深度学习课程实验二深层神经网络搭建及优化
一、 实验目的
1、学会训练和搭建深层神经网络;
2、掌握超参数调试正则化及优化。
二、 实验步骤
初始化
1、导入所需要的库
2、搭建神经网络模型
3、零初始化
4、随机初始化
5、He初始化
6、总结三种不同类型的初始化
正则化
1、导入所需要的库
2、使用非正则化模型
3、对模型进行L2正则化(包括正向和反向传播)
4、对模型进行dropout正则化(包括正向和反向传播)
5、总结三种模型的结果
梯度检验
1、导入所需要的库
2、理解梯度检验原理
3、一维梯度检验
4、N维梯度检验(包括前向和反向传播)
梯度下降的优化
1、导入所需要的函数
2、进行梯度下降
3、进行Mini-Batch梯度下降
4、Momentum优化算法
5、Adam优化算法
三、 实验代码分析
1、import numpy as np:提供了Python进行科学计算的基础工具,包括支持多维数组和矩阵运算的功能。
2、import matplotlib.pyplot as plt:用于绘制图形和数据可视化的库。
3、from reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_dec:reg_utils:一个自定义的模块,其中包含了一些常用的辅助函数,用于实现正则化的机器学习模型应用,sigmoid:一个自定义的函数,用于计算sigmoid函数的值。relu:一个自定义的函数,用于计算ReLU(Rectified Linear Unit)函数的值。plot_decision_boundary:一个自定义的函数,用于绘制分类器的决策边界。initialize_parameters:一个自定义的函数,用于初始化参数。load_2D_dataset:一个自定义的函数,用于加载一个二维数据集。predict_dec:一个自定义的函数,用于绘制分类器的预测结果。
4、from reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parameters:compute_cost:一个自定义的函数,用于计算代价函数的值。predict:一个自定义的函数,用于进行预测,forward_propagation:一个自定义的函数,用于进行前向传播过程。backward_propagation:一个自定义的函数,用于进行反向传播过程。update_parameters:一个自定义的函数,用于更新参数。
5、import sklearn:用于机器学习的库,提供了许多用于数据预处理、模型选择和评估等功能的函数和类。
6、import sklearn.datasets:sklearn库中的一个模块,包含了许多用于加载示例数据集的函数。
7、import scipy.io:scipy库中的一个模块,提供了与数据输入输出相关的功能,例如读取和写入MATLAB文件等。
8、from testCases import :这是一个自定义的模块,包含了一些测试用例,用于验证代码的正确性。
9、train_X, train_Y, test_X, test_Y = load_2D_dataset():调用了名为 load_2D_dataset()的函数,并将返回的结果赋值给了四个变量:train_X、train_Y、test_X和 test_Y,load_2D_dataset()函数是自定义的一个函数,用于加载一个二维数据集。根据函数的命名,可以猜测该函数会返回训练集的特征矩阵 train_X、训练集的标签向量train_Y、测试集的特征矩阵test_X和测试集的标签向量test_Y。
10、if lambd == 0 and keep_prob == 1:
grads = backward_propagation(X, Y, cache):条件判断,如果 lambd等于0并且keep_prob等于1。这个条件判断的目的是判断是否使用正则化或者Dropout技术。如果lambd等于0且 keep_prob等于1,表示没有进行正则化且没有使用Dropout技术。在这种情况下,通过调用backward_propagation()函数进行反向传播,计算梯度值。backward_propagation()函数接收输入X、标签 Y和缓存cache,返回计算出的梯度值grads。
11、elif lambd != 0:
