【LMM 010】MiniGPT-v2:使用独特的标识符实现视觉语言多任务学习的统一的多模态大模型
论文标题:MiniGPT-v2: Large Language Model As a Unified Interface for Vision-Language Multi-task Learning
论文作者:Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, Mohamed Elhoseiny
作者单位:King Abdullah University of Science and Technology (KAUST), Meta AI Research
论文原文:https://arxiv.org/abs/2310.09478
论文出处:–
论文被引:33(12/31/2023)
论文代码:https://github.com/Vision-CAIR/MiniGPT-4,21.4k star
项目主页:https://minigpt-v2.github.io/
Abstract
大型语言模型作为各种语言相关应用的通用界面(general interface),已经显示出其非凡的能力。受此激励,我们的目标是建立一个统一的界面,用于完成许多视觉语言任务,包括图像描述,VQA和视觉定位(visual grounding)等。我们面临的挑战是如何使用单一模型,通过简单的多模态指令有效地完成各种视觉语言任务。为实现这一目标,我们推出了 MiniGPT-v2,这是一个可被视为统一界面的模型,能更好地处理各种视觉语言任务。我们建议在训练模型时为不同任务使用独特的标识符。这些标识符使我们的模型能更好地轻松区分每个任务指令,同时也提高了模型对每个任务的学习效率。经过三阶段训练后,实验结果表明,与其他视觉语言通用模型相比,MiniGPT-v2 在许多VQA和视觉定位基准测试中都取得了优异的成绩。
Visual Grounding
Visual Grounding涉及计算机视觉和自然语言处理两个模态。简要来说,输入是图片(image)和对应的物体描述(sentence\caption\description),输出是描述物体的box。听上去和目标检测非常类似,区别在于输入多了语言信息,在对物体进行定位时,要先对语言模态的输入进行理解,并且和视觉模态的信息进行融合,最后利用得到的特征表示进行定位预测。visual grounding按照是否要对语言描述中所有提及的物体进行定位,可以进一步划分为两个任务:1)Phrase Localization:又称为Phrase Grounding,对于给定的sentence,要定位其中提到的全部物体(phrase),在数据集中对于所有的phrase都有box标注。2)Referring Expression Comprehension(REC):也称为 Referring Expression Grounding(REG)。每个语言描述只指示一个物体,每句话即使有上下文物体,也只对应一个指示物体的box标注。
参考:link
1 Introduction
多模态大型语言模型(LLM)是一个令人兴奋的研究课题,在视觉语言领域有着丰富的应用,如视觉人工智能助手,图像描述(Image Caption),VQA(VQA)和指代表达理解(Referring Expression Comprehension,REC)等。多模态大型语言模型的一个主要特点是,它们可以继承 LLM 的高级功能(如逻辑推理,常识和强大的语言表达能力)[32, 49, 50, 8]。当使用适当的视觉语言指令进行微调时,多模态 LLMs(特别是视觉语言模型)就会展现出强大的能力,例如生成详细的图像描述,生成代码,定位图像中的视觉物体,甚至进行多模态推理,以更好地回答复杂的视觉问题 [59, 26, 55, 53, 7, 10, 58, 6, 60]。LLM 的这种进化实现了视觉和语言输入在与个人交流时的互动,并已被证明对构建视觉聊天机器人相当有效。
然而,由于不同任务之间固有的复杂性,学习有效执行多种视觉语言任务并制定相应的多模态指令面临着相当大的挑战。例如,当用户输入 “tell me the location of a person” 时,根据具体任务的不同,有多种解释和回应方式。在指代表达理解任务中,可以用一个人的边界框位置来回答。对于 VQA 任务,模型可以使用人类自然语言来描述其空间位置。而在人物检测任务中,模型可能需要识别给定图像中每个人的空间位置。为了缓解这一问题并实现统一的方法,我们提出了一种面向任务的指令训练方案,以减少多模态指令的模糊性,并提出了一种视觉语言模型 MiniGPT-v2。具体来说,我们为每个任务提供一个唯一的任务标识符。例如,我们提供了一个 [vqa] 标识符,用于训练VQA任务的所有数据样本。在模型训练阶段,我们总共提供了六个不同的任务标识符。
我们的模型 MiniGPT-v2 架构设计简单。
- 它直接从 ViT 视觉编码器 [12] 中获取视觉词元/标记(Token),并将其投射到大型语言模型 Llama2 [50] 的特征空间中。
- 为了获得更好的视觉感知,我们在训练过程中使用了更高分辨率的图像(448x448)。但这会导致视觉标记数量增加。
- 为了提高模型训练的效率,我们将每四个相邻的视觉标记串联成一个标记,从而将标记总数减少了 75%。
- 采用了三阶段训练策略,利用弱标签(weakly-labeled),细粒度图像-文本数据集和多模态教学数据集的混合数据对我们的模型进行有效训练,每个阶段的训练重点各不相同。
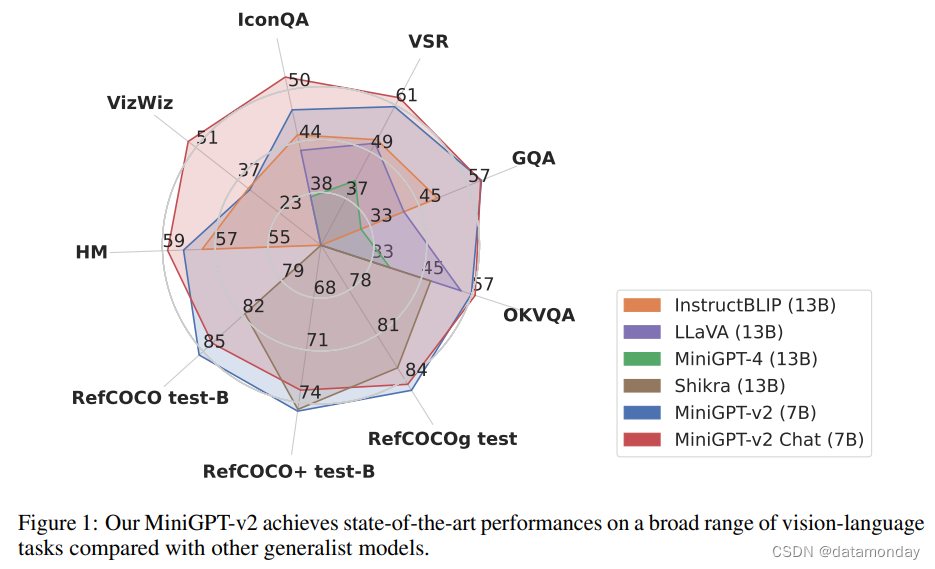
为了评估我们模型的性能,我们在各种视觉语言任务上进行了广泛的实验,包括(详细的)image/grouned captioning,VQA,visual grounding。结果表明,与之前的视觉语言通用模型(如 MiniGPT-4 [59],InstructBLIP [10],LLaVA [26] 和 Shikra [7])相比,我们的 MiniGPT-v2 可以在各种基准测试中取得 SOTA 或相当的性能。例如,在 VSR 基准[25]上,我们的 MiniGPT-v2 比 MiniGPT-4 高出 21.3%,比 InstructBLIP 高出 11.3%,比 LLaVA 高出 11.7%,在 RefCOCO,RefCOCO+ 和 RefCOCOg 的大多数验证中,它的表现也优于之前建立的强基准 Shikra。如图 1 所示,我们的模型在这些基准测试中取得了视觉语言通才模型中的最新成果。
2 Related Work
我们简要回顾了先进大型语言模型和用于视觉对齐的多模态 LLM 的相关工作。
Advanced Large Language Models (LLMs).
GPT-2 [38] 和 BERT [11] 等早期模型是在网络规模文本数据集上训练的基础模型,标志着 NLP 领域的突破。随着基础模型的成功,人们开发出了容量更大,训练数据更多的 LLM,包括 GPT-3 [4],Megatron-turing NLG [46],PaLM [9],Gopher [39],Chinchilla [16],OPT [57] 和 BLOOM [41]。最近,人们的努力集中在改进 LLM,使其能有效地与人类指令和反馈一起工作。这方面的代表作有 InstructGPT [34] 和 ChatGPT [32],它们展示了强大的能力,如回答各种语言问题,与人类进行对话,以及学习执行复杂的任务,如写作提炼和编码助手。
与 LLM 的这些进步同时出现的是 LLaMA [49] 语言模型的兴起。为了实现类似于 ChatGPT 的人类指令遵循(instruction-following)能力,一些研究试图利用更多高质量指令数据集对 LLaMA 模型进行微调[1]。这些模型的例子包括:
- Alpaca [47]
- Vicuna [8]
- MPT [48]
其他一些从人类反馈数据中学习的开源语言模型,也已被引入 NLP 社区,并取得了令人印象深刻的性能。如:
- Falcon [35]
- LLaMA-2 [50]
Visual Aligning with LLMs.
由于 LLMs 具有出色的泛化能力,一些有趣的研究通过将视觉输入与 LLMs 相结合,将 LLMs 扩展到了多模态领域。VisualGPT [5] 和 Frozen [51] 等早期研究使用预训练语言模型来改进图像描述和VQA的视觉语言模型。这一初步探索为 Flamingo [2] 和 BLIP-2 [22] 等后续视觉语言研究铺平了道路。最近发布的 GPT-4 展示了许多先进的多模态能力,例如根据手写文本指令生成网站代码。这些能力启发了其他视觉语言 LLM,包括 MiniGPT-4 [59] 和 LLaVA [26],它们利用适当的指令微调,将图像输入与大型语言模型 Vicuna [8] 对齐。这些视觉语言模型在对齐后还展示了许多先进的多模态功能。最近的一些工作,如 Vision-LLM [53],Kosmos-2 [36],Shikra [7],以及我们同时进行的工作 Qwen-VL [3],也证明了多模型 LLMs 模型也可以通过语言模型生成文本格式的边界框来进行视觉定位。
3 Method
我们首先介绍了视觉语言模型 MiniGPT-v2,然后讨论了利用任务标识符训练多任务指令模板(instruction template)的基本思想,最后调整了任务标识符思想,以实现面向任务的指令调优(instruction tuning)。
3.1 Model Architecture

