,相对公平地分配带宽资源,确保多个连接能够公正地竞争带宽。
- 适应性:BBR算法具有较好的自适应性,能够根据网络条件的变化进行实时调整。它能够快速响应网络的带宽和延迟变化,自动调整发送速率,以适应不同的网络环境和拥塞程度。
- 丢包率减少:由于BBR算法采用了基于带宽和延迟的拥塞控制策略,它能够减少网络中的拥塞和丢包情况。相比传统算法,BBR能够更好地探测和应对网络拥塞,从而减少丢包率。
a. 噪声丢包
如果是噪声丢包,在收到reordering个重复ACK后,由于bbr并不区分一个确认是ACK还是SACK引起的,所以在bbr看来,即时带宽并没有降低,可能还有所增加,所以一个数据包的丢失并不会引发什么,bbr依旧会给出一个比较大的cwnd配额,此时虽然TCP可能已经进入了Recovery状态,但bbr依旧按照自己的bw以及调整后的增益系数来计算cwnd的新值,过程中并不会受到任何TCP拥塞状态的影响。
如此一来,所有的噪声丢包就被区别开来了!bbr的宗旨是:“首先,在我的bw计算指示我发生拥塞之前,任何传统的TCP拥塞判断-丢包/时延增加,均全部失效,我并不care丢包和RTT增加”,随后brr又会说:“但是我比较care的是,RTT在一段时间内(随你怎么配,但我个人倾向于自学习)都没有达到我所采集到的最小值或者更小的值!这也许意味着着链路真的发生拥塞了!”…
b. 拥塞丢包
将a的论述反过来,我们就会得到奇妙的封闭性结论。这样,bbr不光是消除了吞吐曲线的锯齿(ssthresh所致,bbr并不使用ssthresh!),而且还消除了传统拥塞控制算法的判断滞后性问题。在cubic发现丢包进而判断为拥塞时,拥塞可能已经缓解了,但是cubic无法发现这一点。为什么?原因在于cubic在计算新的cwnd的时候,并没有把当前的网络状态(比如bw)当作参数,而只是一味的按照数学意义上的三次方程去计算,这是错误的,这不是一个正确的反馈系统的做法!
基于a和b,看到了吧,这就是新的拥塞判断机制!综合考虑丢包和RTT的增加:
b-1.如果丢包时真的发生了拥塞,那么测量的即时带宽肯定会减少,否则,丢包即拥塞就是谎言。
b-2.如果RTT增加时真的发生了拥塞,那么测量的即时带宽肯定会减少,否则,时延增加即拥塞就是谎言。
bbr测量了即时带宽,这个统一cwnd和rtt的计量,完全忽略了丢包,因此bbr的算法思想是TCP拥塞控制的正轨!事实上,丢包本就不应该作为一种拥塞的标志,它只是拥塞的表现。
拥塞控制算法(如TCP拥塞控制算法)的主要目标是通过监测丢包事件来判断网络的拥塞程度,并调整发送速率以缓解拥塞。然而,对于噪声丢包,这些算法并不会做出相应的调整,因为噪声丢包并不表示网络拥塞。因此,对于拥塞控制算法来说,区分噪声丢包和拥塞丢包是非常重要的。
的调整,因为噪声丢包并不表示网络拥塞。因此,对于拥塞控制算法来说,区分噪声丢包和拥塞丢包是非常重要的。
BBR拥塞控制算法在这方面相对于传统算法具有优势,它通过观察发送数据包的出队情况和接收确认ACK的延迟时间,估计网络的瓶颈带宽,并使用这些信息来动态调整发送速率。BBR算法在设计上能够更好地识别和应对拥塞丢包,从而提供更好的网络性能和拥塞控制。
相关文章:
计算机网络【Google的TCP BBR拥塞控制算法深度解析】
Google的TCP BBR拥塞控制算法深度解析 宏观背景下的BBR 慢启动、拥塞避免、快速重传、快速恢复: 说实话,这些机制完美适应了1980年代的网络特征,低带宽,浅缓存队列,美好持续到了2000年代。 随后互联网大爆发&#x…...
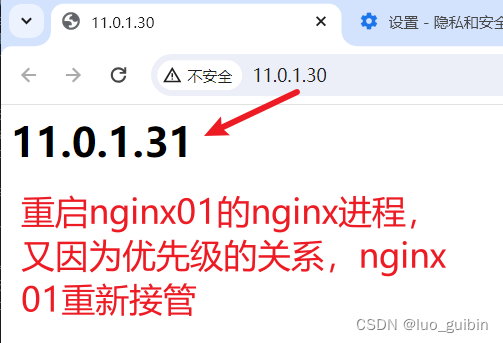
lvs+keepalived+nginx实现四层负载+七层负载
目录 一、lvs配置 二、nginx配置 三、测试 3.1 keepalived负载均衡 3.2 lvskeepalived高可用 3.3 nginx高可用 主机IPlvs01-33 11.0.1.33 lvs02-3411.0.1.34nginx0111.0.1.31nginx0211.0.1.32VIP11.0.1.30 4台主机主机添加host [rootnginx01 sbin]# cat /etc/hosts 127.0.0.…...
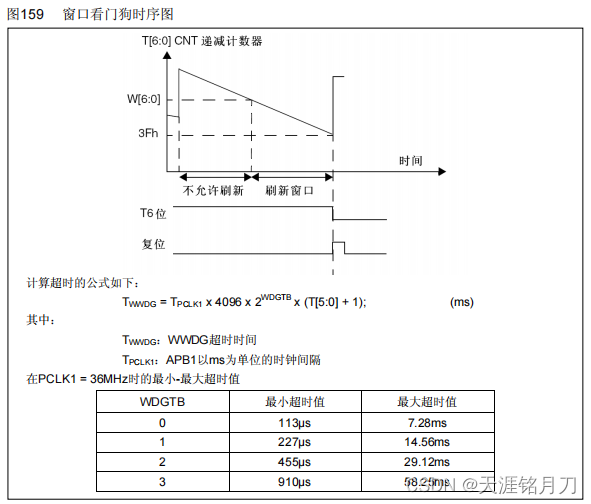
独立看门狗与窗口看门狗
一、简介 STM32F10xxx内置两个看门狗,提供了更高的安全性、时间的精确性和使用的灵活性。两个看门狗设备(独立看门狗和窗口看门狗)可用来检测和解决由软件错误引起的故障;当计数器达到给定的超时值时,触发一个中断(仅适用于窗口型看门狗)或产…...