grads = backward_propagation_with_regularization(X, Y, cache, lambd):条件判断,如果lambd等于0并且keep_prob等于1。这个条件判断的目的是判断是否使用正则化或者Dropout技术。如果 lambd等于0且keep_prob等于1,表示没有进行正则化且没有使用Dropout技术。然后通过调backward_propagation()函数进行反向传播,计算梯度值。backward_propagation()函数接收输入X标签、Y和缓存cache,返回计算出的梯度值grads。
12、elif keep_prob < 1:
grads = backward_propagation_with_dropout(X, Y, cache, keep_prob):条件判断,如果lambd不等于0。这个条件判断的目的是判断是否使用L2正则化。如果lambd不等于0,表示使用L2正则化。
在这种情况下,通过调用backward_propagation_with_regularization()函数进行反向传播,计算带有L2正则化的梯度值。backward_propagation_with_regularization()函数接收输入X、标签Y、缓存 cache和正则化参数lambd,返回计算出的梯度值grads。
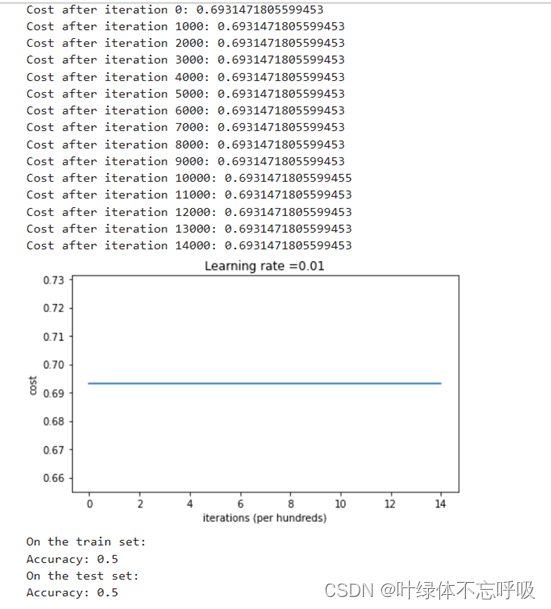
13、plt.plot(costs):使用plot()函数绘制图形。costs是一个列表,包含了每次迭代后计算得到的代价函数值。该函数会将costs中的值连接起来,生成一条曲线,表示代价函数随着迭代次数的变化情况。
14、plt.ylabel(‘cost’):设置y轴标签为"cost"。ylabel()函数用于设置y轴的标签文本。
15、plt.xlabel(‘iterations (x1,000)’):设置x轴标签为"iterations (x1,000)“。xlabel()函数用于设置x轴的标签文本。
16、plt.title(“Learning rate =” + str(learning_rate)):设置图形的标题为"Learning rate = learning_rate”。title()函数用于设置图形的标题。
17、plt.show():显示绘制的图形。show()函数用于显示所有已创建的图形。
18、axes.set_xlim([-0.75,0.40]):设置x轴的范围为[-0.75, 0.40]。set_xlim()函数用于设置x轴的取值范围。
19、axes.set_ylim([-0.75,0.65]):设置y轴的范围为[-0.75, 0.65]。set_ylim()函数用于设置y轴的取值范围。
20、plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y):调用 plot_decision_boundary()函数来绘制决策边界。
21、plot_decision_boundary()函数接受三个参数,一个是一个lambda表达式,用于定义如何预测数据点的标签,第二个是训练集的特征矩阵train_X,第三个是训练集的标签向量train_Y。lambda x: predict_dec(parameters, x.T)是一个lambda表达式,用于定义如何预测数据点的标签。parameters是模型的参数,x.T是数据点的特征向量。
22、cross_entropy_cost = compute_cost(A3, Y):计算交叉熵损失的代价。A3是模型的输出,即预测的结果。Y是样本的真实标签值。compute_cost()函数接收两个参数,即预测值和真实值,返回计算得到的交叉熵损失。
23、 L2_regularization_cost = (1./mlambd/2)(np.sum(np.square(W1))+np.sum(np.square(W2))+np.sum(np.square(W3))):计算L2正则化项的代价。L2_regularization_cost是L2正则化项的代价。
m是样本的数量。lambd是正则化超参数。W1、W2、W3是模型的权重参数。通过 np.sum(np.square(W1))的方式,计算了W1的平方和,依此类推计算了W2和W3的平方和。最终通过(1./mlambd/2)来计算L2正则化项的惩罚,得到L2正则化项的代价。