我们提出的模型架构 MiniGPT-v2 如图 2 所示。它由三个部分组成:
- Visual backbone
- Linear projection layer
- Large language model
我们将对每个组件进行如下描述:
Visual backbone.
MiniGPT-v2 采用 EVA [12] 作为视觉骨干模型骨干。在整个模型训练过程中冻结视觉主干。我们以 448x448 的图像分辨率来训练模型,并根据更高的图像分辨率对位置编码进行插值。
Linear projection layer.
我们的目标是将冻结视觉骨干中的所有视觉标记投射到语言模型空间中。然而,对于 448x448 等更高分辨率的图像,投射所有图像标记会导致非常长的序列输入(例如 1024 个标记),从而大大降低训练和推理效率。因此,我们只需将嵌入(embedding)空间中相邻的 4 个视觉标记串联起来,投射到大语言模型同一特征空间中的单个嵌入中,从而将视觉输入标记的数量减少 4 倍。通过这一操作,我们的 MiniGPT-v2 可以在训练和推理阶段更高效地处理高分辨率图像。
Large language model.
MiniGPT-v2 采用开源的 LLaMA2-chat (7B) [50] 作为语言模型骨干。在我们的工作中,语言模型被视为各种视觉语言输入的统一接口。我们直接依赖 LLaMA-2 语言标记来执行各种视觉语言任务。对于需要生成空间位置的视觉定位任务,我们直接要求语言模型生成边界框的文本表示,以表示其空间位置。
3.2 Multi-task Instruction Template
当针对多个不同任务(如VQA,图像描述,指代消解,grounding图像描述和区域识别)训练一个统一模型时,多模态模型可能无法通过将视觉标记与语言模型对齐来区分每个任务。例如,当问 “Tell me the spatial location of the person wearing a red jacket?” 时,模型既可以用边界框格式(例如,< Xlef t >< Ytop >< Ybottom >)回答位置,也可以用自然语言(例如,右上角)描述物体的位置。为了减少这种歧义并使每个任务易于区分,我们在设计的多任务指令模板中引入了特定任务标记,用于训练。下面我们将详细介绍我们的多任务指令模板。
General input format.
我们沿用 LLaMA-2 会话模板设计,并将其调整为多模态指令模板。该模板表示如下:
[INST] <Img> < ImageFeature> </Img> [Task Identifier] Instruction [/INST]
在这个模板中,[INST] 被视为用户角色,[/INST] 被视为助手角色。我们将用户输入分为三个部分:
- 第一部分是图像特征
- 第二部分是任务标识符
- 第三部分是指令输入
Task identifier tokens.