【CTF杂项】常见文件文件头文件尾格式总结 各类文件头
常见文件文件头文件尾格式总结及各类文件头 以下是常见文件的文件头格式总结及各类文件头的描述: 图像文件: JPEG:文件头格式为FF D8 FF,文件尾格式为FF D9。PNG:文件头格式为89 50 4E 47 0D 0A 1A 0A,文件…...

深度学习-模型转换_所需算力相关
模型转换相关 tensflow转onnx python -m tf2onnx.convert \--graphdef /root/autodl-tmp/warren/text-detection-ctpn/data/ctpn.pb \--output ./model.onnx --inputs Placeholder:0 --outputs Reshape_2:0,rpn_bbox_pred/Reshape_1:0 pytorch转onnx #!/usr/…...
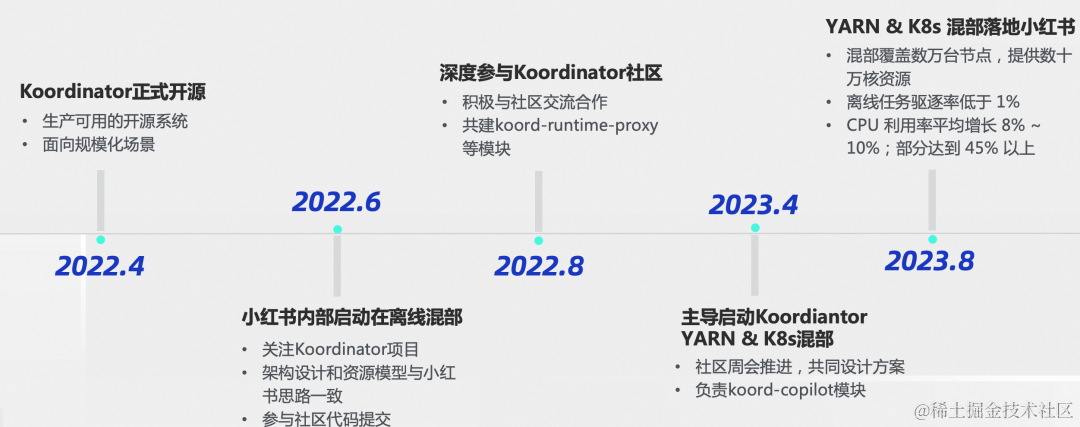
Koordinator 助力云原生应用性能提升:小红书混部技术实践
作者:宋泽辉(小红书)、张佐玮(阿里云) 编者按: Koordinator 是一个开源项目,是基于阿里巴巴内部多年容器调度、混部实践经验孵化诞生,是行业首个生产可用、面向大规模场景的开源混…...
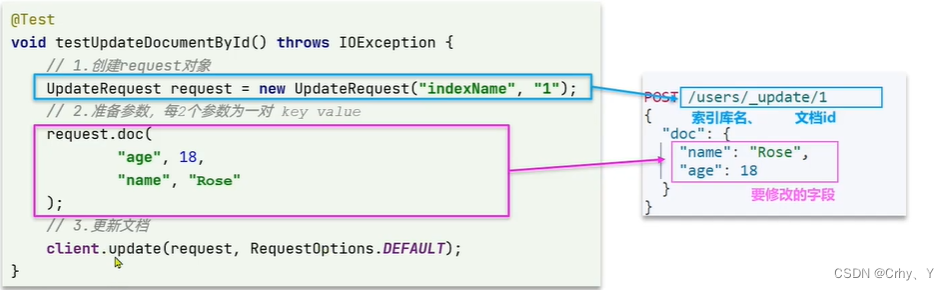
java中如何使用elasticsearch—RestClient操作文档(CRUD)