24、cost = cross_entropy_cost + L2_regularization_cost:将交叉熵损失代价与L2正则化项的代价相加,得到总的代价。cost是模型总的代价,即交叉熵损失代价与L2正则化项的代价之和。
25、dZ3 = A3 - Y:将交叉熵损失代价与L2正则化项的代价相加,得到总的代价。cost是模型总的代价,即交叉熵损失代价与L2正则化项的代价之和。
26、dW3 = 1./m * np.dot(dZ3, A2.T) + lambd/m*W3:计算输出层的激活值A3与真实标签Y之间的差异。dZ3是输出层的误差项,计算参数矩阵W3的梯度。dW3是参数矩阵W3的梯度。A2.T是A2的转置,表示上一层的激活值。lambd是正则化超参数。
27、db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True):计算偏置项b3的梯度。db3是偏置项b3的梯度。axis=1表示在行方向上求和。keepdims=True表示保持求和后的维度与原来一致。
28、dA2 = np.dot(W3.T, dZ3):计算前一层的激活值A2的误差。dA2是前一层的激活值A2的误差。
29、dZ2 = np.multiply(dA2, np.int64(A2 > 0)):计算隐藏层2的误差项。dZ2是隐藏层2的误差项。np.int64(A2 > 0)用于生成一个与A2形状相同的矩阵,其中元素值为0或1,表示A2中大于0的位置。np.multiply()用于按元素进行相乘运算。计算隐藏层2的误差项。dZ2是隐藏层2的误差项。np.int64(A2 > 0)用于生成一个与A2形状相同的矩阵,其中元素值为0或1,表示A2中大于0的位置。np.multiply()用于按元素进行相乘运算。
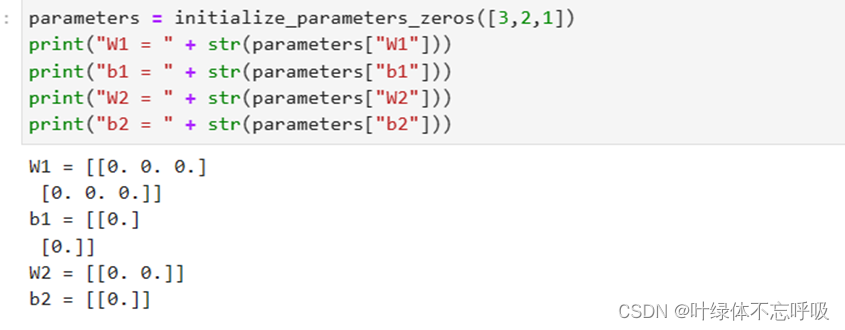
30、parameters[‘W’ + str(i)] = np.zeros((layers_dims[i], layers_dims[i - 1])):初始化权重矩阵W。parameters[‘W’ + str(i)]表示第i层的权重参数矩阵W。layers_dims[i]表示第i层的神经元数量。layers_dims[i - 1]表示第i-1层的神经元数量。np.zeros((layers_dims[i], layers_dims[i - 1]))创建了一个形状为 (layers_dims[i], layers_dims[i - 1])的全零矩阵,用于存储第i层的权重参数。
31、 parameters[‘b’ + str(i)] = np.zeros((layers_dims[i], 1)):初始化偏置parameters[‘b’ + str(i)]表示第i层的偏置项b。layers_dims[i]表示第i层的神经元数量。np.zeros((layers_dims[i], 1))创建了一个形状为(layers_dims[i], 1)的全零矩阵,用于存储第i层的偏置项。
32、parameters[‘W’ + str(i)] = np.random.randn(layers_dims[i], layers_dims[i - 1]) * 10:np.random.randn(layers_dims[i], layers_dims[i - 1]):生成一个形状为 (layers_dims[i], layers_dims[i - 1])的随机数矩阵,服从标准正态分布(均值为0,方差为1),layers_dims[i]表示第i层的神经元数量。layers_dims[i - 1]表示第i-1层的神经元数量。np.random.randn(layers_dims[i], layers_dims[i - 1]) * 10:将上面生成的随机数矩阵中的值都乘以10。这样做的目的是将权重矩阵的初始值放大10倍,以增加模型的表达能力。parameters[‘W’ + str(i)] = np.random.randn(layers_dims[i], layers_dims[i - 1]) * 10:将生成的随机数矩阵赋值给对应的权重矩阵W。parameters[‘W’ + str(i)]表示第i层的权重参数矩阵W。