我们的模型为每项任务设定了不同的标识符,以减少不同任务之间的歧义。如表 1 所示,我们分别为VQA,图像描述,grounded图像描述,指代消解,指代表达生成以及短语解析和执行提出了六个不同的任务标识符。对于与视觉无关的指令,我们的模型不使用任何任务标识符。
Spatial location representation.
对于诸如 REC,REG 和 grounded image captioning 等任务,我们的模型需要准确识别引用对象(referred objects)的空间位置。在我们的设置中,我们通过边界框的文本格式来表示空间位置,具体如下:
“{}”
-
X 和 Y 的坐标用整数值表示,归一化范围为 [0, 100]
-
和 表示生成的边界框左上角的 x 和 y 坐标
-
和 表示右下角的 x 和 y 坐标
3.3 Multi-task Instruction Training
现在,我们将设计好的多任务指令模板用于指令训练。其基本思想是将带有特定任务标识符的指令作为 MiniGPT-v2 的任务导向指令训练的输入。当输入指令带有任务标识符时,我们的模型在训练过程中就更容易理解多任务。为了更好地进行视觉对齐,我们分三个阶段使用任务标识符指令训练模型。
- 第一阶段:通过许多弱标签图像文本数据集和高质量细粒度视觉语言注释数据集(我们将为弱标签图像文本数据集分配较高的数据采样率),帮助 MiniGPT-v2 建立广泛的视觉语言知识。
- 第二阶段:利用多个任务的细粒度数据改进模型。
- 第三阶段:使用更多的多模态指令和语言数据集对模型进行微调,以便更好地回答各种多模态指令,并表现出多模态聊天机器人的特征。
表 2 列出了每个阶段用于训练的数据集。