目录 一、案例分析 二、Java代码中操作文档 2.1 初始化JavaRestClient 2.2 添加数据到索引库 2.3 根据id查询数据 2.4 根据id修改数据 2.4 删除操作 三、java代码对文档进行操作的基本步骤 一、案例分析 去数据库查询酒店数据,导入到hotel索引库࿰…...

MySQL自定义函数
MySQL自定义函数 函数与存储过程类似,也是一组预先编译好的SQL语句的集合,但是存储过程可以有0个或多个返回,函数就只能有一个返回 创建函数 #语法 参数列表包含两部分 参数名和参数类型 #函数体必须有return语句 且每个sql语句后要以;结尾 所…...
)
技术学习|CDA level I 数据库应用(数据操作语言DML)
数据操作语言(DML)是对表中记录进行添加、更新、删除等操作的语言。 一、添加数据 在数据表中填充数据有两种方法,第一种方法是使用insert into语句向数据表中直接录入每行数据信息,但并不常用,因为分析使用的数据很…...
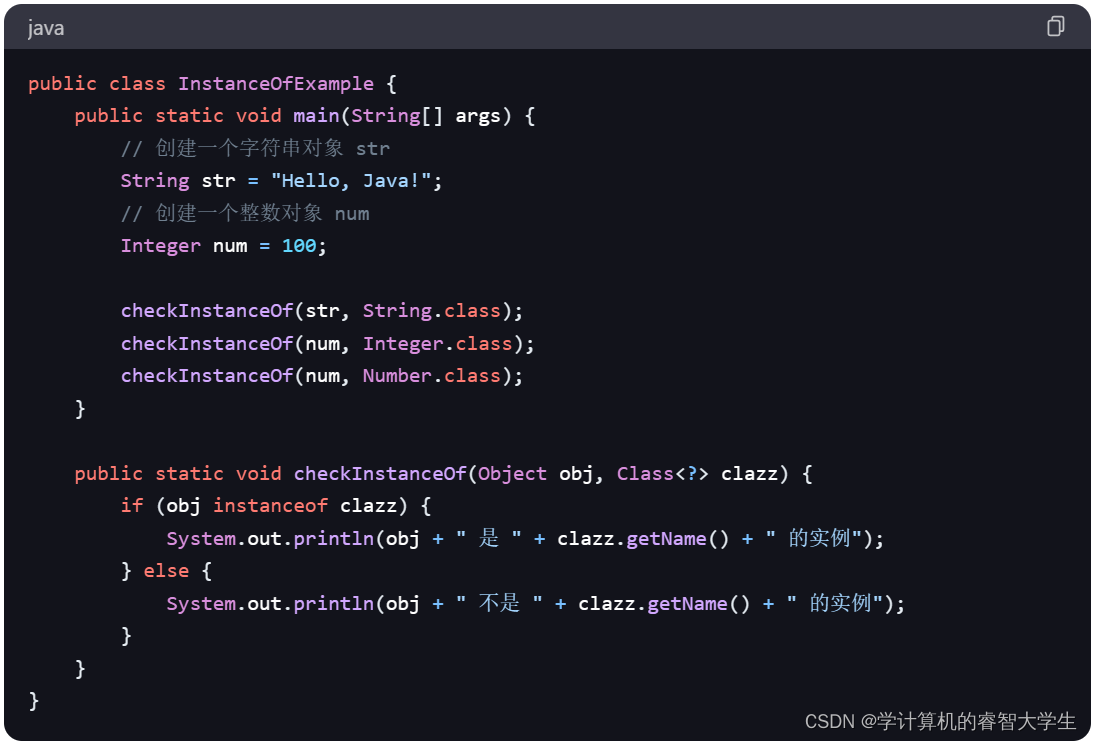
关键字:instanceof关键字
在 Java 中,instanceof关键字用于检查一个对象是否是某个特定类或其子类的实例。它的语法如下: 其中,Object是要检查的对象,Class是要检查的类或接口。 instanceof关键字的返回值是一个布尔值,如果对象Object是类Cla…...