33、parameters[‘W’ + str(i)] = np.random.randn(layers_dims[i],layers_dims[i - 1]) * np.sqrt(2.0 / layers_dims[i - 1]):np.random.randn(layers_dims[i], layers_dims[i - 1]):生成一个形状为(layers_dims[i], layers_dims[i - 1])的随机数矩阵,服从标准正态分布(均值为0,方差为1)。layers_dims[i]表示第i层的神经元数量。
layers_dims[i - 1]表示第i-1层的神经元数量。np.random.randn(layers_dims[i], layers_dims[i - 1]) * 10:将上面生成的随机数矩阵中的值都乘以10。这样做的目的是将权重矩阵的初始值放大10倍,以增加模型的表达能力。parameters[‘W’ + str(i)] = np.random.randn(layers_dims[i], layers_dims[i - 1]) * 10:将生成的随机数矩阵赋值给对应的权重矩阵W。parameters[‘W’ + str(i)]表示第i层的权重参数矩阵W。
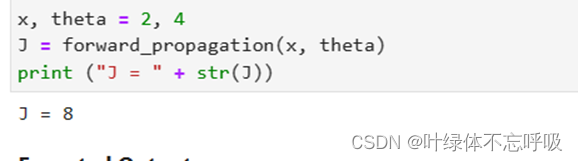
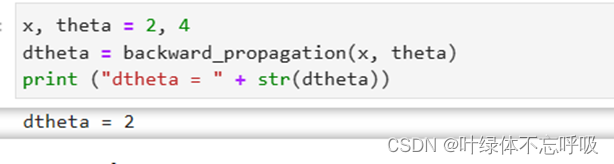
34、thetaplus = theta + epsilon:将参数theta的每个元素加上一个小的扰动值epsilon,得到thetaplus。thetaplus表示theta的加扰动后的值。
35、thetaminus = theta - epsilon:将参数theta的每个元素减去一个小的扰动值epsilon,得到thetaminus。thetaminus表示theta的减扰动后的值。
36、Jplus = forward_propagation(x, thetaplus):通过前向传播计算thetaplus对应的代价函数。Jplus表示使用thetaplus计算得到的代价函数值。
37、Jminus = forward_propagation(x, thetaminus):通过前向传播计算thetaminus对应的代价函数。Jminus表示使用thetaminus计算得到的代价函数值。
38、gradapprox = (Jplus - Jminus) / (2 * epsilon):计算数值梯度。gradapprox表示通过数值计算得到的梯度值,使用了代价函数在thetaplus和thetaminus下的差分来近似计算梯度。
39、grad = backward_propagation(x, theta):使用反向传播计算解析梯度。grad表示使用解析方法计算得到的梯度值。
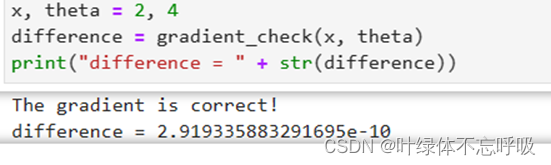
40、numerator = np.linalg.norm(grad -gradapprox):计算差分梯度和解析梯度之间的范数(欧几里得距离)作为分子。numerator表示差分梯度和解析梯度之间的范数。
41、denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox):计算解析梯度和差分梯度的范数之和作为分母。denominator表示解析梯度和差分梯度的范数之和。
42、difference = numerator / denominator:计算差分梯度和解析梯度之间的差异。difference表示差分梯度和解析梯度之间的差异,即相对误差。
43、mini_batch_X = shuffled_X[:, k * mini_batch_size : (k + 1) * mini_batch_size]
44、mini_batch_Y = shuffled_Y[:, k * mini_batch_size : (k + 1) * mini_batch_size]:mini_batch_X和mini_batch_Y分别表示当前的 mini-batch 对应的输入和输出数据,shuffled_X和shuffled_Y是经过打乱顺序后的输入数据和输出数据。在生成 mini-batches 的过程中,通过k * mini_batch_size和(k + 1) * mini_batch_size计算出当前mini-batch的起始和终止位置,然后从shuffled_X和shuffled_Y中分别取出对应部分作为当前的 mini-batch 数据。