Stage 1: Pretraining.
为了获得广泛的视觉语言知识,我们的模型在弱标记和细粒度数据集上进行混合训练。我们对弱标记数据集采用高采样率,以便在第一阶段获得更多样化的知识。
对于弱标签数据集,我们使用了 LAION [42],CC3M [44],SBU [33] 和来自 Kosmos v2 [36] 的 GRIT-20M 数据集,它们构建了用于 REC,REG 和 grounded 图像描述的数据集。
对于细粒度数据集,我们使用 COCO caption [24] 和 Text Captions [45] 等数据集来处理图像描述,使用 RefCOCO [20],RefCOCO+ [56] 和 RefCOCOg [29] 等数据集来处理 REC。对于 REG,我们对 ReferCOCO 及其变体的数据进行了重组,将短语 → 边框的顺序颠倒为边框 → 短语。对于 VQA 数据集,我们的训练采用了多种数据集,如 GQA [19],VQA-v2 [14],OCR-VQA [31],OK-VQA [30] 和 AOK-VQA [43]。
Stage 2: Multi-task training.
为了提高 MiniGPT-v2 在每个任务上的性能,我们在这一阶段只专注于使用细粒度数据集来训练模型。我们在第一阶段排除了 GRIT-20M 和 LAION 等弱监督数据集,并根据每个任务的频率更新数据采样比例。这一策略使我们的模型能够优先处理高质量的对齐图像-文本数据,从而在各种任务中取得优异的性能。
Stage 3: Multi-modal instruction tuning.
随后,我们将重点放在利用更多的多模态教学数据集调整我们的模型,并增强其作为聊天机器人的对话能力。我们继续使用第二阶段的数据集,并增加了教学数据集,包括 LLaVA [26],Flickr30k 数据集 [37],我们构建的混合多任务数据集和语言数据集 Unnatural Instruction [17]。我们对第二阶段的细粒度数据集采用较低的数据采样率,而对新的指令数据集采用较高的数据采样率。
- LLaVA instruction data. 我们添加了多模态指令调优数据集,包括来自 LLaVA [26] 的详细描述和复杂推理,分别有 23k 和 58k 个数据示例。
- Flicker 30k. 经过第二阶段的训练,我们的 MiniGPT-v2 可以有效地生成有依据的图像描述。然而,这些描述往往很短,而且通常只涵盖极少数的视觉物体。这是因为我们的模型所使用的 KOSMOS-v2 GRIT-20M 数据集[36],每个标题中的基础视觉物体数量有限,而我们的模型缺乏适当的多模态指令调整,无法教会它识别更多的视觉物体。为了改善这一问题,我们使用 Flickr30k 数据集[37]对模型进行了微调,该数据集在标题中提供了更多的实体上下文基础。
我们准备了两种不同格式的 Flickr30k 数据集,用于训练我们的模型,以执行grounded图像描述和新任务 "object parsing and grounding:
1)Grounded image caption。我们选择至少包含 5 个基础短语的标题,其中包含约 2.5k 个样本,并直接指示模型生成基础图像描述。例如,房间中央有一张
木桌
{}。2)Object parsing and grounding。这项新任务是解析输入标题中的所有对象,然后将每个对象 grounded。为此,我们使用了任务标识符[detection],以区别于其他任务。此外,我们使用 Flickr30k 构建了两种指令数据集:caption→ grounded phrases 和 phrase → grounded phrase,每个数据集分别包含约 2.5k 和 3k 个样本。然后,我们向模型发出指令:[detection] description,模型将直接从输入的图像描述中解析出对象,并将对象边界框化。
- Mixing multi-task dataset. 在使用单轮指令-答案对进行大量训练后,由于上下文变得更加复杂,模型在多轮对话中可能无法很好地处理多个任务。为了缓解这种情况,我们通过混合不同任务的数据创建了一个新的多轮对话数据集。我们将该数据集纳入第三阶段模型训练。
- Unnatural instruction. 经过大量的视觉语言训练后,语言模型的对话能力会有所下降。为了解决这个问题,我们在模型的第三阶段训练中加入了语言数据集 Unnatural Instruction [17],以帮助恢复语言生成能力。
4 Experiments
在本节中,我们将介绍实验设置和结果。我们主要就 (detailed) image/grounded captioning,VQA和视觉定位任务(包括指代消解)进行了实验。我们同时给出了定量和定性结果。
Implementation details.
在整个训练过程中,MiniGPT-v2 的视觉主干保持冻结状态。我们的重点是训练线性投影层,并使用 LoRA [18] 对语言模型进行高效微调。利用 LoRA,我们通过低秩自适应性对 Wq 和 Wv 进行微调。在我们的实施过程中,我们设置了等级 r = 64。在所有阶段,我们都使用 448x448 的图像分辨率来训练模型。在模型训练的每个阶段,我们都使用了为各种视觉语言任务设计的多模态指令模板。
Training and hyperparameters.
我们使用带有余弦学习率调度器的 AdamW 优化器来训练模型。
- 在初始阶段,使用 8 卡 A100 GPU 训练 400,000 步,全局批量大小为 96,最大学习率为 1e-4。这一阶段大约需要 90 个小时。
- 在第二阶段,模型在 4 卡 A100 GPU 上训练了 50,000 步,最大学习率为 1e-5,全局批量大小为 64,这一训练阶段持续了大约 20 个小时。
- 最后一个阶段,在 4 卡 A100 GPU 上再执行 35000 步训练,采用 24 的全局批量大小,这一训练阶段耗时约 7 小时,最大学习率仍为 1e-5。
4.1 Quantitative Evaluation
Dataset and evaluation metrics.
我们通过一系列 VQA 和视觉基础基准来评估我们的模型。对于 VQA 基准,我们考虑了 OKVQA [43],GQA [19],视觉空间推理 (VSR) [25],IconVQA [28],VizWiz [15],HatefulMemes 和 (HM) [21]。在视觉基础方面,我们在 RefCOCO [20] 和 RefCOCO+[56] 以及 RefCOCOg[29] 基准上对我们的模型进行了评估。
Visual question answering results.
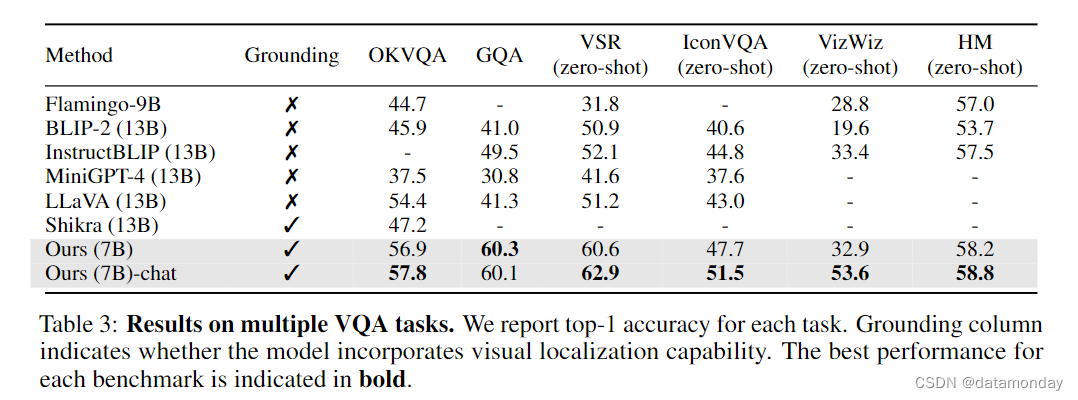
表 3 列出了我们在多个 VQA 基准上的实验结果。在所有 VQA 任务中,我们的结果都优于 MiniGPT-4 [59],Shikra [7],LLaVA [26] 和 InstructBLIP [10]。例如,在 QKVQA 上,我们的 MiniGPTv2 分别比 MiniGPT-4,Shikra,LLaVA 和 BLIP-2 高出 20.3%,10.6%,3.4% 和 11.9%。这些结果表明我们的模型具有很强的VQA能力。此外,我们还发现我们的 MiniGPT-v2 (Caht) 变体比经过第二阶段训练的版本表现出更高的性能。在 OKVQA,VSR,IconVQA,VizWiz 和 HM 上,MiniGPT-v2 (Caht) 分别比 MiniGPT-v2 高出 0.9%,2.3%,4.2%,20.7% 和 0.6%。我们认为,更好的表现可归因于第三阶段训练中语言技能的提高,这有利于视觉问题的理解和回答,尤其是在 VizWiz 上,top-1 准确率提高了 20.7%。
Referring expression comprehension results.
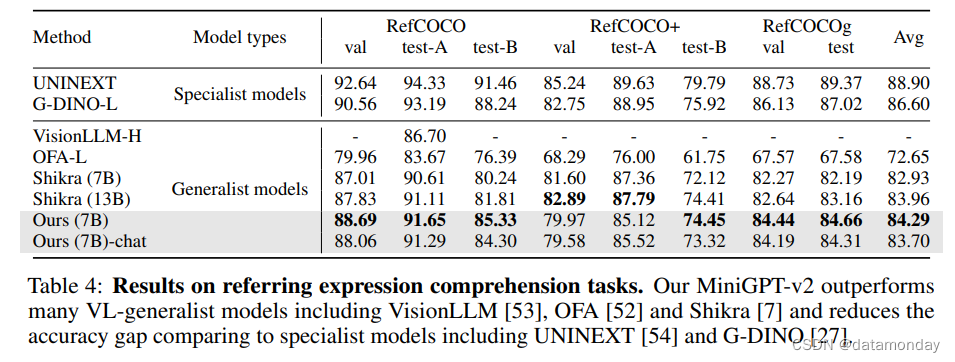
表 4 比较了我们的模型与 REC 基准的基线。在 RefCOCO,RefCOCO+ 和 RefCOCOg 上,我们的 MiniGPT-v2 显示出很强的 REC 性能,优于其他视觉语言通用模型。在 RefCOCO/RefCOCO+/RefCOCOg 的所有任务中,MiniGPT-v2 的准确率超过 OFA-L [52] 8%。与强大的基准模型 Shikra (13B) [7] 相比,我们的模型仍然显示出更好的结果,例如,平均准确率为 84.29% vs 83.96%。这些结果直接证明了 MiniGPT-v2 在视觉基础方面的竞争能力。虽然我们的模型在性能上不如专业模型,但其可喜的表现表明其在 visual grounding 方面的能力正在不断增强。
Ablation on task identifier.
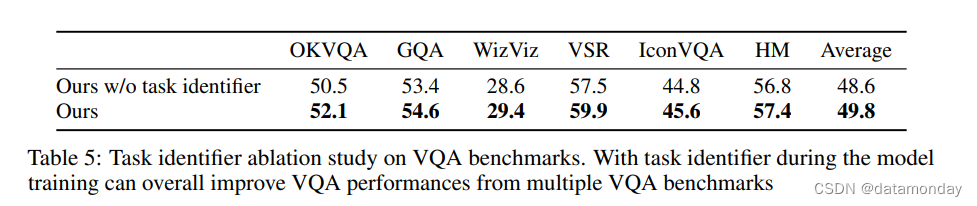
我们就任务标识符对 MiniGPT-v2 性能的影响进行了消融研究。我们在 VQA 基准上比较了我们的模型和不使用任务标识符的变体。两个模型都在 4xA100 GPU 上进行了 24 小时的训练,对多个视觉语言任务进行了相同数量的训练。表 5 中的结果显示了多个 VQA 基准的性能,并一致表明Token标识符训练有利于提高 MiniGPT-v2 的整体性能。具体来说,采用任务导向指令训练的 MiniGPT-v2 平均提高了 1.2% 的 top-1 准确率。这些消融结果可以验证添加任务标识符Token的明显优势,并支持使用多任务标识符提高多任务学习效率。
Hallucination.