【LeetCode:34. 在排序数组中查找元素的第一个和最后一个位置 | 二分】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...

年度征文|回顾2023我的CSDN
一年转眼而逝,回顾这一年在csdn的创作,学习,记录历程。回顾过去,才能展望未来,首先看图说话。 今年在csdn的访问量已由年初的2万到年末的50w。粉丝有年初的300个左右,增加到4000个左右。我年初的目标是粉丝…...
)
3.无重复字符的最长子串(滑动窗口,C解答)
题目描述: 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2: 输入: s "bbbbb&quo…...

什么是系统设计 – 学习系统设计
系统设计被定义为为系统的不同组件、接口和模块创建架构并提供有助于在系统中实现这些元素的相应数据的过程。系统设计是任何分布式系统设计背后的核心概念。 系统设计涉及识别数据源,它是描述、创建和规划框架以满足特定业务的必要性和先决条件的直觉。 为什么要…...

基于Python的城市热门美食数据可视化分析系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 本项目利用网络爬虫技术从XX点评APP采集北京市的餐饮商铺数据,利用数据挖掘技术对北京美食的分布、受欢迎程度、评价、评论、位置等情况进行了深入分析,方便了解城市美食店…...
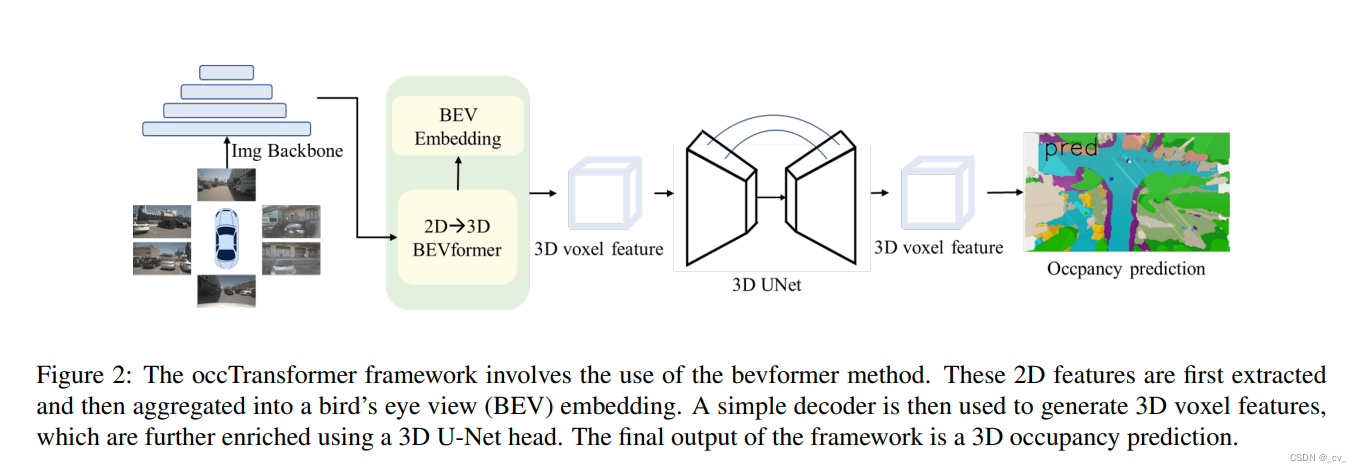
万字长文谈自动驾驶occupancy感知