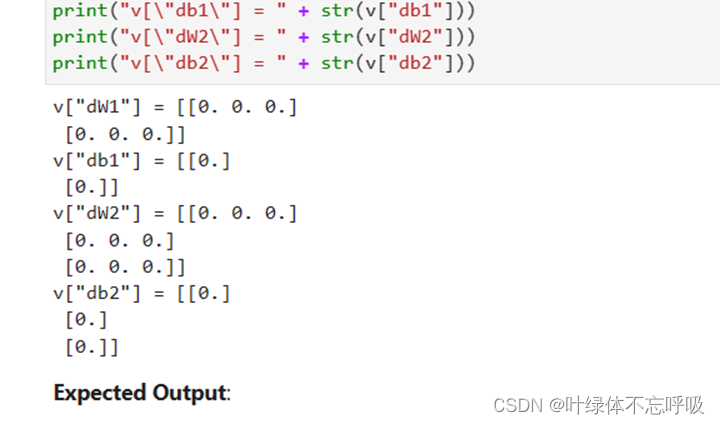
45、v[‘dW’ + str(i + 1)] = np.zeros(parameters[“W” + str(i + 1)].shape):初始化权重矩阵W的速度为零矩阵。v[‘dW’ + str(i + 1)]表示第i+1层的权重矩阵W的速度。np.zeros(parameters[“W” + str(i + 1)].shape)创建了一个与参数W相同形状的全零矩阵。初始化权重矩阵W的速度为零矩阵。v[‘dW’ + str(i + 1)]表示第i+1层的权重矩阵W的速度。np.zeros(parameters[“W” + str(i + 1)].shape)创建了一个与参数W相同形状的全零矩阵。
46、v[‘db’ + str(i + 1)] = np.zeros(parameters[“b” + str(i + 1)].shape):初始化偏置向量b的速度为零矩阵。v[‘db’ + str(i + 1)]表示第i+1层的偏置向量b的速度。
np.zeros(parameters[“b” + str(i + 1)].shape)创建了一个与参数b相同形状的全零矩阵。
四、 运行结果
regularization
1、加载数据集load_2D_dataset
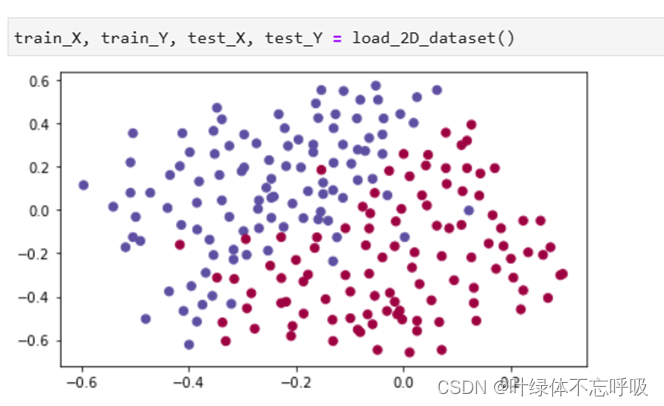
2、无正则化的模型迭代结果以及绘制的代价函数曲线图
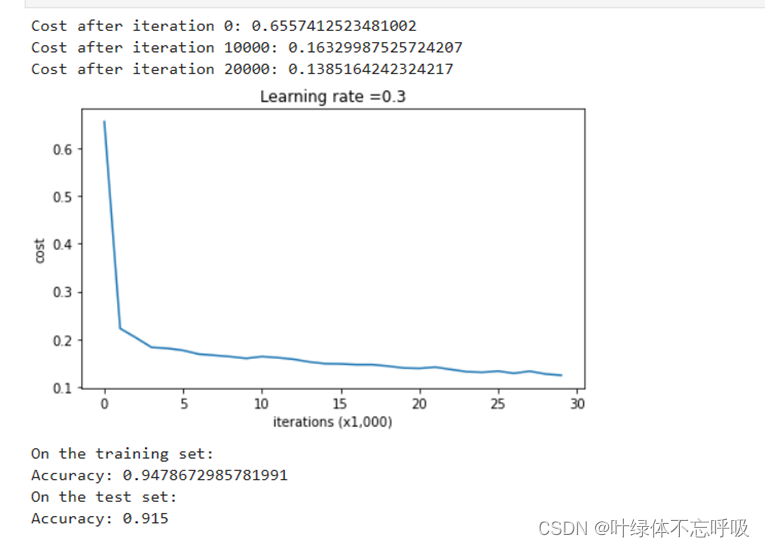
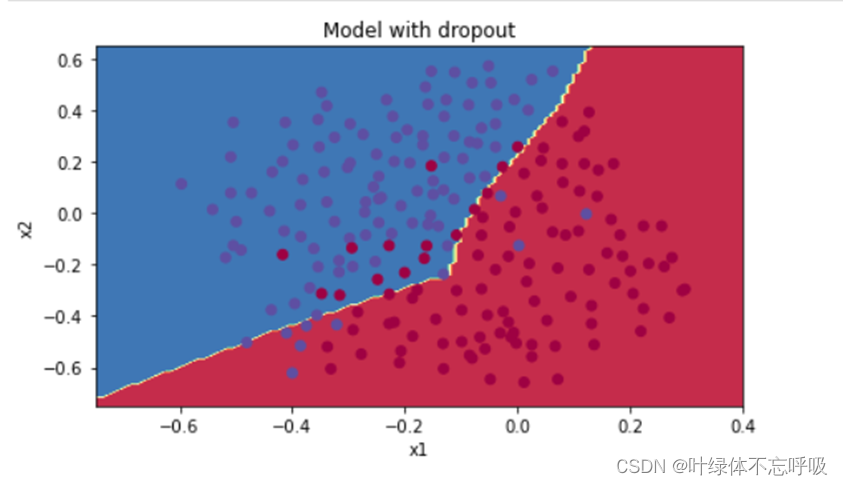
3、无正则化的模型绘制的决策边界
4、L2正则化模型的输出代价函数值

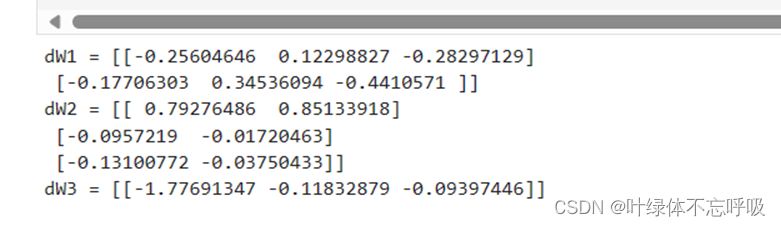
5、带有L2正则化模型反向传播结果
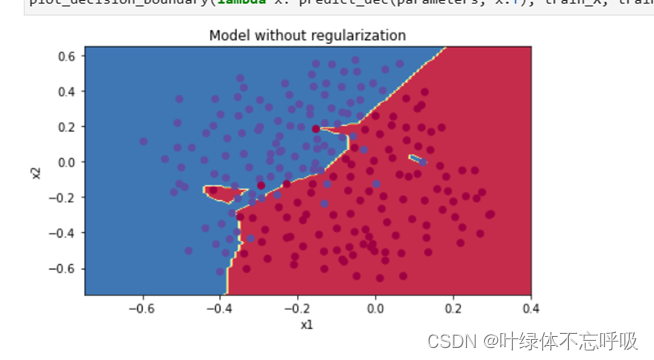
6、带有L2正则化的模型迭代结果以及绘制的代价函数曲线图
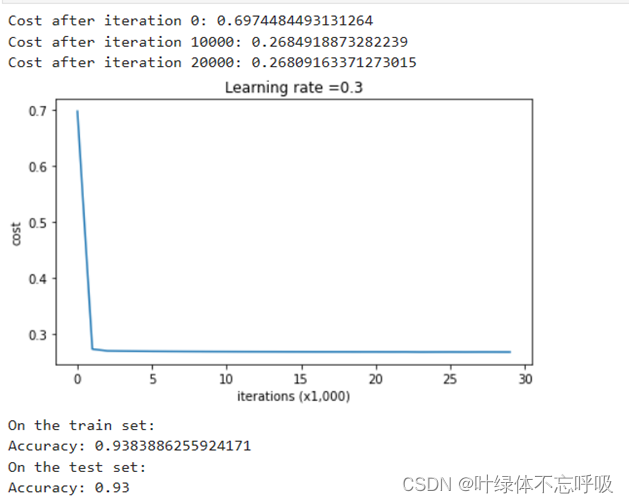
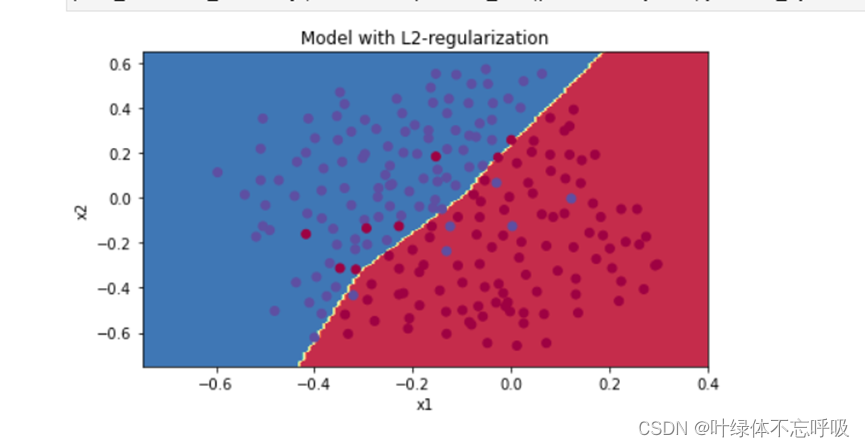
7、带有L2正则化的模型绘制的决策边界
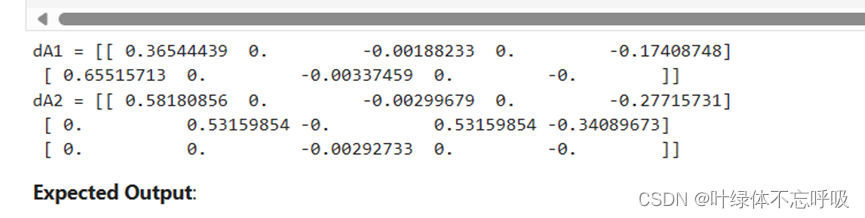
8、带有dropout正则化模型的前向传播结果

9、带有dropout正则化模型的反向传播结果
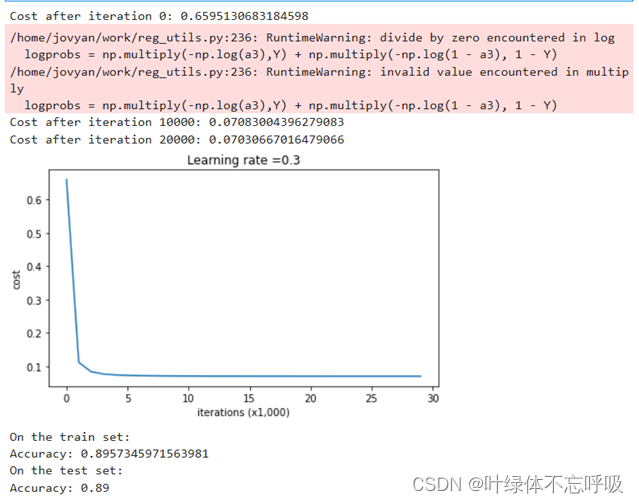
10、带有dropout正则化的模型迭代结果以及绘制的代价函数曲线图
11、带有dropout正则化的模型绘制的决策边界
initialization
1、加载数据集结果
2、零初始化参数
3、零初始化迭代结果及绘制的代价函数
4、零初始化预测结果

5、零初始化模型决策边界
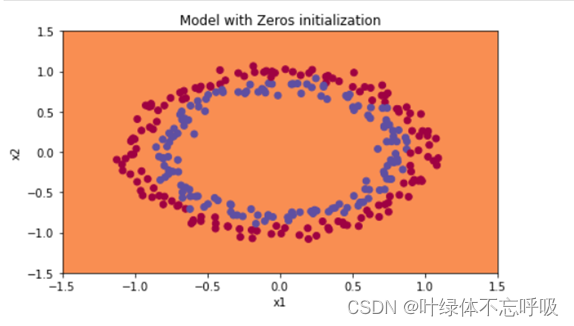
Random initialization
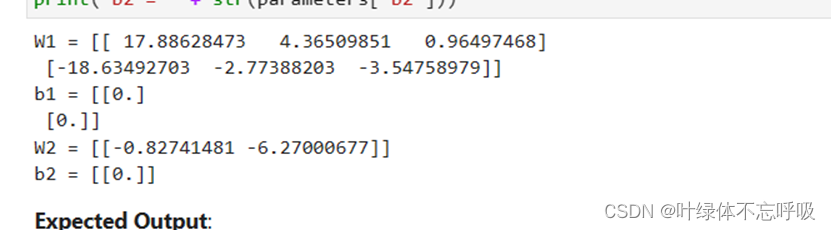
1、随机初始化参数输出结果
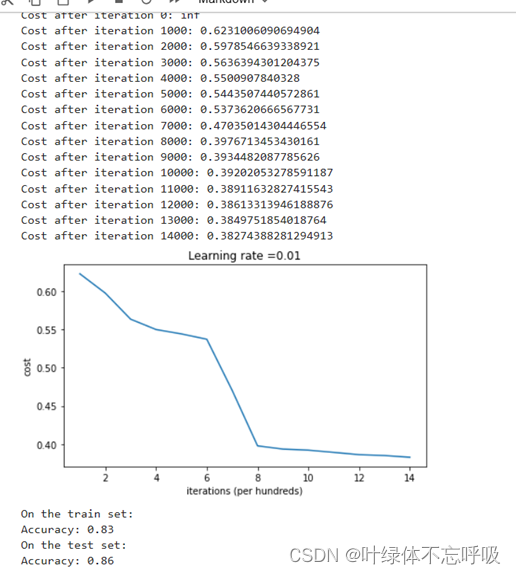
2、Random initialization迭代结果及绘制的代价函数曲线图
3、Random initialization预测结果

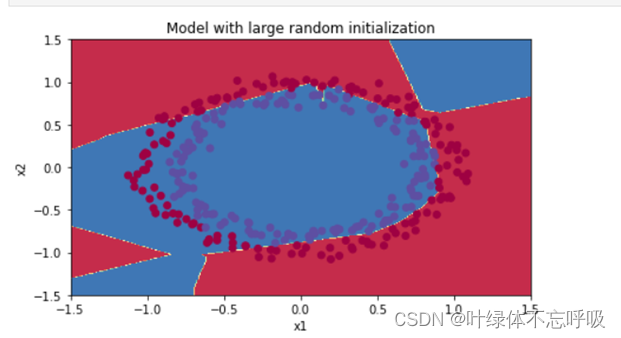
4、Random initialization模型决策边界
He-initialization
1、He-initialization初始化参数结果
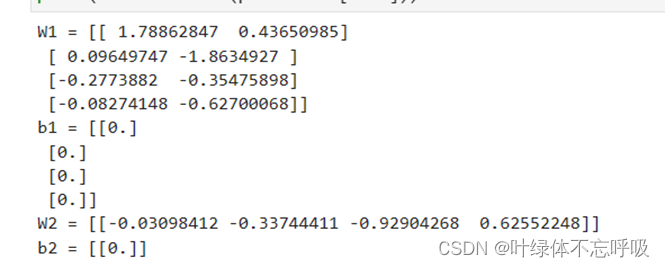
2、He-initialization迭代结果及绘制的代价函数曲线图
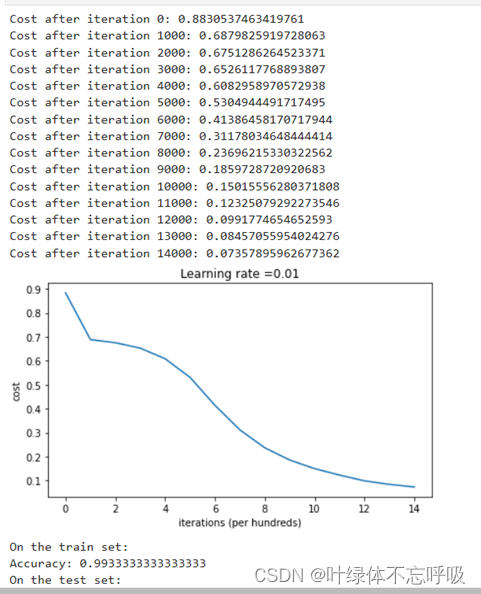
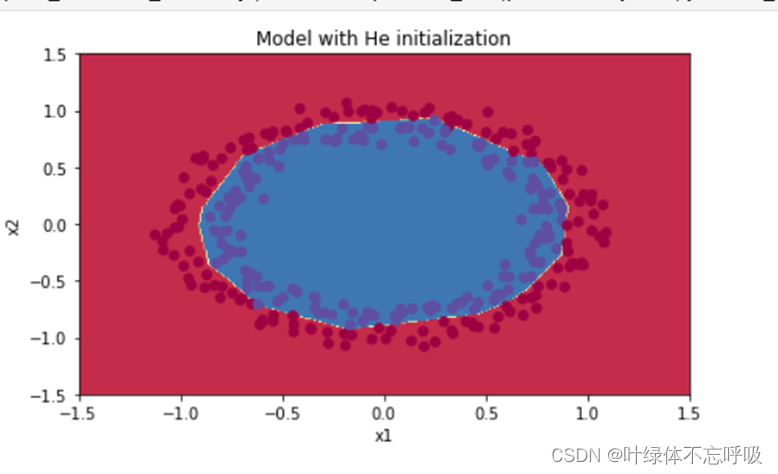
3、He-initialization模型决策边界
Gradient Checking
Optimization Methods
1、随机梯度下降更新参数
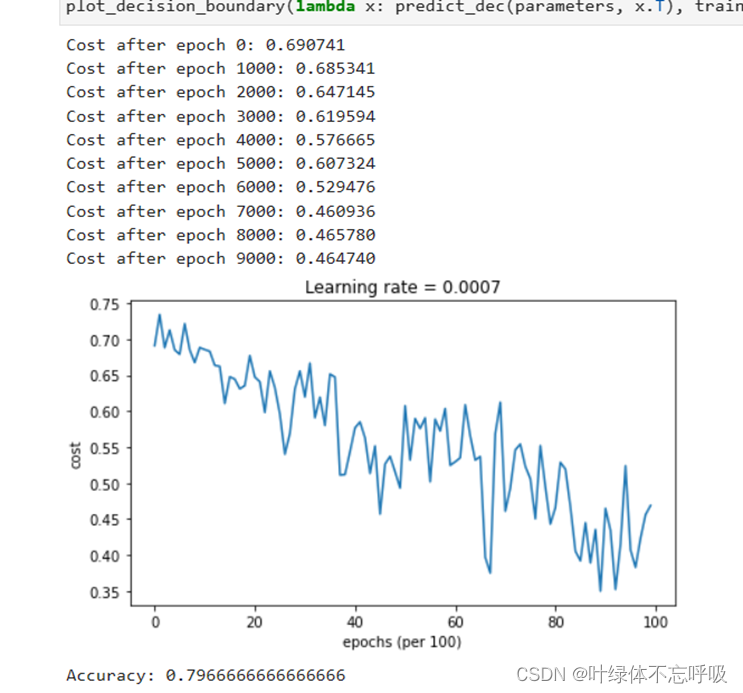