我们测量了我们的模型在生成图像描述时产生的幻觉,并将结果与其他视觉语言基线进行了比较,包括 MiniGPT-4 [59],mPLUGOwl [55],LLaVA [26]和 MultiModal-GPT [13]。按照[23]的方法,我们使用 CHAIR [40]来评估对象和句子层面的幻觉。如表 6 所示,我们发现与其他基线相比,我们的 MiniGPT-v2 在生成图像描述时更倾向于减少幻觉。我们在 MiniGPT-v2 中评估了三种类型的提示。
- 首先,我们使用提示生成给定图像的简要描述,而不使用任何特定的任务标识符,这往往能生成更详细的图像描述。
- 然后,我们提供 [grounding] 指令提示,尽可能详细地描述这张图片,以评估grounded image captions。
- 最后,我们用 [caption] 提示模型简要描述图像。
有了这些任务标识符,MiniGPT-v2 就能生成各种不同幻觉程度的图像描述。因此,所有这三种指令变体的幻觉程度都低于我们的基线,尤其是在使用 [caption] 和 [grounding] 任务标识符时。
4.2 Qualitative Results

我们现在提供定性结果,以补充说明我们模型的多模态能力。图 3 显示了一些示例。具体来说,我们在示例中展示了各种能力,包括:
- a) object identification
- b) detailed grounded image captioning
- c) VQA
- d) referring expression comprehension
- e) visual question answering under task identifier
- f) detailed image description
- g) object parsing and grounding from an input text
- 更多定性结果见附录
这些结果表明,我们的模型具有视觉语言理解能力。此外,请注意,在第三阶段,我们只用几千个 object parsing and grounding 任务的指令样本来训练我们的模型,而我们的模型可以有效地遵循指令,并在新任务中进行泛化。这表明我们的模型具有适应许多新任务的灵活性。
请注意,我们的模型在生成图像描述或视觉定位时偶尔仍会出现幻觉。例如,我们的模型有时可能会生成不存在的视觉物体的描述,或生成不准确的定位对象的视觉位置。我们相信,使用更多高质量的图像-文本对齐数据进行训练,并与更强大的视觉骨干或大型语言模型进行整合,有可能缓解这一问题。
5 Conclusion
本文介绍了 MiniGPT-v2,它是一种多模态 LLM,可作为各种视觉语言多任务学习的统一接口。为了开发能够处理多种视觉语言任务的单一模型,我们建议在训练和推理过程中为每个任务使用不同的标识符。这些标识符有助于我们的模型轻松区分各种任务,同时提高学习效率。我们的 MiniGPT-v2 在许多VQA和引用表达理解基准测试中都取得了一流的成绩。我们还发现,我们的模型可以高效地适应新的视觉语言任务,这表明 MiniGPT-v2 在视觉语言领域有许多潜在的应用。
A Appendix
在补充中,我们提供了从我们的模型中生成的更多定性结果,以展示视觉语言的多任务能力。
A.1 Instruction template for various vision-language tasks
RefCOCO/RefCOCO+/RefCOCOg: [refer] give me the location of question
VizWiz: [vqa] Based on the image, respond to this question with a single word or phrase: question, and reply ‘unanswerable’ when the provided information is insufficient
Hateful Meme: [vqa] This is an image with: question written on it. Is it hateful? Answer:
VSR: [vqa] Based on the image, is this statement true or false? question
IconQA, GQA, OKVQA: [vqa] Based on the image, respond to this question with a single word or phrase: question
A.2 Additional Qualitative Results
为了研究我们的模型在接收视觉输入并根据任务导向标识符回答问题方面的能力,我们使用我们的模型执行了多项视觉语言任务,包括:
- grounded image captioning:Fig. 4, Fig. 5, Fig. 6 and Fig. 7
- Object parsing and grounding:Fig. 8, Fig. 9, Fig. 10 and Fig. 11
- Referring expression comprehension:Fig. 12, Fig. 13, Fig. 14 and Fig. 15
- Object identification:Fig. 16, Fig. 17, Fig. 18 and Fig. 19
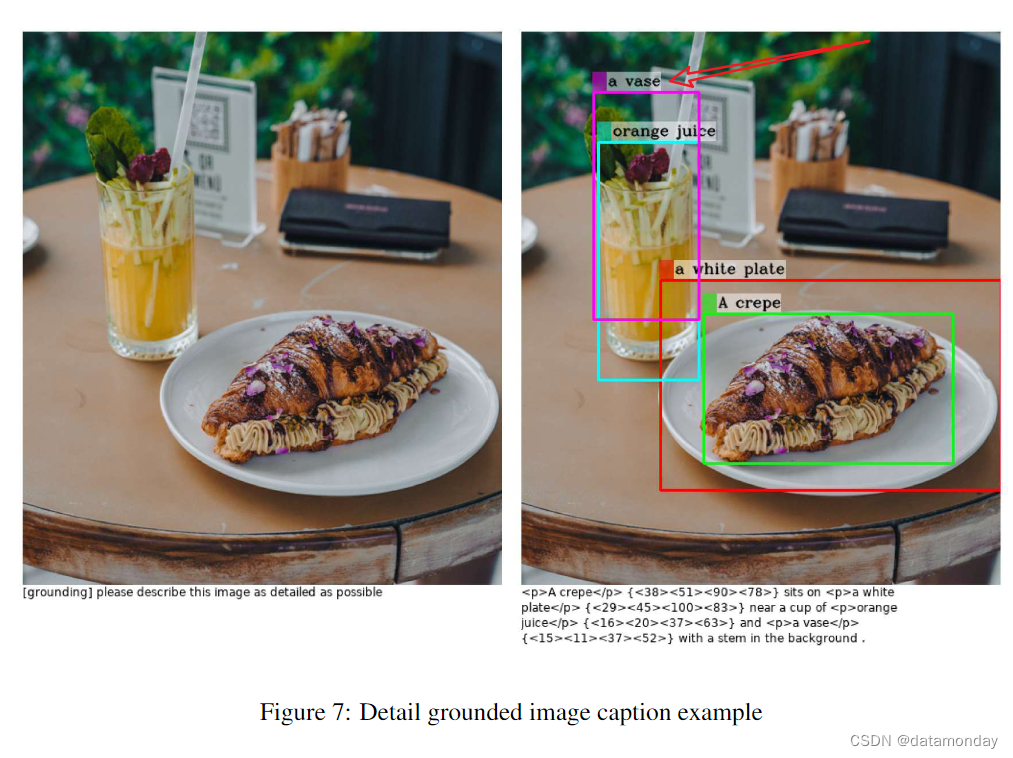
针对每个任务,我们分享了 4 个示例,以展示我们模型的视觉语言能力。演示中的结果直接证明了 MiniGPT-v2 在多个视觉语言任务中的竞争性视觉理解能力。例如,在 grounded caption 任务中,我们的模型能给出正确的有根据的图像说明,并能提供物体的详细空间位置。在识别的情况下,模型还能生成我们期望的物体名称。MiniGPT-v2 可以理解新的场景,并根据问题标识符做出响应。但我们也需要注意到,我们的模型仍然存在一些幻觉,例如,在图 6 中,有几个人没有被准确定位,在图 7 中,图像中不存在一个花瓶。

相关文章:
【LMM 010】MiniGPT-v2:使用独特的标识符实现视觉语言多任务学习的统一的多模态大模型
论文标题:MiniGPT-v2: Large Language Model As a Unified Interface for Vision-Language Multi-task Learning 论文作者:Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yun…...