文章目录 prologue欢迎大家点赞收藏与我交流讨论paper listVision-based occupancy :1. [MonoScene: Monocular 3D Semantic Scene Completion [CVPR 2022]](https://arxiv.org/pdf/2112.00726.pdf)2. [Tri-Perspective View for Vision-Based 3D Semantic Occupancy Predictio…...
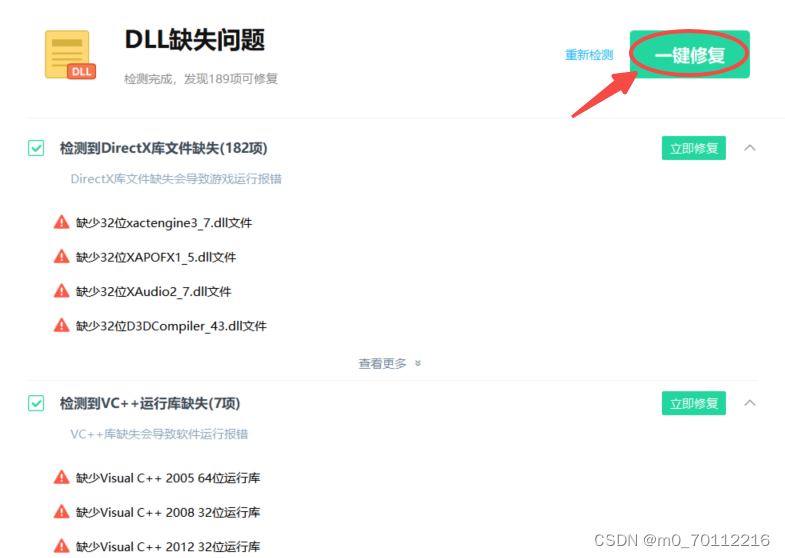
KBDNO1.DLL文件缺失,软件或游戏无法启动运行,怎样快速修复
不少小伙伴,求助电脑报错“KBDNO1.DLL文件缺失,软件或游戏无法启动或运行”,应该怎么办? 首先,我们先来了解“KBDNO1.DLL文件”是什么? KBDNO1.DLL是Windows操作系统中的一个动态链接库文件,主…...
计算机网络【EPOLL 源码详解】
IO多路复用 在以前,传统的网络编程是多线程模型,一个线程单独处理一个请求。 然而,线程是很昂贵的资源: 线程的创建和销毁成本很高,linux的线程实际上是特殊的进程;因此通常会使用线程池来减少线程创建和…...

第82讲:MySQL Binlog日志的滚动
MySQL Binlog日志的滚动 MySQL Binlog日志滚动指的就是产生一个新的Binlog日志,然后进行记录,因为如果都在一个Binlog中记录,查询是非常慢的,检索的效率也很低。 Binlog日志滚动有三种方法: 重启MySQL 数据库一般不重…...

2024.1.3C语言补录 宏函数
在C语言中,宏函数可以使用预处理器指令 #define 来定义。宏函数与常规函数类似,但它们在预处理阶段进行替换,而不是在运行时。 定义:#define 宏名称(参数列表) 宏体 其中: #define 是预处理器指令,用于定义宏。宏名…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...