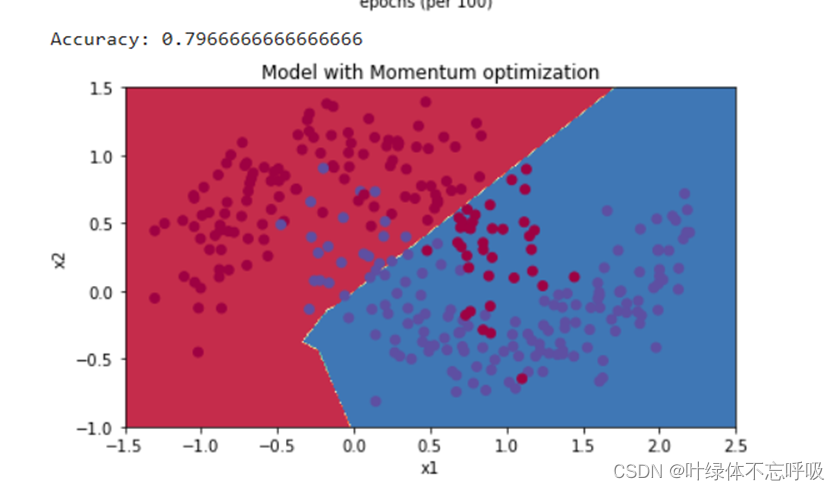
2、Momentum
3、Momentum更新参数
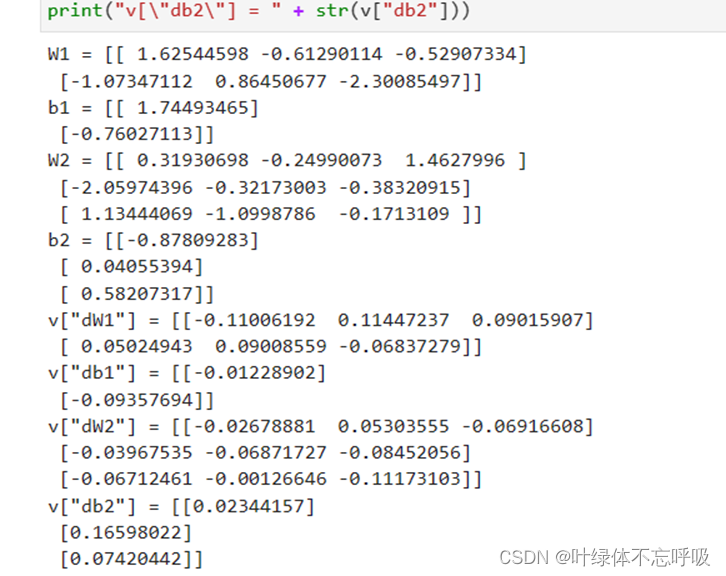
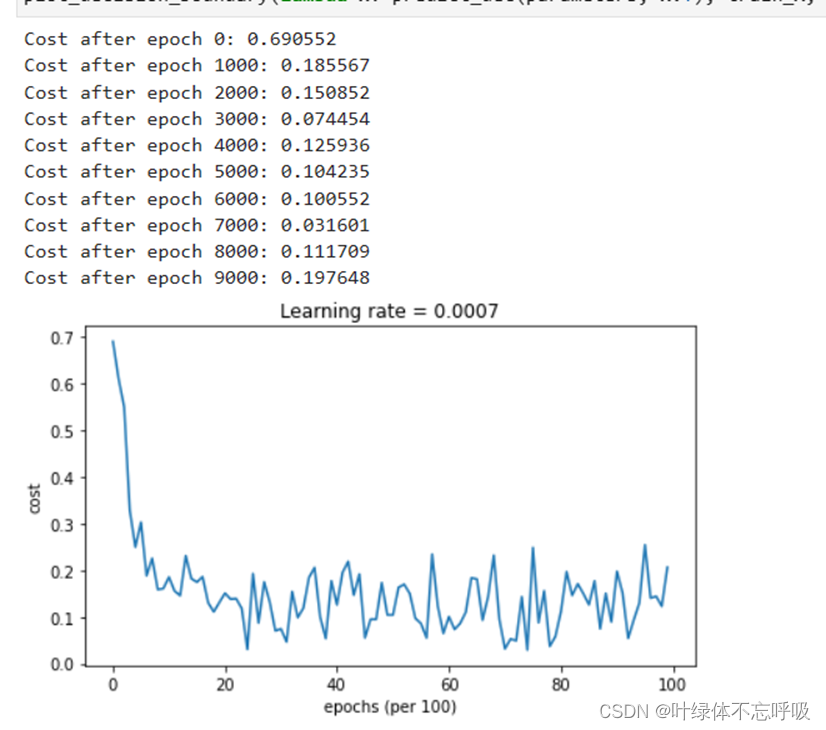
4、Adam初始化参数

5、Adam更新参数
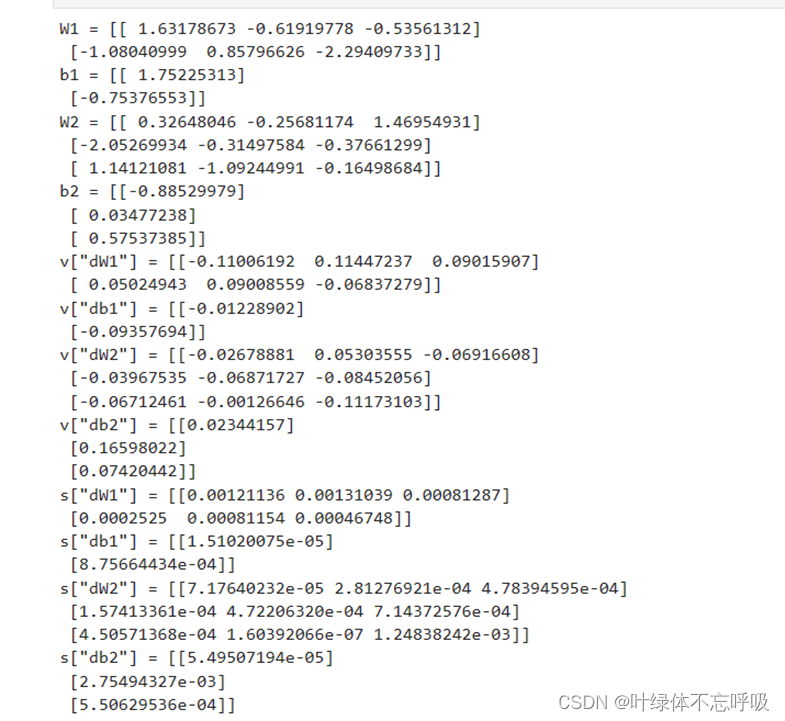
6、不同优化算法模型加载数据
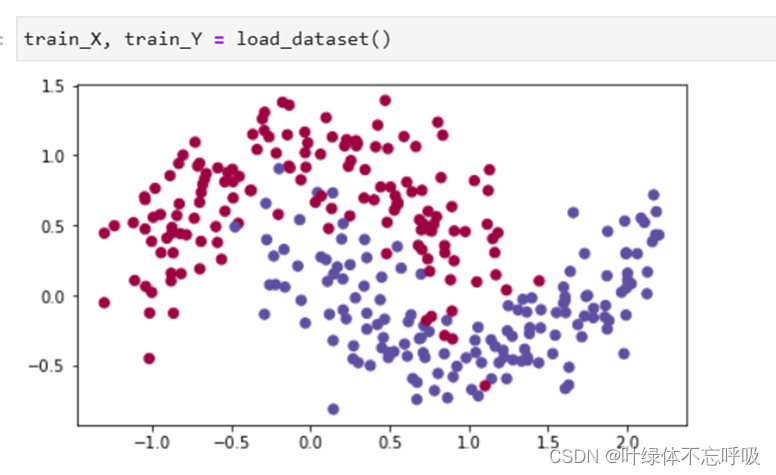
7、小批量梯度下降
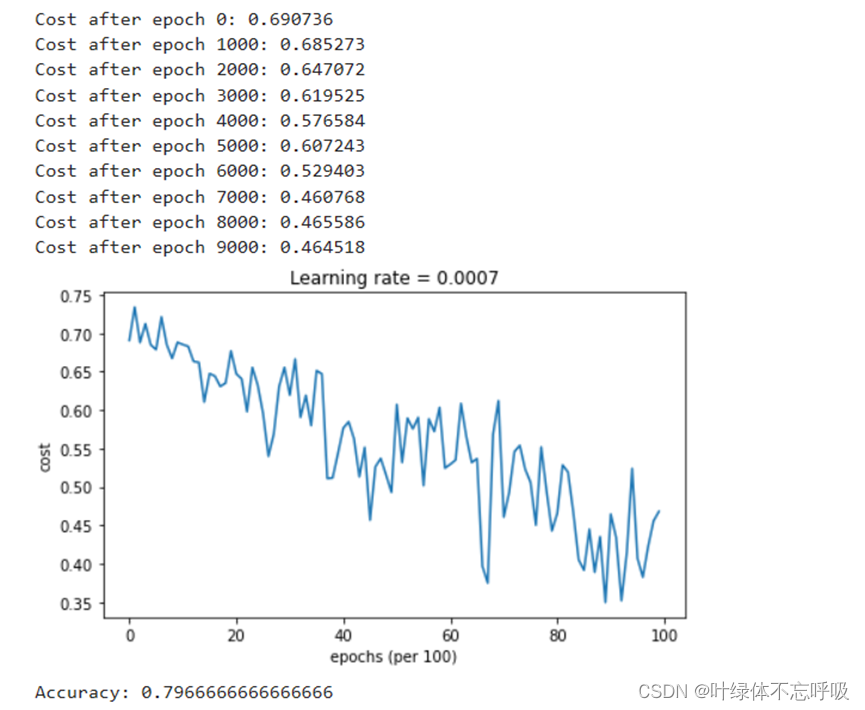
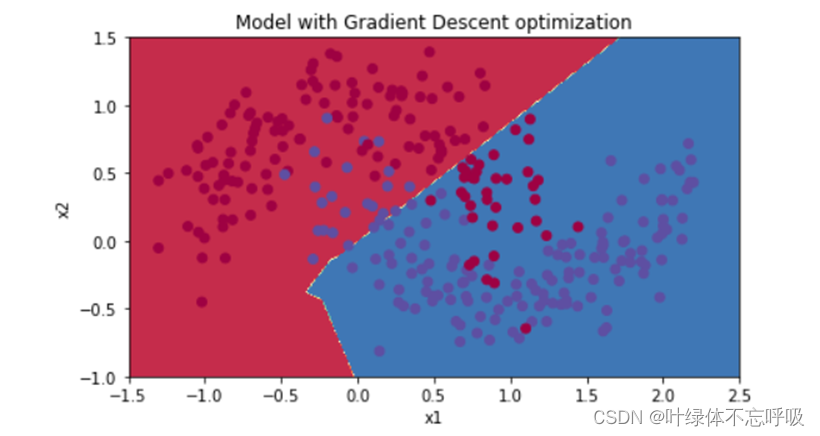
8、带冲量的小批量梯度下降
9、Adam模式的小批量梯度下降
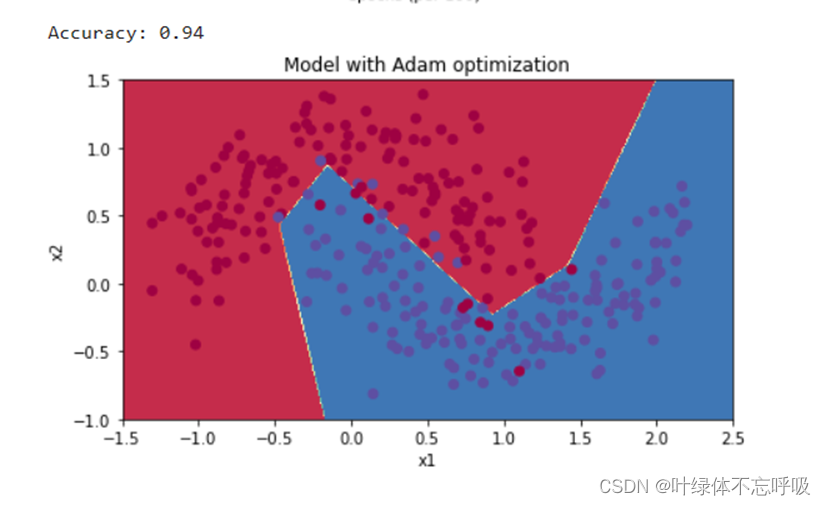
五、 实验结果分析、体会
- 参数初始化:通过实验可以观察到不同的参数初始化方法对模型收敛速度和性能的影响。可能会发现使用随机初始化或者He初始化方法能够加速模型的收敛,并改善性能。体会到合适的参数初始化可以提高模型的稳定性和准确性。
- 正则化:实验可以比较未使用正则化和使用L2和Dropout正则化方法下模型的表现差异。观察模型在训练集和测试集上的表现,从而体会到正则化在减少过拟合方面的重要作用。
- 梯度检验:实验中可以通过数值梯度和解析梯度的对比来验证反向传播算法的正确性。如果数值梯度和解析梯度之间有较小的差异,就可以确认反向传播的实现是正确的。这样的实验可以帮助加深对反向传播算法的理解。
- 优化算法:尝试使用不同的优化算法(如梯度下降、随机梯度下降、Momentum、Adam等)进行实验,并对比它们在模型训练过程中的表现。体会不同优化算法对模型收敛速度和性能的影响,以及适用于不同类型任务的优化算法选择。
相关文章:
深度学习课程实验二深层神经网络搭建及优化
一、 实验目的 1、学会训练和搭建深层神经网络; 2、掌握超参数调试正则化及优化。 二、 实验步骤 初始化 1、导入所需要的库 2、搭建神经网络模型 3、零初始化 4、随机初始化 5、He初始化 6、总结三种不同类型的初始化 正则化 1、导入所需要的库 2、使用非正则化…...
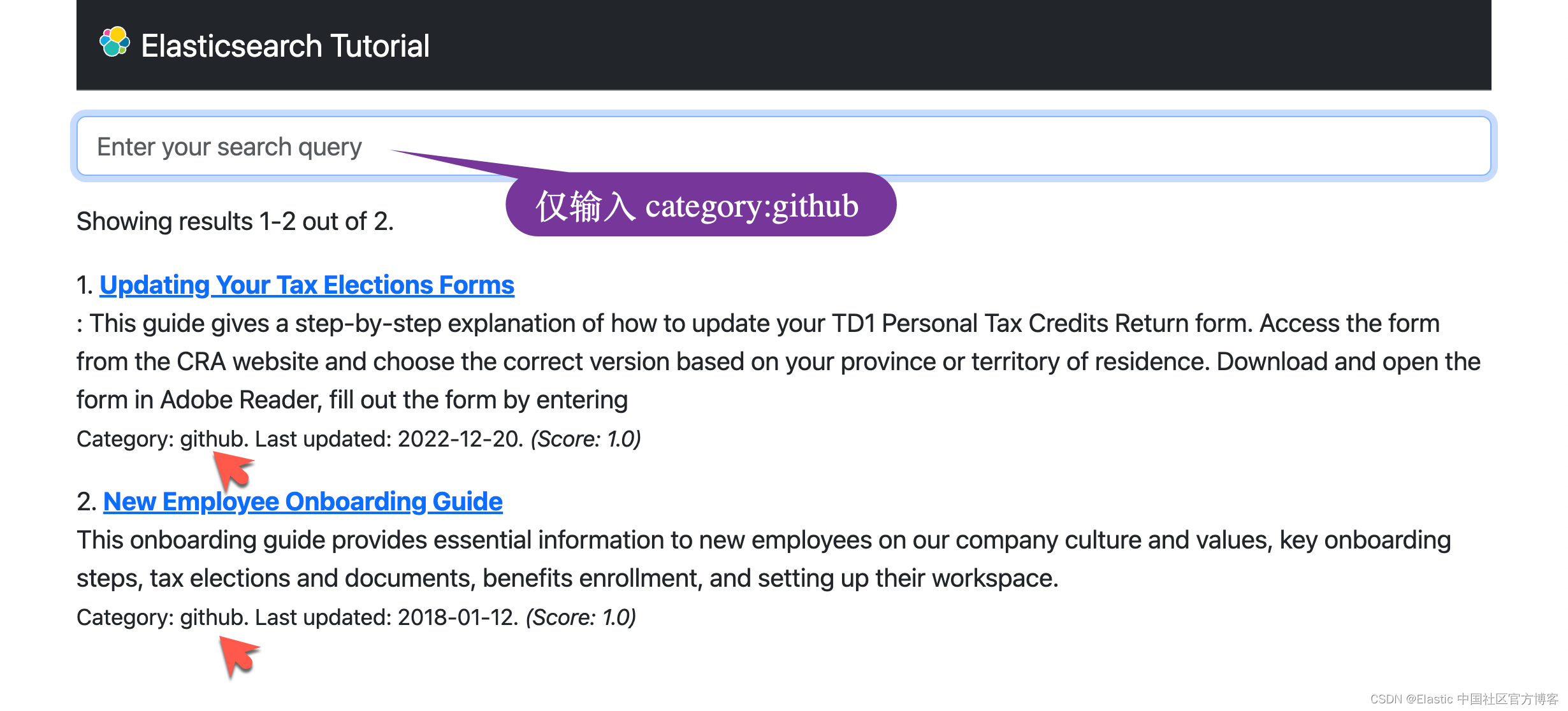
Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (二)
这个是继上一篇文章 “Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (一)” 的续篇。在今天的文章中,我们接着来完成如何进行分页及过滤。 分页 - pagination 应用程序处理大量结果通常是不切实际的。 因此࿰…...

力扣labuladong——一刷day84
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣743. 网络延迟时间 前言 Dijkstra 算法(一般音译成迪杰斯特拉算法)无非就是一个 BFS 算法的加强版,它们都是从二叉…...

Linux环境vscode clang-format格式化:vscode clang format command is not available
问题现象 vscode安装了clang-format插件,但是使用就报错 问题原因 设置中配置的clang-format插件工具路径不正确。 解决方案 确认本地安装了clang-format工具:终端输入clang-format(也可能是clang-format-13等版本,建议tab自…...
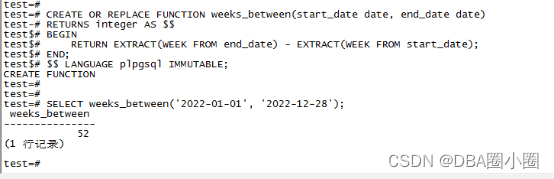
【KingbaseES】实现MySql函数WEEKS_BETWEEN
WEEKS_BETWEEN CREATE OR REPLACE FUNCTION weeks_between(start_date date, end_date date) RETURNS integer AS $$ BEGIN RETURN EXTRACT(WEEK FROM end_date) - EXTRACT(WEEK FROM start_date); END; $$ LANGUAGE plpgsql IMMUTABLE;结果展示...