人工智能如何重塑金融服务业
在体验优先的世界中识别金融服务业中的AI使用场景 人工智能(AI)作为主要行业的大型组织的重要业务驱动力,持续受到关注。众所周知,传统金融服务业在采用新技术方面相对滞后,一些组织使用的还是上世纪50年代和60年代发…...

Iterable 对象转换为 Stream 对象
在 Java 8 中,可以使用 Stream API 来对集合进行操作。要将 Iterable 对象转换为 Stream 对象,可以使用 StreamSupport 类的 stream() 方法。具体来说,可以按照以下步骤进行转换: 调用 Spliterators.spliteratorUnknownSize(iter…...
基于Java+SpringBoot+vue+elementUI私人健身教练预约管理系统设计实现
基于JavaSpringBootvueelementUI私人健身教练预约管理系统设计实现 欢迎点赞 收藏 ⭐留言 文末获取源码联系方式 文章目录 基于JavaSpringBootvueelementUI私人健身教练预约管理系统设计实现一、前言介绍:二、系统设计:2.1 性能需求分析2.2 B/S架构&…...

2024,启动(回顾我的2023)
零.前言 打开博客想写个年度总结,发现已经半年没有更新文章了,排名从几千掉到了几万,不过数据量还是不错的。 时间过得可真快,2023年是充满动荡的一年,上半年gpt横空出世,下半年各种翻车暴雷吃瓜吃到嘴软…...

Web网页开发-盒模型-笔记
1.CSS的三种显示方式 (1)块级元素:标签所占区域默认为一行 特点:一行一个 可设宽高 (2)行内元素:标签所占区域由内容顶开,行内元素无法使用text-align 特点:一行多个 不可设宽高,margin上下和padding上下都不能改变位…...

Java打成压缩包的方法汇总
文章目录 1.将指定目录下的文件打包成 .zip2.将指定目录下的文件打包成 .tar.gz3.将指定目录下的文件打包成 .tar4.将指定目录下的文件打包成 .rar5.生成若干个txt并打包到zip中 1.将指定目录下的文件打包成 .zip 代码示例: import java.io.*; import java.util.z…...

2023年第2季社区Task挑战赛贡献者榜单
基于FISCO BCOS及Weldentity,实现SSO单点登录服务;提供食品溯源、电商运费险7天退保、电子病历等智能合约库业务场景案例;基于FISCO BCOS更新游戏体验;体验并分析解读最新发布的分布式数据协作管理解决方案DDCMS,提供相…...

Clickhouse 为什么快
ClickHouse是一个用于联机分析处理(OLAP)的开源列式数据库管理系统(DBMS)。它之所以能提供出色的查询性能和处理速度,主要归功于以下几个方面的设计和优化: 列式存储 ClickHouse存储数据按列而不是按行组织…...
【React系列】react-router
本文来自#React系列教程:https://mp.weixin.qq.com/mp/appmsgalbum?__bizMzg5MDAzNzkwNA&actiongetalbum&album_id1566025152667107329) 一. 认识react-router 1.2. 前端路由原理 前端路由是如何做到URL和内容进行映射呢?监听URL的改变。 UR…...

[数据集][目标检测]车辆检测数据集VOC+YOLO格式1.6w张3类别
一共分为3个压缩包: 【车辆检测数据集AVOCYOLO格式5423张3类别】 数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):5423 标注数…...

FindMy技术用于鼠标
鼠标是计算机的标准配置之一,其设计初衷是为了使计算机的操作更加简便快捷,减少用户在操作中的负担。用户可以通过移动鼠标,实现光标的精确移动,进而选择、拖拽、复制、粘贴等操作。这种操作方式,使得计算机的操作变得…...
已解决‘ping‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。”的问题
已解决‘ping‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。”的问题 文章目录 问题介绍 问题分析 解决思路 解决方法 检查并修复环境变量 进入c:\windows\system32再ping 使用系统工具修复系统文件 Q1 - 问题介绍 当您尝试在Windows命令提示符下…...

基于PGPGPOOL-II部署PostgreSQL高可用环境
PGPOOL-II是一个位于PostgreSQL服务器和 PostgreSQL 数据库客户端之间的中间件,具有以下功能: 1. 连接池:PGPOOL-II可以保持已经连接到 PostgreSQL 服务器的连接,并在使用相同参数(例如:用户名、数据库、协议版本)连接进来时重用它们。这可以减少连接开销,并增加系统的…...

【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行环境搭建
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 概述-CSDN博客 【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行环境搭建-CSDN博客 【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行模式-CSDN博客 1、模板虚拟机环境准备 1.1、 hadoop100 虚拟机配置要求如下 &…...

Python 操作 JMeter 探索:pymeter 实操指南
概要 JMeter 是一个流行的性能测试工具,用于测试 Web 应用程序的性能和负载。它通常与 GUI 一起使用,但如果您想在自动化测试中集成 JMeter,或者以编程方式创建和运行测试计划,那么 pymeter 库将是一个强大的工具。本文将介绍如何…...

微软 Power Platform 使用Power Automate发送邮件以Dataverse作为数据源的附件File Column
微软Power Platform使用Power Automate发送邮件添加Power Apps以Dataverse作为数据源的附件File Column方式 目录 微软Power Platform使用Power Automate发送邮件添加Power Apps以Dataverse作为数据源的附件File Column方式1、需求背景介绍2、附件列File Column介绍3、如何在Po…...

雾天条件下 SLS 融合网络的三维目标检测
论文地址:3D Object Detection with SLS-Fusion Network in Foggy Weather Conditions 论文代码:https://github.com/maiminh1996/SLS-Fusion 论文摘要 摄像头或激光雷达(光检测和测距)等传感器的作用对于自动驾驶汽车的环境意识…...
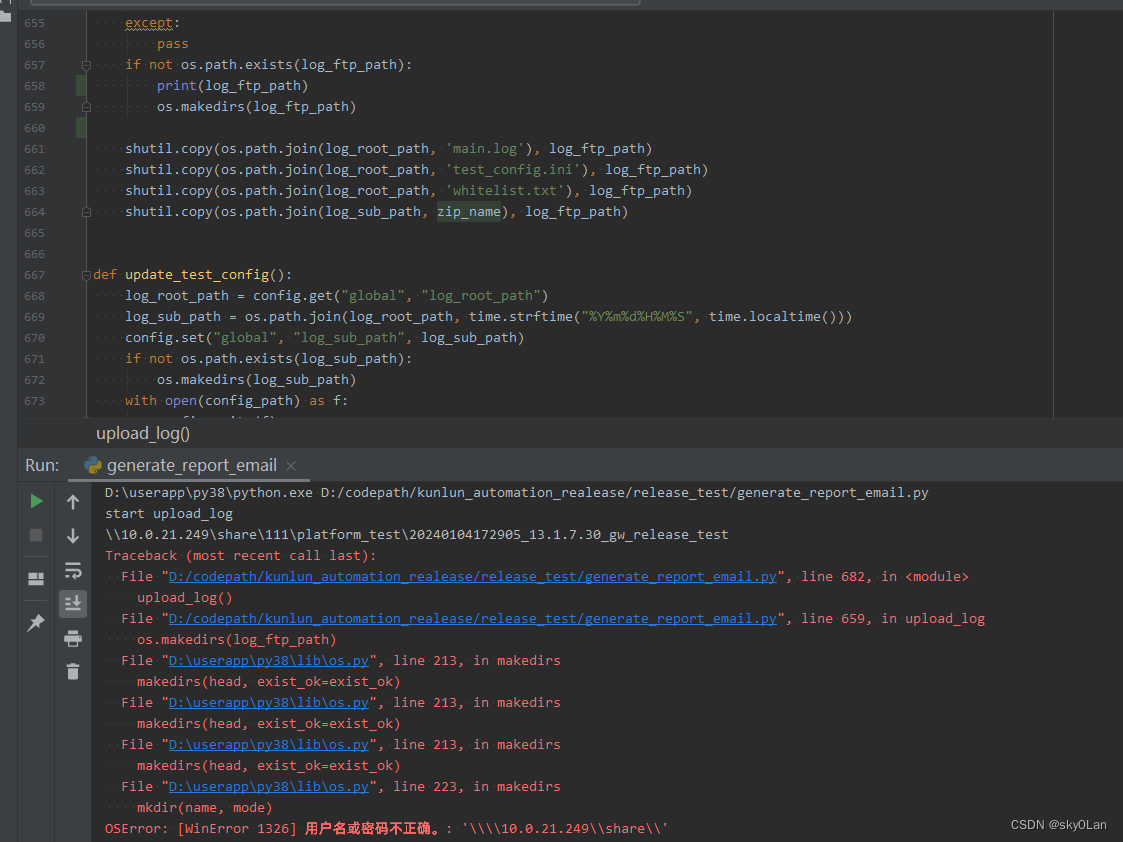
在pycharm中执行 os.makedirs 提示用户名或密码不正确
问题:在pycharm中运行脚本,在 \10.0.21.249\share 共享目录下创建目录提示错误 发现:手动在该目录下创建目录没有问题。 解决方法: 切换到cmd 命令行运行该脚本成功创建 猜测:感觉应该是pycharm中使用的用户名和密码存…...