@Scheduled定时任务现状与改进
项目场景: 定时任务现状:每个项目都会有一些配置信息,这些信息我们是都放在一个配置服务中,这个服务会定时从配置表中加载所有配置存入本地JVM内存,以供调用方获取(调用方集成了配置服务的SDK,…...
python+selenium爬虫笔记
本文只是做例子,具体网站路径麻烦你们换下,还有xpath路径也换下 一、安装所需要的组件(此处采用谷歌) 1、安装驱动 查看你的浏览器版本,去安装对应的版本 下载驱动 下载驱动路径 之前版本的 输入这个路径下载下来解压…...
【LMM 009】MiniGPT-4:使用 Vicuna 增强视觉语言理解能力的多模态大模型
论文描述:MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models 论文作者:Deyao Zhu∗ Jun Chen∗ Xiaoqian Shen Xiang Li Mohamed Elhoseiny 作者单位:King Abdullah University of Science and Techn…...
SpringBoot学习(三)-整合JDBC、Druid、MyBatis
注:此为笔者学习狂神说SpringBoot的笔记,其中包含个人的笔记和理解,仅做学习笔记之用,更多详细资讯请出门左拐B站:狂神说!!! 一、整合JDBC使用(理解) 创建项目 勾选依赖启动器 查看依赖 …...

如何选择合适的语音呼叫中心?
市场上不同的语音呼叫中心提供商,都有其独特的优势和不足。企业在选择语音呼叫中心服务公司时,主要考虑以下因素:服务质量、价格、技术支持、客户支持等。 首先,服务质量是选择语音呼叫中心需关注的最重要因素之一。 为确保语音…...
使用qtquick调用python程序
一. 内容简介 使用qtquick调用python程序 二. 软件环境 2.1vsCode 2.2Anaconda version: conda 22.9.0 2.3pytorch 安装pytorch(http://t.csdnimg.cn/GVP23) 2.4QT 5.14.1 新版QT6.4,,6.5在线安装经常失败,而5.9版本又无法编译64位程序…...
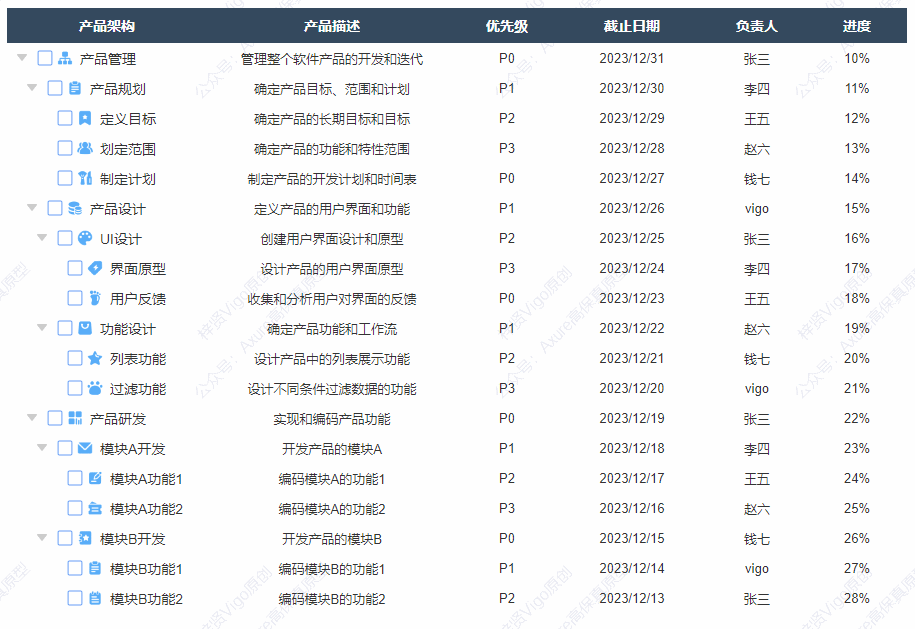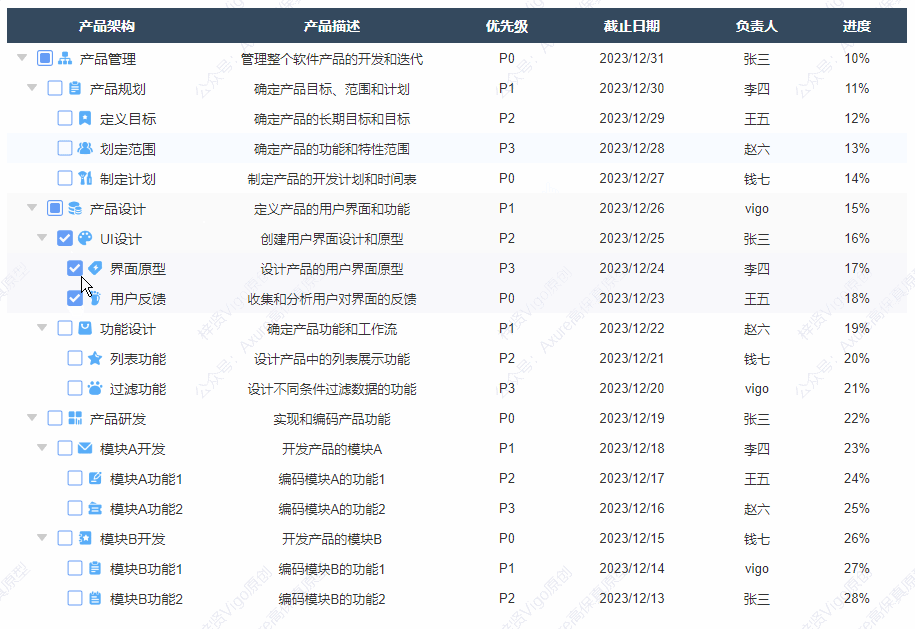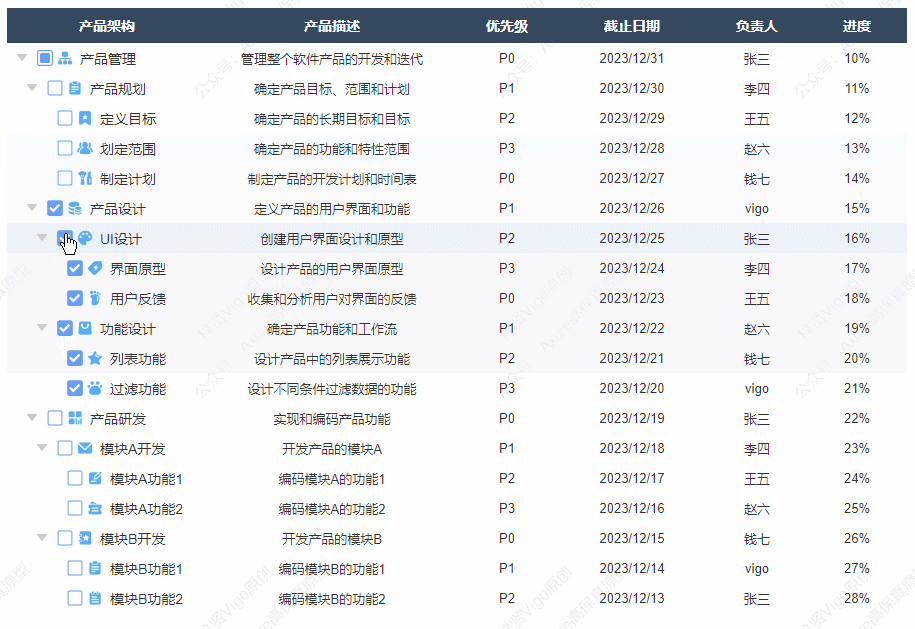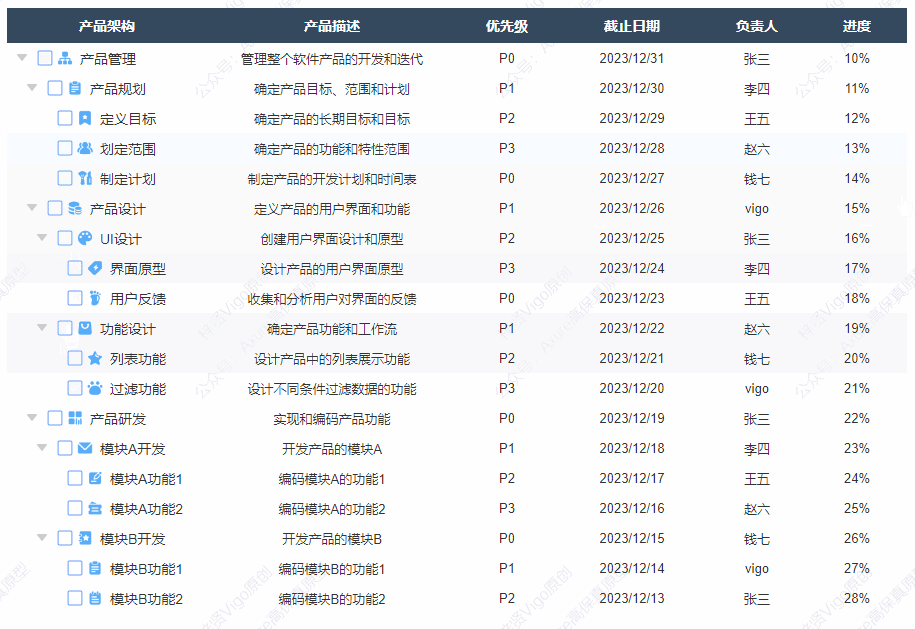
【Axure高保真原型】树形表格_多选效果
今天和大家分享树形表格_多选效果的原型模板,点击树的箭头可以展开或者收起子节点,点击多选按钮可以选中或取消选择该行以及子级行内容,同时反选父级行内容,父级行内容能根据子级选中的数量自动反选,包括全选、半选和未…...