使用Go语言编写高效的HTTP服务器
随着互联网的快速发展,HTTP服务器在Web开发中扮演着越来越重要的角色。而Go语言作为一种高效、并发性强的编程语言,为编写高性能的HTTP服务器提供了强大的支持。本文将探讨如何使用Go语言编写高效的HTTP服务器。 首先,我们需要了解Go语言的H…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...
实现跳一跳小游戏)
鸿蒙(HarmonyOS5)实现跳一跳小游戏
下面我将介绍如何使用鸿蒙的ArkUI框架,实现一个简单的跳一跳小游戏。 1. 项目结构 src/main/ets/ ├── MainAbility │ ├── pages │ │ ├── Index.ets // 主页面 │ │ └── GamePage.ets // 游戏页面 │ └── model │ …...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...
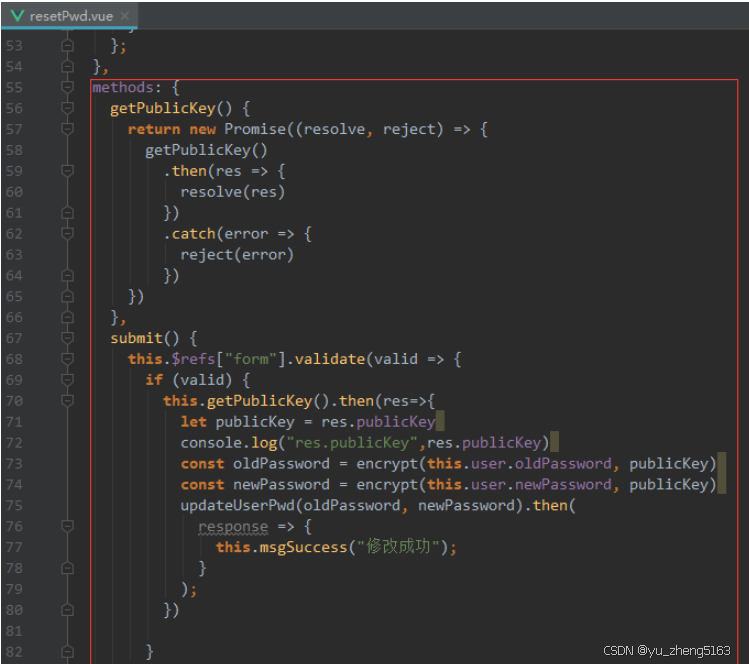
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...
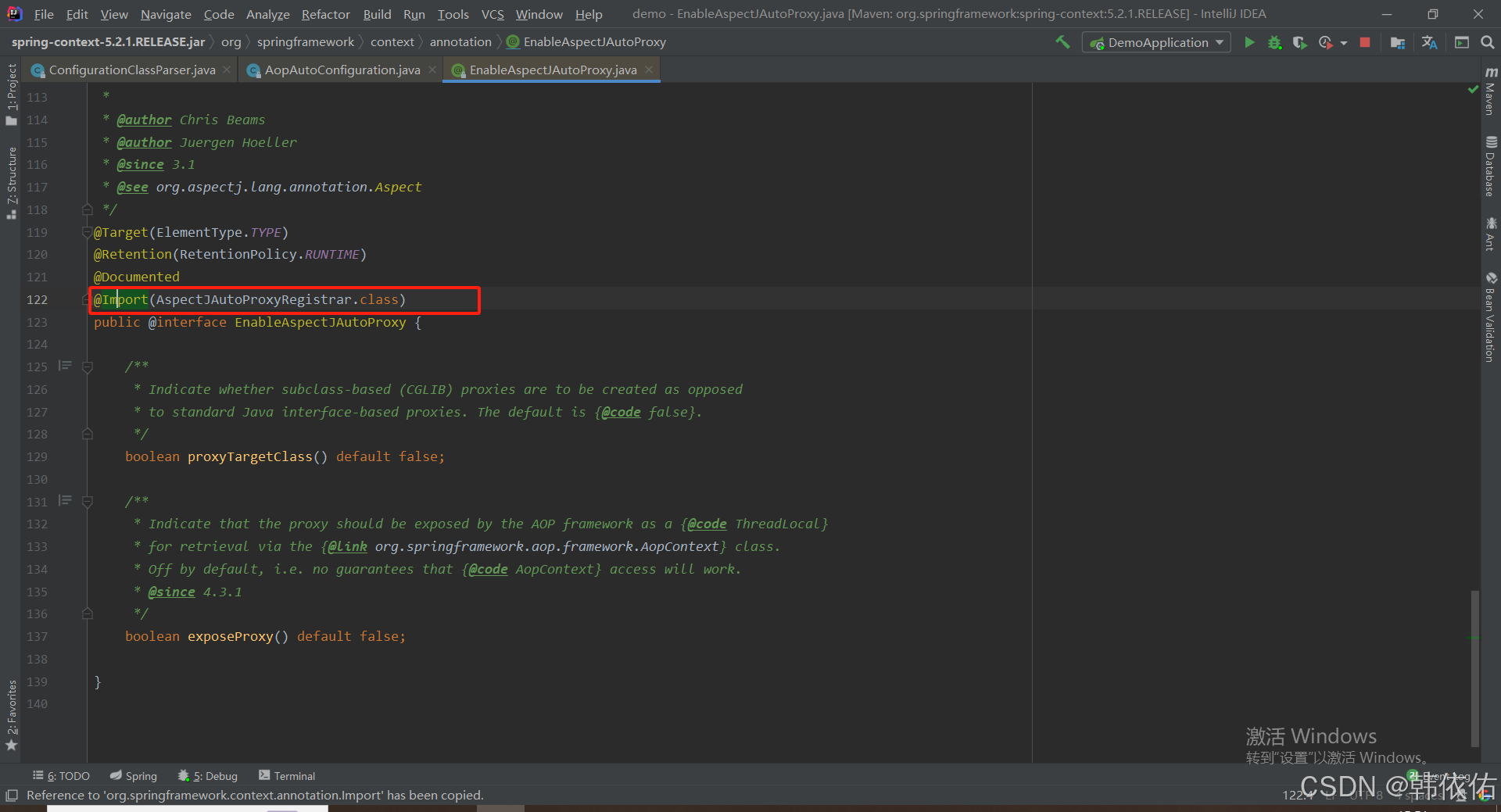
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...
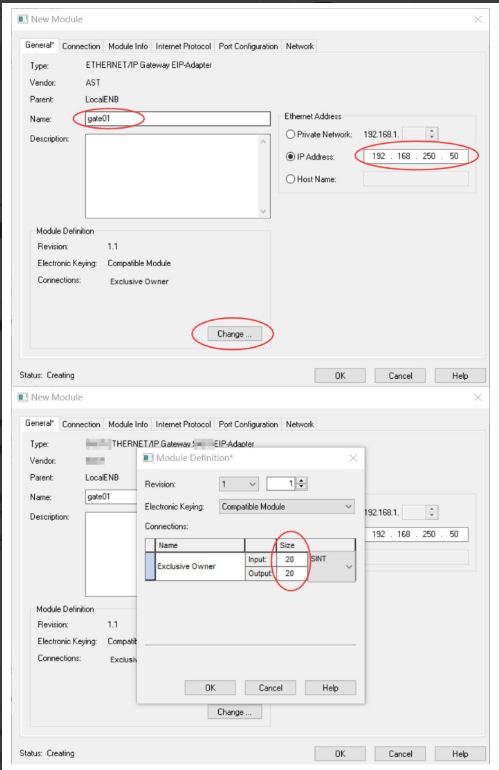
开疆智能Ethernet/IP转Modbus网关连接鸣志步进电机驱动器配置案例
在工业自动化控制系统中,常常会遇到不同品牌和通信协议的设备需要协同工作的情况。本案例中,客户现场采用了 罗克韦尔PLC,但需要控制的变频器仅支持 ModbusRTU 协议。为了实现PLC 对变频器的有效控制与监控,引入了开疆智能Etherne…...
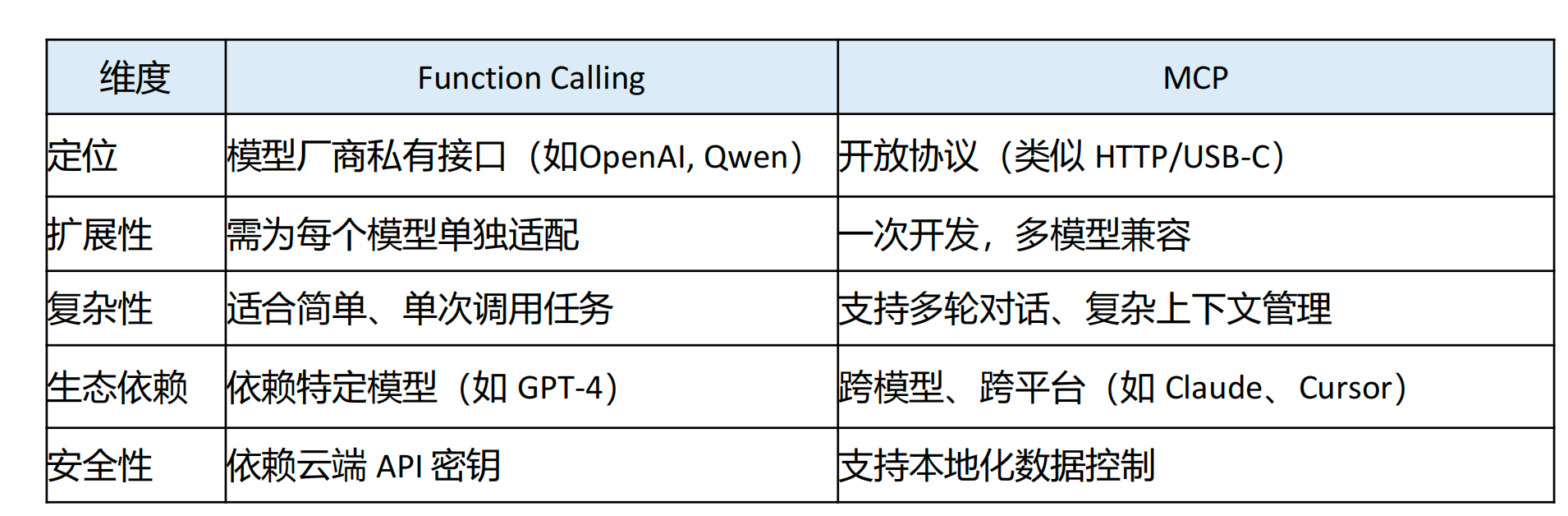
MCP和Function Calling
MCP MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由 Anthropic 推出的一种开放标准,旨在统一大模型与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而…...