【Filament】加载obj和fbx模型
1 前言 3D 模型的常用格式主要有 obj、fbx、gltf 等,Filament 中的 filamesh.exe 工具可以将 obj、fbx 格式转换为 filamesh 格式,然后再加载显示。对于 gltf 格式模型,可以通过 ModelViewer 加载显示,这不在本文的讨论范围内。 1…...

[USACO04OPEN] The Cow Lineup
题目描述 约翰的 N ( 1 ≤ N ≤ 100000 ) N ( 1 \leq N \leq 100000 ) N(1≤N≤100000) 只奶牛站成了一列。每只奶牛都写有一个号牌,表示她的品种,号牌上的号码在 1 … K &#x…...

软件工具集合
代码文档自动生成工具: Doxygen download 软件分析工具: perf gdb flamegraph 代码量统计: vscode插件:VS Code Counter 代码备注 vsocde插件: Line Note...

C#利用openvino部署PP-TinyPose人体姿态识别
【官方框架地址】 github.com/PaddlePaddle/PaddleDetection 【算法介绍】 关键点检测算法往往需要部署在轻量化、边缘端设备上,因此长期以来都存在一个难题:精度高、速度则慢、算法体积也随之增加。而PP-TinyPose的出世彻底打破了这个僵局,…...
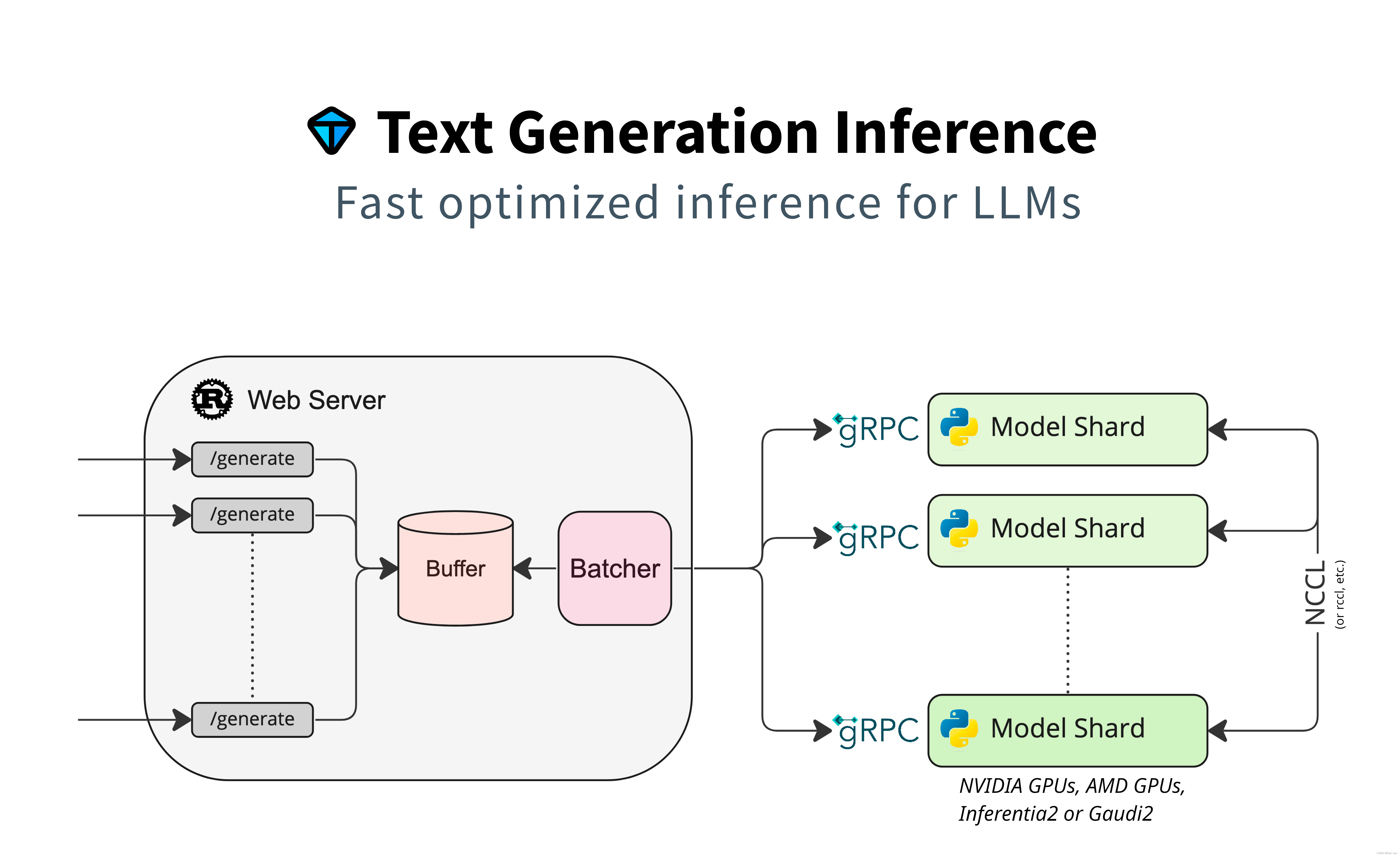
MindSpore Serving与TGI框架 の 对比
一、MindSpore Serving MindSpore Serving是一款轻量级、高性能的服务工具,帮助用户在生产环境中高效部署在线推理服务。 使用MindSpore完成模型训练>导出MindSpore模型,即可使用MindSpore Serving创建该模型的推理服务。 MindSpore Serving包含以…...
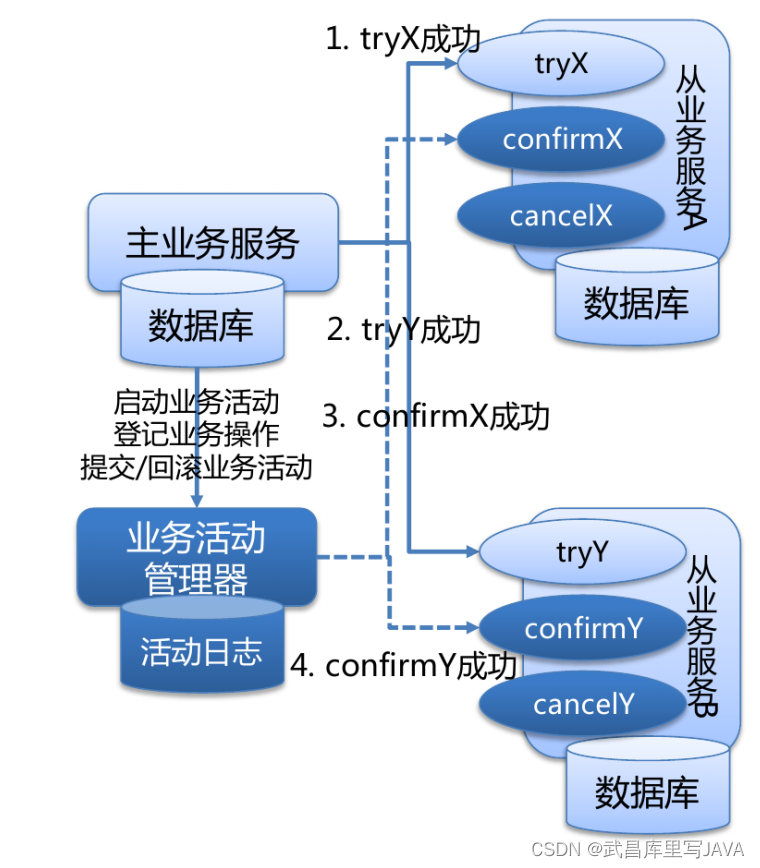
两阶段提交协议三阶段提交协议
两阶段提交协议 分布式事务是指会涉及到操作多个数据库的事务,在分布式系统中,各个节点之间在物理上相互独立,通过网络进行沟通和协调。 XA 就是 X/Open DTP 定义的交易中间件与数据库之间的接口规范(即接口函数),交易…...
)
6-Docker Compose-tomcat application(指定官方镜像)
1.创建docker-compose.yml文件,添加如下内容并保存 vim docker-compose.yml [root@centos79 ~]# cat docker-compose.yml #yml文件 version: 3 #版本号,默认为3 services:tomcat-ztj: #定…...

宝塔安装的imagemagick不能用,必须自己手动安装
1 安装 用composer安装 2 宝塔安装的imagemagick不能用,必须自己手动安装(3.4.3版本 php 7.3) 1 步骤: wget https://pecl.php.net/get/imagick-3.4.3.tgz tar -zxf imagick-3.4.3.tgz cd imagick-3.4.3 /www/server/php/73…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...
MySQL的pymysql操作
本章是MySQL的最后一章,MySQL到此完结,下一站Hadoop!!! 这章很简单,完整代码在最后,详细讲解之前python课程里面也有,感兴趣的可以往前找一下 一、查询操作 我们需要打开pycharm …...